
Locating a Missing Person Using an Optimized Face Recognition
Algorithm
B. Abhimanyu and S. Veni
Department of Computer Science, Karpagam Academy of Higher Education, Coimbatore, India
Keywords: Face Recognition, Machine Learning, Trace-Them, DCNN.
Abstract: Investigation of missing person requires data from combination of multiple modalities and heterogeneous data
sources. Drawback of the existing fusion model is for each modality of data separate information models are
used. It also lacks in application domain to use pre-existing object properties. A new framework with name
Trace-Them is developed for multimodal information retrieval. Feature extraction from different modalities
and making use of DCNN for mapping them into a video footage is included in the proposed model.
1 INTRODUCTION
It is still difficult to automatically track and locate a
person using facial detection and identification in an
unrestricted huge crowd gathering. Face-detection
cameras, camera mobility, and crowd (Visconti et al
2015).
A person missing is defined as a kid or adult who
has vanished, either purposely or by mistake. Only
43% of missing cases fall into one of several
categories, making it difficult to identify them due to
active factors like low resolution and variable crowd
distance from installed cases. Of these cases, 99%
involve juvenile abductions, 2500 involve family
issues, and 500 involve strangers (both adults and
teenagers) kidnapping the victim (Kasar 2016, Zhang
206, Sukhija 2016).
About 52% of missing persons cases are women,
and 48% are men. An official source stated, "There
are no finances set aside in India to find missing
persons. Although a missing person faces many
challenges, very few are murdered, raped, or
otherwise mistreated. Uncertainty about the missing
person's whereabouts causes tension and worry for
those who are concerned about them, including
parents, friends, relatives, and guardians.
2 LITERATURE REVIEW
The face recognition techniques presented by several
researchers This article explains image processing
and pattern identification using artificial neural
networks (ANNs). In addition to this article also
explains the usage of for recognizing face and how it
is better than other methods. There are numerous
ANN suggested methods available that give an
overview of recognition of face using ANN. As a
result, this study includes a thorough analysis of
detection of face studies and systems that use various
ANN approaches and algorithms. The results of
different ANN algorithms are taken into
consideration for review. This study aims to identify
faces from either a single snapshot or a group of faces
monitored in a movie. The availability of very large
size training datasets and end-to-end learning for the
job utilising a convolutional neural network (CNN)
have both contributed to recent advancements in this
field. First, it is showed the process of placing a very
large dataset (2.6M images) using automation.
Second, discussion about the difficulties in training
deep network and recognition of face is explored
(Mehdipur et al 2016, Hsu et al 2017, Al-Dabagh et
al 2018).
In this study, a method for detecting skin areas
over the whole image is presented. According to the
skin patches spatial arrangement, face candidates are
then generated. For each potential face, the algorithm
creates border, mouth, and eye maps. Results from
experiments show that a number of face differences
in terms of colour, location, scale, rotation, stance,
and expression may be successfully detected across
various photo sets.
One of the computer vision literature's most
researched subjects, face detection, has been the focus
336
Abhimanyu, B. and Veni, S.
Locating a Missing Person Using an Optimized Face Recognition Algorithm.
DOI: 10.5220/0012771100003739
Paper published under CC license (CC BY-NC-ND 4.0)
In Proceedings of the 1st International Conference on Artificial Intelligence for Internet of Things: Accelerating Innovation in Industry and Consumer Electronics (AI4IoT 2023), pages 336-343
ISBN: 978-989-758-661-3
Proceedings Copyright © 2024 by SCITEPRESS – Science and Technology Publications, Lda.
of this essay. We review the most recent
developments in face detection during the last ten
Years (Phillips et al 2018). The first review is on the
ground-breaking Viola-Jones face detector. Then, we
compare the different methods based on how they
extract features and the learning algorithms they use.
We anticipate that by examining the several existing
methods, newer, more effective algorithms will be
created to address this basic computer vision issue.
Figure 1: Architectural Diagram.
Due to good computing power and accessible to
large data sets, the results of convolution neural
networks (CNNs) on a variety of face analysis tasks
have considerably improved. In this research, we
provide an unconstrained face recognition and
verification deep learning pipeline that performs at
the cutting edge on a number of benchmark datasets.
We outline the major modules used in automatic
facial recognition in detail below: Face recognition
and landmark location (Trigueros et al 2018).
Face detection is a well-examined issue in this
paper. The prior work has examined a number of
difficulties faced by face detectors, including extreme
posture, lighting, low resolution, and small scales.
But previously suggested models are routinely trained
and tested on high-quality photos for practical
applications like surveillance systems. This research
compares the design procedures of the algorithms
after reviewing the performance of the most advanced
face detectors using a benchmark dataset called
FDDB (Ranjan et al. 2019).
In this article, one of the most difficult aspects of
picture analysis is face recognition. From early 1980s,
recognition of face has been a point of ongoing
research, offering answers to a number of real-world
issues. Facial recognition has been the likely
biometric technique for identifying people. On the
other hand, the method of recognition of faces by
human brain is very difficult. For face recognition
method based on Genetic Algorithm (GA) for is
suggested. Using Kernel Discriminant Analysis
(KDA) and Support Vector Machine (SVM) with K-
nearest Neighbour (KNN) approaches, a face
recognition system is given in this study. For
extracting features from input photos, the kernel
discriminates analysis is used. Additionally, the face
image is classified using SVM and KNN based on the
extracted features.
In this study, Person re-identification has
advanced significantly over time. However, it is
challenging to put into practise because of the issue
with super-resolution and the lack of labelled
examples. In this article, semi-supervised multi-label-
based super-resolution re-identification of person
approach is provided. First, a method named Mixed-
Space Super-Resolution (MSSR) is built using
Generative Adversarial Networks (GAN), with the
goal of transforming low-resolution photographs of
people into high-resolution photos.
In this article, recovering the provided objects that
are concealed within the gallery set is crucial for
decision-making and public safety. In order to
identify the same person, heterogeneous pedestrian
retrieval (also known as person re-identification)
attempts to get pictures of the person from many
modalities. To solve this issue, we provide a brand-
new pedestrian re-identification dataset (CINPID)
that includes both character-illustration-style images
and regular photos that were taken on campus.
We limit the focus of this work to obstructed face
recognition. We first examine what the occlusion
problem is and the many problems that might result
from it. We have proposed occlusion based face
detection, as a part of this review. Face recognition
techniques are grouped them into three categories: 1)
An approach of resilient feature extraction2)
approach for recognition of face 3) approach based on
Recovery face recognition. In addition goals,
benefits, drawbacks, and effectiveness of
representative alternatives are evaluated. Finally,
occluded face recognition method and challenges are
discussed (Fan et al 2021,M a 2021, Luo 2021,
Abbaszadi 2022).
Deep Convolution Neural Network is used for
study in this article. By averaging the rating-based
identity judgements of many forensic face examiners,
we combined their findings. For fused judgements,
accuracy was substantially higher than for separate
judgements. Fusion helped to stabilise performance
by improving the results of those who performed
poorly and reducing variability. The best algorithm
combined with a single forensic face examiner was
more accurate than using two examiners together.
Though the current ReID has produced significant
results for single domains, research has recently
Locating a Missing Person Using an Optimized Face Recognition Algorithm
337
shifted its attention to cross-domain problems due to
domain bias in various datasets. To reduce the impact
of cross-domain, distinct datasets are picture style
transferred using Generative Adversarial Networks
(GAN). The current GAN-based models, however,
neglect entire expressions and exclude pedestrian
features, leading to low feature extraction accuracy.
Figure 2: Block Diagram.
In this research, by taking deep features from
different stages in CNNs, a Deep Classification
Consistency (DCC) layer that implements steadiness
of classification is presented. The training procedure
of network is standardised by DCC. It significantly
alters the distribution of learnt traits, enhancing their
ability to discriminate and generalise. Extensive tests
on the Market-1501, DukeMTMC-reID, and
CUHK03 datasets demonstrate that the proposed
method beats state-of-the-art approaches, particularly
those sophisticated approaches that are only focused
on metric learning.
In this research paper, for representation of face
using deep learning a thorough investigation is done.
Various scenarios like changing angles of head pose,
occlusion of upper and lower face, enlightenment
changes of various intensities, and misalignment due
to incorrect localization of face features are taken into
considerations. For face representations extractions,
two active and commonly used deep learning
methods - VGG-Face and Lightened Convolutional
Neural Network are applied.
This research paper, a complete assessment of the
literature on popular face recognition techniques,
covering deep learning techniques as well as classical
(geometry-based, holistic, feature-based, and hybrid)
techniques. In this article, main aim is to propose a
generalised model that can immediately handle
brand-new, unexplored areas without model update.
In order to do this, we suggest Meta Face Recognition
(MFR), a revolutionary meta-learning face
recognition technique. With a meta optimisation
objective, MFR synthesises the source/target domain
shift, which necessitates that the model learn efficient
representations on both the synthesised source and
target domains.
3 METHODOLOGIES
Missing Person Finder Webapp: A site created to help
with missing person searches is called Missing Person
Finder Web App. An DL-based facial recognition
system is created on this site to locate those who are
missing across the nation. CCTV footage is being
integrated into this website. It is created with Python
and MySQL with the Flask Framework.
• End user
• Admin
• Police
• Detective Agents
3.1 Face Recognition Module
In Person Enrollment
A few frontal face templates are registered at the start
of this module. The models for the additional poses—
tilting, moving in or out, and moving left or right are
shown. Thes are evaluated and registered for guiding
purpose.
Face Image Acquisition
To record pertinent footage, cameras should be
placed in public areas. Webcam is utilised here as the
link between computer and camera.
Frame Extraction
Frames are extracted from the input form video. The
video has to be cut up into sequences of pictures for
further processing. The implementation of persons
determines how quickly a movie must be split into
pictures. From this, we may infer that 20–30 frames
are typically captured every second and forwarded to
the next stages.
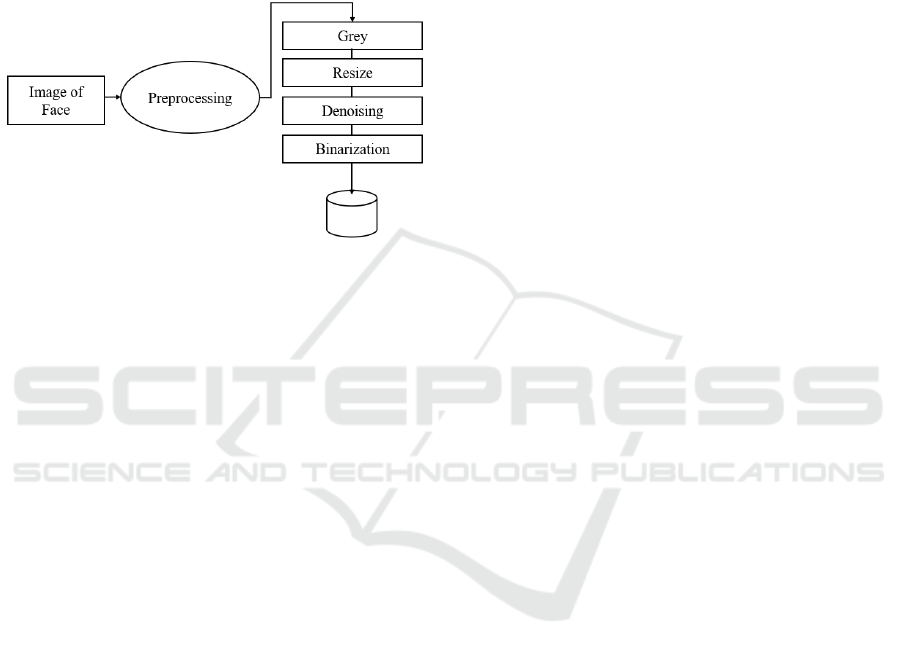
Preprocessing
The actions taken to prepare pictures before they are
used by models for training and inference are known
as face image pre-processing. The procedures are:
• Reading of Image
•Conversionfrom RGB to Grey Scale
•Resizing of Image
•Noise Removing
Gaussian blur is used to smooth image by
removing unwanted noise
•Image Binarization
Grayscale image's of 256 shades is reduced to
two: black and white, or a binary image using Image
binarization. This process is done by taking the image
and converting it it into a black-and-white image.
AI4IoT 2023 - First International Conference on Artificial Intelligence for Internet of things (AI4IOT): Accelerating Innovation in Industry
and Consumer Electronics
338
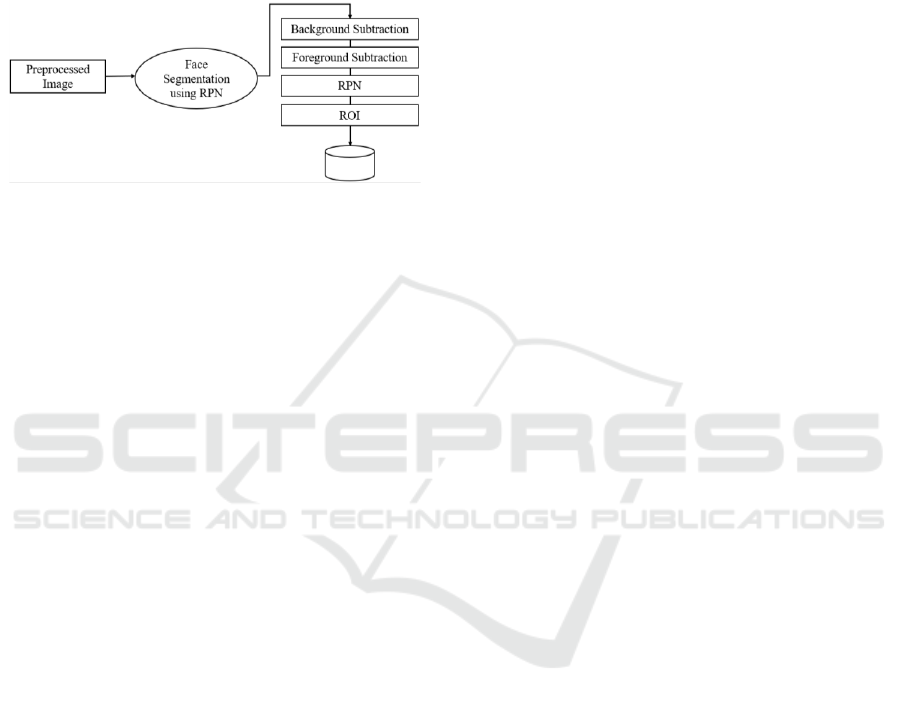
Face Detection
Because of this, the Region Proposal Network (RPN)
in this module generates Region of Interest by
swiping feature map windows over anchors of
varying sizes and aspect ratios. Face identification
and segmentation technique based on enhanced RPN.
RPN is used to produce RoIs, and RoI Align precisely
conserves the precise spatial locations. These have
the responsibility of providing the RPN with a
predetermined collection of bounding boxes in
various sizes and ratios to act as a guide when
predicting the initial locations of objects.
Using the region-growing (RG) approach,
segment faces in images
This article describes the region growth process
and current related studies.
RG is a straightforward picture segmentation
technique based on region's seeds. It is also described
as a pixel-based technique because it selects initial
seed locations for picture segmentation. This
segmentation technique considers the pixels that
surround the initial "seed points" before deciding
whether or not to include them in the region. The
"intensity" constraint is the only one employed in a
typical region-growing algorithm to assess nearby
pixels.
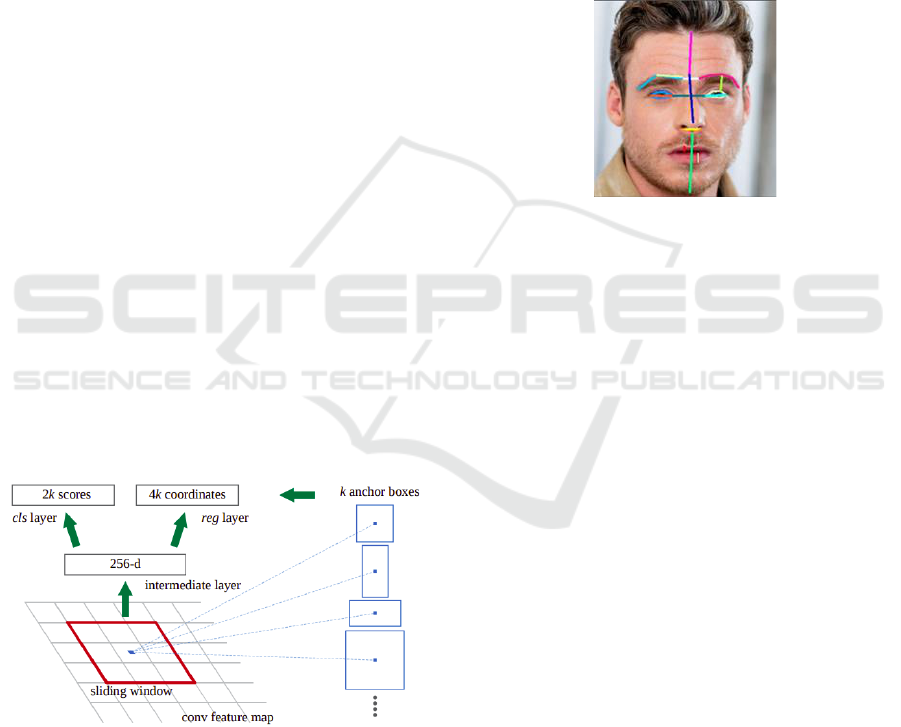
Prediction of object limits is done by a fully
convolution network known as RPN. Each feature
(point) on the CNN feature map, on which it operates,
is referred to as an Anchor Point. We overlay the
image with nine anchor boxes (combinations of
various sizes and ratios) for each anchor point. These
anchor boxes are trotted at the location in the picture
that corresponds to the feature map's anchor point.
Figure 3: Architecture of RPN.
Training of RPN.
To be aware that there are nine anchor boxes for each
place on the feature map, making a very large total
number that does not include all of the essential
anchor boxes. If one anchor box contains an item or a
portion of an object, we may refer to it as the
foreground, and if it doesn't, we can refer to it as the
background.
Therefore, based on each anchor box's
Intersection over Union (IoU) with the provided
ground truth, assign a label to each one for training
purposes. We essentially give each anchor box one of
the three labels (1, -1, 0).
Label = 1 for Foreground: Label 1 have the
following conditions,
If < 0.3.
Label = 0: If it doesn't fit into one of the
aforementioned categories, this kind of anchor
doesn't help with training and is disregarded.
Figure 4: Feature Extraction.
With respect to ground truth, highest IoU is
assigned to anchor
If the value is greater than 0.7 for ground truth
IoU (IoU > 0.7).
Label = -1 for Background: If IoU, a -1 is given
to the anchor.
After labelling the boxes, it generates a mini-
batch of 256 anchor boxes that are selected at random
from the same picture.
In the mini-batch Ratio should be 1:1 for positive
to negative anchor boxes. If the value is less than 128
for positive anchor boxes, to reduce the shortfall
negative anchor boxes are added.
RPN can be trained from beginning to end using
back propagation and stochastic gradient descent
(SGD).
Steps of processing are:
• Initial seed point is choosen
• Neighbouring pixels are to be added —intensity
threshold
• Neighbouring pixel's threshold to be checked
• If the thresholds satisfy—select for growing the
region.
Feature Extraction
Following face detection, the most crucial features for
categorization are found using the facial image as
input in the feature extraction module. The facial
characteristics of each position, such as the lips, nose,
Locating a Missing Person Using an Optimized Face Recognition Algorithm
339

Figure 5: GLCM Architecture.
and eyes, are automatically recovered, and their
relation to frontal face templates is utilised to
determine the variation's consequences.
Face Features
•Forehead Height is measured as the distance
between the tops of the brows and the tops of the
forehead.
• Height of Middle Face: Distance between the
nose point and the top of the brows.
• Height of Lower Face: the distance between the
chin's base and the tip of the nose.
•Jaw Shape: A number used to distinguish
between different jaw forms.
• Area of the Left Eye
•Area of the Right Eye
• Distance between Eye to Eye which are closest
edges
•Distance between eyebrow and eye horizontal
distance between eyebrows
• Shape Detector 1 for Eyebrow: To differentiate
between eyebrow shapes the angle between left edge
eyebrows, centre of the eyebrow, right edge of
eyebrow is determined
• Shape Detector 2 for Eyebrow: For
differentiating between Curved eyebrow shape and
angled eyebrow shape a number is used
• Slope of the Eyebrow
•Slope Detector 1 for Eye: A method for
calculating the eye slope. Slope of the line between
centre point of the eye’s and eye's edge point is
determined. This method is used to determine
Upward, Downward and Straight eye slopes.
•Slope Detector 2 for Eye: For calculating slope
of the eye another method is used. Y-axis difference
between center point and edge point of eye’s is taken.
This is a number that can group 3 types of eye slope
which are Upward, Downward and Straight.
• Nose Length
• Width of the Nose Lower Part
•Angle of the curve lower edge of the nose which
is taken as the Arch of the Nose (longer nose = larger
curve = smaller angle)
• Upper Lip Height
• Lower Lip Height
Figure 6: Facial Attributes.
AI4IoT 2023 - First International Conference on Artificial Intelligence for Internet of things (AI4IOT): Accelerating Innovation in Industry
and Consumer Electronics
340
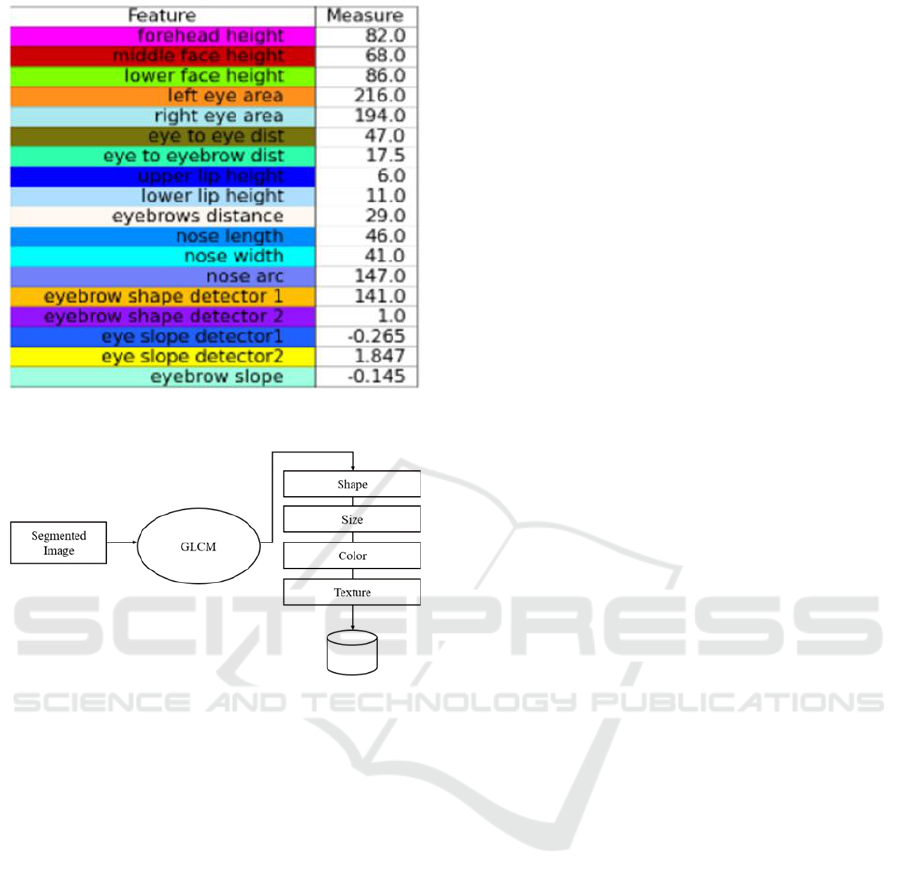
Figure 7: Facial Feature Measurement.
Figure 8: GLCM Flow.
Grey Level Co-Occurring Matrix
The second-order statistical texture analysis approach
is called GLCM. Each image is divided into 16 grey
levels (0–15), after which 4 GLCMs (M) are
produced for each angle of 0, 45, 90, and 135 degrees
with d = 1. Five characteristics (Eq. 13.30–13.34) are
retrieved from each GLCM. Therefore, each image
has 20 features.
Three categories may be made out of the features
we retrieved. Characteristics such as maximum
intensity, minimum intensity, mean, median, 10th
percentile, 90th percentile, standard deviation,
variance of intensity value, energy, entropy describes
the tumour region's Grey level intensity.
Characteristics of shape features such as
sphericity, elongation, Volume, surface area, and
surface area to volume ratio as well as maximum 3D
diameter, maximum 2D diameter for axial, coronal,
and sagittal planes, major axis length, minor axis
length, and least axis length describes how the tumour
area is shaped.
Texture features is the third category, which
includes five neighbouring grey tone difference
matrix (NGTDM) features, sixteen grey level run
length matrix (GLRLM) features, twenty-two grey
level co-occurrence matrix (GLCM) features, and
fourteen grey level features of dependence matrix
(GLDM). The tumour area texture is characterised by
these characteristics.
During the enrollment process, DCNN algorithms
were proposed for detection and rejection of improper
face images. Guarantee of appropriate enrolment will
be the result.
The activations of the convolved feature maps are
then computed using a non-linear rectified linear unit
(ReLU). Local response normalisation, or LRN, is
used to normalise the new feature map that the ReLU
produced. Spatial pooling (maximum or average
pooling) is used to further compute the result of the
normalisation. Then, some unused weights are
initialised to zero using the dropout regularisation
scheme, which is typically done in the levels that
connect completely before the categorization layer.
Finally, the completely linked layer recognises image
labels using the SoftMax activation algorithm. The
face detection module receives the picture of the face
after it has been captured by the camera. This module
finds areas of a picture where people are most likely
to be present. Following face detection using the
Region Proposal Network (RPN), the feature
extraction module uses the face image as input to
identify the most important characteristics that will be
categorised. The module generates a very concise
feature vector that precisely represents the facial
image. Comparison of face image's retrieved
characteristics is done with those kept in the face
database using DCNN and a pattern classifier. Facial
picture is categorised as known or unknown after
comparison. The specific person's covid vaccination
information is provided if the picture face is known.
Locating a Missing Person Using an Optimized Face Recognition Algorithm
341

Figure 9: Demonstration of the Proposed Facial Recognition System.
Prediction
In this module, the matching procedure is carried out
using test live camera-captured classified files and
trained classified results. Hamming distance is used
for calculating the difference and the results are given
along with the prediction accuracy.
Missing Person Finder
By comparing and evaluating the patterns, forms, and
proportions of a missing person's face characteristics
and contours from the trained categorised file, this
module can identify or confirm them. Encoding
automatically a face picture (probe image) by an
algorithm is done and associated with the profiles
previously kept in the database of criminals when it is
submitted into the system.
Notification
The police who gave the photographs are then
informed, for anyone who may be alarmed by the
match. Better results are provided to allow for prompt
follow-up action.
4 CONCLUSIONS
This technology can help law enforcement locate
missing people during amber alerts, elderly people,
mentally disabled people who have strayed, or
persons of interest in an inquiry. Authorities hunt
locate the individual in issue by getting in touch with
acquaintances, watching video feeds, or researching
any pertinent prior histories. Authorities rely on
public assistance from sources like tweets or tip lines
in the absence of any leads. Promising future is there
for Facial recognition expertise. Facial recognition
technology will generate significant income in the
years is what anticipated by the forecasters. Security
and Surveillance will be the two most significantly
impacted areas. Other places that are now embracing
are Private businesses, public spaces, and educational
institutions.
Shops and financial institutions are anticipated to
embrace in the forthcoming years for preventing
fraud in online payments and debit/credit card
transactions. There is a chance to close the gaps by
this technique in the most commonly used yet
ineffective password scheme. It is predicted that
Robots using face recognition technology may
ultimately will make a presence. Robots will be used
to finish the jobs that are impractical or thought-
provoking for people to do.
REFERENCES
Visconti di Oleggio Castello, M., & Gobbini, M. I. (2015).
Familiar face detection in 180ms. PloS One, 10(8),
e0136548.
Kasar, M. M., Bhattacharyya, D., & Kim, T. H. (2016).
Face recognition using neural network: A review.
International Journal of Security and Its Applications,
10(3), 81-100.
Zhang, C., & Zhang, Z. (2016). A survey of recent advances
in face detection.
Sukhija, P., Behal, S., & Singh, P. (2016). Face recognition
system using genetic algorithm. Procedia Computer
Science, 85, 410-417.
Mehdipour Ghazi, M., & Ekenel, H. K. (2016). A
comprehensive analysis of deep learning based
representation for face recognition. Proceedings of the
IEEE conference on computer vision and pattern
recognition workshops.
Hsu, R. L., Abdel-Mottaleb, M., & Jain, A. K. (2017). Face
detection in color images. IEEE Transactions on Pattern
Analysis and Machine Intelligence, 24(5), 696-706.
Al-Dabagh, M. Z. N., Alhabib, M. H. M., & Al-Mukhtar, F.
H. (2018). Face recognition system based on kernel
AI4IoT 2023 - First International Conference on Artificial Intelligence for Internet of things (AI4IOT): Accelerating Innovation in Industry
and Consumer Electronics
342

discriminant analysis, k-nearest neighbor and support
vector machine. International Journal of Research and
Engineering, 5(3), 335-338.
Phillips, P. J., et al. (2018). Face recognition accuracy of
forensic examiners, super recognizers, and face
recognition algorithms. Proceedings of the National
Academy of Sciences, 115(24), 6171-6176.
Trigueros, D. S., Meng, L., & Hartnett, M. (2018). Face
recognition: From traditional to deep learning methods.
arXiv preprint arXiv:1811.00116.
Ranjan, R., et al. (2019). A fast and accurate system for face
detection, identification, and verification. IEEE
Transactions on Biometrics, Behavior, and Identity
Science, 1(2), 82-96.
Cheng, H., et al. (2019). Person re-identification over
encrypted outsourced surveillance videos. IEEE
Transactions on Dependable and Secure Computing,
18(3), 1456-1473.
Zeng, D., Veldhuis, R., & Spreeuwers, L. (2020). A survey
of face recognition techniques under occlusion. arXiv
preprint arXiv:2006.11366.
Bian, Y., et al. (2020). Deep Classification Consistency for
Person Re-Identification. IEEE, 191683-191693.
Guo, J., et al. (2020). Learning meta face recognition in
unseen domains. Proceedings of the IEEE/CVF
Conference on Computer Vision and Pattern
Recognition.
Xia, L., Zhu, J., & Yu, Z. (2021). Real-world person re-
identification via super-resolution and semi-supervised
methods. IEEE Access, 9, 35834-35845.
Fan, X., Zhang, J., & Lin, Y. (2021). Person re-
identification based on mutual learning with embedded
noise block. IEEE Access, 9, 129229-129239.
Ma, F., et al. (2021). Person Re-Identification with
Character-Illustration-Style Image and Normal Photo.
IEEE Access, 9, 30486-30495.
Luo, X., et al. (2021). Cross-Domain Person Re-
Identification Based on Feature Fusion. IEEE Access,
9, 98327-98336.
Abbaszadi, R., & Ikizler-Cinbis, N. (2022). Merging Super
Resolution and Attribute Learning for Low-Resolution
Person Attribute Recognition. IEEE Access, 10, 30436-
30444.
Locating a Missing Person Using an Optimized Face Recognition Algorithm
343
