
Fruit Image Classification Based on SVM, Decision Tree and KNN
Xiang Han
Faculty of Information Science and Engineering, Ocean University of China, Qingdao, China
Keywords: Fruit Image Classification, SVM, Decision Tree, KNN.
Abstract: Image classification is becoming more and more popular in today’s daily life. Image classification is widely
used in many fields. For example, the market demand for face recognition technology has increased
significantly in recent years. The foundation of these new technologies is still image classification. In order
to explore the efficiency of different image classification algorithms and help guide the use of different image
classification algorithms in the market, this paper uses a variety of algorithms to classify images in the fruit360
dataset. Fruit360 dataset is a dataset with 90483 images of 131 kinds of fruits and vegetables. Images in this
dataset have a size of 100×100 pixels. As a result, the Support Vector Machine algorithm is 89% accurate,
the decision tree algorithm is 94% accurate, and the K-nearest Neighbors algorithm is nearly 100% accurate.
Apart from the accuracy of these algorithms, this paper also analyzes the difference in classification accuracy
among different classes. For the Support Vector Machine algorithm, the classification accuracy of class 1 and
class 2 is low, which is caused by the algorithm itself. For the decision tree algorithm, the accuracy of each
classification group is similar. For the K-nearest Neighbors algorithm, the overall accuracy is very high. In
addition, this paper also compares the characteristics of these three algorithms, analyzes the performance
difference between the Support Vector Machine algorithm and the decision tree algorithm, and discusses the
relationship between the Support Vector Machine algorithm efficiency and the number of classes.
1 INTRODUCTION
Nowadays, image classification is widely used in
people’s daily life. Taking the campus as an example,
schools need to use a face recognition system at the
entrance of the library to help determine whether
there is access permission. But the author sometimes
sees such cases: some people outside the school can
also successfully pass the face recognition system.
This means that the current image classification still
has the problem of low accuracy. In this paper, SVM,
decision tree and KNN, three different algorithms are
used, and based on fruit360 dataset, various
classification algorithms are compared and analyzed,
so as to give a reasonable method selection for image
classification problems.
There have been many scientific studies based on
these algorithms. Boumedine Ahmed Yassine et al.
used KNN for 3D face recognition. They used KNN
for feature extraction (Yassine et al 2023). In other
research, they did glass component classification
based on decision tree (Guo et al 2023). However,
most of the existing research lack the comparison
between algorithms.
In addition, there are many research on image
classification using neural networks (Zhang et al
2014). However, a neural network is an end-to-end
model, which remains a “black box” for users, and
people cannot intuitively see the operation process of
its internal algorithms (Wang et al 2020)0. Also, the
training time of neural network algorithm is long, and
the interpretation is not strong enough. So this paper
focuses on the SVM, decision tree and KNN
algorithm.
Support Vector Machine is a supervised machine
learning algorithm, and it is widely used for
regression and classification tasks (Chandra and Bedi
2018 & Nie et al 2023). In addition to image
classification, SVM can be applied to text
classification, such as sentiment analysis, topic
classification, etc. SVM can extract text features and
make decisions for classification. SVM can also be
used for financial forecasting. In the financial field,
SVM can be used to predict stock prices and calculate
the risk of investments.
The decision tree algorithm is used in the financial
field and medical field. In the financial field, banks
can use a decision tree model to predict a customer’s
Han, X.
Fruit Image Classification Based on SVM, Decision Tree and KNN.
DOI: 10.5220/0012815800003885
Paper published under CC license (CC BY-NC-ND 4.0)
In Proceedings of the 1st International Conference on Data Analysis and Machine Learning (DAML 2023), pages 367-373
ISBN: 978-989-758-705-4
Proceedings Copyright © 2024 by SCITEPRESS – Science and Technology Publications, Lda.
367
credit rating by taking factors such as a customer’s
personal information and historical loan history. In
the medical field, the decision tree algorithm can be
used for disease diagnosis, drug therapy, etc. For
doctors, they can use decision tree models to predict
the situation of a patient by taking plenty of factors
such as symptoms and other indexes.
A machine learning approach called K-nearest
neighbors may be applied to tasks involving
regression and classification (Soucy and Mineau
2002). For speech recognition, it can classify audio
signals into different speech or voice types by
analyzing and comparing those given data. As long as
the scene meets the standard classification or
regression problem, it can try to use the KNN
algorithm to solve it. However, it should be noted that
the main disadvantage of the KNN algorithm is high
computational complexity, especially when the data
set is large, and the calculation distance requires more
time and computing resources.
In this paper, the author uses various methods,
including SVM, decision tree and KNN, to finish this
image classification task. By using different
algorithms for image classification, the differences of
different algorithms on this task would appear. Using
a variety of evaluation indexes to estimate the
efficiency of different algorithms.
2 METHOD
2.1 Dataset Analysis
In this section, the author will have a brief introduction
to the dataset. The name of this dataset is “fruit-360”,
which means that it has a large quantity of fruit
images. So here, the author first calculates the amount
of images in the folder. There are 90483 images in the
dataset. The training set contains 67692 images and
the test set contains 22688 images. There are 131
classes of fruits. Fig. 1. shows some pictures in the
dataset in Jupyter Notebook.
To simplify the problem, only 10 classes of fruits
were used for image classification. Doing this can
reduce the expense of time, which can highly develop
the efficiency of evaluating different algorithms.
2.2 Data Preprocessing
By fetching images from the given folder, the author
imports pictures into Python for further classification.
Using Python to get those folders’ names and list them
in an array. Then, with a random rate of 100%, the
original training data are divided into 2 sets. The
training set accounts for 80% and the test set accounts
for 20%.
Figure 1: Some Pictures in the Dataset (Picture credit:
Original).
After that, by resizing images, they are adjusted to
the same scale. Then calculate the image histogram for
further preparation.
2.3 Support Vector Machine
Support Vector Machine is a data-based classification
algorithm, which focuses on establishing a hyperplane
to divide data.
By finding the best hyperplane in space, SVM
could reach a result that the distance between positive
samples and negative samples is the farthest. In binary
classification, SVM could be a line in a 2-
dimensionality figure. It can also be used in a n-
dimensionality question, where n is larger than 2. Fig.
2 shows the utilization in solving binary classification
problems (Guo et al 2023) and Fig. 3. shows the
utilization in solving 3-dimensionality problems.
Figure 2: SVM Principle (2-dimensionality).
DAML 2023 - International Conference on Data Analysis and Machine Learning
368
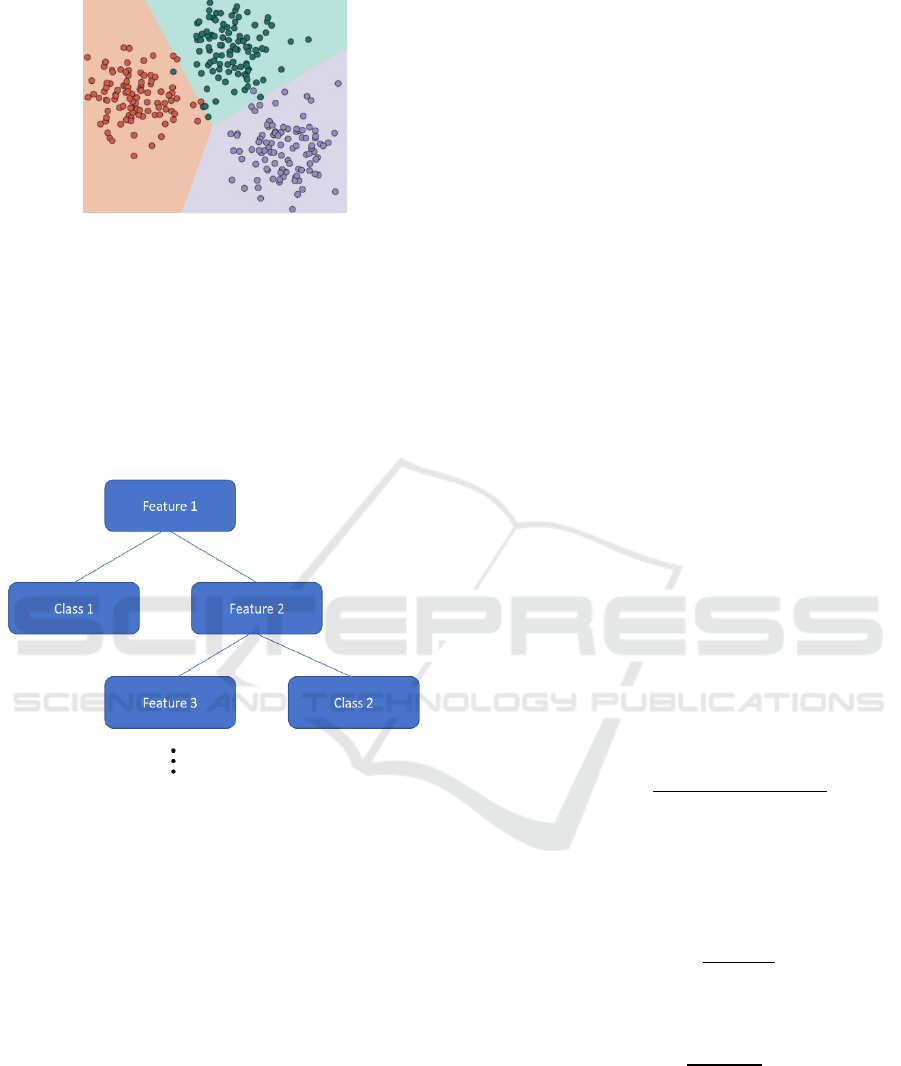
Figure 3: SVM Principle (3-dimensionality).
2.4 Decision Tree
The decision tree algorithm is a method of
approximating discrete function values. It is an
algorithm with a tree structure, and each point means
an attribute for judgements. Leaves refer to a
classification result. By using decisions, the decision
tree algorithm can analyze data using readable rules.
Figure 4: Train of Thought of Decision Tree (Picture credit:
Original).
The decision tree algorithm is a common
supervised learning algorithm. By determining
whether the input data has a label, people can know
whether it is supervised learning. If the input data is
labeled, it is supervised learning. In this task, the data
set is given labels for different pictures, which can be
seen as supervised learning. With supervised learning,
the model can use previous experience for evaluating
the output result, and the accuracy of prediction can be
high.
The train of thought of decision tree is shown in
Fig. 4.
2.5 K-Nearest Neighbors
For classification problems, K-Nearest Neighbors is
an efficient technique that may be applied broadly.
The K-nearest data points may be used to forecast a
specific query point, and the labels of these neighbors
can then be used to predict the query point. In
classification tasks, the predicted label for query
points is determined by the weight of those K-nearest
neighbors. The KNN algorithm can also be used for
text classification. By extracting the features of words,
the text is classified according to different dimensions
(Li 2021).
2.6 Evaluation
By calculating the value of Accuracy, Precision,
Recall and F1-score, the rationality of the algorithm
would be evaluated. Also, by using the test dataset
and calculating the probability of correct
classifications, the model can be proved to be
practical or not. During programming, by
automatically generating the result of Precision,
Recall and F1-score, the accuracy of a certain model
can be found, which is helpful for evaluation.
Confusion matrix is an important tool for
supervised learning. It is a form, which contains rows
representing the practical classes and columns
representing the predicted classes. Each cell
expresses the frequency in a certain state. By
analyzing the confusion matrix, the accuracy of the
model will be further indicated.
Accuracy reflects the proportion of those true
predictions for positive and negative examples. When
a model has a high level of accuracy, it means that the
amount of correct prediction is large. Using (1) can
calculate the value of accuracy.
Precision can reflect the proportion of accurate
predictions based on all predictions. It shows the
proportion of actual predictions in all positive
samples. Equation (2) shows the process of
calculating the value of Precision.
The process of calculating Recall can be explained
by (3).
F1-score is a comprehensive evaluation index for
evaluation, which is based on Precision and Recall. If
a model has a high F1-score, it would be balanced,
which means that one of the values of Precision and
Recall would not be too high. F1-score can be
calculated by (4).
𝐴
𝑐𝑐𝑢𝑟𝑎𝑐𝑦 =
𝑇𝑁 + 𝑇𝑃
𝑇𝑁 + 𝑇𝑃 + 𝐹𝑁 + 𝐹𝑃
1
𝑃𝑟𝑒𝑐𝑖𝑠𝑖𝑜𝑛 =
𝑇𝑃
𝑇𝑃 + 𝐹𝑃
2
𝑅𝑒𝑐𝑎𝑙𝑙 =
𝑇𝑃
𝑇𝑃 + 𝐹𝑁
3
Fruit Image Classification Based on SVM, Decision Tree and KNN
369

3 RESULT
3.1
Runtime Environment
The environment for these algorithm is Jupyter
Notebook 6.6.4. All the code is run on a Dell Inspiron
7400 laptop, with 11
th
Gen Intel® Core™ i7-1165G7
@ 2.80GHz CPU and Intel® Iris® Xe Graphics GPU.
3.2 SVM Result
Using SVM for image classification, and results are
shown in Table 1.
Table 1: SVM Result.
No. Precision Recall F1-score Support
0 0.52 0.58 0.55 106
1 0.69 0.71 0.70 87
2 1.00 1.00 1.00 99
3 1.00 1.00 1.00 91
4 1.00 1.00 1.00 87
5 1.00 1.00 1.00 92
6 1.00 0.97 0.98 92
7 0.99 0.98 0.98 100
8 0.94 0.84 0.89 113
9 0.89 0.88 0.88 83
accuracy - - 0.89 950
macro avg 0.90 0.90 0.90 950
weighted avg 0.90 0.89 0.90 950
The confusion matrix is shown in Fig. 5.
Figure 5: Confusion Matrix for SVM (Picture credit:
Original).
Code execution time: 386.26s.
The SVM algorithm requires a long time to finish
this image classification challenge. There are some
reasons for this:
• When the scale of the dataset is large, the distance
between each sample point and all other sample
points needs to be calculated, which causes the
computational complexity to increase
dramatically as the number of samples increases.
• When dealing with non-linear problems, SVM
requires kernel functions to map primitive
features into higher-dimensional Spaces. This
process can lead to computational complexity,
making the training process slow.
• Binary classification problems were the initial
purpose of SVM's creation. Various binary
classifications are necessary when handling
various classification problems. This process can
lead to increased computational complexity,
making the training process slower. This aspect
will be discussed in the discussion part of this
paper.
There are some characteristics in Fig. 5. In Fig. 5.,
class 0 and class 1’s results are not as good as
expected. Some pictures in class 1 are classified as
class 2, and some pictures in class 2 are classified as
class 1. It is inferred that there is little difference
between class 1 and class 2 in image data features,
which leads to an inaccurate result. Also, due to the
fact that images from class 0 and class 1 are quite
similar to images from class 8 and class 9, which
leads to misclassification.
3.3 Decision Tree Result
Using the decision tree algorithm for image
classification, the results are shown in Table 2.
Table 2: Decision Tree Result.
No. Precision Recall F1-score Support
0 0.94 0.84 0.89 106
1 0.96 0.98 0.97 87
2 0.95 0.98 0.97 99
3 0.98 0.95 0.96 91
4 0.94 0.95 0.95 87
5 0.97 0.95 0.96 92
6 0.95 0.95 0.95 92
7 0.91 0.96 0.94 100
8 0.92 0.93 0.93 113
9 0.93 0.98 0.95 83
accuracy - - 0.94 950
macro avg 0.94 0.95 0.94 950
weighted avg 0.94 0.94 0.94 950
2
𝐹
1
=
1
𝑃𝑟𝑒𝑐𝑖𝑠𝑖𝑜𝑛
+
1
𝑅𝑒𝑐𝑎𝑙𝑙
4
DAML 2023 - International Conference on Data Analysis and Machine Learning
370

The confusion matrix is shown in Fig. 6.
Figure 6: Confusion Matrix for Decision Tree (Picture
credit: Original).
Code execution time: 25.34s.
In Fig. 6., the accuracy of different classes is very
close. There is no longer a phenomenon that the
classification accuracy of some groups is very low as
in the results obtained by the SVM algorithm.
Consider that this effect is caused by image noise.
Superfluous information in photographs is
referred to as image noise. Image noise can be defined
as any variety of elements present in image data that
may impede individuals from making accurate
decisions. Image noises are random and
unpredictable. Usually, while acquiring a picture,
image noise data are produced. The working
environment is often the cause of image noise. Circuit
construction and electronic components may also be
to blame. Image noise can occasionally be produced
as a result of pollution that occurs during media
transmission and recording equipment.
In Fig. 6., each group has a margin of error, which
means they have something in common. Due to the
limited number of image pixels in the dataset, the
prediction accuracy cannot be further improved.
3.4 KNN Result
Using KNN for image classification, the results are
shown in Table 3.
Table 3: KNN Result.
No. precision recall f1-score support
0
0.99
1.00 1.00 106
1 1.00 0.99 0.99 87
2 1.00 1.00 1.00 99
No. precision recall f1-score support
3 1.00 1.00 1.00 91
4 1.00 1.00 1.00 87
5
1.00
1.00 1.00 92
6
0.99
1.00 0.99 92
7 1.00 1.00 1.00 100
8 1.00 1.00 1.00 113
9 1.00 0.99 0.99 83
accuracy - - 1.00 950
macro avg 1.00 1.00 1.00 950
weighted avg 1.00 1.00 1.00 950
The confusion matrix is shown in Fig. 7.
Figure 7: Confusion Matrix for KNN (Picture credit:
Original).
Code execution time: 14.20s.
In Fig. 7., the accuracy of KNN is quite high. In
the experiment, merely a few data have wrong
prediction results. KNN can handle classification
problems, and it can naturally handle multiple
classification problems compared with SVM. The
accuracy of the KNN algorithm is improved by
finding the appropriate K value through loop
traversal. Therefore, the classification results of the
KNN algorithm can be interpreted more accurately
from the perspective of its characteristics.
3.5 Classification Result Evaluation
There is a significant variation in algorithm efficiency
in Fig. 8. SVM is more time-consuming than KNN
and decision trees. The SVM algorithm's
performance generally declines as the number of
classes increases. It was initially created to solve
binary classification problems.
Fruit Image Classification Based on SVM, Decision Tree and KNN
371
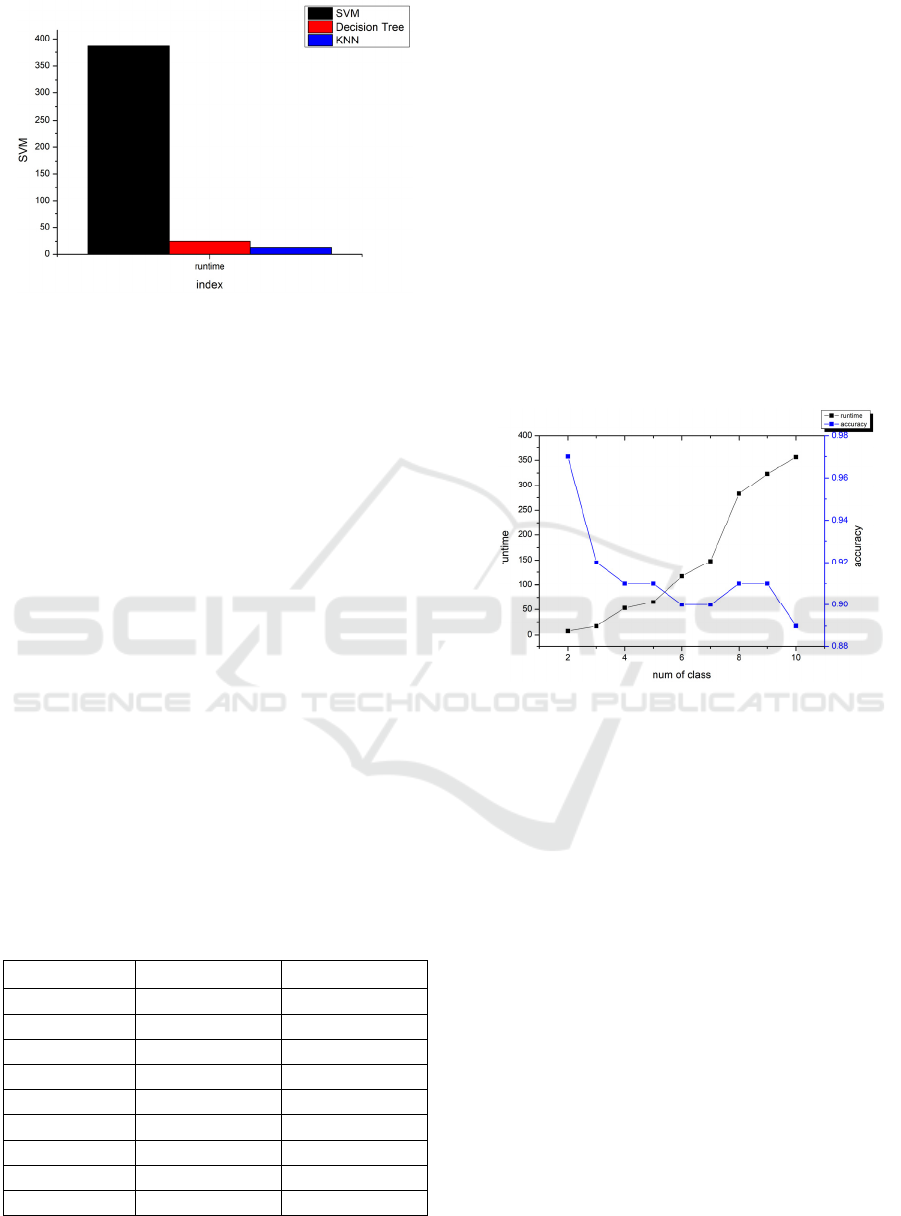
Figure 8: Classification Runtime (Picture credit: Original).
Compared to SVM and the decision tree
algorithm, SVM needs to find the optimal hyperplane
to distinguish data during training, which requires
repeated calculations until a hyperplane satisfying the
conditions is found. It can take a long time to
complete this procedure, particularly when working
with big datasets. In contrast, in the training stage, the
decision tree algorithm simply uses a rectangle to
divide the feature space, so the decision tree
algorithm has a relatively small calculation amount.
In contrast to SVM and KNN, KNN requires less
computation and operates more quickly because it
just has to store training data during the training stage
and compute the distance between the sample to be
predicted and the training data during the prediction
stage.
3.6 Results for SVM Algorithm
Efficiency
In order to find out the law between code execution
time and the amount of classes, the author did further
research on efficiency. By adjusting the amount of
classes from 2 to 10, the result is shown in Table 4.
Table 4: SVM Runtime and Accuracy.
Num of classes Runtime Accuracy
2 7.73 0.97
3 17.43 0.92
4 53.00 0.91
5 65.34 0.91
6 117.26 0.90
7 147.65 0.90
8 282.63 0.91
9 323.07 0.91
10 356.27 0.89
4 DISCUSSION
4.1 Accuracy Differences Between
SVM and Decision Tree
This may caused by the characteristics of SVM and
decision tree. Image data usually has a large number
of features, and the relationships between features can
be very complex. SVM may have difficulty in dealing
with high-dimensional features, especially when
dealing with non-linear problems. In contrast, decision
trees may be more flexible when dealing with
nonlinear problems.
4.2 SVM Algorithm Operation
Efficiency
Figure 9: SVM Algorithm Operation Efficiency (Picture
credit: Original).
In Table 4 and Fig. 9., the tendency of runtime and
accuracy change over time. Also, there is an obvious
increase when the number of classes rises from 7 to 8.
These phenomena can explain the reason for the long
time cost of using SVM in this image classification
task.
5 CONCLUSION
For this image classification task, using SVM,
decision tree and the KNN algorithm can acquire a
precise result. These methods can be widely used in
other image classification tasks by combining with
other technology. If the algorithm listed in this paper
is combined them with the camera, it can be used for
the statistics of supermarkets. This will greatly
improve the operating efficiency of the supermarket
and reduce operating costs. However, there are still
some details that need to be improved. Due to the
limitations of those given data, future research needs
DAML 2023 - International Conference on Data Analysis and Machine Learning
372

to focus on enhancing algorithm accuracy. For
example, add an analysis of some of the features of the
image. By analyzing the texture of the image and the
shape of fruit, the accuracy of the classification
algorithm is improved.
REFERENCES
B. A. Yassine, B. Samia and O. Abdelaziz, An Improved
KNN Classifier for 3D Face Recognition Based on
SURF Descriptors. Journal of Applied Security
Research(4), 2023.
Y. Guo, Z. Tan and Y. Zhang, Glass component
classification model based on decision tree and cluster
analysis..(eds.)Proceedings of 2023 International
Conference on Mathematical Modeling, Algorithm and
Computer Simulation (MMACS 2023), 2023, pp. 221-
227.
Y. Zhang, S. Wang, G. Ji, P. Phillips, Fruit classification
using computer vision and feedforward neural network.
Journal of Food Engineering,2014, 143, pp. 167–177.
B. Wang, R. Ma, J. Kuang and Y. Zhang, "How Decisions
Are Made in Brains: Unpack “Black Box” of CNN
With Ms. Pac-Man Video Game," in IEEE Access, vol.
8, 2020, pp. 142446-142458.
M. A. Chandra and S. S. Bedi, Survey on SVM and their
application in image classification. International
Journal of Information Technology, 2018, 13(5), 1–11.
https://doi.org/10.1007/s41870-017-0080-1
J. Nie, K. Xu and Y. Chen, A glass classification model for
glass artifacts based on PCA and
SVM..(eds.)Proceedings of 2023 International
Conference on Mathematical Modeling, Algorithm and
Computer Simulation (MMACS 2023), 2023, pp. 286-
291.
P. Soucy and G. W. Mineau, A simple KNN algorithm for
text categorization. Proceedings 2001 IEEE
International Conference on Data Mining, 2002.
https://rachelchen0104.medium.com/hands-on-machine-
learning-with-scikit-learn-tensorflow-bbb1c91cb128
https://zhuanlan.zhihu.com/p/141472361
H. Li, An Overview on Remote Sensing Image
Classification Methods with a Focus on Support Vector
Machine.Ying Xing.(eds.)Proceedings of the 2021
International Conference on Signal Processing and
Machine Learning (CONF-SPML 2021), 2021, pp. 64-
70.
Fruit Image Classification Based on SVM, Decision Tree and KNN
373
