
Enhancing Object Detection Accuracy with Variational Autoencoders as
a Filter in YOLO
Shubham Kumar Dubey
1
, J. V. Satyanarayana
2
and C. Krishna Mohan
1
1
Computer Science Department, Indian Institute of Technology Hyderabad, Hyderabad, India
2
RCI-DRDO, India
Keywords:
Object Detection, YOLO, False Positive, Variational Autoencoders.
Abstract:
Object detection is an important task in computer vision systems, encompassing a diverse spectrum of appli-
cations, including but not limited to autonomous vehicular navigation and surveillance. Despite considerable
advancements in object detection models such as YOLO, the issue of false positive detections remain a preva-
lent concern, thereby causing misclassifications and diminishing the reliability of these systems. This research
endeavors to present an innovative methodology designed to augment object detection accuracy by incorporat-
ing Variational Autoencoders (VAEs) as a filtration mechanism within the YOLO framework. This integration
seeks to rectify the issue of false positive detections, ultimately fostering a marked enhancement in detection
precision and strengthening the overall dependability of object detection systems.
1 INTRODUCTION
1.1 Background and Motivation
Object detection is a fundamental task in computer vi-
sion, and it plays a vital role in various applications
such as autonomous vehicles, surveillance, health-
care and defence. The advent of deep learning and
the availability of large-scale annotated datasets have
propelled the field of object detection, with models
like YOLO (You Only Look Once) (Redmon et al.,
2016) achieving real-time performance. However,
despite these advancements, false positive detections
continue to challenge the reliability of these systems.
False positives are instances where objects are in-
correctly identified, leading to misclassifications, in-
creased computational load, and even safety risks in
applications like autonomous driving.
The motivation for this research stems from the
need to reduce false positive detections in object de-
tection systems, thereby improving their precision
and reliability. By addressing this issue, the proposed
approach aims to enhance the overall performance
and safety of these systems.
1.2 Objective
The primary objective of this research is to enhance
object detection accuracy by reducing false positive
detections. This research proposes integrating Varia-
tional Autoencoders (VAEs) (An and Cho, 2015) into
the YOLO framework to serve as a filtering mecha-
nism. VAEs, renowned for their anomaly detection
capabilities, aim to improve the precision and relia-
bility of object detection systems.
2 LITERATURE SURVEY
There have been various approaches in the past for
object detection. Detection methods like YOLO are
widely used today.
2.1 Traditional Hand-Crafted Object
Detection Methods
The Viola Jones (Viola and Jones, 2001) method
uses a sliding window approach searching for haar
wavelets as features in an image. HOG (Dalal and
Triggs, 2005)used a dense pixel based grid called
blocks where the gradients are given by the magni-
tude and direction change in the pixel intensity of the
grid.
Deep convolutional neural networks performed
much better for object detection due to their ability
to learn detailed feature representations of an image.
270
Dubey, S., Satyanarayana, J. and Mohan, C.
Enhancing Object Detection Accuracy with Variational Autoencoders as a Filter in YOLO.
DOI: 10.5220/0012347700003660
Paper published under CC license (CC BY-NC-ND 4.0)
In Proceedings of the 19th International Joint Conference on Computer Vision, Imaging and Computer Graphics Theory and Applications (VISIGRAPP 2024) - Volume 4: VISAPP, pages
270-277
ISBN: 978-989-758-679-8; ISSN: 2184-4321
Proceedings Copyright © 2024 by SCITEPRESS – Science and Technology Publications, Lda.

2.2 Deep Learning Object Detection
Methods
Generally two stage object detection methods like
Faster RCNN (Ren et al., 2015) produce more accu-
rate results compared to single stage detectors. On
the other hand single stage detectors are much faster
in terms of their computation time. With the advent
of modern single stage detectors like YOLO we find
detection accuracy to be on par with two staged de-
tectors, while also being much faster than them.
The most widely used object detection methods
today include CNN based methods. The state of the
art methods include Faster RCNN, YOLO and SSD
(single shot multi box detectors) (Liu et al., 2016).
(Lin et al., 2017) emphasizes honing the model’s
skills on a limited set of challenging examples while
simultaneously safeguarding against an inundation of
numerous straightforward negatives that could other-
wise overwhelm the training process.
(Ye et al., 2020) explored the use of YOLO along
with VAE to detect and classify garbage from other
objects. A trained gaussian curve representation of
training samples is used for classifying new samples.
It focuses on the classification task based on recon-
struction and KL divergence losses along with the
YOLO spatial information loss. Use of VAE along
with YOLO could thus be further used to remove false
positives while targeting the detection of objects of
a single class like drones. The threshold can be in-
creased or decreased by the factor (δ) to suit the spe-
cific detection task and scenario.
3 RESULTS BY YOLO
YOLO improves upon other object detection meth-
ods by re framing object detection as a regression
task rather than a classification task. The working of
YOLO starts by taking an image of dimensions H x
W, where H represents the height and W represents
the width of the image. Then we have the feature ex-
tractor module made of strong CNN networks like the
VGG1 (Simonyan and Zisserman, 2014), ResNet-50
(He et al., 2016) etc. The next stage involves a single
shot detector module using a grid layout on the im-
age, where each grid cell is scanned for detecting an
object of the required class.
While results from YOLO are majorly precise, the
limitations of YOLO show up when the objects in the
image are small (Liu et al., 2021), or are of unusual
aspect ratios. This can be seen in the example image
1 below.
4 VARIATIONAL ENCODERS
(VAEs)
4.1 VAE Theory
Variational Autoencoders, or VAEs, are a class of
generative models that merge neural networks with
probabilistic modeling. VAEs extend traditional au-
toencoders, a type of neural network designed for data
representation learning. In a VAE, data is encoded
into a probability distribution in a lower-dimensional
latent space, from which data samples can be gen-
erated. This probabilistic approach (Kingma and
Welling, 2013) enables VAEs to model complex data
distributions effectively.
At the core of VAEs is the idea of learning a prob-
ability distribution over the latent space, which allows
for the generation of new data points. This is achieved
through two main components: the encoder and the
decoder. The encoder maps input data to a probabil-
ity distribution in the latent space, while the decoder
reconstructs data samples from this distribution.
4.2 VAEs for Anomaly Detection
VAEs excel in anomaly detection due to their inher-
ent ability to model the distribution of normal data.
Normal data points cluster densely in the latent space,
whereas anomalies reside in less dense regions. As
a result, anomalies yield higher reconstruction errors
when decoded from the latent space, making them
distinguishable from normal data (Li et al., 2019).
VAEs employ a loss function that measures the
dissimilarity between input data and its reconstruc-
tion. In the context of anomaly detection, this loss
function provides a quantifiable measure of how well
a data point aligns with the model’s understanding of
normality. Anomalies exhibit significantly higher loss
values, allowing for their identification.
4.3 Applications of VAEs
VAEs have found applications across diverse fields,
including natural language processing, image gener-
ation, and healthcare. One of their most compelling
uses is in anomaly detection. By utilizing the latent
space learned by VAEs, anomalies in data can be iden-
tified based on their deviation from normal patterns.
In the realm of healthcare, VAEs have been ap-
plied to detect anomalies in medical images, such as
X-rays and MRIs. Similarly, in finance, VAEs have
been employed to detect fraudulent transactions by
flagging deviations from typical spending patterns.
Enhancing Object Detection Accuracy with Variational Autoencoders as a Filter in YOLO
271

Figure 1: YOLO output shows how it detects bird(on top) as a drone thus giving a false positive in a video from the Drone vs.
Bird dataset.
VAEs can also be useful in defence applications to
give accurate target detection.
5 PROPOSED METHOD
We wish to apply the VAE-as a filter on YOLO
method to reduce false positives for defence applica-
tions. In crucial on-field scenarios where we need to
target drones accurately and discard any birds as false
positives, our approach is implemented.
5.1 VAE Training and Architecture
To effectively harness VAEs for false positive reduc-
tion in object detection, a comprehensive training pro-
cess is indispensable.
5.1.1 Data Collection
A crucial aspect of VAE training is the collection of
a comprehensive dataset. This dataset should consist
of normal, non-anomalous objects that are representa-
tive of real-world scenarios. To ensure the model’s ro-
bustness, the dataset (Everingham et al., 2010) should
encompass diverse environmental conditions and sce-
narios.
Data: YOLO object detection results
D = {(b
i
, c
i
)}
Result: Filtered object detections D
f iltered
initialization;
D
f iltered
←
/
0;
while frame is captured do
Perform YOLO object detection to obtain
D;
foreach detection (b
i
, c
i
) in D do
Compute reconstruction error R
i
with
VAE: R
i
= ||x
i
− ˆx
i
||
2
;
if R
i
is below a predefined threshold
then
Add (b
i
, c
i
) to D
f iltered
;
end
end
Process D
f iltered
for further use or display;
end
Algorithm 1: Integrating VAE as a Filter in YOLO Object
Detection.
5.1.2 Drone vs Bird Dataset
The Drone-vs.-Bird dataset was released as a De-
tection Challenge in 2021. Seventy seven different
video sequences were made available as training data.
The Fraunhofer IOSB research institute, ALADDIN2
project and SafeShore jointly used the MPEG4-coded
static cameras to record the dataset.
On average, the video sequences consist of 1,384
frames, while each frame contains 1.12 annotated
drones. The video sequences are recorded with both
VISAPP 2024 - 19th International Conference on Computer Vision Theory and Applications
272

static cameras and moving cameras and the resolution
varies between 720×576 and 3840×2160 pixels. In to-
tal, 8 different types of drones exist in the dataset, i.e.
3 with fixed wings and 5 rotary ones.
5.1.3 Training Procedure
The VAE is rigorously trained on this dataset to cap-
ture the distribution of normal objects effectively. We
trained our VAE model on drone images from 45
videos of the Drone vs. Bird dataset with batch size
32 and for 100 epochs. The validation and testing was
done on 16 videos each.
Our VAE is made of 7 convolutional layers, with
batch normalization and ReLU activation, for both the
encoder and decoder. Firstly, the VAE is completely
trained on the 24,000 (approx. 60 % of total images)
frame wise cropped images of drones, from the drone
vs. bird dataset. Then, validation is done on 6000 im-
ages (approx. 20 % total images) of drones. Testing is
done on the remaining 20 % of the images. This train-
ing process optimizes the VAE’s parameters to mini-
mize the reconstruction error between input data and
its reconstructed counterpart. The objective is to cre-
ate a latent space representation that accurately mod-
els the characteristics of normal objects.
5.2 Filtering in the Detection Pipeline
The core of the proposed approach is the integra-
tion of the VAE as a filtering mechanism within the
YOLO-based object detection pipeline.
5.2.1 YOLO Object Detection
The YOLO (You Only Look Once) object detection
system is a state-of-the-art model for real-time ob-
ject detection. YOLO divides an image into a grid
and assigns bounding boxes and class labels to ob-
jects within grid cells. Deep learning techniques, such
as convolutional neural networks (CNNs), are used to
achieve these detections.
5.2.2 VAE Filtering
In the proposed approach, YOLO generates a list of
potential detections during the object detection pro-
cess, denoted as D = {(b
i
, c
i
)}, where b
i
represents
the bounding box coordinates, and c
i
represents the
class label. These candidates are then passed through
the trained Variational Autoencoder (VAE), which
calculates the reconstruction error for each detection
as:
R
i
= ||x
i
− ˆx
i
||
2
(1)
Here, x
i
is the original detection, and ˆx
i
is the re-
constructed detection obtained by passing b
i
through
the VAE. The reconstruction error, R
i
, from equation
1 serves as a critical indicator of the detection’s qual-
ity. A low reconstruction error indicates that the ob-
ject is well-defined and easily recognizable (R
i
≈ 0),
while a high error suggests that the detection might
be uncertain or noisy (R
i
≫ 0). By using the VAE
to assess the quality of each detection, the proposed
approach effectively filters out false positives and fo-
cuses on the most reliable object candidates, ulti-
mately improving the overall accuracy and robustness
of object detection in computer vision applications.
5.2.3 Anomaly Classification
The VAE quantifies the dissimilarity between the
original image patch and its VAE-reconstructed coun-
terpart through the reconstruction error. Detections
with reconstruction errors surpassing a predetermined
threshold are identified as anomalies. This threshold
can be adjusted to control the trade-off between sen-
sitivity (recall) and specificity (precision).
5.2.4 Threshold Calculation
The threshold calculation method in this context in-
volves utilizing the mean (µ) and standard deviation
(σ) of reconstruction errors on a validation set to es-
tablish a threshold for anomaly detection in test data.
By computing the pixel-wise mean squared errors be-
tween original and reconstructed images, the method
captures the normal variability of the validation set.
T hreshold = µ + 2σ (2)
In this work, assuming a normal distribution, our
threshold is set as the mean error plus two times the
standard deviation, providing a statistical measure to
identify anomalies in the test data as shown in 2. This
approach is advantageous as it adapts to the specific
characteristics of the dataset, dynamically establish-
ing a boundary for normalcy. It leverages statistical
measures to discern anomalies, accommodating vari-
ations in image content and noise levels, making it a
robust method for anomaly detection in the context of
the Variational Autoencoder.
6 EXPERIMENTS AND RESULTS
6.1 Experiment Setup
To evaluate the effectiveness of the proposed ap-
proach, a series of experiments were conducted on
Enhancing Object Detection Accuracy with Variational Autoencoders as a Filter in YOLO
273
the drone vs bird dataset. The dataset encompasses a
wide range of conditions, including different lighting,
weather, and occlusion levels. The experiments aimed
to assess the reduction in false positive detections and
the impact on overall object detection precision.
For test evaluation, parameters λ = 0 and A
max
=
30 frames were used. All our evaluation and testing
was done on a machine with NVIDIA GeForce GTX
1050 Ti graphic card.
6.2 Experimental Results
The results of the experiments demonstrated a signif-
icant reduction in false positive detections when uti-
lizing the VAE filtering mechanism. In particular, un-
der challenging conditions such as distant, small tar-
gets and heavy occlusion, the approach exhibited a
remarkable increase in precision. For the anomaly
classification threshold, we choose to stay with the
standard threshold as shown in equation 2.
6.2.1 Quantitative Results
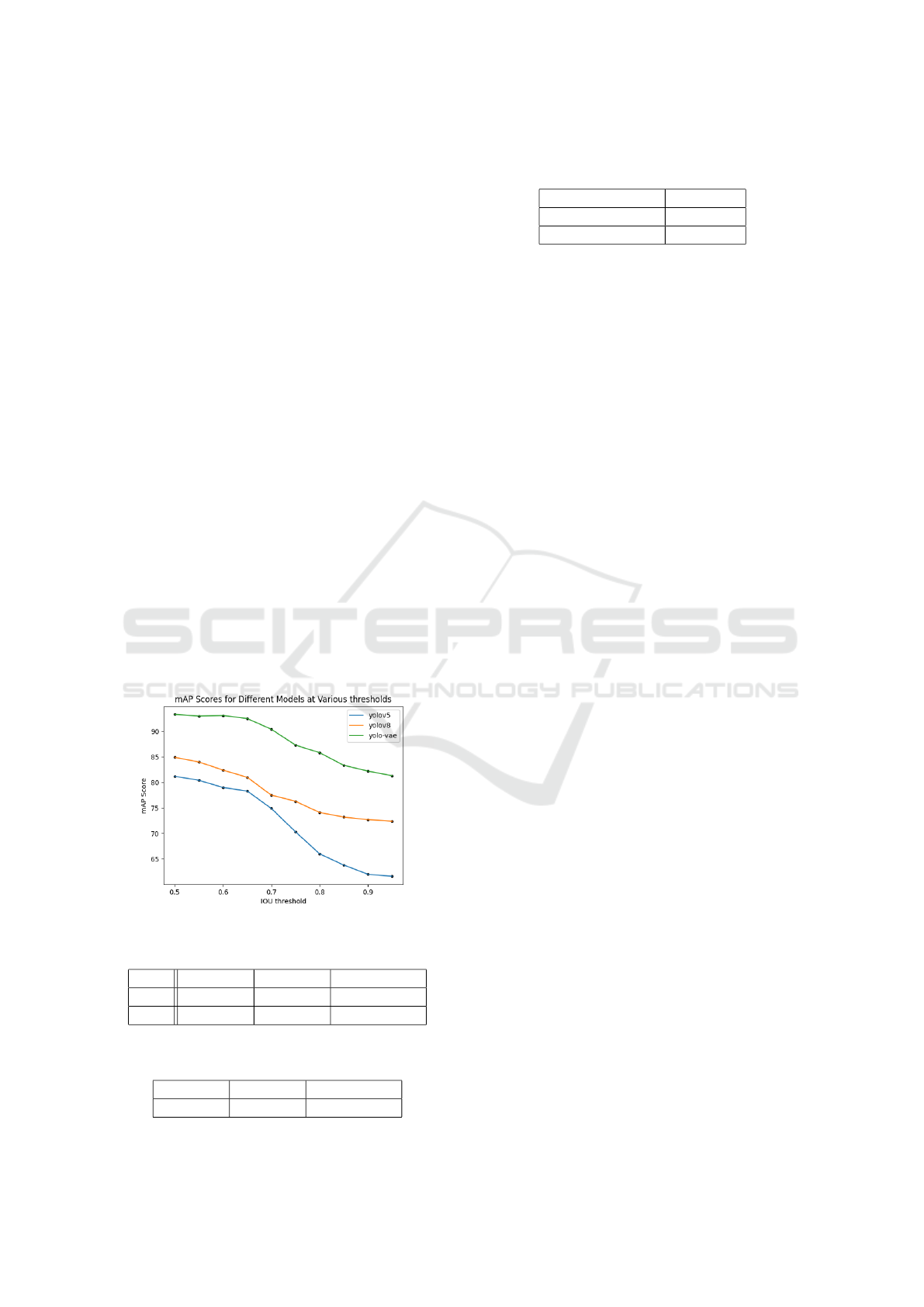
The mAP scores compared for YOLO and YOLO
with VAE filter at different IOU thresholds can be
seen in figure 2 and table 1. Table 2 shows the per-
centage of false positive detections given by YOLO
compared to YOLO-VAE. Table 3 compares the aver-
age execution time taken by YOLO and YOLO with
VAE filter approaches.
Figure 2: Comparing mAP at different thresholds.
Table 1: Comparing mAP at different IOU thresholds.
IOU YOLOv5 YOLOv8 YOLO-VAE
0.5 81.2 84.9 93.3
0.95 61.6 72.4 81.3
Table 2: Comparing percentage of false positive detections
by YOLO and YOLO with VAE filter.
YOLOv5 YOLOv8 YOLO-VAE
33.6 % 22.3 % 15.9 %
Table 3: Comparing execution times of YOLO and YOLO
with VAE filter.
Model Exec.time
YOLO 0.016s
YOLO with VAE 0.021s
6.2.2 Qualitative Results
Figure 3 below shows sample of how YOLO with
VAE compares to the results by YOLO on the Drone
vs. Bird dataset. We can observe that the birds falsely
detected as drones by YOLO (on left), have been
clearly rectified and only true drones were detected
by our work (on right). In the first image (a), the two
small black birds on the top, are detected as drones
by YOLO, and the small white drone below is not de-
tected at all, whereas YOLO with VAE detects only
the white drone correctly. In the second image (b),
the white bird is detected as a drone by YOLO, but
YOLO with VAE correctly discards it as a false posi-
tive. In the third comparison, we see how only a bird’s
image has been detected as a drone by YOLO, but our
work does not detect it as a drone.
7 BENEFITS AND
IMPLICATIONS
7.1 Reduced False Positives
One of the primary benefits of the proposed approach
is a significant reduction in false positive detections.
By leveraging VAEs’ anomaly detection capabilities,
the system is better equipped to distinguish anomalies
from normal objects, contributing to a more reliable
object detection process.
The proposed approach markedly improves object
detection precision. Even in complex and dynamic
real-world scenarios, the system maintains high accu-
racy, minimizing the chances of misclassification and
mislabeling.
7.2 Application in Safety-Critical
Scenarios
The application of this approach is pivotal in safety-
critical fields. For instance, in autonomous vehicles,
where precise object detection is essential, the reduc-
tion of false positives significantly contributes to sys-
tem safety. This has the potential to save lives and
reduce accidents.
VISAPP 2024 - 19th International Conference on Computer Vision Theory and Applications
274

Figure 3: Results by YOLO (left) vs. Results by YOLO
with VAE filter (right). Image (a) has 2 small black birds on
top and 1 small white drone below. Image (b) has 1 white
drone and 1 white bird. Image(c) has a single small black
bird on top.
7.3 Threshold Adaptability
The classification threshold for anomaly detection can
be adjusted to meet specific application requirements.
This adaptability allows users to balance precision
and recall based on the desired performance charac-
teristics. This flexibility makes the approach applica-
ble to a wide range of use cases.
7.4 Potential for Real-Time
Applications
The proposed approach is amenable to real-time ap-
plications, making it suitable for scenarios where
timely decision-making is crucial, such as targeting
a drone.
8 CHALLENGES AND
CONSIDERATIONS
8.1 Dataset Bias
One significant challenge is dataset bias. The perfor-
mance of the VAE as a filter heavily depends on the
quality and representativeness of the training dataset.
A biased or incomplete dataset may lead to unin-
tended filtering outcomes.
8.2 Threshold Tuning
Selecting an appropriate reconstruction error thresh-
old for anomaly detection is a non-trivial task. It re-
quires a balance between false positives and false neg-
atives, and the optimal threshold may vary across ap-
plications.
8.3 Computational Overhead
The introduction of VAE filtering adds a computa-
tional overhead to the object detection pipeline. En-
suring real-time performance in resource-constrained
environments is a critical consideration.
8.4 Ethical and Privacy Concerns
The use of object detection systems in surveillance
and other applications raises ethical and privacy con-
cerns. Enhanced object detection should be paired
with appropriate ethical frameworks to address these
issues.
8.5 Adversarial Attacks
Adversarial attacks against VAE-based filtering sys-
tems pose a significant threat, as attackers may ma-
nipulate input data to deceive the filtering mechanism
and bypass security measures (Xu et al., 2020). Re-
search efforts should focus on enhancing the robust-
ness of VAE-based systems to defend against such at-
tacks, ensuring the reliability and integrity of these
systems, particularly in critical applications like au-
tonomous vehicles, surveillance, and industrial au-
tomation.
9 CONCLUSION
In conclusion, the integration of Variational Autoen-
coders as a filtering mechanism within the YOLO
Enhancing Object Detection Accuracy with Variational Autoencoders as a Filter in YOLO
275

architecture holds great promise for enhancing ob-
ject detection precision. By harnessing the VAE’s
anomaly detection capabilities, a substantial reduc-
tion in false positives can be achieved, thereby im-
proving the reliability of object detection systems.
This approach is particularly pertinent in safety-
critical applications, and further research and exper-
imentation will be essential to fine-tune the system
for optimal performance in diverse and dynamic real-
world scenarios.
10 FUTURE WORK
The proposed approach opens the door to various av-
enues for future research and development:
10.1 Robustness Testing
To assess the robustness of the VAE filtering mecha-
nism, a comprehensive testing plan should cover var-
ious environmental conditions and scenarios. This in-
cludes evaluating performance under different light-
ing, temperature, humidity, indoor and outdoor set-
tings, static and dynamic scenarios, crowded or sparse
environments, and adverse conditions like rain, fog,
and sensor interference. The VAE should also be
tested with various sensor types, calibrations, and
occlusions. Assessing its adaptability to temporal
changes and real-world applications is crucial. Quan-
titative metrics and qualitative user feedback should
be used to evaluate performance, and an iterative test-
ing process should be employed for continuous im-
provement.
10.2 Integration with Multi-Modal Data
Extending the approach to accommodate multi-modal
data, such as the fusion of images and lidar data
in autonomous driving, holds significant promise.
Combining these data modalities can enhance the
perception capabilities of autonomous vehicles, en-
abling them to better understand their surroundings
and make more informed decisions. The synergy be-
tween image and lidar data can provide depth infor-
mation, object detection, and contextual awareness,
which is crucial for safe and efficient navigation. Re-
search in this direction has the potential to unlock ad-
vanced solutions for autonomous systems, improving
their reliability and safety in complex real-world en-
vironments.
10.3 Real-World Deployment
Real-world deployment and testing in safety-critical
applications, such as autonomous vehicles, will pro-
vide valuable insights into the practicality and effec-
tiveness of the approach.
10.4 Ethical Frameworks
The development of ethical frameworks and guide-
lines for the use of object detection systems enhanced
with Variational Autoencoder (VAE) filters is imper-
ative to tackle privacy and fairness concerns. VAE
filters have the potential to significantly impact data
privacy by filtering sensitive or unnecessary infor-
mation, yet their implementation can raise ethical
questions about what information is filtered and re-
tained. Furthermore, fairness concerns arise when
decisions made based on filtered data disproportion-
ately affect certain groups or individuals. Robust
ethical frameworks (Diakopoulos, 2016) are essential
to establish guidelines for responsible use, data han-
dling, transparency, and accountability, ensuring that
VAE-enhanced object detection systems operate eth-
ically, respecting privacy and promoting fairness in
their decision-making processes.
REFERENCES
An, J. and Cho, S. (2015). Variational autoencoder based
anomaly detection using reconstruction probability.
Special lecture on IE, 2(1):1–18.
Dalal, N. and Triggs, B. (2005). Histograms of oriented
gradients for human detection. In 2005 IEEE com-
puter society conference on computer vision and pat-
tern recognition (CVPR’05), volume 1, pages 886–
893. Ieee.
Diakopoulos, N. (2016). Algorithmic accountability: A
primer. Data Society Research Institute.
Everingham, M., Van Gool, L., Williams, C. K., Winn, J.,
and Zisserman, A. (2010). The pascal visual object
classes (voc) challenge. International journal of com-
puter vision, 88:303–338.
He, K., Zhang, X., Ren, S., and Sun, J. (2016). Deep resid-
ual learning for image recognition. In Proceedings of
the IEEE conference on computer vision and pattern
recognition, pages 770–778.
Kingma, D. P. and Welling, M. (2013). Auto-encoding vari-
ational bayes. arXiv preprint arXiv:1312.6114.
Li, Y., Huang, X., Li, J., Du, M., and Zou, N. (2019).
Specae: Spectral autoencoder for anomaly detection
in attributed networks. In Proceedings of the 28th
ACM international conference on information and
knowledge management, pages 2233–2236.
Lin, T.-Y., Goyal, P., Girshick, R., He, K., and Doll
´
ar, P.
(2017). Focal loss for dense object detection. In
VISAPP 2024 - 19th International Conference on Computer Vision Theory and Applications
276

Proceedings of the IEEE international conference on
computer vision, pages 2980–2988.
Liu, W., Anguelov, D., Erhan, D., Szegedy, C., Reed, S.,
Fu, C.-Y., and Berg, A. C. (2016). Ssd: Single shot
multibox detector. In Computer Vision–ECCV 2016:
14th European Conference, Amsterdam, The Nether-
lands, October 11–14, 2016, Proceedings, Part I 14,
pages 21–37. Springer.
Liu, Y., Sun, P., Wergeles, N., and Shang, Y. (2021). A
survey and performance evaluation of deep learning
methods for small object detection. Expert Systems
with Applications, 172:114602.
Redmon, J., Divvala, S., Girshick, R., and Farhadi, A.
(2016). You only look once: Unified, real-time ob-
ject detection. In 2016 IEEE Conference on Computer
Vision and Pattern Recognition (CVPR), pages 779–
788.
Ren, S., He, K., Girshick, R., and Sun, J. (2015). Faster
r-cnn: Towards real-time object detection with region
proposal networks. Advances in neural information
processing systems, 28.
Simonyan, K. and Zisserman, A. (2014). Very deep con-
volutional networks for large-scale image recognition.
arXiv preprint arXiv:1409.1556.
Viola, P. and Jones, M. (2001). Rapid object detection us-
ing a boosted cascade of simple features. In Proceed-
ings of the 2001 IEEE computer society conference on
computer vision and pattern recognition. CVPR 2001,
volume 1, pages I–I. Ieee.
Xu, H., Ma, Y., Liu, H.-C., Deb, D., Liu, H., Tang, J.-L., and
Jain, A. K. (2020). Adversarial attacks and defenses
in images, graphs and text: A review. International
Journal of Automation and Computing, 17:151–178.
Ye, A., Pang, B., Jin, Y., and Cui, J. (2020). A yolo-based
neural network with vae for intelligent garbage detec-
tion and classification. In Proceedings of the 2020 3rd
International Conference on Algorithms, Computing
and Artificial Intelligence, pages 1–7.
Enhancing Object Detection Accuracy with Variational Autoencoders as a Filter in YOLO
277
