
Reinforcement Learning for Multi-Objective Task Placement on
Heterogeneous Architectures with Real-Time Constraints
Bakhta Haouari
1,2,3 a
, Rania Mzid
1,4 b
and Olfa Mosbahi
2 c
1
ISI, University Tunis-El Manar, 2 Rue Abourraihan Al Bayrouni, Ariana, Tunisia
2
LISI Lab INSAT, University of Carthage, Centre Urbain Nord B.P. 676, Tunis, Tunisia
3
Tunisia Polytechnic School, University of Carthage, B.P. 743, La Marsa, Tunisia
4
CES Lab ENIS, University of Sfax, B.P:w.3, Sfax, Tunisia
Keywords:
Real-Time, Task Placement, Multi-Objective, Refactoring, Pareto Q-Learning.
Abstract:
This paper introduces a novel approach for multi-objective task placement on heterogeneous architectures
in real-time embedded systems. The primary objective of task placement is to identify optimal deployment
models that assign each task to a processor while considering multiple optimization criteria. Given the NP-
hard nature of the task placement problem, various techniques, including Mixed Integer Linear Programming
and genetic algorithms, have been traditionally employed for efficient resolution. In this paper, we explore
the use of reinforcement learning to solve the task placement problem. We initially modeled this problem
as a Markov Decision Process. Then, we leverage the Pareto Q-learning algorithm to approximate Pareto
front solutions, balancing system extensibility and energy efficiency. The application of the proposed method
to real-world case studies showcases its effectiveness in task placement problem resolution, enabling rapid
adaptation to designer adjustments compared to related works.
1 INTRODUCTION
Real-time embedded systems (RTES) are computing
system designed to perform specific functions with
precise timing constraints. Nowadays, these systems
are commonly found in various aspects of everyday
life, ranging from customer electronics to healthcare
applications (Akesson et al., 2020). They typically
consist of both hardware and software components
tightly integrated to execute tasks efficiently. Indeed,
RTES are characterized by their ability to promptly
respond to external stimuli within strict timing con-
straints, offering reliability and performance crucial
for a wide array of applications. Developing such sys-
tems is inherently challenging, given that any failure
could have critical implications for human safety.
The software engineering community is facing
various challenges today during the development of
RTES, including the task placement problem (Las-
soued and Mzid, 2022). This problem involves as-
signing tasks to processors in a manner that satisfies
a
https://orcid.org/0000-0002-5336-6300
b
https://orcid.org/0000-0002-3086-370X
c
https://orcid.org/0000-0002-0971-2368
real-time constraints while optimizing system per-
formance metrics. As real-time embedded systems
become more complex, solving the task placement
problem becomes much harder. In fact, task place-
ment turns into an NP-hard problem, which essen-
tially means that finding the best solutions becomes
extremely difficult within a reasonable amount of
time. In response, researchers have explored vari-
ous optimization techniques, including exact methods
such as Mixed Integer Linear Programming (MILP)
(Mehiaoui et al., 2019; Lakhdhar et al., 2020), Re-
inforcement Learning (RL) (Haouari et al., 2022;
Haouari et al., 2023b), and Genetic Algorithms (GA)
(Lassoued and Mzid, 2022), to tackle task placement
efficiently.
In this paper, we explore the use of reinforcement
learning to solve the multi-objective task placement
problem in RTES. We introduce a new method called
Pareto Q-learning Placement (PQP). This method re-
lies on the Pareto Q-learning algorithm (Van Moffaert
and Now
´
e, 2014), an emerging artificial intelligence
technique known for its effectiveness in such scenar-
ios. The PQP method is designed to generate a set of
Pareto-optimal solutions for the task placement prob-
Haouari, B., Mzid, R. and Mosbahi, O.
Reinforcement Learning for Multi-Objective Task Placement on Heterogeneous Architectures with Real-Time Constraints.
DOI: 10.5220/0012721500003687
Paper published under CC license (CC BY-NC-ND 4.0)
In Proceedings of the 19th International Conference on Evaluation of Novel Approaches to Software Engineering (ENASE 2024), pages 179-189
ISBN: 978-989-758-696-5; ISSN: 2184-4895
Proceedings Copyright © 2024 by SCITEPRESS – Science and Technology Publications, Lda.
179

lem in RTES, adhering to all specified constraints,
particularly those related to real-time requirements,
while simultaneously improving system extensibility
and reducing energy consumption. In addition to its
ability to produce Pareto-optimal solutions, the pro-
posed PQP method addresses the challenge of refac-
toring. Refactoring refers to the process of modifying
the system properties such as updating tasks proper-
ties (Haouari et al., 2022). The main contributions
of this paper may be summarized as follows: (i) We
model the task placement problem as a Markov Deci-
sion Process (MDP), (ii) We use the Pareto Q-learning
algorithm to propose a multi-objective decision maker
called PQP. The latter offers to the designer a set of
deployment models referring to the possible task-to-
processor assignments, balancing the system extensi-
bility and energy efficiency. (iii) We apply and simu-
late the proposed PQP method to real-life case stud-
ies. The results obtained demonstrate the effective-
ness of the proposed methods in efficiently identify-
ing Pareto solutions compared to existing approaches.
Additionally, they showcase the capability of the pro-
posed methods to address the refactoring issue.
The rest of the paper is organized as follows: Sec-
tion 2 discusses the relevant literature. Section 3 in-
troduces key concepts related to multi-objective opti-
mization. Section 4 presents the RTES formalization.
The description of the task placement problem as a
MDP is introduced in Section 5. Section 6 introduces
the PQP method and provides detailed explanations of
the RL algorithms. Experimental results are detailed
in Section 7, and the paper concludes with Section 8,
which discusses future directions of our research.
2 RELATED WORK
Several approaches have been proposed in the litera-
ture to deal with the task allocation problem in RTES.
In (Zhu et al., 2013), the authors utilize MILP tech-
nique to optimize task and message allocation within
a distributed system, aiming to meet end-to-end dead-
lines and minimize latencies. In (Vidyarthi and Tri-
pathi, 2001), a GA-based method is proposed for
maximizing reliability in the task allocation problem.
In (Kashani et al., 2017), the authors deal with the
same problem and propose a method based on GA
to minimize the communication cost. In (Haouari
et al., 2023a), RL techniques are applied to intro-
duce a novel approach to real-time task placement and
scheduling. Unlike previous approaches, this paper
systematically explores all feasible placements be-
fore assigning a scheduling to each solution, defining
the optimal scheduling as the one that minimizes re-
sponse time. Additionally, in (Haouari et al., 2023b),
the authors delve into self-adaptive systems, propos-
ing a new method capable of effectively functioning
under both predictable and unpredictable online sys-
tem updates. Their proposed approach, represented
by a set of RL algorithms, aims to optimize system
extensibility while ensuring real-time feasibility. An-
other notable work by (Haouari et al., 2022) leverages
the Q-learning algorithm for task placement, with
the goal of reducing the number of utilized proces-
sors. This study also addresses the refactoring is-
sue, demonstrating the effectiveness of RL methods
in coping with updates to system parameters. De-
spite the significance of these works in addressing
the placement problem in RTES, they are limited to
single-objective optimization, which may not fully
capture the complexities of real-world scenarios.
In addressing multi-objective optimization in the
task allocation problem in RTES, the authors of
(Mehiaoui et al., 2019) propose an approach aimed
at addressing placement and scheduling challenges
within embedded distributed architectures, where
multiple objectives need to be optimized collectively.
They employ both MILP and GA (Mirjalili, 2019) to
handle the scalability issues associated with MILP.
To address the set of objectives comprehensively, the
authors suggest consolidating them into a single ob-
jective function, assigning weights to each objective.
This process yields an optimal solution that strikes
a balance among the objectives for the entire prob-
lem. However, as discussed in (Coello, 2007), the au-
thors demonstrate that despite executing this process
multiple times with varying weights, certain solutions
that do not align with any combination of weights re-
main undetected. In (Lassoued and Mzid, 2022) a
multi-objective algorithm based on evolutionary algo-
rithms, specifically SPEA2 (Huseyinov and Bayrak-
dar, 2022), was proposed to optimize both the slack
capacity and the consumed energy of the system for
distributed processors. Nevertheless, the scalability of
the GA model is evident. The authors of (Mehiaoui
et al., 2019) conclude that evaluating and ensuring
the quality of solutions generated by the GA is chal-
lenging, given its dependency on various factors such
as encoding, crossover, and mutation operators. De-
spite their importance, these works do not address
the refactoring issue, as the MILP and GA formula-
tions must be re-executed from scratch after applica-
tion properties changes.
Some studies have achieved success utilizing RL
techniques to address problems akin to task placement
in domains beyond RTES, including the work refer-
enced as (Caviglione et al., 2021). In this paper, the
authors introduce a multi-objective approach utiliz-
ENASE 2024 - 19th International Conference on Evaluation of Novel Approaches to Software Engineering
180
ing a deep reinforcement learning (RL) technique for
addressing the online placement of virtual machines
(VMs) across a group of servers within cloud data
centers. Nevertheless, their methodology employs the
weighted sum function, imposing constraints on its
applicability to linear problems. The study presented
in (Yang et al., 2020) introduces a multi-policy con-
vex hull reinforcement learning algorithm designed
for managing the operations of We-Energy in the con-
text of the Energy Internet. The algorithm lever-
ages Q-learning twice: initially, to construct a set of
Pareto multi-objective solutions within a continuous
state space, and subsequently, to select the optimal
solution that minimizes We-Energy production costs
while maximizing the security of each We-Energy
unit in the system. This proposed algorithm incor-
porates multi-objective reinforcement learning tech-
niques, and it incorporates human involvement in the
adjustment of the application to ensure system control
and enhance the confidence of intelligent systems. In-
spired by the aforementioned approaches, this work
aims to cope with the limitations of existing meth-
ods for task placement in RTES. In this paper, we
aim to extend the work proposed in (Haouari et al.,
2022) to deal with multi-objective task placement to
be mapped in heterogeneous architectures.
3 BACKGROUND
The resolution of optimization problems where a sin-
gle or non conflicting objective is considered leads
to a single solution, which may be the optimal or
near optimal one. In multi-objective optimization
where objectives may be conflicting, the resolution
step is not as simple. In fact, we are faced to a col-
lection of solutions representing a trade-off between
the objectives. The decision maker can navigate in
this collection and choose the one that best fits their
needs. In this section, some necessary definitions
commonly used in multi-objective optimization prob-
lems are given :
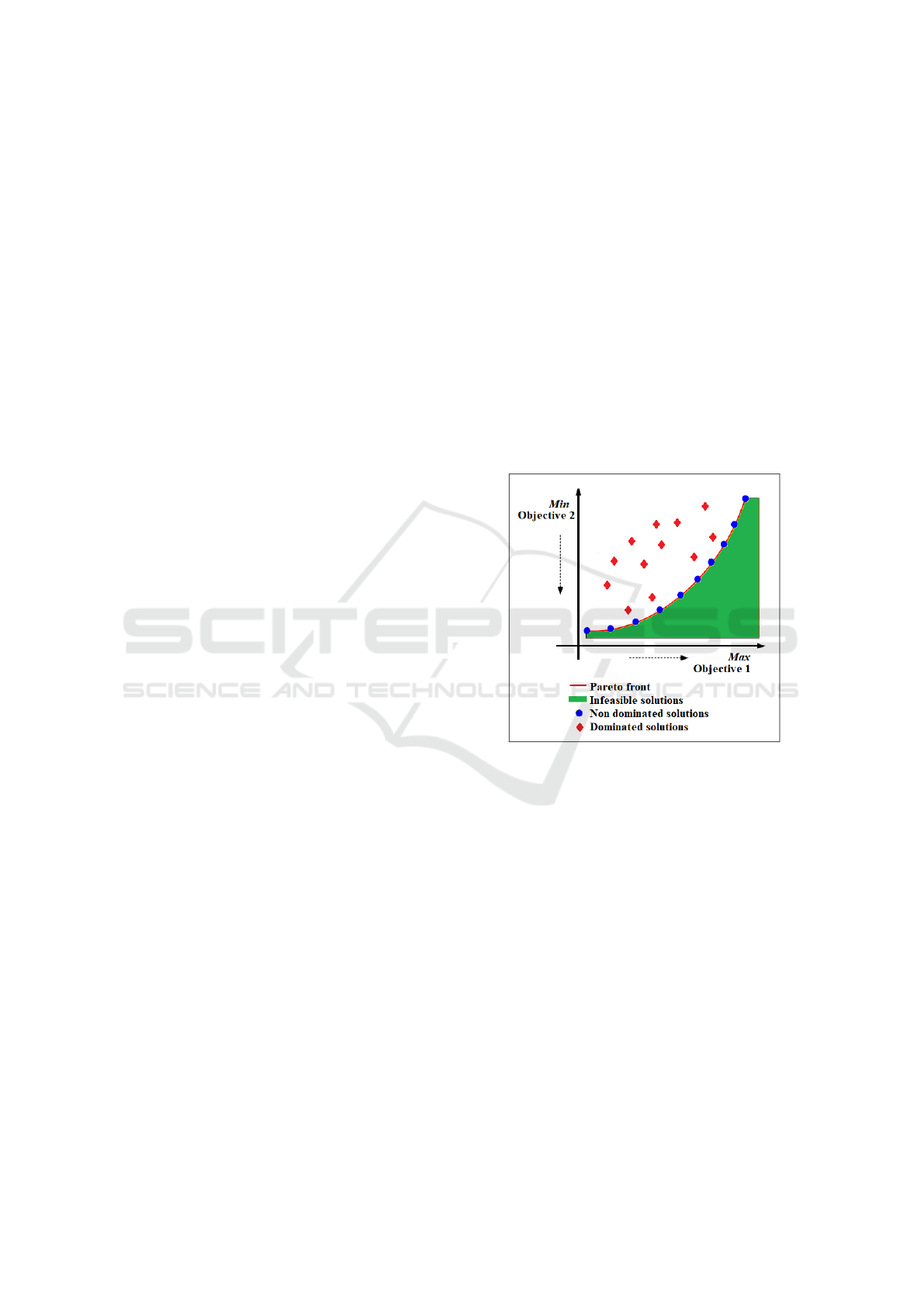
• Pareto dominance: In a multi-objective optimiza-
tion approach, optimization problems are defined
by conflicting objectives. This implies that en-
hancing the solution with respect to one criterion
may potentially worsen another. In these scenar-
ios, there is no singular optimal solution ; instead,
there exists a set of non-dominated solutions, each
representing a trade-off between the objectives.
For instance, if we consider two solutions, π
1
and
π
2
, for the same problem, to dominate π
2
, it is
sufficient and necessary for π
1
to be at least better
than π
2
on all the considered objectives. In Figure
1, solutions depicted as red diamonds are domi-
nated by solutions depicted as large blue circles.
• Pareto optimality: π
1
is deemed a Pareto optimal
solution when there is no other solution π that
dominates π
1
. The set of Pareto-optimal solutions
constitutes the Pareto set. In Figure 1, this collec-
tion is illustrated by the set of solutions shown as
large blue circles.
• The Pareto front: Represents a specific subset of
the Pareto set, encompassing only solutions along
the frontier. These solutions are characterized by
the trade-off phenomenon, wherein the enhance-
ment of one objective results in the degradation of
another. The Pareto front is the line that delineates
the portion of the plane containing the dominated
points. The solutions illustrated as large blue cir-
cles in Figure 1 comprise the Pareto front.
Figure 1: Pareto front curve.
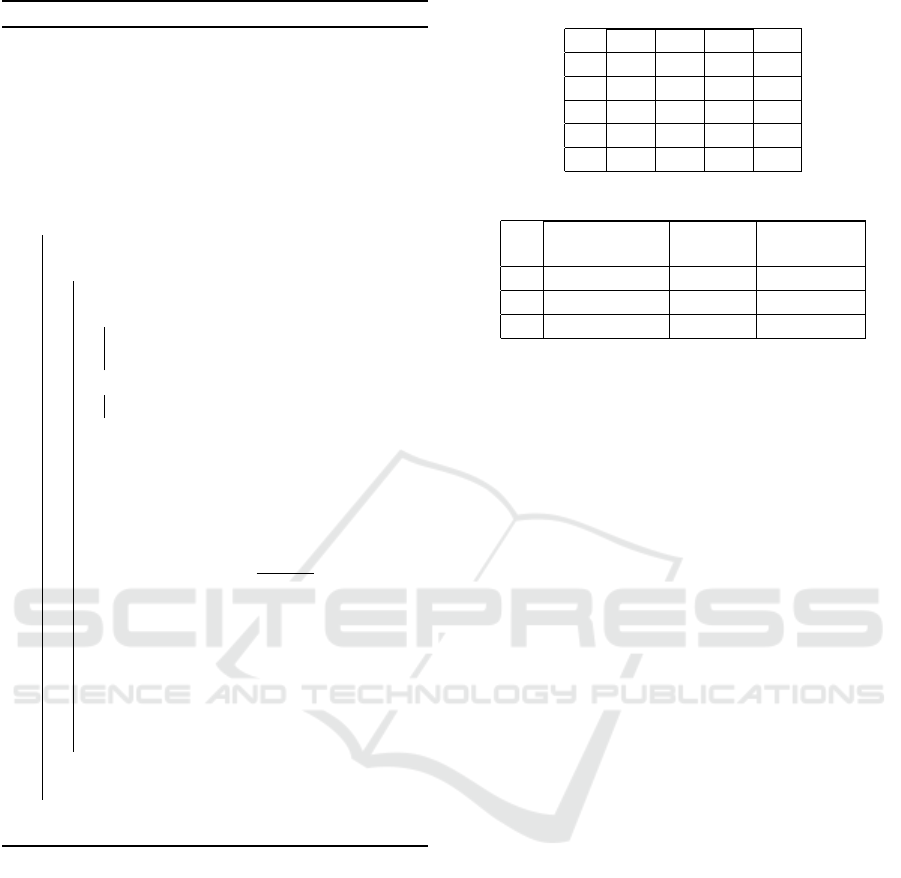
• Hypervolume: In a multi-objective scenario, we
encounter a collection of solutions that approxi-
mate the Pareto front. It has been demonstrated
in (Zitzler and Thiele, 1998; Fonseca et al., 2006)
that hypervolume serves as the most effective met-
ric for evaluating the quality of a given set of so-
lutions. Figure 2 illustrates the region (colored
in green) to which the hypervolume measurement
pertains. This region delineates the space occu-
pied by solutions dominated by the approximated
Pareto front, bounded by this front and a reference
point (i.e., a designated point dominated by all so-
lutions). Therefore, a higher hypervolume value
corresponds to superior solution quality.
Reinforcement Learning for Multi-Objective Task Placement on Heterogeneous Architectures with Real-Time Constraints
181

Figure 2: Hypervolume.
4 SYSTEM FORMALIZATION
The task placement problem, involves three differ-
ent types of models: the task model, the platform
model, and the deployment model. It is assumed
in this work that the task model, that we denote by
τ, is composed of n synchronous, periodic, and in-
dependent tasks (i.e.,τ = {T
1
, T
2
. .. T
n
}). Each task
T
i
is characterized by static parameters T
i
= (C
i
, Pr
i
)
where C
i
= (c
1
, . . . , c
m
) such as c
i j
represents an es-
timation of the worst case execution time of the task
T
i
on the processor P
j
; i ∈ {1 . . . n} and j ∈ {1. . . m},
and Pr
i
is the activation period of the task T
i
. The
platform model, that we denote by P , represents the
execution platform of the system. We assume that
this model is composed of m heterogeneous proces-
sors (i.e., P = {P
1
, P
2
, . . . , P
m
}). Each processor has
its own memory and runs a Real-Time Operating Sys-
tem (RTOS). The task placement step produces a de-
ployment model that we denote by D in this work.
The deployment model consists of a set of tuples D =
{(P
1
, ξ
1
), (P
2
, ξ
2
), . . . (P
k
, ξ
k
)} where k represents the
number of active (or used) processors such as k ≤ m
and ξ
j
represents the subset of tasks allocated to the
processor P
j
after the placement step. The primary
objective of the approach developed in this paper is
to minimize the energy consumption (denoted by E)
of the processors responsible for executing the des-
ignated tasks. To quantify E for a specific deploy-
ment model, we rely on the energy model outlined in
(Lakhdhar et al., 2018). In this model, each proces-
sor P
j
is associated with a constant ζ
j
representing its
capacitance (assumed to be equal to 1 in this work),
a frequency f
j
denoting the processing speed, and a
voltage v
j
corresponding to the electrical supply. The
energy required for the proper operation of processor
P
j
, denoted as E
j
, is calculated using Equation 1
E
j
=
∑
i∈{K
j
}
E
i j
=
∑
i∈{K
j
}
ζ
j
f
j
V
2
j
∗c
i j
, j ∈ {1. . . m} (1)
where K
j
is the set of tasks allocated to P
j
, E
i j
is the
energy required for processor P
j
to perform task T
i
and the global energy E is computed as Equation 2
E =
m
∑
j=1
E
j
(2)
For real-time embedded systems, it is imperative that
the deployment model is deemed feasible. Feasibility,
in this context, entails that placing real-time tasks on
various processors ensures the timing specifications
of the system are met. In this regard, Liu and Lay-
land (Liu and Layland, 1973) defined a schedulabil-
ity test that is both necessary and sufficient when the
task model satisfies the Rate Monotonic (RM) opti-
mality conditions. The feasibility test serves to as-
certain whether a given set of tasks will consistently
meet all deadlines under all release conditions. This
test relies on the calculation of the processor utiliza-
tion factor U
p
and is defined as follows:
U
P
j
=
n
∑
i=1
c
i j
Pr
i
≤ 0.69 (3)
In tackling refactoring, our approach involves
maximizing the system’s adaptability, referred to as
extensibility. Extensibility denotes the system’s abil-
ity to accommodate changes while preserving fea-
sibility. We measure this extensibility through the
concept of ”slack capacity,” which signifies the min-
imum remaining processor capacity post task place-
ment over all the considered processors. The sec-
ond objective pursued by PQP is the maximization of
slack capacity, defined as:
SlackCapacity(P
j
) = min
1..m
(0.69 −U
P
j
) (4)
Essentially, the greater the available capacity on the
processors, the more adaptable the system is to po-
tential changes.
5 TASK PLACEMENT PROBLEM
AS AN MDP
In this study, the task placement challenge is designed
as a sequential decision problem. Specifically, at
each time step t, the system is characterized by the
states of the processors (i.e., the list of tasks placed
on each processor which is required to compute its
available utility) and the list of tasks that has not yet
ENASE 2024 - 19th International Conference on Evaluation of Novel Approaches to Software Engineering
182

been placed. Consequently, the new task placement
is contingent solely upon the current state of the sys-
tem. This adherence to the Markov property (Bell-
man, 1957), defined as an essential condition for ap-
plying RL (Barto, 2021), justifies the utilization of
this technique in our context. The application of RL
techniques necessitates the establishment of key con-
cepts, such as:
• State (S
t
) : denoted by S, it reflects the state of the
system at time step t. It undergoes changes based
on the actions performed by the agent at each step
until reaching the final stage. In the context of
the task placement problem, S
t
consists of sets,
each composed of a processor and its currently as-
signed tasks, along with the set of unplaced tasks.
The final stage aligns with the completion of the
task placement process, involving the assignment
of all tasks.
• Epoch of Decision : It aligns with the completion
of the placement of the entire set of tasks on the
designated processors. It concludes with the gen-
eration of a deployment model.
• Agent : It serves as the decision-maker for the sys-
tem, responsible for selecting an action to tran-
sit from state S
t
to S
t+1
with the goal of maxi-
mizing its reward in accordance with a policy π.
The decision-maker undergoes a learning process
from one epoch to another to fulfill its mission,
and its performance is contingent upon both the
action selection process and the received reward.
In the task placement problem, the objective is to
discover an optimal deployment model within a
multi-objective context.
• Action Space : Denotes the set of feasible ac-
tions available to the agent when it is in state
S
t
following a policy π. For the task placement
problem, the action involves determining the op-
timal processor for a given task from the list of
unplaced tasks, adhering to an ε-greedy policy
(Barto, 2021), where ε is a small number that have
to be initialized. Initially, a high value of ε is as-
signed to promote environmental exploration in
the early stages. The ε-value is systematically
reduced after each epoch by an ε-decrease fac-
tor. This decline in ε is justified by the agent’s
learning progression from one epoch to the next.
As the learning process advances, new states are
explored, leading to a preference for exploitation
over exploration.
• Reward R : The reward holds paramount signifi-
cance in system modeling, serving as the agent’s
motivator that influences its choices during each
action selection. In the context of the task place-
ment problem, the reward functions as positive re-
inforcement, resembling a gift, when the agent
makes an appropriate selection, or as a penalty
in alternative scenarios. Additionally, given the
multi-objective nature of our approach, it be-
comes essential to designate specific rewards for
each objective. In the ensuing discussion, we de-
fine two rewards: one for addressing slack capac-
ity and another for consumed energy.
Slack-Capacity Reward.
Rsc = SP
j
−U
jt
+U
i j
(5)
Where
– U
jt
is the available utilization of processor P
j
at
time step t
– U
i j
is the required utilization for a task T
i
to turn
on P
j
(i.e., U
i
=
C
i
Pr
i
)
– S P
j
reflects the processor state such as
SP
j
=
−(m + δ), When there is not enough
space on P
j
to support T
i
(with δ > 0)
-m, When T
i
is placed on P
j
and
it is not the processor with
the most free capacity
0, Otherwise
Where m denotes the number of processors de-
fined in the hardware model.
Energy Consumption Reward.
Re =
1
E
i j
, when E
i j
is the minimum over all P
j
−m Otherwise
(6)
Where
– E
i j
represents the energy needed for processor
p
j
to execute task T
i
– m is the number of processors defined in the
hardware model.
6 PQP DESCRIPTION
The proposed Pareto Q-learning Placement (PQP)
method aims to address placement problems charac-
terized by a set of tasks that need to be assigned to
a set of heterogeneous processors (as discussed in
Section 4). This method comprises a series of algo-
rithms designed to generate the Pareto-optimal set.
Reinforcement Learning for Multi-Objective Task Placement on Heterogeneous Architectures with Real-Time Constraints
183

Initially, the RL Initialization algorithm (Algorithm
1) is called to start with essential initialization steps.
The objective of this algorithm is to configure vari-
ous data structures accommodating inputs such as the
task model and the platform model for the given prob-
lem and some initialization variables such as γ that
denotes the discounting factor, which reflects the im-
portance given to expected rewards, ε, and ε-decrease
(as defined in Section 5).
After the initialization step, Algorithm 3 uses an ε-
greedy technique for the action selection step, which
consists of randomly generating a number nb in [0,
1]. This algorithm compares the nb number with ε;
if nb is equal to or less than ε then the action ((task,
processor) pair) is randomly chosen; otherwise, it in-
vokes the Task Selection algorithm, referred to as Al-
gorithm 2, to determine the optimal task placement.
Following the execution of this procedure, the agent
receives a reward pair (r.sl, r.e), where r.sl and r.e cor-
respond to the slack-capacity and energy objectives,
respectively. This pair of immediate rewards is em-
ployed to update the average reward R, which is in
turn combined with the non-dominated set ND
t
(S, a)
to compute the Qset. Here, ND
t
(S, a) signifies the re-
ward pairs of non-dominated solutions at time step t
for the state S and the action a. It undergoes updates
based on the non-dominated vectors of S
′
with all pos-
sible actions a
′
. Similarly, Qset(S, a) represents a col-
lection of vectors for the state-action pair (S, a). It
stores the non-dominated set of Q-values obtained by
adding the average immediate reward R to the non-
dominated set ND
t
(S, a) expected in state S
′
and dis-
counted by γ. Subsequently, the agent transits to state
S
′
, removes the placed task from the list of unplaced
tasks, updates the deployment model D
t
with the new
placement, and the agent is replenished for another
task placement until all tasks in the unplaced list are
exhausted. At this moment, the final D
t
is added to D,
and a new epoch searching for another non-dominated
optimal model is stated. The algorithm concludes by
generating a set of non-dominated deployment mod-
els D. Underlining its importance, it must be em-
phasized that the epoch count is a critical parameter
that needs to be carefully chosen to ensure the con-
vergence of PQP. Convergence is realized when no
new deployment model is generated that differs from
those already present in.
The strategy employed for action selection plays a
pivotal role as it significantly impacts both the speed
and quality of the agent’s learning process. In the
context of multi-objective optimization, this step be-
comes intricate, deviating from the straightforward
process in classical Q-learning, where the action eval-
uation considers a single optimal solution. Here, the
Algorithm 1: RL Initialization.
Data: τ: The task model;
P : The platform model;
ε, ε − decease, γ : Initialization parameters;
Result: Q : The Q-table;
S: the initial state;
Q ← Create Q − table(S, A);
Initialize Q[Qset] to empty sets;
Initialize S to initial state;
return Q, S
Algorithm 2: Task Selection.
Data: S: Current state;
Q: Q-table;
Result: a: action (task,processor);
foreach a in S
t
do
Qsg ← empty set;
foreach vector v in Qset(S,a) do
Append (a,v) to Qsg ;
end
end
NDQS ← ND(QSG);
a ← choose randomly one element from
NDQS;
return a
evaluation must account for non-dominated solutions
concerning two conflicting objectives, namely, the
slack capacity and the consumed energy. Various
strategies for the action selection process have been
proposed in (Van Moffaert and Now
´
e, 2014). We
specifically adopt the Pareto action selection method,
identified as the most efficient in (Van Moffaert and
Now
´
e, 2014). The implementation of Pareto action
selection is detailed in Algorithm 2. Initially, the Q-
values associated with each pair (action and its cor-
responding Q-set) for all available actions at state S
are collected into a list called Qsg. Subsequently, the
ND operator is applied to Qsg, eliminating dominated
elements and retaining only the non-dominated ones
in the NDQ list. From this list, the agent randomly
selects an action. This random choice allows, for the
agent, more exploration of the NDQ set.
7 CASE STUDY
This section illustrates the applicability of the pro-
posed PQP method based on the case study outlined
in (Haouari et al., 2022). The case study involves an
RTES implemented in a car to assist the driver in ve-
hicle control. The task model of the RTES consists of
five independent, periodic, and synchronous tasks:
ENASE 2024 - 19th International Conference on Evaluation of Novel Approaches to Software Engineering
184
Algorithm 3: Pareto Q-learning Placement (PQP).
Data: S: The initial state;
τ: The task model;
P : The platform model;
ε, ε − decease, γ : Initialization parameters;
Result: D : the deployment models;
Notations:
D
t
: deployment model at time step t;
a: the action (Task,Processor);
for t from 1 to number o f epochs do
(S, Q) ← RL Initialization (τ, P ) ;
while τ <>
/
0 do
nb ← random number ∈ [0, 1];
if nb ≤ ε then
Select a random possible action a
;
else
a ← Task Selection(S, Q);
end
Perform placement a, Observe state S′
;
r.sc ← Rsc;
r.e ← Re;
Q.nb(S, a) ← Q.nb(S, a) + 1 ;
R(S, a) ← R(S, a) +
r−R(S,a)
nb(S,a)
;
ND
t
← ND(∪
a′
(Qset(S′, a′)) ;
Qset(S, a) ← R(S, a) ⊕ γ ND
t
(S, a);
S ← S
′
;
update τ /* /* remove the
placed task from τ */ */
;
update D
t
with the new placement a;
end
D ← D ∪ D
t
;
end
return D
three dedicated to sensor measurements such as the
car’s speed, the car’s temperature, and the car’s GPS
location, and two for displaying the measured values
such as the measurement summary and the map of the
current car location. In this paper, we expand upon the
platform model described in (Haouari et al., 2022) by
incorporating three heterogeneous processors instead
of homogeneous ones. Table 1 offers a detailed de-
scription of the case study where T
i
denotes the task
names (i ∈ [1..5]), Pr
i
corresponds to the task periods,
and C
1
, C
2
, and C
3
match the worst-case execution
time of T
i
on P
j
.
In order to determine the appropriate deployment
model for the specified case study, the designer em-
ploys the PQP method, implemented in Python 3 with
the NumPy library. This analysis is conducted us-
ing the task model outlined in Table 1 on the plat-
Table 1: Task model description.
T
i
Pr
i
C
1
C
2
C
3
T
1
10 1 1.5 2
T
2
10 2 3 4
T
3
40 3.2 4.8 6.4
T
4
12 2 3 4
T
5
6 1 1.5 2
Table 2: Hardware model description.
P
j
Capacitance Voltage Frequency
(V ) (GHz)
P
1
1 2 2
P
2
1 4 3
P
3
1 6 4
form model described in Table 2. Certain parameters
need to be initialized to ensure the proper function-
ing of the PQP algorithms, including γ, which serves
as the discount factor quantifying the significance as-
signed to future rewards. In our approach, we deem
future task placements important for generating the
final deployment model, and therefore, we assign a
sufficiently high value to γ (= 0.9). For the action
selection, ε is assigned a value of 0.9, and we con-
sider an ε-decrease value of 0.001 (c.f. Section 5).
Table 3 illustrates the non-dominated solutions (de-
ployment models) derived from the PQP algorithm’s
execution. There are four ways for the designer to
allocate tasks across various processors, offering a
trade-off between system extensibility (slack capac-
ity) and energy consumption. These four solutions
provide the designer with valuable insights on how to
implement the car system under optimal conditions.
Importantly, these insights are presented without any
a posteriori imposition of designer preferences. In-
deed, the designer has the opportunity to analyze the
various solutions and select from Table 3 the one that
aligns best with his preferences and constraints re-
lated to the two objectives. For instance, the first
deployment model enables maximum system exten-
sibility, albeit at the expense of consuming the high-
est amount of energy. Nevertheless, the third model
exhibits the least slack capacity in exchange for min-
imizing energy consumption. It prohibits any updates
to the task model due to the overload on processor P
1
.
Moreover, extending the properties of the tasks would
render the current deployment model infeasible. The
second solution is also noteworthy as it maintains an
acceptable extensibility level while having a very rea-
sonable energy consumption value.
In multi-policy RL techniques like Pareto Q-
learning, when multiple solutions are generated for
a given problem, algorithm convergence signifies the
conclusion of the agent’s learning process, indicat-
Reinforcement Learning for Multi-Objective Task Placement on Heterogeneous Architectures with Real-Time Constraints
185

Table 3: Deployment models description (The Pareto front).
P
j
P
1
P
2
P
3
Slack-capacity Energy
DeploymentModel
1
{T
1
, T
3
, T
4
} {T
2
} {T
5
} 0.34 349.6
DeploymentModel
2
{T
2
, T
3
, T
4
} {T
1
, T
5
} {} 0.24 165.6
DeploymentModel
3
{T
1
, T
2
, T
3
, T
4
} {T
5
} {} 0.14 119.6
DeploymentModel
4
{T
1
, T
4
, T
5
} {T
2
, T
3
} {} 0.26 312.8
ing that the agent is no longer able to discover new
or superior solutions compared to the current ones,
regardless of the number of epochs used for train-
ing (Van Moffaert and Now
´
e, 2014). To investigate
the convergence of the PQP algorithm, we conduct
multiple PQP executions while varying the number of
epochs (incrementing by 50 each time) and observe
the generated solutions as illustrated in Table 4. The
NB NG in this table represents the total number of so-
lutions generated by the PQP, whereas the Nb NDS
refers to the number of non-dominated ones. It is
noteworthy that stability in solutions and convergence
are observed from 250 epochs onward. The spike
recorded at 150 epochs in the number of generated
solutions (7 solutions) can be attributed to the agent’s
immaturity at this stage, where it is still exploring its
environment through random task selection. Figure 3
depicts the learning progress of the agent. This learn-
ing progress is represented by the ratio of the num-
ber of non-dominated solutions (NB NDS) to the to-
tal number of generated solutions (NB GS) at each
algorithm iteration. We can see from this figure that,
after 250 epochs, PQP achieves convergence, yielding
a set of deployment models that align with the Pareto
front described in Table 3. From the data in Table 4
and the curve trend depicted in Figure 3, we observe
that as agents converge towards Pareto-optimal solu-
tions, the total number of generated placement mod-
els decreases. The decrease in overall count can be
attributed to the dominance of non-dominated solu-
tions during generation, leading to a reduction in the
total number of solutions. This trend is particularly
noticeable at epoch 150, where merely 7 solutions
exist, and only one among them is Pareto-optimal.
Conversely, at epoch 100, despite the agent’s less ad-
vanced learning stage, there are still 5 solutions in to-
tal. This occurrence can be explained by the fact that
the agent stumbles upon two non-dominated solutions
randomly, resulting in the effective elimination of the
majority of dominated ones.
Despite its significance, convergence alone is in-
sufficient to determine the efficiency of the algorithm.
Even if the algorithm converges and produces a set
of feasible task placements, these placements may be
dominated and far from the Pareto front solutions.
To address this issue and ensure a faithful evaluation
of PQP, we computed the Pareto front for this case
Table 4: PQP results with respect to the number of epochs.
Number o f epochs Nb GS Nb NDS
50 8 1
75 6 1
100 5 2
125 5 2
150 7 1
175 5 2
200 4 3
225 4 3
250 4 4
275 4 4
300 4 4
Figure 3: Process of agent learning.
study. Initially, we generated the complete set of po-
tential task placements (finding 230 possible deploy-
ment models), then filtered out only the feasible ones
(132 deployment models are feasible). Subsequently,
we applied the non-dominated function to retain only
the task placements that constitute the Pareto front
(4 deployment models are non-dominated). Figure 4
compares the Pareto solutions produced by the PQP
algorithm, which correspond to the deployment mod-
els described in Table 3, with the true Pareto solu-
tions already computed for the considered case study.
As we can see from the figure, the obtained solutions
from the PQP execution (indicated by red diamonds)
perfectly match the actual deployment models (repre-
sented by black marks), proving the efficiency of our
method in producing accurate solutions. It’s worth
noting that determining the Pareto front is an NP-hard
ENASE 2024 - 19th International Conference on Evaluation of Novel Approaches to Software Engineering
186
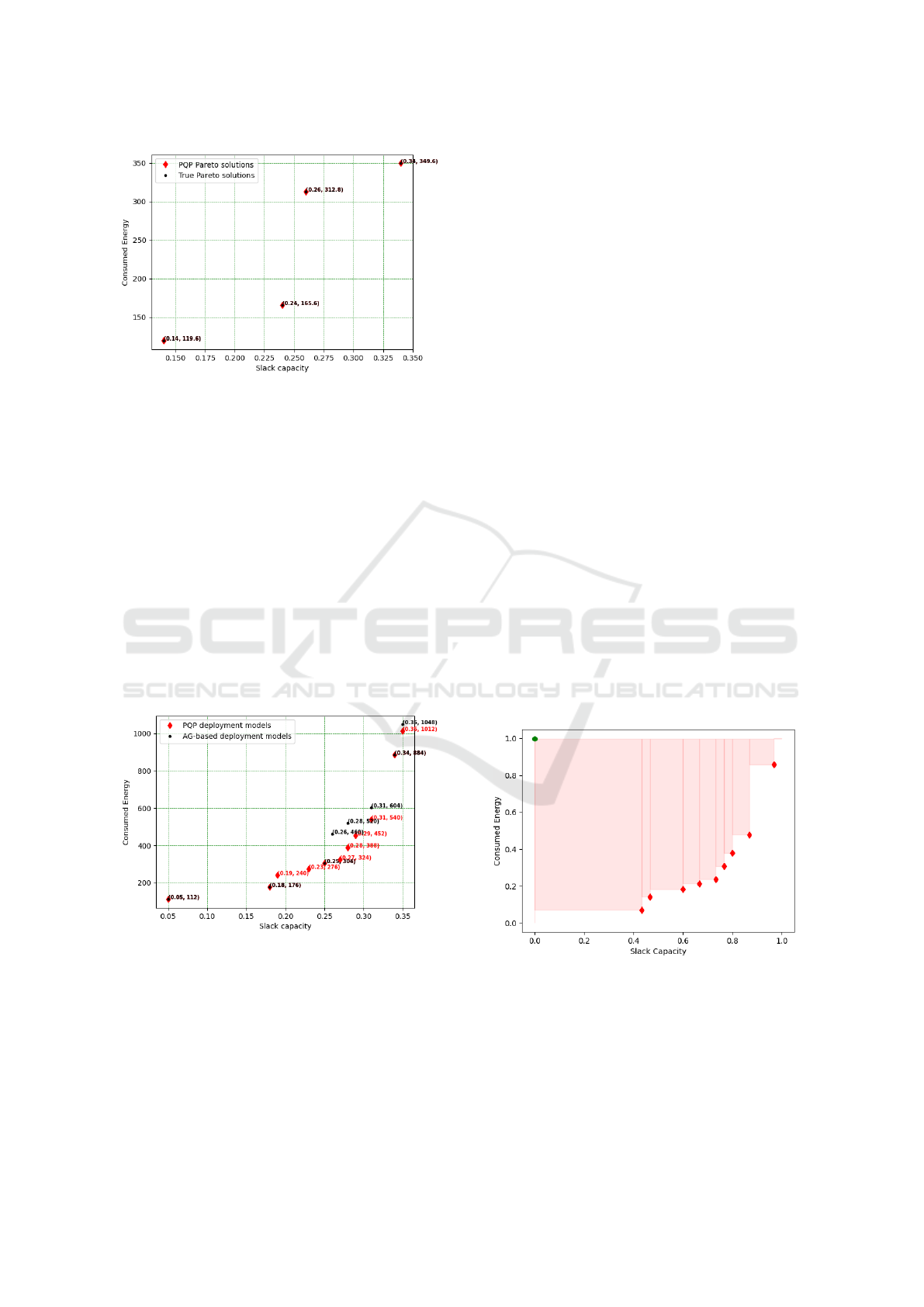
Figure 4: Non dominated solutions for PQP approach Vs
true Pareto optimal solutions.
problem, and our success in computing it for this case
study is attributed to the small number of tasks and
processors considered.
8 EXPERIMENTAL RESULTS
We experiment PQP algorithm on a more extended
general case (for simplicity reason we call it GC) that
has been defined in (Lassoued and Mzid, 2022). In
the study by (Lassoued and Mzid, 2022), a method-
ology (that we call GA based algorithm) employing
genetic algorithms was presented to generate place-
ment models that strike a balance between system ex-
tensibility and energy consumption. The eight black
Figure 5: Non dominated solutions for PQP approach Vs
GA based approach (Lassoued and Mzid, 2022).
markers shown in Figure 5 illustrate the results ob-
tained from running their algorithm on GC. Similarly,
in the same Figure 5, the eleven red diamonds corre-
spond to the solutions derived from executing the PQP
algorithm under the same conditions. As a first in-
terpretation, we observe that the PQP algorithm pro-
duces a larger number of solutions compared to GA
based algorithm. Then the two algorithms share four
solutions (denoted by red diamond and a black mark):
(0.05, 112), (0.18, 176), (0.25, 304), and (0.34, 884).
However, the remaining four solutions from the other
algorithm are dominated by additional solutions from
PQP. Specifically, the solutions (0.26, 460), (0.28,
520), (0.31, 604), and (0.35, 1048) from the other al-
gorithm are respectively dominated by the PQP solu-
tions (0.29, 452), (0.29, 452), (0.31, 540), and (0.35,
1012). Additionally, PQP provides three solutions not
present in the GA based algorithm’s results: (0.19,
240), (0.23, 276), and (0.27, 324).
Delving deeper into the analysis, it would be ad-
vantageous to compare the results against the true
Pareto front. However, due to the relatively com-
plex system involved, this task is not as straightfor-
ward as outlined in section 7. In such circumstances,
where the true Pareto front is unavailable, many stud-
ies (Zitzler and Thiele, 1998; Cao et al., 2015) have
advocated for the use of the hypervolume as an ef-
fective measure to evaluate multi-objective solutions.
The hypervolume, a scalar value, quantifies the area
bounded by a reference point (i.e., a solution that is
dominated by all generated solutions) and the non-
dominated solutions discovered by an algorithm (see
Section 3). What sets the hypervolume apart from
other multi-objective metrics is its ability to simul-
taneously quantify both the extent and diversity of
a set of solutions provided by an algorithm. Hence,
The higher the hypervolume value, the larger space
of dominated solutions covered by the non-dominated
solutions. Figures 6 and 7 exhibit the hypervolumes
Figure 6: (Lassoued and Mzid, 2022) Hypervolume.
of the solution spaces for the GA-based algorithm and
PQP, respectively. Figure 8 presents the juxtaposition
of the two hypervolume figures under consideration to
facilitate comparison. It is evident that PQP covers a
larger extent compared to (Lassoued and Mzid, 2022).
However, since visual interpretation alone may not
suffice, we compute the hypervolume values of the
Reinforcement Learning for Multi-Objective Task Placement on Heterogeneous Architectures with Real-Time Constraints
187
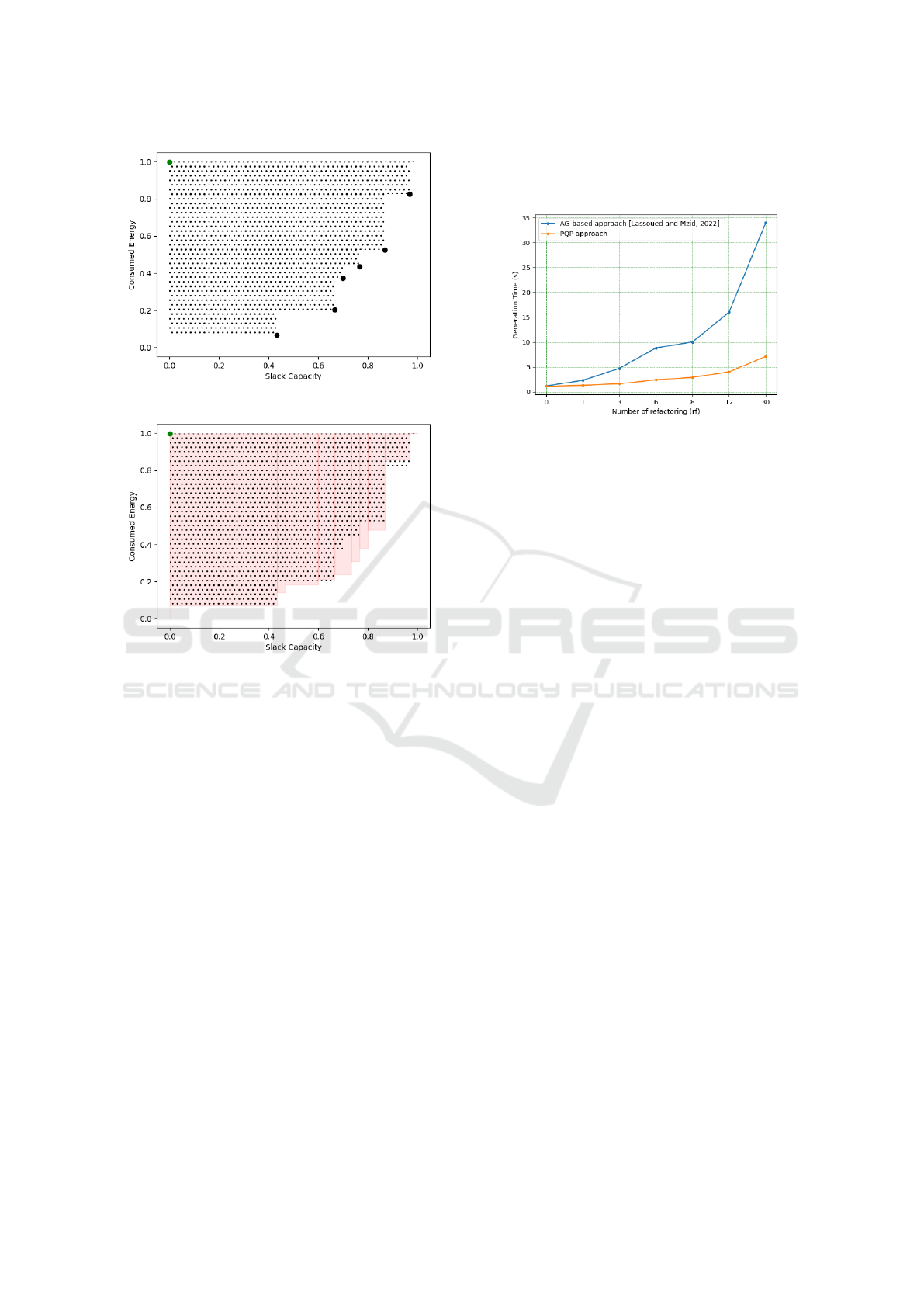
Figure 7: PQP algorithm Hypervolume.
Figure 8: Hypervolume comparison.
two algorithms following the methodology outlined
in (Van Moffaert and Now
´
e, 2014; Cao et al., 2015).
The computed values are 0.714 for GA based algo-
rithm and 0.734 for PQP, confirming the superior per-
formance of the latter.
To more show the capabilities of PQP algorithm
and the utility of maximising the extensibility (slack
capacity) of the system, we maintain a set of new ex-
periments where we tackle the refactoring issue in
a multi-objective setting. For that we refer to the
two random systems data used for experiments in
(Haouari et al., 2022) and we run the refactoring pro-
cess many times to compare PQP and GA based algo-
rithm performances. To measure the time of refac-
toring we compute the T
generation
factor (defined in
(Haouari et al., 2022)) which refers to the necessary
time spent to take into consideration the system up-
dates and to generate the new task placement models.
Equation 7 precises the compute of T
generation
:
T
generation
= T
initial
+ r f ∗ T
re f actoring
(7)
Where T
initial
represents the duration required to sup-
ply the deployment models for the initial system ver-
sion, T
re f actoring
denotes the time necessary to gener-
ate new solutions for considering system updates, and
r f is the number of times the designer updates the
system properties. Figure 9 illustrates the T
generation
Figure 9: Evaluation of the generation time for randomly
generated system.
evolution during the refactoring process for both PQP
and AG based methods on the two random systems
(e.i system1 and system2). The curves depicted in
Figure 9 illustrate that AG-based algorithm requires
more time to accommodate adjustments in both sys-
tems. Furthermore, this necessary time becomes in-
creasingly substantial with the rise in refactoring fre-
quency, as well as with the increase in tasks and pro-
cessors within the system, as seen in system 2. These
results can be explained by the fact that in AG based
approach, a new system is established for every refac-
toring request, requiring the algorithm to be executed
anew each time. In the PQP approach, system up-
dates are handled differently. Specifically, to define
the external structure (i.e., tasks and processor num-
bers) of the system, the PQP algorithm utilizes the Q-
table. As in the refactoring process the aspect of the
system is preserved, the construction of the Q-table is
also maintained, thereby saving the time initially in-
vested in this phase of the algorithm. Consequently,
to address updates related to tasks properties, only the
computation of Q-values needs to be recalculated, re-
quiring a time of T
re f actoring
.
9 CONCLUSION
In this paper, we have presented a novel approach
leveraging reinforcement learning to address the
multi-objective optimization challenges inherent in
task placement problems. The optimization objec-
tives entail maximizing system extensibility while
minimizing energy consumption. To achieve this,
we introduce the PQP method, rooted in Pareto Q-
learning and tailored for the task placement prob-
lem in real-time embedded systems. The proposed
ENASE 2024 - 19th International Conference on Evaluation of Novel Approaches to Software Engineering
188

method approximates the Pareto front for mapping
tasks to heterogeneous processors. The Pareto front
represents the optimal deployment models that strike
a balance between the optimized objectives within
real-time constraints. Through empirical evaluation,
PQP demonstrates its efficacy compared to genetic al-
gorithms while also providing a solution to the refac-
toring problem, enabling designers to efficiently ex-
plore system configurations and adjustments.
As future work, we aim to extend PQP’s applica-
bility to more diverse case studies, incorporating addi-
tional objectives and refactoring scenarios. Addition-
ally, we plan to address the task scheduling process
from a multi-objective perspective, aiming to mini-
mize both worst-case response time and energy re-
quirements simultaneously.
REFERENCES
Akesson, B., Nasri, M., Nelissen, G., Altmeyer, S., and
Davis, R. I. (2020). An empirical survey-based study
into industry practice in real-time systems. In 2020
IEEE Real-Time Systems Symposium (RTSS), pages
3–11. IEEE.
Barto, A. G. (2021). Reinforcement learning: An introduc-
tion by Richards’ Sutton. SIAM Rev, 6(2):423.
Bellman, R. (1957). A markovian decision process. Journal
of mathematics and mechanics, pages 679–684.
Cao, Y., Smucker, B. J., and Robinson, T. J. (2015). On
using the hypervolume indicator to compare pareto
fronts: Applications to multi-criteria optimal exper-
imental design. Journal of Statistical Planning and
Inference, 160:60–74.
Caviglione, L., Gaggero, M., Paolucci, M., and Ronco,
R. (2021). Deep reinforcement learning for multi-
objective placement of virtual machines in cloud dat-
acenters. Soft Computing, 25(19):12569–12588.
Coello, C. A. C. (2007). Evolutionary algorithms for solv-
ing multi-objective problems. Springer.
Fonseca, C. M., Paquete, L., and L
´
opez-Ib
´
anez, M. (2006).
An improved dimension-sweep algorithm for the hy-
pervolume indicator. In 2006 IEEE international con-
ference on evolutionary computation, pages 1157–
1163. IEEE.
Haouari, B., Mzid, R., and Mosbahi, O. (2022). On the use
of reinforcement learning for real-time system design
and refactoring. In International Conference on Intel-
ligent Systems Design and Applications, pages 503–
512. Springer.
Haouari, B., Mzid, R., and Mosbahi, O. (2023a). Psrl: A
new method for real-time task placement and schedul-
ing using reinforcement learning. In Software Engi-
neering and Knowledge Engineering, pages 555–560.
ksi research.
Haouari, B., Mzid, R., and Mosbahi, O. (2023b). A re-
inforcement learning-based approach for online opti-
mal control of self-adaptive real-time systems. Neural
Computing and Applications, 35(27):20375–20401.
Huseyinov, I. and Bayrakdar, A. (2022). Novel nsga-ii and
spea2 algorithms for bi-objective inventory optimiza-
tion. Studies in Informatics and Control, 31(3):31–42.
Kashani, M. H., Zarrabi, H., and Javadzadeh, G. (2017). A
new metaheuristic approach to task assignment prob-
lem in distributed systems. In 2017 IEEE 4th Interna-
tional Conference on Knowledge-Based Engineering
and Innovation (KBEI), pages 0673–0677. IEEE.
Lakhdhar, W., Mzid, R., Khalgui, M., and Frey, G. (2018).
A new approach for optimal implementation of multi-
core reconfigurable real-time systems. In ENASE,
pages 89–98.
Lakhdhar, W., Mzid, R., Khalgui, M., Frey, G., Li, Z., and
Zhou, M. (2020). A guidance framework for synthesis
of multi-core reconfigurable real-time systems. Infor-
mation Sciences, 539:327–346.
Lassoued, R. and Mzid, R. (2022). A multi-objective evo-
lution strategy for real-time task placement on het-
erogeneous processors. In International Conference
on Intelligent Systems Design and Applications, pages
448–457. Springer.
Liu, C. L. and Layland, J. W. (1973). Scheduling algo-
rithms for multiprogramming in a hard-real-time en-
vironment. Journal of the ACM (JACM), 20(1):46–61.
Mehiaoui, A., Wozniak, E., Babau, J.-P., Tucci-
Piergiovanni, S., and Mraidha, C. (2019). Optimiz-
ing the deployment of tree-shaped functional graphs
of real-time system on distributed architectures. Auto-
mated Software Engineering, 26:1–57.
Mirjalili, S. (2019). Genetic algorithm. In Evolutionary
algorithms and neural networks, pages 43–55.
Van Moffaert, K. and Now
´
e, A. (2014). Multi-objective re-
inforcement learning using sets of pareto dominating
policies. The Journal of Machine Learning Research,
15(1):3483–3512.
Vidyarthi, D. P. and Tripathi, A. K. (2001). Maximizing
reliability of distributed computing system with task
allocation using simple genetic algorithm. Journal of
Systems Architecture, 47(6):549–554.
Yang, L., Sun, Q., Zhang, N., and Liu, Z. (2020). Opti-
mal energy operation strategy for we-energy of energy
internet based on hybrid reinforcement learning with
human-in-the-loop. IEEE Transactions on Systems,
Man, and Cybernetics: Systems, 52(1):32–42.
Zhu, Q., Zeng, H., Zheng, W., Natale, M. D., and
Sangiovanni-Vincentelli, A. (2013). Optimization of
task allocation and priority assignment in hard real-
time distributed systems. ACM Transactions on Em-
bedded Computing Systems (TECS), 11(4):1–30.
Zitzler, E. and Thiele, L. (1998). Multiobjective opti-
mization using evolutionary algorithms—a compara-
tive case study. In International conference on par-
allel problem solving from nature, pages 292–301.
Springer.
Reinforcement Learning for Multi-Objective Task Placement on Heterogeneous Architectures with Real-Time Constraints
189
