
Artificial Intelligence-Machine Learning Techniques Promoting
SDG's: An Exploratory Approach
Pratyush Prasad
1
, Pranjal Prasad
2
and Asim Prasad
3
1
Manipal University Jaipur, India
2
Ajay Kumar Garg Engineering College, Ghaziabad, India
3
Amity University, Noida, India
Keywords: SDG, Artificial Intelligence, Machine Learning, Linear Models, Decision Trees, Random Forest, Naïve
Bayes.
Abstract: This article provides an overview of the Machine Learning (ML) techniques, models, and ideas utilized to
analyze datasets to achieve Sustainable Development Goals (SDG) targets. Furthermore, this study
investigates the use of Artificial Intelligence (AI) in facilitating the attainment of SDGs. An exploratory
approach and a concept-centric literature review were employed to address the study issues. The study reveals
the fundamental principles of Supervised, Unsupervised, and Reinforced ML methodologies, as well as
several algorithms like k-Nearest Neighbours, Linear Models, Naïve Bayes, Decision trees, Random forests,
gradient boosted decision trees, Support vector machines, and Neural networks. The study implications
pertain to the use of artificial intelligence and machine learning techniques to advance the aims of the SDGs
for the betterment of society, the economy, and the environment.
1 INTRODUCTION
The seventeen Sustainable Development Goals
(SDGs), agreed by the UN in 2015, call for
collaborative action to end poverty, protect the
environment, and promote peace and prosperity for
all by 2030. However, complex issues related to these
require the application of Artificial Intelligence(AI)
and Machine Learning(ML) algorithms, models to
support SDG objectives(International
Telecommunication Union, 2021). Machine and
system intelligence is called artificial intelligence
(AI). They can perform duties independently and
work with humans and nature due to their
intelligence. AI software can perceive, decide,
forecast, extract information, recognize patterns from
data, communicate, and think logically(Sætra, 2021).
ML as defined by Arthur Samuel is the “field of study
that allows computers to learn without being
explicitly programmed.” The growing field of data
science uses ML to extract knowledge from datasets.
It combines computer science, statistics, and
AI(Müller & Guido, 2016). ML uses computerized
approaches to solve problems using past data and
expertise without changing critical operations
(Sandhu, 2018). Unlike AI, ML involves discovering
patterns in datasets (data mining) and using them to
classify or predict occurrences related to a problem
(Alpaydın, 2004). ML enables intelligent machines to
maintain their talents. Statistical methods train
algorithms to classify or predict, providing data
mining insights. These insights guide application and
business decisions to improve growth indicators. ML
has several applications that relate to real-world
problems supporting automation (Khanum et al.,
2015) in fields related to bioinformatics(Tan &
Gilbert, 2003), Population Genetics (Schrider &
Kern, 2018), autonomous vehicle (AV), healthcare,
natural language processing (NLP), business
applications, intelligent robots, climate modeling,
gaming, voice processing, image processing(Rustam
et al., 2020), cancer detection(Prasad, 2023). ML
involves data storage, abstraction, generalization, and
evaluation(H, 2023). Data Storage stores and
retrieves large amounts of data, essential to ML.
Cognitive abstraction involves obtaining useful
information from a dataset. Developing broad
concepts that include all data is required. Abstraction
(knowledge generation) uses current and new models.
Training establishes model parameters from a dataset.
After training, the model abstracts the data to capture
its key points. Generalizing stored data knowledge
Prasad, P., Prasad, P. and Prasad, A.
Artificial Intelligence-Machine Learning Techniques Promoting SDG’s: An Exploratory Approach.
DOI: 10.5220/0013405700003882
Paper published under CC license (CC BY-NC-ND 4.0)
In Proceedings of the 2nd Pamir Transboundary Conference for Sustainable Societies (PAMIR-2 2023), pages 1717-1726
ISBN: 978-989-758-723-8
Proceedings Copyright © 2024 by SCITEPRESS – Science and Technology Publications, Lda.
1717
allows it to be used for future decision-making or
action. These actions should be performed on similar
tasks but not identical to earlier ones. The goal of
generalization is to discover the data traits or qualities
that will be most relevant to future activities.
Evaluation involves systematic feedback to the user
to measure the effectiveness or utility of acquired
knowledge. Feedback is then used to improve
learning. ML system knowledge acquisition involves
decision process, error function, and model
optimization. In light of these deliberations,
considering the growing importance of ML, this
article, through an exploratory approach, aims to
provide answers to the following research questions:
RQ1: What ML techniques, models, and concepts
facilitate dataset analysis for SDG
targets?
RQ2: Does the application of AI promote the
achievement of SDGs?
2 LITERATURE REVIEW
The researcher conducted a critical analysis to present
the ML algorithm, models to understand what is
known about the study topic, the related concepts, and
the perspectives(Grant & Booth, 2009). The ML
algorithms (H, 2023; Müller & Guido, 2016) are of
three types: (1) Supervised ML, (2) Unsupervised
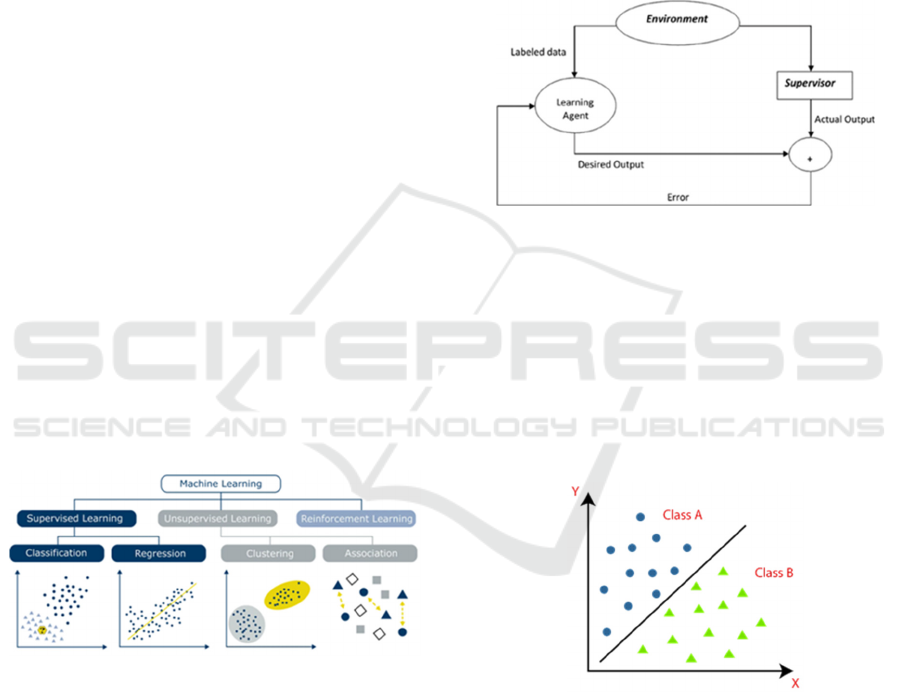
ML, and (3) Reinforced ML, as detailed in Figure 1.
Source: (Polzer, 2021).
Figure 1: Machine Learning Types.
2.1 Supervised ML
Supervised ML is where the user provides the
algorithm with a series of input-output pairs. The
input/output data pair teaches the ML algorithm. The
program finds input-based techniques for output
generation. Supervised ML train models to produce
the desired output using a training set. The training
dataset contains input data and target outputs to help
the model learn iteratively. The approach uses a loss
function to evaluate its performance and iteratively
adjust its settings to minimize error until it reaches a
desirable accuracy. Supervised ML techniques work
in two steps. Analytical tasks begin with training data
analysis. These algorithms then create dependent
functions to map new attribute instances. ML
approaches have found that a training subset of 66%
of the data can achieve the desired result while
minimizing processing needs. (Ng, 2005). The
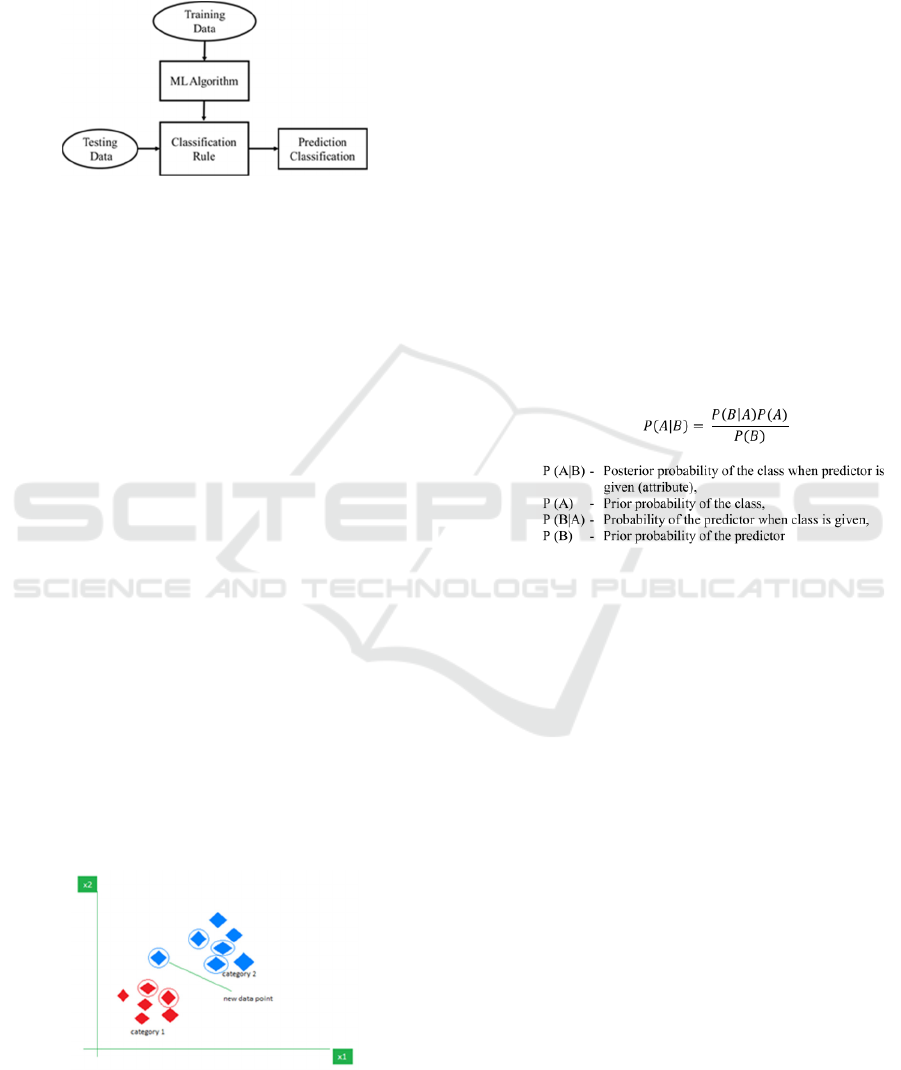
process diagram of supervised ML is in Figure 2. The
Supervised ML problems are of two types:
Source:
https://ebrary.net/136995/computer_science/machine_learning
Figure 2: Process diagram for Supervised Learning.
(a) Classification: Classification refers to the
systematic procedure of utilizing a model to
make predictions about values that are not yet
known, specifically output variables, by
leveraging a set of known values, namely input
variables(Muhammad & Yan, 2015). It aims to
predict a class label (Figure 3).
Source: https://www.javatpoint.com/classification-
algorithm-in-machine-learning
Figure 3: Class Labelling.
It uses an algorithm to assign test data into specific
categories accurately. It recognizes specific entities
within the Dataset and attempts to draw some
conclusions on how those entities should be labeled
or defined. The classifier is the algorithm that is
utilized to classify a given dataset. Classification
problems are either binary classification or multiclass
classification. A binary classifier has two possible
PAMIR-2 2023 - The Second Pamir Transboundary Conference for Sustainable Societies- | PAMIR
1718
outcomes: Yes or No, Male or Female, etc. The
multiclass classifier has more than two outcomes, like
classifying fruits, vegetables etc. Figure 4 shows a
general classification architecture.
Figure 4: General Classification Architecture.
(b) Regression: This technique helps understand
dependent and independent variables. Predicting
a real or continuous number is the goal. Common
regression methods include linear, logistic, and
polynomial. If the outcome is continuous, it's
regression; otherwise, classification. Different
ML algorithms (Bhavsar & Ganatra, 2012) are k-
Nearest Neighbors, Linear Models, Naïve Bayes,
Decision trees, Random forests, Gradient
boosted decision trees, Support vector machines,
and Neural networks( Deep Learning). These are
eleborrated herein.
(i) k-Nearest Neighbors(KNN): K-nearest
neighbor (Lindholm et al., 2019) is an
instance-based supervised ML learning
method that does not rely on parameters and
is one of the simplest to understand using
small datasets. The idea is that "like"
samples tend to cluster together. K-nearest
neighbor classifiers are used to determine
the most common class label given an
unlabeled sample by searching the pattern
space for the k-objects that are closest to it
(Burges, 1998). If k=1, then the unknown
sample is placed in the training sample class
that most closely matches it in the pattern
space. Figure 5 shows the KNN.
Source: https://www.geeksforgeeks.org/k-nearest-neighbours/
Figure 5: KNN Visualization.
(ii) Linear models:
Linear models (Matloff,
2017) are another machine-learning
technique class that explicitly learns from
labeled datasets and maps the data points to
the best-performing linear functions. This
can be applied for prediction purposes on
large multidimensional datasets.
(iii) Naïve Bayes: A category of supervised
learning algorithms known as naive Bayes
methods utilize Bayes' theorem with the
"naive" assumption that each pair of features
is conditionally independent given the value
of the class variable(Maertens et al., 2017).
It is used for Sentiment Analysis, Text
Classification, Credit Scoring, Medical Data
Classification, and Text Filtering for Spam.
The naive Bayesian classifiers presume that,
given the class variables, the value of one
characteristic is independent of the value of
any other characteristic. Accordingly, the
following equation gives the posterior
probability (Gianey & Choudhary, 2018).
(1)
Where,
(iv) Decision trees: A decision tree is a graphical
representation used to facilitate decision-
making or produce numerical forecasts by
utilizing the information contained within a
given dataset. It is a form of supervised
learning methodology that is utilized to
make predictions about response values,
achieved by acquiring decision rules formed
from the Dataset's features. The decision tree
comprises three essential components: a root
node, leaf nodes, and branches. Regardless
of the precise form of the decision tree
employed, the process invariably
commences with a distinct decision. The
choice is visually represented by a box
serving as the root node. A tree structure's
root and leaf nodes include inquiries or
criteria that necessitate a response. Nodes
are typically observed in the form of squares
or circles. In this context, squares are
utilized to symbolize decisions, whilst
circles are employed to indicate ambiguous
outcomes(Müller & Guido, 2016) . Decision
Tree models can potentially be employed in
both regression and classification scenarios.
Artificial Intelligence-Machine Learning Techniques Promoting SDG’s: An Exploratory Approach
1719
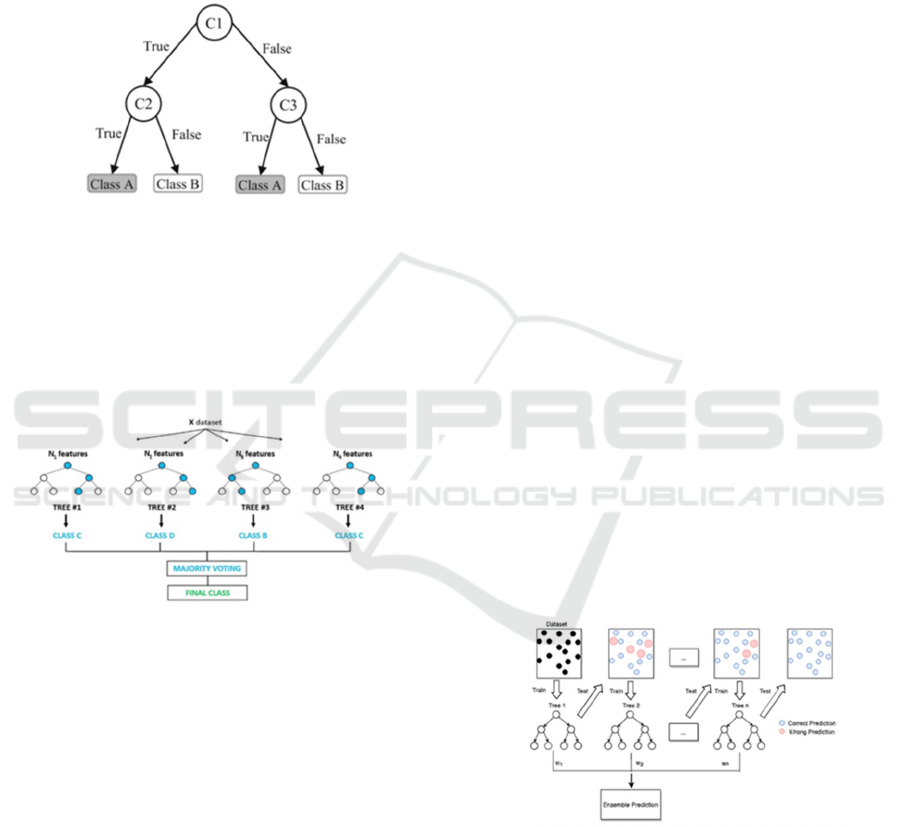
Hence, they are frequently described as
Classification And Regression Trees
(CART). Decision trees are utilized in the
medical domain for diagnostic purposes and
in risk management, personal management,
corporate strategy, financial management,
and project management requirements.
Figure 6 shows a Decision Tree structure.
Source:(Uddin et al., 2019).
Figure 6: Decision Tree.
(v) Random forests: The Random Forest
algorithm (Schrider & Kern, 2018)
integrates the predictions of numerous
decision trees in order to arrive at a
consolidated outcome, as shown in Figure 7.
Source:(David, 2020).
Figure 7: Random Forest.
The high level of user-friendliness and
adaptability of this tool has significantly
contributed to its widespread adoption since
it effectively addresses both classification
and regression tasks. The Random Forest
algorithm is extensively employed in
domains such as E-commerce, banking,
medicine, and the stock market. In the
context of the Banking business, this
technique can be employed to identify
customers who are likely to fail on a loan. It
is employed to forecast the factors that
contribute to optimal functioning. It helps
predict customer behavior and evaluate
medical records.
(vi) Gradient-boosted decision trees: Gradient-
boosted decision trees (Natekin & Knoll,
2013), also referred to as Gradient boosting
machine (GBM) or Gradient Boosted
Regression Tree (GBRT) represent a
machine learning methodology aimed at
enhancing the prediction efficacy of a model
by iteratively refining the learning
process(Chen & Guestrin, 2016; Z. Zhang &
Jung, 2021). The concept of Gradient refers
to the rate of change of a function with
respect to its independent Boosting is
particularly advantageous in scenarios when
the data has a lower number of dimensions,
where a basic linear model exhibits poor
performance, interpretability is of lesser
importance, and there are no stringent
constraints on latency. Boosting algorithms
have demonstrated their suitability for
artificial intelligence projects in several
industries, including a wide spectrum of
sectors. These algorithms have proven to be
effective and efficient in enhancing the
performance of AI systems. In healthcare,
boosting techniques are employed to
mitigate errors in the prediction of medical
data, namely in areas like the estimation of
cardiovascular risk factors and the prognosis
of cancer patient survival rates. Gradient
boosting is a commonly employed technique
in the field of marketing to optimize the
allocation of budget across various channels,
with the ultimate goal of maximizing the
return on investments. Figure 8 shows a
GBM learning model.
Source:
(T. Zhang et al., 2021).
Figure 8: GBM learning model.
(vii) Support vector machine(SVM): The SVM
(Vanneschi & Silva, 2023) is a highly
effective ML technique that has
demonstrated its versatility in numerous
applications, encompassing text
classification, picture classification, spam
PAMIR-2 2023 - The Second Pamir Transboundary Conference for Sustainable Societies- | PAMIR
1720
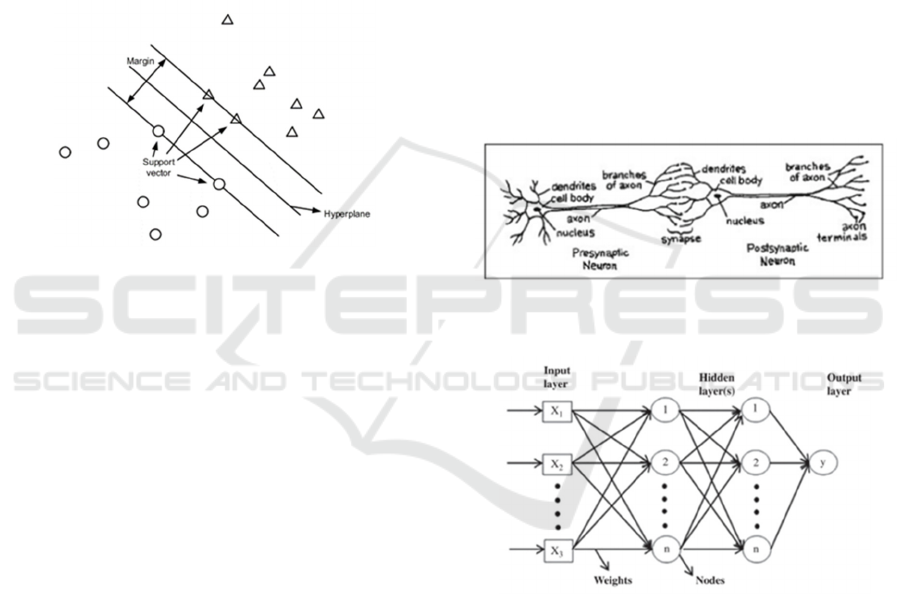
detection, handwriting identification, gene
expression analysis, face detection, and
anomaly detection. SVMs exhibit
adaptability and efficiency across various
applications because they can effectively
handle high-dimensional data and capture
nonlinear correlations. Its algorithms have
demonstrated high efficacy in identifying
the largest separation hyperplane across
several classes within the target
feature(Awad & Khanna, 2015; Jakkula,
2011). Figure 9 displays SVM for binary
classification of data.
Source: Source:(Fan et al., 2021).
Figure 9: SVM for Binary Classification.
(viii) Neural networks: A neural network
(Gurney, 1997) is a type of ML model that is
specifically designed to replicate the
functional and structural characteristics of
the human brain. Neural networks, also
known as artificial neural networks (ANNs)
or deep neural networks have gained
significant popularity as machine learning
techniques that aim to replicate the learning
mechanisms observed in biological
organisms(Charu C. Aggarwal, 2018). This
deep learning technology falls within the
broader domain of AI.. Many people use
ANN to learn computers in a way that is
similar to how living things learn. The cells
that make up the nervous system are called
neurons. Axons and dendrites link the
neurons to each other. The areas where
axons and dendrites meet are called
synapses. Synaptic connections often
change how strong they are in reaction to
things outside of the brain. Figure 10
displays the biological neural network
(BNN) connections. The way living things
learn changed because of this. Neural
networks can build complex models for
large datasets composed of interconnected
neurons, which work together to address
complex challenges. Neural networks are
extensively employed throughout many
domains, encompassing image
identification, predictive modeling, and
natural language processing (NLP). Since
2000, notable instances of commercial
applications have demonstrated
considerable significance(Mijwel et al.,
2019). These include using handwriting
recognition for cheque processing,
transcribing speech into text, analyzing data
for oil and gas exploration, predicting
weather patterns, and implementing facial
recognition technology. Neural networks are
sensitive to parameter choice and data
scaling. Figure 11 shows an ANN general
structure.
Source: (Westbrook et al., 2010).
Figure 10: BNN.
Source: (Sairamya et al., 2019).
Figure 11: ANN General Structure.
2.2 Unsupervised ML
An unsupervised ML algorithm has no known output
and teacher[1]. Unsupervised ML approaches can
find patterns and relationships in a dataset without a
preset output variable, making them useful for
description jobs. This type of ML classification is
called unsupervised ML because there is no response
variable to guide the study. Unsupervised ML seeks
latent dimensions, components, clusters, and
trajectories in data. Principle components analysis,
Artificial Intelligence-Machine Learning Techniques Promoting SDG’s: An Exploratory Approach
1721

factor analysis, and mixture modeling are
unsupervised learning methods(Hastie et al., 2006).
Source: (Morimoto & Ponton, 2021).
Figure 12: Supervised and Unsupervised Learning Model.
Figure 12 depicts a typical supervised and
unsupervised learning model. The types of
unsupervised ML algorithms are discussed
herein.
(a) Dataset Transformation: Dataset
Transformation is the process of
transforming a dataset for ease of
understanding. This involves reducing the
dimension of the data set with high
dimensions and many features with fewer
features without compromising its essential
characteristics.
(b) Clustering: Clustering is a data mining
technique that facilitates the organization of
unlabelled data by grouping them based on
their commonalities or
differences(Alloghani et al., 2020).
Clustering refers to the procedure of
grouping a Dataset based on the similarity of
its components. Clustering algorithms
(Khanum et al., 2015) generate distinct
groups characterized by similar items within
the various categories. Clustering techniques
are utilized for the analysis of raw and
unclassified data elements, aiming to
arrange them into separate groups that
exhibit inherent structures or patterns within
the data. Figure 13 shows a clustering
model. Clustering methods can be
categorized into various classes, including
exclusive, overlapping, hierarchical, and
probabilistic.
Source: (Dutt et al., 2019).
Figure 13: Clustering Model.
(i) Exclusive clustering: Exclusive clustering is
a type of clustering that enforces the
constraint that each data point can belong to
only one cluster. The K-means clustering
algorithm exemplifies the concept of
exclusive clustering.
Pattern identification,
image analysis, consumer analytics, market
segmentation, social network analysis, and
many more domains apply the clustering
technique.
(ii) Overlapping: Overlapping clustering
techniques permit data points to be attached
to multiple clusters. Partitioning methods
are more prevalent than overlapping
clustering algorithms due to their simplicity
and effectiveness on large datasets.
(iii) Hierarchical clustering: Hierarchical
Clustering aims to identify inherent clusters
by considering the Dataset's attributes. The
primary objective of the hierarchical
clustering algorithm is to identify and
construct a hierarchical structure that reveals
the presence of nested groups within the
Dataset. The concept resembles the
biological taxonomy in classifying
organisms within the plant or animal
kingdom. Hierarchical clusters are typically
depicted through a hierarchical tree structure
referred to as a dendrogram. Hierarchical
clustering can be classified into two distinct
approaches: agglomerative, also known as
the bottom-up technique, and divisive, also
referred to as the top-down approach.
(iv) Probabilistic clustering: Probabilistic
clustering is a technique that addresses
density estimation or "soft" clustering
challenges. It is utilized for the purpose of
addressing density estimation or "soft"
clustering difficulties. Probabilistic
clustering is a technique wherein data points
PAMIR-2 2023 - The Second Pamir Transboundary Conference for Sustainable Societies- | PAMIR
1722
are grouped based on their probability of
belonging to a specific distribution.
(c) Association: Association rule is a form of
unsupervised learning methodology that
examines the interdependence between
different data elements and is designed to
enhance cost-effectiveness. Market basket
analysis is a commonly employed approach
for examining the association between
various items, enabling firms to enhance
their comprehension of these relationships.
(d) Apriori algorithms: Apriori is an
unsupervised learning methodology due to
its frequent application in identifying and
extracting remarkable patterns and
associations. The Apriori algorithm can be
adapted to perform classification tasks using
labeled data. The popularity of Apriori
algorithms has been primarily driven by
their application in market basket research,
resulting in the development of diverse
recommendation engines for music
platforms and online stores.
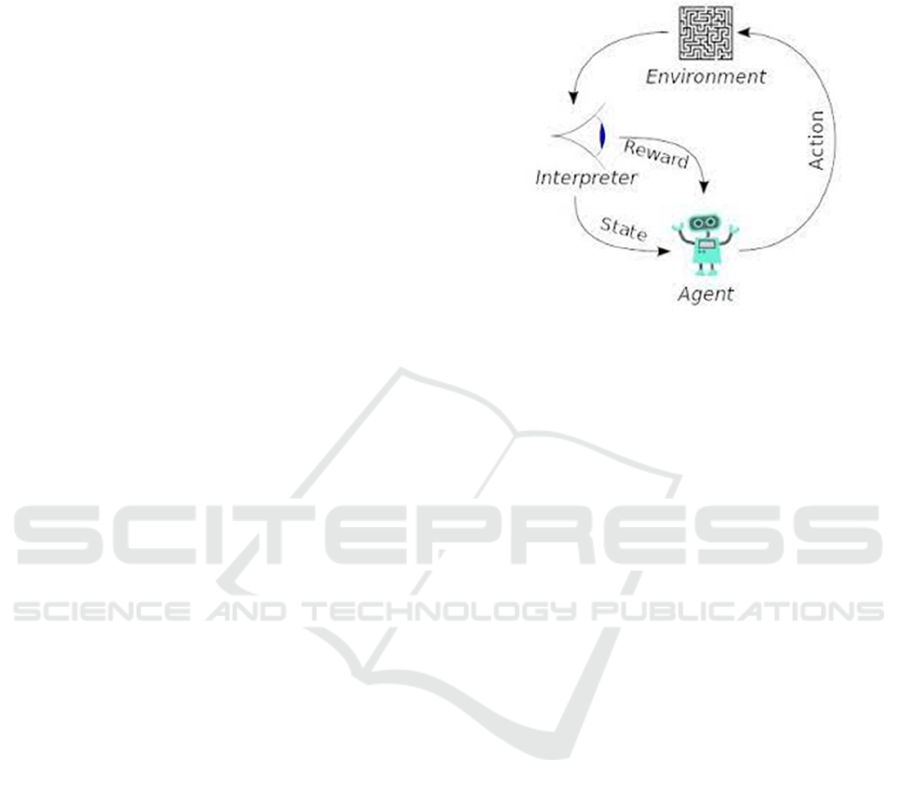
2.3 Reinforced ML
ML is a scientific study of decision-making, and
reinforcement ML (Naeem et al., 2020; Sutton &
Barto, 2018) is a subfield. A software agent interacts
with an unknown environment. The agent's behaviors
reveal the environment's dynamics. To maximize
reward, obtain the best actions in a specific context.
It involves using appropriate measures to maximize
advantages in a given setting. This self-teaching
system learns by trial and error. The agent optimizes
rewards through trial-and-error behavior. As the
reinforcement agent chooses how to complete the job,
reinforcement learning has no predetermined answer.
The machine may learn from its own experiences if
there is no training dataset. This data is collected
using trial-and-error ML techniques. Reinforcement
learning algorithms learn from observed outcomes
and select the best action. After each step, the
algorithm receives feedback to determine whether its
choice was correct, neutral, or erroneous. This
technique is useful in automated systems that must
make many incremental judgments without human
interaction. Reinforced Learning has an agent,
environment, policy, reward signal, and value
function. Environment models may also be present. A
common reinforcement learning model is in Figure
14. Reinforcement learning is used in robotics,
autonomous control, healthcare, communication and
networking, gaming, natural language processing,
scheduling management, and self-organized
systems(Naeem et al., 2020).
Source: (Mahesh Batta, 2020).
Figure 14: Reinforced Learning.
3 AI-ML AND SDGs
(Vinuesa et al., 2020) grouped SDGs into societal,
economic, and environmental categories, arguing that
the increasing influence of AI through technological
improvement will likely enable 134 (79 %) targets
across all SDGs. Sixty-seven societal targets (82%)
benefit from AI that positively impact the provision
of energy services, water, food, good health, and low
carbon systems, promoting a circular economy.
Forty-two economic group targets (70%) will benefit
from AI-enabled technologies related to decent work,
industry innovation, infrastructure, and inequality.
Further, twenty five targets (93%) from the
environmental group will be positively impacted.
These relate to life below water, life on land, and
climate action. As AI may inhibit some targets, it is
necessary to overcome safety, transparency, and
ethical standards and put regulatory standards in place
to plug perceived gaps.(Sætra, 2021) supports these
arguments, viewing AI as part of a sociotechnical
system that includes bigger structures economic and
political processes, not as a standalone tool. (Nasir et
al., 2023) imply that while the advancement of AI
technology is concentrated on enhancing present
economic growth, significant societal and
environmental challenges may be overlooked. Thus
AI is poised to assume a more prominent position in
the field of achieving SDGs. Its potential to provide
support and facilitate coordination in this domain is
expected to grow significantly in the future(Leal
Filho et al., 2023).
Artificial Intelligence-Machine Learning Techniques Promoting SDG’s: An Exploratory Approach
1723

4 FINDINGS AND CONCLUSION
The findings briefly present the answers to the
research questions.
RQ1: What ML techniques, models, and concepts
facilitate dataset analysis for SDG targets?
In a general sense, machine learning encompasses
the use of diverse models to discern patterns inside
data and subsequently generate precise predictions by
leveraging the observed patterns. These subjects are
interconnected with supervised learning, a technique
that uses training data to teach the model.
Generalization refers to the ability of a machine
learning model to make accurate predictions about
unseen data based on its training data. Overfitting
occurs when a model exhibits excessive fidelity to the
training data, diminishing the ability to generalize to
unseen data. Underfitting occurs when the model fails
to predict outcomes accurately using training and
fresh, unseen data. Supervised learning involves
partitioning data into three distinct categories:
training, development, and testing datasets. The test
dataset is employed post-model development to
evaluate the model's performance on previously
unseen data.
Additionally, the selection of pertinent fields
within a dataset was deliberated upon. Subsequently,
an analysis was conducted on ANN, which serve as
the first model inside this sequence of blog entries.
Neural networks typically consist of three layers: an
input layer, a hidden layer, and an output layer.
Neural networks emerged as pioneering machine
learning models, with subsequent investigations
delving into numerous versions of this paradigm. The
utilization of several hidden layers in deep neural
networks enhances their performance in certain tasks
compared to simple neural networks, owing to their
inherent complexity.
The research presented Supervised,
Unsupervised, and Reinforced ML algorithms.
Under Supervised ML, the classification and
regression models were deliberated. The different ML
algorithms presented are k-Nearest Neighbors, Linear
Models, Naïve Bayes, Decision trees, Random
forests, Gradient boosted decision trees, Support
vector machines, and Neural networks. The types of
unsupervised ML and reinforced ML with concepts
were discussed.
RQ2: Does the application of AI promote the
achievement of SDGs?
The findings reveal that AI-ML research
supports and promotes the achievement of SDG
targets. AI-ML helps to model worldwide complex
challenges related to overcoming poverty, inequality,
climate change, environmental degradation, peace,
and justice(Leal Filho et al., 2023). AI can help solve
humanity's biggest problems in almost all fields, like
human health. agriculture and forest ecosystems that
affect our planet, but large-scale AI adoption also
poses unanticipated hazards(Holzinger et al., 2021).
Thus, stakeholders, governments, policymakers,
industry, and academia must ensure that AI is
developed with these potential threats in mind. Also,
it needs to be ensured that AI applications are safe,
traceable, transparent, explainable, valid, and
verifiable. This will be possible if stakeholders
employ trustworthy and ethical AI and avoid
misusing AI technologies. AI provides many
opportunities to solve complex problems, manage
climate change, and help nations achieve their stated
targets for net zero carbon emissions in the long run.
This response aims to outline the essential principles
and insights that must be embraced to ensure a
constructive transformation of AI advancements and
implementations, ultimately facilitating the
achievement of the SDGs by the year 2030.
REFERENCES
Alloghani, M., Al-Jumeily, D., Mustafina, J., Hussain, A.,
& Aljaaf, A. J. (2020). A Systematic Review on
Supervised and Unsupervised Machine Learning
Algorithms for Data Science.
https://doi.org/10.1007/978-3-030-22475-2_1
Alpaydın, E. (2004). Introduction to Machine Learning
(2nd ed.). The MIT Press.
Awad, M., & Khanna, R. (2015). Efficient learning
machines: Theories, concepts, and applications for
engineers and system designers. In Efficient Learning
Machines: Theories, Concepts, and Applications for
Engineers and System Designers (Issue April 2015, pp.
1–248). https://doi.org/10.1007/978-1-4302-5990-9
Bhavsar, H., & Ganatra, A. (2012). A Comparative Study
of Training Algorithms for Supervised Machine
Learning. International Journal of Soft Computing and
Engineering, 2(4), 74–81.
Burges, C. J. C. (1998). A Tutorial on Support Vector
Machines for Pattern Recognition. Data Mining and
Knowledge Discovery, 2(2), 121–167.
https://doi.org/10.1023/A:1009715923555
Charu C. Aggarwal. (2018). Neural Networks and Deep
Learning. In Neural Networks and Deep Learning.
Springer. https://doi.org/110.1007/978-3-319-94463-0
Chen, T., & Guestrin, C. (2016). XGBoost: A Scalable Tree
Boosting System. KDD ’16: Proceedings of the 22nd
PAMIR-2 2023 - The Second Pamir Transboundary Conference for Sustainable Societies- | PAMIR
1724

ACM SIGKDD International Conference on
Knowledge Discovery and Data Mining.
David, D. (2020). Random Forest Classifier Tutorial: How
to Use Tree-Based Algorithms for Machine Learning.
FreeCodeCamp.
https://www.freecodecamp.org/news/how-to-use-the-
tree-based-algorithm-for-machine-learning/
Dutt, S., Chandramouli, S., & Das, A. K. (2019). Machine
Learning. In Pearson. Pearson India Educa?ion
Services Pvt. Ltd.
Fan, J., Lee, J., & Lee, Y. (2021). A transfer learning
architecture based on a support vector machine for
histopathology image classification. Applied Sciences
(Switzerland), 11(14).
https://doi.org/10.3390/app11146380
Gianey, H. K., & Choudhary, R. (2018). Comprehensive
Review On Supervised Machine Learning Algorithms.
Proceedings - 2017 International Conference on
Machine Learning and Data Science, MLDS 2017,
2018-Janua(December 2017), 38–43.
https://doi.org/10.1109/MLDS.2017.11
Grant, M. J., & Booth, A. (2009). A typology of reviews:
An analysis of 14 review types and associated
methodologies. Health Information and Libraries
Journal, 26(2), 91–108. https://doi.org/10.1111/j.1471-
1842.2009.00848.x
Gurney, K. (1997). Introduction to neural networks. In
Routledge (Vol. 317). UCL Press Limited.
https://doi.org/10.1016/S0140-6736(95)91746-2
H, V. M. (2023). What Is Machine Learning? Components
And Applications. VTUPulse.
https://www.vtupulse.com/machine-learning/what-is-
machine-learning-components-and-applications/
Hastie, T., Tibshirani, R., James, G., & Witten, D. (2006).
An Introduction to Statistical Learning Second Edition.
Springer Texts, 102, 618.
Holzinger, A., Weippl, E., Tjoa, A. M., & Kieseberg, P.
(2021). Digital Transformation for Sustainable
Development Goals (SDGs) - A Security, Safety and
Privacy Perspective on AI. International Cross-
Domain Conference for Machine Learning and
Knowledge Extraction, 1–20.
https://doi.org/10.1007/978-3-030-84060-0
International Telecommunication Union. (2021). United
Nations Activities on Artificial Intelligence.
Jakkula, V. (2011). Tutorial on Support Vector Machine
(SVM). School of EECS, Washington State University,
1–13.
http://www.ccs.neu.edu/course/cs5100f11/resources/ja
kkula.pdf
Khanum, M., Mahboob, T., Imtiaz, W., Abdul Ghafoor, H.,
& Sehar, R. (2015). A Survey on Unsupervised
Machine Learning Algorithms for Automation,
Classification and Maintenance. International Journal
of Computer Applications, 119(13), 34–39.
https://doi.org/10.5120/21131-4058
Leal Filho, W., Yang, P., Eustachio, J. H. P. P., Azul, A.
M., Gellers, J. C., Gielczyk, A., Dinis, M. A. P., &
Kozlova, V. (2023). Deploying digitalisation and
artificial intelligence in sustainable development
research. In Environment, Development and
Sustainability (Vol. 25, Issue 6). Springer Netherlands.
https://doi.org/10.1007/s10668-022-02252-3
Lindholm, A., Wahlström, N., Lindsten, F., & Schön, T. B.
(2019). Supervised Machine Learning: Statistical
Machine Learning course (p. 112).
http://www.it.uu.se/edu/course/homepage/sml/literatur
e/lecture_notes.pdf
Maertens, R. M., Long, A. S., & White, P. A. (2017).
Performance of the in vitro transgene mutation assay in
MutaMouse FE1 cells: Evaluation of nine misleading
(“False”) positive chemicals. Environmental and
Molecular Mutagenesis, 58(8), 582–591.
https://doi.org/10.1002/em.22125
Mahesh Batta. (2020). Machine Learning Algorithms - A
Review. International Journal of Science and Research
(IJSR), January 2019.
https://doi.org/10.21275/ART20203995
Matloff, N. (2017). Statistical Regression and
Classification. Statistical Regression and
Classification. https://doi.org/10.1201/9781315119588
Mijwel, M. M., Esen, A., & Shamil, A. (2019). Overview
of Neural Networks. In Neural Networks and Fuzzy
Systems (Issue April). https://doi.org/10.1007/978-1-
4615-6253-5_1
Morimoto, J., & Ponton, F. (2021). Virtual reality in
biology: could we become virtual naturalists?
Evolution: Education and Outreach, 14(1), 1–14.
https://doi.org/10.1186/s12052-021-00147-x
Muhammad, I., & Yan, Z. (2015). Supervised Machine
Learning Approaches: a Survey. ICTACT Journal on
Soft Computing, 05(03), 946–952.
https://doi.org/10.21917/ijsc.2015.0133
Müller, A. C., & Guido, S. (2016). Introduction to Machine
Learning with Python (D. Schanafelt (ed.); 3rd ed.).
O’Reilly Media, Inc.
https://www.oreilly.com/library/view/introduction-to-
machine/9781449369880/
Naeem, M., Rizvi, S. T. H., & Coronato, A. (2020). A
Gentle Introduction to Reinforcement Learning and its
Application in Different Fields. IEEE Access, 8,
209320–209344.
https://doi.org/10.1109/ACCESS.2020.3038605
Nasir, O., Javed, R. T., Gupta, S., Vinuesa, R., & Qadir, J.
(2023). Artificial intelligence and sustainable
development goals nexus via four vantage points.
Technology in Society, 72(November 2022), 102171.
https://doi.org/10.1016/j.techsoc.2022.102171
Natekin, A., & Knoll, A. (2013). Gradient boosting
machines, a tutorial. Frontiers in Neurorobotics,
7(DEC). https://doi.org/10.3389/fnbot.2013.00021
Ng, A. (2005). Lecture notes Supervised Learning (Issue 0).
Polzer, D. (2021).
7 of the Most Used Regression
Algorithms and How to Choose the Right One. Towards
Data Science. https://towardsdatascience.com/7-of-the-
most-commonly-used-regression-algorithms-and-how-
to-choose-the-right-one-fc3c8890f9e3
Prasad, P. (2023). The Application of Machine Learning
Techniques to the Diagnosis of Breast Cancer. 2023 3rd
International Conference on Artificial Intelligence and
Artificial Intelligence-Machine Learning Techniques Promoting SDG’s: An Exploratory Approach
1725

Signal Processing (AISP).
https://doi.org/10.1109/AISP57993.2023.10134824
Rustam, F., Reshi, A. A., Mehmood, A., Ullah, S., On, B.
W., Aslam, W., & Choi, G. S. (2020). COVID-19
Future Forecasting Using Supervised Machine
Learning Models. IEEE Access, 8, 101489–101499.
https://doi.org/10.1109/ACCESS.2020.2997311
Sætra, H. S. (2021). Ai in context and the sustainable
development goals: Factoring in the unsustainability of
the sociotechnical system. Sustainability (Switzerland),
13(4), 1–19. https://doi.org/10.3390/su13041738
Sairamya, N. J., Susmitha, L., George, S. T., & Subathra,
M. S. P. (2019). Hybrid Approach for Classification of
Electroencephalographic Signals Using Time–
Frequency Images With Wavelets and Texture Features
- ScienceDirect. In Intelligent Data Analysis for
Biomedical Applications Challenges and Solutions (pp.
253–273). Academic Press.
https://doi.org/10.1016/B978-0-12-815553-0.00013-6
Sandhu, T. H. (2018). Machine learning and natural
language processing - a review. International Journal
of Advanced Research in Computer Science, 9(2), 582–
584.
Schrider, D. R., & Kern, A. D. (2018). Supervised Machine
Learning for Population Genetics: A New Paradigm.
Trends in Genetics, 34(4), 301–312.
https://doi.org/10.1016/j.tig.2017.12.005
Sutton, R. S., & Barto, A. G. (2018). Reinforcement
Learning- An Introduction (2nd ed.). The MIT Press.
Tan, A. C., & Gilbert, D. (2003). An Empirical Comparison
of Supervised Machine Learning Techniques in
Bioinformatics BT - First Asia-Pacific Bioinformatics
Conference (APBC2003). 19(Apbc), 219–222.
http://www.cs.waikato.ac.nz/~ml/weka/%0Ahttp://crpi
t.com/confpapers/CRPITV19Tan.pdf
Uddin, S., Khan, A., Hossain, M. E., & Moni, M. A. (2019).
Comparing different supervised machine learning
algorithms for disease prediction. BMC Medical
Informatics and Decision Making, 19(1), 1–16.
https://doi.org/10.1186/s12911-019-1004-8
Vanneschi, L., & Silva, S. (2023). Support Vector
Machines. Natural Computing Series, 271–281.
https://doi.org/10.1007/978-3-031-17922-8_10
Vinuesa, R., Azizpour, H., Leite, I., Balaam, M., Dignum,
V., Domisch, S., Felländer, A., Langhans, S. D.,
Tegmark, M., & Fuso Nerini, F. (2020). The role of
artificial intelligence in achieving the Sustainable
Development Goals. Nature Communications, 11(1),
1–10. https://doi.org/10.1038/s41467-019-14108-y
Westbrook, A. L., Hannigan, D. A., Developer, C.,
Dougherty, M., College, H., Friedman, D., & Carolina,
N. (2010).
The Brain : Understanding Neurobiology
Through the Study of Addiction.
Zhang, T., Lin, W., Vogelmann, A. M., Zhang, M., Xie, S.,
Qin, Y., & Golaz, J. C. (2021). Improving Convection
Trigger Functions in Deep Convective
Parameterization Schemes Using Machine Learning.
Journal of Advances in Modeling Earth Systems, 13(5),
1–19. https://doi.org/10.1029/2020MS002365
Zhang, Z., & Jung, C. (2021). GBDT-MO: Gradient-
Boosted Decision Trees for Multiple Outputs. IEEE
Transactions on Neural Networks and Learning
Systems, 32(7), 3156–3167.
https://doi.org/10.1109/TNNLS.2020.3009776
PAMIR-2 2023 - The Second Pamir Transboundary Conference for Sustainable Societies- | PAMIR
1726
