
Challenges in Reverse Engineering of C++ to UML
Ansgar Radermacher, Marcos Didonet Del Fabro, Shebli Anvar and Frédéric Chateau
Université Paris-Saclay, CEA List, France
fi
Keywords:
UML, Reverse Engineering, C++, Tool Support.
Abstract:
Model-driven engineering provides several advantages compared to a direct manual implementation of a sys-
tem. In reverse-engineering applications, an existing code basis needs to be imported into the modeling lan-
guage. However, there is an abstraction gap between the programming language (C++) and the modeling
language, in our case UML. This gap implies that the model obtained via reverse engineering is a model that
directly mirrors the object-oriented implementation structures and does not use higher-level modeling mecha-
nisms such as component-based concepts or state-machines. In addition, some concepts of the implementation
languages can not be expressed in UML, such as advanced templates. Therefore, new systems are often either
developed from scratch or model-driven approaches are not applied. The latter has become more attractive
recently, as IDEs offer powerful refactoring mechanisms and AI based code completion - model-driven ap-
proaches need to catch up with respect to AI support to remain competitive. We present a set of challenges,
based on examples, that need to be handled when reverse engineering C++ code. We describe how we handle
them by improving reverse engineering capabilities of an existing tool.
1 INTRODUCTION
Model-driven engineering (MDE) provides several
advantages compared to the direct implementation
of a system. These include notably the possibility
to specify requirements and perform analysis on the
model. MDE also offers the option to define high-
level behaviors with state-machines which are seman-
tically close to the system specification. Code gen-
eration assures that the implementation is well syn-
chronized with the model. Refactoring with architec-
tural impact can be better done on model level, for
instance changing inheritance hierarchies. In case of
UML (OMG, 2017), the Object Management Group
(OMG) standardized the modeling language which
fostered its adoption by the industry and the devel-
opment of several modeling tools.
Reverse engineering is not only interesting for
legacy systems. It also plays a role during system
evolution. Fig. 1 shows the different steps in round-
trip engineering: (1) an initial model representation
can be obtained using reverse engineering of legacy
code, (2) the generation of code, (3) the evolution of
the code, for instance in the context of debugging, (4)
the reverse of the model from the code, and (5) evo-
lution of the model. Please note that the reverse from
code (4) is quite different from the initial reverse of
legacy code (1). First, it needs to update an exist-
ing model which implies identifying elements in the
source model in order to update them instead of re-
creating them. Both (2) and (4) become synchroniza-
tion tasks. While this aspect makes the reverse engi-
neering task more difficult, it is effectively easier due
to more knowledge about the generated code, as we
will see in section 2. Note that steps from (2) to (5)
are iterative.
However, an existing codebase often hinders the
use of a model-driven approach, as reverse engineer-
ing mechanisms have some limitations that we will
discuss in section 2. These range from issues re-
lated to the representation of programming details in
a modeling language to the more fundamental prob-
lem that higher level concepts offered by the model-
ing language are hard to detect and the UML model
often remains too close to the implementation. We
categorize six kinds of challenges that are currently
not or only partly handled by related work. We ex-
plain the difficulties and then outline how we handle
them in a later section. In this case, many advantages
of modeling can not be used. We show some of these
aspects based on code that we have found in real re-
verse engineering projects.
The paper is structured as follows. In section 2,
we explain the challenges in reverse engineering, no-
272
Radermacher, A., Fabro, M., Anvar, S. and Chateau, F.
Challenges in Reverse Engineering of C++ to UML.
DOI: 10.5220/0012720200003690
Paper published under CC license (CC BY-NC-ND 4.0)
In Proceedings of the 26th International Conference on Enterprise Information Systems (ICEIS 2024) - Volume 2, pages 272-279
ISBN: 978-989-758-692-7; ISSN: 2184-4992
Proceedings Copyright © 2024 by SCITEPRESS – Science and Technology Publications, Lda.
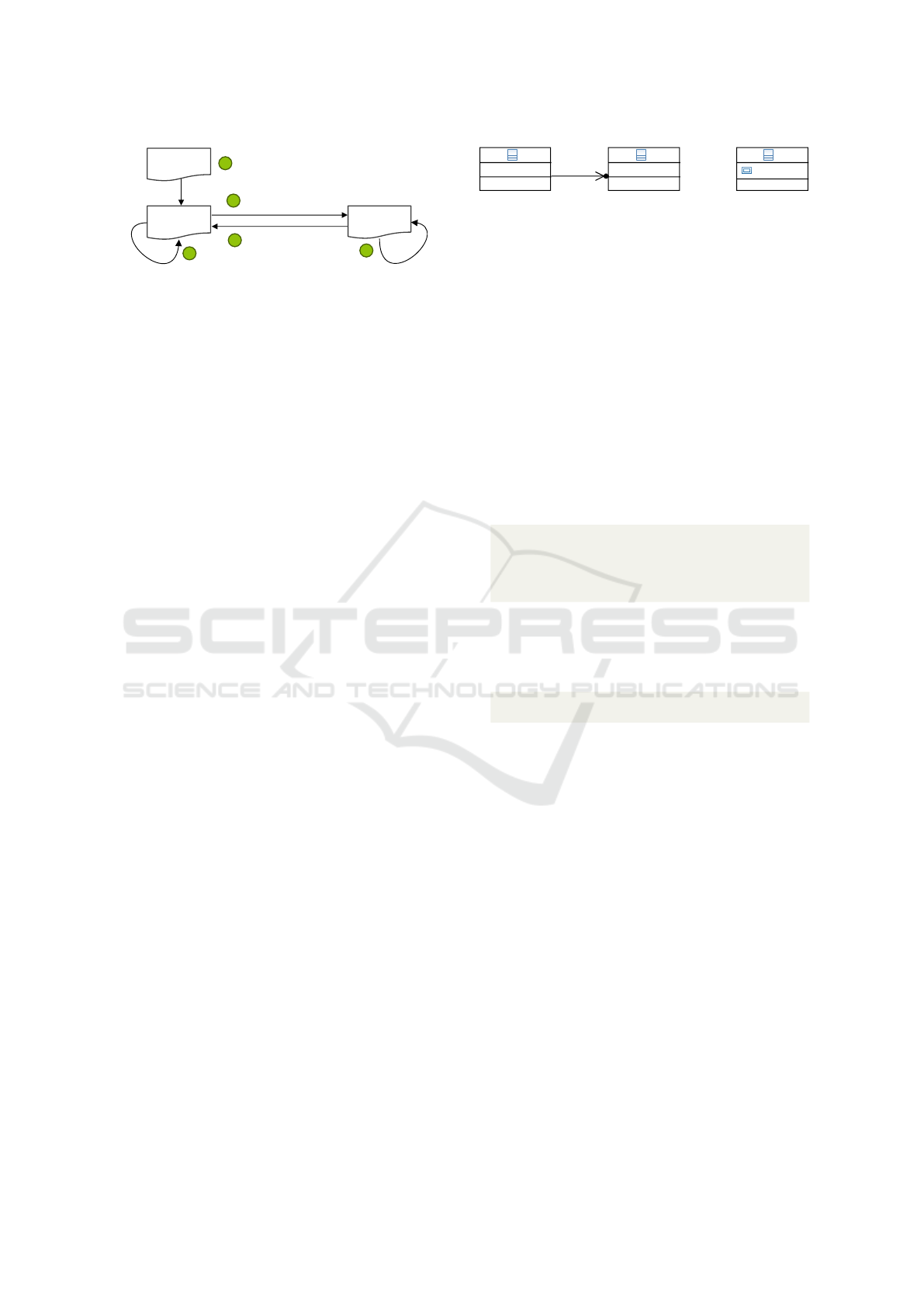
1
Legacy reverse (optional)
4
Reverse code
Edit Model
3
Edit code
2
Generate code
code
Model
Legacy
code
5
Figure 1: Different phases in round-trip engineering.
tably from non-generated code. Section 3 shows tool
support for many of these challenges in our tooling.
We outline related work on reverse engineering in sec-
tion 4, including commercial tools and academic ap-
proaches. We present our conclusions in section 5.
2 REVERSE ENGINEERING
CHALLENGES
Object-oriented languages are in principle compatible
with the modeling concepts offered by UML. How-
ever, programming languages have some subtleties
that cannot be expressed directly. As UML is an ex-
tensible language, a suitable profile may add support
for these issues, but this is not always possible. In
the following subsections, we expose the typical prob-
lems encountered when applying reverse engineering
to real-life systems.
2.1 Mapping Between UML and Code
Is not Bijective
Mappings from a source to target set have mathemati-
cal properties. An injective mapping implies that dis-
tinct elements of the source model map to distinct el-
ements of the target model. A surjective mapping de-
notes that every element in the target model has an
associated element in the source model. If both crite-
ria are satisfied, the mapping is bijective.
In general, the transformation from pure UML to
code is not surjective: we can find constructs in the
source code that have no direct counterpart in UML.
To address this issue, UML meta-model elements can
be extended via stereotypes as parts of a UML pro-
file. Consequently, the model of the mapping in ques-
tion will be based on a combination of UML and a
language profile. However, this mapping is also not
injective, as the same source code could be mapped
to different model elements. One example is the use
of a directed association between two classes A and B.
A typical mapping to code is that class A has a refer-
ence (pointer) to class B. If we find such a case in the
code, we can either map it to an attribute stereotyped
A
B
A'
«Ptr» b: B
+ b
1
Figure 2: Map C++ pointer to an attribute or an association
as pointer or to the directed association, as shown in
diagram 2: The result of reversal could be either class
A or class A’.
2.2 C Pre-Processor
The C++ language inherits a very old mechanism
from C, a textual pre-processor that expands macro
definitions and resolves file includes. A UML pro-
file cannot adequately handle the text replace mech-
anisms, as these may have arbitrary effects. For in-
stance, several declarations may be only processed
optionally (# ifdef) or parts of a name might be modi-
fied. Let us look at a relatively complex pre-processor
definition and usage that has been found in existing
code.
1 # de f i n e DECLARE_ALIAS_PARAM( s u f f i x ) \
2 using CfgParam## s u f f i x =Cfg : : Param<Cfg : :
Type : : s u f f i x >;
3 . . .
4 DECLARE_ALIAS_PARAM(U8)
The double hash symbol enables the concate-
nation of an argument without added white-space.
When expanded, the previous definition results in the
following declaration.
1 us ing CfgParamU 8=Cfg : : Param<Cfg : : Type : : U8
>;
This declaration defines an alias (via the using
statement, discussed in subsection 2.3) for a type that
is based on an existing template Cfg::Param and an
enumeration called Type within class Cfg (the enumer-
ation has among others a literal called U8). It is not
clear how such a macro should be represented in the
model, nor whether it needs to be represented at all.
The pre-processor may be used at compile time
for configuration purposes, including conditional ex-
pansion with # ifdef . The reversed model corresponds
therefore to a particular variant of the original code
and needs to be modified manually in order to gener-
alize it.
2.3 Language Details
The following code serves as an example for several
nitty-gritty C++ details. It declares a class template
that takes a class called Svc (Service) as a formal pa-
rameter. The template class also includes a variadic
template method.
Challenges in Reverse Engineering of C++ to UML
273

1 template < c l a ss Svc> c l a s s Activa b l e S v c {
2 p u b l i c :
3 Activ a b l e S v c ( ) = d e f a u l t ;
4
5 template <typename . . . Args>
6 bool a c t i v a t e ( Svc& svc , Args & & . . . args ) ;
7 bool d e a c t i va t e ( ) ;
8
9 bool i s A c t i v e ( ) cons t ;
10
11 usin g ExecStatus = typename Svc : :
ExecStatus ;
12
13 s t a t i c co n ste x pr ExecStatus
STATUS_INACTIVE = Svc : : STATUS_INACTIVE
;
The first observation is that this class is a template;
we will come back to this aspect further. Line 3 in-
structs the C++ compiler to define a default construc-
tor even when other constructors are defined. This
possibility exists since C++11. UML does not have a
means to express this, so we need to rely on UML’s
extension mechanism via a suitable profile. The dec-
laration in line 5 and 6 has several C++ specific ele-
ments that can not be expressed in UML. It declares
a template method with two additional aspects: the
declaration uses the keyword typename and is variadic
as indicated by the three dots. The keyword indicates
that Args denotes a type, the variadic declaration that
the method can be bound to an arbitrary list of argu-
ments. The method itself (in line 6) has two parame-
ters. The first parameter is passed by reference. The
second is a so-called rvalue reference (a feature that
has been introduced in C++11, it references a tempo-
rary object. Without going into detail, it is often used
to implement move semantics). Like the template pa-
rameter, it is variadic.
Line 9 contains a method declaration that is con-
stant, implying that it does not change the attributes
of the owning class (which is an important hint in the
context of code analysis and multi-threading). This
information can be modeled using the isQuery prop-
erty of an operation or via a stereotype.
The using statement in line 11 declares an alias,
it imports the name ExecStatus from the Svc class into
the ActivableSvc template class. Again, the keyword
typename indicates that the imported element is indeed
a type (to overcome the template “dependent name”
limitations in C++). With respect to UML, alias types
are not supported and need again the help of a stereo-
type. This stereotype needs to reference the imported
type. It seems that an attribute in the stereotype point-
ing towards the imported type is a possible solution.
However, in that case, the type is unknown at template
declaration time, as it depends on the binding of the
Svc template parameter. Another option is to stick to
the qualified name, as C++ does. However, this op-
tion breaks the modeling philosophy which states that
objects are referenced by identity and not by name,
implying for instance that a renaming of the Svc pa-
rameter would break the reference in the alias decla-
ration (if not automatically renamed by tooling). A
pragmatical way out is to use a combination where
model reference and textual binding are both possi-
ble, but only the latter should be used, if the former is
not possible.
Line 13 declares a constant using the C++ key-
word constexpr in combination with static . While the
latter can be expressed with UML, the former requires
a stereotype.
2.4 Higher Level Concepts
The goal of a reverse engineering step is to recover a
UML model. Ideally, this model makes use of higher
level constructs such as component-based abstrac-
tions for structural specifications or state-machines
for behavioral ones. Since programming languages
do not have these mechanisms, we cannot find them
directly in the code. Instead, we find artifacts of an
implementation of these concepts in a specific lan-
guage.
During forward engineering the code generation
applies an implementation pattern that defines how to
map higher level concepts to the programming lan-
guage. In the case of component-based modeling,
the pattern denotes for instance how a port should be
represented in the programming language. A state-
machine requires a more complex pattern. Several
variants have been examined and compared in (Pham
et al., 2017). The key issue is that applying a pattern
during forward engineering is a relatively simple task
while the detection of the used pattern is challenging.
The main reasons are outlined as follows
(1) The reverse engineering algorithm does not
know which implementation pattern has been ap-
plied for a specific concept. A simple example is
attributes or parameters with a non-1 multiplicity.
In the code, we have elements typed with instanti-
ated container classes such as std :: list or std :: vector
. Should a reverse mechanism obtain exactly what it
finds or should it replace the template container with
the bound type and star multiplicity? This issue is
already not trivial for simple cases, it is impossible
to recover a state-machine (and not the implementa-
tion artifacts) from the code, since there are more than
a dozen common implementation variants. The main
exception is when the reverse engineering code knows
exactly which pattern has been applied.
(2) The artifacts belonging to a single concept are
ICEIS 2024 - 26th International Conference on Enterprise Information Systems
274

ComponentA
«Ptr» p: SampleIntf
connect_p( in ref: SampleIntf)
ComponentA
p: Use_SampleIntf
«Port»
Figure 3: (Upper part) recovery of implementation model,
(lower part) higher level model.
typically spread within the code and mixed with man-
ual code or code related to other patterns. For in-
stance, a port enabling access to operations provided
by a connected component can be associated with an
attribute storing a reference to the interface of the con-
nected component and a method to setup this refer-
ence, as shown in the following code. A very simple
option is to use a pointer to store the reference to an
interface, another to instantiate a template.
1 c l as s ComponentA {
2 Sa m p l e Intf
*
p ; / / RPort < Sam pl eIn tf > p ;
3 p u b l i c :
4 / / i n i t i a l i z e po r t r e f e r e nc e
5 void connect_p ( Samp l e I ntf
*
r e f ) ;
6 } ;
Obviously, a class diagram of ComponentA is not
very helpful for understanding the architecture, while
a composite structure diagram is, as shown in Fig. 3.
(3) If the original code has been developed man-
ually (i.e., without code generators), the pattern is
likely not applied consistently, even in the same
project, notably if implemented by multiple develop-
ers or in order to apply optimizations.
This means that, up to now, the extraction of
higher level concepts only works in specific cases,
notably for reversing code that has originally been
generated with annotations about the used design pat-
terns.
2.5 Granularity
A larger system may contain a thousand or more files,
each possibly containing several class declarations
(exactly one in Java). Such a setup does not scale well
enough to be able to store the whole model in a single
file, even if database solutions such as CDO (Stepper
et al., 2023) may offer a workable solution. The re-
verse engineering mechanism must therefore find the
right level of granularity to store artifacts.
Libraries pose an additional problem. Attributes
of application classes and method parameters are of-
ten typed with classes from libraries. The question
is whether the reverse engineering tool should con-
tinue analysing the library code or stop. It can only
do the latter, if it creates at least one incomplete type
with the right qualified name (i.e., in the right hier-
archy of UML packages) to avoid leaving application
elements untyped. If we consider rich libraries, such
as the classes and interfaces of the java.lang package
or the standard template libraries of C++, the mod-
eling tool ideally already provides the libraries and
stops reverse engineering at this step. However, pro-
viding complete libraries for each version of a certain
language is very costly and most tool vendors do not
provide them.
3 TOOL SUPPORT
Papyrus (Papyrus-developers, 2024) is an open-
source, Eclipse-based UML modeling tool. It has an
extension called Papyrus SW designer (Radermacher
et al., 2024). This extension comes with a C/C++ pro-
file for UML and supports code generation as well as
reverse engineering. During forward engineering, the
tool applies the formatter of the Eclipse CDT (CDT-
developers, 2024) project. In this way, the code
formatting can be adapted to one’s particular needs.
There are other preferences that are currently not con-
figurable, for instance whether the attributes section
should be placed before (default behaviour) or after
the methods section; or the preferred order of appear-
ance of the public, protected and private sections of a
class (regardless of being properties or operations).
3.1 Bijective Transformations, Recovery
of Higher Level Models
In section 2.1, we discussed the problem that a trans-
formation from model to code is not bijective, i.e., it
cannot be reversed non-ambiguously. This hinders in
particular the recovery of higher level concepts from
the code (see section 2.4). In the the following para-
graphs, we look at a simple variant of the reverse en-
gineering task: the design recovery from a model that
has been generated previously with the same tool.
For CBSE concepts and state-machine code gen-
eration, the tool supports the execution of a chain of
model to model transformations, as shown in Fig. 4.
The objective is to keep the code generator (model-to-
text) simple and implement advanced code generation
features in separate transformations that can be ex-
changed without touching other parts of the generator.
The transformation realizes an implementation pat-
tern of the concept. This idea has been initially pre-
Challenges in Reverse Engineering of C++ to UML
275
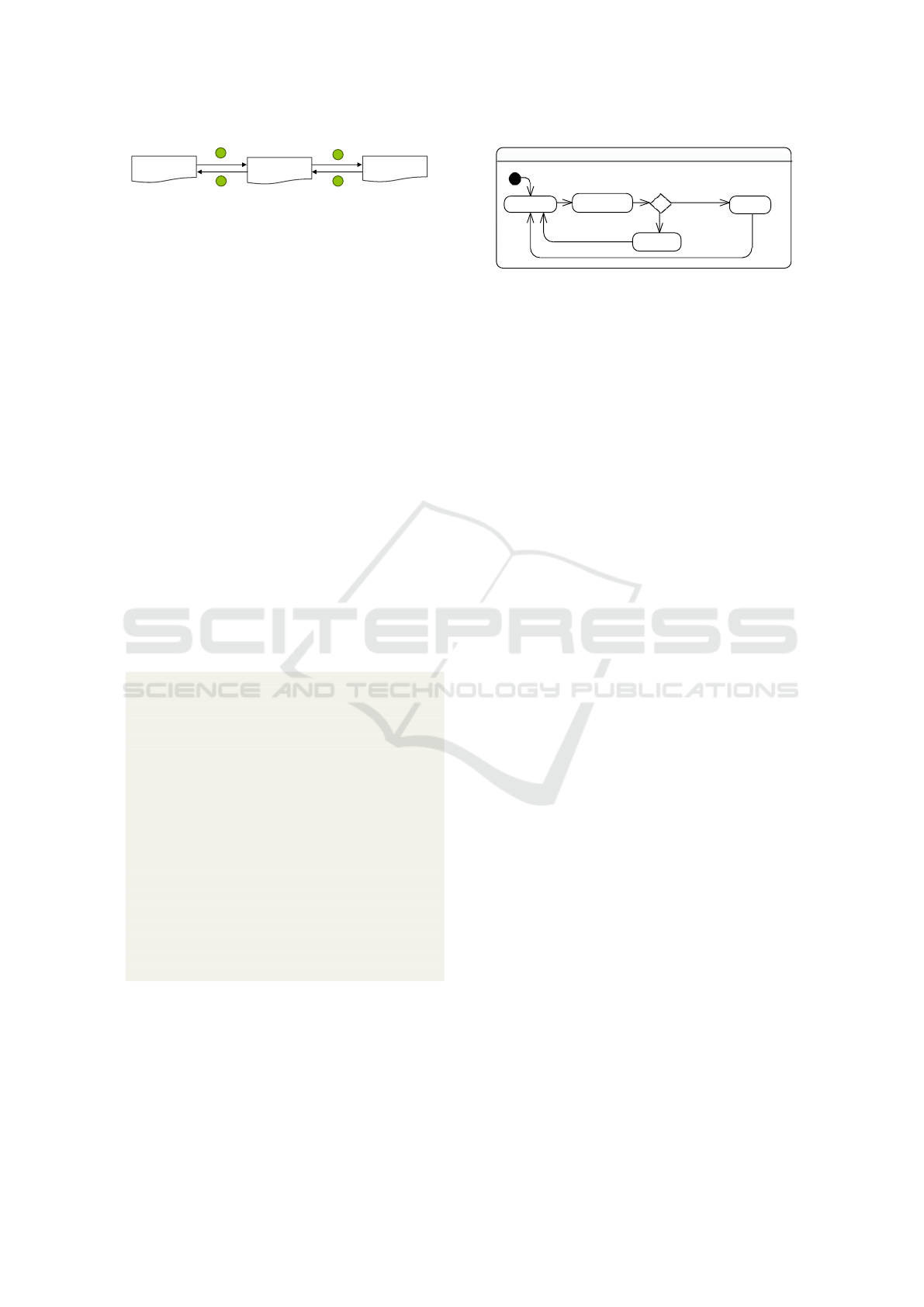
1
Code
HL Model
LL Model
2
34
M2M M2T
Figure 4: Generating concepts with model to model trans-
formations (HL = high-level, LL = low-level).
sented in (Radermacher et al., 2009) for component-
based structures).
For these transformations, (Pham et al., 2018)
proposed a technical trick to assure that the map-
ping from model to code remains bijective: the code
generator produces code that has been called ex-
tended in the sense that it seems to add seman-
tic features to a programming language that support
component-based concepts or state-machines in C++.
However, these concepts are mainly based on meta-
programming via template definitions (and some pre-
processor macros), the resulting code can be compiled
with C++. In case of CBSE, the example in section
2.4 for representing a port contained two options to
map a port to code. In the case where a simple pointer
is used to store the reference, the reverse mechanism
cannot conclude that the reference belongs to a port.
However, if a specific template class (here RPort) is
used instead, the reverse is possible given that the im-
plementation pattern is known.
In the sequel, we examine the generated code of
a state machine, as shown in the following code frag-
ment.
1 Statemachine FIFOMachine {
2 I n i t i a l S t a t e
3 I d l e { } ;
4 St a t e SignalChecking {
5 S t a t e E nt r y entryCheck ( ) ;
6 S t a t e E x i t e xi tCh ec k ( ) ;
7 } ;
8 St a t e D i s c a r d i n g {
9 } ;
10 St a t e Queuing ( ) {
11 S t a t e E nt r y entryQueue ( ) ;
12 } ;
13 T ra n s i t i o n T ab l e {
14 ExT ( I d le , Sig nal Che cki ng ,
15 DataPushEvent , NULL, si gnalCheck ) ;
16 ExT ( SignalChecking , dataChoice ,
17 NULL , NULL, NULL) ;
18 ExT ( dataChoice , Queuing , NULL, v a l i d ,
NULL)
19 } ,
Although the code looks like a textual state-
machine specification, it is valid C++ code that ex-
ecutes a state-machine. Technically, the execution
uses preprocessor macros and C++ templates. This
is a major difference to textual modeling languages
(TMLs) such as Umple (Badreddin et al., 2014) that
provide bi-directional mapping from the TML to code
FIFOMachine
Idle
SignalChecking
dataChoice
Discarding
Queuing
[!isValid &&
!isQueueFull]
push
[else]
Figure 5: Result of reverse engineering a state-machine.
(today, PlantUML (PlantUML, 2023) is more widely
used, but it does not come with a code mapping). In
our approach, programmers can use their favorite IDE
while TMLs force programmers to change their work-
ing environment. In (Maro et al., 2015), the authors
integrate graphical and textual editors for UML pro-
files to allow developers to work in both of the repre-
sentations.
Due to the declarative character, the recovery
of the state-machine is relatively simple. In fig.
5, we have reversed the code of this state-machine
(again, the reverse mechanism only covers the seman-
tic model). The Machine contains several states, in-
cluding a choice states with guards and entry actions.
This only works, since the code has initially been gen-
erated in a specific way that is known by the reverse
engineering mechanism.
3.2 C Pre-Processor
The tool has a specific stereotype «Include» that can
be applied to a class. It stores textual elements
that should be copied in the generated file. Thus,
it can handle macros which are automatically filled
by the reverse process, but the mechanism only han-
dles macros that are within specific markers produced
by code generation. Thus, macros are currently ig-
nored during legacy reverse. The reverse mecha-
nism operates on an AST with macro expansions,
i.e. we get the using declaration that we have seen
in section 2.2 but not the original macro use (DE-
CLARE_ALIAS_PARAM). In this case, the expan-
sion is not a disadvantage. Otherwise, it would not be
possible to represent the alias type in a suitable way
on the model level.
3.3 Language Details
We’ve applied our tool to the ActivableService class
shown in section 2.3 and fixed deficiencies with re-
spect to C++11 in an iterative way. The model has
been automatically created, the diagram in Fig. 6 has
been created manually via drag and drop of the Ac-
tivableService from the model explorer to the class
diagram.
ICEIS 2024 - 26th International Conference on Enterprise Information Systems
276

«Template»
ActivableService
«Constexpr» STATUS_INACTIVE: ExecStatus = Servi...
«Create, Default» ActivableService()
«Variadic» activate( service, args): bool
deactivate(): bool
«Const» isActive(): bool
«Variadic» delegateIfActive( method, args): ExecS...
«Variadic» delegateIfActive( method, args)
«Const» operator ->(): ActiveContext
«Using» ActiveContext
«Using» ExecStatus
«Using» ActiveCommand
«Using» ActiveProcedure
Service: Class
Figure 6: Reverse engineering of class ActivableService.
The application of the C/C++ profile has pre-
served the programming language details, notably
with respect to pointers, (rvalue) references, const and
variadic directives. The constructor has a «Create»
stereotype from the UML2 standard profile. Alias
types have been created as nested classes. Therefore,
they appear in the nested classifier compartment.
3.4 Granularity
In order to handle libraries, as discussed in 2.5, the
profile contains the stereotypes «External» and «Ex-
ternalLibrary» (on the package level) that are applied
to empty classes and provide information how to in-
clude a specific class or the whole library (include di-
rectory setup and linker information). If an analysed
class is located outside of the directory/project that
is reversed, the mechanism checks first whether the
type is already in one of the standard libraries. If not,
it creates an empty class which is marked as external.
In case of C/C++, a specialization of the stereotype
provides information about include directives.
3.5 Efficient Template Binding
Papyrus SW designer provides an additional stereo-
type «TemplateBinding» that can be applied to typed
elements, e.g. attributes or parameters. This stereo-
type has an attribute that stores a list of (actual) types
that bind the formal parameters simply via the order,
in a similar way as C++ does. For instance an attribute
"vector<string> strList" becomes an attribute strList
that is typed with a vector. The stereotype «Template-
Binding» is applied to the strList attribute and ref-
erences the string class, enabling template bindings
without an auxiliary class.
3.6 Performance Evaluation
We have applied the Papyrus C++ reverse engineering
mechanism to a larger project, consisting of several
source folders and a mix of C++ and C code. The
lines of code are indicated in table 1. The process took
about 50 seconds, based on an already indexed CDT
project. The execution time is thus quite acceptable
for a relatively large project.
Table 1: Size of code (number of lines) and obtained model
of larger reverse engineering project.
C++ body C body header
42221 116647 77976
#model elements #stereotypes
43646 5634
The reverse mechanisms above are not new, ex-
cept for the mentioned C++11 enhancements and the
support of multiple source folders. Our tool can re-
cover high-level concepts from components and state-
machines, but only if it knows the used implementa-
tion pattern, i.e. if the code has been generated by
the forward engineering part of the tool. This is not
the case for legacy code in which we neither know the
implementation patterns nor whether a single pattern
has been applied rigorously.
4 RELATED WORK
4.1 Commercial Tools
Many commercial tools, notably Enterprise Architect
(SparxSystems, 2023a) from Sparx-Systems, Visual
Paradigm (Visual Paradigm, 2023) and IBM’s Rhap-
sody (IBM, 2023) support reverse engineering. How-
ever, little information about the details of the re-
verse mechanisms are available. It can import a state-
machine from a specific file .sm, but does not support
reverse engineering from source code. In case of En-
terprise Architect, rather generic information can be
found in (SparxSystems, 2023b).
Rhapsody has a quite good support for reverse en-
gineering. On the one hand, it supports the capability
to define the mapping of types to external code which
avoids the import of elements from standard libraries
into code. On the other, it supports preserving the
structure / location of the code when re-generating.
While this allows to start modeling quickly, it has
also a drawback: the location of generated code fol-
lows the location within the legacy code and is there-
fore possibly inconsistent with standard rules. For
instance, a rule prescribing that sub-folders should
correspond to the package structure might not be re-
spected by the legacy code (we have seen that folder
names do not correspond to namespace definitions
used by C++ files within these folders).
Challenges in Reverse Engineering of C++ to UML
277

Table 2: Selected reverse engineering support by commercial and open source tools.
C Pre-processor High-level models granularity
Enterprise architect pre-define macros no select folders
Visual paradigm pre-define macros no (import from .sm file) select folders
Rhapsody centralized no select folders
Papyrus SW designer associated with class
definition
components and SMs, if code pre-
viously generated with same tool
CDT project
With respect to macros, Rhapsody collects and
stores macros in a specific header file which is part of
the model project configuration. Within this header
file (that can be modified by the developer), macros
are grouped according to the appearance in the orig-
inal file. The handling is similar for the other two
tools which offer the possibility to pre-define macros
in a project central way.
All tools use a UML profile to store language spe-
cific properties. Unfortunately, the OMG has not stan-
dardized a UML profile for C++ implying that each
tool vendor has its own variant of the C++ profile.
With respect to granularity, the three commercial
tools support the selection of one or more folders. In
case of Papyrus, SW designer, the granularity is a
CDT project which can contain one or more source
folders. Code that is outside of these folders is ana-
lyzed in a shallow way: if not defined already in an
existing model library, empty primitive types are cre-
ated. The comparison is summarized in table 2.
4.2 Academic Approaches
There is not much recent activity in the field. Most
publications are already a bit older. We think that
this is mainly caused by the following factors: (1) re-
verse engineering only recovers implementation mod-
els (as opposed to high level models). This reduces
the interest in these models as architectural decisions
are not visible or requirements not explicit. (2) code
based IDEs have become more and more powerful.
IDE refactoring operations take care of identifying
and performing changes in all concerned source files.
Today, they can execute more complex refactoring op-
erations with architectural impact, such as restructur-
ing the inheritance hierarchy. While it is still prefer-
able to do these operations on the model level, it is
technically not necessary any more.
Sutton and Maletic (Sutton and Maletic, 2007)
proposed a set of rules for reverse engineering the
elements within a class diagram. The paper is quite
detailed with respect to the class diagram elements
and includes for instance the multiplicity aspects and
the question whether to map a C++ class to a UML
datatype or UML class (we omitted this example).
Since the semantics behind UML data-types is based
on data equality, the paper proposes to base that de-
cision on the presence a public default constructor, a
copy constructor, and an assignment operator. The
rule is quite questionable, as classes might be wrongly
classified (the authors admitted this possibility in the
paper). While the paper is very complete with respect
to the class diagram, it does not cover component-
based concepts nor state-machines. The paper also
contains information about the reverse engineering
tool called Pilfer, written in Python. The work around
this tool has been discontinued. Sutton also observed
that these tools are used less frequently during soft-
ware maintenance and evolution compared to forward
engineering. Although this statement has been done
more than 15 years ago, it still probably holds due to
the challenges we described.
Tonella (Tonella and Potrich, 2002) analysed not
only the class declarations, but also the instances of
classes that are created statically or dynamically. The
former information can be captured by UML instance
specifications (object diagrams), but as of today, this
analysis is not supported by most tools.
Hafeez-Osman and Chaudron (Hafeez Osman,
2012) analysed the reverse engineering capabilities
of eight different UML tools with respect to pack-
age, class and sequence diagrams. However, the pa-
per remains at a very high level of abstraction: the
reader only gets to know if a tool supports the reverse-
engineering mechanisms for a given diagram and if
yes, if this support is “good”. The paper is thus not
very helpful to get a deeper insight into the topic.
A relatively recent work from Rosca (Rosca and
Domingues, 2020) compared round-trip engineering
approaches for the UML Class Diagram for three dif-
ferent UML tools (in the context of a hospital man-
agement case study. As we have seen in Fig. 1,
reverse-engineering is part of round-trip. The paper
examines three scenarios, in the first generated source
code without changes is reversed again. In the second,
reverse is executed after code changes, and in the third
both existing model and code are modified before re-
versal. While the scenarios are promising, the paper
ICEIS 2024 - 26th International Conference on Enterprise Information Systems
278

falls short to examine the scenarios in more detail. As
the focus is more on methodology, we only get a ta-
ble that compares the numbers of reversed elements
(theoretical vs. obtained) for the three tools without
a discussion about programming language specific is-
sues and the correctness of the results.
5 CONCLUSIONS
In this paper, we have shown several challenges to re-
verse C++ code to UML. These include language de-
tails as well as the recovery of high-level models. The
latter is currently in general not supported by tools.
In our approach, it only works for a rather small sub-
set of projects: the design recovery from code that
has been previously generated with our approach, as
the implementation patterns are known and carefully
chosen during the design of the code generator with
respect to a bijective mapping.
For the design recovery of legacy code, informa-
tion of applied implementation patterns must be pro-
vided. We hope that deep learning can provide a
means in the future to recover this information, as it
should cope with the fuzzy application of implemen-
tation patterns by developers. In order to train these
mechanisms, we plan to use the code base from the
SW heritage project (Software-Heritage, 2023) and
the fact that a certain subset of the projects contain
both design documents and the associated code allow-
ing us to obtain a training dataset.
ACKNOWLEDGEMENTS
This work has been funded by CEA through the plat-
form Deeplab and by ANR PIA: ANR-20-IDEES-
0002.
REFERENCES
Badreddin, O., Lethbridge, T. C., Forward, A., Elasaar, M.,
and Aljamaan, H. (2014). Enhanced Code Generation
from UML Composite State Machines. Modelsward
2014, pages 1–11.
CDT-developers (2024). Eclipse c/c++ development tools
(cdt). https://projects.eclipse.org/projects/tools.cdt.
Oct. 2023.
Hafeez Osman, M. R. C. (2012). Correctness and Com-
pleteness of CASE Tools in Reverse Engineering
Source Code into UML Model. GSTF Journal on
Computing, 2(1):193–201.
IBM (2023). IBM Rhapsody. https://www.ibm.com/
products/uml-tools. [Online; accessed Oct-2023].
Maro, S., Steghöfer, J.-P., Anjorin, A., Tichy, M., and Gelin,
L. (2015). On Integrating Graphical and Textual Ed-
itors for a UML Profile Based Domain Specific Lan-
guage: An Industrial Experience. In Proceedings of
the 2015 ACM SIGPLAN SLE, pages 1–12. ACM.
OMG (2017). Unified Modeling Language (OMG UML),
Version 2.5.1. OMG Document formal/2017-12-05.
Papyrus-developers (2024). Eclipse Papyrus. https://
eclipse.dev/papyrus/download.html. Oct. 2023.
Pham, V. C., Radermacher, A., Gérard, S., and Li, S.
(2017). Complete code generation from UML state
machine. In Proceedings of the 5th MODELSWARD,
Porto, Portugal, February.
Pham, V. C., Radermacher, A., Gérard, S., and Li, S. (2018).
A New Approach for Reflection of Code Modifica-
tions to Model in Synchronization of Architecture De-
sign Model and Code. In Proceedings of the 6th
MODELSWARD, Funchal, Portugal.
PlantUML (2023). PlantUML website.
https://plantuml.com/. [Online; accessed 10-2023].
Radermacher, A., Cuccuru, A., Gerard, S., and Ter-
rier, F. (2009). Generating Execution Infrastructures
for Component-oriented Specifications With a Model
Driven Toolchain – A case study for MARTE’s GCM
and real-time annotation. In Eighth GPCE’09, pages
127–136. ACM press.
Radermacher, A. et al. (2024). Papyrus Software De-
signer. https://wiki.eclipse.org/Papyrus_Software_
Designer. Oct. 2023.
Rosca, D. and Domingues, L. (2020). A systematic com-
parison of roundtrip software engineering approaches
applied to UML class diagram. In Cruz-Cunha, M. M.
et al., editors, 2020 International Conference on EN-
TERprise Information Systems, volume 181, pages
861 – 868.
Software-Heritage (2023). Software Heritage.
https://www.softwareheritage.org. [Online; ac-
cessed 10-2023].
SparxSystems (2023a). Enterprise Architect.
http://www.sparxsystems.com/products/ea/. [On-
line; accessed Oct-2023].
SparxSystems (2023b). Enterprise Architect, Source
code import. https://sparxsystems.com/enterprise_
architect_user_guide/14.0/model_domains/notes_
on_source_code_import.html. [Online; accessed
Oct-2023].
Stepper, E. et al. (2023). Eclipse CDO Model Repos-
itory. https://projects.eclipse.org/projects/modeling.
emf.cdo. [Online; accessed Oct-2023].
Sutton, A. and Maletic, J. I. (2007). Recovering UML class
models from C++: A detailed explanation. Informa-
tion and Software Technology, 49:212–229.
Tonella, A. and Potrich, A. (2002). Static and Dynamic
C++ Code Analysis for the Recovery of the Object
Diagram. In Proceedings of the International Confer-
ence on Software Maintenance (ICSM’02), Toronto,
Canada. IEEE.
Visual Paradigm (2023). Visual Paradigm Homepage Web-
site. https://www.visual-paradigm.com/. [Online; ac-
cessed 10-2023].
Challenges in Reverse Engineering of C++ to UML
279
