
Attentional Sentiment and Confidence Aware Neural Recommender
Model
Lamia Berkani
1
, Lina Ighilaza
2
and Fella Dib
2
1
Department of Artificial Intelligence & Data Sciences, Faculty of Informatics, USTHB University, Algiers, Algeria
2
Department of Computer Science, Faculty of Informatics, USTHB University, Algiers, Algeria
Keywords: Recommender System, Deep Learning, Hybrid Sentiment Analysis, Word Embedding, Confidence Matrix.
Abstract: One of the major problems of recommendation systems is the rating data sparseness and information
overload. To address these issues, some studies are leveraging review information to construct an accurate
user/item latent factor. We propose in this article a neural hybrid recommender model based on attentional
hybrid sentiment analysis, using BERT word embedding and deep learning models. An attention mechanism
is used to capture the most relevant information. As reviews may contain misleading information (" fake
good reviews / fake bad reviews "), a confidence matrix has been used to measure the relationship between
rating outliers and misleading reviews. Then, the sentiment analysis module with fake reviews detection is
used to update the user-item rating matrix. Finally, a hybrid recommendation is processed by combining the
generalized matrix factorization (GMF) and the multilayer perceptron (MLP). The results of experiments on
two datasets from the Amazon database show that our approach significantly outperforms state-of-the-art
baselines and related work.
1 INTRODUCTION
Over the past two decades, recommendation systems
have been widely employed in many domains. With
the information overload problem, finding suitable
products on online platforms is increasingly
becoming difficult for users. Recommender systems
(RSs) are used, for instance, by Amazon to suggest
preferred products for customers, by Facebook and
LinkedIn to recommend people and webpages to
connect and follow, by YouTube to suggest related
videos. RSs learn the interests of users through their
historical behavior data and predict user preference.
Recently, deep learning (DL) techniques have been
applied in RSs to solve the cold start and data
sparsity problems. To further improve the
recommendation effectiveness of traditional
algorithms, He et al. (2017) proposed the neural
collaborative filtering (NCF) model, which is the
widely used model in RSs. They modelled the user-
item assessment matrix using a multilayer feedback
neural network (MLP) to learn the nonlinear
relationship between users and items.
On the other hand, with the considerable
development of social media, users often post
reviews to express their preferences and feelings
about items. These comments are considered reliable
indicators that can reflect the overall satisfaction of
users, expressing their preferable, non-preferable or
neutral opinions. These opinions are very useful for
understanding people’s references on items (Osman
et al., 2021). Several research works are applying
sentiment analysis (SA) in RSs (Wankhade et al.,
2022; Dang et al., 2021; Berkani and Boudjenah,
2023). However, many malicious users often share
misleading information about items in order to
manipulate or trap recommendation systems. As
reviews often contain fake good or fake bad reviews,
Li et al. (2021) leveraged the latent interaction factor
between users and items by exploiting the
interactivity of review information. To reduce the
impact of misleading comments on the model, they
used the confidence matrix to measure the
relationship between rating outliers and misleading
reviews. Birim et al. (2022) explored the most
effective feature combination in fake review
detection including the features of sentiment scores,
topic distributions, cluster distributions and bag of
words.
We focus in this article on these same issues and
we propose a novel recommender model using a
hybrid sentiment-based model and detecting
Berkani, L., Ighilaza, L. and Dib, F.
Attentional Sentiment and Confidence Aware Neural Recommender Model.
DOI: 10.5220/0012193000003598
In Proceedings of the 15th Inter national Joint Conference on Knowledge Discovery, Knowledge Engineering and Knowledge Management (IC3K 2023) - Volume 1: KDIR, pages 323-330
ISBN: 978-989-758-671-2; ISSN: 2184-3228
Copyright © 2023 by SCITEPRESS – Science and Technology Publications, Lda. Under CC license (CC BY-NC-ND 4.0)
323

fakereviews. We aim to enhance the user-item rating
matrix by predicting missing ratings and correcting
inconsistent values by matching the users’ ratings
and their associated comments on the items. Our
sentiment model is based on BERT word embedding
and several combinations of deep learning models
are considered: RNN-LSTM / BiLSTM and CNN-
LSTM / BiLSTM. For the detection of fake reviews,
we were inspired by the same approach of Li et al.
(2022) based on the confidence matrix. By
exploiting the enhanced user-item evaluation matrix,
our system generates predictions using a hybrid
recommendation algorithm using the generalized
matrix factorization (GMF) and the MLP models.
Extensive experiments conducted on two datasets
demonstrated the effectiveness of our model
compared to the state-of-the-art approaches and
baselines.
The rest of this article is organized as follows:
Section 2 provides a literature review about DL and
sentiment-based RSs. Section 3 presents our
sentiment-based approach for the recommendation
of items. The results of experiments are presented
and analysed in Section 4. Section 5 concludes this
work with some future perspectives.
2 LITERATURE REVIEW
With the latest successes in a variety of domains
including computer vision, machine translation,
speech recognition and natural language processing,
DL models have been exploited, in the last few
years, in RSs. Current models mainly use deep
neural networks to learn user preferences on items
for recommendations. Two categories of models can
be distinguished (Ni et al., 2021): (1)
recommendation models using a single neural
network structure (Zhang et al., 2017), such as
Multi-Layer Perceptron (MLP), Convolutional
Neural Network (CNN), Recurrent Neural Network
(RNN) and its variants Long Short Term Memory
(LSTM) and Gated Recurrent Unit (GRU); and (2)
recommendation models that combine the attention
mechanism and neural networks (Hu et al., 2018).
To overcome the rating data sparseness, users’
reviews are used for rating prediction. These reviews
or comments can express users’ overall satisfaction
on the items through their preferred, non-preferred
or neutral opinions. According to Osman et al.
(2021) these opinions will provide a better
understanding of user preferences on items.
Recently, the application of SA in RSs has been the
focus of extensive research. There are currently
three approaches to address the SA problem
(Bhavitha et al., 2017): (1) lexicon-based techniques,
including dictionary-based and corpus-based
methods (Salas-Zárate et al., 2017); (2) machine-
learning-based techniques (Zhang and Zheng, 2016),
including traditional techniques and DL techniques;
and (3) hybrid approaches, combining machine
learning and lexicon-based approaches (Pandey et
al., 2017). Bhattacharya et al. (2022) discussed and
analysed recent developments and related works
providing an overview of the different aspects of
SA. Among these works we reference the following
as examples: Diao et al. (2014) integrated two
parallel neural networks, and developed DeepCoNN
that jointly models users and items through reviews,
where the two CNNs are connected by a shared layer
facilitated by factorization machines. ConvMF
leverages the information in user-contributed
reviews and integrates CNN into the matrix
factorization (Kim et al., 2016). Chen et al. (2018)
developed a neural attentional regression model with
review-level explanations (NARRE) taking the
review usefulness into consideration.
Furthermore, some approaches combining two
models, such as SVM-enhanced CNN (Xue et al.,
2016), CNN with RNN (Rehman et al., 2019), have
yielded improved results. Dang et al. (2021) applied
a SA in RSs based on hybrid DL models and
collaborative filtering. According to the authors, the
system architecture can integrate a variety of
techniques including the pre-processing strategy,
hybrid DL models for SA and methods for RSs.
After studying the proposed approaches, we
noticed the lack of a neural recommendation model
based on hybrid sentiment analysis exploiting both
attention mechanisms and fake reviews. Therefore,
we are motivated to propose a novel approach that
brings these features together, demonstrating the
contribution of each component in improving the
performance and the quality of recommendation.
The following section presents the proposed model.
3 OUR ASCAD-Rec MODEL
The proposed ASCAD-Rec model is summarized as
two main modules, as shown in Figure 1: (1) The
rating matrix enhancement module, which adjusts
the original rating matrix by combining it with our
sentiment model, which is based on fake reviews
detection; and (2) the recommendation module,
which aims to predict the user's rating on a given
item using the neural hybrid filtering (NHF) model.
KDIR 2023 - 15th International Conference on Knowledge Discovery and Information Retrieval
324
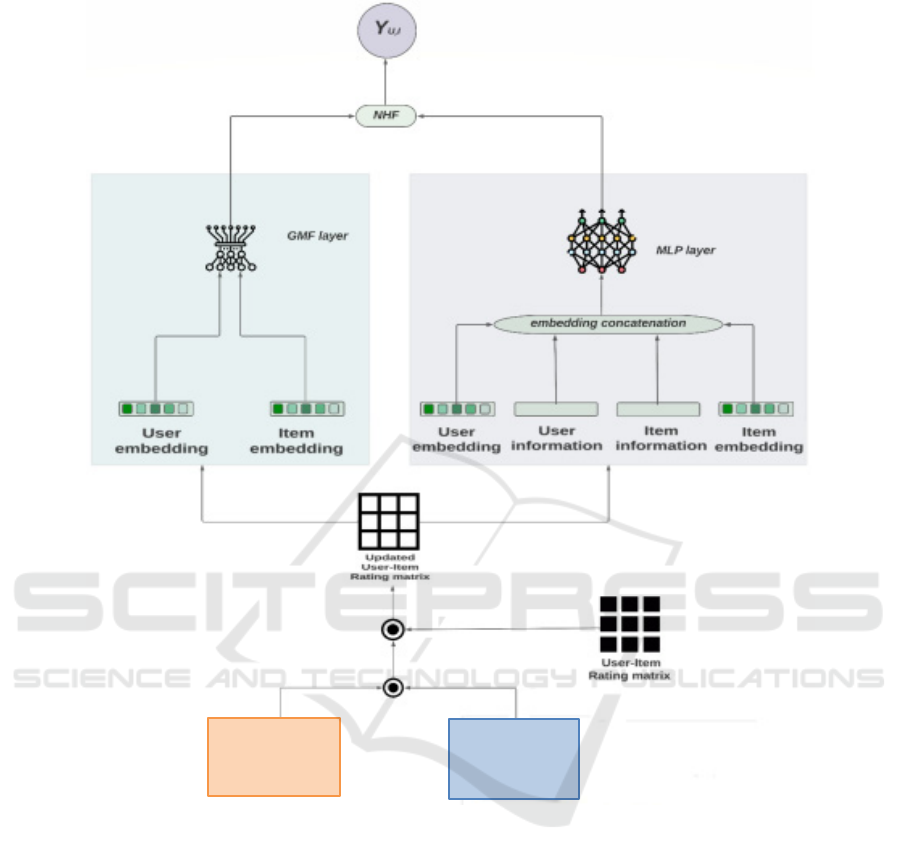
Figure 1: The proposed ASCAD-Rec model.
3.1 Rating Matrix Enhancement
3.1.1 Attentional Sentiment-Based Model
The sentiment module is based on users’ reviews on
items and ratings assigned on a 1-5 rating scale.
Figure 2 illustrates the different steps of this model.
First, we performed a set of pre-processing
operations on the data in order to convert it into an
interpretable and understandable form by our
system. We converted all words to lower case,
removed punctuation and stop words, and extracted
the stems of the words using the Snowball Stemmer
algorithm. Stemming is reducing a word to its base
word or stem where the words of similar kind lie
under a common stem.
Then, the second step is the embedding layer.
Processing textual data requires a conversion to
numbers before using any machine learning model.
Several methods allow this conversion, including the
traditional one-hot encoding on categorical data.
Currently, word embedding allows a better
representation of textual data. The embedding layer
allows converting each word into a fixed length
vector of defined size in order to better represent
words with reduced dimensions. I can understand
the context of a word and thus have similar
embeddings for similar words. The output vector
represents the input of the neural network’s hidden
layer. In this work, we used BERT, the Bidirectional
Encoder Representations from Transformers
proposed by (Devlin et al. 2018).
Sentiment-based
Hybrid DL
Fake reviews
detection
Attentional Sentiment and Confidence Aware Neural Recommender Model
325
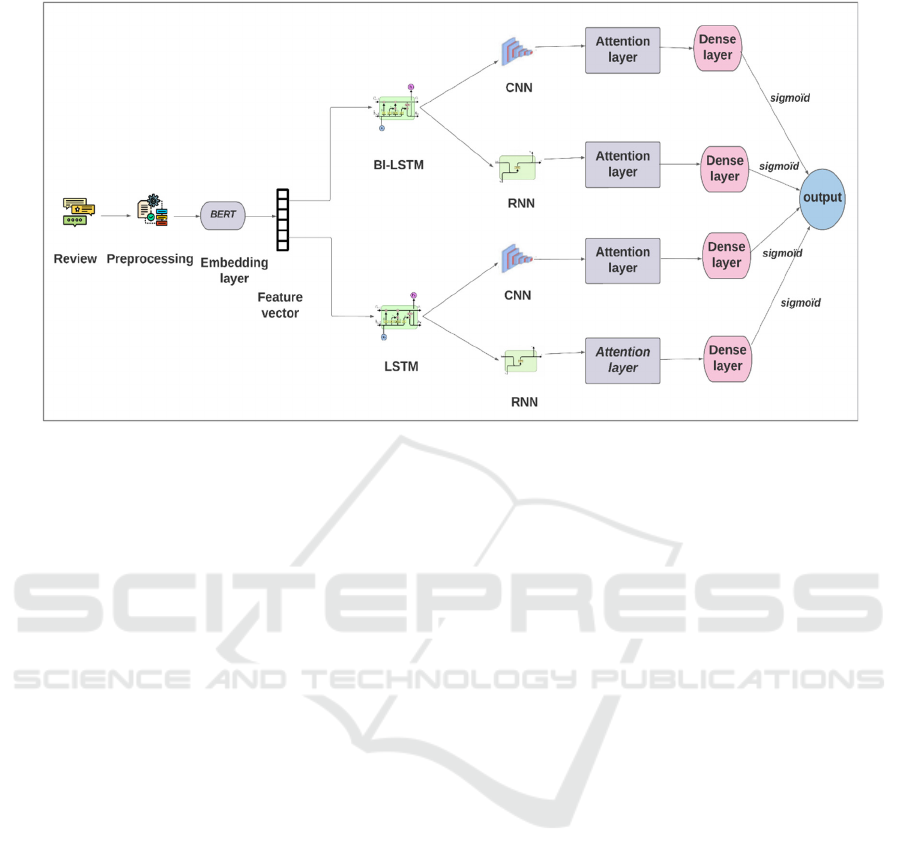
Figure 2: Hybrid sentiment analysis module based on attention mechanism.
BERT is used to transform text data to word
embedding. It was used to create the feature
vectors.Different combinations of DL models were
considered CNN → BiLSTM; and CNN → LSTM;
RNN → Bi-LSTM and RNN→ LSTM). These
models are followed by an attention layer to capture
only the most relevant information. The attention
mechanism is used to calculate the attention weight
for each component of the input sequence. The latter
are used to assign weights to the sequence so that the
most important components receive a higher weight
and therefore have a greater impact on the output.
The attention layer returns the context vector
representing the weighted sum of the sequence
elements, where the weights are the attention
weights. The attention mechanism takes as input the
output of the previous model. The result is used to
perform the final classification of the comments. It is
connected to a dense layer whose activation function
is "sigmoid". In order to train and validate the
sentiment analysis results, the reviews were labelled
with the sentiment score of the review, which can be
either positive or negative (value 1 or 0). Finally, the
output layer presents the result of the final rating of
an item i generated from the attentional sentiment
model.
3.1.2 Fake Reviews Detection
Misleading reviews are mainly caused by fake good
and fake bad reviews. When a user rates an item too
low (resp. too high) compared to his/her average low
ratings (resp. average high rating) compared to the
item's average rating, it will be considered as an
outlier value. Therefore, these ratings are given low
weights.
The confidence matrix is considered as a
regularization that aims to adjust the opinions,
taking into account the general opinion. It calculates
the difference between the score given by the user to
the item and the average of scores given by the user
to other items. Then it calculates the difference
between the score given by the user to the item and
the average of scores given to the item by other
users. If the difference is greater than a given
threshold (deviation rate), then it will be considered
as an outlier. The confidence level function used is
the same proposed in (Li et al., 2021).
3.1.3 Sentiment and Fake Reviews Detection
The sentiment score is combined with the fake
review detection module. The results obtained from
both the sentiment model and the fake reviews
detection model will be used to adjust the initial
rating matrix. Each initial rating will be combined
with the predicted rating using the following
weighted formula:
Score
α∗ Score
1α
∗Score
(1)
where:
Score
: is the final score; Score
: is the
predicted score using SA with fake reviews
detection;
KDIR 2023 - 15th International Conference on Knowledge Discovery and Information Retrieval
326
Score
: is the real score assigned by the
user on the item; and
α: is a parameter used to adjust the
importance of each term of the equation.
3.2 Neural Hybrid Recommendation
The NHF model proposed in a previous work
(Berkani et al., 2019) was exploited for the
recommendation. NHF is an extension of the very
popular NCF model (He et al., 2017), which
concatenates the results of the two models GMF and
MLP, then passes the result through a dense layer
with a "Sigmoid" activation function to obtain the
prediction result.
The GMF model considers the latent user and
item factors as input, representing the hidden
characteristics that determine user preferences and
item features. These vectors are given as input to a
neural layer which performs the product of the two
vectors. The result is then sent to the predictive layer
represented by a dense layer with a "sigmoid"
activation function. On the other hand, the vectors of
the user and item latent factors, concatenated with
their respective information, are passed through an
MLP network, providing as output the prediction of
the evaluation score.
3.3 Training
The data extracted from the datasets must be pre-
processed and transformed before passing through
the different models. Then, these data are divided
into two sets considering 80% of the data for
training and the rest for testing in order to evaluate
the performance of our models. To guarantee a good
performance of our models, we used the "Binary
Cross-Entropy" cost function. In order to improve
the performance of our models, we use the Adam
(Adaptive Moment estimate) algorithm, a stochastic
optimization method (Kingma and Ba, 2014). This
algorithm will minimize the cost function, as a lower
loss means a better performance of our models.
4 EXPERIMENTS
We present in this section the experiments carried
out to evaluate the hybrid SA including the
contribution of the attention and fake review model.
Then we evaluated the hybrid recommender model
by comparing its performance with some exiting
models. Finally, we compared our approach with the
state-of-the art recommender models.
4.1 Datasets and Evaluation Metrics
For the training and evaluation of our sentiment
analysis models, we used the IMDB database, which
includes 50,000 reviews classified into two
categories (positive and negative comments). For
our experiments, we used a dataset from the Yelp
database, considering the shopping category. This
dataset, with a density of 0.25%, comprises 2,472
users, who have carried out 55,738 reviews on 8,785
items.
For the experiments, we used the Mean Absolute
Error (MAE) and the Root Mean Square Error
(RMSE) evaluation metrics. MAE and RMSE have
been used as they are the most popular predictive
metrics to measure the closeness of predictions
relative to real scores.
4.2 Evaluation Results
4.2.1 Evaluation of Sentiment Models
To generate the embedding vectors for each
comment, we performed the pre-processing of the
texts using the Python libraries (tokenization,
removal of empty words and punctuation, encoding,
padding, etc.). Then we generated the embedding
vectors using the BERT model. Next, we varied the
hyper-parameter values.
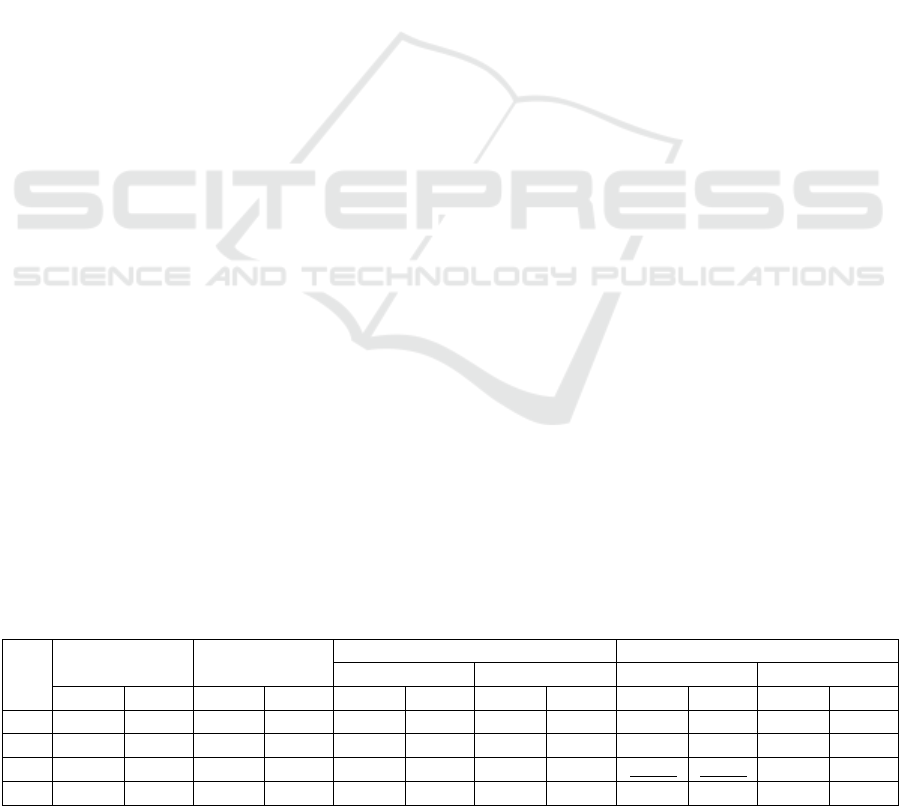
We varied the number of neurons in the last
dense layer of our models. We can notice from
Table 1 that 128 performed better than the other
models, with the exception of the hybrid LSTM-
RNN model, which requires 32 neurons.
Table 1: Evaluation of hybrid SA models varying the number of neurons.
NN
LSTM BiLSTM
LSTM BiLSTM
CNN RNN CNN RNN
RMSE MAE RMSE
MAE
RMSE MAE RMSE MAE RMSE MAE RMSE MAE
32
0.2755 0.1375 0.3230 0.1336 0.2640 0.1059 0.2679 0.1135 0.2659 0.1140 0.2777 0.1110
64
0.2811 0.1354 0.2824 0.1282 0.2777 0.1178 0.2897 0.1217 0.2740 0.1099 0.2707 0.1149
128
0.2770 0.1331 0.2746 0.1324 0.2653 0.1029 0.2708 0.1124 0.2607
0.1074 0.2710 0.1126
256
0.2855 0.1448 0.2797 0.1335 0.2649 0.1074 0.2724 0.1174 0.2651 0.1143 0.2835 0.1180
Attentional Sentiment and Confidence Aware Neural Recommender Model
327
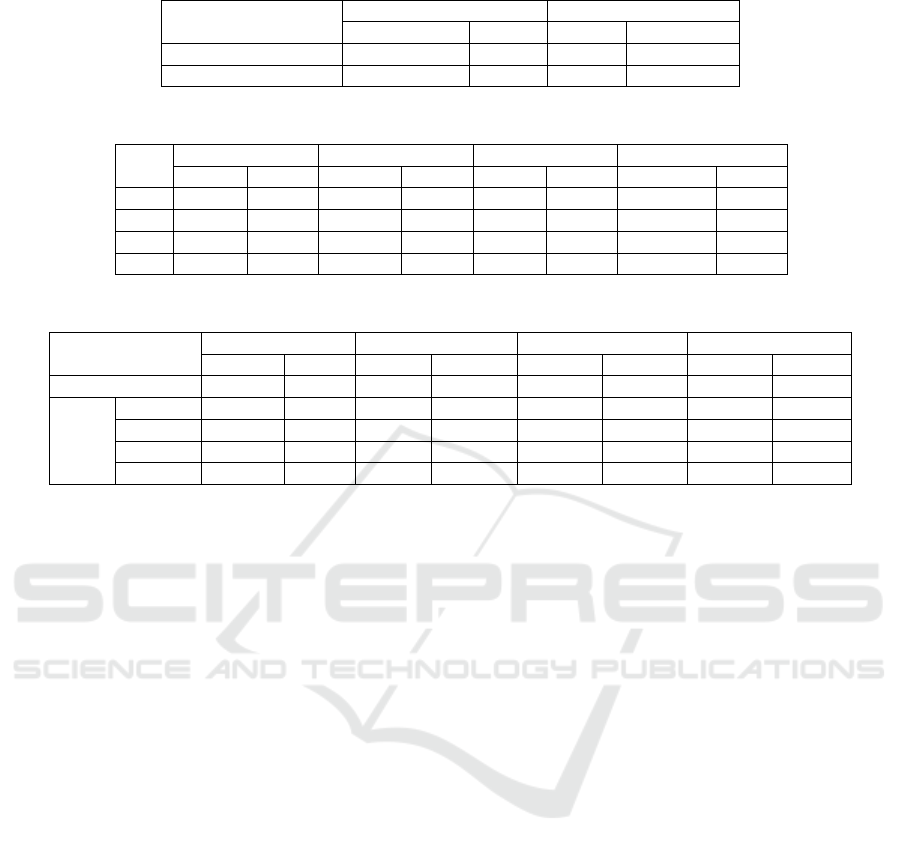
Table 2: Contribution of the attention mechanism on the performance of our models.
Models
Without attention With attention
MAE RMSE MAE RMSE
BiLSTM 0.1307 0.2817 0.1324 0.2746
BiLSTM-CNN 0.1202 0.2705 0.1074 0.2607
Table 3: Variations of PF and MLP Layers of the hybrid model.
PF
4 5 6 7
RMSE MAE RMSE MAE RMSE MAE RMSE MAE
8 0.2037 0.1540 0.2042 0.1533 0.2052 0.1523 0.2064 0.1521
12 0.2056 0.1537 0.2051 0.1530 0.2067 0.1538 0.2052 0.1506
16 0.2061 0.1535 0.2031 0.1510 0.2062 0.1516 0.2052 0.1513
18 0.2050 0.1532 0.2051 0.1522 0.2064 0.1522 0.2065 0.1509
Table 4: Variations of α.
Models
NHF GMF PMF SVD++
RMSE MAE RMSE MAE RMSE MAE RMSE MAE
Without SA 0.2031 0.1510 0.2318 0.1689 2.1399 1.7754 0.9997 0.7684
With
SA
α = 0.3 0.2012 0.1491 0.2280 0.1785 2.1136 1.7482 0.9818 0.7632
α = 0.4 0.2074 0.1547 0.2335 0.1848 2.0574 1.7207 1.0085 0.7916
α = 0.6 0.2327 0.1743 0.2537 0.2053 2.0982 1.7764 1.1116 0.8887
α = 0.7 0.2501 0.1879 0.2676 0.2182 2.1387 1.8052 1.1929 0.9580
We can observe that the BiLSTM-CNN model
performed better than the other models. The
BiLSTM network takes into account the context
before and after each word in the sequence,
providing a better understanding of the overall
context. Convolution layers are particularly useful
for capturing local features.
We have demonstrated the contribution of the
attention mechanism on the performance of the
BiLSTM and BiLSTM-CNN models. The results
presented in Table 2 show that the attention
mechanism considerably improves the predictions of
our models.
4.2.2 Recommendation Evaluation
We varied the vector size (T.E) of the hybrid model
(NHF), considering T.E equal to 8, 16, 32 and 64.
The best results were obtained with a T.E equal to 8
and a performance in terms of MAE equal to 0.1510
and RMSE equal to 0.2031.
Furthermore, as presented in Table 3, we varied the
number of MLP layers and the predictive factor (PF)
of the MLP network of the NHF model. Given that
the PF represents the number of neurons in the last
layer.
We can notice that the best results were obtained
with PF equal to 16 and a number of layers equal
to5. This configuration will be considered in the rest
of our experiments. Then, we varied the parameter
α, which adjusts the balance between the original
and the predicted ratings, of the NHF hybrid model.
We compared its performance with three simple
matrix factorization models GMF, PMF and SVD++
(see Table 4). We can see from the results that the
NHF, GMF and SVD++ models perform better with
α=0.3, while the PMF model performed better with
α = 0.4. Moreover, the results proved the
contribution of SA on NHF compared to the model
without SA.
To assess the contribution of fake reviews
detection on our model, we have shown in the table
a performance comparison between the model with
fake reviews (ASCAD-Rec) and the model without
fake reviews (ASAD-Rec). We obtained the
performance of MAE = 0.1438 and RMSE = 0.1964
with the ASCAD-Rec model, while with the ASAD-
Rec model, we obtained the performance of MAE =
0.1491 and RMSE = 0.2012. These results
demonstrate that the detection of fake reviews and
the regularization of the sentiment score improve the
performance of our model and enable more efficient
learning.
4.2.3 Comparison with Related Work
We present in this sub-section a comparison of our
approach with existing work (see Table 5):
• PMF: is a machine learning model based on
probabilistic principles for matrix factorization.
• SVD++: is a matrix factorization technique
based on singular value decomposition.
KDIR 2023 - 15th International Conference on Knowledge Discovery and Information Retrieval
328

• NCF: is a matrix factorization method based on
deep learning techniques for collaborative
filtering.
• DeepCoNN: is a deep learning-based approach
that exploits user comments to generate
recommendations.
• NARRE: exploits user comments by integrating
an attention mechanism to create vectors of
latent user and item factors.
Table 5: Performance comparison of different models.
Models MAE RMSE
PMF 1.7207 2.0574
SVD++ 0.7632 0.9818
NCF 0.1689 0.2318
NAREE 0.8767 1.1360
Dee
p
CoNN 0.6370 0.8192
NHF 0.1510 0.2031
ASAD-REC 0.1491 0.2012
ASCAD-Rec 0.1438 0.1964
The results obtained show the effectiveness of
our approach, compared with other state-of-the-art
models. Furthermore, the sentiment-based
recommender model with fake reviews detection
outperformed the model without fake reviews
detection.
4.3 Overall Discussion of Our Results
The experiments carried out on our approach using
the shopping yelp dataset demonstrated the impact
of sentiment analysis and fake review detection on
the effectiveness of the recommendation. We
obtained an MAE equal to 0.1438, compared with an
MAE equal to 0.1491 for the model without fake
reviews detection.
Experiments carried out on the sentiment
analysis model demonstrated the importance of
combining DL models with the significant
contribution of the attention mechanism in
improving the sentiment predictions. The model
with the attention mechanism yielded a MAE equal
to 0. 1074, compared with a MAE equal to 0.1202
obtained with the model without the attention
mechanism. Furthermore, it should be noted that the
hyper-parameter values considerably affect the
performance of the models.
5 CONCLUSION
In this article, we have presented a neural hybrid
recommendation model that combines the
Generalized Matrix Factorization (GMF) and the
Multilayer Perceptron (MLP) models to learn
respectively the linear and the nonlinear relationship
between users and items. This model leverages a
user-item rating matrix that has been adjusted by a
sentiment model to predict the sentiment scores
through users' textual comments on items. To further
improve our sentiment model, we used the attention
mechanism to capture the most important
information, and we identified fake reviews using a
confidence matrix. The results of our experiments
carried out on the Yelp shopping dataset
demonstrated the effectiveness of our model, which
outperformed the state-of-the-art models. Our
evaluations demonstrated the contribution of the
hybrid sentiment model compared to the simple
models, and the added value of the attention
mechanism and the detection of fake reviews. On the
other hand, our hybrid model performs better than
several factorization matrix-based models.
In our future work we plan to carry out further
experiments on larger datasets with higher density,
use multilingual comments and explore other deep
learning models such as the transformers.
REFERENCES
Al-Saqqa, S., Awajan, A. (2019). The use of word2vec
model in sentiment analysis: A survey. In Proceedings
of the 2019 International Conference on Artificial
Intelligence, Robotics and Control, pp. 39-43.
Berkani, L. Kerboua, I. Zeghoud, S. (2020).
Recommandation hybride basée sur l’apprentissage
profond. In Proceedings of EDA Conference, Revue
des Nouvelles Technologies de l’Information, RNTI
B.16, pp. 69–76. ISBN: 979-10-96289-13-4.
Berkani, L., Zeghoud, S., Kerboua. I. 2022. Chapter 19 -
Neural hybrid recommendation based on GMF and
hybrid MLP, Editor(s): Rajiv Pandey, Sunil Kumar
Khatri, Neeraj kumar Singh, Parul Verma, Artificial
Intelligence and Machine Learning for EDGE
Computing, Academic Press, 287-303,
https://doi.org/10.1016/B978-0-12-824054-0.00030-7.
Berkani, L., Boudjenah, L. (2023). S-SNHF: sentiment
based social neural hybrid filtering. Int. J. Gen.
Syst. 52(3), pp. 297-325
Bhattacharya, S., D., Sarkar, D-K., Kole, Jana, P. (2022).
Chapter 9 - Recent trends in recommendation systems
and sentiment analysis”, Editor(s): Sourav De, Sandip
Dey, Siddhartha Bhattacharyya, Surbhi Bhatia, In
Hybrid Computational Intelligence for Pattern
Analysis, Advanced Data Mining Tools and Methods
for Social Computing, Academic Press, pp. 163-175.
Bhavitha, B.; Rodrigues, A.P.; Chiplunkar, N.N. (2017).
Comparative Study of Machine Learning Techniques
in Sentimental Analysis. In Proceedings of the 2017
Attentional Sentiment and Confidence Aware Neural Recommender Model
329

International Conference on Inventive Communication
and Computational Technologies (ICICCT),
Coimbatore, India, 10–11 March 2017; IEEE: New
York, NY, USA, pp. 216–221.
Birim, S.O, Kazancoglu, I., Mangla, S. K., Kahraman, A.,
Kumar, S., Kazancoglu, Y. (2022). Detecting fake
reviews through topic modeling. Journal of Business
Research 149, 884–900
Chen, C., Zhang, M., Liu, Y., Ma, S. (2018). Neural
attentional rating regression with review-level
explanations. In Proceedings of the 2018 World Wide
Web Conference, pp. 1583-1592.
Dang, C.N., Moreno-García, M.N., De la Prieta, F. (2021).
An Approach to Integrating Sentiment Analysis into
Recommender Systems. Sensors 21, 5666,
https://doi.org/10.3390/s21165666.
Devlin, J., Chang, M-W., M-W., Lee, K., Toutanovan, K.
(2018). Bert: Pre-training of deep bidirectional
transformers for language understanding. ArXiv,
arXiv:preprint/04805.
Diao, Q., Qiu, M., Wu, C.Y., Smola, A.J., Jiang, J., Wang,
C. (2014). Jointly modeling aspects, ratings and
sentiments for movie recommendation. In Proceedings
of the 20th ACM SIGKDD International Conference
on Knowledge Discovery and Data Mining, pp. 193-
202.
Duantengchuan L., Liu, H., Zhang, Z., Lin, K., Fang, S.,
Li, Z., N-N. Xiong, N-N. (2021). CARM: Confidence-
aware recommender model via review representation
learning and historical rating behaviourin the online
platforms. Neurocomputing 455, pp. 283-296.
He, X., Liao, L., Zhang, H., Nie, L., Hu, X., Chua, T-S.
(2017). Neural collaborative filtering. In Proceedings
of the 26th Internet Conference on World Wide Web,
pp. 173–182.
Hu, B., Shi, C., Zhao, W.X., Yu, P.S. (2018). Leveraging
meta-path based context for top-n recommendation
with a neural co-attention model. In Proceedings of
the International Conference ACM SIGKDD, pp. 153-
1540.
Kim, D., Park, C., Oh, J., Lee, S., Yu, H. (2016).
Convolutional matrix factorization for document
context-aware recommendation. In Proceedings of the
10th ACM Conference on Recommender Systems
(RecSys), pp. 233-240.
Kingma DP, Ba J. (2014). Adam: A method for stochastic
optimization. In arXiv preprint arXiv: 1412.6980.
Li, D., Liu, H., Zhang, Z., Lin, K., Fang, S., Li, Z., Xiong,
N. (2021). CARM: Confidence-aware recommender
model via review representation learning and historical
rating behavior in the online platforms.
Neurocomputing 455, pp. 283–296
Mikolov, T., Chen, K., Corrado, G., Dean, J. (2013a)
Efficient Estimation of Word Representations in
Vector Space. ICLR - Workshop Poster,
Mikolov, T., Sutskever,I., Chen, K., Corrado, G.S., Dean,
J. (2013b). Distributed Representations of Words and
Phrases and their Compositionality. In Proceedings of
the 26th International Conference on Neural
Information Processing Systems NIPS'13, Volume 2,
Advances in Neural Info. Processing Systems 26.
Mnih, A., Salakhutdinov, R. (2007). Probabilistic matrix
factorization. In advances in neural information
processing systems.
Ni, J., Huang, Z., Cheng, J., Gao, S. (2021). An effective
recommendation model based on deep representation
learning. Information Sciences, Vol. 542, N °1, pp.
324-342.
Osman, N.A., Mohd Noah, S.A. Darwich, M., Mohd, M.
(2021). Integrating contextual sentiment analysis in
collaborative recommender systems. PLoS ONE Vol.
16, N° 3: e0248695,.
Pandey, A.C.; Rajpoot, D.S.; Saraswat, M. (2017). Twitter
sentiment analysis using hybrid cuckoo search
method. Info. Process. and Manag., 53, pp. 764–779.
Pennington, J., Socher, R., Manning, C-D. (2014). GloVe:
Global Vectors for Word Representation. Empirical
Methods. In Natural Language Processing (EMNLP),
https://nlp.stanford.edu/pubs/glove.pdf.
Rehman, A.U., Malik, A.K., Raza, B., Ali, W. (2019). A
hybrid CNN-LSTM model for improving accuracy of
movie reviews sentiment analysis. Multimedia Tools
and Applications 78, pp. 26597–26613.
Salas-Zárate, M.D.P., Medina-Moreira, J., Lagos-Ortiz,
K., Luna-Aveiga, H., Rodriguez-Garcia, M.A.,
Valencia-García, R. (2017). Sentiment analysis on
tweets about diabetes: An aspect-level approach.
Computational and Mathematical methods. pp. 1–9.
Wankhade, M., Sekhara Rao, A-C., Kulkarni, C. (2022). A
survey on sentiment analysis methods, applications,
and challenges. Artificial Intelligence Review.
Xue, D-X., Zhang, R., Feng, H., Wang, Y.-L. (2016).
CNN-SVM for microvascular morphological type
recognition with data augmentation. Journal of
Medical and Biological Engineering. 36, pp. 755–764.
Zhang, S., Yao, L., Sun, A. (2017). Deep learning based
recommender system: A survey and new perspectives.
In arXiv preprint arXiv: 1707.07435.
Zhang, X., Zheng, X. (2016). Comparison of Text
Sentiment Analysis Based on Machine Learning. In
Proceedings of the 2016 15th International
Symposium on Parallel and Distributed Computing
(ISPDC), Fuzhou, China, 8–10 July 2016; IEEE: New
York, NY, USA, pp. 230–233.
Zheng, L., Noroozi, V., Yu, P-S. (2017). Joint deep
modeling of users and items using reviews for
recommendation. In Proceedings of the tenth ACM
international conference on websearch and data
mining, pp. 425-434.
KDIR 2023 - 15th International Conference on Knowledge Discovery and Information Retrieval
330
