
Accelerating Federated Learning Within a Domain with
Heterogeneous Data Centers
M. Vishnu and G. Anitha
Dept. of Computer Applications, Karpagam Academy of Higher Education, Coimbatore, India
Keywords: Federated Learning, Distributed Machine Learning, Distributed Optimization, Heterogeneous Computing.
Abstract: In the current scenario accelerating with heterogeneous data centers tends to be required for federated learning
in that case we have proposed a novel approach for accelerating the training process. The authors introduce a
new communication-efficient algorithm called "Federated Momentum SGD," which reduces the amount of
communication required between the data centers during the training process. They also present a technique
for adjusting the learning rate to improve convergence speed. The proposed approach is evaluated on several
benchmark datasets, and the results show significant improvements in training time and accuracy compared
to existing methods. The authors conclude that their approach can effectively accelerate the domains that are
within the federated learning data by this we could make the solution for large-scale machine learning tasks.
1 INTRODUCTION
Here rapid development of huge information is
speeding up for creation of smart tenders across a
range of industries, however these data are typically
dispersed among independent parties and are unable
to be linked due to some security reasons also
protocols. As a way to accomplish secure
collaborative learning, McMahan et al. (McMahan et
al 2017) suggested FL, which would allow n number
of portable strategies to work together to train a single
ML technique while maintaining the training data on
the clients. The FL idea was then expanded to
incorporate mega-party collaboration by Yang et al.
(Yang et al 2019). Based on the distribution of data
techniques, security and performance, Li et al. (Li et
al 2020) got a recent survey on alternate devices that
hold the data as per the distribution, techniques,
security and performance.
The primary objective of alternate device and
alternate silo FL is on situations in which server and
client may able to communicate using the ML
techniques at the central server through interdomain
networks with bandwidth restrictions (cross WAN).
The most typical FL types are these two, however we
also find a third type is called the domain within the
range. In this scenario, separated parties are situated
on the same LAN, despite having enough bandwidth,
the parties' disparate computing capabilities result
Figure 1: Architecture of cross-device.
from this disparate computing equipment. By
enabling extensive federated computing, this
increases the capabilities of services computing. For
instance, teams at a research Centre might pool their
resources to create a shared data Centre, after which
they could offer teams or users outside the facility
web services geared towards federated computing.
These teams segment first-class interacting services
even though but consume computing authority
because of their combination of computation devices.
Figure 1 and Table 1 compare alternate devices
within the limited range in order to move with the
DML parties. This is used to share the information
using the wired network that is we might use LAN
connection for the proper transmission of
information. In the earlier stage we could not able to
remove the information among the devices which
move under the alternate solutions for the
communication at the bottleneck.
344
Vishnu, M. and Anitha, G.
Accelerating Federated Learning Within a Domain with Heterogeneous Data Centers.
DOI: 10.5220/0012771300003739
Paper published under CC license (CC BY-NC-ND 4.0)
In Proceedings of the 1st International Conference on Artificial Intelligence for Internet of Things: Accelerating Innovation in Industry and Consumer Electronics (AI4IoT 2023), pages 344-348
ISBN: 978-989-758-661-3
Proceedings Copyright © 2024 by SCITEPRESS – Science and Technology Publications, Lda.

Fed Avg, Moreover, produces poor convergence
and introduces gradient biases into model
aggregation, according to Yao et al. (Yao et al 2019).
Fed Avg requires 1400 epochs (280 synchronization
cycles) to accomplish 80% sorting precision on the
dataset, whereas SGD only needs 36 epochs [2]. Fed
Avg-based algorithms are not recommended for the
domain under the FL in that case we may able to
communicate with any interrupt under the key feature
of bottleneck, due to the disadvantage.
The huge rate of recurrence could be coordinated
with SSGD that is based on the algorithms chosen by
the domain within the range of FL due to their higher
conjunction and lack of communication bottleneck.
However, the main constraint is the significant
computational heterogeneity. There is collection in
the collective information Centre since the computers
donated by dissimilar gatherings have computation
strategies with varying authority and it is expensive
and difficult to exchange all the outdated
technologies. Because straggler machines will block
powerful technologies in every single organization up
till the barricade is grasped, heterogeneity results in
significant inefficiency.
Asynchronous and synchronous approaches can
be used to solve the straggler problem. The
coordinated gathering shave a tendency to be
standardized. since synchronous approaches choose
participants with comparable processing capabilities.
Models supplied within a predetermined time
frame were accepted by Bonawitz et al. (Zinkevich et
al 2010), but timeout models from lagging parties
were rejected. Chai et al.'s (Zinkevich et al 2010)
division of parties into many tiers with uniform
processing power allowed them to choose one tier for
synchronization based on chance. These techniques
impair the generalization of the global model and
make it harder for lone parties to contribute their
models.
Asynchronous and synchronous approaches can
be used to solve the straggler problem. Coordinated
gatherings have a habit of to be standardized since
synchronous approaches choose participants with
comparable processing capabilities.
This study provides an effective synchronization
technique which could able to evade the obstructive
brought on by dawdlers in order to lecture the
dawdlers in the very assorted domain in the range of
FL while retaining accurateness without any loss of
data.
The fundamental concept is to encourage
powerful parties to meet the required that has to be
trained as per many repetitions as they can previously
lagging gatherings finish an repetition, allowing
authoritative gatherings to discover advanced
excellence copies through the obstructive time.
Number of local iterations for each party must be
adaptively coordinated via an online scheduling
method in order to realism this concept. The
following is a summary of this paper's contributions:
• In our new FL proposal, called the domain
within the range on FL, the gatherings work together
to set the ML models in a collective information
Centre with significant computational heterogeneity.
We compare the proposed intra-domain.
• To synchronize the speed of all gatherings, we
suggest a novel scheduler State Server. By State
Server, which may also update scheduling choices in
response to changing circumstances.
• For strongly heterogeneous situations, we
suggest the effective synchronization technique
Essynce. Essynce, which is coordinated by State
Server, enables gatherings to train numerous
repetitions nearby depending on their possessions,
resolving the dawdler issue & quickening the working
out procedure.
2 RELATED WORKS
Stragglers occur in both FL and conventional
machine learning algorithm which is not in the
information on only in the present FL because of the
information separation. We summarize the many
approaches that have been suggested to deal with the
problems provided by straggler.
2.1 Cross-Device and Cross-Silo FL
The most popular federated optimization approach,
called synchronous Fed Avg, requires that all parties
grasp the limited representations for synchronizing
their limited representations. The assortment of
calculating hardware, encourages the appearance of
dawdlers, that results in lengthy obstructive period,
severe training inefficiency, and resource waste.
Some techniques use deadlines and time limitations
to weed out stragglers. First M models were approved
by Bonawitz et al. (Krichevsky et al 2009) but
timeout models from stragglers (Fed Drop) were
refused.
Parties were able to provide numerous repetitions
in the vicinity throughout the predetermined period
space. Parties have until the deadline to upload their
local models, according to Rafizadeh et al. (Coates et
al 2013).
Non-I.I.D.
Accelerating Federated Learning Within a Domain with Heterogeneous Data Centers
345
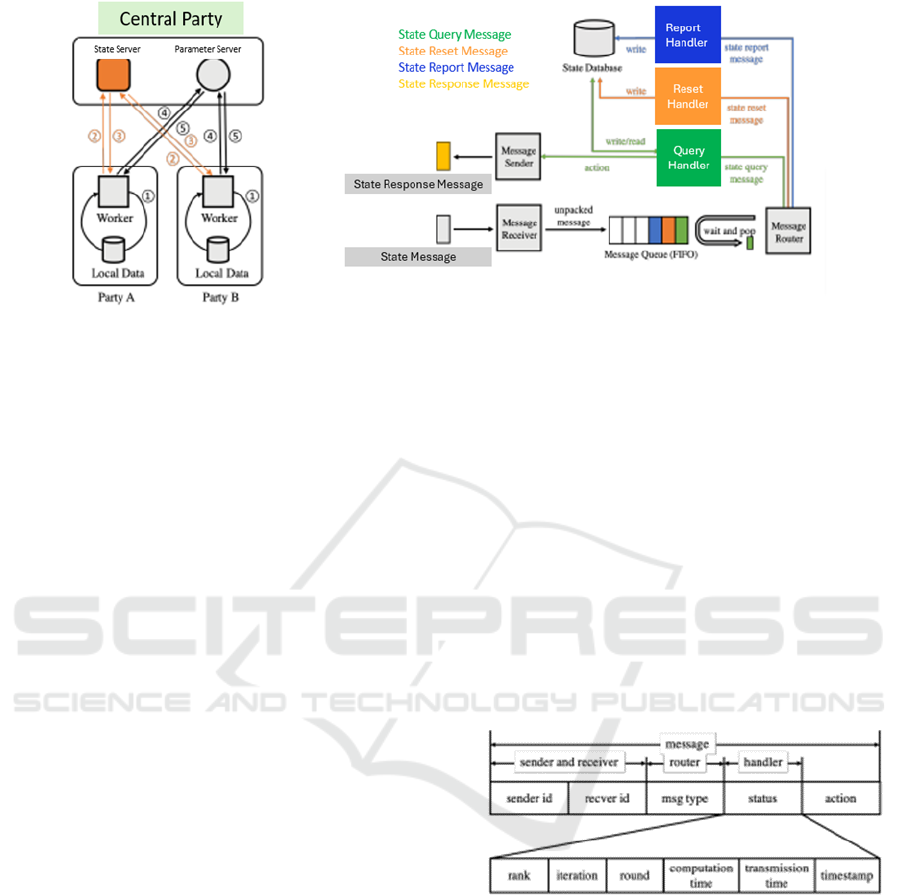
Figure 2: Proposed architecture.
In order for contrast to conventional DML, data
between isolated parties follows separate
distributions and is not combined. The incline
preconceptions may cause harm to the fault
boundaries of Fed Avg, particularly in non-i.i.d.
situations. By defining the weight divergence, Zhao
et al. (McMahan et al 2017) went on to analyze the
Fed Avg's performance degradation on skewed data.
Approximately strategies attempt towards
modifying wired limitations and enhance unbiassed.
To suppress the gradient biases, Yu et al. (Krichevsky
et al 2009) advised lowering the count of limited
repetitions. They keep a convergence rate constant, Li
et al. (McMahan et al 2017) suggested decelerating
the learning rate.
2.2 Conventional DML
Stragglers. However, institutions find it challenging
to replace all outdated equipment due to the quickly
evolving computing gear, which causes stragglers in
data centers and slows down the system.
Additionally, synchronous and asynchronous
approaches can be used to categories the solutions.
Chen et al. (Kayrouz et al 2019) deleted subsequent
models from stragglers and added backup workers for
the synchronous procedures. Min-max integer
programming was suggested by Yang et al. (Li et al
2020) as a way towards the stability of the batch size
dependent scheduled on the computational resources.
The technique that can reestablish the misplaced
information on dawdlers using the superfluous
information on supplementary blocks by
decomposing information into secure wedges and
distributing to each wedge to abundant workers. The
asynchronous algorithms modelled by ASGD (Yang
et al 2019) have a built-in tolerance for computing
heterogeneity because they permit dawdlers to
apprise the world wide prototypical values lacking
obstructing additional employees. But ASGD uses
dated gradients to inform the worldwide prototypical
information. The gradient and prototypical
information mismatch could lead to the optimization
formula to become confused and lose precision. The
approaches (Yao et al 2019) (Krichevsky et al 2009)
(Yang et al 2019) penalized decayed slopes through a
carefully thought-out knowledge frequency in order
to reduce their impact. Strong workers could
outperform stragglers within a limited number of
repetitions, according to Ho et al. (Yang et al 2019).
Workers were divided into homogenous groups by
MXNet-G.
Figure 3: Structure of the Message.
3 STRUCTURAL DESIGN
The management should postpone actions until all
workers have confirmed receipt of instructions. Each
worker must determine the appropriate number of
limited repetitions to maintain balance and facilitate
effective communication, thus avoiding bottlenecks.
Workers cannot autonomously decide on the
number of local iterations due to their lack of
awareness regarding each other's status and progress.
AI4IoT 2023 - First International Conference on Artificial Intelligence for Internet of things (AI4IOT): Accelerating Innovation in Industry
and Consumer Electronics
346
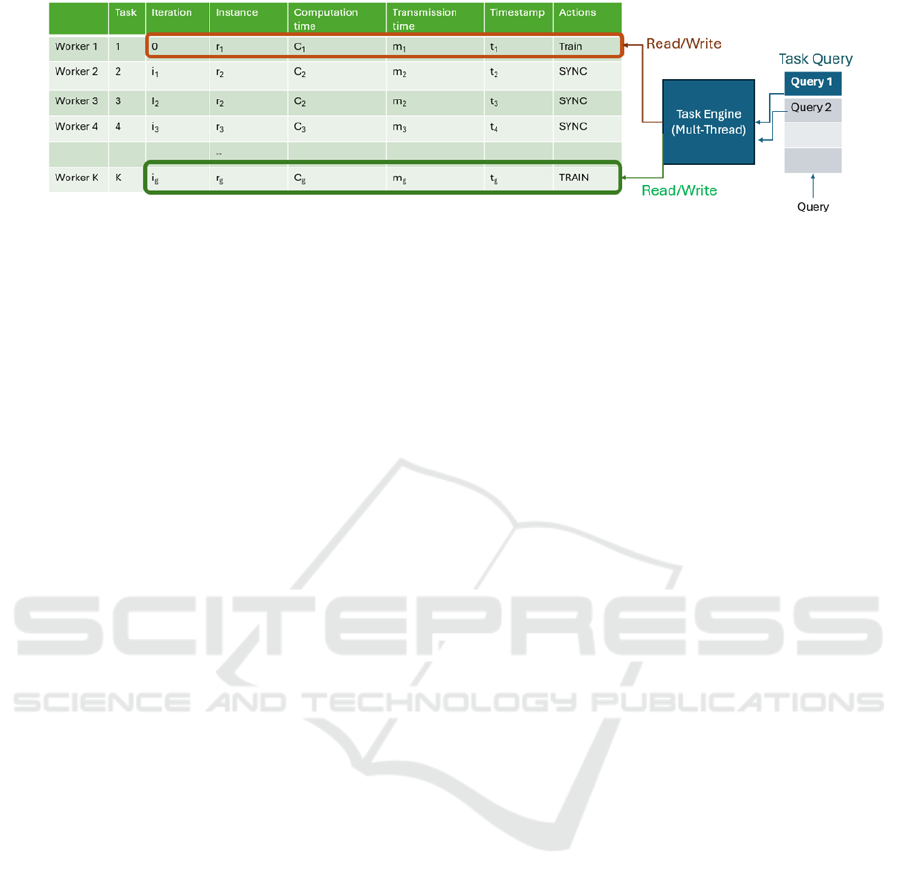
Figure 4: State Database implementation.
To synchronize the pace of all tasks under
management's direction, this training introduces a
new scheduler called the State-run Server into the
Restriction Server system. Future planning involves
coordination among the state, parameters, and
multiple workers. Each employee is part of a
contributing group with modified information, while
both the State and Limited Server reside in a
dominant group.
After training the resident prototypical using
several repetitions on its resident information, the
operative forces an update to the limitation attendant
for management. The number of repetitions is
adaptively synchronized by the state attendant. This
update is synchronized across all tasks via the
restriction server, which also averages the updates.
It's important to note that when dealing with a large
number of workers, multiple restriction servers might
be utilized to balance the circulation burden. In such
cases, the parameter server coordinates changes
across various components.
The State Server determines the count of resident
repetitions for inquiring tasks based on the position
and progress of all tasks in the current environment.
It employs a multithreaded mission engine to operate
at state counter and uses lightweight state control
messages to communicate with workers, ensuring
high concurrent state querying.
The computing power and space allocation of all
groups may fluctuate due to resource competition in
the shared data center. As a result, the server responds
to dynamic resource availability rather than adhering
strictly to a mathematically determined count of
limited repetitions. Sequence notation can be
employed to illustrate the workflow: {1 2 ... 3 1 2 3 |
{z} initial local iterations 4} 5.
K workers should be used for querying the state
server.
3.1 Main Server
Our implementation relies on the 0MQ chatting
framework (Jia et al 2018) for communication
between the source and destination. Standard data is
buffered, and tasks are assigned smoothly using a
message queue. The receiver monitors
communications from workers and queues up any
received messages, which are then held in the queue
until processed by the message router.
Based on the message type information, the router
forwards the data to the appropriate receiver. In our
scenario, the request manager updates the state file
with the best score of the querying employee,
considering all fields involved in the message.
Subsequently, the request handler triggers a TRAIN
or SYNC action based on whether the querying
employee needs further repetitions before sharing its
update. The message sender then responds to the
querying worker by encapsulating the result in a state
answer communication.
Message Structure: The message structure, as
depicted in Figure 4, includes sender and receiver
identification numbers, message type, latest status,
and upcoming action. Sender and receiver socket
channels are indexed using sender and receiver ID
attributes. The querying worker is informed about the
next action to be taken using the action field. This
field is relevant only when its optional values are
"TRAIN" or "SYNC," and the message type is
RESPONSE.
Types of Messages: State answer communication
and request communication. The parameter server
initiates the state reset message to clear histories in
the public file. The worker sends the public account
communication to the State Server to synchronize its
position and progress (linked to the communication's
spark). A state inquiry message is sent to the state
server by the worker to determine the next steps. The
status field of the message includes the latest status
and progress information.
State Database: Efficient processing of messages
by the message handler can prevent message
congestion and damage. The mission appliance
operates multiple idle threads to execute tasks from
the queue in parallel, submitted to the thread pool.
These threads read and write to a lock-free state table
Accelerating Federated Learning Within a Domain with Heterogeneous Data Centers
347

simultaneously. The state table tracks the ongoing
action (action ak).
4 MODELLING AND METHODS
Training a C-session organizational prototype value
in a shared information center entails collaborative
efforts from isolated parties to address a Federated
Learning (FL) challenge, which we formally
characterize. The samples belonging to party k are
divided into batches of size b and consist of nk
samples.
5 CONCLUSIONS
In this research article, a innovative intra-domain FL
type was proposed. Wherein dispersed parties work
together to train machine learning reproductions in a
mutual information centre. Here we have provided a
cross-device immediate results. Strong computational
heterogeneity has been identified as the main
bottleneck for intra-domain FL.
In various scenarios, we have found through an
experiment linked Essynce with Fed Avg, Fed Async,
TiFL, and Fed Drop while theoretically analyzing the
conjunction accurateness and frequency of Essynce.
The effectiveness in training effectiveness and
convergence precision under significant computing
heterogeneity is shown by numerical findings. In
conclusion, State Server's algorithm design takes into
account communication heterogeneity and because
ESync is inherently compatible with methods for
upstream and downstream traffic compression that
use scarification.
REFERENCES
Voigt, P., Von dem Bussche, A., & Hornung, G. (2017).
The EU General Data Protection Regulation (GDPR).
Cham: Springer International Publishing.
McMahan, B., Moore, E., Ramage, D., Hampson, S., &
Agüera y Arcas, B. (2017). Communication-efficient
learning of deep networks from decentralized data.
Proceedings of Machine Learning Research, 70, 1273-
1282.
Yang, Q., Liu, Y., Chen, T., & Tong, Y. (2019). Federated
machine learning: Concept and applications. ACM
Transactions on Intelligent Systems and Technology,
10(2), 1-19.
Kayrouz, P., Rekatsinas, T., Noy, A., & Mahlknecht, S.
(2019). Advances and open problems in federated
learning. arXiv preprint arXiv:1912.04977.
Li, Q., Liu, L., & Kairouz, P. (2020). A survey on federated
learning systems: Vision, hype and reality for data
privacy and protection. arXiv preprint
arXiv:1907.09693.
Coates, A., Huval, B., Wang, T., Wu, D., Ng, A., &
Catanzaro, B. (2013). Deep learning with COTS HPC
systems. International Conference on Machine
Learning.
Jia, X., Cao, Y., Chen, L., & Wei, H. (2018). Highly
scalable deep learning training system with mixed-
precision: Training ImageNet in four minutes. arXiv
preprint arXiv:1807.11205.
Yao, X., Wang, Z., Chen, Y., & Liu, H. (2019). Federated
learning with unbiased gradient aggregation and
controllable meta updating. Advances in Neural
Information Processing Systems (FL-NeurIPS).
Krichevsky, A., & Trofimov, V. (2009). Learning multiple
layers of features from tiny images. Technical report,
University of Toronto.
Zinkevich, M., Weimer, M., Li, L., & Smola, A. (2010).
Parallelized stochastic gradient descent. Advances in
Neural Information Processing Systems.
AI4IoT 2023 - First International Conference on Artificial Intelligence for Internet of things (AI4IOT): Accelerating Innovation in Industry
and Consumer Electronics
348
