
multiBERT: A Classifier for Sponsored Social Media Content
Kshitij Salil Malvankar
1,2
, Enda Fallon
1
, Paul Connolly
2
and Kieran Flanagan
2
1
Software Research Institute, Technological University of Shannon, Athlone, Ireland
2
Circana Inc, Athlone, Ireland
Keywords: Bert, Social Media, Influencer.
Abstract: Social media's rise has given birth to a new class of celebrities called influencers. People who have amassed
a following on social media sites like Twitter, YouTube, and Instagram are known as influencers. These
people have the ability to sway the beliefs and purchase choices of those who follow them. Consequently,
companies have looked to collaborate with influencers in order to market their goods and services. But as
sponsored content has grown in popularity, it has becoming harder to tell if a piece is an independent opinion
of an influencer or was sponsored by a company. This study investigates the use of machine learning models
to categorise influencer tweets as either sponsored or unsponsored. By utilising transformer language models,
like BERT, we are able to discover relationships and patterns between a brand and an influencer. Machine
learning algorithms may assist in determining if a tweet or Instagram post is a sponsored post or not by
examining the context and content of influencer tweets and their Instagram post captions. To evaluate data
from Instagram and Twitter together, this work presents a novel method that compares the models while
accounting for performance criteria including accuracy, precision, recall, and F1 score.
1 INTRODUCTION
The social media sector has experienced significant
growth, not only enabling individuals to communicate
with one another, but also creating career prospects that
were previously unimaginable. Social media has
provided opportunities for content writers and
influencers to gain recognition, popularity, and
financial success. Additionally, it serves as a platform
for online purchasing. One kind of social media
marketing is Influencer Marketing, when an individual
with expertise in a certain sector use their knowledge
to promote the brand and products of others.
Many businesses these days make use of
influencer marketing as part of their overall
marketing strategy. When the influencer promotes the
brand or it’s products, the brand then compensates the
influencer appropriately. Potential methods of
marketing including product placement or
evaluations, sponsored postings, or sponsored events.
The influencer's objective is to enhance brand
recognition among their followers and stimulate the
purchase of the brand's items. The influencer
marketing industry is seeing rapid expansion.
Influencer marketing offers a distinct advantage for
businesses by providing more precise targeting
capabilities in comparison to traditional advertising
tactics. Brands can engage in partnerships with
influencers that specialise in targeting certain
demographics that align well with their business
objectives, therefore streamlining the process of
reaching their desired audience. For example, a Sport
or Health drink brand may form a partnership with a
fitness influencer or an online fitness coach who
possesses a significant following of other fitness
enthusiasts. The followers of the influencer place their
trust in the influencer and their recommendations, thus
leading to an increase in the brand’s sales figures.
With the growth of the industry, it has become
essential to differentiate between genuine sponsored
content and non-sponsored content. This is true from
both the consumer's and the business's point of view.
For the consumer, it is essential to be aware of and
differentiate between whether the influencers they
follow are posting organic content or whether that
content is being paid for. Additionally, for the brand,
this would provide the brand with a more
comprehensive understanding of the shifting
dynamics of influencers and assist them in
quantifying the impact of such influencers.
The objective of this study is to utilise actual
influencer data collected from Twitter and Instagram
706
Malvankar, K., Fallon, E., Connolly, P. and Flanagan, K.
multiBERT: A Classifier for Sponsored Social Media Content.
DOI: 10.5220/0012632400003690
Paper published under CC license (CC BY-NC-ND 4.0)
In Proceedings of the 26th International Conference on Enterprise Information Systems (ICEIS 2024) - Volume 1, pages 706-713
ISBN: 978-989-758-692-7; ISSN: 2184-4992
Proceedings Copyright © 2024 by SCITEPRESS – Science and Technology Publications, Lda.

to train BERT, along with a modified approach based
on BERT, named multiBERT in order to effectively
determine whether a tweet or Instagram post from an
influencer is sponsored or not by the brand. The
performance of these models will also be compared
and evaluated based on evaluation metrics such as
accuracy, precision, recall and F1 score.
2 RELATED WORK
Regarding work that involves data derived from
Twitter and Instagram, multiple studies have been
done to explore the potential of using this data,
providing valuable insights into its applicability.
Yadav et al. proposed utilising a machine learning
classifier to do sentiment analysis on Twitter. The
researchers utilised the Kaggle dataset, which
comprised phrases and keywords pertaining to a
certain product. The writers intended to categorise
types of positive and negative attitudes. During the
pre-processing stage, the tweets' case was modified,
appropriate spaces were inserted, unnecessary spaces
were deleted. Making use of both unigrams and
bigrams, the features for the model were retrieved.
The process of lemmatization and removal of stop
words was thereafter carried out. Their recommended
technique was assessed for its efficacy using three
prominent machine learning classifiers: Naive Bayes,
Logistic Regression, and Support Vector Machine.
(Yadav, Kudale, Rao, Gupta, & Shitole, 2021).
Twitter has shown to be beneficial in the realm of
disaster management. Shah et al. (2018) conducted a
comprehensive analysis of Twitter data to examine
the Nepal Earthquake and identify several aspects
related to the catastrophe. Using Twitter data
acquired during the final week of April and the first
week of May 2015, a total of 40,236 unprocessed
tweets that appeared to be relevant to the Nepal
earthquake were obtained. These messages were then
pre-processed for analysis and subsequently
analysed. This study demonstrates the utilisation of
geolocation tag to identify hazardous areas and using
visual analytics to analyse the dataset. The use of
automated keyword identification led to the
development of a disaster management module. This
module is capable of identifying keywords associated
with any particular catastrophe, enabling further
investigation. The findings indicate that the disaster
module used in the research may effectively operate
on various hashtags without requiring manual
parameter definition, as long as the dataset specific to
the given situation is accessible. (Shah, Agarwal,
Dubey, & Correia, 2018).
The results of recent research have shown that
tweets may be used to make predictions about a wide
range of significant events, such as elections and
national revolutions as well as criminal activity. This
is the primary concept, which states that the context,
timing, and content of tweets can give insight into
what will occur in the future. Whether local criminal
activities can be predicted based on the tweets sent
was the question that was addressed in a report that
was published by the University of Virginia in
November of 2014. According to the findings of the
study, the inclusion of information from Twitter
improves the accuracy of prediction for 19 out of 25
different types of criminal activity, and it does so
considerably for a number of different surveillance
scopes. (Gerber, 2014).
When it comes to twitter data, a lot of studies have
been conducted, but most of them pertain to sentiment
analysis regarding a particular topic. There exists a
substantial gap in the research when it comes to
influencers on Twitter.
In a study that was carried out by Briliani et al.,
the researchers looked for instances of hate speech
that were found in the comments area of an Instagram
post. Responses can be either good or negative,
depending on the context. The use of hate speech is
included in the negative comments on Instagram.
Speech that promotes hatred is one of the most
significant issues, and it is extremely hard for
authorities to combat. In light of this, the K-Nearest
Neighbour classification approach was utilised in this
research project to develop a system that was capable
of determining whether or not one was engaging in
hate speech in the Instagram comment area. The
results of this study have produced an accuracy of
98.13 percent, as well as precision, recall, and F1-
score of 98 percent when employing K-Nearest
Neighbour with K equal to three. (Briliani, Irawan, &
Setianingsih, 2019).
Ekosputra et al. in their 2021 study made use of
Supervised Machine Learning algorithms to detect
fake accounts on Instagram. Logistic Regression,
Bernoulli Naive Bayes, Random Forest, Support
Vector Machine, and Artificial Neural Network
(ANN) are the techniques that were utilised in the
process of developing the supervised machine
learning model. In this study, two tests were
conducted. In the first test, the model is in its default
state, which means that it does not have any
parameters and no features are introduced.
Furthermore, in order to enhance the precision of the
experiment, new features and tuning factors were
incorporated into the process in the second test.
Logistic Regression and Random Forest, both of
multiBERT: A Classifier for Sponsored Social Media Content
707

which have an accuracy of 0.93, are the models that
perform better than other models based on the second
experiment with additional variables and parameters
thanks to their superior performance. (Ekosputra,
Susanto, Haryanto, & Suhartono, 2021).
M. Singh presented an alternative method for
identifying fraudulent accounts on Instagram in
research done in 2023. One form of malicious
behaviour on the Instagram platform is the creation
and use of counterfeit accounts. This study employs a
hybrid technique that takes into consideration both
the content of the post and the photographs to identify
phoney accounts on Instagram. The author assessed
the presence of text spam using machine learning
models such as Random Forest classification and
identified picture spam using CNN models. The
picture dataset was sourced from picture Spam
Hunter, while the model was trained using a Kaggle
dataset to categorise images based on their content.
The suggested hybrid model has also undergone
testing using the dataset obtained through web
scraping from Instagram. The experimental
classification results demonstrate that the suggested
model achieves a classification accuracy of 97.1%.
(Singh, 2023).
When it comes to BERT, there are a lot of studies
that have been published.
M.T. Riaz et al. published a study in 2022 which
introduced TM-BERT or twitter modified BERT for
COVID 19 vaccination sentiment analysis. Within the
scope of this research, a Twitter Modified BERT
(TM-BERT) that is based on Transformer
architecture is shown. Additionally, a new Covid-19
Vaccination Sentiment Analysis Task (CV-SAT) and
a COVID-19 unsupervised pre-training dataset
consisting of 70,000 tweets have been produced by
this group. After being fine-tuned on CV-SAT, BERT
attained an accuracy of 0.70 and 0.76, however TM-
BERT achieved an accuracy of 0.89, which is a 19%
and 13% improvement over BERT respectively.
(Riaz, Shah Jahan, Khawaja, Shaukat, & Zeb, 2022).
The application of BERT for the detection of
cyberbullying in the digital age is discussed by Yadav
et al. in their article that was released in the year 2020.
Using a novel pre-trained BERT model with a single
linear neural network layer on top as a classifier, a
new strategy is suggested to the identification of
cyberbullying in social media platforms. This
approach is an improvement over the results that have
been obtained previously. During the training and
evaluation process, the model is trained on two
different social media datasets, one of which is very
small in size, and the other of which is fairly large in
size. (Yadav, Kumar, & Chauhan, 2020).
Software vulnerabilities pose a significant risk to
the security of computer systems, and there has been
a recent increase in the discovery and disclosure of
these weaknesses. Ni et al. did a study in which they
introduced a novel approach called BERT-CNN. This
approach combines the specialised task layer of Bert
with CNN to effectively collect crucial contextual
information in the text. Initially, a BERT model is
employed to analyse the vulnerability description and
other data, such as Access Gained, Attack Origin, and
Authentication Required, in order to provide the
feature vectors. Subsequently, the feature vectors
representing vulnerabilities together with their
corresponding severity levels are fed into a
Convolutional Neural Network (CNN), from which
the CNN parameters are obtained. Subsequently, the
fine-tuned Bert model and the trained CNN model are
employed to predict the degree of severity associated
with a vulnerability. This method has demonstrated
superior performance compared to the current leading
method, with an F1-score of 91.31%. (Ni, Zheng,
Guo, Jin, & Li, 2022).
Guo et al. did a study in 2022 focusing on
developing methods to detect false news. Current
suggested methods for false news identification in
centralised platforms do not consider the location of
news announcements, but rather prioritise the
analysis of news content. This study presents a
distributed architecture for detecting false news based
on regions. The framework is used inside a mobile
crowdsensing (MCS) setting, where a group of
workers are chosen to collect news depending on their
availability in a particular location. The chosen
workers disseminate the news to the closest edge
node, where the local execution of pre-processing and
detection of counterfeit news takes place. The
detection technique used a pre-trained BERT model,
which attained a 91% accuracy rate. (Guo, Lamaazi,
& Mizouni, 2022).
Text categorization has consistently been a
significant undertaking in the field of natural
language processing. Text categorization has become
extensively utilised in several domains such as
emotion analysis, intention identification, and
intelligent question answering in recent years. In a
2021 publication, Y. Cui et al. introduced a novel
methodology. This study used the Bert model to
produce word vectors. The text characteristics
collected by a Convolutional Neural Network (CNN)
were then combined to get more efficient features,
enabling the completion of Chinese text
classification. Experiments were performed using a
publicly available dataset. Recent studies have
demonstrated that the Bert+CNN model outperforms
ICEIS 2024 - 26th International Conference on Enterprise Information Systems
708

other text classification models in properly
categorising Chinese text, mitigating overfitting, and
exhibiting strong generalisation capabilities. (Cui &
Huang, 2021).
A lot of studies have been conducted on the
application of BERT and also on the data collected
from social media sites such as Twitter and
Instagram. However, there exists a significant gap in
research when it comes to influencer behaviour on
such sites. While there have been studies regarding
the authenticity of accounts on such sites, detecting
the authenticity of the content posted on such sites is
also of equal importance.
3 METHODOLOGY
The general research methodology is outlined in
figure 1. The data pre-processing step will be
completed first. The data has been cleansed at this
point. Once the data pre-processing step is completed,
the next step is to determine the classification model
that will be applied. To determine which model
performs best, a classification evaluation will be done
once each model has been trained. The methodology
is visualized in Figure 1.
Figure 1: Methodology flow diagram.
3.1 Dataset
For the purpose of this study, real world user data was
collected from Instagram and Twitter. The data was
collected using the respective APIs provided by
Twitter and Instagram. Twitter API allows us to
extract either Tweets pertaining to a hashtag ("#”)
passed as keywords into the API or user information
as data. All the tweets pertained to “#beauty” and
“#gaming”. The Instagram API allows us to extract
post captions along with URL links to the photo itself.
However, for the purpose of this study, only captions
related to the hashtags mentioned above were
collected. The data was divided into 4 datasets.
Dataset 1 (D1) comprised of 1000 samples of Twitter
data, Dataset 2 (D2) comprised of 80000 samples of
Twitter Data, Dataset 3 (D3) comprised of 1000
samples of Instagram Data and Dataset 4 (D4)
comprised of 80000 samples of Instagram data. 2 test
sets were also created, Test set 1 (T1) comprised of
200 samples of Instagram and Twitter data and Test
set 2 (T2) which comprised of 20000 samples of
Instagram and Twitter data combined. The
tweets/Instagram captions were manually annotated
based on the “sponsored” and “Paid Partnership
With” tags available in Twitter and Instagram
respectively. The details of the datasets are detailed in
Table I.
Table 1: Datasets.
Dataset Sample size Source
D1 1000 Twitter
D2 80000 Twitter
D3 1000 Instagram
D4 80000 Instagram
T1 200 Twitter + Instagram
T2 20000 Twitter + Instagram
As it can be observed in Table 1, the sample size for
training was increased from 1000 samples to 80000
samples. This was done to measure the performance
of the model when limited data is available and also
when there is no limit on the data.
3.2 Data Preprocessing
The significance of the data pre-processing step lies
in the fact that it has an impact on the efficiency of
the future phases. Altering the syntax of tweets,
removing information that is not essential from the
text, and identifying any additional elements that are
helpful are all included in this process. Python regular
expressions were utilised in order to exclude special
characters, emoji symbols, hashtags, and links from
the text in order to accomplish the objectives of this
study. It was decided not to remove the user handles
and handles that were referenced in the tweets since
doing so would be necessary in order to establish the
relationships between influencers in the later phases
of this experiment.
Preprocessing steps followed:
• Removal of hashtags
• Removal of links
• Removal of emoji
• Removal of special characters
• Removing extra spaces
3.3 Models
BERT (Bidirectional Encoder Representations from
Transformers) is a publicly available machine
multiBERT: A Classifier for Sponsored Social Media Content
709
learning framework designed for the purpose of
natural language processing (NLP). BERT is
specifically engineered to enhance computers'
comprehension of the semantic nuances in ambiguous
textual language by using the surrounding text to
construct a comprehensive context. The BERT
framework underwent pre-training using textual data
sourced from Wikipedia and may thereafter be
refined through the use of question-and-answer
datasets. reference
BERT is a deep learning model that utilises
Transformers. In this model, each output element is
linked to every input element, and the weightings
between them are dynamically computed depending
on their relationship. This technique is referred to as
attention in the field of natural language processing
(NLP).
In the past, language models were limited to
reading text input in a sequential manner, either from
left to right or from right to left but were unable to do
both simultaneously. BERT stands out due to its
unique ability to do bidirectional reading
simultaneously. The capacity to process information
in both forward and backward directions, made
possible by the use of Transformers, is referred to as
bidirectionality.
BERT is trained bidirectionally, meaning it is trained
on two distinct yet interconnected NLP tasks: Masked
Language Modelling and Next Sentence Prediction.
The primary goal of Masked Language Model
(MLM) training is to obfuscate a word within a phrase
and thereafter enable the program to forecast the
concealed word (masked) by leveraging the
contextual cues of the hidden word. The goal of Next
Sentence Prediction training is to enable the program
to accurately determine whether two provided
phrases exhibit a coherent, sequential link or whether
their relationship is just arbitrary.
There are two primary variants of pre-trained BERT
models, which differ based on the magnitude of their
architectural design.
• The BERT-Base model consists of 12 layers,
each with 768 hidden nodes and 12 attention
heads. In all, it includes 110 million training
parameters.
• The BERT-Large model consists of 24 layers,
1024 hidden nodes, 16 attention heads, and a
total of 340 million training parameters.
The BERT-Base model was utilised for this
project as it is relatively easier on the system as
compared to BERT large model while keeping the
architectural intricacies.
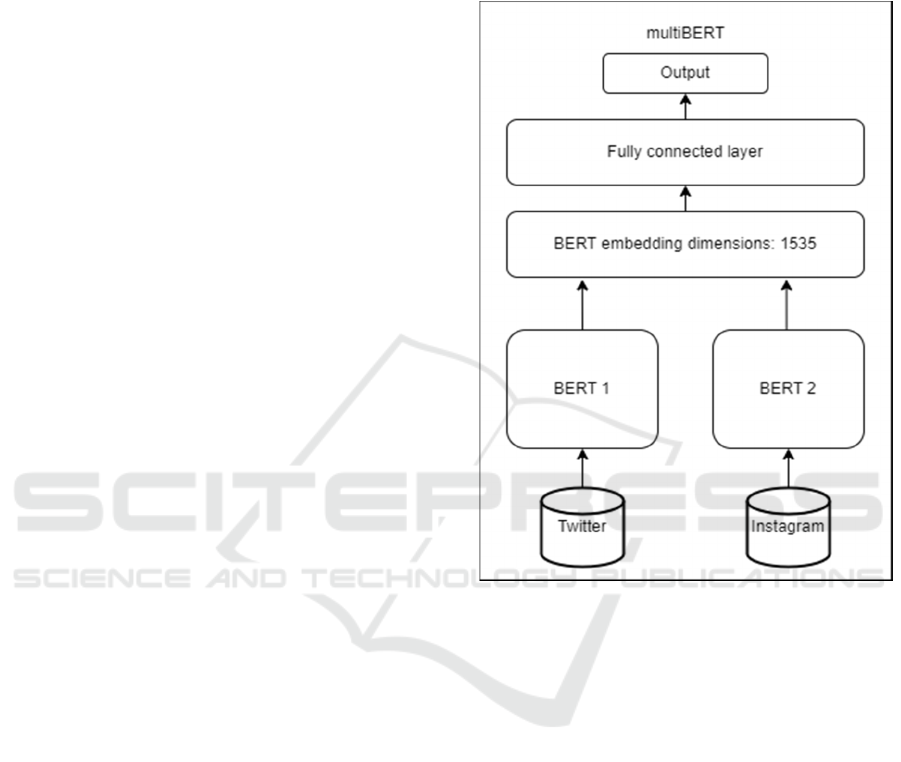
3.3.1 Proposed Model
To incorporate the use of multiple datasets in one
model, an approach based on the BERT architecture
is proposed. The architecture is outlined in Figure 2.
Figure 2: multiBERT.
Two BERT models, one to be trained on twitter data
(BERT1) and one to be trained on Instagram data
(BERT2), were paired together, with a fully
connected layer and a 2-class linear layer on top.
To set the appropriate hyperparameters for tuning,
a simple grid search strategy was utilized. The search
space utilized was the search space recommended by
the authors of BERT (Devlin, Chang, Lee, &
Toutanova, 2019).
Parameter search space:
• Num_epochs: [2,3,4,5]
• Learning_rate: [2e-5, 3e-5, 5e-5]
• Batch_size: [16, 32]
• Weight_decay: [0, 0.1, 0.3]
A total of 72 trials were run, with each combination
of the parameters for both BERT1 and BERT2. The
best performing combination of parameters was
selected for the model.
The hyper parameters set for BERT1 were:
• Epochs: 5
• Batch size: 16
ICEIS 2024 - 26th International Conference on Enterprise Information Systems
710

• Learning rate: 3e-5
• Weight decay: 0.1
The hyper parameters set for BERT2 were:
• Epochs: 5
• Batch size: 16
• Learning rate: 2e-5
• Weight decay: 0.1
3.4 Experiments
A total of 6 experiments were conducted as part of
this study. The BERT model was trained and tested
separately on both Twitter and Instagram data to
evaluate the results. The combined model was also
trained and tested along with the BERT models. The
first rounds of experiments were conducted with 1000
samples in the training set followed by the second
round of experiments, where the training sets were
populated with 80000 samples. The details of the
experiments are given below:
• Experiment 1: BERT
t
trained on Twitter Data
(1000 Samples)
• Experiment 2: BERT
t
trained on Twitter Data
(1000 Samples)
• Experiment 3: BERT
i
trained on Instagram
data (1000 Samples)
• Experiment 4: BERT
i
trained on Instagram
Data (80000 Samples)
• Experiment 5: multiBERT (1000 Samples)
• Experiment 6: multiBERT (80000 Samples)
4 RESULTS
The objective of this study was to evaluate whether
BERT-base and the proposed model multiBERT can
be effectively used to classify user tweets and
Instagram caption as sponsored or not sponsored. The
results are detailed in Table 2.
Table 2 details the results of Experiment 1. While
conducting training with 1000 samples, the model
BERT
t
achieved an accuracy of 73.5%. The model
had a precision score of 74.6% and a recall score of
73.5%, with the F1 score being 73.02.
Results observed for Experiment 2 are detailed in
Table 2. While training with 80000 records on the
twitter dataset, the model BERT
t
was able to achieve
an accuracy of 79.5%, showing a 6% increase in
performance due to additional training. The precision
score of the model went up by 4.6% to achieve 79.2%
precision and the recall score increased by 6%, to
achieve a recall score of 79.5%. The model has a F1
score of 79.3%.
Table 2: Experimental Results.
Model Accuracy
Precision Recall
F1
Score
BERT
t
(1000 samples)
73.5% 74.6% 73.5% 73.02%
BERT
t
(80000 samples)
79.5% 79.2% 79.5% 79.3%
BERT
i
(1000 samples)
78.3% 78.9% 78.5% 78.7%
BERT
i
(80000 samples)
84% 85.05% 84% 84.5
multiBERT
(1000 samples)
82% 83.1% 82% 82.5%
multiBERT
(80000 samples)
89% 90.1% 89.3% 89.7%
Results observed for Experiment 3 are detailed in
Table 2. While conducting training with 1000
samples, it is observed that BERT
i
achieves an
accuracy of 78.3%. The model achieved a precision
score of 78.9% and a recall score of 78.5%, with an
F1 score of 78.7%. As compared to the BERT model
trained on twitter data, the model trained on
Instagram data is able to achieve a 6.5% increase in
performance at the same task and same number of
training samples.
Results observed from Experiment 4 are detailed
in Table 2. While conducting training with 80000
samples, it is observed that in this experiment, the
BERT
i
achieves an accuracy of 84%, showing an 4%
increase in performance with additional training. The
model achieved a precision score of 85.05% and a
recall score of 84%, getting a F1 score of 84.5%. As
seen with the previous experiment, even with
additional training, the model trained on Instagram
data with 80000 records achieves an accuracy
improvement of 4.5% over the model trained on
twitter data.
Results observed in Experiment 5 are detailed in
Table 2. While training on 1000 samples, multiBERT
was able to achieve an accuracy of 82% which is an
8.5% increase over the BERT
t
model trained on the
same number of samples in Experiment 1 and a 2.1%
increase over the BERT
i
model trained on the same
number of samples in Experiment III. The model was
also able to achieve a precision score of 83.1% and a
recall score of 82%, with a F1 score of 82.5%
Results observed in Experiment 6 are detailed in
Table 2. While training on 80000 samples,
multiBERT was able to achieve an accuracy of 89%
which is an 9.5% increase over the BERT
t
model
trained on the same number of samples in Experiment
2 and a 5% increase over the BERT
i
model trained on
the same number of samples in Experiment 4. The
model was also able to achieve a precision score of
90.1% and a recall score of 89.3%, with a F1 score of
89.7%
multiBERT: A Classifier for Sponsored Social Media Content
711
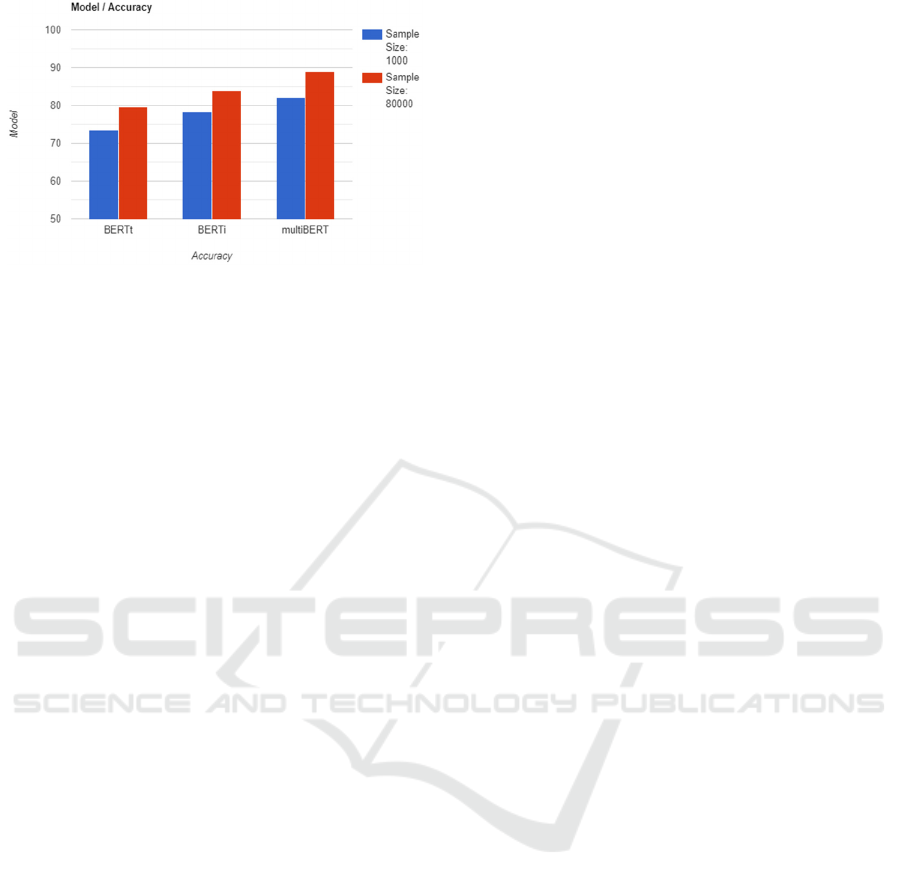
Figure 3: Training samples used & accuracy score of the
models.
Figure 3 shows the results of all the experiments put
together in terms of the accuracy of the models. It can
be observed that the proposed model multiBERT
achieves better performance while being trained on
the same amount of data.
5 CONCLUSIONS AND FUTURE
WORK
In this study, both BERT-Base as well as the
proposed model, multiBERT were correctly able to
classify Influencer posts as sponsored or not. With
regards to performance, it was found that the new
proposed model was the best in terms of accuracy,
both with limited data as well as a large sample size.
The multiBERT model achieved an accuracy of 82%
when trained on 1000 samples, which is a 3.7%
increase over the BERT-Base model trained on
Instagram data (BERT
i
) and an 8.5% increase over
the BERT-Base model trained on Twitter (BERT
t
).
The performance increase is slightly more significant
when the multiBERT model is trained on 80000
samples. The multiBERT model trained on 80000
samples achieved an accuracy of 89%, which is a 5%
increase over the BERT-Base model trained on
Instagram data and 9.5% increase over the model
trained on Twitter data. An interesting observation
here would be that the models trained with Instagram
data outperformed the models trained with Twitter
data consistently. When trained on 1000 samples, the
BERT
i
achieved
an accuracy of 78.3% which is an
increase of 4.8% and when trained on 80000 samples,
BERT
i
achieved an accuracy of 84% which was a
4.5% increase over the BERT
t
model. This inferior
performance of the models trained on Twitter data
may be attributed to the use of more slang words or
the increased use of abbreviations as compared to
Instagram.
Transformer models, like BERT, have previously
been proven to be extremely effective and applicable
in a wide range of machine learning applications. The
findings of this study demonstrate that the proposed
model, multiBERT, is capable of effectively
categorizing tweets or Instagram posts as either
sponsored or non-sponsored. Future work will focus
on correlating influencer data with real world sales
data using knowledge graphs. These graphs would
effectively illustrate the evolving dynamics between
influencers and ordinary users, in order to determine
the effect that these influencers have on social media
users and their behaviour and spread of online trends.
Circana provides clients with data, industry insight,
and advanced analytics to enhance their
understanding of the retail sector. With access to
propriety real world sales and POS data provided by
Circana, future work will focus on implementing a
system that can detect and quantify the effects of such
influencers and the impact they can have on the
purchase decisions of their followers by correlating
influencer behaviour with real world sales data. Work
will also focus on developing a system in tandem
which would identify anomalous behaviour of the
influencers on social media.
REFERENCES
Briliani, A., Irawan, B., & Setianingsih, C. (2019). Hate
Speech Detection in Indonesian Language on Instagram
Comment Section Using K-Nearest Neighbor
Classification Method,. IEEE International Conference
on Internet of Things and Intelligence System (IoTaIS),
(pp. 98-104). Bali.
Cui, Y., & Huang, C. (2021). A Chinese Text Classification
Method Based on BERT and Convolutional Neural
Network. 7th International Conference on Systems and
Informatics (ICSAI) (pp. 1-6). Chongqing: IEEE.
Devlin, J., Chang, M., Lee, K., & Toutanova, K. (2019).
BERT: Pre-training of Deep Bidirectional
Transformers for Language Understanding. . North
American Chapter of the Association for
Computational Linguistics.
Ekosputra, M. J., Susanto, A., Haryanto, F., & Suhartono,
D. (2021). Supervised Machine Learning Algorithms to
Detect Instagram Fake Accounts. 4th International
Seminar on Research of Information Technology and
Intelligent Systems (ISRITI) (pp. 396-400). Yogyakarta:
IEEE.
Gerber, M. S. (2014). Predicting crime using Twitter and
kernel dencity estimation. Decision Support Systems,
115-125.
Guo, Y., Lamaazi, H., & Mizouni, R. (2022). Smart Edge-
based Fake News Detection using Pre-trained BERT
Model. 18th International Conference on Wireless and
ICEIS 2024 - 26th International Conference on Enterprise Information Systems
712

Mobile Computing, Networking and Communications
(WiMob) (pp. 437-442). Thessaloniki: IEEE.
Machuca, C., Gallardo, C., & Toasa, R. (2021). Twitter
Sentiment analysis on coronavirus: Machiene Learning
Approach. Journal of Physics: Conference Series.
Ni, X., Zheng, J., Guo, Y., Jin, X., & Li, L. (2022).
Predicting severity of software vulnerability based on
BERT-CNN. International Conference on Computer
Engineering and Artificial Intelligence (ICCEAI) (pp.
711-715). Shijiazhuang: IEEE.
Riaz, M. T., Shah Jahan, M., Khawaja, S. G., Shaukat, A.,
& Zeb, J. (2022). TM-BERT: A Twitter Modified
BERT for Sentiment Analysis on Covid-19 Vaccination
Tweets. 2nd International Conference on Digital
Futures and Transformative Technologies (ICoDT2),
(pp. 1-6). Rawalpindi.
Shah, B., Agarwal, V., Dubey, U., & Correia, S. (2018).
Twitter Analysis for Disaster Management. Fourth
International Conference on Computing
Communication Control and Automation (ICCUBEA)
(pp. 1-4). Pune: IEEE.
Singh, M. (2023). Advanced Machine Learning Model to
Detect Spam on Instagram. 2023 IEEE International
Conference on Blockchain and Distributed Systems
Security (ICBDS) (pp. 1-6). New Raipur: IEEE.
Yadav, J., Kumar, D., & Chauhan, D. (2020).
Cyberbullying Detection using Pre-Trained BERT
Model. International Conference on Electronics and
Sustainable Communication Systems (ICESC), (pp.
1096-1100). Coimbatore.
Yadav, N., Kudale, O., Rao, A., Gupta, S., & Shitole, A.
(2021). Twitter sentiment analysis using supervised
Machine Learning. In Intelligent Data Communication
Technologies and Internet of Things (pp. 631-642).
Zhu, J., Xia, Y., Wu, L., He, D., Qin, T., Zhou, W., . . . Liu,
T.-Y. (2020). Incorporating BERT into Neural Machine
Translation. International Conference on Learning
Representations.
multiBERT: A Classifier for Sponsored Social Media Content
713
