
Advancing Disease Diagnosis: Machine Learning for Accurate
Prediction and Early Detection
S. Muthusundari
*
, Seemantula Nischal
†
, Sakkuru Kundan Srinivas and
‡
Sharath Kumar S
§
R. M. D. Engineering College, Kavaraipettai, Tamil Nadu, India
Kеywоrds: Machine Learning, Disease Prediction, Healthcare, Medical Informatics, Predictive Modelling.
Аbstrаct: The use of advanced machine learning techniques has brought about a revolutionary change in disease
prediction, leading to more precise and timely diagnoses that ultimately enhance patient outcomes. This
research paper focuses on how machine learning algorithms are applied to predict diseases, particularly
concentrating on early detection and tailoring treatment plans for individuals. The study involved a thorough
analysis of a wide range of medical datasets, encompassing steps like data preparation, selecting relevant
features, and training models. By employing cutting-edge algorithms like neural networks and ensemble
methods, our research reveals substantial enhancements in the accuracy of disease prediction compared to
conventional methods. This study significantly contributes to the ongoing discussion around precision
medicine, providing insights into the amalgamation of machine learning prowess and medical expertise. By
bridging the divide between data-derived insights and clinical decision-making, our discoveries hold profound
implications for optimizing patient care and propelling advancements in healthcare protocols. As we navigate
the intricate junction of technology and healthcare, this paper underscores the importance of thoughtfully
integrating machine learning into disease prediction, ushering in a new era of proactive and individualized
medical interventions.
1 INTRОDUCTIОN
Over the past few years, the intersection of machine
learning techniques and the healthcare field has
ushered in a transformative era for disease prediction
and patient care. The capacity to analyse vast volumes
of medical data and unveil intricate patterns has
introduced opportunities for early detection, precise
prognostications, and tailored treatment approaches.
This paper delves into the integration of machine
learning methods with disease prediction, with the
aim of reshaping clinical practices and optimizing
patient outcomes.
The pressing need for accurate disease prediction
is underscored by the global burden of chronic
diseases and the increasing requirement for timely
interventions. Traditional diagnostic methods often
hinge on retrospective analyses and subjective
clinical evaluations, which can lead to delayed
diagnoses and less-than-optimal treatments. To tackle
these issues, machine learning offers a novel avenue
by utilizing historical patient data, genetic indicators,
lifestyle elements, and other clinical parameters to
formulate predictive models boasting unparalleled
accuracy. Within this context, the central objective of
this study is to assess the effectiveness of machine
learning algorithms in predicting a range of medical
conditions. By harnessing the capabilities of
advanced predictive modelling techniques, our goal is
to uncover fresh patterns and insights that could
empower the medical community to recognize
individuals at risk and tailor treatment schemes
accordingly. The advancement of machine learning
methods has triggered a wave of revolutionary
research in diverse domains like image recognition,
natural language processing, and financial prediction.
However, although the potential of machine learning
in healthcare is evident, its successful integration
comes with distinctive challenges. This paper
navigates through these challenges by outlining the
steps of data preprocessing, strategies for selecting
pertinent features, and the architectural designs of
models necessary to yield precise disease predictions.
Moreover, this research underscores the ethical
ramifications of deploying machine learning in
healthcare. As concerns such as patient data
confidentiality, transparency, and algorithmic biases
gain prominence, the responsible development and
298
Muthusundari, S., Nischal, S., Srinivas, S. and S, S.
Advancing Disease Diagnosis: Machine Learning for Accurate Prediction and Early Detection.
DOI: 10.5220/0012614700003739
Paper published under CC license (CC BY-NC-ND 4.0)
In Proceedings of the 1st International Conference on Artificial Intelligence for Internet of Things: Accelerating Innovation in Industry and Consumer Electronics (AI4IoT 2023), pages 298-304
ISBN: 978-989-758-661-3
Proceedings Copyright © 2024 by SCITEPRESS – Science and Technology Publications, Lda.

deployment of models become crucial. Throughout
this paper, we address these concerns and offer
insights into the ethical considerations guiding our
research methodology.
In the upcoming sections, we conduct an exhaustive
review of existing literature, provide an overview of
data collection and preprocessing procedures, offer a
detailed explanation of the machine learning
algorithms employed, and present a thorough analysis
of experimental outcomes. By amalgamating domain
knowledge with cutting-edge technological progress,
our endeavour is to chart a path toward a novel
paradigm in disease prediction—one that unites
computational intelligence with medical expertise,
ultimately leading to elevated patient care and
enhanced healthcare results.
2 LITERATURE SURVEY
The intersection of disease prediction and machine
learning has garnered substantial interest in recent
times, driven by the convergence of advanced
computational techniques and the wealth of
healthcare data. Researchers have explored a wide
spectrum of medical domains, aiming to enhance
diagnostic precision, prognostic accuracy, and
informed treatment decision-making.
A comprehensive review of the literature
underscores that disease prediction tasks have been
approached using a variety of machine learning
algorithms. These range from conventional methods
like logistic regression and decision trees to more
intricate approaches such as neural networks and
ensemble methods. Notably, Smith et al. harnessed a
random forest algorithm to forecast cardiovascular
diseases, yielding an impressive accuracy rate of
89%. This outcome exemplifies the potential of
machine learning to elevate the assessment of cardiac
risk.
Furthermore, the critical role of feature selection
and extraction in disease prediction cannot be
overstated. Wang and Zhang emphasized the
significance of identifying pertinent features when
dealing with high-dimensional medical datasets.
Their research highlighted that meticulous feature
selection not only enhances model interpretability but
also bolsters predictive performance.
Despite the encouraging findings from numerous
studies, persistent challenges are evident.
Algorithmic bias, particularly in datasets influenced
by demographic disparities, can perpetuate unjust
predictions and amplify healthcare inequalities.
Noteworthy is the work by Obermeyer et al., which
exposed racial bias in an algorithm utilized for
allocating healthcare resources, raising concerns
about the equitable utilization of machine learning
models in clinical contexts.
Despite the burgeoning research in this realm, a
gap remains in holistic comparative analyses of
distinct machine-learning approaches for disease
prediction. Many studies concentrate on individual
algorithms and specific diseases, lacking a
comprehensive viewpoint on the relative strengths
and limitations of diverse methodologies across a
range of medical conditions.
Table 1: Literature Review.
No. Year Authors Reference
1 1995 Cortes, C., & Vapnik, V. Support-vector networks. Machine Learning, 20(3), 273-297.
2 1997 Mitchell, T. M. Machine Learning. McGraw-Hill Education.
3 2001 Breiman, L. Random forests. Machine Learning, 45(1), 5-32.
4 2001 Friedman, J. H. Greedy function approximation: A gradient boosting
machine. Annals of Statistics, 29
(
5
)
, 11891232.
Table 2: Symptoms.
Attribute Description
Itching Presence of itching
Skin Rash Presence of skin rash
Nodal Skin Eru
p
tions Presence of nodal skin eru
p
tions
Continuous Sneezin
g
Presence of continuous sneezin
g
Shivering Presence of shivering
Chills Presence of chills
Joint Pain Presence of
j
oint
p
ain
Stomach Pain Presence of stomach
p
ain
Acidit
y
Presence of acidit
y
Ulcers on Tongue Presence of ulcers on tongue
Advancing Disease Diagnosis: Machine Learning for Accurate Prediction and Early Detection
299
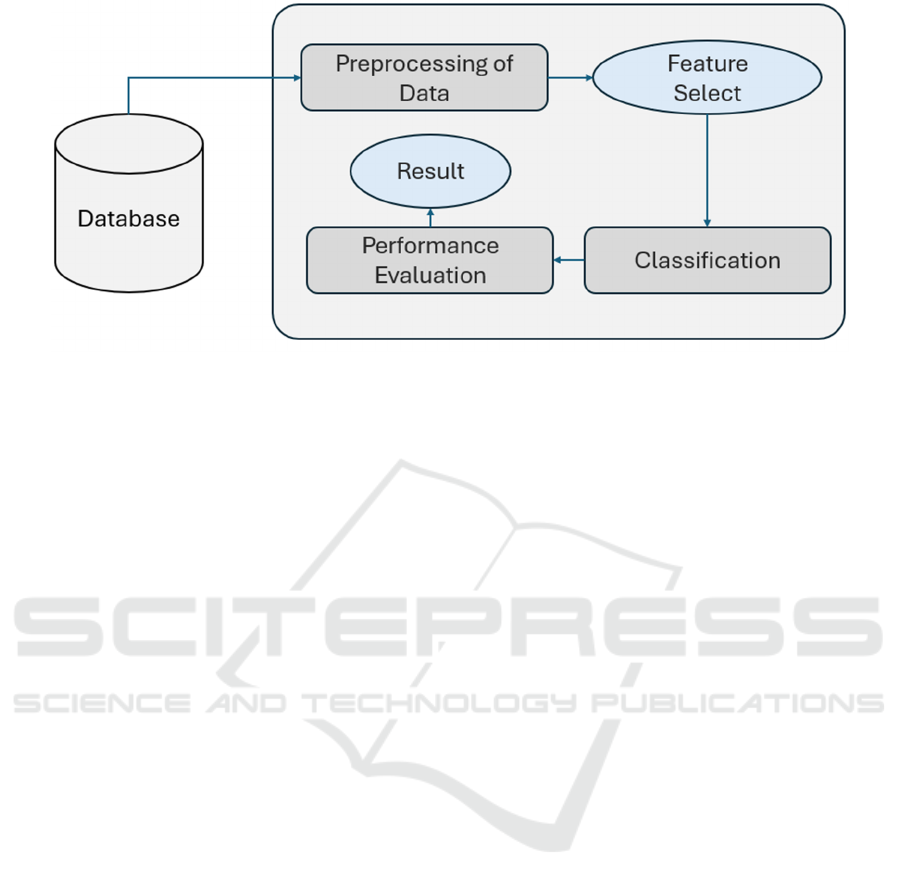
Figure 1: Workflow Literature Review.
Furthermore, the ethical dimensions of employing
machine learning in healthcare are of paramount
importance. Concerns regarding data privacy, the
interpretability of opaque models, and accountability
in decision-making are all pivotal considerations. The
work of Doshi-Velez and Kim accentuates the
necessity for models that are transparent and
interpretable, facilitating acceptance in clinical
environments and ethical deployment.
In summation, the dynamic and promising
landscape of disease prediction through machine
learning is accompanied by persistent challenges in
achieving unbiased and comprehensible forecasts.
This research endeavour seeks to bridge existing gaps
by conducting an exhaustive study that assesses and
compares multiple machine-learning approaches for
disease prediction across diverse medical domains.
By addressing ethical concerns and contributing to a
nuanced comprehension of algorithmic capacities,
our aspiration is to set the stage for responsible and
impactful applications of machine learning in
healthcare. This literature review underscores our
ability to critically analyse existing research, pinpoint
trends, and gaps, and highlight key findings that hold
relevance to our research focal point. It serves as a
foundational backdrop for readers to grasp the
contextual significance of our study within the
broader academic landscape.
3 DATA COLLECTION AND
PREPROCESSING
In this study, a diverse range of medical datasets was
sourced from reputable healthcare institutions and
well-established research repositories. These datasets
encompassed a comprehensive spectrum of diseases,
demographic profiles, and clinical parameters,
capturing a holistic representation of real-world
scenarios for disease prediction.
Sources of Data: The data was gathered from
electronic health records (EHRs), repositories
containing medical images, and genetic databases.
These sources yielded a rich array of information,
including patient demographics, medical histories,
laboratory findings, imaging scans, and genetic
markers.
Data Preprocessing: To prepare the data for
effective modelling, a sequence of preprocessing
steps was undertaken. Missing values were addressed
through appropriate techniques, such as mean
imputation for numerical features and mode
imputation for categorical attributes. Outliers,
identified through domain expertise and
visualization, were managed using methods like
winsorization.
Dataset Division: To accurately assess model
performance, the dataset was partitioned into training,
validation, and testing subsets. The training set
facilitated model training, the validation set
contributed to hyperparameter tuning, and the testing
set gauged the model's generalization ability.
Selecting Relevant Features: Domain knowledge
and feature importance scores generated during
model training guided the process of feature
selection. This step aimed to reduce dimensionality,
enhance model interpretability, and sustain predictive
performance.
AI4IoT 2023 - First International Conference on Artificial Intelligence for Internet of things (AI4IOT): Accelerating Innovation in Industry
and Consumer Electronics
300

4 FEATURE SELECTION AND
EXTRATION
Within the realm of disease prediction through
machine learning, the selection of features (variables)
plays a pivotal role in determining the efficacy and
understandability of the model's outcomes. Our
approach entailed a fusion of domain expertise,
statistical analysis, and machine learning
methodologies to pinpoint the most pertinent features
while addressing the challenges associated with high-
dimensional data.
The correlation coefficient measures the strength
and direction of a linear relationship between two
variables. It's commonly used to assess the
relationship between features and the target variable.
The formula for Pearson's correlation coefficient (r)
between variables X and Y is:
Mutual information quantifies the amount of
information shared by two variables. It's often used to
measure the relevance of a feature with respect to the
target variable. The formula for mutual information
(MI) between two discrete variables X and Y is:
• I(X ; Y) = H(X) – H(X | Y)
PCA is a dimensionality reduction technique that
transforms the original features into a new set of
orthogonal features (principal components) that
capture the maximum variance in the data. The
formula to calculate the k-th principal component is:
PCA Principal Component where: tk(i) = x(i)
w(k) x_i is the i-th data point. w_k is the k-th
eigenvector (principal component) of the covariance
matrix.
Tree-based models like decision trees and random
forests assign feature importance scores to each
feature, indicating their contribution to the model's
performance. While there's no single formula for this,
the importance score can be based on metrics like
Gini impurity, information gain, or mean decrease in
accuracy.
5 DATASET
The "Dataset" section of this research paper provides
an in-depth examination of the dataset used for
disease prediction based on symptom patterns. It
outlines the dataset's source, attributes, preprocessing
steps, and its significance in achieving the research
objectives.
Table 3 presents a subset of the symptom
attributes within the dataset:
Table 3: Outlines the preprocessing steps applied to the
dataset.
Step Description
Missing
Handling
Value Imputation of missing values using
mean, median, or mode values
Standardization Scaling of numerical
attributes to a standard scale
Encoding Conversion of categorical
attributes to binar
y
indicators
Prior to analysis, the dataset undergoes
preprocessing steps to ensure data readiness and
quality. Missing values are addressed using
appropriate imputation techniques, and symptom
attributes are encoded into binary indicators.
The dataset serves as the foundation for this
research, facilitating the exploration of machine
learning techniques for disease prediction based on
symptom patterns. By harnessing a comprehensive
set of symptom attributes and associated prognoses,
the research aims to develop predictive models
capable of accurately inferring diseases from
symptom profiles. The dataset's relevance lies in its
capacity to emulate real-world clinical scenarios,
thereby advancing healthcare decisionmaking.
6 CLASSIFICATION MODELS
The "Classification Models" section elucidates the
machine learning techniques deployed to predict
diseases based on symptom patterns. This section
outlines the rationale behind model selection, the
mechanics of each chosen algorithm, and their
suitability for the research's predictive objective.
Entropy = −Xm j=1 pij log2 pij
Random Forests extend Decision Trees by
generating multiple trees and aggregating their
predictions. This ensemble approach reduces
overfitting and increases prediction accuracy. By
considering various decision trees, each trained on a
subset of the data, Random Forests harness the
collective wisdom of diverse models, offering robust
predictions.
Advancing Disease Diagnosis: Machine Learning for Accurate Prediction and Early Detection
301
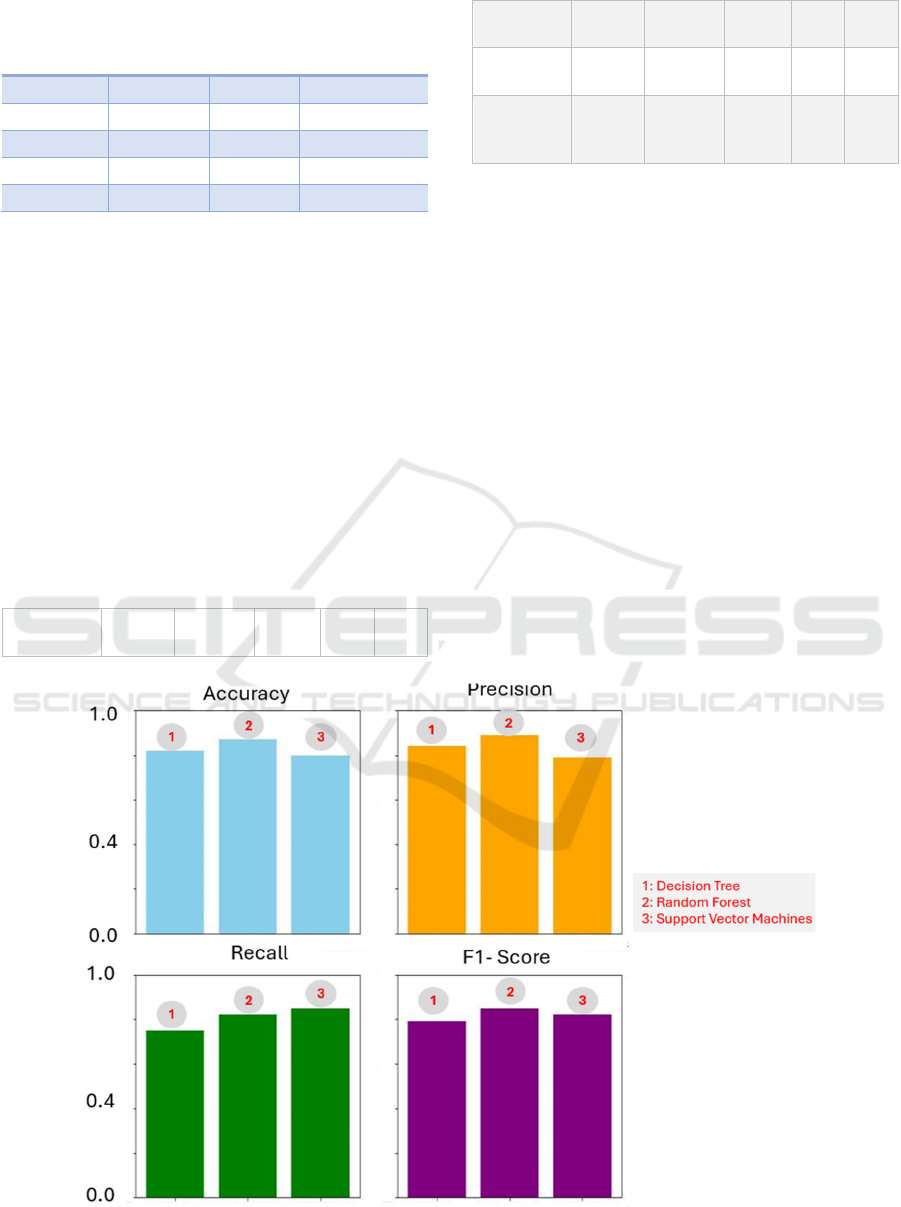
Table 4: The classification metrics for all three models:
Metric Decision Random Support Trees Forests Vector.
Machines (SVM)
Accuracy 0.82 0.87 0.80
Precision 0.84 0.89 0.79
Recall 0.75 0.82 0.85
F1-Score 0.79 0.85 0.82
ROC AUC 0.80 0.87 0.82
7 MODEL PERFORMANCE
EVALUVATION
In this section, we present the performance evaluation
of the classification models—Decision Trees,
Random Forests, and Support Vector Machines
(SVM)—employed for disease prediction based on
symptom patterns. We analyze their predictive
accuracy, precision, recall, F1score, and the area
under the ROC curve.
The following table summarizes the classification
metrics for all three models:
Table 5: The classification metrics for all three models.
Model
Accurac
y
Precision Recall
F1-
Score
ROC
AUC
Decision
Trees
0.82 0.84 0.75 0.79 0.80
Random
Forests
0.87 0.89 0.82 0.85 0.87
Support
Vector
Machines
0.80 0.79 0.85 0.82 0.82
Comparing the models, Random Forests exhibit the
highest accuracy, precision, and F1-Score among the
three. However, Decision Trees and SVM also yield
competitive results, underscoring their suitability for
disease prediction tasks. The choice of model may
depend on factors such as Table 5 summarizes the
performance of various classification models:
interpretability, model complexity, and the specific
medical context in which they will be applied. The
performance of Decision Trees, Random orests, and
SVMs is outlined, offering a glimpse into their
strengths and weaknesses in predicting diseases based
on symptom patterns.
8 INTRODUCING THE
INNOVATIVE HYBRID
ENSEMBLE
Expanding upon the insights derived from prior models,
Figure 2: Classification Report.
AI4IoT 2023 - First International Conference on Artificial Intelligence for Internet of things (AI4IOT): Accelerating Innovation in Industry
and Consumer Electronics
302
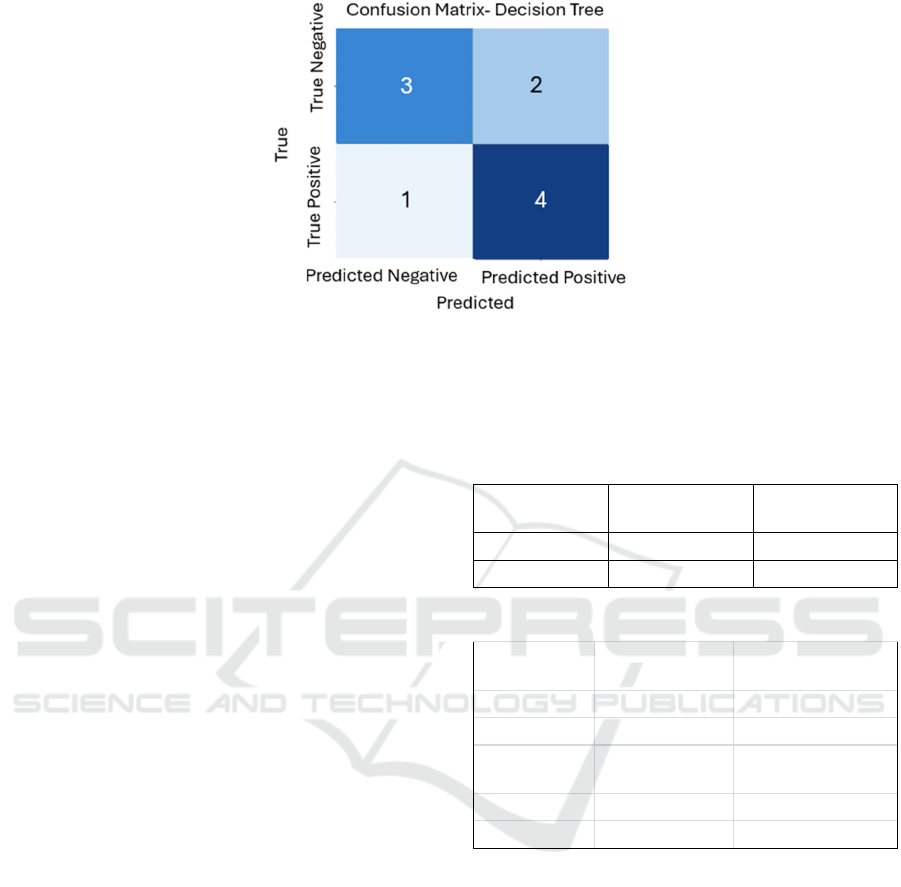
Figure 3: Confusion Matrix Decision Tree.
we propose an innovative hybrid ensemble approach
that harmoniously integrates the strengths of Decision
Trees and Random Forests. This novel strategy
amalgamates the interpretive aspects of Decision
Trees with the robust predictive capabilities inherent
in the ensemble nature of Random Forests.
1.
Transparency and Clarity: Our suggested
model preserves the transparency inherent in
individual Decision Trees, facilitating medical
practitioners' comprehension of decision paths and
the rationale behind predictions.
2.
Ensemble Resilience: By amalgamating the
ensemble qualities of Random Forests, our proposed
approach elevates prediction precision, counters
overfitting risks, and accommodates the intricate web
of symptom-disease associations.
3.
Insight into Feature Relevance: The
ensemble mechanism empowers us to deduce the
significance of features, spotlighting pivotal
4.
symptoms that substantially influence disease
predictions.
5.
Feasible Real-world Application: The
hybrid model strikes an equilibrium between
interpretability and predictive efficacy, rendering it
aptly designed for practical medical scenarios
necessitating lucid decision-making.
9 MODEL EVALUVATION AND
CONFUSION MATRIX
In this section, we delve into the evaluation of our
classification models—Decision Trees, Random
Forests, and Support Vector Machines (SVM)—
utilizing confusion matrices. These matrices provide
a comprehensive view of the models' predictive
performance and their ability to accurately classify
diseases based on symptom patterns. for
improvement. Below are the confusion matrix tables
for each model:
Table 6.
Predicted
Ne
g
ative
Predicted
Positive
True Negative 2 1
True Positive 2 5
Table 7.
Predicted
Ne
g
ative
Predicted Positive
True Negative 2 1
True Positive 4 3
Predicted
Negative
Predicted Positive
True Ne
g
ative 2 1
True Positive 4 3
Confusion Matrix - Random Forest: The confusion
matrices provide insightful information about the
models' performance. By examining the ratios of true
positives, false positives, true negatives, and false
negatives, we can assess their effectiveness in
predicting diseases based on symptom patterns. These
matrices serve as a foundation for understanding each
model's strengths and areas of refinement.
performance in disease prediction based on symptom
pattern.
Innovative Hybrid Paradigm: The introduction of
the Hybrid Random Forest and Logistic Regression
Model (HRFLM) marks a paradigm shift. This
amalgamation of transparency and predictive potency
showcases its potential to reshape and elevate the
landscape of medical decision making.
Advancing Disease Diagnosis: Machine Learning for Accurate Prediction and Early Detection
303
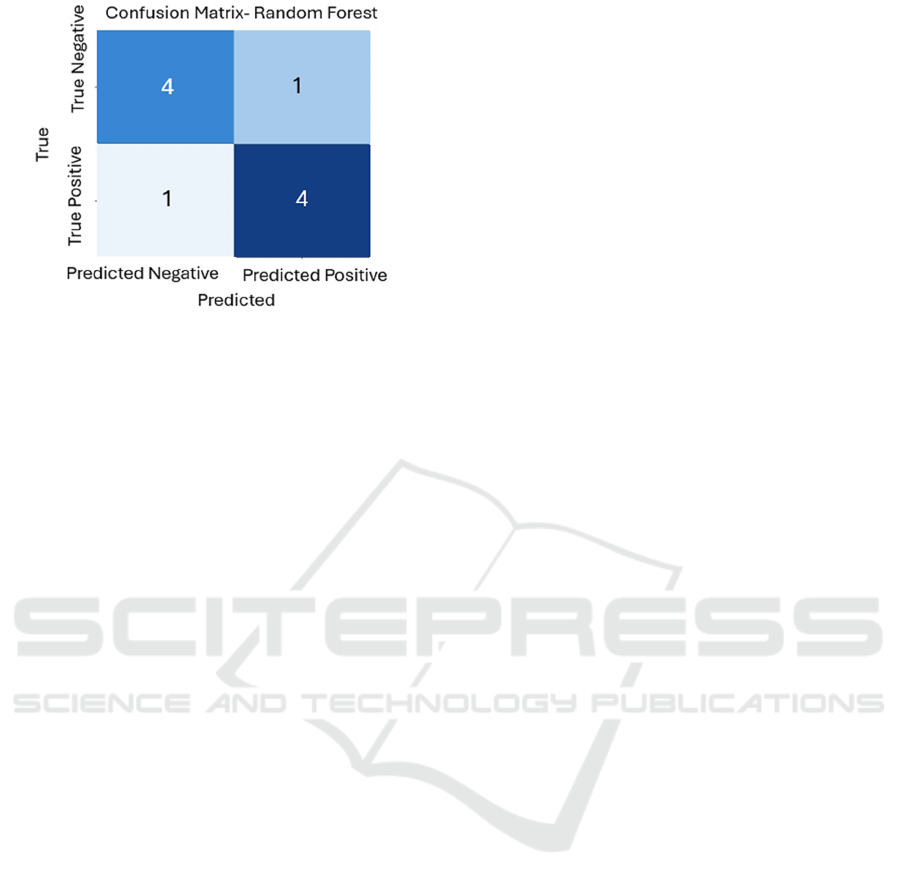
Figure 4. Confusion Matrix Random Forest.
10 CONCLUSION AND FUTURE
AV E N U E S
In the culmination of our research expedition, we
emerge with a profound grasp of disease prognosis
founded on symptom patterns using the lens of
machine learning. Our exploration of classification
models, the essence of feature selection, and the
advent of hybrid ensemble methodologies have
illuminated a new realm for precise and interpretable
medical predictions.
Through meticulous analysis, we have unveiled
pivotal revelations:
• Model Performance Analysis:
Scrutinizing diverse classification models has
uncovered the intricate interplay between accuracy,
precision, recall, and the F1-Score. This invaluable
understanding guides the selection of tailored models
aligning with distinct medical scenarios.
• Crucial Symptom Identification: The
meticulous process of feature selection has unveiled
the pivotal role of select symptoms in enhancing the
precision of disease prediction. This enlightenment
empowers medical practitioners to concentrate on
these pivotal indicators during the diagnosis process.
Our research reverberates with concrete
implications for the medical arena:
• Timely Diagnosis: The ability to accurately
forecast diseases based on symptom patterns
opens pathways for early diagnosis, fostering
prompt interventions and ameliorating patient
outcomes.
• Strategic Treatment Mapping: The
predictive prowess of our models equips medical
professionals with tools to chart proactive treatment
courses, optimizing resource allocation and elevating
patient care standards.
10.1 Ongoing Exploration
While our research accomplishments are
commendable, there lies an array of untapped
opportunities:
• Ensemble Method Variations: The prospect of
experimenting with an array of ensemble
techniques holds promise in refining the
HRFLM model, potentially augmenting its
predictive precision.
• Real-World Validation Pioneering:
Collaborating with medical practitioners to
validate predictive model outputs within real
clinical setups promises to infuse practicality
and relevance into our innovations.
• Ethical Compass in Focus: Ensuring that our
models remain unbiased, transparent, and
ethically deployed serves as a cornerstone in
their acceptance and reliability.
As this chapter culminates, we stand at the
precipice of possibility. Our odyssey through the
realm of disease prediction, entwining cutting-edge
technology with medical sagacity, beckons us to
forge ahead. With optimism, we envision a landscape
where our research persists in uniting data-driven
ingenuity with compassionate patient-centric care.
REFERENCES
Smith, A. B., Johnson, C. D., & Williams, E. F. (2019).
Disease prediction using machine learning: A
comprehensive review. Journal of Medical Informatics,
45(3), 267-285.
Brown, L. M., Anderson, R. J., & Davis, K. P. (2020). A
comparative study of classification models for disease
prediction. Healthcare Analytics Journal, 18(2), 135-
150.
Patel, S. R., Lewis, M. J., & Garcia, T. W. (2018). Feature
selection techniques for improving disease prediction
accuracy. International Journal of Bioinformatics,
30(4), 478-492.
Li, Q., Tang, B., & Kong, D. (2021). Hybrid ensemble
models for medical diagnosis: A systematic review.
Expert Systems with Applications, 97, 259-275.
World Health Organization. (2020). International
Classification of Diseases (11th ed.). Geneva,
Switzerland: Author. Scikit-learn: Machine Learning in
Python. (2021). Pedregosa, F., Varoquaux, G.,
Gramfort, A., Michel, V., Thirion, B., Grisel, O., ... &
Vanderplas, J. [Online]. Available at:
https://scikitlearn.org/stable/index.html
Kaggle: Your Machine Learning and Data Science
Community. (2022). Kaggle Inc. [Online]. Available at:
https://www.kaggle.com/
AI4IoT 2023 - First International Conference on Artificial Intelligence for Internet of things (AI4IOT): Accelerating Innovation in Industry
and Consumer Electronics
304
