
DRL4HFC: Deep Reinforcement Learning for Container-Based
Scheduling in Hybrid Fog/Cloud System
Ameni Kallel
1 a
, Molka Rekik
1 b
and Mahdi Khemakhem
2,1 c
1
Data Engineering and Semantics Research Unit, Faculty of Sciences of Sfax, University of Sfax, Sfax, Tunisia
2
Department of Computer Science, College of Computer Engineering and Sciences, Prince Sattam Bin Abdulaziz
University, AlKharj 11942, Saudi Arabia
Keywords:
Hybrid Fog/Cloud Environment, Containerized Microservices Problem, Scheduling Model, Multi-Objective
Optimization, Deep Reinforce Learning.
Abstract:
The IoT-based applications have a set of complex requirements, such as a reliable network connection and
handling data from multiple sources quickly and accurately. Therefore, combining a Fog environment with a
Cloud environment can be beneficial for IoT-based applications, as it provides a distributed computing system
that can handle large amounts of data in real time. However, the microservice provision to execute such
applications with achieving a high Quality of Service (QoS) and low bandwidth communications. Thus, the
container-based microservice scheduling problem in a hybrid Fog and Cloud environment is a complex issue
that has yet to be fully solved. In this work, we first propose a container-based microservice scheduling model
for a hybrid architecture. Our model is a multi-objective scheduler, named DRL4HFC, for Hybrid Fog/Cloud
architecture. It is based on two Deep Reinforce Learning (DRL) agents. DRL-based agents learn the inherent
properties of the various microservices, nodes, and environments to determine the appropriate placement of
each microservice instance required to execute each task within the Business Process (BP). Our proposal
aims to reduce the execution time, compute and network resource consumption, and resource occupancy rates
of Fog/Cloud nodes. Second, we present a set of experiments in order to evaluate the effectiveness of our
algorithm in terms of cost, quality, and time. The experimental results demonstrate that DRL4HFC achieves
faster execution times, lower communication costs and better balanced resource loads.
1 INTRODUCTION
As software technology evolved, web application ar-
chitecture is shifting from monolithic to microser-
vices (Guo et al., 2022). Nowadays, the microser-
vice architecture is being used for developing com-
plex Internet of Things (IoT) applications. Driven by
container technology, microservice architecture sepa-
rates the monolithic application into several microser-
vices that can interact but run independently (Kallel
et al., 2022; Kallel et al., 2021). In the comput-
ing platform, loosely coupled microservices are dis-
tributed, created independently, and maintained. In
order to offer low-latency services with IoT devices,
the microservice-oriented Fog computing platform is
emerging (Bonomi et al., 2014; Dastjerdi and Buyya,
a
https://orcid.org/0000-0002-7354-1276
b
https://orcid.org/0000-0002-8639-4922
c
https://orcid.org/0000-0001-5603-1947
2016; Mahmud et al., 2018). Moreover, Docker
1
and
Kubernetes
2
(Muddinagiri et al., 2019) are gaining
more and more attention from academia and indus-
try due to their popularity as tools for container or-
chestration and application deployment. With the ad-
vancement of container and virtualization technolo-
gies, Edge and Fog computing technologies are grow-
ing thanks to their rapid implementation and low op-
erational costs. Several open source systems, such
as KubeEdge (Kim and Kim, 2023) and FogAtlas
3
,
are trying to extend native containerized orchestration
capabilities to host applications at Edge/Fog environ-
ment. They aimed to provide rapid development and
operation of microservice-based applications. Due to
the limited resources of the Fog nodes, it is often not
possible to deploy all containers of a Business Pro-
cess (BP) on a single Fog environment. Combining
1
https://docs.docker.com/engine/
2
https://kubernetes.io/
3
https://fogatlas.fbk.eu/
Kallel, A., Rekik, M. and Khemakhem, M.
DRL4HFC: Deep Reinforcement Learning for Container-Based Scheduling in Hybrid Fog/Cloud System.
DOI: 10.5220/0012356800003636
Paper published under CC license (CC BY-NC-ND 4.0)
In Proceedings of the 16th International Conference on Agents and Artificial Intelligence (ICAART 2024) - Volume 2, pages 231-242
ISBN: 978-989-758-680-4; ISSN: 2184-433X
Proceedings Copyright © 2024 by SCITEPRESS – Science and Technology Publications, Lda.
231

a Fog environment with a Cloud one can be benefi-
cial for IoT-based applications, as this provides a dis-
tributed computing system that is able to handle large
amounts of data in real-time (Taneja and Davy, 2017;
Bittencourt et al., 2018). Consequently, end devices,
Fog nodes, and Cloud servers are the three comput-
ing tiers for deploying microservices-based IoT ap-
plications (Kallel et al., 2021; Sabireen and Neela-
narayanan, 2021; Hu et al., 2017). Therefore, one
should consider the communication between the dif-
ferent containers that need to be distributed on mul-
tiple nodes and resources. The distribution and man-
agement of containerized IoT applications deployed
in a hybrid (i.e., Fog/Cloud) federation system is a
critical issue that may have an impact on system per-
formance. However, such systems have yet to be
proven to support the deployment of containerized
IoT applications across widely distributed resources
coupled by heterogeneous network connectivity. In
the IoT-Fog network, a task scheduling method was
proposed to allocate resources to IoT tasks, which op-
timally selects the best nodes to execute the tasks (Liu
et al., 2023; Wadhwa and Aron, 2023). There are, in
the literature, several VM-based and container-based
solutions (Brogi et al., 2018; Funika et al., 2023; Guo
et al., 2022; Han et al., 2021; Lv et al., 2022; Wang
et al., 2020) that focus on the microservice schedul-
ing problem. However, some research studies ignored
the workflow between the set of microservice con-
tainer instances, and others considered only optimiza-
tion of execution time, compute resource usage, or
network resource consumption. In this paper, we pro-
pose a multi-objective mathematical model for Hy-
brid Fog/Cloud architecture. In addition, we suggest
a Binary Quadratic Program (BQP) based on the pro-
posed model to efficiently reduce the execution time,
compute and network resource consumption, and re-
source occupancy rates of Fog/Cloud nodes. Fur-
thermore, we present an algorithm for BQP based
on the proposed model, named DRL4HFC. Further-
more, it is based on the deep learning techniques
to reduce system imprecision by addressing its be-
havior and/or estimations, hence it helps businesses
and organisations in developing trust between humans
and complicated deep learning models (Yang et al.,
2022). The DRL4HFC is a container-based microser-
vice scheduler for hybrid (i.e., Fog/Cloud) federation
system, which comports two Deep Reinforce Learn-
ing (DRL) based agents (Sutton and Barto, 2018;
Li, 2017; Franc¸ois-Lavet et al., 2018). Indeed, the
first agent is based on a Q-Learning technique (Deep
QLearning or DQN), while the second one is a policy
gradient-based agent (REINFORCE). The DRL4HFC
may learn the inherent parameters of the set of BP’s
microservices, nodes, and environments to ensure the
efficient distribution of microservice instances for a
given BP into a hybrid federation.In conclusion, the
following are the contributions of this work: (i) We
propose a container-based microservice scheduling
model for a hybrid Fog/Cloud architecture and then a
BQP-based model to effectively reduce the compute
and network resource execution time, and resource
occupancy rates of Fog/Cloud nodes. (ii) We develop
an algorithm for BQP based on the proposed model,
named DRL4HFC, in a Python environment. (iii) We
implement two DRL-based agents, such as DQN and
REINFORCE, and train them as scheduling agents in
the DRL4HFC algorithm. (iv) We conduct a set of ex-
periments with five different real-world BP use cases
to evaluate the DRL4HFC algorithm performance in
terms of cost, quality and time. Moreover, we com-
pare the results obtained with some existing sched-
ulers.
The rest of the paper is organized as follows. In
Section 2, we discuss some similar existing work.
In Section 3, we formulate the scheduling problem
mathematically. In Section 4, we define the proposed
DRL4HFC algorithm. Section 5 presents the experi-
mentation and our scheduler performance evaluation.
Section 6 concludes the paper by outlining our future
plans.
2 RELATED WORK
The containerized deployment technique is a virtual-
ization technique that provides a low overhead and
securely segregated execution environment for mi-
croservices (Tan et al., 2020). Today, the deploy-
ment of containerized microservices is gaining atten-
tion from researchers. For example, the author in
(Funika et al., 2023) has presented a novel approach
based on the deep reinforcement learning technique
for automating the distribution of heterogeneous re-
sources in a real-world Cloud architecture. In ad-
dition, Wang et al., in (Wang et al., 2020), created
an elastic scheduling for microservices that combines
task scheduling with auto-scaling in the Cloud in or-
der to reduce the cost of virtual machines while still
satisfying deadline requirements. In the same context,
in order to reduce the total VM usage cost, the authors
in (Islam et al., 2021) developed a novel method to al-
locate executors of the Spark Job to virtual machines.
They implemented two DRL-based agents known as
DQN and REINFORCE.
However, the IoT-based apps have evolved, and
consequently, they are now built on a set of microser-
vices, replacing the old monolithic architectures. This
ICAART 2024 - 16th International Conference on Agents and Artificial Intelligence
232

shift is necessary because of the advantages it offers,
such as scalability, flexibility, ease of management,
and responsiveness to the dynamic needs of connected
devices. Obviously, Fog and Edge computing are cur-
rently being adopted for microservice delivery to get
better response times and reduce network traffic.
All the aforementioned methods, which have
taken into account the deployment of IoT applications
in a Cloud environment, are not directly applicable to
the execution of containers on Fog servers. This find-
ing is in line with recent studies recommending de-
ploying a distributed scheduler and combining Cloud
computing with Edge networking.
The authors in (Lv et al., 2022) proposed a Re-
ward Sharing Deep Q-Learning algorithm (RSDQL)
trying to achieve load balancing between Edge nodes
while reducing communication costs. The authors in
(Guo et al., 2022) proposed a multi-objective opti-
mized microservice composition approach to reduce
the service access delay and network resource con-
sumption during the microservice composition pro-
cess (Valderas et al., 2020; Ma et al., 2020). As shown
in Table 1, the two proposals ((Lv et al., 2022) and
(Guo et al., 2022)) aim to deploy reliable microser-
vices in Edge computing while taking into account
the number of container instances deployed by the mi-
croservice. However, these studies have focused only
on the optimization of network resource usage and
ignored the bandwidth variations of communication
links (i.e., inter- and intra-environment communica-
tion) and the management of compute resources (i.e.,
the capacity of nodes, etc.).
Figure 1: DRL4HFC Framework.
Other researchers were focused on optimizing the
use of computing resources and their costs. In fact, for
Edge-Cloud systems, Han et al. (Han et al., 2021) de-
veloped a Kubernetes-oriented scheduler (KaiS). This
scheduler is a multi-agent decentralized dispatcher
based on deep reinforcement learning. The authors’
primary goal was to find the best way for Edge access
points to handle computing requests coming from nu-
merous Edge nodes. Only the load-balancing IT re-
sources in a hybrid Edge-Cloud environment are op-
timized by KaiS scheduler. An innovative cost model
for deploying apps on a Fog infrastructure has been
proposed by (Brogi et al., 2018). The deployment
strategy is based on a simulation prototype called
FogTorch that helps make a decision about deploy-
ment in Fog environment while considering the actual
resource usage and cost needs. In fact, it selects the
appropriate virtual machine for deploying the compo-
nents of the IoT application in a hybrid Fog and Cloud
computing environment. In this work, microservice
containerization was not taken into account; only
computing resources and inter-environment commu-
nication costs were taken into account (see Table 1).
Therefore, as shown in table 1, our approach serves as
a microservice scheduler that manages the workflows
between the multiple container instances in a hybrid
Fog and Cloud environment. Using a meticulous op-
timization model, the proposed scheduler is based on
an algorithm that takes into consideration the mini-
mization of several costs (computational, inter/intra-
communication, and load-balancing resource utiliza-
tion in hybrid environments Fog/Cloud).
3 SYSTEM MODEL AND
PROBLEM FORMULATION
As depicted in Figure 1, we consider a hybrid environ-
ment composed by Fog and Cloud systems. There-
fore, the scheduling problem consists in assigning a
set of microservice instances to a set of nodes dis-
tributed in heterogeneous Fog and Cloud environ-
ments. The selection of nodes should take into ac-
count the optimization (i.e., minimization) of: (i)
computation cost of each node, (ii) inter- and intra-
environment(s) communication costs by simulating
bandwidth variations of communication links, and
(iii) resource load balancing. In this section, we pro-
pose a BQP-based model to optimally solve such a
scheduling problem. The proposed BQP is defined
by its parameters, decision variables, constraints, and
objective function.
DRL4HFC: Deep Reinforcement Learning for Container-Based Scheduling in Hybrid Fog/Cloud System
233

Table 1: Existing IoT-aware scheduler within distributed environment.
Related Work
Features
(Lv et al., 2022)
(Han et al., 2021)
(Brogi et al., 2018)
(Islam et al., 2021)
(Guo et al., 2022)
(Funika et al., 2023)
(Wang et al., 2020)
Our approach
Dependable microservice orchestration • • • • •
Computing resources of Fog/Edge • • • • •
Computation cost • • • •
Communication cost • • • • •
Balancing resource load • • •
Multi-environments • • • •
Intra/Inter communication (a) •
Distributed container in hybrid Fog/Cloud env. • (b) • •
Microservice instances • • (c) • • •
Deep learning • • • • • •
Resources management • • • • •
•
Full consideration,
(a)
Only the inter-communication,
(b)
Distributed VMs,
(c)
Executor number of a job.
3.1 Parameters
As illustrated in Figure 1, we consider the parame-
ters of both the infrastructure and the BP contexts.The
infrastructure context specifies the available network
and computing resources to be used to execute mi-
croservices within the BP. This context should be con-
sidered by the scheduler as a component(s) of the
multiobjective optimization function. The BP context
refers to the microservices to be executed in the con-
tainers. As the same, the properties of such context
shall be taken into account by the scheduler. In the
following, we will detail all relevant parameters.
3.1.1 Infrastructure Context
We identify a set of key notations to formalize the
infrastructure context, as follows:
▷ E = {E
1
,E
2
,...,E
|E|
}: set of |E| = φ Fog/Cloud
environments.
▷ ∀E
i
∈ E, E
i
= {N
i1
,N
i2
,...,N
i|E
i
|
}: set of |E
i
| = ω
i
nodes (VMs and/or PMs) deployed in a Fog/Cloud
environment E
i
∈ E.
▷ ∀E
i
∈ E, ∀N
i j
∈ E
i
,core
i j
∈ N
∗
: number of
CPU/vCPU cores of the node N
i j
.
▷ ∀E
i
∈ E, ∀N
i j
∈ E
i
,mips
i j
∈ N
∗
: CPU/vCPU
core speed of the node N
i j
expressed in million
instructions per second (MIPS).
▷ ∀E
i
∈ E, ∀N
i j
∈ E
i
,mem
i j
∈ N
∗
: memory (RAM)
capacity of the node N
i j
expressed in Gigabytes (Gb).
▷ ∀E
i
∈ E, ∀N
i j
∈ E
i
,intraNbw
i j
∈ N
∗
: maximum
bandwidth offered by the node N
i j
to each deployed
container for intra-node communications.
▷ ∀E
i
∈ E, intraEbw
i
∈ N
∗
: bandwidth capacity
between two nodes deployed in the same environment
E
i
.
▷ ∀E
i
∈ E, ∀E
j
∈ E, j ̸= i, interEbw
i j
∈ N
∗
: band-
width capacity between each node deployed in E
i
and
each node deployed in E
j
.
▷ ∀E
i
∈ E,∀N
i j
∈ E
i
,Stypes
i j
⊂ Π =
{π
1
,π
2
,...,π
|Π|
}: set of micro-service types that can
be performed by the node N
i j
(i.e., task types), where
Π represents the set of all micro-services types that
depends on the considered scenario usage. For ex-
ample, a smart home scenario requires a surveillance
camera that may detect the motion whilst in other
scenarios, one can need the storage and processing
tasks, etc. Thus, the type of task shall be specified to
make the right execution decision.
▷ ∀E
i
∈ E, coreT hreshold
i
,memT hreshold
i
: a
predefined values specified by the provider of E
i
in
order to ensure that the occupancy rates of each node,
deployed in the E
i
, in terms of CPU and memory
(respectively), cannot exceed these values.
3.1.2 BP Context
In the following, we identify the key notations to
model the BP context:
▷ BP = {BP
1
,BP
2
,...,BP
|BP|
}: set of |BP| = θ
Business Processes.
▷ ∀BP
p
∈ BP,BP
p
= {MS
p1
,MS
p2
,...,MS
p|BP
p
|
}: set
of |BP
p
| = α
p
micro-services needed to execute the
business process BP
p
.
▷ ∀BP
p
∈ BP,∀MS
pq
∈ BP
p
,MS
pq
=
{msi
pq1
,msi
pq2
,...,msi
pq|MS
pq
|
}: set of |MS
pq
| = β
pq
instances of the micro-service MS
pq
needed by the
business process BP
p
.
▷ ∀BP
p
∈ BP, ∀MS
pq
∈ BP
p
,typeM
pq
∈ Π =
{π
1
,π
2
,...,π
|Π|
}: the set of the micro-service in-
stance types MS
pq
.
▷ ∀BP
p
∈ BP, ∀MS
pq
∈ BP
p
,miM
pq
∈ N
∗
: the number
of instructions to be executed by any instance msi
pqr
of the micro-service MS
pq
expressed in Millions of
Instructions (MI).
▷ ∀BP
p
∈ BP, ∀MS
pq
∈ BP
p
,cpuM
pq
∈ N
∗
: number
of CPU/vCPU cores needed by any instance msi
pqr
of the micro-service MS
pq
.
ICAART 2024 - 16th International Conference on Agents and Artificial Intelligence
234

▷ ∀BP
p
∈ BP, ∀MS
pq
∈ BP
p
,memM
pq
∈ N
∗
: memory
(RAM) capacity needed by any instance msi
pqr
of the
micro-service MS
pq
.
▷ ∀BP
p
∈ BP, ∀MS
pq
,MS
pr
∈ BP
p
,r ̸=
q,dataSize
pqr
∈ N: transferred data size from
any instance msi
pqs
of micro-service MS
pq
to any in-
stance msi
prt
of micro-service MS
pr
. dataSize
pqr
> 0
if the micro-service MS
pr
gets the output of micro-
service MS
pq
as an input, otherwise dataSize
pqr
= 0.
▷ ∀BP
p
∈ BP, ∀MS
pq
,MS
pr
∈ BP
p
,r ̸= q, bw
pqr
∈ N:
minimum bandwidth capacity required to transfer
data from any instance of the micro-service MS
pq
to any instance of the micro-service MS
pr
. If
dataSize
pqr
> 0 then bw
pqr
> 0, otherwise bw
pqr
= 0.
3.2 Decision Variables
We specify the following set of decision variables in
our BQP model: ∀BP
p
∈ BP, ∀MS
pq
∈ BP
p
,∀msi
pqr
∈
MS
pq
,∀E
i
∈ E, ∀N
i j
∈ E
i
,X
i j
pqr
∈ {0,1}: a binary de-
cision variable that is equal to 1 if instance msi
pqr
, of
micro-service MS
pq
of business process BP
p
, is de-
ployed into a container of node N
i j
of Cloud/Fog en-
vironment E
i
, 0 otherwise.
3.3 Objective Function
Deploying a BP in a Fog and Cloud federation con-
sists in selecting a suitable Fog or Cloud node, which
may be a physical or virtual machine for launching the
container associated with each instance of the BP’s
microservice. Indeed, this same node may be allo-
cated to run other instances of the BP’s microservices.
Thus, our objective function is a quadratic equation. It
includes: (i) the sum of intra- and inter-environment
communication costs, (ii) the sum of computational
costs of all resources, and (iii) the sum of variance of
all resource occupancy.
3.3.1 Communication Cost
The communication cost among micro-services is re-
lated to two key factors:
• The size of data transmitted in a request between
two different micro-service instances, and
• The capacity of bandwidth between the nodes
where the two micro-service instances are allo-
cated.
CommCost
pqrst
= dataS ize
pqr
×
"
∑
E
i
∈E
∑
N
i j
∈E
i
X
i j
pqs
× X
i j
prt
intraNbw
i j
+
∑
E
i
∈E
∑
N
i j
∈E
i
∑
N
ik
∈E
i
k̸= j
X
i j
pqs
× X
ik
prt
intraEbw
i
+
∑
E
i
∈E
∑
E
j
∈E
j̸=i
∑
N
ik
∈E
i
∑
N
jℓ
∈E
j
X
ik
pqs
× X
jℓ
prt
interEbw
i j
#
,
∀BP
p
∈ BP,∀MS
pq
,MS
pr
∈ BP
p
,r ̸= q, ∀msi
pqs
∈ MS
pq
,∀msi
prt
∈ MS
pr
(1)
Expression (1) calculates the total communication
cost CommCost
pqrst
between different micro-services
of a given business process. It is composed by three
summation terms, which are:
• The first summation term calculates the intra-
node communication cost (i.e., communication
cost between two micro-service instances de-
ployed in the same node).
• The second summation term computes the cost of
intra-environment communication (i.e., commu-
nication cost between two micro-service instances
deployed in two different nodes but in the same
environment).
• The third summation term determines the cost of
inter-environment communication (i.e., commu-
nication cost between two micro-service instances
deployed in two different nodes but in two differ-
ent environments).
Thus, the total communication cost C
comm
be-
tween all instances of all micro-services of a given
business process can be calculated by equation (2) as
follows:
C
comm
=
∑
BP
p
∈BP
∑
∀MS
pq
∈BP
p
∑
MS
pr
∈BP
p
r̸=q
∑
msi
pqs
∈MS
pq
∑
msi
prt
∈MS
pr
CommCost
pqrst
(2)
The normalized communication cost
NormalizedC
comm
can be defined by expression
(3) as follows:
NormalizedC
comm
=
C
comm
MaxC
comm
(3)
where the maximum communication cost MaxC
comm
can be defined by expression (4) as follows:
MaxC
comm
=
∑
BP
p
∈BP
∑
∀MS
pq
∈BP
p
∑
MS
pr
∈BP
p
r̸=q
∑
msi
pqs
∈MS
pq
∑
msi
prt
∈MS
pr
dataSize
pqr
×
"
∑
E
i
∈E
∑
N
i j
∈E
i
1
intraNbw
i j
+
∑
E
i
∈E
∑
N
i j
∈E
i
∑
N
ik
∈E
i
k̸= j
1
intraEbw
i
+
∑
E
i
∈E
∑
E
j
∈E
j̸=i
∑
N
ik
∈E
i
∑
N
jℓ
∈E
j
1
interEbw
i j
#
3.3.2 Computation Cost
CompCost
pq
=
∑
E
i
∈E
∑
N
i j
∈E
i
∑
msi
pqr
∈MS
pq
miM
pq
× X
i j
pqr
mips
i j
× core
i j
,
∀BP
p
∈ BP, ∀MS
pq
∈ BP
p
(4)
The Expression (4) computes the total compu-
tation cost CompCost
pq
of each micro-service of a
given business process. The total computation cost
C
comp
of all micro-services of a given business pro-
cess can be calculated by expression (5) as follows:
C
comp
=
∑
BP
p
∈BP
∑
∀MS
pq
∈BP
p
CompCost
pq
(5)
The normalized computation cost
NormalizedC
comp
can be defined by expression
(6) as follows:
NormalizedC
comp
=
C
comp
MaxC
comp
(6)
DRL4HFC: Deep Reinforcement Learning for Container-Based Scheduling in Hybrid Fog/Cloud System
235

where the maximum computation cost MaxC
comp
is
calculated as:
MaxC
comp
=
∑
BP
p
∈BP
∑
∀MS
pq
∈BP
p
∑
E
i
∈E
∑
N
i j
∈E
i
∑
msi
pqr
∈MS
pq
miM
pq
mips
i j
× core
i j
3.3.3 Variance of Resource Occupancy
In order to avoid the degradation of services execu-
tion performance, the load balancing has to be con-
sidered. We characterize the load balancing by cal-
culating the variance of resource occupancy rates of
Fog/Cloud nodes:
▷ ∀E
i
∈ E, ∀N
i j
∈ E
i
, occ
Resource
i j
∈ R
+
represents the
occupancy of the resource (CPU/vCPU cores or mem-
ory) on node N
i j
. It is calculated as follows using the
general expression (7):
occ
Resource
i j
=
∑
BP
p
∈BP
∑
MS
pq
∈BP
p
∑
msi
pqr
∈MS
pq
resourceM
pq
× X
i j
pqr
resource
i j
(7)
▷ av
Resource
∈ R
+
represents the average occupancy
of the resource (CPU/vCPU cores or memory) on all
nodes. It is calculated as follows using the general
expression (8):
av
Resource
=
∑
E
i
∈E
∑
N
i j
∈E
i
occ
Resource
i j
ω
i
(8)
▷ var
Resource
∈ R
+
represents the variance of the
resource (CPU/vCPU cores (var
Core
) or memory
(var
Mem
)) and is calculated as follows using the gen-
eral expression (9):
var
Resource
=
∑
E
i
∈E
∑
N
i j
∈E
i
(occ
Resource
i j
− av
Resource
)
2
ω
i
(9)
The total occupancy variance V
occ
of all nodes of
all clusters of all environments can be identified by
expression (10) as follows:
V
occ
= γ × var
Core
+ (1 − γ) × var
Mem
(10)
With γ ∈ {0, 1} is a weighting coefficient representing
the relative contribution of CPU variance (var
Core
) to
memory variance (var
Mem
) in the calculation of total
occupancy variance (V
occ
). Its value, between 0 and 1,
determines the weight attributed to each component in
the overall variability of node occupancy in an HFC
environment.
3.3.4 Objective Function
The global objective function aims to minimize the
multiple aggregated costs, such as communication
cost, computation cost, and resource occupancy vari-
ance. We adopt the weighted sum method since it
is the most frequently used multi-objective optimiza-
tion technique (Marler and Arora, 2010). In fact,
the method regroups all objective functions into only
one normalized and aggregated function by summing
them with the use of weighting factors, as shown by
expression (11):
Min Z = λ
1
× NormalizedC
comm
+
λ
2
× NormalizedC
comp
+ λ
3
×V
occ
(11)
The above expression represents the global objec-
tive function where λ
1
, λ
2
and λ
3
present the weight-
ing factors aggregating the three dependent nor-
malized sub-objective functions NormalizedC
comm
(time), NormalizedC
comp
(time) and V
occ
(rate) cal-
culated by expressions (3), (6), and (10), respectively.
Such function is subject to a set of constraints detailed
as follows.
3.4 Constraints
We categorize the set of constraints into: capac-
ity constraints, resource occupancy constraints and
placement constraints. These constraints are defined
as follows.
3.4.1 Capacity Constraints
▷Constraints (12) and (13) ensure that the required
capacities, in terms of CPU and memory, respectively,
by each micro-service instance should not exceed the
infrastructure resource capabilities.
∑
BP
p
∈BP
∑
MS
pq
∈BP
p
∑
msi
pqr
∈MS
pq
cpuM
pq
× X
i j
pqr
≤ core
i j
,
∀E
i
∈ E, ∀N
i j
∈ E
i
(12)
∑
BP
p
∈BP
∑
MS
pq
∈BP
p
∑
msi
pqr
∈MS
pq
memM
pq
× X
i j
pqr
≤ mem
i j
,
∀E
i
∈ E, ∀N
i j
∈ E
i
(13)
▷ Constraints (14) ensure that the bandwidth occu-
pied to transfer data between two micro-service in-
stances, deployed in the same node, should not ex-
ceed the bandwidth capacity offered by that node.
∑
BP
p
∈BP
∑
MS
pq
∈BP
p
∑
MS
pr
∈BP
p
r̸=q
∑
msi
pqs
∈MS
pq
∑
msi
prt
∈MS
pr
bw
pqr
×
X
i j
pqs
× X
i j
prt
≤ intraNbw
i j
,∀E
i
∈ E, ∀N
i j
∈ E
i
(14)
▷ Constraints (15) ensure that the bandwidth occu-
pied to transfer data between two micro-service in-
stances, deployed in two different nodes in the same
environment, should not exceed the bandwidth ca-
pacity offered between these nodes.
∑
BP
p
∈BP
∑
MS
pq
∈BP
p
∑
MS
pr
∈BP
p
r̸=q
∑
msi
pqs
∈MS
pq
∑
msi
prt
∈MS
pr
bw
pqr
×
X
i j
pqs
× X
ik
prt
≤ intraEbw
i
,∀E
i
∈ E, ∀N
i j
,N
ik
∈ E
i
,k ̸= j
(15)
ICAART 2024 - 16th International Conference on Agents and Artificial Intelligence
236

▷ Constraints (16) ensure that the bandwidth occu-
pied to transfer data between two micro-service in-
stances, deployed in two different nodes in two dif-
ferent environments, should not exceed the band-
width capacity offered between these environments.
∑
BP
p
∈BP
∑
MS
pq
∈BP
p
∑
MS
pr
∈BP
p
r̸=q
∑
msi
pqs
∈MS
pq
∑
msi
prt
∈MS
pr
bw
pqr
× X
ik
pqs
×
X
jℓ
prt
≤ interEbw
i j
,∀E
i
∈ E, ∀E
j
∈ E, j ̸= i, ∀N
ik
∈ E
i
,∀N
jℓ
∈ E
j
(16)
3.4.2 Resource Occupancy Constraints
▷ Constraints (17) and (18) ensure that occupancy
rates of each nodes, of given environment, in terms
of CPU and memory don’t exceed the predefined val-
ues coreT hreshold and memT hreshold, respectively,
specified by the environments providers.
occCore
i j
≤ coreThreshold
i
,∀E
i
∈ E, ∀N
i j
∈ E
i
(17)
occMem
i j
≤ memT hreshold
i
,∀E
i
∈ E, ∀N
i j
∈ E
i
(18)
3.4.3 Placement Constraints
▷ Constraints (19) ensure that each instance of a
micro-service of a given business process should be
assigned to only one node of a given environment.
∑
E
i
∈E
∑
N
i j
∈E
i
X
i j
pqr
= 1, ∀BP
p
∈ BP, ∀MS
pq
∈ BP
p
,∀msi
pqr
∈ MS
pq
(19)
▷ Constraints (20) ensure that ∀BP
p
∈ BP, ∀MS
pq
∈
BP
p
, each micro-service instance msi
pqr
∈ MS
pq
hav-
ing a type typeM
pq
must be deployed in a node that
supports this type.
If X
i j
pqr
= 1, then typeM
pq
∈ Stypes
i j
,
∀E
i
∈ E, ∀N
i j
∈ E
i
,∀BP
p
∈ BP, ∀MS
pq
∈ BP
p
,∀msi
pqr
∈ MS
pq
(20)
4 DRL4HFC ALGORITHM
DESIGN
After proposing the container-based microservice
scheduling model for a hybrid architecture, we will
define in this section our algorithm (see Algorithm 1),
which is based on two DRL-based agents to imple-
ment it. The first agent adopts the Q-Deep Learning
(QDN) technique while the second one is a policy gra-
dient based technique, known as REINFORCE. The
authors, in (Islam et al., 2021), explained the role
and the features of each techniques. In fact, the DRL
agent will receive an instant reward each time it con-
ducts an action (i.e., each time it places a microser-
vice instance in a container on a specific node). It
should be noted that reward value is initialized by
0 (see line 4 of Algorithm 1 and first term of equa-
tion (21)) and it is updated according to the following
cases:
• Each time one constraint is verified, the algorithm
assigns a small positive value (see line 10 of Al-
gorithm 1 and second term of equation (21))
• One of the nine above-listed constraints is unver-
ified, the algorithm assigns a negative value (see
line 13 of Algorithm 1 and third term of equation
(21))
• Each time the episode is successfully terminated,
the algorithm calculates an episodic value (see
line 30 of Algorithm 1 and fourth term of equa-
tion (21)).
After each microservice instance/container place-
ment, the next state will be modified according to the
previous state (see line 20 of Algorithm 1). It is worth
mentioning that the DRL agent should finally be able
to learn the capacity, resource occupancy, and place-
ment constraints of each microservice within the BP
in order to complete one episode and get the episodic
reward. In this work, we consider: (i) the state space
that contains all nodes’ states and the next microser-
vice’s state, (ii) the action that is proposed by the
DRL-agent (see line 6 of Algorithm 1). It can take
only a value in [0 . . . θ], where θ =
∑
E
i
∈E
ω
i
, indicat-
ing the index of the selected node that is able to deploy
the container, and (iii) the instant reward inst
reward
of
each step, is calculated as follows:
inst
reward
=
0 initially
inst
reward
+ 1 if constraint is verified
inst
reward
− const
total
∗ msi
total
if constraint is not verified
inst
reward
+ r
f ixed
∗ cost
reward
if the current instance is
the last one to place
(21)
where, (i) const
total
is the total number of con-
straints, in our case we have nine constraints (see
sections 3.4.1, 3.4.2, and 3.4.3), (ii) msi
total
=
∑
BP
p
∈BP
∑
MS
pq
∈BP
p
β
pq
is the total number of mi-
croservices instances of all business processes, (iii)
r
f ixed
is the fixed episodic reward set to a very high
value (i.e., 1000), and (vi) cost
reward
= 1 − Z (see line
29 of Algorithm 1). In order to make our algorithm
flexible and customizable, it accepts, as inputs, the
agent’s name and the fixed episodic reward r
f ixed
(see
Algorithm 1).
5 EVALUATION
In this section, first we specify the experimental set-
tings (i.e., the infrastructure, the BP, and some exist-
DRL4HFC: Deep Reinforcement Learning for Container-Based Scheduling in Hybrid Fog/Cloud System
237

Input : episode
no
= 0
1 for iteration from 0 to N do
2 if iteration == 0 then
3 Initialize state;
4 inst
reward
= 0;
5 end
6 DRL agent proposes an action;
7 for i from 0 to const
total
do
8 Veri f y = ”Const
i
is validated for the current MS instance”;
9 if Veri f y then
10 inst
reward
+ = 1;
11 end
12 else
13 inst
reward
− = const
total
× msi
total
;
14 episode
no
+ = 1;
15 Initialize state;
16 break;
17 end
18 end
19 if Veri f y then
20 Update state;
21 last
msi
== ”currentMSinstanceisthelastonetoplace”;
22 if last
msi
then
23 Calculate the total computation cost C
comp
(eq. 5);
24 Calculate the total communication cost C
comm
(eq. 2);
25 Calculate the total variance V
occ
(eq. 10);
26 Calculate the normalized computation cost
NormalizedC
comp
(eq. 6);
27 Calculate the normalized communication cost
NormalizedC
comm
(eq. 3);
28 Calculate the global objective function Z (eq. 11);
29 cost
reward
= 1 − Z;
30 inst
reward
+ = r
f ixed
× cost
reward
;
31 episode
no
+ = 1;
32 Initialize state;
33 end
34 end
35 end
Algorithm 1: DRL4HFC Algorithm.
ing schedulers parameters). Secondly, we evaluated
our scheduler versus current existing scheduling al-
gorithms such as:
▷ Default Kubernetes scheduler
4
: is the Kubernetes
Scheduler’s default method for evenly distributing
pods among nodes. The default schedule is split into
two parts: (i) Predicates which apply the scheduling
policy to all nodes in the current cluster and filter out
any node that doesn’t fit the requirements, and (ii) Pri-
orities: After scoring each node, choose the one with
the highest priority and attach it to the pod.
▷ RSDQL (Lv et al., 2022) is a microservice sched-
uler to balance the load between nodes while reducing
communication costs.
▷ DRL-Based Scheduler (Islam et al., 2021): is a job
scheduler to minimize both the cost of using the nodes
and the average job completion time for the jobs.
5.1 Experimental Settings
▷ Infrastructure Parameters: Our scheduler is con-
figured on two environments containing four nodes.
Each node capacity is defined by the compute, net-
work resources. Let us assume that each node has ran-
dom values of CPU/vCPU core number, CPU/vCPU
core speed, memory capacity and communication link
4
https://github.com/kubernetes-sigs/
kube-scheduler-simulator
bandwidth capacity. Note that such values should be
in specific ranges as illustrated in Table 2.
▷ BP Parameters: To evaluate our proposal, we con-
sider five real-world use cases:
• BookInfo BP (BIBP)
5
(Joseph and Chan-
drasekaran, 2020): is a microservices-based sys-
tem that manages book information and reviews.
It comprises 4 microservices, including product-
page, details, reviews, and ratings, which collab-
orate to provide a comprehensive book informa-
tion platform. Additionally, it involves 2 commu-
nications between these microservices to ensure
smooth operation.
• Hotel Reservation BP (HRBP)
6
: is a system cre-
ated to facilitate the reservation of hotel accom-
modations, comprising 8 microservices and fea-
turing a network of 16 communications. These
microservices collectively manage functions such
as reservations, availability, pricing, and customer
management, ensuring a seamless hotel booking
experience.
• Improved Hotel Reservation BP (I-HRBP): is
an enhanced version of the original HRBP. In this
improved iteration, we have increased the number
of communications between microservices to 30
in order to enhance data flow and further optimize
the hotel reservation process. It offers improved
efficiency and responsiveness in managing hotel
bookings.
• Interconnected Enterprise Management Sys-
tem BP (IEMS BP) used by ZettaSpark Com-
pany
7
: is a comprehensive system designed to
manage various aspects of enterprise operations.
Additionally, as depicted in Figure 2, it encom-
passes 16 microservices and features a network of
30 communications, covering user management,
product catalog, order processing, inventory man-
agement, and more. All these microservices are
interconnected to streamline business processes
effectively.
• Improved Interconnected Enterprise Manage-
ment System BP (I-IEMS BP): is an advanced
version of the IEMS BP. In this improved variant,
we have increased the number of communications
to 50, facilitating a more robust data exchange
and optimizing overall enterprise management. It
offers advanced capabilities for efficient business
operations.
5
https://istio.io/latest/docs/examples/bookinfo
6
https://github.com/delimitrou/DeathStarBench/tree/
master/hotelReservation
7
https://zettaspark.io/
ICAART 2024 - 16th International Conference on Agents and Artificial Intelligence
238

Figure 2: IEMS BP.
The left part of Table 3 presents the parameters of
each BP, including the number of CPU/vCPU cores,
the number of instructions, and the memory capacity
needed by any instance of the BP’s micro-service.
▷ DRL-Based Agents Parameters: We use the pa-
rameters mentioned in the right part of Table 3 to con-
figure the DQN and REINFORCE agents. It should
be noted that these parameters are used by both our
DRL4HFC scheduler and the DRL-Based Scheduler.
Table 2: Infrastructure parameter settings.
Parameter Value
core
i j
{16, 32, 64, 128, 256, 384, 512}
mips
i j
[25000 − 2500000]
mem
i j
(GB) {16, 32, 64, 128, 256, 384, 512, 768, 1024}
intraNbw
i j
(MB/s) [1000 − 10000]
intraEbw
i
(MB/s) [100 − 1000]
interEbw
i j
(MB/s) [10 − 1000]
coreT hreshold
i
=
{0.85,0.9, 0.95}
memT hreshold
i
Table 3: BP and DRL-based agents parameter settings.
BP DRL-based agents
Parameter Value Parameter Value
cpuM
pq
{1,2,4,8} Batch Size 64
miM
pq
[1000-1000000] Epsilon 0.001
memM
pq
(GB) {1,2,4,8} Learning Rate 0.001
dataSize
pqr
(MB) [1-20] Optimization Priority 1
bw
pqr
(MB/s) [1-10] Number Training Iteration 2000
|MS
pq
| {1,2,3}
5.2 Performance Evaluation
To evaluate the performance of our DRL-based mi-
croservices scheduler for Fog/Cloud architecture, we
developed a simulation environment in Python lan-
guage. It is worth mentioning that by evaluating per-
formance, we mean assessing the quality, cost, and
time required/taken by our solution. Let us start by
the execution time metric. It is determined by di-
viding the number of MI required by a microservice
instance by the number of MIPS offered by the node
(Rekik et al., 2016). The cost of traffic communi-
cation metric is the cost of data transfer while con-
sidering the different types of communication links.
Regarding the third metric, it focuses on the load bal-
ancing rate that calculates the variance of resource
occupancy rates of all Fog/Cloud nodes. In fact, our
Figure 3: Cost & Quality Efficiency Evaluation.
approach aims at improving the QoS. Thus, we will
evaluate in the following the cost & quality effi-
ciency through comparing the value obtained by our
previously proposed objective function with existing
schedulers as well as the time efficiency during the
model execution.
▷ Cost & Quality Efficiency Evaluation: On the
one hand, let us start with the total cost metric. As
shown in Figure 3, the DRL4HFC algorithm, regard-
less of the agent adopted, outperforms all others and
achieves the lowest cost for all BP use cases. In more
detail, the DRL4HFC algorithm and kubernetes as a
startup using the BP with the smallest number of mi-
croservices achieved the lowest total cost, but as the
number of microservices increases, the DRL4HFC
algorithm outperforms even kubernetes with a more
consistent difference because it learns the parame-
ters inherent in the RDL agent: it learns the inher-
ent parameters of different types of nodes, networks,
and BP’s microservices when selecting the best place-
ment strategy into an appropriate container for a given
microservice. On the other hand, we focus on the
total communication cost metric. The obtained re-
sults demonstrate that our DRL algorithm provides
always the minimum communication cost (see Fig-
ure 4). These two figures show that (i) our algorithm
is the better scheduler than the other ones in terms
of Cost and Quality Efficiency Evaluation and (ii) the
Figure 4: Communication Cost Evaluation.
DRL4HFC: Deep Reinforcement Learning for Container-Based Scheduling in Hybrid Fog/Cloud System
239

(a) BI BP. (b) HR BP.
(c) I-HR BP. (d) IEMS BP.
(e) I-IEMS BP.
Figure 5: Time Efficiency Evaluation.
results of the two agents DQN and Reinforce, after
20,000 iterations, converged towards the same values.
This means that our algorithm has converged to an
optimal or near-optimal solution for the problem we
are trying to solve. That finding is confirmed by com-
paring it with the optimal value obtained solving the
BQP-based model using the high-performance opti-
mization solver CPLEX
8
. The optimal value is shown
as an orange-hatched bar in Figure 3. This figure
demonstrates that these two agents constantly provide
an optimal or nearly optimal solution, regardless of
the specific use case. Therefore, our DRL agent is
the first algorithm that seeks to minimize simultane-
ously the computation and communication times and
the variance of the resources’ occupancy rates.
▷ Time Efficiency Evaluation: In this section, we
monitor the response time of all microservice in-
8
https://www.ibm.com/products/ilog-cplex-
optimization-studio/cplex-optimizer
stances running within a BP and then compare our
obtained results (i.e., response time) with those of
other scheduling algorithms (see Figure 5). It should
be noted that since only our algorithm, regardless of
the adopted agent, and the RSDQL algorithm take
into consideration the communication cost of a BP,
we have presented only these three algorithms in Fig-
ure 5b and Figure 5d to calculate the response time
for I-HR BP and I-IEMS BP. In fact, the other al-
gorithms, including Kubernetes, offer the same val-
ues for the response time of IEMS BP and IIEMS
BP as well as HR BP and IHR BP because they do
not account for the number of communications be-
tween microservices. As shown in Figure 5, Kuber-
netes consistently provides a poor value in terms of
response time, regardless of the BP adopted, due to
the absence of deep learning agent adoption, which
helps minimize response time. As illustrated in Fig-
ure 5, the DRL4HFC based on the DQN agent and
ICAART 2024 - 16th International Conference on Agents and Artificial Intelligence
240
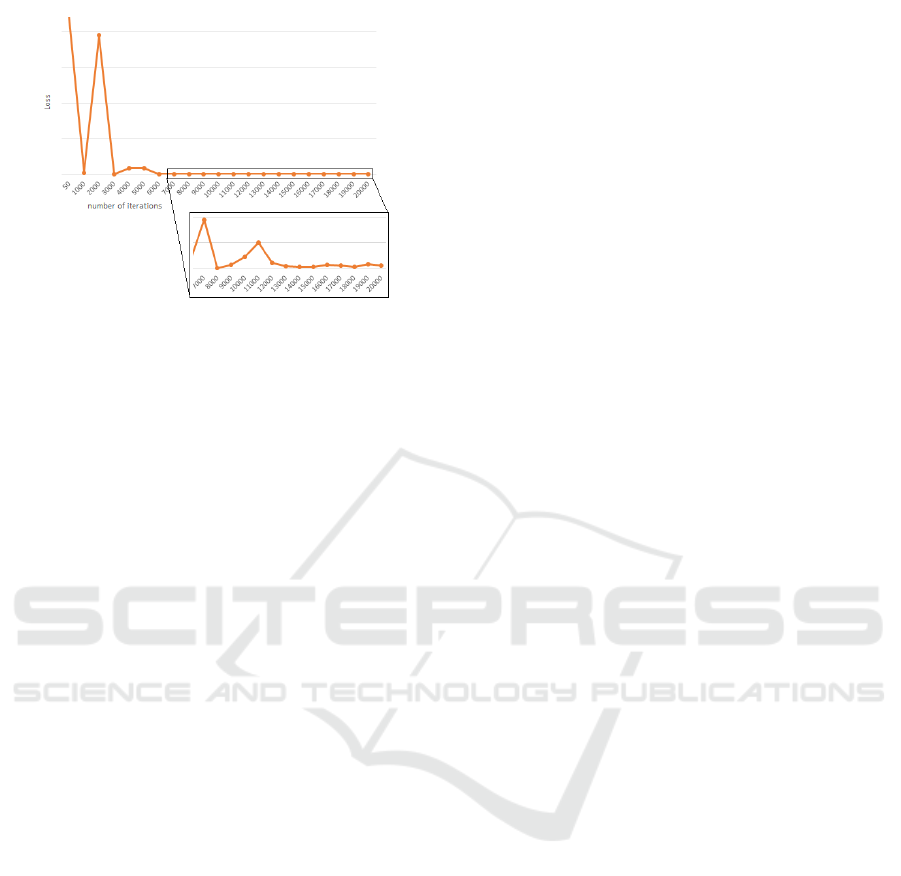
Figure 6: Loss Evolution during Deep Learning Model
Training.
the RSDQL technique consistently offer the best re-
sponse time, regardless of the number of competing
requests and the BP adopted. Additionally, we at-
tempted to increase the number of microservices, and
dependencies between microservices to evaluate the
effectiveness of our proposal. We observed that RS-
DQL provides better response time values in most
BPs, but it remains our top-performing algorithm, es-
pecially when we increase the number of microser-
vice instances to 16, and dependency links between
microservices to 50 (see Figure 5d). This demon-
strates the effectiveness of our proposal, which en-
ables us to achieve more efficient results in terms of
response time compared to other algorithms.
Additionally, the graph illustrated in Figure 6,
with the x-axis representing the number of iterations
and the y-axis representing the loss value, signifi-
cantly illustrates the process of training a deep learn-
ing model. This type of graph is essential for several
important reasons. Firstly, it highlights the evolution
of our model’s performance as it undergoes training.
By plotting the loss as a function of the number of
iterations, we visualize how the model progressively
adjusts to minimize the error between its predictions
and the actual values in the training data. This ongo-
ing reduction in loss is a positive indicator, demon-
strating that the model is effectively learning from the
data. In summary, this loss-versus-iteration graph is
a crucial tool for monitoring and evaluating the train-
ing of a deep learning model. Figure 6 shows that
the loss converges towards a minimum value, and this
convergence suggests that our model has achieved sta-
ble performance.
6 CONCLUSION
It is a difficult challenge to schedule microservices
for IoT applications within a hybrid Fog and Cloud
environment. Indeed, it must take into account the
heterogeneity of nodes and the diverse requirements
of the microservices in the BP. Traditional sched-
ulers have not focused on multi-objective optimiza-
tion or learning from the states of both assigned
Fog/Cloud node(s) and deployed microservices. In
response to this, we have proposed an scheduling
model for container-based microservice execution in
a hybrid architecture. The proposed scheduler, named
DRL4HFC, employs two DRL-based agents. The
first agent, DQN, is a Q-Learning-based agent, while
the second agent, REINFORCE, is a policy gradient-
based agent. The DRL4HFC algorithm aims to pro-
vide an appropriate solution, minimizing execution
time, computing and network resource consumption,
and resource occupancy rates of Fog/Cloud nodes. Si-
multaneously, it takes into account the heterogene-
ity of environments, nodes, communication links, mi-
croservices, and their dependencies. The effective-
ness of our proposed approach is validated through
a series of simulation experiments aimed at improv-
ing the total cost of microservices execution in a
hybrid environment for business processes. These
experiments were conducted using two real-world
business processes. In the future, we plan to in-
vestigate the development of a generic model for
a microservice-based scheduling system that can be
adopted in large-scale Fog/Cloud real-world scenar-
ios to further train the agents. Additionally, we in-
tend to explore whether the DRL agents can recog-
nize new contextual changes within Fog/Cloud envi-
ronments to obtain an accurate model for an optimal
or near-optimal container-based scheduler in a hybrid
environment.
REFERENCES
Bittencourt, L., Immich, R., Sakellariou, R., Fonseca, N.,
Madeira, E., Curado, M., Villas, L., DaSilva, L., Lee,
C., and Rana, O. (2018). The internet of things, fog
and cloud continuum: Integration and challenges. In-
ternet of Things, 3:134–155.
Bonomi, F., Milito, R., Natarajan, P., and Zhu, J. (2014).
Fog computing: A platform for internet of things and
analytics. Big data and internet of things: A roadmap
for smart environments, pages 169–186.
Brogi, A., Forti, S., and Ibrahim, A. (2018). Deploying
fog applications: How much does it cost by the way?
small, 1(2):20.
Dastjerdi, A. V. and Buyya, R. (2016). Fog computing:
DRL4HFC: Deep Reinforcement Learning for Container-Based Scheduling in Hybrid Fog/Cloud System
241

Helping the internet of things realize its potential.
Computer, 49(8):112–116.
Franc¸ois-Lavet, V., Henderson, P., Islam, R., Bellemare,
M. G., Pineau, J., et al. (2018). An introduction
to deep reinforcement learning. Foundations and
Trends® in Machine Learning, 11(3-4):219–354.
Funika, W., Koperek, P., and Kitowski, J. (2023). Auto-
mated cloud resources provisioning with the use of the
proximal policy optimization. The Journal of Super-
computing, 79(6):6674–6704.
Guo, F., Tang, B., and Tang, M. (2022). Joint optimization
of delay and cost for microservice composition in mo-
bile edge computing. World Wide Web, 25(5):2019–
2047.
Han, Y., Shen, S., Wang, X., Wang, S., and Leung,
V. C. (2021). Tailored learning-based scheduling for
kubernetes-oriented edge-cloud system. In IEEE IN-
FOCOM 2021-IEEE Conference on Computer Com-
munications, pages 1–10. IEEE.
Hu, P., Dhelim, S., Ning, H., and Qiu, T. (2017). Survey
on fog computing: architecture, key technologies, ap-
plications and open issues. Journal of network and
computer applications, 98:27–42.
Islam, M. T., Karunasekera, S., and Buyya, R. (2021).
Performance and cost-efficient spark job scheduling
based on deep reinforcement learning in cloud com-
puting environments. IEEE Transactions on Parallel
and Distributed Systems, 33(7):1695–1710.
Joseph, C. T. and Chandrasekaran, K. (2020). Intma: Dy-
namic interaction-aware resource allocation for con-
tainerized microservices in cloud environments. Jour-
nal of Systems Architecture, 111:101785.
Kallel, A., Rekik, M., and Khemakhem, M. (2021). Iot-
fog-cloud based architecture for smart systems: Pro-
totypes of autism and covid-19 monitoring systems.
Software: Practice and Experience, 51(1):91–116.
Kallel, A., Rekik, M., and Khemakhem, M. (2022). Hybrid-
based framework for covid-19 prediction via federated
machine learning models. The Journal of Supercom-
puting, 78(5):7078–7105.
Kim, S.-H. and Kim, T. (2023). Local scheduling in
kubeedge-based edge computing environment. Sen-
sors, 23(3):1522.
Li, Y. (2017). Deep reinforcement learning: An overview.
arXiv preprint arXiv:1701.07274.
Liu, Q., Kosarirad, H., Meisami, S., Alnowibet, K. A.,
and Hoshyar, A. N. (2023). An optimal scheduling
method in iot-fog-cloud network using combination
of aquila optimizer and african vultures optimization.
Processes, 11(4):1162.
Lv, W., Wang, Q., Yang, P., Ding, Y., Yi, B., Wang,
Z., and Lin, C. (2022). Microservice deployment
in edge computing based on deep q learning. IEEE
Transactions on Parallel and Distributed Systems,
33(11):2968–2978.
Ma, W., Wang, R., Wang, W., Wu, Y., Deng, S., and
Huang, H. (2020). Micro-service composition de-
ployment and scheduling strategy based on evolution-
ary multi-objective optimization. Systems Engineer-
ing and Electronics, 42(1):90–100.
Mahmud, R., Kotagiri, R., and Buyya, R. (2018). Fog
computing: A taxonomy, survey and future directions.
Internet of Everything: Algorithms, Methodologies,
Technologies and Perspectives, pages 103–130.
Marler, R. T. and Arora, J. S. (2010). The weighted
sum method for multi-objective optimization: new in-
sights. Structural and multidisciplinary optimization,
41:853–862.
Muddinagiri, R., Ambavane, S., and Bayas, S. (2019). Self-
hosted kubernetes: deploying docker containers lo-
cally with minikube. In 2019 international conference
on innovative trends and advances in engineering and
technology (ICITAET), pages 239–243. IEEE.
Rekik, M., Boukadi, K., Assy, N., Gaaloul, W., and Ben-
Abdallah, H. (2016). A linear program for opti-
mal configurable business processes deployment into
cloud federation. In 2016 IEEE international con-
ference on services computing (SCC), pages 34–41.
IEEE.
Sabireen, H. and Neelanarayanan, V. (2021). A review on
fog computing: architecture, fog with iot, algorithms
and research challenges. Ict Express, 7(2):162–176.
Sutton, R. S. and Barto, A. G. (2018). Reinforcement learn-
ing: An introduction. MIT press.
Tan, B., Ma, H., and Mei, Y. (2020). A nsga-ii-based ap-
proach for multi-objective micro-service allocation in
container-based clouds. In 2020 20th IEEE/ACM In-
ternational Symposium on Cluster, Cloud and Internet
Computing (CCGRID), pages 282–289. IEEE.
Taneja, M. and Davy, A. (2017). Resource aware place-
ment of iot application modules in fog-cloud comput-
ing paradigm. In 2017 IFIP/IEEE Symposium on Inte-
grated Network and Service Management (IM), pages
1222–1228. IEEE.
Valderas, P., Torres, V., and Pelechano, V. (2020). A mi-
croservice composition approach based on the chore-
ography of bpmn fragments. Information and Soft-
ware Technology, 127:106370.
Wadhwa, H. and Aron, R. (2023). Optimized task schedul-
ing and preemption for distributed resource manage-
ment in fog-assisted iot environment. The Journal of
Supercomputing, 79(2):2212–2250.
Wang, S., Ding, Z., and Jiang, C. (2020). Elastic schedul-
ing for microservice applications in clouds. IEEE
Transactions on Parallel and Distributed Systems,
32(1):98–115.
Yang, Z., Liu, N., Hu, X. B., and Jin, F. (2022). Tutorial
on deep learning interpretation: A data perspective.
In Proceedings of the 31st ACM International Con-
ference on Information & Knowledge Management,
pages 5156–5159.
ICAART 2024 - 16th International Conference on Agents and Artificial Intelligence
242
