
Interactive Storytelling Apps: Increasing Immersion and Realism with
Artificial Intelligence?
Pierre-Benjamin Monaco
1 a
, Per Backlund
2 b
and St
´
ephane Gobron
3,∗ c
1
Master of Software Engineering, University of Applied Sciences and Arts Western Switzerland (HES-SO),
avenue de Provence 7, Lausanne, Switzerland
2
Department of Game Technologies, School of Computer Science, University of Sk
¨
ovde, Sk
¨
ovde, Sweden
3
HE-Arc School of Engineering, University of Applied Sciences and Arts Western Switzerland (HES-SO),
Espace de l’Europe 11, Neuch
ˆ
atel, Switzerland
Keywords:
Natural Language Processing, Hostage-Taking, Immersion, Negotiation, Decision-Making, Chatbot,
Dialogue, LLM, Interactive Content, Virtual Reality, Multimodal Systems.
Abstract:
The advent of Large Language Models (LLMs) has revolutionized digital narration, moving beyond the rigid
and time-consuming process of creating conversational trees. These traditional methods required significant
multidisciplinary expertise and often disrupted dialogue coherence due to their limited pathways. With LLMs
character simulation seems to become accessible and coherent, allowing the creation of dynamic personas
from text descriptions. This shift raises the possibility of streamlining content creation, reducing costs and
enhancing immersion with interactive dialogues through expansive conversational capabilities. To address re-
lated questions, a digital hostage-taking simulation was set up, and this publication reports the results obtained
both on the feasibility and on the immersion aspects. This paper is proposed as a twin paper detailing the
implementation of a simulation that use an actual mobile phone to communicate with the hostage-taker.
1 INTRODUCTION
Figure 1: Illustration of the dual architecture for interactive storytelling – created using PIXLR
(R)
and Photoshop
(R)
image
generators+artistic work. Negotiation is viewed through a conversational tree and as a maze of possibilities with an AI/LLM.
a
https://orcid.org/0000-0002-4487-8195
b
https://orcid.org/0000-0001-9287-9507
c
https://orcid.org/0000-0003-3796-6928
∗
Corresponding author
250
Monaco, P., Backlund, P. and Gobron, S.
Interactive Storytelling Apps: Increasing Immersion and Realism with Artificial Intelligence?.
DOI: 10.5220/0012720400003758
Paper published under CC license (CC BY-NC-ND 4.0)
In Proceedings of the 14th International Conference on Simulation and Modeling Methodologies, Technologies and Applications (SIMULTECH 2024), pages 250-257
ISBN: 978-989-758-708-5; ISSN: 2184-2841
Proceedings Copyright © 2024 by SCITEPRESS – Science and Technology Publications, Lda.

The generation of high-quality interactive content de-
mands a high level of proficiency in storytelling and
domain knowledge within which such content is de-
veloped. The time dedicated to content research and
the creation of a coherent dialogue typically consti-
tutes the major portion of the work (Padilla et al.,
2017). In the case of an interactive dialogue con-
structed in a tree-like structure, the ratio between the
quantity of created content and the content explored
by users exponentially decreases with the length of
the dialogue. Techniques aimed at reducing the scope
of the dialogue are also likely to diminish both its co-
herence and the user’s sense of control (Kerly et al.,
2007). In light of these challenges, the notion of ex-
ploring alternative solutions has germinated and led
to a project focused on seeking solutions leveraging
current artificial intelligence (AI) technologies.
Conversational agents (chatbots) have emerged
since the 1960s with ELIZA, PARRY, and SHRDLU,
which relied on pattern matching techniques. Sub-
sequently, software entities such as A.L.I.C.E., Jab-
berwacky (now Cleverbot), and D.U.D.E demon-
strated noteworthy outcomes (Car et al., 2020), with
the first two even being awarded the Loebner Prize.
Ultimately, the chatGPT model made its debut in
2022, exhibiting impressive results in terms of coher-
ence and dialogue quality. This recent advancement
now opens the door to considering the use of these
tools for interactive digital narrative creation (Park
et al., 2023).
Building upon this recognition, this applied re-
search was undertaken, focusing on the implemen-
tation of a dialogue simulation with an autonomous
agent (Monaco et al., 2023). The outcomes of this re-
search have been disseminated through two twin pub-
lications: the current one, outlines the implementation
of an AI-generated hostage-taker (Figure 1) and a im-
mersion study between traditional conversational tree
and this new approach. The second one resumes the
implementation and challenges of a hostage-taking
simulation using mobile phone as interactive tool to
dialogue with the hostage-taker (Monaco et al., 2024).
2 CONVERSATIONAL AGENTS
2.1 Online Chatbots
A wide range of conversational agent services is avail-
able online. Among them, ChatGPT stands out as
the most recognized and reputable. However, it’s not
the only option. Other services like Google Bard and
Azure OpenAI also offer comparable functionalities.
Table 1 outlines different chatbot services and their
unique features. The most critical requirement is for
the chatbot to be able to assume the role of a hostage-
taker. This aspect poses a significant challenge, as
most conversational agents come with built-in ethical
or moral constraints. These constraints are designed
to prevent discussions on sensitive subjects, particu-
larly those involving violence. Since the scenario of
hostage-taking is inherently tied to such sensitive top-
ics, it falls into the category of discussions that these
models are programmed to avoid, due to its immoral
implications. As a result, most available chatbot ser-
vices do not fulfill the project’s specific needs.
Table 1: Evaluated online LLM services for the project.
Service name API Limit Timing [s]
Google Bard Yes Yes 1 - 10
Shako Yes Yes 2 - 15
ChatGPT Yes Yes 10 - 20
Azure OpenAI Yes Yes 10 - 30
Character.ai Yes No 1 - 3
HuggingChat Yes Y/N 2 - 15
Table 1 identifies two services (marked in green)
that have fewer or no restrictions compared to others.
The HuggingChat service offers a selection of eight
different models, each with varying degrees of moral
constraints, yet all models enforce some level of
restriction. Even the most lenient responses include
a cautionary note regarding the potentially unethical
nature of the content. This warning changes with
each response, making it impractical to filter out
through pattern matching to isolate the pertinent
information.
Jailbreaking – The idea of “jailbreaking” involves
bypassing ethical limitations in models like LLMs.
To jailbreak an LLM, one must craft a complex
prompt to navigate around its moral safeguards. This
could include framing requests as educational and
harmless. However, finding effective prompts is
challenging as updates quickly make old methods
obsolete. Using such techniques risks interrupting or
compromising the chatbot’s simulation. Additionally,
modifying chatbot behavior without permission may
violate terms of service and intellectual property
rights, raising legal concerns (Zou et al., 2023).
Character.ai – Also known as c.ai or Character AI,
is a chatbot platform powered by a neural language
model to mimic human-like conversations. Founded
by Noam Shazeer and Daniel De Freitas, involved
in Google’s LaMDA development, it launched pub-
licly in September 2022. Users can craft personalized
“characters” with unique traits and share them. No-
tably, it allows simulating diverse characters, even a
Interactive Storytelling Apps: Increasing Immersion and Realism with Artificial Intelligence?
251
hostage-taker. Character.ai offers detailed characters,
quick responses, and consistent interactions, making
it suitable for projects needing unrestricted character
creation and engagement.
2.2 Self Hosted Models
The development and progression of Large Language
Models (LLMs) specialized in character conversa-
tion represent a notable leap forward in AI. These
models, often built on transformer technology, are
crafted to process and produce language with greater
context, fostering more natural interactions with
virtual characters. The increasing application of
these character-focused LLMs opens up fascinating
prospects (Shao et al., 2023). Increasingly, LLMs
are being made available in open source, particularly
through platforms like the Hugging Face Hub (Jain,
2022).
Character Description – To guide a LLM in simulat-
ing a specific character, a unique prompting method is
employed: it entails appending a character description
and a history of past interactions to each message sent
to the model. This strategy keeps the model informed
about the ongoing conversation’s context, preventing
repetitive or circular responses.
Ali:Chat (github.com/alicat22), introduces an in-
ventive method for character description formatting.
It utilizes LLM principles to create detailed charac-
ter profiles. This format employs example dialogues
to showcase a character’s distinct features, presented
through interview-style interactions or direct mes-
sages. It not only highlights the character’s person-
ality but also trains the model for consistent char-
acter responses, enabling dynamic and personalized
communication. Additionally, Ali:Chat fosters cre-
ative freedom, allowing creators to emphasize various
traits, from personal preferences to special abilities.
PLists – “Property Lists” – offer another efficient
method for listing a character’s traits. They provide
a systematic approach to detailing a character’s
appearance, personality, preferences, and preferred
role-play situations. Utilizing PLists is particularly
useful for succinctly communicating a wide range of
traits. To optimize token usage, traits listed in PLists
should be kept concise.
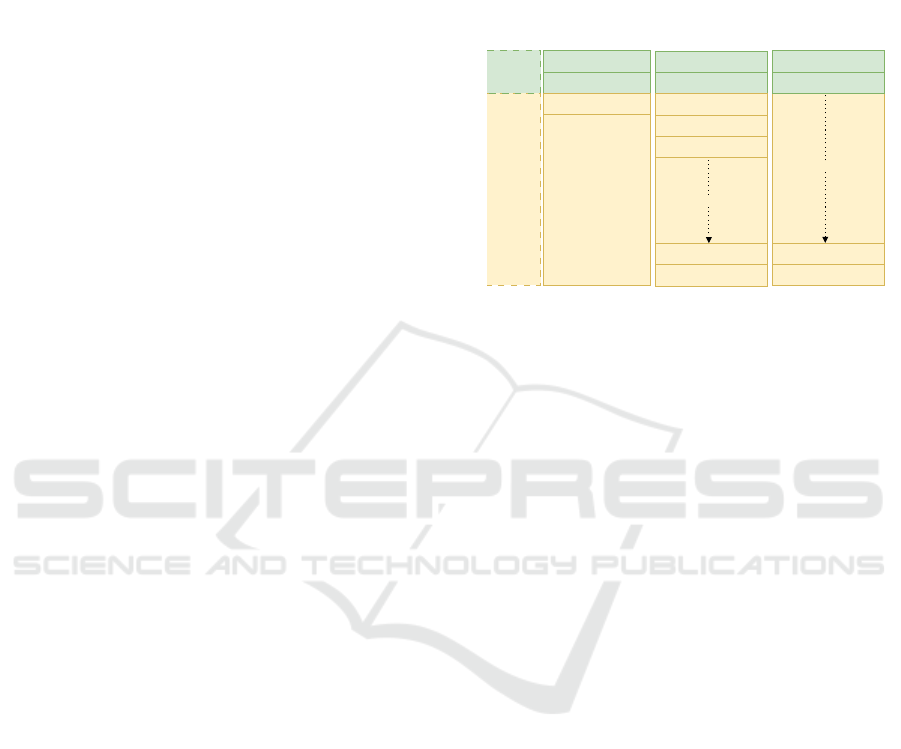
Memory Context – The context works as a “first in,
first out” stack, containing the character’s description,
conversation history, and pertinent details. In contrast
to temporary tokens, permanent tokens in the descrip-
tion box remain in the context stack, consistently in-
fluencing the model’s responses during the dialogue.
Initially, the elements at the bottom of the context
have the greatest impact on the model’s replies, high-
lighting the significance of thoughtfully positioning
key components like PLists and example dialogues at
the lower end of the description box.
Description
Author's Note
Greeting message
(a) Character
context
pile empty
Description
Author's Note
Last user message
Last char. message
Chat history
(c) Character context
pile full -- first
messages forgotten
Description
Author's Note
Greeting message
1st user message
1st char. message
Last user message
Last char. message
Chat history
(b) Character
context pile filled
Temporary
Permanent
Figure 2: Concept of memory context within character de-
scription in a prompt to the LLM.
During a conversation, the context can be visual-
ized as consisting of “memory basket” within the con-
text stack, sorted by the timeliness and relevance of
messages (Figure 2). To counteract the reducing im-
pact of the description box as the dialogue progresses,
the Author’s Note becomes key, ensuring the content.
The context of the situation and specific reactions or
action from the character can be described here. The
usage of a PList is also recommended in this section.
2.3 Performances of the LLM
The effectiveness of LLMs hinges on their parameter
count (Ding et al., 2023), with more parameters en-
abling a finer understanding and generation of human-
like language. However, the complexity associated
with larger models necessitates significant computa-
tional resources. While models with around 230 mil-
lion parameters can run on standard laptops, those
with up to 13 billion parameters demand high-end
GPUs and TPUs.
Running LLMs efficiently requires high-
performance hardware tailored to the model’s
complexity. For models up to 230 million param-
eters, a simple laptop is adequate. However, for
models with 13 billion parameters, the hardware
requirements significantly increase, necessitating
server-grade CPUs (such as Intel Xeon or AMD
EPYC), 128 GB or more of fast RAM, and multiple
top-tier GPUs (like NVIDIA A100 Tensor Core
GPUs) arranged in parallel. Cloud services (e.g.
AWS EC2 P4 instances, Google Cloud’s A100
VMs) provide scalable computing resources with
SIMULTECH 2024 - 14th International Conference on Simulation and Modeling Methodologies, Technologies and Applications
252
access to state-of-the-art GPUs, allowing for larger
models high computational demands without major
on-premises infrastructure.
2.4 Model Selection
character.ai /Cloud hosted
airoboros-l2-13b-2.2.1
mythalion-13b
Mistral-7B-claude-chat
pygmalion-2-13b
pygmalion-2.7b
Pygmalion-2-7B-GPTQ
pygmalion-6b
pygmalion-350m
Timings (s)
0
1
2
3
4
5
6
Timings for different model with RTX A6000 48GB
most coherent, prompts > 20
coherent, 20 > prompts > 10
somehow coherent, 10 > prompts > 5
not coherent, 5 > prompts
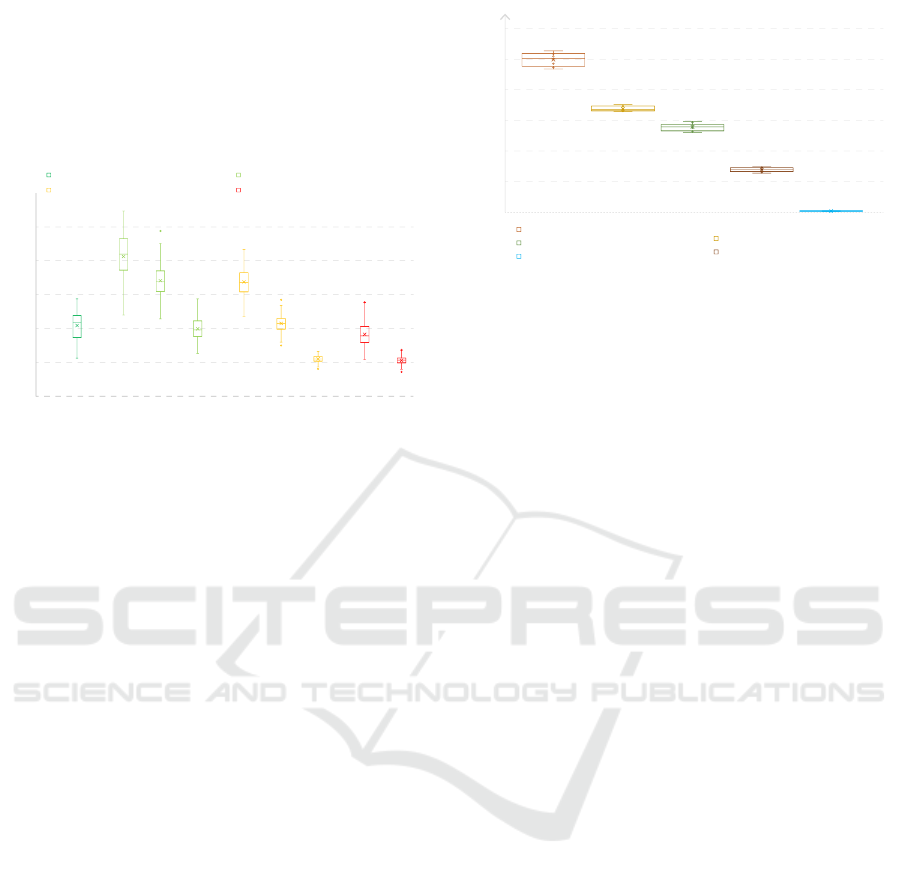
Figure 3: Comparison between 9 LLMs recommended for
character interaction.
Tests were conducted on a server equipped with an
NVIDIA RTX A6000 GPU with 48GB of GDDR6
RAM, an AMD EPYC 7232P 8-Core CPU, and
128GB of RAM. This setup was chosen to meet the
recommended specifications for handling large mod-
els with 13 billion parameters. The evaluation of vari-
ous models is presented in Figure 3. The models were
assessed for coherence in four categories: Very co-
herent, Coherent, Somewhat coherent, and Not coher-
ent. Coherence was judged based on the quality of
the models’ responses after several interactions, with
incoherence determined by specific criteria. Illogi-
cal responses: The hostage-taker doesn’t address the
question or responds illogically, such as discussing
off-topic matters. Role changes: The hostage-taker
assumes the role of the negotiator or a hostage, or
even adopts a completely different personality. Mis-
understanding: The hostage-taker cannot grasp sim-
ple concepts or misunderstands the negotiator. Rep-
etitions: The model repeats itself or forgets prior
exchanges, which can be influenced by the model’s
token limit and context capacity. Incomplete mes-
sages: Occurrences where the model, especially those
with 350 million or 2.7 billion parameters, produces
partial responses.
These models were tested following the same dis-
cussion phases outlined in the simulation. Firstly,
gathering information about the motives behind the
hostage-taking, the personality and history of the
hostage-taker, and the condition of the hostages. Sec-
0
50
100
150
200
250
300
LLM Timings for Mistral - 7B - Claude-Chat
laptop RTX 2060 6 GB
desktop RTX2060 6 GB
desktop RX 6750 XT 12 GB
desktop RTX 4060 Ti 16 GB
server RTX A6000 48 GB
(t)
s
Figure 4: Performance comparison for Mistral-7B-Claude-
chat on different platforms.
ondly, initiating the negotiation process by attempt-
ing to free hostages and disarm the hostage-taker. Fi-
nally, making the hostage-taker understand that their
only way out is to surrender and be escorted out.
Each phase consists of an information prompt indicat-
ing the beginning of a phase, followed by 5 free ex-
changes, and then another information prompt mark-
ing the end of the phase and asking the hostage-taker
to take an action. In total, there are 21 prompts per
test. These tests were conducted 5 times for 8 self-
hosted models and 1 online service (Character.ai).
The Mistral-7B-Claude-chat model emerges as
the test champion in the self-hosted models. With
consistency between 15 and 20 coherent prompts.
A new series of performance tests was conducted
with this specific model on different platforms (lap-
top, desktop, and server) to determine whether using
it locally is feasible or if an external service is re-
quired. The results of this performance test with dif-
ferent graphics cards in Figure 4) indicate that host-
ing the model for the hostage-taker locally is impos-
sible for now. The only platform that provides rea-
sonable time frame (2’800 ms +/- 300 ms) is the
server equipped with a graphics card featuring 48GB
of Graphic GRAM.
Based on the results, character.ai has been iden-
tified as the top performer in terms of speed and co-
herence, making it the chosen model for the hostage-
taker simulation. This selection was primarily driven
by considerations of resources and time. The devel-
opment of a custom model demands a significant in-
vestment in terms of time, data, and finances. Never-
theless, the previously evaluated services and models
present an attractive alternative. The ability to control
both the model and the deployment infrastructure is
crucial for the development of a high-quality profes-
sional service. The data collected earlier remains then
relevant for future research in this domain.
Interactive Storytelling Apps: Increasing Immersion and Realism with Artificial Intelligence?
253
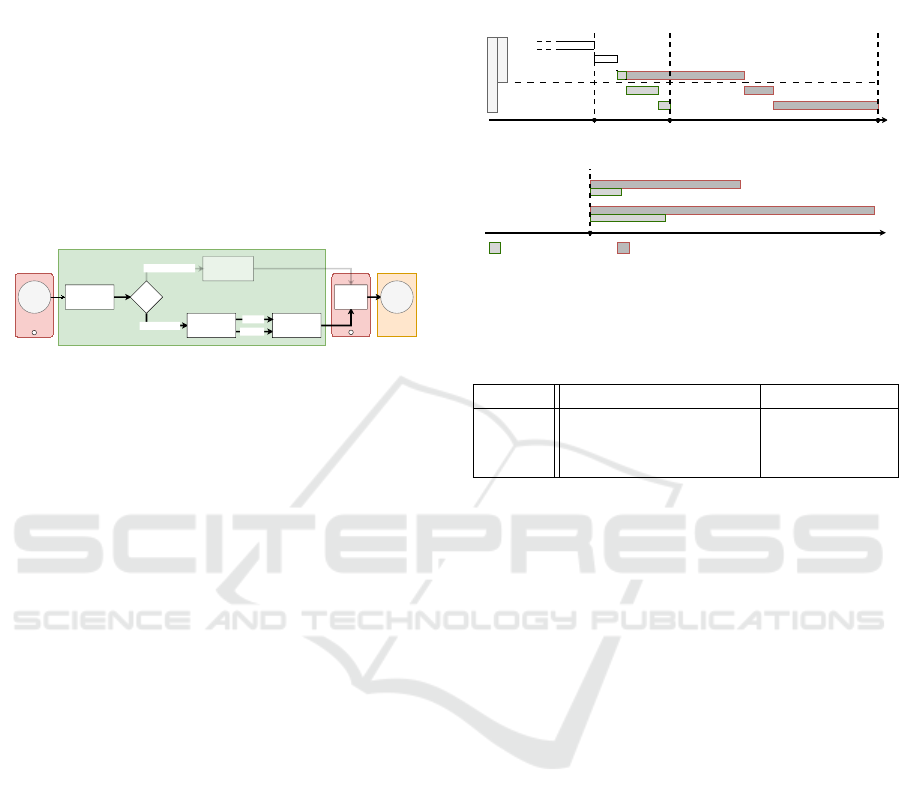
3 INTEGRATION
Based on the initial project “The Negotiator”(Monaco
et al., 2024), the pipeline has been modified to inte-
grate the new version of dialogues using a LLM rather
than a conversational tree (Figure 5). The first version
already integrates a speech-to-text (STT) system and
a sentence comparison system. This new version re-
quires an STT but also implements a Chatbot (LLM)
and a speech synthesizer (TTS). Most TTS offer ac-
ceptable performance but in order to make the hostage
taker more realistic, the use of an TTS with an emo-
tional component has been favored.
User
speaks
Transcription
STT
Free dialogue
Version
Answer selection
NLP
emotion
Chatbot
LLM
Speech creation
TTS
Playing
answer
Perform
action
answer
Directed dialogue
Computer
app
Phone
app
Phone
app
Microservices -- NLP server
Figure 5: Pipeline of the AI processing for the new version
of the simulation. Note that details of the CS architecture
are described in the twin paper (Monaco et al., 2024) ac-
cording to the above color code.
To add this emotional component to the hostage
taker’s speech, the negotiator’s sentence is sent to the
LLM, and the response is generated. Once the LLM’s
response is sent, a predefined prompt asks it to spec-
ify its emotion – from a selected range of emotions.
Once both responses are received, they are sent to the
TTS service (Azure Speech Services), and the audio
version of the hostage taker’s speech is played on the
mobile phone.
4 RESULTS
4.1 Application Performance
The performance of the application was assessed
through processing times. Figure 6(a) – depicts the
sequence of processing for two versions of the appli-
cation: version 1, which employs directed dialogue,
and version 2, which allows for free dialogue. In-
cluded in the overall processing time is the “End of
Speech Detection” phase, which, while part of the to-
tal time, does not utilize machine learning (ML) ser-
vices. Transcription is a shared step between both
versions. For version 1, the time taken for sentence
comparison is not shown in the figure because it is
minimal, amounting to only 0.03s.
Figure 6(b) shows the total time taken by differ-
ent versions of the app. It compares two ways of run-
ning it: a self-hosted mode, where you can control and
change all parts of the process, and an online-services
mode, where online tools are used for the work.
8.5 s
(t)
s
(t)
s
Speech capture
End of speech
detection
0.
1.
1.5 s
Transcription
2.
0.6 s
Chatbot answer
3.
1.9 s
2.3 s
Speech synthesis
4.
0.8 s
7.0 s
Version 1
Version 2
(a)
Beginning of
NLP processing
End of online
processing
End of local
processing
self hosted
online services
V1
self hosted
online services
V2
10 s
2.1 s
18.9 s
5.2 s
(b)
End of
speech capture
online-services
self-hosted
Figure 6: (a) Timings sequence comparisons between self-
hosted and online-services; (b) Total timing comparison be-
tween the two solutions.
Table 2: Self-hosted and online-services tested at each stage
of the pipeline.
Stage Self-hosted Online
2 STT Whisper Azure Speech
3 LLM Mistral-7B-Claude-chat Character.ai
4 TTS dl-for-emo-tts Azure Speech
The table above shows the technology used for
each step and mode (Table 2). Note that the Mistral-
7B-Claude-chat model is set up on a server (Vast.ai).
This means we have control over how it is set up.
However, as seen in Figure 4, it is not possible right
now to run a model like this on the computer doing
the simulation.
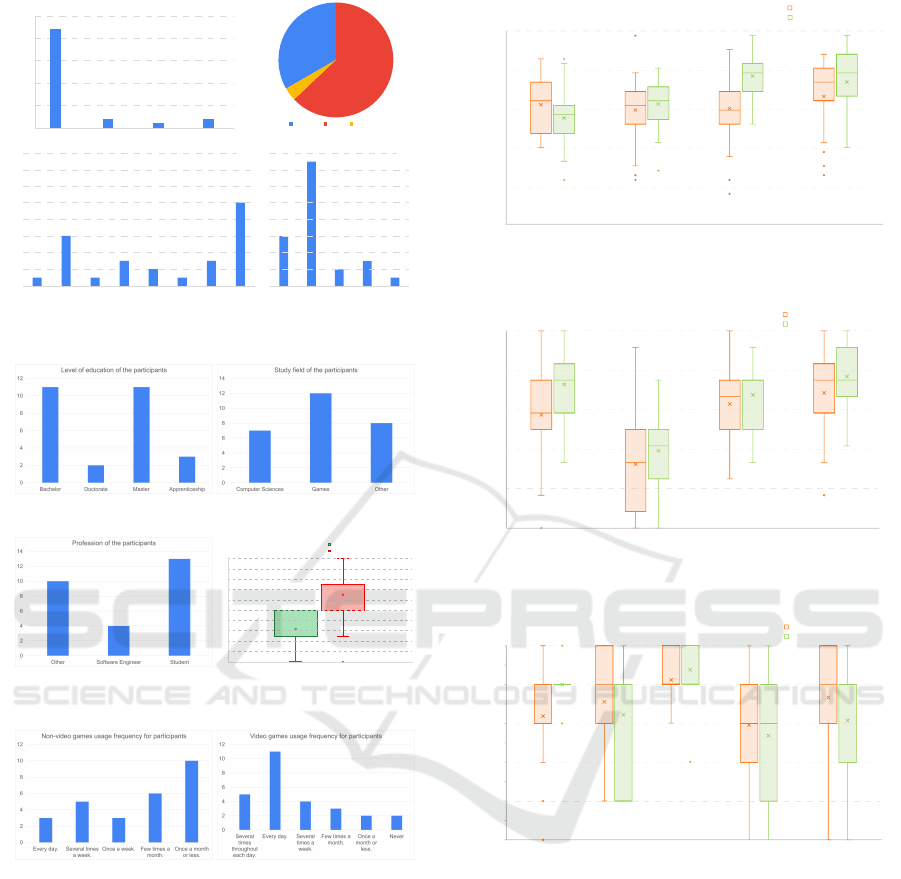
4.2 User Testing
The evaluations were performed on 27 naive individ-
uals (Figure 7) in accordance with the procedure out-
lined in the appendix. This test used a randomized
controlled crossover trials methodology. A consistent
testing environment has been ensured. This included
maintaining a quiet setting devoid of background mu-
sic or noise, ensuring normal lighting conditions, pro-
viding a detailed briefing about the participant’s role
prior to each testing session, prohibiting interaction
with other participants during the session, and requir-
ing the completion of questionnaires immediately fol-
lowing the testing sessions.
Feedback from participants highlighted a desire
for a longer simulation experience. The use of a mo-
bile phone was frequently cited as a key factor en-
hancing the sense of immersion, making the simula-
tion feel more realistic and engaging. Additionally,
the ability of the hostage taker to convey various emo-
tions added depth to the experience, further immers-
ing participants in the scenario.
SIMULTECH 2024 - 14th International Conference on Simulation and Modeling Methodologies, Technologies and Applications
254
[20, 35]
(35, 50]
(50, 65]
(65, 80]
0
5
10
15
20
25
Belgium
Chinese
Cypriot
French
Russian
Spanish
Swedish
Swiss
Chinese
French
Russian
Swedish
Turkish
(c)
(d)
10
12
14
16
0
2
4
6
8
Female
Male
Non-binary
33%
63%
4%
(b)
(y.o.)
(a)
Figure 7: Demographic information about the participants:
(a) age; (b) gender; (c) nationality; (d) language.
Figure 8: Educational profile of the participants.
Interests of the participants
Interest in negotiation and security
Interest in AI technologies
0
0.2
0.4
0.6
0.8
1.0
Figure 9: Professional information and interests of the par-
ticipants.
Figure 10: Gaming habits of the participants.
The 3D environment was praised for contributing
to the immersive quality of the simulation, indicat-
ing that the visual aspect was appreciated by many.
However, some participants noted that managing the
mobile phone alongside an external device, such as a
laptop, could detract from the immersion, as it divided
their attention between two different interfaces.
Issues with the timing of animations were men-
tioned, suggesting that smoother integration or
synchronization might improve the overall experi-
ence. Furthermore, participants reported encounter-
ing blocking bugs, including interrupted dialogues,
which could disrupt the flow and engagement with the
simulation. Addressing these technical issues could
significantly enhance the user experience.
Pragmatic quality
HQ - Identity
HQ - Stimulation
Attractivity
0
0.2
0.4
0.6
0.8
1.0
Tree based dialogue
Free dialogue
Figure 11: AttrakDiff (Hassenzahl et al., 2003) question-
naire results.
Focused
attention
Perceived
usability
Aesthetic
appeal
Reward
factor
Tree based dialogue
Free dialogue
0
0.2
0.4
0.6
0.8
1.0
Figure 12: User Engagement Scale Short Form (O’Brien
et al., 2018) results.
Feeling of
immersion
3D
environment
Cellphone
immersion
Making
decisions
Dialogue
coherence
0
0.2
0.4
0.6
0.8
1.0
Tree based dialogue
Free dialogue
Figure 13: Simulation specific questionnaire results.
5 DISCUSSION
5.1 Quality and Performances
The setup was devised to interact naturally with a
hostage-taker, employing four language processing
tools: Speech-to-Text, text comparison, a chatbot,
and Text-to-Speech capable of expressing emotions.
These machine learning technologies enhance con-
versation realism with a virtual hostage-taker but re-
quire significant computing power, often beyond in-
dividual means. Models, built on specific technology,
demand substantial memory and perform better with
Interactive Storytelling Apps: Increasing Immersion and Realism with Artificial Intelligence?
255

GPUs. However, due to GPU resources already al-
located to the simulation’s 3D component, process-
ing time for Speech-to-Text and Text-to-Speech spans
seven to height seconds on a laptop with an RTX2060
graphics card, inadequate for real-time conversation
simulations. Even with full GPU capacity utilization,
performance remains poor across various laptops and
desktops. The fastest coherent model requires about 4
minutes to process on the designated work computer.
Hosting the customizable chatbot on a server with 48
GB of graphics RAM is the only feasible option, al-
beit expensive, hindering widespread distribution.
Using online services offers advantages such as
quicker processing times: one second for Speech-
to-Text and Text-to-Speech, and an average of 2.3s
for the chatbot. However, limited model customiza-
tion is a drawback, although Azure Speech Services
adequately meet project requirements. Online ser-
vices may become overloaded, leading to extended
response times, with internet connection quality di-
rectly impacting simulation efficacy. Consolidating
services under a single provider may mitigate this,
but audio file transmission consumes significant data
bandwidth. Despite risks associated with downtime
or diminished performance, online services are meet-
ing the simulation’s computational demands.
In the final setup, average processing times are
2.1s for the dialogue tree-based version and 5.2s for
the chatbot-based version, ideal but subject to occa-
sional delays due to inadequate end-of-speech detec-
tion. Significant improvements are needed to prevent
conversation flow disruptions. Azure Speech Services
struggle with speech containing over two seconds of
initial silence, solutions include editing audio files to
remove silence or using Azure’s asynchronous API
to reduce transcription delay. Incorporating footsteps
sound during conversations enhances realism, main-
taining participant engagement even with longer re-
sponse times from the hostage-taker.
5.2 Testers Feedback
As seen in Figure 7, a majority aged 20 to 35 (a). In-
cluding more individuals aged 35 to 50 could pro-
vide valuable insights (a). The gender distribution
shows 63% males, 33% females, and 4% non-binary
(b). The diversity in languages(d) and nationalities(c),
with height nationalities and five languages repre-
sented, highlights the simulation’s adaptability.
Most participants are students in technical fields
(Figure 8), potentially biasing their interest towards
technological aspects like AI and smartphones. Their
focus on technical aspects may overshadow consider-
ations of security and negotiation (Figure 9). Includ-
ing testers from law enforcement and security sec-
tors could offer valuable comparisons. However, par-
ticipants with gaming backgrounds reinforce positive
feedback on immersive qualities (Figure 10).
The AttrakDiff study (Hassenzahl et al., 2003)
(Figure 11) indicates overall satisfaction, with partic-
ipants engaged intellectually and emotionally. Pref-
erence is shown for the dialogue tree version for
its logical approach, while the chatbot version is fa-
vored for its intellectual challenge. The User En-
gagement Scale-Short Form (Figure 12) reveals high
satisfaction, with the “Free dialogue” version foster-
ing greater engagement and immersion due to its AI-
driven interactivity.
The simulation-specific questionnaire’s outcomes
(Figure 13) affirm earlier observations, particularly
about immersion levels. Participants felt a height-
ened sense of immersion with the “Free dialogue”
version. Feedback on aesthetic appeal was positive,
though slightly lower for the “Free dialogue” version
due to greater intellectual involvement. Dialogue co-
herence received high marks, indicating natural flow,
but occasional lapses suggest room for improvement
in maintaining consistency.
6 CONCLUSION
The initial research inquiry examines the feasibility
of conducting natural dialogues with virtual charac-
ters via phone. This investigation resulted in the de-
velopment of a simulation that facilitates natural in-
teractions with a virtual hostage-taker, demonstrating
the practicality of engaging in natural conversations
with NPCs over the phone. The subsequent ques-
tion explores the capability of leveraging LLMs, such
as ChatGPT, for creating more immersive dialogues.
The project produced two simulation versions: one
based on a dialogue tree and another utilizing an LLM
for the hostage-taker’s responses. Findings indicate
that modern Machine Learning (ML) models can ef-
fectively simulate dialogue with humans, enhancing
user engagement and immersion. The timing of the
models used in the simulation vary significantly, with
high latencies potentially disrupting realism. These
latencies are influenced by the operational platform of
the models. To maintain acceptable performance, the
solution adopted involves utilizing cloud services in-
stead of local models, ensuring more consistent and
manageable response times essential for preserving
the simulation’s coherence.
User testing revealed that incorporating the tele-
phone enhances immersion and is well-received.
However, using two separate devices (a computer for
SIMULTECH 2024 - 14th International Conference on Simulation and Modeling Methodologies, Technologies and Applications
256

simulation support and a phone as a simulation ele-
ment) can diminish the sense of immersion. A pro-
posed solution is to project the simulation onto a large
screen, allowing participants to stand in front of it for
a more immersive experience without resorting to Vir-
tual Reality technologies. Feedback from AttrakDiff
and UES-SF questionnaires indicates positive partic-
ipant reception, highlighting emotional and intellec-
tual engagement, particularly with the LLM version.
This suggests a promising avenue for learning simula-
tions and serious games, as intellectual stimulation is
crucial for Experiential Learning, enhancing the edu-
cational quality of the simulations.
Integrating LLMs into simulations introduces
challenges with controlling variables and event trig-
gers, unlike dialogue trees where each node directly
impacts simulation outcomes. A workaround in this
project involved prompting the LLM to suggest ac-
tions, yet interpreting complex, variable-rich LLM re-
sponses remains a hurdle. A second LLM could the-
oretically parse the first’s output, though this raises
issues around its training and increased timings. This
approach complicates the balance between maintain-
ing simulation integrity and leveraging LLMs for dy-
namic, naturalistic dialogue generation. The distinc-
tion between dialogue trees and LLM in dialogue gen-
eration highlights a trade-off between control and nat-
uralness. Dialogue trees offer complete control, en-
suring consistency, while LLMs provide a more natu-
ral interaction but with less predictability. This raises
the question of merging both methods to harness their
respective strengths, suggesting a hybrid approach
where a dialogue tree could potentially guide an LLM
for improved consistency, opening avenues for inno-
vative solutions in dialogue generation.
REFERENCES
Car, L. T., Dhinagaran, D. A., Kyaw, B. M., Kowatsch, T.,
Joty, S., Theng, Y.-L., and Atun, R. (2020). Con-
versational agents in health care: Scoping review and
conceptual analysis. Journal of Medical Internet Re-
search, 22:e17158.
Ding, N., Qin, Y., Yang, G., Wei, F., Yang, Z., Su, Y.,
Hu, S., Chen, Y., Chan, C.-M., Chen, W., et al.
(2023). Parameter-efficient fine-tuning of large-scale
pre-trained language models. Nature Machine Intelli-
gence, 5(3):220–235.
Hassenzahl, M., Burmester, M., and Koller, F.
(2003). AttrakDiff: Ein Fragebogen zur Messung
wahrgenommener hedonischer und pragmatischer
Qualit
¨
at, pages 187–196. B. G. Teubner.
Jain, S. M. (2022). Hugging Face, pages 51–67. Apress.
Kerly, A., Hall, P., and Bull, S. (2007). Bringing chatbots
into education: Towards natural language negotiation
of open learner models. Knowledge-Based Systems,
20:177–185.
Monaco, P.-B., Backlund, P., and Gobron, S. (2024). The
negotiator: Interactive hostage-taking training simula-
tion. In 14th International Conference on Simulation
and Modeling Methodologies, Technologies and Ap-
plications (SIMULTECH 2024). SCITEPRESS.
Monaco, P.-B., Villagrasa, D., and Canton, D. (2023).
The negotiator. In Gamification and Serious GameS
(GSGS’23), pages 94–97. HES-SO.
O’Brien, H. L., Cairns, P., and Hall, M. (2018). A practi-
cal approach to measuring user engagement with the
refined user engagement scale (ues) and new ues short
form. International Journal of Human-Computer
Studies, 112:28–39.
Padilla, J. J., Lynch, C. J., Kavak, H., Evett, S., Nelson,
D., Carson, C., and del Villar, J. (2017). Storytelling
and simulation creation. In 2017 Winter Simulation
Conference (WSC), pages 4288–4299. IEEE.
Park, J. S., O’Brien, J. C., Cai, C. J., Morris, M. R., Liang,
P., and Bernstein, M. S. (2023). Generative agents:
Interactive simulacra of human behavior. Proceedings
of the 36th Annual ACM Symposium on User Interface
Software and Technology.
Shao, Y., Li, L., Dai, J., and Qiu, X. (2023). Character-
LLM: A trainable agent for role-playing. In Bouamor,
H., Pino, J., and Bali, K., editors, Proceedings of
the 2023 Conference on Empirical Methods in Nat-
ural Language Processing, pages 13153–13187, Sin-
gapore. Association for Computational Linguistics.
Zou, A., Wang, Z., Carlini, N., Nasr, M., Kolter, J. Z., and
Fredrikson, M. (2023). Universal and transferable ad-
versarial attacks on aligned language models. ArXiv,
abs/2307.15043.
APPENDIX
• Surveys: Raw Data and Test Protocol
https://drive.google.com/drive/folders/
1n8QGcq6Jvid82Q1erJp YXv8eLv7kVSp?
usp=sharing
Interactive Storytelling Apps: Increasing Immersion and Realism with Artificial Intelligence?
257
