
New Approach Based on Substantial Derivative and LSTM for
Online Arabic Handwriting Script Recognition
Hasanien Ali Talib Alothman
1,2,3
, Wafa Lejmi
1,3
and Mohamed Ali Mahjoub
3
1
ISITCom, Higher Institute of Computer Science and Communication Technologies of Sousse,
University of Sousse, 4011 Sousse, Tunisia
2
College of Education for Pure Science, Computer Science Department, University of Mosul, Iraq
3
LATIS - Laboratory of Advanced Technology and Intelligent Systems, University of Sousse, 4011 Sousse, Tunisia
Keywords: Handwriting, Arabic, Script, Text, Character, Descriptor, Substantial Derivative, Feature, Extraction,
Acceleration, ADAB Dataset, Recognition, LSTM.
Abstract: As some tasks easily performed by man seem to be hard to be accomplished by the machine, the Artificial
Intelligence field examines more and more the reproduction of thinking methods and human intuition by
studying some mental faculties and substituting them by calculating approaches. Among the major fields of
such interest, we can focus on recognizing handwritten characters. However, most handwritten characters
are written in Latin, which makes the recognition of Arabic characters handwriting a delicate process
compared to other languages, due to the specificity of Arabic words. In this paper, we aim to conceive a
framework that offers the ability to recognize online Arabic handwriting applied to a dataset named ADAB
(Arabic DAtaBase), using a particular descriptor based on a substantial derivative and a neural network
handling Arabic handwritten characters features and then electing the appropriate output for the final
decision.
1 INTRODUCTION
Handwriting recognition is among the oldest
problems faced by artificial intelligence, since its
advent in the 1950s (Mori et al., 1992). An essential
playground for new learning algorithms, it
represents a real scientific and technical challenge
and an imminent need requested by many business
sectors.
1.1 Applications
Recognizing handwritten text is being applied in
several various human activity fields, including:
Education (Wu et al., 2021): through the
recognition and translation of texts, such as
texts in Braille, and writing learning.
Photosensors and tactile simulators are used
for the blind and low vision (BLV) persons
with a sound output.
Banks and Insurance companies (Singh et al.,
2015): through the check authentication
(correspondence between amounts and
denomination, and between the identity of the
signatory and his signature), and verification
of insurance contracts.
Post services (Charfi et al., 2012): through
reading postal addresses and automatic sorting
of mails.
Business and Industry (Nagy, 2016): through
inventory management and technical
documents recognition (electronic diagrams,
technical drawings, architectural plans, etc.).
Office automation (Chherawala & Cheriet,
2014): through indexing and automatic
archiving of documents, and for electronic
publication.
Automatic reading of administrative
documents and recognition of cartographic
maps (Velázquez & Levachkine, 2004).
1.2 Modes of Character Writing
Two writing modes of character writing are used:
static mode for characters already written and
dynamic mode for handwritten characters to be
recognized while writing. Below, we explain both
modes in more detail:
Alothman, H., Lejmi, W. and Mahjoub, M.
New Approach Based on Substantial Derivative and LSTM for Online Arabic Handwriting Script Recognition.
DOI: 10.5220/0012385000003636
Paper published under CC license (CC BY-NC-ND 4.0)
In Proceedings of the 16th International Conference on Agents and Artificial Intelligence (ICAART 2024) - Volume 3, pages 689-698
ISBN: 978-989-758-680-4; ISSN: 2184-433X
Proceedings Copyright © 2024 by SCITEPRESS – Science and Technology Publications, Lda.
689

Static mode (ElKessab et al., 2013): It mainly
uses scanners. The scanner scans the text line
by line and digitizes each line into a larger or
smaller series of dots. The resolution of a
scanner, expressed in number of dots per inch
(dpi), refers to its ability to digitize fine lines.
In OCR, the most common values range from
200 to 400 dpi (Abuhaiba, 2004); a higher
resolution does not increase the precision of
the digitization; on the contrary it increases
the number of points to be processed and
generates noise (grain of the paper). Several
types of scanners exist on the market offering
several input modes: flatbed, drum, or
handheld, providing a choice of raster images,
binary images, grayscale images and color
images.
Continuous mode (Begum et al., 2021): It uses
a graphic tablet which sends coordinates of
points to the contact of the pen. Capturing fine
lines depends on the regular support of the pen
so as not to cause discontinuities in the lines.
This mode is quite valuable in OCR because it
gives very useful information for recognition
such as the number of pencil strokes and
therefore the reading direction, and the
number of points per pencil stroke significant
of the curvature of the line.
1.3 Categories of Handwritten
Characters Recognition
Several kinds of handwritten character recognition
exist such as:
Online or offline (Kannan et al., 2008; Tappert
et al., 1990): Online recognition is a dynamic
recognition that takes place during writing. A
slight delay of a word or a character allows the
recognition not to encroach on the input. The
continuous response of the system allows the
user to correct and modify writing directly and
instantaneously. Offline or delayed
recognition starts after the acquisition of the
entire document. It is suitable for printed
documents and already written manuscripts.
This mode allows the instantaneous
acquisition of a large number of characters but
imposes costly pre-processing to find the
reading order.
With or without learning (Stremler &
Karácsony, 2016): A system with learning
includes a module for introducing reference
character models. Significant samples of
writing (printed or handwritten) in sufficient
numbers (tens or even hundreds of samples
per character) are entered in manual or
automatic mode. In the first case, the user
indicates to the system the identity of each
sample allowing the system to organize its
classes according to the vocabulary which is
being studied. For the handwritten script, the
ideal would be to learn characters directly
from a text, but this presents obvious
segmentation problems. In the second case,
the samples are grouped automatically from
morphological analyses, without knowledge of
their name. In a non-learning system, a
knowledge base is built into the system and
particular analysis algorithms are used.
Direct, scaled or with labelling (Zhang et al.,
2023): In systems with direct recognition, the
learning includes a reference model per
character. The recognition compares the
candidate character to each of these models
and retains the closest model. In scaled
recognition, learning is divided into
progressively selective classification levels.
Each level contains separation tests for the
different classes represented, allowing
recognition to refine its decision if necessary.
Labelling in the latter case consists of
identifying the different characters in a text,
thus distinguishing patterns, and then
recognizing them. This mode has the
advantage of limiting recognition only to the
patterns found and being able to quickly make
corrections, but it has the disadvantage of
perpetuating any recognition error through all
the characters of the same model.
1.4 Challenges
It is not obvious to be able to accurately recognize
human writing. Indeed, the form of a handwritten
character often varies, reflecting the style of writing,
the state of mind, and the personality of the writer,
which makes it difficult to characterize.
Among the variations that affect it, we can
mention the contour distortion that produces curls
and rounding, as well as the inclination that
produces a rotation of the base of the character or a
flattening of its shape, and the asymmetry generating
an occlusion of the character parts or a closure of its
cavities, and the poor connection of the lines leading
to their sudden extensions and interruptions.
The remnant of this paper is structured as
follows: In the following section we provide an
overview around the related works and the most
ICAART 2024 - 16th International Conference on Agents and Artificial Intelligence
690

known datasets in terms of Arabic handwritten text
recognition. Then, we present an innovative
approach for features extraction step followed by
applying LSTM deep neural model for classification
step. Afterwards, we describe the experimentation
implemented. A summarized conclusion is provided
in the last section.
2 RELATED WORKS
2.1 Standardization and Famous
Datasets
Despite the artifacts of handwriting, attempts of
standardization have been elaborated. Indeed,
committees from different countries have proposed
standards of handwritten characters for recognition.
In 1974, the American National Standards Institute
(ANSI) (Alphabetic Handprint Reading, 1978)
developed a character set introducing additional
features to remove ambiguities. We can also
mention the “Japanese Industry Standard” proposed
by the “Japanese OCR Committee” and the
standards of the “OCR Committee of Canada”. In
order to be able to check the performance of
handwritten character recognition systems and to
compare them, test datasets were established,
containing several samples of different handwritten
characters, including uppercase and lowercase
letters, digits, and punctuation marks. These
databases were created to support research in the
field of pattern recognition and machine learning
and have been widely used in numerous research
papers and projects. The most frequently used
datasets are those of Munson (Munson, 1968) and
Highleyman (Highleyman, 1961).
The Munson database includes the 46 characters
of Fortran II, represented by matrices of size 24 X
24. It includes 12,760 samples of which 6,762 are
written by different writers on special sheets. The
others were taken either from particular authors or
from documents. Munson instructed scripters to
strike through the characters O and Z, to print 1
without a slash, and to place horizontal strokes over
the I. Highleymann's dataset consists of the 36
alphanumeric characters represented by 12 X 12 size
matrices. It includes 1,800 letters and 500 numbers
from 50 writers who were instructed to write on grid
paper in a writing frame.
We also mention many other recent datasets such
as Mori handwriting dataset (Mori et al., 1984)
which is a collection of handwritten Japanese
characters created by the Mori Laboratory at the
University of Tokyo. It contains over 3,000
handwritten characters written by 100 different
writers and is widely used in the development of
handwriting recognition systems. Moreover, the
Modified National Institute of Standards and
Technology (MNIST) dataset was introduced in
1998 (Lecun et al., 1998) and is a widely used as a
benchmark dataset for handwritten digit recognition.
It consists of 60,000 training images and 10,000
testing images of a 28 × 28 size of handwritten digits
from 0 to 9. Furthermore, EMNIST (Cohen et al.,
2017) dataset is an extension of the MNIST dataset
and includes handwritten letters in addition to digits.
It contains 240,000 training images and 40,000
testing images. Also, IAM Handwriting dataset
(Marti & Bunke, 2002) contains handwritten words
and sentences in English including over 5,000 pages
of handwritten text from 657 writers.
CEDAR dataset (Hull, 1994) is composed of
handwritten forms, including surveys,
questionnaires, and tax forms. It contains over 1,000
forms with over 50,000 fields. Besides the
mentioned, ICDAR is a collection of datasets (Lucas
et al., 2003; Lucas, 2005; Shahab et al., 2011) for
handwritten text recognition, including Chinese,
Japanese, and Arabic text. RIMES (Reconnaissance
et Indexation de données Manuscrites et de fac
similÉS / Recognition and Indexing of handwritten
documents and faxes) (Grosicki et al., 2009) is a
modern dataset of handwritten words in French with
over 1 million words written by over 1,300 writers.
Additionally, the Street View House Numbers
(SVHN) (Netzer et al., 2011) is a Google’s dataset
of street view house numbers, which includes
handwritten digits from 0 to 9. It contains over
600,000 images. One more dataset that we should
consider is the ADAB dataset (Arabic DAtaBase)
(Kherallah et al., 2011; Tagougui et al., 2012;
Boubaker et al., 2012) made up of 15,000 Arabic
names of Tunisian towns and villages, handwritten
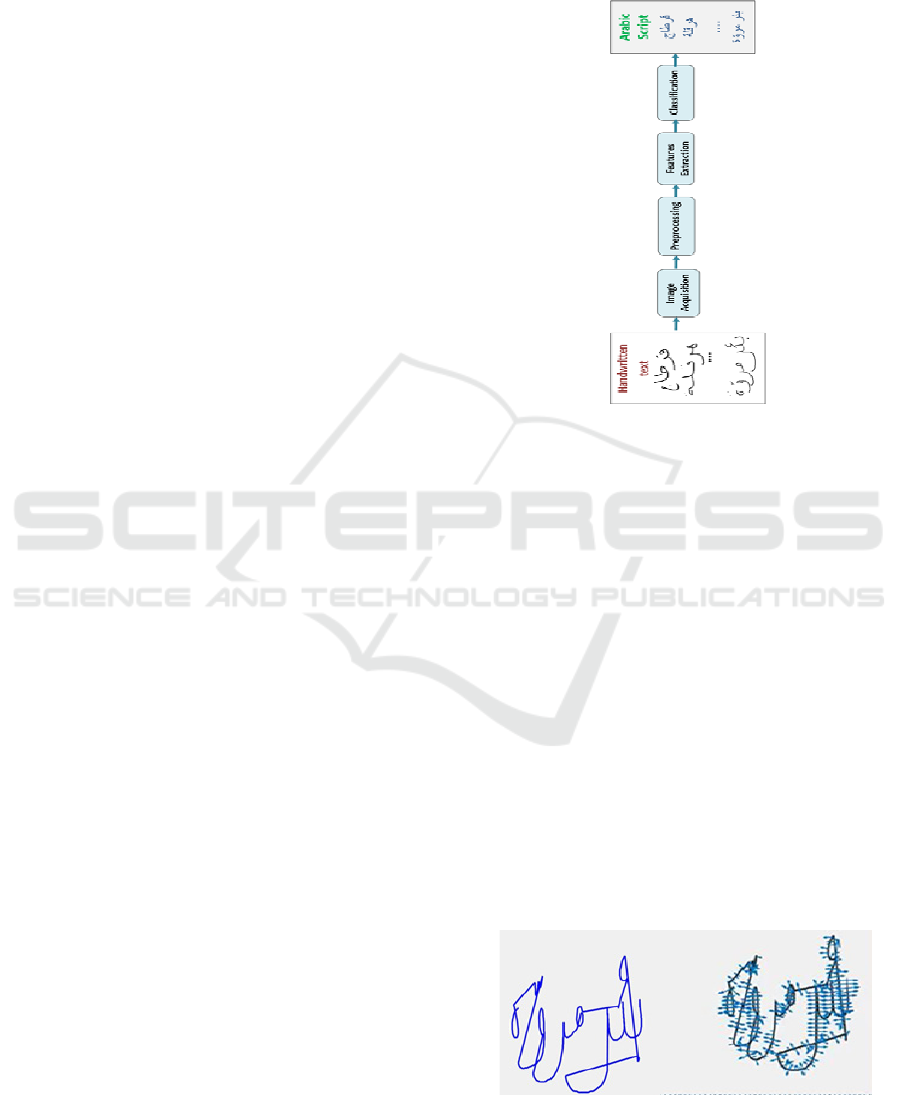
by more than 166 different writers. Figure 1 shows
the appearance of some sample images from ADAB
database displaying handwritten Arabic names of
some Tunisian towns and villages.
Figure 1: Appearance of some sample images from ADAB
dataset.
New Approach Based on Substantial Derivative and LSTM for Online Arabic Handwriting Script Recognition
691
2.2 Works on Arabic Handwritten
Recognition
Various approaches have been used to automate the
process of identifying and converting handwritten
Arabic text into digital format, which is essential for
many applications related to document analysis, text
mining, and machine translation. This task mainly
relies on using advanced algorithms and machine
learning techniques to recognize the unique features
of Arabic handwriting, such as the shape and size of
letters, the direction of strokes, and the spacing
between words. It has become an important research
area in the field of computer vision and natural
language processing and has the potential to
revolutionize the way we interact with Arabic
language documents.
There have been numerous research studies and
developments in the field of Arabic handwritten
recognition. Among the notable works, the
comprehensive review of the state-of-the-art
techniques and methodologies used in Arabic
handwritten recognition (Cheriet, 2007) as well as
many studies presented throughout the last decade
such as a survey (Tagougui et al., 2012) where
different approaches and techniques used for online
Arabic handwriting recognition have been exposed.
Another system that combines different feature
extraction methods and classifiers for Arabic
handwritten text recognition was proposed (Al-
Maadeed, 2012).
Furthermore, the literature was examined on the
most significant work in Arabic optical character
recognition (AOCR) and a survey of databases on
Arabic offline handwritten character recognition
system was provided (Abdalkafor, 2018) as well as a
recognition system of Arabic cursive handwriting
using embedded training based on hidden Markov
models (Rabi et al., 2017).
Later, various papers (Noubigh et al., 2020;
Altwaijry & Al-Turaiki, 2020; AlJarrah et al., 2021;
Ali & Mallaiah, 2022) presented some deep learning
approaches such as convolutional neural networks
(CNNs) for Arabic handwritten text recognition.
These works demonstrate the ongoing research
and development in the field of Arabic handwritten
recognition, and the potential for further
advancements in this area.
3 PROPOSED METHOD
Enlightened by a main concept emerging from the
physics of fluid mechanics previously explained
(Lejmi et al., 2020), we suggest an innovative
framework to recognize handwritten text from
ADAB dataset. The overall framework phases of the
proposed model are depicted in figure 2.
Figure 2: Framework phases of online Arabic handwriting
recognition.
Specifically, we suggest performing the features
extraction step using the optical flow and the
substantial derivative (SD).
The latter describes the rate of change of a
particle while in motion with respect to time.
Analogically to the particle derivative stemming
from the physics of fluid mechanics, we estimate
local and convective accelerations from ADAB
dataset frames. In fact, the local or temporal
acceleration represents the increase rate of a pixel’s
speed over time at a specific point of the flow. The
convective acceleration describes the increase rate of
speed due to the change in pixel position.
To estimate local and convective accelerations,
we need first to calculate the optical flow (Lejmi et
al., 2017). It represents a set of vector fields that
relates a frame to an upcoming one (figure 3). Each
vector field describes the obvious movement of each
pixel from frame to frame.
Figure 3: Plot of optical flow vector for an image from
ADAB dataset.
ICAART 2024 - 16th International Conference on Agents and Artificial Intelligence
692
Considering the “Brightness Conservation
Theorem” which means that "The brightness of an
object is constant from one image to another.”:
I
x,y,t
=I
x+ dx, y+dy, t+dt
(1)
‘I’ represents an image sequence, ‘dy’ and ‘dx’
represent displacement vectors for the pixel with
coordinates
x,y
and ‘t’ and ‘dt’ the frame and
temporal displacement of the image sequence. The
optical flow equation is derived from the above
equation as follows:
f
U+f
V+ f
=0 (2)
‘fx’ , ‘fy’ represent pixel intensity gradients and
‘f
’ represents the first temporal derivative.
If we solve (2) we obtain a couple of flow vector
maps U and V that dictate perceived motion in both
the x and y coordinate plane.
For each frame
I
, the optical flow
f
represents each pixel’s velocity in x and y
directions:
F
x,y
=v
,v
(3)
When we apply (3), the local acceleration gets
the value of the rate of change of velocity over time
at a fixed point in a flow field.
Generally, the rate of change of the quantity
undergone by an observer who moves with the flow
is described in (4) and (5).
=
∗v
+
∗v
+
=v
⃗
grad
⃗
f +
(4)
≡v.∇f+
(5)
Let a
be the local acceleration in an “x”
direction and a
the local acceleration at “y”
direction as detailed below:
a
=v
−v
(6)
a
=v
−v
(7)
The calculation of the local acceleration a
of a
couple of successive optical flows is obtained as
follows:
a
=
a
+a
(8)
To obtain the rate of change of velocity with
respect to position at a fixed time in a flow field, the
convective acceleration should be calculated. It is
combined with spatial velocity gradients in the flow
field. We consider a
as the convective acceleration
in an “x” direction and a
as the convective
acceleration in a “y” direction:
a
=
+
∗v
(9)
a
=
+
∗v
(10)
Let a
be the convective acceleration magnitude
defined as follows:
a
=
a
+a
(11)
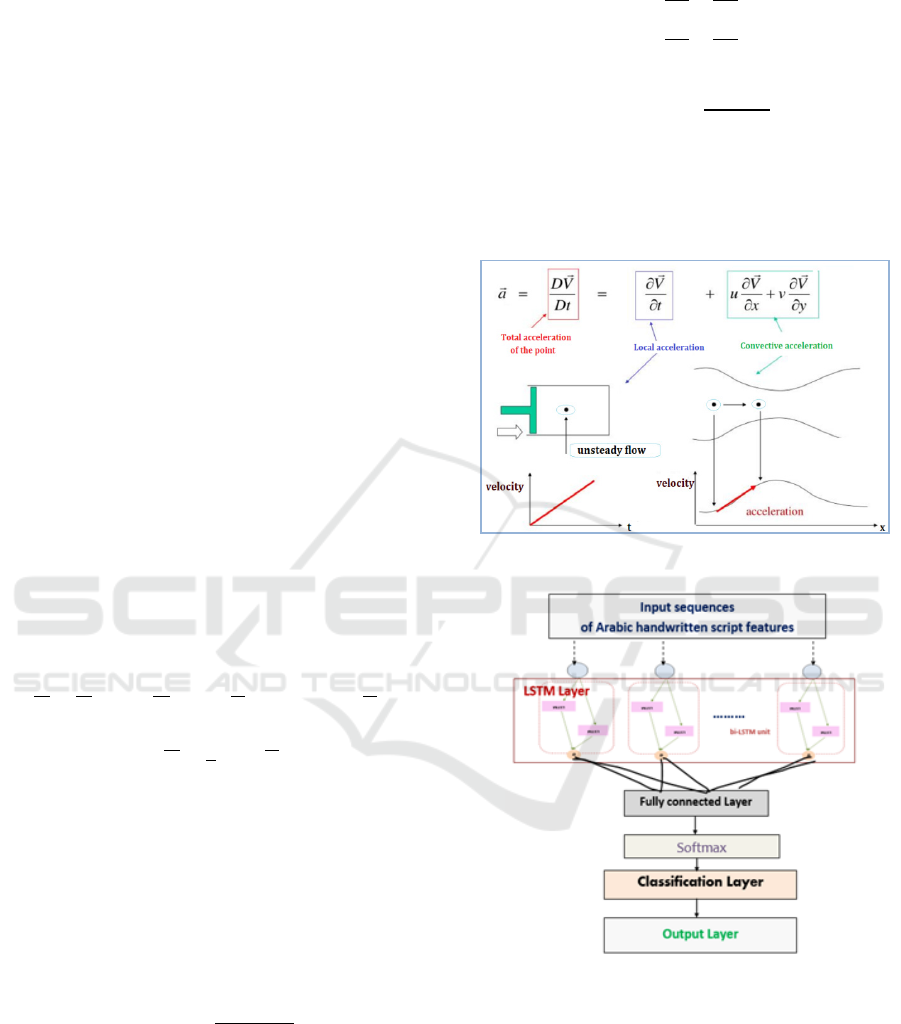
Overall, the physical interpretation of the
substantial derivative (SD) is highlighted in figure 4
indicating the total acceleration of the pixel moving
along its trajectory.
Figure 4: Physical interpretation of the SD concept.
Figure 5: Bidirectional-LSTM classification network (SD-
LSTM).
Afterwards, the classification algorithm will be
implemented using a recurrent neural network (Long
Short-Term Memory LSTM) (Lejmi et al., 2020),
which can process both isolated data as well as
sequences. This helps avoid long-term dependency
issues, by interacting through four layers of neural
network and gates indicating which data is useful to
keep and which is not. Thus, only relevant data
New Approach Based on Substantial Derivative and LSTM for Online Arabic Handwriting Script Recognition
693

passes through the sequence chain to facilitate
prediction. The LSTM deep learning classification
technique allows to classify the generated features
and to calculate a prediction value for each word.
Figure 5 illustrates how to create a Bidirectional-
LSTM (Bi-LSTM) classification network.
We concatenate the extracted features and feed
them to a Softmax classifier through a fully
connected operator. The classification ability of the
model will be later evaluated on confusion matrices
which will present the system predictions and their
actual labels.
4 EXPERIMENTS
We resorted to MATLAB R2022a software to carry
out experimental work on an Intel (R) Core (TM) i9-
11980HK, 2.6 GHz and 32 GB RAM under
Windows 11 operating system (64-bit).
4.1 ADAB Dataset and Preprocessing
In addition to input files in Tag(ged) Image File
Format (TIFF) of ADAB dataset, one more
alternative is considering the files in the Ink Markup
Language (InkML) format that was created by the
W3C (Watt & Underhill, 2011; Xavier et al., 2014)
as a standard for data storage ink. Indeed, the
features inside them are called “traces” where each
one represents a continuous writing curve, as shown
in figure 6. Traces consist of series of points. Each
Figure 6: Schematization of one handwritten script from
ADAB dataset generated by connecting the dots of 7
stored InkML traces. The displayed lines of the inkml file
below represent the 7 traces of this Arabic word.
represents a number of coordinate values whose
meanings are provided by a <traceFormat> element.
These coordinates are able to give us information
on values for quantities like pen position, angle, tip
force, button state, etc. More clearly, the data is
recorded in consecutive elements within <trace>
tags.
Each one includes a comma-separated
"coordinate" tuple representing points pairs (x , y).
For each point, the pair (x , y) describes the position
of the pen relative to the origin (0 , 0) placed in the
upper left corner of the screen. Thus, we read the
files into the ADAB dataset composed of three sets
(set1, set2 and set3) containing the names of 937
Tunisian towns and villages written in Arabic and in
more than one handwriting, and presented in Ink
Markup Language (InkML) files.
The hypothesis of our research is to read the
ADAB online Arabic handwriting dataset in order to
perform the main procedures below:
Calculating substantial derivative equations
and then getting features using optical flow
and taking advantage of the results to compute
convective and local acceleration in order to
get local and convective features which will
be concatenated to obtain the total ones.
Using total features with taxonomic
information in order to train and test the
obtained characteristics before utilizing them
for classification based on the LSTM recurrent
neural network.
A first difficulty in obtaining meaningful
features (Al-Helali & Mahmoud, 2016; Wilson-
Nunn et al., 2018) using optical flow, is that it
accepts input datasets only in video format. We,
therefore, need to find a technique to convert the
INKML files of our dataset into a suitable form that
can efficiently compute and calculate the optical
flow.
One more important issue is the need for an
approach to prepare files names, so that we can read
them and associate each INKML file with its
intended label. The latter can be found in the UPX
file having the same name, precisely in the
"alternative value tag", for example in the case of the
name "ﺔ
ّ
ﻄﺤﻤﻟﺍ ﻥﻭﺪﻌﺳ ﺏﺎﺑ", or as depicted in line 17 of
the example previously shown in figure 5. We also
need to take into consideration, when preparing the
file name, the association of the INKML file with all
the other ones having the same label, i.e. the same
"alternative value tag". In addition, we need to
prepare these names based on their occurrences in
the dataset so that they are easy to read and to use
during the training and classification phases.
ICAART 2024 - 16th International Conference on Agents and Artificial Intelligence
694

4.2 Features Extraction Using
Substantial Derivative and
Acceleration Features
The traces marks are selected in order to convert
data into video with an AVI (Audio Video
Interleave) format and then deduce the dimensions
of the x and y coordinates from the InkML files so
that the video starts drawing the word from the first
point of its intersection and continues until this word
is completed as a whole. First, we managed to use
the *.inkml files and extract x and y coordinates
from traces which represent the words, in order to
store the source files names and their coordinates in
the file 'inkmlFileName_X_Y.mat' and use them
later. This is performed for dataset set1 while
making sure, through two subsequent steps for set 2
and set 3 of this same dataset, to store the results
later in the matrices ‘inkmlFileName_X_Ys2.mat’
and ‘inkmlFileName_X_Ys3’. Then, the generated
inkmFileName_X_Y.mat will be used to read and
convert data from inkml files to AVI video file with
the same name, using the coordinates for each file to
extract each video in a new way: The graphics axis
limits will be set according to the actual x and y
point limits without affecting the size of the output
video. This starts by exploiting the current
coordinates and changing them according to the
following ones to adapt simultaneously to the
successive coordinates as depicted in figure 7.
Figure 7: An example of converting the data read from
inkml file in case of the word “
ﻱﺩﺍﻭ ﻞﻣ
ّ
ﺮﻟﺍ
” which
represents one file.
Through the first part of the following figure, we
highlight a new way of reading Arabic writing in
order to benefit from the largest possible number of
video image coordinates, unlike the usual way where
most of the video image remains empty or
stationary, particularly for short words, as shown for
example in the case of the word “ﺓﺩﺎﻣﺭ” (figure 8).
Figure 8: Example of empty part of video image in case of
ADAB short words.
This helps us to collect more features in the next
step. This new method is beneficial in terms of
homogeneity of the data used for analysis, as all the
video files and their frames have the same size and
line thickness. This will help us to achieve more
accurate results in the classification process.
4.3 Classification Results
This section presents our experimentation in the
field of multilingual online handwriting script
recognition. First, we introduce the datasets used in
our study. Then, we provide an in-depth discussion
of the results. Both kinds of acceleration features are
mixed and then divided into a Training set and a test
set. In this context, it is noteworthy to mention the
number of frames that have been processed.
To deal with challenging aspects of online
handwriting recognition (Mahmoud et al., 2018), it
is recommended to use a standardized database that
accommodates different writing styles and
encompasses various classes in the target language.
To evaluate the performance and effectiveness of
our proposed system, we used ADAB dataset
(Boubaker et al., 2012), tailored for Arabic words
which collectively serve as pivotal components of
our experimentation.
Figure 9: LSTM minimizes loss function for total
acceleration features.
This ADAB dataset, consisting of over 33,000
handwritten Arabic words by 170 different writers,
has been widely utilized in the literature. It contains
937 names of Tunisian towns and villages. This
database is segmented into six distinct sets,
originally collected for the ICDAR 2011 online
Arabic handwriting recognition competition
(Elleuch et al., 2016).
To improve the training accuracy, we applied
some data augmentation techniques (Hamdi et al.,
2021) and we focused on sets 1, 2, and 3 which
altogether contain more than 45,158 words for the
training process. When testing the network, the
recognition rate was quite high for the Bi-LSTM
New Approach Based on Substantial Derivative and LSTM for Online Arabic Handwriting Script Recognition
695

neural network trained with an SGDM optimizer and
a learning rate of 0.01 during 100 epochs (figure 9).
Indeed, the accuracy was around 90% and 95%.
Specifically, for the Training set, it reached 99%.
Based on features extraction results, further
implementation is on the way to enhance the
classification performance. Indeed, we are planning
to increase the size of the ADAB dataset as it
currently has a considerable imbalance in terms of
content occurrences. We believe that this will
significantly improve the results. Besides, we
performed a comparative analysis of the suggested
system against other ones that have been
experimented in the field of online Arabic character
recognition. The results are summarized in Table 1.
Regarding the ADAB dataset, our results are like the
state of the art.
Table 1: Comparison of recognition rate between the
suggested approach and some existing models.
Models
Recognition
rate
(
%
)
Elleuch et al.
(
2016
)
97,5
Abdelaziz an
d
Abdou
(
2014
)
97,1
Tagougui and Kherallah (2017) 96,2
SD-LSTM 95,3
5 CONCLUSIONS
In this paper, we presented various well-known
datasets and crucial works underlying the
approaches of handwritten recognition and we
specially outlined those used to process identifying
Arabic handwriting as well. Then, enlightened by a
main concept of fluid mechanics, we presented a
novel model based on an initial phase of spatio-
temporal features extraction using the optical flow
and the substantial derivative to calculate local,
convective and total accelerations. Afterwards, we
suggested a classification model relying on the deep
learning LSTM neural network. The last part was
mainly devoted to the experiments we performed on
ADAB dataset as well as the implementation of the
descriptor and the technical tricks that we proposed
in order to effectively classify the Arabic characters.
We believe that further research on this can lead to
fruitful results.
REFERENCES
Mori, S., Suen, C. Y., & Yamamoto, K. (1992). Historical
review of OCR research and development.
Proceedings of the IEEE. Institute of Electrical and
Electronics Engineers, 80(7), 1029–1058.
doi:10.1109/5.156468
Wu, Z., Yu, C., Xu, X., Wei, T., Zou, T., Wang, R., & Shi,
Y. (2021). LightWrite: Teach Handwriting to The
Visually Impaired with A Smartphone. In Proceedings
of the 2021 CHI Conference on Human Factors in
Computing Systems. CHI ’21: CHI Conference on
Human Factors in Computing Systems. ACM.
https://doi.org/10.1145/3411764.3445322
Singh, S., Kariveda, T., Gupta, J. D., & Bhattacharya, K.
(2015). Handwritten words recognition for legal
amounts of bank cheques in English script. In 2015
Eighth International Conference on Advances in
Pattern Recognition (ICAPR). 2015 Eighth
International Conference on Advances in Pattern
Recognition (ICAPR). IEEE. https://doi.org/10.
1109/icapr.2015.7050716
Charfi, M., Kherallah, M., El, A., & M., A. (2012). A New
Approach for Arabic Handwritten Postal Addresses
Recognition. In International Journal of Advanced
Computer Science and Applications (Vol. 3, Issue 3).
The Science and Information Organization.
https://doi.org/10.14569/ijacsa.2012.030301
Nagy, G. (2016). Disruptive developments in document
recognition. In Pattern Recognition Letters (Vol. 79,
pp. 106–112). Elsevier BV. https://doi.org/10.
1016/j.patrec.2015.11.024
Chherawala, Y., & Cheriet, M. (2014). Arabic word
descriptor for handwritten word indexing and lexicon
reduction. In Pattern Recognition (Vol. 47, Issue 10,
pp. 3477–3486). Elsevier BV. https://doi.org/10.
1016/j.patcog.2014.04.025
Velázquez, A., & Levachkine, S. (2004). Text/Graphics
Separation and Recognition in Raster-Scanned Color
Cartographic Maps. In Graphics Recognition. Recent
Advances and Perspectives (pp. 63–74). Springer
Berlin Heidelberg. https://doi.org/10.1007/978-3-540-
25977-0_6
ElKessab, B., Daoui, C., & Bouikhalene, B. (2013).
Handwritten Tifinagh Text Recognition using Neural
Networks and Hidden Markov Models. In
International Journal of Computer Applications (Vol.
75, Issue 18, pp. 54–60). Foundation of Computer
Science. https://doi.org/10.5120/13354-0127
Abuhaiba, I. S. I. (2004). Discrete Script or Cursive
Language Identification from Document Images. In
Journal of King Saud University - Engineering
Sciences (Vol. 16, Issue 2, pp. 253–268). Elsevier BV.
https://doi.org/10.1016/s1018-3639(18)30790-6
Begum, N., Akash, M. A. H., Rahman, S., Shin, J., Islam,
M. R., & Islam, M. E. (2021). User Authentication
Based on Handwriting Analysis of Pen-Tablet Sensor
Data Using Optimal Feature Selection Model. In
Future Internet (Vol. 13, Issue 9, p. 231). MDPI AG.
https://doi.org/10.3390/fi13090231
Kannan, R. J., Prabhakar, R., & Suresh, R. M. (2008). Off-
line Cursive Handwritten Tamil Character
Recognition. In 2008 International Conference on
ICAART 2024 - 16th International Conference on Agents and Artificial Intelligence
696

Security Technology. (SECTECH). IEEE. https://doi.
org/10.1109/sectech.2008.33
Tappert, C. C., Suen, C. Y., & Wakahara, T. (1990). The
state of the art in online handwriting recognition. In
IEEE Transactions on Pattern Analysis and Machine
Intelligence (Vol. 12, Issue 8, pp. 787–808). Institute
of Electrical and Electronics Engineers (IEEE).
https://doi.org/10.1109/34.57669
Stremler, S., & Karácsony, Z. (2016). Efficient
Handwritten Digit Recognition Using Normalized
Cross-Correlation. In The publications of the
MultiScience - XXX. MicroCAD International
Scientific Conference. MultiScience. University of
Miskolc. https://doi.org/10.26649/musci.2016.058
Zhang, Y., Li, Z., Yang, Z., Yuan, B., & Liu, X. (2023).
Air-GR: An Over-the-Air Handwritten Character
Recognition System Based on Coordinate Correction
YOLOv5 Algorithm and LGR-CNN. In Sensors (Vol.
23, Issue 3, p. 1464). MDPI AG. https://doi.
org/10.3390/s23031464
Alphabetic Handprint Reading. (1978). In IEEE
Transactions on Systems, Man, and Cybernetics (Vol.
8, Issue 4, pp. 279–282). Institute of Electrical and
Electronics Engineers (IEEE). https://doi.org/10.
1109/tsmc.1978.4309949
Munson, J. H. (1968). Experiments in the recognition of
hand-printed text, part I. In Proceedings of the
December 9-11, 1968, fall joint computer conference,
part II on - AFIPS ’68 (Fall, part II). ACM Press.
https://doi.org/10.1145/1476706.1476735
Highleyman, W. H. (1961). An Analog Method for
Character Recognition. In IEEE Transactions on
Electronic Computers: Vol. EC-10 (Issue 3, pp. 502–
512). Institute of Electrical and Electronics Engineers
(IEEE). https://doi.org/10.1109/tec.1961.5219239
Mori, S., Yamamoto, K., & Yasuda, M. (1984). Research
on Machine Recognition of Handprinted Characters.
In IEEE Transactions on Pattern Analysis and
Machine Intelligence: Vol. PAMI-6 (Issue 4, pp. 386–
405). Institute of Electrical and Electronics Engineers
(IEEE). https://doi.org/10.1109/tpami.1984.4767545
Lecun, Y., Bottou, L., Bengio, Y., & Haffner, P. (1998).
Gradient-based learning applied to document
recognition. In Proceedings of the IEEE (Vol. 86,
Issue 11, pp. 2278–2324). Institute of Electrical and
Electronics Engineers (IEEE). https://doi.org/10.
1109/5.726791
Cohen, G., Afshar, S., Tapson, J., & van Schaik, A.
(2017). EMNIST: Extending MNIST to handwritten
letters. In 2017 International Joint Conference on
Neural Networks (IJCNN). IEEE. https://doi.org/10.
1109/ijcnn.2017.7966217
Marti, U.-V., & Bunke, H. (2002). The IAM-database: an
English sentence database for offline handwriting
recognition. In International Journal on Document
Analysis and Recognition (Vol. 5, Issue 1, pp. 39–46).
Springer Science and Business Media LLC.
https://doi.org/10.1007/s100320200071
Hull, J. J. (1994). A database for handwritten text
recognition research. In IEEE Transactions on Pattern
Analysis and Machine Intelligence (Vol. 16, Issue 5,
pp. 550–554). Institute of Electrical and Electronics
Engineers (IEEE). https://doi.org/10.1109/34.291440
Lucas, S. M., Panaretos, A., Sosa, L., Tang, A., Wong, S.,
& Young, R. (n.d.). ICDAR 2003 robust reading
competitions. In Seventh International Conference on
Document Analysis and Recognition, 2003.
Proceedings. Seventh International Conference on
Document Analysis and Recognition. IEEE Comput.
Soc. https://doi.org/10.1109/icdar.2003.1227749
Lucas, S. M. (2005). ICDAR 2005 text locating
competition results. In Eighth International
Conference on Document Analysis and Recognition
(ICDAR’05). IEEE. https://doi.org/10.1109/icdar.
2005.231
Shahab, A., Shafait, F., & Dengel, A. (2011). ICDAR
2011 Robust Reading Competition Challenge 2:
Reading Text in Scene Images. In 2011 International
Conference on Document Analysis and Recognition.
IEEE. https://doi.org/10.1109/icdar.2011.296
Grosicki, E., Carré, M., Brodin, J.-M., & Geoffrois, E.
(2009). Results of the RIMES Evaluation Campaign
for Handwritten Mail Processing. In 2009 10th
International Conference on Document Analysis and
Recognition. IEEE. https://doi.org/10.1109/icdar.
2009.224
Netzer, Y., Wang, T., Coates, A., Bissacco, A., Wu, B. &
Ng, A. Y. (2011). Reading Digits in Natural Images
with Unsupervised Feature Learning
Kherallah, M., Tagougui, N., Alimi, A. M., Abed, H. E., &
Margner, V. (2011). Online Arabic Handwriting
Recognition Competition. In 2011 International
Conference on Document Analysis and Recognition.
(ICDAR). IEEE. https://doi.org/10.1109/icdar.
2011.289
Tagougui, N., Kherallah, M., & Alimi, A. M. (2012).
Online Arabic handwriting recognition: a survey. In
International Journal on Document Analysis and
Recognition (IJDAR) (Vol. 16, Issue 3, pp. 209–226).
Springer Science and Business Media LLC.
https://doi.org/10.1007/s10032-012-0186-8
Boubaker, H., Elbaati, A., Tagougui, N., El Abed, H.,
Kherallah, M., & Alimi, A. M. (2012). Online Arabic
Databases and Applications. In Guide to OCR for
Arabic Scripts (pp. 541–557). Springer London.
https://doi.org/10.1007/978-1-4471-4072-6_22
Cheriet, M. (2007). Strategies for visual arabic
handwriting recognition: Issues and case study. In
2007 9th International Symposium on Signal
Processing and Its Applications. (ISSPA). IEEE.
https://doi.org/10.1109/isspa.2007.4555620
Al-Maadeed, S. (2012). Text-Dependent Writer
Identification for Arabic Handwriting. In Journal of
Electrical and Computer Engineering (Vol. 2012, pp.
1–8). Hindawi Limited. https://doi.org/10.1155/
2012/794106
Abdalkafor, A. S. (2018). Survey for Databases On Arabic
Off-line Handwritten Characters Recognition System.
In 2018 1st International Conference on Computer
New Approach Based on Substantial Derivative and LSTM for Online Arabic Handwriting Script Recognition
697

Applications & Information Security (ICCAIS). IEEE.
https://doi.org/10.1109/cais.2018.8442001
Rabi, M., Amrouch, M., & Mahani, Z. (2017).
Recognition of Cursive Arabic Handwritten Text
Using Embedded Training Based on Hidden Markov
Models. In International Journal of Pattern
Recognition and Artificial Intelligence (Vol. 32, Issue
01, p. 1860007). World Scientific Pub Co Pte Lt.
https://doi.org/10.1142/s0218001418600078
Noubigh, Z., Mezghani, A., & Kherallah, M. (2020).
Contribution on Arabic Handwriting Recognition
Using Deep Neural Network. In Hybrid Intelligent
Systems (pp. 123–133). Springer International
Publishing. https://doi.org/10.1007/978-3-030-49336-
3_13
Altwaijry, N., & Al-Turaiki, I. (2020). Arabic handwriting
recognition system using convolutional neural
network. In Neural Computing and Applications (Vol.
33, Issue 7, pp. 2249–2261). Springer Science and
Business Media LLC. https://doi.org/10.1007/s00521-
020-05070-8
AlJarrah, M. N., Zyout, M. M., & Duwairi, R. (2021).
Arabic Handwritten Characters Recognition Using
Convolutional Neural Network. In 2021 12th
International Conference on Information and
Communication Systems (ICICS). IEEE. https://doi.
org/10.1109/icics52457.2021.9464596
Ali, A. A. A., & Mallaiah, S. (2022). Intelligent
handwritten recognition using hybrid CNN
architectures based-SVM classifier with dropout. In
Journal of King Saud University - Computer and
Information Sciences (Vol. 34, Issue 6, pp. 3294–
3300). Elsevier BV. https://doi.org/10.1016/j.
jksuci.2021.01.012
Lejmi, W., Khalifa, A. B., & Mahjoub, M. A. (2020). A
Novel Spatio-Temporal Violence Classification
Framework Based on Material Derivative and LSTM
Neural Network. In Traitement du Signal (Vol. 37,
Issue 5, pp. 687–701). International Information and
Engineering Technology Association. https://doi.org/
10.18280/ts.370501
Lejmi, W., Mahjoub, M. A., & Ben Khalifa, A. (2017).
Event detection in video sequences: Challenges and
perspectives. In 2017 13th International Conference
on Natural Computation, Fuzzy Systems and
Knowledge Discovery (ICNC-FSKD). IEEE.
https://doi.org/10.1109/fskd.2017.8393354
Watt, S. M., & Underhill, T. (Eds.). (2011). Ink Markup
Language (InkML).
Retrieved from http://www.w3.
org/TR/InkML/
Xavier, C., Ambrosio, A. P., & Georges, F. (2014).
Written Assessments with Digital Ink. In 2014 14th
International Conference on Computational Science
and Its Applications (ICCSA). IEEE. https://doi.
org/10.1109/iccsa.2014.35
Al-Helali, B. M., & Mahmoud, S. A. (2016). A Statistical
Framework for Online Arabic Character Recognition.
In Cybernetics and Systems (Vol. 47, Issue 6, pp. 478–
498). Informa UK Limited. https://doi.org/
10.1080/01969722.2016.1206768
Wilson-Nunn, D., Lyons, T., Papavasiliou, A., & Ni, H.
(2018). A Path Signature Approach to Online Arabic
Handwriting Recognition. In 2018 IEEE 2nd
International Workshop on Arabic and Derived Script
Analysis and Recognition (ASAR). IEEE.
https://doi.org/10.1109/asar.2018.8480300
Hamdi, Y., Boubaker, H., & Alimi, A. M. (2021). Data
Augmentation using Geometric, Frequency, and Beta
Modeling approaches for Improving Multi-lingual
Online Handwriting Recognition. In International
Journal on Document Analysis and Recognition
(IJDAR) (Vol. 24, Issue 3, pp. 283–298). Springer
Science and Business Media LLC. https://doi.
org/10.1007/s10032-021-00376-2
Elleuch, M., Zouari, R., & Kherallah, M. (2016). Feature
Extractor Based Deep Method to Enhance Online
Arabic Handwritten Recognition System. In Artificial
Neural Networks and Machine Learning – ICANN
2016 (pp. 136–144). Springer International Publishing.
https://doi.org/10.1007/978-3-319-44781-0_17
Abdelaziz, I., & Abdou, S.M. (2014). AltecOnDB: A
Large-Vocabulary Arabic Online Handwriting
Recognition Database. ArXiv, abs/1412.7626.
Tagougui, N., & Kherallah, M. (2017). Recognizing
online Arabic handwritten characters using a deep
architecture. In A. Verikas, P. Radeva, D. P. Nikolaev,
W. Zhang, & J. Zhou (Eds.), SPIE Proceedings. SPIE.
https://doi.org/10.1117/12.2268419
Mahmoud, S. A., Luqman, H., Al-Helali, B. M.,
BinMakhashen, G., & Parvez, M. T. (2018). Online-
KHATT: An Open-Vocabulary Database for Arabic
Online-Text Processing. In The Open Cybernetics &
Systemics Journal (Vol. 12, Issue 1, pp. 42–59).
Bentham Science Publishers Ltd. https://doi.org/
10.2174/1874110x01812010042.
ICAART 2024 - 16th International Conference on Agents and Artificial Intelligence
698
