
Knowledge Graph Generation from Text Using Supervised Approach
Supported by a Relation Metamodel: An Application in C2 Domain
Jones O. Avelino
1,2 a
, Giselle F. Rosa
1 b
, Gustavo R. Danon
1 c
, Kelli F. Cordeiro
3 d
and Maria Cl
´
audia Cavalcanti
1 e
1
Instituto Militar de Engenharia (IME), Rio de Janeiro, RJ, Brazil
2
Centro de An
´
alise de Sistemas Navais (CASNAV), Rio de Janeiro, RJ, Brazil
3
Subchefia de Comando e Controle (SC-1), Minist
´
erio da Defesa, Bras
´
ılia, DF, Brazil
Keywords:
Named Entity Recognition, Relation Extraction, Knowledge Graph, Command and Control.
Abstract:
In the military domain of Command and Control (C2), doctrines contain information about fundamental con-
cepts, rules, and guidelines for the employment of resources in operations. One alternative to speed up per-
sonnel (workforce) preparation is to structure the information of doctrines as knowledge graphs (KG). How-
ever, the scarcity of corpora and the lack of language models (LM) trained in the C2 domain, especially in
Portuguese, make it challenging to structure information in this domain. This article proposes IDEA-C2, a
supervised approach for KG generation supported by a metamodel that abstracts the entities and relations ex-
pressed in C2 doctrines. It includes a pre-annotation task that applies rules to the doctrines to enhance LM
training. The IDEA-C2 experiments showed promising results in training NER and RE tasks, achieving over
80% precision and 98% recall, from a C2 corpus. Finally, it shows the feasibility of exploring C2 doctrinal
concepts through an RDF graph, as a way of improving the preparation of military personnel and reducing the
doctrinal learning curve.
1 INTRODUCTION
Military performance in the Command and Control
(C2) scenario may be impacted by personnel turnover,
which is inherent to military careers. Thus, the Armed
Forces (AF) provide a list of doctrinal documents
comprising a set of principles, concepts, standards,
and procedures that guide actions and activities for
the full employment of its personnel in military opera-
tions and exercises. Despite this, studying these docu-
ments can lead to a long and costly learning curve. On
the other hand, as educational sources, they serve for
extracting helpful and structured information, which
could shorten the learning curve (Chaudhri et al.,
2013).
Advances in the Information Extraction (IE) tech-
nique in Natural Language Processing (NLP) have
made it possible to extract data from texts (structured,
a
https://orcid.org/0000-0001-9483-7220
b
https://orcid.org/0009-0004-8512-7883
c
https://orcid.org/0009-0005-2881-6030
d
https://orcid.org/0000-0001-5161-8810
e
https://orcid.org/0000-0003-4965-9941
semi-structured, and unstructured) through Named
Entity Recognition (NER) and Relation Extraction
(RE), based on the search for occurrences of object
classes (Luan et al., 2018). Since the emergence of
the self-attention mechanism and Language Models
(LM) based on Transformers, it has been possible to
expand NLP tasks (Devlin et al., 2019). By training
an LM with examples from the domain, it is possible
to create a specialized LM (Lee et al., 2019). On the
other hand, approaches that train LMs with fixed cate-
gories of entities limit their application, the extraction
of knowledge, and the expansion of the trained LM.
This work aims to minimize this limitation using
the IDEA-C2 approach, a supervised approach that
supports the generation of KG based on the training
of LM from C2 doctrinal texts in Portuguese. To
support the training, the approach encompasses pre-
annotation and curation processes, both supported by
a metamodel that defines high-level constructs to an-
notate the texts. In addition, the metamodel supports
the generation of the KG based on the mapping of
its constructs to the resources of controlled vocabu-
laries or the approach itself. To this end, we imple-
mented the IDEA-C2-Tool prototype, which uses the
Avelino, J., Rosa, G., Danon, G., Cordeiro, K. and Cavalcanti, M.
Knowledge Graph Generation from Text Using Supervised Approach Supported by a Relation Metamodel: An Application in C2 Domain.
DOI: 10.5220/0012629300003690
Paper published under CC license (CC BY-NC-ND 4.0)
In Proceedings of the 26th International Conference on Enterprise Information Systems (ICEIS 2024) - Volume 1, pages 281-288
ISBN: 978-989-758-692-7; ISSN: 2184-4992
Proceedings Copyright © 2024 by SCITEPRESS – Science and Technology Publications, Lda.
281

BERTimbau LM to perform the training. By submit-
ting C2 Texts to the trained LM, it extracts by infer-
ence sets of entities and relations, which can then be
explored through an RDF graph. The contributions of
this work include: (i) an approach to support extract-
ing entities and relations and generating knowledge
graphs; (ii) a prototype that implements the activities
of the approach; and (iii) an experiment that demon-
strates the viability and usefulness of IDEA-C2.
2 BACKGROUND
Machine Learning algorithms have been used to train
LM by different approaches. The supervised ap-
proach is characterized by the work of the domain
expert, in addition to the need for a corpus of anno-
tated texts based on categories of entities and relations
(Russell and Norvig, 2010). The text annotation task
is the identification of which category is appropriate
for a given term. In NER tasks, named entities are cat-
egorized, for example, as person, organization, and
location, while in RE tasks, the categories are used
to express the semantics between two named entities,
such as born-in, married-to, etc. However, manually
annotating the corpus is very time-consuming. The
supervised distance approach emerged as an alterna-
tive to minimize annotation costs (Mintz et al., 2009).
It uses regular expression rules to automate the anno-
tation task.
The Bidirectional Encoder Representations from
Transformers (BERT) (Devlin et al., 2019) is an LM
that allows for training models based on examples
from the domain. BERT training consists of two
stages. The first stage is pre-training, feature-based,
and does not require labeled data. The second stage
involves fine-tuning the weights of the pre-trained
model to adjust it based on the domain dataset (De-
vlin et al., 2019). At this stage, the categories of en-
tities and relations are usually defined with the help
of the domain expert and according to the application
domain. This is not an easy task and it has been rec-
ognized as so by database and conceptual modelers
for decades (Kent, 2012).
Due to the difficulty of identifying categories of
entities and relations for any domain, a viable alter-
native is to use a metamodel that allows abstracting
and flexibilizing this definition using high-level con-
structs. To represent constructs of different abstrac-
tion levels (models and metamodels) in a single view,
it is necessary to use flexible modeling approaches,
such as Knowledge Graphs (KG). As in (Hogan et al.,
2021), a KG is a graph of (meta)data intended to ac-
cumulate and convey knowledge of the real world,
whose nodes represent entities of interest and whose
edges represent relations between these entities. The
Resource Description Framework (RDF)
1
is a largely
used implementation of KG. It represents (meta)data
as a directed graph, made up of triples, formed by a
subject, a predicate, and an object (s, p, o), where
subjects and objects correspond to the vertices of the
graph, and predicates correspond to the edges.
3 RELATED WORK
In general, works focused on generating KG apply-
ing LM are diverse. However, they share some com-
mon characteristics. One of these is the use of rela-
tion extraction to create triples. In (Liu et al., 2023),
an aviation field KG is generated from textbook chap-
ter texts. Pairs of entities and relations are extracted
and combined with reinforcement learning methods,
using five entity categories and three relations. The
Hidden Markov Model (HMM), Conditional Random
Field model (CRF), Bidirectional Long Short-Term
Memory (BiLSTM), and BiLSTM + CRF are used
for this purpose. However, the definition of these cat-
egories limits training. In addition, the Transformers
architecture outperforms these models by searching
for more distant terms in a bidirectional manner.
In (Dang et al., 2023), a KG is created based
on extractions of five categories of entities and rela-
tions from nutrition and mental health PubMed ar-
ticles. A hybrid model deals with NER tasks, sup-
ported by ontologies. For RE, the authors applied a
model that combines patterns of word syntactic de-
pendencies with part of speech in a sentence. To
this end, scispaCy
2
, a pipeline of models based on
biomedical data, is used. However, the approach is
limited to fixed categories. In addition, using super-
vised distance methods outperforms syntactic depen-
dency methods (Mintz et al., 2009).
In (Zhou et al., 2022), the supervised distance
method is used to minimize manual annotation. Mil-
itary simulation scenarios are established based on
NER tasks. Four categories of entities are defined for
training using a recurrent neural network with short-
and long-term memory (LSTM). The LSTM learns
the dependencies between elements in a sequence. An
Embedding layer converts text into a vector repre-
sentation. Another BiLSTM layer, made up of two
LSTMs in opposite directions, extracts the context.
Finally, the entities are converted into class diagrams
to transform them into RDF graphs. Despite mini-
mizing annotation, the categories of entities are fixed.
1
https://www.w3.org/RDF/
2
https://allenai.github.io/scispacy/
ICEIS 2024 - 26th International Conference on Enterprise Information Systems
282
In addition to the fact that the approach does not deal
with RE tasks, it impacts analysis in RDF.
Finally, in (Zhao et al., 2021), a KG based on
military regulations is generated. The annotation is
supported by a statistical word segmentation method
combined with dependency parsing for NER tasks.
For the RE task, the authors applied Conditional Ran-
dom Fields and Part-of-speech tagging (POS) to in-
dicate the grammatical class of the word that denotes
the action between the pairs of entities, obtaining the
triples e
i
, r
j
, e
k
for generating the KG. It should be
noted that recognizing entities without defining fixed
categories is an aspect to be considered. However, the
extraction of relations based on POS is limited to the
structure of the text.
Table 1 presents the related works and the com-
parison parameters to our proposal. We can highlight
three important characteristics to evaluate in these
works: (i) approaches to minimize the impact of man-
ual annotation, which contribute to a greater number
of labeled data; (ii) good recall of the domain, i.e., not
limited to a fixed set of entity categories; (iii) usage of
didactic texts, glossaries or ontologies to increase the
LM adherence to the domain.
Table 1: Comparison with related works.
Approach i ii iii
(Liu et al., 2023) X - X
(Dang et al., 2023) - - X
(Zhou et al., 2022) X - X
(Zhao et al., 2021) - X -
Although the approaches apply various strategies
to generate KGs, the problem of defining annotation
categories remains open. One of the challenges is to
find a representation that can deal with more flexi-
ble categories of entities and relations. Unlike these
other approaches, this work aims to offer a solution
that meets the three characteristics.
4 C2RM: COMMAND AND
CONTROL RELATIONS
METAMODEL
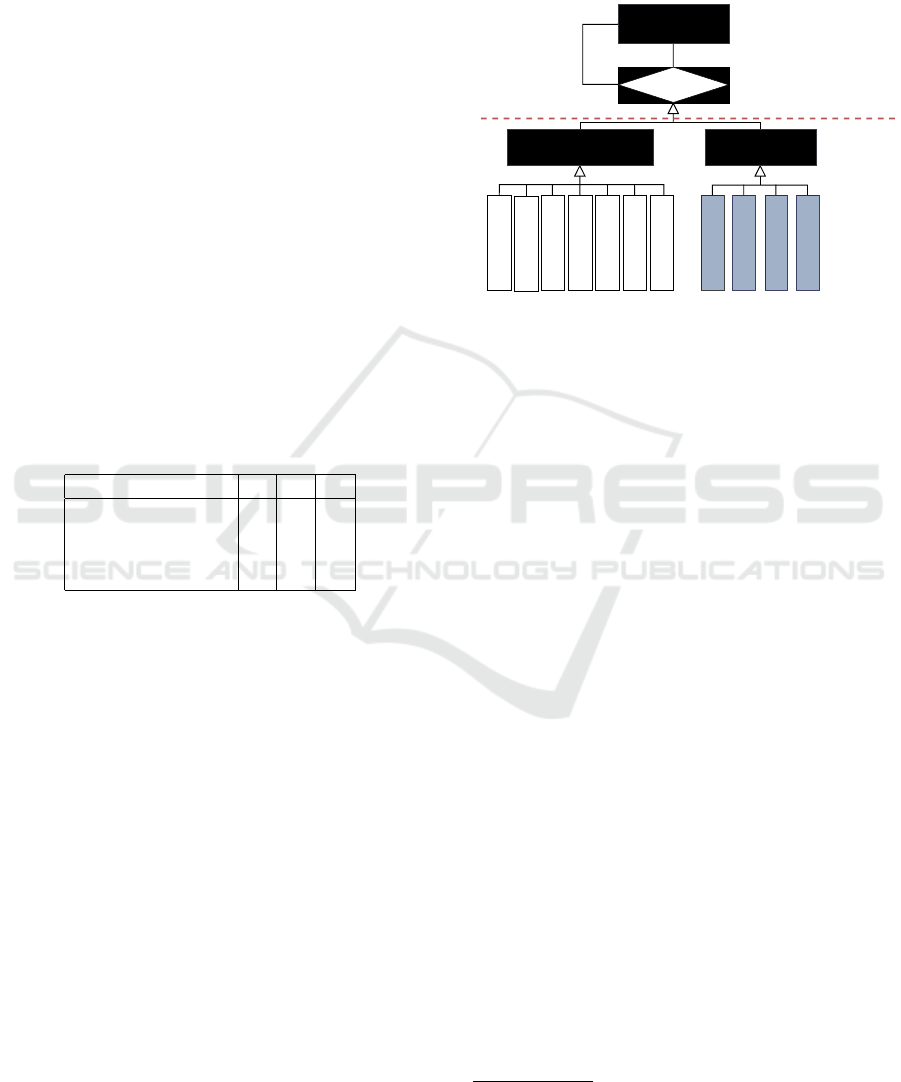
The proposed Command and Control Relations Meta-
model (C2RM) aims to define a structure to represent
the recognized entities and provide the semantics of
the relations between them based on the use of doctri-
nal texts and glossaries of terms of the C2 domain. To
address the challenge of dealing with the flexibility of
categories, the C2RM defines high-level abstraction
constructs, Entity and Relation, capable of providing
comprehensive categories for extracting information
from the corpus, including relations of general appli-
cation (such as term-definition, hyperonym-hyponym,
whole-part, equivalent-synonym) as well as C2 do-
main relations (such as action-responsible).
(0,N)
(0,N)
Relation
Entity
composed_of
defined_by
instance_of
type_of
associated_with
equivalent_to
co-referenced
r
1
r
2
r
3
r
4
r
5
r
6
r
7
General Domain
Relation
C2 Domain
Relation
Metamodel
Entities
Metamodel
Relations
Specializations
applied_to
capacity_of
occurs_in
responsible_for
r
8
r
9
r
10
r
11
Figure 1: C2RM Diagram.
As illustrated in Figure 1, the C2RM represents
two high-level constructs: Entity and Relation. The
Entity construct, E = {e
1
, e
2
, ...e
n
}, represents the
named entities recognized from the text, for example,
Person, Brigade, Operation, Alpha Operation, etc.
Similarly, the Relation construct, R = {r
1
, r
2
, ...r
m
},
represents the instances of relations that may occur
between two Entity instances. Note that it was a
choice not to represent a predefined set of entity cat-
egories. There is just a single generic category, the
ENTITY. The idea is to increase the flexibility of the
approach, named Singlecategory classification. On
the other hand, the Relation construct was special-
ized into Multicategory classifications. It has two
specializations: General Domain Relation and C2
Domain Relation, which represent the relations out-
side and inside the C2 domain, respectively. The self-
relationship aggregation has characteristics that allow
each relationship to be specialized. Also, it has eleven
sub-specializations
3
which are defined to represent
the semantics of the relationships. Specializations r
1
,
r
2
, and r
7
were inspired by RDF properties, denoting
equivalence, association, and instance, respectively.
Specializations r
3
and r
4
were inspired by (Augen-
stein et al., 2017), denoting compositions and hierar-
chies, while r
5
and r
6
were inspired by (Spala et al.,
2020), denoting term-definition and co-reference, re-
spectively. Finally, r
8
to r
11
are specializations in-
volving C2 domain, denoting responsibility, capacity,
occurrence, and application, respectively.
The main benefit of the C2RM is that it allows
3
Although the specializations are in English, they ex-
press semantics in Portuguese
Knowledge Graph Generation from Text Using Supervised Approach Supported by a Relation Metamodel: An Application in C2 Domain
283
one to work only with pre-established relations, most
of them general-domain relations, and some of them
C2-related relations, but that can also be considered
generic to a certain extent. Besides, all these rela-
tions may be identified in texts at multiple levels of
abstraction. Sometimes they appear at the instance
level, and sometimes they may be seen as connect-
ing high-level concepts. In the sentence “Operac¸
˜
ao
de Garantia da Lei e da Ordem - Operac¸
˜
ao Mil-
itar conduzida pelas Forc¸as Armadas...”, extracted
from a C2 Glossary (BRASIL, 2009), it was anno-
tated that “Operac¸
˜
ao de Garantia da Lei e da Or-
dem” and “Forc¸as Armadas” are instances of the En-
tity construct, and are connected by an instance of
the Relation construct responsible for. In the sen-
tence “Fica autorizado o emprego das Forc¸as Ar-
madas (Marinha do Brasil,...) para a Garantia da
Lei e da Ordem”, extracted from the Presidential De-
cree establishing the military operation to Guarantee
Law and Order (GLO) in 2017
4
, it was annotated that
“Garantia da Lei e da Ordem (GLO 2017)” and “Mar-
inha do Brasil” are instances of the Entity construct,
and are connected by an instance of the Relation con-
struct responsible
for. Note that at this point, there
is no information about the categories of those En-
tity instances. However, an additional annotation of
instances of the Relation construct instance of, con-
nects “Marinha do Brasil” to “Forc¸as Armadas”, and
connects “GLO 2017” to “Operac¸
˜
ao de Garantia da
Lei e da Ordem”. This example illustrates that with
C2RM metamodel it is possible to generate a do-
main model (C2 Model) with two levels of abstrac-
tion. From the first sentence two high-level concepts
(categories) are identified, and from the second sen-
tence two instances of those concepts are identified,
both pairs are connected through an instance of the
Relation construct responsible for.
5 IDEA-C2: KG GENERATION
FROM TEXT SUPPORTED BY
C2RM
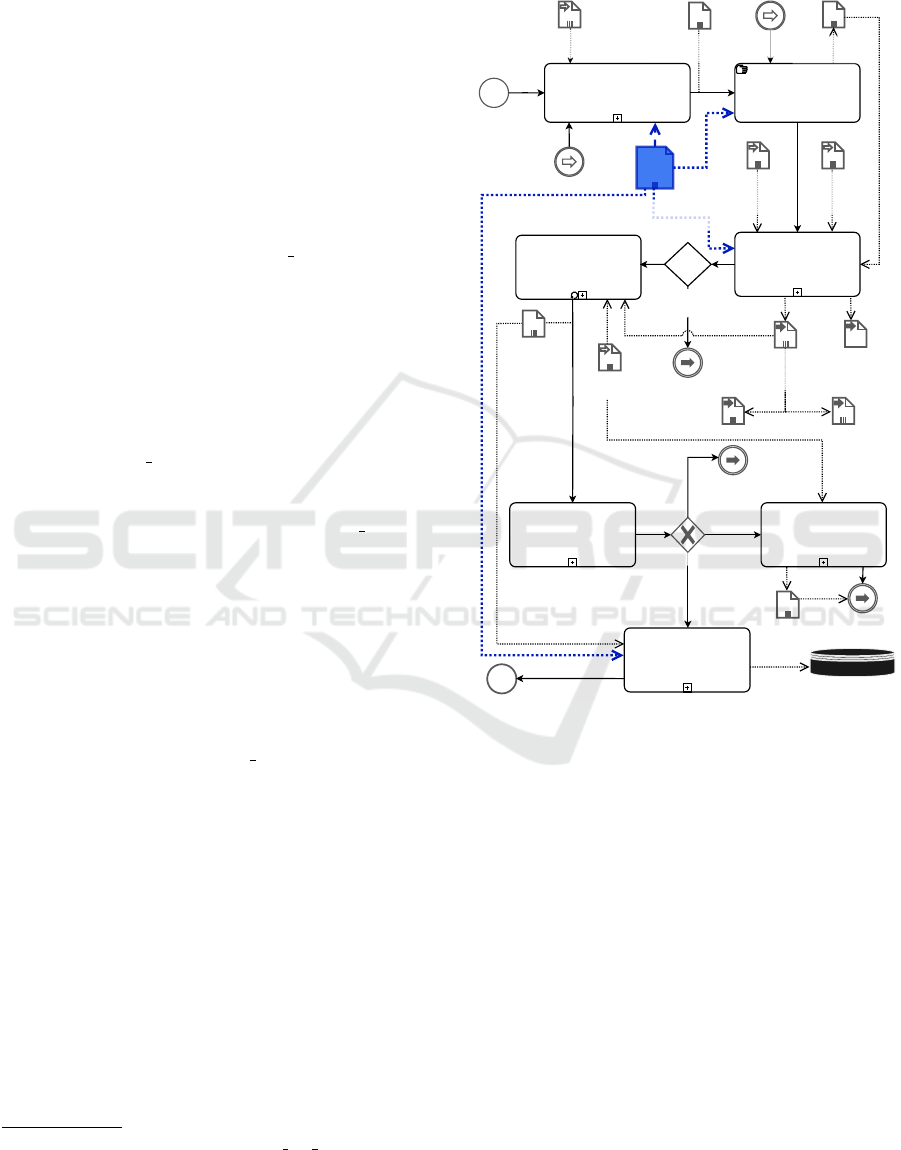
The IDEA-C2 (generatIon of knowleDge graphs
basEd on Artificial intelligence of C2 Domain) su-
pervised approach is a process made up of seven sub-
processes, illustrated in Figure 2. The IDEA-C2 aims
to generate KG in the C2 domain, in Portuguese, sup-
ported by the BERTimbau LM (Souza et al., 2020),
from a corpus of semi-structured texts, which are
based on C2 glossaries and doctrinal documents. In
4
https://www.planalto.gov.br/ccivil 03/ ato2015-
2018/2017/dsn/dsn14485.htm
addition, IDEA-C2 uses the C2RM that contributes to
the pre-annotation of the input texts, the curation, the
fine-tuning of the LM and the generation of the KG.
No
Training metrics
results satisfactory?
Pre-annotate entities
and relations
Apply Fine-Tuned
Language Model
Generate
Knowledge Graph
Train Fine-Tuned
Language Model
Pre-trained
language
model
IDEA-C2-KG
Metric
Training
Results
Annotated
C2 Domain
Text (CT'')
Yes
Validate
EE and ER
Adjust
annotation
Results of validation
Annotate more
EE and ER
Submit more
C2 Texts
EE and ER
satisfactory
Curate
Annotation
Comand and Control Relations
Metamodel (C2RM)
C2 Training
Data (C'')
C2 domain
Texts (CT)
Generate re-
training data
Adjust annotation
C2 Identified
Entities (EE)
and
Relations (ER)
(DM)
PT-BR
language
vocabulary
Adjust
annotation
C2 Doctrines and
Military Glossary (C)
NER
RE
C2 Fine-tuned
Language Model
(IDEA-C2-Model (D)
Adjust pre-annotation
Adjust pre-
annotation
C2 Pre-annotated
document (C')
Figure 2: Overview of IDEA-C2 Approach.
Departing from a set of doctrine texts named UC2,
which constitutes a C2 Corpus, a representative sub-
set of it (C Corpus) is selected and submitted to the
IDEA-C2 approach. The C Corpus is first annotated
using the C2RM constructs, and then submitted to
BERTimbau LM for NER and RE training, resulting
in the IDEA-C2-Model. In reality, IDEA-C2-Model
represents two trained LMs, one for the NER task
and the other for RE. Another sample of C2 Texts is
then submitted to IDEA-C2-Model in order to extract
named entities and their relations. The extracted data
is stored in the KG Database, generating IDEA-C2-
KG. Next, the IDEA-C2 sub-processes are presented
in detail.
The Pre-annotate entities and relations sub-
process has as its input the sentences, s
i
, from the
unlabeled doctrines and military glossary text cor-
pus, represented by C = {s
1
, s
2
, . . . , s
n
}, for pre-
ICEIS 2024 - 26th International Conference on Enterprise Information Systems
284

annotation. Pre-annotation was inspired by the dis-
tance supervision method (Mintz et al., 2009) in order
to increase the labeling of terms and minimize the cu-
ration effort. Using the specializations of the C2RM,
detailed in Section 4, pre-annotation rules are devel-
oped using regular expressions to annotate terms, gen-
erating as output a new pre-annotated corpus, C
′
, in
JSON Lines (JSONL) format.
The Curate Annotation sub-process has as its in-
put the corpus, C
′
, for the expert to curate. The curator
in the supervised approach can either revise or ratify
the annotated entities and relations or insert new an-
notations. The Doccano tool
5
, previously configured
with the C2RM constructs, supports the curator. At
the end, a new corpus is generated, C
′′
, C2 training
data, containing the finalized annotations.
The Train Fine-Tuned Language Model sub-
process has as its input the corpus, C
′′
, the BERTim-
bau LM, the Portuguese language vocabulary and the
C2RM. It also submits C
′′
, annotated with the cate-
gories from the C2RM, to BERTimbau LM for train-
ing in order to identify named entities and extract re-
lations. Initially, the sentences of C
′′
are retrieved,
standardized to lowercase and stopwords removed. In
the tokenization activity, the SpaCy
6
library pipeline
is used, which retrieves each sentence s
i
, splits their
terms into tokens and transforms these tokens into
identifiers to create a spaCy Doc object.
The D dataset is split into training, validation, and
test sets, that are used to train the IDEA-C2-Model,
the NER/RE model for the C2 domain. After that, the
precision and recall metrics are evaluated, as well as
the inferences from the NER and RE tasks identified
by IDEA-C2-Model. If the results are not satisfactory,
it returns to Pre-annotate entities and relations for to
pre-annotate. Otherwise, once the IDEA-C2-Model
is ready, the Apply Fine-Tune language Model sub-
process is activated, and may submit a subset of not
annotated C2 texts (CT ⊂ UC2 −C) to the NER and
RE tasks. Thus, this sub-process has as its input CT =
{st
1
, st
2
, ...st
m
}, and as the output the DM dataset,
consisting of entities, EE = {e
1
, e
2
, ...e
n
}, and the
triples of relations, ER = {(e
i
, r
j
, e
k
) | e
i
, e
k
∈ EE are
semantically related by r
j
∈ R, in some st
l
∈ CT }.
In the Validate EE and ER sub-process, the cu-
rator is responsible for evaluating the inferences of
the NER and RE tasks identified by IDEA-C2-Model
through EE and ER compatible with the named enti-
ties and CT relations. If the results are satisfactory,
the Generate Knowledge Graph sub-process is acti-
vated. Otherwise, the curator can either choose to
re-evaluate the annotation, in which case it returns
5
https://github.com/doccano/doccano.
6
https://spacy.io/
to Cure pre-annotation, or the curator can introduce
more texts into the C2 domain, in which case Gener-
ate re-training data is activated.
In the Generate re-training data sub-process, the
curator can reinput the CT texts that were submitted
to IDEA-C2-Model. In this case, IDEA-C2 retrieves
CT , including the annotations already identified by
IDEA-C2-Model, has as its output the corpus CT
′′
as
a result. The sub-process Curate Annotation is ac-
tivated with the CT
′′
texts for the curator to review
and/or include new annotations of both named enti-
ties and relations.
Finally, after the iterative cycles of curation
and retraining, the Generate Knowledge Graph sub-
process retrieves the entities, EE, the triples, ER, and
the properties, R, in order to generate IDEA-C2-KG.
Initially, the entities, EE, are created as rdfs:Class.
The triples ER are created according to the mapping,
R, between the specializations of the metamodel and
the properties of the RDF graph, as expressed in Ta-
ble 2. In addition, the namespace c2rm was created to
deal with specializations with no corresponding prop-
erty in the RDF graph, as in the following cases: r
6
,
r
8
, r
9
, r
10
and r
11
.
Table 2: Mapping between C2RM and the RDF Graph.
r
n
Specializations
of C2RM
RDF Property
r
1
equivalent to owl:equivalentClass
r
2
associated with rdfs:seeAlso
r
3
composed of rdf:Bag
r
4
type of rdfs:subClassOf
r
5
defined by rdfs:comment
r
6
co-referenced c2rm:coreferenced
r
7
instance of rdf:type
r
8
responsible for c2rm:responsible for
r
9
capacity of c2rm:capacity of
r
10
occurs in c2rm:occurs in
r
11
applied to c2rm:applied to
An example of a C2 Text submitted to the IDEA-
C2-Model is described as follows. Previously, the
Pre-anotate Entities and Relations sub-process, us-
ing distance-supervised methods, annotated relations
e
1
, e
3
, e
4
, e
7
and e
8
of Table 3, while the others were
manually annotated at the Curate Annotation process.
In addition, the following relations were also manu-
ally annotated: type of, capacity of, and applied to.
These annotations were used as input to the Train
Fine-Tuned Language Model sub-process, generat-
ing the IDEA-C2-Model. In the example, the fol-
lowing sentence st
1
of CT was submitted to the sub-
process Apply Fine-Tuned Language Model: “Os el-
ementos do poder de combate terrestre representam
Knowledge Graph Generation from Text Using Supervised Approach Supported by a Relation Metamodel: An Application in C2 Domain
285
a ess
ˆ
encia das capacidades que a F Ter emprega em
situac¸
˜
oes – sejam de guerra ou de n
˜
ao guerra. S
˜
ao
eles: Lideranc¸a, Informac¸
˜
oes e as Func¸
˜
oes de Com-
bate.”
7
. The result was that all the annotated entity
and relation instances (Table 3) were identified by the
application of the IDEA-C2-Model.
Table 3: Entities and Relations identified by the IDEA-C2.
(e
n
) Entities Relations
e
1
Elementos do poder
de combate
-
e
2
elementos do poder
de combate terrestre
(e
2
, r
4
, e
1
)
(e
2
, r
9
, e
3
)
(e
2
, r
11
, e
4
)
(e
2
, r
11
, e
5
)
e
3
F Ter -
e
4
guerra -
e
5
n
˜
ao guerra -
e
6
Lideranc¸a (e
6
, r
4
, e
2
)
e
7
Informac¸
˜
oes (e
7
, r
4
, e
2
)
e
8
Func¸
˜
oes de Combate (e
8
, r
4
, e
2
)
rdf:Property
c2rm:type_of
c2rm:capacity_of
c2rm:applied_to
rdfs:subPropertyOf
c2rm:relation
rdfs:domain
cnt:f_ter
cnt:nao_guerra
rdfs:subClassOf
c2rm:capacity_of
rdfs:Class
cnt:guerra
c2rm:entity
rdf:type
rdf:type
rdf:type
rdf:type
rdf:type
rdf:type
rdf:type
rdf:type
rdf:type
rdfs:subClassOf
rdfs:subClassOf
cnt:funcoes_de_combate
rdfs:subClassOf
c2rm:applied_to
cnt:informacoes
cnt:elemento_poder_de_combate
c2rm:applied_to
rdfs:range
cnt:elemento_do_poder_de_combate_terrestre
cnt:lideranca
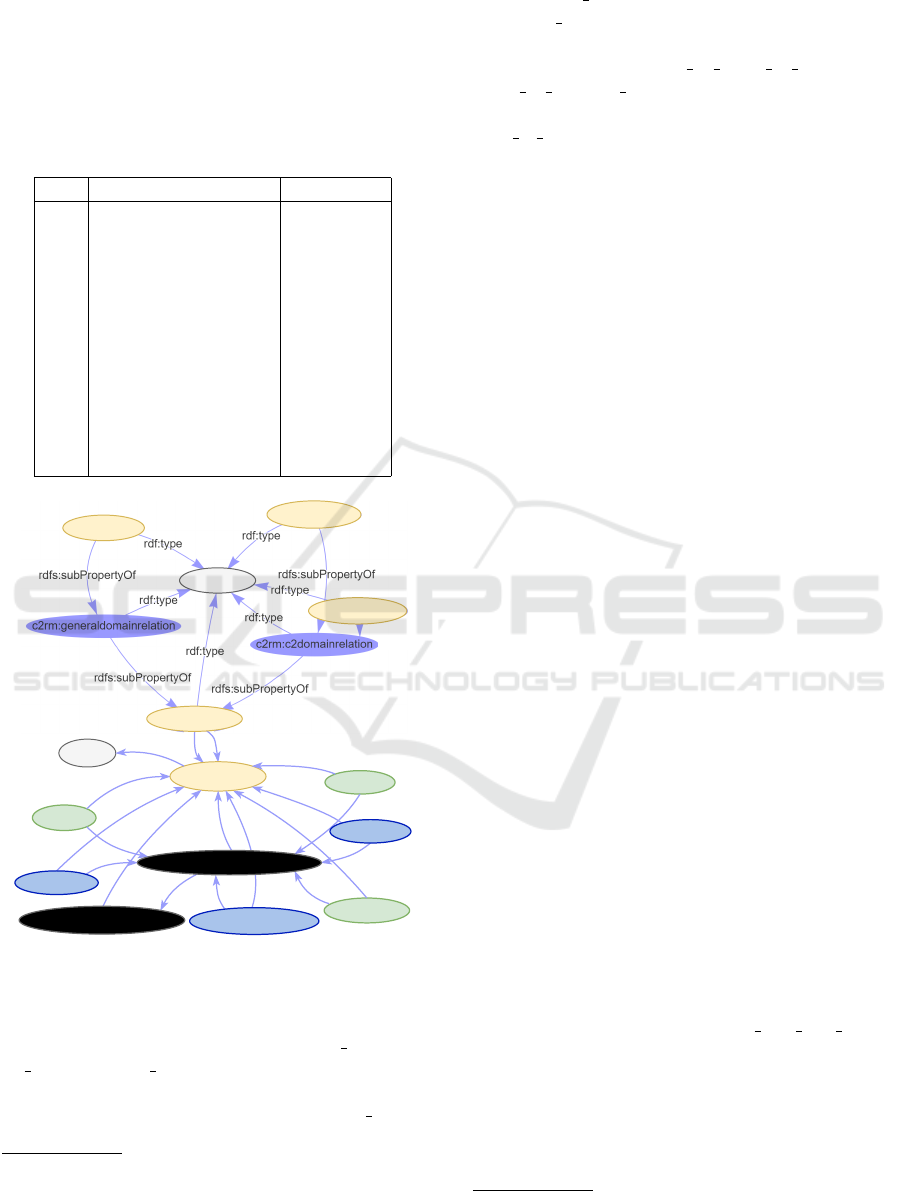
Figure 3: Example of IDEA-C2-KG: RDF graph result.
In Figure 3, the resources in gray, rdfs:Class
and rdf:Property, are RDF metaclasses. In addi-
tion, in yellow, c2rm:entity, relation, type of, capac-
ity of and applied to represent the constructs of the
C2RM. Moreover, cnt is the namespace of IDEA-
C2-KG. The resources in green, cnt:nao guerra,
7
Translation: The elements of ground combat power
represent the essence of the capabilities that the F Ter em-
ploys in situations - both war and non-war. They are: Lead-
ership, Intelligence and the Combat Functions.
guerra and f ter are entities. As the specializa-
tion “type of” is a relation of hyperonymy and hy-
ponymy between two entities, the superclasses are
represented by cnt:element do poder de combate and
poder de combate terrestre in black. The subclasses,
in blue, are represented by cnt:lideranca, func-
tions of combate and informacoes and are related to
the superclass through the property rdfs:subClassOf.
6 EXPERIMENTS AND RESULTS
To validate the IDEA-C2 approach with C2RM sup-
port, two experiments were performed. They showed
promising results in terms of flexibility in the annota-
tion of entities and relations and of the training sub-
process performance. To carry out the experiments
the IDEA-C2-Tool
8
was developed in Python v.3 us-
ing the spaCy pipeline with Transformers component,
spacy-transformers.TransformerModel.v3
9
.
6.1 Annotation Strategy Based on
Singlecategory NER Classification
The first experiment aimed to validate the strategy for
defining high-level C2RM constructs in the IDEA-
C2 approach. To this end, the LM was trained for
the NER and RE tasks by submitting two corpora,
the SciERC with 500 scientific abstracts annotated
with scientific entities, their relations and corefer-
ence clusters (Luan et al., 2018) and Material Sci-
ence with 800 abstracts annotated manually (Weston
et al., 2019). After training the LM, the results of the
training metrics were collected. Table 4 shows the
experiment results of the IDEA-C2 approach, which
is based on a single category strategy for annotat-
ing entities (Singlecategory NER), and on the multi-
category for annotating relations Multicategory RE,
compared to the results of the application of the mul-
ticategory strategy for both NER and RE tasks.
The Train Fine-Tuned Language Model sub-
process, implemented as a spaCy pipeline, was con-
figured as follows. For both corpora, the Dropout was
set to 20%, as the tests showed good results. Sim-
ilarly, the vocabulary used was en core web sm be-
cause the corpora were in English. Finally, the BERT
Model used as input (highlighted in Table 4), was set
to two different values. In the case of SciERC corpus,
we set it to allenai/scibert LM, according to (Luan
et al., 2018). For the Material Science corpus, we
8
https://github.com/jonesavelino/idea-c2-tool
9
https://spacy.io/api/transformer
ICEIS 2024 - 26th International Conference on Enterprise Information Systems
286
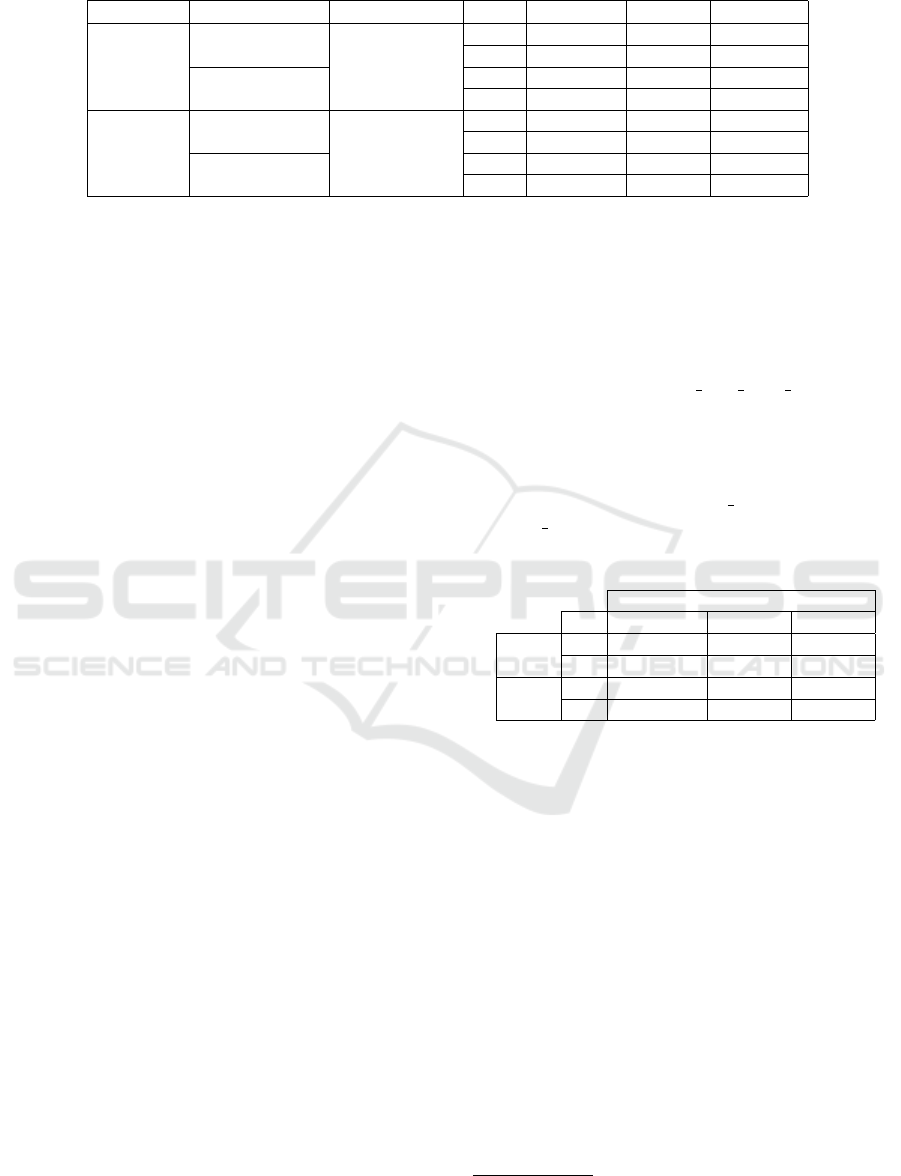
Table 4: Comparison Multi and Single Category of the application of IDEA-C2.
Corpus Category BERT Model Task Precision Recall F1-Score
SciERC
Multicategory
allenai/scibert
NER 65.11% 63.20% 64.14%
RE 48.27% 20.21% 28.49%
Singlecategory
NER 76.67% 79.13% 77.88%
RE 43.68% 26.13% 32.70%
Material
Science
Multicategory
roberta-base
NER 79.37% 79.09% 79.23%
RE 49.76% 29.64% 34.66%
Singlecategory
NER 70.46% 75.46% 77.41%
RE 43.28% 40.62% 41.91%
used roberta-base LM because the initial tests’ results
were superior then when using other LMs.
In the case of SciERC corpus, we can see that the
use of the Singlecategory NER strategy in training
the LM obtained significantly superior results than the
Multicategory NER strategy, for the three metrics: i)
precision: 11.56%; ii) recall: 15.23%; and F1-Score:
13.74%. Even for the RE task, both recall and F1-
Score also obtained higher results because the training
of the RE task depended on the result of the NER task.
On the other hand, in the case of Material Science cor-
pus, the results of the Multicategory NER strategy
were inferior to the Singlecategory NER strategy, but
the average loss was 4.8%. In this case, differences in
the number of annotated terms or the BERT Model
choice may have influenced the results. Varying pa-
rameter configurations and other LM model choices
may lead to better results, but for the present writing,
it was not possible to perform new experiments.
Therefore, based on the results and analysis of this
experiment, adopting the Singlecategory NER strat-
egy is promising, especially concerning RE results,
which showed gains with both corpora. Moreover,
there is also the flexibility of the approach that avoids
the dependency of pre-defining a set of multiple cate-
gories for each domain.
6.2 IDEA-C2-Model Training
Evaluation
The second experiment aimed to extend the previous
one, and validate the effectiveness of the model train-
ing, using the whole set of texts of the Glossary C2
Corpus (BRASIL, 2009). The idea was to evaluate the
evolution of the Train Fine-Tuned Language Model
sub-process, mentioned in Section 5, and its config-
uration choices. To this end, the experiment was di-
vided into two stages, initial and final, to analyze and
compare the results of the precision, recall, and F1-
Score metrics obtained from training the IDEA-C2-
Model. The first stage used a previous version of the
sub-process, which implemented only r1 and r2 rules,
and that did not fully cover the text of each Glossary
entry. The second stage used the latest version of the
sub-process, which implemented the full set of rules
and extended the annotation coverage.
To carry out the experiment, the hyperparameters
were defined as follows: the Bert model was set to
neuralmind/bert-base-portuguese-cased
10
LM (Souza
et al., 2020), the Dropout was set to 20% and the
vocabulary used was the pt core news sm
11
to meet
the language of the C2 Glossary corpus (BRASIL,
2009). The remaining hyperparameters were initially
assigned their default values. However, for the sec-
ond stage, there were some adjustments: the spaCy
pipeline hyperparameters batch size were set to 500
and max length to 100.
Table 5: IDEA-C2-Model training results.
Metrics Results
Ex Precision Recall F1
NER
1 9.93% 17.19% 12.58%
2 86.56% 86.48% 86.51%
RE
1 0.36% 56.48% 0.72%
2 98.06% 98.37% 98.21%
Table 5 shows the results of the IDEA-C2-Model
training in the two stages, for both NER and RE train-
ing tasks. In the first stage, the results obtained in
training for the precision, recovery and F1 score met-
rics were below expectations. In particular, for both
tasks, precision was relatively low. However, the re-
call results, 17.19% for NER task and 56.48% for RE
task, confirmed the tendency of a better performance
of the Singlecategory NER strategy.
In the second stage, the results improved con-
siderably (see Table 5). For the NER task, 22,754
words were processed, with 304 epochs, and LM
IDEA-C2-Model obtained about 86% for all metrics.
These results confirm that the Singlecategory NER
strategy is credited with achieving satisfactory results
due to its flexibility and scope. For the RE task,
the IDEA-C2-Model training supported by the C2RM
sub-specializations was executed in 66 epochs, with a
10
https://github.com/neuralmind-ai/portuguese-bert
11
https://spacy.io/models/pt
Knowledge Graph Generation from Text Using Supervised Approach Supported by a Relation Metamodel: An Application in C2 Domain
287

threshold value of 0.5 for all evaluation metrics. In
this case, it achieved excellent results, reaching 98%
for all metrics.
Therefore, this experiment results showed that
the pre-annotation and training sub-processes of the
IDEA-C2 approach evolved to the point of reach-
ing a very good performance. However, improve-
ments can still be made, such as: improving the
pre-annotation task with new rules and replacing the
spaCy pipeline to use other existing architectures such
as BERT Large. Additionally, new experiments using
other C2 corpora may consolidate the initial good per-
formance results.
7 CONCLUSION
This article presented the IDEA-C2, a supervised
knowledge graph generation approach supported by
a high-level metamodel with Command and Control
Relations constructs, called C2RM. This metamodel
provides high flexibility to the approach since the
domain entities categories are not prefixed. In the
experiments carried out, promising results were ob-
tained, achieving more than 70% precision and recall
in the training of the LM based on the corpus from
other published works. The approach uses distance
supervision methods to pre-annotate Command and
Control Doctrinal Text for model fine-tuning. Like-
wise, the implemented IDEA-C2-Model application
showed remarkable results in training NER and RE
models, achieving over 80% precision and 98% recall,
using as input the Glossary C2 corpus. Finally, these
experiments using the IDEA-C2-Tool proved the use-
fulness and feasibility of the proposed approach and it
is already able to generate the IDEA-C2-KG, which is
available for queries and inferences. Future work in-
cludes improving pre-annotation tasks and evaluating
entity and relation categories statistically.
ACKNOWLEDGEMENTS
This research has been funded by
FINEP/DCT/FAPEB (no. 2904/20-01.20.0272.00)
under the S2C2 project.
REFERENCES
Augenstein, I., Das, M., Riedel, S., Vikraman, L., et al.
(2017). ScienceIE - Extracting keyphrases and rela-
tions from Scientific Publications. In Proc Int Work on
Semantic Evaluation, pages 546–555, Canada. ACL.
BRASIL (2009). Gloss
´
ario de Termos e Express
˜
oes para
uso no Ex
´
ercito. Estado Maior do Ex
´
ercito.
Chaudhri, V. K., Cheng, B., Overtholtzer, A., et al. (2013).
Inquire biology: A textbook that answers questions.
AI Magazine, 34(3):55–72.
Dang, L. D., Phan, U. T., and Nguyen, N. T. (2023). GENA:
A knowledge graph for nutrition and mental health.
Journal of Biomedical Informatics, 145:104460.
Devlin, J., Chang, M.-W., Lee, K., and Toutanova, K.
(2019). BERT: Pre-training of deep bidirectional
transformers for language understanding. In Proc the
Conf of the North American Chapter of the ACL: Hu-
man Language Technologies, Volume 1, pages 4171–
4186, Minnesota. ACL.
Hogan, A., Blomqvist, E., Cochez, M., et al. (2021).
Knowledge Graphs. ACM Computing Surveys, 54(4).
Kent, W. (2012). Data and Reality: A Timeless Perspective
on Perceiving and Managing Information. Technics
publications.
Lee, J., Yoon, W., Kim, S., Kim, D., et al. (2019).
BioBERT: a pre-trained biomedical language repre-
sentation model for biomedical text mining. Bioin-
formatics, 36(4):1234–1240.
Liu, P., Qian, L., Zhao, X., and Tao, B. (2023). The
construction of knowledge graphs in the aviation as-
sembly domain based on a joint knowledge extraction
model. IEEE Access, 11:26483–26495.
Luan, Y., He, L., Ostendorf, M., and Hajishirzi, H. (2018).
Multi-task identification of entities, relations, and
coreference for scientific knowledge graph construc-
tion. In Proc Conf on Empirical Methods in NLP,
pages 3219–3232, Brussels, Belgium. ACL.
Mintz, M., Bills, S., Snow, R., and Jurafsky, D. (2009). Dis-
tant supervision for relation extraction without labeled
data. In Proc of the Joint Conf of the 47th Annual
Meeting of the ACL and the Int Joint Conf on NLP of
the AFNLP, pages 1003–1011, Singapore. ACL.
Russell, S. and Norvig, P. (2010). Artificial Intelligence: A
Modern Approach. 3ed. Prentice Hall.
Souza, F., Nogueira, R., and Lotufo, R. (2020). BERTim-
bau: Pretrained BERT Models for Brazilian Por-
tuguese. In Cerri, R. and Prati, R. C., editors, Intelli-
gent Systems, pages 403–417, Cham. Springer Int Pub.
Spala, S., Miller, N., Dernoncourt, F., and Dockhorn, C.
(2020). SemEval-2020 task 6: Definition extraction
from free text with the DEFT corpus. In Proc of the
Fourteenth Workshop on Semantic Evaluation, pages
336–345, Barcelona. ICCL.
Weston, L., Tshitoyan, V., Dagdelen, J., Kononova, O., et al.
(2019). Named entity recognition and normalization
applied to large-scale information extraction from the
materials science literature. Journal of Chemical In-
formation and Modeling, 59(9):3692–3702.
Zhao, Q., Huang, H., and Ding, H. (2021). Study on
military regulations knowledge construction based on
knowledge graph. In 2021 7th Int Conf on Big Data
and Information Analytics (BigDIA), pages 180–184.
Zhou, J., Li, X., Wang, S., and Song, X. (2022). NER-
based military simulation scenario development pro-
cess. Journal of Defense Modeling and Simulation.
ICEIS 2024 - 26th International Conference on Enterprise Information Systems
288
