
Recommendation Systems: A Deep Learning Oriented Perspective
Igor Luiz Lampa
a
, Vitoria Zanon Gomes
b
and Geraldo Francisco Doneg
´
a Zafalon
c
Department of Computer Science and Statistics, Universidade Estadual Paulista (UNESP),
Rua Crist
´
ov
˜
ao Colombo, 2265, Jardim Nazareth, S
˜
ao Jos
´
e do Rio Preto - SP, 15054-000, Brazil
Keywords:
Recommendation Systems, Deep Learning, Collaborative Filtering, Content-Based, Hybrid Approach.
Abstract:
The massive use of the digital platforms has provided an exponential increase at the amount of data consumed
and daily generated. Thus, there is a data overload which directly affects the consume experience of digital
products, whether at find a news, consume an e-commerce product or to choose a movie in a streaming
platform. In this context, emerge the recommendation systems, which have the finality of provide an efficient
way to comprehend the user predilections and to recommend direct items. Thus, this work brings the classical
concepts and techniques already used, as well as analyzes their use along with deep learning, which through
evaluated results has a grater capability to obtain implicit relationships between users and items, providing
recommendations with better quality and accuracy. Furthermore, considering the review of the literature and
analysis provided, an architectural model for recommendation system based on deep learning is proposed,
which is defined as a hybrid system.
1 INTRODUCTION
The high volume of digital data currently available,
whether these generated on social media, e-commerce
platforms, search, news agencies and other applica-
tions, caused an overload of information. In this con-
text, users when consuming services available on the
web, are faced with an excess of options, which in
many cases are divergent to their interests and not use-
ful for their personal profile. So it is necessary to em-
ploy some methodology that is efficient to provide the
information tailored to the profile and interests of the
person requesting it.
According to Sarker and Matin (2021), with the
increase in web development, around 2.5 quintillion
of bytes are produced daily. In this sense, it is stated
this high amount of data harms the taking of de-
cisions. Thus, this situation has contributed to the
development of a segment of computing called rec-
ommendation systems, which using algorithmic ap-
proaches enables the customization of content tar-
geted at users and aligned with their expectations.
The main objective of a recommendation system
is to indicate to its users what they are most willing to
be interested in, providing an personalized experience
a
https://orcid.org/0009-0005-2099-9020
b
https://orcid.org/0000-0003-4176-566X
c
https://orcid.org/0000-0003-2384-011X
and avoiding excessive and unnecessary information
(Negi and Patil, 2021). Recommendation systems is
vital to improve access to information in order to sup-
port the decision-making process (Zhang et al., 2019;
Petter. and Jablonski., 2023).
The recommendation system primarily ability is
to understand users behaviors and habits in relation to
the items they are interacting to (Zhou, 2020). That
is, recognizing which trends of user preferences and
then indicate the items that match their expectations.
As specified by Da’u and Salim (2019), the devel-
opment of systems recommendation systems based on
deep learning has become a growing trend in present.
This condition is justified by the capacity of this new
technique to provide better representation learning of
the interaction between users and items, when com-
pared to traditional methods previously established in
literature. In this scenario, the hybrid use of tradi-
tional methods combined with deep learning, proved
to be innovative in discovering non-linear and im-
plicit relationships between users and items. There-
fore, high-quality and non-trivial recommendations
are generated.
For this reason, considering the literature review
and analysis provided in this work, we propose an
architectural model by applying innovative machine
learning techniques associated with the traditional
recommendation systems, with the aim of developing
682
Lampa, I., Gomes, V. and Zafalon, G.
Recommendation Systems: A Deep Learning Oriented Perspective.
DOI: 10.5220/0012622700003690
Paper published under CC license (CC BY-NC-ND 4.0)
In Proceedings of the 26th International Conference on Enterprise Information Systems (ICEIS 2024) - Volume 1, pages 682-689
ISBN: 978-989-758-692-7; ISSN: 2184-4992
Proceedings Copyright © 2024 by SCITEPRESS – Science and Technology Publications, Lda.

a hybrid approach. In this scenario, we seek to re-
duce individual deficiencies of these methods while
improving the quality of the results by using them
together. So, this work focuses on providing a op-
timized strategy, which favors the recommendation
process in terms of quality and error reduction.
This work is organized as follows: in section 2,
we present a review concerning recommendation sys-
tems and deep learning; in section 3, related works are
presented; in section 4, a hybrid architectural model
is proposed supported by the review; and, finally, in
section 5, the conclusions are showed.
2 RECOMMENDATION
SYSTEMS AND DEEP
LEARNING
Traditional recommendation systems are classified
into three groups: content based, collaborative filter-
ing and hybrid approaches. These classification are
explained at sections below.
2.1 Content Based
The content based approach directly depends on
meta-data regarding to users and items, that is, it re-
quires detailed information related to the user profile,
as well as the attributes that describe the item. In the
case of users, data such as age, gender, geolocation,
among others can be considered registration data. For
items, assuming the example of a movie, they can
be observing the attributes of gender, title, summary,
classification tags, running time, year of release, ac-
tors and other data deemed necessary to describe them
(Sarker and Matin, 2021). Therefore, this data is used
at comparisons between the user profile and the items,
to obtain the recommendations (Bhanuse and Mal,
2021).
To establish the user’s preference profile, it is nec-
essary to use of some learning technique, that is, al-
gorithms that reveal the relationship implicit in the di-
rect interaction between users and items. In this sense,
artificial neural networks, Support Vector Machine –
SVM and Bayesian classifiers are frequently used to
obtain the user profile (Da’u and Salim, 2019).
One of the positive factors of content-based rec-
ommendation is user independence, since indications
are carried out in isolation, that is, disconnected from
the preferred profile of other users. Another factor is
transparency, denoted by the clarity of the process of
obtaining items recommended. Also it is able to avoid
the absence of first-rater problem, because when new
items are included and it is capable to make recom-
mendations, even without prior assessments of them.
On the other hand, one of the negative factors is
the occurrence of obviousness in recommendations
and this condition can result in predictable indica-
tions. According to Saat et al. (2018), this phe-
nomenon is classified as the filter bubble problem
recommendation, due to the mechanism of this strat-
egy being specific per user and not consider the rest
of the community’s preferences, that is, a cycle of
recommendations self-referenced by the user’s own
predilections. This fact along the time provide a re-
duction at variations and diversity that are considered
fundamental for the recommendations, moreover this
point was target of critics, because it can make user to
lose opportunities and newer possibilities (Grossetti
et al., 2019).
Although the content based approach is capable of
handling the insertion of new items, when new users
are included it becomes an obstacle. This condition
occurs due to the lack of interaction history of new
users with the available items, which would be used
for training and learning your preferences.
As described by Bhanuse and Mal (2021), there
are two types of content-based approaches:
• Case Dependent Reasoning Method: in this
model, items that are highly related are associ-
ated with those that have already been previously
appreciated by the user. There is a tendency to
increasing the quality of indications as the user
interacts with the items available, as your history
will be increased and new connections will be able
to be established.
• Attribute Dependent Method: Recommenda-
tions are made based on the list of item attributes
and its adherence in relation to the user profile.
In this sense, there is no dependence in relation
to user interaction with items, therefore the inclu-
sion of new users do not create difficulties, as the
recommendations will use your profile as a ba-
sis previously declared. For example, if a user is
registered at a computer science area of interest,
then the recommendation algorithm will use this
explicitly defined attribute to make indications.
2.2 Collaborarive Filtering
Collaborative Filtering is one of the most widely used
methods (Da’u and Salim, 2019) and as opposed to
content based, this approach does not depend of the
attributes of users and items, but only of the rela-
tionship between them. In general, the mechanism
is based on extracting a user’s interaction history with
Recommendation Systems: A Deep Learning Oriented Perspective
683

the items and establish comparisons with the histori-
cal records of interaction of the other users with the
items, with the purpose of obtaining new classifica-
tions (Sarker and Matin, 2021).
The fundamental concept employed by this ap-
proach is to consider the assumption that similar users
have similar interests (Bhanuse and Mal, 2021). The
recommendation is based on the assessment of the be-
havior of the community of users with the items, or
even the links between the items themselves (Da’u
and Salim, 2019). One of the most used algorithms
and considered the best calculation methods for this
purpose is called cosine similarity (Guo and Liu,
2019) .
In real system applications, a lack of data about
users or items is common, either due to their non-
existence or difficulty in processing to obtain it (Peng
et al., 2020). Therefore, the ability of this method
not to depend on these attributes for its operation, is
considered a positive advantage. Furthermore, it has
the ability to provide indications with diversity, since
does not consider the user exclusively and encom-
passes the analysis of all user-item relationships.
One of the factors that degrade the performance
of this approach is called cold start, which refers to
the condition in which there is a new item or new
user. In this context, there is an absence of a user
or item history, which causes a lack of resources to
recognize preferences. Therefore, the system will be
unable to generate assertive indications, a fact that
will reduce system performance of recommendation.
(Fayyaz et al., 2020; Liu et al., 2020)
Another factor that negatively impacts this method
is the scarcity of data, which occurs when the vol-
ume of interaction between user and items is low.
That condition generates a sparse user-item matrix
(Isinkaye et al., 2015), which causes the inability to
locate similar neighbors and therefore a recommen-
dation process with low assertiveness.
The constant increase in the volume of data used
in the recommendation is also considered a problem
for this method. The scalability problem, is related
to the difficulty that the method at deal with constant
data increase. A technique called Singular Value De-
composition - SVD which is based on dimensional-
ity reduction, also others strategies based on cluster-
ing process can be applied to mitigate this problem
(Fayyaz et al., 2020).
The collaborative filtering strategy is subdivided
into two segments as follows:
• Memory Based:
Memory based is also categorized into two types,
user based and item based. In the first approach,
the recommendation process focuses on under-
standing similar interests among users (Bhanuse
and Mal, 2021). In practical terms, items are rec-
ommended to the target user considering that they
have been rated or acquired by users who resem-
ble him. At the item based method, the objective
is to establish the relationship between the items
themselves and the interest in them, that is, based
on the item a particular user chose to make recom-
mendations for items that are similar to the same
(Anil et al., 2018).
In item and user-based techniques, there are fac-
tors that influence the choose between them.
Firstly, the similarity of items is considered with
greater importance stability, that is, the relation-
ship established between them is very likely to
stay. However, when considering the similarity
between users it is the opposite, since that users’
interests evolve and transform over time, as a re-
sult, new similarity calculations will be required
more frequently. Furthermore, another positive
factor of the item based technique is that, in gen-
eral, there are more users than items, therefore,
the item-item matrix is smaller in dimensions than
the user-user, that is, it can mean a competitive ad-
vantage in environments with resource limitation,
whether in terms of time or even hardware.
• Model Based:
On the other hand, model based is a category of
collaborative filtering algorithms, that use statis-
tical and machine learning techniques to perform
model training and classifications. In this context,
the core of the strategy is detect how likely a given
user is to rate an item according to your interest or
not, based on the classifications previously carried
out (Bhanuse and Mal, 2021). Matrix factoriza-
tion is a classic algorithm of this area, whose ba-
sic function is based on a sparse user-item matrix,
produce probabilistic values for unfilled gaps, that
is, items without prior evaluation, which will be
used for recommendations.
In the meantime and given the scientific contri-
butions in the area of machine learning and pri-
marily advances at the sub-area of deep learning,
provided a fundamental ally for recommendation
systems. Since the use of models, such as auto-
encoders, Convolution Neural Network - CNN,
Recurrent Neural Network – RNN, among others,
aim to improve the performance of traditional rec-
ommendation algorithms by providing greater ef-
ficiency and lower error rate.
ICEIS 2024 - 26th International Conference on Enterprise Information Systems
684

2.3 Hybrid Approach
Hybrid recommendation systems arise from the com-
bination of positive aspects of one or more recom-
mendation system strategies, with the aim of provid-
ing an optimized methodology, but also to mitigate
individual deficiencies inherent to them when used
in isolation (Da’u and Salim, 2019). The hybridiza-
tion of the recommendation process can be achieved
by combination of different techniques, for example,
there is the classic union of algorithms content based
with collaborative filtering, which has the function of
providing greater accuracy of the prediction results.
Several current researches reveal the importance
and increase of quality of results obtained when rec-
ommendation strategies are used together. In this con-
text, one of the fastest growing areas in joint applica-
tion with traditional recommendation systems algo-
rithms is called deep learning (Zhang et al., 2019),
whose definition and use cases will be discussed in
the following section of this work.
2.4 Deep Learning
This concept is considered the new generation of ar-
tificial neural networks, which traditionally has been
one of the pillars of artificial intelligence and machine
learning (Da’u and Salim, 2019). The objective of its
application is to improve the representation of learn-
ing through multiple layers and stages of data pro-
cessing, being able to learn various levels of repre-
sentations and data abstraction (Zhang et al., 2019),
therefore, discover implicit relationships when mov-
ing between layers.
Currently, the application of deep learning is
growing and expanding, standing out in satisfactory
results in areas such as computer vision, natural lan-
guage processing, image processing and in recom-
mendation (Xu et al., 2021). As Da’u and Salim
(2019) highlighted, since the first publications in-
volving deep learning with recommendation systems,
there was an accelerated growth of related studies and
most has been published in the last six years.
In the meantime, there is a massive demand from
both academia and in industry to use deep learning for
a wide range of applications, with in order to take ad-
vantage of their intrinsic ability to deal with complex
tasks processes and obtain improved results. Further-
more, this methodology surprises not only due to the
increase in performance in several aspects in these ar-
eas as well as its ability to learn representations from
the beginning of application, that is, from zero stage
(Zhang et al., 2019).
The effectiveness demonstrated in several scien-
tific studies regarding the application of this approach
with recommendation systems, enabled the develop-
ment and progress in the use of this method. In this
context, several algorithms that combine these two
approaches, created an important scientific field with
a range of emerging applications capable to produce
results with greater performance than compared to
traditional algorithms (Peng et al., 2020; Sarker and
Matin, 2021).
3 RELATED WORKS
Some of the state of the art researches that consider
the recommendation systems based on deep learning
are presented as follows.
Zhou (2020) proposed a recommendation system
approach with the objective of reducing the problem
of high computational cost inherent to traditional al-
gorithms when new items or users are included. In
this sense, was used deep neural networks to perform
similar content search for new users or new products,
and then dynamically include them in the original sys-
tem. Through this strategy, it reduced the number of
recalculations that would be necessary and in compar-
ison to other algorithms, there were better results for
the mean squared error parameters (RMSE) and mean
absolute error (MAE).
A collaborative filtering methodology applied
with deep learning was proposed by Negi and Patil
(2021), whose objective is to unite these two areas
and obtain better results in recommendations. Two
models were built, one based on stacked autoencoder
– AE, with the function of identifying multiple com-
pressed representations of the same data, and another
based on Restricted Boltzmann Machine – RBM,
used in the stage of building recommendations.
Sarker and Matin (2021) defined a recommenda-
tion system hybrid based on matrix factorization and
deep neural networks, in addition used auxiliary in-
formation about users and items. The proposed model
aims to obtain internal and implicit relationships be-
tween users and items, for this it uses factorization
matrix and the Multilayer Perceptron – MLP model.
4 HYBRID MODEL OF
RECOMMENDATION SYSTEM
This section aims to describe the proposed model for
the system of recommendation. In this sense, it is ex-
plored the concepts of the hybrid model proposed for
recommendation based on collaborative filtering and
Recommendation Systems: A Deep Learning Oriented Perspective
685
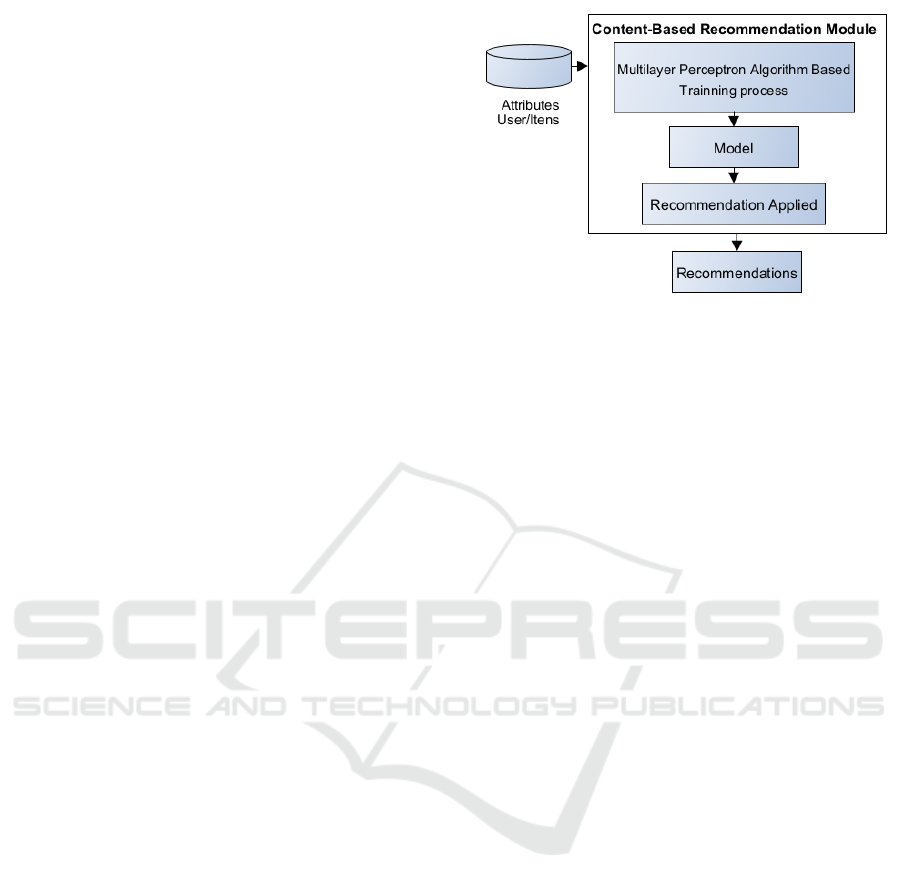
also content-based, both supported by deep learning.
According to Dellal-Hedjazi and Alimazighi
(2020) the most of the works that use recommenda-
tion systems based on deep learning uses collabora-
tive filtering strategy and these approaches provide
high diversification are capable to deal with the con-
stant evolution of volume of data. However, they are
impacted by the cold start problem and data scarcity.
On the other hand, although the content-based ap-
proach is less explored through the implementation
of algorithms based on deep learning, it is essential
to address the problem of cold start and data scarcity.
In that sense, it is a technique capable of providing
predilections, through descriptive attributes individ-
uals, regardless of the historical interaction relation-
ships between users and items.
In this context, the basic idea is to use a hybrid
model that is capable to unify the qualities of col-
laborative filtering strategies with the content-based
type, and that is implemented with fundamental deep
learning algorithms. Furthermore, this is confirmed
by Huang et al. (2019), that the hybrid recommenda-
tion algorithms are still little explored by deep learn-
ing approaches, and therefore it is an area with scope
to be explored for innovative contributions.
The architecture of the proposed is organized
into two main modules, namely Content-Based Deep
Learning and Collaborative-Filtering Deep Learning.
The first uses as input data the user attributes and
items, and from them generates a model that is used
to generation of recommendations. The second uses
historical data of the relationship between users and
items to train the model and generate preferences. Fi-
nally, the results are combined and a recommendation
list is presented.
4.1 Content-Based Deep Learning
Module
This module has an architecture based on the recom-
mendation system developed by Dellal-Hedjazi and
Alimazighi (2020) and has two concepts which are
the demographic and content-based approach. That
is, consider both the attributes that describe and qual-
ify the items as well as those that are referring to
users, in order to be the basis for training and gen-
eration of recommendations. In Figure 1 are showed
the sequence of steps that are performed to obtain the
recommendation.
The steps that make up this module are described
below:
Pre-Processing:
Phase of receiving raw input data, in which the at-
tributes of interest are selected. Additionally, a data
Figure 1: Content-based Deep Learning Module.
cleaning process is applied for removing discrepant
(outliers) or unstructured data, and filling of missing
data. There is data coding, a stage in which the con-
version of data from the original format to digital for-
mat so that it can be used in mathematical calcula-
tions. Finally, the application of normalization called
Min-Max to reduce the data range between 0 and 1,
this operation being carried out with the in order to
facilitate the learning process of the neural network.
Learning Module:
One of the most suitable architectures for classifica-
tion problems based on the attributes and characteris-
tics of the input data is called Multilayer Perceptron
– MLP, which is a deep neural network. In this case,
it was dimensioned to be composed of an input layer,
twelve hidden layers and a about to leave.
The input layer will be fed with the characteristics
of the items, for example, in the MovieLens database
the attributes of title, year of release and gender, and
also user attributes, as age and occupation. Regarding
the intermediate part, it will be composed of twelve
hidden layers, which may be resized to adapt the net-
work in relation to the results obtained and thus allow
their optimization. In observation, the choice of num-
ber of hidden layers is a relevant decision point for
the algorithm, since which can generate two types of
problems called overfitting and missfitting, the first
occurs when the number of hidden layers is high and
this generates a very large in relation to the input data,
that is, the model in practice becomes specialized and
is not able to generalize to new evaluated data (Sabiri.
et al., 2022). The second problem is related to the in-
ability of the model to adhere to the behavior of input
data and becomes too much generic.
Finally, the output layer is responsible for gener-
ating the result of the recommendation, whose neuron
with the best probability is considered the network
prediction.
Furthermore, it has a variable number of neurons,
grouped functionally and fully connected. Basically,
ICEIS 2024 - 26th International Conference on Enterprise Information Systems
686
the learning process starts with the pre-processed
data, of which 80% will be for training, 10% vali-
dation and 10% testing, so learning occurs by passing
data through the deep neural network and calculating
the error between the expected result and the found
result. In this way, at each interaction the error is min-
imized through backpropagation and the weights for
each parameter matrix are saved.
Recommendation Phase:
Step that considers the previously trained and learned
model, thus, loads the saved weights and uses them
under the new pre-processed data. The result obtained
is a list in descending order containing the largest val-
ues that were predicted.
4.2 Collaborative Filtering Deep
Learning Module
The main objective of this module is to enable the ex-
traction of predilections that are intrinsic to the his-
tory of user and item relationships. According to lit-
erary review research, there is a model that stands out
for its capacity extract the relationship between users
and items through multiple perspectives and that has
proven efficiency in obtaining results with greater per-
formance and quality. Therefore, this model proposed
by Huang et al. (2019) is called Deep Matrix Factor-
ization Learning – DMFL, and is used as a basis for
reference so that it can be adapted and coupled to the
hybrid algorithm proposed in this work. This module
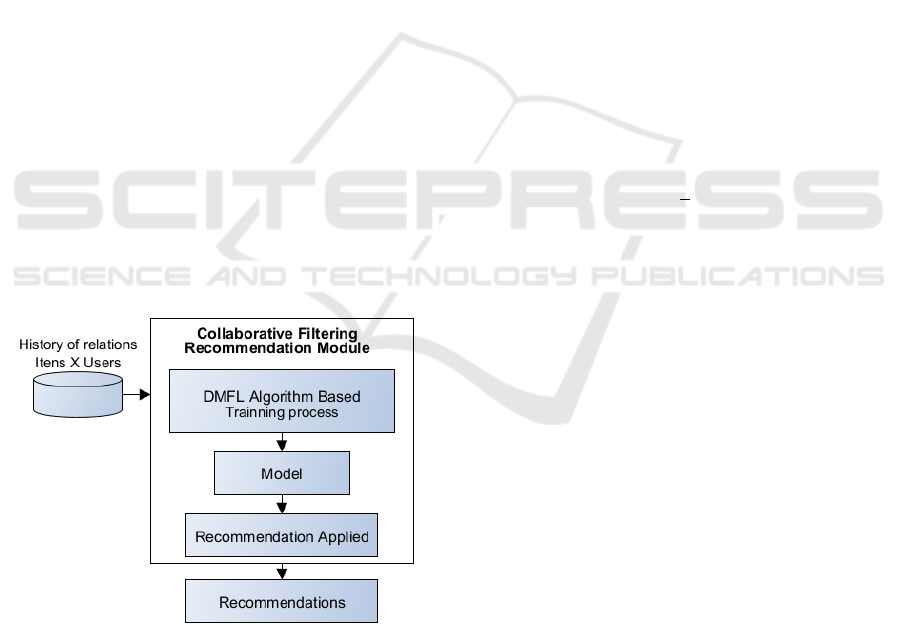
is visually represented at Figure 2.
Figure 2: Collaborative Filtering Deep Learning Module.
The basic operating structure is segmented into
two stages, namely, feature learning and preference
generation, which are described in follow:
Feature Learning:
Composed of two parallel neural networks that are re-
sponsible for extract the latent feature vectors of items
and users. In this context, Multilayer Perceptron –
MLP structures are used with the aim of extract deep
and hidden characteristics regarding users and items.
Due to the characteristics of the items that will be
recommended are considered stable because they do
not change frequently, a method is established static
for training and extracting them. Therefore, the la-
tent vector data of item characteristics are extracted
directly from the static descriptive data of the items.
The characteristics are considered: id, name, year,
gender and other data that can describe it and that are
available in the MovieLens database.
On the other hand, data relating to user char-
acteristics can change more frequently according to
changes in preferences. Therefore, this method is a
process of dynamic learning which considers both ba-
sic and static data, for example, age, gender, occupa-
tion and region, as well as using the history of inter-
actions with items. Through this history, the vectors
of characteristics of the k items that the user “liked”
most recently and thus allows consider the natural dy-
namics of changes in user preferences.
The user’s preference history vector is defined
through the equation 1, whose parameter k represents
the number of items that the user recently liked and y
i
is the preferred history item of user u
i
:
x
h
i
=
1
k
k
∑
t=1
y
i
t
(1)
Furthermore, in order to obtain the final vector of
user characteristics, the vectors x
c
i
and y
h
i
, which refer
respectively to the basic data vector and static images,
and the preference history vector, are inserted into the
input layer of a Multilayer Perceptron. This final vec-
tor is described by equation 2:
x
i
= f (W
a
[x
c
i
: x
h
i
] + b
a
) (2)
Where f is the activation function of the neural
network layer, W
a
represents the weights and b
a
is the
bias of the network layer.
Generation of Preferences:
The result of the step described previously, which are
the characteristics of items and users, is used as in-
put to the algorithm responsible for generating user
preferences. This process is based on the concept of
simultaneously combining several models, so that it is
possible to extract characteristics of data from multi-
ple perspectives. In this way, in addition of being able
to combine the advantages of these different models,
also minimizes their deficiencies, therefore it makes
it possible to provide results with greater precision.
In this context, there are three sub-modules that
run in parallel and their results are merged to obtain
user preferences. The modules are called SDAE-FM,
Recommendation Systems: A Deep Learning Oriented Perspective
687
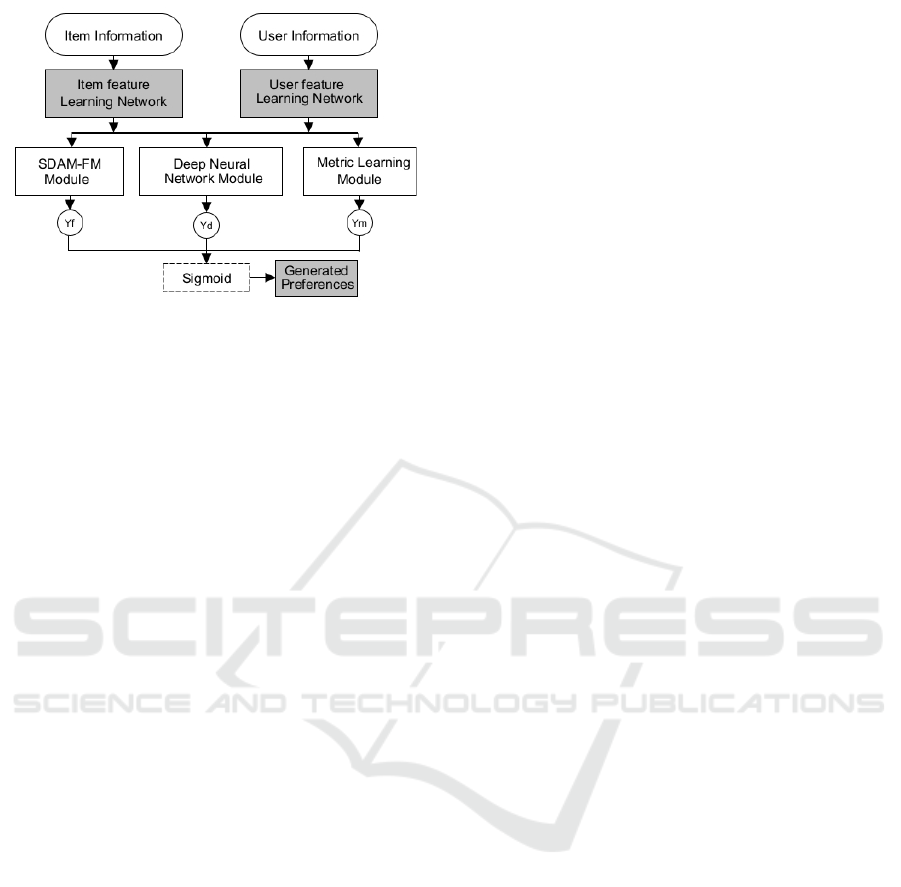
Figure 3: DMFL Architecture.
Deep Neural Network – DNN, Metric Learning as
presented in Figure 3.
The sub-modules of the preference generation
process are detailed below:
• SDAE-FM:
Based on two Matrix Factorization strategies
– FM and Stacked Denoising AutoEncoder –
SDAE, which together are responsible for reduc-
ing the dimension of features and extracting deep
latent features. In this way, it is used to learn the
importance of each characteristic, as well as the
relationship that occurs between them and, conse-
quently, obtains the user’s preferences.
• Deep Neural Network:
The main objective of this module is to explore
the relationships deep and non-linear relationships
arising from the relationship between items and
users, and finally, generate user preferences with
greater precision. Consider a neural network with
four layers, with the calculation in each of them
being carried out as equation 3:
a
(l+1)
= f (W
l
a
l
+ b
l
) (3)
Where a represents the input, W is the weights,
b is the bias, with all parameters referring to the
l − th layer. The function f corresponds to the
function of activation, in which in this case the
Rectified Linear Units – ReLUs method was used.
In observation, at this stage the use of the Batch
normalization with the aim of standardizing in-
puts at each layer of the neural network and pre-
vent the model overfitting problem.
• Metric Learning: At this stage the main objective
is to consider the users and items, and also mea-
sure them from a distance perspective. Uses two
parallel convolutional neural network models with
different parameters. The computational process
of these networks is represented by equation 4:
h
t
= f (x
i
∗ k
t
+ b
t
) (4)
Where x
i
refers to the input data, k
t
represents the
t- th filter, b
t
is the bias, f is the ReLUs activation
function and, finally, the symbol ∗ is the convolu-
tion.
In summary, each of the sub-modules aims to ob-
tain user preference for through specific perspectives:
linearity, non-linearity and distance. Thus, at the end
of executing the three steps there are three user pref-
erence vectors which will be processed through the
sigmoid operation. In this context, when executing In
this operation, the main objective is to obtain a com-
bination of results in order to effectively optimize rec-
ommendation accuracy. This operation is defined by
equation 5:
z
i j
= sigmoid(y
f
i j
+ y
d
i j
+ y
m
i j
) (5)
In summary, the individual results of each of the
modules will be unified and then the recommendation
will be presented to the user. This process of joining
the results will initially be the simple union of the fi-
nal prediction vectors individual issues arising from
each of the modules, however, it is a decision point
for the algorithm design and that it can be evolved
and used some specific operation when it is subjected
to evaluation criteria and tests.
5 CONCLUSIONS
The amount of resources that are offered and con-
sumed digitally through the Internet is constantly in-
creasing, involving information from work, leisure,
studies or simply for communication. In this con-
text, it is noted an overload of information that is con-
sidered harmful in relation to experience of users of
these resources and of the enterprises that are not able
to target the content that really matters to their cus-
tomers. In this way, it was verified how fundamental
it is to use recommendation to support the resolution
of the problem of information overload and thus em-
ploy useful strategies for it. Furthermore, it was found
that the use of lonely classical recommendation tech-
niques is not such efficient when compared to its hy-
brid use or supported by other methodologies.
The study and analysis of approaches that adopt
deep learning in conjunction with traditional rec-
ommendation system techniques demonstrate greater
quality and accuracy than classical algorithms. In
addition, they provide the discovery of implicit rela-
tionships between users, items and user-items, there-
fore, providing better understanding of user prefer-
ICEIS 2024 - 26th International Conference on Enterprise Information Systems
688

ences and then making predictions with greater effi-
ciency and degree of assertiveness.
Finally, this work was conducted with the objec-
tive of provide improvements and optimizations to
recommendation systems based on development of
the proposed hybrid architectural model, considering
both aspects of content-based strategy and collabora-
tive filtering supported by deep learning.
ACKNOWLEDGEMENTS
The authors would like to thank Coordenac¸
˜
ao de
Aperfeic¸oamento de Pessoal de N
´
ıvel Superior -
Brasil (CAPES), under grant 88887.686064/2022-00,
and S
˜
ao Paulo Research Foundation (FAPESP), under
grant 2020/08615-8, for the partial financial support.
REFERENCES
Anil, D., Vembar, A., Hiriyannaiah, S., G.M., S., and Srini-
vasa, K. (2018). Performance analysis of deep learn-
ing architectures for recommendation systems. In
2018 IEEE 25th International Conference on High
Performance Computing Workshops (HiPCW), pages
129–136.
Bhanuse, R. and Mal, S. (2021). A systematic review:
Deep learning based e-learning recommendation sys-
tem. pages 190–197.
Da’u, A. and Salim, N. (2019). Recommendation system
based on deep learning methods: a systematic review
and new directions. Artificial Intelligence Review,
53:2709–2748.
Dellal-Hedjazi, B. and Alimazighi, Z. (2020). Deep learn-
ing for recommendation systems. pages 90–97.
Fayyaz, Z., Ebrahimian, M., Nawara, D., Ibrahim, A., and
Kashef, R. (2020). Recommendation systems: Algo-
rithms, challenges, metrics, and business opportuni-
ties. Applied Sciences, 10(21).
Grossetti, Q., du Mouza, C., and Travers, N. (2019).
Community-based recommendations on twitter:
Avoiding the filter bubble. In Cheng, R., Mamoulis,
N., Sun, Y., and Huang, X., editors, Web Information
Systems Engineering – WISE 2019, pages 212–227,
Cham. Springer International Publishing.
Guo, W.-w. and Liu, F. (2019). Research on collabora-
tive filtering personalized recommendation algorithm
based on deep learning optimization. In 2019 Inter-
national Conference on Robots & Intelligent System
(ICRIS), pages 90–93.
Huang, Z., Yu, C., Ni, J., Liu, H., Zeng, C., and Tang, Y.
(2019). An efficient hybrid recommendation model
with deep neural networks. IEEE Access, 7:137900–
137912.
Isinkaye, F., Folajimi, Y., and Ojokoh, B. (2015). Recom-
mendation systems: Principles, methods and evalua-
tion. Egyptian Informatics Journal, 16(3):261–273.
Liu, F., Song, Y.-j., Han, Y.-h., Wu, M.-y., Dong, W., Cai,
P., Long, C.-h., and Wang, B.-q. (2020). Research on
personalized recommendation model and algorithm in
deep learning mode. In 2020 International Confer-
ence on Robots & Intelligent System (ICRIS), pages
116–119.
Negi, R. and Patil, A. B. (2021). Deep collaborative filter-
ing based recommendation system. In 12th Interna-
tional Conference on Computing Communication and
Networking Technologies, ICCCNT 2021, Kharagpur,
India, July 6-8, 2021, pages 1–5. IEEE.
Peng, M., Zhang, J., Wen, S., and Liu, C. H. (2020). Com-
paring recommendation algorithms in session-based
e-commerce sites. In 2020 International Conference
on Intelligent Computing, Automation and Systems
(ICICAS), pages 377–380.
Petter., S. and Jablonski., S. (2023). Recommender systems
in business process management: A systematic litera-
ture review. In Proceedings of the 25th International
Conference on Enterprise Information Systems - Vol-
ume 2: ICEIS, pages 431–442. INSTICC, SciTePress.
Saat, N., Mohd Noah, S. A., and Mohd, M. (2018). Towards
serendipity for content–based recommender systems.
International Journal on Advanced Science, Engi-
neering and Information Technology, 8:1762.
Sabiri., B., El Asri., B., and Rhanoui., M. (2022). Mech-
anism of overfitting avoidance techniques for train-
ing deep neural networks. In Proceedings of the
24th International Conference on Enterprise Informa-
tion Systems - Volume 1: ICEIS, pages 418–427. IN-
STICC, SciTePress.
Sarker, M. R. I. and Matin, A. (2021). A hybrid col-
laborative recommendation system based on matrix
factorization and deep neural network. In 2021
International Conference on Information and Com-
munication Technology for Sustainable Development
(ICICT4SD), pages 371–374.
Xu, G., Cai, J., Jiang, S., Cai, J., Ouyang, M., and Li, J.
(2021). Physical examination package intelligent rec-
ommendation system based on deep learning. In 2021
6th International Conference on Computational Intel-
ligence and Applications (ICCIA), pages 21–25.
Zhang, S., Yao, L., Sun, A., and Tay, Y. (2019). Deep learn-
ing based recommender system: A survey and new
perspectives. ACM Computing Surveys, 52(1):1–38.
Zhou, Y. (2020). A dynamically adding information rec-
ommendation system based on deep neural networks.
In 2020 IEEE International Conference on Artificial
Intelligence and Information Systems (ICAIIS), pages
1–4.
Recommendation Systems: A Deep Learning Oriented Perspective
689
