
Load-Aware Container Orchestration on Kubernetes Clusters
Angelo Marchese
a
and Orazio Tomarchio
b
Dept. of Electrical Electronic and Computer Engineering, University of Catania, Catania, Italy
Keywords:
Microservices Applications, Container Technology, Kubernetes Scheduler, Kubernetes Descheduler, Node
Monitoring, Application Monitoring, Cloud Continuum.
Abstract:
Microservice Architecture is quickly becoming popular for building extensive applications designed for de-
ployment in dispersed and resource-constrained cloud-to-edge computing settings. Being a cloud-native tech-
nology, the real strength of microservices lies in their loosely connected, autonomously deployable, and scal-
able features, facilitating distributed deployment and flexible integration across powerful cloud data centers
to heterogeneous and often constrained edge nodes. Hence, there is a need to devise innovative placement
algorithms that leverage these microservice features to enhance application performance. To address these
issues, we propose extending Kubernetes with a load-aware orchestration strategy, enhancing its capability
to deploy microservice applications within shared clusters characterized by dynamic resource usage patterns.
Our approach dynamically orchestrates applications based on runtime resource usage, continuously adjusting
their placement. The results, obtained by evaluating a prototype of our system in a testbed environment, show
significant advantages over the vanilla Kubernetes scheduler.
1 INTRODUCTION
The orchestration of modern applications, includ-
ing Internet of Things (IoT), data analytics, video
streaming, process control, and augmented reality ser-
vices, poses a complex challenge (Salaht et al., 2020;
Oleghe, 2021; Luo et al., 2021). These applica-
tions impose stringent quality of service (QoS) re-
quirements, particularly in terms of scalability, fault
tolerance, availability, response time and throughput.
To address these requirements the microservices ar-
chitecture paradigm has become the predominant ap-
proach for designing and implementing such applica-
tions. This paradigm involves breaking down appli-
cations into multiple microservices that interact with
each other to fulfill user requests.
Furthermore, Cloud Computing offers a reliable
and scalable environment to execute these applica-
tions, while the recent adoption of Edge Computing
allows executing workloads near the end user (Vargh-
ese et al., 2021; Kong et al., 2022). In this context,
both Cloud and Edge infrastructure are combined to-
gether to form the Cloud-to-Edge continuum, a shared
environment for executing distributed microservices-
based applications. However the orchestration of such
a
https://orcid.org/0000-0003-2114-3839
b
https://orcid.org/0000-0003-4653-0480
applications in these environments is a complex prob-
lem, considering the heterogeneity in the computa-
tional resources between Cloud and Edge nodes and
that multiple microservices compete to use these re-
sources (Khan et al., 2019; Kayal, 2020; Manaouil
and Lebre, 2020; Goudarzi et al., 2022).
Kubernetes
1
is a widely adopted orchestration
platform that supports the deployment, scheduling
and management of containerized applications (Burns
et al., 2016). Today different Kubernetes distributions
are maintained by the major Cloud providers, while
Edge-oriented distributions like KubeEdge
2
have re-
cently been proposed. However, the default Kuber-
netes static orchestration policy presents some lim-
itations when dealing with complex microservices-
based applications that share the same node cluster.
In particular, Kubernetes does not evaluate the run-
time resource usage of microservices when schedul-
ing them, thus leading to higher shared resource inter-
ference between microservices and then reduced ap-
plication performance in terms of response time.
To deal with those limitations, in this work, start-
ing from our previous works (Marchese and Tomar-
chio, 2022b; Marchese and Tomarchio, 2022a), we
propose to extend the Kubernetes platform with a
1
https://kubernetes.io
2
https://kubeedge.io
92
Marchese, A. and Tomarchio, O.
Load-Aware Container Orchestration on Kubernetes Clusters.
DOI: 10.5220/0012738800003711
Paper published under CC license (CC BY-NC-ND 4.0)
In Proceedings of the 14th Inter national Conference on Cloud Computing and Services Science (CLOSER 2024), pages 92-102
ISBN: 978-989-758-701-6; ISSN: 2184-5042
Proceedings Copyright © 2024 by SCITEPRESS – Science and Technology Publications, Lda.

load-aware orchestration strategy to make it suitable
for the deployment of microservices applications with
dynamic resource usage patterns on shared node clus-
ters. Our approach enhances Kubernetes by im-
plementing a dynamic application orchestration and
scheduling strategy able 1) to consider the runtime ap-
plication resource usage patterns when determining a
placement for each application microservice and 2)
to continuously tune the application placement based
on the ever changing infrastructure and application
states. While different aspects can be considered for
optimization, like cost, application dependability and
availability, the main goal of our approach in this
work is to improve the application performance.
The rest of the paper is organized as follows. Sec-
tion 2 provides some background information about
the Kubernetes platform and discusses in more detail
some of its limitations that motivate our work. In Sec-
tion 3 the proposed approach is presented, providing
some implementation details of its components, while
Section 4 provides results of our prototype evaluation
in a testbed environment. Section 5 examines some
related works and, finally, Section 6 concludes the
work.
2 BACKGROUND AND
MOTIVATION
2.1 Kubernetes Scheduler
Kubernetes, a container orchestration platform, auto-
mates the lifecycle management of distributed appli-
cations deployed on large-scale node clusters (Gan-
non et al., 2017). A typical Kubernetes cluster com-
prises a control plane and a set of worker nodes. The
control plane encompasses various management ser-
vices running within one or more master nodes, while
the worker nodes serve as the execution environment
for containerized application workloads. In Kuber-
netes, the fundamental deployment units are Pods,
each containing one or more containers and man-
aged by Deployments resources. In a microservices-
based application, each Deployment corresponds to
a microservice, and the Pods managed by that De-
ployment represent individual instances of that mi-
croservice. Various properties of a Deployment re-
source are configurable by application architects, with
Pod resource requests being one of them. These re-
quests specify the computational resources to reserve
for Pods managed by a Deployment when running on
worker nodes
3
. For example, Listing 1 illustrates a
Deployment with specified CPU and memory Pod re-
source requests.
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx
spec:
replicas: 1
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:latest
resources:
requests:
cpu: 1
memory: 64Mi
Listing 1: Example of Kubernetes Deployment resource.
The Kube-scheduler
4
is a control plane compo-
nent responsible for selecting a cluster node for each
Pod, considering both Pod requirements and resource
availability on cluster nodes. Every Pod scheduling
attempt undergoes a multi-phase process, illustrated
in Figure 1, where the sorting, filtering, and scor-
ing phases encompass the primary execution logic.
Each phase is implemented by one or more plugins,
and these plugins can further implement additional
phases. During the sorting phase, an ordering for the
Pod scheduling queue is established. In the filtering
phase, each plugin executes a filtering function for
each cluster node to determine if that node satisfies
specific constraints. The output of the filtering phase
is a list of candidate nodes that are deemed suitable
for running the Pod. In the scoring phase, each plugin
executes a scoring function for each candidate node,
assigning a score based on specific criteria. The fi-
nal score for each node is determined by the weighted
sum of the individual scores assigned by each scor-
ing plugin. Subsequently, the Pod is assigned to the
node with the highest final score. If there are multi-
ple nodes with equal scores, one of them is randomly
selected. It’s important to note that the Kubernetes
scheduler is designed to be extensible. Each schedul-
ing phase serves as an extension point where one or
3
https://kubernetes.io/docs/concepts/configuration/
manage-resources-containers
4
https://kubernetes.io/docs/concepts/scheduling-
eviction/kube-scheduler
Load-Aware Container Orchestration on Kubernetes Clusters
93
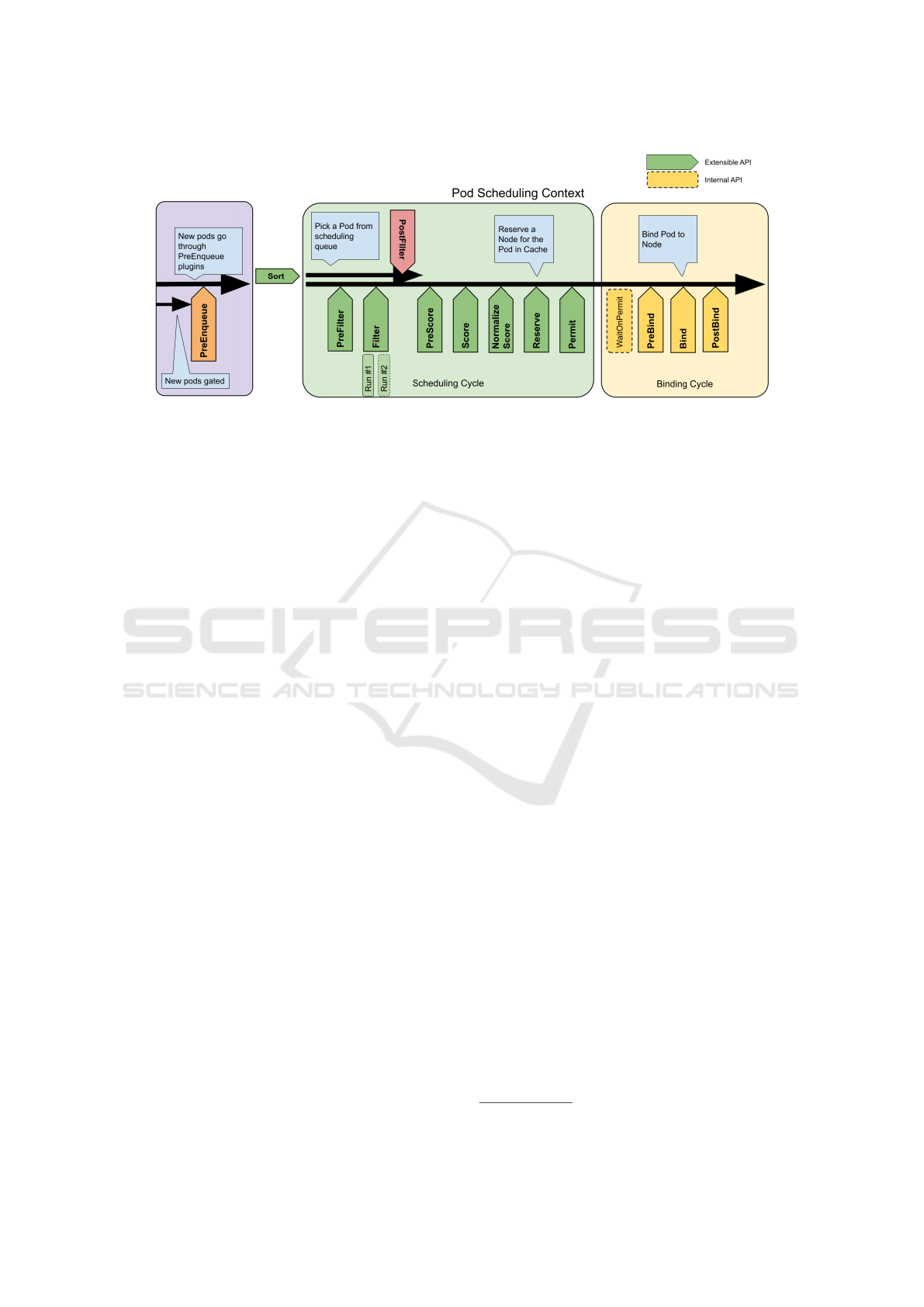
Figure 1: Kubernetes scheduling framework.
more custom plugins can be registered.
Among the default scheduler plugins, the NodeRe-
sourcesFit plugin handles both the filtering and scor-
ing phases, ensuring that nodes lacking adequate
computational resources to satisfy Pod resource re-
quests are filtered out. Additionally, the NodeRe-
sourcesBalancedAllocation plugin is responsible for
the scoring phase. The NodeResourcesFit plugin as-
signs scores to nodes based on mutually exclusive
strategies:
• LeastAllocated: it favors nodes with the lowest
ratio between the weighted sum of requested re-
sources of Pods running on nodes (including the
resource requests of the Pod to be scheduled) and
the total amount of allocatable resources on those
nodes. The objective is to achieve a balanced re-
source utilization among cluster nodes.
• MostAllocated: it favors nodes with the highest
ratio between the weighted sum of requested re-
sources of Pods running on nodes (including the
resource requests of the Pod to be scheduled) and
the total amount of allocatable resources on those
nodes. This strategy aims to enhance resource uti-
lization among cluster nodes while concurrently
reducing the number of nodes required to effi-
ciently run the workload.
• RequestedToCapacityRatio: It distributes Pods to
ensure a specified ratio between the sum of re-
quested resources of Pods running on nodes and
the total amount of allocatable resources on those
nodes.
The NodeResourcesBalancedAllocation plugin
prioritizes nodes that would achieve a more balanced
resource usage if the Pod is scheduled there. Despite
the flexibility offered by the default NodeResources-
Fit and NodeResourcesBalancedAllocation scheduler
plugins to define strategies based on different goals,
they necessitate knowledge about the resource re-
quirements of each Pod to be scheduled and those al-
ready running in the cluster. This information typi-
cally comes from resource requests on Pods, which
must be specified by application architects before the
deployment phase. However, this task is intricate,
given that microservices’ resource requirements are
dynamic parameters strongly dependent on the run-
time load and distribution of user requests. Defining
Pod resource requirements before the runtime phase
can result in inefficient scheduling decisions, subse-
quently impacting application performance. Over-
estimating resource requirements for Pods may de-
crease the resource usage ratio on cluster nodes, lead-
ing to increased costs. Conversely, underestimat-
ing resource requirements may elevate Pod density
on cluster nodes, intensifying shared resource inter-
ference and consequently increasing application re-
sponse times.
2.2 Kubernetes Descheduler
Kubernetes scheduler placement decisions are influ-
enced by the cluster state at the time a new Pod
appears for scheduling. Given the dynamic nature
of Kubernetes clusters and their evolving state, op-
timal placement decisions can be enhanced concern-
ing the initial scheduling of Pods. Various reasons
may prompt the migration of a Pod from one node
to another, including node under-utilization or over-
utilization, changes in Pod or node affinity require-
ments, and events such as node failure or addition.
To achieve this goal, a descheduler component has
recently been proposed as a Kubernetes sub-project
5
.
This component is responsible for evicting running
Pods so that they can be rescheduled onto more suit-
5
https://github.com/kubernetes-sigs/descheduler
CLOSER 2024 - 14th International Conference on Cloud Computing and Services Science
94
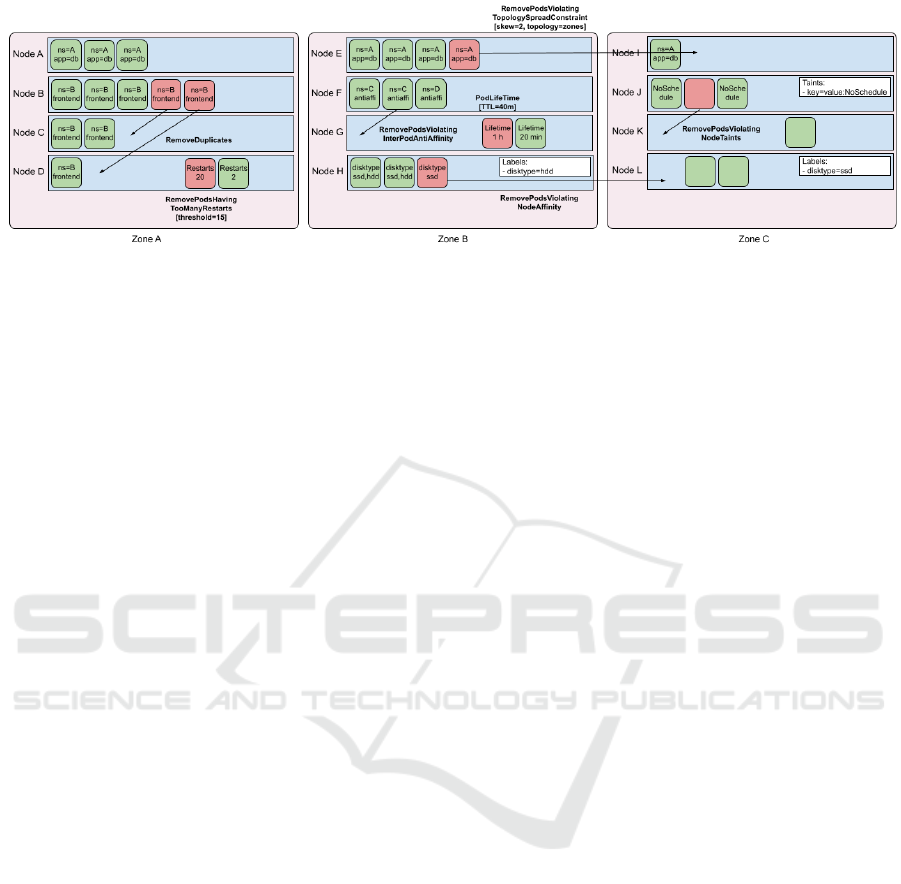
Figure 2: Kubernetes descheduling strategies.
able nodes. It’s important to note that the descheduler
itself does not schedule the replacement of evicted
Pods; rather, it relies on the default scheduler for that
task. The descheduler’s policy is configurable and in-
cludes default eviction plugins that can be enabled or
disabled. It features a common eviction configuration
at the top level, along with configuration options from
the Default Evictor plugin. Figure 2 displays the var-
ious default eviction plugins available in the Kuber-
netes descheduler at the time of writing. Similar to the
Kubernetes scheduler, the descheduler is designed to
be extensible, allowing integration of custom eviction
plugins.
Among the default eviction plugins, the LowN-
odeUtilization and HighNodeUtilization evict Pods
based on the resource utilization of cluster nodes.
The LowNodeUtilization plugin identifies underuti-
lized nodes and evicts Pods, with the expectation that
recreating evicted pods will be scheduled on these un-
derutilized nodes. Conversely, the HighNodeUtiliza-
tion plugin targets nodes with high utilization, evict-
ing Pods in the hope of scheduling them more com-
pactly onto fewer nodes.
It’s worth noting that, similar to the NodeRe-
sourcesFit and NodeResourcesBalancedAllocation
scheduler plugins, these eviction plugins determine
resource usage on each node as the ratio between the
weighted sum of requested resources of Pods running
on nodes and the total allocatable resources on those
nodes. Consequently, the actual resource usage on
nodes is not considered, potentially leading to inef-
ficient rescheduling decisions.
3 PROPOSED APPROACH
3.1 Overall Design
Considering the limitations described in Section 2,
this work proposes an extension to the Kubernetes
platform. The aim is to incorporate a load-aware
scheduling and descheduling strategy, rendering the
platform suitable for orchestrating microservices-
based applications with dynamic resource usage pat-
terns. The primary concept underlying this approach
is that the scheduling and descheduling processes
for complex microservices-based applications should
take into account both the dynamic state of the in-
frastructure and the real-time resource requirements
of the microservices. Although various scheduling
and descheduling strategies could be defined based
on specific optimization goals, our focus in this work
is to minimize runtime shared resource interference
among microservices Pods. This, in turn, contributes
to improving application response time. A notable
distinction from the default Kubernetes scheduler and
descheduler components lies in our proposed ap-
proach’s utilization of runtime telemetry data for mi-
croservices resource usage profiling. Unlike statically
defined Pod resource requests, this dynamic profiling
lessens the burden on application architects to predict
resource usage and communication relationships be-
tween microservices ahead of time when defining Pod
resource requirements.
The overall architecture of the proposed approach,
which is based on our previous work (Marchese and
Tomarchio, 2023), is depicted in Figure 3. The con-
tinuous monitoring of runtime infrastructure and ap-
plication microservices resource usage is facilitated
through a metrics server. This server collects teleme-
try data, including CPU, memory, network, and disk
bandwidth resources for both cluster nodes and Pods
within the cluster. The node monitor operator, lever-
aging infrastructure telemetry data, annotates each
cluster node with resource usage information, pro-
viding a runtime view of the cluster state. Simi-
larly, the application monitor operator utilizes ap-
plication telemetry data to annotate each application
microservice Deployment with resource usage infor-
mation, determining the runtime view of the applica-
tion state. The custom scheduler employs these run-
time cluster and application states to determine op-
Load-Aware Container Orchestration on Kubernetes Clusters
95

timal placements for each application Pod. Mean-
while, the custom descheduler is responsible for tak-
ing Pod rescheduling actions if better scheduling deci-
sions can be made. Further details regarding the com-
ponents of the proposed approach are provided in the
following subsections.
Kubernetes control plane
worker node
Prometheus server
Custom deschedulerCustom scheduler
P
1
node exporter
worker node
P
2
node exporter
worker node
P
3
node exporter
Node monitor Application monitor
Pods resource usage metrics
nodes resource usage metrics
Figure 3: General architecture of the proposed approach.
3.2 Node Monitor
The node monitor component periodically determines
the runtime total usage of CPU, memory, network,
and disk bandwidth resources on each cluster node.
This component is a Kubernetes operator writ-
ten in the Java language using the Quarkus Operator
SDK
6
and runs as a Deployment in the Kubernetes
control plane. Being a Kubernetes operator, it is trig-
gered by a Kubernetes custom resource, specifically
the Cluster custom resource, whose schema is shown
in Listing 2.
apiVersion: v1alpha1
kind: Cluster
metadata:
name: sample-cluster
spec:
runPeriod: 30
nodeSelector: {}
Listing 2: Example of a Cluster custom resource.
A Cluster resource includes a spec property with
two sub-properties: runPeriod and nodeSelector. The
runPeriod property determines the interval in seconds
6
https://github.com/quarkiverse/quarkus-operator-sdk
between two consecutive executions of the operator
logic. Meanwhile, the nodeSelector property acts as
a filter, selecting the list of nodes in the cluster that
should be monitored by the operator.
The primary logic of the node monitor is executed
by the ClusterReconciler class, specifically within its
reconcile() method. In this method, the list of Node
resources that satisfy the nodeSelector condition is
retrieved from the Kubernetes API server. Subse-
quently, the updateResourceUsage() method of the
ClusterReconciler class is invoked. This method de-
termines, for each node n, the runtime total usage
of CPU, memory, network, and disk bandwidth re-
sources on that node, denoted as cpu
n
, mem
n
, net
n
,
and disk
n
, respectively.
These values are determined from metrics fetched
by the operator from a Prometheus
7
metrics server.
The Prometheus server collects these metrics from
node exporters
8
, which run as DaemonSets on each
cluster node. A DaemonSet is a Kubernetes re-
source that manages identical Pods each running on
a different cluster node. The metrics, stored on the
Prometheus server, exist as time series collections of
measures. The runtime usage of each resource type is
calculated as the average over a configurable period
of the corresponding metric.
The parameters cpu
n
, mem
n
, net
n
, and disk
n
are
then assigned by the operator as the values for the an-
notations cpu-usage, memory-usage, net-usage, and
disk-usage of node n, respectively.
3.3 Application Monitor
The application monitor component periodically de-
termines the runtime usage of CPU, memory, net-
work, and disk bandwidth resources for each appli-
cation microservice running in the cluster. Similar to
the node monitor, this component is a Kubernetes op-
erator written in the Java language using the Quarkus
Operator SDK. It runs as a Deployment in the Kuber-
netes control plane and is activated by a Kubernetes
custom resource, specifically the Application custom
resource, whose schema is shown in Listing 3.
An Application resource contains a spec property
with three sub-properties: runPeriod, namespace, and
deploymentSelector. The runPeriod property deter-
mines the interval between two consecutive execu-
tions of the operator logic. The namespace and de-
ploymentSelector properties are used to select the
set of Deployment resources that compose a specific
microservices-based application. The Deployments
selected by the Application resource are those created
7
https://prometheus.io/
8
https://github.com/prometheus/node exporter
CLOSER 2024 - 14th International Conference on Cloud Computing and Services Science
96

apiVersion: v1alpha1
kind: Application
metadata:
name: sample-application
spec:
runPeriod: 30
namespace: default
deploymentSelector: {}
Listing 3: Example of an Application custom resource.
in the namespace specified by the namespace prop-
erty and with labels that satisfy the deploymentSelec-
tor property condition.
The primary logic of the application monitor is
executed by the ApplicationReconciler class, specif-
ically by its reconcile() method. In this method, the
list of Deployment resources selected by the names-
pace and deploymentSelector properties is fetched
from the Kubernetes API server. Then, the updateRe-
sourceUsage() method of the ApplicationReconciler
class is invoked to determine, for each Deployment d,
its runtime usage of CPU, memory, network, and disk
bandwidth resources denoted as cpu
d
, mem
d
, net
d
,
and disk
d
, respectively. These values, representing
the average CPU, memory, network, and disk band-
width consumption of all the Pods managed by the
Deployment d, are fetched by the operator from the
Prometheus metrics server. The metrics server, in
turn, collects them from CAdvisor
9
agents. These
agents run on each cluster node, monitoring the run-
time usage of each resource type for the Pods exe-
cuted on that node.
Similar to the node monitor, the application mon-
itor determines the runtime usage of each resource
type as the average over a configurable period of the
corresponding metric. The parameters cpu
d
, mem
d
,
net
d
, and disk
d
are then assigned by the operator as
the values for the annotations cpu-usage, memory-
usage, net-usage, and disk-usage of Deployment d,
respectively.
3.4 Custom Scheduler
The custom scheduler operates as a Deployment in
the Kubernetes control plane and enhances the de-
fault Kubernetes scheduler by implementing a custom
LoadAware scoring plugin written in the Go language.
This custom plugin is based on the Kubernetes sched-
uler framework.
For each Pod scheduled, the plugin assigns a score
to each candidate node in the cluster that has passed
the filtering phase. This is achieved by executing a
scoring function. The scores computed by the custom
9
https://github.com/google/cadvisor
plugin are then aggregated with the scores from other
scoring plugins within the default Kubernetes sched-
uler.
During the scoring phase, the Score() function of
the LoadAware scheduler plugin is invoked to assign
a score to each cluster node n when scheduling a Pod
p. This function assesses the following parameters:
• cpu
p
: the runtime CPU usage of Pod p, as spec-
ified by the value of the cpu-usage annotation of
the Deployment owning the Pod.
• mem
p
: the runtime memory usage of Pod p, as
specified by the value of the memory-usage anno-
tation of the Deployment owning the Pod.
• net
p
: the runtime network bandwidth usage of
Pod p, as specified by the value of the network-
usage annotation of the Deployment owning the
Pod.
• disk
p
: the runtime disk bandwidth usage of Pod
p, as specified by the value of the disk-usage an-
notation of the Deployment owning the Pod.
• cpu
n
: the runtime total CPU usage on node n.
• mem
n
: the runtime total memory usage on node n.
• net
n
: the runtime total network bandwidth usage
on node n.
• disk
n
: the runtime total disk bandwidth usage on
node n.
• totcpu
n
: the total amount of allocatable CPUs on
node n.
• totmem
n
: the total amount of allocatable memory
on node n.
• totnet
n
: the total amount of allocatable network
bandwidth on node n.
• totdisk
n
: the total amount of allocatable disk
bandwidth on node n.
The score of node n for the Pod p is determined
by Equation (1):
score(p, n
i
) = (1 − std(cpur
n
, memr
n
, netr
n
, diskr
n
)) × MaxNodeScore
(1)
where:
MaxNodeScore = 100 (2)
cpur
n
=
cpu
p
+ cpu
n
totcpu
n
(3)
memr
n
=
mem
p
+ mem
n
totmem
n
(4)
netr
n
=
net
p
+ net
n
totnet
n
(5)
Load-Aware Container Orchestration on Kubernetes Clusters
97

diskr
n
=
disk
p
+ disk
n
totdisk
n
(6)
The resulting score is higher on nodes where the
ratio between the runtime usage and the total allocat-
able amount of different resource types is more bal-
anced. The runtime usage of a resource type on a
node is determined as the sum of the usage of that
resource of the Pod p and the total usage of Pods run-
ning on that node. The lower the standard deviation
between each resource type usage ratio on a node, the
more heterogeneous the Pods running on that node
are, and consequently, the higher the node score. The
fundamental rationale behind the proposed schedul-
ing strategy is to reduce shared resource interference
among Pods to minimize QoS violations on applica-
tion response time. To achieve this, Pods competing
for the same resource type should be placed on differ-
ent nodes whenever possible. Unlike the default Ku-
bernetes scheduler NodeResourcesFit and NodeRe-
sourcesBalancedAllocation scheduler plugins, which
consider microservices’ resource requirements stati-
cally determined by application architects ahead of
time to assign node scores, the proposed LoadAware
scoring plugin utilizes runtime resource usage teleme-
try data. This approach allows tuning scheduling de-
cisions based on dynamically changing Pod resource
usage patterns.
3.5 Custom Descheduler
The custom descheduler operates as a CronJob in
the Kubernetes control plane and enhances the de-
fault Kubernetes descheduler by implementing a cus-
tom LoadAware evictor plugin. This custom plugin is
written in the Go language and is based on the Kuber-
netes descheduler framework.
The descheduler CronJob is configured to period-
ically run Jobs that execute the descheduling logic,
comprising both the default evictor plugin and the
proposed LoadAware evictor plugin. The custom de-
scheduler is set to evict at most one Pod for each iter-
ation.
During each execution of the descheduler Cron-
Job, the Deschedule() function of the LoadAware plu-
gin is invoked. This function takes as input the list
of nodes in the cluster and the Pods running on them,
determining the Pod to be evicted. For each node, a
score is assigned as the standard deviation of the run-
time total usage of CPU, memory, network, and disk
bandwidth resources. These values are determined
based on the annotation values of the corresponding
Node resource.
Starting from the node with the highest score,
Equation 1 is used to assign node scores for Pods run-
ning on that node. For each Pod, if there is at least
one node with a higher score than the node where the
Pod is currently executed, the Pod becomes a candi-
date for eviction. The Pod that is evicted, if any, is
the one with the highest difference between the score
of the node where it is currently executed and another
node in the cluster. These operations are repeated for
the other nodes until a Pod to be evicted is found.
The configuration of the Default evictor plugin en-
sures that nodes where the Pod cannot be executed
due to scheduling constraints are not considered as
candidate nodes for migrating the Pod. This pre-
vents the Pod from being unable to be rescheduled
after eviction. Similar to the default Kubernetes de-
scheduler, the proposed custom descheduler does not
schedule replacements for evicted Pods; instead, it re-
lies on the custom scheduler for that task.
The purpose of the proposed custom desched-
uler is to provide running Pods the opportunity to
be rescheduled based on their runtime resource usage
patterns. This approach aims to optimize application
placement at runtime. By evicting currently running
Pods and subsequently forcing them to be resched-
uled, the balance between the usage of different re-
source types on each node can be maintained. This
helps reduce the impact of shared resource interfer-
ence among Pods on the application response time.
One limitation of the proposed approach is that
Pod eviction can cause performance degradation in
the overall application. However, it should be con-
sidered that cloud-native microservices are typically
replicated, so the temporary shutdown of one instance
generally causes only a graceful degradation of the
application quality of service. Furthermore consid-
ering that the descheduler is configured to evict at
most one Pod for each iteration, no downtime for mi-
croservices is caused by Pod eviction if more than one
replica is executed for each of them.
4 EVALUATION
The proposed solution has been evaluated by us-
ing a sample microservices-based application gen-
erated using the µBench benchmarking tool (Detti
et al., 2023). µBench enables the generation of
service-mesh topologies with multiple microservices,
each running a specific function. Among the pre-
built functions in µBench, the Loader function mod-
els a generic workload that stresses node resources
when processing HTTP requests. When invoked, the
Loader function computes an N number of decimals
of π. The larger the interval, the greater the complex-
ity and stress on the CPU. Additional stress on node
CLOSER 2024 - 14th International Conference on Cloud Computing and Services Science
98

Figure 4: Sample application topology.
memory and disk bandwidth can be configured by ad-
justing the amount of memory and the number of disk
read and write operations required by the function for
each computation. Finally, function network band-
width usage can be configured by adjusting the num-
ber of bytes returned by the function in response to
each request.
Figure 4 depicts the sample application topology
created using the µBench tool. The application com-
prises sixteen microservices, each running two repli-
cas. Microservice m
0
serves as the entry point for ex-
ternal user requests, which are then handled by back-
end microservices. These backend microservices in-
teract with each other through the exchange of HTTP
requests. The sixteen microservices are grouped into
groups of four items, where microservices within the
same group run the Loader function with the same
configuration parameters. Four versions of the Loader
function are defined, f
0
, f
1
, f
2
and f
3
, each configured
to stress a different resource type, including CPU,
memory, network, and disk bandwidth.
The test bed environment for the experiments con-
sists of a Rancher Kubernetes Engine 2 (RKE2)
10
Ku-
bernetes cluster with one master node and five worker
nodes. These nodes are deployed as virtual machines
on a Proxmox
11
environment and configured with
2 vCPU, 8GB of RAM, a Gigabit virtual network
adapter and a virtual disk with read and write band-
width of around 500 MB/s.
Black box experiments are conducted by evaluat-
ing the end-to-end response time of the sample appli-
10
https://docs.rke2.io
11
https://www.proxmox.com
cation when HTTP requests are sent to the microser-
vice m
0
with a specified number of virtual users each
sending one request every second in parallel. Re-
quests to the application are sent through the k6 load
testing utility
12
from a node inside the same network
where cluster nodes are located. This setup minimizes
the impact of network latency on the application re-
sponse time. Each experiment consists of 10 trials,
during which the k6 tool sends requests to the mi-
croservice m
0
for 30 minutes. For each trial, statis-
tics about the end-to-end application response time
are measured and averaged with those of the other
trials of the same experiment. For each experiment,
we compare both cases when our node and applica-
tion monitor operators and custom scheduler and de-
scheduler components are deployed on the cluster and
when only the Kubernetes scheduler is present with
the default configuration. We consider three differ-
ent scenarios based on different configurations for the
four loader functions reported in Table 1.
Table 1: Loader functions configurations for the three sce-
narios.
Scenario 1 Scenario 2 Scenario 3
f
0
(number of decimals of π generated) 1000 1500 2000
f
1
(memory usage) 100MB 200MB 400MB
f
2
(network bytes returned per request) 10KB 20KB 40KB
f
3
(bytes written on disk per request) 10MB 20MB 40MB
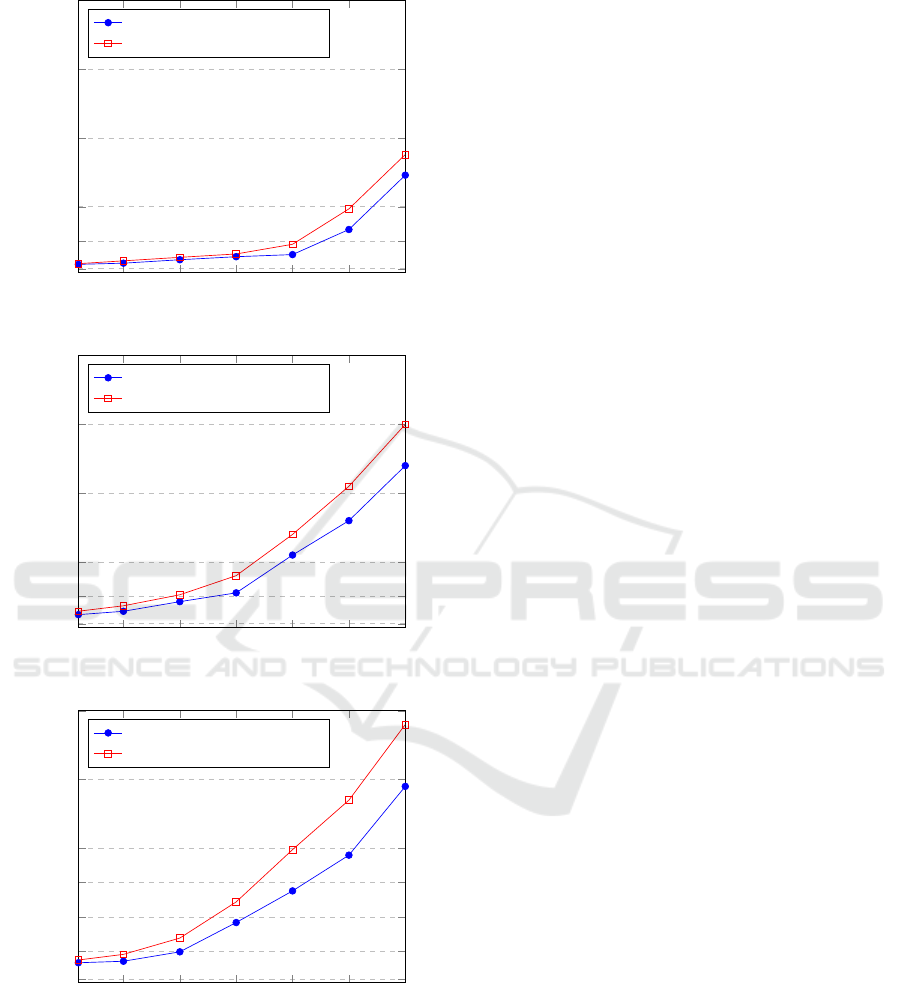
Figure 5 illustrates the results of three experi-
ments, each representing a different scenario. The
graph depicts the 95th percentile of the application re-
sponse time in relation to the number of virtual users
concurrently sending requests to the application. In
all scenarios, the proposed approach consistently out-
performs the default Kubernetes scheduler, showcas-
ing average improvements of 23%, 31%, and 37%, re-
spectively. For a low number of virtual users, the pro-
posed approach exhibits similar performance to the
default scheduler due to limited shared resource inter-
ference between Pods placed on the same nodes by
the default scheduler. However, as the number of vir-
tual users increases, the proposed approach surpasses
the default scheduler, with more substantial improve-
ments observed at higher virtual user counts. The re-
sponse time with the default scheduler grows faster
compared to the proposed approach. Furthermore, the
disparity in response time becomes higher between
the three scenarios as the resource usage of each func-
tion increases.
12
https://k6.io
Load-Aware Container Orchestration on Kubernetes Clusters
99
10
50
100
150
200
250
300
100
500
1,000
2,000
3,000
4,000
Virtual users
95th percentile response time (ms)
Scenario 1
Proposed approach
Kubernetes default scheduler
10
50
100
150
200
250
300
100
500
1,000
2,000
3,000
4,0004,000
Virtual users
95th percentile response time (ms)
Scenario 2
Proposed approach
Kubernetes default scheduler
10
50
100
150
200
250
300
100
500
1,000
1,500
2,000
3,000
4,000
Virtual users
95th percentile response time (ms)
Scenario 3
Proposed approach
Kubernetes default scheduler
Figure 5: Experiments results.
5 RELATED WORK
In the literature, various works propose extending
the Kubernetes platform to address the limitations
of its static orchestration strategy when applied to
microservices-based applications sharing the same
node cluster (Senjab et al., 2023).
A novel approach for scheduling the workloads in
a Kubernetes cluster, which are sometimes unequally
distributed across the environment or deal with fluc-
tuations in terms of resources utilization, is presented
in (Ungureanu et al., 2019). The proposed approach
looks at a hybrid shared-state scheduling framework
model that delegates most of the tasks to the dis-
tributed scheduling agents and has a scheduling cor-
rection function that mainly processes the unsched-
uled and unprioritized tasks. The scheduling deci-
sions are made based on the entire cluster state which
is synchronized and periodically updated by a master-
state agent.
In (Fu et al., 2021) Nautilus is presented, a run-
time system that includes, among its modules, a
contention-aware resource manager and a load-aware
microservice scheduler. On each node, the resource
manager determines the optimal resource allocation
for its microservices based on reinforcement learning
that may capture the complex contention behaviors.
The microservice scheduler monitors the QoS of the
entire service and migrates microservices from busy
nodes to idle ones at runtime.
Boreas (Lebesbye et al., 2021) is a Kubernetes
scheduler which is designed to evaluate bursts of de-
ployment requests concurrently. Boreas finds the op-
timal placements for service containers with their de-
ployment constraints by utilising a configuration op-
timiser.
In (Jian et al., 2023) DRS is proposed, a deep re-
inforcement learning enhanced Kubernetes scheduler,
to mitigate the resource fragmentation and low uti-
lization issues caused by the inefficient policies of
the default Kubernetes scheduler. The Kubernetes
scheduling problem is modeled as a Markov decision
process with designed state, action, and reward struc-
tures to increase resource usage and decrease load im-
balance. Then, a DRS monitor is designed to perceive
parameters concerning resource utilization and create
a thorough picture of all available resources globally.
Finally, DRS is configured to automatically earn the
scheduling policy through interaction with the Ku-
bernetes cluster, without relying on expert knowledge
about workload and cluster status.
In (Kim et al., 2024) a dynamic resource manage-
ment and provisioning scheme for Kubernetes infras-
tructure is presented, which is capable of dynamically
adjusting the resource allocation of Pods while over-
coming the weakness of the existing resource restric-
tion problem.
Finally, in our previous works (Marchese and
Tomarchio, 2022b) and (Marchese and Tomarchio,
CLOSER 2024 - 14th International Conference on Cloud Computing and Services Science
100

2022a) a network-aware Kubernetes scheduler is pro-
posed, aimed to reduce the network distance among
the microservices with a high degree of communica-
tion to improve the application response time. The
load-aware scheduler plugin proposed in this work is
complementary to the network-aware one and both
can be used together on the same scheduler.
6 CONCLUSIONS
In this work we proposed to extend the Kubernetes
platform with a real load-aware orchestration strat-
egy aimed at reducing the shared resource interfer-
ence among distributed microservices-based applica-
tions running on the same clusters in order to min-
imize QoS violations on their response times. The
main goal is to overcome the limitations of the Ku-
bernetes static scheduling and descheduling policies
that require ahead of time knowledge of computa-
tional resource requirements of each microservice to
make optimal container placement and rescheduling
decisions. Considering the dynamic nature of dis-
tributed microservices applications, the idea is to ex-
tend the Kubernetes scheduler and descheduler com-
ponents with custom plugins that make use of runtime
microservices resource usage telemetry data to make
their decisions. In this way, the effort for static appli-
cation resource usage profiling can be reduced, while
at the same time guaranteeing the expected applica-
tion performances.
As a future work, we plan to improve the proposed
custom scheduling and descheduling strategies by us-
ing time series analysis techniques in order to design
more sophisticated algorithms that take into account
long-term telemetry data to improve application re-
source usage predictions.
ACKNOWLEDGEMENTS
This work was partially funded by the European
Union under the Italian National Recovery and Re-
silience Plan (NRRP) of NextGenerationEU, Mission
4 Component C2 Investment 1.1 - Call for tender No.
1409 of 14/09/2022 of Italian Ministry of University
and Research - Project ”Cloud Continuum aimed at
On-Demand Services in Smart Sustainable Environ-
ments” - CUP E53D23016420001.
REFERENCES
Burns, B., Grant, B., Oppenheimer, D., Brewer, E., and
Wilkes, J. (2016). Borg, omega, and kubernetes:
Lessons learned from three container-management
systems over a decade. Queue, 14(1):70–93.
Detti, A., Funari, L., and Petrucci, L. (2023). µbench: An
open-source factory of benchmark microservice ap-
plications. IEEE Transactions on Parallel and Dis-
tributed Systems, 34(3):968–980.
Fu, K., Zhang, W., Chen, Q., Zeng, D., Peng, X., Zheng,
W., and Guo, M. (2021). Qos-aware and resource effi-
cient microservice deployment in cloud-edge contin-
uum. In IEEE International Parallel and Distributed
Processing Symposium (IPDPS), pages 932–941.
Gannon, D., Barga, R., and Sundaresan, N. (2017). Cloud-
native applications. IEEE Cloud Computing, 4:16–21.
Goudarzi, M., Palaniswami, M., and Buyya, R. (2022).
Scheduling iot applications in edge and fog comput-
ing environments: A taxonomy and future directions.
ACM Comput. Surv., 55(7).
Jian, Z., Xie, X., Fang, Y., Jiang, Y., Lu, Y., Dash, A.,
Li, T., and Wang, G. (2023). Drs: A deep rein-
forcement learning enhanced kubernetes scheduler for
microservice-based system. Software: Practice and
Experience, n/a(n/a).
Kayal, P. (2020). Kubernetes in fog computing: Feasibil-
ity demonstration, limitations and improvement scope
: Invited paper. In 2020 IEEE 6th World Forum on
Internet of Things (WF-IoT), pages 1–6.
Khan, W. Z., Ahmed, E., Hakak, S., Yaqoob, I., and Ahmed,
A. (2019). Edge computing: A survey. Future Gener-
ation Computer Systems, 97:219–235.
Kim, J., No, J., and Park, S.-s. (2024). Effective resource
provisioning scheme for kubernetes infrastructure. In
Nagar, A. K., Jat, D. S., Mishra, D., and Joshi, A.,
editors, Intelligent Sustainable Systems, pages 75–85,
Singapore. Springer Nature Singapore.
Kong, X., Wu, Y., Wang, H., and Xia, F. (2022). Edge
computing for internet of everything: A survey. IEEE
Internet of Things Journal, 9(23):23472–23485.
Lebesbye, T., Mauro, J., Turin, G., and Yu, I. C. (2021).
Boreas – A Service Scheduler for Optimal Kubernetes
Deployment. In Hacid, H., Kao, O., Mecella, M.,
Moha, N., and Paik, H.-y., editors, Service-Oriented
Computing, pages 221–237, Cham. Springer Interna-
tional Publishing.
Luo, Q., Hu, S., Li, C., Li, G., and Shi, W. (2021). Resource
scheduling in edge computing: A survey. CoRR,
abs/2108.08059.
Manaouil, K. and Lebre, A. (2020). Kubernetes and the
Edge? Research Report RR-9370, Inria Rennes - Bre-
tagne Atlantique.
Marchese, A. and Tomarchio, O. (2022a). Extending the
kubernetes platform with network-aware scheduling
capabilities. In Service-Oriented Computing: 20th In-
ternational Conference, ICSOC 2022, Seville, Spain,
November 29 – December 2, 2022, Proceedings, page
465–480, Berlin, Heidelberg. Springer-Verlag.
Load-Aware Container Orchestration on Kubernetes Clusters
101

Marchese, A. and Tomarchio, O. (2022b). Network-aware
container placement in cloud-edge kubernetes clus-
ters. In 2022 22nd IEEE International Symposium
on Cluster, Cloud and Internet Computing (CCGrid),
pages 859–865, Taormina, Italy.
Marchese, A. and Tomarchio, O. (2023). Sophos: A Frame-
work for Application Orchestration in the Cloud-to-
Edge Continuum. In Proceedings of the 13th Interna-
tional Conference on Cloud Computing and Services
Science (CLOSER 2023), pages 261–268. SciTePress.
Oleghe, O. (2021). Container placement and migration
in edge computing: Concept and scheduling models.
IEEE Access, 9:68028–68043.
Salaht, F. A., Desprez, F., and Lebre, A. (2020). An
overview of service placement problem in fog and
edge computing. ACM Comput. Surv., 53(3).
Senjab, K., Abbas, S., Ahmed, N., and Khan, A. u. R.
(2023). A survey of kubernetes scheduling algorithms.
Journal of Cloud Computing, 12(1):87.
Ungureanu, O.-M., Vl
˘
adeanu, C., and Kooij, R. (2019).
Kubernetes cluster optimization using hybrid shared-
state scheduling framework. In Proceedings of the
3rd International Conference on Future Networks and
Distributed Systems, ICFNDS ’19, New York, NY,
USA. Association for Computing Machinery.
Varghese, B., de Lara, E., Ding, A., Hong, C., Bonomi, F.,
Dustdar, S., Harvey, P., Hewkin, P., Shi, W., Thiele,
M., and Willis, P. (2021). Revisiting the arguments for
edge computing research. IEEE Internet Computing,
25(05):36–42.
CLOSER 2024 - 14th International Conference on Cloud Computing and Services Science
102
