
An Alternative Way to Analyze and Predict Consonant Clusters
Productions in Brazilian Portuguese Phonological Assessments
Jo
˜
ao V
´
ıctor B. Marques
1 a
, Jo
˜
ao Carlos D. Lima
1 b
, M
´
arcia Keske-Soares
2 c
and Fabr
´
ıcio Andr
´
e Rubin
3 d
1
Centro de Tecnologia, Universidade Federal de Santa Maria, Santa Maria, Brazil
2
Centro de Ci
ˆ
encias da Sa
´
ude, Universidade Federal de Santa Maria, Santa Maria, Brazil
3
Petroleo Brasileiro S.A., Rio de Janeiro, Brazil
Keywords:
Inference Logic, Speech Therapy, Phonological Assessments Tools, Consonant Clusters, Predicting Phonetics.
Abstract:
To conduct phonological assessments in children, it is necessary to have a set of words that contains a repre-
sentative sample of adult vocabulary. One of the obstacles to obtain a minimal set is the need to include words
with various consonant clusters so that such complex phonetic structures can be validated. In the current liter-
ature, there is only one way to determine whether a child is capable of producing a consonant cluster: through
the application of a phonological assessment, which contains several words with diverse phonetic structures
to be evaluated. In this context, logical inferences are one of the fundamental pillars in any learning area,
as they establish logical connections between information to form knowledge about a specific subject. This
work proposes an alternative way to indirectly assess a child’s ability to produce consonant clusters, based on
their ability to articulate similar clusters. The proposed algorithm is fed with the consonant clusters produced
and not produced by the child during the assessment. The goal is to discern which other clusters the child
is capable or incapable of producing, using the separation of consonant clusters into simpler phonetic struc-
tures. The method was validated with a database containing over 1200 phonological assessments conducted
in school-age children, native speakers of Brazilian Portuguese. The accuracy of our approach was 97% with
12% false positives and 8% false negatives, indicating that the method is interesting and significantly faithful
to real-world results but still leaves room for future improvements. Nevertheless, it is believed that it can
be used to reduce the number of words needed in a phonological assessment, through indirect evaluation of
specific phonetic structures.
1 INTRODUCTION
In the context of speech therapy, phonological as-
sessments are conducted in school-age children to
identify the phonemes they can produce satisfactorily
and to detect possible phonological disorders (Usha
and Alex, 2023). However, this task demands time
from both the therapist and the child, often extend-
ing to approximately 1 to 1.5 hours (Combiths et al.,
2022), and the process is influenced by the number
of target words included in the assessment. In the
southern region of Brazil, where this work was con-
ducted, Brazilian Portuguese is used as the native lan-
a
https://orcid.org/0009-0007-3206-725X
b
https://orcid.org/0000-0001-9719-3205
c
https://orcid.org/0000-0002-5678-8429
d
https://orcid.org/0009-0009-5154-7843
guage, and there are different phonological assess-
ment tools in the country containing different sets of
words (Yavas et al., 2001; Savoldi et al., 2013; Ceron
et al., 2020). Each of these tools is adapted to the
regional context and incorporates words representing
familiar figures in children’s vocabulary (Sotero and
Pagliarin, 2018).
Despite advances in the field, traditional meth-
ods of phonological assessment still rely on pen-and-
paper approaches, lacking software-based solutions
(H
´
odi and T
´
oth, 2023). Such solutions are compatible
with speech therapy due to their audiovisual nature
(Uberti et al., 2022) and represent cost-effective alter-
natives to traditional methods (Usha and Alex, 2023).
Internationally, there is a growing effort to develop
computational solutions aimed at making this area of
pediatric speech therapy more efficient and accessi-
ble to society (R
¨
as
¨
anen et al., 2021; Str
¨
ombergsson
216
Marques, J., Lima, J., Keske-Soares, M. and Rubin, F.
An Alternative Way to Analyze and Predict Consonant Clusters Productions in Brazilian Portuguese Phonological Assessments.
DOI: 10.5220/0012555600003690
Paper published under CC license (CC BY-NC-ND 4.0)
In Proceedings of the 26th International Conference on Enterprise Information Systems (ICEIS 2024) - Volume 1, pages 216-223
ISBN: 978-989-758-692-7; ISSN: 2184-4992
Proceedings Copyright © 2024 by SCITEPRESS – Science and Technology Publications, Lda.

et al., 2022). However, it is noteworthy that these
solutions are often applied mainly for research pur-
poses and lack effective commercial implementation
(Uberti et al., 2020).
In the field of speech therapy, determining an in-
dividual’s ability to produce a phoneme requires that
the phoneme to be articulated correctly on at least
two occasions (Stoel-gammon, 1985). This require-
ment implies the need for equivalent words in phono-
logical assessment, i.e., words that possess the same
phonemes in the same positions. However, this ap-
proach contributes to an increased number of words
in the assessment (Marques. et al., 2023), resulting in
a potential redundancy in the evaluation of phonemes.
Thus, consonant clusters also represent a signifi-
cant challenge in the quest for a reduced set of words,
as assessing each consonant cluster demands the iden-
tification of two other words with the same occur-
rence. Additionally, it is important to note that conso-
nant clusters are complex linguistic structures, mak-
ing the task of finding words that not only share these
structures but also represent familiar elements in chil-
dren’s vocabulary non-trivial. This aspect adds an ad-
ditional layer of complexity to the lexical selection
process, highlighting the need for more refined strate-
gies in phonological assessments.
Therefore, this study aimed to computationally
analyze the set of 84 words proposed by (Ceron et al.,
2020) as the basis for a pediatric phonological assess-
ment tool. Our proposal introduces a computational
logic capable of inferring whether a child can produce
a consonant cluster “XY” through words that contain
at least a part of it, i.e., words with other similar con-
sonant clusters like “XW”, “ZY”, “QX” etc. This idea
is based on the hypothesis that if a child can produce
at least parts of consonant clusters, they can produce
the consonant clusters formed by those parts. Addi-
tionally, we applied the reverse logic to identify the
structures that the child would not be able to produce.
To validate our proposal, we used a database
containing over 1200 phonological assessments con-
ducted on 1357 school-age children (3–7 years old) in
the southern region of Brazil. Each assessment used
the set of 84 words from (Ceron et al., 2020), and all
words were verbalized by the children and transcribed
in the database by the speech therapist.
Our results indicate that analyzing consonant clus-
ters separately reduces the minimum number of words
needed to validate the phonemes the child can articu-
late. Furthermore, the reduction of words does not im-
pact the indication of phonological disorder observed
in the assessment, meaning the same conclusions can
be reached using fewer words.
Finally, our inference logic was validated, and we
observed that 97% of the inferred consonant clusters
that the child would be able to produce were indeed
produced by the child. Conversely, we obtained 12%
false positives, indicating that the child would be able
to produce more phonemes than they actually did.
Additionally, the negative predictive value was 74%,
suggesting that the reverse logic to identify consonant
clusters the child would not be able to produce still
has room for improvement in future work.
The structure of the paper is as follows. In Sec-
tion 2, we present the main concepts related to this
work. In Section 3, we detail our proposal, and in
Section 4, we present how the proposal was validated.
Finally, in Section 5, we conclude the paper with our
final considerations.
2 BACKGROUND AND CONTEXT
The study conducted by (Marques. et al., 2023)
revealed a notable overrepresentation of certain
phonemes in specific positions within the set pro-
posed by (Ceron et al., 2020). This implies that us-
ing this set in a phonological assessment tool may re-
sult in generating redundant data. In this scenario, the
speech therapist, when guiding the patient in produc-
ing a word, may at times be requesting the articula-
tion of phonemes that have already been previously
validated at least twice, a redundancy that could com-
promise the efficiency of the evaluation process (Mar-
ques. et al., 2023).
Through exploratory research, we found that there
is a collaborative effort between the fields of speech
therapy and information systems to develop tools that
assist in the identification and diagnosis of phono-
logical disorders (Jothi and Mamatha, 2020; Attwell
et al., 2022). The interest in telemedicine solutions
in speech therapy has also increased, especially after
the global outbreak of COVID-19 (Uberti et al., 2022;
Bahar et al., 2022; Patel et al., 2022; Gallant et al.,
2023). The use of computational tools in this field
is also attractive as they represent cost-effective solu-
tions compared to traditional methods of identifying
speech deficiencies and subsequent therapeutic mon-
itoring (Usha and Alex, 2023). However, the large
number of words in a comprehensive phonological as-
sessment complicates the screening process for cases
that truly require special attention.
Focusing on reducing the 84 words in the set pro-
posed by (Ceron et al., 2020), our work aims to pre-
dict the child’s ability to produce consonant clusters
based on their successes and errors. We introduce
a simplified method to verify which of these clus-
ters the child can or cannot produce, breaking down
An Alternative Way to Analyze and Predict Consonant Clusters Productions in Brazilian Portuguese Phonological Assessments
217

these complex phonetic structures into simpler units.
Then, by permuting these units to reconstruct com-
plex structures, we identify other consonant clusters
not yet assessed, suggesting the child’s ability to re-
produce them. Thus, it was possible to observe that in
97% of cases, if the child could produce the hypothet-
ical consonant clusters “XY” and “ZW”, they could
also reproduce the similar clusters “XW” and “ZY”.
This approach represents a perspective on evalu-
ating phonetic structures indirectly, substantially re-
ducing the need for a large number of words in a
phonological assessment. As advances in telepractice
in speech therapy continue to emerge (Chronopoulos
et al., 2021), similar approaches can even be used to
replace traditional methods of phoneme assessment,
since logical and statistical conclusions can be drawn
from the analysis of a limited set of data without com-
promising the quality of results.
2.1 Speech Therapy Concepts
In speech therapy, phonemes are analyzed in differ-
ent positions within the syllable and word (Armostis
et al., 2022). According to (Stoel-gammon, 1985), in
order to validate that a child is capable of articulating
a specific phoneme, it is necessary to assess them at
least twice. In the context of Brazilian Portuguese,
phonemes are evaluated in each of the following po-
sitions.
• (OI) Initial Onset: beginning of syllable, word be-
ginning - ca.sa [house];
• (OM) Medial Onset: beginning of syllable, mid-
dle of the word - ca.va.lo [horse];
• (CM) Medial Coda: end of syllable, middle of the
word - ca.dar.c¸o [shoelace];
• (CF) Final Coda: end of syllable, end of the word
- a.mor [love];
• (OCI) Initial Complex Onset: beginning of sylla-
ble, beginning of word - Bra.sil [Brasil];
• (OCM) Medial Complex Onset: beginning of syl-
lable, middle of the word - bi.blio.te.ca [library].
In this work, we are particularly interested in the
positions OCI and OCM as they indicate the presence
of consonant clusters. In Figure 1, it is emphasized
that the productions of the phonemes “br(OCI)” and
“br(OCM)” need to be differentiated, despite being
productions of the same cluster “br”. This is because
a child may find it easy to produce the cluster at the
beginning of words but may have difficulty of pro-
ducing it in the middle of words. Such differentiation
helps the speech therapist better identify the phono-
logical articulation skills of children and possible re-
lated deviations. To validate the assessment, we need
two more words that stimulate the production of these
same consonant clusters, or in the best-case scenario,
a word that simultaneously contains the same cluster
in both OCI and OCM. Thus, there is a tendency for a
significant increase in the number of words in an as-
sessment, stemming from the need to directly evaluate
consonant clusters.
a brirbra sil
OCI OCM
br
(OCM)
br
(OCI)
≠
Figure 1: Productions of the same consonant cluster in dif-
ferent positions are considered as different productions.
Thus, if we were able to apply a logic to infer an
individual’s ability to articulate a consonant cluster in
a specific position without the need for a direct assess-
ment, it would be possible to reduce the set of words
in the evaluation. This would lead to the exclusion
of words whose sole purpose is to encourage the pro-
duction of clusters that have already been indirectly
evaluated. Consequently, it would increase the effi-
ciency of the assessment by using fewer resources to
reach the same conclusions. This is the focal point of
our study.
3 INFERRING CONSONANT
CLUSTERS PRODUCTIONS BY
SPLITTING
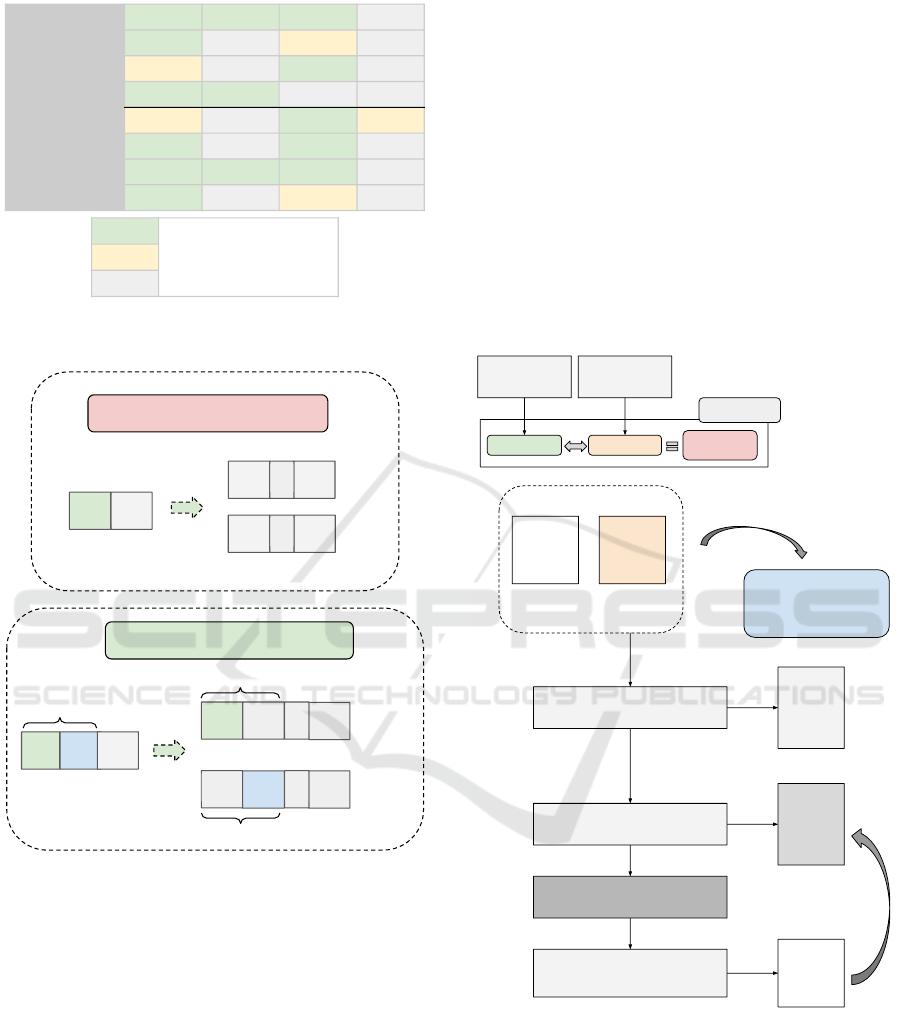
After analyzing the set from (Ceron et al., 2020) and
identifying all target phonemes, it was found that
there are 16 consonant clusters in the set. To ana-
lyze all of them at the word-initial position (OCI) and
word-medial position (OCM), we would need 2 oc-
currences for each phoneme, totaling 32 occurrences.
However, only 19 of these possibilities are evaluated
in the studied set, and of those, 14 are evaluated at
least 2 times, as shown in Figure 2. This indicates that
there would still be a shortage of words to adequately
evaluate all the consonant clusters in the set.
This work observed that the search for another
word with the same consonant cluster becomes eas-
ier when separating them into smaller phonetic struc-
tures, as shown in Figure 3. So, we start to break
the consonant clusters into smaller parts, instead of
analyzing them as they appear on the words, and we
observed that a inference logic could be applied.
ICEIS 2024 - 26th International Conference on Enterprise Information Systems
218
OCI
pɾ pl bɾ bl
tɾ tl dɾ dl
kɾ kl gɾ gl
fɾ fl vɾ vl
OCM
pɾ pl bɾ bl
tɾ tl dɾ dl
kɾ kl gɾ gl
fɾ fl vɾ vl
evaluated in 2 words
evaluated in just 1 word
not evaluated
Figure 2: All consonant clusters found in the set proposed
by (Ceron et al., 2020).
w1
w2
bra
sil
bl
k
OCI
b
r
OCI
…
vr
v
OCI
OCI
OM
OM
No word with the exact br(OCI)
w1
sil
v
2 words with b(OCI) + r(OCI)
b
l
OCI
OM
w2
k
v
OCI
…
…
…
r
Figure 3: Searching for words with the exact consonant
cluster vs searching for words with parts of the consonant
cluster.
3.1 Inferring Phonemes Capable of
Reproduce
Our approach introduces an inference logic capable of
predicting the consonant clusters that a child would be
able to produce based on the clusters that the child
has already produced at least once. This approach
analyzes each phoneme individually that constitutes
the consonant cluster, based on the premise that if the
child was able to articulate the clusters XY and ZW in
a specific position, then they are also capable of pro-
ducing XW and ZY in the same position. If this logic
holds true, it would be possible to test by inference
the other clusters highlighted in gray in Figure 2 with-
out the need to include more words in the assessment
solely for these clusters. Moreover, it would be pos-
sible to remove words from the assessment that serve
only to evaluate a consonant cluster that has already
been inferred that the child is capable of producing,
making the assessment shorter as it takes place.
We implemented a simple verification method
presented in Figure 4. It is important to note that we
validated only the inferences of the colored phonemes
presented in Figure 2, which are present in the tar-
get words. This is because it would not be possible
to validate inferences of phonemes that the child was
not stimulated to produce, as we would not have the
necessary basis for validation.
pɾ (OCI)
bɾ (OCI)
pl (OCI)
bl (OCI)
…
Child’s
Assessment
Compare with
the validation set
Combine all the parts to form
known consonant clusters
Split all consonant clusters
in small parts
Validation
pl (OCI)
vɾ (OCI)
…
p (OCI)
ɾ (OCI)
b (OCI)
l (OCI)
…
compare
Inferred Consonant Clusters
Expected Produced
Target Words
Not
Produced
Phonemes
Non Repeated List
By looking only to this
list, we can’t know which
clusters was actually in
the entry data
pɾ (OCI)
bɾ (OCI)
bl (OCI)
pl (OCI)
vɾ (OCI)
…
Produced Phonemes
Entry
Set
Validation
Set
Figure 4: Algorithm to infer consonant clusters that the
child is able to reproduce.
3.2 Inferring Phonemes not Capable of
Reproduce
In addition, we employ reverse logic to infer the con-
sonant clusters that the child would not be able to pro-
duce. This approach is based on the consonant clus-
ters that the child was unable to produce in the assess-
An Alternative Way to Analyze and Predict Consonant Clusters Productions in Brazilian Portuguese Phonological Assessments
219

ment, using the same strategy shown in Figure 4.
From here, we have the following analysis: for
each word in the assessment, we check which con-
sonant clusters were expected to be produced by the
child and what was actually produced; then, we add to
a list the parts of the consonant clusters that were not
reproduced. For example, if it was expected in a word
that the child would reproduce the cluster “br” but
they produced “bl”, making a substitution, then only
the “r” should be added to the list of non-reproduced
parts.
4 VALIDATION AND RESULTS
We introduced a method that involves analyzing con-
sonant clusters in smaller parts, allowing the inference
of which clusters the child would or would not be able
to produce based on these parts.
To validate whether our approach is consistent
with real-world results, we executed the method on
our database to verify if the observed results align
with real-world data. In total, 1294 phonological as-
sessments were analyzed, conducted with 1357 chil-
dren aged 3-7 years. In each assessment, children re-
produced the 84 words from the set of (Ceron et al.,
2020), and their transcriptions were stored in our
database by a speech therapy specialist. Finally, each
transcription was analyzed using the method shown in
Figure 4.
It was observed that 76% of the inferences made
are of clusters that the child would be able to pro-
duce, while only 24% are from the reverse logic. This
is explained by the fact that our database consists
of 82% correct transcriptions, which represents an
imbalance regarding incorrect cases. Consequently,
this reflects in the quantity of inferences of consonant
clusters that the child would not be able to produce, as
such inferences are primarily based on cases contain-
ing phonemes that the child was unable to produce,
which are present mostly in incorrect transcriptions.
The complete result is shown in Figure 5.
As shown in Figure 6, our method was able to
cover all possibilities to evaluate consonant clus-
ters in the phonological assessment of (Ceron et al.,
2020). This indicates that, by employing an inference
method like ours, we can indirectly evaluate other
phonemes without the need to expose the child to ad-
ditional words in the assessment, providing greater ef-
ficiency to the process.
Currently, our research group is working on a
digital platform for phonological assessments, which
should include functionalities such as obtaining the
child’s phonetic inventory – a list of all the phonemes
Real Classification
True False
Total Population 24974 19994 4980
Predicted Classification
True 19511 581
False 1586 4605
Accuracy 0,97
Negative Predictive Value 0,74
Sensibility 0,98
False Positive Rate 0,12
False Negative Rate 0,08
Specificity 0,92
Figure 5: Confusion Matrix of our logic of inference.
OCI
pɾ pl bɾ bl
tɾ tl dɾ dl
kɾ kl gɾ gl
fɾ fl vɾ vl
OCM
pɾ pl bɾ bl
tɾ tl dɾ dl
kɾ kl gɾ gl
fɾ fl vɾ vl
evaluated in 2 words
evaluated in just 1 word
not evaluated directly (but inferred)
Figure 6: All possible consonant clusters in Brazilian Por-
tuguese with inferred phonemes by our method.
they are able to articulate satisfactorily. Additionally,
the platform will also have a contrastive analysis mod-
ule, which aims to identify the contrasts between the
child’s speech and that of an adult, providing a report
on which phonemes the child struggles with the most.
We developed the method proposed in this study
with the assistance of speech therapy specialists from
our group, and we already received a partial positive
validation from them. However, this method will need
to be validated in-depth when the platform is released
to our research colleagues, who will test it and pro-
vide their feedback. This way, our method can be
validated in field and we can launch it to the gen-
eral public in the next months, after adjustments to
the platform containing the proposed method as part
of the system.
4.1 Analysis in Real Context
Finally, this subsection will present how the logic in-
troduced by this work can be applied in the real world
in phonological assessments.
In the algorithm proposed by (Marques. et al.,
2023), words were processed as they appeared in the
ICEIS 2024 - 26th International Conference on Enterprise Information Systems
220
set, without any specific criteria. The present study
analyzed how many words would be necessary in
the set of (Ceron et al., 2020) to evaluate the same
phonemes in the same positions by varying two crite-
ria:
• The order of evaluation of the words;
• Whether or not to separate consonant clusters.
Regarding the order of evaluation of the words,
the analysis occurred in two ways: first, analyzing
the easiest words to the most difficult, and then in re-
verse order. The degree of difficulty of the words was
directly related to the number of errors recorded for
each word in our database. In short, words with more
errors would be the most difficult words. Finally, we
applied a flag that would determine whether conso-
nant clusters would be evaluated separately or not to
determine the impact of the logic introduced by our
study.
It was observed that, when not separating conso-
nant clusters, the number of words needed to validate
the child’s phonetic inventory was higher, as shown
in the graph in Figure 7. This is because it is more
difficult to find an exact consonant cluster separately
than the combination of simple phonemes that form
the cluster. Thus, we can replace a direct production
with an inference, eliminating the need to evaluate
consonant clusters entirely, only their parts.
Finally, as the number of words was reduced,
we also assessed the impact of this reduction on the
indication of speech disorder, obtained through the
PCC-R (Percent of Consonants Correct-Revised) by
(Shriberg et al., 1997) shown in Equation 1. This in-
dex is widely used in the field of child speech therapy
as an indication of the level of phonological disorder
present in the child’s speech (McCabe et al., 2023;
Ceron et al., 2017), as shown in Table 1. The value
is calculated based on the number of correct produc-
tions of phonemes (PC) divided by the total number
of productions (TP), and them can be multiplied by
100 to have the percentage.
PCC-R =
PC
T P
× 100 (1)
Table 1: Indication of speech disorder according with PCC-
R value (Shriberg et al., 1997).
PCC-R Value Indication of Disorder
Less than 50% High
Between 50% e 65% Moderate-High
Between 65% e 85% Low-Moderate
Greater than 85% Low
We measured the PCC-R for each of the assess-
ments observed in this study using all 84 words, and
associated an indication of speech disorder according
to Table 1. This indicator was taken as the validation
base, since it uses all words of the original set. The
next step was to perform the same measurements, but
now using subsets of words obtained in each scenario
addressed earlier.
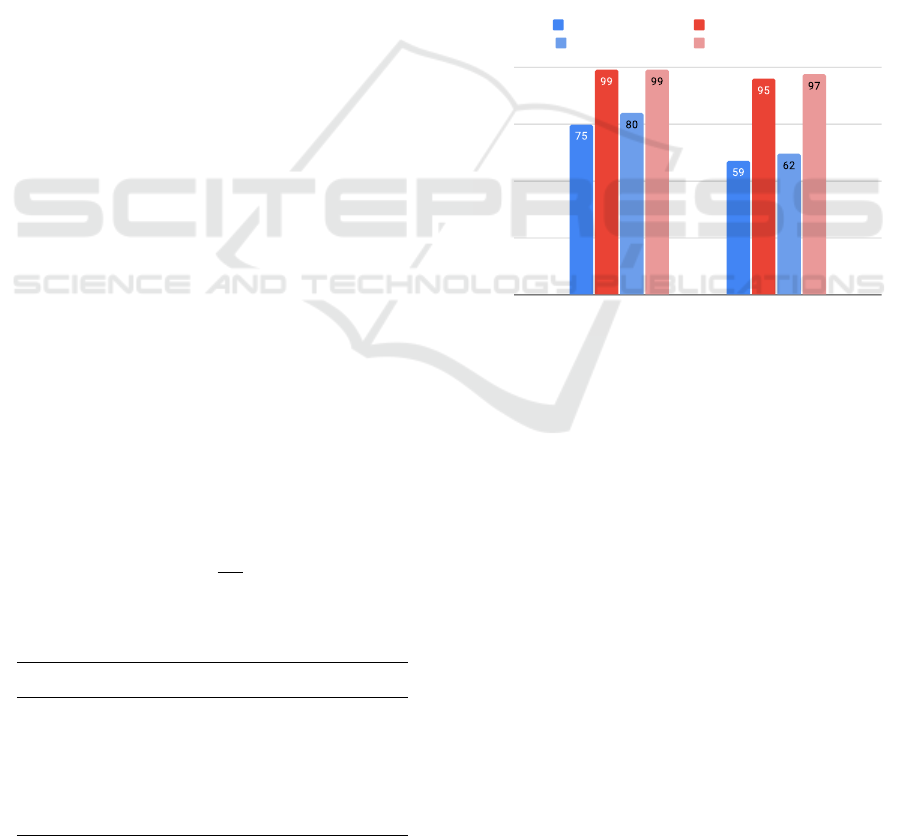
The result is shown in Figure 7. It was observed
that, by using the logic introduced by this study and
separating consonant clusters to reduce the number
of words in the assessment, there were no significant
changes in the accuracy of the indication of phono-
logical disorder compared to the original set. Further-
more, by not separating consonant clusters, the num-
ber of words needed in the subset slightly increases
without changing the accuracy, indicating an unnec-
essary amount in words.
0
25
50
75
100
Easiest First Hardest First
Qt Words [splitting] Precision [splitting]
Qt Words [no split] Precision [no split]
Figure 7: Number of words needed in the set and the re-
lationship with the accuracy in predicting the indication of
phonological disorder.
5 CONCLUSIONS
In this study, we introduced a method to infer a child’s
ability to produce consonant clusters based on their
ability to articulate similar clusters. In the literature,
computational methods have been applied in the field
of pediatric speech therapy. An example of this is
the paper of (Franciscatto et al., 2019), where exist-
ing phonological processes in a child’s speech were
predicted through audio analysis and the application
of machine learning. However, while this study is be-
ing writing, no evidence has been found linking the
ability to articulate consonant clusters with the ability
to articulate similar clusters.
We employed a logic based on breaking down
these complex phonetic structures into elementary
structures. Our logic is grounded in the premise that:
An Alternative Way to Analyze and Predict Consonant Clusters Productions in Brazilian Portuguese Phonological Assessments
221

“if a child can produce the consonant clusters XY and
ZW in a specific position, then they can also produce
XW and ZY in the same position”. The phonological
assessment model studied in this work consists of 84
words, a considerably high number for a 3–7 years old
child to verbalize in a speech therapy session. With
our method, we could eliminate words from phono-
logical assessments by inferring consonant clusters
that the child can produce indirectly.
To validate our approach, we analyzed 1294
phonological assessments conducted in Southern
Brazil. Each assessment contained the 84 words pro-
posed by (Ceron et al., 2020), which were verbalized
by the children and transcribed in our database by ex-
perts in the field. In each assessment, we obtained a
list of consonant clusters that the child produced and
that were present in the target words, which are the
clusters expected to be produced by the child during
the assessment. The list of clusters that the child did
not produce was also collected.
Finally, we reanalyzed each assessment with our
method, going through all transcriptions and breaking
down the consonant clusters that the child produced
and did not produce into smaller phonetic parts. At
the end of the analysis, our method was able to pre-
dict with 97% accuracy the articulation ability of the
inferred consonant clusters. However, our approach
had a false positive rate of 12% and a false negative
rate of 8%, indicating that the method predicts more
than ideal and still has room for improvements.
As future work, we will include adaptations to the
method to predict consonant clusters that the child
would not be able to produce, as the negative predic-
tive value was 74%, a value slightly low compared
with the general accuracy of the method. Addition-
ally, we believe that there is potential to apply the
same logic to predict other types of phonemes in the
language, based on their similarity and position in
words.
In conclusion, our approach introduces a fast way
to infer the child’s capability of producing consonant
clusters, eliminating the need for more words in the
phonological assessment tool. By proposing a new
set of target words for an assessment, our method can
be used to discard the need to directly evaluate cer-
tain consonant clusters in the language. This also re-
duces the assessment time and subsequent report fill-
ing by the speech therapist, as fewer words would be
needed in the analysis. Thus, the assessment used
by speech therapists would become more efficient,
achieving equally reliable results with less effort.
REFERENCES
Armostis, S., Petinou, K., and Kyprianou, A. (2022). The
implementation of the ‘testing of phonological skills
(tops)’ tool: a computer-based phonological analysis
algorithm. Clinical Linguistics & Phonetics, 0(0):1–
20.
Attwell, G. A., Bennin, K. E., and Tekinerdogan, B. (2022).
A systematic review of online speech therapy systems
for intervention in childhood speech communication
disorders. Sensors, 22(24).
Bahar, N., Namasivayam, A. K., and van Lieshout, P.
(2022). Telehealth intervention and childhood apraxia
of speech: a scoping review. Speech, Language and
Hearing, 25(4):450 – 462.
Ceron, M. I., Gubiani, M. B., Oliveira, C. R. d., and Keske-
Soares, M. (2017). Factors influencing consonant ac-
quisition in brazilian portuguese–speaking children.
Journal of Speech, Language, and Hearing Research,
60(4):759–771.
Ceron, M. I., Gubiani, M. B., Oliveira, C. R. d., and Keske-
Soares, M. (2020). Phonological assessment instru-
ment (infono): A pilot study. CoDAS, 32(4).
Chronopoulos, S. K., Kosma, E. I., Peppas, K. P., Tafiadis,
D., Drosos, K., Ziavra, N., and Toki, E. I. (2021).
Exploring the speech language therapy through infor-
mation communication technologies, machine learn-
ing and neural networks. In 2021 5th International
Symposium on Multidisciplinary Studies and Innova-
tive Technologies (ISMSIT), pages 193–198.
Combiths, P., Amberg, R., Hedlund, G., Rose, Y., and Bar-
low, J. A. (2022). Automated phonological analysis
and treatment target selection using autopatt. Clini-
cal Linguistics & Phonetics, 36(2-3):203–218. PMID:
34085574.
Franciscatto, M. H., Lima, J. a. C. D., Trois, C., Maran,
V., Soares, M. K., and Rocha, C. C. d. (2019). A
case-based approach using phonological knowledge
for identifying error patterns in children’s speech. In
Proceedings of the 34th ACM/SIGAPP Symposium on
Applied Computing, SAC ’19, page 968–975, New
York, NY, USA. Association for Computing Machin-
ery.
Gallant, A., Watermeyer, J., and Sawasawa, C. (2023). Ex-
periences of south african speech-language therapists
providing telepractice during the covid-19 pandemic:
A qualitative survey. International journal of lan-
guage & communication disorders, 58.
H
´
odi, A. and T
´
oth, E. (2023). Exploring the opportuni-
ties for online assessment of phonological awareness
at the beginning of schooling. International Journal
of Early Childhood, pages 1–20.
Jothi, K. R. and Mamatha, V. L. (2020). A systematic re-
view of machine learning based automatic speech as-
sessment system to evaluate speech impairment. In
2020 3rd International Conference on Intelligent Sus-
tainable Systems (ICISS), pages 175–185.
Marques., J., Lima., J., Keske-Soares., M., Rocha., C., Ru-
bin., F., and Miollo., R. (2023). Algorithm for select-
ing words to compose phonological assessments. In
ICEIS 2024 - 26th International Conference on Enterprise Information Systems
222

Proceedings of the 25th International Conference on
Enterprise Information Systems - Volume 1: ICEIS,,
pages 80–88. INSTICC, SciTePress.
McCabe, P., Preston, J. L., Evans, P., and Heard, R. (2023).
A pilot randomized control trial of motor-based treat-
ments for childhood apraxia of speech: Rapid sylla-
ble transition treatment and ultrasound biofeedback.
American Journal of Speech-Language Pathology,
32(2):629–644.
Patel, R., Loraine, E., and Gr
´
eaux, M. (2022). Impact of
covid-19 on digital practice in uk paediatric speech
and language therapy and implications for the future:
A national survey. International Journal of Language
& Communication Disorders, 57(5):1112–1129.
R
¨
as
¨
anen, O., Seshadri, S., Lavechin, M., Cristia, A., and
Casillas, M. (2021). Alice: An open-source tool
for automatic measurement of phoneme, syllable, and
word counts from child-centered daylong recordings.
Behavior Research Methods, 53:818–835.
Savoldi, A., Ceron, M. I., and Keske-Soares, M. (2013).
What are the best words to compose an evaluation
phonological instrument? Audiology-Communication
Research, 18(3):194–202.
Shriberg, L. D. et al. (1997). The speech disorders classi-
fication system (sdcs). Journal of Speech, Language
and Hearing Research, 40(4):723–740.
Sotero, L. K. B. and Pagliarin, K. C. (2018). The use of
software in cases of speech sound disorders. CoDAS,
30(6).
Stoel-gammon, C. (1985). Phonetic inventories, 15–24
months. Journal of Speech, Language, and Hearing
Research, 28(4):505–512.
Str
¨
ombergsson, S., G
¨
otze, J., Edlund, J., and Bj
¨
orkenstam,
K. N. (2022). Simulating speech error patterns across
languages and different datasets. Language and
Speech, 65:105–142.
Uberti, L., Rodrigues Portalete, C., Pagliarin, K., and
Keske-Soares, M. (2020). Speech articulation assess-
ment tools: a systematic review. Journal of Speech
Sciences, 8(1):01–35.
Uberti, L. B., da Motta Forneck, L. L., Keske-Soares, M.,
and Pagliarin, K. C. (2022). How do speech-language
pathologists assess speech production through tele-
health? Audiology - Communication Research, 27.
Usha, G. P. and Alex, J. S. R. (2023). Speech assessment
tool methods for speech impaired children: a system-
atic literature review on the state-of-the-art in speech
impairment analysis.
Yavas, M., Hernandorena, C., and Lamprecht, R. (2001).
Avaliac¸
˜
ao fonol
´
ogica da crianc¸a: reeducac¸
˜
ao e ter-
apia. Biblioteca Artmed. Fonoaudiologia. Artmed Ed-
itora.
An Alternative Way to Analyze and Predict Consonant Clusters Productions in Brazilian Portuguese Phonological Assessments
223
