
Forgetting in Knowledge Graph Based Recommender Systems
Xu Wang
1 a
and Christopher Brewster
1,2 b
1
Institute of Data Science, Maastricht University, Paul-Henri Spaaklaan 1, 6229 GT, Maastricht, The Netherlands
2
Data Science Group, TNO, Kampweg, Soesterberg, The Netherlands
Keywords:
Recommender System, Knowledge Graph, Forgetting, Datalog.
Abstract:
Recommender systems need to contend with continuous changes in both search spaces and user profiles. The
set of items in the search space is usually treated as continuously expanding, however, users also purchase items
or change their requirements. This raises the issue of how to ”forget” an item after purchase or consumption.
This paper addresses the issue of “forgetting” in knowledge graph-based recommender systems. We propose an
innovative method for identifying and removing unnecessary or irrelevant triples from the graph itself. Using
this approach, we simplify the knowledge graph while maintaining the quality of the recommendations. We also
introduce several metrics to assess the impact of forgetting in knowledge graph-based recommender systems.
Our experiments demonstrate that incorporating consideration of impact in the forgetting process can enhance
the efficiency of the recommender system without compromising the quality of its recommendations.
1 INTRODUCTION
Recommender systems function as a specialized sub-
set within decision-making or information filtering
frameworks and are widely used across diverse appli-
cations/platforms (Roy and Dutta, 2022; Kreutz and
Schenkel, 2022). Platforms like Netflix
1
and Amazon
2
use these systems to predict and recommend content
tailored to user preferences. Typically, these systems
are categorized into three or four distinct types: collab-
orative filtering, content-based, knowledge-based (oc-
casionally regarded as a derivative of content-based),
and hybrid recommender systems (Lu et al., 2015).
Knowledge graph-based recommender systems use
domain knowledge for decision making and form an
important category of system as they can be used to ad-
dress the cold start problem. Unlike collaborative filter-
ing, which operates on the premise ”other similar users
also liked this,” and content-based systems, which sug-
gest ”you might be interested in the content of this”,
knowledge graph-based systems can be summarized
as ”based on certain attributes of yours, it is inferred
that you would like this.” In other words, knowledge
graph-based recommender systems use rules, reason-
ing, or constraints applied to domain knowledge to
a
https://orcid.org/0000-0002-7585-759X
b
https://orcid.org/0000-0001-6594-9178
1
https://www.netflix.com/
2
https://www.amazon.com/
make recommendation decisions (Le et al., 2023; Ai
et al., 2018).
The concept of forgetting has been a part of com-
puter science and artificial intelligence research for at
least 30 years. Following Lin and Reiter in 1995 with
the introduction of the ”Forget” concept in artificial
intelligence (Lin and Reiter, 1994), a plethora of stud-
ies focusing on forgetting in AI research have since
emerged. In the realm of knowledge representation and
reasoning, the theoretical study of forgetting has been
prominently featured in numerous recent research pa-
pers (Eiter and Kern-Isberner, 2018; Delgrande, 2017).
In this paper, we aim to integrate the idea of ”for-
getting” into knowledge graph-based recommender
systems (KG-based recommender systems) in order to
adapt to the dynamic changing needs of a user. The
”forgetting” used in this paper is equivalent to ”becom-
ing unaware” in (van Ditmarsch et al., 2008). The
knowledge graph-based recommender system we con-
sidered in this paper will be one with path-based meth-
ods or unified methods as described in (Guo et al.,
2022). In other words, this kind of recommender sys-
tem uses the knowledge graph as background knowl-
edge and applies some knowledge-based methods (in-
cluding machine learning methods and/or symbolic
reasoning methods) to make recommendation deci-
sions. The following is a boxology representation
(boxology notation is introduced in (Harmelen and
Teije, 2019)) of this kind of recommender system:
Wang, X. and Brewster, C.
Forgetting in Knowledge Graph Based Recommender Systems.
DOI: 10.5220/0012757300003756
Paper published under CC license (CC BY-NC-ND 4.0)
In Proceedings of the 13th International Conference on Data Science, Technology and Applications (DATA 2024), pages 309-317
ISBN: 978-989-758-707-8; ISSN: 2184-285X
Proceedings Copyright © 2024 by SCITEPRESS – Science and Technology Publications, Lda.
309
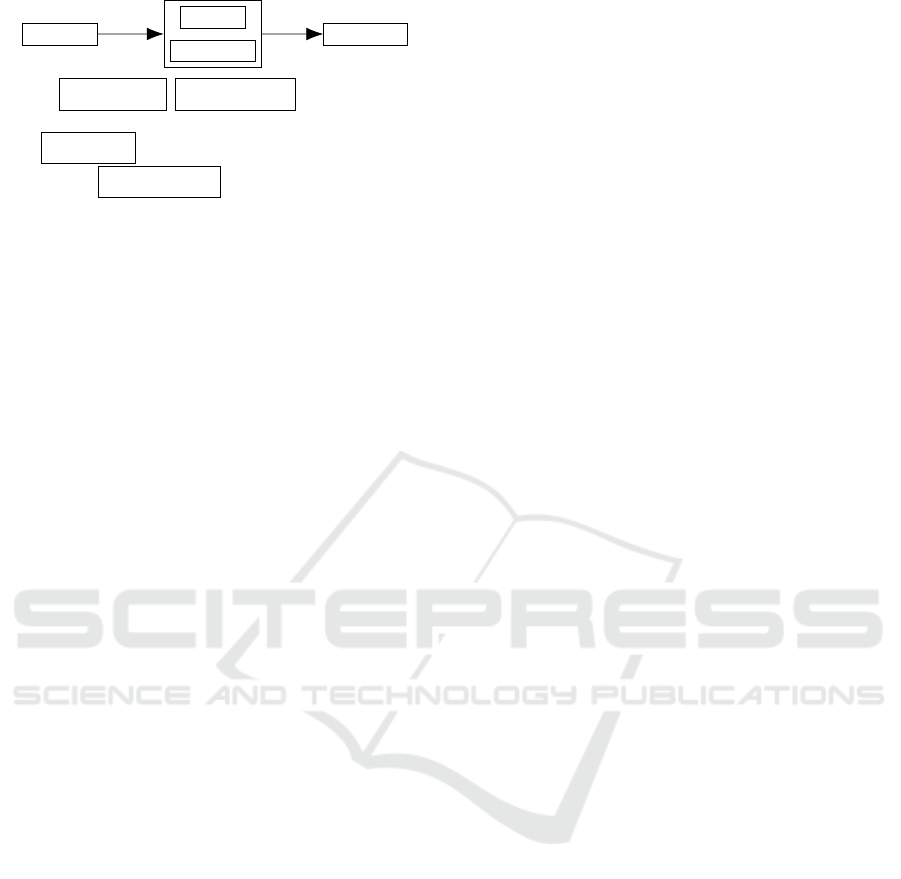
+
KG (sym)
Method (KR)
Input (data) Output (data)
where
Input (data) Output (data)
means ”model-
free” input and output data of recommender sys-
tem;
KG (sym)
means the ”model-based” knowledge
graph data;
Method (KR)
means some forms of de-
ductive inference, which would be a rule based reason-
ing method over a knowledge graph (Ma et al., 2019;
Balloccu et al., 2022) or the symbolic explanation of
some machine learning based method.
The main contribution of this paper is to provide:
1) a function for identifying facts (triples) to forget
from a knowledge graph-based recommender system;
2) a novel task in the forgetting of facts (triples) in
knowledge graph-based recommender systems; 3) a
number of metrics to measure the impact of forgetting
in knowledge graph-based recommender systems.
In this paper, we will mainly focus on three re-
search questions: 1. What is forgetting in KG-baesd
recommender system? 2. How to perform forgetting
in KG-based recommender system? 3. How to quanti-
tatively measure the impact of forgetting?
2 RELATED WORK
Recent research in recommender systems has incor-
porated knowledge graphs and ontologies. Tarus et
al. (Tarus et al., 2017) develop a hybrid system for
e-learning that combines an ontology with sequential
pattern mining to enhance personalization and address
challenges like cold-start. Carrer-Neto et al. (Carrer-
Neto et al., 2012) propose a hybrid movie recom-
mendation system using knowledge-based techniques
and social data, guided by Semantic Web principles.
Dong et al. (Dong et al., 2020) introduce an inter-
active fashion design recommender that merges sen-
sory evaluation, fuzzy logic, and an ontology-based
knowledge base. Brisse et al. (Brisse et al., 2022)
present KRAKEN, a knowledge-based system for se-
curity analysis, utilizing a knowledge base of adver-
sarial tactics with a visual tool. Esheiba et al. (Es-
heiba et al., 2021) offer a hybrid system for selecting
Product-Service Systems, using ontologies, constraint
satisfaction, and utility functions for customer align-
ment. Arnaoutaki et al. (Arnaoutaki et al., 2019) de-
scribe a recommender for Mobility as a Service plans,
combining Constraint Satisfaction Problem solving
with weighted similarity.
There is some existing research which considers
forgetting in recommender system. Jin et. al. (Jin
et al., 2023) introduce PMORS, a recommender sys-
tem incorporating the Ebbinghaus Forgetting Curve
for recent negative feedback, optimized for video plat-
forms and showing improved results on WeChat Chan-
nels. Liu et. al. (Liu et al., 2022) propose AltEraser,
an unlearning technique for neural recommendation
models, focusing on efficiency and effectiveness with
a warm-start strategy and second-order optimization.
Zhang et. al. (Zhang and Lu, 2020) present the MTMF
model for temporal recommender systems, combining
a personalized time weight and item transition matrix,
leading to superior accuracy on MovieLens. Matuszyk
et. al. (Matuszyk et al., 2015) explore new forget-
ting techniques in incremental matrix factorization for
recommender systems, enhancing predictive accuracy
and confirming the benefits of strategic forgetting. Ve-
rachtert et. al. (Verachtert et al., 2022) emphasize
the importance of an optimal training window size in
recommender systems, showing improved recommen-
dation quality with recent data usage. Matuszyk et. al.
(Matuszyk et al., 2017) introduce unsupervised forget-
ting techniques with algorithms for recommender sys-
tems, significantly enhancing accuracy across datasets.
Tavakolian et. al. (Tavakolian et al., 2012) develop
WmIDForg, a recommender system using web and
content mining with a forgetting mechanism, improv-
ing precision on the EachMovie dataset. Li et. al.
(Li et al., 2024) address unlearning in recommender
systems with the LASER framework, enabling effi-
cient data deletion while maintaining model utility,
validated with real-world datasets.
3 MOTIVATION
Online streaming platforms like YouTube and Netflix
enable users to flag content as uninteresting through
options like ’Not Interested’ or ’Do Not Recommend
This’. This feedback leads to updates in the plat-
form’s recommendation algorithms, aligning them
more closely with user preferences by filtering out
content that users have indicated they don’t like or
have already seen. In knowledge-based recommender
systems, such updates are crucial as they involve ”for-
getting” outdated information to keep pace with chang-
ing user demands.
The introduction of the concept of knowledge for-
getting in recommender system is intended to make the
recommendation process more efficient and adaptive.
Motivations to introduce a forgetting capability into
recommender systems include: • Reducing Compu-
tational Complexity: Recommender systems can en-
hance efficiency and conserve computational resources
by regularly removing outdated or irrelevant data, par-
DATA 2024 - 13th International Conference on Data Science, Technology and Applications
310

ticularly in fast-paced sectors like news or fashion
where current information is essential. • Products
No Longer Available on the Server: In e-commerce,
regularly updating product lines and removing discon-
tinued items from the recommendation pool saves stor-
age and maintains high-quality, relevant suggestions,
enhancing customer satisfaction and increasing conver-
sion rates. • Changing the Knowledge Graph Rather
Than User Profiles (due to product risks, techno-
logical updates, or changing trends): A Knowledge
Graph (KG) in recommendation systems needs timely
updates when products become unsafe or unpopular
due to safety risks, technological changes, or trends,
ensuring accurate recommendations and preventing the
negative impact on overall user profiles from specific
product issues. • Legal Implications: Recommenda-
tion systems must quickly delete certain data, such as
user information due to privacy laws or details about
banned or restricted products, to comply with legal
changes, protect users and the platform from legal
risks, and maintain user trust.
Applying forgetting to knowledge-based recommender
system is a novel and unusual research topic in the
domain of recommender system research. We ex-
pect this approach will be beneficial by removing ir-
relevant knowledge/information, and optimising the
knowledge-based recommender system to the dynamic
user preferences or needs.
4 PRELIMINARIES
In this section, we introduce the foundational concepts
and notations that will be used throughout. We denote
by
Γ
the set of all rules,
Φ
the set of all triples, and
Ψ
the set of all atoms.
Definition 1 (Datalog Rule). A Datalog rule is an ex-
pression composed of positive atoms
Ψ
P
⊂ Ψ
. It takes
the form of a Horn clause, which is an implication
where the consequent (head) is a single atom and the
antecedent (body) is a conjunction of atoms:
head ← body
1
∧ body
2
∧ ... ∧ body
n
Here, each of
head, body
1
,body
2
,.. . ,body
n
is an
atom element of
Ψ
P
. Datalog rules are character-
ized by having only positive literals in both the head
and body of the rule, reflective of their origin in logic
programming.
Definition 2 (Least Model). Given a set of Datalog
rules
R ∈ Γ
. Given a set of atom
F ∈ Φ
to represent
the ground-true facts. For any set of atom
M
,
M
is the
model of
F ∪R
if and only if
F ∪R |= M
. For one model
M
0
of
F ∪R
,
M
0
is the Least Model of
F ∪R
if and only
if for any other model
M
00
of
F ∪ R
,
M
0
≺ M
00
where
≺
means subsume which is the more-general-relation
between models.
The concept of a recommender system is formal-
ized building upon the definition provided by (Ado-
mavicius and Tuzhilin, 2005).
Definition 3 (Recommender System). Let
U
be the
set of all users, and
I
the set of all items that can
be recommended. Let
R
be the set of non-negative
real numbers representing utility values. The utility
function
f : U ×I → R
evaluates the usefulness of item
i ∈ I
to user
u ∈ U
. A recommender system aims to
recommend an item
i ∈ I
to a user
u ∈ U
such that
f (u, i) ≥ f (u,i
0
)
for any other item
i
0
∈ I
, effectively
maximizing the perceived utility for the user.
To facilitate the integration of knowledge graphs
into logic-based systems, we introduce an atomic rep-
resentation for triples:
Definition 4 (Atomic Representation of Triples). For
each triple
t ∈ Φ
, represented as
t = hs, p,oi
where
s
,
p
, and
o
correspond to the subject, predicate, and
object of t, respectively, we define the atomic formula
representation a f (t) as follows:
a f (t) = p
0
(s
0
,o
0
)
Here,
p
0
is a predicate symbol representing the rela-
tionship
p
, and
s
0
and
o
0
are the corresponding argu-
ments for the subject
s
and object
o
within the logical
framework. This representation enables the direct use
of triples in logical inference processes, aligning the
structure of knowledge graphs with formal reasoning
mechanisms.
5 METHODOLOGY
In this section, we introduce a comprehensive method-
ology for identifying forgettable triples in a knowledge
graph, detailing the process of forgetting these triples
and proposing methods to measure the impact of such
forgetting. Assuming
Γ
is a set of all Datalog rules,
Φ
a set of all triples, Ψ a set of all atoms in this section.
5.1 Forgetting Task in Knowledge
Graph Based Recommender System
A forgetting task involves selectively removing certain
triples from the knowledge graph to better match a
user’s changing needs.
Definition 5 (Forgetting Task in KG-based Recom-
mender System). Let
G
denote a knowledge graph
that comprises a set of triples
T ⊆ Φ
. Suppose
RS
is a
recommender system based on the knowledge graph
G
,
Forgetting in Knowledge Graph Based Recommender Systems
311

Figure 1: Example of forgetting.
Top Left
: The KG consists
of elements q, p, and r, and there are two rules in KG-based
recommender system: one that implies A from q and p (q,p
→
A) and another that implies B from r and p (r,p
→
B).
Top Right
: We decided to forget r or p.
Bottom Left
: At-
tempts to demonstrate the forgetting of element r. However,
the rule (r,p
→
B) is now problematic. If r is forgotten, the
rule simplifies to p
→
B, which would affect the other rule
(q,p
→
A), effectively transforming it into (q,p
→
A,B) be-
cause p alone would now trigger both A and B. This is not
the desired outcome, as it conflates the conditions for recom-
mending A and B.
Bottom Right
: Attempts to demonstrate
the forgetting of element p.
incorporating a set of Datalog rules
R ⊆ Γ
which dic-
tate the recommendation logic of
RS
. Consider
hI, Oi
as the input-output pair for
RS
, where
I ⊆ Φ
represents
the inputs and
O ⊆ Φ
represents the outputs such that
the intersection
I ∩ T ∩ R
logically entails
O
. A forget-
ting task is then defined as a transformation function
forget : Φ × Γ → Φ × Γ
which accepts a set of triples
T
and a set of Datalog rules
R
, and yields a modified
set of triples
T
0
⊆ T
and a revised set of Datalog rules
R
0
, ensuring that for any input
I
, the new system
RS
0
with its updated knowledge graph
G
0
(
T
0
) and recom-
mendation mechanism representation
R
0
provides the
same recommendations
O
such that
I ∩ T
0
∩ R
0
|= O
if and only if
I ∩ T ∩ R |= O
, excluding any elements
related to the forgotten aspects.
Figure 1 exemplifies the challenges in a forgetting
task where removing an element from a KG-based
recommender system can lead to unintended conse-
quences in the recommendation logic, as seen when
trying to forget ’r’, which disrupts the distinct recom-
mendation conditions for ’A’ and ’B’.
A recommendation task in KG-based recom-
mender system can be considered as a ”link-prediction”
task, where we try to predict the missing recommenda-
tion relations between user and item. This means that
the output
O
of recommender system
RS
is not in the
background knowledge graph
G
or
G
0
. Then we have
a proposition about this.
Proposition 1. Let
G
denote a knowledge graph that
comprises a set of triples
T ⊆ Φ
. Suppose
RS
is a
recommender system based on the knowledge graph
G
, incorporating a set of Datalog rules
R ⊆ Γ
which
dictate the recommendation logic of
RS
. Consider
hI, Oi
as the input-output pair for
RS
, where
I ⊆ T
represents the inputs and
O ⊆ Φ
represents the outputs
such that the intersection
I ∩ T ∩ R
logically entails
O
.
We have that ∀t ∈ O, t /∈ T .
The input-output pair
hI, Oi
follows the Least
Model semantics according to the recommendation
mechanism representation
R
or
R
0
in the KG-based rec-
ommender system.Then we have a proposition about
the input-output pair hI, Oi.
Proposition 2. Let
G
denote a knowledge graph that
comprises a set of triples
T ⊆ Φ
. Suppose
RS
is a
recommender system based on the knowledge graph
G
, incorporating a set of Datalog rules
R ⊆ Γ
which
dictate the recommendation logic of
RS
. Consider
hI, Oi
as the input-output pair for
RS
, where
I ⊆ Φ
represents the inputs and
O ⊆ Φ
represents the outputs
such that the intersection
I ∩ T ∩ R
logically entails
O
.
Then we have that
I ∪ R
has the Least Model
O
. This
means that with input
I
, recommender system
RS
could
have least output
O
as recomendation results. For the
set of all outputs of
RS
, denoted as
Os
, we have that
T ∪ R
has the Least Model
Os
, such that
RS
always
output
Os
with background knowledge graph
G
and
recommendation logic R.
5.2 Passive and Intentional Forgetting
Passive forgetting in the context of a KG-based recom-
mender system refers to the process of omitting certain
knowledge due to changes in user needs or external
factors. Unlike other forms of forgetting, passive for-
getting is reactive, occurring in response to shifts in
the external environment, particularly the preferences
and requirements of users.
Definition 6 (Passive Forgetting in KG-based Recom-
mender System). Let
RS
be a KG-based recommender
system, utilizing a background knowledge graph
KG
with triples
T ⊆ Φ
, and a set of Datalog rules
R
rep-
resenting the recommendation logic of
RS
. Define the
search space as the subset of triples encompassing all
outputs no longer aligning with the updated user needs
and any triples that infer these outputs via
R
. Passive
forgetting is then defined as a transformation function
PF : Φ × Γ × Φ × Φ → Φ
, where a change in user
needs from
O
to
O
0
prompts
PF
to produce a refined
set of triples
T
0
⊆ T
by excluding elements from
T
.
This ensures logical consistency in recommendations,
where
T ∪ R |= O
if and only if
T
0
∪ R |= O
0
, effec-
tively adapting the knowledge graph to the updated
preferences.
DATA 2024 - 13th International Conference on Data Science, Technology and Applications
312

In contrast to passive forgetting, intentional forget-
ting is a proactive approach that considers the entirety
of the background knowledge graph, rather than just
the parts related to immediate user needs. This form
of forgetting is about optimizing the knowledge graph
by removing information that is deemed irrelevant or
unnecessary for the current state and goals of the rec-
ommender system.
Definition 7 (Intentional Forgetting in KG-based Rec-
ommender System). Let
RS
be a KG-based recom-
mender system, utilizing a background knowledge
graph
KG
with triples
T ⊆ Φ
, and a set of Datalog
rules
R
representing the recommendation logic of
RS
.
Intentional forgetting is characterized as an optimiza-
tion function
IF : Φ × Γ → Φ
, which processes
T
and
R
to yield a streamlined set of triples
T
00
⊆ T
. This
operation is designed to preserve the recommendation
capabilities of the system, such that for the set of all
outputs
O
of
RS
,
T
00
∪ R |= O
if and only if
T ∪ R |= O
.
The purpose of this function is to enhance the efficiency
and relevancy of the knowledge graph by deliberately
discarding superfluous or outdated information.
5.3 Forgetting Triple
We use the ”fires” definition inspired from (Betz et al.,
2022) for rules. Informally, a rule ”fires” means that
the triples in the body of this rule should be covered
by knowledge graph.
Definition 8 (Rule ”Fires”). Let
r ∈ Γ
be a Datalog
rule. Let
G
be a knowledge graph that contains a set
of triples
T ⊆ Φ
.
r
fires w.r.t. (with respect to)
G
iff
the body
b
of
r
satisfies
b ⊆ T
. We also call
r
the fired
rule w.r.t. graph G.
The subsequent definitions and propositions con-
sider only the rules that ”fire”.
We now discuss how to identify triples suitable for
forgetting. Our concept of forgetting is motivated by
(Lin and Reiter, 1994), which discusses forgetting facts
or relations. The first step is to determine which triples
in the knowledge graph can be forgotten. The aim
of forgetting is to simplify knowledge while retaining
essential capabilities, akin to Occam’s Razor: ”Keep
things simple”.
Definition 9 (Search Space for Passive Forgetting).
Let
G
be a knowledge graph that contains a set of
triples
T ⊆ Φ
. Let
R ⊆ Γ
be a set of fired rules
w.r.t.
G
. Let
RS
be a KG-based recommender sys-
tem, with background knowledge
G
and recommen-
dation logic representation
R
. Let
OT ⊆ T
be a set
of triples that would be forgotten in the output of
RS
. Then the search space for passive forgetting
in
RS
w.r.t.
OT
is
SSPas
RS
(OT ) = {t|t ∈ body(r) ∪
head(r) ∪ T,head(r) ∈ OT, where r ∈ R}
. We also
call the search space
SSPas
R
S(OT )
as the forgettable
triple set in G w.r.t. OT .
Differ from passive forgetting, search space for in-
tentional forgetting
SSInt
RS
is the background knowl-
edge graph
G
of the KG-based recommender system
RS
, or we can say that the forgettable triple set of
intentional forgetting would be all the triples in the
background knowledge graph.
Following is a proposition related to the intersec-
tionality of the search space for passive forgetting:
Proposition 3. Let
G
be a knowledge graph that con-
tains a set of triples
T ⊆ Φ
. Let
OT 1, OT 2 ∈ T
be two
triple sets that would be forgotten in the output of
RS
.
We have
SSPas
RS
(OT 1 ∩ OT 2) = SSPas
RS
(OT 1) ∩
SSPas
RS
(OT 2).
Having constructed the search space, we can opti-
mize the rules. As we mentioned above, forgetting in
this paper is equivalent to ”becoming unaware”, which
means that we will no longer consider the truth of a
triple when we decide to forget this triple. Then, we
can optimise the Datalog rules by ignoring the forget-
ting triples. The optimisation of a rule
r
with forgetting
involves creating an optimized rule
r
0
by excluding for-
gettable triples from the body
b
of
r
, while keeping
the head
h
unchanged. This process refines the rule
by removing redundant elements without altering its
logical impact.
Definition 10 (Rule optimisation with Forgetting). Let
G
be a knowledge graph that contains a set of triples
T ⊆ Φ
. Let
r ∈ R
is a fired Datalog rule w.r.t.
G
. Let
RS
be a KG-based recommender system. Let
t
be the
one triple in search space for (passive or intentional)
forgetting in
RS
. If
t 6= h
and
t ∈ b
, we have rule
r
0
: h ← b \{t}
is the optimised rule of
r
w.r.t.
G
with
forgetting
t
, where
h
is the head of
r
and
b
is the body
of r.
This optimization ensures the rule still fires as it
only removes triples from the rule’s body.
Proposition 4. Let
G
be a knowledge graph that con-
tains a set of triples
T ⊆ Φ
. Let
r ∈ Γ
be a fired rule
w.r.t.
G
. If
r
0
is the optimised rule of
r
w.r.t.
G
with
forgetting, we have that r
0
is the fired rule w.r.t. G.
5.4 Quantitative Measures of Impact
In the realm of KG-based recommender systems, the
act of forgetting specific triples can have a profound
impact on various aspects of system performance and
behavior. To effectively quantify and understand these
impacts, we introduce two distinct metrics: impact on
Least Model, and impact on weakest sufficient condi-
tions. Assuming
G
a knowledge graph that contains
Forgetting in Knowledge Graph Based Recommender Systems
313
a set of triples
T ⊆ Φ
,
R ⊆ Γ
a set of fired Datalog
rules w.r.t.
G
,
RS
a KG-based recommender system
that has background
G
and recommendation logic rep-
resentation
R
, and
SS
the search space for (passive or
intentional) forgetting in RS.
Least Model represents consistent and complete
sets of conclusions that can be drawn from a knowl-
edge graph under a given set of rules. Assessing the
impact on Least Model is essential for understanding
how the omission of certain triples affects the integrity
and coherence of the system’s logical foundations.
Impact
LM
= 1 −
|Least Model after Forgetting|
|Least Model before Forgetting|
(1)
The impact on weakest sufficient conditions (WSC)
is evaluated by comparing the normalized scores of
paths within the knowledge graph before and after the
forgetting of a specific triple. We use the Personal-
ized Page Rank (PPR) algorithm for the personlized
importance of entities relative to a target entity, and
the eigenvector centrality algorithm for the global im-
portance of entities(Schoenberg, 1969). Then we have
the entity importance:
Imp(e) = α ∗ eigenvector(e)
+ β ∗ PPR(e)
− τ ∗ (eigenvector(e) ∗PPR(e))
(2)
where
eigenvector(e)
is the eigenvector centrality of
entity
e
and
PPR(e)
is the personalized page rank score
of entity
e
.
α
and
β
are the weight of eigenvector
centrality and PPR.
τ
serves as a damping factor to
reduce the score of nodes that are highly central both
globally and from the perspective of the target node,
addressing potential redundancy.
For predicate in triples, we use the degree centrality
to compute the importance of predicates. Then, we
have the WSC impact of forgetting one triples in graph:
Impact
W SC
(t) = ω
predicate
∗ degree(p)
+ ω
entity
∗ Imp(s)
+ ω
entity
∗ Imp(o)
(3)
where
ω
predicate
and
ω
entity
are the weight of impor-
tance score of predicate
p
and entity.
degree(p)
is the
degree centrality of predicate
p
.
s
,
p
,
o
are the subject,
predicate and object of triple t respectively.
6 EXPERIMENTS AND RESULTS
6.1 Dataset
We use the dataset from the paper of Balloccu et.
al(Balloccu et al., 2022). Balloccu et. al. introduce
KG
RS
Rule (Path)
Original
Result
Forget
KG’
RS
Rule’
(Path’)
Result after
forgetting
Evaluation
build new KG
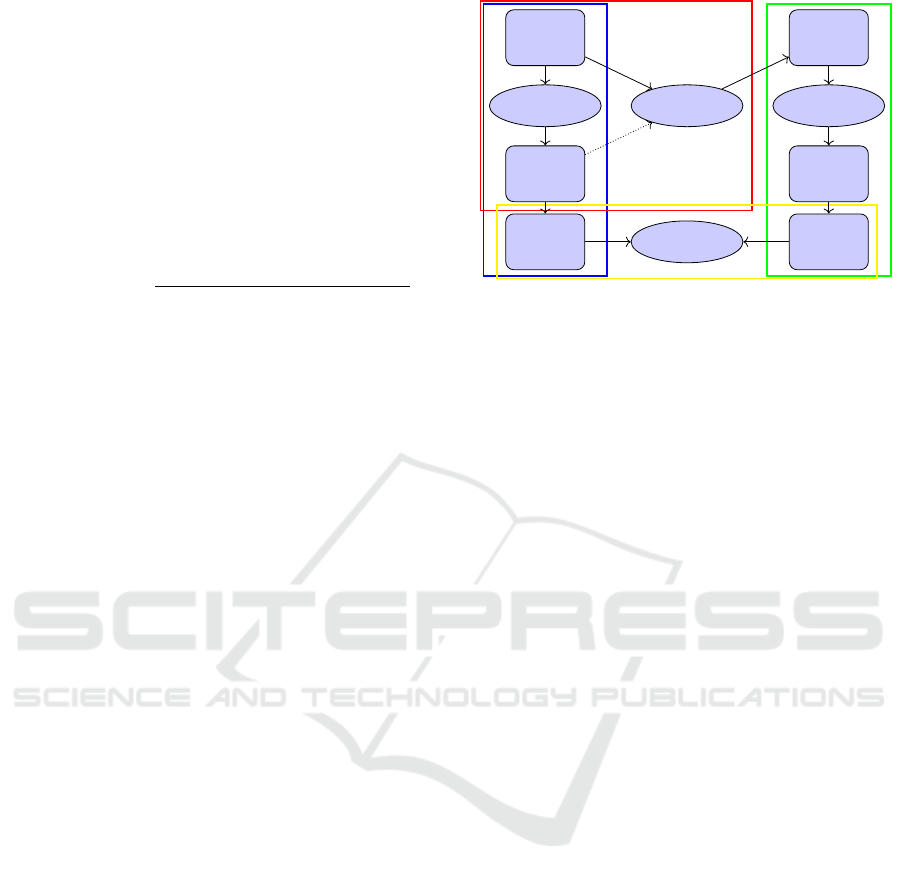
Figure 2: Overview of experiment setup. Step1 (Reproduce):
Running recommendation experiments with original knowl-
edge graph and datasets. Step2 (Forget): Forgetting based
on original recommendation process to build new KG. Step3
(Rerun): Using new-built KG to rerun recommendation ex-
periments. Step4 (Evaluation): Evaluating the results of
original experiments and rerun experiments.
an innovative path-based recommendation approach
that leverages user-item interaction paths to generate
more transparent and interpretable recommendations,
focusing on the significance of the path’s context and
its contribution to enhancing the explainability of the
recommendations. They provide the knowledge graph
which is used for path-based recommendations and
also the path explanation for recommendation, where
the path explanations could be considered as the rule
in our paper.
6.2 Experiment Setup
We conduct experiments on forgetting using existing
recommendation systems based on knowledge graphs
and paths (where paths can be considered as logical
rules). The experiment is divided into several parts:
1) Reproducing recommendations using the original
knowledge graph and paths from experiments of (Bal-
loccu et al., 2022), 2) Based on the reproduced rec-
ommendation results and paths, two kinds (with con-
sidering impact of Least Model or Weakest Sufficient
Condition) of intentional forgetting are used to con-
struct a new knowledge graph, 3) Re-experimenting
using the new knowledge graph and measuring the
impact of forgetting using two different methods.
In Figure 2, we illustrate the experimental setup
employed in our study, which is structured into four
distinct steps: 1. Reproduce: Initially, we conduct rec-
ommendation experiments using the original Knowl-
edge Graph (KG) and datasets (highlighted in blue).
The recommendation system (RS) utilizes the KG
to derive rules (paths) for generating original results.
2. Forget: Subsequently, we implement a ’forgetting’
process based on what we introduced in Methodology
DATA 2024 - 13th International Conference on Data Science, Technology and Applications
314

section (highlighted in red) that modifies the original
KG based on original recommendation. This step in-
volves selectively forgetting certain triples to refine the
KG, leading to the construction of a new knowledge
graph (KG’). 3. Rerun: With the newly constructed
KG’, we rerun the recommendation experiments (high-
lighted in green). The updated KG’ provides a revised
set of rules (paths’) that the RS employs to generate
new results after forgetting. 4. Evaluation: Finally,
we evaluate the outcomes of the recommendation pro-
cesses (highlighted in yellow) by comparing the origi-
nal results with the results obtained after the forgetting
process. This evaluation aims to assess the impact
of the forgetting process on the quality and relevance
of the recommendations. This experimental frame-
work allows us to systematically explore the effects
of information forgetting on recommendation systems
and to understand how the selective omission of data
influences the generation of recommendations.
Two forms of forgetting are applied in the ex-
periments: intentional forgetting influenced by the
Least Model and intentional forgetting influenced by
the Weakest Sufficient Condition (WSC). When com-
pared individually to WSC, forgetting influenced by
the Least Model can be regarded as a form of active
forgetting impacted by the Strongest Necessary Con-
dition, as it considers the intuitive effects on the rec-
ommendation outcomes. For the Forgetting with Least
Model approach, we assess whether the candidate for-
getting triplets are present in the Least Model of the
input-output process of recommendation. In the case
of Forgetting with WSC, we calculate the WSC score
for each candidate forgetting triplet, then select and
retain the top 95% of triplets by descending order, thus
constructing a new knowledge graph. The code of our
experiments are open access
3
.
6.3 Evaluation
Our evaluation method investigates the impact of al-
terations to different knowledge graphs on a recom-
mendation system, employing metrics such as NDCG,
Hit Ratio (HR), recall, precision, Linking Interaction
Recency (LIR), Shared Entity Popularity (SEP), and
Explanation Type Diversity (ETD) (Wang et al., 2013;
Gunawardana and Shani, 2015). NDCG assesses rank-
ing quality by valuing highly relevant items at the top.
HR reflects the occurrence of relevant items in recom-
mendations. Recall measures the system’s capacity
to identify all relevant items, whereas precision evalu-
ates the accuracy of positive predictions. LIR explores
how recent interactions between users and items af-
fect recommendations. SEP considers the influence
3
https://github.com/XuWangDACS/Forget KGRS
of item popularity among users on recommendation
quality. ETD measures the diversity of explanations
for recommendations, aiming to improve user trust and
satisfaction.
6.4 Results
Table 1 provides an in-depth analysis of the impact of
various forgetting methods and optimization strategies
on recommendation system performance, assessed
across a range of metrics such as NDCG, HR, recall,
precision, LIR, SEP, and ETD. These metrics evalu-
ate the recommendation system’s ranking quality, hit
rate, recall, precision, long-tail item recommendation
efficacy, sequence preference, and recommendation
diversity.
Our primary focus is on the degradation of the
recommendation results (M, W) after forgetting, com-
pared to the original recommendation results (O), un-
der the same optimization parameters (opt). Analysis
of Table 1 reveals that the maximum reduction is less
than 0.01.
Key findings include: 1. Performance Stability:
Compared to traditional methods, the forgetting ap-
proaches Least Model and Weakest Sufficient Condi-
tion consistently impact recommendation system per-
formance across various strategies, notably in NDCG
and HR metrics, demonstrating their ability to effec-
tively modify the knowledge graph without reducing
recommendation quality. 2. Optimal Configurations:
Optimal performance under each setup is denoted by
bold figures within the table. For instance, the EM con-
figuration excels in the NDCG metric, suggesting that
the Least Model forgetting approach, when paired with
ETD optimization, significantly enhances recommen-
dation list quality. This pattern recurs across different
metrics and configurations, facilitating the identifica-
tion of the most influential forgetting strategies and
optimization combinations for specific performance
indicators. 3. Forgetting Methods’ Efficacy: Despite
the informational reduction by the forgetting meth-
ods, there is no notable decline in the recommendation
systems’ performance, indicative of a deliberate bal-
ance in forgetting strategy design that preserves the
recommendation systems’ core functionalities and per-
formance. This equilibrium suggests that carefully
crafted forgetting methods can modify and optimize
the knowledge graph while preserving or even improv-
ing recommendation quality.
In essence, this table not only details the specific
impacts of diverse forgetting methods and optimization
strategies on recommendation system performance but
also accentuates the forgetting methods’ efficacy and
stability in maintaining or enhancing system perfor-
Forgetting in Knowledge Graph Based Recommender Systems
315

Table 1: Average score of each metrics for each opt. ’E’, ’S’, and ’L’ stand for optimization of ETD, SEP, and LIR
respectively, while ’O’, ’M’, and ’W’ denote Original recommendation, recommendation of forgetting with Least Model, and
recommendation of forgetting with Weakest Sufficient Condition.
Metric EO EM EW SO SM SW LO LM LW ELO ELM ELW SLO SLM SLW ESO ESM ESW ESLO ESLM ESLW
NDCG 0.081 0.083 0.079 0.097 0.097 0.097 0.088 0.085 0.086 0.086 0.084 0.082 0.093 0.092 0.092 0.095 0.095 0.094 0.094 0.092 0.091
HR 0.152 0.156 0.148 0.184 0.186 0.185 0.166 0.165 0.163 0.161 0.157 0.153 0.176 0.176 0.174 0.173 0.173 0.171 0.174 0.169 0.168
recall 0.006 0.006 0.006 0.008 0.008 0.008 0.007 0.006 0.006 0.007 0.006 0.006 0.008 0.007 0.007 0.007 0.007 0.007 0.007 0.007 0.007
precision 0.018 0.019 0.017 0.023 0.023 0.023 0.020 0.020 0.020 0.019 0.019 0.018 0.022 0.022 0.021 0.021 0.021 0.021 0.021 0.021 0.021
LIR 0.149 0.151 0.149 0.138 0.141 0.141 0.357 0.359 0.359 0.345 0.346 0.346 0.353 0.354 0.354 0.137 0.137 0.137 0.340 0.340 0.341
SEP 0.613 0.612 0.612 0.927 0.927 0.927 0.588 0.587 0.587 0.655 0.655 0.655 0.881 0.881 0.881 0.884 0.883 0.884 0.853 0.853 0.853
ETD 0.385 0.383 0.383 0.198 0.198 0.198 0.129 0.129 0.130 0.390 0.388 0.390 0.165 0.165 0.165 0.396 0.395 0.396 0.369 0.369 0.370
mance. These insights are invaluable for future re-
search, highlighting the potential for designing forget-
ting strategies that flexibly adjust and optimize knowl-
edge without compromising key performance metrics.
7 CONCLUSION AND
DISCUSSION
This study successfully integrates knowledge for-
getting mechanisms into recommendation systems,
demonstrating through empirical validation that the
selective removal of triples does not compromise rec-
ommendation quality. Our findings underscore the
resilience and efficacy of the Least Model and Weak-
est Sufficient Condition forgetting methods, which
adeptly adjust the knowledge graph while maintaining
system performance. The research confirms that so-
phisticated forgetting strategies can enhance system
efficiency without impacting the core functionalities
of recommendation systems.
Looking ahead, the potential for expanding the
scope of forgetting to include more complex elements
like predicates presents a significant opportunity for
further research. Future studies should also explore
broader metrics for measuring the impact of forget-
ting and extend the applicability of these techniques
to a wider range of recommendation systems. By ad-
dressing these areas, research can develop innovative
strategies that adapt to the evolving preferences of
users and the dynamic nature of knowledge, thereby
advancing the field of recommendation systems.
ACKNOWLEDGEMENT
This work is funded by HORIZON EUROPE project
”EU-FarmBook: supporting knowledge exchange be-
tween all AKIS actors in the European Union” (Grant
ID: 101060382).
REFERENCES
Adomavicius, G. and Tuzhilin, A. (2005). Toward the
next generation of recommender systems: a survey
of the state-of-the-art and possible extensions. IEEE
Transactions on Knowledge and Data Engineering,
17(6):734–749.
Ai, Q., Azizi, V., Chen, X., and Zhang, Y. (2018). Learn-
ing heterogeneous knowledge base embeddings for
explainable recommendation. Algorithms, 11(9):137.
Arnaoutaki, K., Magoutas, B., Bothos, E., and Mentzas, G.
(2019). A hybrid knowledge-based recommender for
mobility-as-a-service. In Proceedings of the 16th Inter-
national Joint Conference on e-Business and Telecom-
munications. SCITEPRESS - Science and Technology
Publications.
Balloccu, G., Boratto, L., Fenu, G., and Marras, M. (2022).
Post processing recommender systems with knowledge
graphs for recency, popularity, and diversity of expla-
nations. In Proceedings of the 45th International ACM
SIGIR Conference on Research and Development in
Information Retrieval, SIGIR ’22, page 646–656, New
York, NY, USA. Association for Computing Machin-
ery.
Betz, P., Meilicke, C., and Stuckenschmidt, H. (2022). Ad-
versarial explanations for knowledge graph embed-
dings. In Proceedings of the Thirty-First International
Joint Conference on Artificial Intelligence, IJCAI-2022.
International Joint Conferences on Artificial Intelli-
gence Organization.
Brisse, R., Boche, S., Majorczyk, F., and Lalande, J.-F.
(2022). KRAKEN: A Knowledge-Based Recommender
System for Analysts, to Kick Exploration up a Notch,
page 1–17. Springer International Publishing.
Carrer-Neto, W., Hern
´
andez-Alcaraz, M. L., Valencia-
Garc
´
ıa, R., and Garc
´
ıa-S
´
anchez, F. (2012). Social
knowledge-based recommender system. application to
the movies domain. Expert Systems with Applications,
39(12):10990–11000.
Delgrande, J. P. (2017). A knowledge level account of for-
getting. Journal of Artificial Intelligence Research,
60:1165–1213.
Dong, M., Zeng, X., Koehl, L., and Zhang, J. (2020). An
interactive knowledge-based recommender system for
fashion product design in the big data environment.
Information Sciences, 540:469–488.
Eiter, T. and Kern-Isberner, G. (2018). A brief survey on for-
getting from a knowledge representation and reasoning
perspective. KI - K
¨
unstliche Intelligenz, 33(1):9–33.
DATA 2024 - 13th International Conference on Data Science, Technology and Applications
316

Esheiba, L., Elgammal, A., Helal, I. M. A., and El-Sharkawi,
M. E. (2021). A hybrid knowledge-based recommender
for product-service systems mass customization. Infor-
mation, 12(8):296.
Gunawardana, A. and Shani, G. (2015). Evaluating Recom-
mender Systems, page 265–308. Springer US.
Guo, Q., Zhuang, F., Qin, C., Zhu, H., Xie, X., Xiong, H.,
and He, Q. (2022). A survey on knowledge graph-
based recommender systems. IEEE Transactions on
Knowledge and Data Engineering, 34(8):3549–3568.
Harmelen, F. v. and Teije, A. t. (2019). A boxology of de-
sign patterns forhybrid learningand reasoning systems.
Journal of Web Engineering, 18(1):97–124.
Jin, J., Zhang, Z., Li, Z., Gao, X., Yang, X., Xiao, L., and
Jiang, J. (2023). Pareto-based multi-objective recom-
mender system with forgetting curve.
Kreutz, C. K. and Schenkel, R. (2022). Scientific paper
recommendation systems: a literature review of re-
cent publications. International Journal on Digital
Libraries, 23(4):335–369.
Le, N. L., Abel, M.-H., and Gouspillou, P. (2023). A
constraint-based recommender system via rdf knowl-
edge graphs. In 2023 26th International Conference
on Computer Supported Cooperative Work in Design
(CSCWD). IEEE.
Li, Y., Chen, C., Zheng, X., Liu, J., and Wang, J. (2024).
Making recommender systems forget: Learning and
unlearning for erasable recommendation. Knowledge-
Based Systems, 283:111124.
Lin, F. and Reiter, R. (1994). Forget it ! In Working Notes of
AAAI Fall Symposiumon Relevance, pages 154–159.
Liu, W., Wan, J., Wang, X., Zhang, W., Zhang, D., and Li,
H. (2022). Forgetting fast in recommender systems.
Lu, J., Wu, D., Mao, M., Wang, W., and Zhang, G. (2015).
Recommender system application developments: A
survey. Decision Support Systems, 74:12–32.
Ma, W., Zhang, M., Cao, Y., Jin, W., Wang, C., Liu, Y., Ma,
S., and Ren, X. (2019). Jointly learning explainable
rules for recommendation with knowledge graph. In
The World Wide Web Conference, pages 1210–1221.
ACM.
Matuszyk, P., Vinagre, J., Spiliopoulou, M., Jorge, A. M.,
and Gama, J. (2015). Forgetting methods for incremen-
tal matrix factorization in recommender systems. In
Proceedings of the 30th Annual ACM Symposium on
Applied Computing, SAC 2015. ACM.
Matuszyk, P., Vinagre, J., Spiliopoulou, M., Jorge, A. M.,
and Gama, J. (2017). Forgetting techniques for stream-
based matrix factorization in recommender systems.
Knowledge and Information Systems, 55(2):275–304.
Roy, D. and Dutta, M. (2022). A systematic review and
research perspective on recommender systems. Journal
of Big Data, 9(1).
Schoenberg, I. J. (1969). Publications of Edmund Landau,
page 335–355. Springer US.
Tarus, J. K., Niu, Z., and Yousif, A. (2017). A hybrid
knowledge-based recommender system for e-learning
based on ontology and sequential pattern mining. Fu-
ture Generation Computer Systems, 72:37–48.
Tavakolian, R., Taghi Hamidi Beheshti, M., and Moghad-
dam Charkari, N. (2012). An improved recommender
system based on forgetting mechanism for user interest-
drifting. International Journal of Information and Com-
munication Technology Research, 4(4):69–77.
van Ditmarsch, H., Herzig, A., Lang, J., and Marquis, P.
(2008). Introspective Forgetting, page 18–29. Springer
Berlin Heidelberg.
Verachtert, R., Michiels, L., and Goethals, B. (2022). Are
we forgetting something? correctly evaluate a recom-
mender system with an optimal training window. In
Proceedings of the Perspectives on the Evaluation of
Recommender Systems Workshop, volume 3228.
Wang, Y., Wang, L., Li, Y., He, D., Liu, T.-Y., and Chen,
W. (2013). A theoretical analysis of ndcg type ranking
measures.
Zhang, J. and Lu, X. (2020). A multi-trans matrix factor-
ization model with improved time weight in temporal
recommender systems. IEEE Access, 8:2408–2416.
Forgetting in Knowledge Graph Based Recommender Systems
317
