
Machine Learning Models with Fault Tree Analysis for Explainable
Failure Detection in Cloud Computing
Rudolf Hoffmann
a
and Christoph Reich
b
Institute for Data Science, Cloud Computing and IT Security, Furtwangen University, Germany
Keywords:
Cloud Computing, Reliability, Machine Learning, AI, XAI, Transparency, Explainability, Surrogate Model,
Failure Detection, Fault Tree Analysis, Root Cause Analysis.
Abstract:
Cloud computing infrastructures availability rely on many components, like software, hardware, cloud man-
agement system (CMS), security, environmental, and human operation, etc. If something goes wrong the root
cause analysis (RCA) is often complex. This paper explores the integration of Machine Learning (ML) with
Fault Tree Analysis (FTA) to enhance explainable failure detection in cloud computing systems. We introduce
a framework employing ML for FT selection and generation, and for predicting Basic Events (BEs) to enhance
the explainability of failure analysis. Our experimental validation focuses on predicting BEs and using these
predictions to calculate the Top Event (TE) probability. The results demonstrate improved diagnostic accuracy
and reliability, highlighting the potential of combining ML predictions with traditional FTA to identify root
causes of failures in cloud computing environments and make the failure diagnostic more explainable.
1 INTRODUCTION
In the rapidly evolving domain of cloud computing,
ensuring the reliability of systems has become a major
concern among users (Mesbahi et al., 2018). As cloud
services grow more complex, the potential for faults
increases, making it crucial to employ sophisticated
methods for fault detection and analysis (Ng’ang’a
et al., 2023).
One traditional approach for understanding and
mitigating system failures is Fault Tree Analysis
(FTA). FTA utilizes a Fault Tree (FT), a graphical rep-
resentation that describes the logical connections be-
tween various faults and their root causes through the
use of logical gates. At the heart of the FT are Basic
Events (BE), which are the fundamental fault condi-
tions or failures that can occur within the system com-
ponents. These BEs are interconnected through logi-
cal gates (such as AND, OR, NOT gates) that define
how combinations of these BEs can lead to higher-
level faults or system failures, ultimately leading to
the Top Event (TE) or system failure. FTA is in-
herently deductive, starting with a system failure or
TE and tracing back through the network of faults to
identify root causes. This structured approach allows
a
https://orcid.org/0000-0002-9061-5417
b
https://orcid.org/0000-0001-9831-2181
for a comprehensive analysis of the pathways leading
to system failures, emphasizing how combinations of
component failures or specific environmental condi-
tions can converge to trigger a system fault. By me-
thodically breaking down the fault process from the
TE to the BEs via logical gates, FTA provides a clear
and detailed map of potential fault pathways, thereby
facilitating targeted interventions to increase system
reliability and prevent failures (Mani and Mahendran,
2017).
Simultaneously, the field of Machine Learning
(ML) has shown great promise in enhancing the ca-
pabilities of fault detection and prediction in cloud
computing environments (Yang and Kim, 2022). ML,
particularly through its subfield of Deep Learning
(DL), offers powerful tools for identifying patterns
and anomalies in data that may indicate impend-
ing failures. However, many ML techniques, espe-
cially those involving DL, suffer from a lack of trans-
parency. When these models predict a TE or sys-
tem failure, they often do not provide insight into the
underlying causes or the logical pathway leading to
that prediction. This ”black box” nature of ML es-
pecially DL models poses a significant challenge in
fault analysis, where understanding the root causes is
crucial for effective mitigation and prevention (Hoff-
mann and Reich, 2023).
Cloud computing infrastructures availability rely
Hoffmann, R. and Reich, C.
Machine Learning Models with Fault Tree Analysis for Explainable Failure Detection in Cloud Computing.
DOI: 10.5220/0012727600003711
Paper published under CC license (CC BY-NC-ND 4.0)
In Proceedings of the 14th International Conference on Cloud Computing and Services Science (CLOSER 2024), pages 295-302
ISBN: 978-989-758-701-6; ISSN: 2184-5042
Proceedings Copyright © 2024 by SCITEPRESS – Science and Technology Publications, Lda.
295
on many components, like software, hardware, Cloud
Management System (CMS), security, environmental,
and human operation, etc. If something goes wrong
the Root Cause Analysis (RCA) is often complex.
To overcome these challenges, our research proposes
an innovative integration of ML and FTA to enhance
fault detection and analysis in cloud computing sys-
tems. This approach aims to combine the predictive
power of ML with the systematic analysis capabili-
ties of FTA, offering a pathway to not only predict
system failures more accurately but also to provide
insights into their underlying causes. Through this
work, we try to bridge the gap between advanced
computational models and interpretable fault analy-
sis. The rest of our paper is structured as follows. Sec-
tion 2 delves into the background, providing a com-
prehensive overview of FTA, the role of ML in fault
detection, and the emerging significance of eXplain-
able Artificial Intelligence (XAI). This section also
introduces the concept of surrogate models as a bridge
between complex ML models and interpretable analy-
sis. In section 3, we present our theoretical framework
proposed in this work, describing how ML can be
combined with FTs. This section lays the groundwork
for integrating ML with FTA to achieve a transparent
and interpretable fault detection system. In section
4, we conduct an experimental validation, where we
test the approach of using ML for BE predictions and
calculating the TE, demonstrating the practical appli-
cation of our theoretical framework. In section 5 we
present our results and discuss the benefits and chal-
lenges of our proposed theoretical frameworks. Fi-
nally, section 6 concludes our paper, summarizing key
findings, and future research directions.
2 BACKGROUND
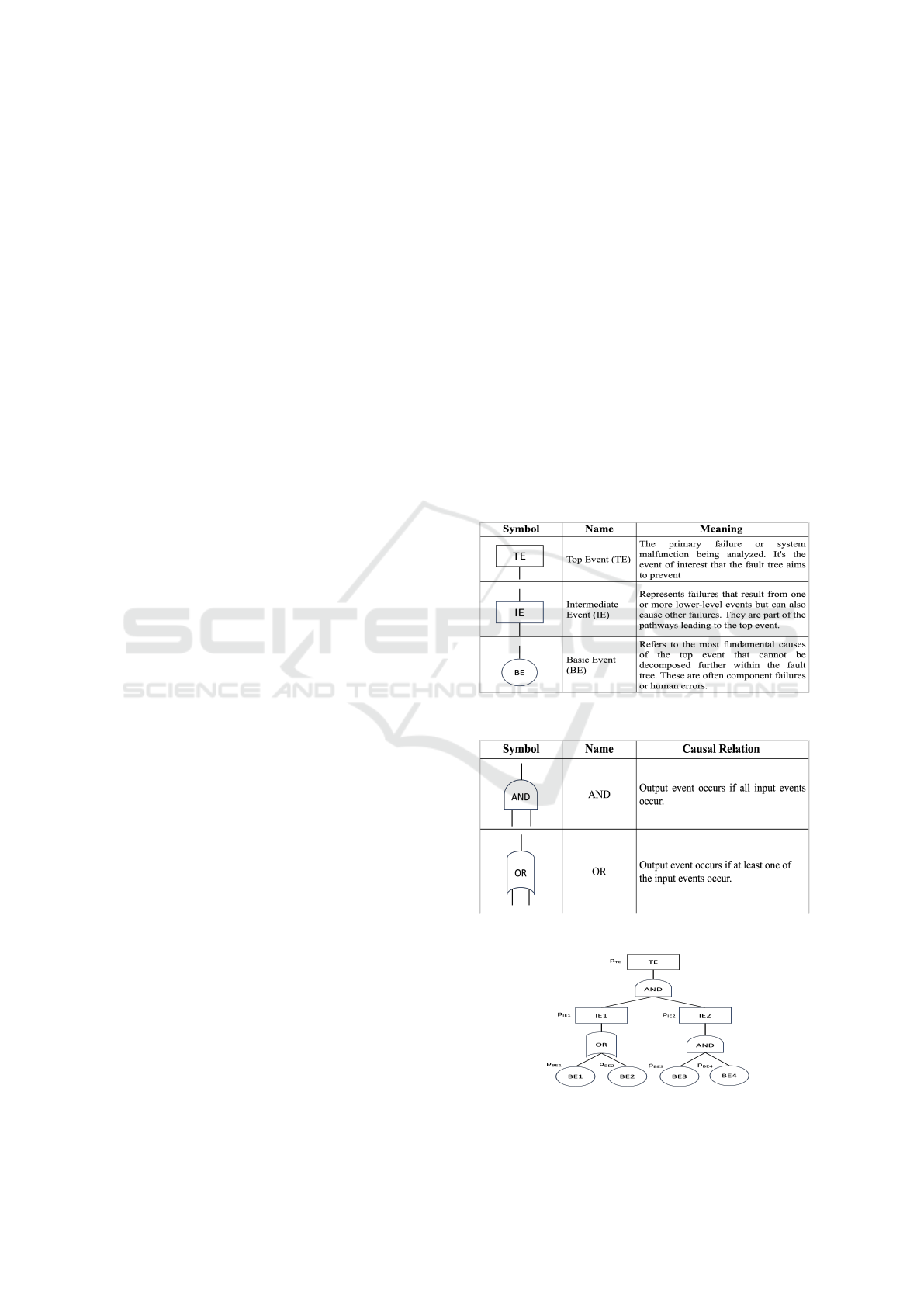
2.1 Fault Tree Analysis (FTA)
In cloud computing, the reliability of systems and the
minimization of failures are crucial. FTA is an es-
sential tool for systematically analyzing the factors
contributing to system failures. A FT visually rep-
resents the logical relationships between various fail-
ure events, categorized into Intermediate Events (IEs)
and BEs, which lead to a top-level failure, known as
the TE. IEs represent combined underlying causes,
while BEs denote fundamental root causes or failure
modes. FTs employ logical gates like AND and OR to
demonstrate how different events interact, influencing
the occurrence of the top-level failure (Fazlollahtabar
and Niaki, 2018). Figure 1 illustrates typical exam-
ples of event symbols used in the FT structure. The
events in the FT are linked using gate symbols. Com-
mon gates are shown in figure 2 (Nieuwhof, 1975).
Figure 3 represents an abstract FT that consists of
these symbols as an example. Having the probabil-
ities for the BEs, we can compute the TE. Let’s break
the formulas to calculate the probability for the TE
down to use the probabilities for the BEs for that task.
(Xie et al., 2021)
Both IEs are connected by an AND-gate. We can
calculate them with:
P
T E
= P
IE1
∧ P
IE2
(1)
The IEs can be calculated with the following for-
mulas:
P
IE1
= (P
BE1
∨ P
BE2
) (2)
P
IE2
= (P
BE3
∨ P
BE4
) (3)
Now, let’s use the probabilities for the BEs to cal-
culate the probability for the TE.
P
T E
= (P
BE1
∨ P
BE2
) ∧ (P
BE3
∨ P
BE4
) (4)
Figure 1: Event symbols.
Figure 2: Gate symbols.
Figure 3: Example of an fault tree.
CLOSER 2024 - 14th International Conference on Cloud Computing and Services Science
296

2.2 Artificial Intelligence (AI) and
Explainable Artificial Intelligence
(XAI)
The integration of Artificial Intelligence (AI), includ-
ing ML and DL, has significantly advanced fault de-
tection by analyzing complex data patterns to indi-
cate potential system issues. However, the opacity of
DL models, often described as ”black box” systems,
poses a challenge in understanding, interpreting and
trusting their predictions. This opacity has catalyzed
a shift towards XAI, that aim to make the decision-
making processes more understandable. It empha-
sizes the need for transparency and interpretability in
AI systems. By explaining the relationships between
input variables and the failure outcomes, it helps iden-
tify the underlying causes of failures. XAI aims to
bridge the gap between AI’s complex algorithms and
user comprehensibility, ensuring that the rationale be-
hind AI decisions is transparent, fostering trust and
wider acceptance in AI-driven solutions (Hoffmann
and Reich, 2023).
Surrogate models, as a method within XAI, serve
as an interpretable approximations of complex AI sys-
tems. These models, also known as response surfaces
or meta-models, are utilized to simplify the relation-
ships between input and output data. This simplifica-
tion is particularly valuable when the actual connec-
tions are unknown or too complex to compute effi-
ciently. By applying surrogate models, XAI aims to
make AI’s decision-making processes more transpar-
ent and understandable, enhancing user trust and fa-
cilitating more informed decision-making in critical
applications (Williams and Cremaschi, 2019).
3 THEORETICAL FRAMEWORK
3.1 The Role of Fault Trees in Surrogate
Model-Based Fault Analysis
In section 2 we explained that surrogate models act as
interpretable approximations of complex models, pro-
viding insights into how inputs affect outputs. Sim-
ilarly, FTs systematically map the relationships be-
tween BEs and the TE, offering a clear view of causal
pathways. Our approach leverages ML models to pre-
dict BEs within the FT framework. By predicting
these BEs, we gain insight into the specific events
or conditions that directly contribute to the system
failure. Subsequently, FTs are employed to com-
pute the likelihood of the TE based on the occur-
rence of these predicted BEs. Moreover, ML tech-
niques can aid in the selection or generation of FTs
of complex systems. This integration of ML with
FT enhances the traceability and comprehension of
failure occurrences, facilitating the identification of
root causes. Thus, our approach not only enhances
the transparency of failure detection but also enables
a deeper understanding of failure mechanisms within
complex systems.
3.2 Combining Fault Trees with
Machine Learning
In this section we describe the different combination
methods in more detail.
(A) Machine Learning for the Fault Tree Selection
In the field of cloud computing, navigating through
multiple failure scenarios efficiently is pivotal due to
the complex interaction of system components and
external variables. This complexity makes it neces-
sary to use an automated method to identify suitable
FTs in a collection of FTs or from a huge FT (see
Figure 4). Instead of relying solely on manual ex-
pertise or predefined rules, ML algorithms analyze
observed symptoms or failure modes to match them
with the most appropriate FT. This predictive capabil-
ity significantly enhances the fault diagnosis process
by narrowing down the search space and pinpoint-
ing potential root causes. Importantly, by automat-
ing this selection process, we reduce the influence of
subjective biases, ensuring more objective and con-
sistent fault diagnosis. Furthermore, by selecting the
best-suited FT, our approach indirectly leverages it as
a surrogate model to approximate the underlying fail-
ure mechanisms. This surrogate model aids in mak-
ing complex diagnostics more manageable, providing
insights into the causal relationships between various
system events and failures. However, this strategy re-
quires the availability of multiple expert FTs, under-
scoring the need for a rich repository of FTs to cover
the spectrum of potential failures in cloud computing
environments.
(B) Machine Learning for the Fault Tree
Generation
In this method, we use observational or historical data
to automate the generation of FTs that encapsulate the
system’s failure modes, thereby serving as a surrogate
model (see Figure 5).
By leveraging ML techniques, we can derive in-
sights from the data to construct FTs that accurately
represent the complex relationships between system
Machine Learning Models with Fault Tree Analysis for Explainable Failure Detection in Cloud Computing
297
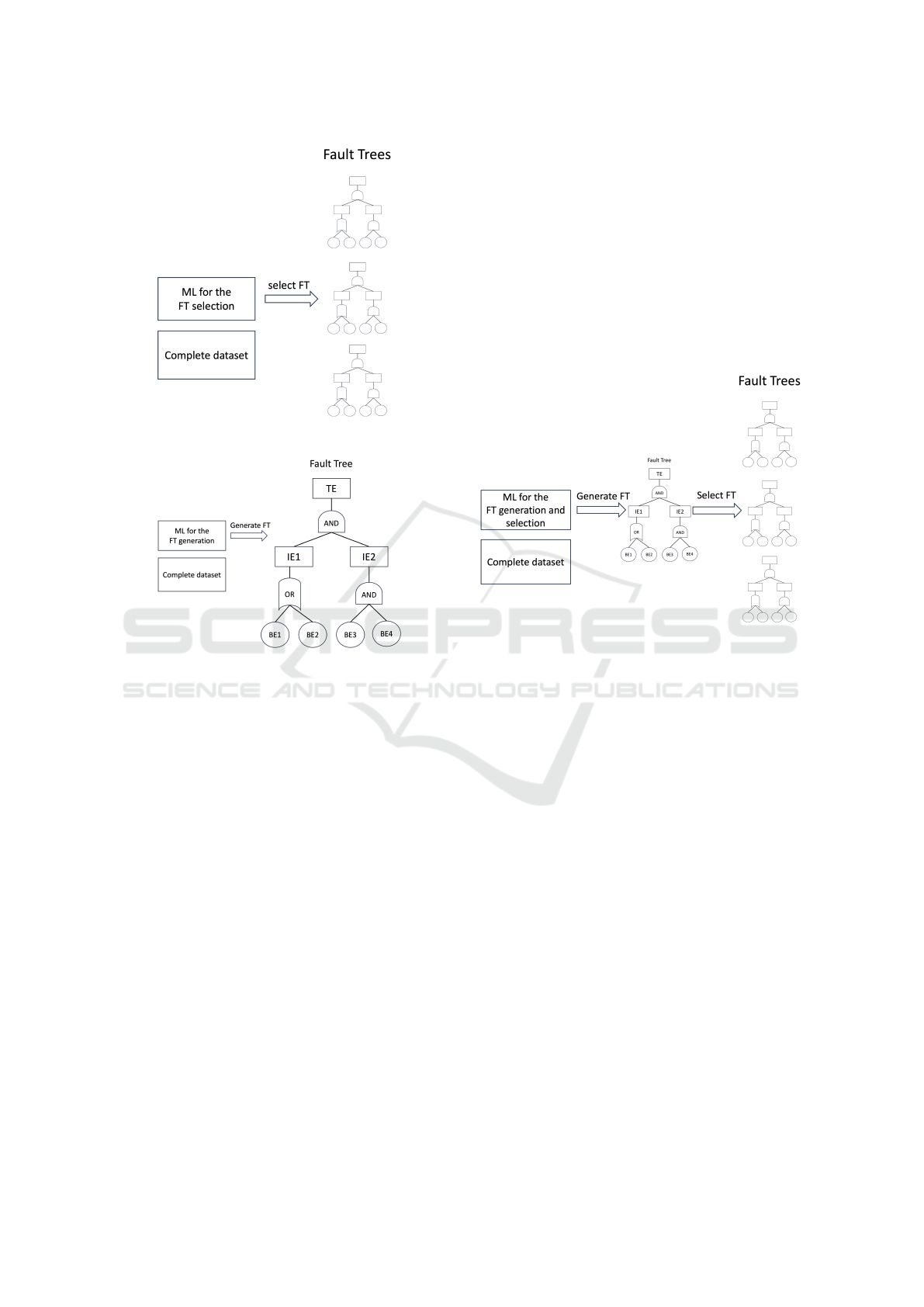
Figure 4: Using ML for the FT selection.
Figure 5: Using ML for the FT generation.
components and failure events. The use of observa-
tional or historical data enables us to capture real-
world scenarios and patterns, facilitating the creation
of comprehensive FTs. However, it’s crucial to ensure
that these generated FTs strike a balance between in-
terpretability and relevance. This often involves re-
fining the FTs by simplifying or pruning excessive
details to enhance clarity without compromising the
representation of critical failure pathways. Moreover,
generating an effective FT requires the integration of
expert knowledge to ensure alignment with the sys-
tem’s failure modes. This fusion of ML-driven data
analysis with expert insights enhances the accuracy
and relevance of the generated FTs, enabling them to
serve as valuable tools for fault diagnosis and sys-
tem understanding. However, generating a FT with
expert knowledge and ensuring it accurately repre-
sents the system’s failure modes, can be difficult. De-
spite these challenges, the automated generation of
FTs through ML offers a powerful means of captur-
ing and understanding the underlying mechanisms of
system failures, ultimately facilitating more effective
analysis and decision-making in fault diagnosis and
system maintenance.
(C) Machine Learning for the Fault Tree
Generation and Selection
This approach merges the generation and selection
of FTs through ML (see Figure 6). ML algorithms
are employed to generate FTs based on observational
or historical data, and then to select the most fitting
FT for a given situation. This strategy aims to en-
hance the efficiency of diagnosing system failures by
leveraging ML’s capability to analyze complex data
and identify significant patterns, thereby providing an
analysis tool for different failure scenarios.
Figure 6: Using ML for the FT generation and selection.
(D) Machine Learning for the Basic Event
Prediction
This approach utilizes ML models to predict BEs
within FTs, translating these predictions into proba-
bilities to determine the TE’s likelihood (see Figure
7). By predicting BEs of the superior events like the
TE, allows the identification of root causes behind
failure occurrences. Furthermore, the deductive na-
ture of FTs allows to determine the TE and thus acts as
a surrogate model, thereby boosting the explainability
of TE predictions. This mechanism not only enhances
the explainability of TE predictions but also provides
insights into the causal relationships between individ-
ual events and system failures. Furthermore, this ap-
proach leverages the adaptability of ML models to
continually refine prediction accuracy through itera-
tive data learning. By incorporating new data and in-
sights, the ML models can dynamically adjust their
predictions, improving the accuracy and reliability of
failure predictions over time. In essence, this method
explains failure modes and their connections within
complex systems. By combining the interpretability
of FTs with the predictive power of ML, our approach
offers understanding and addressing system failures
in diverse environments.
CLOSER 2024 - 14th International Conference on Cloud Computing and Services Science
298
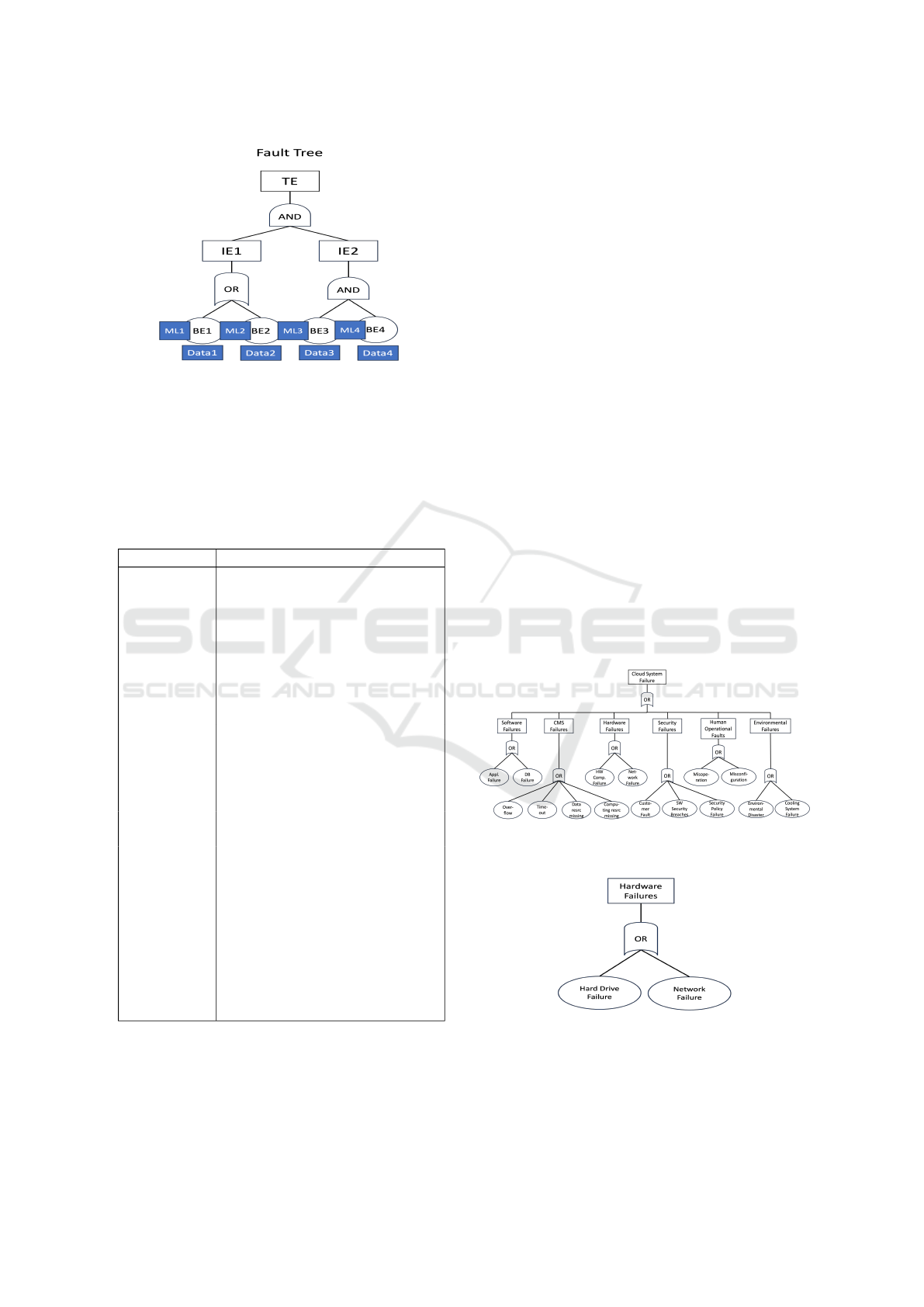
Figure 7: Using ML for the BEs prediction.
3.3 Overview of all Combinations
Table 1 provides an overview of the described combi-
nation cases. It describes, in what way the FT acts as
a surrogate model.
Table 1: FT acting as a surrogate model in different combi-
nation cases.
Combination FT Act as Surrogate Model
(A) By selecting a FT, the system
indirectly uses it to approximate
the underlying failure mechanism,
making complex diagnostics more
manageable. This conceptualiza-
tion of the FT as a surrogate model
aids in simplifying fault analysis
and identifying root causes effec-
tively.
(B) The generated FTs act as surro-
gate model by modeling the sys-
tem’s complex failure mechanisms
through a structured and simplified
representation.
(C) Integrates both the generation and
selection of FTs.
(D) The FT acts as a surrogate model
by providing a simplified, yet ef-
fective, representation of the sys-
tem’s failure mechanisms. The
FT allows the estimation of TEs
based on BE probabilities, which
can be seen as approximating the
overall system’s failure behavior
through a more manageable and
interpretable framework.
4 EXPERIMENT
4.1 Fault Tree Selection
In the paper (Mesbahi et al., 2018), diverse failure
classifications within cloud computing systems are
detailed, including software, hardware, CMS, secu-
rity, environmental, and human operation failures,
along with their respective modes. Based on this com-
prehensive classification, we constructed a FT with
”Cloud System Failure” as the TE, categorized the
failure classifications as IEs, and detailed their modes
as BEs, as illustrated in Figure 8. Drawing from our
theoretical framework in Section 3, our validation fo-
cuses on the ”Hardware Failure” class. We simpli-
fied the overarching FT by isolating the ”Hardware
Failure” branch, yielding a focused sub-tree that is
used for the proof of concept of our approach ML for
the BE prediction (see section 3.2). You see the fo-
cused FT in Figure 9. The hardware failures occurs,
if a hardware component (hard drive in this case) or
network indicates a failure. While network failures
can occur from various sources, not just hardware is-
sues, for our experiment, we proceed with a specific
assumption. This focus allows us to streamline our
analysis within the context of our FTA, concentrat-
ing on hardware-related aspects to provide clarity and
specificity to our investigation.
Figure 8: Cloud System Failure FT based on the description
in (Mesbahi et al., 2018).
Figure 9: FT focusing on the hardware failure.
Machine Learning Models with Fault Tree Analysis for Explainable Failure Detection in Cloud Computing
299

4.2 Dataset Description
4.2.1 SOFI Dataset
The SOFI (Symptom-Fault relationship for IP-
Network) dataset contains information about an ex-
tensive enterprise network’s performance, indicating
well-known faults across various times and days, to-
taling approximately 649 hours of monitoring. No-
tably, 10 hours of this dataset capture periods when
faults were intentionally induced to study their im-
pact. The dataset includes 34 attributes covering
performance metrics and fault indicators, classifies
network status into faulty (F) or healthy (NE), and
comprises 12,971 instances, offering a rich resource
for analyzing network fault dynamics and developing
fault detection models (Vargas-Arcila et al., 2021).
4.2.2 SMART Dataset
The dataset encompasses S.M.A.R.T. attributes from
four distinct hard drives within the BackBlaze Data
Center, detailing aspects like model, serial number,
date, and capacity, all preprocessed for analysis. The
dataset specifically contains records of failed Sea-
gate hard drive S.M.A.R.T information, with data
on 56 attributes across 128,818 failure instances and
1,031,502 instances indicating normal operation, pro-
viding a valuable dataset for predicting hard drive fail-
ures. (Backblaze, 2023)
4.3 Merging Datasets
To integrate the SOFI network dataset with the
S.M.A.R.T. hard drive dataset from BackBlaze, we
adopted an approach to merge the dataset, aimed at
analyzing the interplay between network and hard
drive health. This process involved horizontally
merging features of operational (good) hard drives
and networks, appending indicators (class hd=0,
class nw=0, class hw=0) to imply the absence of fail-
ures. Conversely, combinations of operational and
faulty states between hard drives and networks were
similarly merged, with appended classifications to re-
flect the presence or absence of failures in each do-
main, thereby enabling a comprehensive analysis of
hardware health in relation to network and hard drive
performance. The merged dataset contains 25942
records with 90 attributes.
4.4 Modeling
In our experiment, we compared two modeling ap-
proaches. In the first approach, we used the merged
dataset with a DL model to predict, if a hardware fail-
ure exist. In the second approach, we tried the pro-
posed approach to use DL models to predict the BEs
and then determine the TE. For both approaches, we
used the same model architecture. The architecture
is shown in Table 2. We created the DL model us-
ing TensorFlow and Keras. For the architecture, we
used four sequential Dense layers. We used Recti-
fied Linear Unit (ReLU) as activation function for
the hidden layers, while Sigmoid for the classification
layer to constrain output between zero and one. Ad-
ditionally, we adopted a k-fold cross-validation strat-
egy with 10 splits to ensure the robustness and gen-
eralizability of our model across different subsets of
the data. This methodological choice aims to miti-
gate overfitting and assess the model’s performance
more accurately. The hyperparameters used to build
the model were: (Hoffmann et al., 2022)
optimizer: Adam with a learning rate of 0.001
loss: ’binary
crossentropy’
epochs: 30
batch size: 32
Table 2: Architecture of the DL Model.
Layer Units Activation Function
Dense1 128 ReLu
Dense2 64 ReLu
Dense3 32 ReLu
Dense4 1 Sigmoid
4.4.1 Approach 1 - Predicting the Top Event
In this common approach, we utilize the merged
dataset, comprising 90 attributes, to directly pre-
dict the target variable ’class hw’, which indicates
the presence of a hardware failure. This predic-
tion is made by the DL model described in Table 2.
This method uses a comprehensive dataset to predict
the hardware failure risk using a singular predictive
model.
4.4.2 Approach 2 - Predicting the Basic Events
In this new approach described in our theoretical
framework (see section 3.2) we utilize two DL mod-
els with the architecture described in Table 2. The
first model uses attributes of the hard drive to pre-
dict, whether a hard drive failure exists (class hd).
The other model uses the other attributes to predict,
whether a network failure exists (class nw). The con-
fidence values of both predictions are used to calcu-
late the confidence value of the TE (hardware failure).
We treat the confidence values as probabilities of a FT
CLOSER 2024 - 14th International Conference on Cloud Computing and Services Science
300

and calculate the probabilities of both BEs:
P
hw
= P
hd
∨ P
nw
(5)
Both events are independent from each other.
Thus, we can calculate it with: (Kaptein and van den
Heuvel, 2022)
P
hw
= P
hd
+ P
nw
− (P
hd
× P
nw
) (6)
Classifying the hardware failure using this ap-
proach makes the prediction more explainable, since
the failures, that lead to this occurrence, are known.
After predicting the BEs (hard drive and network fail-
ure), the FT acts as a surrogate model.
5 RESULTS AND DISCUSSION
The results presented in this section represent the
mean values obtained after executing the algorithms
ten times. This approach was chosen to ensure the
reliability and stability of our findings, aiming to ac-
count for variability in performance across different
runs. By averaging the outcomes, we tried to provide
a more accurate and robust assessment of the model-
ing approaches. Table 3 compares the results of the
different approaches.
The results indicate that both modeling ap-
proaches yield excellent outcomes, with the pro-
posed method (predicting BE and calculating the TE)
slightly outperforming the traditional approach across
all metrics: accuracy, precision, recall, F1-score, and
Area Under the ROC (Receiver Operating Curve)
Curve (AUC-ROC). Crucially, the proposed approach
offers additional value by identifying the root causes
of the TE failure, enhancing the interpretability of the
results. This contrasts with the common approach,
which predicts the occurrence of the TE without indi-
cating the underlying reasons for its occurrence.
Table 3: Results of our Experiments.
Metric TE Prediction BEs Prediction
Accuracy 99.1 % 99.4 %
Precision 99.7 % 99.8 %
Recall 98.6 % 99.1 %
F1-Score 99.2 % 99.5 %
AUC-ROC 99.9 % 99.6 %
In this study, we explored four methods to inte-
grate ML with FTs, but our experimental validation
focused solely on the technique of using ML to pre-
dict BEs. The potential approaches involving ML for
selecting, generating, or both selecting and generat-
ing FTs were not explored in this work. Instead, we
concentrated on predicting the BEs within an exist-
ing or readily available FT, demonstrating the practi-
cal application and benefits of this specific approach
in enhancing fault diagnosis.
Although we validate only one approach, we
want to discuss the challenges and benefits of all
approaches described in section 3. The first ap-
proach, utilizing ML to select the most appropriate
FT, presents a strategic advantage in narrowing down
the search space for RCA. This way, the FT approxi-
mates the underlying failure mechanism. Acting as a
surrogate model, it enhances diagnostic efficiency and
reduces the reliance on computational resources. This
method, however, faces challenges in managing the
complexity inherent in FTs, especially as system dy-
namics evolve, requiring continuous updates and ad-
justments.
The second strategy, employing ML for the auto-
mated generation of FTs, marks a significant shift to-
wards reducing dependency on expert knowledge for
FT construction. This approach not only streamlines
the fault diagnosis process, but also opens ways for
uncovering hidden patterns and relationships within
system’s complex failure mechanisms by modeling
it using FTs, offering a new perspective on system
improvements. Since the FT models complex fail-
ure mechanisms, it can be viewed as a surrogate
model. Despite these benefits, the risk for generating
complex or redundant FTs poses a significant chal-
lenge, emphasizing the need for sophisticated post-
processing techniques to ensure the usability and in-
terpretability of the generated trees. Additionally,
generating a FT with expert knowledge and ensuring
it accurately represents the system’s failure modes can
be difficult.
Combining the generation and selection of FTs
through ML, our third approach attempts to harness
the strengths of both mentioned strategies. This inte-
grated method promises a comprehensive solution to
fault diagnosis, but it introduces complexity in effec-
tively merging these processes, particularly in verify-
ing the appropriateness of the selected or generated
FTs.
Our fourth and final approach focuses on employ-
ing ML to predict BEs within the FT framework, sig-
nificantly enhancing the fault diagnosis’s reliability
and interpretability, since the FT allows the estima-
tion of the TE based on BE probabilities and thus act
as a surrogate model. This method allows the identifi-
cation of root causes and offers the understandibility
of the TE’s occurrence, thereby increasing the trans-
parency of the entire process. However, it’s important
to note that while this approach brings explainability
to the occurrence of the TE, the occurrence of the BEs
Machine Learning Models with Fault Tree Analysis for Explainable Failure Detection in Cloud Computing
301

themselves remains opaque. The ”black box” nature
of DL models used for predicting these events limits
our ability to fully understand and interpret the occur-
rence of the BEs.
In future work, our research will explore the un-
validated approaches of using ML for selecting, gen-
erating, or both selecting and generating FTs. We
will investigate methodologies for employing ML al-
gorithms to automate the selection of appropriate
FTs based on observed symptoms or failure modes.
This will involve developing algorithms that navi-
gate through multiple failure scenarios to identify the
most suitable FTs for RCA. Furthermore we will in-
vestigate how ML can be utilized to automate the
genreration of FTs based on observational or histor-
ical data. This involves developing algorithms that
construct FTs that accurately represent the complex
failure mechanisms within cloud computing systems,
while also ensuring interpretability and relevance for
effective fault diagnosis.By pursuing these paths, we
aim to enhance fault diagnosis by fully leveraging the
integration of ML with FTs. Additionally, we will
explore the implementation of our approach in real-
world settings to evaluate its applicability and robust-
ness across various cloud computing environments.
Through these efforts, we try to unlock advanced ca-
pabilities for more precise analysis and understanding
of system failures.
6 CONCLUSION
Our investigation into integrating ML with FTA
presents a significant advancement in fault detection
methodologies for cloud computing systems. By con-
centrating on the prediction of BEs and the subse-
quent calculation of TE probability, we not only en-
hance the precision of fault diagnosis but also in-
crease the system’s interpretability and transparency.
Although our experimental validation focused on
this particular approach, we discussed the theoretical
framework and potential benefits of using ML for se-
lecting and generating FTs. Future work will explore
these unvalidated approaches to further refine and ex-
pand our understanding of integrating ML with FTA,
aiming to develop more robust and intuitive fault di-
agnosis tools for complex computing environments.
FUNDING
This research was funded by the Deutsche
Forschungsgemeinschaft (DFG, German Research
Foundation), under grant DFG -GZ: RE 2881/6-1
and the French Agence Nationale de la Recherche
(ANR), under grant ANR-22-CE92-0007.
REFERENCES
Backblaze (2023). Harddrive cleaned smart dataset. Ac-
cessed: 2024-02-15.
Fazlollahtabar, H. and Niaki, S. (2018). Fault tree analy-
sis for reliability evaluation of an advanced complex
manufacturing system. Journal of Advanced Manu-
facturing Systems, 17:107–118.
Hoffmann, R. and Reich, C. (2023). A systematic literature
review on artificial intelligence and explainable artifi-
cial intelligence for visual quality assurance in manu-
facturing. Electronics, 12(22).
Hoffmann, R., Reich, C., and Skerl, K. (2022). Eval-
uating different combination methods to analyse ul-
trasound and shear wave elastography images auto-
matically through discriminative convolutional neu-
ral network in breast cancer imaging. International
Journal of Computer Assisted Radiology and Surgery,
17(12):2231–2237.
Kaptein, M. and van den Heuvel, E. (2022). Probability
Theory, pages 81–102. Springer International Pub-
lishing, Cham.
Mani, D. and Mahendran, A. (2017). An approach to evalu-
ate the availability of system in cloud computing using
fault tree technique. International Journal of Intelli-
gent Engineering and Systems, 10:245–255.
Mesbahi, M. R., Rahmani, A. M., and Hosseinzadeh, M.
(2018). Reliability and high availability in cloud com-
puting environments: a reference roadmap. Human-
centric Computing and Information Sciences, 8(1):20.
Ng’ang’a, D. N., Cheruiyot, W., and Njagi, D. (2023). A
machine learning framework for predicting failures in
cloud data centers -a case of google cluster -azure
clouds and alibaba clouds. Accessed: 2024-02-17.
Nieuwhof, G. (1975). An introduction to fault tree analysis
with emphasis on failure rate evaluation. Microelec-
tronics Reliability, 14(2):105–119.
Vargas-Arcila, A. M., Corrales, J. C., Sanchis, A., and
Rend
´
on, A. (2021). Dataset of symptom-fault causal
relationships for an ip-based network. Accessed:
2024-02-15.
Williams, B. and Cremaschi, S. (2019). Surrogate model se-
lection for design space approximation and surrogate-
based optimization. In Mu
˜
noz, S. G., Laird, C. D., and
Realff, M. J., editors, Proceedings of the 9th Interna-
tional Conference on Foundations of Computer-Aided
Process Design, volume 47 of Computer Aided Chem-
ical Engineering, pages 353–358. Elsevier.
Xie, X., Wang, Y., Hu, K., and Du, J. (2021). Quantitative
analysis of fault diagnosis based on fault tree reason-
ing. In 2021 3rd International Conference on Applied
Machine Learning (ICAML), pages 7–10.
Yang, H. and Kim, Y. (2022). Design and implementation
of machine learning-based fault prediction system in
cloud infrastructure. Electronics, 11(22).
CLOSER 2024 - 14th International Conference on Cloud Computing and Services Science
302
