
BeRTo: An Efficient Spark-Based Tool for Linking Business Registries in
Big Data Environments
Andrea Colombo
a
and Francesco Invernici
b
Dipartimento di Elettronica, Informazione e Bioingegeneria, Politecnico di Milano, Via G. Ponzio 34, Milan, Italy
Keywords:
Record Linkage, Entity Resolution, Apache Spark, Hadoop, Big Data Integration.
Abstract:
Linking entities from different datasets is a crucial task for the success of modern businesses. However,
aligning entities becomes challenging as common identifiers might be missing. Therefore, the process should
rely on string-based attributes, such as names or addresses, thus harming precision in the matching. At the
same time, powerful general-purpose record linkage tools require users to clean and pre-process the initial
data, introducing a bottleneck in the success of the data integration activity and a burden on actual users.
Furthermore, scalability has become a relevant issue in modern big data environments, where a lot of data
flows daily from external sources. This work presents a novel record linkage tool, BeRTo, that addresses
the problem of linking a specific type of data source, i.e., business registries, containing information about
companies and corporations. While being domain-specific harms its usability in other contexts, it manages
to reach a new frontier in terms of precision but also scalability, as it has been built on Spark. Integrating
the pre-processing and cleaning steps in the same tool creates a user-friendly end-to-end pipeline that requires
users only to input the raw data and set their preferred configuration, allowing to focus on recall or precision.
1 INTRODUCTION
In an evolving data analytics landscape, connecting
diverse and heterogeneous data sources is paramount
for enhancing the data-driven decision-making of any
organization. This task is usually referred to as record
linkage or entity matching, whose common obstacle
is the integration of datasets when no shared identifier
exists (Herzog et al., 2007; Getoor and Machanava-
jjhala, 2012). In such cases, the issue is reconcil-
ing and linking disparate data records based on at-
tributes that are not primary keys, with the aim of
identifying the same real-world entity, such as cus-
tomers or products. Linking those entities becomes
critical to fully unlock the potential of data analytics
activities (Dong and Srivastava, 2013; Christophides,
2020; Chen et al., 2018). Furthermore, the advent of
big data has added a new layer of complexity to data
integration activities due to the volume and the vari-
ety of data sources involved. Traditional tools have
in fact become inefficient since such exercises, fol-
lowing the flow of data from repository sources, are
performed on a daily basis (Yan et al., 2020), due to
a
https://orcid.org/0000-0002-7596-8863
b
https://orcid.org/0009-0002-5423-6978
the constant changes in the received data and the need
of keep-to-date internal business processes.
Various tools have been developed over time to
assist in record linkage activities, mostly general-
purpose ones, which serve and assist users over differ-
ent record linkage scenarios. However, such tools are,
by definition, incapable of natively capturing domain-
specific rules or patterns that might impact the over-
all success, i.e., recall and precision, of matched enti-
ties, without undergoing specific and time-consuming
training, mostly based on machine learning tech-
niques. This is also the case of integrating business
registries, a particularly relevant problem for any sta-
tistical agency and companies, especially those op-
erating worldwide. Business registries contain infor-
mation about business entities, their legal structures,
ownership details, and financial information. Such
data play a central role in producing national and in-
ternational statistics (Eurostat, 2024) and are critical
for authorities to enable more specific analysis, such
as malicious market behaviors (Ryan et al., 2020),
for instance, by allowing the connection of owner-
ship data with financial information. Linking busi-
ness registries usually relies on registration numbers
or other national and cross-national identifiers. How-
ever, it is not rare that different data repositories are
Colombo, A. and Invernici, F.
BeRTo: An Efficient Spark-Based Tool for Linking Business Registries in Big Data Environments.
DOI: 10.5220/0012718000003756
Paper published under CC license (CC BY-NC-ND 4.0)
In Proceedings of the 13th International Conference on Data Science, Technology and Applications (DATA 2024), pages 259-268
ISBN: 978-989-758-707-8; ISSN: 2184-285X
Proceedings Copyright © 2024 by SCITEPRESS – Science and Technology Publications, Lda.
259

based on distinct identifiers, often internal IDs, that
are not worldwide and internationally adopted (Gu-
ralnick, 2015). Thus, they do not allow a full in-
tegration to users who might want to combine such
information with internal datasets or factual knowl-
edge. In such cases, utilizing non-standard and string-
based attributes for entity matching can help recon-
cile and create a bridge between the business reg-
istries. However, accounting for attribute-specific
pre-processing is essential for improving matching
performance. For instance, business and organiza-
tional names can adopt conventions, such as abbre-
viations, which might heavily harm and limit the pre-
cision and recall of entity matching.
In this paper, we contribute to a novel open-
source Spark-based entity matching tool, BeRTo, im-
plemented in Python, that tackles the challenge of in-
tegrating business registries by exploiting legal en-
tities’ name and address information. It combines
widely used techniques for record linkage, such as
fuzzy matching, with standard string processing and
string similarity techniques. Its implementation is
based on the Apache Spark paradigm (Salloum et al.,
2016), thus leveraging the most recent big data pro-
cessing solutions, allowing smooth use in fast-paced
and big-data contexts (Shaikh et al., 2019). This tool
is a domain-specific solution that focuses on a specific
record linkage problem related to companies. Such
nature, while limiting its usage for general-purpose
tasks, allows it to reach a new frontier in the recall-
precision trade-off, as it can be precise and successful,
due to its domain-aware features, and scalable, thanks
to its Spark implementation. Additionally, BeRTo al-
lows users to set their preferred configuration by set-
ting its parameters, to obtain the desired level of pre-
cision and recall without the need to perform any kind
of pre-processing or cleaning of original data.
Overview. In Section 2 we discuss related works,
Section 3 presents the approach and the system while
in Section 4 we conduct the experiments testing our
system. Section 5 concludes the paper.
2 RELATED WORK
The problem of record linkage has received much at-
tention in the past few decades. It deals with find-
ing the tuple pairs (a,b) that refer to the same entity,
be it a person, product, or institution, between two
tables or, more in general, two databases (Christen,
2012). Traditional record linkage techniques focus on
connecting sets of records sharing the same schema,
with numerous entity-matching algorithms being pro-
posed (Koudas et al., 2006; Elmagarmid et al., 2007).
To address the big data context, new algorithms have
been proposed based on techniques such as adaptive
blocking (Bilenko et al., 2006), incremental cluster-
ing techniques (Nentwig and Rahm, 2018) or by uti-
lizing new big data processing paradigms, which bal-
ance load among different nodes (Kolb et al., 2012b;
Kolb et al., 2012a). Although such techniques are
popular, little or no guidance is typically provided on
selecting appropriate blockers or settings for such al-
gorithms. Furthermore, few systems also integrate
a data-cleaning workflow, with most ones leaving
such a pre-processing burden on users. The data
cleaning part is a critical component for the suc-
cess of any of these algorithms and is one of the
main bottlenecks in data integration workflows (Kr-
ishnan et al., 2016). Some systems based on machine
learning techniques have been proposed to link en-
tities, which mitigate the problem of pre-processing
and data cleaning (Wang et al., 2021). Such solu-
tions achieve great results in terms of accuracy but
become easily impracticable when moving to large
volumes of data (Ebraheem et al., 2018). More re-
cent works design so-called meta-blocking technique,
such as SparkER (Gagliardelli et al., 2019) that allow
a more sophisticated LLM-based solution as Ditto (Li
et al., 2020) to scale nicely. However, such a combi-
nation is hard to set and does not account for specific
cleaning over raw data, which is still left to users.
Magellan (Konda et al., 2016) is one of the first
ecosystems that proposes a general-purpose tool to
tackle the data cleaning issue. It offers an Entity
Matching (EM) system that is novel in providing how-
to guides and support for the entire EM pipeline,
combined with tight integration with the Python data
ecosystem. With Magellan, users have been able to
achieve high matching accuracy on several multiple
datasets. However, its general-purpose nature still
leaves a high portion of the burden on users, who need
both dataset knowledge and at least data integration
skills to follow the guides. Therefore, in a fast-paced,
big data and problem-specific environment, e.g., con-
necting two data sources that are regularly updated, a
domain-aware tool might be preferred over a general-
purpose one. Other systems, such as LinkageWiz
1
and Dedupe.io (Forest and Eder, 2015), devote more
attention to the data cleaning phase and have been
designed to tackle entity matching issues; however,
they suffer when moving to the big data context. For
instance, LinkageWiz states on their website that it
can process files containing up to 4-5 million records
and Dedupe.io considers databases up to 700k rows,
far from the big data paradigm that is required nowa-
days. More recently, Splink (Linacre et al., 2022) has
1
https://www.linkagewiz.net/ListManagement.htm
DATA 2024 - 13th International Conference on Data Science, Technology and Applications
260

been developed for scalable deduplication and record
linkage. However, its probabilistic-based approach
still requires a heavy burden on users to design the
most suitable combination of blocking rules and sys-
tem configuration to optimize it, both in terms of ex-
ecution time and final precision, with some data pre-
processing also suggested.
3 METHODOLOGY AND TOOL
IMPLEMENTATION
In this section, we present BeRTo
2
, our entity-
matching tool for integrating large business registries
in an effective and scalable way. First, we discuss the
nature of business registries and the algorithms we de-
signed and integrated into the tool for performing data
cleaning and preparing the information available in a
business registry for record linkage. Then, we delve
into the actual matching records strategy that has been
developed and we present the precision-recall trade-
off that arises from utilizing BeRTo. In Figure 1, we
depict an overview of the architecture of our tool.
3.1 Business Registries
Business registries, often called also company or
entity databases, are repositories that systematically
record and store information about businesses. Tradi-
tionally, such repositories were maintained by author-
ities for their jurisdiction. However, with the rise of
commercial data providers, usually on a global scale,
we have experienced a rise in this kind of database,
reaching also large volumes. For instance, Moody’s
has its own company database, Orbis
3
, which is the
resource for entity data and provides information on
close to 462 million companies and entities across
the globe, with many having detailed financial infor-
mation, which is of interest to many investors and
customers, be they individuals or authorities (Bajgar
et al., 2020). Another example is OpenCorporates
dataset
4
, which allows one to search for over 220
million companies to understand better who is be-
hind companies, which is of interest to businesses,
governments, journalists, and even researchers. Al-
though such commercial databases provide some na-
tional and international identifiers, they are not used
as primary keys, and there is no guarantee that they
are not null values. For instance, the International Se-
curities Identification Number (ISIN) code is a glob-
2
The tool is available at: https://bitly.ws/3d3aJ
3
https://bvdinfo.com/R0/Orbis
4
Website: https://opencorporates.com/
Business
Registry
D1
Business
Registry
D2
Data
Preprocessing
Data
Preprocessing
Pattern Dictionary
Fuzzy
Name
Matching
Fuzzy
Name
Matching
Matching
Records
and Linking
Clean D1
Clean D2
Mapping
Table B
Figure 1: BeRTo’s architecture.
ally recognized identifier and can be used to identify
a company through its stocks, but it is assigned only
to listed companies. Therefore, many unlisted com-
panies might not have such an identifier. In addi-
tion, commercial providers often use OCR pipelines
for extracting such identifiers (Arief et al., 2018),
which do not provide the same level of trustworthi-
ness as a legally binding business registry. However,
linking to such an enormous database is essential to
leverage the fine-grained worldwide data commercial
providers collect. A business registry usually contains
data about:
• Name of the entity, i.e., the company name. It is a
string attribute with multiple possible variants of
the same name, i.e., abbreviations.
• Country of residence of the entity, encoded in ac-
tual names or in standard defined codes, such as
ISO 3166 (alpha-2 or alpha-3 digits).
• Street address, string denoting the union of an
actual street name, postal code, and city of resi-
dence. Such information might be parsed into dis-
tinct attributes.
We consider these attributes the minimum require-
ment that enables accurate matching across business
registries. In technical terms, we consider them as our
main primary key. While other company-specific in-
formation might be available, such as the telephone
number, we consider the above as the most stable
over time and spread across business registries. As
we shall see, our tool also allows the use of custom
attributes that might be available in the target reg-
istries. However, for such attributes, no specific pre-
processing technique is foreseen.
3.2 Data Preprocessing
We developed a specific string pre-processing
pipeline for each attribute we considered in the pre-
vious section, including some usual and common
preliminary steps. These include accent conversion,
multiple whitespaces, punctuation removal, and case-
sensitive transformation (from lower to capital). For
instance, an entity whose original name is Alpha Co.
Ltd becomes ALPHA COMPANY LTD. Then, for each
BeRTo: An Efficient Spark-Based Tool for Linking Business Registries in Big Data Environments
261

attribute, specific preprocessing and cleaning meth-
ods have been implemented.
Name-Specific Processing. Company names are
characterized by the presence of an entity-specific
string followed by the corresponding business entity
string, which denotes the business type. For instance,
the LTD in ALPHA COMPANY LTD denotes that AL-
PHA COMPANY is a Private Limited Company. In
many cases and jurisdictions, for such specification,
if present, many variations are allowed, most im-
portantly abbreviations. Therefore, to increase the
matching chances between two business registries,
entity names must be pre-processed to align such
cases. To achieve that, our tool implements an empir-
ical fuzzy name matching system, which can capture
a set of the most relevant and commonly used abbre-
viations and variations that affect entity names. The
system is described by Algorithm 1.
Algorithm 1: Empirical Fuzzy Name Matching.
Data: D
1
, D
2
business registries
Input: y
1
and y
2
common ID, T threshold
Output: Fuzzy Pattern Rules
1 Function FuzzyPattern(Z):
2 Z = Z ∪ (ρ
(Z
name
2
,Z
name
1
←Z
name
1
,Z
name
2
)
Z)
3 Z
patterns
= ndiff (Z
name
1
, Z
name
2
)
4 P = Z.GroupBy(name
1
, name
2
, patterns)
5 P
f
=
P.count()
length(Z)
6 return P
7 Function Main:
8 Z ← D
1
▷◁
y
1
=y
2
D
2
9 K = FuzzyPattern(Z).OrderBy(P
f
)
10 if HumanEvaluation = False then
11 K = σ
f >T
K
12 return K
Essentially, our tool contains a sub-module run
over a set of safe matches, obtained by linking busi-
ness registries whose foreign key was available (y
1
and y
2
). We integrated an ndiff function on such
linked entities, which returns the string difference be-
tween two strings. The returned differences Z
patterns
define string patterns, i.e., sub-strings that do not al-
low to join entities directly using the name. For in-
stance, if Z
name
1
= corp and Z
name
1
= corporation
then Z
patterns
= oration. Then the frequency of the
patterns is computed and, whenever the relative fre-
quency is high, the pattern can be added to a pattern
dictionary, which collects, per country, official and
unofficial patterns, such as abbreviations. Continu-
ing our example, the pattern dictionary will contain
the fuzzy transformation corporation → corp. The
idea is that the most frequent patterns might affect all
business registries and, therefore, the pattern dictio-
nary is reusable for all repositories. New patterns can
be added by defining a (relative) frequency threshold,
a level over which such patterns are widely adopted,
or by a human check. In our case, the pattern dic-
tionary has been built via human validation, accept-
ing or rejecting patterns based on common sense.
5
This system is a one-off exercise and, as the tool is
use case-specific, users can decide to enrich the pat-
tern dictionary by running the sub-module over their
internal databases, increasing the final matching per-
formances. For instance, through this approach, we
discovered that a widely used abbreviation affects the
entities that contain the substring in liquidation, as it
is often truncated as in liqui.
For European-based entities, we also collected a
dictionary of officially used abbreviations, that we
also share. For instance, in Germany, the legal busi-
ness type Investmentaktiengesellschaft is usually ab-
breviated as InvAG, and all German-based entities
containing such substring can be replaced by the cor-
responding abbreviation.
Country-Specific Processing. Depending on the
business registry rules, country information might be
inserted in one of the internationally recognized dif-
ferent formats, such as the ISO codes or the country
name itself. Therefore, an entity-matching tool needs
to swiftly recognize each format and move from one
system to another in a seamless way. Our tool has
been designed to support the following international
standards: ISO alpha-2, ISO alpha-3 and M49 code,
plus the country names version, which includes some
heuristics designed to treat specific country names,
such as Republic of or abbreviations, e.g., the USA
or the UK. The type of formats used by the business
registries must be specified by the user to the tool,
which then will handle them.
Address-Specific Processing. If not collected prop-
erly, street addresses are, by nature, messy, with mul-
tiple formats allowed and much information being
usually omitted or abbreviated. Furthermore, differ-
ent jurisdictions can have very different address sys-
tems, adding complexity to treating such attributes
as country-specific processing needs to be applied.
While the entity name and the country attribute are
well-defined and unambiguous attributes, in terms of
their content, the same does not apply to the address
attribute. Conceptually, an address can usually be
made of multiple components, namely, road name,
house number, city, and country.
5
The pattern dictionary we created is integrated into the
tool and available in the same repo as a CSV file
DATA 2024 - 13th International Conference on Data Science, Technology and Applications
262

Figure 2: Mapping table, connecting primary keys, i.e., IDs,
of the initial business registries.
First, as for the rest of the character attributes, the
standard pre-processing is applied. Then, our tool
implements a standardization strategy of addresses.
Given the high instability of this attribute, we ap-
ply a set of heuristics that re-order the content of the
address attribute: all integers are moved at the start
of the string, followed by characters, with whites-
paces deleted. Such standardization might lead, in
some cases, to apparently mixing different parts of
the string. For instance, let’s suppose we have the
street address: ”1st July Road, 25, Manchester”, with
25 being the corresponding house number. Our stan-
dardization strategy would convert the street address
as: 125STJULYROADMANCHESTER, with the house
number being mixed with the road name. However,
such transformation provides more consistency in the
join, as it normalizes all addresses and helps minimize
the distance between two strings. Finally, an abbrevi-
ation dictionary is applied, and country names are re-
moved from the address. The abbreviation dictionary
for the address is also available and has been con-
structed using the technique outlined in Algorithm 1.
Alternative Address Attributes. In some cases, ad-
dresses might be parsed into multiple attributes. In
our tool, we support cases where postal codes and
cities are stored in dedicated attributes and specific
pre-processing methodologies are envisioned. For in-
stance, we use the information in these fields to re-
move the redundancy in the address attribute.
3.3 Matching Records
Once processed and cleaned, the target business reg-
istries, D
1
and D
2
can be joined to create a mapping
table B, as in Figure 2. The mapping table is a three-
column table, with the identifiers of the two business
registries, i.e., the primary keys, as the first two at-
tributes. The third attribute of the table is a similarity
score, which is computed by the tool and provides a
confidence degree of the pair match.
Linking Business Registries. The join over the busi-
ness registries is performed by applying a set y of con-
ditions, which the user can control. Such conditions
are restricted to a set of minimal requirements that we
consider the baseline for obtaining an acceptable level
of record-matching precision. In particular, we re-
quire that at least the name and country attributes are
available between the business registries, which can
also be considered an essential requirement for the
business registry itself and, therefore, almost always
satisfied. In the join, we require the equality of such
attributes, and we set the country attribute as the de-
fault blocking rule, which creates blocks for records
that share the same country and reduces the number
of comparisons. In addition, the following conditions
can be added:
1. String similarity or equality on the address. We
will use the Levehnstein distance as our string
similarity algorithm, but any other algorithms can
be easily implemented. Users can arbitrarily
choose and parameterize the distance level.
2. Equality on postal code information.
3. Equality on cities’ names.
4. Equality on other custom attributes, for which no
pre-processing is implemented.
The tool supports any combination of the above con-
ditions. BeRTo doesn’t allow users to choose to ap-
ply string similarity over the entities’ legal names, as
we empirically observed far too many incorrect re-
sults while testing it.
Similarity Score. For each match found, we compute
a similarity score, regardless of the conditions set by
users. This is computed based on the concept of string
similarity, i.e., the number of edit operations needed
to transform a string into another one (Wandelt et al.,
2014). Anyone interacting with the mapping table can
use such a score to filter inaccurate matches further,
after the mapping table has been built. In other words,
our similarity score accounts for possibly harmful
fuzzy transformations applied to strings. The score is
obtained by a mean over the ratio of differences found
per attribute used in the join, considering only basic
string pre-processing techniques such as accent con-
version. Formally, the similarity score for an entity e
is computed as:
S
e
=
1
N
N
∑
k=1
Levenshtein(k
1
, k
2
)
len(k
1
) + len(k
2
)
(1)
where N is the number of attributes used in the join,
while k
1
and k
2
denote the same string attribute in D
1
and D
2
for the same entity e, respectively.
Precision-Recall Trade-Off. The available attributes
and the join conditions, chosen by users, influence
BeRTo: An Efficient Spark-Based Tool for Linking Business Registries in Big Data Environments
263
the results and the position over the precision-recall
trade-off. With precision, we indicate the case in
which we minimize the number of potential mistakes
in the record linkage at the cost of discarding good-
but-not-perfect matches, which might include true
matches. With recall, we indicate the opposite case,
in which likely matches are included in the result. For
instance, the latter case might be chosen by users who
are performing aggregate and non-critical analysis in
which wrong matches contribution is mitigated by the
overall accuracy of the system. The maximum preci-
sion is reached by requiring equality over all attributes
available and by disabling the use of the name dictio-
naries containing the fuzzy pattern rules, discussed in
Section 3.2. The maximum recall is reached by run-
ning the name-country-only version of the tool. In the
middle, all potential combinations of attributes and
string similarity thresholds allow us to adapt the tool
to more balanced trade-offs.
3.4 System Implementation
BeRTo has been implemented in PySpark (Drabas
and Lee, 2017), an open-source Apache Spark Python
API that facilitates the development of large-scale,
distributed data processing applications and leverages
Hadoop as its technological framework. PySpark
comines the strengths of the Python programming
language with resilient distributed dataset (RDD) ab-
straction, to enable parallel data processing, making it
well-suited for tasks such as record linkage. Hadoop,
with its distributed file system (HDFS) and MapRe-
duce programming model, provides a robust infras-
tructure for storing and processing large volumes of
data across clusters of commodity hardware.
4 EXPERIMENTAL EVALUATION
In this section we first present our data sources and
our environment settings, then we present our ex-
periments and results, assessing our entity-matching
tool. We aim to demonstrate the effectiveness of our
tool, in terms of precision and recall, in the entity
matching task, by running it over a controlled sce-
nario in which common identifiers are available and
we discuss how parameters can be chosen according
to the desired positioning in the precision-recall trade-
off. Then, we evaluate the scalability of our solution.
We will benchmark with two state-of-the-art general-
purpose record linkage open-source tools, Dedupe.io
and Splink, and show how BeRTo behaves under dif-
ferent configurations.
Environment and Settings. The experiments were
conducted on a dedicated server running Ubuntu
18.04.5 LTS with a 48-core Intel Xeon Gold 5118
CPU, 376GB of RAM, and 781 GB of swap parti-
tion. The server hosted both Apache Hadoop 3.3.6
and Apache Spark 3.5.0. Hadoop has been configured
to run on a single node cluster in pseudo-distributed
mode, while Spark has been deployed in cluster mode
with its standalone cluster manager. Spark’s config-
uration included dynamic allocation with 4 executor
cores and 20GB of executor memory, and 16GB of
driver’s memory.
4.1 Data Sources
To guarantee the complete reproducibility of our re-
sults, we will use only public and openly available
data sources, which we detail in Table 1.
Table 1: Data sources used in our experiments.
Dataset Entities
Available
Attributes
Source
ECB List 110k
Name, Addr.,
City, Postcode,
Country
European
Central
Bank
GLEIF 2.5M
Name, Addr.,
City, Postcode,
Country
Financial
Stability
Board
National
Registries
10M
Name, Addr.,
Country
Individual
Countries
The first data source we use is a list of finan-
cial institutions based in the European Union, main-
tained by the European Central Bank (ECB) and pub-
licly available.
6
It includes monetary financial insti-
tutions, investment funds, financial vehicle corpora-
tions, payment statistics relevant institutions, insur-
ance corporations and pension funds, for a total num-
ber of around 110k entities, identified by the so-called
RIAD code.
7
The Global LEI Index (GLEIF) is a global on-
line source for open, standardized and high-quality
legal entity reference data.
8
The Legal Entity Identi-
fier (LEI) is a 20-character, alpha-numeric code based
on the ISO 17442 standard developed by the Interna-
tional Organization for Standardization (ISO). It con-
nects to key reference information, enabling clear and
unique identification of legal entities participating in
financial transactions. It also includes information
about the names and addresses of entities. In addi-
tion, the LEI number is also available in the data that
6
ECB Data: https://bitly.ws/3b3uQ
7
Guideline (EU) 2017/2335 of the European Central
Bank of 23 November 2017
8
GLEIF Data: https://www.gleif.org/en
DATA 2024 - 13th International Conference on Data Science, Technology and Applications
264

the ECB collects, thus enabling a precision and recall
analysis of the entity matching between these two data
sources. Finally, we collected national business reg-
istry data from individual countries’ statistical offices,
which make them available open-licensed, namely the
UK, some USA states, Romania, Latvia and India,
for a total of 10M entities. Here, only names and ad-
dresses were available across the data sources. There-
fore, it is a big data source to demonstrate only BeRTo
scalability, given the absence of a shared identifier
with other datasets that would enable precision anal-
ysis. All collected data have been stored in parquet.
4.2 Experiments and Results
To assess the precision and recall abilities of BeRTo,
we leverage the ECB List and GLEIF datasets, with
the LEI being the golden truth. For evaluating
scalability and computational performances, we test
BeRTo under different settings and configurations that
users might choose, as outlined in Section 3.3. Fur-
thermore, we also adopt a resampling approach to in-
crease the size of our datasets, simulating real com-
pany datasets such as Orbis’ and OpenCorporates’
ones, and demonstrating the scalability of BeRTo.
4.2.1 Precision and Recall
We compute precision and recall by adapting their
definition to the specific problem, as in (Wang et al.,
2011) . In particular, we consider true positives (TP)
as the correct pairs of entities that have been linked,
by comparing them with our golden truth benchmark,
obtained by joining the ECB List with GLEIF via
LEI. The official mapping comprises 61k companies,
which we can consider as the total number of com-
panies available in both datasets. In other words,
it represents the denominator of the recall. Preci-
sion is instead computed by dividing the TPs by the
total number of tuples linked by the tool, exclud-
ing additional matches, i.e., RIAD-LEI pairs that are
completely new and can be used to enrich the ECB
List dataset. The presence of additional matches,
for which we could not say anything about correct-
ness, is a natural consequence of dealing with real
data. In fact, while LEI is the official foreign key be-
tween the two datasets, LEIs might still be missing
in real-world contexts. We run four configurations
of BeRTo to demonstrate its abilities over different
settings: recall-focus (R), balanced-recall (BR), bal-
anced precision (BP) and precision-focus (P), as dis-
cussed in Section 3.3. Additionally, we run Dedupe
by manually tuning it for this domain, and Splink, re-
quiring an exact match on cities and countries, and
levensthein similarity on addresses with a blocking
Table 2: Precision and Recall of BeRTo, Dedupe and
Splink. Last column indicates additional matches with re-
spect to the golden truth.
Tool Recall Precision
Additional
Matches
BeRTo-R 0.67 0.94 12k
BeRTo-BR 0.63 0.96 4k
BeRTo-BP 0.48 0.97 3k
BeRTo-P 0.37 0.99 2k
Dedupe 0.66 0.78 18k
Splink 0.32 0.97 4k
rule on names.
9
The results are presented in Table 2. BeRTo
achieves a very high precision in all its configurations,
outperforming Dedupe’s precision in all cases and
also maximising recall in the case of BeRTo-R config-
uration. Overall, the recall obtained by all tools is not
too high. This is mostly due to the fact that our experi-
ments are conducted over real data, in which attributes
might be missing or incorrect, and cleaning efforts in
such cases are irrelevant. Additional matches found
are higher for Dedupe, but considering its lower pre-
cision, it’s questionable whether all of these are true
new matches. Regarding BeRTo’s configurations, we
assist in wide drops of recall performance when mov-
ing to more precision-focused settings. We consider
this a natural behavior of any precision-recall trade-
off. BeRTo also returns a similarity score for each ID
pair found, as described in Section 3.3. The average
similarity scores in these experiments have been 0.85
for BeRTo-R, 0.89 for BeRTo-BR, 0.90 for BeRTo-
BP and 0.97 BeRTo-P.
Computational Performances. We then tested
BeRTo on its scalability performances. To this aim,
we first present the average running times (over five
runs) for the experiments conducted in the previous
section in Figure 3. Execution times have been com-
puted on the actual running time of the tools, i.e., not
considering the dataset loading time and, for Dedupe,
excluding the required active learning labeling task.
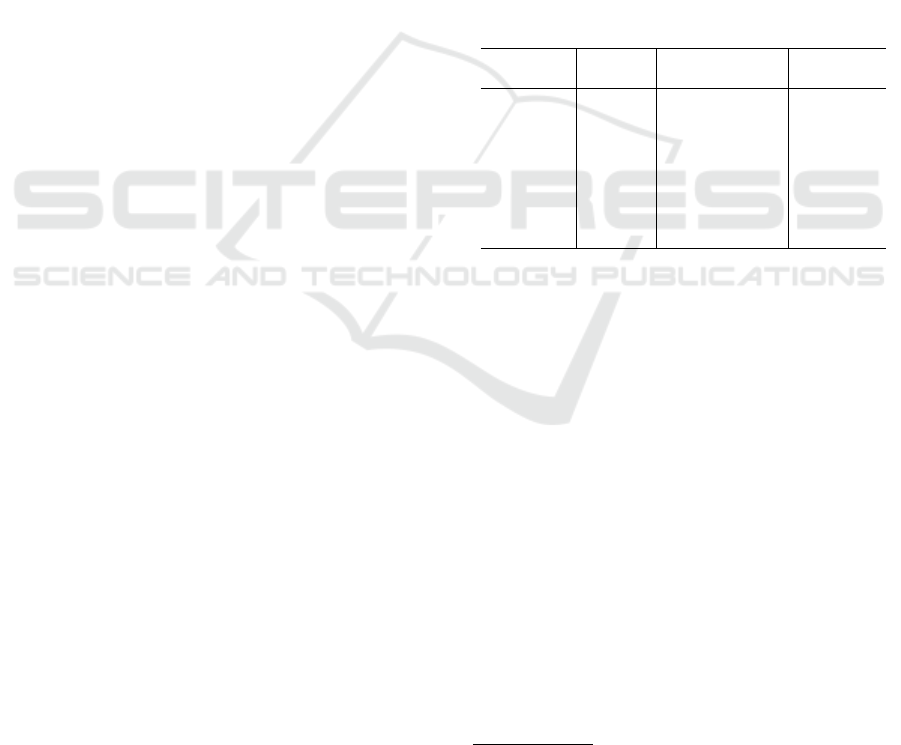
In this experiment, BeRTo is nearly as efficient as
Splink in the record linkage task. However, we had to
set up Splink with a blocking rule on names whose re-
call is much lower than BeRTo’s. Under other block-
ing rules, for instance, by blocking on countries as
our tool, we experienced out-of-memory Spark errors,
which highlights its much higher computational costs
since we conducted the experiment under the same
Spark configuration of BeRTo. Dedupe lags far be-
hind, with its execution time being more than eight
times higher than both BeRTo’s and Splink’s ones.
Although a Spark implementation of Dedupe would
9
Testing other blocking rule combinations, we experi-
enced worse precision-recall performances
BeRTo: An Efficient Spark-Based Tool for Linking Business Registries in Big Data Environments
265
Running Time (Seconds)
BeRTo-R
BeRTo-BR
BeRTo-BP
BeRTo-P
Dedupe
Splink
0 200 400 600 800 1000 1200 1400 1600
Figure 3: Average running times over five runs in the ECB
List-GLEIF record linkage experiment.
Input Records (Millions)
Running Time (Hours)
0
5
10
15
20
50 100 150 200
BeRTo-R
BeRTo-BR
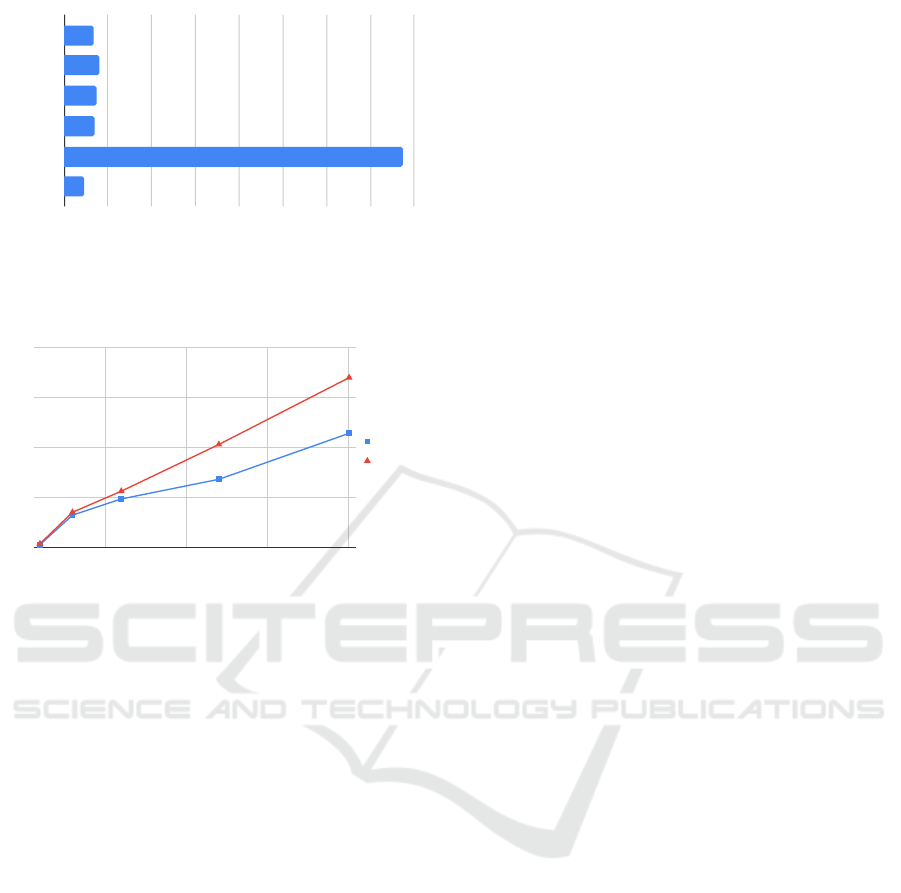
Figure 4: Running time results of merging the GLEIF and
National Registries datasets. Input records refer to the to-
tal number of legal entities summing the two data sources.
We increased the input dataset sizes via resampling with re-
placement, maintaining the original relative proportions.
surely recover speed, we recall its much lower preci-
sion when compared to BeRTo and the need for active
learning from users.
Then, we tested the execution times of BeRTo in
a big data setting, i.e., linking the GLEIF and Na-
tional Registries datasets. As mentioned, nothing
can be said about precision and recall for this sce-
nario. Therefore, we limit to observe the results in
terms of the running times of the tool. As BeRTo-
BP and BeRTo-P configurations require the presence
of additional address’ attributes, namely cities and
postcodes, we can run only BeRTo-R and BeRTo-BR
configurations, as the National Registries data source
only contains a generic attribute of addresses. In this
experiment, we also adopted an incremental resam-
pling approach of the data sources, reaching similar
sizes of the largest worldwide data sources of legal
entity data, e.g., Orbis and OpenCorporates. Results
are presented in Figure 4. Both tested configurations
display a sub-linear increase in running time, mak-
ing the tool is well-suited for industrial deployments
in a big-data context, where regular updates and runs
are required. As expected, BeRTo-R demonstrates a
shorter running time, due to fewer attributes involved
in the join operation. However, we recall the superior
precision of BeRTo-BR, which justifies the observed
difference in running time.
4.3 Discussion and Limitations
While obtaining an overall good trade-off in the ex-
periments, demonstrating better overall performances
compared to state-of-the-art tools we analyzed, we
acknowledge that few reliable and open-data repos-
itories of company information, especially the ones
containing the golden truth, i.e., shared identities, are
available. Therefore, we can’t guarantee the same
level of accuracy across all business registry repos-
itories. In addition, we recognize that our solution
might be European-biased since it has been mostly
trained on data from European countries. However,
BeRTo’s open-source nature allows the community to
contribute to optimization, for instance, by using the
fuzzy system to enrich the dictionary of patterns with
repository-specific characteristics.
Regarding our benchmarks, we report how both
Dedupe and Splink require a significant effort to be
set up, either for performing active learning, such as
in the case of Dedupe, or to find the complex set of
setting combinations to adapt the tool to the problem
at hand, a particularly relevant and time-consuming
activity. BeRTo, instead, offers a pre-defined and
flexible set of possible configurations and choices,
achieving a more user-friendly setup. While it is not
general-purpose as Dedupe or Splink, we think that
similar solutions can be easily implemented by repli-
cating the same components of our tool in other re-
curring and relevant record linkage activities, such
as linking persons or financial transactions, to ob-
tain domain-aware tools that are user-friendly and less
time consuming, with users only tasked to choose
their preferred recall-precision configuration.
5 CONCLUSIONS
We presented BeRTo, an open-source end-to-end
record linkage tool that exhibits high precision and
scalability. By being domain-specific, our tool can
integrate pre-processing, data cleaning components,
and fuzzy-based rules that allow it to achieve similar
or higher precision-recall results to general-purpose
and machine learning-based record linkage tools, but
with the advantages of being user-friendly and scal-
able, thus fully adaptable to big data and fast-paced
environments, in which record linkage activities are
performed daily. Furthermore, it doesn’t require a
golden truth to be tuned on, but, if available, can be
DATA 2024 - 13th International Conference on Data Science, Technology and Applications
266

used as an additional resource to improve the final re-
sults.We have also developed a plain Python version
of BeRTo for smaller record linkage tasks, which we
have also made available in our repository. While not
scalable, it can be used for small data business reg-
istry record linkage. For future work, we will work on
a graphical user interface for BeRTo, unlocking even
more user-friendly uses of our tool.
ACKNOWLEDGEMENTS
Andrea Colombo kindly acknowledges INPS for
funding his Ph.D. program.
REFERENCES
Arief, R., Achmad, B. M., Tubagus, M. K., and Husti-
nawaty (2018). Automated extraction of large scale
scanned document images using google vision ocr in
apache hadoop environment. International Journal of
Advanced Computer Science and Applications, 9(11).
Bajgar, M., Berlingieri, G., Calligaris, S., Criscuolo, C., and
Timmis, J. (2020). Coverage and representativeness of
orbis data. OECD Library.
Bilenko, M., Kamath, B., and Mooney, R. J. (2006). Adap-
tive blocking: Learning to scale up record linkage.
In Sixth International Conference on Data Mining
(ICDM’06), pages 87–96. IEEE.
Chen, X., Schallehn, E., and Saake, G. (2018). Cloud-scale
entity resolution: current state and open challenges.
Open Journal of Big Data (OJBD), 4(1):30–51.
Christen, P. (2012). The data matching process. Springer.
Christophides, V. e. a. (2020). An overview of end-to-end
entity resolution for big data. ACM Comput. Surv.,
53(6).
Dong, X. L. and Srivastava, D. (2013). Big data integration.
In 2013 IEEE 29th International Conference on Data
Engineering (ICDE), pages 1245–1248.
Drabas, T. and Lee, D. (2017). Learning PySpark. Packt
Publishing Ltd.
Ebraheem, M., Thirumuruganathan, S., Joty, S., Ouzzani,
M., and Tang, N. (2018). Distributed representations
of tuples for entity resolution. Proc. VLDB Endow.,
11(11):1454–1467.
Elmagarmid, A. K., Ipeirotis, P. G., and Verykios, V. S.
(2007). Duplicate record detection: A survey. IEEE
Transactions on Knowledge and Data Engineering,
19(1):1–16.
Eurostat (2024). Statistical business registers. https://ec.
europa.eu/eurostat/web/statistical-business-registers/
information-data Accessed: 01/2024.
Forest, G. and Eder, D. (2015). Dedupe. https://github.com/
dedupeio/dedupe. [Accessed January-2024].
Gagliardelli, L., Simonini, G., Beneventano, D., Berga-
maschi, S., et al. (2019). Sparker: Scaling en-
tity resolution in spark. In Advances in Database
Technology-EDBT 2019, 22nd International Confer-
ence on Extending Database Technology, Lisbon, Por-
tugal, March 26-29, Proceedings. PRT.
Getoor, L. and Machanavajjhala, A. (2012). Entity resolu-
tion: Theory, practice & open challenges. Proc. VLDB
Endow., 5(12).
Guralnick, R. P. e. a. (2015). Community next steps for
making globally unique identifiers work for biocollec-
tions data. ZooKeys, (494):133.
Herzog, T. N., Scheuren, F. J., and Winkler, W. E.
(2007). Data Quality and Record Linkage Techniques.
Springer Publishing, 1st edition.
Kolb, L., Thor, A., and Rahm, E. (2012a). Dedoop: Effi-
cient deduplication with hadoop. Proc. VLDB Endow.,
5(12):1878–1881.
Kolb, L., Thor, A., and Rahm, E. (2012b). Load balancing
for mapreduce-based entity resolution. In 2012 IEEE
28th International Conference on Data Engineering,
pages 618–629.
Konda, P., Das, S., C., P. S. G., Doan, A., Ardalan, A., Bal-
lard, J. R., Li, H., Panahi, F., Zhang, H., Naughton, J.,
Prasad, S., Krishnan, G., Deep, R., and Raghavendra,
V. (2016). Magellan: Toward building entity matching
management systems over data science stacks. Proc.
VLDB Endow., 9(13):1581–1584.
Koudas, N., Sarawagi, S., and Srivastava, D. (2006). Record
linkage: Similarity measures and algorithms. In Pro-
ceedings of the 2006 ACM SIGMOD International
Conference, SIGMOD ’06, page 802–803. Associa-
tion for Computing Machinery.
Krishnan, S., Haas, D., Franklin, M. J., and Wu, E.
(2016). Towards reliable interactive data cleaning: a
user survey and recommendations. In Proceedings of
the Workshop on Human-In-the-Loop Data Analytics,
HILDA ’16. ACM.
Li, Y., Li, J., Suhara, Y., Doan, A., and Tan, W.-C. (2020).
Deep entity matching with pre-trained language mod-
els. Proceedings of the VLDB Endowment, 14.
Linacre, R., Lindsay, S., Manassis, T., Slade, Z., Hepworth,
T., Kennedy, R., and Bond, A. (2022). Splink: Free
software for probabilistic record linkage at scale. In-
ternational Journal of Population Data Science, 7(3).
Nentwig, M. and Rahm, E. (2018). Incremental cluster-
ing on linked data. In 2018 IEEE International Con-
ference on Data Mining Workshops (ICDMW), pages
531–538. IEEE.
Ryan, L., Thompson, C., and Jones, J. (2020). A sta-
tistical business register spine as a new approach to
support data integration and firm-level data linking:
An abs perspective. Statistical Journal of the IAOS,
36(3):767–774.
Salloum, S., Dautov, R., Chen, X., Peng, P. X., and Huang,
J. Z. (2016). Big data analytics on apache spark. In-
ternational Journal of Data Science and Analytics,
1:145–164.
Shaikh, E., Mohiuddin, I., Alufaisan, Y., and Nahvi, I.
(2019). Apache spark: A big data processing en-
BeRTo: An Efficient Spark-Based Tool for Linking Business Registries in Big Data Environments
267

gine. In 2019 2nd IEEE Middle East and North Africa
COMMunications Conference (MENACOMM).
Wandelt, S., Deng, D., Gerdjikov, S., Mishra, S., Mitankin,
P., Patil, M., Siragusa, E., Tiskin, A., Wang, W., Wang,
J., and Leser, U. (2014). State-of-the-art in string sim-
ilarity search and join. SIGMOD Rec., 43(1):64–76.
Wang, J., Li, G., Yu, J. X., and Feng, J. (2011). Entity
matching: how similar is similar. Proc. VLDB Endow.,
4(10):622–633.
Wang, J., Li, Y., and Hirota, W. (2021). Machamp: A
generalized entity matching benchmark. In Proceed-
ings of the 30th ACM International Conference on
Information & Knowledge Management, CIKM ’21,
page 4633–4642, New York, NY, USA. Association
for Computing Machinery.
Yan, Y., Meyles, S., Haghighi, A., and Suciu, D. (2020).
Entity matching in the wild: A consistent and versa-
tile framework to unify data in industrial applications.
Proceedings of the 2020 ACM SIGMOD International
Conference on Management of Data.
DATA 2024 - 13th International Conference on Data Science, Technology and Applications
268
