
Exploring Multimodal Interactions with a Robot Assistant in an
Assembly Task: A Human-Centered Design Approach
Simona D’Attanasio
a
, Théo Alabert, Clara Francis and Anna Studzinska
b
Icam School of Engineering, Toulouse Campus, 75 av. de Grande Bretagne, CS 97615, 31076 Toulouse Cedex 3, France
Keywords: Human-Robot Interaction, Multimodality, Human-Centered Design, Bidirectional Interaction, Robot Assistant.
Abstract: The rise of collaborative robots, or cobots, has opened up opportunities for shared operations between humans
and robots. However, the transition to true human-robot collaboration faces challenges depending on the
context and on the implemented interactions. This article aims to contribute to the evolving field of Human-
Robot Interaction by addressing practical challenges in real-world scenarios and proposing a comprehensive
approach to bidirectional communication between humans and robots. In particular, our research focuses on
an elemental operation during an assembly task, observed in real SMEs (Small and Medium Sized Enterprises).
We propose a multimodal bidirectional approach incorporating voice, gesture, visual, haptic, and feedback
cues. The study involves a Wizard of Oz series of experiments with test subjects to evaluate user satisfaction,
and the overall feeling of interaction, among other aspects. Preliminary analysis supports hypotheses related
to the effectiveness of multimodality, the positive reception of simple interactions, and the impact of feedback
on user experience.
1 INTRODUCTION
Collaborative robotics is spreading thanks to the
availability of collaborative robots, also known as
cobots. Those robots are designed to safely operate
alongside humans in a shared workspace. In the
industrial environment, the cobot manipulators
available today allow SMEs (Small and Medium
Sized Enterprises) to implement robotics, offering
flexible solutions and reducing the integration costs.
Cobots are in fact easily reprogrammable by an
operator by means of an intuitive programming
interface. Depending on the application, the
installation of physical barriers can be avoided and
cobots can be moved from one place to another.
These factors make it possible to adapt them to small
batch sizes and facilitate their integration, which are
both important constraints for SMEs. In addition,
cobots integrate force sensing technology that
evaluate and limit the force exerted by the robot. This
allows as already mentioned the sharing of the
working space (coexistence), but also the execution
of a whole new set of operations where robots and
humans can work together, not only interacting one
a
https://orcid.org/0000-0002-8595-836X
b
https://orcid.org/0000-0002-7694-4214
next to the other (cooperation), but also jointly on the
same task (collaboration).
Even if the technology is available to create
interactions with cobots, few real industrial
applications exist that accomplish a real human-robot
collaboration (Kopp et al., 2020; Michaelis et al.,
2020). Since the introduction of robot manipulators in
manufacturing, there has been a clear physical
separation by design between robots and humans and
consequently between tasks allocated to each of them:
automated tasks are for robots and manual operations
are for humans. Many processes are not designed to
be collaborative and applications of cobots are mainly
limited to automation solutions, as if they were (not
collaborative) robots, exploiting only the advantages
mentioned above: ease of programming and
flexibility in the installation process. According to
(Michaelis et al., 2020), cobot applications should be
seen from a worker perspective. Therefore, as stated
by the authors, the design of cobots needs to be
reframed “to be viewed as augmented supports for
human worker activity with an on-board capacity for
responding to human action and intent”. (Kopp et al.,
2020) state that the worker perception of a robot as a
D’Attanasio, S., Alabert, T., Francis, C. and Studzinska, A.
Exploring Multimodal Interactions with a Robot Assistant in an Assembly Task: A Human-Centered Design Approach.
DOI: 10.5220/0012570800003660
Paper published under CC license (CC BY-NC-ND 4.0)
In Proceedings of the 19th International Joint Conference on Computer Vision, Imaging and Computer Graphics Theory and Applications (VISIGRAPP 2024) - Volume 1: GRAPP, HUCAPP
and IVAPP, pages 549-556
ISBN: 978-989-758-679-8; ISSN: 2184-4321
Proceedings Copyright © 2024 by SCITEPRESS – Science and Technology Publications, Lda.
549

trustworthy (affective) supporting device is also
considered to be an important factor, which heavily
influences acceptance.
Following similar guidelines, industry 5.0 pushes
towards a human-centered approach of industrial
processes (Adel, 2022) and in particular towards
human-robot coworking requiring human-robot
interaction (HRI) (Alves et al., 2023), where personal
preferences, psychological issues and social
implications among other factors should be
considered during the design (Demir et al., 2019).
In this context, HRI plays a key role in the
accomplishment of a truly collaborative task. The
following paragraph proposes related works in the
area.
1.1 Related Works
The state of the art is full of very interesting research
in the field of HRI. (Kalinowska, 2023) and (Strazdas
et al., 2022) propose an exhaustive description of the
available modalities, such as gesture, vocal, haptic,
vibrotactile, augmented or virtual reality feedback,
eye tracking, and many more.
In HRI, multimodality is often implemented to
obtain a more effective interaction. As an example,
the use of a haptic device is explored by (Alegre Luna
et al., 2023) which illustrates the development of a
glove for a robot assisting a surgeon, integrating an
accelerometer to recognize gestures. The system also
integrates the possibility to control a robot with vocal
commands using predefined words, each
corresponding to a specific action. Another glove is
tested by (Rautiainen et al., 2022) also for gestural
analysis. The Data Glove is studied in (Clemente,
2017): force and vibration feedbacks are provided to
control a robot hand with the assistance of AR
(Augmented Reality) in a clinical scenario. Real time
eye tracking is performed with glasses in the research
conducted by (Penkov et al., 2017). In this
experience, an operator is wearing AR glasses with an
eye tracking device and a camera. The goal is to
achieve a “natural exchange” with the robot, in the
sense that the robot will detect which tool the human
needs. Also, the robot knows the plan that the
operator is executing, so it can anticipate which tool
will be needed. More recently, (Villani, 2023)
proposes wrist vibration feedback together with light
feedback. The challenge is the recognition of
vibration patterns and tests are carried out in a
simulated industrial environment to perform a
collaborative assembly task. In a study by (Male and
Martinez Hernandez, 2021), a cobot collaborates with
a human in an assembly task by proving the
components needed at the right moment, without
having to explicitly ask for them. The collaborative
actions are predicted by an AI-based cognitive
architecture, using inertial measurements to estimate
human movements and a camera for environment
perception.
Overall, the state of the art shows a big variety of
methods and devices and some general conclusions
can be drawn with respect to two main issues. The
first one is the context issue. Few studies propose an
experimental set-up related to a real use-case. Most of
them are proof of concepts tested in the laboratory
environment, that don’t always consider all the
constraints of a real working environment, such as
noise or vision related problems (obstruction,
lightning conditions). This means that although
human-centered design should be at the very core of
HRI research, efforts still need to be made to consider
user needs and psychology. Moreover, the
experimental set-ups often concern the execution of a
predefined sequence of steps to which the robot can
contribute in more or less intelligent way.
The second one is the interaction issue. Even if
the integration of technology to foster bidirectional
communication between a robot (or an agent in
general) and a human, to “improve mutual
understanding and enable effective task
coordination” (Marathe, 2018) is studied, research is
more focused on the robot’s ability to understand the
human (Wright et al., 2022). Multimodality is often
implemented, but the number of patterns and
modality can rapidly add complexity to the
interaction and, paradoxically, end up contributing to
the human workload. Moreover, interactions between
the human and the robot are rarely designed to
explicitly manage failure (errors of the robot) and
misunderstanding.
1.2 Research Objectives
The research proposed in this article by a team of
engineers and of psychologists aims to improve the
understanding concerning the above two issues, by
designing a multimodal bidirectional interaction for
an elementary operation in an assembly task.
To explore the context issue, we consider the
operation “bring me that / put it away” without
referring to a particular sequence of operations. We
carried out informal observations in two SMEs, a
manufacturing plant and a cabinetmaker, and found
that workers spent a significant proportion of their
time looking for tools and other materials. It is
difficult to produce a proper quantified analysis and
no data could be found in the literature, but they move
HUCAPP 2024 - 8th International Conference on Human Computer Interaction Theory and Applications
550
several times per hour, depending on the particular
task. In the case of the cabinetmaker, the task is
always different. The idea is to explore the added
value of the assistance from a robot in an elementary
operation that is widely applicable in any SME
context and type, as well in a variety of service
environments (e.g. medical, or assistance in general).
To explore the interaction issue, we made the
choice of testing multimodal bidirectional interaction
implementing simplified patterns providing:
- Voice control through a limited set of words,
perceived as a natural way of communicating,
especially useful when hands are not free.
- Simple gesture control through a laser
pointing device, to offer an alternative to
voice control failures, due to noisy
environment or to difficulty of the available
technology in recognizing accents.
- Control through a tactile device, to provide a
well known, smartphone-like interaction
device.
- Haptic feedback through vibration, to prevent
the operator that the robot is approaching.
- Visual feedback through a moving light spot,
to visualize the robot’s understanding of the
instruction.
- Simple visual feedback of the robot state
(happy/unhappy) to communicate to the
operator the understanding by the robot of the
instruction.
A Wizard of Oz (WoZ) series of tests have been
designed (scenario and test protocol) and conducted
on a set of trial users, also called test subjects in the
paper. Feedbacks from the users have been collected
and a preliminary analysis has been performed. The
hypotheses that we test with our research are the
following:
- Multimodality contributes to higher
satisfaction and lower frustration in
accomplishing the task.
- Simple interaction is positively and not
poorly considered.
- Feedbacks and error recovery improve the
“feeling of interaction” and thus the user
experience.
The rest of the paper is organized as follows. The
next section presents in details the experimental set-
up: the implemented interactions, the scenario, and
the test protocol. The Results and Discussion section
presents the preliminary analysis of the user’s
feedbacks. The Conclusion section concludes the
paper illustrating the next steps of our research.
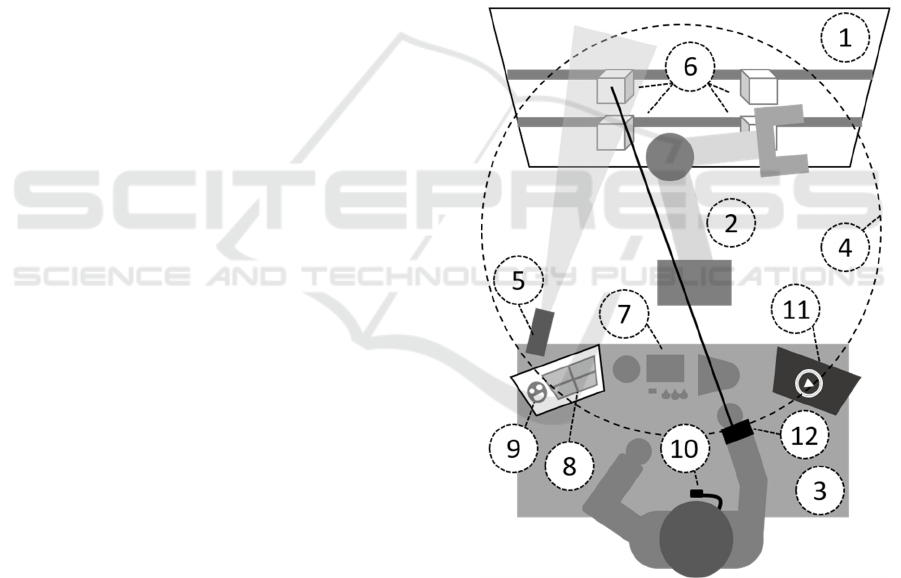
2 EXPERIMENTAL SET-UP
The experimental set-up, shown in the diagram of
Figure 1, proposes to carry out an assembly operation
with the help of a robot assistant, whose task is to
bring and put away the tools needed for the assembly.
The robot is a UR5 cobot from Universal Robots, a 6
degrees-of-freedom industrial manipulator having a
reach radius of 850mm and a payload of up to 5Kg.
Tools are stored on a vertical wall out of reach of the
human within plastic boxes, while the robot’s
workspace covers the wall and part of the assembly
table, allowing the human to reach the robot’s end-
effector. The implemented interactions allow
bidirectional communication between the robot and
the human. The scenario is controlled by human WoZ
operators. The interactions, the scenarios and the test
protocol are detailed in the following paragraphs.
Figure 1: The diagram of the experimental set-up showing
the following components: 1) vertical wall, 2) UR5, 3)
assembly table, 4) robot workspace, 5) light spot, 6) tool
boxes, 7) material for the assembly, 8) touch screen, 9)
robot state, 10) tie microphone, 11) video with the assembly
instructions, 12) wristband with laser pointer and vibration
motor.
Exploring Multimodal Interactions with a Robot Assistant in an Assembly Task: A Human-Centered Design Approach
551

2.1 The Interactions
The interactions implemented in the experimental set-
up are summarized in Table 1 and are described
hereafter.
Table 1: List of the interactions with the corresponding
technologies. The table is divided into 2 sections: the
control commands from human to robot in the upper part;
the feedbacks from the robot to the human in the lower part.
Interaction type Technology
From human to robot (control)
Voice A tie microphone connected
to 2 Picovoice AI en
g
ines
Gesture Laser pointe
r
Visual Touch screen
From robot to human (feedback)
Ha
p
tic Vibration moto
r
Visual Movin
g
li
g
ht s
p
ot
Visual Robot state images on a
screen
2.1.1 From Human to Robot (Control)
The voice control is implemented using Picovoice, an
end-to-end voice AI (Artificial Intelligence) powered
platform. Two engines of the platform are used: the
Porcupine wake word and the Rhino speech-to-intent.
The first one allows the voice control to be started
using the wake words “U R five”. The second one
infers user intents from utterances. Table 2
summarize the intents that have been used to train the
AI model. The voice control allows the control of the
robot assistant.
Table 2: The following table illustrates the intents that are
coded in Rhino speech-to-intent engine. Each intent is an
expression made of several slot words and macros that form
phrases. The addition of words like “the”, “a”, “an” in the
phrase is possible. As an example, the phrase “Bring the
scissors” is recognized as a valid intent. Each macro can
contain synonyms that are equally processed. All the words
are translations of the original French words.
M
acros
(
s
y
non
y
ms
)
Slot Tools
Bring me (the)
Bring (the)
Get me (the)
Get (the)
Screwdriver
Small key
Big key
Scissors
Put back (the)
Put away (the)
Slot Answe
r
Slot Corrections
No
Right
Left
Up
Down
Yes
The gesture control is a laser pointer integrated
into a wristband, illustrated in Figure 2, that was
custom-made using a 3D printer. The laser is
constantly switched on during the test. By pointing
the laser at a tool on the wall, the human asks the
robot to pick the tool.
Figure 2: A picture of the wristband integrating the
vibration motor and the laser pointer.
Figure 3: A picture of the touch screen and of the wall
where tools are stored. The division in 4 areas is highlighted
by the dotted yellow lines. The buttons on the screen are
positioned in the same way. A fifth button allows to put
away the tool.
The visual control consists of a touch screen
displaying four buttons, allowing to select a
corresponding area where a tool is stored. The
position of the button corresponds visually to the area
where the tool is stored, as shown in Figure 3. The
HUCAPP 2024 - 8th International Conference on Human Computer Interaction Theory and Applications
552

effect of the touch screen on the robot is the same as
that of the laser pointer.
2.1.2 From Robot to Human (Feedback)
The haptic feedback consists of a 3V mini-vibration
motor of 1cm diameter integrated in the same
wristband containing the laser pointer. It is activated
manually by a WoZ operator as the robot approach
the half of the workspace in the test subject’s
direction.
The visual feedback consists of a light spot that
points towards the tool selected by the test subject.
This feedback allows the human to correct the
command in case of misunderstanding of the robot.
For the experimental the spot is manually controlled
by the WoZ operator.
The second visual feedback consists of a smiley
that appears on the same screen used for touch
control. Two types of smileys are available: happy
and unhappy. The happy smiley is displayed when the
spot points to the right tool if the human answer is
“yes” or when a voice intention is recognized. The
unhappy smiley is displayed when the spot points to
the wrong tool or when the voice control is
unsuccessful. This feedback is controlled by a WoZ
operator.
2.2 The Scenario
The complete scenario consists of performing an
assembly operation that needs four different sets of
tools and consists of 5 steps, with a total duration of
about 15 minutes. The step sequence is shown on a
video displayed on a screen on the assembly table.
The test subjects can pause the video and perform any
step at their own rhythm. The material for the
assembly is available on the same table. Only the
tools are stored on the vertical wall in front of the
subject. The robot is installed between the table and
the wall. The scenario layout is illustrated in Figure 4
and in Figure 5. Two WoZ operators are hidden from
the test subject that sits on a chair in front of the
assembly table in an isolated environment (without
other people).
A WoZ operator receives the Picovoice output
and the touch screen selection and executes the
corresponding robot movement through the teaching
pendant. For this experimental set-up, it is important
to use a real voice control interaction to be as close as
possible to actual conditions of use. The WoZ
operator, that has a view of the vertical wall, can also
control the robot following the laser pointer, as well
as the robot state on the touch screen. A second WoZ
operator controls the light spot and the vibration
motor. All the robot movements are pre-recorded and
executed at reduced speed for safety reasons. In fact,
we don’t take speed into account at this stage of the
research because we considered that this aspect is not
a priority.
Figure 4: A diagram of the scenario showing the position of
the two WoZ operators (in black in the diagram).
Figure 5: A picture of the scenario layout taken from above.
2.3 The Test Protocol
The study subject group was composed of N=20
students and employees of an engineering school (10
female and 10 male test subjects, including 13
students and 7 employees, as shown in Table 3).
Nobody knew about the experiment in advance.
They were all confident with technology and have
already seen an industrial robot in action. During the
second half of the assembly operation, a sound of
people’s voices was produced on a loudspeaker to
simulate a noisy environment disturbing voice
control. At the end of the assembly operation, the
subjects filled out a questionnaire inspired by the
System Usability Scale (Brooke, 1995) and the USE
Exploring Multimodal Interactions with a Robot Assistant in an Assembly Task: A Human-Centered Design Approach
553

Usefulness, Satisfaction and Ease (Lund, 2001). The
questionnaire is composed of 27 questions divided
into 5 parts to evaluate the usability, the ease of use,
ease of learning, global satisfaction, and
multimodality interactions (intuitiveness and
usefulness). Each item is evaluated on a 5-point
Likert scale ranging from 1 (strongly disagree) to 5
(strongly agree). Each subject could comment freely
on the interaction.
Table 3: The following table shows the age distribution of
all the test subjects to the experiment. It is divided into two
sections: the students and the employees. Each section is
divided into two further sections: male (M) and female (F).
Age categories
(years old)
Students Employees
M
F
M
F
21-25 6 7 -
31-35 - 3 1
51-55 - 0 1
61-65 - 1 1
3 PRELIMINARY RESULTS AND
DISCUSSION
Tables 4 and 5 show the mean scores of the questions
of the questionnaire.
The assistant robot was positively evaluated. The
highest scores are recorded for the items in the ease
of learning category, confirming the low workload
associated with the use of the interactions. The lowest
score concerns the perception of the need of the
assistant robot, while its usefulness has a fair score of
3,1. We think that a reason for the score is that the
proposed assembly operation is too simple, as there
are too few tools and assembly steps to manage and it
is hard to justify the use of a robot in this context. This
hypothesis is confirmed by some free comments
made by the test subjects. Moreover, although
assembly time was not measured, the subjects had to
wait for the robot to make the movements and found
this waiting time annoying.
Concerning interaction modalities, most subjects
preferred screen-related modalities: the touch screen
was often preferred to the laser pointer as an
alternative control modality to voice command in the
event of failure; feedback on the robot’s state was
judged to be clearer than other feedback modalities.
Nevertheless, we believe that the advantage of using
an alternative to the screen could be better perceived
in a more realistic dynamic working configuration,
where there is no space on the assembly table to
install a screen. From direct observation, we noticed
that voice control was always the first choice for
Table 4: The following table shows the mean scores of the
15 questions of the questionnaire aiming to evaluate
usability, ease of use, ease of learning, and global
satisfaction. For each part, the overall mean value is
calculated.
Question
Mean
s
core
Utility
I save time by using the multimodal
interface
3,3
The system is useful for assembly wor
k
3,1
The robot and its multimodal interface
corres
p
ond exactl
y
to m
y
needs
3,2
The feedback is useful 3,9
Overall score for utility 3,3
Ease of use
The s
y
stem is intuitive to use 4,3
I need little effort to use the s
y
stem 4,3
There are no inconsistencies in use 4,1
I can correct any misunderstandings in the
robot
q
uickl
y
and easil
y
3,7
Overall score for ease of use 4,1
Ease o
f
learnin
g
I learnt to use the syste
m
very quickl
y
4,4
I remember how to use each modality
b
efore each use
4,6
The interactions are easy to learn 4,5
Overall score for ease of learning 4,5
Satisfaction
I am satisfied with the use of the s
y
stem 4,0
I would recommend the use of the s
y
ste
m
3,9
I think I need this assistant robot 2,6
The system is pleasant to use 4,1
Overall score for satisfaction 3,6
Table 5: The following table shows the mean scores of the
evaluation of the intuitiveness and of the usefulness of the
interaction modalities.
M
odalit
y
Intuitive Use
f
ul
Laser
p
ointer
(g
esture control
)
3,9 3,3
Vibration (haptic feedback) 4,1 3,6
Touch screen (tactile control) 4,5 4,4
Robot state (visual feedback) 4,2 4,3
Voice control 3,9 3,9
Li
g
ht s
p
ot
(
visual feedback
)
3,7 4,0
interaction, even though it generated a lot of
frustration due to the poor results obtained mainly
during the noisy second half of the tests. In this case,
it was appreciated to have an alternative way of
controlling the robot. The vibration motor was seen
more as a safety feature that simply added
information that was already known: in fact, the
subject was always looking at the robot while waiting
for the tool when the motor started to vibrate.
Moreover, test subjects were invited to freely
comment on the following statements:
HUCAPP 2024 - 8th International Conference on Human Computer Interaction Theory and Applications
554

1) Multimodality contributes to greater
satisfaction and reduces frustration.
2) A simple interaction is interesting and
preferable to a more complex interaction
(richer in information).
3) The presence of feedback improves the 'feel'
of the interaction (user experience).
All the subjects agreed unanimously with the
statements. For example, concerning multimodality
and simple interactions, we could record the
following quotes: “I think multimodality offers the
user choice, which reduces frustration”, “Above all,
multimodality allows me to adapt to different
situations”, or “The simpler it is to operate, the faster
and more pleasant it is to run”. They considered that
feedback is very important for a successful and
satisfactory collaboration. An additional comment
was made that simple feedback is important, but the
content of the information to be provided should not
be reduced because of that: “Simple feedback is
important, but in the event of an error other than non-
comprehension, adding a corresponding interaction
seems interesting”.
3.1 Limitations of the Study
The goal of this paragraph is to discuss the main
limitations of our study. First of all, the number of test
subjects is too small. In order to have more significant
results, a higher number of subjects is necessary for
future works. More in particular, to be able to truly
evaluate multimodality, comparative tests and
analysis should be performed.
Secondly, we didn’t measure the following
parameters: the duration of the assembly task, the
subjects’ errors, and the subjects’ level of
comfort. Consequently, the efficiency was not
evaluated. And even if all the subjects successfully
finished the task, the effectiveness was also not
evaluated. The main reason is that the current use-
case does not completely reflect a real working
situation, even if it is meant to implement elementary
real operations. The study is at a preliminary stage
and can be defined as a theoretical one, contributing
to the comprehension of multimodal HRI.
Finally, the proposed assembly task was also not
always adapted to the goal of evaluating
multimodality. As an example, the presence in the
sequence of unwanted waiting times was detrimental
to the assessment of the haptic feedback and of the
user experience in general.
4 CONCLUSIONS
In this study, we have explored the complexities of
HRI in the context of a collaborative assembly task
with a robot assistant. In particular, we focused on the
elementary yet widely applicable operation
“bring/put away”, very common and very often
performed in SMEs and service contexts. Our
experimental set-up, featuring a UR5 robot, allows
voice, gesture and visual control and provides visual
and haptic feedbacks. A series of Wizard of Oz tests
were carried out with twenty test subjects,
implementing an assembly operation scenario, with
the objective of exploring the potential of simple
multimodal interaction for enhancing the feeling of
interaction and the user experience. The preliminary
results indicate positive feedbacks, with test subjects
expressing satisfaction with the simplicity and the
intuitiveness of the interactions. The inclusion of
feedback mechanisms, incorporating mainly visual
but also haptic cues, contributes to a more immersive
and satisfying collaborative experience. The findings
from this preliminary study offer valuable insight for
further research. The experiment not only highlighted
the ease of use and effectiveness of the different
interaction modalities, but also underlined the
importance of feedbacks in shaping the overall user
experience.
Future work should strive to develop more
realistic scenarios, bridging the gap between
laboratory proof-of-concept and real-world use cases,
taking greater account of user needs, psychological
factors, and the dynamic nature of the working
environment. This will allow us to plan a longitudinal
research to assess long-term effectiveness. In
addition, a more integrated multimodality, proving
that content is still simple but richer, needs to be
designed and tested with more precise test protocols.
In further research, different types of interaction
configuration will be established and tested in order
to assess one, two or three modalities at a time.
However, robot feedbacks are assumed essential and
will be evaluated in all configurations. Following the
new test protocol, there will be one questionnaire for
each test configuration, adjusted to quantify the
efficiency and effectiveness. Behavioural analysis
will be needed to make a more accurate evaluation of
the user experience.
Exploring Multimodal Interactions with a Robot Assistant in an Assembly Task: A Human-Centered Design Approach
555

REFERENCES
Adel, A. (2022). Future of industry 5.0 in society: human-
centric solutions, challenges and prospective research
areas. In Journal of Cloud Computing 11, 40.
Alegre Luna, J., Vasquez Rivera, A., Loayza Mendoza, A.,
Talavera S., J., Montoya, A. (2023). Development of a
Touchless Control System for a Clinical Robot with
Multimodal User Interface. In International Journal of
Advanced Computer Science and Applications
(IJACSA), 14(9).
Alves, J., Lima, T.M., Gaspar, P.D. (2023). Is Industry 5.0
a Human-Centred Approach? A Systematic Review.
In Processes 2023, 11, 193.
Brooke, J. (1995). SUS: A quick and dirty usability scale.
In Usability Evaluation in Industry 189, 4-7.
Clemente, F., Dosen, S., Lonini, L., Markovic, M., Farina,
D., Cipriani, C. (2017). Humans Can Integrate
Augmented Reality Feedback in Their Sensorimotor
Control of a Robotic Hand. In IEEE Transactions on
Human-Machine Systems, 47(4): 583-589.
Demir, K.A., Döven, G., Sezen, B. (2019). Industry 5.0 and
Human-Robot Co-working. In Procedia Computer
Science, 158: 688-695.
Kalinowska, A., Pilarski, P. M., Murphey, T. D. (2023).
Embodied Communication: How Robots and People
Communicate Through Physical Interaction. In Annual
Review of Control, Robotics, and Autonomous
Systems 6:1, 205-232.
Kopp, T., Baumgartner, M., Kinkel, S. (2020). Success
factors for introducing industrial human-robot
interaction in practice: an empirically driven
framework. In the International Journal of Advanced
Manufacturing Technology, 112(3-4): 685-704.
Lund, A.M. (2001). Measuring Usability with the USE
Questionnaire. In Newsletter of the society for technical
Communication, October 2001, Vol 8, No. 2.
Male, J, Martinez Hernandez, U. (2021). Collaborative
architecture for human-robot assembly tasks using
multimodal sensors. In Proceeding of the International
Conference on Advanced Robotics, ICRA 2021,
Ljubljana, Slovenia.
Marathe, A.R., Schaefer, K.E., Evans, A.W., Metcalfe, J.S.
(2018). Bidirectional Communication for Effective
Human-Agent Teaming. In: Chen, J., Fragomeni, G.
(eds) Virtual, Augmented and Mixed Reality:
Interaction, Navigation, Visualization, Embodiment,
and Simulation. VAMR 2018. Lecture Notes in
Computer Science, vol 10909. Springer, Cham.
Michaelis, J. E., Siebert-Evenstone, A., Shaffer, D. W.,
Mutlu, B. (2020). Collaborative or simply uncaged?
understanding human-cobot interactions in automation.
In Proceedings of the 2020 CHI Conference on Human
Factors in Computing Systems.
Penkov, S., Bordallo, A., Ramamoorthy, S. (2016). Inverse
eye tracking for intention inference and symbol
grounding in human-robot collaboration. In Robotics:
Science and Systems Workshop on Planning for
Human-Robot Interaction, 2016.
Rautiainen, S., Pantano, M., Traganos, K., Ahmadi, S.,
Saenz, J., Mohammed, W.M.; Martinez Lastra, J.L.
(2022). Multimodal Interface for Human–Robot
Collaboration. In Machines, 10, 957.
Strazdas, D., Hintz, J., Khalifa, A., Abdelrahman, A.A.,
Hempel, T., Al-Hamadi, A. (2022). Robot System
Assistant (RoSA): Towards Intuitive Multi-Modal and
Multi-Device Human-Robot Interaction. In
Sensors, 22(3), 923.
Villani, V., Fenech, G., Fabbricatore, M., Secchi, C.
(2023) Wrist Vibration Feedback to Improve Operator
Awareness in Collaborative Robotics. In Journal of
Intelligent and Robotic Systems 109: 45.
Wright, J., L., Lakhmani, S., G., Chen J., Y.,
C. (2022). Bidirectional Communications in Human-
Agent Teaming: The Effects of Communication Style
and Feedback. In International Journal of Human–
Computer Interaction, 38:18-20, 1972-1985.
HUCAPP 2024 - 8th International Conference on Human Computer Interaction Theory and Applications
556
