
Generating Videos from Stories Using Conditional GAN
Takahiro Kozaki, Fumihiko Sakaue and Jun Sato
Nagoya Institute of Technology, Nagoya 466-8555, Japan
{kozaki@cv., sakaue@, junsato@}nitech.ac.jp
Keywords:
Generative AI, Story, Multiple Sentences, Video, GAN, Captioning.
Abstract:
In this paper, we propose a method for generating videos that represent stories described in multiple sentences.
While research on generating images and videos from single sentences has been advancing, the generation of
videos from long stories written in multiple sentences has not been achieved. In this paper, we use adversarial
learning to train pairs of multi-sentence stories and videos to generate videos that replicate the flow of the
stories. We also introduce caption loss for generating more contextually aligned videos from stories.
1 INTRODUCTION
In recent years, techniques for generating images
from text information have progressed much, mak-
ing it possible to generate a high-quality image from
text information that describes the content of the im-
age (Rombach et al., 2022; Ramesh et al., 2021). Fur-
thermore, research on video generation from text in-
formation is also progressing (Ho et al., 2022), and
it is becoming possible to generate short videos from
text information.
However, generating a long video that represents a
long story composed of multiple sentences has not yet
been achieved. If long story videos could be automat-
ically generated from long stories, it could be used in
a variety of fields such as movie production. Thus, in
this paper, we propose a method for generating long
videos from multiple sentences in a story. This repli-
cates the human ability to imagine and visualize the
scenes described in the text while reading a novel.
For visualizing stories, Li et al. proposed Story-
GAN (Li et al., 2019), which takes the entire text of
a story as input and generates a sequence of keyframe
images that represent the overall flow of the story. The
StoryGAN successfully generates keyframe images
corresponding to each sentence in the story. However,
since only one keyframe image is generated from a
single sentence, the resulting image sequence can-
not represent the motions of characters and moving
scenes described in the sentence.
Thus, in this research, we propose a method for
generating long videos from input stories composed
of multiple sentences as shown in Fig. 1. In con-
trast to StoryGAN, which generates a single image
Figure 1: Generating long videos from long story sentences.
The proposed method generates long videos with scene
changes according to the story sentences. Our method gen-
erates multiple short videos from multiple sentences in a
story, and then combines these videos to form a long video
that represents the entire story.
from each sentence, our method generates a short
video from each sentence and then combines these
videos to generate a long video representing the en-
tire story. In our network, we introduce a caption loss
that focuses on the appropriateness of regenerated sto-
ries from the generated videos, aiming to reproduce
long videos from multiple sentences more accurately.
Our network is trained and tested by using the Pororo
dataset (Li et al., 2019) as in the case of StoryGAN.
2 RELATED WORK
In the field of image generation, Generative Adversar-
ial Networks (GANs) have achieved significant suc-
cess (Goodfellow et al., 2014; Zhu et al., 2017; Brock
et al., 2019). Furthermore, the introduction of con-
ditional GANs (cGANs), which allow the generation
Kozaki, T., Sakaue, F. and Sato, J.
Generating Videos from Stories Using Conditional GAN.
DOI: 10.5220/0012405300003660
Paper published under CC license (CC BY-NC-ND 4.0)
In Proceedings of the 19th International Joint Conference on Computer Vision, Imaging and Computer Graphics Theory and Applications (VISIGRAPP 2024) - Volume 2: VISAPP, pages
671-677
ISBN: 978-989-758-679-8; ISSN: 2184-4321
Proceedings Copyright © 2024 by SCITEPRESS – Science and Technology Publications, Lda.
671

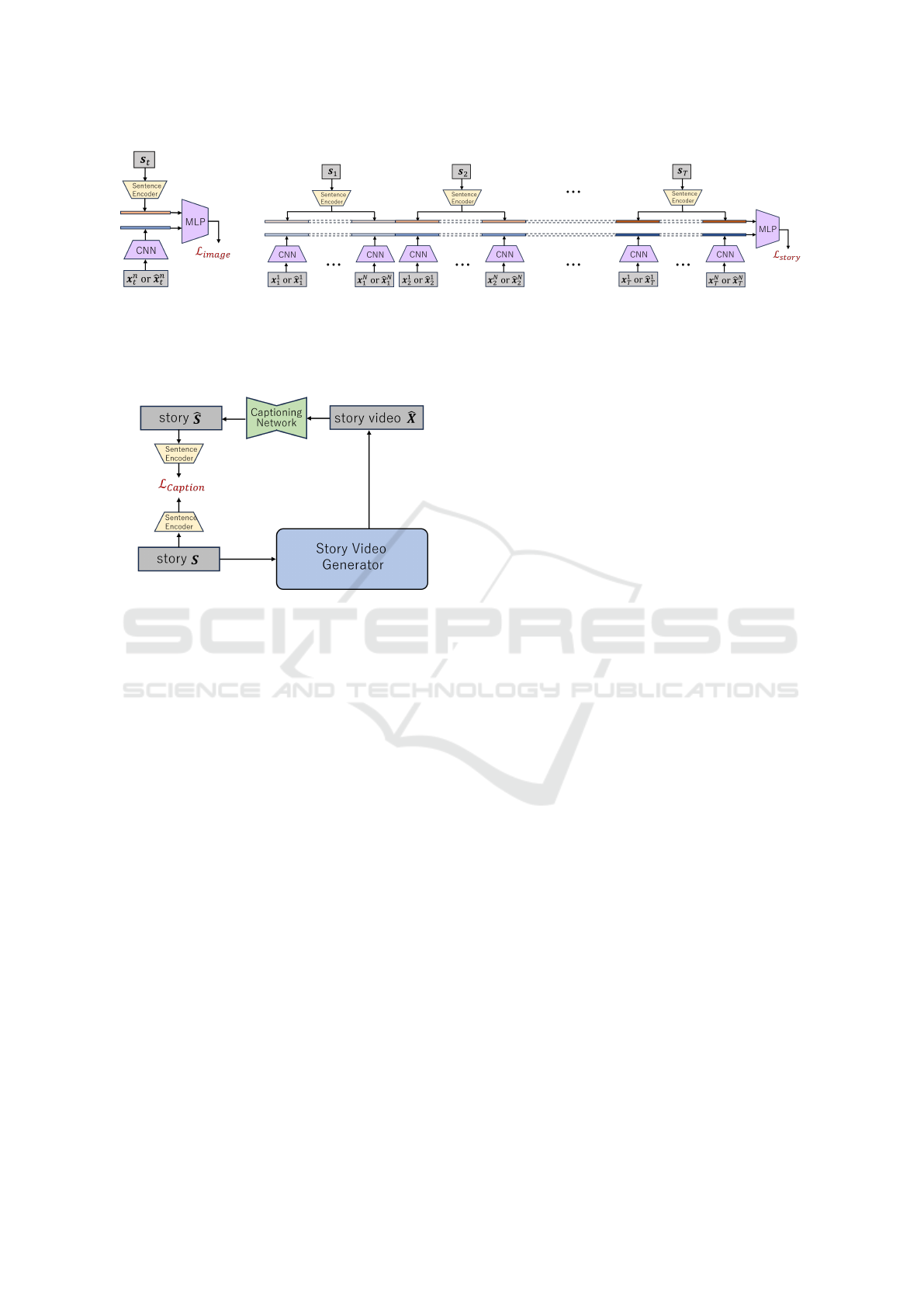
Figure 2: Network structure of the proposed method. Our story video generator consists of GRU, Text2Gist (T2G) and
convolutional image generator (G
I
). G
I
generates N frames of continuous images from each sentence s
t
. As a result, T × N
story video images are generated from T sentences. The image discriminator D
I
compares generated image ˆx
n
t
with sentence
s
t
, while the story video discriminator D
S
compares a set of T ×N images with a set of T sentences. Initial vector h
0
for T2G
is obtained from input story S by using story encoder proposed in (Li et al., 2019).
of images that adhere to specific conditions, has fur-
ther improved the capabilities of GANs (Isola et al.,
2017). Moreover, recent research is also advancing in
generating videos from text (Li et al., 2018). How-
ever, these GANs typically receive very short text in-
puts, often as short as a single sentence, and are not
capable of generating videos from longer texts, such
as stories composed of multiple sentences.
Research on text-based image generation has
made significant progress in recent years (Reed et al.,
2016; Ramesh et al., 2021; Rombach et al., 2022;
Ramesh et al., 2022). One major trend in im-
age generation from text is to combine well-trained
text encoders (Radford et al., 2021) with image
decoders (Jonathan Ho, 2020; Dosovitskiy et al.,
2021), and generate an image representing multi-
ple pieces of text. There has been significant tech-
nological progress in the field of image generation,
and nowadays we can generate quite good high-
resolution images which represent the content of mul-
tiple texts (Ramesh et al., 2021; Rombach et al.,
2022).
Another important task in the field of text-based
image generation is generating videos from text in-
formation (Li et al., 2018; Ho et al., 2022). In this
field, research has been conducted to generate short
videos representing a single sentence. However, un-
like generating a single image, generating a video is
a very difficult problem. For this reason, it has not
yet been possible to generate a long video represent-
ing a long text such as a novel. Thus, generating long
videos from long story sentences, such as novels is a
very challenging problem.
For visualizing long stories in multiple images, Li
et al. proposed StoryGAN (Li et al., 2019) which
generates multiple keyframe images from long story
sentences. In StoryGAN, the generator performs ad-
versarial learning with two discriminators, an image
discriminator and a story discriminator, and generates
a keyframe image from each sentence in the story. As
a result, it generates a set of keyframe images that
represent the long story. Furthermore, several im-
provements have been proposed based on this Sto-
ryGAN (Zeng et al., 2019; Li et al., 2020; Maha-
rana et al., 2021). Li et al. (Li et al., 2020) intro-
duced Weighted Activation Degree (WAD) for im-
proving the discriminator in StoryGAN. Maharana et
al. (Maharana et al., 2021) introduced a MART-based
transformer (Lei et al., 2020) to model the correlation
between the text and image in StoryGAN. They also
used video captioning to improve the quality of gen-
erated images.
However, in these methods, only a single
keyframe image is generated from each sentence, and
it is not possible to generate a video from each sen-
tence. Thus, generating long videos from long story
sentences is still a challenging problem.
3 GENERATING VIDEOS FROM
STORIES
3.1 Generating Videos from Multiple
Sentences
In this research, we aim to generate long videos
from stories composed of multiple sentences. Build-
ing upon StoryGAN (Li et al., 2019), we propose
a method for generating contextually aligned videos
VISAPP 2024 - 19th International Conference on Computer Vision Theory and Applications
672
(a) D
I
(b) D
S
Figure 3: Image discriminator (D
I
) and story video discriminator (D
S
). Story video discriminator identifies whether generated
entire video aligns with story sentences by comparing video vector obtained from T × N images [ ˆx
1
1
, ··· , ˆx
N
T
] through CNN
and story vector obtained from T sentences [s
1
, ··· , s
T
] by using sentence encoder (Cer et al., 2018). Image discriminator
evaluates each image and sentence in the same way.
Figure 4: Input story sentences S and sentences
ˆ
S obtained
by captioning the generated story video
ˆ
X are converted
into sentence vectors by sentence encoder (Cer et al., 2018),
and are used for computing caption loss L
caption
.
from stories with multiple sentences, where instead
of keyframes, we generate videos for each sentence.
In the following, we will refer to each individual sen-
tence as a ”sentence” and the collection of sentences
as a ”story.”
In this study, we utilize data where sentences are
paired with videos for GAN training. By inputting
multiple sentences from this dataset into the gener-
ator, we train it to generate videos corresponding to
each input sentence. By concatenating all the videos
generated from these sentences, we create a long
video representing the flow of the entire story.
The basic network structure of the proposed
method is shown in Figure 2. First, the story en-
coder converts an input story, S = [s
1
, s
2
, ·· · , s
T
],
consisting of T sentences into a low-dimensional ini-
tial vector h
0
. This is achieved by using the story
encoder proposed in StoryGAN (Li et al., 2019). Sub-
sequently, the generator generates T sequences of N
frames of videos ˆx
t
= [ ˆx
1
t
, ˆx
2
t
, ·· · , ˆx
N
t
] (t = 1, ·· · , T )
from this initial vector h
0
, each sentence s
t
and
noise ε. Then, the generated T videos are con-
catenated in sequence to form the final video
ˆ
X =
[ ˆx
1
, ˆx
2
, ·· · , ˆx
T
].
This generator was built by extending the genera-
tor proposed in StoryGAN (Li et al., 2019). In Sto-
ryGAN, the generator consists of a convolutional im-
age generator, GRU and Text2Gist, and generates a
single image ˆx
t
from a single sentence s
t
. In this re-
search, we also use a convolutional image generator,
GRU and Text2Gist, but we generate N frames of con-
tinuous images [ ˆx
1
, ·· · , ˆx
N
] from each sentence s
t
.
This is achieved by iteratively using a pair of GRU
and Text2Gist (T2G) N times inputting the same sen-
tence s
t
as shown in Figure 2. As a result, we generate
a total of T × N images from T sentences.
On the other hand, the discriminator receives gen-
erated videos ˆx
t
(t = 1, · ·· , T ) or ground truth videos
x
t
(t = 1, ··· , T ) corresponding to the sentences s
t
(t = 1, ·· · , T ) in the story S, and evaluate the authen-
ticity of the generated videos. We use two types of
discriminator, that is image discriminator and story
video discriminator. The image discriminator identi-
fies whether each frame image aligns with the corre-
sponding sentence, while the story video discrimina-
tor identifies whether the entire video aligns with the
story. The image discriminator D
I
compares an image
vector obtained from a generated image ˆx
n
t
through
CNN and a sentence vector obtained from a sentence
s
t
by using a sentence encoder (Cer et al., 2018),
while the story video discriminator D
S
compares a
video vector obtained from T × N images through
CNN and a story vector obtained from T sentences
by using the sentence encoder as shown in Figure 3.
The comparison of the image vector and the sentence
vector or the video vector and the story vector is con-
ducted by MLP with two layers. These two types of
discriminators enhance the accuracy of both the over-
all consistency of the video and the alignment with
the original sentences, improving the overall quality
of the generated story videos.
The story video generator G is trained by using the
image discriminator D
I
and the story video discrimi-
nator D
S
as follows:
G
∗
= argmin
G
max
D
I
,D
S
αL
image
+ βL
story
+ L
KL
(1)
Generating Videos from Stories Using Conditional GAN
673

Figure 5: Some of the characters in Pororo dataset.
where, L
image
represents the loss associated with the
image discriminator D
I
, while L
story
represents the
loss associated with the story video discriminator D
S
as follows:
L
image
=
T
∑
t=1
N
∑
n=1
logD
I
(x
n
t
, s
t
, h
0
)
+ log(1 − D
I
(G(ε
n
t
, s
t
), s
t
, h
0
)) (2)
L
story
= log D
S
(X, S)
+ log(1 − D
S
([[G(ε
n
t
, s
t
)]
N
n=1
]
T
t=1
, S))(3)
The story video discriminator D
S
discriminates
the ground truth story video X and the story video
ˆ
X = [[G(ε
n
t
, s
t
)]
N
n=1
]
T
t=1
generated by the generator G
from the noise ε
n
t
and the story s
t
.
Following StoryGAN (Li et al., 2019), we also use
the following KL divergence L
KL
between the stan-
dard Gaussian distribution and the learned distribu-
tion, which helps prevent mode collapse in the gener-
ation of the initial vector.
L
KL
= KL(N (µ(S), diag(σ
2
(S)))∥N (0, I )) (4)
where, µ(S) and σ
2
(S) are the mean and the variance
of initial vectors derived from input story S.
3.2 Improving Accuracy by Caption
Loss
Next, we will consider improving the accuracy of
video generation using video captioning. It is not
easy to quantitatively evaluate the appropriateness of
videos generated from text. One way to perform such
difficult evaluations is to input the generated video
into a well-trained captioning network to generate
sentences that represent the video and see how close
the generated sentences are to the original input sen-
tences.
Thus, in this research, we perform caption-
ing on the video
ˆ
X generated by the story video
generator using a trained video captioning net-
work (Vladimir Iashin, 2020), and compute the cap-
tion loss L
caption
by comparing the generated story
sentences
ˆ
S with the original input story sentences
S as shown in Fig. 4. The loss obtained in this way is
a measure of how well the generated video represents
the input sentence. Therefore, by adding this loss to
the network training, we can further improve the ac-
curacy of the generator.
Table 1: Cosine similarity between input sentences and sen-
tences obtained from generated videos.
proposed w/o caption loss
cos similarity (↑) 0.211 0.154
The similarity between the input story sentences
S and the sentences
ˆ
S obtained by captioning the
generated story video is evaluated by using the cosine
similarity between sentence vectors, v and ˆv, derived
from S and
ˆ
S by using the sentence encoder (Cer
et al., 2018). Therefore, the caption loss L
caption
is
defined as follows:
L
caption
= 1 − cos(v, ˆv) (5)
By adding this L
caption
to the network training as fol-
lows, the video generation accuracy of the generator
can be further improved:
G
∗
= argmin
G
max
D
I
,D
S
αL
image
+ βL
story
+γL
caption
+L
KL
(6)
4 DATASET
Since the proposed method generates videos from sto-
ries consisting of multiple sentences, a dataset con-
sisting of paired stories and videos is required. Thus,
in this research, we construct a dataset based on the
Pororo dataset (Kim et al., 2017), which consists of
short video clips and their description texts.
The Pororo dataset is an anime video dataset with
Pororo as the main character of the stories. Fig. 5
shows some of the characters in the story. The anime
video is divided into short video clips every few sec-
onds, and each short video clip is annotated with a
sentence. Therefore, the Pororo dataset consists of
pairs of short video clip and its description text. The
Pororo dataset consists of a series of episodes, so the
stories are connected in continuous data.
The story GAN and other related research use
Pororo-SV dataset (Li et al., 2019) which is created by
extracting a single image randomly from each short
video clip, so that the dataset consists of pairs of an
image and a sentence. On the other hand, in this re-
search, we need to train our network to generate N
images from each sentence. Thus, we extracted N
consecutive images from each video clip at equal in-
tervals and created pairs of N images and a sentence.
Since the stories are connected in continuous data, we
cut out T consecutive pairs of an image sequence and
a sentence as one set of story data. Therefore, one set
of data is composed of T ×N images and T sentences.
In this research, we set T = 5 and N = 10, and gen-
erated 2995 sets of data. Each story sentence in this
VISAPP 2024 - 19th International Conference on Computer Vision Theory and Applications
674

(a) story 1
(b) story 2
(c) story 3
Figure 6: Generated video images. Proposed method can generate a series of short videos from multiple sentences, while
StoryGAN can only generate a single keyframe image from each sentence and cannot visualize the motion of the characters
and scenes described in each sentence.
Generating Videos from Stories Using Conditional GAN
675

dataset was encoded into a fixed-length sentence vec-
tor using the Universal Sentence Encoder (Cer et al.,
2018).
5 EXPERIMENTS
We next show the results of some experiments on gen-
erating story videos from story sentences. We trained
our network for 120 epochs using 2500 sets of train-
ing data described in section 4. The trained network
was tested by using 495 sets of test data.
We first show video images generated from test
story sentences. Fig. 6 (a), (b) and (c) show three
different story sentences and video images generated
from our method. For comparison, we also show
the results from StoryGAN (Li et al., 2019) and our
method trained without using caption loss. As shown
in this figure, the proposed method can generate a se-
ries of short videos from multiple sentences, while
StoryGAN can only generate a single keyframe im-
age from each sentence and cannot visualize the mo-
tion of the characters and scenes described in the
sentence. We can also see that the characters men-
tioned in the sentences are properly generated in the
videos obtained from the proposed method. Compar-
ing methods with and without the caption loss, the
proposed method using the caption loss can generate
videos with larger changes, indicating that the gener-
ated videos have richer expressions.
To evaluate the accuracy of the generated videos
quantitatively, we captioned the generated video by
using the captioning network (Vladimir Iashin, 2020)
trained by using the Pororo dataset, and computed
the cosine similarity with the input sentence. Ta-
ble 1 shows the cosine similarity between the input
sentences and the sentences obtained from the gener-
ated videos. For comparison, we also show the co-
sine similarity when we do not use the caption loss in
our method. As shown in Table 1, the caption loss in
our method can improve the quality of the generated
videos.
6 CONCLUSION
In this paper, we proposed a method for generating
videos that represent stories described in multiple sen-
tences.
The existing methods of text-to-video can only
generate short videos from texts, and generating long
story videos from long story sentences is a challeng-
ing problem. We in this paper extended the Story-
GAN and showed that we can generate story videos
from story sentences. Furthermore, we showed that
by using the caption loss, we can further improve the
accuracy of generated story videos.
Our method replicated the human ability to imag-
ine and visualize the scenes described in the sen-
tence while reading a novel. On the other hand, a
large amount of experience is required to imagine rich
scenes from story sentences, so using the foundation
model may improve its ability to perform this task.
REFERENCES
Brock, A., Donahue, J., and Simonyan, K. (2019). Large
scale gan training for high fidelity natural image syn-
thesis. In Proc. ICLR.
Cer, D., Yang, Y., yi Kong, S., Hua, N., Limtiaco, N.,
John, R. S., Constant, N., Guajardo-Cespedes, M.,
Yuan, S., Tar, C., Sung, Y.-H., Strope, B., and
Kurzweil, R. (2018). Universal sentence encoder. In
arXiv:1803.11175.
Dosovitskiy, A., Beyer, L., Kolesnikov, A., Weissenborn,
D., Zhai, X., Unterthiner, T., Dehghani, M., Minderer,
M., Heigold, G., Gelly, S., Uszkoreit, J., and Houlsby,
N. (2021). An image is worth 16x16 words: Trans-
formers for image recognition at scale. In Proc, ICLR.
Goodfellow, I., Pouget-Abadie, J., Mirza, M., Xu, B.,
Warde-Farley, D., Ozair, S., Courville, A., and Ben-
gio, Y. (2014). Generative adversarial nets. In Proc.
Advances in neural information processing systems,
pages 2672–2680.
Ho, J., Salimans, T., Gritsenko, A., Chan, W., Norouzi, M.,
and Fleet, D. J. (2022). Video diffusion models. In
arXiv:2204.03458.
Isola, P., Zhu, J.-Y., Zhou, T., and Efros, A. A. (2017).
Image-to-image translation with conditional adversar-
ial networks. In Proc. IEEE Conference on Computer
Vision and Pattern Recognition, pages 1125–1134.
Jonathan Ho, Ajay Jain, P. A. (2020). Denoising diffusion
probabilistic models. In Proc. Conference on Neural
Information Processing Systems.
Kim, K., Heo, M., Choi, S., and Zhang, B. (2017). Deep-
story: video story qa by deep embedded memory net-
works. In Proc. of International Joint Conference on
Artificial Intelligence, page 2016–2022.
Lei, J., Wang, L., Shen, Y., Yu, D., Berg, T. L., and Bansal,
M. (2020). Mart: Memory-augmented recurrent trans-
former for coherent video paragraph captioning. In
arXiv:2005.05402.
Li, C., Kong, L., and Zhou, Z. (2020). Improved-
storygan for sequential images visualization. Journal
of Visual Communication and Image Representation,
73(102956).
Li, Y., Gan, Z., Shen, Y., Liu, J., Cheng, Y., Wu, Y., Carin,
L., Carlson, D., and Gao, J. (2019). Storygan: A se-
quential conditional gan for story visualization. In
Proc. of IEEE Conference on Computer Vision and
Pattern Recognition, pages 6329–6338.
VISAPP 2024 - 19th International Conference on Computer Vision Theory and Applications
676

Li, Y., Min, M. R., Shen, D., Carlson, D., and Carin, L.
(2018). Video generation from text. In Proc. AAAI
Conference on Artificial Intelligence.
Maharana, A., Hannan, D., and Bansal, M. (2021). Improv-
ing generation and evaluation of visual stories via se-
mantic consistency. In Proc. Conference of the North
American Chapter of the Association for Computa-
tional Linguistics: Human Language Technologies,
page 2427–2442.
Radford, A., Kim, J. W., Hallacy, C., Ramesh, A., Goh, G.,
Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark,
J., Krueger, G., and Sutskever, I. (2021). Learning
transferable visual models from natural language su-
pervision. In Proc. ICML.
Ramesh, A., Dhariwal, P., Nichol, A., Chu, C., and Chen,
M. (2022). Hierarchical text-conditional image gener-
ation with clip latents. In arXiv:2204.06125.
Ramesh, A., Pavlov, M., Goh, G., Gray, S., Voss, C., Rad-
ford, A., Chen, M., and Sutskever, I. (2021). Zero-shot
text-to-image generation. In arXiv:2102.12092.
Reed, S., Akata, Z., Yan, X., Logeswaran, L., Schiele, B.,
and Lee, H. (2016). Generative adversarial text to im-
age synthesis. In Proc. ICML.
Rombach, R., Blattmann, A., Lorenz, D., Esser, P., and Om-
mer, B. (2022). High-resolution image synthesis with
latent diffusion models. In Proc. IEEE Conference
on Computer Vision and Pattern Recognition, page
10684–10695.
Vladimir Iashin, E. R. (2020). A better use of audio-visual
cues: Dense video captioning with bi-modal trans-
former. In Proc. British Machine Vision Conference.
Zeng, G., Li, Z., and Zhang, Y. (2019). Pororogan: An im-
proved story visualization model on pororo-sv dataset.
In Proc. International Conference on Computer Sci-
ence and Artificial Intelligence, page 155–159.
Zhu, J., Park, T., Isola, P., and Efros, A. (2017). Unpaired
image-to-image translation using cycle-consistent ad-
versarial networks. In Proc. International Conference
on Computer Vision, pages 2223–2232.
Generating Videos from Stories Using Conditional GAN
677
