
Toward Physics-Aware Deep Learning Architectures for LiDAR Intensity
Simulation
Vivek Anand
1 a
, Bharat Lohani
1 b
, Gaurav Pandey
2 c
and Rakesh Mishra
2 d
1
Geoinformatics, Department of Civil Engineering, Indian Institute of Technology Kanpur, India
2
Department of Engineering Technology & Industrial Distribution (ETID),Texas A&M University, U.S.A.
3
Geodesy and Geomatics Engineering, University of New Brunswick, Canada
Keywords:
Simulation, LiDAR, LiDAR Intensity, Autonomous Vehicle, Deep Learning.
Abstract:
Autonomous vehicles (AVs) heavily rely on LiDAR perception for environment understanding and navigation.
LiDAR intensity provides valuable information about the reflected laser signals and plays a crucial role in
enhancing the perception capabilities of AVs. However, accurately simulating LiDAR intensity remains a
challenge due to the unavailability of material properties of the objects in the environment, and complex
interactions between the laser beam and the environment. The proposed method aims to improve the accuracy
of intensity simulation by incorporating physics-based modalities within the deep learning framework. One of
the key entities that captures the interaction between the laser beam and the objects is the angle of incidence.
In this work, we demonstrate that adding the LiDAR incidence angle as a separate input modality to the deep
neural networks significantly enhances the results. We integrated this novel input modality into two prominent
deep learning architectures: U-NET, a Convolutional Neural Network (CNN), and Pix2Pix, a Generative
Adversarial Network (GAN). We investigated these two architectures for the intensity prediction task and
used SemanticKITTI and VoxelScape datasets for experiments. The comprehensive analysis reveals that both
architectures benefit from the incidence angle as an additional input. Moreover, the Pix2Pix architecture
outperforms U-NET, especially when the incidence angle is incorporated.
1 INTRODUCTION
Autonomous vehicles (AVs) have emerged as a trans-
formative technology that promises to revolutionize
transportation systems worldwide (Schwarting et al.,
2018). These vehicles, equipped with advanced sen-
sors and intelligent algorithms, are capable of navi-
gating and making decisions without human interven-
tion. One of the key sensors used in AVs is LiDAR
(Light Detection and Ranging), which plays a cru-
cial role in perceiving the surrounding environment
and ensuring safe and efficient autonomous naviga-
tion (Royo and Ballesta-Garcia, 2019) (Li and Ibanez-
Guzman, 2020). These sensors work on the princi-
ple of emitting laser beams and measuring the time
it takes for the laser pulses to return after reflect-
ing off objects in the scene (Li and Ibanez-Guzman,
a
https://orcid.org/0000-0001-7503-5484
b
https://orcid.org/0000-0001-8589-192X
c
https://orcid.org/0000-0002-4838-802X
d
https://orcid.org/0000-0001-6856-4396
2020). In addition to distance measurements, LiDAR
sensors can also capture other attributes, such as in-
tensity, which refers to the strength of the reflected
laser signal. LiDAR intensity carries valuable infor-
mation about the characteristics of objects and sur-
faces, making it an important parameter in various
applications, including object recognition, scene un-
derstanding, obstacle detection, classification, and se-
mantic segmentation (Wang et al., 2018)(Wang et al.,
2019) (Yang et al., 2018a) (Yang et al., 2018b) (Wang
and Shen, 2017) (Meyer et al., 2019) (Liang et al.,
2020).
To train and validate LiDAR perception algo-
rithms, large-scale datasets with ground truth inten-
sity information are required. However, collecting
data in the real world is a very expensive and time-
consuming task, hence, simulation turns out to be the
most promising alternative (Yang et al., 2021). Cur-
rently, LiDAR simulation methods heavily rely on
physics-based models and assumptions about material
properties and surface interactions. However, accu-
rately simulating LiDAR intensity using these meth-
Anand, V., Lohani, B., Pandey, G. and Mishra, R.
Toward Physics-Aware Deep Learning Architectures for LiDAR Intensity Simulation.
DOI: 10.5220/0012741500003758
Paper published under CC license (CC BY-NC-ND 4.0)
In Proceedings of the 14th International Conference on Simulation and Modeling Methodologies, Technologies and Applications (SIMULTECH 2024), pages 47-56
ISBN: 978-989-758-708-5; ISSN: 2184-2841
Proceedings Copyright © 2024 by SCITEPRESS – Science and Technology Publications, Lda.
47

ods is a complex and computationally expensive task
as it presents significant challenges due to the depen-
dence on multiple factors, including incidence angle,
material properties, and surface interactions among
others (Dai et al., 2022)(Vacek et al., 2021). Among
these factors, the incidence angle plays a vital role
in determining the intensity of the reflected laser sig-
nal (Dai et al., 2022) (Tatoglu and Pochiraju, 2012).
As the angle between the incident laser beam and the
surface normal changes, the intensity observed by the
LiDAR sensor also changes.
The physics-based approaches and learning-based
approaches have quite complimentary challenges. For
example, physics-based approaches require that the
material property of the environmental objects is
known whereas learning-based methods learn the ma-
terial properties directly from the data but they strug-
gle to capture the intricate interactions between laser
pulse and the object surfaces accurately. These lim-
itations hinders the realism and fidelity of simulated
LiDAR data, impeding the development and evalua-
tion of perception algorithms for autonomous vehi-
cles. To overcome these challenges, we propose a hy-
brid learning-based approach that not only leverages
the power of deep learning algorithms but also cap-
tures the complex interactions between the laser pulse
and the object surface more effectively. By incorpo-
rating the incidence angle into the learning model, it
becomes possible to leverage this contextual informa-
tion and improve the realism and accuracy of LiDAR
intensity simulation.
In this paper, we conduct a comparative study
of two different deep learning architectures, namely
U-NET(Ronneberger et al., 2015) and Pix2Pix(Isola
et al., 2017a), for LiDAR intensity simulation. The
novel methodology we propose involves incorporat-
ing the incidence angle as an input modality, en-
hancing both architecture’s performance. We con-
duct extensive experiments using SemanticKITTI
data (Behley et al., 2019), which is collected in the
real world, and VoxelScape data (Saleh et al., 2023),
which is simulated using physics-based methods, ex-
ploring both established and unexplored methods in
the field. The results showcase the importance of
the incidence angle in accurately predicting LiDAR
intensity and demonstrate that the Pix2Pix architec-
ture, a new addition to the literature for this task,
outperforms the existing U-NET approach. Our find-
ings pave the way for more realistic and reliable Li-
DAR perception in AVs, offering valuable insights
into the comparative strengths and weaknesses of dif-
ferent deep learning methodologies in LiDAR inten-
sity simulation.
2 RELATED WORK
2.1 Simulation for Autonomous Vehicles
Simulation plays a vital role in the development and
evaluation of autonomous vehicles, particularly in
mimicking real-world driving conditions, enabling
comprehensive testing of perception algorithms and
the assessment of their performance(Yang et al.,
2021). It provides a controlled and repeatable envi-
ronment for algorithm development and evaluation,
allowing researchers to precisely control variables
and compare different approaches. Additionally, sim-
ulation overcomes limitations in data availability of
different sensors used in autonomous vehicles includ-
ing LiDAR by generating large-scale datasets with
diverse scenarios, supporting algorithm training and
validation (Geiger et al., 2012) (Caesar et al., 2020)
(Sun et al., 2020).
2.2 Physics-Based LiDAR Simulation
Physics-based LiDAR simulation is a widely used ap-
proach for generating synthetic LiDAR data to test
and evaluate autonomous driving systems(Yang et al.,
2021). This method involves modeling the physical
processes of laser beam emission, propagation, and
interaction with objects in the environment(Elmquist
and Negrut, 2020). By considering factors such as
surface reflectance, material properties, and light scat-
tering effects, physics-based simulations aim to ac-
curately replicate the behavior of real-world LiDAR
sensors. However, simulating LiDAR intensity poses
significant challenges due to the complex nature of
interactions between the laser beam and the objects
in the scene(Vacek et al., 2021). Precisely model-
ing these interactions and accounting for various en-
vironmental factors are extremely difficult, compu-
tationally expensive, and may result in inaccuracies
when compared to real-world LiDAR intensity mea-
surements.
2.3 Learning-Based LiDAR Simulation
Learning-based approaches are emerging as a promis-
ing alternative for simulating LiDAR sensors. Instead
of relying on complex physics-based models, these
methods leverage the power of deep learning algo-
rithms to learn the complexity of the factors involved
from the data itself (Marcus et al., 2022). Learning-
based LiDAR simulation offers several advantages,
including improved computational efficiency, flexi-
bility in handling different environmental conditions,
and the potential to capture subtle nuances that may
SIMULTECH 2024 - 14th International Conference on Simulation and Modeling Methodologies, Technologies and Applications
48

Figure 1: Data Preparation: The LiDAR point cloud is projected on a spherical surface to create LiDAR spherical projection
images.
be challenging to model using physics-based meth-
ods. By training neural networks on large datasets of
real-world LiDAR measurements, these models can
capture the underlying patterns and dependencies be-
tween input features and intensity values. Recently,
a generative adversarial network (GAN) for intensity
rendering in LiDAR simulation was introduced by
(Mok and Kim, 2021) where they transform the 3D
point cloud to a 2D spherical image and project the
intensity data on the pixel values to learn intensity
based on unpaired real and synthetic data. Some of
the recent works ((Nakashima and Kurazume, 2021),
(Caccia et al., 2019) and (Manivasagam et al., 2020))
have also tried to predict the reflected signal (also
called ray-drop) and estimate the intensity from the
returned signal by applying some detection thresh-
old and hence do not predict the intensity values di-
rectly. (Guillard et al., 2022) aims to simulate an en-
hanced point cloud with ray drops and intensity val-
ues but they project the LiDAR data and the corre-
sponding intensity values on the RGB image space
and the model learns and generates the value in the
RGB image space itself and hence the intensity val-
ues can not be generated for all the points in the Li-
DAR data. (Vacek et al., 2021) utilize a fully su-
pervised training approach with Convolutional Neural
Networks (CNNs) using LiDAR data and its derived
modalities like range, RGB, and label image to pre-
dict intensity values. They employ their trained model
to generate synthetic LiDAR data with intensity by
applying it to ray-casted point clouds generated in the
gaming engine.
In this paper, we included the incidence angle in
conjunction with range, RGB values, and semantic la-
bels, building upon the work of (Vacek et al., 2021)
and extended the comparative study to include Gen-
erative Adversarial Network (GAN) by implementing
Pix2Pix architecture. By including incidence angle as
an input, learning-based models can better account for
the influence of surface orientation on LiDAR inten-
sity, leading to more accurate simulations. The rest
of the paper is organized as follows: section 3 de-
scribes the proposed methodology, section 4 presents
results on open source datasets and provides discus-
sions about the findings, and finally section 5 provides
concluding remarks.
3 METHOD
We propose to develop a hybrid learning-based ap-
proach that takes into account the physical interac-
tions between the laser and the environment objects.
We propose to use the physics-based models com-
bined with the novel deep learning architectures to
improve the realism and accuracy of LiDAR inten-
sity. To achieve this, we employ a spherical projec-
tion technique (Li et al., 2016) to transform the 3D
LiDAR points into a structured 2D image represen-
tation (Fig. 1). This involves mapping the LiDAR
points onto a virtual spherical surface centered at the
LiDAR sensor origin. Each LiDAR point’s coordi-
nates are converted into spherical coordinates, includ-
ing azimuth and elevation angles, which determine
their positions on the spherical surface. This spherical
projection preserves the geometric relationships and
distances between LiDAR points, enabling the cap-
ture of spatial information in a structured format. The
resulting LiDAR spherical projection image serves as
a foundation for deriving various modalities used in
the study.
The derived modalities from LiDAR and other
complementary sensor (e.g., camera) data include
depth image, logical binary Mask, segmented spheri-
cal image, RGB spherical image, LiDAR color mask,
and LiDAR incidence angle image. The LiDAR depth
image captures the distance information of LiDAR
points from the sensor, providing a depth-based repre-
sentation. The LiDAR logical binary mask indicates
Toward Physics-Aware Deep Learning Architectures for LiDAR Intensity Simulation
49

Figure 2: Incidence Angle Calculation: (a) LiDAR point cloud (b) Estimating surface normal (c) Orienting surface normal
towards the sensor (d) Computing the direction vector of LiDAR rays (e) Computing the dot product between the direction
and normal vectors of the point to get the incidence angle.
the presence or absence of returned LiDAR rays. The
LiDAR segmented image represents the semantic seg-
mentation of LiDAR points based on their assigned
labels. The LiDAR RGB spherical image projects
RGB values onto LiDAR points from corresponding
camera images, providing color information. The Li-
DAR color mask is a binary mask indicating the pres-
ence or absence of RGB values for each LiDAR point.
The LiDAR incidence angle image represents the an-
gle of incidence of the laser beam at the given 3D
coordinate point. Integrating these diverse modalities
enhances the accuracy and realism of LiDAR inten-
sity prediction.
Calculation of the incidence angle for each point
in the LiDAR point cloud is a critical component
of our proposed methodology, the entire process is
shown in Fig 2. The incidence angle represents the
angle between the LiDAR ray direction and the sur-
face normal at a given point. To determine the local
orientation of the underlying surface, we estimate the
surface normal at each point in the point cloud. The
estimated normal is then oriented towards the sensor
origin to ensure consistent directionality. By consid-
ering the Euclidean distance from the sensor origin
to each point, we calculate the radial position of the
point. Next, we compute unit direction vectors from
the sensor origin to each point by normalizing the di-
rection vectors. The dot product between the direc-
tion vectors and the normal vector for each point is
then calculated to determine the angle between them.
To ensure the correct orientation of the normal vec-
tors towards the sensor, we check if the dot product
is negative for any point. If a negative dot product is
found, indicating that the normal vector points away
from the sensor, the normal vector is flipped to ensure
it points toward the sensor. The dot product is recalcu-
lated after flipping the normal vectors. The incidence
angle for each point is obtained by taking the arcco-
sine of the dot product. These calculated incidence
angles serve as valuable information for understand-
ing the interaction between the LiDAR sensor and the
surfaces.
3.1 Network Architecture
In this study, we investigate two different categories
of deep learning architectures for the task of LiDAR
intensity prediction, namely U-NET and Pix2Pix,
each offering distinct characteristics and capabilities.
3.1.1 U-NET Architecture
The widely used UNET architecture is employed in
the first part of the study, popular for semantic seg-
mentation tasks and recognized for its ability to cap-
ture fine-grained spatial details. To adapt UNET for
this specific task, the last layer is removed, allow-
ing the direct output of the predicted LiDAR intensity
and bypassing non-linear transformations. Multiple
modalities are fed into the network as separate chan-
nels which are described earlier along with the novel
addition of LiDAR Incidence Angle image. This
multi-channel input enables the network to utilize the
diverse information captured by each modality dur-
ing the prediction process.The output of the network
is the predicted LiDAR intensity, which aims to ac-
curately represent the intensity values associated with
each corresponding point in the input LiDAR point
cloud. The loss function used is an extended version
of L2 loss called masked L2 loss. The masked L2 loss
incorporates a binary mask (B) as an additional input
channel in the loss calculation, enabling the model to
SIMULTECH 2024 - 14th International Conference on Simulation and Modeling Methodologies, Technologies and Applications
50

Figure 3: Training Pipeline: LiDAR Spherical images are fed into the architecture to predict LiDAR intensity.
Table 1: Comparison of MSE Loss for U-NET Architecture [D - Depth, I - Incidence Angle, L - Label, RGB - Color].
Dataset D D+I D+L D+L+I D+RGB D+RGB+I D+RGB+L D+RGB+L+I
SemanticKiTTI 0.353 0.349 0.339 0.321 0.317 0.301 0.298 0.234
VoxelScape 0.373 0.291 0.341 0.263 - - - -
focus on the returned scan points during training.
L =
1
n
∑
i, j
(I
i, j
−
ˆ
I
i, j
)
2
· B
i, j
(1)
It measures the difference between the real in-
tensity values(I) and predicted intensity values(
ˆ
I )
for each pixel(i,j) in the spherical image. The bi-
nary mask(B) indicates the presence of returned scan
points, and the loss is calculated by summing the
squared errors and normalizing by the total num-
ber of successful rays. The loss quantifies the accu-
racy of intensity predictions in the image. To opti-
mize the model, we employed the Adam algorithm
with a learning rate of 0.003 and weight decay of
0.001 building upon the work of (Vacek et al., 2021).
The experiments were performed on SemanticKITTI
and VoxelScape datasets respectively and the train-
ing dataset was divided into 7500 training frames and
2500 validation frames. To evaluate the performance
of the LiDAR intensity prediction model, test sets
consisting of 2500 frames each were used. By us-
ing these test sets, we assessed the model’s accuracy
and its ability to generalize to different datasets and
scenarios.
3.1.2 Pix2Pix Architecture
In the second part of the study, we introduce the novel
use of the Pix2Pix architecture for this specific task.
The Pix2Pix architecture, unlike U-NET, leverages
a conditional generative adversarial network (cGAN)
that consists of a generator and a discriminator. The
generator aims to transform an input image into the
desired output (LiDAR intensity in this case), while
the discriminator’s task is to distinguish between real
and generated images. For this study, the generator
part of the Pix2Pix model was adapted to take in the
same multi-channel inputs as the U-NET. The gener-
ator part employs a series of encoder-decoder layers
to capture the relationship between the different input
modalities and the LiDAR intensity. The discrimina-
tor which employs a PatchGAN structure (Isola et al.,
2017b), in parallel, assesses the authenticity of the
generated LiDAR intensity image. By being trained
to recognize real-intensity images, it provides feed-
back to the generator, guiding it to produce more re-
alistic predictions.
The loss function used in the Pix2Pix model is a
combination of a conditional adversarial loss and an
L1 loss (Isola et al., 2017a), as defined below:
L = λ · L1 Loss + Adversarial Loss (2)
Here, the L1 Loss measures the absolute differ-
ence between the real intensity values (I) and pre-
dicted intensity values (
ˆ
I) for each pixel (i,j) in the
spherical image, and the Adversarial Loss quantifies
how well the generator fools the discriminator.
The Pix2Pix architecture was optimized using the
Adam algorithm with a learning rate of 0.0002, λ
value of 100, and a gradient penalty term with a coef-
ficient of 10. Similar to the U-NET model, the exper-
iments were carried out on SemanticKITTI and Vox-
Toward Physics-Aware Deep Learning Architectures for LiDAR Intensity Simulation
51
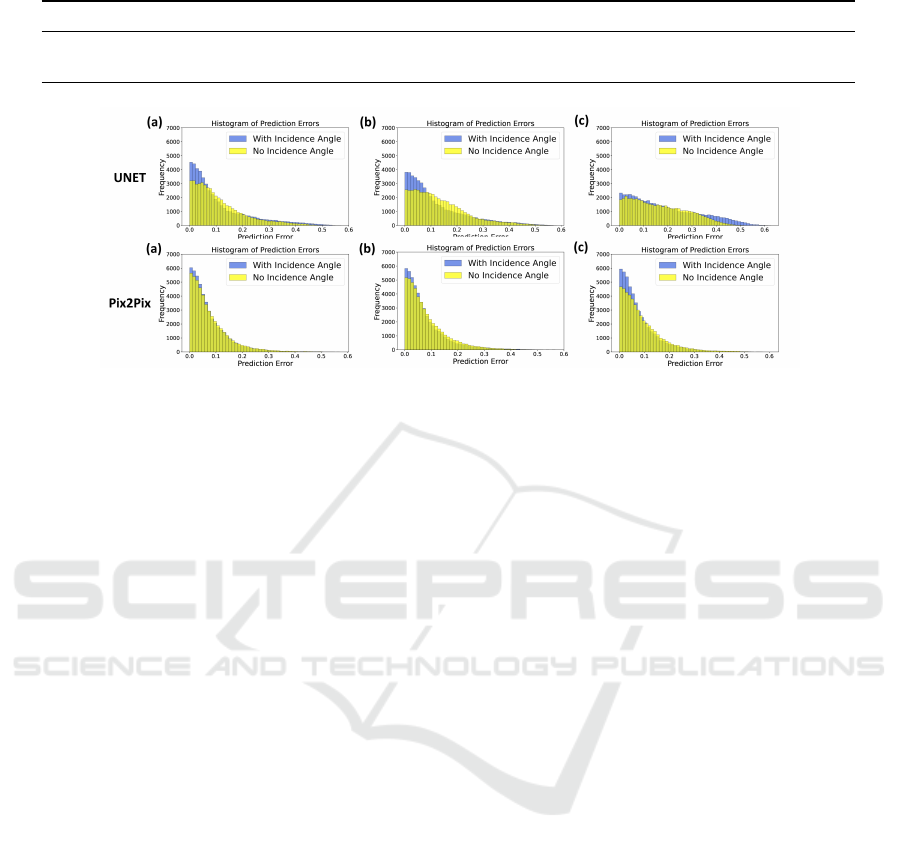
Table 2: Comparison of MSE Loss for Pix2Pix Architecture [D - Depth, I - Incidence Angle, L - Label, RGB - Color].
Dataset D D+I D+L D+L+I D+RGB D+RGB+I D+RGB+L D+RGB+L+I
SemanticKiTTI 0.334 0.325 0.319 0.299 0.295 0.272 0.253 0.201
VoxelScape 0.247 0.192 0.211 0.182 - - - -
Figure 4: Error Histogram: SemanticKITTI Data - Input combinations: (a) Depth + RGB + Label (b) Depth + RGB (c)
Depth.
elScape datasets. The division of training and valida-
tion frames and the evaluation metrics were kept con-
sistent with the U-NET model to ensure a fair com-
parison.
4 RESULTS AND DISCUSSION
The LiDAR intensity prediction experiments
were conducted using two datasets: Se-
manticKITTI(Behley et al., 2019) and Vox-
elScape(Saleh et al., 2023). To assess the per-
formance of different input modalities, the mean
squared error (MSE) loss was calculated for both
U-NET and Pix2Pix GAN architectures on the
test set. Further, error histograms and heatmaps
were generated to analyze the prediction errors and
their spatial distribution. The experiments were
performed on SemanticKitti and Voxelscape datasets,
respectively, and the training dataset was divided into
7500 training frames and 2500 validation frames.
To evaluate the performance of the Lidar intensity
prediction model, test sets consisting of 2500 frames
each were used.
4.1 Mean Squared Error (MSE)
In ablation studies involving both the SemanticKITTI
and VoxelScape datasets, the performances of U-NET
and Pix2Pix architectures were compared using vari-
ous input modalities. As highlighted in Table 1 and
Table 2, the results show that the Pix2Pix architec-
ture outperforms U-NET in all instances. Importantly,
adding the incidence angle across both architectures
consistently led to improved performance. This high-
lights the significance of incorporating the incidence
angle as an informative input modality for LiDAR
intensity prediction. The VoxelScape data does not
contain RGB images; hence, the experiment results
involving RGB information for Voxelscape are not
present in Table 1 and Table 2.
4.2 Error Histogram
To further analyze the prediction errors between the
ground truth and predicted intensity values, error
histograms for each frame from the SemanticKITTI
and VoxelScape datasets were generated. These his-
tograms visualize the distribution of prediction errors
across the intensity range. As shown in Fig 4 and Fig
5, it was observed that in the results from Pix2Pix ar-
chitecture, the error distribution is concentrated more
around zero error compared to the U-NET architec-
ture, and when the incidence angle was included it
was further improved indicating a better alignment
between predicted and ground truth intensity values.
This supports the notion that incorporating the inci-
dence angle enhances the accuracy of the LiDAR in-
tensity prediction.
4.3 Error Heatmaps
Furthermore, error heatmaps were generated to visu-
alize the spatial distribution of prediction errors and
assess the impact of incorporating incidence angle
on LiDAR intensity prediction. Upon examining the
SIMULTECH 2024 - 14th International Conference on Simulation and Modeling Methodologies, Technologies and Applications
52
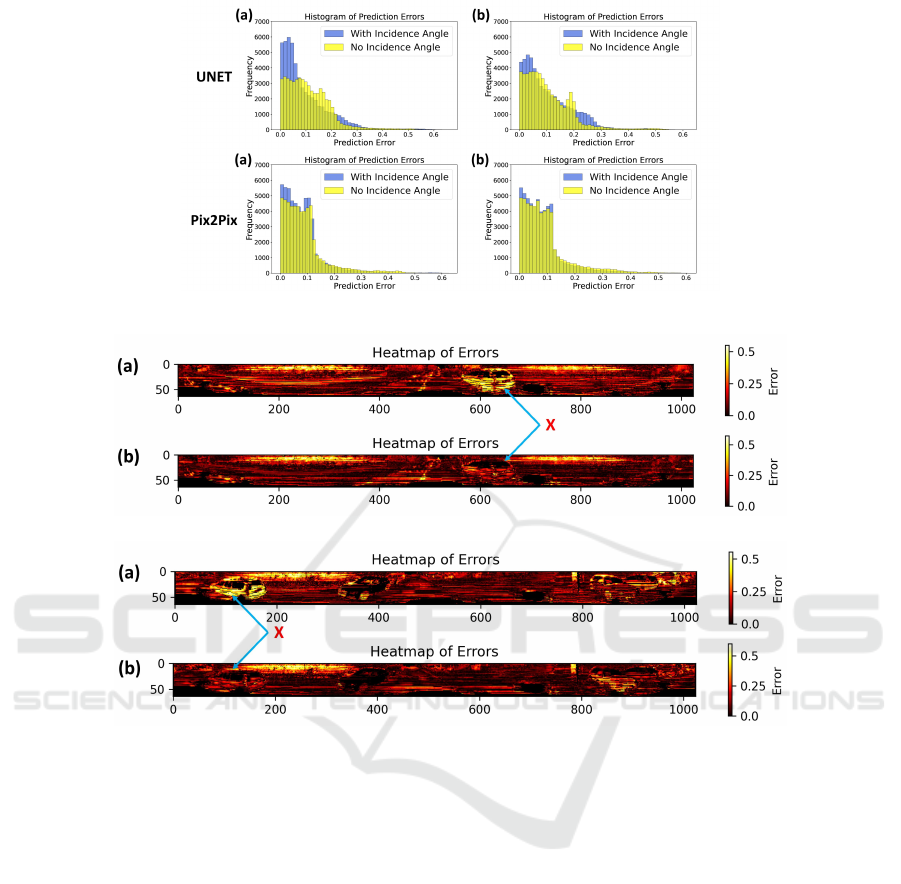
Figure 5: Error Histogram: VoxelScape Data - Input combinations: (a) Depth + Label (b) Depth.
(i) U-NET
(ii) Pix2Pix
Figure 6: Error Heatmap: Illustrating the impact of Incidence Angle on LiDAR Intensity Simulation a) Without Incidence
Angle b) With Incidence Angle.
heatmaps, a distinct pattern emerges, showcasing lo-
calized improvements in predicted intensity; as shown
in Fig 6, the error is significantly reduced for the cars
present in the image (marked as X). Integrating the in-
cidence angle results in localized refinements, reduc-
ing prediction errors in distinct regions, thereby en-
hancing the spatial consistency and accuracy of the in-
tensity prediction. This phenomenon can be attributed
to the significant influence that incidence angle has on
the intensity of LiDAR reflections. By incorporating
this crucial factor, the model gains a deeper under-
standing of the underlying knowledge of the interac-
tions between the LiDAR rays and the surface, cap-
turing the variations in reflectivity based on surface
orientation, resulting in more precise and contextually
aware intensity predictions.
4.4 Qualitative Analysis
For a visual assessment, we looked closely at the
images generated by both U-NET and Pix2Pix and
compared them to the reference images from the Se-
manticKITTI and VoxelScape datasets as shown in
Fig 7. In this comparison, it was clear that the Pix2Pix
images are closer to the reference images than the U-
NET ones. U-NET produces blurry output as also
mentioned by (Isola et al., 2017b) and Pix2Pix did
a far better job at capturing the details present in the
scene.
While both the architectures share U-NET as the
core architecture, Pix2Pix leverages a Generative Ad-
versarial Network (GAN) training framework, setting
it apart from U-NET’s reliance solely on pixel-wise
loss (L2 loss). This distinction in loss objectives ex-
plains the Pix2Pix’s edge. U-NET minimizes pixel-
wise errors, while Pix2Pix’s adversarial loss encour-
Toward Physics-Aware Deep Learning Architectures for LiDAR Intensity Simulation
53

(i) SemanticKITTI
(ii) VoxelScape
Figure 7: Qualitative Analysis: Visual assessment of results from U-NET and Pix2Pix architectures. a) Reference LiDAR
intensity image b) U-NET architecture c) Pix2Pix architecture.
ages the model to match ground truth and generate
outputs that deceive a discriminator network, poten-
tially leading to more refined and realistic outcomes,
hence outlining the importance of generative adver-
sarial network (GAN) in simulating LiDAR data.
5 CONCLUSION
In this research paper, we presented a comprehensive
study involving two different deep learning architec-
tures U-NET and Pix2Pix for LiDAR intensity simu-
lation. The core novelty of this approach lies in in-
corporating the incidence angle as an additional input
modality, enhancing both the accuracy and context
awareness of LiDAR intensity predictions. Through
extensive experiments using both SemanticKITTI and
VoxelScape data, we demonstrated the effectiveness
of the U-NET and Pix-2Pix architecture with the in-
clusion of the incidence angle. We showed that this
combination leads to improvements in prediction per-
formance. Further, our implementation of the Pix2Pix
architecture in this context, a novel approach in the lit-
erature, exhibited even better results, thus underscor-
ing the potential of generative adversarial networks
in LiDAR intensity simulation. Our findings consis-
tently revealed that the integration of the incidence
angle, along with other modalities led to superior per-
formance across both architectures. This success not
only addresses the inherent challenges posed by the
complex nature of intensity simulation but also re-
flects a significant step forward in narrowing the gap
between simulated and real-world LiDAR data.
The successful integration of the incidence angle
and the comparative analysis of U-NET and Pix2Pix
represent innovative and meaningful contributions to
the field of LiDAR intensity simulation. These ad-
vancements have tangible implications for various ap-
plications, including autonomous driving, robotics,
and environmental mapping, where accurate LiDAR
intensity plays a crucial role in perception, object
recognition, and scene understanding. For future re-
search, we will explore other factors, such as material
properties, surface reflectance, and the development
of network architectures and loss functions designed
specifically for LiDAR intensity simulation and incor-
porating the physics of LiDAR intensity into it.
ACKNOWLEDGEMENTS
This work was supported by the Mitacs Globalink Re-
search Award. We are also grateful to the Univer-
sity of New Brunswick, Canada, for providing access
to Compute Canada, the national high-performance
compute (HPC) system, for our experiments.
REFERENCES
Behley, J., Garbade, M., Milioto, A., Quenzel, J., Behnke,
S., Stachniss, C., and Gall, J. (2019). Semantickitti:
A dataset for semantic scene understanding of lidar
sequences. In Proceedings of the IEEE/CVF inter-
SIMULTECH 2024 - 14th International Conference on Simulation and Modeling Methodologies, Technologies and Applications
54

national conference on computer vision, pages 9297–
9307.
Caccia, L., Van Hoof, H., Courville, A., and Pineau, J.
(2019). Deep generative modeling of lidar data. In
2019 IEEE/RSJ International Conference on Intelli-
gent Robots and Systems (IROS), pages 5034–5040.
IEEE.
Caesar, H., Bankiti, V., Lang, A. H., Vora, S., Liong, V. E.,
Xu, Q., Krishnan, A., Pan, Y., Baldan, G., and Bei-
jbom, O. (2020). nuscenes: A multimodal dataset for
autonomous driving. In Proceedings of the IEEE/CVF
conference on computer vision and pattern recogni-
tion, pages 11621–11631.
Dai, W., Chen, S., Huang, Z., Xu, Y., and Kong, D. (2022).
Lidar intensity completion: Fully exploiting the mes-
sage from lidar sensors. Sensors, 22(19):7533.
Elmquist, A. and Negrut, D. (2020). Methods and mod-
els for simulating autonomous vehicle sensors. IEEE
Transactions on Intelligent Vehicles, 5(4):684–692.
Geiger, A., Lenz, P., and Urtasun, R. (2012). Are we ready
for autonomous driving? the kitti vision benchmark
suite. In 2012 IEEE conference on computer vision
and pattern recognition, pages 3354–3361. IEEE.
Guillard, B., Vemprala, S., Gupta, J. K., Miksik, O., Vineet,
V., Fua, P., and Kapoor, A. (2022). Learning to sim-
ulate realistic lidars. In 2022 IEEE/RSJ International
Conference on Intelligent Robots and Systems (IROS),
pages 8173–8180. IEEE.
Isola, P., Zhu, J.-Y., Zhou, T., and Efros, A. A. (2017a).
Image-to-image translation with conditional adversar-
ial networks. In Proceedings of the IEEE conference
on computer vision and pattern recognition, pages
1125–1134.
Isola, P., Zhu, J.-Y., Zhou, T., and Efros, A. A. (2017b).
Image-to-image translation with conditional adversar-
ial networks. In Proceedings of the IEEE Conference
on Computer Vision and Pattern Recognition (CVPR).
Li, B., Zhang, T., and Xia, T. (2016). Vehicle detection
from 3d lidar using fully convolutional network. arXiv
preprint arXiv:1608.07916.
Li, Y. and Ibanez-Guzman, J. (2020). Lidar for autonomous
driving: The principles, challenges, and trends for au-
tomotive lidar and perception systems. volume 37,
pages 50–61. IEEE.
Liang, Z., Zhang, M., Zhang, Z., Zhao, X., and Pu, S.
(2020). Rangercnn: Towards fast and accurate 3d ob-
ject detection with range image representation. arXiv
preprint arXiv:2009.00206.
Manivasagam, S., Wang, S., Wong, K., Zeng, W.,
Sazanovich, M., Tan, S., Yang, B., Ma, W.-C., and
Urtasun, R. (2020). Lidarsim: Realistic lidar simu-
lation by leveraging the real world. In Proceedings
of the IEEE/CVF Conference on Computer Vision and
Pattern Recognition, pages 11167–11176.
Marcus, R., Knoop, N., Egger, B., and Stamminger, M.
(2022). A lightweight machine learning pipeline for
lidar-simulation. arXiv preprint arXiv:2208.03130.
Meyer, G. P., Laddha, A., Kee, E., Vallespi-Gonzalez, C.,
and Wellington, C. K. (2019). Lasernet: An effi-
cient probabilistic 3d object detector for autonomous
driving. In Proceedings of the IEEE/CVF conference
on computer vision and pattern recognition, pages
12677–12686.
Mok, S.-c. and Kim, G.-w. (2021). Simulated intensity
rendering of 3d lidar using generative adversarial net-
work. In 2021 IEEE International Conference on Big
Data and Smart Computing (BigComp), pages 295–
297. IEEE.
Nakashima, K. and Kurazume, R. (2021). Learning to drop
points for lidar scan synthesis. In 2021 IEEE/RSJ In-
ternational Conference on Intelligent Robots and Sys-
tems (IROS), pages 222–229. IEEE.
Ronneberger, O., Fischer, P., and Brox, T. (2015). U-
net: Convolutional networks for biomedical image
segmentation. In Medical Image Computing and
Computer-Assisted Intervention–MICCAI 2015: 18th
International Conference, Munich, Germany, October
5-9, 2015, Proceedings, Part III 18, pages 234–241.
Springer.
Royo, S. and Ballesta-Garcia, M. (2019). An overview of
lidar imaging systems for autonomous vehicles. Ap-
plied sciences, 9(19):4093.
Saleh, K., Hossny, M., Abobakr, A., Attia, M., and Iskan-
der, J. (2023). Voxelscape: Large scale simulated
3d point cloud dataset of urban traffic environments.
IEEE Transactions on Intelligent Transportation Sys-
tems, pages 1–14.
Schwarting, W., Alonso-Mora, J., and Rus, D. (2018). Plan-
ning and decision-making for autonomous vehicles.
Annual Review of Control, Robotics, and Autonomous
Systems, 1:187–210.
Sun, P., Kretzschmar, H., Dotiwalla, X., Chouard, A., Pat-
naik, V., Tsui, P., Guo, J., Zhou, Y., Chai, Y., Caine,
B., et al. (2020). Scalability in perception for au-
tonomous driving: Waymo open dataset. In Proceed-
ings of the IEEE/CVF conference on computer vision
and pattern recognition, pages 2446–2454.
Tatoglu, A. and Pochiraju, K. (2012). Point cloud segmen-
tation with lidar reflection intensity behavior. In 2012
IEEE International Conference on Robotics and Au-
tomation, pages 786–790. IEEE.
Vacek, P., Ja
ˇ
sek, O., Zimmermann, K., and Svoboda, T.
(2021). Learning to predict lidar intensities. IEEE
Transactions on Intelligent Transportation Systems,
23(4):3556–3564.
Wang, W. and Shen, J. (2017). Deep visual attention pre-
diction. IEEE Transactions on Image Processing,
27(5):2368–2378.
Wang, Y., Shi, T., Yun, P., Tai, L., and Liu, M.
(2018). Pointseg: Real-time semantic segmenta-
tion based on 3d lidar point cloud. arXiv preprint
arXiv:1807.06288.
Wang, Z., Fu, H., Wang, L., Xiao, L., and Dai, B. (2019).
Scnet: Subdivision coding network for object detec-
tion based on 3d point cloud. IEEE Access, 7:120449–
120462.
Yang, B., Liang, M., and Urtasun, R. (2018a). Hdnet: Ex-
ploiting hd maps for 3d object detection. In Confer-
ence on Robot Learning, pages 146–155. PMLR.
Toward Physics-Aware Deep Learning Architectures for LiDAR Intensity Simulation
55

Yang, B., Luo, W., and Urtasun, R. (2018b). Pixor: Real-
time 3d object detection from point clouds. In Pro-
ceedings of the IEEE conference on Computer Vision
and Pattern Recognition, pages 7652–7660.
Yang, G., Xue, Y., Meng, L., Wang, P., Shi, Y., Yang, Q.,
and Dong, Q. (2021). Survey on autonomous vehi-
cle simulation platforms. In 2021 8th International
Conference on Dependable Systems and Their Appli-
cations (DSA), pages 692–699. IEEE.
SIMULTECH 2024 - 14th International Conference on Simulation and Modeling Methodologies, Technologies and Applications
56
