
Car Parking Space Detection Using YOLOv8
Muhammad Sobirin
1a
, Tiorivaldi
2b
and Choirul Mufit
1c
1
Department of Electrical Engineering, Universitas 17 Agustus 1945 Jakarta, Jl. Sunter Permai Raya, Sunter Agung,
Tanjung Priok, Jakarta Utara, Indonesia
2
Department of Civil Engineering, Universitas 17 Agustus 1945 Jakarta, Jl. Sunter Permai Raya, Sunter Agung, Tanjung
Priok, Jakarta Utara, Indonesia
Keywords: Parking Lot Detection, YOLOv8, Car Detection, Available Space Detection.
Abstract: For many years, parking has been a major issue in many cities all around the world. Air pollution and traffic
congestion can be decreased by providing information about available parking spaces. Thus, the purpose of
this study is to use YOLOv8 algorithm to identify the quantity of cars and available spaces in parking lots.
Videos were captured with a camera in different scenarios at UTA'45 Jakarta, and the dataset was prepared
by extracting frames from these videos. There are no pre-labeled images in the dataset, so all of the images
have been manually annotated. Multiple object detection has been accomplished by implementing YOLOv8
algorithm to detect cars and available spaces. This paper discusses two architectures: YOLOv8 and YOLOv5.
The performance of various designs is assessed by comparing the precision, recall, and mAP values. YOLOv8
performs better than YOLOv5 when both performances are applied. In terms of mAP 0.5, mAP 0.5:0.95, and
recall, the YOLOv8 model performs better than the YOLOv5 model; the differences in the values of each
performance are 0.8%, 1.6%, and 1.2%. With a 0.5% difference in accuracy performance value, the YOLOv5
model outperforms the YOLOv8 model.
1
INTRODUCTION
Parking is a basic facility in every facility and
infrastructure service provider such as shopping
centers, ports, airports, etc. As time goes by the need
for parking space tends to increase with the increase
in visitors bringing private vehicles, especially cars.
Adequate parking facilities are needed for the
convenience of visitors, so parking managers provide
spacious parking spaces even with multi-level
parking patterns. This condition will become difficult
if there are only a few remaining parking slots. This
makes the driver have to search the parking lot to find
a parking lot that is still available. (Sani & Ayyasy,
2022)
Object detection or commonly called object
detection is a process used to determine the presence
of certain objects in a digital image. The detection
process can be carried out using various methods
which basically read the features of all objects in the
a
https://orcid.org/0009-0008-8872-0016
b
https://orcid.org/0000-0002-9816-573X
c
https://orcid.org/0000-0002-9275-1973
input image. The features of the object in the image
will be compared with the features of the reference
object or template and then compared and determining
whether the detected object is the object you want to
detect or not. (Rizkatama et al., 2021)
Artificial intelligence technology such as You
Only Look Once (YOLO) has been applied and used
in many different industries. This article presents a
smart parking system using artificial intelligence. In
complex urban environments where the number of
vehicles continues to increase, vehicle drivers have
time to find parking and traffic congestion increases
during rush hours (Acharya et al., 2018). After
entering the parking lot, it took time to find a parking
space. To alleviate these problems, a camera-based
Parking Guidance Information (PGI) system has been
investigated. (Chen & Chang, 2011).
394
Sobirin, M., Tiorivaldi, . and Mufit, C.
Car Parking Space Detection Using YOLOv8.
DOI: 10.5220/0012582600003821
Paper published under CC license (CC BY-NC-ND 4.0)
In Proceedings of the 4th International Seminar and Call for Paper (ISCP UTA ’45 JAKARTA 2023), pages 394-398
ISBN: 978-989-758-691-0; ISSN: 2828-853X
Proceedings Copyright © 2024 by SCITEPRESS – Science and Technology Publications, Lda.
2
METHODS
This research discusses about car parking detection
using YOLOv8. The research was carried out by
taking 5000 image of the parking space which were
checked manually one by one and classified from
morning to evening. This is because the parking space
is only busy at that time.
2.1 Original YOLO Algorithm
YOLO was introduced to the computer vision
community through a paper publication in 2016 with
titled “You Only Look Once: Unified, Real-Time
Object Detection.” (Redmon et al., 2016). The paper
reframed object detection, essentially presenting it as
a one-shot regression problem, starting with image
pixels and moving on to bounding boxes and class
probabilities. The proposed approach, based on the
concept of “unification”, allows the simultaneous
prediction of multiple bounding boxes and class
probabilities, improving both speed and accuracy.
Since its founding in 2015 until this year (2023),
the YOLO family has continued to grow at a rapid
pace. Although the original author (Joseph Redmon)
discontinued his research in the field of computer
vision with YOLO-v3 (Vidyavani et al., 2019) , the
effectiveness and potential of the main ‘unified’
concept has been expanded upon by several authors,
with the newest addition to the YOLO family coming
in the form of YOLO-v8. Figure 1 shows the
evolution timeline of YOLO.
Figure 1: Timeline of YOLO.
2.2 YOLO v8
The newest of the YOLO family was confirmed in
January 2023 with the release of YOLO-v8 (Jocher &
Tune, 2023) by Ultralytics (YOLO-v5 was also
released). Although the release of the paper is just
around the corner and many features have yet to be
added to the YOLO v8 repository, a first comparison
between the newcomer and its predecessor shows the
advantages of the new cutting-edge as his YOLO is
shown.
Figure 2 shows that when comparing YOLO-v8
with YOLO-v5 and YOLOv6 trained at image
resolution 640, all YOLO-v8 variants achieve better
throughput with a similar number of parameters,
demonstrating hardware-efficient architectural
innovations. YOLO-v8 and YOLO-v5 are introduced
by Ultralytics, YOLO-v5 offers superior real-time
performance, and based on initial benchmark results
published by Ultralytics, YOLO-v8 can focus on
Constrained Edge. There are high expectations.
Provides device provisioning with high inference
speeds.
Figure 2: YOLO-v8 comparison with predecessors (Jocher
& Tune, 2023).
The backbone part of YOLOv8 is fundamentally
the same as that of YOLOv5, and the C3 module is
supplanted by the C2f module based on the CSP
thought. The C2f module learned from the ELAN
thought in YOLOv7 and combined C3 and ELAN to
create the C2f module (Wang et al., 2022).
In the neck part, the feature fusion method used in
YOLOv8 is still PAN-FPN, which enhances the
fusion and utilization of feature layer information at
different scales. To assemble the neck module, the
creator of YOLOv8 used two up-sampling modules
and multiple her C2f modules, along with the final
separated head structure. The idea of cutting off
Car Parking Space Detection Using YOLOv8
395

YOLOx's head was used in her YOLOv8 for the last
part of the neck. We achieved a new level of accuracy
by combining confidence and regression boxes.
YOLOv8 supports all versions of YOLO and
allows you to switch between different versions at
will. It can also run on different hardware platforms
(CPU-GPU), giving you great flexibility. The
YOLOv8 network architecture diagram is shown in
Figure 3. The CBS in Figure 3 consists of a
convolution function, a batch normalization function,
and a SiLu activation function.
Figure 3: The network structure of YOLOv8.
Figure 4: SPFF and CBS structure.
Figure 5: C2f and Detect structure.
2.3 Parking Lots Detection
YOLOv8 is the latest version of YOLO by
Ultralytics. As a cutting-edge, state-of-the-art
(SOTA) model, YOLOv8 builds on the success of
previous versions, introducing new features and
improvements for enhanced performance, flexibility,
and efficiency. YOLOv8 supports a full range of
vision AI tasks, including detection, segmentation,
pose estimation, tracking, and classification as seen in
Figure 3. This versatility allows users to leverage
YOLOv8's capabilities across diverse applications
and domains.
Figure 6: YOLOv8 Ultralytics performs.
YOLOv8 Detect, Segment and Pose models pre-
trained on the COCO dataset are available, as well as
YOLOv8 Classify models pre-trained on the
ImageNet dataset. Track mode is available for all
Detect, Segment and Pose models. All models can be
seen in Table 1.
ISCP UTA ’45 JAKARTA 2023 - THE INTERNATIONAL SEMINAR AND CALL FOR PAPER (ISCP) UTA ’45 JAKARTA
396
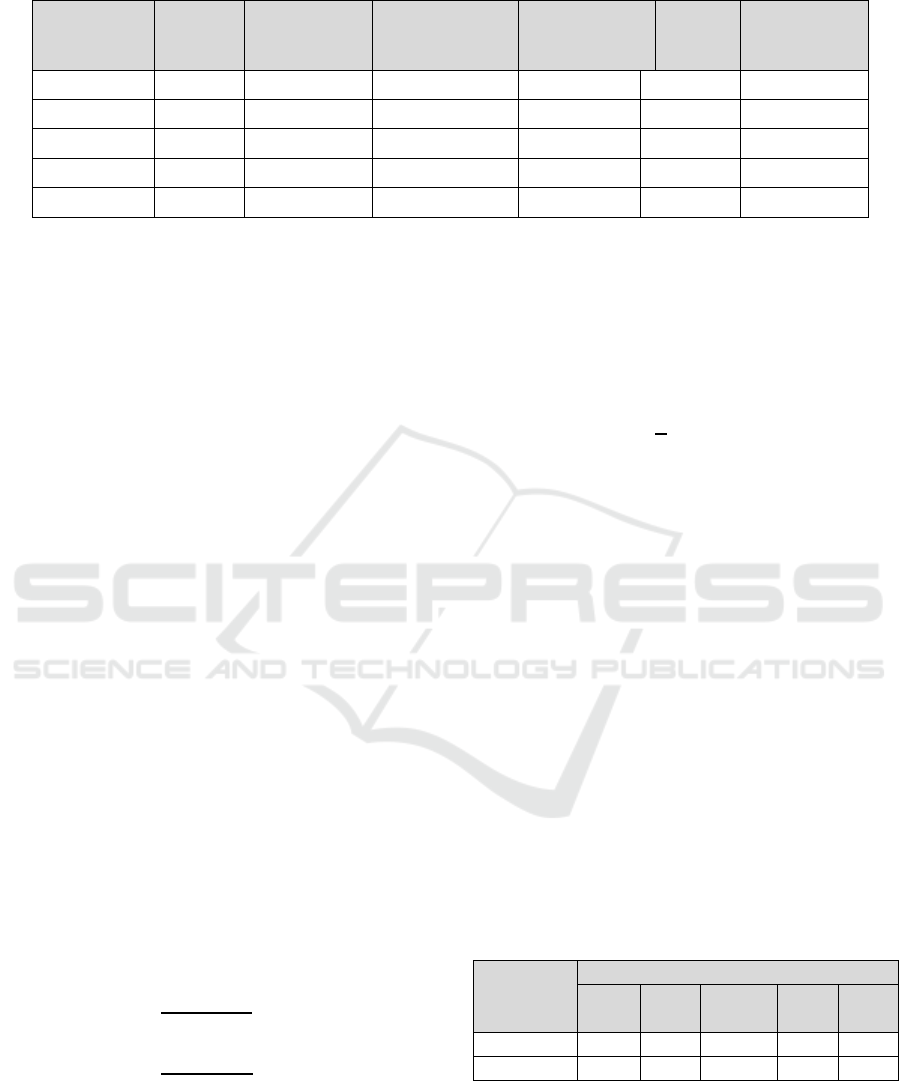
Table 1: Models on YOLOv8.
Model
size
(pixels)
mAP
50-95
Speed
CPU ONNX
(ms)
Speed A100
TensorRT
(ms)
Params
(M)
FLOPS
(B)
YOLOv8n 640 37.3 80.4 0.99 3.2 8.7
YOLOv8s 640 44.9 128.4 1.20 11.2 28.6
YOLOv8m 640 50.2 234.7 1.83 25.9 78.9
YOLOv8l 640 52.9 375.2 2.39 43.7 165.2
YOLOv8x 640 53.9 479.1 3.53 68.2 257.8
3
RESULTS AND DISCUSSION
To enhance each step, the YOLOv8s algorithm was
tested and trained on the UTA’45 Jakarta Lot Parking
dataset, and its results were compared with those of
YOLOv5 to confirm that this approach could increase
the precision of space availability and car targets
detection. Lastly, in order to compare the detection
outcomes of the suggested approach and the YOLOv5
algorithm in real scenes, we chose images of
complicated sceneries in various scenarios.
It has been determined after numerous testing that
the algorithm basically iterates 438 before starting to
converge. We determined the following parameters
based on the hardware available and several testing
runs: batch size=16, epoch=2000.
3.1 Experimental Platform
Google Colab served as the online platform for the
experiments in this work, and the system hardware
included an NVIDIA T4 GPU and 16GB of RAM
(software platform: torch-2.0.1+cu118, Google
Colab).
3.2 Valuation Index
Evaluation metrics: Mean average precision (mAP),
average precision (AP), precision (P), and recall (R).
The formulas for P and R are as follows:
𝑃=
𝑇𝑃
(
𝑇𝑃+𝐹𝑃
)
(1)
𝑅=
𝑇𝑃
(
𝑇𝑃+𝐹𝑁
)
(2)
TP is the number of correctly predicted bounding
boxes, FP is the number of incorrectly judged positive
samples, and FN is the number of undetected targets.
Average Precision (AP) is the average accuracy of
the model. Mean Average Precision (mAP) is the
average value of the AP. K is the number of
categories (Lou et al., 2023). The formulas for AP and
mAP are as follows:
𝐴
𝑃=𝑝
(
𝑟
)
𝑑𝑟
(3)
𝑚𝐴𝑃 =
1
𝑘
𝐴
𝑃
(4)
3.3 Experimental Result Analysis
We performed the training and inference procedure
using the UTA'45 Jakarta Lot Parking dataset and
compared it with YOLOv5s to validate the detection
effect of the suggested approach on available space
and cars in this research. Students studying electrical
engineering at UTA'45 Jakarta, Indonesia, gathered
the UTA'45 Jakarta Lot Parking dataset. The dataset
was gathered from the sixth floor of the UTA'45
Jakarta building using a Logitech C270 HD Webcam.
The camera captured a variety of situations and
lighting conditions, resulting in a large number of
parking spaces and cars in complex environments.
The assessment index for this experiment is
mAP0.5, mAP0.5:0.9, which amply demonstrates the
experiment's authenticity. Table 2 displays the test
results.
Table 2: Algorithm comparison at each stage.
Detection
Algorithm
Resul
t
Epoch
mAP
0.5
mAP
0.5:0.95
P R
YOLOv8s 371 0.955 0.828 0.953 0.924
YOLOv5s 1237 0.947 0.812 0.958 0.912
Table 2 demonstrated that the YOLOv8s
algorithm has a certain improvement at each stage for
the detection of available spaces and cars in complex
scenarios. Furthermore, there is a 1% improvement in
the mAP 0.5 and mAP 0.5:0.95, indicating significant
Car Parking Space Detection Using YOLOv8
397

room for development. It is demonstrable that the
YOLOv8s in this experiment work quite well. The
experimental findings demonstrated that the
YOLOv8s outperforms the YOLOv5s in terms of
performance.
4
CONCLUSION
In contrast to conventional approaches, this study
suggests a camera sensor-based algorithm for
detecting cars and available space for smart parking
projects. It is known that the YOLOv5 and YOLOv8
models have successfully detected cars and available
spaces in parking lot images based on the research
findings that have been described. Variations exist in
parking lot detecting performance metrics. For recall,
mAP 0.5, and mAP 0.5:0.95, the YOLOv8 model
performs better than the YOLOv5 model; the
differences in the values of each performance are
0.8%, 1.6%, and 1.2%. With a 0.5% difference in
accuracy performance value, the YOLOv5 model
outperforms the YOLOv8 model.
We will keep researching camera sensors in-depth
in the future in an effort to meet our target of being
able to recognize objects in different parking lots
more accurately than current detectors as soon as
feasible.
ACKNOWLEDGEMENTS
This work was supported by UTA’45 Jakarta. The
source code for the experiments is available at the
author.
REFERENCES
Acharya, D., Yan, W., & Khoshelham, K. (2018). Real-time
image-based parking occupancy detection using deep
learning. CEUR Workshop Proceedings,
2087(September 2020), 33–40.
Chen, M., & Chang, T. (2011). A parking guidance and
information system based on wireless sensor network.
2011 IEEE International Conference on Information
and Automation, 601–605.
https://doi.org/10.1109/ICINFA.2011.5949065
Jocher, G., & Tune, M. (2023). Ultralytics YOLOv8.
Github.
Lou, H., Duan, X., Guo, J., Liu, H., Gu, J., Bi, L., & Chen,
H. (2023). DC-YOLOv8: Small-Size Object Detection
Algorithm Based on Camera Sensor. Electronics,
12(10), 2323.
https://doi.org/10.3390/electronics12102323
Redmon, J., Divvala, S., Girshick, R., & Farhadi, A. (2016).
You Only Look Once: Unified, Real-Time Object
Detection. 2016 IEEE Conference on Computer Vision
and Pattern Recognition (CVPR), 779–788.
https://doi.org/10.1109/CVPR.2016.91
Rizkatama, G. N., Nugroho, A., & Suni, A. F. (2021).
Sistem Cerdas Penghitung Jumlah Mobil untuk
Mengetahui Ketersediaan Lahan Parkir berbasis Python
dan YOLO v4. Edu Komputika Journal, 8(2), 91–99.
https://doi.org/10.15294/edukomputika.v8i2.47865
Sani, A., & Ayyasy, D. H. (2022). Prototipe Deteksi
Ketersediaan Slot Parkir Berbasis Pengolahan Citra.
Journal of Applied Electrical Engineering, 6(2), 59–63.
https://doi.org/https://doi.org/10.30871/jaee.v6i2.4452
Vidyavani, A., Dheeraj, K., Reddy, M. R. M., & Kumar, K.
N. (2019). Object Detection Method Based on
YOLOv3 using Deep Learning Networks. International
Journal of Innovative Technology and Exploring
Engineering, 9(1), 1414–1417.
https://doi.org/10.35940/ijitee.A4121.119119
Wang, C.-Y., Bochkovskiy, A., & Liao, H.-Y. M. (2022).
YOLOv7: Trainable bag-of-freebies sets new state-of-
the-art for real-time object detectors.
ISCP UTA ’45 JAKARTA 2023 - THE INTERNATIONAL SEMINAR AND CALL FOR PAPER (ISCP) UTA ’45 JAKARTA
398
