An Efficient Hash Function Construction for Sparse Data
Nir Soffer
1
a
and Erez Waisbard
2 b
1
IBM, Givataim, Israel
2
CyberArk, Petach Tikva, Israel
Keywords:
Integrity Verification, Hash Functions, Storage Virtualization, Sparse Disks, Parallel Computation.
Abstract:
Verifying the integrity of files during transfer is a fundamental operation critical to ensuring data reliability and
security. This is accomplished by computing and comparing a hash value generated f rom the file’s contents by
both the sender and the receiver. This process becomes prohibitively slow when dealing with large fi les, even
in scenarios involving sparse disk images where significant portions of the file may be unallocated. We in-
troduce blkhash, the first hash construction tailored specifically for optimizing hash computation performance
in sparse disk images. Our approach addresses the i nefficiencies inherent in traditional hashing algorithms by
significantly reducing the computational overhead associated with unallocated areas within the file. Moreover,
blkhash implements a parallel computation strategy that leverages multiple cores, further enhancing efficiency
and scalability. We have implemented the blkhash construction and conducted extensive performance eval-
uations to assess its efficacy. Our results demonstrate remarkable improvements in hash computation speed,
outperforming state-of-the-art hash functions by up to four orders of magnitude. This substantial acceleration
in hash computation offers immense potential for use cases requiring rapid verification of large virtual disk
images, particularly in virtualization and software-defined storage.
1 INTRODUCTION
In the realm of virtualization, efficient disk space
management is paramount for resource utilization.
One approach is the utilizatio n of sparse disk images
for virtual disks. Sparse disk images offer a flexi-
ble and efficient means of disk allocation, particularly
beneficial in scenarios where disk space conservation
and dynamic allocation are priorities. Sparse disk im-
ages differ from pre-allocated disk images in their al-
location strategy. Rather than pre-allocating the entire
disk space upon creation, sparse disk images dynami-
cally allocate storage space as data is written, utilizin g
only the space ne c essary to sto re ac tual data. Unallo-
cated areas in the file are represented by file metadata
to minimize storage space. This dynamic allocation
makes sparse disk ima ges particularly advantageous
in environments where disk space is at a premium.
Virtual disk images are typically sparse. A virtual
machine that is reading from a sparse virtual disk is
oblivious to the fact that the disk is sparse and unallo-
cated areas are seen as areas full of zeros (null bytes).
A sparse virtual disk ca n be stored as a sparse file on a
a
https://orcid.org/0009-0001-9265-7792
b
https://orcid.org/0000-0001-5634-5436
file system supporting sparseness, or a non-sparse file
using image forma t supporting sparsene ss.
Virtual disk images are mostly empty. When pro-
visioning a new v irtual machine we install an operat-
ing system into a completely empty disk. While the
virtual machine is run ning more data is added, how-
ever discarding deleted data can punch h oles in the
image. If the disk becomes too full it can be extended,
adding large unallocated areas. Typically large por-
tions of the image rem a in unallocated for the entire
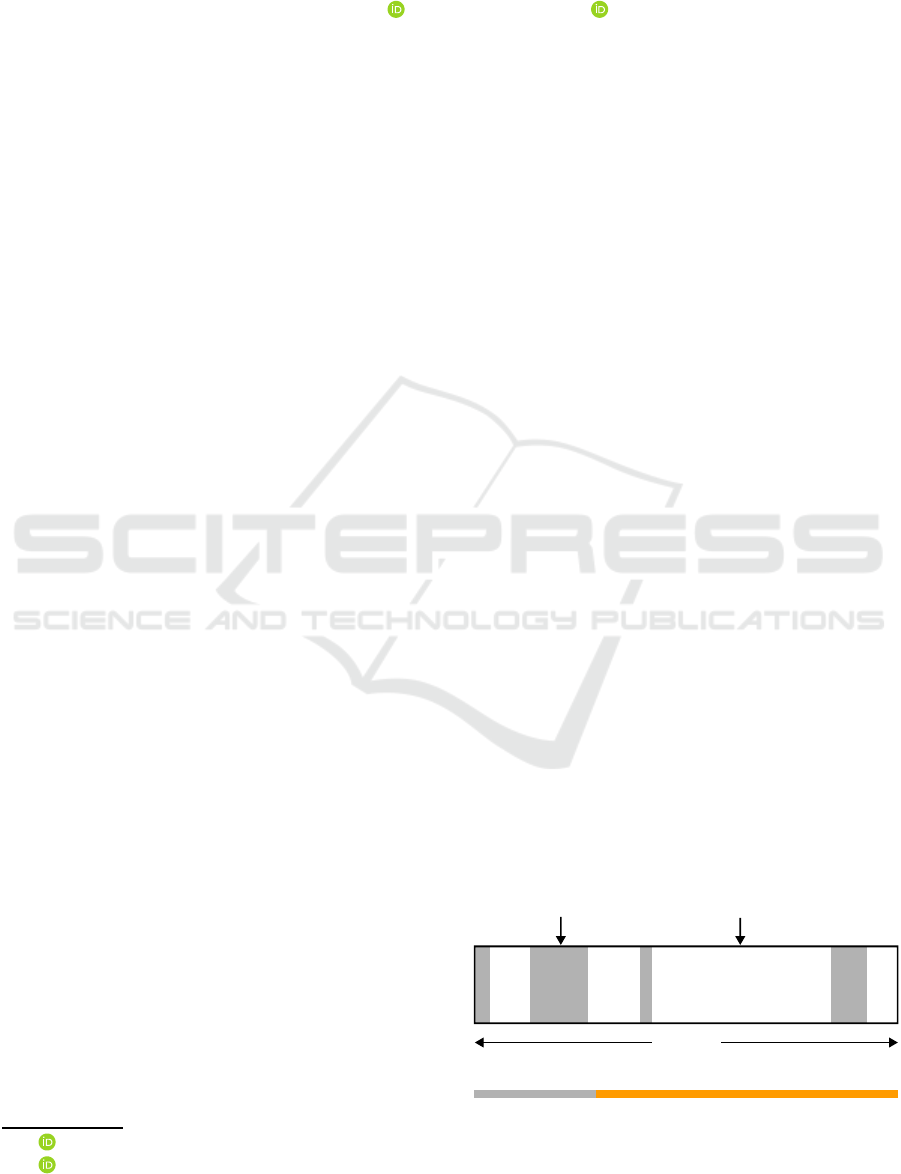
lifetime of the virtual machine. Figure 1 shows a typ-
ical disk image space allocation.
unallocated area
(read as zeros)
data
500 GiB
29% data 71% zeros
Figure 1: A typical sparse virtual disk image. In this exam-
ple 71% of the image is unallocated.
698
Soffer, N. and Waisbard, E.
An Efficient Hash Function Construction for Sparse Data.
DOI: 10.5220/0012764500003767
Paper published under CC license (CC BY-NC-ND 4.0)
In Proceedings of the 21st International Conference on Security and Cryptography (SECRYPT 2024), pages 698-703
ISBN: 978-989-758-709-2; ISSN: 2184-7711
Proceedings Copyright © 2024 by SCITEPRESS – Science and Technology Publications, Lda.
Disk utility tools are aware of image sparseness
and take advantage of it when pro cessing disk im-
ages. When a tool such as qemu-img (Bellard and
the QEMU Project developers, 20 03) c opies a disk
image, it first detects the allocated areas in the image
using file system or image metadata. Using this info it
skips reading unallocated areas from storage. Further-
more, when readin g allocated areas, it uses zero de-
tection to discover areas full of actual zeros, and treat
them as una llocated areas. When writing to the target
image, it can use efficient system calls to write zeros
to storage . Th e entire software stack works in concert
to enable efficient handling of zeros, leading to dra-
matic speed up and minimize I/O load when reading
or writing sparse images.
However, existing checksum
1
tools like
sha256 sum, using the SHA256 algorithm (Hansen
and 3rd, 2006), are not aware of sparseness, and do
not take advantage unallocated areas in the image
or a reas fu ll of zeroes. Such tools read the entire
image f rom storage, possibly transferring gigabytes
of z e ros over the wire when using remote storage.
Then they compute a hash for the entire image , bit by
bit. They do the same work regardless if the image
is completely empty or completely full, which makes
them very slow for typical virtual disk images.
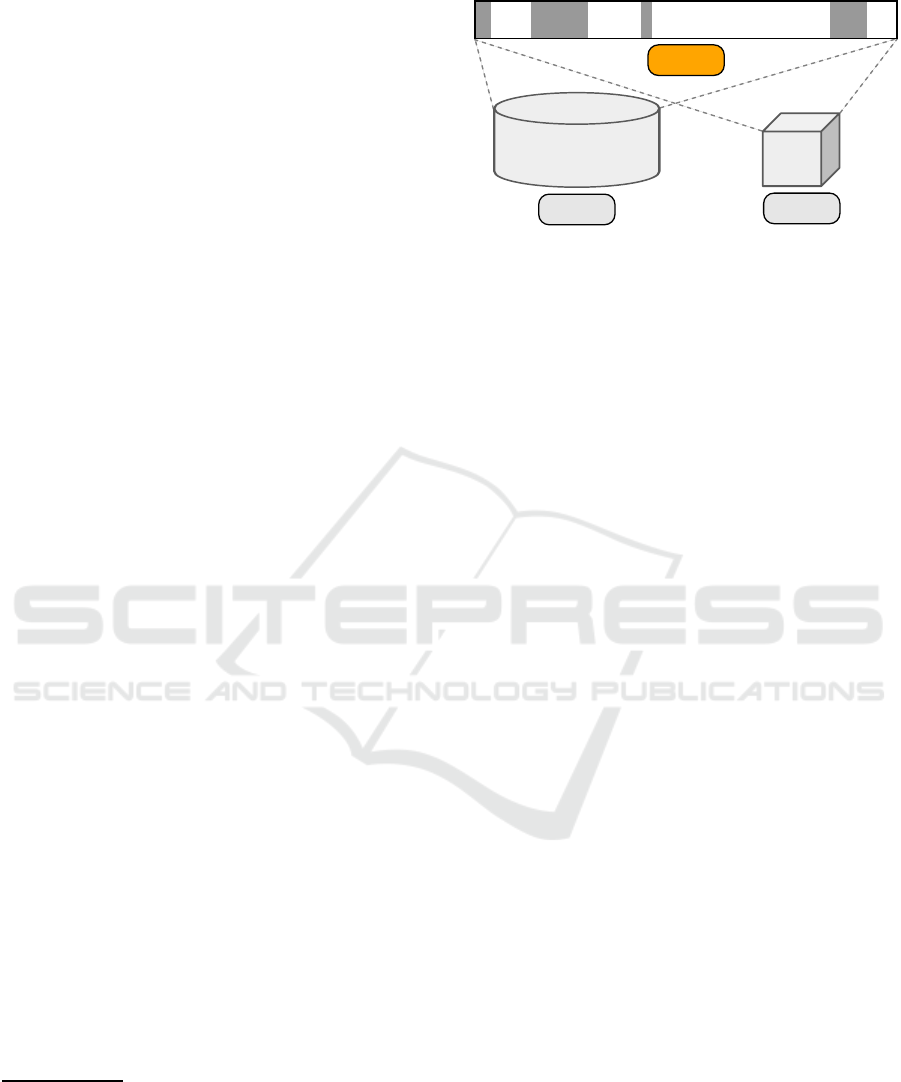
Virtual disk imag es are commonly published as a
compressed non-sparse image. A check sum is cre-
ated using cryptographic hash function and published
as well for verifying a downloaded image. However
when one tr a nsfers the downloaded image to an actual
storage in a virtualization system, the disk content is
not stored in the same form at, and the checksum of
the downloaded image cannot be used to verify the
image in the virtualization system. To verify an im-
age using a checksum, you must compute a ch ecksum
of the image content, the same data as seen by the vir-
tual machine using the image, and not a checksum of
the box holding the image data. To do this efficiently,
we need a hash function supporting sparse data. This
is illustrated in Figure 2.
In th e past computing a hash was considere d much
faster than copyin g a file, but due to improvements
in network and storage, copying a file can be around
3 times faster than computing a hash
2
. Bearing in
mind that the hash has to be computed over the en-
tire disk image, while the copy operation is done only
1
The term checksum is often used to describe the oper-
ation of computing a succinct representation value and it is
commonly computed using a cryptographic hash function.
In this paper when we use the term checksum, w e refer to a
computation of a cryptographic hash function.
2
Recent NVMe devices provides read/write throughput
of 6 GiBs, whil e the best hardware accelerated SHA256 can
achieve at most 2 GiB/s
bbd3e7c2
4f5023a8
636b2ac8
Figure 2: Two identical disk images with different physi-
cal representation. Computing a checksum over the phys-
ical representation of the image yields different values,
while computing a checksum over the logical representa-
tion yields the same.
over the allocated parts significantly increases that
gap. Namely, if the image is 80% empty then the data
on which the hash is computed is 5 times larger and
computing the hash can be 15 times slower.
These d a ys most computing devices, including en-
try level phones, have multiple cores. Large servers
can have up to hu ndreds of cores. However the state
of the art cryptographic hash functions like SHA 256
and SHA3-256 ( D workin, 2015) use only a single core
because the algorithm is is inherently sequential and
cannot be par allelized to leverage the multiple co res.
Consequently, these hash functions, that have to go
over the entire image are limited in their comput-
ing power to a single core. Recent algorithms like
BLAKE3 (O’Connor et al., 2019) can use all avail-
able cores when using regular file via me mory map-
ping, but use only one core in other cases, for example
when reading from a block device or a pipe.
We propose a new hash construction optimized for
sparse virtual disk images that is up to 4 orders of
magnitude more efficient, which results in being both
faster and energy efficient compared with state of the
art cryptographic hash functions. Our most impor-
tant contribution is an efficient way to update the hash
with zeros - unallocate d areas in the image, without
reading anything from storage, or adding any data to
the hash. When adding actual data to the ha sh, we use
fast zero detection to treat b locks full of zeros as un-
allocated a rea, eliminating the com putation. In addi-
tion, our construction allows parallel processing, that
scales linearly with the number of threads.
Our solution is a modular construc tion that turns
any secure hash function into a hash function that
works efficiently with sparse input. This modular
construction that uses two layers enables using either
the same hash function on both the inner and outer
layers or using different one s. Using different hash
functions allows enhancing security or tuning perfor-
mance by adding a stronger or faster hash function.
An Efficient Hash Function Construction for Sparse Data
699
2 THE CONSTRUCTION
The blkhash (Soffer, 2021) constru c tion is designed
to work efficiently with sparse disk images. Unlike
common hash functions that go over the entire image
sequentially, including the unallocated a reas, blkhash
works more efficiently by:
1. Minimizing the computation over unallocated
blocks or blocks full of zeros.
2. Computing hashes of data blocks in parallel.
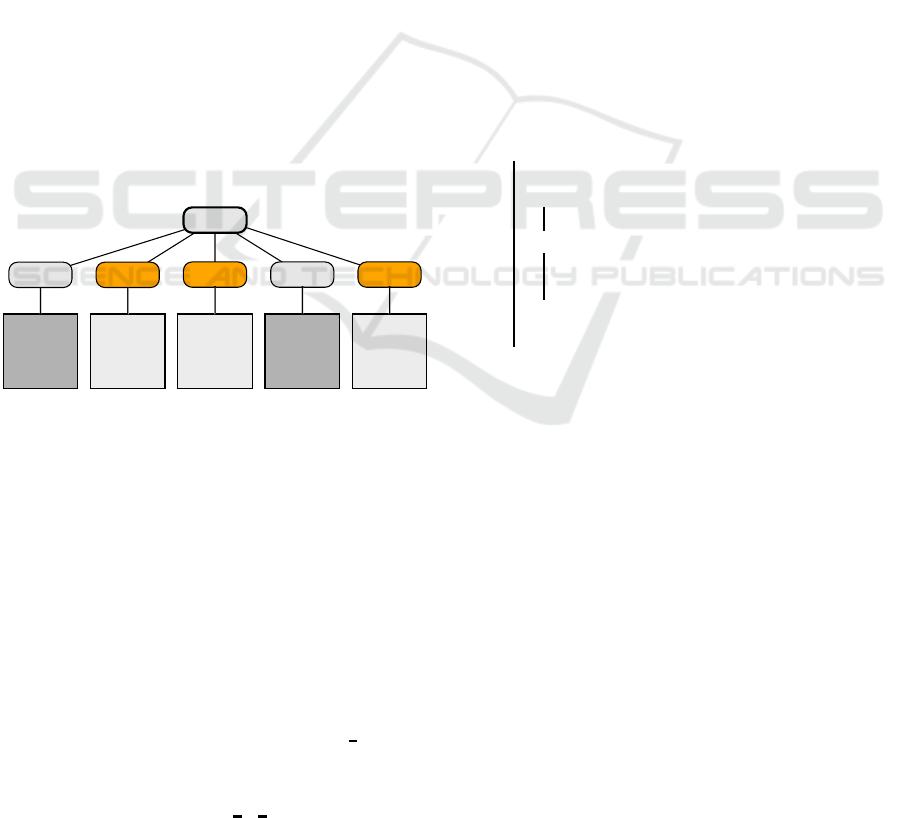
Loosely speaking, the blkhash construction is uti-
lizing a two levels Merkle tree (Merkle, 1988) con-
struction. On the first level, we split the inpu t image
into fixed sized blocks and compute the hash value
of every block. In the second level, we perform an-
other hash com putation o f all the hashed values of the
blocks in the order in which they were split and the re-
sult is the output value of blkhash. This is illustrated
in Figure 3
This enables performing the computation in paral-
lel and utilizing all the available cores. We note that
if two blo c ks are of the same value then their hash
value is the same. As a result, we do not need to com -
pute the hash value of the all-zero block repeatedly. In
fact, we can pre-compute the hash value of an all-zero
block in advance.
636b2ac8
0000 0000
0000 0000
5905 f334
be3d 6e25
05d4f20b
0000 0000
0000 0000
0000 0000
0000 0000
bbd3e7c2
0000 0000
0000 0000
0000 0000
0000 0000
bbd3e7c24f5023a8
80c8 d2b7
1582 7280
5715 ed58
a34d 41bb
0000 0000
0000 0000
0000 0000
0000 0000
bbd3e7c2
Figure 3: The blkhash construction with a an example im-
age with 5 blocks. We can see t hat 3 blocks are full of zeros
and have the same hash value. The blkhash algorithm el im-
inates the computation of the zero blocks.
We now describe the construction more formally.
Let us denote by H our blkhash function that uses two
collision resistant hash function s h
inner
and h
outer
. In
practice, the inner and outer hash functions are ex-
pected to be the sam e function, but they can also dif-
fer and we discuss this c ase later. Le t x ∈ {0, 1}
∗
be
the input to H. We denote by l the length of x in bytes.
We set th e block size to k and we split x into blocks
of size k. We note that if the length of x is not a mul-
tiplicity of k , then the final block will be shor te r than
k. We calculate th e number of blocks n =
l
k
.
The resulting split looks as follows:
x = x
1
|{z}
k
||. . . ||(x
n−1
)
|
{z }
k
|| x
n
|{z}
≤k
where n − 1 blocks are of size k and the fin al block
may be shorter than k.
We compute blkhash H as follows:
H(x) = h
outer
(h
inner
(x
1
)||. . . ||h
inner
(x
n
)||l)
Namely, we hash each of the blocks separately us-
ing H
inner
and then ha sh the resulting values in the
original order along with the length of x using H
outer
.
This construction enables parallel comp utation for the
inner block hashes, since computing a hash of one
block does no t depend on the hash of the pr evious
blocks. This enables linear scaling with number of
threads computing the block hashes.
Blocks that are unalloca te d or full of zeros results
in the same hash value, and can use a pre-co mputed
zero block hash value.
Input :
H
outer
: collision resistant hash
H
inner
: collision resistant hash
k : block size
x : message to hash
Output: Hash value of message x
h
zero
← H
inner
(zero block of length k);
i ← 0;
while i < |x| do
x
i
← x[i, i + k];
if |x
i
| = k and x
i
is a zero block then
add h
zero
to H
outer
;
else
h
i
← H
inner
(x
i
);
add h
i
to H
outer
;
end
i ← i + k;
end
add |x| to H
outer
;
return the result of H
outer
evaluation;
Algorithm 1: The blkhash construction.
Detecting zero blocks is done in 2 ways:
1. Detect the unallocated areas in the image from
file system or image metadata, avoiding reading
the data from storage and eliminating all the com-
putation. This is the most important optimiza-
tion, speeding up proc essing by multiples orders
of magnitude.
2. Efficiently detect blocks full of zeros (e.g. using
memcmp) and avoiding the computation of block
hashes. Scanning blocks for zeros is faster than
computing a hash, even when using a fast cryp to-
graphic hash such as BLAKE3, that can take ad-
vantage of widest SIMD instructions.
Note that zero block optimization only affects the
performance of comp uting the inn er hash. The com-
SECRYPT 2024 - 21st International Conference on Security and Cryptography
700

putation yields the same hash value regardless of the
efficiency of the computation.
3 PROOF OF SECURITY
Collision resistance is a fundamenta l property of
cryptographic hash functions. Collision resistance
guaran tees tha t it is compu ta tionally infeasible to find
two distinct inputs that hash to the same output value.
This property is vital for maintaining data integrity as
it prevents malicious actors from pro ducing two dif-
ferent files with identical hash values
3
.
In this section we prove tha t if the underlying hash
functions h
inner
and h
outer
are collision resistant then
so is our construction.
Assume toward contradiction that one can find
two inputs x and x
′
, such that H(x) = H(x
′
), then we
show a collision either for h
inner
or h
outer
.
We split our proof into two cases:
• Case 1: x and x
′
are of different length
• Case 2: x and x
′
are of the same length
In case 1 since the length is part of the input to the
h
outer
, th e n the input for h
outer
is different when x and
x
′
are of different length. Thus, if H(x) = H(x
′
) then
we have a collision in the outer hash function.
More formally, let us denote by l the leng th of x
and by l
′
the length of x
′
.
H(x) = h
outer
(·· ·||l)
= h
outer
(·· ·||l
′
) = H(x
′
)
(1)
and since l 6= l
′
, if H(x) = H(x
′
) then we get a
collision for h
outer
.
In case 2, we focus on blo ck i in which x
i
6= x
′
i
,
noting that there has to be at least one such block,
otherwise x and x
′
are identical.
If h
inner
(x
i
) = h
inner
(x
′
i
) then we h ave a collision
for h
inner
.
If h
inner
(x
i
) 6= h
inner
(x
′
i
) then we get that
H(x) = h
outer
(·· · ||h
inner
(x
i
)||· ·· ||l)
= h
outer
(·· · ||h
inner
(x
′
i
)||· ·· ||l) = H(x
′
)
(2)
and we got a collision for h
outer
.
3
Consider an att acker that can create two files, one be-
nign and one containing malware, that result in the same
hash value, then he can get the benign version signed by
a trusted authority and then have the malware version dis-
tributed along with the same signature.
4 SPECIFICATION
Here we specify how a single threaded blkhash hash
function can be implemented.
The construction requires the following parame-
ters. Changing any of the parameters changes th e con-
struction and the hash value.
• outer-hash-algorithm - a collision resistant hash
algorithm .
• inner-hash-algorithm - a collision resistant hash
algorithm .
• block-size - block size in bytes. A power of 2,
equal or larger tha n 64 KiB is reco mmended to
match common image formats internal structure.
The construction must maintain the following
state:
• outer-hash - an instance of outer-hash-algorithm.
The hash m ust be initialized befor e feeding data
into the hash function.
• input- le ngth - if the input length in bytes is un-
known when creating the hash, initialize it to 0,
and update it incrementally when feeding data
into the hash.
To implement zero optimiz ation (as noted before,
zero optimization is optional), the constructio n must
also m aintain the following state:
• zero-block-hash - a hash value of an all zero block
of length block-size bytes, computed using inner-
hash-algorithm.
Split the inp ut of the hash func tion to fixed size
blocks of block-size bytes. If the input length is not
a multiple of the bloc k size, the last block may be
shorter than block-size, but it can not be empty. If the
input length is zero no block need to be processed.
For each input block perform th e following oper-
ations:
1. If th e block length is eq ual to block-size and zero
optimizations ar e implemented, check if the block
contents are zeros. We have 2 cases:
• If file system or image metadata are available,
and the image is known to read a s zeros.
• Otherwise if no metadata is available, check if
the block is full of zeros.
If blo c k contents are ze ros, update outer-hash
with the pre -computed zero-block-hash value.
2. Otherwise compute a hash value of the block
using the inner-hash-algorithm, and update the
outer-hash with the computed hash value.
An Efficient Hash Function Construction for Sparse Data
701
When all input blocks we re processed, update the
outer-hash with input-length as a 64 bit little-endian
integer.
Finalize the outer-hash, producing the hash value.
This is the blkhash h ash value of the input.
5 EMPIRICAL RESULTS
We measured the throughp ut of blkhash ha sh function
using both BLAKE3 and SHA256 provided by openssl
(The Open SSL Project, 2003) for the outer and inner
hash functions. SHA256 is considere d the industry
standard and re cent CPUs also feature hardware ac-
celeration of it. BLAKE3 is an extremely fast hash
function on 64-bit platform supporting AVX-512 in-
structions. These functions demonstrate how blkhash
adapts the most widely used cryptographic h ash func-
tions into sparse optimized hash functions.
We use the notation blk-ALGORITHM to describe
application of blkhash using ALGORITHM for the
outer and inner hash functions.
Real disk images are typically comprised of three
types of data and blkhash’s performance varies a c -
cording to it. We generated these input types and mea-
sured how blkhash per forms on each of them. The
three types are:
• data: all blocks in the input are non-zero. This
is th e worst case where blkhash must compute a
hash for all blocks.
• zero: all blocks in the input contain only zeros.
This is a be tter case, where all blocks must be
scanned to detect zeros, but no ha sh is computed
for any block.
• hole: all blocks are unallocated. This is the best
case where no data is scanned and no hash is com-
puted for any block.
We ran the tests on two AWS bare metal instances:
• c7i.metal-24xl (Amazon Web Services, 2023b)
powered by 4 th Generation Intel Xeon Scalable
processor (Sapphire Rapids 8488C), featuring 48
cores and 96 vCPUs. We tested with Hyper-
Threading d isabled since it is not a good match
for this type of workload.
• c7g.metal (Amazon Web Services, 2023a) pow-
ered by Arm-based AWS Graviton3 processors,
featuring 64 c ores.
We measure u sin g the blkhash-b e nch (Soffer,
2022) program, providing an easy to use command
line interface to measure any input type with any con-
figuration supported by th e blkhash library. The pro-
gram allocates a fixed size pool of buffers and feed
the data as fast as possible to the blkhash hash func-
tion without doing any I/O. Actual results with real
images will be much lower since reading data from
storage is typica lly the bo ttleneck.
To reproduce our results p le a se refer to th e
benchm arking documentation in the blkhash repos-
itory: https://gitlab.com/nirs/blkhash/-/blob/paper/
docs/benchmarkin g.md
5.1 Zero Optimization
This benchmark shows the effect of zero optimiza-
tion on the hash throughput whe n using different al-
gorithms for the internal hash function s. We focus on
the fastest algorithms for th e tested machine, BLAKE3
on Intel Xeon and SHA256 on AWS Gravitron3, using
SIMD instructions or crypto extensions.
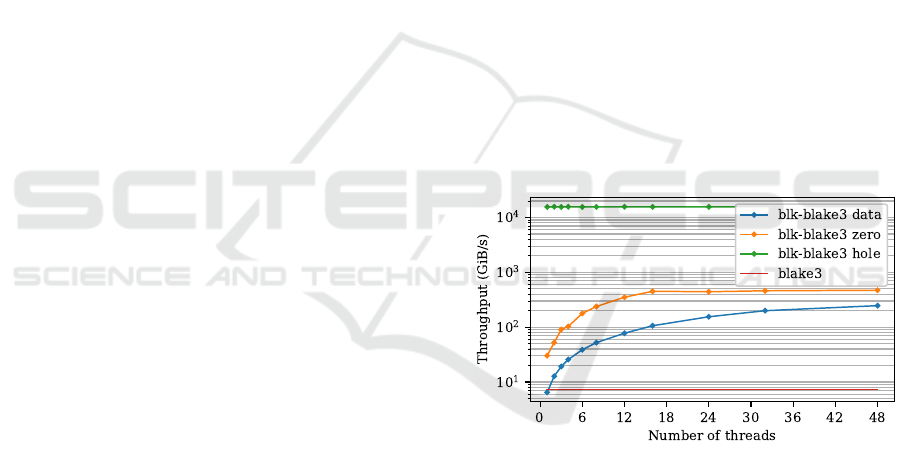
Figure 4 shows blkhash throughput on AWS
c7i.metal-2 4xl instance using BLAKE3 for the outer
and inner hash functions. Hashing unallocated ar-
eas (hole) reached the maximum throughput with
1 thread, 2223 times faster than single threaded
BLAKE3. Hashing blocks full of zeros (z ero) is up to
64.3 times faster than single threaded BLAKE3. Hash-
ing blocks full of no n-zero b ytes (data) is up to 33 .6
times faster than single threaded BLAKE3.
Figure 4: Throughput of blk-blake3, higher is faster.
Figure 5 shows blkhash throughput on AWS
c7g.metal instance using SHA256 for the outer a nd in-
ner hash functions. Hashing unallocated areas ( hole)
reached the maximum throughput with 1 thread,
15323 time s faster than single threaded SHA256.
Hashing blocks full of zeros (zero) is up to 270.9
times faster than single threaded SHA256. Hashing
blocks full of non-zero bytes (data) is up to 62.9 times
faster than single threaded SHA256.
5.2 Carbon Footprint
We measured the thro ughput in cycles per byte as a
good proxy for amo unt of energy used to compute a
SECRYPT 2024 - 21st International Conference on Security and Cryptography
702
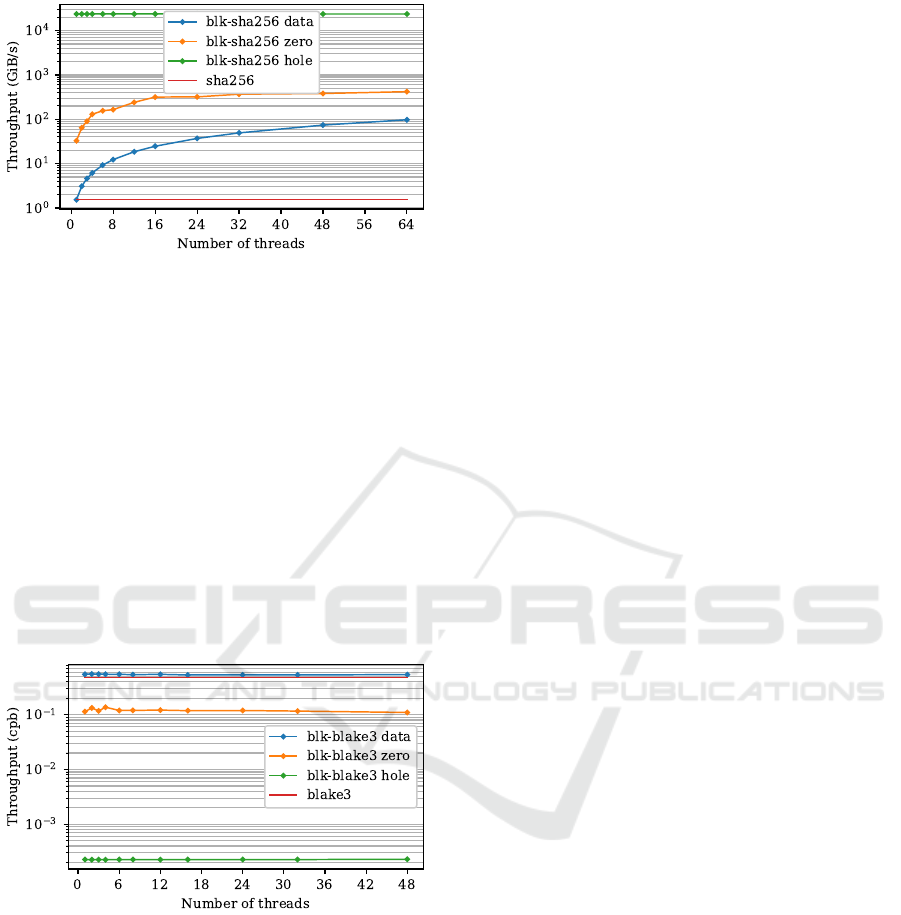
Figure 5: Throughput of blk-sha256, higher is faster.
hash. Zero optimization not only speeds up hash com-
putation by up to 4 orders of magnitude but it also
lowers the carbon footprint of the computatio n by 4
orders of magnitude - at the same time.
Figure 6 shows blkhash efficiency on AWS
c7i.metal-2 4xl instance using BLAKE3 for the outer
and inn er hash functions. Hashing unallocated areas
(hole) shows through put of 0.000 2 cycles per byte,
2400.0 times lower than BLAKE3. Hashing blocks
full of zeros ( zero) shows constant throughput of 0.1
cycles per byte for any number of threads, 4.8 times
lower than single threaded BLAKE3. Hashing blocks
full of n on-zero bytes (da ta ) show constant through-
put of 0.54 cycles per bytes fo r any number of th reads,
1.12 times higher than single threaded BLAKE3.
Figure 6: Throughput of blk-blake3 in cycles per byte,
lower is better.
6 CONCLUSIONS
As the world increasingly shifts into the cloud, the
demand for secure hash functions of high throughput
becomes more pronou nced than ever before. The tra-
ditional a pproach to verifying file integrity th rough
hash computation has long been plagued by ineffi-
ciencies when dealin g with large files. The perception
that computing the hash value is negligible compared
to the time it takes to copy a file, no longer holds in
modern computing. Optimizing the performance over
sparse disk images needs to consider hash computa-
tion in addition to the copying op e ration.
The introduction of blkhash marks a new direc-
tion in the realm of hash function design. We address
these challenges head-on by minimizing the computa-
tional overhead associated with empty or unallocated
areas within the file and also by leveraging the multi
core techn ology by parallelization of the computation.
An important feature of blkhash is its modular design,
which allows it to utilize any existing hash function
as a building block. Whether it be well-established
standards like SHA256 or modern alternatives like
BLAKE3, blkhash seamlessly integrates these hash
functions into its framework. This modular approach
not only enhances the flexibility and versatility of
blkhash, but also leverages the p roven security prop-
erties of established hash algorithms. We provide a
referenc e implementatio n along with a suite of bench -
marks. Our results reveal tha t blkhash achieves accel-
eration levels o f up to four orders of magnitude, po-
sitioning it as a game-changer for use cases requiring
rapid verification of large virtual disk image s.
REFERENCES
Amazon Web Services (2023a). Amazon ec2 c7g instances.
https://aws.amazon.com/ec2/instance-types/c7g/.
Amazon Web Services (2023b). Amazon ec2 c7i instances.
https://aws.amazon.com/ec2/instance-types/c7i/.
Bellard, F. and the QEMU Project developers (2003).
Qemu disk image utility. https://www.qemu.org/docs/
master/tools/qemu-img.html.
Dworkin, M. (2015). Sha-3 standard: Permutation-based
hash and extendable-output functions.
Hansen, T. and 3rd, D. E. E. (2006). US Secure Hash Algo-
rithms (SHA and HMAC-SHA). RFC 4634.
Merkle, R . C. (1988). A Digital Signature Based on
a Conventional Encryption Function. In Advances
in Cryptology–CRYPTO ’87: Proceedings, page
369–378. Springer-Verlag.
O’Connor, J., Aumasson, J.-P., Neves, S., and Wilcox-
O’Hearn, Z. (2019). Blake3 - one function,
fast everywhere. https://github.com/BLAKE3-team/
BLAKE3-specs.
Soffer, N. (2021). blkhash - block based hash optimized
for disk images. https://gitlab.com/nirs/blkhash/-/tree/
paper.
Soffer, N. (2022). blkhash-bench - blkhash benchmark
tool. https://gitlab.com/nirs/blkhash/-/blob/paper/test/
blkhash-bench.c.
The OpenSSL Project (2003). OpenSSL: The open source
toolkit for SSL/ TLS. www.openssl.org.
An Efficient Hash Function Construction for Sparse Data
703
