
Enhancing Privacy in Machine Learning: A Robust Approach for
Preventing Attribute Inference Attacks
Myria Bouhaddi and Kamel Adi
Computer Security Research Laboratory, University of Quebec in Outaouais, Gatineau, Quebec, Canada
Keywords:
Machine Learning Security, Attribute Inference Attacks, Confidence Masking, Adversarial Machine Learning.
Abstract:
Machine learning (ML) models, widely used in sectors like healthcare, finance, and smart city development,
face significant privacy risks due to their use of crowdsourced data containing sensitive information. These
models are particularly susceptible to attribute inference attacks, where adversaries use model predictions
and public or acquired metadata to uncover sensitive attributes such as locations or political affiliations. In
response, our study proposes a novel, two-phased defense mechanism designed to efficiently balance data
utility with privacy. Initially, our approach identifies the minimal level of noise needed in the prediction
score to thwart an adversary’s classifier. This threshold is determined using adversarial ML techniques. We
then enhance privacy by injecting noise based on a probability distribution derived from a constrained con-
vex optimization problem. To validate the effectiveness of our privacy mechanism, we conducted extensive
experiments using real-world datasets. Our results indicate that our defense model significantly outperforms
existing methods, and additionally demonstrates its adaptability to various data types.
1 INTRODUCTION
The rapid revolution of artificial intelligence, par-
ticularly in deep learning, has marked a significant
shift across various sectors including computer vi-
sion, healthcare, autonomous driving, and natural lan-
guage processing. In recent times, prominent technol-
ogy companies such as Google, Microsoft, Amazon,
and IBM have made these models available through
APIs. This development means that a broad audience
can now access and implement advanced AI without
the necessity of developing models from the ground
up. This democratization of AI has ignited unpar-
alleled innovation, especially since many ML tech-
nologies are based on proprietary datasets that span
domains such as personalized medicine (Weiss et al.,
2012), product recommendation (Linden et al., 2003),
finance (Dunis et al., 2016), law (Hildebrandt, 2018)
and social networks (Farnadi et al., 2016).
However, as the deployment of these models
grows, there is an increased need for extensive
datasets to train them effectively. This rise in data
requirements intensifies privacy concerns, complicat-
ing their implementation (Hu et al., 2022; Bouhaddi
and Adi, 2023). Such concerns are further accen-
tuated by risks associated with data privacy, most
notably through inference attacks that compromise
the confidentiality of training data, revealing sensi-
tive information via methods like membership, at-
tribute (Shokri et al., 2017), property inference (Ate-
niese et al., 2015), and partial memorization (Carlini
et al., 2019). Particularly, Attribute Inference Attacks
(AIA) exploit partial knowledge of training records to
deduce sensitive attributes from model predictions, a
technique akin to data imputation but uniquely lever-
aging the model’s learned patterns in addition to the
available data.
Recent studies, such as those by Fredrikson et
al. (Fredrikson et al., 2014), have further categorized
them into two main categories: Model Inversion At-
tribute Inference (MIAI) attacks and Typical Instance
Reconstruction (TIR) attacks. While the former fo-
cuses on discerning sensitive attributes of individuals
used in training, the latter attempts to generate a ’typ-
ical’ instance for a specific class, e.g., reconstructing
a facial image similar to a target individual.
Illustratively, consider healthcare care, a domain
rich in sensitive information. ML models that pre-
dict patient outcomes or aid diagnostics may use per-
sonal health data. Exploiting a model inversion at-
tack, adversaries can infer patients’ health histories
from predictions, even without names. This breach
compromises confidentiality, allowing, hence, misuse
like discriminatory insurance practices.
224
Bouhaddi, M. and Adi, K.
Enhancing Privacy in Machine Learning: A Robust Approach for Preventing Attribute Inference Attacks.
DOI: 10.5220/0012768700003767
Paper published under CC license (CC BY-NC-ND 4.0)
In Proceedings of the 21st International Conference on Security and Cryptography (SECRYPT 2024), pages 224-236
ISBN: 978-989-758-709-2; ISSN: 2184-7711
Proceedings Copyright © 2024 by SCITEPRESS – Science and Technology Publications, Lda.

In this paper, we specifically examine attribute in-
ference vulnerabilities in classification models used in
Machine Learning as a Service (MLaaS), where pri-
vate data about individuals are employed. We focus
on scenarios where an adversary, with black-box ac-
cess to an MLaaS model, attempts to infer sensitive
attributes of a target individual. By using prediction
scores from these machine learning models, an ad-
versary can apply a classifier to accurately predict a
user’s gender, demonstrating the technique’s surpris-
ing precision (Weinsberg et al., 2012). The success of
attribute inference attacks in identifying sensitive at-
tributes from publicly accessible data hinges on the
statistical correlations between a user’s private and
public information.
In this context, the attackers do not have direct
visibility into the model’s internal workings or its
training algorithms. Instead, they have access to the
model’s prediction scores and, potentially, partial in-
formation regarding the training dataset and its prob-
ability distribution. This accessibility allows for a nu-
anced understanding of the model’s output behavior
in response to various inputs, providing a covert path-
way for sophisticated attacks. Such a scenario posits
significant challenges in safeguarding sensitive infor-
mation, as it exposes the model to indirect inference
attacks, where adversaries can cleverly deduce sen-
sitive attributes from seemingly innocuous prediction
scores.
In addressing the pressing issue of privacy within
the ML as a service framework, it becomes evident
that traditional privacy-preserving methods, such as
differential privacy, fall short when it comes to miti-
gating the risk of attribute inference attacks (Jayara-
man and Evans, 2019; Jayaraman and Evans, 2022).
Although differential privacy provides a mathemat-
ical guarantee against the identification of individu-
als within a dataset, it struggles to maintain a benefi-
cial balance between data utility and privacy, often re-
sulting in reduced model accuracy. Furthermore, the
complexity of managing noise in prediction scores to
maintain differential privacy complicates its applica-
tion in practical settings (Dwork et al., 2014). This
method does not directly counter the nuanced threat
posed by adversaries leveraging prediction scores to
infer sensitive attributes, thereby highlighting the lim-
itations of conventional approaches in the face of
evolving attack vectors within machine learning ap-
plications.
Exploring alternative solutions, game-theoretic
approaches emerge as a promising avenue for de-
vising strategic defenses against inference attacks
(Shokri, 2014; du Pin Calmon and Fawaz, 2012).
By modeling the interactions between attackers and
defenders as a game, these methods aim to predict
and neutralize adversarial strategies. However, de-
spite their potential for creating dynamic and adaptive
defense mechanisms, the implementation of game-
theoretic solutions in real-time applications presents
significant challenges. The complexity and computa-
tional demands of these approaches often render them
impractical for deployment in scenarios requiring im-
mediate response, underscoring the need for more ef-
ficient and scalable solutions.
In this context, defense techniques centered on
score masking strategies offer a viable and effective
means of preserving privacy (Jia and Gong, 2018).
By manipulating or obscuring the prediction scores
provided by ML models, these techniques can sig-
nificantly reduce the risk of sensitive attribute infer-
ence without compromising the utility of the model’s
output. One significant advantage of score masking
is that it can be applied to existing classifiers with-
out the need for retraining, which avoids the often
costly and time-consuming process of updating mod-
els. The adaptability of score masking methods al-
lows for tailored applications across various contexts
and constraints, ensuring that privacy measures can be
implemented in a manner that aligns with the specific
requirements and risks of each scenario. This flexibil-
ity, coupled with the relative ease of implementation,
positions score masking as a cornerstone of privacy
preservation in the ML as a service paradigm.
In the present work, we propose a practical so-
lution designed to operate efficiently in real-time ap-
plications, effectively perturbing the prediction score
vector of the target ML model. This perturbation aims
to randomize the adversary’s sensitive attribute clas-
sifier’s predictions, constituting the first phase of our
solution. We propose leveraging adversarial machine
learning, traditionally viewed as an offensive tech-
nique, as a defensive tool. Specifically, we use ad-
versarial examples to deceive the adversary, a novel
application that turns the tables on traditional attack
vectors. The primary challenge of this approach is
to maintain the predictive utility of the score vector,
ensuring it continues to accurately predict the correct
class while simultaneously safeguarding privacy. To
address the absence of the adversary’s sensitive at-
tribute classifier, our defense constructs its classifier
to link the score vector with the sensitive attribute
value. Given the shared classification boundaries be-
tween the adversary’s and our classifiers, the princi-
ple of transferability in adversarial machine learning
(Papernot et al., 2017; Liu et al., 2016) ensures that
a score vector perturbed for our defense classifier is
also effective against the adversary’s classifier. The
second phase involves devising a mechanism to deter-
Enhancing Privacy in Machine Learning: A Robust Approach for Preventing Attribute Inference Attacks
225

mine the optimal probability of a noise vector, con-
strained by the utility of the perturbed score vector,
essentially framing it as an optimization problem to
be solved.
In summary, our contributions are as follows:
• We propose a practical model designed to mask
the prediction score vector of the target ML
model. This approach aims to randomize the
sensitive attribute predictions by an adversary’s
classifier, leveraging adversarial machine learning
techniques—typically seen as offensive tools—in
a defensive capacity. Our method focuses on ma-
nipulating the score vector in such a way that it
confounds the attacker’s efforts while preserving
the utility of the predictions for legitimate uses.
• Our algorithm (called NOISY) leverages the Jaco-
bian based Saliency Map Attack (JSMA) tech-
nique to craft adversarial examples that disrupt
adversaries’ attribute inference efforts. By inte-
grating JSMA’s approach to inject noise into the
prediction score vector, NOISY renders attempts
to infer sensitive attributes as unreliable as ran-
dom guesses, all while preserving the original
model’s accuracy.
• Through rigorous experimentation, we have sub-
stantiated the efficacy of our approach, witness-
ing its prowess across diverse datasets, thereby re-
inforcing its practicality and applicability in real-
world scenarios.
2 RELATED WORK
In this section, we provide an exploration of the
landscape surrounding sensitive attribute inference at-
tacks. We define these attacks, their different strate-
gies, and the methods used to address them.
2.1 Attribute Inference Attacks
Recent studies (Kosinski et al., 2013; Gong and Liu,
2016; Weinsberg et al., 2012; Fredrikson et al., 2014)
have revealed that users are at risk of attribute in-
ference attacks, which aim to exploit machine learn-
ing models to expose sensitive information. Using
publicly available data, attackers can deduce sensi-
tive attributes of individuals, including but not lim-
ited to their gender, location, or political views. The
core issue arises from the tendency of machine learn-
ing models to inadvertently leak sensitive informa-
tion during the prediction process. Malicious entities
are thus able to extract private or sensitive data from
readily available sources, such as model predictions.
This ability to infer details about the training data or
inputs, which would otherwise remain hidden with-
out the model’s intervention, poses significant privacy
challenges.
The sensitive attribute inference attacks can be
broadly categorized into two main types: imputation-
based and representation-based attacks. Both these
classifications employ distinct strategies, assump-
tions, and techniques to target and exploit vulnerabil-
ities inherent within machine learning models.
2.1.1 Imputation-Based Attacks
Focusing on the strategy of harnessing non-sensitive
attributes, imputation-based attacks use the model’s
predictions and contextual data, such as the marginal
prior over a sensitive attribute and the confusion ma-
trix. The core objective of these attacks is to employ
statistical inference in order to derive or impute con-
cealed or missing data.
Jayaraman and Evans (Jayaraman and Evans,
2022) challenged the belief that standard blackbox
imputation-based attacks outperformed others, show-
ing they were equivalent to data imputation. Their
research highlighted the distinction between authen-
tic privacy risks and simple statistical deductions.
Fredrikson et al. (Fredrikson et al., 2014) created a
method based on target classifier responses to crafted
inputs, evaluating the probability of correct confiden-
tial attribute values based on model feedback. Yeom
et al. (Yeom et al., 2018) assumed a distribution
over the confidential attribute, uncovering various at-
tribute inference strategies, each with unique assump-
tions. Building on Fredrikson’s work, Mehnaz et al.
(Mehnaz et al., 2022) argued that model output preci-
sion is highest when matched with the right sensitive
attribute in training. They proposed two attacks: the
”Confidence only attack” that uses model confidence
for sensitive attribute deduction, and the ”Label-only
attack” that zeroes in on select data entries to under-
stand relationships between attributes.
2.1.2 Representation-Based Attacks
Representation-based attacks are particularly notable
for their adeptness at leveraging the discernible dis-
parities found within intermediate layer outputs or
predictions, making them highly attuned to changes
in attribute values. A clear illustration of this is seen
in the distinct prediction output distributions associ-
ated with gender classifications, such as distinguish-
ing between male and female.
Research by Song et al. (Song and Shmatikov,
2019) and Mahajan et al. (Mahajan et al., 2020)
are based on the premise that the training data em-
SECRYPT 2024 - 21st International Conference on Security and Cryptography
226

ployed by machine learning models do not explicitly
contain sensitive attributes. They design adversarial
models to reverse-engineer the main model’s outputs
to reveal these attributes, typically using a 0.5 clas-
sification threshold. In contrast, Malekzadeh et al.
(Malekzadeh et al., 2021) introduced a method using
a custom loss function, aiming to embed the sensi-
tive attribute in the model’s output for easy retrieval
during inference. This approach suggests a potential
malicious intent by the model’s creator, similar to im-
planting a system ”backdoor” to later reveal the sen-
sitive attribute.
2.2 Mitigation Strategies for Sensitive
Attribute Inference Attacks
Mitigation strategies for countering sensitive attribute
inference attacks in machine learning (ML) models
have become increasingly sophisticated as the threat
landscape evolves.
Game-theoretic frameworks offer a strong theoret-
ical foundation for privacy but are often computation-
ally intensive, as noted by Shokri et al. (Shokri et al.,
2016). For more practical applications, Salamatian et
al.’s Quantization Probabilistic Mapping (QPM) sim-
plifies the defense model for better efficiency (Sala-
matian et al., 2015).
Cryptography advancements like Homomorphic
Encryption (HE) and Fully Homomorphic Encryption
(FHE) allow computations on encrypted data, ensur-
ing that cloud servers can process data without pri-
vacy breaches (Rivest et al., 1978; Chen et al., 2021).
While these methods offer promising pathways to se-
cure data processing, they are not without their chal-
lenges. Specifically, HE and FHE are known for
their significant computational overhead, leading to
increased processing time and energy consumption.
This computational intensity can limit their practical-
ity for real-time applications or those requiring rapid
data processing, presenting a notable barrier to their
widespread adoption in MLaaS contexts.
Differential Privacy (DP) offers a mathematically
grounded method for protecting individual privacy
by introducing noise into the dataset, thus mask-
ing the contributions of individual data points (Ja-
yaraman and Evans, 2022). While DP is founded
on solid mathematical principles ensuring privacy
(Abadi et al., 2016), it tends to provide suboptimal
solutions from a utility perspective (Jia et al., 2019).
The added noise, though beneficial for privacy, can
significantly reduce the utility of the data, making it
less effective for certain analyses, especially where
precision is critical. This trade-off highlights a fun-
damental challenge in privacy-preserving data anal-
ysis: balancing the need for robust privacy protec-
tion with the imperative to maintain data utility. To-
gether, these approaches offer a multifaceted defense,
tailored to balance privacy preservation with the prac-
tical demands of ML deployment.
3 PROBLEM FORMULATION
In our problem formulation, we clearly define the
roles of three critical entities: the machine learning
model, the attacker and the defense mechanism.
The machine learning model operates as the cen-
tral system in our study. It is rigorously trained on
user data with the sole aim of delivering precise and
efficient predictions. This model, given its exposure
and access to vast amounts of user data, inadvertently
becomes a prime target for malicious entities.
The attacker, a malicious entity with a singular
mission: to exploit the machine learning model. Its
objective is clear: leverage the model’s predictions
to uncover private and potentially sensitive user at-
tributes.
The defense mechanism emerges as the system’s
shield. It is meticulously designed to efficiently
counter the attacker. This is achieved by ingeniously
altering the score prediction. The catch, however, is
to ensure that while the attacker is misled, the core
utility and efficiency of the model remain untouched
and unharmed.
3.1 Machine Learning Service Provider
Model
A machine learning model is commonly viewed as a
deterministic function:
f : X → Y (1)
The input of this function is a d-dimentional vec-
tor x = [x
1
,x
2
,··· ,x
d
] ∈ X = R
d
, representing d non-
sensitive input attributes. For regression tasks, the
output space Y is defined as the set of real numbers,
Y = R. However, our focus is on classification tasks,
where the output space is distinct.
In the context of classification, the function f :
R
d
→ Y maps first the input vector x to a set of confi-
dence scores υ = [υ
1
,υ
2
,...,υ
m
], where each υ
j
rep-
resents the model’s confidence in assigning the j
th
class label to x. The predicted class label, y, is then
determined by selecting the label associated with the
highest confidence score in υ, formally represented as
y = argmax
j
υ
j
, where j ∈ {1,...,m}. Here, Y is the
set of possible labels {y
1
,y
2
,...,y
m
}.
Enhancing Privacy in Machine Learning: A Robust Approach for Preventing Attribute Inference Attacks
227

The model’s parameters, denoted by θ, are itera-
tively refined based on the gradient of the loss func-
tion, which quantifies the discrepancy between the
model’s predictions f (x; θ) and the actual labels. .
Training uses the dataset D ⊆ X ×Y, aiming to opti-
mize θ so that f (x; θ) can accurately map inputs x to
their corresponding labels. Consequently, for any in-
put x, the model’s prediction is given as f (x; θ), where
θ are the parameters refined through training to ide-
ally minimize the loss function.
We consider p as a sensitive attribute belonging
to the set P. An individual, linked to a data record
within our training dataset, aims to keep this attribute
p confidential. We suppose that this attribute p can as-
sume k distinct values and our input attributes x ∈ X
are deemed non-sensitive. P represents the compre-
hensive set of all possible values that the sensitive
attribute can take. Consequently, a data record is
encapsulated as z = (x, p,y), where x stands for the
non-sensitive attributes, p represents the sensitive at-
tribute, and y corresponds to the classification label.
The association is defined as (x, p) ∈ X ×P.
While data is typically considered ”public” for the
purpose of training machine learning models, there
exist scenarios in which ”sensitive attributes” can be
deduced from it. In one hand, these sensitive at-
tributes might be used by the machine learning model
to enhance prediction accuracy, raising the possibil-
ity that the model retains some memory of this infor-
mation, which an adversary could exploit by looking
for traces within the model’s predictions. In another
hand, the machine learning model may not have di-
rectly encountered or utilized this sensitive attribute;
however, there could still be a link between this at-
tribute and the public data of a record, which might
allow for inference by an adversary. Data owners
share their information for machine learning applica-
tions with the expectation that such sensitive details
remain concealed, relying on the commitment to con-
fidentiality of these attributes.
Let D ⊆ X ×Y be the training dataset of the target
model, denoted f
target
. In subsequent discussions, y ∈
Y denotes the real value in D, whereas y
′
= f
target
(x)
corresponds to the model’s prediction. A congruence
between y and y
′
signifies accurate prediction by the
model, whereas a discrepancy highlights a predictive
error.
In the context of our study, once the model is
trained on the dataset D = {(x
i
,y
i
),i = 1..n}, it is
deployed as an Application Programming Interface
(API). Transitioning machine learning models into
services via APIs is known as Machine Learning as
a Service (MLaaS). MLaaS simplifies the use of these
trained models, eliminating the intricacies of training
and backend infrastructure. Yet, this convenience also
amplifies data privacy concerns. MLaaS models are
vulnerable to various inference attacks, underscoring
the need for robust defense strategies.
3.2 Attacker
In our scenario, we introduce the presence of an ad-
versarial entity A intent on exploiting MLaaS facil-
ities. This adversary interacts with the MLaaS by
sending a series of queries and, in return, receives
the associated confidence score vectors. Further-
more, this adversary has previously trained a classi-
fication model f
adv
using supervised learning tech-
niques. This prior training was facilitated by data
they acquired, often from users who inadvertently dis-
closed their sensitive attributes.
The adversary is assumed to have access to
a significant amount of information. Specifically,
he owns all or a subset of the following capabili-
ties/knowledge:
• Capability to interact with the target model,
treated as a black-box. Specifically, the adversary
can submit an inputs x = [x
1
,x
2
,...,x
d
] to obtain
the associated class label y
′
.
• Insight into the target model’s confidence scores
across m distinct class labels, υ.
• Knowledge of comprehensive or selective infor-
mation about the non-sensitive attributes, while
the sensitive aspect remains concealed.
• Availability of a supplementary dataset, D
aux
,
originating from a similar data distribution as D,
on which f
target
is trained. Notably, D and D
aux
share no common entries, i.e. D ∩ D
aux
=
/
0.
• Knowledge of the complete set of (l) potential
outcomes for the sensitive attribute p.
Although the adversary only has black-box access
to the actual model, they can utilize the received con-
fidence score vectors to guide their pre-trained clas-
sifier, f
adv
. This adversarial classifier learns from an
auxiliary dataset, D
aux
, which is believed to share the
same distribution as D. The dataset D
aux
consists of
set of tuples {x
i
, p
i
,y
i
}
i
, representing public data, the
sensitive attribute, and the prediction of the model.
The adversary’s primary goal is to analyze re-
sponses from MLaaS to uncover users’ concealed
sensitive attributes. As part of this strategy, the ad-
versary models f
adv
using D
aux
, establishing the rela-
tionship f
adv
: (x, f (x)) → p.
A detailed visualization of these interactions is
provided in Figure 1, illustrating the extent of the
adversary’s efforts to deduce sensitive information
through systematic querying.
SECRYPT 2024 - 21st International Conference on Security and Cryptography
228
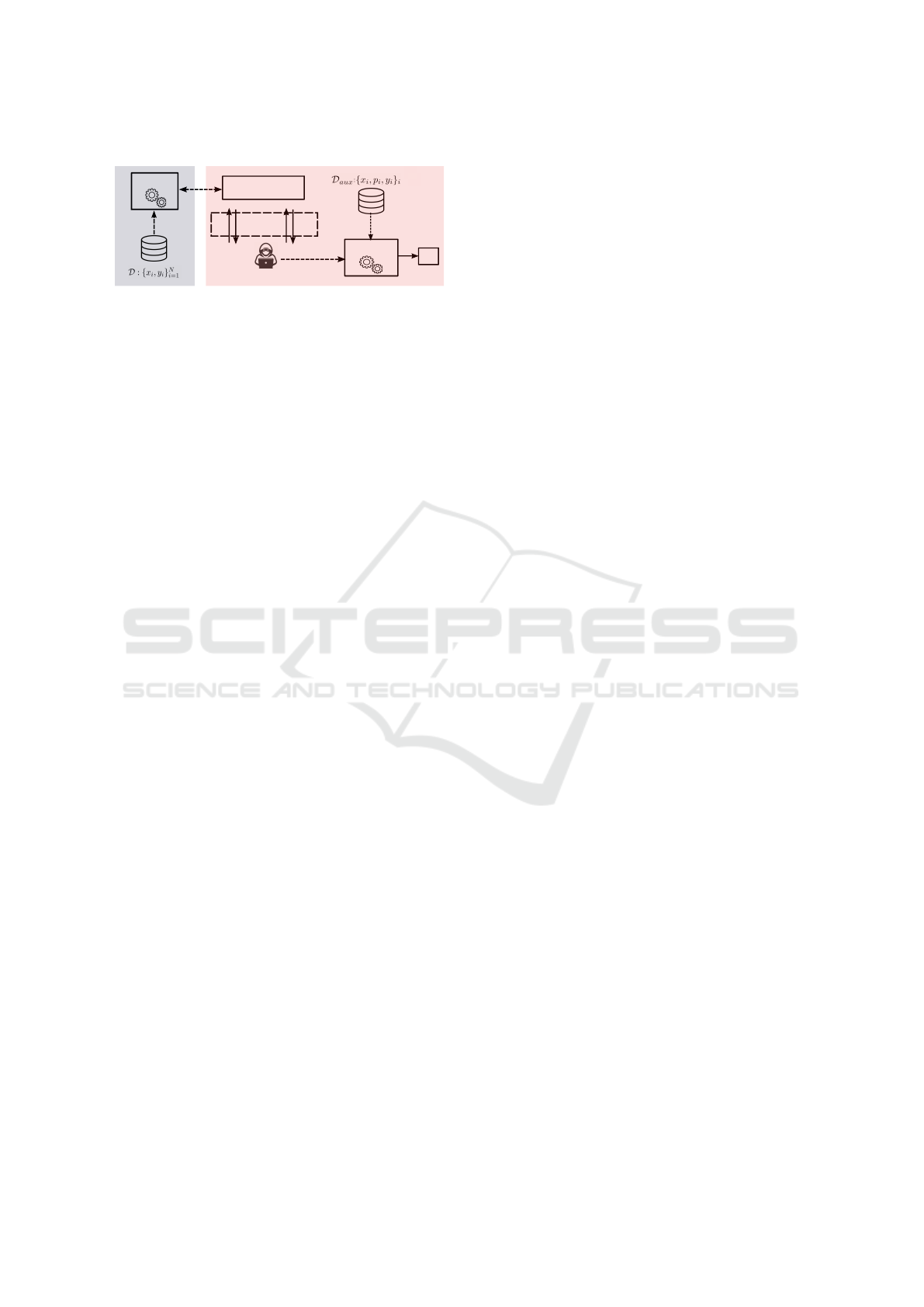
Train
Model f
Model f
adv
Adversary
Prediction API
p
x
1
x
q
...
f(x
1
)
f(x
q
)
Train
Accessible to A
Accessible to D
Figure 1: Attribute Inference Attack via MLaaS.
Our methodology centers on the assumption that
an adversary can exploit biases and residual informa-
tion memorized by the target classifier f
target
to infer
sensitive attributes. The adversary sets out to con-
struct an inference classifier that uses as inputs the
data point x and the prediction score vector provided
by f
target
, aiming to predict the value of the sensitive
attribute. This strategy relies on utilizing a dataset
D
aux
, carefully selected to mirror the distribution of
the training set used to train f
target
. By conducting su-
pervised learning with D
aux
, where each record con-
tains the corresponding value of the private attribute,
the adversary aims to establish a correlation between
the input data x, the prediction score vectors, and the
values of the sensitive attribute. The effectiveness of
this approach stems from the adversary’s ability to
identify and exploit specific prediction patterns and
inherent biases in f
target
, which are indicative of the
sensitive attribute values.
3.3 Defense Mechanism
We introduce the third crucial entity of our model:
the defender, denoted by D. Our proposal is based
on the strategic perturbation of confidence score, de-
liberately introducing noise to confound and mislead
adversarial classifiers. This requires meeting the fol-
lowing challenges:
1. Building upon our defensive strategy, the primary
objective of our defense mechanism, denoted as
N , is to determine an optimal noise vector δ for
addition to the prediction score vector υ, with the
aim of mitigating the impact of sensitive attribute
inference attacks. The mechanism N is designed
to select a noise vector δ
i
such that υ + δ
i
= υ
′
,
when used by the adversary’s classifier f
adv
, re-
sults in a random prediction of attribute i. This
is achieved by leveraging the probability µ
i
to
choose the noise δ
i
, ensuring that, once added to
the score vector to produce υ
′
, f
adv
is led to pre-
dict the attribute p
i
randomly.
This methodology represents a careful balancing
act: it involves devising a mechanism that intro-
duces enough randomness to confuse the adver-
sary’s classifier while maintaining the integrity
and utility of the original score vector. The goal is
for N to subtly alter the prediction output so that
f
adv
can no longer accurately infer the sensitive at-
tribute, thus safeguarding user privacy. However,
the challenge lies in accomplishing this without
significantly compromising the quality or utility
of υ, ensuring that the perturbed vector υ
′
contin-
ues to provide accurate and valuable predictions.
2. Within our framework, the defense confronts a
significant hurdle: it does not have access to the
adversary’s classifier, f
adv
. This limitation neces-
sitates an inventive approach to counteract poten-
tial inference attacks effectively. As a solution, we
propose the construction of our classifier, desig-
nated as f
de f
, to mirror the adversary’s decision-
making process. This model, developed through
supervised machine learning techniques, aims to
approximate the behavior and decision boundaries
of f
adv
, thereby serving as a proxy to anticipate
and neutralize adversarial strategies.
This strategy lies on the phenomenon of transfer-
ability, a well-documented characteristic in adver-
sarial machine learning (Papernot et al., 2016).
Transferability suggests that if a noise vector in-
duces a misprediction in f
de f
, there is a high like-
lihood that the same noise vector will cause sim-
ilar mispredictions in f
adv
, assuming both clas-
sifiers have been trained on similar data distri-
butions or share comparable decision boundaries.
This premise underpins our defense tactic; by it-
erating over various noise vectors and evaluating
their impact on f
de f
, we can identify those most
likely to disrupt f
adv
without necessitating direct
access to the adversary’s model.
4 A TWO-STAGE DEFENSE
MODEL AGAINST AIA
The primary challenge in identifying noise vectors to
perturb score vectors in machine learning models lies
in the combinatorial explosion of parameters. Find-
ing a noise vector δ to add to another vector υ to
meet specific requirements dramatically increases the
number of possibilities exponentially, making the im-
plementation of a real-time optimization solution ex-
ceedingly difficult. Consequently, we considered cat-
egorizing noise vectors. Suppose there are k possible
values for the sensitive attribute; we then have 10 cat-
egories of noise vectors, each designed to mislead the
adversary’s classifier into predicting a different sensi-
Enhancing Privacy in Machine Learning: A Robust Approach for Preventing Attribute Inference Attacks
229

tive attribute value.
To add another layer of complexity for the at-
tacker, we select one of these vectors randomly ac-
cording to a mechanism N based on certain prob-
abilities, under the constraint that the utility of the
perturbed vector υ
′
always predicts the same class,
arg maxυ = arg maxυ
′
. The mechanism will have k
different probabilities to pick a noise vector in each
category. Our mechanism ensures that our defense
strategy not only confuses the adversary but also
maintains the predictive accuracy of the perturbed
score vector.
4.1 Step 1: δ
i
Determination
In this work, we begin with our confidence score vec-
tor. The objective is to identify elements to perturb
such that the noise vector δ is determined. Our goal
is to introduce noise by making minimal manipula-
tions to this confidence score vector. This formulation
closely mirrors an adversarial machine learning (ML)
problem, where the primary aim is to subtly alter the
input data to cause misclassification.
The constraints we consider ensure that the per-
turbed score vector remains a probability distribution,
maintaining the essential characteristic that the sum
of its elements equals one, and each element’s value
is between 0 and 1. Formally, the optimization prob-
lem is defined as:
δ
i
= argmin
δ
∥δ∥
2
subject to f
adv
(x,υ + δ
i
) = i,
argmax
j
υ = argmax
j
υ + δ
i
,
m
∑
j=1
(υ
j
+ δ
i
j
) = 1,
0 ≤ (υ
j
+ δ
i
j
) ≤ 1, ∀ j = 1, . . . , m.
(2)
This optimization framework aims to pinpoint the
optimal noise vector δ that satisfies these conditions,
striking a balance between effectiveness in deceiv-
ing the classifier and adherence to the constraints that
maintain the integrity of the probability distribution.
Traditional adversarial machine learning (ML) al-
gorithms often fall short when faced with optimiza-
tion problems that include constraints as detailed pre-
viously. The complexity introduced by these con-
straints, specifically the requirement for the perturbed
score vector to remain a valid probability distribution,
renders standard approaches less effective. This limi-
tation highlights the need for innovative solutions tai-
lored to handle such intricacies.
In our pursuit of a viable solution, we turn to a
method proposed by Papernot et al., known as the
Jacobian-based Saliency Map Attack (JSMA). JSMA
is an adversarial attack algorithm that identifies and
perturbs a small subset of input features to signifi-
cantly impact the output classification. The original
JSMA algorithm focuses on the manipulation of input
features based on their saliency, calculated by assess-
ing the impact of each feature on the target classifica-
tion. However, JSMA in its standard form does not
inherently adhere to our constraint of maintaining the
score vector as a probability distribution.
To bridge this gap, we propose an inspired vari-
ant of JSMA, tailored to our constrained optimization
problem. Our approach modifies the JSMA method-
ology to incorporate the probability distribution con-
straint, ensuring that the perturbed score vector, when
passed through a normalization function, remains a
valid probability distribution. This adaptation allows
us to explore the solution space more effectively while
adhering to the essential constraints of our problem.
Therefore, we introduce a novel algorithm,
NOISY (Noise Optimizer Inference Sensitive
Yielder), designed to strategically navigate our
optimization challenge. NOISY’s core mission
is to meticulously discover and apply an optimal
perturbation vector δ
i
to the existing confidence score
vector υ. This vector is engineered not only to induce
a specific prediction error within the adversary’s
classifier, aiming for the i
th
value of the private
attribute, but also to ensure that the resulting vector,
when adjusted, adheres to the constraints of being a
valid probability distribution. The algorithm operates
through a series of iterative adjustments, carefully
balancing the goal of causing the desired misclassifi-
cation with the imperative to maintain the integrity of
the original prediction. This is achieved by adhering
to a rigorous constraint: the perturbed score vector
must continue to predict the same class as it did
prior to the perturbation. Through this approach,
NOISY aims to achieve a delicate manipulation of the
confidence scores, ensuring that while the adversary’s
classifier’s accuracy is deliberately compromised,
the utility and validity of the score vector remain
uncompromised.
1. Calculating the gradient of the loss function with
respect to the input vector to identify directions in
which a perturbation would most likely lead to a
misclassification.
2. Applying a constrained optimization to find δ
i
that minimizes the perturbation under the set con-
straints.
3. Iteratively adjusting δ and verifying if the per-
turbed score vector υ + δ, after the normalization,
SECRYPT 2024 - 21st International Conference on Security and Cryptography
230

predicts the target attribute i.
Algorithm 1 shows our algorithm to find δ
i
.
NOISY’s iterative nature allows for a refined search
for the optimal perturbation, balancing the need to in-
duce misclassification with the constraints of main-
taining a probability distribution.
Algorithm 1: NOISY: Noise Optimizer Inference Sensitive
Yielder.
Require: Confidence score vector υ, classifier f
def
,
target attribute value i, step size α, maximum it-
erations maxiter
Ensure: Perturbation vector δ
i
1: Initialize iteration count t = 0
2: Initialize δ
i
= 0, υ
′
= υ
3: while f
def
(softmax(υ
′
+ δ
i
)) ̸= i and t < maxiter
do
4: // Identify the entries to modify based on
saliency and constraints
5: e
inc
= argmax
j
n
∂ f
def
∂x
j
(υ
′
)
δ
i
j
= 0
o
6: e
dec
= argmax
j
n
−
∂ f
def
∂x
j
(υ
′
)
δ
i
j
> 0
o
7: // Modify the entries based on constraints
8: δ
e
inc
= clip(δ
i
e
inc
+ α,0,1)
9: δ
e
dec
= clip(δ
i
e
dec
− α,0,1)
10: // Adjust δ
i
to maintain the original predicted
class
11: if argmax
j
(υ
j
) ̸= argmax
j
(υ
j
+ δ
i
j
) then
12: Reduce the magnitude of δ
i
e
inc
and δ
i
e
dec
to
satisfy the constraint
13: end if
14: // Adjust δ
i
to maintain υ
′
+δ
i
as a valid prob-
ability distribution
15: total =
∑
m
j=1
(υ
′
j
+ δ
i
j
)
16: δ
i
= δ
i
/total
17: Update υ
′
= (υ + δ
i
)/total
18: t = t +1
19: Update υ
′
= υ + δ
i
20: end while
21: return δ
i
Our algorithm initializes with a zero perturbation
vector δ
i
and utilizes a saliency map to identify which
elements to modify within the [0, 1] range, using a
step size α. It carefully adjusts δ
i
to ensure that the ad-
justed confidence score vector, υ
′
+δ
i
, remains a valid
probability distribution. The process iterates, focus-
ing on modifying the confidence score vector to mis-
lead the adversary’s classifier into predicting a spe-
cific target class, while simultaneously ensuring that
the original prediction class of the vector is preserved.
4.2 Step 2: N
∗
Determination
Upon concluding Step 1, we are equipped with k dis-
tinct categories of perturbation vectors, denoted as
δ
1
,··· ,δ
k
. In the Step 2, our goal is to construct
a probability distribution that is the outcome of this
mechanism. This distribution aims to be uniform (or
’flat’) across the different perturbation vectors to in-
troduce uncertainty into the adversary’s choice. This
uncertainty is crucial for ensuring that any selected
noise vector maintains the classifier’s prediction to the
same class.
Our optimization problem can thus be formulated
as the search for a probability distribution over the
perturbation vectors that maximizes entropy, ensuring
flatness, subject to the constraint of consistent class
prediction. In mathematical terms, this problem is
framed as:
maximize
µ
−
k
∑
i=1
µ
i
logµ
i
subject to argmax
j
υ
′
= argmax
j
υ,
k
∑
i=1
µ
i
= 1,
µ
i
≥ 0, ∀i ∈ {1,...,k}.
(3)
To approach solving this optimization problem,
we apply the Karush-Kuhn-Tucker (KKT) conditions,
a fundamental method for solving constrained opti-
mization problems. Initially, primal feasibility en-
sures that our solution adheres to all established
constraints, maintaining the integrity of our prob-
lem’s formulation. Then, stationarity is achieved
when we identify appropriate Lagrange multipliers—
λ for equality constraints and ν
i
for inequality
constraints—such that the gradient of the Lagrangian
with respect to µ vanishes at the optimum point. This
guarantees that our solution is not only feasible but
also optimally aligned with our objective function
and constraints. Dual feasibility requires that the La-
grange multipliers associated with our inequality con-
straints are non-negative, a condition ensuring that
our solution resides within the permissible solution
space. Lastly, complementary slackness insists that
for each inequality constraint, the product of its La-
grange multiplier and the constraint itself equals zero
at the optimum, blending the boundary between fea-
sibility and optimality. Together, these conditions
meticulously guide us to a solution that is not only
within bounds but also optimal, ensuring a rigorous
adherence to both our problem’s structure and its in-
herent constraints.
Enhancing Privacy in Machine Learning: A Robust Approach for Preventing Attribute Inference Attacks
231

L(µ,λ,ν) = −
∑
k
i=1
µ
i
logµ
i
+ λ
∑
k
i=1
µ
i
− 1
+
∑
k
i=1
ν
i
(−µ
i
)
(4)
Our optimization strategy employs the Lagrangian
L(µ,λ,ν) to maximize entropy in the perturbation
vector distribution µ, under specific constraints. The
objective, −
∑
k
i=1
µ
i
logµ
i
, seeks a uniform distribu-
tion across k vectors, enhancing unpredictability. The
term λ(
∑
k
i=1
µ
i
− 1) ensures the distribution’s normal-
ization, while
∑
k
i=1
ν
i
(−µ
i
) imposes non-negativity on
each µ
i
, with λ and ν
i
as Lagrange multipliers for
equality and inequality constraints, respectively.
4.2.1 Practical Interpretation of N
∗
The mechanism N plays a pivotal role in our op-
timization framework, serving as the strategic core
for selecting the optimal noise vector under tightly
defined constraints. This mechanism is designed to
navigate through the complex landscape of adver-
sarial perturbations, aiming to identify a perturba-
tion strategy that not only adheres to operational con-
straints—such as maintaining the classifier’s predic-
tion—but also introduces a level of indeterminacy and
diversity in the adversarial examples generated.
In practical terms, N determines the distribution
of probability across various noise vectors (δ
1
,...,δ
k
)
in a manner that keeps the classifier’s output con-
sistent, yet makes the adversary’s actions less dis-
cernible. By doing so, N effectively increases the dif-
ficulty for defensive mechanisms to predict and miti-
gate these adversarial perturbations, securing a strate-
gic advantage.
5 EXPERIMENTATION
In this section, we discuss our experimental frame-
work employed to validate the effectiveness of our
proposed security mechanism against attribute infer-
ence attacks. The core objective of our investigation
is to substantiate that our model can significantly de-
ceive the attacker’s classifier, thereby safeguarding
sensitive attributes deductible from the score vector.
Simultaneously, we aim to preserve the inherent util-
ity of the score vector for legitimate purposes. This
dual achievement is facilitated through strategic per-
turbations introduced to the confidence scores.
5.1 Dataset and Setup
Texas-100X (Jayaraman, 2022): the data set we em-
ploy, termed Texas-100X, serves as an expanded ver-
sion of the Texas-100 hospital dataset, previously in-
troduced by Shokri et al. (Shokri et al., 2017). Each
entry in this dataset provides comprehensive demo-
graphic details of patients—spanning from age, gen-
der, and ethnicity—to nuanced medical data like the
length of hospital stays, mode of admission, diagnos-
tic reasons, patient outcomes, incurred charges, and
primary surgical interventions. The objective set for
this dataset is to anticipate one out of 100 possible
surgical interventions, grounded on individual health
records.
While the predecessor, Texas-100, comprised 60,000
entries with 6,000 obscured binary attributes, the
Texas-100X dataset contains an impressive 925,128
patient records gathered from 441 distinct hospitals.
Specially, this dataset retains the primary 10 demo-
graphic and medical traits in their original, decipher-
able state.
Census19: the Census19 dataset (cen, 2019) is a
modern extension of the well-known Adult dataset
(Asuncion and Newman, 2007), derived from the
1994 Census data. While the original housed around
48,000 records with 14 attributes, Census19 version
pulls from the U.S. Census Bureau’s 2019 database,
offering 1,676,013 entries with 12 pivotal attributes.
These records, organized based on Public Use Mi-
crodata Areas (PUMAs), capture key demographic
aspects of U.S. residents: age, gender, race, mari-
tal status, education, occupation, work hours, coun-
try of origin, and certain disability indicators. The
primary classification challenge with Census19 is to
determine whether an individual’s annual income sur-
passes $90,000 an inflation-adjusted figure from the
Adult dataset’s $50,000 threshold.
In our evaluations involving both Texas-100X and
Census19, we randomly pick 50,000 entries to estab-
lish the training dataset and employ it to train a two-
layer neural network. Additionally, we isolate an-
other 25,000 distinct records from the leftover data
to constitute the testing dataset, ensuring no overlap
between the training and test datasets.
The neural network employed for our defense
model is structured as follows:
• Input Layer: configured to match the dimension-
ality of the feature space in the Texas-100X and
Census19 datasets. This ensures that the network
can process each input attribute without loss of in-
formation.
• Hidden Layers: comprises multiple layers to en-
hance the model’s ability to capture nonlinear re-
lationships within the data. Each layer is equipped
with a ReLU activation function to introduce non-
linearity, facilitating complex decision boundary
formations essential for effective defense.
• Output Layer: the final layer is designed to out-
put the perturbed score vector. The dimension-
SECRYPT 2024 - 21st International Conference on Security and Cryptography
232

ality of this layer corresponds to the number of
classes in the dataset, with a softmax activation
function applied to convert the network’s out-
put into a probability distribution over potential
classes.
5.1.1 Defense Mechanism Integration
The core of our defense strategy involves the N
∗
determination mechanism, which dynamically intro-
duces perturbations into the confidence score vec-
tor. This neural network architecture is pivotal in
evaluating the impact of such perturbations, allowing
for real-time adjustments to ensure that the perturbed
vector deceives the attacker’s classifier while preserv-
ing the integrity and utility of the original score vec-
tor.
To implement the N
∗
mechanism, the network
is trained on adversarially perturbed data alongside
clean data, optimizing for two primary objectives:
minimizing the success rate of attribute inference at-
tacks and maintaining high accuracy on legitimate
classification tasks. This dual-objective training reg-
imen is instrumental in hardening the defense model
against sophisticated adversarial strategies.
5.1.2 Training and Evaluation
The model undergoes rigorous training using a cu-
rated dataset that amalgamates samples from both
Texas-100X and Census19, ensuring comprehensive
exposure to diverse data representations. The train-
ing process leverages a cross-entropy loss function,
which is effective for classification tasks and facili-
tates the optimization of the network’s weights in the
context of our defense objectives.
5.1.3 Evaluation Metrics
In our evaluation, we aim to conduct a comprehen-
sive comparison of our two-step model against two
established privacy-preserving techniques: Local Dif-
ferential Privacy (LDP) (Avent et al., 2017) and k-
Anonymity (Zhao et al., 2018). These methods are
well-regarded for their ability to mitigate the risks
associated with sensitive attribute inference attacks
within Machine Learning as a Service (MLaaS) envi-
ronments, each utilizing distinct mechanisms that im-
pact data utility and processing efficiency in unique
ways.
Our two-step model leverages sophisticated adver-
sarial examples and a strategic selection mechanism
to preserve privacy against Attribute Inference At-
tacks (AIA). It will be assessed alongside LDP rather
than standard Differential Privacy due to LDP’s suit-
ability for environments where the central aggrega-
tion of data is not feasible or where the trust in a cen-
tral curator is limited. LDP applies controlled statis-
tical noise directly at the data source, masking indi-
vidual contributions before the data aggregation oc-
curs. This method enables greater privacy assurance
directly on the user’s device without requiring trust
in the central server’s handling of their data. An ε
parameter, randomly selected from the interval [0,10]
(Avent et al., 2017), will be tuned to balance privacy
protection and the utility of predictions.
Conversely, k-Anonymity protects privacy by en-
suring each record in a dataset is indistinguishable
from at least k − 1 other records with similar at-
tributes. We will choose a k value that maximizes the
difficulty of associating data with specific individu-
als while maintaining sufficient data granularity for
meaningful analysis.
The evaluation focuses on three critical metrics:
the rate of successful inference attacks, the impact on
confidence score utility, and the computational speed
of each method. By measuring the inference rate,
we aim to understand how well each method con-
ceals sensitive attributes from potential attackers. The
utility loss metric will help us gauge the extent to
which the protection method affects the data’s useful-
ness for legitimate analytical tasks. Finally, compu-
tational speed will be assessed to determine the effi-
ciency and practicality of implementing each method
in real-world scenarios. This comparative analysis
will not only highlight the strengths and weaknesses
of our model but also contribute valuable insights
into the trade-offs involved in implementing privacy-
preserving techniques in data-driven applications.
5.2 Results and Analysis
Figure 2 illustrates the comparative analysis of sen-
sitive attribute inference rates across our developed
model, the ”Two-Step Adversarial Defense”, Local
Differential Privacy (LDP), and k-Anonymity meth-
ods. Our ”Two-Step Adversarial Defense” method
consistently shows the lowest inference rates, indi-
cating its effectiveness in minimizing the likelihood
of sensitive attributes being accurately inferred by ad-
versaries. This performance highlights the advantages
of our approach in enhancing data privacy compared
to both LDP and k-Anonymity.
In Figure 3, we examine the impact of each
privacy-preserving method on classification error
rates. Our ”Two-Step Adversarial Defense” method
not only provides substantial protection against at-
tribute inference attacks but does so with minimal im-
pact on the classification accuracy.This result under-
Enhancing Privacy in Machine Learning: A Robust Approach for Preventing Attribute Inference Attacks
233
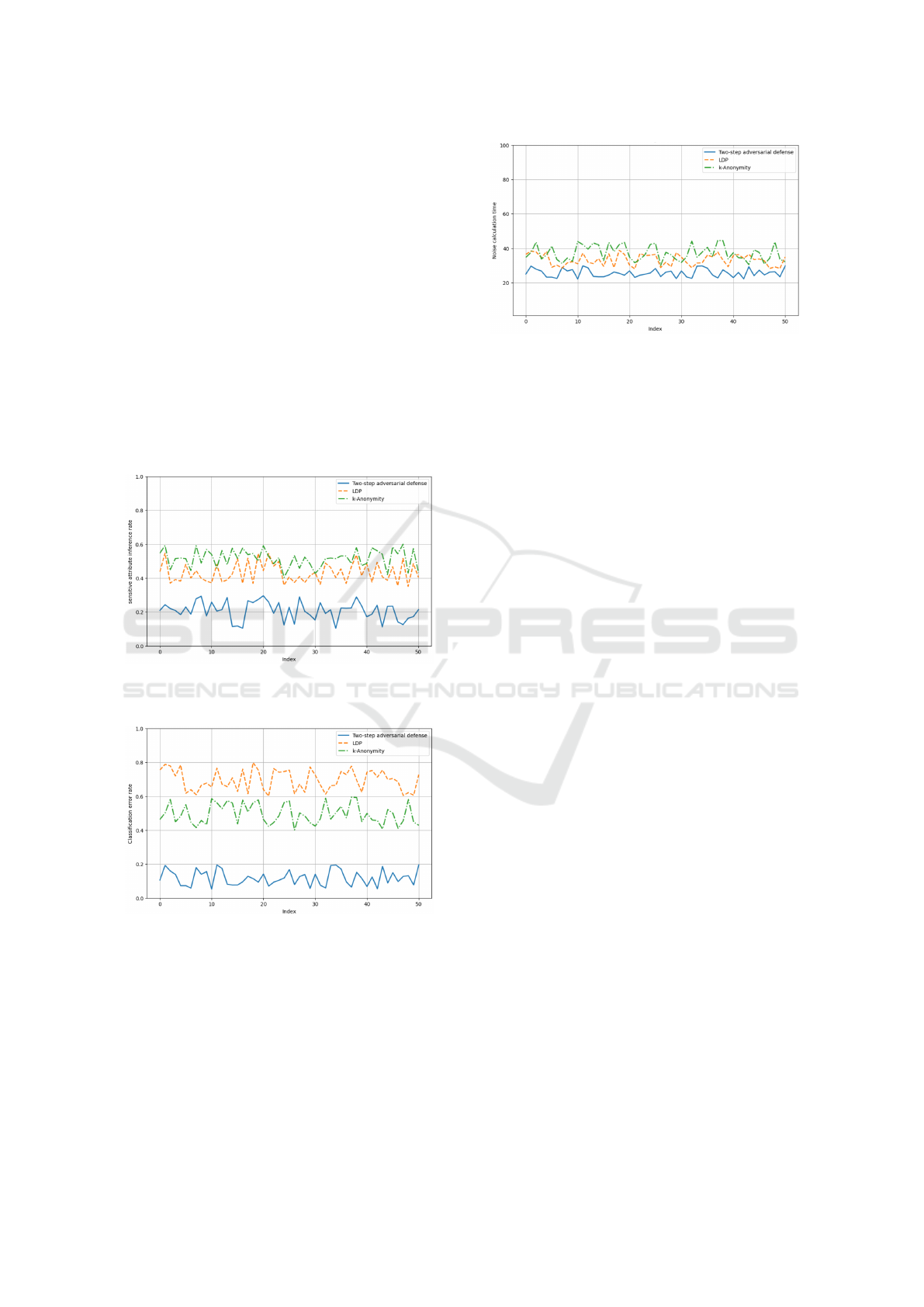
scores our method’s capability to maintain data util-
ity for legitimate analytical purposes while providing
robust defense mechanisms. It effectively balances
security with data utility, outperforming both Local
Differential Privacy (LDP) and k-Anonymity in this
regard.
The Figure 4 focuses on the efficiency of gen-
erating noise vectors, a critical aspect in the practi-
cal application of privacy-preserving techniques. Our
”Two-Step Adversarial Defense” method is demon-
strated to generate noise vectors more swiftly than
both LDP and k-Anonymity. This suggests that our
method not only enhances privacy protection but also
does so more efficiently. Such efficiency makes our
proposed method particularly suitable for environ-
ments where rapid data processing is essential, thus
offering significant advantages over the compared
methodologies.
Figure 2: Comparison of Sensitive Attribute Inference
Rate between Two-Step Adversarial Defense, LDP and k-
Anonymity.
Figure 3: Evaluation of the Impact on Classification Error
Rate: Two-Step Adversarial Defense vs. Privacy Methods.
In each figure, our ”Two-Step Adversarial De-
fense” method consistently surpasses its counterparts,
demonstrating comprehensive advantages in protect-
ing sensitive information, preserving data utility, and
ensuring operational efficiency. These results affirm
the effectiveness of our approach in balancing robust
privacy protection with the practical demands of real-
world applications.
Figure 4: Noise Generation Speed Performance: Compara-
tive Analysis between Two-Step Adversarial Defense, LDP
and k-Anonymity.
6 CONCLUSION
In this study, we developed and evaluated the ”Two-
Step Adversarial Defense” method to enhance privacy
in MLaaS environments susceptible to attribute in-
ference attacks. Our approach, which introduces so-
phisticated adversarial examples followed by strategic
noise vector selection, has proven effective in reduc-
ing the likelihood of sensitive attribute exposure while
maintaining the utility of the data for legitimate ana-
lytical purposes.
Moving forward, we plan to further enhance our
model by incorporating strategic concepts from game
theory into the noise vector selection process. This
adjustment will allow for a more calculated and
context-aware application of noise, potentially in-
creasing the robustness of our privacy protections.
Additionally, we will expand our comparative anal-
ysis with existing privacy-preserving methods. This
expanded comparison will provide a clearer under-
standing of the impact our proposed approach has
in various operational contexts, helping to refine our
strategies and solidify our defenses against evolving
threats to sensitive data.
REFERENCES
(2019). Census19 data set.
https://www.census.gov/programs-surveys/acs/
Accessed: 2023-08-24.
Abadi, M., Chu, A., Goodfellow, I., McMahan, H. B.,
Mironov, I., Talwar, K., and Zhang, L. (2016). Deep
learning with differential privacy. In Proceedings of
the 2016 ACM SIGSAC conference on computer and
communications security, pages 308–318.
Asuncion, A. and Newman, D. (2007). Uci machine learn-
ing repository.
Ateniese, G., Mancini, L. V., Spognardi, A., Villani, A.,
Vitali, D., and Felici, G. (2015). Hacking smart ma-
chines with smarter ones: How to extract meaningful
SECRYPT 2024 - 21st International Conference on Security and Cryptography
234

data from machine learning classifiers. International
Journal of Security and Networks, 10(3):137–150.
Avent, B., Korolova, A., Zeber, D., Hovden, T., and
Livshits, B. (2017). {BLENDER}: Enabling local
search with a hybrid differential privacy model. In
26th USENIX Security Symposium (USENIX Security
17), pages 747–764.
Bouhaddi, M. and Adi, K. (2023). Mitigating membership
inference attacks in machine learning as a service. In
2023 IEEE International Conference on Cyber Secu-
rity and Resilience (CSR), pages 262–268. IEEE.
Carlini, N., Liu, C., Erlingsson,
´
U., Kos, J., and Song, D.
(2019). The secret sharer: Evaluating and testing un-
intended memorization in neural networks. In 28th
USENIX Security Symposium (USENIX Security 19),
pages 267–284.
Chen, J., Li, K., and Philip, S. Y. (2021). Privacy-preserving
deep learning model for decentralized vanets using
fully homomorphic encryption and blockchain. IEEE
Transactions on Intelligent Transportation Systems,
23(8):11633–11642.
du Pin Calmon, F. and Fawaz, N. (2012). Privacy against
statistical inference. In 2012 50th annual Allerton
conference on communication, control, and comput-
ing (Allerton), pages 1401–1408. IEEE.
Dunis, C., Middleton, P. W., Karathanasopolous, A., and
Theofilatos, K. (2016). Artificial intelligence in finan-
cial markets. Springer.
Dwork, C., Roth, A., et al. (2014). The algorithmic founda-
tions of differential privacy. Foundations and Trends®
in Theoretical Computer Science, 9(3–4):211–407.
Farnadi, G., Sitaraman, G., Sushmita, S., Celli, F., Kosin-
ski, M., Stillwell, D., Davalos, S., Moens, M.-F.,
and De Cock, M. (2016). Computational personal-
ity recognition in social media. User modeling and
user-adapted interaction, 26:109–142.
Fredrikson, M., Lantz, E., Jha, S., Lin, S., Page, D., and
Ristenpart, T. (2014). Privacy in pharmacogenetics:
An {End-to-End} case study of personalized war-
farin dosing. In 23rd USENIX security symposium
(USENIX Security 14), pages 17–32.
Gong, N. Z. and Liu, B. (2016). You are who you know and
how you behave: Attribute inference attacks via users’
social friends and behaviors. In 25th USENIX Security
Symposium (USENIX Security 16), pages 979–995.
Hildebrandt, M. (2018). Law as computation in the era
of artificial legal intelligence: Speaking law to the
power of statistics. University of Toronto Law Jour-
nal, 68(supplement 1):12–35.
Hu, H., Salcic, Z., Sun, L., Dobbie, G., Yu, P. S., and Zhang,
X. (2022). Membership inference attacks on machine
learning: A survey. ACM Computing Surveys (CSUR),
54(11s):1–37.
Jayaraman, B. (2022). Texas-100x data set.
https://github.com/bargavj/texas100x. Accessed:
2023-08-24.
Jayaraman, B. and Evans, D. (2019). Evaluating differen-
tially private machine learning in practice. In 28th
USENIX Security Symposium (USENIX Security 19),
pages 1895–1912.
Jayaraman, B. and Evans, D. (2022). Are attribute inference
attacks just imputation? In Proceedings of the 2022
ACM SIGSAC Conference on Computer and Commu-
nications Security, pages 1569–1582.
Jia, J. and Gong, N. Z. (2018). {AttriGuard}: A practi-
cal defense against attribute inference attacks via ad-
versarial machine learning. In 27th USENIX Security
Symposium (USENIX Security 18), pages 513–529.
Jia, J., Salem, A., Backes, M., Zhang, Y., and Gong, N. Z.
(2019). Memguard: Defending against black-box
membership inference attacks via adversarial exam-
ples. In Proceedings of the 2019 ACM SIGSAC con-
ference on computer and communications security,
pages 259–274.
Kosinski, M., Stillwell, D., and Graepel, T. (2013). Pri-
vate traits and attributes are predictable from digital
records of human behavior. Proceedings of the na-
tional academy of sciences, 110(15):5802–5805.
Linden, G., Smith, B., and York, J. (2003). Amazon. com
recommendations: Item-to-item collaborative filter-
ing. IEEE Internet computing, 7(1):76–80.
Liu, Y., Chen, X., Liu, C., and Song, D. (2016). Delving
into transferable adversarial examples and black-box
attacks. arXiv preprint arXiv:1611.02770.
Mahajan, A. S. D., Tople, S., and Sharma, A. (2020). Does
learning stable features provide privacy benefits for
machine learning models. In NeurIPS PPML Work-
shop.
Malekzadeh, M., Borovykh, A., and G
¨
und
¨
uz, D. (2021).
Honest-but-curious nets: Sensitive attributes of pri-
vate inputs can be secretly coded into the classifiers’
outputs. In Proceedings of the 2021 ACM SIGSAC
Conference on Computer and Communications Secu-
rity, pages 825–844.
Mehnaz, S., Dibbo, S. V., De Viti, R., Kabir, E., Branden-
burg, B. B., Mangard, S., Li, N., Bertino, E., Backes,
M., De Cristofaro, E., et al. (2022). Are your sensi-
tive attributes private? novel model inversion attribute
inference attacks on classification models. In 31st
USENIX Security Symposium (USENIX Security 22),
pages 4579–4596.
Papernot, N., McDaniel, P., and Goodfellow, I. (2016).
Transferability in machine learning: from phenomena
to black-box attacks using adversarial samples. arXiv
preprint arXiv:1605.07277.
Papernot, N., McDaniel, P., Goodfellow, I., Jha, S., Celik,
Z. B., and Swami, A. (2017). Practical black-box at-
tacks against machine learning. In Proceedings of the
2017 ACM on Asia conference on computer and com-
munications security, pages 506–519.
Rivest, R. L., Adleman, L., Dertouzos, M. L., et al. (1978).
On data banks and privacy homomorphisms. Founda-
tions of secure computation, 4(11):169–180.
Salamatian, S., Zhang, A., du Pin Calmon, F., Bhamidi-
pati, S., Fawaz, N., Kveton, B., Oliveira, P., and Taft,
N. (2015). Managing your private and public data:
Bringing down inference attacks against your privacy.
IEEE Journal of Selected Topics in Signal Processing,
9(7):1240–1255.
Enhancing Privacy in Machine Learning: A Robust Approach for Preventing Attribute Inference Attacks
235

Shokri, R. (2014). Privacy games: Optimal user-centric data
obfuscation. arXiv preprint arXiv:1402.3426.
Shokri, R., Stronati, M., Song, C., and Shmatikov, V.
(2017). Membership inference attacks against ma-
chine learning models. In 2017 IEEE symposium on
security and privacy (SP), pages 3–18. IEEE.
Shokri, R., Theodorakopoulos, G., and Troncoso, C.
(2016). Privacy games along location traces: A game-
theoretic framework for optimizing location privacy.
ACM Transactions on Privacy and Security (TOPS),
19(4):1–31.
Song, C. and Shmatikov, V. (2019). Overlearning reveals
sensitive attributes. arXiv preprint arXiv:1905.11742.
Weinsberg, U., Bhagat, S., Ioannidis, S., and Taft, N.
(2012). Blurme: Inferring and obfuscating user gen-
der based on ratings. In Proceedings of the sixth ACM
conference on Recommender systems, pages 195–202.
Weiss, J. C., Natarajan, S., Peissig, P. L., McCarty, C. A.,
and Page, D. (2012). Machine learning for person-
alized medicine: predicting primary myocardial in-
farction from electronic health records. Ai Magazine,
33(4):33–33.
Yeom, S., Giacomelli, I., Fredrikson, M., and Jha, S. (2018).
Privacy risk in machine learning: Analyzing the con-
nection to overfitting. In 2018 IEEE 31st computer se-
curity foundations symposium (CSF), pages 268–282.
IEEE.
Zhao, P., Jiang, H., Wang, C., Huang, H., Liu, G., and Yang,
Y. (2018). On the performance of k-anonymity against
inference attacks with background information. IEEE
Internet of Things Journal, 6(1):808–819.
SECRYPT 2024 - 21st International Conference on Security and Cryptography
236
