
Building Damage Segmentation After Natural Disasters in Satellite
Imagery with Mathematical Morphology and Convolutional Neural
Networks
Ant
ˆ
onio dos Santos Ramos Neto
a
and Daniel Oliveira Dantas
b
Departamento de Computac¸
˜
ao, Universidade Federal de Sergipe, S
˜
ao Crist
´
ov
˜
ao, SE, Brazil
Keywords:
Morphological Operations, Registered Images, Damage Level Classification, Unet, BDANet, CutMix.
Abstract:
In this study, our main motivation was to develop and optimize an image segmentation model capable of
accurately assessing damage caused by natural disasters, a critical challenge today where the frequency and
intensity of these events are increasing. In order to predict damage categories, including no damage, minor
damage, and major damage, we compared several models and approaches. we explored and compared several
models, focusing on the Unet architecture employing BDANet and other architectures such as ResNet18,
VGG16, and ResNet50. Layers with mathematical morphology operations were applied as a filtering strategy.
The results indicated that the Unet model with the BDANet backbone had the best performance, with an F1-
score of 0.761, which increased to 0.799 after applying mathematical morphology operations.
1 INTRODUCTION
Image segmentation is a fundamental technique in the
field of image processing and computer vision that in-
volves dividing an image into meaningful and non-
overlapping regions. The process of image segmenta-
tion is essential for natural scene understanding, as
it allows for the identification of objects and their
boundaries within an image (Yu, 2023).
The importance of image segmentation lies in its
ability to extract relevant information from an image,
which can be used for various applications such as ob-
ject recognition, image compression, and image en-
hancement (Li et al., 2020).
One such application of image segmentation is in
assessing damage to buildings and in identifying land-
scape changes before and after natural disasters. This
allows the location and identification of buildings and
other structures, which can then be analyzed for dam-
age.
A neural network can be used to locate the most
affected areas and segment damage to buildings (Da
et al., 2022). Similarly, Wang (Wang and Li, 2022)
used automatic image segmentation technology to
identify comprehensive disaster reduction capability
assessment of regional disaster hotspots. However, to
a
https://orcid.org/0009-0000-3122-8292
b
https://orcid.org/0000-0002-0142-891X
perform this task of image segmentation after natural
disasters, the availability of datasets that have pre and
post-disaster quality annotations is crucial.
The xBD dataset, is widely used to evaluate
building damage segmentation from satellite im-
agery (Gupta et al., 2019). This dataset includes high-
resolution satellite images from 19 natural disaster
events, such as hurricanes, earthquakes, floods, for-
est fires, volcanic eruptions, and tsunamis, covering
more than 45,000 square kilometers of various natu-
ral disasters that have happened around the world.
Various neural network architectures have been
used in satellite image segmentation after natural dis-
asters. UNet is a popular architecture that uses a
contraction path to capture context and a symmetric
expansion path to enable accurate localization (Ma
et al., 2020).
Multiscale convolutional neural network with
cross-directional attention (BDAnet) is an architec-
ture that uses multidirectional attention and multi-
scale feature fusion to improve building damage as-
sessment from satellite imagery (Shen et al., 2021).
Like BDAnet, the Siamese hierarchical transformer
framework is another architecture that uses a segmen-
tation network (Da et al., 2022).
The successful application of architectural mod-
els for segmenting pre and post-disaster images de-
pends on using registered images. This presents sub-
828
Neto, A. and Dantas, D.
Building Damage Segmentation After Natural Disasters in Satellite Imagery with Mathematical Morphology and Convolutional Neural Networks.
DOI: 10.5220/0012706300003690
Paper published under CC license (CC BY-NC-ND 4.0)
In Proceedings of the 26th International Conference on Enterprise Information Systems (ICEIS 2024) - Volume 1, pages 828-836
ISBN: 978-989-758-692-7; ISSN: 2184-4992
Proceedings Copyright © 2024 by SCITEPRESS – Science and Technology Publications, Lda.

stantial challenges, such as the identification of sta-
ble features in multitemporal images (Lyu and Jiang,
2017) and the segmentation and clustering of planar
images, both critical issues in the field of computer vi-
sion (Burdescu et al., 2014). It is also crucial to main-
tain the spatial relationship between these images for
accurate segmentation (Da et al., 2022).
The studies from Shen (Shen et al., 2021) and
Weber (Weber and Kan, 2020) propose new con-
volutional neural network architectures for building
damage assessment from satellite imagery after nat-
ural disasters. Shen (Shen et al., 2021) proposes
the BDANet, a two-stage CNN that uses multidimen-
sional and multidirectional attention mechanisms to
improve the F1-score of image segmentation. We-
ber (Weber and Kan, 2020) proposes an improved
CNN Inception V3 architecture that combines remote
sensing imagery and block vector data to assess the
degree of damage of groups of buildings.
Both studies aimed to improve the F1-scores of
building damage segmentation models from satellite
imagery using deep learning techniques. Despite the
contributions of the mentioned studies, there is still a
gap regarding the exploration of mathematical mor-
phology and different approaches for registered im-
ages in the evaluation of building damage in post-
disaster satellite images.
Mathematical morphology, with its operations of
dilation, erosion, opening, and closing, allows for the
improvement of the mask predicted by the model,
removing noise and imperfections generated by the
model, thus facilitating the identification of damaged
buildings.
In addition, we seek to develop and implement
new approaches for handling registered images while
maintaining the spatial relationship between pre and
post-disaster images. This strategy will allow a more
accurate comparison of the state of buildings before
and after the catastrophic event, contributing to a
more accurate damage assessment.
The goal of this study is to improve the segmen-
tation of building damage from satellite images us-
ing the xBD dataset (Gupta et al., 2019), particularly
in post-disaster situations, by testing different neu-
ral network architectures and by using mathematical
morphology techniques as layers in the neural net-
works and new approaches for registered images.
2 BACKGROUND
2.1 Data Preparation Methods for
Image Segmentation
Data preparation is a crucial step in image segmen-
tation that involves preparing the image conditions to
meet the segmentation requirements.
1. Cropping: select a part of the image, perform a
cropping, and use it as input to the segmentation
model. This technique helps to increase the diver-
sity of the training data and avoid overfitting (He
et al., 2022).
2. Data augmentation transformations: applying var-
ious transformations to the input image to create
new training samples. Common transformations
include rotation, scaling, flipping, color jittering,
shear, translation, and color distortions. These
transformations help to increase the size of the
training dataset and improve the robustness of the
model (He et al., 2022).
3. Resize: changing the size of the input image to
match the input size of the segmentation model.
This technique is useful when the input image size
is different from the model’s input size (Alamin
et al., 2016).
4. CutMix: the technique is a data augmentation
strategy proposed by Yun (Yun et al., 2019) that
involves cutting and pasting patches among train-
ing images, where the ground truth labels are also
mixed proportionally to the area of the patches.
2.2 Approaches for Registered Images
There are several possible approaches for segmenting
registered images, such as disaster images where we
have one image pre and one post-disaster.
One possible approach for segmenting registered
images, such as pre and post-disaster images, is to
concatenate the two input images in the channels di-
mension, i.e., stacking them generating an image with
six channels. This approach has been used by Li (Li
et al., 2019) and Muhadi (Muhadi et al., 2020). In this
approach, the concatenated image is fed into a seg-
mentation network to obtain the segmented output.
Another possible approach is to feed the pre and
post-disaster separated images into a Siamese net-
work. This approach has been used by Da (Da
et al., 2022) and Chowdhury (Chowdhury and Rah-
nemoonfar, 2021). In this approach, the Siamese net-
work learns a similarity metric between the pre and
post-disaster images, which can be used to identify
changes in the scene.
Building Damage Segmentation After Natural Disasters in Satellite Imagery with Mathematical Morphology and Convolutional Neural
Networks
829

A third possible approach is to calculate the differ-
ence between the pre and post-disaster images. This
approach has been used by Rudner (Rudner et al.,
2019) and Yang (Yang et al., 2020). In this approach,
the difference image is fed into a segmentation net-
work to obtain the segmented output.
2.3 Neural Network Architectures in
Image Segmentation
UNet is a fully convolutional encoder-decoder net-
work architecture with skip connections between
encoder-decoder modules, which was introduced by
Gaj (Gaj et al., 2019).
Feature pyramid network (FPN), is a neural net-
work architecture that was originally proposed for ob-
ject detection but has also been applied to segmenta-
tion tasks (Minaee et al., 2021).
LinkNet is a neural network architecture that
was proposed for semantic segmentation tasks (Basu,
2023). It is a fully convolutional network that uses a
combination of encoder and decoder modules to ex-
tract features from the input image and generate the
segmentation map.
PSPNet is a neural network architecture that
stands for pyramid scene parsing network. It was pro-
posed for semantic segmentation tasks and is based on
a pyramid pooling module (PPM) that captures mul-
tiscale contextual information (Li, 2023).
BDAnet is a neural network architecture that was
proposed for image segmentation tasks (Mochalov
and Mochalova, 2019). It is a fully convolutional net-
work that uses a combination of dilated convolutions
and atrous spatial pyramid pooling (ASPP) to capture
multiscale contextual information.
2.4 Mathematical Morphology
Mathematical morphology is a field of image process-
ing that deals with the analysis and manipulation of
geometric structures in images. The two primitive
operations of mathematical morphology are dilation
and erosion. Additionally, there are the operations
of opening and closing, which are derived from the
primitives (Chen et al., 2021).
Dilation is an operation that expands the bound-
aries of a bright region in an image, while erosion
shrinks them. Opening is an erosion followed by a
dilation, which can be used to remove small bright
objects from an image. Closing is a dilation followed
by an erosion, which can be used to fill small holes in
an image (Banon and Barrera, 1994).
2.5 Visualization and Evaluation
There are several visualization and evaluation tech-
niques that can be used to measure the results of
image segmentation models. For visualization we
use visual semantic segmentation (Benkhoui et al.,
2021) and for evaluation of the results we use the F1-
score (Laine et al., 2021).
3 METHODOLOGY
This section begins with a description of the dataset,
followed by the four steps of the methodology. Data
preparation, models training, application of mathe-
matical morphology filters, and model evaluation.
The code was developed in Python and is available
in GitHub for future reference
1
.
3.1 xBD Dataset from xView2 Challenge
The xBD database from xView2 challenge (Defense
Innovation Unit, DoD, 2023) contains high resolution
satellite imagery of six different types of natural dis-
asters around the world, covering a total area of over
45,000 square kilometers (Gupta et al., 2019).
Each pixel in the image has a value that corre-
sponds to one of the five labels defined to classify
the state of each building. These labels were defined
according to the degree of damage presented by the
building and are as follows: background, no dam-
age, building with minor damage, building with ma-
jor damage, and destroyed building. Table 1 shows
the values corresponding to each damage level. The
levels range from 1, no damage, to 4, destroyed. The
0 corresponds to the background.
Table 1: Scale of damage noted on buildings. Adapted
from (Defense Innovation Unit, DoD, 2023).
Score Label
Visual description
of the structure
1 No damage
Undisturbed. No sign of water,
structural damage, shingle damage,
or burn masks.
2 Minor damage
Building partially burnt, water surrounding
the structure, volcanic flow nearby,
roof elements missing, or visible cracks.
3 Major damage
Partial wall or roof collapse, encroaching
volcanic flow, or the structure is
surrounded by water or mud.
4 Destroyed
Structure is scorched, completely collapsed,
partially or completely covered with water
or mud, or no longer present.
The xBD dataset was divided into 9,162 training
images, 906 test images and 906 validation images,
1
https://github.com/ddantas-ufs/2024 building
ICEIS 2024 - 26th International Conference on Enterprise Information Systems
830

for a total of 10,974 images. This division ensures
effective learning, evaluation and validation of the
model, avoiding overfitting and improving general-
ization.
3.2 Data Preparation
The data preparation step plays a crucial role in build-
ing robust image segmentation models, allowing the
model to capture the diversity of the input images and
minimize the risk of overfitting. The image and mask
are cropped to a specific size (512×512 pixels). After
cropping, we use three approaches to prepare the data
input:
1. Stacked images: concatenate two RGB input im-
ages into a single one with six channels, three
channels from each input image.
2. Separated images: passing pre and post-disaster
images separately to feed a Siamese network.
3. Difference between images: the difference be-
tween the two input images, forming a single in-
put image with three channels corresponding to
the intensity difference between the images.
3.3 Models Training
In the model training step, four neural net-
work models, available in the Python libraries
segmentation models and Pytorch, were tested:
UNet, FPN, Linknet, and PSPNet. Each of these
models was implemented using seven backbones:
BDANet, VGG16, ResNet18, ResNet50, ResNet34,
ResNeXt50, and SENet154. A total of 28 combina-
tions were trained. All of these models were trained
using pre-trained weights from ImageNet.
For training the models, the Dice loss function
was used, which is a commonly used metric to eval-
uate the overlap between the predicted mask and the
groundtruth mask. We also used the focal loss func-
tion, which aims to solve the class unbalance prob-
lem.
Additionally, a weight was applied to the loss
function to deal with class unbalance. These weights
were set based on the frequency of the classes in the
training images. The optimizer used was AdamW
with a learning rate of 10
−4
and a weight decay of
10
−6
. The metric used to evaluate the model was the
F1-score.
In each epoch of the training, the model receives
every image of the training set. Transformations are
randomly applied to each image to increase the vari-
ability of the data. Increasing the variability of the
data allows the model to generalize better to new and
unknown data. The following transformations were
applied.
1. Horizontal mirroring: mirrors the image along the
vertical axis.
2. Vertical mirroring: mirrors the image along the
horizontal axis.
3. Rotation: rotates the image by a random angle be-
tween -10 and 10 degrees.
4. Scale: applies a random scale to the image be-
tween 0.8 and 1.2.
5. Additive gaussian noise: adds Gaussian noise to
the image with a random scale between 0 and
0.05.
6. Contrast normalization: adjusts the contrast of the
image to a random value between 0.8 and 1.2.
7. Elastic transformation: applies an elastic defor-
mation to the image.
To increase the amount of examples per class, the
CutMix technique was implemented. This technique
consists of selecting a random rectangular part, with
a probability of 87%, from an image and replacing it
with a corresponding part from another image, with
the respective annotation masks adjusted similarly as
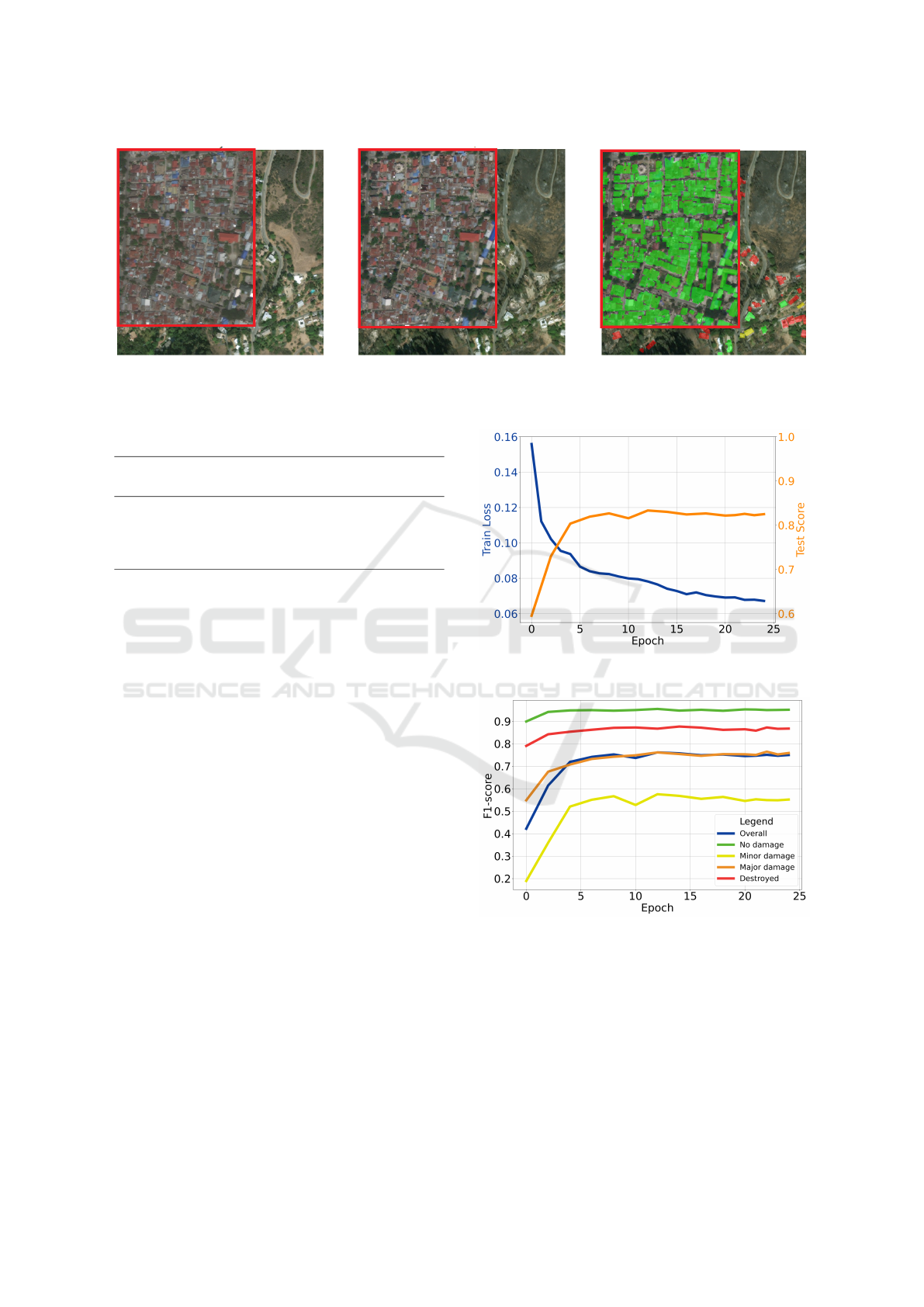
shown in Figure 1.
3.4 Morphological Filters
The application of mathematical morphology opera-
tions was performed in order to improve the F1-score
of the best segmentation model that was obtained in
the training. The use of morphological layers was
composed of tests considering the sizes of the struc-
turing elements 3×3 pixels (SeSize) and the shapes of
the structuring elements squares (SeShape).
We tested four traditional morphological opera-
tions: erosion, dilation, opening and closing. These
layers were inserted immediately after the Unet model
softmax layer with the BDANet backbone. This layer
has an image of dimension 512×512×5, each one of
five channels in this image predicted represents a seg-
mentation label. The training was carried out with a
set of all the training images and the convolutional
layers frozen.
3.5 Model Evaluation
We used the F1-score metric to evaluate the perfor-
mance of the segmentation models used in the pre and
post-disaster image segmentation problem.
The F1-score is defined as the harmonic mean be-
tween precision and recall and can vary from 0 to 1,
Building Damage Segmentation After Natural Disasters in Satellite Imagery with Mathematical Morphology and Convolutional Neural
Networks
831
(a) (b) (c)
Figure 1: Example of CutMix application, which is represented in the red rectangles, on images. a) image pre-disaster, b)
image post-disaster and c) post-disaster plus mask image.
Table 2: Models results in test dataset (Top 5 F1-score).
Nº
Different approaches
for registered
images
Model Backbone
F1-score
overall
1 Separated images Unet BDANet 0.761
2 Stacked images Linknet ResNet18 0.433
3 Stacked images Linknet VGG16 0.401
4 Stacked images Linknet ResNet50 0.368
5 Difference between images Linknet ResNet50 0.203
with values closer to 1 indicating a model with better
performance. To calculate the F1-score, the segmen-
tation masks produced by the models were compared
with the grountruth segmentation masks.
In addition, to visualize the model results, we plot-
ted the predictions that the model provided to verify
if the model was generating the masks properly.
4 RESULTS
4.1 Experiments
We ran 28 experiments to identify which models have
a better F1-score. Table 2 shows the F1-score of the
five best models for pre and post-disaster image seg-
mentation. The models were evaluated using the F1-
score with 25 epochs.
The Unet model with the BDANet backbone,
which treated the separated images, performed the
best, with an F1-score of 0.761. This result highlights
the effectiveness of the separated image approach,
suggesting that maintaining image individuality can
retain critical features that may be lost in other ap-
proaches.
Furthermore, the F1-score obtained can also be at-
tributed to the use of the BDANet backbone, since
the model showed high F1-scores compared to other
models tested. The BDANet was proposed by Shen
Figure 2: Train loss and test score by epochs of the best
model.
Figure 3: F1-score per class in each epoch of the best model.
and obtained an F1-score higher than other architec-
tures in the damage segmentation task (Shen et al.,
2021).
After the training step, the model with the high-
est F1-score was chosen to analyze the results and
find opportunities to improve the F1-score. Figure 2
shows the train loss and test score over the training
epochs.
The train loss is consistently decreasing over the
ICEIS 2024 - 26th International Conference on Enterprise Information Systems
832
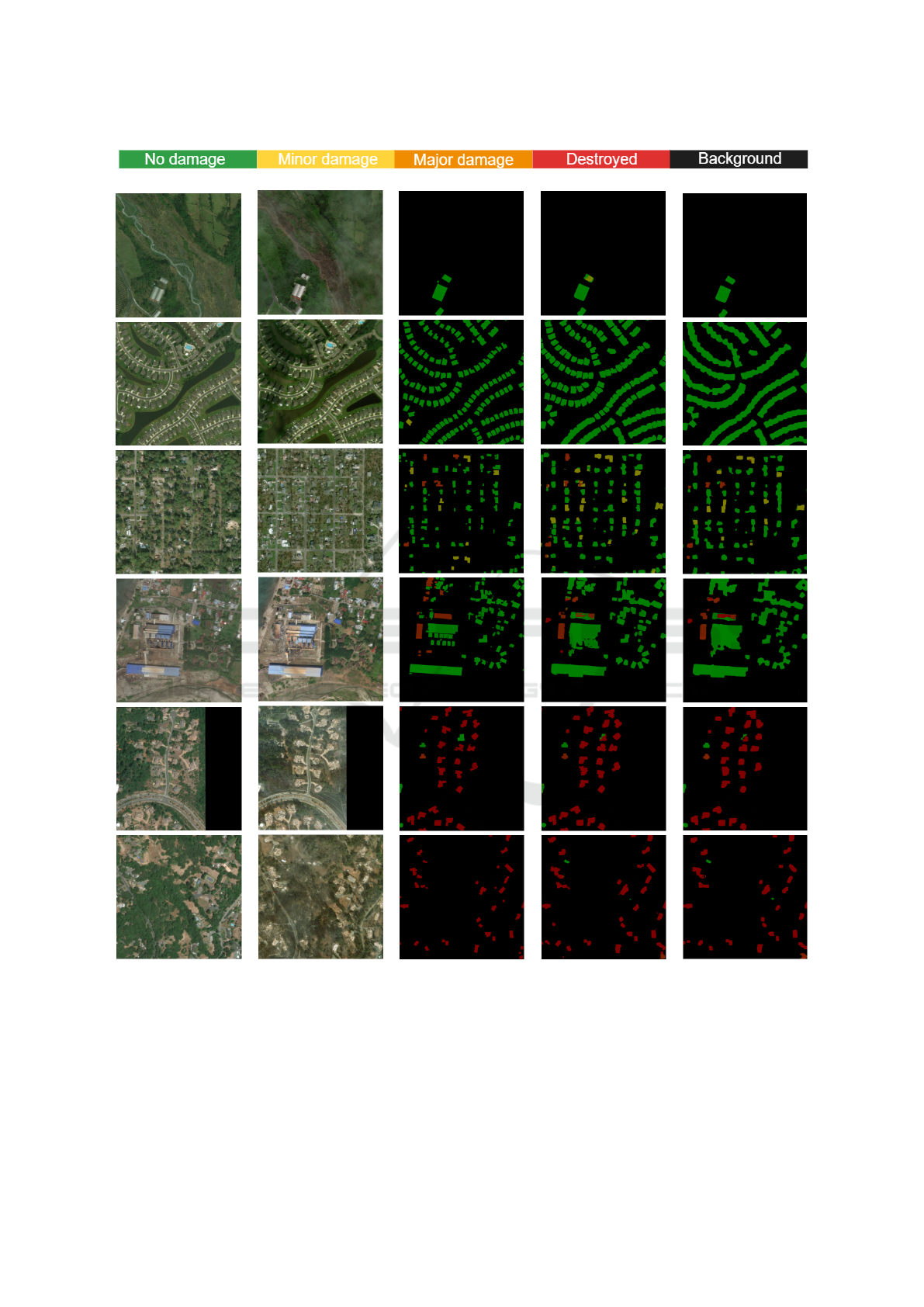
(a)
(b) (c) (d) (e) (f)
Figure 4: Best model prediction on an image example. a) Classes of masks, b) Image pre-disaster, c) Image post-disaster, d)
Mask, e) Mask predicted and f) Mask predicted plus mathematical morphology.
epochs, suggesting that the model is continuously
learning and improving. This is a positive sign that
training is progressing as expected.
The test score was calculated as a weighted av-
erage of these two metrics: 0.3 times the Dice score
plus 0.7 times the F1-score. The test score generally
increases over time. This indicates that the perfor-
mance of the model on the test set is improving.
In addition to analyzing the train loss and test
score. Figure 3 shows the evolution of the F1-score
Building Damage Segmentation After Natural Disasters in Satellite Imagery with Mathematical Morphology and Convolutional Neural
Networks
833

Table 3: Best model results after applying morphological
layers.
Operation F1-score
Increase
F1-score
Dilation
0.799 0.038
Erosion
0.781 0.020
Closing
0.776 0.015
Opening
0.761 0.000
per class in each epoch of the best model.
The overall F1-score had an increasing trend in
the test dataset, although there were some oscilla-
tions. This suggests that the model improved over the
epochs.
We note that the no damage class consistently
has the highest F1-score, suggesting that the model
is more effective at predicting this class which repre-
sents the background.
In contrast, the minor damage and major damage
classes have the lowest F1-scores, suggesting that the
model has more difficulty predicting these classes or
that it may have too few examples of these classes.
In addition to observing the trend by class of the
overall F1-score over the epochs, visual results of the
predictions were also evaluated, as shown in Figure 4.
Despite the model’s F1-score having a satisfactory
result, the model predictions had small errors in the
completeness of the polygons. One of these errors can
be clearly seen in the second row of Figure 4, where
we have some predicted rectangles with small holes
or inadequate fills.
From these observations, an experiment was car-
ried out with the application of layers with mathemat-
ical morphology operations to improve the F1-score.
Table 3 shows the best overall results with mathemat-
ical morphology experiments.
The last column of Table 3 shows the improve-
ment in F1-score obtained with the addition of the
morphological layers. When the morphology layer is
applied after decision layer, there is an increase in the
F1-score, leading to an improvement of 0.038 over the
best model, reaching an F1-score of 0.799.
4.2 Comparison with Other Studies
Table 4, shows how the proposed model in this study
compares to other models from related works.
The proposed model obtained an F1-score of
0.799. This model outperformed BDANet in the no
damage and destroyed classes with an F1-score of
0.954 and 0.879 respectively. However, the proposed
model underperformed in all other classes when com-
pared to BDANet. We may try other techniques to im-
prove the F1-score, such as ensemble methods, Cut-
Mix concentrated on the classes that had lower F1
scores or fine-tuning the hyperparameters with a grid
search.
The FCN (Long et al., 2015; Shen et al., 2021),
MTF (Weber and Kan, 2020), WNet (Hou et al., 2019;
Shen et al., 2021) and Baseline model (Gupta et al.,
2019) models achieved lower F1-scores than the pro-
posed model and BDANet.
5 CONCLUSIONS
In this study, several models were evaluated regard-
ing their F1-score in segmenting pre and post-disaster
images.
The Unet model with the BDANet backbone ob-
tained the best performance, achieving an F1-score of
0.761. This result indicates the effectiveness of the
separated image approach, preserving their individual
features that may be lost in other approaches.
BDANet may have contributed to the high perfor-
mance of this model in extracting relevant features
from images, as evidenced in the study by Shen (Shen
et al., 2021).
The stacked image approach obtained inferior per-
formance, with lower F1-scores than the other tested
models. It was observed that the ResNet18 backbone
architecture obtained a higher F1-score than VGG16
and ResNet50.
The results of these experiments indicate that ap-
plying layers with mathematical morphology opera-
tions can improve the F1-score of the model. The
overall F1-score increased from 0.761 to 0.799.
When comparing the performance of the proposed
model with other studies, it was observed that the
proposed model outperformed the BDANet in the no
damage and destroyed classes. In addition, the pro-
posed model has higher F1-score in all classes com-
pared to FCN, MTF, WNet and the baseline model.
However, the proposed model underperformed in
all other classes when compared to BDANet, suggest-
ing that there is still room for improving the F1-score.
Future works may include strategies to further im-
prove the performance of the proposed model. The
first one would be the implementation of an ensem-
ble method. Secondly, we may apply CutMix concen-
trated on the classes that had lower F1-scores, such as
the minor damage and major damage classes. Finally,
fine tuning the hyperparameters with a grid search or
random search could be an additional strategy to im-
prove performance.
ICEIS 2024 - 26th International Conference on Enterprise Information Systems
834

Table 4: Comparison of the F1-score among other studies. Table is in descending order by F1-score.
Models Overall
No
damage
Minor
damage
Major
damage
Destroyed
BDANet
(Shen et al., 2021)
0.806 0.925 0.616 0.788 0.876
Proposed
model
0.799 0.954 0.601 0.762 0.879
FCN
(Long et al., 2015; Shen et al., 2021)
0.765 0.919 0.532 0.708 0.861
MTF
(Weber and Kan, 2020)
0.741 0.906 0.493 0.722 0.837
WNet
(Hou et al., 2019; Shen et al., 2021)
0.737 0.884 0.518 0.684 0.855
Baseline
model (Gupta et al., 2019)
0.265 0.663 0.143 0.009 0.465
REFERENCES
Alamin, I. M. J., Jeberson, W., and Bajaj, H. (2016). Im-
proved region growing based breast cancer image seg-
mentation. International Journal of Computer Appli-
cations, 975:888.
Banon, G. J. F. and Barrera, J. (1994). Bases da Morfolo-
gia Matem
´
atica para a an
´
alise de imagens bin
´
arias.
UFPE-DI.
Basu, A. (2023). A survey on recent trends in deep learning
for nucleus segmentation from histopathology images.
Evolving Systems, pages 1–46.
Benkhoui, Y., El-Korchi, T., and Reinhold, L. (2021). Ef-
fective pavement crack delineation using a cascaded
dilation module and fully convolutional networks. In
Geometry and Vision: First International Symposium,
ISGV 2021, Auckland, New Zealand, January 28-29,
2021, Revised Selected Papers 1.
Burdescu, D. D., Stanescu, L., Brezovan, M., and Spahiu,
C. S. (2014). Efficient volumetric segmentation
method. In 2014 Federated Conference on Computer
Science and Information Systems, pages 659–668.
Chen, Q., Cheng, Q., Wang, J., Du, M., Zhou, L., and
Liu, Y. (2021). Identification and evaluation of ur-
ban construction waste with vhr remote sensing using
multi-feature analysis and a hierarchical segmentation
method. Remote Sensing, 13(1):158.
Chowdhury, T. and Rahnemoonfar, M. (2021). Self atten-
tion based semantic segmentation on a natural disas-
ter dataset. In 2021 IEEE International Conference on
Image Processing (ICIP), pages 2798–2802.
Da, Y., Ji, Z., and Zhou, Y. (2022). Building damage as-
sessment based on siamese hierarchical transformer
framework. Mathematics, 10(11):1898.
Defense Innovation Unit, DoD (2023). xview2: Assess
building damage. https://xview2.org /dataset.
Acessed: 30/04/2023.
Gaj, S., Yang, M., Nakamura, K., and Li, X. (2019). Au-
tomated cartilage and meniscus segmentation of knee
mri with conditional generative adversarial networks.
Magnetic Resonance in Medicine, 84(1):437–449.
Gupta, R., Goodman, B., Patel, N., Hosfelt, R., Sajeev, S.,
Heim, E., Doshi, J., Lucas, K., Choset, H., and Gas-
ton, M. (2019). Creating xBD: A dataset for assessing
building damage from satellite imagery. In Proceed-
ings of the IEEE/CVF conference on computer vision
and pattern recognition workshops, pages 10–17.
He, W., Liu, M., Tang, Y., Liu, Q., and Wang, Y.
(2022). Differentiable automatic data augmentation
by proximal update for medical image segmentation.
IEEE/CAA Journal of Automatica Sinica, 9(7):1315–
1318.
Hou, B., Liu, Q., Wang, H., and Wang, Y. (2019). From
W-Net to CDGAN: Bitemporal change detection via
deep learning techniques. IEEE Transactions on Geo-
science and Remote Sensing, 58(3):1790–1802.
Laine, R. F., Arganda-Carreras, I., Henriques, R., and
Jacquemet, G. (2021). Avoiding a replication cri-
sis in deep-learning-based bioimage analysis. Nature
Chemical Biology, 18(10):1136–1144.
Li, K. (2023). Upernet optimisation and application to
mousehole segmentation. In International Conference
on Artificial Intelligence, Virtual Reality, and Visual-
ization (AIVRV 2022), volume 12588, pages 157–163.
Li, T.-T., Jiang, C., Bian, Z., Wang, M., and Niu, X. (2020).
Semantic segmentation of urban street scene based
on convolutional neural network. Journal of Physics
Conference Series, 1682(1):012077.
Li, W., Jafari, O., and Rother, C. (2019). Deep object co-
segmentation. In Computer Vision–ACCV 2018: 14th
Asian Conference on Computer Vision, Perth, Aus-
tralia, December 2–6, 2018, Revised Selected Papers,
Part III 14, pages 638–653.
Long, J., Shelhamer, E., and Darrell, T. (2015). Fully con-
volutional networks for semantic segmentation. In
Building Damage Segmentation After Natural Disasters in Satellite Imagery with Mathematical Morphology and Convolutional Neural
Networks
835

Proceedings of the IEEE conference on computer vi-
sion and pattern recognition, pages 3431–3440.
Lyu, C. and Jiang, J. (2017). Remote sensing image regis-
tration with line segments and their intersections. Re-
mote Sensing, 9(5):439.
Ma, H., Liu, Y.-L., Ren, Y., Wang, D.-C., Yu, L., and Abell,
A. D. (2020). Improved CNN classification method
for groups of buildings damaged by earthquake, based
on high resolution remote sensing images. Remote
Sensing, 12(2):260.
Minaee, S., Boykov, Y., Porikli, F., Plaza, A., Kehtarnavaz,
N., and Terzopoulos, D. (2021). Image segmenta-
tion using deep learning: A survey. IEEE Transac-
tions on Pattern Analysis and Machine Intelligence,
44(7):3523–3542.
Mochalov, V. and Mochalova, A. (2019). Extraction of
ionosphere parameters in ionograms using deep learn-
ing. E3s Web of Conferences, 127:01004.
Muhadi, N. A., Abdullah, A. Z., Bejo, S. K., Mahadi, M. R.,
and Mijic, A. (2020). Image segmentation methods
for flood monitoring system. Water, 12(6):1825.
Rudner, T. G. J., Rußwurm, M., Fil, J. E., Pelich, R.,
Bischke, B., Kopackova, V., and Bilinski, P. (2019).
Multi3net: Segmenting flooded buildings via fusion of
multiresolution, multisensor, and multitemporal satel-
lite imagery. Proceedings of the Aaai Conference on
Artificial Intelligence, 33(1):702–709.
Shen, Y., Zhu, S., Yang, T., Chen, C., Pan, D., Chen, J.,
Xiao, L., and Du, Q. (2021). Bdanet: Multiscale con-
volutional neural network with cross-directional atten-
tion for building damage assessment from satellite im-
ages. IEEE Transactions on Geoscience and Remote
Sensing, 60:1–14.
Wang, J. and Li, M. (2022). Evaluation model of regional
comprehensive disaster reduction capacity under com-
plex environment. Journal of Environmental and Pub-
lic Health, 2022.
Weber, E. and Kan, H. (2020). Building disaster damage as-
sessment in satellite imagery with multi-temporal fu-
sion. arXiv preprint arXiv:2004.05525.
Yang, M.-D., Tseng, H.-H., Hsu, Y., and Tsai, H. J. (2020).
Semantic segmentation using deep learning with veg-
etation indices for rice lodging identification in multi-
date uav visible images. Remote Sensing, 12(4):633.
Yu, Y. (2023). Techniques and challenges of image segmen-
tation: A review. Electronics, 12(5):1199.
Yun, S., Han, D., Chun, S., Oh, S. T., Yoo, Y., and Choe,
J. (2019). CutMix: Regularization strategy to train
strong classifiers with localizable features. In Pro-
ceedings of the IEEE/CVF international conference
on computer vision.
ICEIS 2024 - 26th International Conference on Enterprise Information Systems
836
