
Considerations in Prioritizing for Efficiently Refactoring the Data
Clumps Model Smell: A Preliminary Study
Nils Baumgartner
1 a
, Padma Iyenghar
2, 3 b
and Elke Pulverm
¨
uller
1 c
1
Software Engineering Research Group, School of Mathematics/Computer Science/Physics,
Osnabr
¨
uck University, 49090 Osnabr
¨
uck, Germany
2
innotec GmbH, Hornbergstrasse 45, 70794 Filderstadt, Germany
3
Faculty of Engineering and Computer Science, HS Osnabrueck, 49009 Osnabr
¨
uck, Germany
Keywords:
Data Clumps, Model Smell, Refactoring, Prioritizing, Systematic Approach, Weighted Attribute,
Threshold-Based Priority.
Abstract:
This paper delves into the importance of addressing the data clumps model smell, emphasizing the need for
prioritizing them before refactoring. Qualitative and quantitative criteria for identifying data clumps are out-
lined, accompanied by a systematic, simple but effective approach involving a weighted attribute system with
threshold-based priority assignment. The paper concludes with an experimental evaluation of the proposed
method, offering insights into critical areas for developers and contributing to improved code maintenance
practices and overall quality. The approach presented provides a practical guide for enhancing software sys-
tem quality and sustainability.
1 INTRODUCTION
Code smell refers to specific structures in the source
code that may indicate a deeper problem and compro-
mise the maintainability and readability of software.
There are various types of code smells, each point-
ing to potential issues in the design or implementa-
tion of software. Examples of code smells include,
data clumps, god class, duplicated code, large class
and feature envy. For instance, data clumps are a code
smell where groups of data fields frequently appear
together, signalling potential redundancy and sug-
gesting the need for encapsulation or abstraction to
improve code maintainability and flexibility (Fowler,
1999).
Model smells extend the concept of code smells to
the architectural level, encompassing issues that affect
the overall structure and design of the software model.
Data clump model smell refers to a recurring pat-
tern where multiple data fields consistently co-occur
across various entities within a software model, indi-
cating a potential design issue that can be addressed
through refactoring for enhanced clarity and main-
a
https://orcid.org/0000-0002-0474-8214
b
https://orcid.org/0000-0002-1765-3695
c
https://orcid.org/0009-0000-8225-7261
tainability. Refactoring (Fowler, 1999) is a disci-
plined technique for restructuring an existing body of
code, altering its internal structure without changing
its external behaviour.
Data clump model smell in UML (Unified Mod-
eling Language) class diagrams occurs when multiple
classes or methods share a set of attributes in fields or
parameters, indicating a potential design flaw. For ex-
ample, if several classes (e.g., Person, Business, Con-
tactInfo) share a set of the same attributes (street, city,
postalCode), as depicted in Figure 1. This suggests
a data clump model smell, urging consideration for
refactoring. In this example, a possible refactoring
might be to create a class Address with the shared set
of the same attributes.
Person
name: String
street: String
city: String
postalCode: int
Business
owner: String
postalCode: int
street: String
city: String
ContactInfo
street: String
postalCode: int
city: String
phone: String
Figure 1: Example of classes sharing the same set of at-
tributes.
While traditional code smells focus on improving
individual code snippets, model smells address larger-
scale design concerns that impact the software’s ar-
144
Baumgartner, N., Iyenghar, P. and Pulvermüller, E.
Considerations in Prioritizing for Efficiently Refactoring the Data Clumps Model Smell: A Preliminary Study.
DOI: 10.5220/0012698000003687
Paper published under CC license (CC BY-NC-ND 4.0)
In Proceedings of the 19th International Conference on Evaluation of Novel Approaches to Software Engineering (ENASE 2024), pages 144-155
ISBN: 978-989-758-696-5; ISSN: 2184-4895
Proceedings Copyright © 2024 by SCITEPRESS – Science and Technology Publications, Lda.

chitecture. Efficiently refactoring the data clumps
model smell is crucial for improving code maintain-
ability and readability. This practice helps eliminate
redundancy, enhances code structure, and promotes a
more modular and scalable design, leading to a more
maintainable and adaptable software system. How-
ever, not all instances of these data clumps model
smell are created equal, necessitating a systematic ap-
proach to prioritize and address the most critical is-
sues first, for instance by refactoring. Thus, efficiently
refactoring the data clumps model smell (e.g. by pri-
oritizing) is crucial for enhancing code quality, sim-
plifying maintenance, and promoting scalability.
In the aforesaid context, this paper explores the
considerations in prioritizing for efficiently refactor-
ing the data clumps model smell and provides the fol-
lowing novel contributions.
• The importance and benefits of addressing the
data clumps model smell is outlined. The need for
prioritizing data clumps refactoring is discussed.
• Qualitative and quantitative criteria for identify-
ing data clumps are elaborated. The metrics
to measure the quantitative criteria are described
with examples.
• A systematic, customizable, simple but effec-
tive method of a weighted attribute system with
threshold-based priority assignment for systemat-
ically prioritizing data clumps model smells is dis-
cussed.
• An experimental evaluation of the proposed
method for the quantitative criteria is presented.
In summary, the approach presented in this pa-
per offers a systematic and customizable method for
prioritizing data clumps model smell, providing de-
velopers with valuable insights into critical areas that
require attention. By combining attribute weighting,
threshold-based priority assignment and sorting, our
approach contributes to improved code maintenance
practices and overall code quality. The flexibility of
the system allows for seamless integration into di-
verse software development environments. Further,
the proposed considerations aim to provide a practical
guide for software practitioners seeking to enhance
the overall quality and sustainability of their software
systems.
The remainder of the paper is organized as fol-
lows. Next to this introduction section, related work
is presented in section 2 and explaining the need for
prioritizing data clumps refactoring. The qualitative
and quantitative factors for identifying data clumps
are outlined in section 3. Experimental results are
discussed in section 4. Conclusion and insights for
future work are presented in section 5.
2 RELATED WORK AND
INFERENCES
In this section, related work on model smells in gen-
eral, data clumps model smells in model represen-
tations (e.g. UML diagrams) and prioritization ap-
proaches for code/model smells are discussed. Based
on a survey of the related work in the literature, some
key insights on benefits of addressing data clumps
model smell and the need for prioritizing data clumps
refactoring are also outlined briefly.
2.1 Model Smell
The idea of model smell was elaborately discussed in
(Eessaar and K
¨
aosaar, 2019). In this paper, a model
smell is defined as an indication of potential technical
debt in system development, hindering understanding
and maintenance; this paper presents a catalogue of
46 model smells, highlighting their general applica-
bility beyond code smells, with examples grounded
in system analysis models.
Model smells appear in various model represen-
tations, such as UML
1
, Simulink
2
, and LabVIEW
3
,
highlighting their prevalence across popular mod-
elling platforms. In the literature, several approaches
are proposed for model smell detection, underlin-
ing the ongoing efforts to address these issues in di-
verse modelling contexts. For instance, in (Doan and
Gogolla, 2019) an enhanced version of a custom-
defined tool incorporating reflective queries, metric
measurement, smell detection and quality assessment
features for UML representations is presented. In this
work, design smells are stored as XML files, each en-
try containing elements like name, description, type,
severity, definition, and context. However, an ex-
perimental evaluation is not provided in this paper.
In (Popoola and Gray, 2021), an analysis of smell
evolution and maintenance tasks in Simulink mod-
els reveals that larger models show more smell types,
increased smell instances correlate with model size,
and bad smells are primarily introduced during ini-
tial construction. It was inferred that adaptive mainte-
nance tasks tend to increase smells, while corrective
maintenance tasks often reduce smells in Simulink
models. Similarly, in (Zhao et al., 2021), a survey-
based empirical evaluation of bad model smells in
LabVIEW system models is presented. The study
explores model smells specific to LabVIEW systems
models, revealing diverse perceptions influenced by
1
https://www.uml.org/
2
https://www.mathworks.com/help/simulink/
3
https://www.ni.com/documentation/en/labview/
Considerations in Prioritizing for Efficiently Refactoring the Data Clumps Model Smell: A Preliminary Study
145

users’ depth of knowledge, providing valuable rec-
ommendations for practitioners to enhance software
quality.
2.2 Data Clumps
Martin Fowler initially provided broad definitions for
various code smells, which are generally applicable
but not sufficiently detailed for automated analysis
and refactoring (Fowler, 1999). In the study (Zhang
et al., 2008) the definitions of selected code smells,
including data clumps, were examined and refined.
This research included conducting expert interviews
to achieve a uniform consensus on these definitions.
Building on the improved definition for data
clumps, (Baumgartner et al., 2023) introduced a plu-
gin for the first time that enables live detection of
data clumps with semi-automatic refactoring capabil-
ities. The research demonstrated that, for different
open-source projects, the time required for analysis
remained under one second on average. However, the
selection of data clumps to be refactored still requires
manual initiation. This development represents a sig-
nificant step forward in the practical application of
these refined definitions in real-world software devel-
opment scenarios.
In the field of software development, projects
evolve over time, leading to changes in software qual-
ity, both positive and negative. These changes in
projects over time result in various life cycles of code
smells and model smells. The work of (Baumgart-
ner and Pulverm
¨
uller, 2024) focuses on the analy-
sis and examination of data clumps throughout their
temporal progression. Their findings reveal that data
clumps tend to group together into what are known as
clusters. These clusters are characterized by multiple
classes being interconnected through data clump code
smells. One of the challenges highlighted by the au-
thors is the challenge in refactoring these connections,
as it requires making decisions on how to resolve each
of these links. In their study, they analyzed seven
well-known open-source projects, considering up to
25 years of their development history. The results
indicate that, over time, the number of data clumps
tends to increase in almost all the projects examined.
This observation underscores the ongoing challenge
in managing and improving software quality in evolv-
ing software projects.
2.3 Prioritization of Model Smell
While, the refactoring process (Fowler, 1999) en-
hances the software design by modifying the struc-
ture of design parts impaired with model smells with-
out altering the overall software behaviour, handling
these smells without proper prioritization will not pro-
duce the anticipated effects (AbuHassan et al., 2022).
Several approaches exist in the literature in the afore-
said direction of prioritization, of which some are dis-
cussed below.
In (Zhang et al., 2011) the need for prioritiza-
tion of code smells is outlined. An approach based
on developer-driven code smell prioritization is pre-
sented in (Pecorelli et al., 2020). In this paper, the
authors perform a first step toward the concept of
developer-driven code smell prioritization and pro-
pose an approach based on machine learning to rank
code smells according to the perceived criticality that
developers assign to them. The solution presented has
an F-Measure up to 85% and outperforms the base-
line approach. In (AbuHassan et al., 2022) prioriti-
zation of model smell refactoring in UML class di-
agrams using a multi-objective optimization (MOO)
algorithm is discussed. While the authors claim that
the work presented achieves longer refactoring se-
quences without added computational cost, it does
not specifically concentrate on addressing the data
clumps model smell. (Alkharabsheh et al., 2022)
introduces a multi-criteria merge strategy for prior-
itizing the design smell of god classes in software
projects, employing an empirical adjustment with a
dataset of 24 open-source projects. The empirical
evaluation highlights the need for improvement in
the strategy, emphasizing the importance of analysing
differences between projects where the strategy corre-
lates with developers’ opinions and those where there
is no correlation. Prioritization of model smell refac-
toring using a covariance matrix-based adaptive evo-
lution algorithm is discussed in (AbuHassan et al.,
2022), where the proposed solution leads to longer
refactoring sequences at no additional computational
cost. However, an approach for prioritization for data
clumps model smell is not available in the literature.
2.4 Inferences
In this subsection, we examine the importance of ad-
dressing data clumps model smells in software de-
velopment, which are groups of frequently used data
items in code. We highlight the benefits of prioritizing
the refactoring of data clumps
2.4.1 Addressing Data Clumps Model Smell
From our review of existing literature and related
work, we derive insights on the significance and ad-
vantages of addressing data clumps model smells.
They are listed below:
ENASE 2024 - 19th International Conference on Evaluation of Novel Approaches to Software Engineering
146

• Enhanced code maintainability through the con-
solidation of related data, making it easier to un-
derstand and maintain.
• Improved modularity and flexibility by organizing
related data into separate structures, promoting a
more adaptable design.
• Reduced code duplication by centralizing com-
mon data structures, minimizing redundancy re-
lated to data clumps.
• Adherence to design principles, such as the Single
Responsibility Principle, by separating concerns
related to data representation.
• Efficient resource utilization through streamlined
data structures, optimizing resource allocation for
data associated with the data clumps smell.
2.4.2 Prioritizing Data Clumps Before
Refactoring
The need for prioritizing and adopting a systematic
approach in addressing the data clumps model smell
stems from several reasons:
• Efficient Resource Utilization. By prioritizing,
development teams can allocate resources effec-
tively, addressing the most critical instances first
to maximize impact and minimize technical debt.
• Systematic Handling of Issues. A systematic ap-
proach allows for a structured and organized way
of identifying and addressing data clumps, pre-
venting ad-hoc or inconsistent fixes and ensuring
a comprehensive solution.
• Scale and Complexity. In large codebases, there
might be numerous occurrences of data clumps.
Prioritization helps manage the scale and com-
plexity by tackling the most impactful instances
initially.
• Risk Mitigation. Identifying and addressing crit-
ical data clumps early reduces the risk of future
maintenance challenges, enhancing code quality
and reducing the likelihood of introducing new is-
sues.
Possible approaches to prioritizing and systemati-
cally addressing data clumps include:
• Weighted Scoring. In this approach, weights are
assigned to different factors such as impact on
maintainability, code duplication, and violation of
design principles (to name a few) to prioritize in-
stances with higher scores.
• Business Impact Analysis. Using this approach,
the impact of data clumps on critical business
functions can be analysed. Instances that have a
higher impact on strategic objectives can be prior-
itized.
• Collaborative Decision Making. By this ap-
proach, one can involve developers, architects,
and other stakeholders in the prioritization pro-
cess. Collective insights can contribute to a more
comprehensive and informed decision-making
process.
• Historical Records and Use of Artificial Intelli-
gence (AI). The historical records of code mainte-
nance can be analysed to identify instances caus-
ing frequent issues or requiring frequent modifi-
cations, prioritizing these for refactoring. When
such a metric dataset is available for large code
bases, then an AI/Machine Learning (ML) ap-
proach can be used to integrated to enhance the
prioritization of data clumps model smells.
In summary, the analysis of existing literature and
related work provides valuable insights into the im-
portance of addressing data clumps model smells.
The benefits include enhanced code maintainability,
improved modularity, reduced code duplication, ad-
herence to design principles, and efficient resource
utilization. To effectively address data clumps, priori-
tization and a systematic approach are crucial. Priori-
tization ensures efficient resource allocation, system-
atic issue handling, scalability management in large
codebases, and risk mitigation by addressing critical
data clumps early on, enhancing overall code quality.
Notably, there is a lack of a systematic, cus-
tomizable, and effective method for prioritizing data
clumps model smell. The work discussed in this paper
addresses this gap, introducing a weighted attribute
system with threshold-based priority assignment, pro-
viding a comprehensive solution to systematically pri-
oritize data clumps before refactoring.
3 CRITERIA FOR IDENTIFYING
DATA CLUMPS MODEL SMEll
Identifying data clumps model smell involves evalu-
ating both qualitative and quantitative factors to en-
sure a comprehensive assessment of the software’s
quality and refactoring needs. Qualitative factors of-
fer insights into subjective aspects. On the other
hand, quantitative factors provide measurable data for
a more precise evaluation. Both these factors are dis-
cussed below. Further, the quantitative factors are dis-
cussed in detail, accompanied by examples and spe-
cific metrics for each criterion, contributing to a sys-
tematic approach to identifying and addressing data
clumps.
Considerations in Prioritizing for Efficiently Refactoring the Data Clumps Model Smell: A Preliminary Study
147

3.1 Qualitative Factors
Qualitative factors typically involve characteristics
that are descriptive, subjective, and not easily quan-
tifiable in numerical terms. In the context of software
development, qualitative factors often capture aspects
related to strategic alignment, maintainability impact,
adaptability to changes, and feedback from the devel-
opment team. These factors provide valuable insights
into the overall quality, alignment with goals, and col-
laborative aspects of the software, which may not be
expressed solely through quantitative metrics but in-
volve subjective evaluations and considerations.
• Business-Critical Functions. Prioritizing data
clumps within classes related to essential business
logic or critical functionalities aligns with strate-
gic goals.
• Security and Compliance. Prioritizing data
clumps within classes related to crucial security
aspects, contributing to support a more reliable
software.
• Impact on Maintainability. This criterion in-
volves detecting data clumps with a substantial
influence on the maintainability of the codebase,
contributing to overall codebase health and facili-
tating future modifications.
• Integration with Other Systems. Examining
how well the software integrates with existing sys-
tems and third-party services, which can affect its
functionality and the efficiency of workflows.
• Technical Debt Management. Prioritizing the
refactoring of classes with high technical debt is
crucial for future development efforts. This in-
cludes understanding the potential costs and risks
associated with delaying necessary updates or
refactorings.
• Strategic alignment and Architecture Vision.
Ensuring that refactoring for data clumps aligns
with the overall architectural vision promotes con-
sistency and adherence to design principles.
• Adaptability to Changes. Prioritizing refactor-
ing for data clumps hindering the system’s adapt-
ability to evolving requirements ensures ease of
accommodation for changes.
• Feedback from Development Team. Incorpo-
rating team feedback and prioritizing data clumps
identified as challenging or hindering ensures that
improvements address real pain points and en-
hance developer efficiency.
3.2 Quantitative Factors
Quantitative factors refer to measurable and numer-
ical characteristics that can be assigned specific val-
ues or quantities. In the context of software devel-
opment and refactoring, quantitative factors often in-
volve metrics or measurements that provide objective
data. These factors can be quantified, allowing for a
more precise and numerical evaluation of various as-
pects of the codebase.
In the given context, factors like the widespread
occurrence, complexity, dependencies, consistency
with design patterns, and degree of code duplication
involve measurable aspects for each data clump that
could contribute to the overall assessment of the code
quality and refactoring needs.
Normalization Score
For experimental evaluation, a normalized metric for
each of these criteria on a scale of 0 to 10 for the men-
tioned factors, we follow a consistent normalization
approach for each factor. So for each of the five quan-
titative aspect, the formula below is used to obtain a
normalized and consistent score:
NS :=
Actual Score
Max. Possible Score
× 10 (1)
The components in the formula in (1) are de-
scribed below:
• Normalized Score (NS). This is the final score
that is derived from the actual score and the max-
imum possible score. It represents a scaled value
on a scale of 0 to 10, providing a standardized
measure for comparison.
• Actual Score. This is the real or observed value
for the specific metric being evaluated. It could be
the number of attributes, occurrences, or any other
measurable quantity related to the data clump
model smell.
• Maximum Possible Score. This represents the
highest or most favourable value that the metric
could achieve. It acts as a reference point for scal-
ing the actual score. For example, if the metric is
the number of attributes or parameters,” the maxi-
mum possible score might be determined by the
total number of attributes or parameters a class
can ideally have.
• Scaling Factor (10). The multiplication by 10 is
used to scale the normalized score to a range of 0
to 10. This standardizes the scores across different
metrics, making them easier to compare.
Thus, the formula in (1) calculates the normalized
score by dividing the actual score by the maximum
ENASE 2024 - 19th International Conference on Evaluation of Novel Approaches to Software Engineering
148

possible score, and then scaling the result to a range of
0 to 10. This normalization process helps in creating a
consistent and comparable assessment across various
metrics used to evaluate data clumps.
3.2.1 Widespread Occurrence
This criterion counts the frequency of occurrence of
data clumps that appear across multiple classes, en-
suring a comprehensive impact on code quality and
system consistency.
• Metric: Count the number of classes in which the
data clump appears.
• Example: Let’s consider an example, as depicted
in Figure 2, where the data clump of class A is
widespread across 5 classes out of a maximum
possible count of 11 classes. The connection lines
in this example are data clumps. Then the normal-
ized score is:
NS =
5
11
× 10 = 4.54 (2)
So, in this case, the data clump’s widespread oc-
currence factor has a normalized score of 4.54 on
a scale of 0 to 10. This indicates that the data
clump is present in a significant portion of the
classes but not in all of them.
A
Figure 2: Widespread occurrence of data clumps.
3.2.2 Size of Attributes or Parameters
Addressing large and intricate data clumps within
classes early on is crucial for achieving more signifi-
cant improvements and simplifications in the system.
• Metric. Measure the number of attributes or pa-
rameters within the data clump relative to the total
number of attributes or parameters.
• Example. A class A as depicted in Figure 3 has
4 attributes. The data clump shows 3 shared at-
tributes. The normalized score for a scenario
where a data clump has 3 attributes out of 4, is
calculated as follows:
NS =
3
4
× 10 = 7.5 (3)
The normalized score of 7 signifies a high level
of complexity and size associated with this data
clump. Such complexity could impact code read-
ability, maintainability, and overall system robust-
ness.
A
field_a
field_b
field_c
field_d
B
field_a
field_b
field_c
field_x
Figure 3: Size of attribute occurrences of data clumps.
3.2.3 Dependencies and Coupling
Tackling data clumps that contribute to tight cou-
pling and complex dependencies early in the process
enhances modularity and mitigates the risk of unin-
tended consequences.
• Metric. Analyse the number of dependencies or
associations between the data clump and other
classes.
• Example. Assume there are 40 classes in total.
The data clump is found in dependencies across
25 classes. Then, the normalized score is:
NS =
25
40
× 10 = 6.25 (4)
In this case, the data clump’s ”dependencies and
coupling” factor has a normalized score of 6.25
on a scale of 0 to 10. This suggests that the data
clump is moderately coupled with a substantial
number of classes, indicating some level of tight
coupling and complex dependencies.
3.2.4 Consistency with Design Patterns
Prioritizing refactoring efforts that do not align with
established design patterns or best practices ensures a
standardized and well-structured approach to resolv-
ing data clumps.
• Metric. Evaluate how bad the data clump adheres
to established design patterns. Use a subjective
assessment or a set of criteria to assign a score.
For example, for a data clump, we may count how
many of our tracked design patterns are followed.
• Example. For example, out of the maximum
10 design patterns considered, if the data clump
aligns with 3 of them only, then the data clump
gets a high normalized score of 7 as determined
below:
NS =
10 − 3 = 7
10
× 10 = 7 (5)
3.2.5 Degree of Code Duplication
This is a measure of how much the data clump con-
tributes to code duplication across classes.
• Metric. Count the number of classes in which the
data clump leads to a significant code duplication
Considerations in Prioritizing for Efficiently Refactoring the Data Clumps Model Smell: A Preliminary Study
149

• Example. Suppose the data clump contributes to
code duplication in 20 different classes out of a
maximum possible count of 30 classes. Then the
normalized score is 6.67 as calculated below:
NS =
20
30
× 10 = 6.67 (6)
In this example, the data clump’s degree of code
duplication factor has a normalized score of ap-
proximately 6.67 on a scale of 0 to 10. This
suggests a substantial, but not overwhelming, de-
gree of code duplication caused by the data clump
across classes. This metric is different from size
of attributes or parameters since, the degree of
code duplication considers the code within the
classes.
4 EXPERIMENTAL EVALUATION
In this section, an experimental evaluation of the pri-
oritization approach proposed in this paper is dis-
cussed in detail. This approach takes as input the data
clumps metrics tuple, which is defined in section 4.1
for each. The algorithm used for the prioritization of
data clumps is described in section 4.3.
4.1 Data Clumps Metrics Tuple
These metrics for data clumps are corresponding to
the respective attributes for the quantitative factors
mentioned in section 3.
Thus, each data clump metric is a defined
as a tuple Data Clump Metrics Tuple (δ):
(Name, WO, SZ, DP, CDP, DC), where
• Name: A unique identifier or label for the data
clump.
• WO: Widespread Occurrence - Indicates the fre-
quency of occurrence of the data clump across
multiple classes.
• SZ: Size - Represents the number of attributes or
parameters within the data clump.
• DP: Dependency - Reflects the level of depen-
dency of the data clump on other components.
• CDP: Consistency with Design Patterns - Mea-
sures the consistency of the data clump with de-
sign patterns.
• DC: Degree of Code Duplication - Indicates the
extent of code duplication within the data clump.
Let us consider an example instance of the data
clump metric tuple, δ
1
=("DataClump1", 8, 3,
5, 4.5, 9). The following provides brief explana-
tion for each metric score in this data clump tuple δ
1
with the name DataClump1.
• WO - 8: A score of 8 indicates that this
data clump is frequently present across multiple
classes. It suggests that the data clump has a sig-
nificant impact on code quality and system con-
sistency due to its widespread use.
• SZ - 3: The score of 3 implies that the data clump
has a moderate number of attributes or param-
eters. While not excessively large, it still con-
tributes to the size of the data clump, impacting
maintainability and readability.
• DP - 5: With a score of 5, this data clump exhibits
a moderate level of dependency on other com-
ponents. This suggests that changes to the data
clump may have implications for other parts of the
system, influencing overall system complexity.
• CDP - 4.5: The score of 4.5 indicates a reason-
ably good consistency of the data clump with de-
sign patterns. It suggests that the structure of the
data clump aligns fairly well with the established
design principles.
• DC - 9: A score of 9 reflects a high degree of
code duplication within the data clump. This im-
plies that there is a significant amount of redun-
dant code, which can negatively impact maintain-
ability and increase the risk of errors.
4.2 Weights and Thresholds
In the proposed approach, weights and thresholds are
pivotal elements in the prioritization of data clumps,
providing a mechanism to customize and refine the
refactoring process. These parameters influence the
assignment of priorities to individual data clumps
based on their quantitative factors.
4.2.1 Weights
Weights are assigned to qualitative factors associ-
ated with data clumps, reflecting their relative impor-
tance in the prioritization process. Each factor, such
as widespread occurrence, size, dependency, consis-
tency with design patterns, and degree of code dupli-
cation, is assigned a weight. Higher weights signify a
greater influence on the overall prioritization. It is to
be noted that the sum of weights is less than or equal
to 1.
In our approach, weights are defined in the
weights data structure as shown below. This al-
lows developers to tailor the prioritization based on
project-specific considerations. For example:
ENASE 2024 - 19th International Conference on Evaluation of Novel Approaches to Software Engineering
150

weights = {
’widespread_occurrence’: 0.25,
’size’: 0.3,
’dependency’: 0.2,
’consistency_DP’: 0.1,
’degree_codeDuplication’: 0.15
}
These weights are used in the calculation of the
weighted score for each data clump, providing a cus-
tomizable approach to emphasize specific factors.
4.2.2 Thresholds
Thresholds are predefined values that categorize data
clumps into distinct priority levels, such as ”High Pri-
ority,” ”Medium Priority,” and ”Low Priority.” These
thresholds enable a quantitative classification based
on the calculated weighted scores, guiding develop-
ers in identifying critical refactoring candidates.
In the provided algorithm, thresholds are defined
in the thresholds data structure as follows.
thresholds = {
’high’: 8,
’medium’: 6,
’low’: 4
}
Adjusting these thresholds allows developers to
set criteria for high-priority refactoring based on the
project’s specific requirements and objectives. The
flexibility of weights and thresholds enhances the
adaptability of the prioritization process across differ-
ent software development scenarios.
4.2.3 Weighted Score
The weighted score is calculated for each instance of
the data clump metrics tuple based on the specified
weights for different quantitative factors. The formula
for calculating the weighted score is as follows:
Weighted Score :=
∑
i
(weight
i
× attribute
i
) (7)
Where:
• Weighted Score is the final-weighted score for the
data clump.
• weight
i
is the weight assigned to the i-th qual-
itative factor (e.g., widespread occurrence, size,
dependency, consistency with design patterns, de-
gree of code duplication).
• attribute
i
is the normalized score (ranging from 0
to 10) for the i-th qualitative factor.
4.3 Implementation
The simple but effective algorithm shown in Algo-
rithm 1 and described below provides a systematic
and customizable approach to prioritize and address
the data clumps model smell.
Algorithm 1: Prioritizing data clumps.
Data: Data clumpls metrics tuple (δ),
Weights, Thresholds
Result: Prioritized data clumps list
1 foreach Data Clump do
2 Normalize scores using (1);
3 Calculate weighted score using
calculate weighted score();
4 Assign priority using
assign priority();
5 Sort Data Clumps by Priority (High to Low);
6 Choose Data Clumps for refactoring;
7 Function
calculate weighted score(DataClump,
Weights):
8 Calculate weighted score using the
weights provided using (7);
9 return Calculated weighted score;
10 Function assign priority(DataClump,
Thresholds):
11 if Weighted Score ≥ Thresholds[’high’]
then
12 return ”High Priority”;
13 else if Weighted Score ≥
Thresholds[’medium’] then
14 return ”Medium Priority”;
15 else
16 return ”Low Priority”;
The algorithm takes as input the metrics of data
clumps as defined in the data clumps tuple (δ) in sec-
tion 4.1, predefined weights and thresholds defined in
section 4.2. It outputs a list of prioritized data clumps.
In the main loop of the algorithm (lines 10-
14), for each data clump, the algorithm normalizes
scores (line 11), calculates weighted scores using the
calculate weighted score() function (line 12) as
described in section 4.2. The result is a single numer-
ical value that reflects the importance of each factor
based on the specified weights. Based on this value,
it assigns priorities using the assign priority()
function (line 13). After calculating weighted scores
and assigning priorities, the algorithm sorts the data
clumps by priority in descending order (high to low)
as seen in line 15. Then, the data clumps are selected
Considerations in Prioritizing for Efficiently Refactoring the Data Clumps Model Smell: A Preliminary Study
151

for refactoring based on their prioritization (line 16).
4.4 Results and Analysis
The algorithm described above is implemented as a
python script. The experiments are run on an Intel
Core i7-8550U-1.8 GHz CPU, X64-based PC system
running Windows 10.
4.4.1 Factor Contribution Visualization
The algorithm is run with varying sizes of the data
clumps. It was observed that the algorithm effectively
prioritized data clumps based on calculated weighted
scores and assigned priorities, demonstrating its capa-
bility to categorize items into low, medium, and high
priority levels.
For example, the data clumps factor contribution
and priority for an input size of 30 data clumps is vi-
sualized in Figure 4. In this plot, each data clump is
represented by a horizontal bar in the plot. The fac-
tors contributing to the weighted score (widespread
occurrence, size, dependency, consistency, degree of
code duplication) are colour-coded for easy identifi-
cation. The total length of each bar corresponds to
the total weighted score of a data clump. The bar is
segmented into different coloured sections, each rep-
resenting the contribution of a specific factor to the
overall weighted score. Higher segments in the bar
indicate that the corresponding factor has a more sig-
nificant impact on the prioritization of that particular
data clump. The length of each coloured segment re-
flects the proportional contribution of each factor to
the overall score. plot provides a visual representa-
tion of why certain data clumps are assigned higher
priorities. Factors with longer segments contribute
more substantially to the overall weighted score, in-
fluencing the final priority assignment. Horizontal
dashed lines in the plot represent the defined thresh-
olds for low, medium, and high priorities. Bars that
cross these lines indicate the priority category of each
data clump: low, medium, or high.
Thus, the stacked bar plot reveals insightful pat-
terns in factor contributions, highlighting the signif-
icant impact of certain factors on prioritization out-
comes.
4.4.2 Scalability
The presented plot in Figure 5 illustrates the scalabil-
ity evaluation of Algorithm 1 across different sizes of
data clumps. The experiment aims to assess the algo-
rithm’s performance and efficiency as the size of the
dataset varies. This evaluation is crucial for under-
standing how well the algorithm adapts to increasing
data complexities, providing valuable insights for de-
velopers and system architects. The blue line in the
plot represents the algorithm’s execution time in log-
arithmic scale concerning the number of data clumps.
The logarithmic scale is employed to accommodate a
wide range of execution times, allowing for a more
comprehensive analysis. The red dashed line signifies
the linear scaling reference, serving as a benchmark
for comparison. This line illustrates the expected lin-
ear scaling behaviour in an ideal scenario.
The algorithm exhibits a positive correlation with
data clump sizes, demonstrating scalability as the
dataset grows. Execution times remain reasonable,
even with a substantial increase in data clump sizes.
The logarithmic scaling of execution times provides a
clear visualization of the algorithm’s efficiency across
varying dataset complexities. The provided experi-
mental data includes realistic sizes of data clumps,
ranging from 5,000 to 250,000. Corresponding exe-
cution times, measured in milliseconds (average of 3
runs), showcase the algorithm’s consistent and man-
ageable response to different dataset sizes.
The positive scalability observed in the presented
plot indicates that Algorithm 1 effectively handles
larger datasets without a disproportionate increase in
execution time. This scalability is crucial for real-
world applications, where datasets can grow in size
over time. The algorithm’s performance remains
within acceptable limits, offering developers a reli-
able solution for processing diverse datasets.
4.4.3 Weight Variations
Figure 6 shows radar charts illustrating the impact
of weight variations on data clump prioritization.
Three subplots in Figure 6 titled Weights Variation
1, Weights Variation 2 and Weight Variation 3 respec-
tively, represents a different set of attribute weights
for the data clumps metrics tuple (cf. section 4.1).
The radar charts display different attributes as axes,
with the length of each axis corresponding to the
normalized attribute values of the data clumps. The
charts are colour-filled to represent the priority re-
gions, and the legend includes the weights used in
each variation.
The configurations represent different emphasis
placed on each factor when calculating the weighted
scores for the data clumps. The weights determine the
relative importance of each factor in the overall priori-
tization process. Experimenting with different weight
configurations allows us to observe how changes in
weights impact the prioritization of data clumps.
The charts in Figure 6 showcase the normalized
attribute values of generated data clumps, revealing
the influence of weight variations on the prioritization
ENASE 2024 - 19th International Conference on Evaluation of Novel Approaches to Software Engineering
152
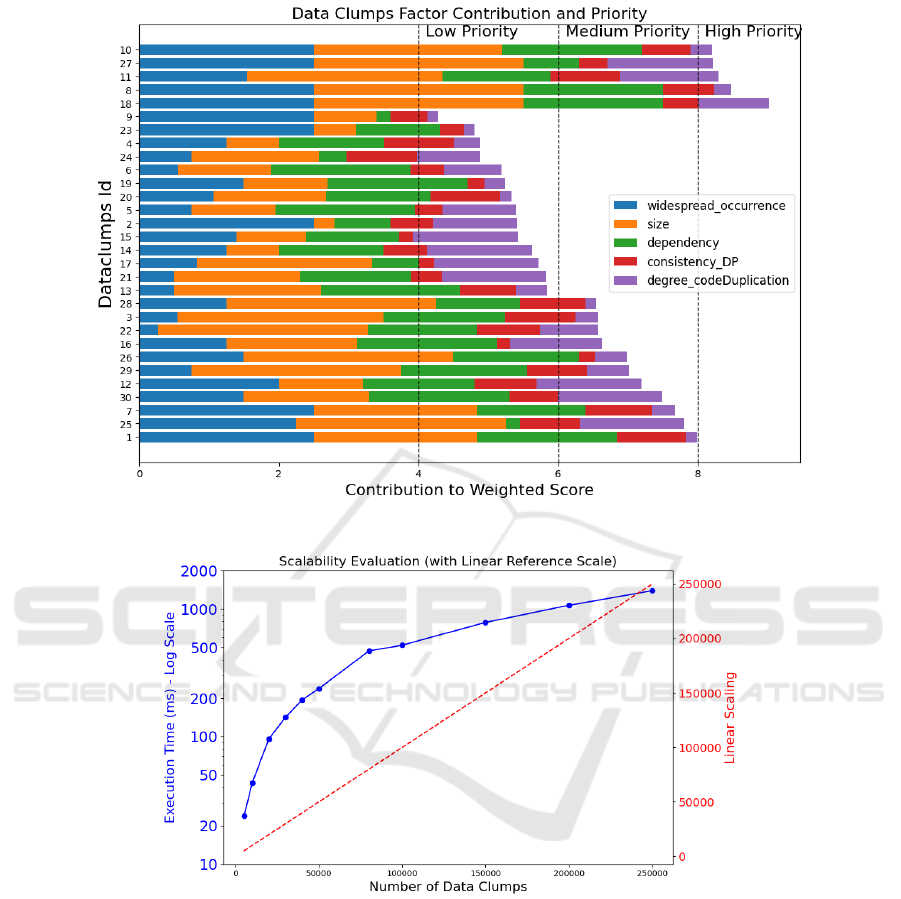
Figure 4: Data clumps factor contribution and priority.
Figure 5: Execution time for various data clumps sizes.
of entities based on calculated weighted scores and
predefined thresholds. The experiment involved 30
random data clumps each with metrics WO, SZ, DP,
CDP, DC and the application of weight variations to
assess the sensitivity of the prioritization algorithm to
different weightings. The charts provide developers
with a valuable overview, facilitating a better under-
standing of potential weight adjustments.
4.5 Directions for Enhancements
While the work presented in this paper is a prelimi-
nary study, this can be extended in several directions
to enhance the applicability, flexibility, and usability
of the metric prioritization approach in various soft-
ware development contexts.
• Evaluate on Large Public Datasets: Apply
the approach to diverse and large-scale public
datasets representing various types of software
systems. Analyse the results to understand the
general trends in factor contributions and priori-
ties across different domains.
• Infer Weights and Thresholds: Extract insights
from the large datasets to suggest default or rec-
ommended values for weights and thresholds.
Considerations in Prioritizing for Efficiently Refactoring the Data Clumps Model Smell: A Preliminary Study
153
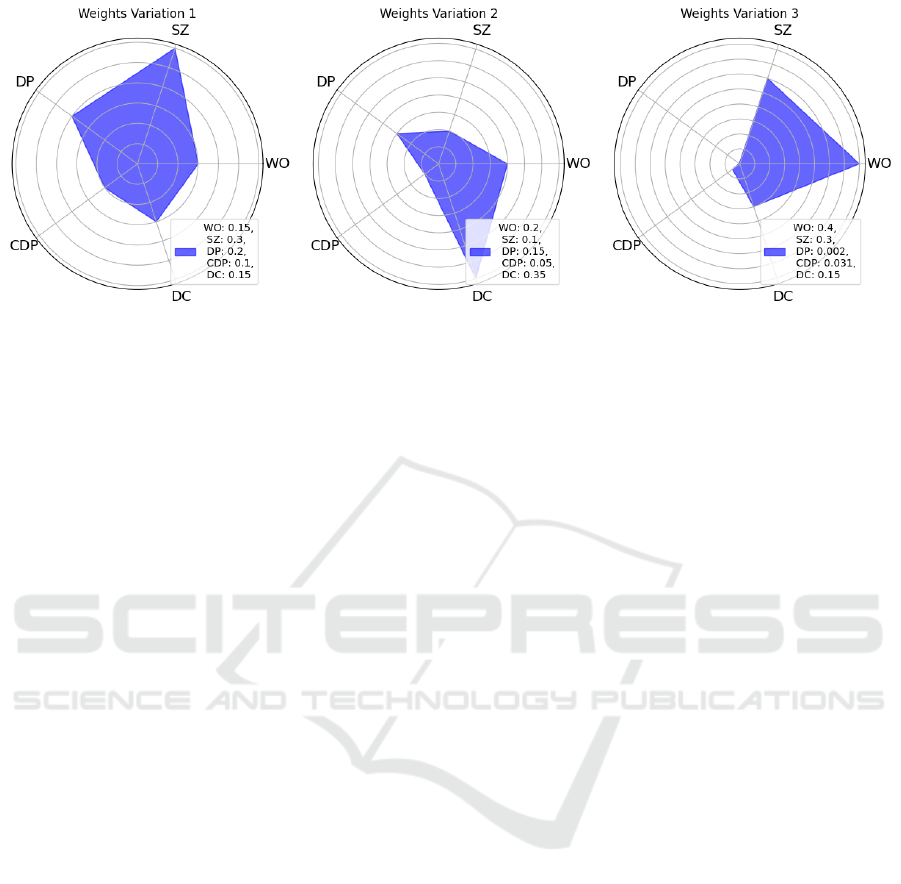
Figure 6: Impact of weight variations on data clump prioritization. Each subplot represents a different set of attribute weights
(’WO’, ’SZ’, ’DP’, ’CDP’, ’DC’).
Consider statistical measures or machine learn-
ing techniques to identify patterns and correla-
tions between factors and priorities.
• Configurability for End Users: Develop a user-
friendly interface allowing end users to customize
weights and thresholds based on their specific re-
quirements. Provide guidance or recommenda-
tions to users based on the analysis of public
datasets, assisting them in making informed de-
cisions.
• Benchmarking Against Existing Approaches:
Compare the performance and effectiveness of
the proposed approach against existing methods
of metric prioritization. Conduct benchmarking
studies to showcase the strengths and weaknesses
of the approach in different scenarios.
5 CONCLUSION
In conclusion, this paper presents a comprehensive
approach for prioritizing data clumps in source-code-
based and model-based environments. The proposed
method emphasizes the importance of addressing data
clumps to enhance software quality and sustainabil-
ity, highlighting the need for systematic prioritiza-
tion before refactoring. Key contributions of this
work include the discussion of both qualitative and
quantitative criteria for prioritizing data clumps, and
the introduction of a practical, weighted system with
threshold-based priority assignment. The approach
provides a flexible and customizable solution, en-
abling developers to tailor their prioritization to their
individual and specific project needs.
The experimental evaluation demonstrates the ef-
fectiveness of the proposed approach in handling data
clumps of varying sizes. The scalability of the al-
gorithm is established through its performance across
different dataset sizes, and the impact of weight varia-
tions on prioritization outcomes is explored, showcas-
ing the adaptability of the method. Although the eval-
uation is experimental, it provides a first step towards
prioritizing data clumps, yet it still requires deeper
analysis.
Future work will focus on extending the approach
to evaluate it on large public datasets, infer optimal
weights and thresholds, enhance configurability for
end-users, and benchmark the approach against ex-
isting prioritization methods. By further refining and
testing the approach, we aim to contribute to im-
proved code maintenance practices and overall soft-
ware quality in diverse development environments.
Overall, this work offers valuable insights and a
practical guide for software practitioners seeking to
prioritize and address data clumps model smell effec-
tively, paving the way for more maintainable, adapt-
able, and high-quality software systems.
REFERENCES
AbuHassan, A., Alshayeb, M., and Ghouti, L. (2022). Prior-
itization of model smell refactoring using a covariance
matrix-based adaptive evolution algorithm. Informa-
tion and Software Technology, 146:106875.
Alkharabsheh, K., Alawadi, S., Ignaim, K., Zanoon, D.,
Crespo, Y., Manso, M., and Taboada, J. (2022). Prior-
itization of god class design smell: A multi-criteria
based approach. Journal of King Saud University-
Computer and Information Sciences, 34(10, Part
B):9332–9342.
Baumgartner, N., Adleh, F., and Pulverm
¨
uller, E. (2023).
Live Code Smell Detection of Data Clumps in an
Integrated Development Environment. In Interna-
tional Conference on Evaluation of Novel Approaches
ENASE 2024 - 19th International Conference on Evaluation of Novel Approaches to Software Engineering
154

to Software Engineering, ENASE-Proceedings, pages
10–12. Science and Technology Publications, Lda.
Baumgartner, N. and Pulverm
¨
uller, E. (2024). The Life-
Cycle of Data Clumps: A Longitudinal Case Study
in Open-Source Projects. In 12th International Con-
ference on Model-Based Software and Systems Engi-
neering, Rome, Italy. Science and Technology Publi-
cations, Lda. [Accepted].
Doan, K.-H. and Gogolla, M. (2019). Quality improve-
ment for uml and ocl models through bad smell and
metrics definition. In 2019 ACM/IEEE 22nd Interna-
tional Conference on Model Driven Engineering Lan-
guages and Systems Companion (MODELS-C), pages
774–778.
Eessaar, E. and K
¨
aosaar, E. (2019). On finding model
smells based on code smells. In Software Engineer-
ing and Algorithms in Intelligent Systems, volume 763
of Advances in Intelligent Systems and Computing.
Springer.
Fowler, M. (1999). Refactoring: Improving the Design of
Existing Code. Addison-Wesley.
Pecorelli, F., Palomba, F., Khomh, F., and De Lucia, A.
(2020). Developer-driven code smell prioritization.
In Proceedings of the 17th International Conference
on Mining Software Repositories, MSR ’20, page
220–231, New York, NY, USA. Association for Com-
puting Machinery.
Popoola, S. and Gray, J. (2021). Artifact analysis of smell
evolution and maintenance tasks in simulink mod-
els. In 2021 ACM/IEEE International Conference on
Model Driven Engineering Languages and Systems
Companion (MODELS-C), pages 817–826.
Zhang, M., Baddoo, N., Wernick, P., and Hall, T. (2008).
Improving the Precision of Fowler’s Definitions of
Bad Smells. In 2008 32nd Annual IEEE Software En-
gineering Workshop, pages 161 – 166. IEEE.
Zhang, M., Baddoo, N., Wernick, P., and Hall, T. (2011).
Prioritising Refactoring Using Code Bad Smells. In
2011 IEEE Fourth International Conference on Soft-
ware Testing, Verification and Validation Workshops,
pages 458–464. IEEE.
Zhao, X., Gray, J., and Rich
´
e, T. (2021). A survey-based
empirical evaluation of bad smells in labview sys-
tems models. In 2021 IEEE International Conference
on Software Analysis, Evolution and Reengineering
(SANER), pages 177–188.
Considerations in Prioritizing for Efficiently Refactoring the Data Clumps Model Smell: A Preliminary Study
155
