
A Topic Modelling Method for Automated Text Analysis of the
Adoption of Enterprise Risk Management
Hao Lu, Xiaoyu Liu and Hai Wang
Sobey School of Business, Saint Mary’s University, Canada
Keywords: Topic Modelling, Natural Language Processing, Machine Learning, Artificial Intelligence, Enterprise Risk
Management, Business Analytics, COVID-19.
Abstract: This paper presents a topic modelling method for automated text analysis of the adoption of enterprise risk
management by publicly traded firms. The topic modelling method applies the Latent Dirichlet Allocation
algorithm on corporate annual financial disclosures to identify whether firms have adopted enterprise risk
management. The preliminary results indicate that the firms that have adopted enterprise risk management
have a smaller reduction in daily abnormal returns during the recession period of the COVID-19 financial
market shock in 2020 (the first quarter of 2020 when the stock market crashed) and a larger increase in daily
abnormal returns during the recovery period (the second and third quarters of 2020 when the stock market
recovered). Moreover, there is no evidence that the adoption of enterprise risk management reduces the
volatility of stock returns of publicly traded firms during the COVID-19 financial market shock in 2020.
1 INTRODUCTION
Enterprise Risk Management (ERM) is a holistic risk
management approach to managing all risks within an
organization as a portfolio, and it has been adopted by
a significant portion of publicly traded firms since the
1990s (Arena et al., 2011). ERM is believed to add
value to a firm from both the micro-level and the
macro-level by creating competitive advantages,
increasing risk awareness, creating synergies among
diversified business units, and reducing the cost of
risk (Ai et al., 2018; Clarke & Varma, 1999; Doherty,
2000; Nocco & Stulz, 2006). Many rating agencies,
professional associations, legislative bodies,
regulators, and international standards organizations
endorse and promote ERM (Gatzert et al., 2016; Hoyt
& Liebenberg, 2011; Khurana et al., 2004; Nair et al.,
2014).
Despite the positive effects of ERM on risk
identification, risk mitigation, information sharing,
and the potential corresponding benefits to firm
performance and value, previous empirical research
indicated mixed results on the role of ERM during
and after a systematic crisis. Some research showed
that firms with sophisticated risk management
experienced a higher failure rate in turbulent
environments because of overconfidence in the
benefits of risk management (Baxter et al., 2013;
Bromiley et al., 2001). For example, insurance
companies such as Countrywide Mortgage faced
bankruptcy during the 2008 financial crisis, despite
having strong ERM (Bromiley et al., 2015).
Starting in 2019, the outbreak and spread of the
COVID-19 virus severely impacted global economics
and organizational performance. COVID-19 has
negatively impacted the financial performance of
many industries, such as transportation, mining and
real estate (He et al., 2020; Mazur et al., 2020). This
has resulted in a decline in gross domestic product
and international trade globally (Iyke, 2020). The
COVID-19 financial market shock in 2020 is of great
interest to the risk management research community
because it has created tremendous challenges and
difficulties for risk management.
In this paper, we propose a topic modelling
method for automated text analysis of the adoption of
ERM of publicly traded firms, and examine the
impact of COVID-19 on ERM. The proposed topic
modelling method applies the Latent Dirichlet
Allocation algorithm on corporate annual financial
disclosures to identify whether publicly traded firms
have adopted ERM. The output of the proposed topic
modelling method is then combined with the financial
market data for further analysis of the impact of ERM
456
Lu, H., Liu, X. and Wang, H.
A Topic Modelling Method for Automated Text Analysis of the Adoption of Enterprise Risk Management.
DOI: 10.5220/0012118500003538
In Proceedings of the 18th International Conference on Software Technologies (ICSOFT 2023), pages 456-462
ISBN: 978-989-758-665-1; ISSN: 2184-2833
Copyright
c
2023 by SCITEPRESS – Science and Technology Publications, Lda. Under CC license (CC BY-NC-ND 4.0)
during the COVID-19 financial market shock in
2020.
The remainder of the paper is organized as
follows. Section 2 formulates the research problem.
Section 3 describes the topic modelling method.
Section 4 presents the results of the topic modelling
method to examine the impact of ERM during the
COVID-19 pandemic. Section 5 presents the
conclusions.
2 RESEARCH PROBLEM
A significant portion of publicly traded firms has
adopted ERM since the 1990s (Arena et al., 2011). As
previous empirical research indicated mixed results
on the role of ERM during and after a systematic
crisis (Baxter et al., 2013; Bromiley et al., 2001), the
impact of ERM during the COVID-19 financial
market shock in 2020 remains unclear. Pagach and
Wieczorek-Kosmala (2020) conceptually examined
the impact of COVID-19 on ERM and provided
important yet unanswered research questions on the
role of ERM in response to the COVID-19 pandemic:
1. Does the financial market recognize the benefits
of ERM during the COVID-19 financial market
shock in 2020?
2. Does ERM help reduce the volatility of firm
stock market returns during the COVID-19
financial market shock in 2020?
Based on the previous research literature (Alexander,
2008; Azar, 2014; Arena et al., 2011; Beasley et al.,
2008; Carpenter & Guariglia, 2008; Eckles et al.,
2014; Farrell & Gallagher, 2015; Gatzert & Martin,
2015; Hentschel & Hall, 1991; Hoyt & Liebenberg,
2011; Liebenberg & Hoyt, 2003; (Farrell &
Gallagher, 2015; Lu et al., 2020; Nocco & Stulz,
2006; Olowe, 2009; Pagach & Warr, 2010; Stulz,
1996; Traub, 2019; Wang, et al., 2009), we examine
the following two hypotheses.
H1: During the COVID-19 financial market shock in
2020, the firms that have already adopted ERM
experienced higher abnormal returns compared with
firms that do not adopt ERM.
H2: During the COVID-19 financial market shock in
2020, the firms that have already adopted ERM
experienced lower stock return volatility compared
with firms that do not adopt ERM.
We collected the stock market data for the first three
quarters of 2020 from the Capital IQ Security Daily
database, as well as all corporate annual financial
disclosures since 1985 of all publicly traded firms in
the US. The first confirmed COVID-19 case in the
US was recorded on January 20, 2020 (Taylor, 2020).
During February, the spread of the coronavirus in the
US was relatively slower compared with other
regions, such as Asia and Europe. The month of
March marked the sign of a full outbreak in the US.
On March 6, 2020, the US government announced the
COVID-19 Emergency Relief Aid Program. The US
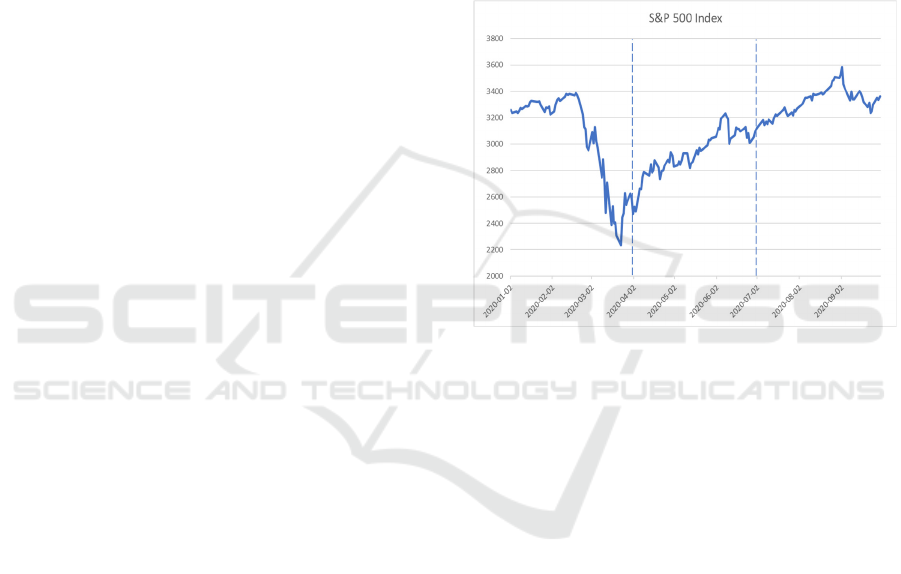
S&P 500 Index Prices in the first 3 quarters of 2020
are shown in Figure 1. For the COVID-19 financial
market shock in 2020, we define the first quarter of
2020 as the recession stage, and the second and third
quarters of 2020 as the recovery stage.
Figure 1: The US S&P 500 Index Prices in the first three
quarters of 2020.
We are interested in how ERM impacts both firm
stock performance and volatility of returns.
Therefore, we have two sets of dependent variables.
We use daily abnormal return (AR) to measure a
firm’s stock market performance (Albuquerque,
Koskinen, Yang, & Zhan, 2020). To calculate AR, we
first calculated the three-year average beta between
2017 and 2019 using the capital asset pricing model.
AR is calculated as the residual returns after the
market-induced return is removed. We first run the
regression based on the market model as follows.
R
it
=α
i
+ β
i
*R
mt
(1)
where i, t, m represents the publicly traded firm i, date
t, and industry m; R
it
is the risk-adjusted daily return;
α
i
is the constant; β
i
is the three-year average beta; and
R
mt
is the risk-adjusted market daily return. We then
calculate AR as the difference between the risk-
adjusted return and the risk-adjusted market return as
follows.
AR
it
=R
it
–(α
i
+ β
i
*R
mt
) (2)
A Topic Modelling Method for Automated Text Analysis of the Adoption of Enterprise Risk Management
457

We use the standard deviation of a firm’s risk-
adjusted daily return to measure a firm’s stock return
risk.
We then use the difference-in-difference (diff-in-
diff) regression method to test the hypothesis H1. We
regress AR on the diff-in-diff estimator and all other
control variables at the firm-day level as follows.
AR
it
= α + β
1
* (ERM
i
* COVID
t
) + β
2
* ERM
i
+ β
3
* COVID
t
+ X’δ + λ
m
+ ε
it
(3)
where i, t, m represents the publicly traded firm i, date
t, and industry m; ERM
i
=1 represents the adoption of
ERM by the publicly traded firm i before 2020, and 0
otherwise; COVID
t
=1 if the date is March 6, 2020 or
after, and 0 otherwise, because the US government
announced the COVID-19 Emergency Relief Aid
Programs on March 6, 2020; X’ is the vector of
control variables; λ
m
is the industry fixed effects; and
ε
it
is the error term. As expressed in the hypothesis
H1, we expect the coefficient β
1
to be positive. This
diff-in-diff estimation has an advantage in estimating
the marginal effects of the treatment group versus the
control group in different periods. In order to further
control for time-invariant factors that may bias the
diff-in-diff coefficient, we also run a firm-day fixed
effect regression with the same diff-in-diff estimator
as follows.
AR
it
= α + γ
1
*(ERM
i
*COVID
t
) + γ
2
K
it
+ μ
i
+ θ
t
+ ε
it
(4)
where K
it
is the daily price range; μ
i
is the firm fixed-
effects and θ
t
is the day fixed-effects. Please note that
the independent variable ERM
i
and all firm-year level
control variables are absorbed in the firm fixed-
effects.
The hypothesis H2 investigates ERM’s impact on
stock return volatility. We use the cross-sectional
estimation by regressing the standard deviation of
daily abnormal returns on the independent variable
ERM
i
and the vector of firm-year level control
variables. Stock volatility is calculated based on the
stock returns in the first quarter, the first two quarters,
and the first three quarters, respectively. We include
industry fixed-effects for all stock volatility risk
regressions as follows.
Volatility
i
= α + β*ERM
i
+ X’δ + λ
m
+ ε
i
(5)
where Volatitity
i
is the stock return volatility of the
publicly traded firm i.
The independent variable ERM
i
in the regressions
(3), (4) and (5) is the adoption of ERM by the publicly
traded firm i. The adoption of ERM by a publicly
traded firm in the US can be found in one of corporate
annual financial disclosures such as the 10-K, DEF-
14A and PRE-14A filings. Because there are a large
number of publicly traded firms in the US in our
dataset, each with multiple financial disclosure filings
every year, it is impossible to manually identify the
adoption of ERM in the corporate annual financial
disclosures. We propose a topic modelling method
for automatically identifying the adoption of ERM by
a publicly traded firm.
3 AUTOMATED TEXT
ANALYSIS OF THE ADOPTION
OF ERM
3.1 The Proposed Topic Modelling
Method
In machine learning, topic modelling refers to a
variety of algorithms for discovering the abstract
“topics” in a collection of text documents. The Latent
Dirichlet Allocation (LDA) algorithm is the most
popular topic modelling algorithm that has been
extensively studied (Blei, Ng, & Jordan, 2003). It is
capable of generating a probabilistic model of a
mixture of hidden topics, each of which is defined as
a probability distribution over the vocabulary.
Recently, the LDA algorithms have been studied for
analyzing corporate annual financial disclosures of
publicly traded firms (Bao & Datta, 2014; Dyer et al.,
2017; Toubia et al., 2019).
The objective of using the LDA algorithm in our
study is to automatically identify the adoption of
ERM by publicly traded firms in their annual
financial disclosures, including the 10-K, DEF-14A
and PRE-14A filings.
Our method for automated text analysis of
corporate annual financial disclosures of publicly
traded firms is summarized in Figure 2. First, we
apply several data preprocessing steps to transform all
original corporate annual financial disclosures into
text documents that are suitable for the input of the
LDA algorithm. Second, we apply the LDA algorithm
to extract different topics of the text documents. If the
topics related to the adoption of ERM are among the
top topics identified by the LDA algorithm and more
important than other irrelevant topics, then we
conclude the corresponding corporate annual
financial disclosure contains the information of such
an ERM adoption by the firm. Third, we perform a
data-driven validation procedure to validate the
results of the LDA algorithm. Finally, we perform an
event analysis to identify the starting year of the
adoption of ERM.
ICSOFT 2023 - 18th International Conference on Software Technologies
458
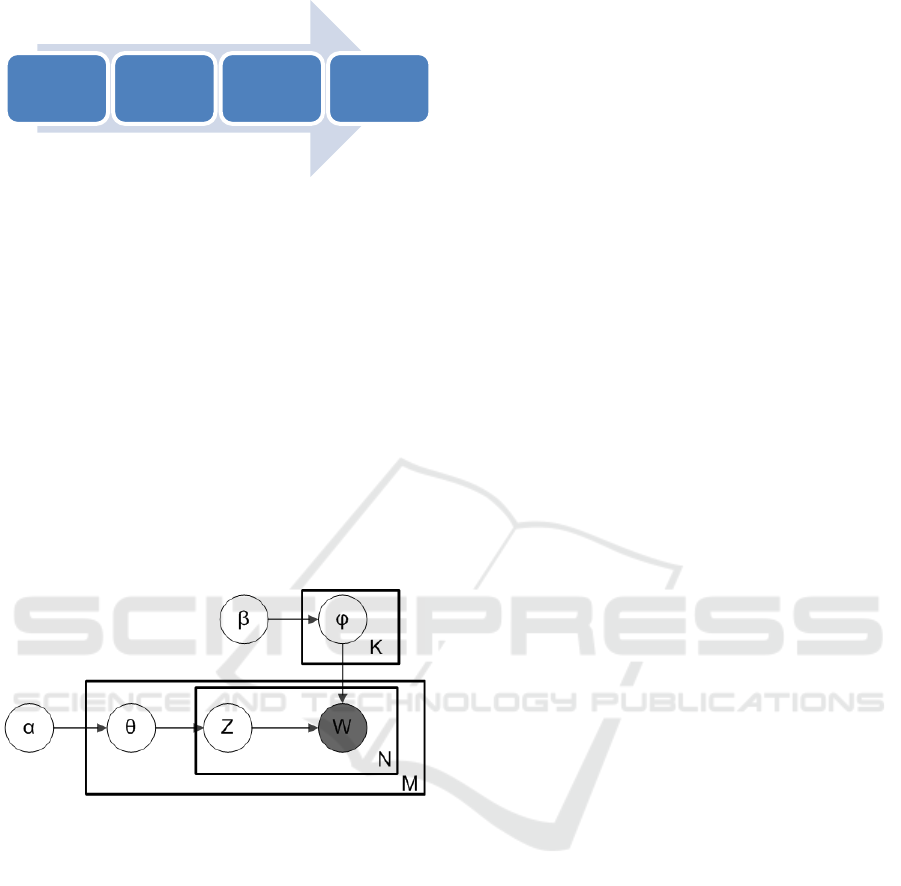
Figure 2: The method for automated text analysis of
corporate annual financial disclosures of publicly traded
firms.
3.2 The LDA Algorithm
The Latent Dirichlet Allocation (LDA) algorithm is
the most popular topic modelling algorithm that has
been extensively studied (Blei, Ng, & Jordan, 2003).
It is a generative machine learning model that
explains a set of observed words through unobserved
topic groups. A text document is associated with a
small number of topics, and each word’s presence in
the document is attributable to one of the document’s
topics. Figure 3 illustrates the probabilistic graphical
representation of the LDA model (Blei, Ng, & Jordan,
2003).
Figure 3: The LDA model.
The notations in Figure 2 are as follows.
M: the number documents
N: the number of words in a document m
K: the number of possible topics
α: the parameter of the Dirichlet prior on the per-
document topic distribution
β: the parameter of the Dirichlet prior on the per-
topic word distribution
θ: the topic distribution for a document m
ϕ: the word distribution for a topic k
Z: the topic for a word n in a document m
W: the specific word
The only observable variable of the LDA model is W,
and the other variables are latent variables. The input
variable of the LDA algorithm is a set of M text
documents, and the desired output of the LDA
algorithm is θ, the topic distribution of every
document. If the topics related to the adoption of
ERM are among the top topics identified by the LDA
algorithm and more important than other irrelevant
topics, then we conclude the corresponding corporate
annual financial disclosure indicates an ERM
adoption by the firm.
Using the LDA algorithm to identify the adoption
of ERM has at least two major advantages compared
to the traditional manual identification process used
in research literature (Berry-Stölzle & Xu, 2018;
Hoyt & Liebenberg, 2011). First, the LDA algorithm
is consistent and free from human errors. This makes
data replicability relatively easy compared with the
human judgment process. The process is objective in
the sense that it does not have a preference over, or
against, any specific firm. Human judgment, in
contrast, is sometimes biased due to personal
preferences, physical and psychological conditions,
and personal errors. Second, the LDA algorithm can
process a huge number of documents while the
human manual process cannot.
Moreover, for automatic text analysis of
identifying the adoption of ERM in the corporate
annual financial disclosures, the LDA algorithm is
capable of yielding much more accurate results than
the exact keyword matching, another alternative
automated process. For example, the sentence “This
combination of legal and management experiences
enables Mr. Carter to provide guidance to the
Company in the areas of legal risk oversight and
enterprise risk management, corporate governance,
financial management and corporate strategic
planning” in a corporate annual financial disclosure
could yield a positive adoption of ERM by the exact
keyword matching of “enterprise risk management”,
but a negative adoption by the LDA algorithm as the
topic “enterprise risk management” is not more
important (i.e., has a higher probability) than the
irrelevant topics “corporate governance” and
“financial management”.
3.3 Data-Driven Validation
The use of the LDA algorithm for identifying the
adoption of ERM by a firm in a corporate annual
financial disclosure is rule-based. In the algorithm, a
corporate annual financial disclosure indicates an
ERM adoption by the firm when the topics of the
financial disclosure related to the adoption of ERM
are more important and thus have higher probabilities
than other irrelevant topics.
As the LDA algorithm is an unsupervised learning
algorithm, it is difficult to assess the quality of its
Data
preprocessing
Topic
modeling
Data‐driven
validation
Eventanalysis
A Topic Modelling Method for Automated Text Analysis of the Adoption of Enterprise Risk Management
459

results. We perform a data-driven validation
procedure to establish the robustness of the results of
the LDA algorithm. First, we manually label a small
set of corporate financial disclosures on the adoption
of ERM. Second, we use this training data set to train
a supervised classification model using the logistic
regression algorithm on all topics identified by the
LDA algorithm. Third, we use this trained
classification model to predict each financial
disclosure whether it is about the adoption of ERM.
Finally, the prediction results are then compared with
the rule-based results from the LDA algorithm in
order to establish the robustness of the results of the
LDA algorithm.
3.4 Event Analysis
We identify the starting year of the adoption of ERM
by the firms in their corporate annual financial
disclosures. This can be achieved by a simple event
analysis, where a firm’s corporate annual financial
disclosures had a change of topics regarding ERM.
4 RESULTS
4.1 Description of the Data
We used the data of the U.S. publicly traded firms for
our study by combining the Compustat Capital IQ
database and the Compustat Security Daily databases.
Since we are interested in how ERM influences
financial market risk and returns during the COVID-
19 financial market shock in 2020, we can only
include firms that still exist at the beginning of 2020.
To construct the dataset, we first obtain financial
information for all firms that still exist in Compustat
Capital IQ by 2019. The stock market information for
these firms was then collected from the Compustat
Security Daily database between January 1st, 2020
and September 30th, 2020. To show the preliminary
results, we randomly selected 1500 firms for our
study. After removing firms with missing values in
key variables, we were able to retain 1468 firms. This
gives us a total of 274,520 firm-day observations.
4.2 Robustness of the LDA Algorithm
Results
We randomly selected 50 corporate annual financial
disclosures from the1468 firms in our dataset, and
manually labelled them on the adoption of ERM. We
use this training data set to train a supervised
classification model using the logistic regression
algorithm on all topics identified by the LDA
algorithm. We use this trained classification model to
predict each financial disclosure whether it is about
the adoption of ERM. Finally, the prediction results
are then compared with the rule-based results from
the LDA algorithm.
For all 50 financial disclosures, we found that the
rule-based results from the LDA algorithm are all
identical to the classification results of the logistic
regression classifier. With 100% accuracy for the 50
randomly selected corporate annual financial
disclosures, the robustness of the LDA algorithm
results is established.
4.3 Impact of ERM on Abnormal
Returns
Table 1 shows the results for the AR regression for
the hypothesis H1. The coefficient for the diff-in-diff
estimator is positive and significant in all models.
Moreover, the significance level of the diff-in-diff
estimator increases as we include longer post-COVID
period (β1=0.150, p=0.043 for Quarter 1; β1=0.118,
p=0.003 for Quarter 1 & 2; β1=0.146, p=0.000 for
Quarters 1, 2 & 3, respectively), indicating that
ERM’s impact on the abnormal return during the
COVID-19 pandemic is long-term. The coefficients
of the diff-in-diff estimator are similar in the firm
fixed-effects models (Models 2, 4, & 6). Therefore,
the hypothesis H1 is supported.
4.4 Impact of ERM on Stock Return
Volatility
Table 2 shows the regression results for the
hypothesis H2. The results show that ERM does not
have a significant impact on the stock return volatility
during both the recession period and the recovery
period. The results are consistent when we use other
measurements of stock return volatility, such as the
standard deviation of daily abnormal returns and the
standard deviation of the daily price range. Therefore,
the hypothesis H2 is not supported.
5 CONCLUSIONS
The proposed topic modelling method for automated
text analysis of the adoption of ERM by publicly
traded firms is superior to the traditional manual
process and alternative automated process. We have
demonstrated the effectiveness and robustness of the
ICSOFT 2023 - 18th International Conference on Software Technologies
460
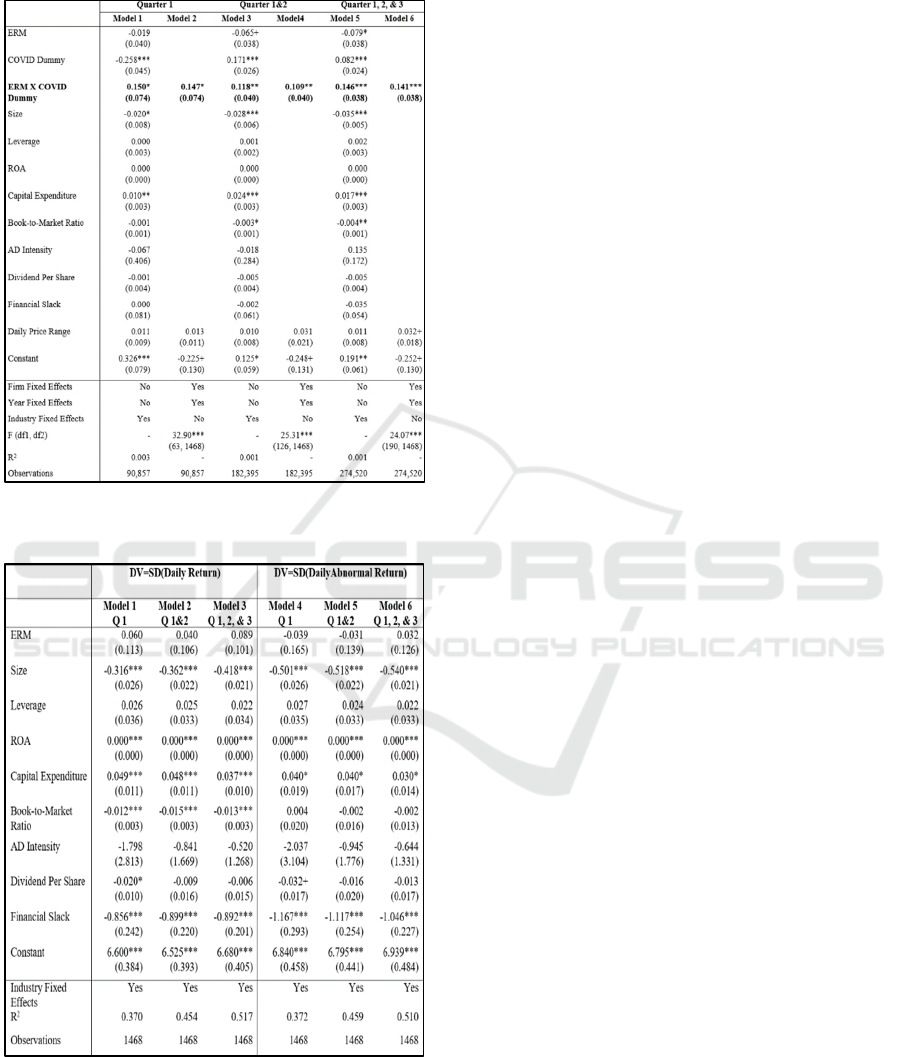
Table 1: Difference in Difference Regression of Abnormal
Return on ERM.
Table 2: Cross-sectional Regression of Stock Market
Volatility on ERM.
results of the proposed method. Using the output of
the proposed method, we have validated the
hypothesis on the relationship between ERM and
abnormal returns of the firms. In particular, the firms
that have adopted ERM have a smaller reduction in
abnormal returns during the recession period of the
COVID-19 pandemic (the first quarter of 2020 when
the stock market crashed) and a larger increase in
abnormal returns during the recovery period (the
second and third quarters of 2020 when the stock
market recovered). Moreover, we have found no
evidence that ERM reduces the volatility of stock
returns of publicly traded firms. Based on these
findings, we would suggest that investors are more
confident about the financial outcome of the firms
with an ERM adoption during the COVID-19
pandemic.
REFERENCES
Ai, J., Bajtelsmit, V., & Wang, T. 2018. The Combined
Effect of Enterprise Risk Management and
Diversification on Property and Casualty Insurer
Performance. Journal of Risk and Insurance, 85(2):
513-543.
Arena, M., Arnaboldi, M., & Azzone, G. 2011. Is enterprise
risk management real? Journal of Risk Research, 14(7):
779-797.
Azar, S. A. 2014. The determinants of US stock market
returns. Open Economics and Management Journal,
1(1).
Bao, Y. & Datta, A. 2014. Simultaneously discovering and
quantifying risk types from textual risk disclosures.
Management Science, 60(6): 1371-1391.
Baxter, R., Bedard, J. C., Hoitash, R., & Yezegel, A. 2013.
Enterprise risk management program quality:
Determinants, value relevance, and the financial crisis.
Contemporary Accounting Research, 30(4): 1264-
1295.
Beasley, M., Pagach, D., & Warr, R. 2008. Information
conveyed in hiring announcements of senior executives
overseeing enterprise-wide risk management processes.
Journal of Accounting, Auditing & Finance, 23(3): 311-
332.
Beasley, M. S., Clune, R., & Hermanson, D. R. 2005.
Enterprise risk management: An empirical analysis of
factors associated with the extent of implementation.
Journal of accounting and public policy, 24(6): 521-
531.
Berry-Stölzle, T. R. & Xu, J. 2018. Enterprise risk
management and the cost of capital. Journal of Risk and
Insurance, 85(1): 159-201.
Blei, D. M., Ng, A. Y., & Jordan, M. I. 2003. Latent
dirichlet allocation. Journal of Machine Learning
Research, 3: 993-1022.
Bromiley, P., Miller, K. D., & Rau, D. 2001. Risk in
strategic management research. The Blackwell
handbook of strategic management: 259-288.
Bromiley, P., McShane, M., Nair, A., & Rustambekov, E.
2015. Enterprise risk management: Review, critique,
and research directions. Long Range Planning, 48(4):
265-276.
A Topic Modelling Method for Automated Text Analysis of the Adoption of Enterprise Risk Management
461

Carpenter, R. E. & Guariglia, A. 2008. Cash flow,
investment, and investment opportunities: New tests
using UK panel data. Journal of Banking & Finance,
32(9): 1894-1906.
Clarke, C. J. & Varma, S. 1999. Strategic risk management:
the new competitive edge. Long Range Planning, 32(4):
414-424.
Doherty, N. 2000. Integrated risk management: Techniques
and strategies for managing corporate risk. New York,
NY: McGraw Hill Companies.
Dyer, T., Lang, M., & Stice-Lawrence, L. 2017. The
evolution of 10-K textual disclosure: Evidence from
Latent Dirichlet Allocation. Journal of Accounting and
Economics, 64(2-3): 221-245.
Eckles, D. L., Hoyt, R. E., & Miller, S. M. 2014. The impact
of enterprise risk management on the marginal cost of
reducing risk: Evidence from the insurance industry.
Journal of Banking & Finance, 43: 247.
Farrell, M. & Gallagher, R. 2015. The valuation
implications of enterprise risk management maturity.
Journal of Risk and Insurance, 82(3): 625-657.
Gatzert, N. & Martin, M. 2015. Determinants and value of
enterprise risk management: Empirical evidence from
the literature. Risk Management and Insurance Review,
18(1): 29-53.
Gatzert, N., Schmit, J. T., & Kolb, A. 2016. Assessing the
risks of insuring reputation risk. Journal of Risk and
Insurance, 83(3): 641-679.
Gordon, L. A., Loeb, M. P., & Tseng, C.-Y. 2009.
Enterprise risk management and firm performance: A
contingency perspective. Journal of Accounting and
Public Policy, 28(4): 301-327.
Grace, M. F., Leverty, J. T., Phillips, R. D., & Shimpi, P.
2015. The Value of Investing in Enterprise Risk
Management. Journal of Risk and Insurance, 82(2):
289-316.
He, P., Sun, Y., Zhang, Y., & Li, T. 2020. COVID–19’s
impact on stock prices across different sectors—An
event study based on the Chinese stock market.
Emerging Markets Finance and Trade, 56(10): 2198-
2212.
Hoyt, R. E. & Liebenberg, A. P. 2011. The value of
enterprise risk management. Journal of Risk and
Insurance, 78(4): 795-822.
Iyke, B. N. 2020. COVID-19: The reaction of US oil and
gas producers to the pandemic. Energy Research
Letters, 1(2): 13912.
Liebenberg, A. P. & Hoyt, R. E. 2003. The determinants of
enterprise risk management: Evidence from the
appointment of chief risk officers. Risk Management
and Insurance Review, 6(1): 37-52.
Mazur, M., Dang, M., & Vega, M. 2020. COVID-19 and
the march 2020 stock market crash. Evidence from
S&P1500. Finance Research Letters: 101690.
Nair, A., Rustambekov, E., McShane, M., & Fainshmidt, S.
2014. Enterprise risk management as a dynamic
capability: A test of its effectiveness during a crisis.
Managerial and Decision Economics, 35(8): 555-566.
Nocco, B. W. & Stulz, R. M. 2006. Enterprise risk
management: Theory and practice. Journal of Applied
Corporate Finance, 18(4): 8-20.
Olowe, R. A. 2009. Stock return, volatility and the global
financial crisis in an emerging market: The Nigerian
case. International Review of Business Research
Papers, 5(4): 426-447.
Pagach, D. & Wieczorek-Kosmala, M. 2020. The
Challenges and Opportunities for ERM Post-COVID-
19: Agendas for Future Research. Journal of Risk and
Financial Management, 13(12): 323.
Pagach, D. P. & Warr, R. S. 2010. The effects of enterprise
risk management on firm performance. Available at
SSRN 1155218.
Stulz, R. M. 1996. Rethinking risk management. Journal of
Applied Corporate Finance, 9(3): 8-25.
Toubia, O., Iyengar, G., Bunnell, R., & Lemaire, A. 2019.
Extracting features of entertainment products: A guided
latent dirichlet allocation approach informed by the
psychology of media consumption. Journal of
Marketing Research, 56(1): 18-36.
Wang, J., Meric, G., Liu, Z., & Meric, I. 2009. Stock market
crashes, firm characteristics, and stock returns. Journal
of Banking & Finance, 33(9): 1563-1574.
ICSOFT 2023 - 18th International Conference on Software Technologies
462
