
Identification and Attribution of Access Roles Using
Hierarchical Team Permission Analysis
Iryna Didinova
1 a
and Karel Macek
1,2 b
1
AI Center of Excellence, Generali Ceska Pojistovna, Na Pankraci 1720, Prague, Czech Republic
2
AI & Data Center of Excellence, Temus, 80 Pasir Panjang Road, Singapore
Keywords:
RBAC, Machine Learning, Clustering, Attribution, Graph Algorithms, Access Control Models.
Abstract:
This paper addresses the challenges of Role-Based Access Control (RBAC) in large organizations, with a
focus on the efficient attribution of access roles. It critiques traditional role-mining algorithms and the use of
Machine Learning (ML) models, which serve as benchmarks due to their lack of practical interpretability and
potential security vulnerabilities. The novel contribution of this work is the introduction of the Hierarchical
Team Permission Analysis (HTPA), a methodology grounded in organizational hierarchy. HTPA is shown
to outperform the benchmark approaches by creating meaningful, interpretable roles that enhance both the
security and efficiency of access control systems in large enterprises. The paper advocates for the potential
integration of HTPA with ML models to further optimize role attribution and suggests avenues for future
research in this evolving field.
1 INTRODUCTION
Access control helps protect sensitive information
like customer data and intellectual property from theft
by hackers or unauthorized access. Therefore, it is
crucial for ensuring data privacy. Access roles are of-
ten not available due to system attribute limitations,
inconsistent access, the impact of mergers, and overly
granular role definitions, based on reflective analysis.
Efficient IT operation in large organizations requires
a reasonable access management that combines secu-
rity and protection on one hand, as well as ease of
use and efficiency on the other hand (Di Pietro et al.,
2012). Additionally, the growing interest in Artificial
Intelligence and Big Data, which often includes per-
sonal information, sparks fresh attention in how ac-
cess controls are applied and developed (Cavoukian
et al., 2015).
Many organizations manage the permissions as-
signment inefficiently by assigning them directly to
the users. A much better and more practical approach
is to group permissions to roles, and assign those ro-
les to users, which is the so-called RBAC (Role-Based
Access Control) model (Sandhu et al., 1996).
This paper addresses a problem that has two com-
a
https://orcid.org/0009-0001-8722-7712
b
https://orcid.org/0000-0002-3914-447X
ponents: i. to identify the RBAC roles, and ii. to have
mechanisms of assigning (attributing) these roles to
users based on some metadata efficiently. Such appro-
ach would be a combination of RBAC and attribute-
based access control (ABAC) (Karp et al., 2010). This
combination has potential to bring the best from both
access control models (Alayda et al., 2020) and is par-
ticularly useful for large organizations (Kuhn et al.,
2010).
2 LITERATURE REVIEW
Our research on role identification highlights
extensive studies, including algorithms like
CompleteMiner and FastMiner, which proceed
through candidate role generation from user-
permission data, followed by prioritizing these roles
to produce a prioritized list (Vaidya et al., 2006).
Another notable method is the Graph Optimization
(GO) algorithm, which initially considers each user’s
permissions as separate roles and then optimizes by
merging or splitting roles based on an optimization
policy (Zhang et al., 2007).
Some role-mining algorithms treat the process as
an optimization problem, focusing on minimizing cri-
teria like the Weighted Structural Complexity (WSC)
Didinova, I. and Macek, K.
Identification and Attribution of Access Roles Using Hierarchical Team Permission Analysis.
DOI: 10.5220/0012675300003690
Paper published under CC license (CC BY-NC-ND 4.0)
In Proceedings of the 26th International Conference on Enterprise Information Systems (ICEIS 2024) - Volume 1, pages 721-728
ISBN: 978-989-758-692-7; ISSN: 2184-4992
Proceedings Copyright © 2024 by SCITEPRESS – Science and Technology Publications, Lda.
721

(Molloy et al., 2008). WSC accounts for various fac-
tors such as the number of roles and errors, as well
as the assignments between users and roles, roles and
permissions, and the role hierarchy. It also allows for
different components of WSC to be weighted diffe-
rently. Molloy et al. developed the HierarchicalMi-
ner algorithm to specifically minimize the total WSC
(Molloy et al., 2008).
The algorithms mentioned above output a mathe-
matically optimized set of roles. Nevertheless, such
roles often lack a reasonable interpretation. In
practice, the generated roles are often examined by a
security administrator, who decides whether these ro-
les are meaningful and whether they should be imple-
mented. As a result, roles often stay unused in practice
due to this problem: the stakeholders do not want to
deploy roles they can’t understand (Ene et al., 2008).
Furthermore, the algorithms mentioned above neither
take into consideration users’ attributes nor allow for
assigning users to roles, and due to this issue, neither
of the algorithms is well-suited for the problem of this
paper.
Another possibility is Rule-Based RBAC, which
involves experts creating rules for assigning roles
to users, which are then automated (Al-Kahtani and
Sandhu, 2004). However, this method can be costly
and time-consuming due to the need for detailed ana-
lysis of user-role relations, leading to only partial au-
tomation (Ni et al., 2009).
Machine learning (ML) and Artificial Intelligence
(AI) are increasingly applied to enhance access con-
trol systems, addressing role attribution challenges.
For example, Lu Zhou et al. introduced an ML ap-
proach for real-time role assignment in SCADA sys-
tems, employing Support Vector Machines (SVM) to
identify roles and Adaboost for classification based on
static and dynamic user attributes (Zhou et al., 2019).
Nobi et al. introduced DLBAC, a Deep Learning
Based Access Control system (Nobi et al., 2022b), ad-
dressing limitations of standard RBAC such as role at-
tribution and maintenance issues. DLBAC employs a
neural network that takes user and resource metadata
as input to make access decisions. The network’s clas-
sification layer outputs probabilities for granting per-
missions, with each neuron representing an operation.
In practice, when the network predicts a probability of
1, access is granted upon user request.
With recent advances in Generative AI, there’s
now talk about its potential to automate the cre-
ation of policies for ABAC (Olabanji et al., 2024).
Jayasundara et al. go even further and introduces
”AccessFormer”- a feedback-driven access control
policy generation framework. Authors use Large Lan-
guage Models (LLMs) to generate policies from high-
Figure 1: Hierarchical Team Permission Analysis (black
box) in the context of other prior efforts.
level requirement specifications, which are refined by
security administrator feedback (Jayasundara et al.,
2024).
The results of the ML methods in access control
are promising. Nevertheless, there are some challen-
ges. The first one is a lack of understandability and in-
terpretation in results produced by non-symbolic mo-
dels (NN, SVM, Random forest, Clustering). Another
pitfall of ML is a need for quality, sizable data sets
with extensive user and policy attributes, and access
control data sets often do not meet these requirements
(Nobi et al., 2022a). Lastly, using ML models in ac-
cess control could be risky due to their probabilistic
nature and some level of inaccuracy. In case model
mistakenly assigns a role or permission to a wrong
person, it could lead to security breaches and high lo-
ses for an enterprise.
Due to such drawbacks, neither the above-
mentioned conventional RBAC algorithms nor ML
methods are well suited for our research question. As
a result, we introduce our solution, a graph algori-
thm based on companies’ hierarchical structure: Hi-
erarchical Team Permission Analysis. It is an evoluti-
onary step from the application of ML techniques in
the combination with attribution, as visually represen-
ted in Figure 1 as a black box. It is important to men-
tion that the method assumes manual review of the
proposed roles (by the line managers). Without that,
the risk of potential security breach would be high, as
depicted in Figure 1 as a dashed box.
The paper is organized as follows. In Section 3,
we define the problem statement, particularly we spe-
cify the business requirements, introduce a notation
as well as an evaluation criterion. In Section 4 we
ICEIS 2024 - 26th International Conference on Enterprise Information Systems
722

propose two approaches to find the solution, particu-
larly the ML approach and Hierarchical Team Permis-
sion Analysis. Section 5 showcases the algorithms in
a real-world case. Finally, Section 6 concludes the pa-
per and outlines possible areas for future research.
3 PROBLEM STATEMENT
3.1 Business Requirements
To better grasp the issue at hand, it’s crucial to specify
the main business needs.
The business objective is to identify accurate roles
that can cover most of the initial user-permission as-
signments while reducing the instances of incorrectly
given permissions. Thus, we encounter the challenge
of balancing two types of errors: the false negative
rate (failing to grant permissions to a user who actu-
ally needs them) and the false positive rate (inaccura-
tely granting permissions to users who shouldn’t have
them). A high false negative rate implies additional
work for security administrators, who must then ma-
nually allocate the missing permissions. Conversely,
a high false positive rate could lead to security vul-
nerabilities. These two error types could be balanced
during the optimization phase by applying different
weights.
Nevertheless, we need to account for the possibi-
lity of false positives, although we acknowledge that
they are less desirable than false negatives. There may
be certain user-permission pairs that do not pose any
risk and may simplify the roles. However, these false
positive cases should be checked manually by line
managers or security professionals.
Another business requirements is, that roles
should be attributed based on metadata. This implies
we aim to understand not just the roles users hold
but also the reasons behind them, based on user in-
formation. This requirement is closely related to the
first one as slightly relaxed roles with controlled false
positives can provide data that can be better generali-
zed by attribution rules. This is meant to ensure that
each person is assigned a role that aligns with their
competencies and position in the organization, balan-
cing the need for functional access with the principle
of least privilege.
Finally, the last business requirement is, that roles
should have a reasonable business interpretation.
3.2 Notation
We adopt the notation from (Molloy et al., 2008) with
a slight modification. Cardinality of a set is denoted
as | · |, composition of relations as R
1
◦ R
2
Given an access control configuration is a tuple
⟨
U, P, UP
⟩
, where U is a set of users, P is a set of
permissions, and UP ⊆ U × P is the user-permission
assignment.
An RBAC policy is a tuple
⟨
U, P, R, UA, PA, RH, DUPA, NUPA
⟩
, where R is
a set of roles, UA ⊆ U × R is the user-role assign-
ment, PA ⊆ R × P is the permission-role assignment,
and RH ⊆ R × R is a partial order over R, which is
called a role hierarchy, and DUPA ⊆ U × P is the di-
rect user-permission assignment relation. In machine
learning, it can also be interpreted as false negative
cases. In addition to the original definition of WSC,
we would like to introduce a metric NUPA ⊆ U × P,
which is the direct corrective unassigments (or false
positive cases).
The RBAC state is consistent with
⟨
U, P, UP
⟩
, if
every user in U has the same set of authorized per-
missions in the RBAC state as in U P.
Additionally, we will consider attributes for each
user A : U → R
n
.
We introduce a structured set of teams, T , orga-
nized hierarchically as a tree H ⊆ T × T . Within this
hierarchy, a pair (t, t
′
) ∈ H signifies that team t is di-
rectly subordinate to a team t
′
. To represent user mem-
bership across these teams, we employ the mapping
function M : U → 2
T
. For each user u within the set
U, the function outputs a subset of teams M(u) ⊆ T
that encapsulates the user’s memberships. It is assu-
med that the teams within M(u) form a path in H,
indicating that a user is affiliated with a distinct team
at the most specific level of the hierarchy (denoted
as µ(u), µ : U → T ) and all its ancestor teams up to
the root of the tree (denoted as t
0
∈ T ). Note that the
”most specific”team µ(u) does not have to be a leaf in
the hierarchy; it can be an internal node representing a
team with further subdivisions or subteams. The user
might be a manager (or her secretary) of that team and
all the subteams.
For better readability, we summarize all the used
symbols in Table 1, including those that will be defi-
ned later in the text:
3.3 Tasks
For reasons summarized in Section 3.1, we split - in
contrast to the algorithms described in the literature -
the RBAC creation problem into two tasks.
3.3.1 Role Mining
The first task is identifying the roles R, their permis-
sions PA, and their hierarchy RH.
Identification and Attribution of Access Roles Using Hierarchical Team Permission Analysis
723
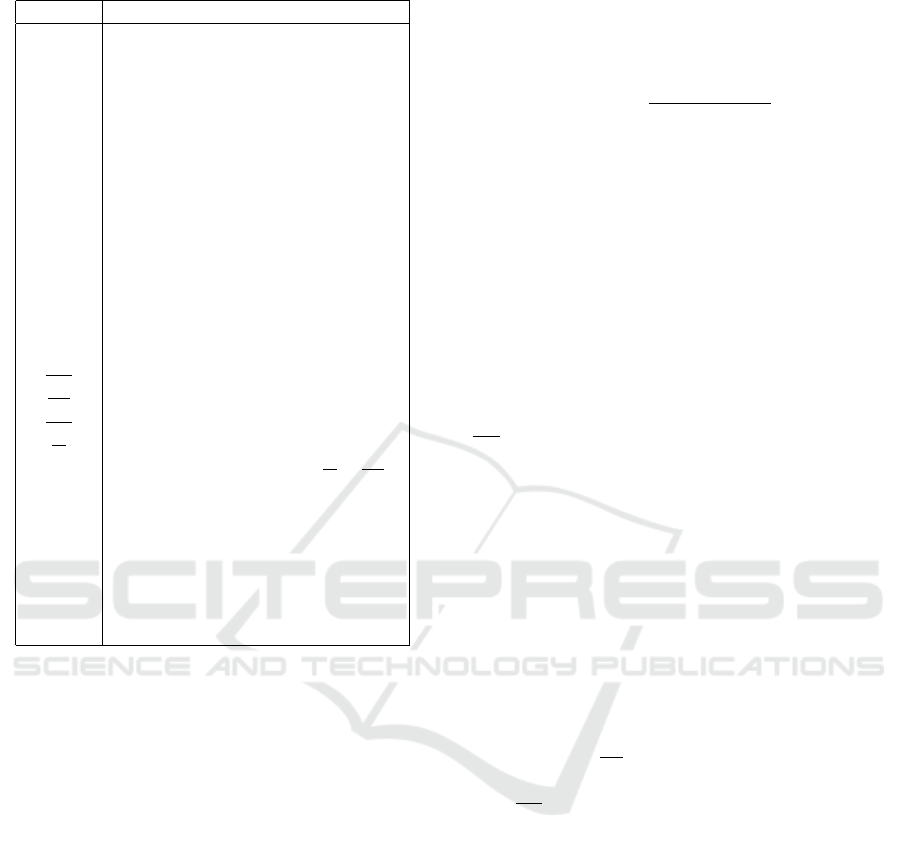
Table 1: Table of Symbols and Their Meanings.
Symbol Meaning
U Set of users
P Set of permissions
UP User-permission assignment
R Set of roles
UA User-role assignement
PA Permission-role assignement
RH Role hierarchy
DU PA Direct corrective assignments
NUPA Direct corrective unassignments
T Set of teams
H Hierarchy tree of teams
M User memberships in teams
µ(u) Most specific team of user u
A(u) Attributes of user u
n Dimension of vector A(u)
F
r
Attribution rule for role r
UP Binary matrix representing U P
PA Binary matrix representing PA
UA Binary matrix representing UA
Q Real matrix - output from clustering
η Threshold for binarization Q to PA
m Minimum number of role’s users
λ Threshold for user-role assignment
θ Threshold percentage for defining
common permissions in HTPA
Π(t
′
) Permissions common for team t
′
ω(t
′
, p) Ratio of users in team t
′
having per-
mission p
3.3.2 Attribution
The second task is attributing the roles to users, using
attribution rules. Instead of a direct construction of
UA, we create a decision rule F
r
: R
n
→ {0, 1} for each
role r ∈ R that decides on the assignment to user u ∈ U
based on their attributes A(u). In the ML language, we
can interpret F
r
as a classification model.
3.4 Evaluation
The task is to find an optimal and attributable RBAC
policy for a given access control configuration so the
overall criterion on the test data set is minimized.
wsc(γ, W ) = w
r
· |R| (1)
+ w
u
· |UA|
+ w
p
· |PA|
+ w
h
· |t
reduce
(RH)|
+ w
d
· |DUPA|
+ w
n
· |NU PA|
This criterion is called Weighted Structural Comple-
xity (Molloy et al., 2008).
Moreover, we will use a secondary metric to eva-
luate the roles: a Covering rate. In machine learning
terminology, this can be considered the true-positive
rate. The Covering rate is calculated as:
CR =
|U P ∩UA ◦PA|
|UP|
4 SOLUTION
In our research, two main approaches were tried: the
standard ML approach, particularly dimensionality
reduction together with clustering, and Hierarchical
Team Permission Analysis (HTPA), based on the hie-
rarchical structure of the organization.
4.1 Description of Data
Input U P is represented by a sparse binary matrix
UP, having rows as users and columns as permissi-
ons. Such conversion is motivated by the application
of ML algorithms as well as HTPA algorithm, since
both of them require matrix inputs.
The hierarchical structure of the organization is re-
presented by a table, where first column represents a
child node, particularly User ID or Organization Unit
ID, and the second column is the parent node. From
this data we are able to generate a hierarchy tree, star-
ting from the top level, which is the whole company,
and moving to the bottom level, which is the user’s
team. For example: Company - IT department - Data
Science team.
The desired data output would be: 1) PA represen-
ted as a binary PA matrix, where rows are roles and
columns are permissions; 2) UA represented as a bi-
nary UA matrix, where rows are users and columns
are roles.
4.2 Machine Learning Approach
4.2.1 Clustering
There have been several attempts to apply clustering
techniques for the role-mining. Kuhlmann and Kern
present a clustering technique similar to the widely-
known k-means clustering, which requires predefi-
ning the number of clusters (Kern et al., 2002). Ano-
ther prominent work in this field was ORCA method
based on the hierarchical clustering algorithm to form
roles and then illustrate the role hierarchy in a graphi-
cal form (Schlegelmilch and Steffens, 2005). Abol-
fathi et al. (2021) suggested a highly scalable solu-
tion to the role-mining problem, suitable for the large
ICEIS 2024 - 26th International Conference on Enterprise Information Systems
724

organizations. Non-negative matrix factorization was
used, which is a dimensionality reduction technique
and is close to the clustering methods (Abolfathi et al.,
2021).
Based on the above-mentioned literature, we de-
cided to use a combination of a dimensionality re-
duction technique and clustering for the role-mining,
which should be applied to the sparse matrix UP.
It is well known, that the clustering algorithms
are sensitive to the so-called ”curse of dimensiona-
lity”(K
¨
oppen, 2000), and so do not perform well in
high dimensional space (Assent, 2012). Moreover,
multiple permissions could appear together and thus
be highly correlated. Due to this fact we first applied a
dimensionality reduction technique to the U P matrix,
particularly - linear dimensionality reduction using
truncated singular value decomposition (SVD). Con-
trary to principal component analysis (PCA), this es-
timator does not center the data before computing the
singular value decomposition, and hence it can work
with sparse matrices efficiently (Sch
¨
utze et al., 2008)
After that, k-means clustering (Lloyd, 1982) is ap-
plied to the new low-dimensional space to find cen-
troids of clusters. Subsequently, these centroids are
decomposed to permissions, which result in a non-
binary matrix Q. Then, this matrix is binarized to PA
that corresponds to PA, using a threshold η. To find an
optimal value of η, the WSC (1) is optimized.
As a result the roles R and permission assignments
PA (represented as a binary PA matrix) is obtained.
4.2.2 Attribution of Roles Using Logistic
Regression
According to the business requirements in
Section 3.1, the roles R should be assigned to
users U, i.e., UA should be constructed based on the
attribution rules. We constructed them as classifiers,
adopting logistic regression as a well-interpretable
model. Each role will have one classifier.
Firstly, the data for machine learning are construc-
ted using users’ attributes X = [A(u)]
u∈U
as an input.
For each user and each role, we test if user u ∈ U has
a role r ∈ R - this serves as output Y . The role r is as-
signed to the user u, if she/he has relatively at least λ
permissions in this role.
|p : p ∈ P, (r, p) ∈ PA, (u, p) ∈ UP|
|p : p ∈ P, (r, p) ∈ PA|
≥ λ
The parameter λ, slightly less than 1, was introdu-
ced to enhance the algorithm’s adaptability. Its imple-
mentation permits some degree of NUPA, while faci-
litating more effective minimization of WSC.
In this logic, a vector Y is built for each role. Mo-
reover, the roles having less than m users were remo-
ved because it is impossible to train a meaningful logit
model on a small number of observations.
Using this approach, multiple logistic regression
models F
r
for r ∈ R were created to predict (attribute)
every role to users. This prediction (not the original
values in Y ) was used for as UA, i.e.
(u, r) ∈ UA if and only if F
r
(A(u)) = 1
4.3 Hierarchical Team Permission
Analysis
Processing the hierarchy of teams, considering stan-
dard processing of a tree, like DFS or BFS. The buffer
contains pairs of (team id, considered permissions).
1. Place the top hierarchy (whole company) into the
buffer, with all permission columns, i.e., (t
0
, P).
Initialize UA ←
/
0, PA ←
/
0 Then, proceed to
Step 2.
2. Take next item (t
′
, P
′
) from the buffer:
• Among the permissions P
′
, identify those per-
missions common for all team members t
′
. We
say they are common if at least the percentage
of team members having permission is larger
than a given θ, where θ is set :
Π(t
′
) ←
p ∈ P
′
: ω(t
′
, p) ≥ θ
where
ω(t
′
, p) =
|u : u ∈ U, t
′
∈ M(u), (u, p) ∈ UP|
|u : u ∈ U, t
′
∈ M(u)|
is ratio of users in t
′
having permission p.
• Define a new role r
′
for these permissions
Π(t
′
), i.e.
PA ← PA ∪ {(r
′
, p)}
p∈Π(t
′
)
The role is attributed by the membership of that
team.
• Add all child teams to the buffer. Their rela-
ted permissions are the related permissions of
the current team without the permissions in the
given role. Formally, for all t
′′
: (t
′
, t
′′
) ∈ H we
add to buffer (t
′′
, P
′
\Π(t
′
))
• If the buffer is empty, stop. If not, iterate step 2.
To illustrate the algorithm, consider a simple hie-
rarchy of teams T = {t
0
, t
1
, t
2
} where t
0
is parent to t
1
and t
2
. Team t
1
has 5 users, t
2
has 5 users, and t
0
has
two additional users (manager and secretary), who do
not belong to either t
1
or t
2
. Assume that the permis-
sions p
0
, p
1
, p
2
, p
3
are assigned as shown in Table 2.
Assume that θ = 0.8, then the roles and attributions
will be the following: the role for t
0
will contain p
0
Identification and Attribution of Access Roles Using Hierarchical Team Permission Analysis
725

and p
1
, and the role will be inherited by the child te-
ams as well, t
1
will get p
2
, and t
2
will get p
3
. The
assignment follows the Principle of Least Privilege
(PoLP), i.e., ensures that access rights are assigned
only to those, who needs them.
Table 2: Example of UP.
U M(u) p
0
p
1
p
2
p
3
u
0
t
0
1 1 0 0
u
1
t
0
1 1 0 0
u
2
(t
0
, t
1
) 1 1 1 0
u
3
(t
0
, t
1
) 1 1 1 0
u
4
(t
0
, t
1
) 1 1 1 0
u
5
(t
0
, t
1
) 1 1 1 0
u
6
(t
0
, t
1
) 1 1 1 0
u
7
(t
0
, t
2
) 1 1 0 1
u
8
(t
0
, t
2
) 1 1 0 1
u
9
(t
0
, t
2
) 1 1 0 1
u
10
(t
0
, t
2
) 1 1 0 1
u
11
(t
0
, t
2
) 1 1 0 0
5 CASE STUDY
We worked with data from a large financial institu-
tion, serving approximately 15,000 users, including
agents. The current access control model is a mix
of different Access control models, mainly Identity-
based access control and Attribute Based Access Con-
trol. Currently, all data about users and their permis-
sions are held in a control database, and they are then
provisioned to different applications. Sometimes the
permissions are set by the application administrators;
sometimes, they are assigned to users automatically
based on their attributes. Currently, permission ma-
nagement is carried out per application; no permission
groups would contain permissions from various appli-
cations. The current model is not effective nor salable
for the big company. As a result, the process of re-
ceiving necessary permissions for the new employees
or in case of changing roles often takes weeks and is
very ineffective.
The company’s ultimate objective was transitio-
ning to a Role-Based Access Control (RBAC) model.
To achieve this, we have been tasked with developing
roles that can be automatically assigned based on user
attributes.
5.1 Role-Mining in Practise
Our objective was to mine roles only for back-office
employees, thus the U P sparse matrix was of shape
3827*4882. Firstly, we tried the ML approach. To re-
duce dimensionality, we used 350 SVD components,
which allowed us to preserve 91% of total variability
in data.
In our k-means clustering experiments, we tested
with k = 350 and k = 450, resulting in 66 and 61
roles, respectively. Despite the high number of clus-
ters, many were excluded in the preparation stage
for logistic regression. As previously discussed (Sub-
section 4.2.2), roles with fewer than m users were
removed since training a meaningful logistic model
with too few observations is not feasible. We chose
m = 10. Therefore, when k was set to less than 350,
the algorithm produced a very small number of roles,
leading to a lower overall WSC.
In order to binarize Q to PA the optimization lib-
rary Hyperopt (Bergstra et al., 2013) was used to opti-
mize the threshold η based on WSC minimisation. To
construct the Y for machine learning, it’s important to
choose the right λ value. Setting λ = 1 creates a lot of
precise and strict roles, eliminating the need for ma-
nual checks by line managers or security experts. On
the other hand, a lower λ value introduces more fle-
xibility and fewer roles, improving generalization but
also increasing the risk of NUPA or false positives,
which require manual review. After trying various λ
values and consulting with the business, we decided
on λ = 0.9 to make the algorithm more flexible. The
same reasoning was used for choosing the θ value for
the HTPA algorithm. Another strategy to determine
the appropriate values for θ and λ would be including
them into the Hyperopt optimization based on WSC,
but it is beyond the scope of this article.
For the logistic-regression-based attribution, we
used these features about the user:
1. CDUUserTypeID - type of user (employee, tech-
nical account, test account, external, etc.)
2. QualificationCodeID - qualification/certification
3. ProfessionID - user profession code
4. GroupOfEmployeesID - user employment type -
full-time, part-time etc.
5. OrganizationUnitID - the user’s organizational
unit
To test the logit model performance we splited a
data set to train (70%) and test (30%). The WSC cri-
terion was afterwards calculated on the test data.
After that we tried the second approach for the
role-mining - HTPA. The algorithm was programmed
in Python utilizing the pandas multiindex functiona-
lity. As a result we set paths in H to Pandas multiin-
dex and looped through it. The threshold percentage
for defining common permissions θ was set to 0.9 af-
ter experimenting with different values and consulting
with the business. Finally, the WSC was calculated for
the test set data.
ICEIS 2024 - 26th International Conference on Enterprise Information Systems
726

5.2 Results
In Table 3 the Weighted Structural Complexity
(WSC) for the both solution approaches can be found
as well as the secondary metric Covering rate (CR).
According to the literature (Molloy et al., 2008), the
WSC weights were set as W = [1, 1, 1, 1, 1, 1]. Since
we do not introduce any additional hierarchy of roles
RH, |t
reduce
(RH)| = 0 for both algorithms.
We can clearly see that our Hierarchical Team Per-
mission Analysis based on the companies’ hierarchy
clearly outperforms the roles created and attributed
using ML approach according to the WSC criterion.
The improvement is drastic: -49 % WSC for Clus-
tering with k = 350 and -47 % WSC for Clustering
with k = 450. The biggest advantage of Hierarchi-
cal Team Permission Analysis is an extensive decline
in costly |NUPA| compared to ML approach, particu-
larly: -95 % and -94 % (!) decline compared to clus-
tering models. There is also a significant decrease in
number of user assignments |UA|: -42 % and -46 %,
and a small decrease in |DUPA|: -8 %.
On the other hand, there is notable increase in the
number of roles compared to ML roles. Due to setting
the minimal number of users for a ML role m = 10,
the majority of roles were removed. The number of
permission assignments |PA| is similar to ML results
with k = 350, and 16 % higher compared to k = 450
suggesting, that HTPA can bring somewhat higher
overlap between roles.
Considering the secondary metric - the Covering
rate, which tells us, how many original permissions
were covered by roles, the HTPA slightly outperfor-
med the ML methods: +6 %.
Another benefit of using HTPA, based on compa-
nies’ hierarchy for the role-mining, is that it provides
meaningful roles with clear business interpretation:
we receive specific roles for different departments and
teams. This improves the probability, that the defined
roles will be actually used in practise by the security
administrators.
A further advantage of our algorithm is, that it pro-
vides very clear assignment rules for the created ro-
les: when new employee arrives to the team, he/she
is going to automatically receive the roles according
to the hierarchy of his team with minimal errors and
security risks. On the other hand, Machine Learning
approach does not allow for such clear, simple and
almost error-less attribution due to its probabilistic
nature, and classical role-mining algorithms do not
allow for any automatic attribution. Moreover our al-
gorithm is quite simple and thus trustworthy for the
business users.
Table 3: WSC for ML approach and HTPA.
Clusters
(k=350)
HTPA vs
Clust.
(k=350)
Clusters
(k=450)
HTPA vs
Clust.
(k=450) HTPA
|R| 66 479% 61 526 % 382
|UA| 8,579 -42 % 9,275 -46 % 4,989
|PA| 4,944 4 % 4,447 16 % 5,147
|t
reduce
(RH)| 0 0 % 0 0 % 0
|DUPA| 37,198 -8 % 37,108 -8 % 34,189
|NUPA| 40,586 -95 % 37,303 -94 % 2,084
wsc(γ, W ) 91,373 -49 % 88,194 -47 % 46,791
CR 58 % 6 % 58 % 6 % 62 %
6 CONCLUSION
Traditional RBAC role-mining algorithms output a
mathematically optimized set of roles, nevertheless,
they often lack a reasonable interpretation, neither
allow for assigning users to roles. ML models in ac-
cess control could be risky due to their probabilistic
nature and some level of inaccuracy. Due to such dra-
wbacks, the above-mentioned methods are not well
suited for our research question, which was finding
the RBAC roles as well as a mechanism of attributing
these roles to users efficiently and precisely.
In this paper, we introduce two possible solutions
for solving the business requirement. Fist approach
was using Machine Learning methods, particularly:
1) reduce dimensionality of data; 2) apply k-means
clustering, where centers are roles; 3) predict/attribute
roles with a logistic regression for every role. The se-
cond approach was creating a Hierarchical Team Per-
mission Analysis algorithm, which was based on the
company’s hierarchical structure.
The results of real-life application of these me-
thods show, that the HTPA algorithm produce roles
with higher Covering rate, and fewer corrective una-
ssignments and assignments. The attribution of roles
based on companies’ hierarchy is straightforward and
error-resistant. Another benefit of the HTPA algori-
thm is, that it’s quite simple, and provides roles with
clear interpretation, thus making them trustworthy for
the business users.
Nevertheless, there are still some ideas to explore,
for example, to combine both suggested solutions,
particularly applying the ML approach to the data,
which were not covered by the HTPA roles, and thus
improve the covering rate. Another future research
idea is to fine-tune the threshold for assigning users to
roles, λ, and the threshold for identifying shared per-
missions in HTPA, θ, aiming to reduce WSC. Additi-
onally, achieving a better balance between two kinds
of errors, specifically DUPA (false negatives) and
NUPA (false positives), could be investigated further
Identification and Attribution of Access Roles Using Hierarchical Team Permission Analysis
727

by using varied weights during the optimization pro-
cess.
REFERENCES
Abolfathi, M., Raghebi, Z., Jafarian, J., and Banaei-
Kashani, F. (2021). A scalable role mining approach
for large organizations. pages 45–54.
Al-Kahtani, M. and Sandhu, R. (2004). Rule-based rbac
with negative authorization. In 20th Annual Computer
Security Applications Conference, pages 405–415.
Alayda, S., Almowaysher, N., Humayun, M., and Jhanjhi,
N. (2020). A novel hybrid approach for access control
in cloud computing. International Journal of Engi-
neering Research and Technology, 13:3404–3414.
Assent, I. (2012). Clustering high dimensional data.
Wiley Interdisciplinary Reviews: Data Mining and
Knowledge Discovery, 2(4):340–350.
Bergstra, J., Yamins, D., and Cox, D. (2013). Making
a science of model search: Hyperparameter optimi-
zation in hundreds of dimensions for vision archi-
tectures. In Dasgupta, S. and McAllester, D., edi-
tors, Proceedings of the 30th International Conference
on Machine Learning, volume 28 of Proceedings of
Machine Learning Research, pages 115–123, Atlanta,
Georgia, USA. PMLR.
Cavoukian, A., Chibba, M., Williamson, G., and Ferguson,
A. (2015). The importance of abac: attribute-based
access control to big data: privacy and context. The
Privacy and Big Data Institute, Canada.
Di Pietro, R., Colantonio, A., and Ocello, A. (2012). Role
mining in business: taming role-based access control
administration. World Scientific.
Ene, A., Horne, W., Milosavljevic, N., Rao, P., Schreiber,
R., and Tarjan, R. (2008). Fast exact and heuristic
methods for role minimization problems. pages 1–10.
Jayasundara, S., Arachchilage, N., and Russello, G. (2024).
Vision: ”accessformer”: Feedback-driven access con-
trol policy generation framework.
Karp, A., Haury, H., and Davis, M. (2010). From abac to
zbac: The evolution of access control models. ISSA
(Information Systems Security Association). Journal,
8:22–30.
Kern, A., Kuhlmann, M., Schaad, A., and Moffett, J. (2002).
Observations on the role life-cycle in the context of
enterprise security management. pages 43–51.
K
¨
oppen, M. (2000). The curse of dimensionality. In 5th on-
line world conference on soft computing in industrial
applications (WSC5), volume 1, pages 4–8.
Kuhn, D., Coyne, E., and Weil, T. (2010). Adding attributes
to role-based access control. Computer, 43:79–81.
Lloyd, S. (1982). Least squares quantization in pcm. IEEE
Transactions on Information Theory, 28(2):129–137.
Molloy, I., Chen, H., Li, T., Wang, Q., Li, N., Bertino, E.,
Calo, S., and Lobo, J. (2008). Mining roles with se-
mantic meanings. pages 21–30.
Ni, Q., Lobo, J., Calo, S., Rohatgi, P., and Bertino, E.
(2009). Automating role-based provisioning by lear-
ning from examples. pages 75–84.
Nobi, M., Gupta, M., Praharaj, L., Abdelsalam, M.,
Krishnan, R., and Sandhu, R. (2022a). Machine lear-
ning in access control: A taxonomy and survey.
Nobi, M. N., Krishnan, R., Huang, Y., Shakarami, M., and
Sandhu, R. (2022b). Toward Deep Learning Based
Access Control. CODASPY ’22: Proceedings of the
Twelfth ACM Conference on Data and Application
Security and Privacy, page 143–154.
Olabanji, S., Olaniyi, O., Adigwe, C., Okunleye, O., and
Oladoyinbo, T. (2024). Ai for identity and access
management (iam) in the cloud: Exploring the poten-
tial of artificial intelligence to improve user authenti-
cation, authorization, and access control within cloud-
based systems. Asian Journal of Research in Compu-
ter Science, 17:38–56.
Sandhu, R., Coyne, E., Feinstein, H., and Youman, C.
(1996). Role-based access control models. Compu-
ter, 29(2):38–47.
Schlegelmilch, J. and Steffens, U. (2005). Role mining with
orca. pages 168–176.
Sch
¨
utze, H., Manning, C. D., and Raghavan, P. (2008).
Introduction to information retrieval, volume 39.
Cambridge University Press Cambridge.
Vaidya, J., Atluri, V., and Warner, J. (2006). Roleminer: mi-
ning roles using subset enumeration. In Proceedings
of the 13th ACM conference on Computer and com-
munications security, pages 144–153.
Zhang, D., Ramamohanarao, K., and Ebringer, T. (2007).
Role engineering using graph optimisation. pages
139–144.
Zhou, L., Su, C., Li, Z., Liu, Z., and Hancke, G. P. (2019).
Automatic fine-grained access control in scada by ma-
chine learning. Future Generation Computer Systems,
93:548–559.
ICEIS 2024 - 26th International Conference on Enterprise Information Systems
728
