
Autoencoder for Detecting Malicious Updates in Differentially Private
Federated Learning
Lucia Alonso
1
and Mina Alishahi
2
1
Informatics Institute, University of Amsterdam, The Netherlands
2
Department of Computer Science, Open Universiteit, The Netherlands
Keywords:
Federated Learning, Differential Privacy, Autoencoder, Anomaly Detection.
Abstract:
Differentially Private Federated Learning (DP-FL) is a novel machine learning paradigm that integrates feder-
ated learning with the principles of differential privacy. In DP-FL, a global model is trained across decentral-
ized devices or servers, each holding local data samples, without the need to exchange raw data. This approach
ensures data privacy by adding noise to the model updates before aggregation, thus preventing any individual
contributor’s data from being compromised. However, ensuring the integrity of the model updates from these
contributors is paramount. This research explores the application of autoencoders as a means to detect anoma-
lous or fraudulent updates from contributors in DP-FL. By leveraging the reconstruction errors generated by
autoencoders, this study assesses their effectiveness in identifying anomalies while also discussing potential
limitations of this approach.
1 INTRODUCTION
Federated learning has emerged as a critical paradigm
in contemporary machine learning, particularly in
scenarios where data privacy and security are
paramount concerns (Li et al., 2020a). With the pro-
liferation of Internet of Things (IoT) devices and edge
computing, federated learning enables collaborative
model training across distributed entities without cen-
tralizing sensitive data (Alishahi et al., 2022). How-
ever, traditional federated learning approaches may
still pose privacy risks, as individual data contribu-
tors’ information could be susceptible to inference at-
tacks. To address this challenge, the integration of
differential privacy into federated learning has gar-
nered significant attention (Wei et al., 2020), (Li et al.,
2020b) (Lopuha
¨
a-Zwakenberg et al., 2021). By aug-
menting federated learning with differential privacy,
organizations can enhance data privacy protections,
ensuring that individual contributors’ data remains
confidential even during model training (Fathalizadeh
et al., 2024). This incorporation of federated learn-
ing and differential privacy not only strengthens pri-
vacy guarantees but also fosters trust and collabora-
tion among participating entities, making it a vital
tool for modern data-driven applications (Yang et al.,
2023).
While Differentially Private Federated Learning
(DP-FL) offers robust privacy guarantees, ensuring
the integrity of model updates from contributing de-
vices or servers is essential for maintaining the ef-
ficacy and reliability of the trained global model.
Anomalies or misbehavior in the contributions of in-
dividual entities can compromise the integrity of the
learning process and undermine the overall perfor-
mance of the federated learning system. Therefore,
there is a growing need to develop mechanisms ca-
pable of detecting and mitigating such anomalies in
DP-FL settings.
This paper explores the use of autoencoders, a
type of artificial neural network, as a potential solu-
tion for detecting anomalous contributions from in-
dividual devices or servers in DP-FL (Bank et al.,
2023). Autoencoders are known for their ability to
learn efficient representations of data and reconstruct
input samples with minimal error (An and Cho, 2015)
(Yan et al., 2023). By leveraging the reconstruction
errors generated by autoencoders, we aim to identify
and flag anomalous model updates, thus safeguarding
the integrity of DP-FL .
In this study, we investigate the effectiveness of
autoencoders as anomaly-detecting mechanisms in
DP-FL and examine their potential limitations. Ulti-
mately, our goal is to contribute to the development of
robust and privacy-preserving federated learning sys-
Alonso, L. and Alishahi, M.
Autoencoder for Detecting Malicious Updates in Differentially Private Federated Learning.
DOI: 10.5220/0012766700003767
Paper published under CC license (CC BY-NC-ND 4.0)
In Proceedings of the 21st International Conference on Security and Cryptography (SECRYPT 2024), pages 467-474
ISBN: 978-989-758-709-2; ISSN: 2184-7711
Proceedings Copyright © 2024 by SCITEPRESS – Science and Technology Publications, Lda.
467

Figure 1: Scheme displaying an overview of the federated
learning with differential privacy process.
tems capable of operating securely in real-world set-
tings.
2 BACKGROUND
This section presents the preliminary concepts em-
ployed in this study.
2.1 Federated Learning
Federated deep learning is a particular form of
federated learning in which the goal is training a
deep learning model in decentralized setting, and
it can be formally defined as follows (Li et al.,
2020a). Let D
1
,D
2
,... ,D
N
denote the local datasets
available at each of the N participating devices
or servers. Each dataset D
i
contains a set of
data samples (or one sample in individual setting)
{(x
i1
,y
i1
),(x
i2
,y
i2
),. .. ,(x
in
i
,y
in
i
)}, where x
i j
repre-
sents the input data and y
i j
represents the correspond-
ing label. The goal of federated learning is to learn a
global model θ by aggregating the local updates from
each device. The global model is updated iteratively
using the following formula:
θ
t+1
= θ
t
− η ·
1
N
N
∑
i=1
∇ℓ
i
(θ
t
)
where θ
t
represents the global model parameters at it-
eration t; η is the learning rate; ∇ℓ
i
(θ
t
) is the gradient
of the loss function ℓ
i
with respect to the model pa-
rameters θ
t
computed using the local dataset D
i
. This
process repeats until convergence, with each device
contributing its local gradient to update the global
model without sharing its raw data.
2.2 Differential Privacy (DP)
Differential privacy aims to protect the privacy of in-
dividuals’ data by ensuring that the presence or ab-
sence of any single individual’s data does not signifi-
cantly affect the outcome of a computation or analysis
(Dwork, 2008). Formally, let D
1
and D
2
be neigh-
boring datasets that differ by at most one individual’s
data, and let A represent a randomized algorithm that
operates on datasets. A randomized algorithm A sat-
isfies ε-differential privacy if, for all possible outputs
S in the algorithm’s output space:
Pr[A(D
1
) = S] ≤ e
ε
· Pr[A(D
2
) = S]
where ε > 0 is a parameter that controls the privacy
guarantee. Smaller values of ε correspond to stronger
privacy guarantees.
2.3 Differentially Private Federated
Learning
Differentially Private Federated Learning aims to
train a global model while preserving the privacy of
individual data contributors by adding DP noise to
the model updates before aggregation (Geyer et al.,
2017). Formally, let D = {D
1
,D
2
,..., D
N
} denote the
set of N decentralized data sources, each holding a
local dataset D
i
. Let M represent the global machine
learning model to be trained. At each iteration of the
federated learning process, a subset of data sources is
selected to participate in model training. Denote the
selected subset as S ⊆ D, where |S| = k. The local
models trained on the data sources in S are denoted
as M
1
,M
2
,..., M
k
. To ensure differential privacy, each
local model M
i
is trained using a differentially pri-
vate algorithm, which adds carefully calibrated noise
to the model updates. Let M denote the set of all pos-
sible global models, and let D denote the set of all
possible datasets that could have been used to train
M. The privacy guarantee ensures that for any two
datasets D
i
,D
j
∈ D that differ in a single element, the
distribution of the global model M learned from D
i
is
close to the distribution of the global model learned
from D
j
. The objective of Differentially Private Fed-
erated Learning is to find the global model M that
minimizes the empirical risk over the union of all lo-
cal datasets while satisfying a given privacy constraint
ε. This can be expressed as:
min
M∈M
1
N
N
∑
i=1
L(M,D
i
)
subject to the constraint that for any pair of adjacent
datasets D
i
,D
j
∈ D and any measurable set S ⊆ M ,
the following differential privacy condition holds:
Pr[M ∈ S] ≤ e
ε
× Pr[M ∈ S
′
]
2.4 Autoencoders
An autoencoder is a type of artificial neural net-
work that learns to encode input data into a lower-
dimensional representation and then decode it back to
SECRYPT 2024 - 21st International Conference on Security and Cryptography
468

its original form. It consists of an encoder network,
which compresses the input data into a latent repre-
sentation, and a decoder network, which reconstructs
the original data from the latent representation. The
goal of an autoencoder is to minimize the reconstruc-
tion error, thereby learning an efficient representation
of the input data (Bank et al., 2023).
Formally, let X ∈ R
d
represent the input data, and
let Z ∈ R
m
represent the latent representation (also
known as the encoding) obtained by the encoder func-
tion f
enc
: R
d
→ R
m
. Similarly, let
ˆ
X ∈ R
d
represent
the reconstructed input data obtained by the decoder
function f
dec
: R
m
→ R
d
. The autoencoder aims to
learn a representation of the input data such that the
reconstructed output closely matches the original in-
put. This is achieved by minimizing a reconstruction
loss function L (X,
ˆ
X), typically the mean squared er-
ror (MSE) or cross entropy, between the input data X
and its reconstruction
ˆ
X. The optimization problem
for training the autoencoder can be expressed as:
min
f
enc
, f
dec
1
N
N
∑
i=1
L(X
i
, f
dec
( f
enc
(X
i
)))
where N is the number of training samples; X
i
is the
i-th training sample; f
enc
and f
dec
are the encoder and
decoder functions, respectively. The encoder func-
tion maps the input data to a lower-dimensional latent
space, while the decoder function reconstructs the in-
put data from the latent representation.
3 FRAMEWORK
This section presents our methodology and the evalu-
ation metrics.
3.1 Methodology
The primary objective of this study is to assess the
efficacy of autoencoders in identifying anomalies
within differentially private federated learning frame-
works. As depicted in Figure 1, our methodology fol-
lows the upcoming steps:
1 Initiation: The process commences with the cen-
tral server transmitting the initial model parame-
ters to each individual client. Subsequently, each
client configures its local model using the pro-
vided parameters and its own dataset.
2 Differential Privacy Integration: Each client aug-
ments their locally trained model and compute
the associated gradients. The clients then add DP
noise to their parameters, ensuring the privacy of
their contributed data.
Algorithm 1: Autoencoders for labeling input data.
1: Run data through autoencoder A
2: α ← the limit of ε for each metric
3: threshold acc,threshold loss ← threshold for accu-
racy, threshold for loss
4: while ε ≤ α do ▷ Working with accuracy for low
values of ε
5: n = array of batches of size y
6: for each batch in n do
7: acc batch = accuracy(batch)
8: if acc batch ≤ accuracy original −
threshold acc then
9: batch contains an anomaly and discard
10: end if
11: end for
12: end while
13: while ε > x do ▷ Working with loss for high values of
ε
14: dict = images submitted by client
15: for each image in dict do
16: loss img = cross entropy(image)
17: if loss img ≥ loss original + threshold loss
then
18: image is an anomaly and discard
19: end if
20: end for
21: end while
3 Data Aggregation: The aggregator receives and
integrates the augmented data from all clients be-
fore forwarding it to the autoencoder for analysis
and discarding malicious updates.
4 Anomaly Detection: Next, the autoencoder care-
fully examines the combined data, identifying
any irregularities or suspicious inputs.
5 Decision and Model Update: Identified mali-
cious data is discarded, while the remainder is
utilized in refining the global model.
Throughout this study, we delve into the efficacy
of autoencoders in pinpointing anomalies within the
steps 4 and 5 of this architecture. Before initiating the
federated learning environment, the dataset undergoes
processing via an autoencoder. Subsequently, the
baseline values for loss, denoted as ”loss original,”
and accuracy, referred to as ”accuracy original,” are
recorded. Algorithm 1 summarizes the process of
labeling data using autoencoder in our framework.
The algorithm’s objective is to identify any poten-
tially malicious data and eliminate it before it impacts
the global model. The first three lines of the pseu-
docode are universal for all ε values and handle pa-
rameter initialization. Afterward, the code branches
into two blocks. The first block is suitable for envi-
ronments with low ε values, where anomaly detection
relies on accuracy. In contrast, the second block is tai-
lored for higher ε values, where the autoencoder’s re-
Autoencoder for Detecting Malicious Updates in Differentially Private Federated Learning
469

construction errors are minimized, enabling anomaly
detection through loss.
3.2 Evaluation Metrics
We measure the performance of our methodology us-
ing two metrics, namely cross-entropy and accuracy
defined as follows.
Cross-Entropy: also known as log loss, is a metric
used to quantify the difference between two probabil-
ity distributions. Formally,
H(y, ˆy) = −
1
N
N
∑
i=1
(y
i
log( ˆy
i
) + (1 − y
i
)log(1 − ˆy
i
))
where y is the true label vector, ˆy is the predicted prob-
ability vector, and N is the number of samples. From
now on, for the sake of simplicity, we use the term
“Loss” instead of “Cross-entropy loss”. In this study,
the overall loss of a dataset is determined by summing
up the reconstruction errors generated by the autoen-
coder for each individual sample, where the lower loss
is better outcome.
Accuracy: represents what proportion of a set is cor-
rectly represented compared to the original value.
Accuracy =
correct labels
the total number of records
× 100
In this study, we evaluate the performance of two key
components using accuracy metrics. Firstly, we as-
sess the accuracy of the autoencoder in reconstructing
images, where higher accuracy indicates greater sim-
ilarity between input and output images. Secondly,
we measure the performance of the classifier in iden-
tifying anomalies, represented by the percentage of
true anomalies correctly detected among all anoma-
lous images. In both cases, achieving higher accuracy
values reflects improved method performance. Fol-
lowing the establishment of specific accuracy and loss
thresholds, data classification is conducted to evaluate
the efficacy of anomaly detection using these metrics.
The outcomes are then presented through a confusion
matrix, providing insights into the effectiveness of au-
toencoders for anomaly detection in DP-FL.
4 RESULTS
This section presents the key findings of our research.
We begin by analyzing the accuracy and loss metrics
generated by the model, followed by an examination
of the model’s sensitivity. Through these analyses, we
aim to assess the effectiveness of autoencoders in de-
tecting anomalies in DP-FL and provide insights into
their performance characteristics.
Figure 2: Comparison between unmodified images (on the
top row) vs poisoned images (on the bottom row).
4.1 Experimental Set-Up
Here we present the dataset and environment em-
ployed in our work.
Dataset: The MNIST dataset consists of 70.000 im-
ages containing handwritten digits. There are 10 dis-
tinct digits ranging from 0-9. Each image is described
with 28 × 28 pixels. Figure 2 presents a comparison
between unaltered images (top row) and poisoned im-
ages (bottom row). Despite the imperceptible changes
to the human eye, subtle alterations to certain pixels
have been inserted. This meticulous manipulation of
noise within the images leads the deep learning model
to misclassify the images, as depicted atop each im-
age.
Environment: This research builds upon the founda-
tion laid by Wenzhuo Yang’s code
1
, which provided
a federated learning framework with differential pri-
vacy. Our work extends this framework by incor-
porating methods for conducting poison attacks and
evaluating model performance under such adversarial
scenarios. These additions were tailored to meet the
specific requirements of our study, enhancing the ver-
satility and applicability of the original codebase. Our
implementation code can be found here
2
.
4.2 Accuracy and Loss
The model’s accuracy across various epsilon values
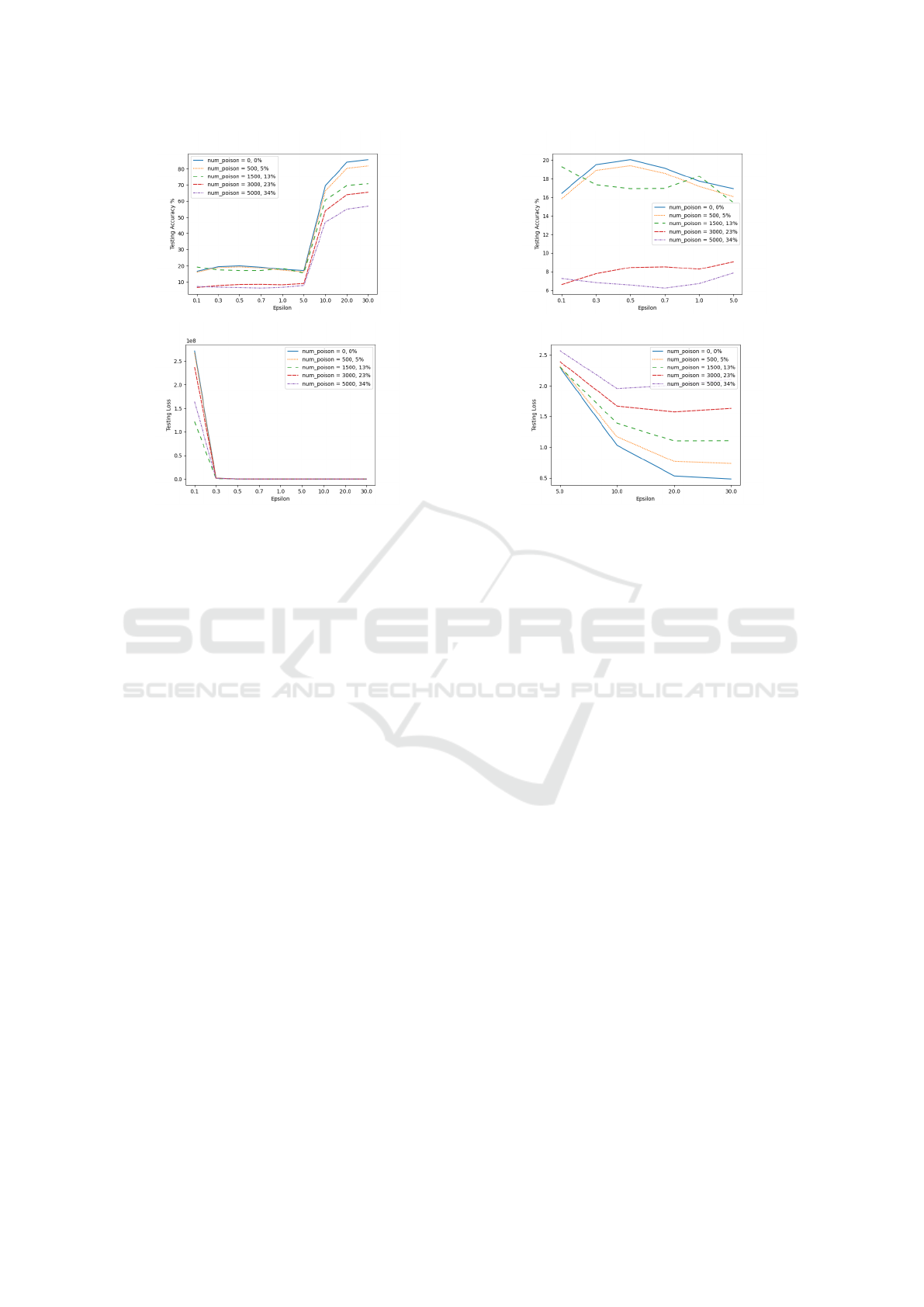
has been illustrated in Figure 3(a). Each line in the
graph corresponds to a different quantity of poisoned
images within the testing set. Initially, the model op-
erates without any poisoned images, after which vary-
ing quantities of poisoned images are introduced, as
indicated in the graph legend. Additionally, the per-
centage of poisoned images within the testing set is
provided alongside the corresponding quantity.
The graph reveals a notable peak point where the
accuracy experiences a significant increase. In this
dataset, the model’s accuracy undergoes a remark-
able improvement when ε ≥ 5. This phenomenon
can be attributed to the noise adjustment facilitated
1
https://github.com/wenzhu23333/
Differential-Privacy-Based-Federated-Learning
2
https://github.com/lucialonso/
Federated-Learning-Differential-Privacy-RP2
SECRYPT 2024 - 21st International Conference on Security and Cryptography
470
(a)
(b)
Figure 3: Autoencoder results in terms of (a) Accuracy over
epsilon from 0.1 ≤ ε ≤ 30 (b) Loss values over epsilon when
0.1 ≤ ε ≤ 30.
by differential privacy, which becomes more relaxed
with higher privacy budgets. Consequently, the model
gradually converges to a notable accuracy level be-
yond a certain threshold of privacy. Additionally, the
graph highlights minimal variance in the model’s ac-
curacy within the range of 0.1 ≤ ε ≤ 5. During this
interval, the presence of considerable noise and recon-
struction errors leads to less accurate predictions. Fur-
thermore, a distinct decrease in accuracy is observed
when the proportion of poisoned images exceeds 23%
of the test set, particularly evident within the range of
0.1 ≤ ε ≤ 5. In machine learning, employing loss to
identify anomalies is favored over accuracy due to its
heightened sensitivity to subtle alterations. However,
as depicted in Figure 3(b), the model’s loss exhibits
significant fluctuations for lower values of epsilon.
The magnitude of loss for smaller epsilon values is
substantial, to the extent that data corresponding to
higher epsilon values becomes indiscernible.
4.3 Optimal Thresholds
Determining whether to utilize accuracy or loss
to establish the threshold for identifying anomalies
presents a formidable challenge. This study aims
to detect anomalies characterized by an increase in
loss of approximately 0.02, akin to methodologies
employed in traditional federated learning. How-
ever, relying solely on loss as a metric proves inade-
(a)
(b)
Figure 4: Autoencoder results in terms of (a) Accuracy over
epsilon for 0.1 ≤ ε ≤ 5 (b) Loss over epsilon for 5 ≤ ε ≤ 30.
quate for discerning anomalies in scenarios featuring
small epsilon values, where the presence of excessive
noise obscures the distinction between reconstruction
errors, anomalies-induced loss, and noise stemming
from differential privacy. Therefore, based on an anal-
ysis of model performance with a specific dataset, this
research advocates for a combined approach lever-
aging both metrics to effectively detect anomalies.
Specifically, accuracy is proposed as a metric for de-
tecting anomalies at lower epsilon values, while loss
is recommended for higher epsilon values. Figure 4
(a) is a scaled-up graph of the accuracy values when
0.1 ≤ ε ≤ 5. The figure shows that when 5% of the
test set is poisoned, a reduction in accuracy is notice-
able. In this case, the accuracy of the model with un-
altered data is 16,4 and 15,8 when 5% of the data is an
anomaly. When more poisoned images are introduced
the decrease in accuracy is more significant. There
is however an irregularity when 13% of the data in
the test set is poisoned. As an increasing quantity of
modified data is added to the test set, a corresponding
decline in accuracy would be anticipated. In Figure
4(b) the trend that the loss value takes for different
amounts of poisoned images and epsilon values can
be distinctly seen. As expected, the unaltered data
yielded the lowest loss values while the more modi-
fied images are added to the test set, the higher the
loss value gets. For reference, the loss value at the
lowest epsilon of this graph (ε = 5), when only un-
altered data has been evaluated, is 2.30. In contrast,
Autoencoder for Detecting Malicious Updates in Differentially Private Federated Learning
471

(a) (b) (c) (d) (e) (f) (g) (h)
Figure 5: For (a,b,c,d) ε = 0.1, and the testing set contains 500, 1500, 3000, and 5000 poisoned images respectively. For
(e,f,g,h) ε = 1, and the testing set contains 500, 1500, 3000, and 5000 poisoned images respectively.
(a) (b) (c) (d) (e) (f) (g) (h)
Figure 6: For (a,b,c,d) ε = 5, and the testing set contains 500, 1500, 3000, and 5000 poisoned images respectively. For (e,f,g,h)
ε = 30, and the testing set contains 500, 1500, 3000, and 5000 poisoned images respectively.
when 5% of data in the test set is altered, the loss
value is 2.32. As epsilon increases, the interval be-
tween loss values for different quantities of anomalies
and the baseline widens.
4.4 Efficacy Testing
In this section, we assess the effectiveness of autoen-
coders in detecting anomalies in DP-FL, following
the threshold determination outlined in the previous
section. Figure 5 illustrates the classification process
based on the autoencoder’s accuracy as the threshold
metric. When the autoencoder’s accuracy decreases
by 0.2, data is classified as anomalous and discarded
accordingly. Among the various threshold values con-
sidered, 0.2 emerged as the most effective in correctly
identifying anomalies. Since accuracy is calculated
over batches rather than individual images, the test-
ing set is evaluated in batch sizes of 200, with each
batch assessed independently. If the classifier identi-
fies a batch as potentially containing an anomaly, the
entire batch is discarded. Through experimentation, a
batch size of 200 was determined to be optimal.
The confusion matrix provides insight into the
classification outcomes: the top left corner denotes
correctly classified anomalies, the top right corner in-
dicates misclassified anomalies, the bottom left cor-
ner represents misclassified unaltered data, and the
bottom right corner signifies correctly classified un-
altered data. With epsilon set to 0.1 and 500 poisoned
images included in the testing set, all poisoned im-
ages are accurately classified, while 4800 unaltered
images are erroneously labeled as anomalies and dis-
carded. At epsilon equal to 1, all images containing
anomalies are correctly identified, but 5400 original
images are discarded. Notably, the least data loss
occurs when 500 poisoned images are added to the
test set. Conversely, with higher volumes of poisoned
Table 1: The classifier’s precision at detecting anomalies
when using accuracy. The percentage of poisoned images
found in each case is shown.
ε
# poison
500 1500 3000 5000
0.1 100 % 13.3 % 100 % 100 %
0.3 100 % 13.3 % 100 % 100 %
0.5 100 % 13.3 % 100 % 100 %
0.7 100 % 13.3 % 100 % 100 %
1 100 % 0 % 100 % 100 %
Average 100 % 10.6 % 100 % 100 %
Table 2: The percentage of unaltered images lost due to a
misclassification when using accuracy.
ε
# poison
500 1500 3000 5000
0.1 48 % 84 % 100 % 98 %
0.3 52 % 98 % 100 % 100 %
0.5 48 % 98 % 100 % 100 %
0.7 52 % 94 % 100 % 100 %
1 54 % 46 % 100 % 100 %
Average 50.8 % 84 % 100 % 99.6 %
images (3000 and 5000), almost all original data is
lost. As seen in Table 1, after examining all the re-
sults for 0.1 ≤ ε ≤ 1 and all the different amounts of
poisoned data, the proposed method has correctly de-
tected 77.7% of anomalies overall. However, 83.6%
of unaltered data has been lost overall due to misclas-
sification as seen in Table 2.
Figure 6 represents how data would be classified
when using the autoencoder’s loss as a deciding met-
ric and setting the threshold to 0.03. Any images with
a loss value 0.03 higher than the loss of the model,
when only unaltered data is processed, will be classi-
fied as an anomaly. Out of different values tested, an
increase of 0.03 in the loss value proved to yield the
most precise classifications. The improvement of the
algorithm can be observed in Figure 6 where less orig-
inal data is lost. In Figure 5, when 3000 or 5000 poi-
soned images are added to the test set, almost all orig-
inal data is discarded and lost. In contrast, at higher
values of epsilon, as shown in Figure 6, when 3000
SECRYPT 2024 - 21st International Conference on Security and Cryptography
472

Table 3: The classifier’s precision at detecting anomalies
when using loss. The percentage of poisoned images found
in each case is shown.
ε
# poison
500 1500 3000 5000
5 83.6 % 86.5 % 80.9 % 98.5 %
10 99.4 % 98.1 % 99.7 % 99.0 %
20 98.4 % 98.5 % 97.8 % 99.4 %
30 97.6 % 98.1 % 96.3 % 98.7 %
Average 94.8 % 95.3 % 93.7 % 98.9 %
or 5000 poisoned images are introduced, less original
data is lost. So, in this specific case, with this spe-
cific dataset, the algorithm performs more efficiently
at higher epsilon values (5 ≤ ε ≤ 30).
As seen in Table 3, after examining all the results
for 5 ≤ ε ≤ 30 and all the different amounts of poi-
soned data, the classifier, overall, has correctly de-
tected 95.7% of anomalies and 41.0% of unaltered
data has been lost due to misclassification as shown
in Table 4.
4.5 Discussion
Based on the findings presented, autoencoders emerge
as a robust tool for anomaly detection in DP-FL
settings. Accuracy proves effective for identifying
anomalies at lower epsilon values, yet the precision
of autoencoder-based reconstructions is compromised
by significant noise levels. Consequently, a sub-
stantial portion (approximately 84%) of legitimate
data is lost when epsilon is less than 5. Conversely,
loss serves as a reliable metric for anomaly detection
at higher epsilon values (ε ≥ 5), correctly identify-
ing and discarding 95.7% of anomalies. However,
both approaches entail the risk of discarding gen-
uine data erroneously classified as anomalous. Thus,
when integrating these methods into the pipeline of a
federated learning environment with differential pri-
vacy, careful consideration must be given to bal-
ancing the trade-off between anomaly detection and
data preservation. It’s essential to acknowledge that
the method proposed in this study does not achieve
100% anomaly detection, implying that certain mali-
cious data may bypass the global model’s defenses.
The considerable noise introduced by differential pri-
vacy renders the autoencoder unreliable until epsilon
reaches 5 in this context. Therefore, deploying the
proposed method at higher epsilon values is advis-
able to optimize anomaly detection while minimizing
the loss of genuine data. This approach ensures the
best balance between detection efficacy and privacy
preservation, particularly when the method is most ef-
fective, thereby guaranteeing a lower level of privacy.
Table 4: The percentage of unaltered images lost due to a
misclassification when using loss.
ε
# poison
500 1500 3000 5000
5 47.3 % 45.4 % 49.8 % 41.0 %
10 40.9 % 61.0 % 55.1 % 38.7 %
20 29.3 % 40.7 % 38.1 % 39.4 %
30 26.9 % 36.0 % 31.5 % 34.9 %
Average 36.1 % 45.8 % 43.6 % 38.5 %
5 RELATED WORKS
Given the pivotal role of AI in modern life, the de-
tection of malicious updates and adversarial instances
has garnered significant attention. Consequently, a
wealth of research efforts has been directed towards
analyzing these types of attacks and defense mecha-
nisms (Cina et al., 2023) . Although much of the ex-
isting research focuses on designing inherently robust
models against security and privacy attacks (Rosen-
berg et al., 2021), fewer efforts address the specific
challenge of detecting malicious updates in decentral-
ized settings, particularly in federated learning envi-
ronments. In (Zhang et al., 2022), FLDetector is in-
troduced to tackle this issue by identifying malicious
clients. The core insight is that in model poisoning
attacks, the model updates from a client across mul-
tiple iterations exhibit inconsistency. Thus, FLDe-
tector detects potentially malicious clients by exam-
ining the consistency of their model updates. In
(Zhao et al., 2022), a poisoning defense mechanism
is proposed to detect and mitigate poisoning attacks
in federated learning by utilizing generative adver-
sarial networks to generate auditing data during the
training process and identifies adversaries by audit-
ing their model accuracy. On the other hand, Fed-
ANIDS (Idrissi et al., 2023) leverages autoencoders
within a federated learning framework for anomaly
detection in distributed networks. However, it pri-
marily focuses on detecting anomalies rather than
specifically targeting malicious updates within feder-
ated learning. While autoencoders have demonstrated
their effectiveness in anomaly detection across vari-
ous domains, their application in detecting malicious
updates or misbehavior in federated learning remains
relatively limited. Schram et al. (Schram et al., 2022)
propose a novel iteration of DP-Fed-Avg GAN, which
integrates denoising techniques, specifically autoen-
coders, to alleviate the typical loss in accuracy en-
countered when applying both differential privacy and
federated learning to GANs. The closest work to
ours is the Fedcvae framework proposed in (Gu and
Yang, 2021), which focuses on detecting and exclud-
ing malicious or misleading information in federated
networks. Fedcvae effectively identifies and removes
Autoencoder for Detecting Malicious Updates in Differentially Private Federated Learning
473

malicious model updates from client contributions in
federated settings.Our research builds upon this foun-
dation by specifically investigating the effectiveness
of autoencoders in detecting malicious updates in dif-
ferentially private federated learning settings. To the
best of our knowledge, our work represents the first
attempt to systematically evaluate and quantify the
performance of autoencoders in this context, thereby
advancing our understanding of their role in ensur-
ing the security and reliability of differentially private
federated learning systems.
6 CONCLUSION AND FUTURE
DIRECTIONS
This paper delves into the potential of autoencoders,
renowned for their data representation and recon-
struction capabilities, as a solution for identifying
anomalous updates in differentially private federated
learning (DP-FL). Through empirical analysis, we as-
sessed autoencoders’ efficacy, addressing associated
challenges to enhance differentially private federated
learning’s integrity in practical scenarios. Future di-
rections for this work encompass exploring other at-
tacks beyond malicious updates, such as adversarial
learning approaches. Additionally, robustness analy-
sis is crucial, requiring evaluation under diverse sce-
narios and datasets to assess its generalization perfor-
mance under varying levels of noise and data distri-
bution.
REFERENCES
Alishahi, M., Moghtadaiee, V., and Navidan, H. (2022).
Add noise to remove noise: Local differential pri-
vacy for feature selection. Computers & Security,
123:102934.
An, J. and Cho, S. (2015). Variational autoencoder based
anomaly detection using reconstruction probability.
Special lecture on IE, 2(1):1–18.
Bank, D., Koenigstein, N., and Giryes, R. (2023). Autoen-
coders, pages 353–374. Springer International Pub-
lishing, Cham.
Cina, A. E., Grosse, K., Demontis, A., Vascon, S., Zellinger,
W., Moser, B. A., Oprea, A., Biggio, B., Pelillo, M.,
and Roli, F. (2023). Wild Patterns Reloaded: A Survey
of Machine Learning Security against Training Data
Poisoning. ACM Computing Surveys, 55(13s):294:1–
294:39.
Dwork, C. (2008). Differential privacy: A survey of results.
In Theory and Applications of Models of Computation
TAMC, volume 4978 of Lecture Notes in Computer
Science, pages 1–19. Springer Verlag.
Fathalizadeh, A., Moghtadaiee, V., and Alishahi, M.
(2024). Indoor geo-indistinguishability: Adopting dif-
ferential privacy for indoor location data protection.
IEEE Transactions on Emerging Topics in Computing,
12(1):293–306.
Geyer, R. C., Klein, T., and Nabi, M. (2017). Differentially
private federated learning: A client level perspective.
CoRR, abs/1712.07557.
Gu, Z. and Yang, Y. (2021). Detecting Malicious Model Up-
dates from Federated Learning on Conditional Varia-
tional Autoencoder. In Parallel and Distributed Pro-
cessing Symposium (IPDPS), pages 671–680.
Idrissi, M. J., Alami, H., El Mahdaouy, A., El Mekki, A.,
Oualil, S., Yartaoui, Z., and Berrada, I. (2023). Fed-
ANIDS: Federated learning for anomaly-based net-
work intrusion detection systems. Expert Systems with
Applications, 234:121000.
Li, L., Fan, Y., Tse, M., and Lin, K.-Y. (2020a). A review
of applications in federated learning. Computers &
Industrial Engineering, 149:106854.
Li, Y., Chang, T.-H., and Chi, C.-Y. (2020b). Secure feder-
ated averaging algorithm with differential privacy. In
IEEE Workshop on Machine Learning for Signal Pro-
cessing (MLSP), pages 1–6.
Lopuha
¨
a-Zwakenberg, M., Alishahi, M., Kivits, J., Klaren-
beek, J., van der Velde, G., and Zannone, N. (2021).
Comparing classifiers’ performance under differential
privacy. In Conference on Security and Cryptography,
SECRYPT, pages 50–61. SCITEPRESS.
Rosenberg, I., Shabtai, A., Elovici, Y., and Rokach, L.
(2021). Adversarial machine learning attacks and de-
fense methods in the cyber security domain. ACM
Comput. Surv., 54(5).
Schram, G., Wang, R., and Liang, K. (2022). Using au-
toencoders on differentially private federated learning
gans.
Wei, K., Li, J., Ding, M., Ma, C., Yang, H. H., Farokhi,
F., Jin, S., Quek, T. Q. S., and Vincent Poor, H.
(2020). Federated learning with differential privacy:
Algorithms and performance analysis. 15:3454–3469.
Conference Name: IEEE Transactions on Information
Forensics and Security.
Yan, S., Shao, H., Xiao, Y., Liu, B., and Wan, J. (2023).
Hybrid robust convolutional autoencoder for unsu-
pervised anomaly detection of machine tools under
noises. Robotics and Computer-Integrated Manufac-
turing, 79:102441.
Yang, Y., Hui, B., Yuan, H., Gong, N., and Cao, Y. (2023).
{PrivateFL}: Accurate, differentially private feder-
ated learning via personalized data transformation. In
USENIX Security Symposium, pages 1595–1612.
Zhang, Z., Cao, X., Jia, J., and Gong, N. Z. (2022). Flde-
tector: Defending federated learning against model
poisoning attacks via detecting malicious clients. In
ACM SIGKDD Conference on Knowledge Discovery
and Data Mining, KDD.
Zhao, Y., Chen, J., Zhang, J., Wu, D., Blumenstein, M.,
and Yu, S. (2022). Detecting and mitigating poison-
ing attacks in federated learning using generative ad-
versarial networks. Concurrency and Computation:
Practice and Experience, 34(7):e5906.
SECRYPT 2024 - 21st International Conference on Security and Cryptography
474
