
Exploratory Data Analysis in Cloud Computing Environments for Server
Consolidation via Fuzzy Classification Models
Rafael R. Bastos
1 a
, Vagner A. Seibert
1 b
, Giovani P. Maia
1
, Bruno M. P. de Moura
3 c
,
Giancarlo Lucca
2 d
, Adenauer C. Yamin
1 e
and Renata H. S. Reiser
1 f
1
Federal University of Pelotas (UFPel/PPGC), Pelotas, Brazil
2
Catholic University of Pelotas (UCPel), Pelotas, Brazil
3
Federal University of Pampa (Unipampa), Bag
´
e, Brazil
Keywords:
Fuzzy Logic, Server Consolidation, Feature Selection, Fuzzy Rule Learning.
Abstract:
The present work addresses the challenges of flexible resource management in Cloud Computing, empha-
sizing the critical need for efficient resource utilization. Precisely, we tackle the problem of dynamic server
consolidation, supported by the capacity of Fuzzy Logic to deal with uncertainties and imprecisions inherent
in cloud environments. In the preprocessing step, we employ a feature selection strategy to perform attribute
selection and, better understand the problem. Data classification was performed by fuzzy rule learning ap-
proaches. Comparative evaluations of algorithm classification highlight the remarkable accuracy of FURIA,
with IVTURS as a close alternative. While FURIA generates 41 rules, indicating a comprehensive model,
IVTURS produces only six, introducing an abstract level to model uncertainties as interval-valued fuzzy mem-
bership degrees. The study underscores the relevance of parameter adaptation in mapping feature selection
and membership functions to achieve optimal performance for flexible algorithms in the Cloud Computing
environment. Our results underlie the structure of a fuzzy system adapted to CloudSim, integrating energy
optimization and Service Level Agreements assurance through different server consolidation strategies. This
research contributes valuable perspectives to decision-making processes in the Cloud Computing environment.
1 INTRODUCTION
The worldwide public Cloud Computing (CC) market
is expected to reach an estimated US$ 679 billion in
2024. This estimate encompasses business processes,
platforms, infrastructure, software, management, se-
curity, and advertising services delivered by public
CC services, as storage, bandwidth, or CPU cycles.
In such scenario, one of the main demands of
the CC environment is the efficient management of
resources. In this point, the energy efficiency is
an interesting issue due its importance on differ-
ent fronts. Additionally, it keep satisfactory Ser-
vice Level Agreements (SLA) and Quality of Ser-
a
https://orcid.org/0009-0005-7494-3495
b
https://orcid.org/0009-0005-2128-6639
c
https://orcid.org/0000-0002-3960-8377
d
https://orcid.org/0000-0002-3776-0260
e
https://orcid.org/0000-0002-7333-244X
f
https://orcid.org/0000-0001-9934-3115
vice (QoS) (Beloglazov and Buyya, 2013; He and
Buyya, 2023). Minimizing energy consumption sat-
isfying QoS constraints is complex and is part of the
research into dynamic Virtual Machine (VM) consol-
idation, characterized as an NP-Hard problem (Fer-
daus et al., 2014).
VM consolidation involves the identification of
underloaded and overloaded hosts, selection of VMs
for migration, and their allocation to alternative
hosts (Mittal et al., 2019). However, this strategy is
a complex task as detecting excessive workload and
initiating migration cannot quickly respond to sudden
and dynamic changes in the environment (Sowrirajan,
2022).
Fuzzy Logic (FL) (Zadeh, 1965) is frequently em-
ployed to assist in decision-making processes, ad-
dressing uncertainties and inaccuracies in the vari-
ables involved in VM consolidation.
In 1975 Sambuc (Sambuc, 1975) presented the
concept of an Interval-valued Fuzzy Set (IvFS), and
636
Bastos, R., Seibert, V., Maia, G., P. de Moura, B., Lucca, G., Yamin, A. and Reiser, R.
Exploratory Data Analysis in Cloud Computing Environments for Server Consolidation via Fuzzy Classification Models.
DOI: 10.5220/0012615900003690
Paper published under CC license (CC BY-NC-ND 4.0)
In Proceedings of the 26th International Conference on Enterprise Information Systems (ICEIS 2024) - Volume 1, pages 636-643
ISBN: 978-989-758-692-7; ISSN: 2184-4992
Proceedings Copyright © 2024 by SCITEPRESS – Science and Technology Publications, Lda.

other studies were established, taking into account
the uncertainty linked to the construction of a precise
interval-valued membership function (Bustince et al.,
2016).
The ability to make decisions under uncertainties
and the tolerance for imprecision of control systems
provide the seminal motivation for development of
IvFS. More recently, this logical approach has con-
tributed to solutions for complex problems, reason-
ing models, deduction, and calculation with imper-
fect information, also integrating techniques from Ar-
tificial Intelligence (AI), such as Machine Learning
(ML) and Neural Networks (Lughofer, 2022).
In this context, the integration of Computa-
tional Intelligence methodologies, especially Ma-
chine Learning, becomes opportune to enhance per-
formance in resource allocation and mitigate energy
consumption within Cloud Computing.
By integrating concepts of CC and FL, the objec-
tive of this work is to stimulate a discussion focused
on flexible approaches to model uncertainties associ-
ated with data analysis related to relevant attributes
of CC environments. These attributes include CPU
usage, memory occupancy, bandwidth, and available
storage.
This paper is structured as follows. The first
section deals with the contextual foundations of the
work. Section 2 introduces Cloud Computing chal-
lenge and basic concepts of Interval-valued Fuzzy
Logic (IvFL) and some Fuzzy Rule-Based Classifi-
cation Systems (FRBCS). Related work is presented
in Section 3. In Section 4, we discuss the details
of Exploratory Data Analysis, including obtaining
the dataset, feature selection, and the definition of
membership functions and rule base. Section 5 de-
scribes the experimental evaluation. Finally, section 6
presents conclusions and future work.
2 MAIN CONCEPTS
In this section, we initiates our exploration by ad-
dressing the challenges in CC and presenting foun-
dational concepts in IvFL. Additionally, we introduce
various FRBCS.
2.1 Cloud Computing
The operational model of Cloud Computing (CC) al-
lows dynamic resource allocation based on demand
(Gourisaria et al., 2020). This elasticity facilitates
the provision of high-performance computational en-
vironments with optimized equipment investments for
the end user, aligning costs with resource requests
(Nathani et al., 2012)
In 2014, US data centers consumed an estimated
70 billion kilowatt-hours (kWh), constituting about
1.8% of the total electricity consumption in the USA,
according to a report by the Natural Resources De-
fense Council (NRDC)
1
(Shehabi et al., 2016).
Energy consumption is expected to rise by approx-
imately 4% from 2014 to 2023, reaching an estimated
73 billion kWh in 2023 for US data centers. Com-
panies like Google, Microsoft, and Amazon work to-
wards this goal by using renewable energy and invest-
ing in on-site green energy generation.
Efficient resource management in CC requires dy-
namic consolidation of VMs, structured by identify-
ing overloaded and underutilized physical machines,
selecting VMs for migration, and allocating them to
other physical machines. However, VM migration,
aiming to optimize resource usage, is a complex task
as it may not promptly respond to sudden dynamic
changes in the CC environment.
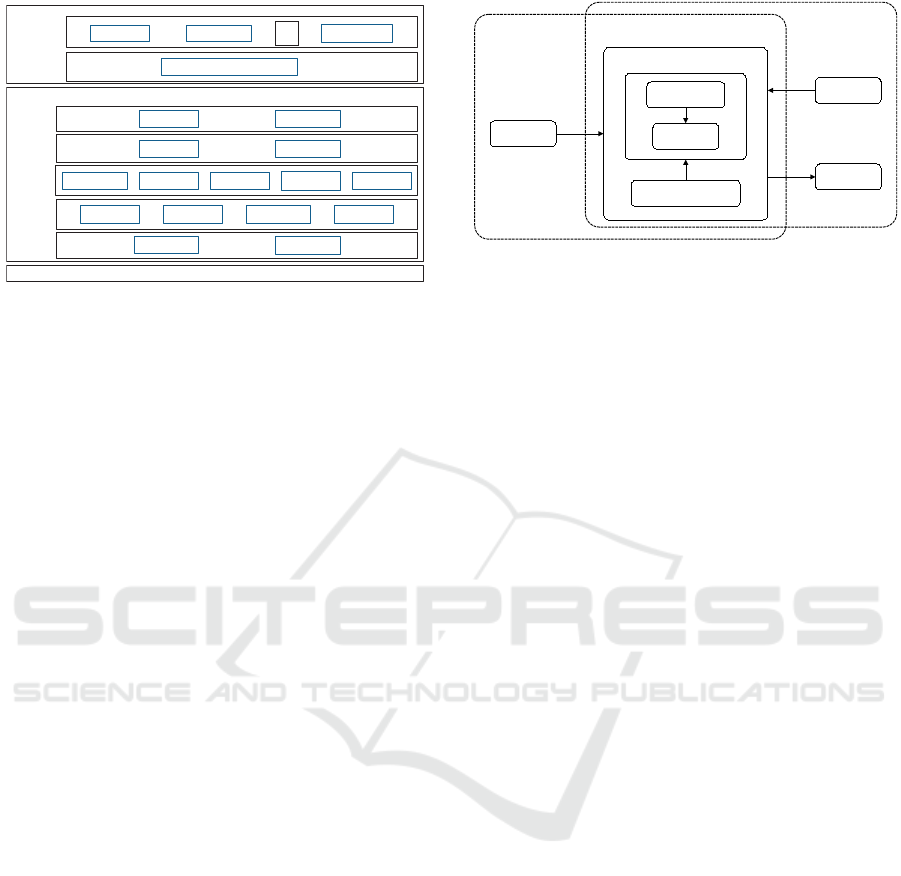
2.1.1 CloudSim Architecture
The assessment of strategies and algorithms in cloud
computing environments requires effective simulation
tools. In this context, CloudSim (Calheiros et al.,
2011) emerges as a widely employed and esteemed
simulation framework, providing researchers with a
modular platform for analyzing policies, algorithms,
and strategies (Arshad et al., 2022).
The CloudSim architecture is designed to enable
a comprehensive and adaptable simulation of CC en-
vironments. Key entities include DatacenterBroker,
Cloudlet, VM, Host, and Datacenter. It operates
across abstraction layers, including hardware, mid-
dleware, and user/broker. The CloudSim architecture
is shown in Figure 1.
This architecture encompasses crucial modules,
such as resource provisioning and scheduling poli-
cies. Extensibility is inherent to CloudSim, allow-
ing the addition of modules and policies to meet spe-
cific research or simulation requirements. The modu-
lar and scalable nature of CloudSim facilitates its ap-
plication in diverse scenarios, contributing to detailed
simulations in cloud computing environments.
Moreover, compared to physical environments,
the possibility of experiment repetitions in a con-
trolled manner is one of the main advantages of sim-
ulation tools, as CloudSim, integrating the synergis-
tic variation of the different conditions in the system
evaluation.
1
https://www.nrdc.org
Exploratory Data Analysis in Cloud Computing Environments for Server Consolidation via Fuzzy Classification Models
637
Events
Handling
CloudSim core simulation engine
Dat a Center
Clo ud
Resources
VM
Provisioning
CPU
Allocation
Memory
Allocation
Storage
Allocation
Bandwidth
Allocation
Clo ud
Services
Cloudlet
Execution
VM
Services
User
Interface
Structures
CloudSim
User code
User or Data Center Broker
Scheduling
Policy
Cloud
Scenario
Application
Configuration
User
Requirements
…
Simulation
Specification
VM
Management
Network
Topology
Message delay
Calculation
Network
Cloud
Coordinator
Sensor
Cloudlet
Virtual
Machine
Figure 1: CloudSim architecture (Calheiros et al., 2011).
2.2 Fuzzy Rule-Based Classification
Systems
Fuzzy Rule-Based Classification Systems (FRBCSs)
represent a potent tool commonly employed to ad-
dress classification problems. These fuzzy classi-
fiers are renowned for their high classification accu-
racy and their ability to provide interpretable mod-
els through the utilization of linguistic labels (Lucca
et al., 2020; Sanz et al., 2021).
The FRBCS consists of two integral components:
the Knowledge Base, comprising a specialized Rule
Base and Data Base adapted to a specific classifi-
cation problem, and the Fuzzy Reasoning Method,
which is responsible for applying fuzzy logic to the
Rule Base and Data Base, managing data uncertainty
to effectively assign class labels (Cord
´
on et al., 1998).
The FRBCS design entails a meticulous process
involving supervised learning, initiated with a set of
correctly classified training examples. The primary
objective is to formulate a Classification System ca-
pable of minimizing errors in assigning class labels to
novel instances. The system’s performance is subse-
quently evaluated comprehensively on test data, pro-
viding an approximation of the FRBCS real error.
This structured approach underscores the systematic
construction and performance assessment intrinsic to
FRBCS, substantiating its utility in intricate classifi-
cation scenarios. Figure 2 shows this process.
This characteristic allows FRBCSs to be applied
effectively in various real-world scenarios, span-
ning industries (Samantaray et al., 2010), health-
care (Czmil, 2023), the economy (Campisi et al.,
2022), and numerous other domains. Their wide-
ranging application is attributed to their capacity to
yield accurate results while ensuring interpretability
in the generated models.
The following are examples of FRBCSs employed
in this study.
Training Data
Testing Data
Testing
Results
Fuzzy Reasoning Method
Data Base
Fuzzy Rule Base
Knowledge Base
Fuzzy Rule Based
Classification System
Learning
Process
Classification
Process
Figure 2: Fuzzy rule-based classification process from
training to testing (Cord
´
on et al., 1998).
The FARC-HD (Alcal
´
a-Fdez et al., 2011) algo-
rithm is a computationally efficient solution tailored
for high-dimensional challenges, leveraging fuzzy
rules and integrating genetic rule selection and pa-
rameter tuning to optimize performance. The FARC-
HD uses a three-phase strategy that involves acquiring
fuzzy association rules through a structured tree ap-
proach, meticulous filtering to penalize redundancy,
and the integration of a genetic algorithm for rigor-
ous rule refinement. This comprehensive methodol-
ogy enhances the algorithm’s efficacy, making it par-
ticularly adept at addressing the nuanced demands in-
herent in high-dimensional problem spaces.
The Chi-RW algorithm (Cord
´
on et al., 1999) is
a classification algorithm discerning the relationship
among variables, establishing an association between
the resource space and the class space. This algo-
rithm defines linguistic partitions, formulates a fuzzy
rule for each example, and assigs the fuzzy region to
the highest membership degree. So, linking the label
class of an application to the consequence of the rule.
The FURIA (Fuzzy Unordered Rule Induction Al-
gorithm) algorithm is a classification algorithm pro-
posed by (H
¨
uhn and H
¨
ullermeier, 2009). In con-
trast to conventional approaches, this algorithm relies
on fuzzy rules to model more flexible classification
boundaries. Rules generated by replacing fuzzy in-
tervals use a trapezoidal membership function and a
rule induction technique. FURIA generates sets of
unordered rules, providing a more flexible represen-
tation of patterns in the data.
The IVTURS algorithm (Sanz et al., 2013)
(Interval-Valued Fuzzy Reasoning Method with Tun-
ing and Rule Selection) is a FARC-HD extension, in-
corporating interval-valued fuzzy rules. It employs a
parameterized Fuzzy reasoning method and an evolu-
tionary algorithm for optimization, allowing flexible
handling of uncertainty in data and effective adapta-
tion to classification problems. IVTURS features a
rule selection mechanism to identify the most rele-
vant and significant rules, enhancing computational
ICEIS 2024 - 26th International Conference on Enterprise Information Systems
638

efficiency and model interpretability.
3 RELATED WORK
This section reports the main projects proposing fuzzy
strategies in the stages of dynamic server consolida-
tion in Cloud Computing. The selected papers re-
sulted from a Systematic Literature Review (SLR) re-
alized in (Bastos et al., 2023).
The SLR analysis reveals the dynamic VM con-
solidation, emerging as an effective strategy to en-
hance efficiency energy in CC, based on four steps: (i)
Overloaded PM Identification; (ii) VM Selection; (iii)
Detection of Underutilized PMs; and (iv) Optimized
VM Allocation. The underlying goal is to achieve dy-
namic consolidation of VMs, aiming to optimize the
trade-off between performance and energy efficiency.
Table 1 presents an analysis of proposals for re-
source management in CC, applying techniques on
dynamic server consolidation, and highlighting their
significance. The description emphasized objectives,
logical approach, variables, and prospected tools.
This analysis reveals a pronounced focus on the
optimization and minimization of energy consump-
tion in CC environments as a crucial theme to meet
the demand for consumption reduction.
Two works stand out for the integration of FL with
ML. In (Negi et al., 2021), ML is used to cluster
VMs based on resource load. Meanwhile, in (Jumnal
and Kumar, 2021), FL is combined with RL to opti-
mize the allocation and/or relocation of VMs. The
integration with ML techniques allows FL systems
to learn from data, adapting automatically to changes
and complexities in the problem. This enables the im-
provement of fuzzy rules based on the characteristics
and relationships present in the data. The other works
do not address ML techniques.
Regarding the considered logical approach, only
in (Moura et al., 2022) and (Negi et al., 2021) is
the multivalued extension of FL considered, specifi-
cally IvFL and T2FL, respectively. In (Rozehkhani
and Mahan, 2022), Granular Computing is consid-
ered. The other works adopt Type-1 Fuzzy Logic.
Regarding the variables considered by Fuzzy sys-
tems, it is observed that the assessment of computa-
tional power and memory usage is a consensus among
the works. In (Negi et al., 2021), (Jumnal and Ku-
mar, 2021), (Braiki and Youssef, 2020), (Mongia and
Sharma, 2021), and (Rozehkhani and Mahan, 2022),
the authors aim to optimize the allocation or minimize
the migration time of VMs. However, they do not
account for communication costs, which can lead to
bottlenecks in the system when congested, and con-
sequently may lead to unsatisfactory performance.
Another convergence among the works is the use
of CloudSim
2
as a simulation tools for CC environ-
ments. Thus, our proposed feature selection also con-
siders variables available by CloudSim.
4 METHODOLOGY
In this section, we provide a comprehensive analy-
sis of the considered dataset. The dataset initially
comprises variables provided by CloudSim, with the
Virtual Machine allocation policy set to Interquartile
Range (IQR), and the VM selection policy using Ran-
dom Selection (RS).
The dataset’s foundation lies in workloads sourced
from PlanetLab
3
. The collected variables represent
the state of each host every 300 seconds, including
memory occupancy, CPU usage, bandwidth, available
storage, power consumption, and MIPS, along with
an indication of the host’s utilization level (underuti-
lized, regular, and overutilized).
Regarding the dataset, a feature selection was
performed using the Sequential Forward Selection
(SFS) (Pudil et al., 1994) technique to eliminate
highly correlated variables. The aim is twofold: to
enhance overall classification performance and re-
duce computational efforts involved in processing
data. The selection process involves iteratively com-
bining variables to achieve optimal subset configura-
tions based on evaluation criteria.
For this study, we chose the Area Under the ROC
Curve (AUC) (Bradley, 1997) as evaluation criteria.
This metric was selected strategically to enhance the
assessment of the classification performance, provid-
ing a comprehensive measure of the trade-off between
true positive rates and false positive rates across dif-
ferent classification thresholds. The AUC metric is
particularly well-suited for our objectives, as it of-
fers a holistic evaluation of the model’s discrimina-
tory capacity, considering various decision thresholds
and encompassing a broader understanding of its pre-
dictive capabilities.
Thus, in the first iteration of SFS, an individ-
ual analysis of variables is conducted, selecting the
one with the best classification performance. In the
next iteration, this variable is combined with others in
search of the combination with the best performance.
This process is repeated until there is no further im-
provement in classification performance.
In this study, the application of SFS considers
2
http://www.cloudbus.org/cloudsim/
3
https://planetlab.cs.princeton.edu/
Exploratory Data Analysis in Cloud Computing Environments for Server Consolidation via Fuzzy Classification Models
639
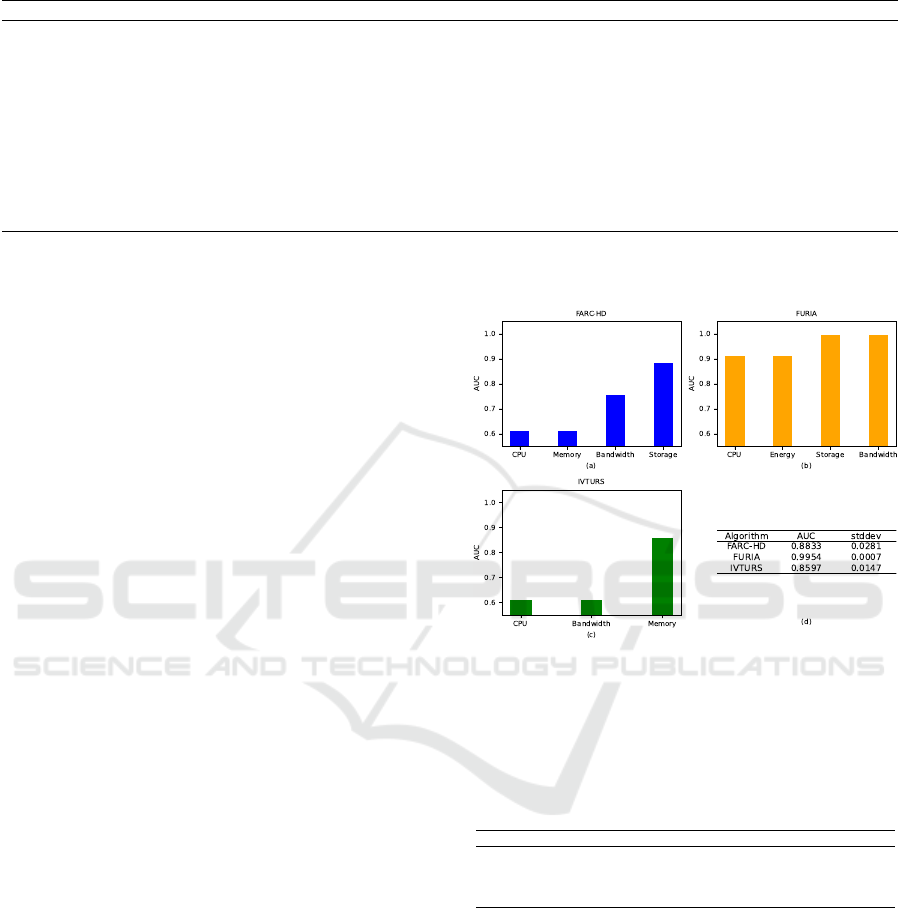
Table 1: Summarized analysis of selected papers in the SRL process.
Strategy Goal LA Variables Tools
Int-FLBCC Optimizing energy consumption, reducing SLA viola-
tions, and minimizing the number of VM migrations
IvFL Computational Power; Communication
Cost; Memory
■ □
CMODLB Improving resource utilization, load balancing and energy
consumption, reducing task and transmission times
ML
T2FL
CPU; Memory; Load Balance in PM ■
FSRL Reduction of energy usage and resource wastage FRL CPU; Memory ■ ▲
Fuzzy-EPO Minimizing VM migration time and reducing energy con-
sumption
FL CPU; Memory; Storage; Bandwidth ■
fuzzyBFD Improving energy consumption and resource utilization FL CPU; Memory; Energy; Storage ■
PRSF Optimizing VM migration for SLA assurance FL CPU; Memory ■
GRC model: Minimizing energy consumption and maximizing QoS
stability
GC CPU; Core Number; Memory; Storage;
Service Time; Request Number
■
Logic Approach FL: Fuzzy Logic; IvFL: Interval-valued Fuzzy Logic; ML: Machine Learning; T2FL: Type-2 Fuzzy Logic; FRL: Fuzzy
Reinforcement Learning; GC: Granular Computing; ■ CloudSim; □ Juzzy; ▲ Matlab
the KEEL software tool (Triguero et al., 2017), ex-
ecuted with the FARC-HD, FURIA, and IVTURS al-
gorithms.
After feature selection, the resulting combinations
were employed as inputs for classification experi-
ments utilizing the FARC-HD, Chi-RW, FURIA, and
IVTURS algorithms within the KEEL environment.
These experiments also provided parameters, defin-
ing the membership function limits and the fuzzy rule
base system, and facilitating future adaptations of the
fuzzy module on CloudSim.
Details of these experiments, including member-
ship functions and rule bases generated by algorithms,
are further elaborated in Section 5.
5 EXPERIMENTAL RESULTS
Comprehending the results of our experiments is cru-
cial for evaluating the effectiveness of the proposed
methodology.
In this section, we explore the evolving process
of feature selection, evaluate the classification perfor-
mance of different algorithms, and examine the com-
plexities of their rule generation mechanisms.
5.1 Feature Selection Dynamics
The dynamics of feature selection are presented in
Figure 3, illustrating the stepwise contribution of vari-
ables in conjunction with the AUC metric for FARC-
HD, FURIA, and IVTURS.
5.2 Classification Performance Review
Further insights into the classification performance
and optimal variable combinations for each algorithm
are detailed in Table 2.
Figure 3: Variables selected by the algorithms: (a) FARC-
HD, (b) FURIA, (c) IVTURS, (d) AUC metric evaluation.
The presented results include the mean classifica-
tion value and standard deviation (stddev) for FARC-
HD, Chi-RW, FURIA, and IVTURS.
Table 2: Global Results of Feature Selection Simulation.
Algorithm Variables Classification stddev
FARC-HD CPU, Memory, Bandwidth, Storage 0.9576 0.0059
Chi-RW CPU, Memory, Bandwidth, Storage 0.9288 0.0011
FURIA CPU, Energy, Storage, Bandwidth 0.9970 0.0007
IVTURS CPU, Energy, Storage, Bandwidth 0.9583 0.0180
5.3 Algorithmic Details
It’s worth noting that the FARC-HD, Chi-RW, and
FURIA algorithms adopt Type-1 Fuzzy Logic, while
IVTURS utilizes interval fuzzy sets, enabling it to
handle more complex uncertainties in server consoli-
dation scenarios.
The membership functions corresponding to the
optimal variable combinations for each algorithm are
outlined in Table 3. Triangular membership functions
are predominantly used, with the exception of FU-
RIA, which adopts a trapezoidal format for model-
ICEIS 2024 - 26th International Conference on Enterprise Information Systems
640

ing membership relations. Each variable represents
an input of fuzzy system, and is categorized into three
linguistic terms: low, medium, and high.
These membership functions are essential for in-
terpreting the output of each algorithm and under-
standing how variables contribute to the classification
process. They provide a linguistic representation of
the input variables, allowing for more intuitive and
human-understandable analysis.
5.4 Rule Interpretability
The generated rule bases for FARC-HD, Chi-RW, FU-
RIA, and IVTURS consist of 9, 7, 41, and 6 rules,
respectively.
We observed a substantial difference in the num-
ber of fuzzy rules generated by the algorithms. No-
tably, FURIA demonstrated a higher complexity, pro-
ducing an extensive set of 41 rules. While a greater
number of rules may imply a more intricate and de-
tailed model, it necessitates careful consideration of
the associated computational demands during imple-
mentation.
In contrast, IVTURS adopted a more parsimo-
nious approach in fuzzy rule generation, generating
a modest total of only 6 rules for data classification.
This difference underscores the inherent trade-off be-
tween achieving a detailed model and ensuring com-
putational efficiency. Balancing these parameters is
essential to optimize the algorithm’s application and
performance.
The format of rules generated by FARC-HD is
based on natural language, where each attribute is as-
sociated with a set of linguistic terms describing its
characteristics: L
0
, L
1
, and L
2
represent low, medium,
and high, respectively. Each rule consists of a series
of antecedent conditions (if-clauses), specifying the
relationships between attributes and their respective
linguistic terms. The result or predicted class is deter-
mined by the conclusion of the rule (then-clause). Ad-
ditionally, each rule may have a certainty factor (CF),
indicating the confidence or certainty in the classifi-
cation made by the rule.
[(i)] FARC-HD Sample Rules
bw IS L_0(3): normal CF: 1.0
cpu IS L_1(3) AND mem IS L_1(3) AND storage
IS L_1(3): under CF: 0.5347
Rules generated by Chi-RW follow a similar for-
mat to FARC-HD (if-then rules). However, instead
of a certainty factor (CF), Chi-RW rules are accom-
panied by a rule weight, indicating the importance or
contribution of the rule to the classification.
[(ii)] Chi-RW Sample Rules
cpu IS L_0 AND mem IS L_0 AND bw IS L_0 AND
storage IS L_0:normal with Rule Weight: 1.0
cpu IS L_1 AND mem IS L_2 AND bw IS L_2 AND
storage IS L_normal with Rule Weight: 0.5910
Rules generated by FURIA follow a different for-
mat, where antecedent conditions are expressed as
scalar values for each attribute that lead to the pre-
dicted class. The classification result is indicated in
the rule conclusion, along with a certainty factor (CF).
[(iii)] FURIA Sample Rules
(cpu >= 0.1637(-> 0.1599)) and (cpu <= 0.1637
(-> 0.1637)) => class=normal (CF = 1.0)
(cpu >= 0.0021(-> 0)) and (storage <= 0.0025
(-> 0.0050)) and (energy <= 0(->253.7326))
and (cpu <= 0.0077(-> 0.0083))=>class=under
(CF = 0.99)
Rules generated by IVTURS also follow a for-
mat based on natural language, where attributes are
associated with linguistic terms. However, IVTURS
adopts an interval approach for the certainty factor
(CF), instead of associating a single value with each
rule. The antecedent conditions of the rules also spec-
ify intervals of values for attributes.
[(iv)] IVTURS Sample Rules
bw IS L_0(3): normal CF: [1.0, 1.0]
energy IS L_0(3) AND storage IS L_0(3) AND bw
IS L_2(3): under CF: [0.4182, 0.4238]
6 CONCLUSIONS
In this study, we focused on the dynamic consolida-
tion of servers, a complex activity that involves vari-
ous aspects such as CPU usage, memory occupancy,
bandwidth, storage, and energy consumption. The
specific characteristics of CC environment and the de-
fined performance requirements guided the choice of
classification algorithms, particularly those based on
fuzzy logic.
The Feature Selection highlighted the most rele-
vant variables for server consolidation, resulting in
simple fuzzy rule sets and a more direct interpreta-
tion. Moreover, this optimized approach simplifies
the fuzzy system implementation and may lead to sav-
ing computational resources. Feature Selection is a
valuable practice to enhance the efficiency and in-
terpretability of fuzzy models, especially in complex
scenarios, as addressed in this study.
The comparative evaluation of classification al-
gorithms revealed differences in their performances
and approaches. FURIA stood out, demonstrating re-
markable precision with a high AUC value of 0.9970,
consolidating its effectiveness in classification. IV-
TURS showed a performance very close, with an
AUC of 0.9583, positioning it as a potential alterna-
tive.
Exploratory Data Analysis in Cloud Computing Environments for Server Consolidation via Fuzzy Classification Models
641

Table 3: Membership Functions.
Variable Linguistic Term
Chi-RW FARC-HD FURIA IVTURS
Triangular MF Triangular MF Trapezoidal MF Triangular MF
Bandwidth
Low -0.0500 0.0000 0.0500 -0.0725, -0.0225, 0.0275 - - - - [-0.05, 0.05] [-0.075, 0.075] [-0.075, 0.075]
Medium 0.0000 0.0500 0.1000 -0.0139, 0.0312, 0.0812 - - - - [0.0, 0.1] [-0.025, 0.125] [-0.025, 0.125]
High 0.0500 0.1000 0.1500 0.0723, 0.1217, 0.1717 - - - - [0.05, 0.15] [0.025, 0.175] [0.025, 0.175]
CPU
Low -0.4994 0.0000 0.4994 -0.4616, 0.0704, 0.5698 -∞ 0 0.1250 0.2987 [-0.4994, 0.4994] [-0.7492, 0.7492] [-0.7492, 0.7492]
Medium 0.0000 0.4994 0.9989 0.0303, 0.494, 0.9934 0.1637 0.3480 0.6432 0.8540 [0.0, 0.9989] [-0.2497, 1.2486] [-0.2497, 1.2486]
High 0.4994 0.9989 1.4983 0.6425, 1.1419, 1.6414 0.5659 0.8705 1 ∞ [0.4994, 1.4983] [0.2497, 1.7481] [0.2497, 1.7481]
Energy
Low -∞ -∞ 0 253.7326 [-23999.55, 23999.55] [-35999.33, 35999.33] [-35999.33, 35999.33]
Medium 0 253.7326 697.0520 1 [0.0, 47999.10] [-11999.78, 59998.88] [-11999.78, 59998.88]
High 697.0520 1 ∞ ∞ [23999.55, 71998.66] [11999.78, 83998.43] [11999.78, 83998.43]
Memory
Low -0.2026 0.0000 0.2026 -0.2850, -0.0067, 0.1959
Medium 0.0000 0.2026 0.4052 -0.0237, 0.1789, 0.3815
High 0.2026 0.4052 0.6078 0.1966, 0.3992, 0.6018
Storage
Low -0.0571 0.0000 0.0571 -0.0736, -0.0165, 0.1892 -∞ 0 0.2506 0.5025 [-0.0571, 0.0571] [-0.0857, 0.0857] [-0.0857, 0.0857]
Medium 0.0000 0.0571 0.1142 -0.0046, 0.0501, 0.1072 0.2506 0.5025 0.5541 0.5820 [0.0, 0.1142] [-0.0286, 0.1428] [-0.0286, 0.1428]
High 0.0571 0.1142 0.1713 0.0750, 0.1321, 0.1892 0.0554 0.0582 1 ∞ [0.0571, 0.1713] [0.0286, 0.1999] [0.0286, 0.1999]
Along with the algorithms FARC-HD and Chi-
RW, FURIA adopts Type-1 Fuzzy Logic. Introducing
an abstract level, IVTURS extends the multi-valued
fuzzy approach by incorporating IvFS, enhancing the
capability to deal with more complex uncertainties in
the server consolidation case studies.
The servers’ dynamic consolidation is a complex
activity that involves various aspects and considera-
tions. Thus, the specific characteristics of the environ-
ment and the well-defined performance requirements
guide the choice of the ideal algorithm. And, the de-
scribed results in this work provide a valuable per-
spective to support decisions regarding resource opti-
mization in CC environments, highlighting the role in
modeling uncertainties and inherent imprecise data.
In conclusion, our work provides a valuable per-
spective for supporting decisions regarding resource
optimization in CC environments, emphasizing the
role of Fuzzy Logic in modeling uncertainties and
inherent imprecise data. The complexities of server
consolidation in CC environments necessitate ongo-
ing research and innovation to address emerging chal-
lenges and ensure sustainable and efficient cloud ser-
vices.
6.1 Future Research Directions
While our study contributes into server consolidation
using fuzzy logic, several promising avenues for fu-
ture research emerge. We propose the development of
an interval-valued fuzzy system for dynamic server
consolidation, aimed at optimizing energy consump-
tion in cloud environments while maintaining a satis-
factory SLA.
To achieve this, we will explore a distinct set of
variables, deviating from those employed in IvFL-
based systems (Moura et al., 2022; Negi et al., 2021).
Leveraging the outcomes of our feature selection pro-
cess, we intend to refine inference modeling, adjust
membership functions, and establish rule bases using
the computational intelligence provided by FRBCS.
Our intention is to enhance the approximate rea-
soning of this approach by integrating ML techniques.
This involves formulating a strategy for dynamic rule
generation, operating in conjunction with the infer-
ence stage of the fuzzy system. Additionally, we
aim to introduce new configurations for the boundary
points defining the membership functions and uncer-
tainty region.
ACKNOWLEDGEMENTS
This research was partially funded by Brazilian
funding agencies CAPES, CNPq (309160/2019-7;
311429/2020-3, 3305805/2021-5, 150160/2023-
2), PqG/FAPERGS (21/2551-0002057-1) and
FAPERGS/CNPq (23/2551-0000126-8), PRONEX
(16/2551-0000488-9).
REFERENCES
Alcal
´
a-Fdez, J., Alcala, R., and Herrera, F. (2011). A fuzzy
association rule-based classification model for high-
dimensional problems with genetic rule selection and
lateral tuning. IEEE Transactions on Fuzzy systems,
19(5):857–872.
Arshad, U., Aleem, M., Srivastava, G., and Lin, J. C.-W.
(2022). Utilizing power consumption and sla viola-
tions using dynamic vm consolidation in cloud data
centers. Renewable and Sustainable Energy Reviews,
167:112782.
Bastos, R., Seibert, V., Silva, G., Moura, B., Lucca, G.,
Yamin, A., and Reiser, R. (2023). Uma revis
˜
ao sis-
tem
´
atica sobre consolidac¸
˜
ao de servidores em am-
bientes de computac¸
˜
ao em nuvem via l
´
ogica fuzzy.
In Anais do VII Workshop-Escola de Inform
´
atica
Te
´
orica, pages 120–128, Porto Alegre, RS, Brasil.
SBC.
Beloglazov, A. and Buyya, R. (2013). Managing overloaded
hosts for dynamic consolidation of virtual machines in
cloud data centers under quality of service constraints.
IEEE Transactions on Parallel and Distributed Sys-
tems, 24(7):1366–1379.
Bradley, A. P. (1997). The use of the area under the
ICEIS 2024 - 26th International Conference on Enterprise Information Systems
642

roc curve in the evaluation of machine learning algo-
rithms. Pattern Recognition, 30(7):1145–1159.
Braiki, K. and Youssef, H. (2020). Fuzzy-logic-based multi-
objective best-fit-decreasing virtual machine realloca-
tion. The Journal of Supercomputing, 76:427–454.
Bustince, H., Barrenechea, E., Pagola, M., Fernandez, J.,
Xu, Z., Bedregal, B., Montero, J., Hagras, H., Her-
rera, F., and Baets, B. D. (2016). A historical account
of types of fuzzy sets and their relationships. IEEE
Transactions on Fuzzy Systems, 24(1).
Calheiros, R. N., Ranjan, R., Beloglazov, A., De Rose,
C. A., and Buyya, R. (2011). Cloudsim: a toolkit for
modeling and simulation of cloud computing environ-
ments and evaluation of resource provisioning algo-
rithms. Software: Practice and experience, 41(1):23–
50.
Campisi, G., De Baets, B., Gambarelli, L., Muzzioli, S.,
et al. (2022). Forecasting returns in the us mar-
ket through fuzzy rule-based classification systems.
DEMB WORKING PAPER SERIES.
Cord
´
on, O., del Jes
´
us, M. J., and Herrera, F. (1998). Ana-
lyzing the reasoning mechanisms in fuzzy rule based
classification systems. Mathware and Soft Computing,
5(2-3):321–332.
Cord
´
on, O., Del Jesus, M. J., and Herrera, F. (1999). A pro-
posal on reasoning methods in fuzzy rule-based clas-
sification systems. International Journal of Approxi-
mate Reasoning, 20(1):21–45.
Czmil, A. (2023). Comparative study of fuzzy rule-based
classifiers for medical applications. Sensors, 23(2).
Ferdaus, M. H., Murshed, M., Calheiros, R. N., and Buyya,
R. (2014). Virtual machine consolidation in cloud data
centers using aco metaheuristic. In European confer-
ence on parallel processing, pages 306–317. Springer.
Gourisaria, M. K., Samanta, A., Saha, A., Patra, S. S., and
Khilar, P. M. (2020). An extensive review on cloud
computing. Data Engineering and Communication
Technology, pages 53–78.
He, T. and Buyya, R. (2023). A taxonomy of live migra-
tion management in cloud computing. ACM Comput.
Surv., 56(3).
H
¨
uhn, J. and H
¨
ullermeier, E. (2009). Furia: an algorithm
for unordered fuzzy rule induction. Data Mining and
Knowledge Discovery, 19:293–319.
Jumnal, A. and Kumar, S. D. (2021). Optimal vm placement
approach using fuzzy reinforcement learning for cloud
data centers. In 2021 Third International Conference
on Intelligent Communication Technologies and Vir-
tual Mobile Networks (ICICV). IEEE.
Lucca, G., Sanz, J. A., Dimuro, G. P., Bedregal, B., and
Bustince, H. (2020). A proposal for tuning the α
parameter in c α c-integrals for application in fuzzy
rule-based classification systems. Natural Computing,
19(3):533–546.
Lughofer, E. (2022). Evolving fuzzy and neuro-fuzzy sys-
tems: Fundamentals, stability, explainability, useabil-
ity, and applications. In Handbook on Computer
Learning and Intelligence: Volume 2: Deep Learn-
ing, Intelligent Control and Evolutionary Computa-
tion, pages 133–234. World Scientific.
Mittal, M., Balas, V. E., Goyal, L. M., and Kumar, R.
(2019). Big data processing using spark in cloud.
Springer.
Mongia, V. and Sharma, A. (2021). Performance and
resource-aware virtual machine selection using fuzzy
in cloud environment. In Progress in Advanced Com-
puting and Intelligent Engineering: Proceedings of
ICACIE 2020, pages 413–426. Springer.
Moura, B. M., Schneider, G. B., Yamin, A. C., Santos, H.,
Reiser, R. H., and Bedregal, B. (2022). Interval-valued
fuzzy logic approach for overloaded hosts in consoli-
dation of virtual machines in cloud computing. Fuzzy
Sets and Systems, 446:144–166.
Nathani, A., Chaudhary, S., and Somani, G. (2012). Policy
based resource allocation in iaas cloud. Future Gen-
eration Computer Systems, 28(1):94–103.
Negi, S., Rauthan, M. M. S., Vaisla, K. S., and Panwar, N.
(2021). Cmodlb: an efficient load balancing approach
in cloud computing environment. The Journal of Su-
percomputing, 77.
Pudil, P., Novovi
ˇ
cov
´
a, J., and Kittler, J. (1994). Floating
search methods in feature selection. Pattern Recogni-
tion Letters, 15(11):1119–1125.
Rozehkhani, S. M. and Mahan, F. (2022). Vm consolida-
tion improvement approach using heuristics granular
rules in cloud computing environment. Information
Sciences, 596.
Samantaray, S., El-Arroudi, K., Joos, G., and Kamwa, I.
(2010). A fuzzy rule-based approach for islanding de-
tection in distributed generation. IEEE transactions
on power delivery, 25(3):1427–1433.
Sambuc, R. (1975). Function φ-flous, application a laiide
au diagnostic en pathologie thyroidienne. These de
Doctorat en Medicine, Univ. Marseille.
Sanz, J., Sesma-Sara, M., and Bustince, H. (2021). A fuzzy
association rule-based classifier for imbalanced clas-
sification problems. Information Sciences, 577:265–
279.
Sanz, J. A., Fern
´
andez, A., Bustince, H., and Herrera, F.
(2013). Ivturs: A linguistic fuzzy rule-based classifi-
cation system based on a new interval-valued fuzzy
reasoning method with tuning and rule selection.
IEEE Transactions on Fuzzy Systems, 21(3):399–411.
Shehabi, A., Smith, S., Sartor, D., Brown, R., Herrlin, M.,
Koomey, J., Masanet, E., Horner, N., Azevedo, I., and
Lintner, W. (2016). United states data center energy
usage report.
Sowrirajan, R. (2022). A literature based study on cyber
security vulnerabilities. International Journal of In-
novative Technology and Research, 10:10138–10141.
Triguero, I., Gonz
´
alez, S., Moyano, J. M., Garc
´
ıa L
´
opez,
S., Alcal
´
a Fern
´
andez, J., Luengo Mart
´
ın, J.,
Fern
´
andez Hilario, A. L., Jes
´
us D
´
ıaz, M. J. d.,
S
´
anchez, L., Herrera Triguero, F., et al. (2017). Keel
3.0: an open source software for multi-stage analysis
in data mining. International Journal of Computa-
tional Intelligence Systems, 10:1238–1249.
Zadeh, L. A. (1965). Fuzzy sets. Information and control,
8(3):338–353.
Exploratory Data Analysis in Cloud Computing Environments for Server Consolidation via Fuzzy Classification Models
643
