
Dataset Characteristics and Their Impact on Offline Policy Learning of
Contextual Multi-Armed Bandits
Piotr Januszewski
a
, Dominik Grzegorzek
b
and Paweł Czarnul
c
Department of Computer Architecture, Gda
´
nsk University of Technology, Gda
´
nsk, Poland
Keywords:
Contextual Multi-Armed Bandits, Offline Policy Learning, Dataset Quality.
Abstract:
The Contextual Multi-Armed Bandits (CMAB) framework is pivotal for learning to make decisions. However,
due to challenges in deploying online algorithms, there is a shift towards offline policy learning, which relies
on pre-existing datasets. This study examines the relationship between the quality of these datasets and the
performance of offline policy learning algorithms, specifically, Neural Greedy and NeuraLCB. Our results
demonstrate that NeuraLCB can learn from various datasets, while Neural Greedy necessitates extensive cov-
erage of the action-space for effective learning. Moreover, the way data is collected significantly affects offline
methods’ efficiency. This underscores the critical role of dataset quality in offline policy learning.
1 INTRODUCTION
The Contextual Multi-Armed Bandits (CMAB)
framework (Lattimore and Szepesv
´
ari, 2020) enables
a myriad of services such as recommendation sys-
tems (Zhao et al., 2013), personalized healthcare (Ko-
morowski et al., 2018), online advertisement (Li et al.,
2010), and resource allocation (Badanidiyuru et al.,
2013) to actively learn and adapt from interactions
with their respective environments.
However, the challenge of continuously deploy-
ing online learning algorithms due to costs, privacy
concerns, or constraints on exploration has brought
offline policy learning to the forefront (Levine et al.,
2020). Offline policy learning, which learns policies
from previously collected datasets without interacting
with the environment, is beneficial in settings where
online interactions are costly, risky, or unethical.
One major determinant of offline policy learning
performance is the quality and nature of the offline
dataset (Fujimoto et al., 2019). This component is
often overlooked, with the majority of studies empha-
sizing algorithmic improvements. Hence, there exists
a research gap in fully understanding the impact of
the offline dataset on the performance of the offline
policy learning algorithms.
This paper seeks to shed light on the relation-
a
https://orcid.org/0000-0003-3817-3479
b
https://orcid.org/0009-0006-0310-7104
c
https://orcid.org/0000-0002-4918-9196
ship between offline datasets and the performance of
offline policy learning algorithms in the contextual
bandits setting. In our empirical investigation, we
gather datasets that meet various conditions. For the
uniform data coverage assumption (Brandfonbrener
et al., 2021), actions need to be chosen uniformly at
random. In contrast, the single-policy concentration
condition (Nguyen-Tang et al., 2022) necessitates the
behavior policy to only cover the target optimal pol-
icy. We also explore datasets that extrapolate between
these two conditions or that satisfy neither, particu-
larly those that predominantly issue suboptimal ac-
tions.
Our work considers two offline methods, Neural
Greedy, referred to as the Direct Method in (Dudik
et al., 2011), and NeuraLCB (Nguyen-Tang et al.,
2022). We chose NeuraLCB due to its state-of-the-
art performance in offline policy learning, offering
cutting-edge insights into how different dataset char-
acteristics impact algorithm efficiency. On the other
hand, Neural Greedy is known for its simplicity and
ease of implementation, and represents a method that
practitioners are likely to adopt first (Dutta et al.,
2019).
We present a comprehensive empirical investiga-
tion that elucidates the relationship between offline
dataset characteristics and the performance of offline
policy learning algorithms. This analysis specifi-
cally contrasts two distinct methods: Neural Greedy
and NeuraLCB, providing a nuanced understanding
of how different dataset conditions influence their ef-
Januszewski, P., Grzegorzek, D. and Czarnul, P.
Dataset Characteristics and Their Impact on Offline Policy Learning of Contextual Multi-Armed Bandits.
DOI: 10.5220/0012311000003636
Paper published under CC license (CC BY-NC-ND 4.0)
In Proceedings of the 16th International Conference on Agents and Artificial Intelligence (ICAART 2024) - Volume 2, pages 87-98
ISBN: 978-989-758-680-4; ISSN: 2184-433X
Proceedings Copyright © 2024 by SCITEPRESS – Science and Technology Publications, Lda.
87

ficiency. Our findings offer practical guidance for
practitioners in preparing offline datasets and select-
ing appropriate offline methods, thus contributing to
improved performance in real-world applications.
2 PRELIMINARIES
We consider Contextual Multi-Armed Bandits
(CMAB) framework (Lattimore and Szepesv
´
ari,
2020). Let the context space X be infinite and
the action space A be finite with |A | = K < ∞.
Additionally, let a reward vector r ∈ [r
min
, r
max
]
K
and
a context x ∈ X be drawn from a joint distribution ρ.
Let H represent the history of past interactions up
to round t − 1, where a history h
1:t−1
is a sequence
h
1:t−1
= {(x
1
, a
1
, r
a
1
), . . . , (x
t−1
, a
t−1
, r
a
t−1
)}.
We now define a policy π : X × H → P(A) that
maps the current context and the history up to that
round to a distribution over actions. At each round
t, a contextual bandit observes a context x
t
, decides
on an action a
t
∼ π(x
t
, h
1:t−1
), and receives an action
reward r
a
t
which is the component of the vector r
t
cor-
responding to the action a
t
— this is termed a bandit
feedback.
For every policy π, the regret R
T
after T rounds is
defined as:
R
T
=
T
∑
t=1
max
a∈A
r
t
− r
a
t
where x
t
, r
t
∼ ρ and a
t
∼ π(x
t
, h
1:t−1
) at each round t.
The suboptimality of a policy π is defined as its
average regret after T rounds:
SubOpt(π) =
R
T
T
In the offline setting, we define a finite dataset
consisting of CMAB rounds played with a behavior
policy β:
S
β
= {(x
i
, a
i
, r
a
i
)}
N
i=1
The goal of an offline CMAB method is to learn an
optimal policy π
∗
= min
π
SubOpt(π), that minimizes
the suboptimality, using only the bandit feedback in
the dataset S
β
.
3 METHODS
3.1 Behavior Policies
In this section, we briefly describe the four online
learning algorithms used in our research to collect
datasets: Neural Greedy, Bayes by Backprop, Lin-
UCB, and NeuralUCB.
The Neural Greedy method was also used as one
of the baselines in (Blundell et al., 2015). The Neu-
ral Greedy method learns from observations at each
round to estimate the reward vectors r with a reward
function f (x; θ). The reward function f (x; θ) is a neu-
ral network with parameters θ. It is then used in place
of the actual reward to evaluate the policy value and
to maximize it by selecting the highest valued action
in the policy π(x) = argmax
a
f
a
(x;θ), where f
a
(x;θ)
is the component corresponding to action a of the out-
put from the neural network. This approach requires
an accurate model of rewards, which can be a restric-
tive assumption in some cases. However, when the
model of rewards is accurate, it can provide a reliable
estimate of the policy value.
The Bayes by Backprop is an algorithm proposed
in (Blundell et al., 2015) that regularizes the neural
network model weights by minimizing a compres-
sion cost. It introduces uncertainty in the weights of
the neural network, which can improve generalization
in non-linear regression problems. The uncertainty
is modeled by a variational posterior q
θ
(w) over the
weights w of the network, where θ is the variational
parameters learned by the algorithm. The compres-
sion cost is given by the KL divergence between the
variational posterior and a prior p(w), and is min-
imized by adjusting the variational parameters. In
areas where the network is less confident in its pre-
dictions (high uncertainty), Bayes by Backprop ex-
plores more, gathering more data to reduce the un-
certainty. In areas where the network is more con-
fident in its predictions (low uncertainty), Bayes by
Backprop exploits its knowledge, making decisions
that maximize the expected reward. This approach
can help to focus more on approximating the reward
in areas that are important for the policy (high un-
certainty), leading to more accurate estimates of the
policy value and better decision-making overall. This
can be particularly beneficial in addressing the lim-
itations of Neural Greedy, where the reward esti-
mate might focus on approximating the reward in ar-
eas that are irrelevant to the policy (low uncertainty).
The policy used by Bayes by Backprop is given by
π(x) = argmax
a
f
a
(x;w), where f
a
(x;w) is the compo-
nent corresponding to action a of the output from the
neural network with weights w ∼ q
θ
, sampled from
the variational posterior, and input context x. Effec-
tively, this policy selects actions that maximize the
expected output of the network under the variational
posterior over the weights.
The LinUCB method is described in (Li et al.,
2010). The authors model personalized recommen-
ICAART 2024 - 16th International Conference on Agents and Artificial Intelligence
88

dation of news articles as a contextual bandit prob-
lem. The LinUCB algorithm assumes that the ex-
pected payoff of an arm is linear in its d-dimensional
feature vector with some unknown coefficient vector.
The algorithm uses ridge regression to estimate the
coefficients θ and computes a confidence interval for
the expected payoff of each arm. The arm with the
highest upper confidence bound (UCB) is selected in
each round. The policy used by LinUCB is given by
π(x) = argmax
a
x
T
θ
a
+ α
p
x
T
A
−1
a
x, where θ
a
is the
ridge regression estimate of the coefficients for action
a, A
a
is the design matrix for action a, and α is a hy-
perparameter controlling the exploration-exploitation
trade-off.
The NeuralUCB method, introduced in (Zhou
et al., 2020), extends the LinUCB approach by using
a neural network f (x; θ) to model the reward func-
tion, allowing it to handle more complex, non-linear
relationships between the context and the expected re-
ward. This is a significant departure from the Lin-
UCB method, which assumes a linear relationship.
The policy used by NeuralUCB is given by π(x) =
argmax
a
f
a
(x;θ) + UCB(x, a, θ), where UCB(x, a, θ) is
an exploration bonus described in the paper.
3.2 Offline Methods
In this section, we briefly describe the two offline
policy learning algorithms trained on the collected
datasets: Neural Greedy and NeuraLCB.
The offline variant of the Neural Greedy method
is used in the context of Offline Contextual Multi-
Armed Bandits (CMAB). Unlike its online counter-
part, the offline Neural Greedy operates under the
constraint that it cannot interact with the environment
or collect more data. It aims to learn an optimal policy
solely from a fixed offline dataset of bandit feedback,
denoted as S
β
. The method uses a neural network to
estimate the reward vectors r from the observations
in the dataset S
β
. The policy π(x) is then defined as
the action that maximizes the estimated reward, i.e.,
π(x) = argmax
a
f
a
(x;θ), where f
a
(x;θ) is the compo-
nent corresponding to action a of the output from the
neural network.
The NeuraLCB method is a novel approach to Of-
fline Contextual Multi-Armed Bandits (CMAB) intro-
duced by (Zhou et al., 2020). It uses a neural net-
work to model any bounded reward function with-
out assuming any functional form. The key feature
of NeuraLCB is its pessimistic formulation, which
constructs a lower confidence bound of the reward
functions for decision-making. The lower confidence
bound is computed for each context and action based
on the current network parameter, and the network
is updated by minimizing a regularized squared loss
function using stochastic gradient descent (SGD).
The policy used by NeuraLCB is given by π(x) =
argmax
a
f
a
(x;θ) − LCB(x, a, θ), where LCB(x, a, θ) is
the lower confidence bound for action a at context x
with network parameters θ.
The offline policy learning faces issues with the
distributional shift problem (Levine et al., 2020), par-
ticularly due to the behavior policy mismatch. This
problem arises when the policy used to collect the
dataset (the behavior policy) is different from the
learned policy by the offline method, leading to sit-
uations in which the learned policy exploits actions
about which it has little to no data. Neural Greedy
addresses this problem by making assumptions about
the uniform data coverage (Brandfonbrener et al.,
2021; Xie et al., 2023). Specifically, Neural Greedy
assumes that the behavior policy has already explored
the entire action space to a sufficient degree. How-
ever, this assumption may not always hold in prac-
tice. To address this limitation, NeuraLCB utilizes
a pessimism principle that constructs lower confi-
dence bounds for the reward functions for conserva-
tive decision-making (Rashidinejad et al., 2022). By
doing so, NeuraLCB reduces the requirement for uni-
form data coverage to the single-policy concentration
condition, which ensures that the behavior policy only
needs to cover the target optimal policy, rather than
the entire action space.
In our approach, we adopt the batch mode training
inspired by NeuraLCB. We replay the dataset S
β
in
the order it was collected. During each replay of a
round t, the reward model is updated using 100 steps
of Stochastic Gradient Descent (SGD) on a random
batch of size 50, sampled from the subset S
(1:t)
β
of the
dataset accumulated from round 1 to t.
3.3 Problems
The algorithms are evaluated on real-world problems
obtained from the UCI Machine Learning Reposi-
tory (Markelle et al., ), including Mushroom, Shut-
tle, Adult, and MNIST. These problems are diverse in
terms of size, dominant actions, and stochastic versus
deterministic rewards. Details on each problem can
be found in Table 1.
The Mushroom problem contains equal numbers
of edible and poisonous mushroom examples. Each
mushroom is represented by a set of attributes. The
learner’s task is to choose from two actions: to eat a
given mushroom or not. If the mushroom is edible
and the learner chooses to eat it, they receive a re-
ward of +5. On the other hand, if the mushroom is
poisonous and the learner chooses to eat it, there is
Dataset Characteristics and Their Impact on Offline Policy Learning of Contextual Multi-Armed Bandits
89
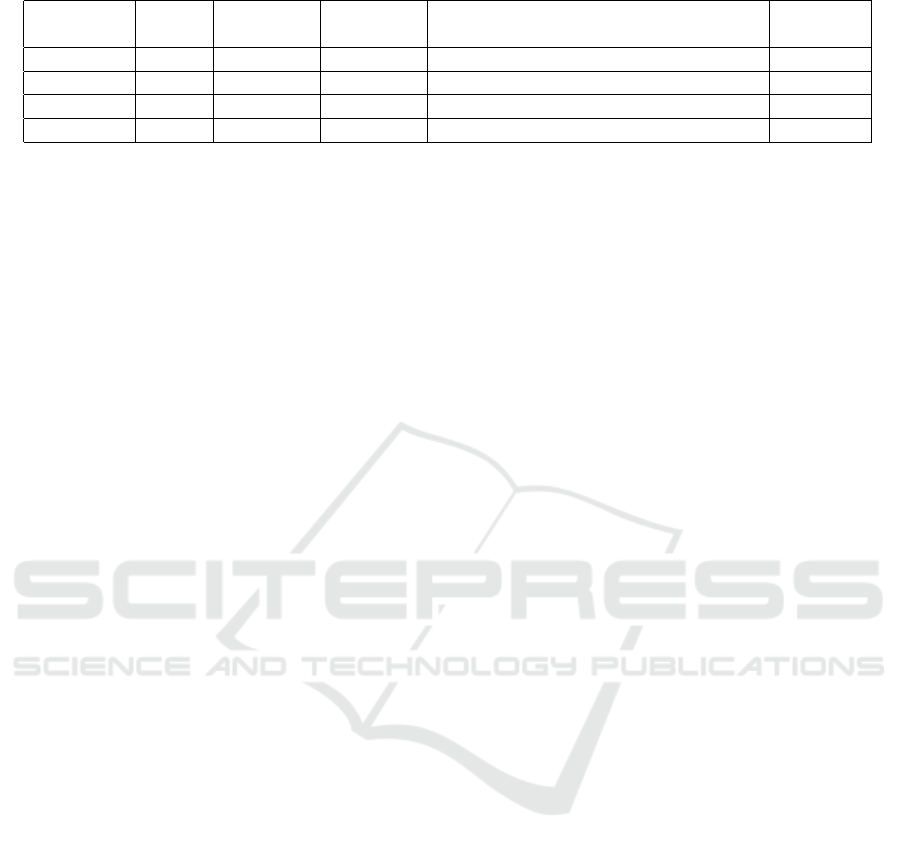
Table 1: Problems characteristics.
size
context
dimension
number of
actions
dominant action
stochastic
rewards
Adult 45,222 94 14 >80% of data belongs to half of actions no
MNIST 70,000 784 10 balanced no
Mushroom 8,124 22 2 balanced yes
Shuttle 43,500 9 7 ∼80% of data belong to one action no
a probability of 0.5 that they receive a reward of +5
and an equal probability that they receive a penalty
of −35 instead. If the learner chooses not to eat the
mushroom, they always receive a reward of 0.
All the other problems are K-class classification
problems:
1. The Adult problem contains personal information
from the US Census Bureau database including
occupations that we take for actions.
2. The MNIST problem contains images of various
handwritten digits from 0 to 9.
3. The Shuttle problem contains data about a space
shuttle flight where the goal is to predict the state
of the radiator subsystem of the shuttle.
We convert these problems into K-armed contex-
tual bandit problems based on the methodology pro-
posed by (Nguyen-Tang et al., 2022). Specifically, the
learner receives a reward of 1 if it selects the action y,
where y is the correct label and 0 otherwise.
3.4 Datasets
We collect datasets that satisfy the uniform data
coverage assumption, the single-policy concentration
condition, extrapolate between the two, or satisfy nei-
ther condition. To do this we run the following behav-
ior policies to collect the datasets:
1. Uniform and stationary policies that fulfill the uni-
form data coverage assumption
• full exploration which issues uniformly random
actions (we later refer to it as uniformly random
data).
2. Non-uniform, but stationary policies that fulfill
the single-policy concentration condition
• full exploitation which issues only optimal ac-
tions, meaning minimizing the suboptimality.
3. Non-uniform, but still stationary policies that ex-
trapolate between the two conditions
• ε-greedy which issues uniformly random ac-
tions with probability ε and optimal actions oth-
erwise.
4. Non-uniform and not-stationary policies that
might not satisfy any of the two conditions are de-
scribed in detail in Section 3.1
• Neural Greedy,
• LinUCB,
• NeuralUCB,
• Bayes by Backprop.
It is crucial to note that the last category includes
learning algorithms that: 1) will gradually make less
and less diverse decisions and 2) may or may not con-
verge to the optimal solution. That is why they might
not satisfy any of the aforementioned conditions.
We run each behavior policy 10 times, with dif-
ferent seeds, for 15,000 rounds in each problem and
record observed contexts, issued actions, and received
action rewards which establish our offline datasets.
4 RESULTS & DISCUSSION
Based on the experimental results, it was observed
that the performance of offline contextual bandits
algorithms is heavily dependent on the nature of
datasets used for training and the specific character-
istics of the problem being addressed. In this section,
we explore this observation from different angles.
4.1 Offline Training on Datasets with
Varying Degrees of Exploration
Our study investigates whether the NeuraLCB and
Neural Greedy algorithms learn better from datasets
collected with the ε-greedy behavior policy, which
mixes the optimal actions with the uniformly random
actions, or the full exploration behavior policy, which
always picks the actions uniformly at random. Ta-
ble 2 shows that the NeuraLCB algorithm performs
better when trained on datasets coming from behav-
ior policies that are more focused on optimal actions,
with one exception. In Figure 5, the NeuraLCB al-
gorithm performed better when trained on uniformly
random data in the Mushroom problem. This excep-
tion might be related to the method’s failure to learn
ICAART 2024 - 16th International Conference on Agents and Artificial Intelligence
90

Table 2: Which random behavior policy collects datasets on which the offline method achieves better performance (AOC)?
Adult MNIST Mushroom Shuttle
NeuraLCB e-greedy e-greedy u. random e-greedy
Neural Greedy u. random u. random u. random u. random
Table 3: Which offline method achieves better performance (AOC) for each dataset?
Adult MNIST Mushroom Shuttle
e-greedy NeuraLCB NeuraLCB NeuraLCB NeuraLCB
u. random Neural Greedy Neural Greedy Neural Greedy Neural Greedy
greedy NeuraLCB NeuraLCB both cannot learn NeuraLCB
Bayes by Backprop NeuraLCB Neural Greedy NeuraLCB NeuraLCB
LinUCB NeuraLCB Neural Greedy NeuraLCB / both cannot learn NeuraLCB
Neural Greedy NeuraLCB / draw Neural Greedy NeuraLCB NeuraLCB
NeuralUCB NeuraLCB NeuraLCB NeuraLCB NeuraLCB
from the optimal actions in this particular problem, as
described in Section 4.2. Figure 7 reveals that Neu-
raLCB can fail to achieve stable convergence with
the dataset coming from the full exploration behav-
ior policy, which is the case in the Shuttle problem.
Table 2 shows that the Neural Greedy offline method
performed better when trained on uniformly random
data. This was expected, as Neural Greedy requires
uniform data coverage for efficient learning under dis-
tributional shift (Nguyen-Tang et al., 2022). In Fig-
ure 8, in the Shuttle problem, the dataset coming from
the uniformly random behavior policy is the only one
that results in the Neural Greedy convergence.
4.2 Offline Training on Datasets with
Only Optimal Actions
We investigate whether the offline methods can learn
from datasets collected with the full exploitation be-
havior policy, which always picks the optimal actions.
Based on the results obtained, it has been observed
that the Neural Greedy algorithm is unable to learn
from datasets consisting solely of optimal actions. In
contrast, the NeuraLCB algorithm has been found to
be capable of learning on such datasets. Neverthe-
less, its performance still benefits from some level of
exploration as can be seen in Figures 1 and 3. The
Mushroom problem is one exception in which Neu-
raLCB cannot learn from the dataset collected by the
full exploitation behavior policy. This is due to the
fact that this dataset does not include the result of eat-
ing a poisonous mushroom, leading offline method
to learn a suboptimal policy which thinks that eat-
ing mushrooms has a higher reward than not eating
them, regardless of their type. Figure 5 shows that
even a small level of exploration, such as 10% in the
ε-greedy collected dataset, can mitigate this problem.
These findings suggest that offline training of contex-
tual bandits from optimal actions can be challenging,
and at least some level of exploration may be neces-
sary for effective training.
4.3 Offline Training on Datasets
Collected by Learning Behavior
Policies
In this experiment, we look at the offline methods’
performance when trained on datasets collected by
behavioral policies that start from the random initial-
ization and are actively learning to issue better ac-
tions.
As Figures 1 and 2 show, in the Adult problem,
there is not much difference in performance across
Bayes by Backprop, LinUCB, Neural Greedy, or
NeuralUCB behavior policies used for datasets col-
lection. Neither performance of the offline methods
trained on these datasets differ.
In the MNIST problem, Figures 3 and 4 nicely
show the situation where, although behavior policies’
performance significantly differs, the NeuraLCB and
Neural Greedy offline methods achieve similar per-
formance across collected datasets – in most cases
exceeding the performance of the corresponding be-
havior policies. This suggests that the offline meth-
ods can pick the optimal solution from a variety of
datasets. However, the slower the behavior policies
learn the slower the NeuraLCB algorithm learns on
their collected datasets.
For the Mushroom problem, in Figures 5 and 6, all
the behavior policies reach similar, near-optimal per-
formance, with the LinUCB reaching it much quicker.
The NeuraLCB algorithm quickly converges on the
optimal policy across the datasets besides the one col-
lected by the LinUCB in which it struggles to learn.
This is most probably because the LinUCB behavior
policy quickly starts to issue mostly optimal actions
Dataset Characteristics and Their Impact on Offline Policy Learning of Contextual Multi-Armed Bandits
91

which causes difficulties described in Section 4.2. For
the Neural Greedy algorithm the situation is similar,
but it does not achieve the optimal performance, it
maintains little bias. It is worth noting that Neural
Greedy can learn the optimal policy from the uni-
formly random data. This suggests that the lack of
ability to directly model the uncertainty about the less
common actions, in this case, the eating of inedi-
ble mushrooms in datasets collected by mostly opti-
mal behavior policies, contributes to the worse per-
formance of Neural Greedy.
Figures 5 and 6 present the results in the Shut-
tle problem. Behavior policies gain similar final per-
formance but at different rates except for the Lin-
UCB which quickly converges on the worse solution
than other learning behavior policies. Similarly, as in
the MNIST problem, the NeuraLCB algorithm learns
slower if the behavior policy learns slowly. However,
it reaches the same final performance across datasets
except for the dataset collected by the LinUCB from
which NeuraLCB is missing optimal actions in the
dataset. Generally, the faster behavior policies con-
verge on some solution, either optimal (see the Neural
Greedy behavior policy) or suboptimal (see the Lin-
UCB behavior policy) the more problems the Neu-
ral Greedy algorithm has to learn from such collected
datasets. This confirms that the Neural Greedy algo-
rithm requires a substantial degree of exploration in
the behavior policies. This conclusion is further rein-
forced by the observation, that Neural Greedy recov-
ers around the middle of the training on the dataset
collected by the Bayes by Backprop behavior policy,
just when the Bayes by Backprop again started to pick
more explorative actions. This exploration increase
can be observed as the slight Bayes by Backprop per-
formance deterioration.
4.4 Can NeuraLCB Learn Where
Neural Greedy Fails and Vice
Versa?
At the high level, the aim of these experiments was
to investigate if NeuraLCB can learn from datasets
where Neural Greedy fails and vice versa. The results
in Figures 7 and 8 show that, in the Shuttle problem,
NeuraLCB learns well from all datasets, while Neu-
ral Greedy can only learn from the uniformly random
data. Across all problems but the Mushroom, Neu-
raLCB can learn from the datasets consisting solely
of optimal actions, whereas Neural Greedy fails to do
so. Interestingly, the study found that NeuraLCB was
not always better than Neural Greedy, see Table 3.
Particularly, when trained on the uniformly random
data which is the most visible in the Adult problem,
in Figures 1 and 2, and in the MNIST problem, in Fig-
ures 3 and 4. However, we argue that it is unreason-
able to expect the deployed policies to be uniformly
random in their decisions in real-world scenarios.
5 RELATED WORK
The existing literature provides valuable insights into
offline policy learning, contextual bandits, and behav-
ior policies. However, the specific exploration of how
different behavior policies influence the performance
of offline policy learning algorithms in the contextual
bandits setting appears to be a novel and underex-
plored aspect.
5.1 Offline Policy Learning
Offline policy learning has been a subject of inter-
est in various domains. Recent works have proposed
frameworks for offline reinforcement learning (Fuji-
moto et al., 2019), with advances like conservative
Q-learning (Kumar et al., 2020), general methods for
data reuse (Xiao and Wang, 2021), and methods to
bridge the sim-to-real gap (Rashidinejad et al., 2022).
Uncertainty-aware approaches have also gained trac-
tion (Hu et al., 2023), with methodologies like dif-
fusion models being proposed (Wang et al., 2023).
Moreover, information-theoretic considerations in of-
fline policy learning have been explored in (Chen and
Jiang, 2019). However, these works primarily focus
on general frameworks and methodologies rather than
the nuanced influence of different behavior policies
on offline policy learning.
5.2 Contextual Bandits
Contextual bandits have been applied to diverse areas
such as interactive recommendation (Li et al., 2010)
and energy optimization (Vannella et al., 2023). The
domain has seen studies that investigated offline pol-
icy optimization (Nguyen-Tang et al., 2022) and those
that delve into the relationship of offline optimiza-
tion with overparametrized models (Brandfonbrener
et al., 2021). Furthermore, Joachims et al. have stud-
ied the use of a counterfactual risk minimization ap-
proach for training deep networks with logged bandit
feedback (Joachims et al., 2018). While these works
consider aspects of offline datasets, they do not delve
into the specific impact of various behavior policies
on offline policy learning performance.
ICAART 2024 - 16th International Conference on Agents and Artificial Intelligence
92

5.3 Off-Policy Evaluation
There is significant research related to off-policy eval-
uation on offline datasets, touching on aspects like
doubly robust policy evaluation (Dudik et al., 2011),
distributionally robust policy gradients (Yang et al.,
2023), and methodologies like variance-minimizing
augmentation logging (Tucker and Joachims, 2023).
The literature has also included works on neural con-
textual bandits with UCB-based exploration (Zhou
et al., 2020) and PAC-Bayesian approaches (Sakhi
et al., 2022). However, a comprehensive examination
of how different behavior policies directly influence
the efficiency and effectiveness of offline policy learn-
ing algorithms remains an underexplored area.
6 CONCLUSIONS
Our study demonstrates the critical impact of dataset
characteristics on offline policy learning of Contex-
tual Multi-Armed Bandits, offering key insights for
their practical application. The Neural Greedy algo-
rithm requires datasets with a substantial degree of ex-
ploration for effective learning. In practical scenarios,
however, it is unreasonable to anticipate the deployed
policies to consistently make highly exploratory deci-
sions e.g. based on uniformly random criteria. We ad-
vise employing the NeuraLCB method, as it can learn
effectively from datasets collected by behavior poli-
cies that leverage problem-specific knowledge. It has
the better performance, the more optimal the actions
in the dataset. Nonetheless, we show NeuraLCB still
benefits from some exploratory actions. We recom-
mend ensuring that each action gets chosen multiple
times in the datasets.
Future work shall tune the proportion of ex-
ploratory actions to the optimal ones for the best per-
formance. Experiments with learning behavioral poli-
cies in Section 4.3 could also be extended by dropping
early, uninformed decisions and checking how this in-
fluences the offline methods performance.
Our investigation adds a new dimension to the
body of knowledge concerning offline policy learn-
ing. While algorithms undoubtedly form the learning
engine, our research underscores the importance of
fuel quality — the offline dataset — for the journey
toward efficient offline policy learning and decision-
making. We hope to contribute to the ongoing dia-
logue on improving the implementation of offline pol-
icy learning in real-world scenarios.
REFERENCES
Badanidiyuru, A., Kleinberg, R., and Slivkins, A. (2013).
Bandits with Knapsacks. IEEE Computer Society.
Blundell, C., Cornebise, J., Kavukcuoglu, K., and Wierstra,
D. (2015). Weight Uncertainty in Neural Networks.
Brandfonbrener, D., Whitney, W. F., Ranganath, R., and
Bruna, J. (2021). Offline Contextual Bandits with
Overparameterized Models.
Chen, J. and Jiang, N. (2019). Information-Theoretic Con-
siderations in Batch Reinforcement Learning. PMLR.
Dudik, M., Langford, J., and Li, L. (2011). Doubly Robust
Policy Evaluation and Learning.
Dutta, P., Cheuk, M. K., Kim, J. S., and Mascaro, M.
(2019). Automl for contextual bandits. CoRR,
abs/1909.03212.
Fujimoto, S., Meger, D., and Precup, D. (2019). Off-Policy
Deep Reinforcement Learning without Exploration.
PMLR.
Hu, B., Xiao, Y., Zhang, S., and Liu, B. (2023). A Data-
Driven Solution for Energy Management Strategy of
Hybrid Electric Vehicles Based on Uncertainty-Aware
Model-Based Offline Reinforcement Learning.
Joachims, T., Swaminathan, A., and de Rijke, M. (2018).
Deep learning with logged bandit feedback. OpenRe-
view.net.
Komorowski, M., Celi, L. A., Badawi, O., Gordon, A. C.,
and Faisal, A. A. (2018). The Artificial Intelligence
Clinician learns optimal treatment strategies for sepsis
in intensive care.
Kumar, A., Zhou, A., Tucker, G., and Levine, S. (2020).
Conservative Q-Learning for Offline Reinforcement
Learning. Curran Associates, Inc.
Lattimore, T. and Szepesv
´
ari, C. (2020). Bandit Algorithms.
Cambridge University Press.
Levine, S., Kumar, A., Tucker, G., and Fu, J. (2020). Offline
reinforcement learning: Tutorial, review, and perspec-
tives on open problems.
Li, L., Chu, W., Langford, J., and Schapire, R. E. (2010). A
contextual-bandit approach to personalized news arti-
cle recommendation.
Markelle, K., Longjohn, R., and Nottingham, K. The uci
machine learning repository.
Nguyen-Tang, T., Gupta, S., Nguyen, A. T., and Venkatesh,
S. (2022). Offline neural contextual bandits: Pes-
simism, optimization and generalization.
Rashidinejad, P., Zhu, B., Ma, C., Jiao, J., and Russell, S.
(2022). Bridging offline reinforcement learning and
imitation learning: A tale of pessimism.
Sakhi, O., Chopin, N., and Alquier, P. (2022). Pac-bayesian
offline contextual bandits with guarantees.
Tucker, A. D. and Joachims, T. (2023). Variance-
minimizing augmentation logging for counterfactual
evaluation in contextual bandits.
Vannella, F., Jeong, J., and Prouti
`
ere, A. (2023). Off-policy
learning in contextual bandits for remote electrical tilt
optimization.
Dataset Characteristics and Their Impact on Offline Policy Learning of Contextual Multi-Armed Bandits
93

Wang, Z., Hunt, J. J., and Zhou, M. (2023). Diffusion poli-
cies as an expressive policy class for offline reinforce-
ment learning.
Xiao, T. and Wang, D. (2021). A general offline reinforce-
ment learning framework for interactive recommenda-
tion.
Xie, T., Foster, D. J., Bai, Y., Jiang, N., and Kakade, S. M.
(2023). The role of coverage in online reinforcement
learning.
Yang, Z., Guo, Y., Xu, P., Liu, A., and Anandkumar, A.
(2023). Distributionally robust policy gradient for of-
fline contextual bandits.
Zhao, X., Zhang, W., and Wang, J. (2013). Interactive col-
laborative filtering.
Zhou, D., Li, L., and Gu, Q. (2020). Neural contextual
bandits with ucb-based exploration.
ICAART 2024 - 16th International Conference on Agents and Artificial Intelligence
94
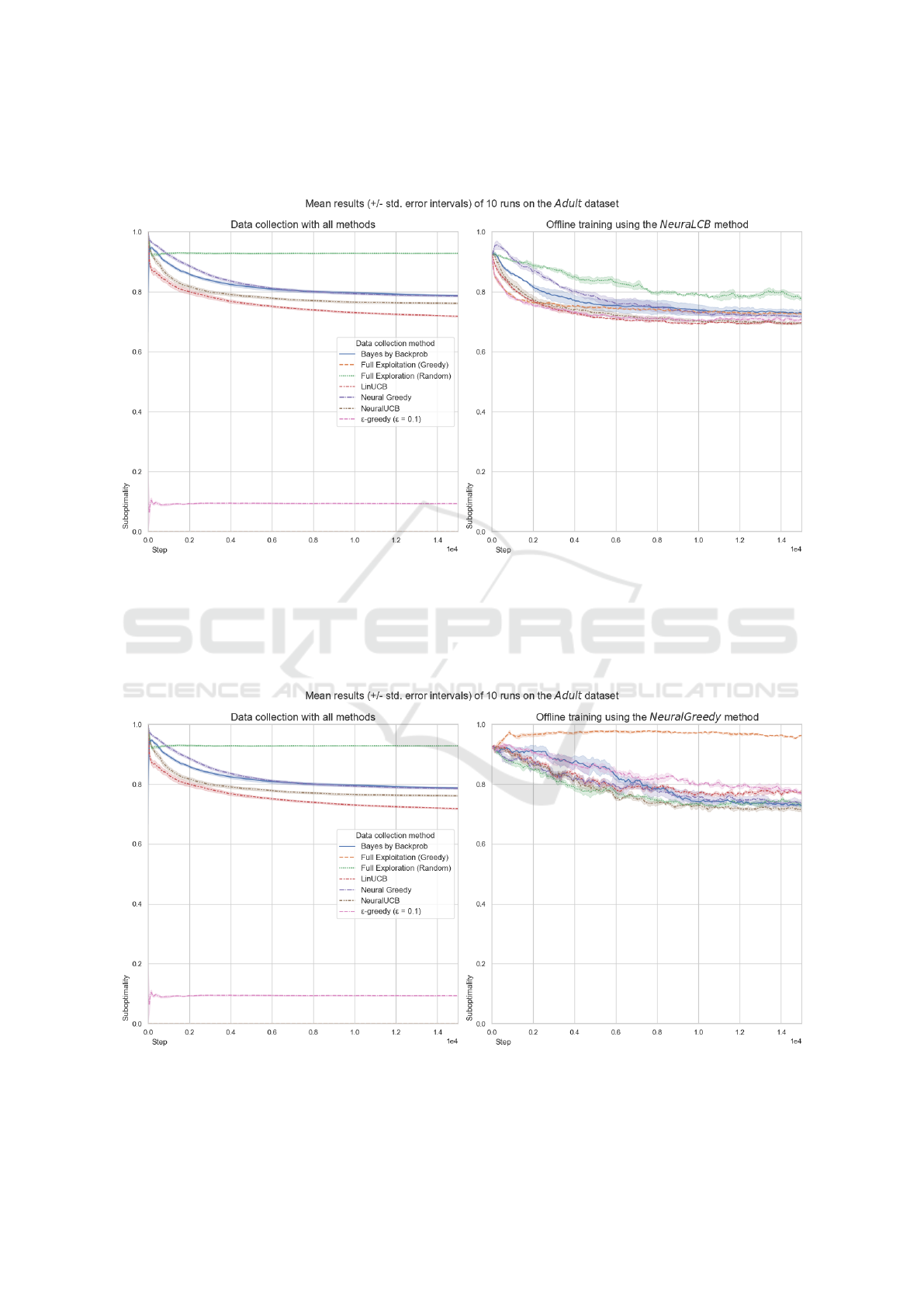
Figure 1: The NeuraLCB offline method results in the Adult problem.
Figure 2: The NeuralGreedy offline method results in the Adult problem.
Dataset Characteristics and Their Impact on Offline Policy Learning of Contextual Multi-Armed Bandits
95
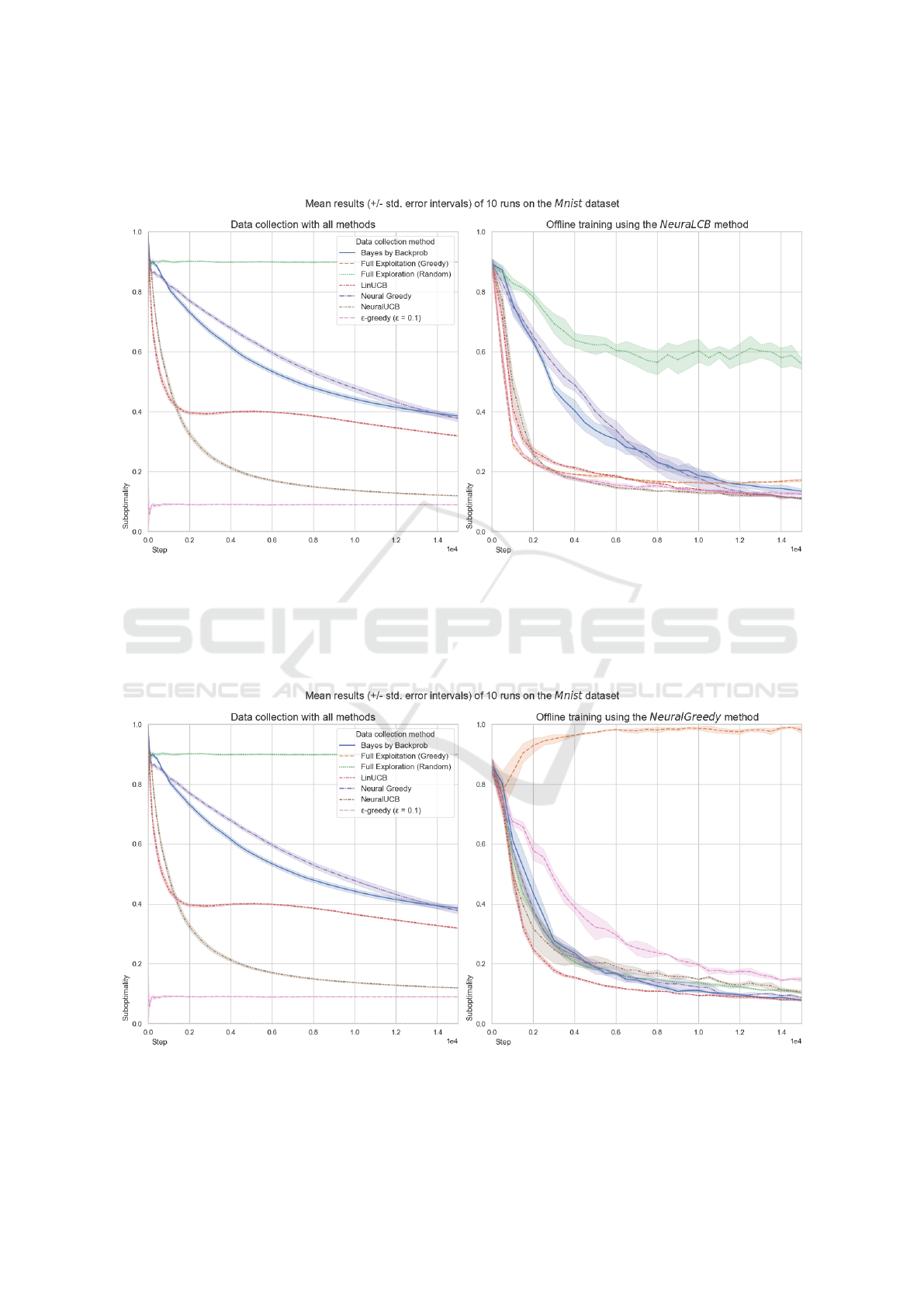
Figure 3: The NeuraLCB offline method results in the MNIST problem.
Figure 4: The NeuralGreedy offline method results in the MNIST problem.
ICAART 2024 - 16th International Conference on Agents and Artificial Intelligence
96
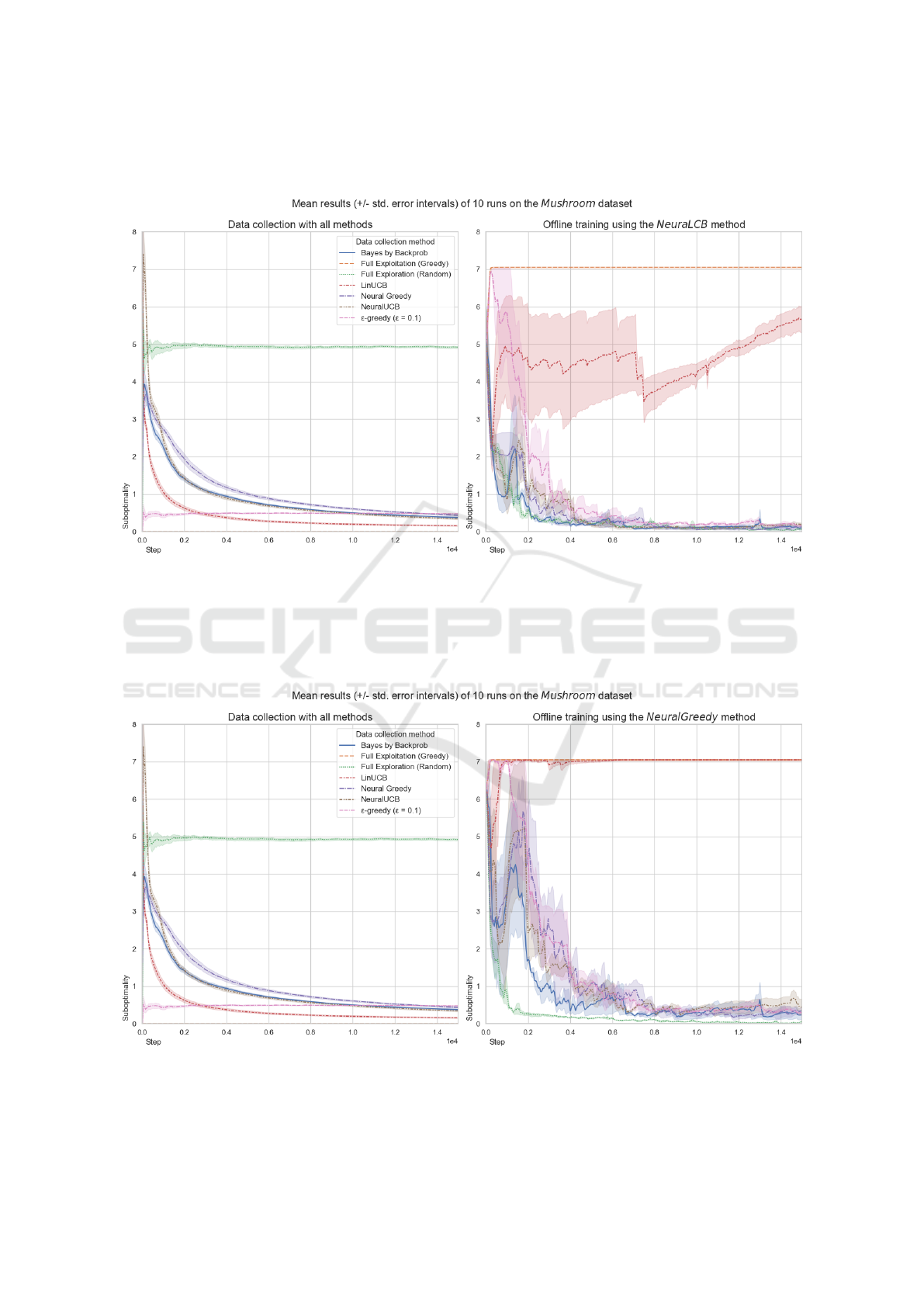
Figure 5: The NeuraLCB offline method results in the Mushroom problem.
Figure 6: The NeuralGreedy offline method results in the Mushroom problem.
Dataset Characteristics and Their Impact on Offline Policy Learning of Contextual Multi-Armed Bandits
97
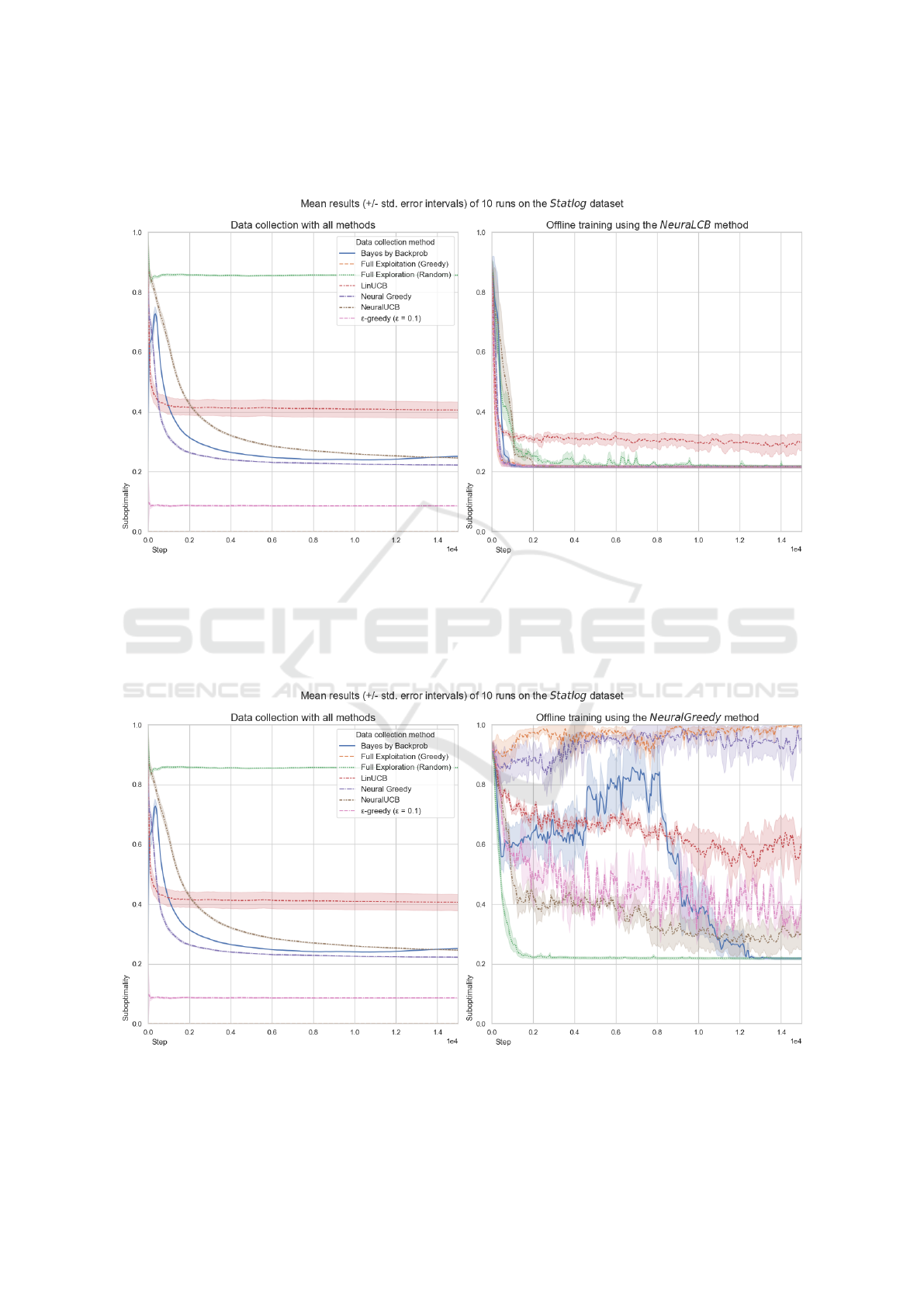
Figure 7: The NeuraLCB offline method results in the Shuttle problem.
Figure 8: The NeuralGreedy offline method results in the Shuttle problem.
ICAART 2024 - 16th International Conference on Agents and Artificial Intelligence
98
