
Making Application Build Safer Through Static Analysis of Naming
Antoine Beugnard
a
and Julien Mallet
b
IMT Atlantique/Lab-STICC, Brest, France
Keywords:
Build Process, Verification, Heterogeneous Name Resolution.
Abstract:
A lot of studies demonstrate that many builds of software fail, due to dependency issues. We make the assump-
tion that failures are caused by the difficulty of tools to check interdependencies in a context of heterogeneity
of languages. This article describes a novel approach to improving applications builds safety based on an
abstract interpretation of name usage. Since application building relies on very heterogeneous resources and
languages, the approach extracts what appears as a common factor: names. We reuse a name dependency
approach (scope graph) already used in single language context, and adapt it to a multi-language environment.
It allows to check external references and ensure the resolution of names. Thanks to an operational semantics
of build operations on scope graphs, the verification can be done statically, prior to any real build run.
1 MOTIVATION
Software engineering is not just about software, it in-
cludes building processes. A strong assumption is that
software quality depends on process quality (Paulk,
2009). If there are many programming languages for
software, there also exist many languages describing
processes. We include among them build scripts and
build languages.
If programming languages have been scrutinized
and complemented with plenty of tools (static and
dynamic checkers, bad smell detectors) it is far the
case for build languages. Most studies concern de-
pendency computation and execution optimization.
Mokhov et al. made the same observation in
(Mokhov et al., 2018) writing “[b]uild systems (such
as MAKE) are big, complicated and used by every
software developer . . . [but] [t]hese complex build
systems use subtle algorithms, but they are often hid-
den away, and not the object of study.”
As a consequence, literature shows many issues in
build execution. For instance, in (Seo et al., 2014) Seo
et al. rely on an empirical study of 26.6 million builds
over nine months by thousands of developers to an-
alyze, among other things, failure frequency. They
observe that 37.4% of C++ builds fail, and 29.7%
of Java’s. They assert that “[t]he most common er-
rors are associated with dependencies between com-
ponents; developers spend significant effort resolving
a
https://orcid.org/0000-0002-3096-237X
b
https://orcid.org/0000-0001-5068-1754
these build dependency issues”. However, they con-
clude that they lack quantifiable evidence on the rea-
sons for builds failure.
Causes of failure and their classifications may
vary from study to study (Miller, 2008; Kerzazi et al.,
2014; Sulír and Porubän, 2016; Vassallo et al., 2017).
However, all these empirical studies converge to the
conclusion that builds frequently fail.
We intend to improve build safety by reducing the
number of failures. Observing the context of builds
and reason of failure, we raise the assumption that
failures may be due to heterogeneity of languages
used and lack of tools checking interdependencies.
Not only programming languages, but also configura-
tion, build and script languages used during the devel-
opment process. Heterogeneity introduces complex-
ity and makes verification difficult. Middleware like
CORBA or .NET, made to improve interoperability
are complex and do not solve semantics issues (Beug-
nard and Salah Sadou, 2007).
The purpose of this article is to propose a cross-
domain and cross-language means of verification that
can be applied to the process of build. The main idea
is to use names and to hide any computation details
and then semantics subtleties. Names are intensively
used to identify artifacts such as files, elements of pro-
grams or processes, resources, tasks, and so on. The
proposed approach relies on the assumption that de-
pendency failures are due to name misspelling and file
misplacement. Naming is error-prone.
In the next section, we introduce prerequisites,
442
Beugnard, A. and Mallet, J.
Making Application Build Safer Through Static Analysis of Naming.
DOI: 10.5220/0012676500003687
Paper published under CC license (CC BY-NC-ND 4.0)
In Proceedings of the 19th International Conference on Evaluation of Novel Approaches to Software Engineering (ENASE 2024), pages 442-449
ISBN: 978-989-758-696-5; ISSN: 2184-4895
Proceedings Copyright © 2024 by SCITEPRESS – Science and Technology Publications, Lda.

then we describe the approach consisting in building
abstract interpretation
1
of the build process based on
scope graph (Neron et al., 2015; Antwerpen et al.,
2016) of names. Then, section 4 applies the approach
on a small C program and its makefile, organized
as a build process. An analysis of the approach is de-
tailed section 5, before the conclusion.
2 PREREQUISITES
Before sketching the approach, we need to introduce
the theory of name resolution introduced by Neron et
al. in (Neron et al., 2015). This theory has been used
to describe, explain and compare many name binding
techniques used in different programming languages.
We do not expect to summarize all aspects in a few
lines, but we intend to provide the minimum concept
understanding.
Name organization is described in a graph. There
are two kinds of vertices: names (rectangles) and
scopes (ovals). There are four kinds of edges: name
definition (scope to name), name use (name to scope),
scope naming (name to scope with a specific white ar-
rowhead), and scope hierarchy (scope to scope).
Resolving a name consists in finding a path from
a name usage to a name definition. This very sim-
ple resolution can be specialized and guided by many
more information that can be attached to the edges
(through edge tags). Moreover, specific rules (such
as naming convention) can be checked, stored and
reused.
One important idea is that this resolution mecha-
nism is universal and reusable, and rely on the seman-
tic encoded in edges (and their attached information).
There is no need for specific or customized develop-
ments. Finally, rules can be accumulated and reused.
Scope graph figures (3 to 5) use this notation.
Red vertices are unresolved names, green ones are re-
solved with the green dotted arrow.
3 APPROACH
Building software relies on diversified artifacts:
source files (possibly in many programming lan-
guages), configuration files, resource files (audio,
video, style, . . . ), databases, scripts, etc. all stored
in the file system. One of the few shared features
among all these resources is that they are named. One
reason is to help human beings understand and deal
1
The computation is reduced to the evolution of name
definition and use through scope graphs.
with these things. Moreover, many resources contain
themselves references to other named resources.
All these names can be organized as name spaces
encoding relationships among these names. The
scope graph approach (Neron et al., 2015; Antwerpen
et al., 2016) proved its usefulness for analyzing pro-
gramming languages. We rely on it, in a more hetero-
geneous environment, but for simpler relationships.
The approach is twofold. First, the abstraction is
applied at a time t, on a set of file system resources,
and results in a large scope graph where identified
names are collected and linked according to their us-
age (defined or used) and to the nature of the location
they are collected (source code, libraries, data files,
etc.). For each file, note that the only collected names
are names that make reference to an external
2
infor-
mation. Other names are assumed to be tackled by
specific tools such as compilers. At this stage, it is al-
ready possible to check the proper use of names, that
is the accessibility of the definition of a name from
its location of use. Note that many definitions may be
reachable, which is the case of ambiguity or that no
definition exists yet, which can be an error or a prema-
ture check, the definition of that name being produced
(or introduced) later by other operations (or humans).
The second stage is the definition of action se-
mantics on the scope graph for build operations. This
second step allows us to avoid applying the previous
stage (the construction of the scope graph) each time
a verification is required, but permits an incremental
evolution of the scope graph. The verification tech-
nique used on the initial stage can then be applied on
the result.
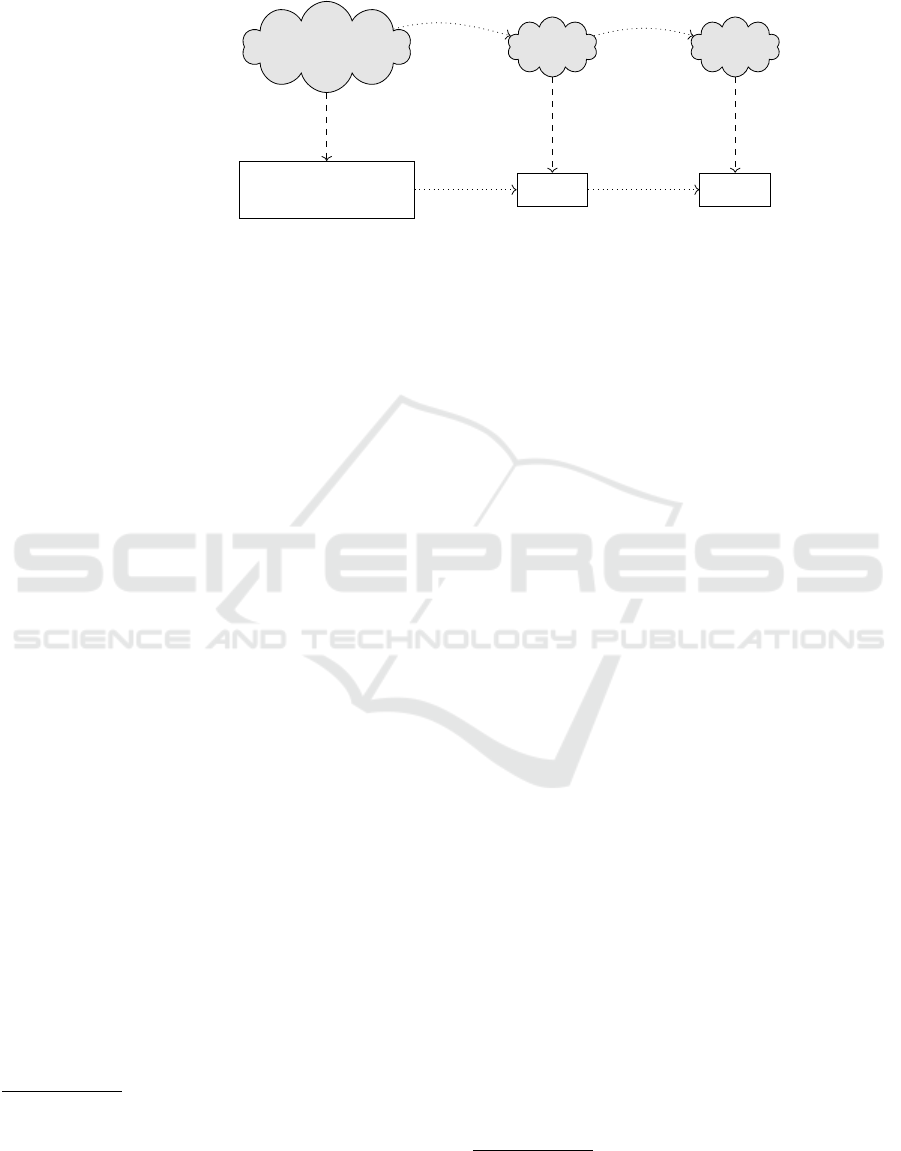
Figure 1 illustrates both stages. The vertical ar-
row a denotes the first stage from the real file system
to scope graphs, while horizontal arrows, op
i
and
c
op
i
respectively denote the actual build operation on the
file system and its semantics on the abstract interpre-
tation domain. The bottom line shows the rules R that
have to be checked at some time. The correctness of
the approach relies on the assertion
c
op
i
(a(FS
i
)) ⊑ a(op
i
(FS
i
))
whose interpretation is: valid rules after abstract ap-
plication
c
op
i
on a(FS
i
) are included in validated rules
after application of the real op
i
on actual FS
i
.
In the following, the first (initial) stage of the ap-
proach is detailled. It consists in 3 steps (See Figure 1
- vertically, reality to abstraction).
a
1
Extract names from resources (including the file
system). Names are filtered. For instance,
function names in a source code are ignored,
2
Outside the file being analyzed.
Making Application Build Safer Through Static Analysis of Naming
443
semantics
operation: op
i
c
op
i
: SG → SG
reality File System
0
FS
1
FS
2
abstraction
Scope graph a(FS
0
) a(FS
1
) a(FS
2
)
rules (R)
c : a(FS
0
) ⊢ R
c
op
i
(a(FS
i
)) ⊑ a(op
i
(FS
i
))
a = a
1
;a
2
a a
op
0
op
1
d
op
0
d
op
1
Figure 1: Principle of the abstract interpretation.
since the compiler is supposed to check the well-
formedness of the program. This is an adhoc pro-
cess depending on the nature of the resources. At
the moment, we extract names manually; how-
ever, automatic extraction has been experimented.
Names of interest are constants, file names and
other values that denote external resources. An
extraction produces a (local/partial) scope graph.
a
2
All (local) scope graphs are gathered in a global
scope graph whose backbone is the file system
scope graph. This is a simple idea, since the file
system gathers itself all other resources
3
c A set of rules R (bottom of the figure) can be set
and checked against the global scope graph. Rules
may depend on the stage of the build. They may
include good practices such as, this is a example,
all videos are in a repository named videos. The
checker produces a diagnostic on the accessibility
of name definitions (missing, correct - only one,
ambiguous - more that one).
This process would already improve build verifi-
cation if applied time to time. But, it needs running
the build leading to a dynamic analysis. In order to
statically check the build, the second stage of the ap-
proach is introduced. It consists in 3 steps (See Fig-
ure 1 - horizontally, operation after operation).
1. The semantics (top of the figure) of all build op-
erations (compile, link, cd, move, copy, . . . ) is
defined as scope graph transformations. This is
done once, and this is reusable.
3
This single file system technique could, in principle,
be easily extended to a set of file systems. The global dis-
tributed system can define a scope in which each single file
system is another scope. The problem of scalability re-
mains, however, if millions of systems are to be analyzed.
2. Each time an operation op
i
is realized in the real
world, or emulated for verification purpose, its in-
terpretation (a scope graph transformation
c
op
i
) is
applied on the current scope graph.
3. After each operation, verifications (c) can be run
on the resulting scope graph as for the first stage.
Once the semantics is defined, it is then possible to
interpret statically (by operation emulation) the build
process in order to detect errors early.
The tricky part of the scope graph transformation
is the need to introduce time dependencies. Fortu-
nately, the flexibility of scope graphs allows tagging
edges with any information. Information concerning
name creation or name suppression, for instance, can
be introduced as tags.
A major interest of scope graph is the reusabil-
ity of rules. Once defined, sometimes relying on spe-
cific tags, they can be stored in libraries of rules. The
checker remains the same.
In the following section a short example is devel-
oped as a proof of concept.
4 EXAMPLE
4.1 Simple C Program
In order to illustrate the approach, we extended a
very small example that was used as a make tu-
torial
4
. This application is developed in C. It
is composed of a main file hellomake.c, a
functional file hellofunc.c with its header file
4
http://www.cs.colby.edu/maxwell/courses/tutorials/
maketutor/
ENASE 2024 - 19th International Conference on Evaluation of Novel Approaches to Software Engineering
444
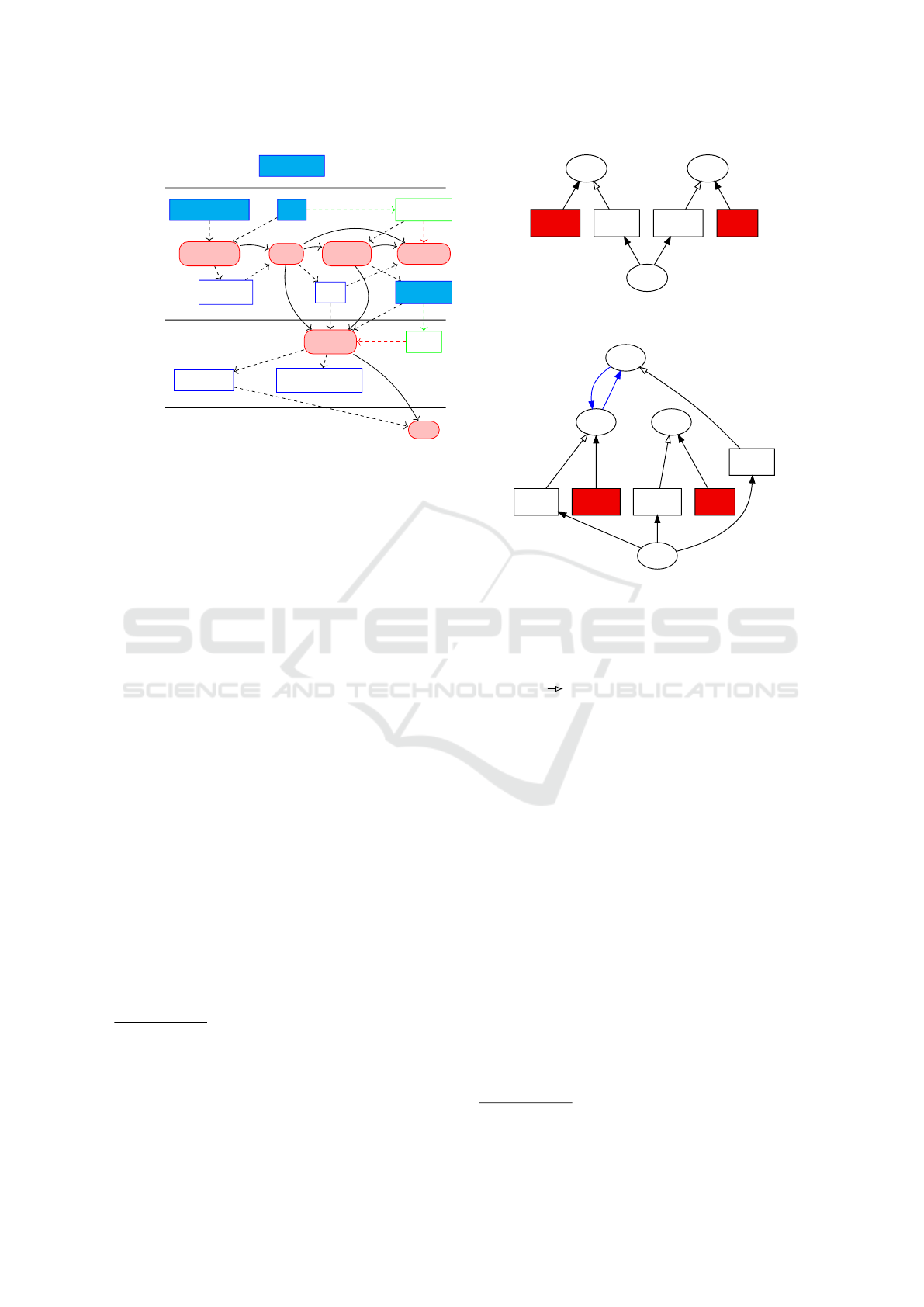
Dev
compile
link
devrun
Deployer deploy
obj/*.o
bin
ProcessManager
Makefile
include/*.h *.c
msg.txt
dest/bin
dest/msg.txt
User
run
msg.txt
<p>
config
Figure 2: Build process model. Makefile abstraction.
hellomake.h
5
. It also uses an external library
stdio.h.
We extended the original application to simulate
a more complex development cycle including a con-
figuration and a deployment stage. This application
writes in the standard output the content of a file
(msg.txt). This message is configured before de-
ployment by replacing a pattern (<p>) by an actual
value (“!”). Four stakeholders are identified: process
manager, developer, deployer, and user. As shown in
figure 2, the process manager provides a Makefile.
The figure is an abstract model of the Makefile
content. It shows the developer that provides re-
sources (*.h, *.c and msg.txt) then compiles, links and
runs to test the program (without configuration); the
deployer copies the binary to the target location and
configures the application replacing <p> by “!” for
instance; then the user runs the deployed and config-
ured application. This simplified process examplifies
that time is essential and that differents rules have to
be verified at different stage of the development.
This example is not very heterogeneous (only C
and text files
6
), but it shows how languages are hidden
(abstracted) behind the use of names.
We have written a small scope graph implementa-
tion in Java with a checker. Applied to the develop-
ment directory
7
, the first stage (extraction) gives Fig-
ure 3 as the result.
The figure shows the result of a manual extrac-
5
The name of the header could have been
hellofunc.h, but the original is named
hellomake.h: author’s choice.
6
We do not extract names from the makefile.
7
For the sake of brevity, libraries and environment vari-
ables are ignored.
hello.c0
2
msg.txt1 msg.txt2
3
<p>3
1
Figure 3: Step 1: scope graph after initial extraction.
hello.c0
2
msg.txt1 msg.txt2
3
<p>3
hello.o4
4
1
CPCP
Figure 4: Step 2: after compilation.
tion of names from the files hello.c and msg.txt which
are grouped in a single (partial) file system scope
graph. Scopes identifying files (or directories) are
round nodes
8
, names are rectangles. An empty ar-
row head ( ) denotes the naming of a scope. In red
appear names that are used but have not yet any defi-
nition. The node msg.txt has not definition because
the C file is not compiled neither linked and then has
no access to the resource; the node <p> because the
configuration is not yet ready.
Figure 4 shows the result of compilation. A new
file has been created (scope 4 : hello.o) which is
equivalent from a naming point of view to its source
hello.c. This is visible thanks to the loop of edges
tagged CP for compilation. From accessibility of
names point of view, nothing changes.
Figure 5 shows the result of linking. A new file has
been created (scope 5 : hello) which is equivalent
from a naming point of view to its source hello.o.
However, since it is executable it has access to the
content of its directory. This new property is denoted
by the edge tagged X (for execution) between the
scope 5 and the scope 1. From accessibility of names
point of view, now, msg.txt is resolved (green). In
fact, there is a path from the green box (use) to the
location in root (node 1) via X edge.
The next step after compilation and linking, as
8
The number inside is a simple id that is single.
Making Application Build Safer Through Static Analysis of Naming
445
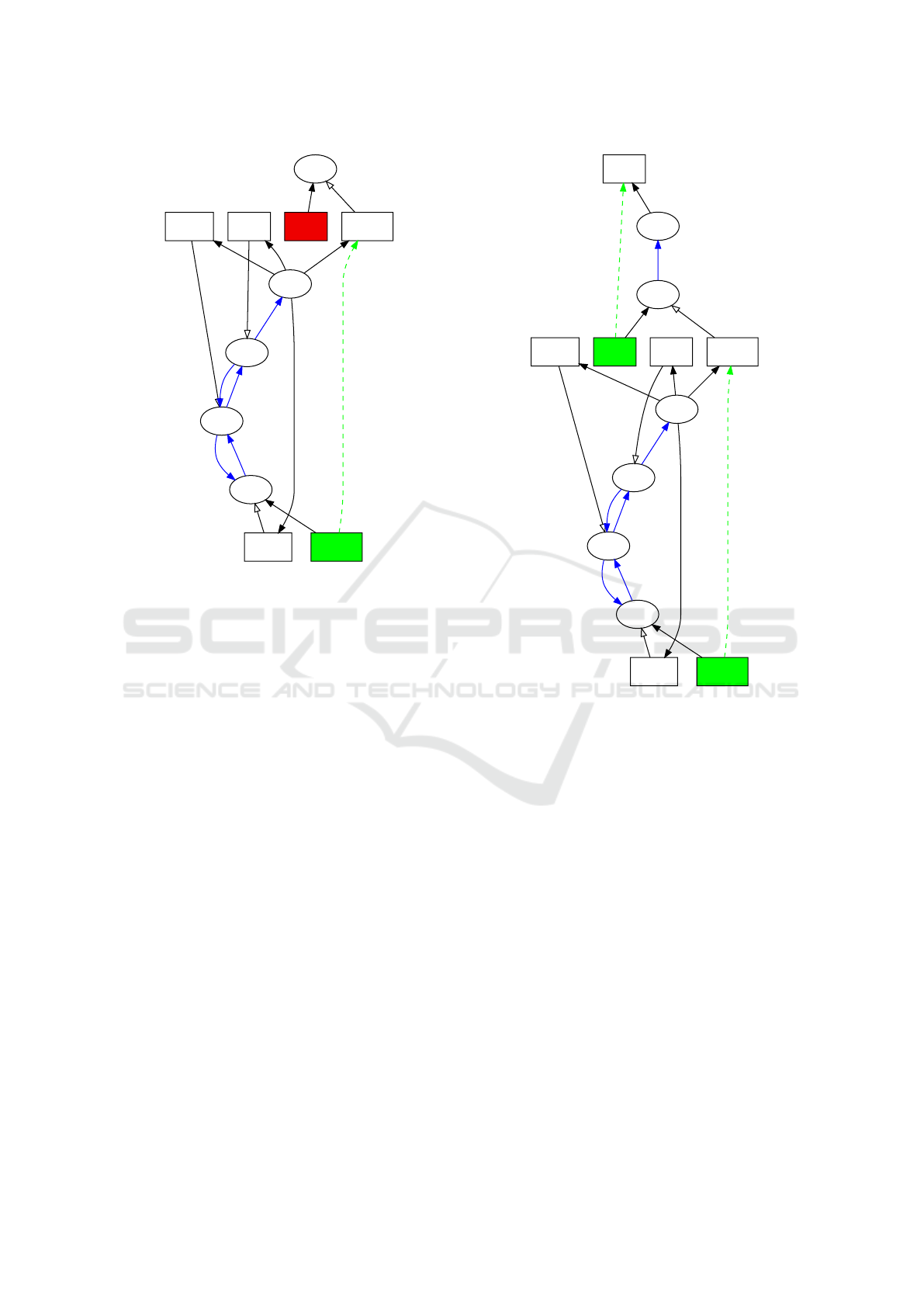
hello.c0
2
msg.txt1
msg.txt2
3
<p>3hello.o4
4
hello5
5
1
CPCP
L
X
L
Figure 5: Step 3: after linking.
shown in Figure 2, is configuration. Whether the bi-
nary would be run (devrun), the msg.txt file would
be found, but the < p > would not be configured yet.
The configuration is a simple sed string substitution
in the msg.txt file that is triggered by make. After
the configuration, the scope graph is given Figure 6.
Now, a run (devrun) would use the configured text.
The resolution path goes through the CF edge.
The last step is deployment. The binary and the
msg.txt file are copied in the dest repository de-
noted by scope 7. This can be seen (from the name
abstraction point of view) on the scope graph, Fig-
ure 7. The copied names are also resolved. For in-
stance, msg.txt9 has a path to msg.txt14 thanks to
the compilation (CP 10 to 9), the linking (L 9 to 8)
and the executability (X 8 to 7) of various nodes.
The sequence of scope graphs produced in this ex-
ample can be obtained after real operations: op
i
fol-
lowed by a (Figure 1). The main advantage of our
approach is that these scope graphs can also be pro-
duced before any operation, thanks to the semantics
of operations on scope graphs:
c
op
i
(same Figure). We
can then statically verify the proper use of names.
4.2 Semantics
We describe here the semantics of operations that de-
scribes how name scopes are composed while the ex-
ecution of the build is emulated. The semantics of
hello.c0
2
msg.txt1
msg.txt2
3
<p>3
<p>6
hello.o4
4
hello5
5
1
CPCP
L
6
CF
X
L
Figure 6: Step 4: after configuration.
operations with respect to scope graphs and naming
abstraction is defined Figure 8.
In following rules, sg denotes scope graphs, s
scopes. A directory name is denoted by d and a file
name by f . o
i
denotes operations. An environment
env is a couple (s,sg) where the scope s is identified
in the sg scope graph as the current scope.
(
d
Seq) If o
1
transforms env into env
′
, the sequence
of operations o
1
;o
2
consumes o
1
and the new state
becomes ⟨o
2
,env
′
⟩.
(
c
Md) When a directory d is created with mkdir,
the current scope does not change, but the scope graph
is completed with a new link from the current scope
to a new name d, and a new scope s
+
named d.
(
c
Cd) If d is the name of a directory linked to the
curent scope s, then cd moves the current directory
from s to s
d
which is the scope named d in sg.
(
\
Compil) If f is a file in the current directory and
s
f
is its associated scope, the result of the compilation
of f into f
′
is a new scope s
+
named f
′
. The scopes
s
f
and s
+
are bidirectionally linked with the tag CP
ENASE 2024 - 19th International Conference on Evaluation of Novel Approaches to Software Engineering
446
hello.c0
2
msg.txt1
msg.txt2
3
<p>3
<p>6
hello.o4
4
hello5
5
dest7
7
hello.o12
9
msg.txt9
msg.txt14
10
11
hello.c8
hello11
8
<p>15
<p>18
1
CP CP
L
6
CF
X
L
X
L L
CPCP
12
CF
Figure 7: Step 5: after deployment.
(for compilation). This means that the defined and
referenced names in the scope s
f
are identical in the
new scope s
+
. This link introduces an equivalence
class containing the scopes s
f
and s
+
.
(
d
Link) If f
i
are files in the current directory, the re-
sult of the linkage of all f
i
is a new scope s
+
named
f
′
, where s
+
are bidirectionally linked with the tag
L (for link) to all original scopes s
i
. Another link la-
beled X (for execution) is introduced between the new
scope s
+
and the current directory s. This means that,
at runtime, the defined names in s are also reachable
from s
+
.
(
\
Con f − sed) If f is a file that contains the name
x, then the configuration with sed does not change the
current scope, but complements the scope graph with
a new scope s
+
that defines the name x. s
f
is linked
to s
+
with the tag CF (for configure). This means that
the defined name x is reachable from s
f
after configu-
ration time.
The semantics of operation cp is introduced
through two rules according to the executabily of
copied file.
(
d
CP1) If f is the name of an executable (
X
) file
linked to the current scope s and d the name of a di-
rectory linked to the current scope and {s
+
,sg
′
} the
copy of the sub-scope graph rooted at s
f
restricted to
CP & L & CF tagged links, then cp does not change
the current scope, but complements the scope graph
with the copy where the new root scope is also named
f and f remains executable in that directory (there is
a link
X
between the new scope s
+
and the desti-
nation one s
d
). This means that all link introduced
through tagged CP, L and CF are copied in order to
make reachable the defined names.
(
d
CP2) If f is the name of a non-executable (
X
/∈
sg) file linked to the current scope s and d the name
of a directory linked to s and {s
+
,sg
′
} the copy of
the sub-scope graph rooted at s
f
restricted to CP & L
& CF tagged links, then cp does not change the cur-
rent scope, but complements the scope graph with the
copy where the new root scope is also named f . Un-
like rule CP1, there is no X link between the copied
scope s
+
and the destination one s
f
.
These semantics rules have been implemented in
Java and where used to produce the previous Figures
3 to 7.
5 ANALYSIS
The proposed approach enables to:
• extract name scope graph from heterogeneous re-
sources;
• build a global name scope graph for a large set of
resources with the file system as a backbone;
• define and store rules as an asset for process man-
agers;
• apply verification of rules at chosen steps of the
building process;
• check the use of names at the right moment in
time. Detect correct use (exactly one path), poten-
tial ambiguity (more than one path), or error (no
path). This can be done prior to any real execution
of the build process;
• produce a diagnostic for each step;
• avoid reconstruction the whole global scope graph
thanks to a transformational semantics on scope
graph.
The proposed approach is generic and extensible.
In order to extend it to new kinds of resources (new
programming language, new build language, etc.),
you need to implement the name extraction stage for
this kind of resource. Further, an extension of the
semantics for the new build operations may be re-
quired. The abstract naming model (scope graph) and
Making Application Build Safer Through Static Analysis of Naming
447

⟨o
1
,env⟩ → env
′
⟨o
1
;o
2
,env⟩ → ⟨o
2
,env
′
⟩
(
d
Seq)
s d /∈ sg
⟨mkdir d, (s,sg)⟩ → (s,sg ∧ s d ∧ d s
+
)
(
c
Md)
s d ∧ d s
d
∈ sg
⟨cd d, (s,sg)⟩ → (s
d
,sg)
(
c
Cd)
s f ∧ f s
f
∈ sg s f
′
/∈ sg
⟨gcc −o f
′
f ,(s, sg)⟩ → (s,sg ∧ s f
′
∧ f
′
s
+
∧ s
+
CP
s
f
)
(
\
Compil)
∀i, s f
i
∧ f
i
s
i
∈ sg s f
′
/∈ sg
⟨gcc −o f
′
f
1
... f
n
,(s,sg)⟩ → (s,sg ∧ s f
′
∧ f
′
s
+
^
i
s
+
L
s
i
∧ s
+
X
s)
(
d
Link)
s
f ∧ f s
f
∈ sg x ∈ contents( f )
⟨sed −i s/x/e/g f , (s,sg)⟩ → (s,sg ∧ s
f
CF
s
+
∧ s
+
x)
(
\
Con f − Sed)
s f ∧ f s
f
∧ s d ∧ d s
d
∈ sg s
f
X
s ∈ sg clone({CP,L,CF},(s
f
,sg)) = (s
+
,sg
′
)
⟨cp f d, (s, sg)⟩ → (s,sg ∧ sg
′
∧ s
d
f ∧ f s
+
∧ s
+
X
s
d
)
(
d
Cp1)
s f ∧ f s
f
∧ s d ∧ d s
d
∈ sg s
f
X
s ̸∈ sg clone({CP,L,CF},(s
f
,sg)) = (s
+
,sg
′
)
⟨cp f d, (s, sg)⟩ → (s,sg ∧ sg
′
∧ s
d
f ∧ f s
+
)
(
d
Cp2)
Figure 8: Abstract semantics of operations.
the verification step apply directly for verifying the
build safety. To achieve this, we made the following
choices:
• use and reuse of the generic verification algorithm
of scope graph that already proof its usability;
• use the scope graph flexibility to adapt the verifi-
cation mecanism to specific needs in various con-
texts.
Main limitations are:
• a single file system on a single machine;
• names are constants. Computation on names are
not taken into account;
• access right on files are neither taken into account;
• a potentially difficult (and adhoc) extraction of
names in unformalized or semi-formalized re-
sources. For instance, Make has no grammar, or
configuration files may be just pairs of key-value.
Possible extensions include:
• extending to distributed file systems;
• introducing access right tags, in scope graphs and
rules;
• formalizing as contract interfaces the name de-
pendencies among resources. The goal would be
to help extraction.
6 RELATED WORKS
We motivate our proposal thanks to many articles on
analysis of the build process, see section 1. In that
context, an approach to improve build in multilingual
context is multilingual abstract interpretation such
as in (Mushtaq et al., 2017; Journault et al., 2020;
Schiewe et al., 2022), but this work relies on pro-
gramming language semantics, that we want to hide.
Our approach also includes non-programming lan-
guages (such configuration files) as the article (Shat-
nawi et al., 2019) on JEE, including Java, JSP and
XML, but that relies on KDM (Pérez-Castillo et al.,
2011), a meta-model of resources, less abstract than
names. The closest abstraction to ours is the recent
work of Ju et al., in (Ju et al., 2023), that focuses
on a cross-language name binding. However, they
use a deep learning model, not a binding graph such
as the scope graph we use. They estimate bindings
where we compute them. Finally, in (Zwaan and van
Antwerpen, Hendrik, 2023), Zwan et al. tell the story
of scope graph that is mainly used for programming
language typing and semantics understanding.
7 CONCLUSION AND FUTURE
WORK
DevOps operations such as build, configure and de-
ploy require a great deal of know-how. A lot of tools
ENASE 2024 - 19th International Conference on Evaluation of Novel Approaches to Software Engineering
448

are available (make, ant, maven, gradle, ansible, chef,
etc.). However, and maybe because of the great het-
erogeneity of languages used, there is almost no for-
malization of the whole process. We propose here
a very high-level abstraction based on name usage
to improve the level of trust in DevOps management
tools.
Resources offer names to other resources and also
require names from them. This can be seen as con-
tracts. These resources are integrated in a process
whose stages expect rules to be ensured. These rules
are part of the quality process management and could
be managed as assets. Operations could then be
(partly) specified thanks to pre and postconditions
built on these rules.
Beyond the extensions listed in section 5, it should
be possible to provide scope graph extractors, opera-
tions with their transformational semantics on scope
graph, and sets of rules so that a full tooling for De-
vOps improve the trust in using names. We also envi-
sion a background diagnostic process for users of the
operating system. Consistency naming rules or good
practices could be checked to ensure a better file sys-
tem management.
We believe that this approach could pave the way
for a safer, more formalized, critical activity of soft-
ware engineering.
ACKNOWLEDGEMENTS
We would like to thank the anonymous reviewers for
their helpful advice in improving this article.
REFERENCES
Antwerpen, H. v., Neron, P., Tolmach, A., Visser, E., and
Wachsmuth, G. (2016). A constraint language for
static semantic analysis based on scope graphs. In the
2016 ACM SIGPLAN Workshop, pages 49–60, New
York, New York, USA. ACM Press.
Beugnard, A. and Salah Sadou (2007). Method overload-
ing and overriding cause distribution transparency and
encapsulation flaws. Journal of Object Technology,
6(2):33–47.
Journault, M., Miné, A., Monat, R., and Ouadjaout, A.
(2020). Combinations of reusable abstract domains
for a multilingual static analyzer. In Chakraborty, S.
and Navas, J. A., editors, Verified Software. Theories,
Tools, and Experiments, pages 1–18, Cham. Springer
International Publishing.
Ju, Y., Tang, Y., Lan, J., Mi, X., and Zhang, J. (2023). A
Cross-Language Name Binding Recognition and Dis-
crimination Approach for Identifiers. In 2023 IEEE
International Conference on Software Analysis, Evo-
lution and Reengineering (SANER), pages 948–955,
Macao, China. ISSN: 2640-7574.
Kerzazi, N., Khomh, F., and Adams, B. (2014). Why
Do Automated Builds Break? An Empirical Study.
In 2014 IEEE International Conference on Software
Maintenance and Evolution, pages 41–50, Victoria,
British Columbia, Canada. IEEE Computer Society.
Miller, A. (2008). A Hundred Days of Continuous Inte-
gration. In Agile 2008 Conference, pages 289–293,
Toronto, ON, Canada. IEEE.
Mokhov, A., Mitchell, N., and Peyton Jones, S. (2018).
Build Systems à la Carte. Proceedings of the ACM
on Programming Languages, 2(ICFP):1–29.
Mushtaq, Z., Rasool, G., and Shehzad, B. (2017). Multilin-
gual Source Code Analysis: A Systematic Literature
Review. IEEE Access, 5:11307–11336. Conference
Name: IEEE Access.
Neron, P., Tolmach, A., Visser, E., and Wachsmuth, G.
(2015). A theory of name resolution. In Vitek, J.,
editor, Programming Languages and Systems, pages
205–231, Berlin, Heidelberg. Springer Berlin Heidel-
berg.
Paulk, M. C. (2009). A history of the capability maturity
model for software. ASQ Software Quality Profes-
sional, 12(1):5–19.
Pérez-Castillo, R., De Guzmán, I. G.-R., and Piattini, M.
(2011). Knowledge Discovery Metamodel-ISO/IEC
19506: A standard to modernize legacy systems.
Computer Standards & Interfaces, 33(6):519–532.
Schiewe, M., Curtis, J., Bushong, V., and Cerny, T. (2022).
Advancing Static Code Analysis With Language-
Agnostic Component Identification. IEEE Access,
10:30743–30761.
Seo, H., Sadowski, C., Elbaum, S., Aftandilian, E., and
Bowdidge, R. (2014). Programmers’ build errors: a
case study (at google). In the 36th International Con-
ference, pages 724–734, New York, New York, USA.
ACM Press.
Shatnawi, A., Mili, H., Abdellatif, M., Guéhéneuc, Y.-G.,
Moha, N., Hecht, G., Boussaidi, G. E., and Privat, J.
(2019). Static Code Analysis of Multilanguage Soft-
ware Systems. arXiv:1906.00815 [cs].
Sulír, M. and Porubän, J. (2016). A quantitative study of
Java software buildability. In the 7th International
Workshop, pages 17–25, New York, New York, USA.
ACM Press.
Vassallo, C., Schermann, G., Zampetti, F., Romano, D.,
Leitner, P., Zaidman, A., Penta, M. D., and Panichella,
S. (2017). A Tale of CI Build Failures: An Open
Source and a Financial Organization Perspective. In
2017 IEEE International Conference on Software
Maintenance and Evolution (ICSME), pages 183–193,
Shanghai, China. IEEE.
Zwaan, A. and van Antwerpen, Hendrik (2023). Scope
Graphs: The Story so Far. In Schloss Dagstuhl,
pages 32:1–32:13, Leibniz-Zentrum für Informatik,
Dagstuhl Publishing, Germany. Editors: Ralf Läm-
mel, Peter D. Mosses, and Friedrich Steimann.
Making Application Build Safer Through Static Analysis of Naming
449
