
Detecting Postpartum Depression Stages in New Mothers: A
Comparative Study of Novel LSTM-CNN vs. Random Forest
P. Srivatsav
*
and S. Nanthini
*
Department of Computer Science and Engineering, Saveetha School of Engineering,
Saveetha Institute of Medical and Technical Sciences, Saveetha University, Chennai, Tamil Nadu, 602105, India
Keywords: Women, Neural Networks, Depression, Prediction, Novel Long-Short Term Memory with Convolutional
Neural Networks, Random Forest Algorithm, Deep Learning, Machine Learning.
Abstract: A Novel long-short term memory with convolutional neural networks (LSTM-CNN) is used to predict
postpartum depression and compared it with Random Forest (RF) Algorithm. Materials and Methods: For this
research two groups were taken: The Novel Long-Short Term Memory with Convolutional Neural Networks
(LSTM-CNN) and for comparison the Random Forest (RF) Algorithm was considered. After careful
consideration each with a sample size of 20 to help in this research. Results: The outcomes of the study are
shown in the following table (LSTM-CNN). The mean accuracy of the LSTM -CNN is 77.75% and the
Random Forest (RF) Algorithm model is 72.12%, respectively. The significance of the Independent sample
t-test is evident with a p-value of 0.04 (p < 0.05), underscoring the statistical significance of the comparison
between the LSTM-CNN model and the Random Forest algorithm in the study. Conclusion: The LSTM-CNN
technique outperformed the Random Forest (RF) Algorithm and other machine learning algorithms in terms
of accuracy, and deep learning algorithms have generally showed promise in the prediction of Postpartum
depression.
1 INTRODUCTION
Artificial intelligence (AI) has the potential to help in
various ways when it comes to postpartum depression
(PPD). AI can help predict which women are most
likely to develop PPD and provide targeted
interventions to prevent or minimize the severity of
the condition. By analyzing data from various
sources, including demographics, medical history,
and social determinants of health, In order to give
women who are at high risk of PPD preventive
measures, healthcare professionals can identify them
using AI algorithms (Liu et al., 2023). There are
several apps available that can help new mothers
assess their risk of PPD and provide information on
symptoms to look out for. Some apps can even
provide a diagnosis based on self-reported symptoms,
although it's important to note that a professional
diagnosis is typically required for treatment (Wisner,
Parry, and Piontek 2002) Deep learning is extensively
used in computer vision applications such as object
recognition, image segmentation, face recognition,
and object detection and is used in NLP tasks such as
*
Research Scholar, Research Guide, Corresponding Author
language translation, sentiment analysis, speech
recognition, and chatbot development (Xu and
Sampson 2022)(Padma, S et al. 2022). Deep learning
is utilized in the healthcare industry for a variety of
activities including disease diagnosis, drug discovery,
and medical picture analysis and The recognition of
speech and images is made possible through machine
learning. Fraud detection systems can act fast to stop
fraud by using machine learning algorithms that can
be trained to recognize patterns of behavior that point
to fraud (G. Ramkumar et al 2022).
There are 447 publications on work done in
postpartum depression and machine learning and 11
IEEE Xplore publications that discuss postpartum
depression with the advancements of machine
learning. Research shows that the dataset validation
provides more accuracy for early detection than other
individual classifiers already in use. Nowadays data
mining and Machine learning plays a vital role in
detecting depression. From past research various
factors can impact the likelihood of developing PPD,
and analyzing tweets from diverse populations can
help to identify those who may be at higher risk. By
Srivatsav, P. and Nanthini, S.
Detecting Postpartum Depression Stages in New Mothers: A Comparative Study of Novel LSTM-CNN vs. Random Forest.
DOI: 10.5220/0012569700003739
Paper published under CC license (CC BY-NC-ND 4.0)
In Proceedings of the 1st International Conference on Artificial Intelligence for Internet of Things: Accelerating Innovation in Industry and Consumer Electronics (AI4IoT 2023), pages 109-115
ISBN: 978-989-758-661-3
Proceedings Copyright © 2024 by SCITEPRESS – Science and Technology Publications, Lda.
109

reaching the conclusion that machine learning
algorithms possess the capacity to analyze extensive
datasets, effortlessly carry out intricate computations
on these data, and deliver predictive or insightful
outcomes, previous studies (Saqib, Khan, and Butt
2021) have demonstrated the capability of machine
learning algorithms in handling substantial data
volumes and generating meaningful predictions or
informative results.
Research has shown that various factors can
impact the likelihood of developing PPD, and
analyzing tweets from diverse populations can help to
identify those who may be at higher risk (Zhong et al.
2022) Due to the broad purpose nature of most
sentiment analysis techniques and their potential
inefficiency when used in contexts like healthcare or
finance, this research gap was discovered in the
current system. There is a need for tools that can
integrate domain-specific knowledge and language to
provide more accurate sentiment analysis results
(Yonkers et al. 2001). The primary goal of the
research is to create a sentiment analysis model that
would combine and evaluate sentiments from all
domains. The research team focussed on building a
sentiment analysis tool for the society that will
improve the accuracy and effectiveness especially in
more complex contexts (Thurgood, Avery, and
Williamson 2009).
2 MATERIALS AND METHODS
The research took place in the Saveetha School of
Engineering's Data Science lab at the Saveetha
Institute of Medical and Technical Sciences in
Chennai. After the datasets were gathered,
preprocessing and data cleaning methods were
carried out to remove any irrelevant or extraneous
information. The hardware to build this model CPU
was: processor Intel Core i3, 4 GB of RAM, and a 500
GB hard drive. The Sentiment140 dataset is a
collection of tweets that allows you to discover the
sentiment of a brand, product, or topic on Twitter
(Dutta and Deshmukh 2022). Originally, tweets in
this dataset were classified according to their
emoticons; for example, tweets with joyful emoticons
were classified as positive, while tweets with sad
emoticons were classified as negative The research
work was conducted on 2 groups of samples size 20
each (Iqbal, Chowdhury, and Ahsan 2018). This
model was run on Windows 10 and Jupyter notebook.
Table 1. shows a snapshot of the benchmark
Sentiment140 dataset that was used to analyze the
early markers of Postpartum Depression and how
deep learning algorithms have improved the
accuracy.
Novel Long-Short Term Memory with
Convolutional Neural Network Algorithm
When combining LSTM with CNNs, the input data is
first processed by the CNN layers to extract relevant
features from the data. The output of the CNN layers
is then fed into the LSTM layers, which process the
sequence of features and capture temporal patterns in
the data. To grow the classifier precision and decrease
the presence of noise and carry out a characteristic
choice (Dadi et al. 2020). In place of using complex
semantic evaluation, a concept is uniquely identified
via hashtags contained in the emotion tweet,
particularly, the metadata tags that are used in Twitter
to suggest the context or the flow of a tweet (Anokye
et al. 2018). Table 6. shows the Novel Long-Short
Term Memory with Convolutional Neural Networks
(LSTM- CNN)
Random Forest Algorithm
The Random Forest algorithm is widely employed in
machine learning for classification tasks, Algorithm,
and other tasks. It uses an ensemble learning
technique to merge various Random Forests to build
a more reliable and accurate model. Here's how the
Random Forest algorithm works:Data preparation:
First, training and testing sets are created from the
data. The testing set is used to assess the model's
performance once it has been built using the training
set. These Random Forests are constructed using a
process called "recursive partitioning," which
involves repeatedly dividing the data into smaller and
smaller subsets depending on the most crucial
qualities. Selecting the best split: At each split, the
algorithm selects the best feature and threshold value
to split the data. This is done by calculating the
information gain or Gini impurity of each feature and
selecting the one that provides the most useful
information for separating the data into the target
classes. For classification problems, the most
common method is to use a majority vote, where the
class with the most votes across all the trees is
selected as the final prediction. The average of all the
individual tree forecasts is frequently used as the final
prediction in algorithm problems. Considering the
model: Finally, the model's performance in terms of
accuracy and generalization is assessed using the
testing set. In doing so, metrics like accuracy,
precision, recall, and F1-score are computed by
comparing the projected values to the actual values.
Statistical Analysis
Data analysis, data management, and data
visualization were all accomplished using IBM's
AI4IoT 2023 - First International Conference on Artificial Intelligence for Internet of things (AI4IOT): Accelerating Innovation in Industry
and Consumer Electronics
110

Statistical Package for the Social Sciences (SPSS).
Accuracy values for both the independent and
dependent variables are enhanced by the former's
unique characteristics, which aid in making accurate
predictions of the former's n values.The G-power of
80%, and a maximum allowable error of 0.05. SPSS
has a number of features, including data analysis,
assumptions, and predictive models.
3 RESULTS
The dataset is displayed in Table 1 for different
backgrounds and locations. The simulated accuracy
analysis of the Random Forest (RF) algorithm and
Novel Long-Short Term Memory with Convolutional
Neural Networks (LSTM-CNN) is shown in Table 2.
For the Novel Long-Short Term Memory with
Convolutional Neural Networks (LSTM-CNN) and
the Random Forest technique, respectively, the mean
values are 77.75% and 72.12%, and the standard
deviations are 4.9 and 5.1, respectively.The
comparison between the LSTM-CNN model and the
Random Forest algorithm is statistically significant,
as indicated in Table 4 by the independent t-test
significance value of p=0.04(p0.05). Figure 1 depicts
the analysis of a bar graph based on the effectiveness
of two algorithms. The mean efficacy of the Random
Forest technique is 72.12% and 77.75% for Novel
Long-Short Term Memory with Convolutional
Neural Networks (LSTM-CNN), respectively.
According to the results, the Novel Long-Short
Term Memory with Convolutional Neural Networks
(LSTM-CNN) is a more effective method than the
Random Forest one. The suggested algorithm's mean
accuracy for the graphed representation is 72.12%
and 77.75%, respectively.A comparison of the
Random Forest method and the Novel Long-Short
Term Memory with Convolutional Neural Networks
(LSTM-CNN) algorithm is shown in Figure 1. Table
5 displays the novel LSTM's convolutional neural
network pseudocode.
Table 1: Snapshot of the Sentiment140 Dataset.
ItemID Sentiment SentimentSource SentimentText
1 0 Sentiment140 is so sad for my APL friend.............
2 0 Sentiment140 I missed the New Moon trailer...
3 1 Sentiment140 omg its already 7:30 :O
4 0 Sentiment140
I was suposed 2 just get a crown put
on (30mins)...
Table 2: Accuracy(%) of Novel Long-Short Term memory with Convolutional Neural Networks is compared with
Accuracy(%) of Random Forest Classifier .
S.NO Accuracy(%)of Novel LSTM-CNN
Accuracy(%)of Random Forest
Classifier
1. 82.90 79.87
2. 76.79 76.00
3. 80.99 73.09
4. 79.09 71.09
5. 73.89 65.69
6. 81.00 72.08
7. 70.78 62.80
8. 68.00 69.09
9. 78.09 70.80
10. 81.09 77.09
Accuracy 77.75 72.12
Detecting Postpartum Depression Stages in New Mothers: A Comparative Study of Novel LSTM-CNN vs. Random Forest
111

Table 3: Mean, standard deviation and error mean of Random Forest and Novel LSTM- CNN algorithm.
groups N Mean Std.Deviation Std.Error mean
Accuracy LSTM-CNN 10 77.7500 4.91859 1.55539
RF 10 72.1200 5.16027 1.63182
Table 4: Independent t- test has a significance value p=0.04(p<0.05) indicating the study between the LSTM-CNN model and
the Random Forest algorithm is statistically significant.
Independent T- Test
Levene's test for equality of variances T-TEST for equality of means
F Sig. t df
Significance
(2-tailed)
Mean
Difference
Std.Error
Differences
95% confidence of the
difference
lower upper
Accura
cy
Equally
Variance
Assumed
.002 .969 2.441 18 .04 5.00200 2.25435 .76579 10.25821
Equal
Variance
not
Assume
d
2.441 17.959 .04 5.00200 2.25435 .76579 10.23899
Table 5: Pseudocode for Novel LSTM with Convolutional Neural Network (CNN).
a: Input data with shape (num_samples, max_seq_length)
b
: Target labels with shape (num_samples, num_classes)
1.Normalize and perform data augmentation on the input data
-Create two ImageDataGenerator objects to normalize the training and validation data
2. Define the convolutional neural layers:
-Define input shape for the model with shape (max_seq_length,)
-Define an input layer for the model with the defined input shape
3. Apply the embedding layer to the input layer
4. Define a convolutional layer with num_filters filters, kernel size of kernel_size, and ReLU activation
5.Apply the convolutional layer to the output of the embedding layer
6.Define a max pooling layer with pool_size pooling window
7.Apply the max pooling layer to the output of the convolutional layer
8.Define LSTM layer with lstm_units units and dropout rate (0.2)
9.Apply the LSTM layer (with 128 units) to the output of the max pooling layer
10. Define a fully connected output layer with num_classes units and softmax activation
11. Define the LSTM-CNN model with the input layer and output layer
12. Compile the model. Prediction measure is Accuracy.
13.Train the model for num_epochs epochs with batch size of batch_size:
-Randomly shuffle the data
-Split the data into batches of size batch_size
-For each batch, do the following:
-Compute the gradients of the loss with respect to the model parameters
-Update the model parameters using the optimizer
AI4IoT 2023 - First International Conference on Artificial Intelligence for Internet of things (AI4IOT): Accelerating Innovation in Industry
and Consumer Electronics
112
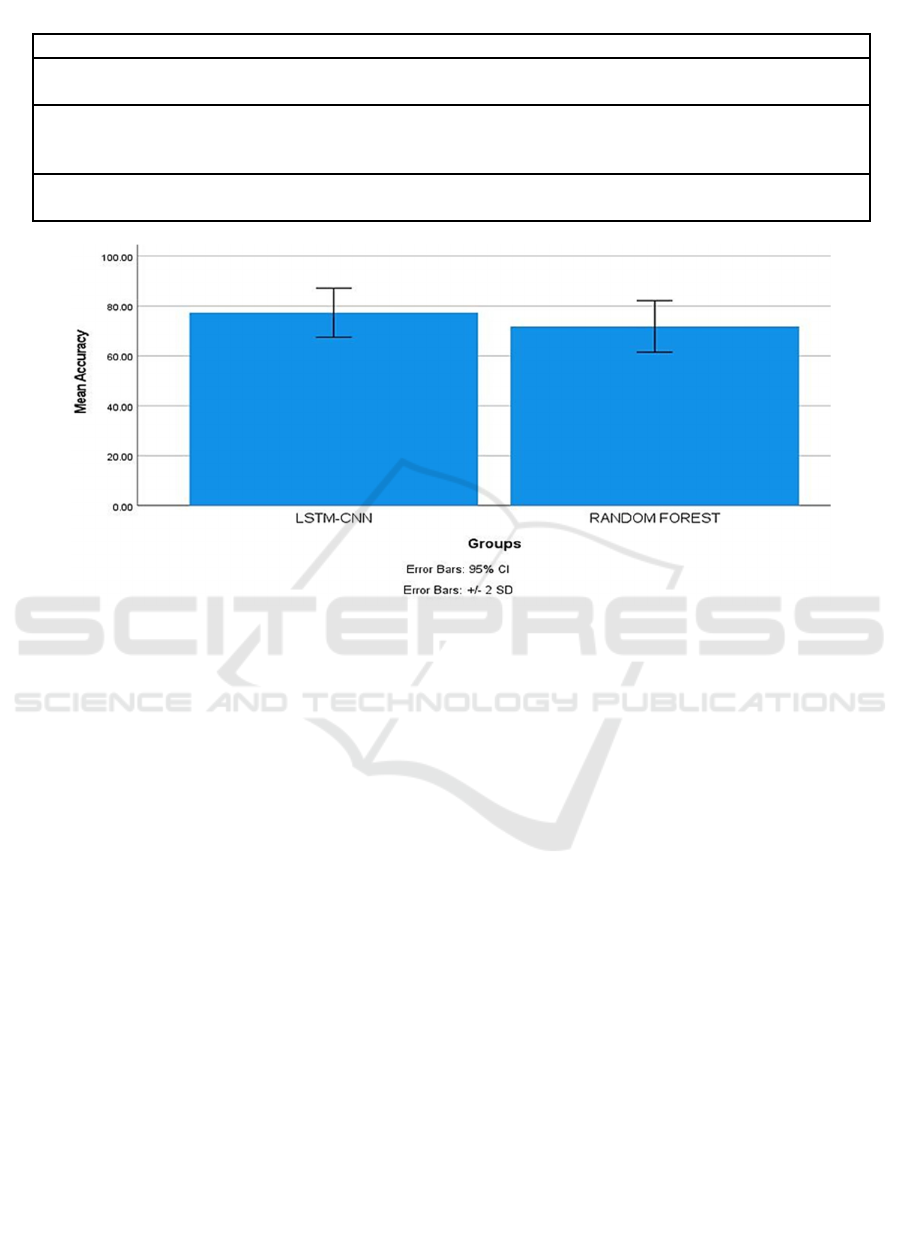
Table 6: Pseudocode for Random Forest.
Input: Sentiment140.csv
1.Start by selecting a random sample of the training data.
2. For each tree in the forest:
-Randomly select a subset of features to use as input for that tree.
- Using the selected features, build a Random Forest model on the subset of data.
3. Once all the trees have been built, predictions are made by taking the average prediction of all the trees in
the forest.
Figure 1: Bar graph analysis of the Random Forest algorithm and Long-Short Term Memory (LSTM-CNN) algorithm. A
graphical representation shows a mean accuracy of 77.75 % and 72.12% for the proposed algorithm, respectively. Random
forest vs. Long-Short Term Memory (LSTM), Y-axis: mean precision +/- 2 SD.
4 DISCUSSION
LSTM -CNN has helped achieve a better
accuracy(77.75%) when compared to Random forest
Algorithm which achieved a lower accuracy
(72.12%). The comparison of the Novel LSTM-CNN
with the Random forest Algorithm (Xin and Rashid
2021) shows that the Novel Long-Short Term
Memory with Convolutional Neural Networks
(LSTM-CNN) is better than the Random forest
Algorithm. The Novel Long-Short Term Memory
with Convolutional Neural Networks (LSTM-CNN)
has an accuracy of 77.75 % and Random forest
Algorithm is 72.12 % showing that the Novel Long-
Short Term Memory with Convolutional Neural
Networks (LSTM-CNN) is better than the Random
forest Algorithm. The two-tailed test has a
significance value p=0.04 (p<0.05) indicating the
study between the LSTM-CNN model and the
Random Forest algorithm is statistically significant.
As a result of the discusses and conclusions above, by
concluding that the Novel Long-Short Term Memory
with Convolutional Neural Networks (LSTM-CNN)
appears to perform and be more accurate than the
Random Forest Algorithm in all circumstances. The
Bar graph analysis seen in Fig. 1 shows the Novel
Long-Short Term Memory with Convolutional
Neural Networks (LSTM-CNN)
The positive effects of using a combination of
LSTM and CNN can make the model more robust to
noise in the input data. LSTM-CNN can be scaled up
to handle large amounts of data and complex tasks.
The negative effects of (LSTM-CNN) is a
computationally expensive model (Karmiani et al.
2019) due to the high number of parameters, which
can make it difficult to train and deploy on low-
resource devices. In order to prioritize input, the
LSTM-CNN employs a sigmoid neural net layer
(Ifriza and Sam'an, 2021). The gates safeguard and
regulate information flow, resolving the vanishing
gradient issue with typical RNNs (Tan and Lim
2019). The algorithm utilized, which is based on
stochastic gradient descent (Nikmah et al., 2022), aids
in enforcing consistent error propagation (neither
bursting nor disappearing) through its internal units.
Detecting Postpartum Depression Stages in New Mothers: A Comparative Study of Novel LSTM-CNN vs. Random Forest
113

When working with large datasets, the use of LSTM
models might be computationally expensive (Nikmah
et al. 2022).
The LSTM-CNN is a complex architecture that
requires a large amount of computational resources
and training data. This makes it difficult to implement
and train on smaller datasets or less powerful
hardware. LSTM-CNN is built to handle long
sequences, however because of the vanishing gradient
problem, it can still have trouble with extremely long
sequences. This happens when the weights' gradients
during backpropagation shrink too much, making it
challenging to update the weights and gain insight
from the data. LSTM-CNN requires large amounts of
labeled training data to achieve good performance.
This can be a limitation in applications where labeled
data is scarce or difficult/expensive to obtain. The
future scope of the Novel LSTM-CNN is vast and
varied, with potential applications in diverse fields
and can be used to analyze speech patterns and detect
changes in tone (Thurgood, Avery, and Williamson
2009; Stewart and Vigod 2016), pitch, and other
vocal characteristics that may indicate depression.
The Novel LSTM-CNN can also be used to analyze
facial expressions and detect changes in emotion that
may indicate depression. The Novel LSTM-CNN can
be used to analyze EEG signals and detect
abnormalities that may indicate depression. As a
future work other datasets like the Multimodal
Dataset for Mental Health Analysis
(MMDMA),(Thurgood, Avery, and Williamson
2009; Stewart and Vigod 2016) that incorporate a
wider range of modalities such as physiological
signals, audio, and video recordings in addition to text
can be used for depression prediction.
5 CONCLUSION
In this research work, it was possible to develop a
reliable and accurate ML model that can accurately
predict Postpartum depression. The Long Novel
Long-Short Term Memory with Convolutional
Neural Networks (77.75%) is more accurate when
compared with Random Forest Algorithm (72.12%)
for predicting depression of new mothers through
social media.
REFERENCES
Anokye, Reindolf, Enoch Acheampong, Amy Budu-
Ainooson, Edmund Isaac Obeng, and Adjei Gyimah
Akwasi. (2018). “Prevalence of Postpartum Depression
and Interventions Utilized for Its Management.” Annals
of General Psychiatry 17 (May): 18.
Byvatov, Evgeny, Uli Fechner, Jens Sadowski, and Gisbert
Schneider. (2003). “Comparison of Support Vector
Machine and Artificial Neural Network Systems for
Drug/nondrug Classification.” Journal of Chemical
Information and Computer Sciences 43 (6): 1882–89.
Cellini, Paolo, Alessandro Pigoni, Giuseppe Delvecchio,
Chiara Moltrasio, and Paolo Brambilla. (2022).
“Machine Learning in the Prediction of Postpartum
Depression: A Review.” Journal of Affective Disorders
309 (July): 350–57.
Chai, Junyi, Hao Zeng, Anming Li, and Eric W. T. Ngai.
(2021). “Deep Learning in Computer Vision: A Critical
Review of Emerging Techniques and Application
Scenarios.” Machine Learning with Applications 6
(December): 100134.
Dadi, Abel Fekadu, Temesgen Yihunie Akalu, Adhanom
Gebreegziabher Baraki, and Haileab Fekadu Wolde.
(2020). “Epidemiology of Postnatal Depression and Its
Associated Factors in Africa: A Systematic Review and
Meta-Analysis.” PloSOne 15 (4): e0231940.
Dutta, Sushmita, and Prasad Deshmukh. (2022).
“Association of Eating Disorders in Prenatal and
Perinatal Women and Its Complications in Their
Offspring.” Cureus 14 (11): e31429.
G. Ramkumar, G. Anitha, P. Nirmala, S. Ramesh and M.
Tamilselvi, "An Effective Copyright Management
Principle using Intelligent Wavelet Transformation
based Water marking Scheme," 2022 International
Conference on Advances in Computing,
Communication and Applied Informatics (ACCAI),
Chennai, India, 2022, pp. 1-7, doi:
10.1109/ACCAI53970.2022.9752516.
Ifriza, Yahya Nur, and Muhammad Sam’an. (2021).
“Performance Comparison of Support Vector Machine
and Gaussian Naive Bayes Classifier for Youtube Spam
Comment Detection.” Journal of Soft Computing
Exploration 2 (2): 93–98.
Iqbal, Nazma, Afifa Mim Chowdhury, and Tanveer Ahsan.
(2018). “Enhancing the Performance of Sentiment
Analysis by Using Different Feature Combinations.” In
2018 International Conference on Computer,
Communication, Chemical, Material and Electronic
Engineering (IC4ME2), 1–4.
Karmiani, Divit, Ruman Kazi, Ameya Nambisan, Aastha
Shah, and Vijaya Kamble. (2019). “Comparison of
Predictive Algorithms: Backpropagation, SVM, LSTM
and Kalman Filter for Stock Market.” In 2019 Amity
International Conference on Artificial Intelligence
(AICAI), 228–34.
Liu, Hao, Anran Dai, Zhou Zhou, Xiaowen Xu, Kai Gao,
Qiuwen Li, Shouyu Xu, et al. (2023). “An Optimization
for Postpartum Depression Risk Assessment and
Preventive Intervention Strategy Based Machine
Learning Approaches.” Journal of Affective Disorders
328 (February): 163–74.
Nikmah, Tiara Lailatul, Muhammad Zhafran Ammar,
Yusuf Ridwan Allatif, RizkiMahjatiPrie Husna, Putu
Ayu Kurniasari, and Andi Syamsul Bahri. 2022.
AI4IoT 2023 - First International Conference on Artificial Intelligence for Internet of things (AI4IOT): Accelerating Innovation in Industry
and Consumer Electronics
114

“Comparison of LSTM, SVM, and Naive Bayes for
Classifying Sexual Harassment Tweets.” Journal of
Soft Computing Exploration 3 (2): 131–37.
O’Hara, Michael W. (1997). “The Nature of Postpartum
Depressive Disorders.” In Postpartum Depression and
Child Development , (pp, edited by Lynne Murray,
322:3–31. New York, NY, US: Guilford Press, xiv.
Padma, S., Vidhya Lakshmi, S., Prakash, R., Srividhya, S.,
Sivakumar, A. A., Divyah, N., ... & Saavedra Flores, E.
I. (2022). Simulation of land use/land cover dynamics
using Google Earth data and QGIS: a case study on
outer ring road, Southern India. Sustainability, 14(24),
16373.
Saqib, Kiran, Amber Fozia Khan, and Zahid Ahmad Butt.
2021. “Machine Learning Methods for Predicting
Postpartum Depression: Scoping Review.” JMIR
Mental Health 8 (11): e29838.
Stewart, Donna E., and Simone Vigod. (2016). “Postpartum
Depression.” The New England Journal of Medicine
375 (22): 2177–86.
Tan, Hong Hui, and King Hann Lim. (2019). “Vanishing
Gradient Mitigation with Deep Learning Neural
Network Optimization.” In 2019 7th International
Conference on Smart Computing & Communications
(ICSCC), 1–4.
Thurgood, Sara, B. S. Daniel M. Avery, and M. D. Lloyda
Williamson. (2009.) “Postpartum Depression (PPD).”
aapsus.org. 2009.
http://www.aapsus.org/articles/11.pdf.
Wisner, Katherine L., Barbara L. Parry, and Catherine M.
Piontek. 2002. “Postpartum Depression.” The New
England Journal of Medicine 347 (3): 194–99.
Xin, Lee Ker, and Nuraini Binti Abdul Rashid. (2021).
“Prediction of Depression among Women Using
Random Oversampling and Random Forest.” In 2021
International Conference of Women in Data Science at
Taif University (WiDSTaif ), 1–5.
Xu, Wen, and Mcclain Sampson. (2022). “Prenatal and
Childbirth Risk Factors of Postpartum Pain and
Depression: A Machine Learning Approach.” Maternal
and Child Health Journal, December.
https://doi.org/10.1007/s10995-022-03532-0.
Yeboa, Naomi Kyeremaa, Patience Muwanguzi, Connie
Olwit, Charles Peter Osingada, and Tom Denis
Ngabirano. (2023). “Prevalence and Associated Factor
of Postpartum Depression among Mothers Living with
HIV at an Urban Postnatal Clinic in Uganda.” Women’s
Health 19: 17455057231158471.
Yonkers, K. A., S. M. Ramin, A. J. Rush, C. A. Navarrete,
T. Carmody, D. March, S. F. Heartwell, and K. J.
Leveno. (2001). “Onset and Persistence of Postpartum
Depression in an Inner-City Maternal Health Clinic
System.” The American Journal of Psychiatry 158 (11):
1856–63.
Zhong, Minhui, Han Zhang, Chan Yu, Jinxia Jiang, and Xia
Duan. 2022. “Application of Machine Learning in
Predicting the Risk of Postpartum Depression: A
Systematic Review.” Journal of Affective Disorders
318 (December): 364–79.
Detecting Postpartum Depression Stages in New Mothers: A Comparative Study of Novel LSTM-CNN vs. Random Forest
115
