
MultiVD: A Transformer-based Multitask Approach for Software
Vulnerability Detection
Claudio Curto
1 a
, Daniela Giordano
1
, Simone Palazzo
1
and Daniel Gustav Indelicato
2
1
Dipartimento di Ingegneria Elettrica, Elettronica e Informatica (DIEEI), Universit
`
a degli Studi di Catania, Catania, Italia
2
EtnaHitech Scpa, Catania, Italia
Keywords:
Vulnerability Detection, Machine Learning, Deep Learning, Transformer.
Abstract:
Research in software vulnerability detection has grown exponentially and a great number of vulnerability
detection systems have been proposed. Recently, researchers have started considering machine learning and
deep learning-based approaches. Various techniques, models and approaches with state of the art performance
have been proposed for vulnerability detection, with some of these performing line-level localization of the
vulnerabilities in the source code. However, the majority of these approaches suffers from several limitations,
caused mainly by the use of synthetic data and by the inability to categorize the vulnerabilities detected.
Our study propose a method to overcome these limitations, exploring the effects of different transformer-
based approaches to extend the models capabilities while enhancing the vulnerability detection performance.
Finally, we propose a transformer-based multitask model trained on real world data for highly reliable results
in vulnerability detection, CWE categorization and line-level detection.
1 INTRODUCTION
In the last decade, research about the application of
machine learning technologies in vulnerability de-
tection in information systems has grown signifi-
cantly, revolutionizing the way cybersecurity experts
identify and mitigate potential threats. Leveraging
the most advanced machine learning algorithm, re-
searchers proposed various tools, methodologies and
techniques (Rahman and Izurieta, 2022) to help de-
velopers to avoid and correct vulnerabilities in their
software that could compromise the integrity of the
software itself. One of these methodologies is the
Static Application Security Testing (SAST), or static
analysis. It is a testing methodology that analyzes
source code to find security vulnerabilities that make
an application susceptible to attack. SAST scans
the application before the code is compiled and it is
also known as white box testing. Given the sequen-
tial nature of programming languages, Natural Lan-
guage Processing (NLP) approaches have achieved
great results in source code analysis (Singh et al.,
2022), leveraging LSTM (Long Short-Term Memory)
architectures (Fang et al., 2018), GNN (Graph Neu-
ral Network) (Zhou et al., 2019), (Li et al., 2021)
a
https://orcid.org/0009-0006-6516-7671
and, most recently, transformers architectures (Fu
and Tantithamthavorn, 2022), (Mamede et al., 2022),
(Hin et al., 2022). Specifically, transformer-based ap-
proaches emerged as state-of-the-art in vulnerability
prediction tasks, both on function-level and line-level
vulnerability prediction (Fu and Tantithamthavorn,
2022), (Hin et al., 2022). However, there are vari-
ous open challenges in this field, as the classification
of the predicted vulnerability and the model’s gener-
alization capability over different projects (Kaloupt-
soglou et al., 2023), (Chen et al., 2023).
To date, multiclass vulnerability classification has
not been fully explored, due to the lack of adequately
varied and quality datasets. In 2021 Zou et al. (Zou
et al., 2021) proposed the first multiclass vulnerabil-
ity classifier, namely µVulDeePecker. However, their
system suffers of two limitations: it is unable to lo-
cate the vulnerability in the code and it is trained
on a synthetic dataset. The datasets nature is a cru-
cial aspect to consider, as a model trained on a syn-
thetic dataset will be limited to detecting only the
simple patterns present in the data, which seldom
occur in real life (Chakraborty et al., 2022). In
contrast, real-world datasets are derived from real-
world sources and generally only contain functions
that went through vulnerability-fix commits. In this
case the model will be able to learn real and more
416
Curto, C., Giordano, D., Palazzo, S. and Indelicato, D.
MultiVD: A Transformer-based Multitask Approach for Software Vulnerability Detection.
DOI: 10.5220/0012719400003767
Paper published under CC license (CC BY-NC-ND 4.0)
In Proceedings of the 21st International Conference on Security and Cryptography (SECRYPT 2024), pages 416-423
ISBN: 978-989-758-709-2; ISSN: 2184-7711
Proceedings Copyright © 2024 by SCITEPRESS – Science and Technology Publications, Lda.

complex patterns.
In this study we explore two possible classification
approaches: multiclass and multitask classification.
We do this first by fine tuning the CodeBERT(Feng
et al., 2020) architecture to perform a multiclass clas-
sification of the known vulnerabilities, to explore the
model vulnerability pattern recognition capabilities;
second, by improving the original approach with the
addition of two classification heads to the model, per-
forming simultaneously a binary classification task
for vulnerability detection and a multiclass classifica-
tion task for vulnerability categorization. The idea is
to leverage the multitask approach to provide a more
informative result from the model, while, at the same
time, enhance the model performance both on the de-
tection and classification fields. Finally, we compare
the attention-based line-level detection performance
between LineVul and our multitask model to show the
effects of the new approach to the original task. In the
last step of our study, we explore if it is possible to
improve the final results of the multitask model by a
different handling of the loss functions.
2 BACKGROUND AND RELATED
WORKS
2.1 Software Vulnerability Assessment
A software security test consists in a validation pro-
cess of a system or application with respect to cer-
tain criteria. There are several approaches to test the
vulnerability of a software; these approaches can be
categorized in three groups:
• Static analysis: the vulnerability assessment is
performed directly on the application’s source
code, usually before its deployment. This form of
testing can be performed using pattern recognition
techniques or, in a machine learning scenario, by
NLP-based techniques (LSTM, GNN, transform-
ers).
• Dynamic analysis: the assessment is performed
on the running application, monitoring its be-
haviour. Generally called “penetration testing”,
the focus of the test is to validate the application
behaviour following some specific inputs given by
the user.
• Hybrid analysis: a hybrid approach takes advan-
tage of strengths and limitations of static and dy-
namic approaches.
Ghaffarian et al. (Ghaffarian and Shahriari, 2017)
identified four classes of methodologies applied in
vulnerability assessment:
• Anomaly detection approaches
• Vulnerable code pattern recognition
• Software metrics based approaches
• Miscellaneous approaches
Vulnerable code pattern recognition is the one ex-
plored in this study.
2.2 Common Weakness Enumerations
(CWE)
Every year the number of possible vulnerabilities that
could affect an information system grows exponen-
tially. It has become necessary to keep track of the
new vulnerabilities discovered day after day, to make
it possible for developers to prevent exposures to their
systems. MITRE plays a prominent role in develop-
ing and maintaining numerous resources and frame-
works to improve security practices. MITRE Com-
mon Weakness Enumeration (CWE) is a community-
developed list of common software security weak-
nesses. It represents a baseline for weaknesses identi-
fication and prevention, providing a hierarchical tax-
onomy of software weaknesses that can lead to one
or more security vulnerabilities. According with the
most recent MITRE CWE List (MITRE, 2023), the
total number of registered Weakness is 934.
2.3 BERT and BERT-Based
Architectures
Bidirectional Encoder Representation from Trans-
formers (BERT) has been introduced by Devlin et
al. in 2018 (Devlin et al., 2019) and has achieved
remarkable results across a wide range of NLP task
(e.g., question answering, sentiment analysis, text
classification and more). Different variants of BERT
have been released, including models for specific do-
mains or models with improved performances like
CodeBERT (Feng et al., 2020) to handle program-
ming languages, understanding source-code data and
programming related tasks. It is pre-trained with a
20 GB source code corpus with bimodal instances
of NL-PL (Natural Language - Programming Lan-
guage) pairs, unimodal codes (not paired with natu-
ral language texts) and natural language texts with-
out paired codes (2.1M bimodal datapoints and 6.4M
unimodal codes across the programming languages
Python, Java, JavaScript, PHP, Ruby, Go). Code-
BERT has been pre-trained on two tasks: Masked
Language Modelling (MLM) and Replaced Token
Detection (RTD).
MultiVD: A Transformer-based Multitask Approach for Software Vulnerability Detection
417

2.4 Models for Vulnerability Detection
Zou et al. (Zou et al., 2021) presented
µVulDeePecker, the first deep learning-based
system for multiclass vulnerability detection. The
underlying system architecture is constructed from
Bidirectional Long-Short Time Memory (BLSTM)
networks and aims to fuse different kinds of features
from pieces of code (called code gadgets) and
code attention to accommodate different kinds of
information. For this purpose, the authors created
from scratch a dataset and used it to evaluate the
effectiveness of the model. The dataset contains
181,641 code gadgets, with 43,119 vulnerable units
and 40 types of vulnerabilities in total. The model
achieved high performance both when tested on their
own test set (94.22% F1) and on real world software
(94.69% F1). However, µVulDeePecker suffers of
some limitation: first, it can detect vulnerability
types, but cannot pin down the precise location of a
vulnerability in the code; second, the current design
and implementation focus on vulnerabilities that are
related to library/API function calls.
Fu et al. (Fu and Tantithamthavorn, 2022) in-
troduced LineVul, a transformer-based vulnerability
prediction system, achieving state-of-the-art perfor-
mance. LineVul addresses the limitations of the
graph-based neural networks when used in this task
(Li et al., 2021) and demonstrates the potentiality of
attention in vulnerability prediction at line-level. The
result is a line-level vulnerability prediction system
with high performance both on function-level detec-
tion and line-level detection tasks. LineVul strengths
can be found in its architecture. The model can be
seen as a composition of three component: Code-
BERT (Feng et al., 2020), Byte Pair Encoding (BPE)
Tokenizer and a single linear layer classifier. BPE is
a data compression algorithm, very popular in NLP
tasks for its high efficiency in building small vocabu-
laries for text tokenization. The strength of the algo-
rithm is its ability to handle rare or out-of-vocabulary
words, using a subword tokenization approach and
leading to a better generalization and coverage, es-
pecially in cases where the training data may have
limited vocabulary coverage. As demonstrated in the
paper, the combined use of the pretrained CodeBERT
model and Byte Pair Encoding is the key for the high
performances of the model: there is a 50% F1-score
reduction when using a word-level tokenization and a
11% reduction when using non-pretrained weights to
initialize BERT.
Mamede et al. (Mamede et al., 2022) explored
different BERT-based models’ performances (Code-
BERT (Feng et al., 2020) and JavaBERT (De Sousa
and Hasselbring, 2021)) for multi-label classification
of Java vulnerabilities, training them on the Juliet
synthetic dataset
1
. The studied models showed high
performance when tested on synthetic data and good
generalizability when tested on unknown vulnerabili-
ties, related with the kind of vulnerabilities which the
models have been trained on, leveraging their belong-
ing SFP (Software Fault Patterns) secondary clusters.
However, it is pointed out that using only synthetic
data is insufficient, since the models’ performance
severely degrade when facing real-world scenarios.
Indeed, all the studied models showed a great loss in
performance when tested with real-world data, with
a 50% and 58% reduction in F1-score and recall re-
spectively for JavaBERT, indicating that the model
can recognise vulnerable patterns but stumble in se-
lecting the type of vulnerability (CWE). Generally, it
has been observed that all the model suffer of an high
false negative rate when tested in realistic contexts.
3 METHODOLOGY
3.1 Classification
The adopted model architecture extends the struc-
ture defined by Fu et al.(Fu and Tantithamthavorn,
2022), consisting of three components: BPE tok-
enizer, CodeBERT and the linear classifier. The lin-
ear classifier has been updated for the multiclass and
the multitask implementation. For the multiclass ap-
proach it consists of a single linear layer with 15 out-
put neurons. For the multitask approach the classi-
fier is built with two classification heads, one for the
multiclass classification with 15 output neurons (one
for each CWE to classify) and the other for the binary
classification (vulnerability target). For both tasks, we
adopt Cross-entropy as loss function. When training
the multitask model, a weighted loss is computed as
loss
W
= α ∗ loss
M
+ β ∗loss
B
where loss
M
is the multiclass loss, loss
B
is the binary
loss, α and β are two arbitrary parameters that assume
values between 0 and 1, with 0 excluded.
3.2 Localization
For line-level vulnerability localization we use the ap-
proach by Fu et al. (Fu and Tantithamthavorn, 2022),
leveraging the attention scores assigned to the tokens
by the model. The idea of this approach is that high
attention tokens are likely to be vulnerable tokens, so
1
https://samate.nist.gov/SARD/test-suites/111
SECRYPT 2024 - 21st International Conference on Security and Cryptography
418

lines with higher attention score are the ones with
higher probability to contain the vulnerability. This
is done by obtaining the self-attention scores from the
trained model for every sub-word token and then in-
tegrate those scores into line scores. Specifically, a
whole function is split to in lists of tokens where every
list represent a line (the split is done by the newline
control character \n). Every token in a list will have
an associated cumulative attention score, so, for each
list of token scores, we summarize it into one atten-
tion line score and rank all the line scores. The rank-
ing of the lines based on the relative attention scores
will show the lines with higher probabilities to be the
location of the vulnerability. This approach is applied
considering the true positive outputs of the vulnerabil-
ity detection task, so in our case we take into account
binary predictions only.
3.3 Dataset
For a fair comparison with LineVul we use the same
benchmark dataset, provided by Fan et al. (Fan et al.,
2020), namely BigVul. BigVul is a large C/C++ vul-
nerability dataset, collected from open-source GitHub
projects. BigVul dataset is the only vulnerability
dataset that provides line-level ground-truth, neces-
sary to our study to compare line-level prediction per-
formance between the two models. All the functions
in the dataset are assigned a CWE ID describing a
vulnerability type, even the not vulnerable functions.
This is explained analyzing the way the methods are
gathered. The data collection procedure is structured
in three steps.
1. First, Fan et al. perform a scraping procedure of
the CVE database, collecting all the vulnerabili-
ties information until the 2019.
2. From all the entries collected, are collected the
ones with a github reference link pointing to a
code repository to retrieve the vulnerable projects.
For every project, the commit history is extracted.
3. Each retrieved commit from the history is con-
sidered as a mini version of its project, and ev-
ery mini version is mapped to the relative CVE
information retrieved in the first step. For each
of the commits explicitly considered as relevant,
they extracted the code changes that fixed the vul-
nerability; in this way, it was possible to build the
vulnerable code. All the other not relevant com-
mits were considered as not vulnerable.
So, different functions are gathered from the same
reference link, reporting both vulnerable and not vul-
nerable samples, all sharing the same CVE informa-
tion previously gathered. These functions, even if not
vulnerable, may share useful information to recog-
nize some hidden pattern typical of that CWE. From
this perspective, we want to explore the results of a
classification-based approach considering both vul-
nerable and not vulnerable samples for CWE classi-
fication.
To avoid possible inconsistencies between the
data, we obtained the dataset from the LineVul
GitHub repository
2
. The dataset in the repository is
available both in its split version (train, validation and
test split) and unsplit. We obtained the unsplit one,
that came with a total of 4.841.688 samples. How-
ever all these samples can’t be used as they present
inconsistent entries e.g. None/NaN values, missing
CVE labels or CWEs as pieces of string or code in-
stead the ID. We performed a cleaning procedure re-
moving all the samples where the CWE ID is not in
the format “CWE-number”, reducing their number to
146,625 functions, with 7,117 vulnerable functions.
Another important aspect of the dataset is its high
imbalance among all the different CWE IDs and be-
tween vulnerable and not vulnerable functions. This
is strictly related to the fact that some vulnerabilities
may occur less frequently than others. To get more
reliable results, we restricted the multiclass classifi-
cation to the top-15 CWE classes in terms of distri-
bution in the dataset. The selected classes are re-
ported in Figure 1. In the end, the final unbalanced
dataset used is composed by 126,313 functions, with
7,089 vulnerable ones. Considering the high imbal-
ance between vulnerable and not vulnerable samples,
we test the model performance by training it with two
variations of the dataset: unbalanced and balanced,
the latter obtained by undersampling the not vulner-
able occurrences. The resulting balanced dataset is
composed by 14,178 functions equally distributed be-
tween vulnerable and not vulnerable. For all tests, the
datasets are split into train, validation, and test sets
with 80/10/10 ratio, with validation and test sets strat-
ified to keep the same CWE ID class distribution as
the train set.
3.4 Evaluation Metrics
Accuracy, precision, recall and F1-score are com-
puted for training, validation, and testing phases. We
take note of the best F1-score on the validation set to
save the model checkpoint for testing. For the line-
level detection, Fu et al. adopt two metrics: Top-10
accuracy and Initial False Alarm (IFA). Top-10 accu-
racy measures, after producing for each function a top
10 ranking of the lines based on their cumulative at-
2
https://github.com/awsm-research/LineVul/tree/main/
data
MultiVD: A Transformer-based Multitask Approach for Software Vulnerability Detection
419
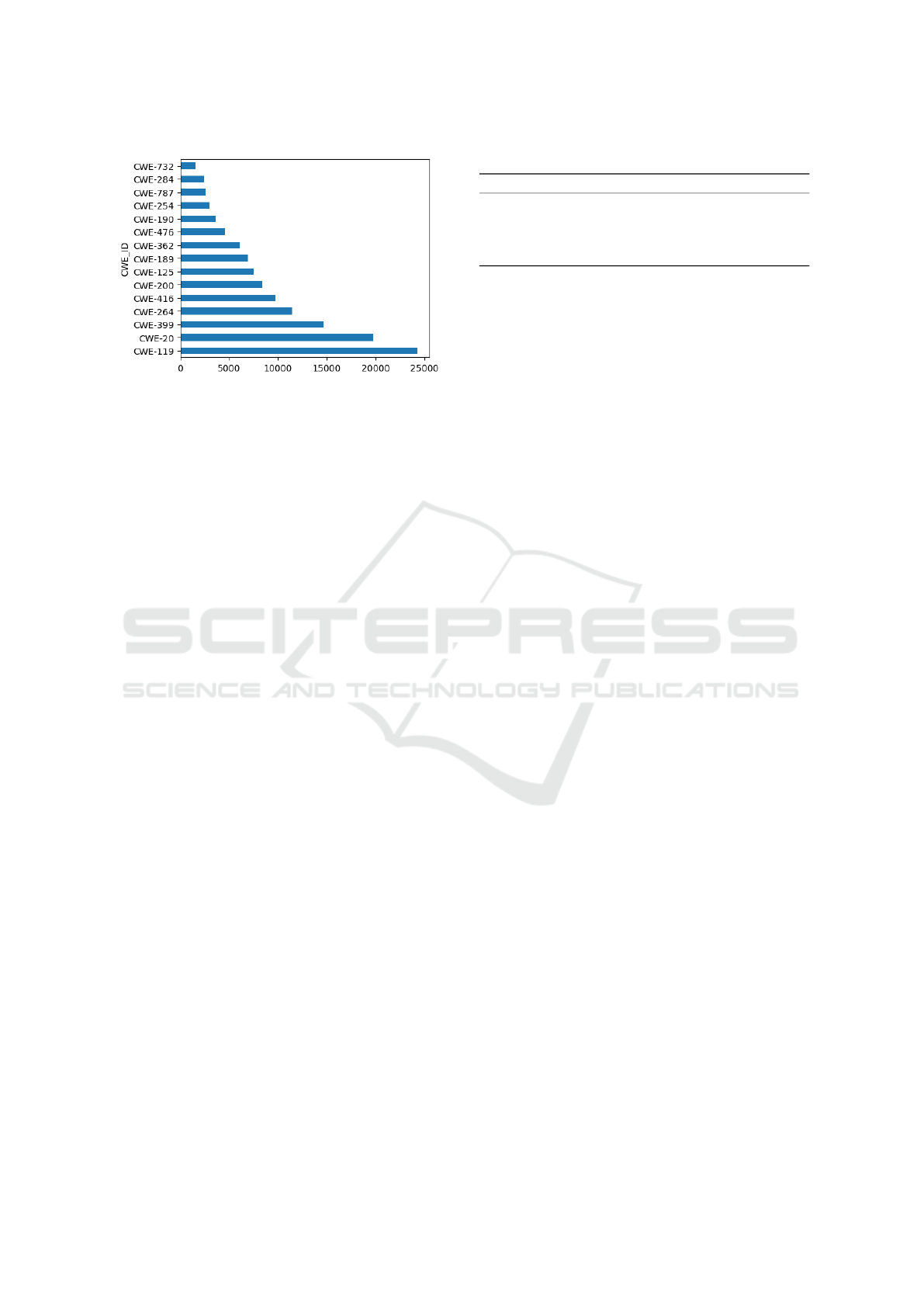
Figure 1: Top 15 CWEs in the dataset.
tention score, the percentage of these functions where
at least one actual vulnerable line appear in the rank-
ing. The idea behind this metric is that security an-
alysts may ignore line-level recommendations if they
do not appear in the top-10 ranking. Thus, a high top-
10 accuracy value if preferred. It is computed by it-
erating all the flaw line indices and verifying if the
current index is in the top-10 ranking. In this way
we determine if it is correctly localized and count it
accordingly. Initial False Alarm (IFA) measures the
number of lines predicted incorrectly as vulnerable
that security analysts need to inspect before finding
the vulnerable one, for a given function: a low IFA
value is preferred, as it indicates that security experts
will spend less time inspecting false alarms raised by
the system. Considering the top-10 line scores rank-
ing previously computed, IFA values are obtained by
looking the position of all the flaw lines in the rank-
ing and then considering the minimum (we consider
the first vulnerable line that appears in the ranking).
The idea is that if a flaw line is, for example, in the
5th position in the ranking, the security analyst will
have to inspect 5 clean lines before finding the flaw
one.
4 EXPERIMENTS SETTING
For the model implementation, the pre-trained Code-
BERT tokenizer and CodeBERT are downloaded
from the HuggingFace repository. For the multiclass
approach the linear classifier consists of a single lin-
ear layer with 15 output neurons; for the multitask ap-
proach the classifier is implemented to return a cou-
ple of outputs, one for multiclass classification and
the other for binary classification. The training is per-
formed on a NVIDIA RTX A6000 GPU. For the hy-
perparameter aspect, we leave the CodeBERT default
settings unchanged and choose 2 ∗ 10
−5
for the learn-
Table 1: Multiclass classification results.
% Accuracy Precision Recall F1
Multiclass (only vulnerable) 53.31 55.68 56.43 55.39
Multiclass (balanced) 70.87 68.06 69.18 68.15
Multiclass (unbalanced) 79.61 77.92 81.81 79.67
Multitask (balanced) 71.86 69.85 72.37 70.79
Multitask (unbalanced) 79.03 77.39 81.40 79.19
ing rate, with AdamW as the optimizer. The model is
trained for 10 epochs with cross-entropy as loss func-
tion for all the classifications. The multitask final loss
is first computed as an average of the two, while in
a second experiment we explore a different approach
with a weighted loss.
5 RESEARCH QUESTIONS
During the study we examine the following research
questions:
1. Which of the explored approaches has the best
performance?
2. What are the effects of the multitask approach in
vulnerability localization?
3. Does a weighted loss increase the model perfor-
mances instead of an average loss?
RQ1. Which of the Explored Approaches
Has the Best Performance?
During the training of the model, we take note of the
test metrics for each task (multiclass, binary and mul-
titask) and for two versions of the dataset, i.e. unbal-
anced and balanced, plus an additional test with only
vulnerable sample in the case of the multiclass clas-
sification. Finally, we compare the results with the
ones obtained with the multitask approach. These re-
sults are reported in Table 1 for all versions of the
datasets. The results show how the multiclass-only
classification model has the better performance when
trained on all the available data, with ∼34% higher
F1-score. In the same way, multitask classifier shows
∼10% higher performance, with a 79.19% F1 score in
the unbalanced data scenario. From these results we
may assume that the amount of available data plays
a key role in the vulnerability classification task and
that a greater amount of data is required to achieve
better results.
For the binary task, we compare the multitask
model with LineVul, retrained on both version of the
dataset. The results are shown in table 2. It is notice-
able, in the unbalanced scenario, that the proposed
model preserves the LineVul performance, with the
SECRYPT 2024 - 21st International Conference on Security and Cryptography
420
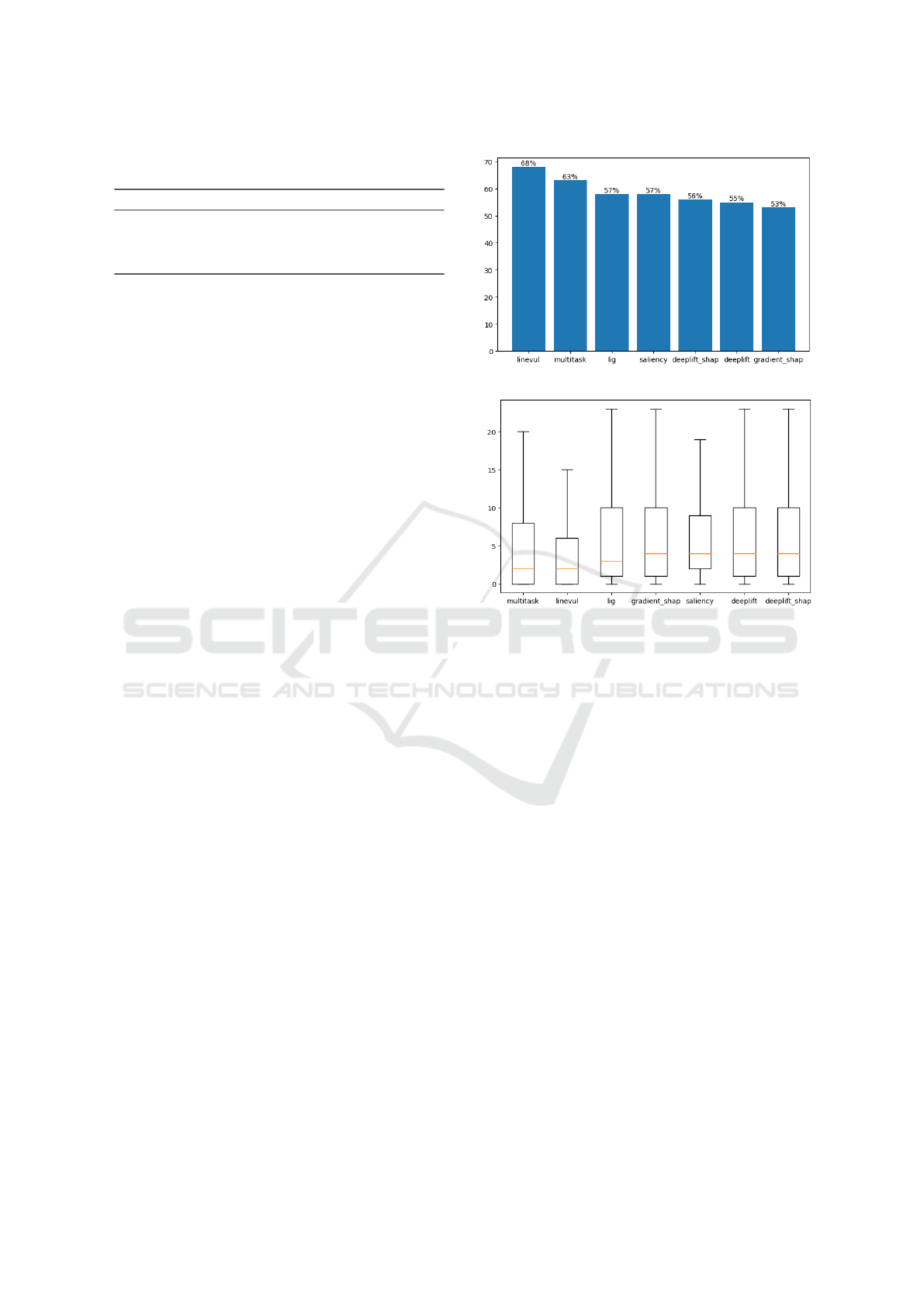
Table 2: Comparison between LineVul and multitask binary
classification.
% Accuracy Precision Recall F1
LineVul (balanced) 97.81 99.39 96.01 97.67
Multitask (balanced) 97.88 97.9 97.94 97.88
LineVul (unbalanced) 99.07 96.89 87.2 91.79
Multitask (unbalanced) 99.03 97.31 93.87 95.51
exception of a higher recall value. In this case, re-
call indicates the rate of function correctly classified
as vulnerable with respect of all vulnerable functions.
So, a higher recall value may indicate that the model
has gained a higher coverage of the vulnerable class.
The models trained on balanced data show the same
overall performance.
RQ2. What Are the Effects of the
Multitask Approach in Vulnerability
Localization?
For this RQ we leverage the attention-based approach
proposed by Fu et al., computing the attention scores
assigned to every line of code and evaluating them
to identify the ones that represent the causes of vul-
nerability. We evaluate the model performance in
line-level localization using the model agnostic tech-
niques introduced by Fu et al.: Layer Integrated Gra-
dient (LIG) (Sundararajan et al., 2017), Saliency (Si-
monyan et al., 2014), DeepLift (Ancona et al., 2018),
(Shrikumar et al., 2017), DeepLiftSHAP (Lundberg
and Lee, 2017), GradientSHAP (Lundberg and Lee,
2017). This choice is justified by the logic behind the
mechanism adopted for the line-level detection task,
that leverages model explainability concepts to iden-
tify the most relevant features in the prediction of the
functions vulnerability status (vulnerable or not vul-
nerable). The benefit from this approach is dual: it
shows the high transformers performance in a line
level task and the attention mechanism potential as a
model explainability tool.
Replicating the tests, the model registered a 63%
top10 Accuracy and an IFA value of 5.22 with median
2. Compared with LineVul our model has slightly
worse performance. This is explained by the task the
models are trained for. LineVul is trained exclusively
for vulnerability detection, so it assigns the higher at-
tention score to the tokens which better help it de-
tecting the vulnerability. Our model is trained instead
for vulnerability detection and vulnerability classifi-
cation, so it needs to assign the attention scores con-
sidering the tokens that help it classify the vulnerabil-
ity. Another aspect that affect the line-level results
is the true positive rate. Considering that only the
vulnerable functions have a flaw-line and flaw-line-
(a) Top-10 accuracy
(b) Initial False Alarm (IFA)
Figure 2: Top-10 accuracy and IFA distributions computed
with attention mechanism and model agnostic techniques
compared.
index in the dataset, the line-level evaluation is per-
formed only on the model’s true positive outputs. Re-
call values in RQ1 indicate that our model achieved
a higher true positive rate than LineVul, consisting
in a higher number of samples evaluated. Therefore,
this could be another possible cause of lower perfor-
mance. However, the results are still better than the
ones of the model agnostic explainability tools, as
shown in Figures 2a and 2b.
RQ3. Does a Weighted Loss Increase the
Model Performances Instead of an
Average Loss?
All the previous evaluations have been done comput-
ing the average loss between multiclass and binary
classification ones. With this RQ we want to study
a different approach to compute the loss of the model.
In this case, we run multiple experiments evaluating
how a weighted loss may have an impact on model
performance. Particularly, from the previous experi-
ments it has been observed that the multiclass task is
the one with the higher loss values when compared
MultiVD: A Transformer-based Multitask Approach for Software Vulnerability Detection
421

Figure 3: Binary loss (orange) and multiclass loss (blue)
computed during evaluation with unbalanced data.
with the binary one, as shown in Figure 3.
The binary loss assumes values between 0.07 and
0.05, while the multiclass one has a value of 1.86 at
epoch 0 and a value of 0.75 at epoch 9. From this ob-
servation, we decided to perform new tests with both
the datasets leveraging different weight values for the
multitask loss, keeping the value of 1.0 for the binary
one. The obtained results, however, do not show sig-
nificant performance improvements. Registered F1-
scores presents slightly different values when com-
pared with the ones obtained with the previous strat-
egy. Further tests are necessary to explore new poten-
tially ways to handle the high loss gap between our
tasks.
6 RESULTS AND DISCUSSION
From the performed studies we obtained the follow-
ing results:
1. The multitask approach outperforms the
multiclass-only one on the balanced dataset,
while the ones with unbalanced data share almost
the same performance. Both apporaches show the
best results when trained with an higher number
of samples, even if highly unbalanced;
2. The binary tasks show better performance when
trained on the balanced dataset. LineVul and our
model share similar results in vulnerability de-
tection at function-level; in the unbalanced data
scenario, the higher recall value indicates that the
multitask approach enhanced the true positive rate
relatively to the false negative rate, that results in
a lower number of vulnerable function predicted
as not-vulnerable.
3. Our model has higher line-level localization per-
formance when compared with the other bench-
mark techniques, but slightly worse than LineVul.
4. A weighted approach to loss functions handling
has near zero impact on the model’s performance.
As pointed out by this study, a critical aspect of re-
search in vulnerability classification is related in par-
ticular to the available data and some compromise
needed to be done:
1. The amount of registered vulnerable functions is
very limited, hence it is very difficult to get a big
and balanced dataset.
2. Some vulnerabilities occur less frequently than
others and there are few registered functions rep-
resentative of these categories. For this reason it
is difficult to learn a representative pattern for a
lot of CWEs.
Another aspect to considered is the method
adopted for line-level localization. The approach pro-
posed by Fu et al. leverages a key aspect of the
transformer-based architectures, achieving state-of-
the-art performance. However, from our results, we
see that this is tied with the task we are training the
model to. Training the model for vulnerability detec-
tion may make it assign the attention scores to the to-
kens that better help it to identify a vulnerability; but
in our case the model needs to recognize the type of
vulnerability too. Indeed, our results in line-level lo-
calization, even if better than the benchmark explain-
ability methods, are lower than LineVul ones. As fu-
ture work, we are interested in continuing the study of
new ways to identify the vulnerable lines in the code
for a more informative implementation of the vulner-
ability detector.
7 CONCLUSIONS
In this study we explored two possible transformer-
based approaches for software vulnerability detec-
tion, extending the previous work by Fu et al. We
performed two evaluations for both approaches to
demonstrate the impact of the data used for the train-
ing on the models. We showed how using a more
populated but unbalanced dataset produces the bet-
ter results in vulnerability categorization, while a bal-
anced one produce better results in vulnerability de-
tection. Furthermore, comparing our results with Fu
et al., we assessed how the multitask approach is at
the same time more informative for a security ana-
lyst and equally accurate on vulnerability detection
at function-level. However, the subset of classes
used is limited to vulnerability distribution in the
BigVul dataset. We need to explore different group-
ing approaches for the vulnerability and more var-
ious dataset to get a wider coverage of the known
flaws in source codes. Our objective for future work
is to extend the capability of our model to cover a
SECRYPT 2024 - 21st International Conference on Security and Cryptography
422

wider range of vulnerabilities or groups of vulnera-
bilities. Moreover, on line-level detection our model
performed slightly worse than LineVul, but still bet-
ter than the other benchmark techniques considered.
Our goal is to explore new approaches to upgrade the
model in this task.
REFERENCES
Ancona, M., Ceolini, E.,
¨
Oztireli, C., and Gross, M. (2018).
Towards better understanding of gradient-based attri-
bution methods for deep neural networks. ICLR.
Chakraborty, S., Krishna, R., Ding, Y., and Ray, B. (2022).
Deep learning based vulnerability detection : Are we
there yet ? IEEE Transactions on Software Engineer-
ing, 48(9):3280–3296.
Chen, Y., Ding, Z., Alowain, L., Chen, X., and Wagner, D.
(2023). DiverseVul: A New Vulnerable Source Code
Dataset for Deep Learning Based Vulnerability Detec-
tion. In Proceedings of the 26th International Sympo-
sium on Research in Attacks, Intrusions and Defenses,
pages 654–668. ACM.
De Sousa, N. T. and Hasselbring, W. (2021). Javabert :
Training a transformer-based model for the java pro-
gramming language. In 2021 36th IEEE / ACM In-
ternational Conference on Automated Software Engi-
neering Workshops ( ASEW ), pages 90–95.
Devlin, J., Chang, M.-W., Lee, K., and Toutanova, K.
(2019). Bert : Pre-training of deep bidirectional trans-
formers for language understanding.
Fan, J., Li, Y., Wang, S., and Nguyen, T. N. (2020). A c
/ c ++ code vulnerability dataset with code changes
and cve summaries. In IEEE/ACM 17th International
Conference on Mining Software Repositories (MSR),
pages 508–512. ACM.
Fang, Y., Li, Y., Liu, L., and Huang, C. (2018). Deepxss :
Cross site scripting detection based on deep learning.
In ACM International Conference Proceeding Series,
pages 47–51. Association for Computing Machinery.
Feng, Z., Guo, D., Tang, D., Duan, N., Feng, X., Gong, M.,
Shou, L., Qin, B., Liu, T., Jiang, D., and Zhou, M.
(2020). Codebert : A pre-trained model for program-
ming and natural languages. Findings of EMNLP.
Fu, M. and Tantithamthavorn, C. (2022). Linevul: A
transformer-based line-level vulnerability prediction.
In 2022 IEEE/ACM 19th International Conference on
Mining Software Repositories (MSR). IEEE.
Ghaffarian, S. M. and Shahriari, H. R. (2017). Software
vulnerability analysis and discovery using machine-
learning and data-mining techniques: A survey. ACM
Computing Surveys (CSUR), 50(4).
Hin, D., Kan, A., Chen, H., and Babar, M. A. (2022).
LineVD: Statement-level vulnerability detection us-
ing graph neural networks. In Proceedings of the 19th
International Conference on Mining Software Reposi-
tories, pages 596–607. ACM.
Kalouptsoglou, I., Siavvas, M., Ampatzoglou, A., Keha-
gias, D., and Chatzigeorgiou, A. (2023). Software
vulnerability prediction: A systematic mapping study.
Information and Software Technology, 164:107303.
Li, Y., Wang, S., and Nguyen, T. N. (2021). Vulnera-
bility detection with fine-grained interpretations. In
Proceedings of the 29th ACM Joint Meeting on Eu-
ropean Software Engineering Conference and Sym-
posium on the Foundations of Software Engineering,
ESEC / FSE, pages 292–303. Association for Com-
puting Machinery.
Lundberg, S. M. and Lee, S.-I. (2017). A unified approach
to interpreting model predictions. In Advances in Neu-
ral Information Processing Systems, volume 30. Cur-
ran Associates, Inc.
Mamede, C., Pinconschi, E., Abreu, R., and Campos, J.
(2022). Exploring transformers for multi-label clas-
sification of java vulnerabilities. In IEEE, editor,
2022 IEEE 22nd International Conference on Soft-
ware Quality , Reliability and Security ( QRS ), pages
43–52.
MITRE (2023). Cwe list version 4.13.
https://cwe.mitre.org/data/index.html. Accessed
15 November 2023.
Rahman, K. and Izurieta, C. (2022). A mapping study of se-
curity vulnerability detection approaches for web ap-
plications. In 2022 48th Euromicro Conference on
Software Engineering and Advanced Applications (
SEAA ), pages 491–494.
Shrikumar, A., Greenside, P., and Kundaje, A. (2017).
Learning important features through propagating ac-
tivation differences. In Proceedings of the 34th In-
ternational Conference on Machine Learning, pages
3145–3153. PMLR.
Simonyan, K., Vedaldi, A., and Zisserman, A. (2014). Deep
inside convolutional networks : Visualising image
classification models and saliency maps.
Singh, K., Grover, S. S., and Kumar, R. K. (2022). Cyber
security vulnerability detection using natural language
processing. In 2022 IEEE World AI IoT Congress (
AIIoT ), pages 174–178.
Sundararajan, M., Taly, A., and Yan, Q. (2017). Axiomatic
attribution for deep networks. In Proceedings of the
34th International Conference on Machine Learning,
pages 3319–3328. PMLR.
Zhou, Y., Liu, S., Siow, J., Du, X., and Liu, Y. (2019). De-
vign: Effective Vulnerability Identification by Learn-
ing Comprehensive Program Semantics via Graph
Neural Networks. In Advances in Neural Information
Processing Systems, volume 32. Curran Associates,
Inc.
Zou, D., Wang, S., Xu, S., Li, Z., and Jin, H. (2021).
µvuldeepecker : A deep learning-based system for
multiclass vulnerability detection. IEEE Transactions
on Dependable and Secure Computing, 18(5):2224–
2236.
MultiVD: A Transformer-based Multitask Approach for Software Vulnerability Detection
423
