
Adaptive Questionnaire Design Using AI Agents for People Profiling
Ciprian Paduraru
1
, Rares Cristea
2
and Alin Stefanescu
1,3
1
Department of Computer Science, University of Bucharest, Romania
2
Research Institute of the University of Bucharest, Romania
3
Institute for Logic and Data Science, Romania
Keywords:
AI, Classification, Behaviors, Profiling.
Abstract:
Creating employee questionnaires, surveys or evaluation forms for people to understand various aspects such
as motivation, improvement opportunities, satisfaction, or even potential cybersecurity risks is a common
practice within organizations. These surveys are usually not tailored to the individual and have a set of pre-
determined questions and answers. The objective of this paper is to design AI agents that are flexible and
adaptable in choosing the survey content for each individual according to their personality. The developed
framework is open source, generic and can be adapted to many use cases. For the evaluation, we present a
real-world use case of detecting potentially inappropriate behavior in the workplace. The results obtained are
promising and suggest that the decision algorithms for content selection approaches and personalized surveys
via AI agents are similar to a real human resource manager in our use case.
1 INTRODUCTION
The main idea of this work is to replace some of the
manual work of professionals in surveying people in
large organizations with AI agents that are able to per-
form the survey process and automatically mark the
answers. AI is used to create dynamic surveys that
ask questions from a pre-built data set of questions
that hide inherent attributes, ambiguities, and impor-
tance factors. The disadvantage of creating a fixed set
of questions (which must also be a small number, oth-
erwise respondents may not focus on the sequence of
questions) is that at the end of the survey, only a text-
based or numerical representation with the same cate-
gories of questions asked for everyone is available for
further offline evaluation of individuals. The task of
the AI system is to identify the sequence of questions
to be asked in order to better score individuals on the
survey objective with the same number of questions
as a typical fixed survey.
The contributions of our work are the following:
1. The first work that implements AI agents capable
of assuming the role of a human expert to create
dynamic, adaptive surveys to evaluate human pro-
files with respect to various goals.
2. An open-source framework that can be cus-
tomized and extended by users to set up AI
agents that can conduct surveys. The imple-
mentation, setup for a new user, and avail-
able internal AI algorithms are independent of
the context, i.e., the characteristics used by
the survey questions and their evaluation goal.
It is available at this link https://github.com/
unibuc-cs/AIForProfilingHumans, containing our
real, anonymized dataset and results.
3. Data science tools to support organizations after
data collection and aggregation at individual and
team levels are provided by the framework.
4. A novel abstraction of survey organization us-
ing questions, videos, and underlying hidden at-
tributes to drive AI agents.
The rest of the article is organized as follows. The
next section contains a literature review of published
work and methodologies that have inspired our frame-
work design, use cases, and methods. Section 3 de-
scribes a specific use case in industry that provided
further insight into the generalizability of the methods
to other use cases. Section 4 presents the implementa-
tion details behind the proposed AI agent and the data
analysis tools used for the post-survey. The evalua-
tion section provides comparative results of methods,
previous experiments and observations. Finally, the
last section is reserved to conclusions.
Paduraru, C., Cristea, R. and Stefanescu, A.
Adaptive Questionnaire Design Using AI Agents for People Profiling.
DOI: 10.5220/0012379600003636
Paper published under CC license (CC BY-NC-ND 4.0)
In Proceedings of the 16th International Conference on Agents and Artificial Intelligence (ICAART 2024) - Volume 3, pages 633-640
ISBN: 978-989-758-680-4; ISSN: 2184-433X
Proceedings Copyright © 2024 by SCITEPRESS – Science and Technology Publications, Lda.
633

2 RELATED WORK
Profiling and clustering individuals using data min-
ing and NLP methods to extract data from textual
data is a common trend in the literature. In (Wibawa
et al., 2022), the authors use AI techniques like clas-
sical NLP to process application documents for open
positions and automatically filter, score, and priori-
tize candidates. This helps recruiters select the most
promising candidates within a limited resource bud-
get. On the other hand, the work in (Bajpai et al.,
2023) discusses methods to automatically create com-
pany profiles and clusters based on employee reviews
on the employer rating platform Glassdoor
1
. The
available reviews are subjected to aspect-based sen-
timent analysis, where the term aspect is used to or-
ganize the sentiment analysis embeddings according
to specific groups of features such as salary, loca-
tion, work life, and so on. Then, the features are
clustered using machine learning to profile the targets
by categories. The social media data extracted from
WeChat
2
is used in (Ni et al., 2017) to build pro-
files of individuals and cluster them according to their
field of activity, using NLP techniques such as those
mentioned above. The work in (Schermer, 2011) dis-
cusses data mining used in automated profiling pro-
cesses, with a focus on ethics and possible discrimi-
nation. Use cases such as security services or internal
organizations that create profiles to evaluate various
characteristics of their employees are mentioned. Pro-
filing individuals for content recommendation, such
as news recommendations, has been used for many
years(Mannens et al., 2013). Automatic detection of
fake profiles on social media platforms such as In-
stagram and Twitter is another widespread use case
for people profiling using data mining and clustering
techniques (Khaled et al., 2018). On the commercial
applications side, we mention Relevance AI
3
, which
handles most of the above cases using data mining
and clustering for industry.
Another interesting application of automated pro-
file identification within an organization is presented
in (Rafae and Erritali, 2023), which creates a recom-
mender system that automatically suggests employees
capable of performing various tasks within internal
projects of an organization. The profile of each em-
ployee is created by analyzing data from the human
resources department, emails, messages and publica-
tions sent by the employee, as well as previous tasks
completed by the employee, including the correctness
of the solution. The recommendation system then
1
glassdoor.com
2
wechat.com
3
https://relevanceai.com/for-analytics-insights
matches the goals of a project and a specific task with
the profile to create an evaluation score. The ques-
tionnaire design is usually a tedious task requiring ex-
pertise (Lietz, 2010) and sometimes must be based on
various types of standards such as Employee Screen-
ing Questionnaire (ESQ-2) (Iliescu et al., 2011). In-
dustry also recently started using AI in questionnaire
creation using chatGPT-like prompts - e.g. Survey-
Monkey Genius
4
, but they cannot be easily dynam-
ically adapted for the person filling-in the question-
naire.
The automated techniques described above com-
plement the techniques we propose. We believe that
our methods are novel in that we profile an individ-
ual in real time using an adaptive technique that asks
questions which lead to the classification of the indi-
vidual into specific profile categories. Data mining
and adapting the language depending on the answers
can also be done in addition to our methods. This is
the reason why we consider our work complementary
to the literature above.
3 METHODOLOGY OF
CREATING SURVEYS’
FEATURES AND DATASETS
The idea for our work and the methods used stem
from a specific use case used by in a client company
to identify potentially inappropriate behaviors of in-
dividuals and teams within the company. The Inap-
propriate workplace behavior is typically engaged in
by a limited number of individuals, but other group
members may be affected by, track, and even partici-
pate in it to varying degrees. Note that for reasons of
confidentiality and general ethics of data science, we
cannot disclose the name of the organization in which
this specific survey was conducted. In the remainder
of this section, we briefly outline the applied use case.
The surveys created in our applied use case are
conducted at the individual level and used to collect
data and predict inappropriate behavior (IB) within
teams in a large organization. The project measures
each employee’s tolerance for inappropriate behavior
and how likely they are to recognize and respond to
that behavior. These results are compared to the orga-
nization’s tolerance policies, and the extent to which
existing sanctions, training, and other methods con-
sidered are likely to be effective. Post-survey anal-
ysis focuses on three areas: (a) the individual, (b)
each individual’s expectations of the team’s response,
4
https://www.surveymonkey.com/mp/
surveymonkey-genius
ICAART 2024 - 16th International Conference on Agents and Artificial Intelligence
634

and (c) the team’s risk profile compared to that of the
organization as a whole. A concrete IB situational
awareness could be to assess the potential for bully-
ing within an organization or team. It can be mea-
sured by prevalence and frequency. However, less se-
vere but frequent incidents are more difficult to de-
tect but represent the most common form of bullying
(Samuel Farley and Niven, 2023), (Staale Einarsen
and Notelaers, 2009).
The methodology for putting the developed
framework into practice can be outlined as follows:
• Work with each client to identify behaviors preva-
lent in the workplace and design a database of
questions that not only help identify behavioral
hotspots, but also provide high response rates,
comparable results, and a high degree of validity.
• Triangulate areas of the organization where un-
healthy behaviors are prevalent down to individ-
ual teams or small groups of individuals (usually
5-10) using data science tools.
• Identifies areas where group behaviors appear un-
healthy and could lead to conflict within the team
or infect other teams.
The recording of videos/images and questions are
specific to the needs of each client and must be created
manually by professionals. They are defined once and
then reused. A library of attributes for each media file
and question is included in the framework, but can be
customized by clients.
4 METHODS
The first part of this section defines the abstrac-
tions needed for defining a database of questions,
videos/images, attributes, and cluster categories, re-
quired for the survey process. As mentioned in Sec-
tion 3, each client has to define these once in their
organization such that their interest is accomplished
at the end of the evaluation through the surveys per-
formed by the AI agents. However, note that the de-
sign of the current framework version promotes shear-
ability between these features, as a unified library that
clients could just reuse out of the box. This could be
valuable both from a community point of view, but
also from an internal organization recurring surveys.
4.1 Surveys Dataset Creation
A survey is composed of several videos/images aka
clips shown to a person. On each clip shown there
will be a collection of questions based on a specified
compatibility graph. In our design, the collection of
abstract items and entities that exist in a survey dataset
is described below:
• Clips. A collection of assets representing video
files, messages, media posts, etc. Clip indices
also have an optional dependency specification,
i.e., the client can impose that a new clip should
depend on an already shown set of other clips:
Dependencies(C
i
) = {C
j
}
j∈1..|C|
.
• Attributes. A set describing the properties of each
clip asset. Examples from our use case of IB
recognition: inappropriate touch, offensive lan-
guage, leadership style, etc. These are set by the
organization creating the content and are not vis-
ible to the respondent. Intuitively, when a ques-
tionnaire record is created, the attributes are set
by the client depending on what they are looking
for.
• Attributes. A set describing the properties of
each clip asset. Examples from our use case
of IB recognition: inappropriate touch, offen-
sive language, leadership style, etc. These are
set by the organization creating the content and
are not visible to the respondent. Intuitively,
when a questionnaire record is created, the at-
tributes are set by the client depending on what
they are looking for. The vector of all attributes
(ordered by index) is given in each clip, with
values between 0-1 representing the importance
of the attribute to the content of the clip, i.e.
a value of 0 means there is no relationship be-
tween them, while a value of 1 represents an im-
portant correlation. Formally, a clip C ∈ Clips
has a set of Attr(C){Attr
C
1
, Attr
C
2
, ..., Attr
C
NAttr
},
where NAttr|Attributes|. Then, the importance of
an attribute A ∈ Attributes within a clip C is rep-
resented by VAttr(A,C).
• Categories. A category of the clips being asked.
Examples from our use-case: Sensitivity, Aware-
ness.
• A collection of questions Q, where each Q
i
∈ Q
has the following properties:
– The set of clips in which this question can be
asked Clips(Q
i
){C
j
inC lips}
j
.
– The dependencies of this question. This takes
the form of a directed acyclic graph where
each Q
i
has a set of dependency questions
Dependencies(Q
i
){Q
k
}
k
, meaning that there is
a hard constraint on asking one of the questions
Q
k
to allow the follow-up question Q
i
.
– Attributes behind the questions, similar to those
in the clip definition above, i.e. Attr(q){A ∈
|Attributes|}, and their numerical importance
value in the respective question, VAttr(A, q).
Adaptive Questionnaire Design Using AI Agents for People Profiling
635

– Severity (Q
i
) - how important is the question
overall.
– Baseline(Q
i
) - expected value of the question
according to the culture of the organization
(customer).
– Ambiguity(Q
i
) - the ambiguity of the question.
There is no reason to design an ambiguous
question, but sometimes survey analysis shows
that some of the questions may indeed be am-
biguous, and this factor is used to mitigate re-
sponses when this is the case.
• Profiles or Clusters specification. The goal of
the survey is to classify a person into a partic-
ular profile or cluster, as described later in the
text. In this process, HR professionals must de-
fine attributes Attr
i
∈ Attributes and categories
Cat
i
∈ Categories that they are interested in for
cluster definition. The aggregation of these fea-
tures is represented by equation 1. As shown in
section 4.2, deviations from the baselines of the
organization in the survey question are used along
with these categories and attributes in computing
the features required to converge to one cluster or
another.
Feats = {Cat
0
,Cat
1
, ...,Cat
N−1
,
Attr
0
, Attr
1
, ...Attr
M−1
} (1)
When defining a cluster, each of these character-
istics is specified as a Gaussian distribution with
a median and standard deviation set by the orga-
nization. By denoting this set with clusters, Eq.
(2) below shows such a specification of a single
cluster using the mentioned features. The argu-
ment of using a multivariate Gaussian distribution
to define each cluster using each feature devia-
tion score (4.2 section) is that the organization can
specify:
1. Intuitively, the median represents the value ex-
pected of a respondent with respect to that fea-
ture in order to place them in the target cluster.
2. The standard deviation, represents how tolerant
they are for the deviation score of the feature
and the target cluster.
Cluster
k
= {(Cat
0
, N (µ
C
0
, σ
2
C
0
)), ...,
(Cat
N−1
, N (µ
C
N−1
, σ
2
C
N−1
))
(Attr
0
, N (µ
A
0
, σ
2
A
0
)), ...,
(Attr
M−1
, N (µ
A
M−1
, σ
2
A
M−1
))},
∀k ∈ Clusters, (2)
Each of the Severity, Baseline, and Ambiguity
properties have a numeric value between 1-7. Am-
biguity can be null, i.e., not taken into account if so.
The features of categories and attributes of a specific
cluster k, as filtered from the Eq (1), are shown in Eq.
(3).
Feats
k
= {Cat, Attr|Cat, Attr ∈ ∩(Feats,Cluster
k
)}
(3)
4.2 Features Computed Inside the AI
Engine
HR professionals typically seek to collect employee
profiles and then generate statistics, both at the level
of the entire company and by team and hierarchy, on
topics of interest to them (in our use case, for exam-
ple, the client wanted to understand IB’s potential and
its degree). The base function for profiling is devia-
tion, which reports the answers of each question on
the baselines of the organization. In the remainder of
this text, we refer to P as the set of individuals in the
organization and team(P
i
), P
i
∈ P as the numerical ID
representing the team of an individual P
i
.
4.2.1 Deviations
To calculate the raw deviation during and after the
survey for each question, the response values and
the organization’s expected tolerance values (base-
line values) (numeric values in the range 1-7) are
compared. The deviation function is either linear or
quadratic by default, as in equation (4), but can also
be customized by the client.
Dev
raw
(Q
i
) = |Response(Q
i
) − Baseline(Q
i
)|
2
(4)
For a better evaluation of the results, the ambigu-
ity levels of the clips are also considered. This is used
to lower the deviation of the question (linearly) if the
client (organization) considers that the clip they se-
lected has a certain level of ambiguity, Eq. (5).
Dev
ambg
(Q
i
) =
Dev
raw
(Q
i
)
Ambuiguity(Q
i
)
(5)
The severity level of the question also affects the
deviation of one question by boosting (or scaling
down) its original value. deviation, Eq. 6.
Dev
f inal
(Q
i
) = Dev
ambg
(Q
i
) × Severity(Q
i
) (6)
ICAART 2024 - 16th International Conference on Agents and Artificial Intelligence
636
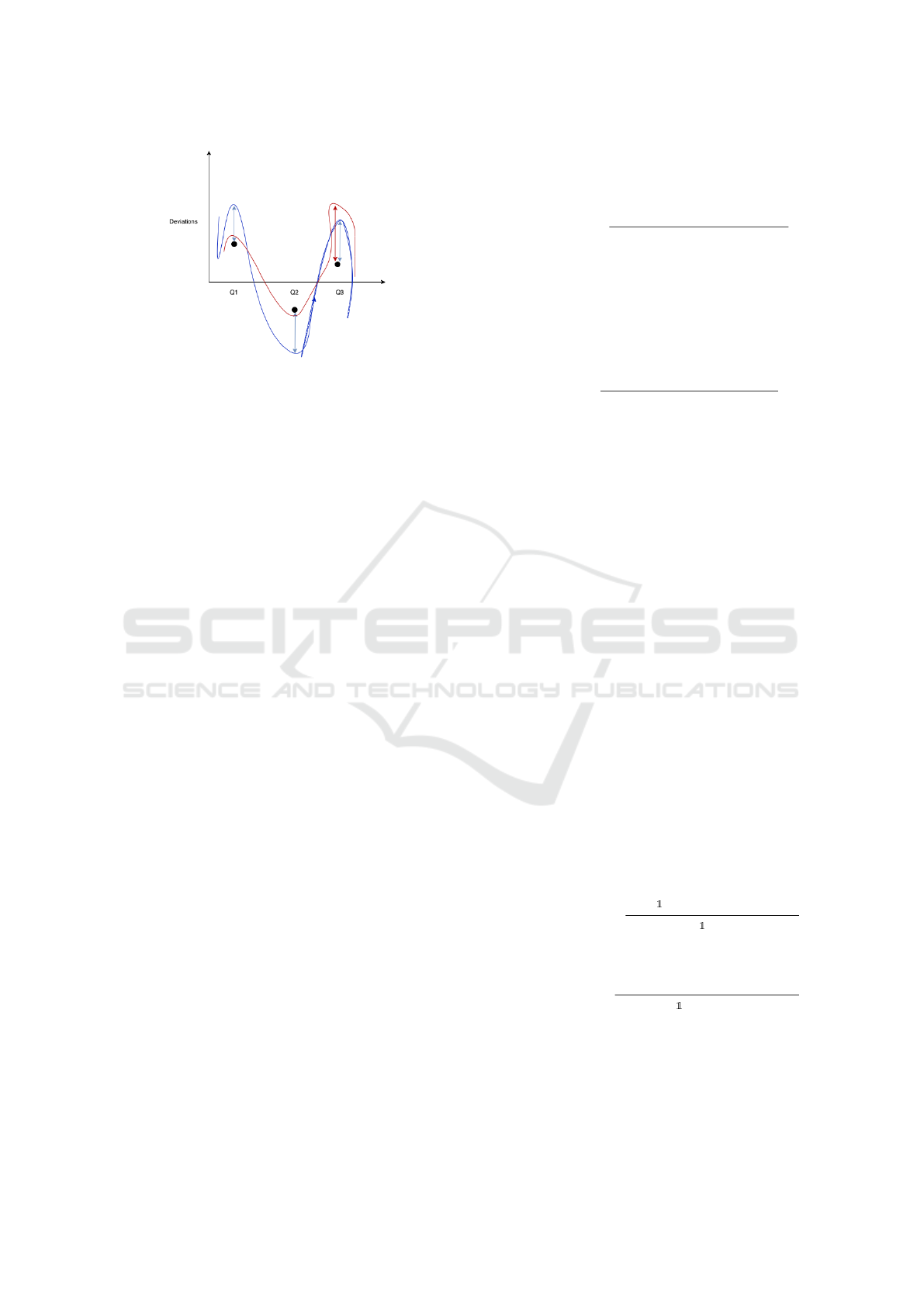
Figure 1: Two users (blue and red curves) answering the
same three questions (Q1, Q2, Q3) in a survey. The black
dots represent the average deviations for each of the ques-
tions (a 0 value deviation represents the baseline set by the
organization). You can see that the blue user’s answers de-
viate with an almost constant value in modulo, which means
that the user may actually be overreacting. This means that
it can be normalized, i.e. its average deviations are sub-
tracted a little from the original response deviations. The
red user, on the other hand, does not maintain the same
constants for his deviations, e.g., the value for Q3 deviates
greatly compared to the other two responses. This could be
a strong signal that the user is very likely to answer Q3 with-
out deviations and that the observed value is indeed correct.
4.2.2 Removing Anchor and Constant
Over/Underscoring the Questions
In a survey, several biases can be observed in prac-
tice (Yan et al., 2018). Some of the most common
are the anchors (attached to or influenced by a pre-
viously seen question) and the constant over- or un-
derscoring of the answers. In order to obtain correct
statistics at the team and organization level, the algo-
rithm attempts to eliminate possible biases in a post-
processing step, which may be more or less frequent
depending on the personality. A concrete example ex-
plaining these biases and their removal is shown in
Figure 1. Briefly, the method used is to try to find pat-
terns in the deviance either throughout the survey or
in short successive sequences (Dee, 2006).
Suppose user U
j
answers the questions in his sur-
vey, denoted QSurvey(U
j
). Dev
f inal
(Q
i
,U
j
) denotes
the deviation of user U
j
on question Q
i
in the survey,
according to the baselines of the organization. Equa-
tion. (7) shows how the mean deviation values are
calculated for a given user and survey. Note that the
modulo operator is used because the deviations from
the baseline can be either positive or negative num-
bers. Also, in practice, the formula is calculated for
all consecutive sequences of questions, but for sim-
plicity, it is presented calculated for all questions in
the survey. The practical reason for this is to cor-
rectly capture anchoring bias, i.e., a question that has
influenced the respondent to overreact over a short se-
quence of questions.
DevMeans(U
j
) =
∑
Q
i
∈QSurvey(U
j
)
|Dev
f inal
(Q
i
)|
|QSurvey(U
j
)|
,
(7)
Next, the mean and standard deviations of the user
responses relative to the overall pattern in the organi-
zation can be calculated to obtain the constant devi-
ation factor in the user responses. This is shown in
equation (8).
ConstDev(U
j
) =
DevMeans(U
j
)
max(1, std(DevMeans(U
j
)))
(8)
Finally, the unbiased deviation of user response to
a question can be adjusted then to the final form with
bias removal, Eq. (9)
Dev
NoBias
f inal
(U
j
, Q
i
) = Dev
f inal
(U
j
, Q
i
) − sign(Dev
f inal
(U
j
, Q
i
)) ∗ConstDev(U
j
)
(9)
4.3 Scores Feature Vector
During a survey and post-survey analysis, the user
U( j) is characterized as a feature vector after each
question:
Scores(U
j
) = {Scores
Categories
U
j
, Scores
Attributes
U
j
}.
These scores can be calculated using the basic set-
tings for variance values mentioned above. Suppose
a user’s survey U
j
consists of a series of questions
QSurvey = {Q
id1
, Q
id2
, .....Q
id
N
. Also remember that
each question asked is part of a clip, C
id
i
∈ Clips. The
equations (10), (11) show how these internal feature
scores are calculated for each defined category of
questions and attributes in the set. Note that the
feature calculations of the scores and intuitively are
a weighted average of the relevance of the attributes
in the set of questions asked, and the same is true for
the categories.
Scores
Categories
U
j
[Cat] =
∑
id
N
i=id
1
(Cat∈Q
id
i
)∗Dev
NoBias
f inal
(U
j
,Q
i
)
∑
id
N
i=id
1
(Cat∈Q
id
i
)
(10)
Scores
Attributes
U
j
[A] =
∑
id
N
i=id
1
VAttr(A,C
id
i
)∗Dev
NoBias
f inal
(U
j
,Q
i
)
∑
id
N
i=id
1
(VAttr(A,C
id
i
)>0)
(11)
4.4 AI Driven Agent
The purpose of an AI agent in this context is to create
an adaptive dynamic survey to help classify as best as
Adaptive Questionnaire Design Using AI Agents for People Profiling
637

possible an individual with a certain number of ques-
tions asked.
With the questions asked for a user U
j
and responses
obtained so far, at step i, i.e., after asking the i
0
th ques-
tion, from the AI agent’s perspective the reviewed per-
son state, Eq. (13), contains:
1. The sequence of questions already and the user
responses, QRset.
2. The Scores vector computed for the reviewed per-
son so far using its deviations and responses.
3. A probability distribution of the user being part of
each cluster is as follows.
Knowing the answers and their deviations com-
puted with Scores
U
j
, the AI agent’s internal state
is a probability distribution over the clusters, i.e.,
P(U
j
∈ Cluster
k
), representing the probability of
U
j
being part of cluster index k. As shown in Eq.
(12), this value is obtained by averaging the prob-
abilities of the user response score deviations be-
ing part of each feature f ’s Gaussian distribution
as initially specified by the organization in Eq. 2.
Graphically, this probability is inversely propor-
tional to the distance to the cluster, i.e. the closer
is a user to a cluster, the higher the probability it
has of being in that cluster.
P(U
j
∈ Cluster
k
) =
∑
f ∈Feats
k
P(Scores
U
j
f
∈N (µ
f
, σ
2
f
))
|Feats
k
|
(12)
The state of the current review process can be for-
malized as in Eq. (13).
S
i
= (QRset
i
= {Q
i
, R
i
}, Scores
i
, P(U
j
∈ Cluster
k
))
(13)
The algorithm starts with a 0-state containing
equally split probabilities across clusters, without any
prior assumption. Intuitively the AI agent must then
choose at each step the next clips and question from
the internal database to contribute in the end to the
characterization of the reviewed person, i.e., classify
as closely as possible according to the real profile of
the person according to the specifications given by the
organization. From a data science perspective, this
is equivalent to eliminating the entropy (Aning and
Przybyła-Kasperek, 2022) in the classification as best
as possible within the limited number of questions in
a survey process.
The method used in the algorithm for the decision-
making part is similar to a contextual bandit prob-
lem in reinforcement learning (Park and Faradonbeh,
2022). The next action Act
i
to take at each step by the
agent corresponds to what pair of clips and follow-up
questions to ask. This policy is denoted as π(S
i
, Act
i
),
where S
i
is the embedded state of the agent (Eq. (13)).
The action Act
i
is also restricted by the constraints of
the survey’s flow and state regarding the set of previ-
ously asked questions and clips (Section 4.1).
At each step i, The decision-making algorithm has
two main steps:
1. Choose the most promising cluster to test the
agent against in the current state S
i−1
.
2. Compute the most interesting clip or question, as
constrained by the flow to ask in the selected clus-
ter.
The second step is presented in Listing 1. Vari-
ables prevClipId and prevQueId represent the pre-
vious clip and question asked. needAClip is True
when the next step is to display a new clip instead of
a question, while numQueInClips contains the num-
ber of asked questions under the previously shown
clip. Note also that a clip selection does not affect the
step progress, Line 13. Also, the process of selecting
the next clip c (Line 7), or a question q (Line 18) is
a sampling process where the probabilities (of com-
patible clusters/clips after filtering by constraints) are
obtained from a cosine similarity (Xia et al., 2015)
of the attributes. This is sketched in the following
text. In the first phase, the list of all compatible ques-
tions or clips filtered by the constraints of the survey’s
flow and cluster TC are gathered in CompatibleSet.
In the second phase, Eq. (14), (15), for each of these
questions or clips, all attributes in the dataset are gath-
ered in separate feature vectors. Another similar fea-
ture vector is composed of the features given by the
characterization of the target cluster, Feats
TC
. In the
third step, the cosine similarity applies between the
pairs of feature vectors of the clips or questions men-
tioned above and the target cluster’s interests. Finally,
a probabilistic sample is drawn from the distribution
obtained, Eq. (16).
VAttr(item
i
) = {(A
i
,VAttr(A
i
, item
i
))
|A
i
∈ Attributes
∧ item
i
∈ CompatibleSet} (14)
VAttr(TC) = {(A
i
,VAttr(A
i
,Cluster
TC
)) (15)
P
selection
(item
i
) = cosSim(VAttr(TC),VAttr(item
i
))
selectedItem ∼ P
selection
(item
i
)
item
i
∈Compat ibleSet
(16)
ICAART 2024 - 16th International Conference on Agents and Artificial Intelligence
638
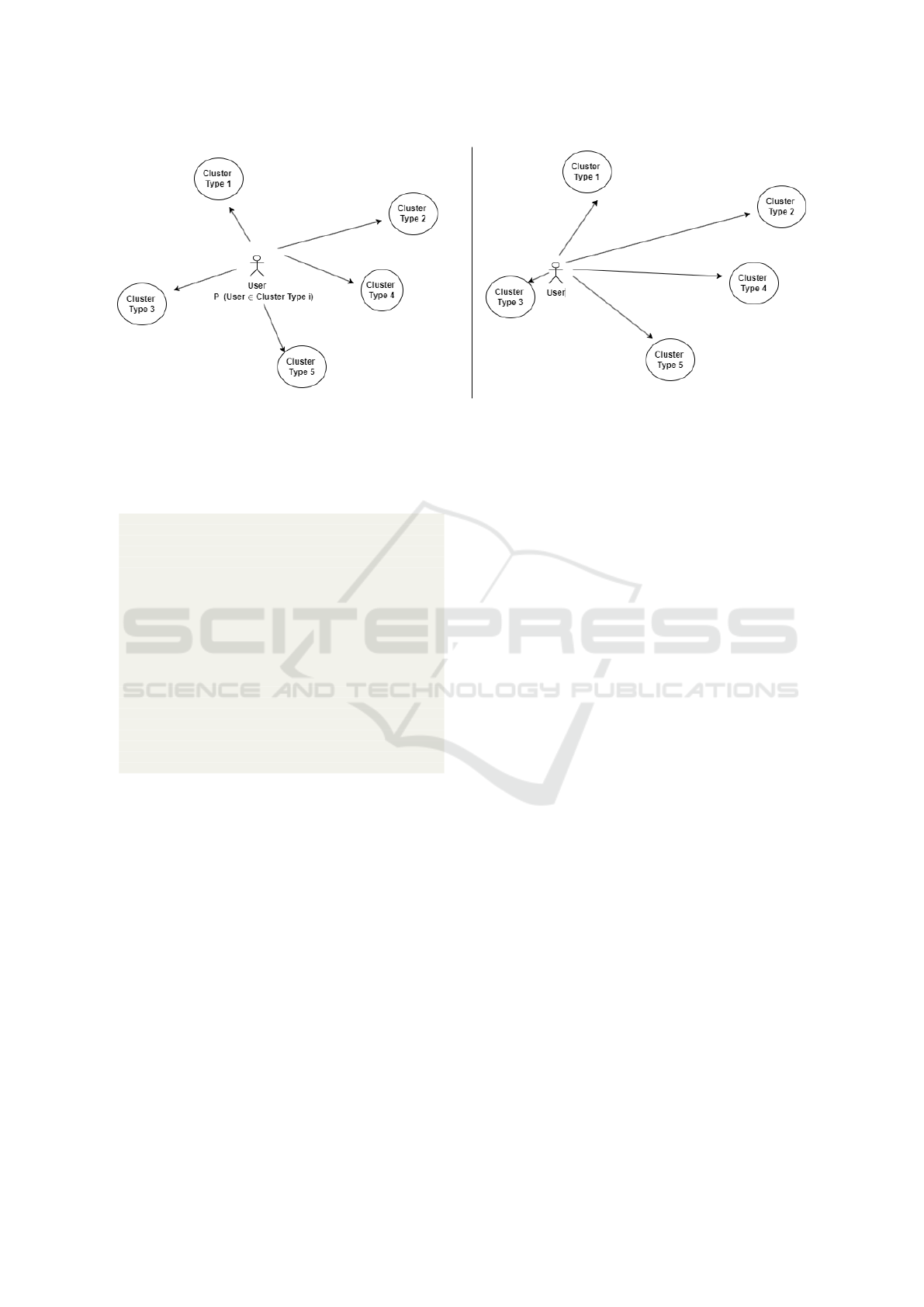
Figure 2: Showing the progress of the AI agent in classifying the user during a survey. Although the visualization is from a
2D Euclidean perspective for presentation, in reality, this is a multidimensional space. In the left part is the initial step, where
the probabilities of the user being a part of each cluster are almost equal. After a sequence of questions is asked, the agent
approaches one or more clusters. The probability of a user being part of a cluster is inversely proportional to the Euclidean
distance to it in the hyperspace of the clusters.
1 p r e v C l i p I d =−1
2 p r evQ u e Id=−1
3 n e e d A Clip = Tr u e
4 num Q ueInC l ip =0
5 G e t N e x t A c t i o n ( i , TC ) :
6 i f n e edACl i p :
7 S e l e c t t h e n e x t c l i p C ∈ Clips c o n t a i n i n g f e a t u r e s o f TC
an d u n d er c o n s t r a i n t s imposed by p r e v C l i p I d
8 Show c l i p C
9 ne e d AClip = F a l s e
10 p r e v C l i p I d =C
11 pr ev Q u e Id=−1
12 numQ u eInC l i p =0
13 Ge t Ne x tA c ti o n ( s t e p , t a r g e t C l u s t e r )
14 e l s e :
15 i f n umQu eIn Cli p>MaxQueInAClip :
16 n e e d A C l ip = T r u e
17 b r e a k
18 S e l e c t Q
i
u n d e r c o n s t r a i n t s imposed by p r e v C l i p I d and
pr e v Que I d
19 i f Q
i
i s None :
20 b r e a k
21 R
i
= ResponseFromUser (Q
i
)
22 numQueInClip+ = 1
Listing 1: Pseudocode for choosing the next clip and
question in the action at a given step i, and target cluster
to test against, TC.
5 EVALUATION
This section describes the setup used for evaluation,
some results obtained from a quantitative and quali-
tative evaluation, the mentioned post-survey analysis
tools with some alternatives in the implementation,
and finally practical observations made from proto-
typing and previous attempts.
5.1 Setup
The use case described in section 3 is used here for
evaluation purposes. A clip describing an IB situation
is shown, followed by a number of questions between
2 and 5 questions. The number of questions per sur-
vey is limited to 15-20 questions and varies depend-
ing on the user’s answers and the path chosen by the
AI agent evaluating the person behind the interview.
These are divided equally
The database of attributes, clips, and questions is
included in the repository. For the evaluation, 16 dif-
ferent attributes were considered, 29 clips evenly dis-
tributed among the four categories, and 35 questions,
19 of which could be asked in each of the clips.
5.2 Quantitative and Quantitative
Evaluation
There are three research questions that we try to ad-
dress in this section.
RQ1: What is the correctness of the AI agent com-
pared with a real HR person?
To evaluate this, we took a sample of 25 people pre-
viously assessed by human HR staff and attempted to
rank them after 6 months using the dataset and the
AI agent (the questions and clips were new to them to
avoid bias). There were a total of 435 responses to the
questions. The observed comparison results follow:
1. The AI agent classified 18 out of 25, ∼ 72%, in
the same cluster as the HR professional.
2. For 5 out of the remaining 7 persons, ∼ 20%, the
AI agent classified in the second scored cluster
the one suggested by HR. According to the for-
mula given in Eq. (12), the measured average er-
ror difference between the first and second AI’s
cluster classification was ∼ 0.183, suggesting that
the agent was not too far.
Adaptive Questionnaire Design Using AI Agents for People Profiling
639

3. The remaining two persons, ∼ 8%, had almost
equally split probabilities to each of the four clus-
ters.
It is however hard to tell which one was correct
since even HR professionals could also have biases,
and be error-prone sometimes.
RQ2: Is anchor and bias removal helpful? When us-
ing the bias and anchoring removal methods proposed
in Section 4.2.2, we observed that results classified
one more person in the same cluster as professionals,
but on the other hand for the rest of 6 persons the av-
erage error difference increased to 0.31.
RQ3: Respondents’ post-evaluation feedback After
finishing the surveys, the 25 persons were asked to
compare it with the ones done face-to-face. Results
show that 21 out of 25 liked more this because they
had more time to think, felt less pressure to give an-
swers, and were satisfied that they had the opportunity
to complete it without prior scheduling from their own
comfort.
6 CONCLUSIONS
After iterating several prototype versions and apply-
ing the framework to our mentioned use case, we
conclude that the proposed method of providing AI
agents to conduct surveys can help organizations in
two ways: a) improve the quality of the results ob-
tained after surveys without having to invest in more
staff to conduct face-to-face surveys, and b) help hu-
man professionals improve alongside AI agents by us-
ing them as assistants during a real-time survey.
ACKNOWLEDGEMENTS
This research was supported by European Union’s
Horizon Europe research and innovation programme
under grant agreement no. 101070455, project DYN-
ABIC.
REFERENCES
Aning, S. and Przybyła-Kasperek, M. (2022). Comparative
study of twoing and entropy criterion for decision tree
classification of dispersed data. Procedia Computer
Science, 207:2434–2443. Proc. of KES2022.
Bajpai, R., Hazarika, D., Singh, K., Gorantla, S., Cam-
bria, E., and Zimmermann, R. (2023). Aspect-
sentiment embeddings for company profiling and em-
ployee opinion mining. In Gelbukh, A., editor, Com-
putational Linguistics and Intelligent Text Processing,
pages 142–160. Springer.
Dee, D. (2006). Bias and data assimilation. PhD thesis,
Shinfield Park, Reading.
Iliescu, D., Ilie, A., and Ispas, D. (2011). Examin-
ing the criterion-related validity of the employee
screening questionnaire: A three-sample investiga-
tion. International Journal of Selection and Assess-
ment, 19(2):222–228.
Khaled, S., El-Tazi, N., and Mokhtar, H. M. O. (2018). De-
tecting fake accounts on social media. In 2018 IEEE
International Conference on Big Data (Big Data),
pages 3672–3681.
Lietz, P. (2010). Research into questionnaire design: A
summary of the literature. International Journal of
Market Research, 52(2):249–272.
Mannens, E., Coppens, S., De Pessemier, T., Dacquin,
H., Deursen, D., Sutter, R., and Van de Walle, R.
(2013). Automatic news recommendations via aggre-
gated profiling. Multimedia Tools and Applications -
MTA, 63.
Ni, X., Zeng, S., Qin, R., Li, J., Yuan, Y., and Wang, F.-Y.
(2017). Behavioral profiling for employees using so-
cial media: A case study based on wechat. In 2017
Chinese Automation Congress (CAC), pages 7725–
7730.
Park, H. and Faradonbeh, M. K. S. (2022). Efficient algo-
rithms for learning to control bandits with unobserved
contexts. IFAC-PapersOnLine, 55(12):383–388. 14th
IFAC Workshop on Adaptive and Learning Control
Systems ALCOS 2022.
Rafae, A. and Erritali, M. (2023). Using a profiling sys-
tem to recommend employees to carry out a project.
Electronics, 12(16).
Samuel Farley, Daniella Mokhtar, K. N. and Niven, K.
(2023). What influences the relationship between
workplace bullying and employee well-being? a
systematic review of moderators. Work & Stress,
37(3):345–372.
Schermer, B. W. (2011). The limits of privacy in automated
profiling and data mining. Computer Law and Secu-
rity Review, 27(1):45–52.
Staale Einarsen, H. H. and Notelaers, G. (2009). Measuring
exposure to bullying and harassment at work: Valid-
ity, factor structure and psychometric properties of the
negative acts questionnaire-revised. Work & Stress,
23(1):24–44.
Wibawa, A. D., Amri, A. M., Mas, A., and Iman, S. (2022).
Text mining for employee candidates automatic profil-
ing based on application documents. EMITTER Inter-
national Journal of Engineering Technology, 10:47–
62.
Xia, P., Zhang, L., and Li, F. (2015). Learning similar-
ity with cosine similarity ensemble. Information sci-
ences, 307:39–52.
Yan, T., Keusch, F., and He, L. (2018). The impact of
question and scale characteristics on scale direction
effects. Survey Practice, 11(2).
ICAART 2024 - 16th International Conference on Agents and Artificial Intelligence
640
