
Utilizing Machine Learning for Optimizing Cybersecurity Spending
in Critical Infrastructures
George Stergiopoulos
1
, Michalis Detsis
2
, Sozon Leventopoulos
2
and Dimitris Gritzalis
2
1
Dept. of Information & Communication Systems Engineering, University of the Aegean, Samos, Greece
2
Dept. of Informatics, Athens University of Economics & Business, Athens, Greece
Keywords: Risk Assessment, Risk Management, Artificial Intelligence, Graph Theory.
Abstract: This research paper presents a methodology and corresponding tool that aim to automate decision-making in
prioritizing cybersecurity investments by identifying a minimal subset of assets based on their risk exposure,
the protection of which would yield maximum risk reduction and cost efficiency. The presented method aims
to assist in strategic security planning, offering significant savings while ensuring robust cyber defense mech-
anisms are in place. To achieve this, we developed an application that identifies and classifies critical assets
within ICT networks using supervised machine learning, graph centrality measurements and cascading attack
paths. We utilize over 100 randomly generated network models taken from existing companies to build a
classifier able to determine ICT critical nodes. We use topological features and dependency risk graphs to
simulate potential cyberattack paths.
1 INTRODUCTION
Cyber threats exploit vulnerabilities across infor-
mation and communication technology (ICT) assets
on an increased pace. To address these threats, organ-
izations follow risk management practices that pro-
vide insights and recommendations on strengthening
organization’s cybersecurity posture. Nevertheless,
the complexity of modern, decentralized networks
complicates the risk assessment process, and the re-
sulting investment prioritization.
Despite these advancements, balancing trade-offs
during the implementation of measures is often man-
ual. Effective resource allocation is crucial to protect
against cyber vulnerabilities and maximize invest-
ments. This research explores the feasibility of using
a supervised machine learning model to classify ICT
assets based on their risk and position within the in-
formation system. The model represents ICT assets as
nodes and their dependencies as edges and uses ma-
chine learning to prioritize investment during risk
treatment.
1.1 Contribution
This research paper proposes a machine-learning
model able to identify an arbitrary group of nodes
within a network whose security enhancement leads
to the greatest reduction of risk across the network.
The targeted group is comprised of nodes character-
ized by their significant cumulative attack risks and
notable positions within the network, indicated by
high eigenvector centrality, functioning as critical
connectors (indicated by high betweenness central-
ity), or being centrally located (highlighted by high
closeness centrality).
The idea of using Centrality Measures in Depend-
ency Risk Graphs (Stergiopoulos et al., 2015) is com-
bined with the estimation of n-order dependency
chains to be used as features and train a machine
learning (ML) process with randomly generated net-
works that are formed over multiple bases. The model
can identify and eliminate critical sub-net paths while
maintaining the network’s connectivity (Kotzaniko-
laou et al., 2013). Our contribution is summarized as
follows:
- Model for Investment Prioritization during Risk
Treatment: We introduce a novel approach by
combining centrality measurements with cascading
attack paths to train a machine learning model for
investment prioritization during risk treatment.
- Testing and Validation: we test and validate the
presented method on simulated ICT systems using
544
Stergiopoulos, G., Detsis, M., Leventopoulos, S. and Gritzalis, D.
Utilizing Machine Learning for Optimizing Cybersecurity Spending in Critical Infrastructures.
DOI: 10.5220/0012837300003767
Paper published under CC license (CC BY-NC-ND 4.0)
In Proceedings of the 21st International Conference on Security and Cryptography (SECRYPT 2024), pages 544-551
ISBN: 978-989-758-709-2; ISSN: 2184-7711
Proceedings Copyright © 2024 by SCITEPRESS – Science and Technology Publications, Lda.

randomized simulations of real-world ICT environ-
ments based on company networks.
Results indicate that our approach can identify a min-
imal subset of critical assets for protection, signifi-
cantly reducing overall risk and associated costs,
thereby improving resource allocation and decision-
making.
2 RELATED WORK
This work extends a previous framework (Stergio-
poulos et al. 2020) for modelling the connections of
ICT asset interdependencies on a company's business
processes through dependency structural risks.
Original work aimed at prioritizing assets based on
their influence using dependency risk graphs, graph
minimum spanning trees, and network centrality
metrics. Attack graphs have been used in literature
(Ray, 2005; Dewri et al., 2007) to model network
devices and systems repeatedly for the purpose of
prioritizing mitigation controls.
More recent related work from (Aksu et al., 2017)
showcased a quantitative asset-centric risk assess-
ment method based on attack-graph analysis,
although their work does not tackle risk mitigation
issues and prioritization. In (Shivraj et al., 2017)
authors presented a model-driven risk assessment
framework that was based on graph theory to model
the flow graph and produce relevant attack trees
according to the underlying ICT architecture. Still,
this work addresses attack vectors and software state
dependencies rather than risk assessment results on
business processes.
Similarly, (Hermanowski, 2018) used graphs to
assess the risk of ICT using the MulVAL attack graph
tool which adapts for risk assessment attack paths
calculation against crucial assets of an IT system.
Authors (Grigoriadis et al., 2021) proposed a situation
-driven security management system to dynamically
implement security controls specific to different use
cases by producing dynamic risks for various
situations. In (Stellios et al., 2021) authors proposed
a graph-based analysis of risk assessment results over
ICT systems.
In (Stergiopoulos et al., 2022), the authors pro-
posed a method to automatically create complex at-
1
https://www.ben-evans.com/benedictevans/2018/06/22/
ways-to-think-about-machine-learning-8nefy
2
Breadth First Search
3
Depth First Search
tack graphs for enterprise networks, relating micro-
services, virtual system states, and cloud services as
graph nodes using mathematical graph series and
group clustering to prioritize vulnerabilities by ana-
lysing system states' effects on the overall network.
This research is based on the relevant results to ana-
lyse graph paths and software state vulnerabilities but
expands its focus, by building a machine learning
classifier for decision support during risk manage-
ment, aiming at cost reduction in implementing safe-
guards through machine learning.
3 BACKGROUND
3.1 Graph Structure and Node
Predictions
According to Evans
1
, there are two major ways that
machine learning can be of service: (a) automate the
functions that are easily understandable by humans,
but hard for computers to comprehend, and (b) trans-
form information on a large scale. Several methods
have been developed to address the representation of
graphs with complex structures in simple forms, such
non-deterministic low-dimensional node embed-
dings.
Techniques like BFS
2
and DFS
3
are instrumental
in generating embeddings that reflect these equiva-
lences, with BFS aligning with structural equivalence
and DFS with homophily equivalence. The effective-
ness of these methods in labelling nodes is further en-
hanced by incorporating heuristic methods that con-
sider structural characteristics and an "influence
spread" factor (Zhang et al, 2016).
Adding "influence spread" to centrality measure-
ments significantly improved model’s performance,
evidenced by an increase in the F1
4
score from 0.65
(not acceptable) to 0.86. Furthermore, we have iden-
tified that the applied methodology can isolate
bridges by controlling the distance of influence and
revealing closely interacting clusters (homophily
equivalence). This factor, crucial for achieving accu-
rate machine learning models, considers the potential
of a subset of nodes to propagate information or mal-
ware through the network.
4
F1 score is an error metric used in classification, which
measures per-formance by calculating the harmonic mean
of precision and recall for the minority positive class. F1
score can be interpreted as a measure of overall model
performance from 0 to 1, where 1 is the best.
Utilizing Machine Learning for Optimizing Cybersecurity Spending in Critical Infrastructures
545
3.2 Active Learning
Active learning (part of Machine Learning) is the pro-
cess when a learning algorithm can interactively
query a human (or other information) source (Settles
B, 2009). This process helps label new data points
with the desired outputs, provided that the infor-
mation source has the required expertise and
knowledge on the subject. The algorithm can actively
query the information source for labels, thus minimiz-
ing the number of examples needed compared to a
normal supervised learning model.
In this work, we use a Feedforward Neural Net-
work (FNN) with ReLU activation functions for the
input layers and SIGMOID activation functions for
the output layers, maintaining a one-to-one corre-
spondence between input values and classification la-
bels. This is proven to be a promising setup for ana-
lyzing information networks of interconnected assets
where information flow is degined by one-to-one re-
lationships of different types of objects.
3.3 Simulating ICTs with Dependency
Risk Graphs
The definition of ICT encompasses the role of unified
communications a business and marketing concept
regarding the integration of enterprise communica-
tion with non-real-time communication services, and
that of information technology, such as enterprise
software, critical business applications, and essential
business development. The visual representation of
these interconnections can be formulated using de-
pendency graphs where the nodes represent assets and
services of the NI, and their directed edges represent
the potential risk that the destination node may suffer
due to its dependency from the source node, in case
of a failure being realized at the source node (Ster-
giopoulos, 2015) (Rinaldi et al., 2001).
Risk management helps organizations allocate
limited resources (manpower and budget) to mitigat-
ing the most significant threats first rather than spend-
ing funds in less critical areas. A plethora of defini-
tions on risk is available, such as the ISO Guide
73:2009, ISO 31000 series, or the NIST SP 800 se-
ries. For the purposes of this research, we used the
definition provided by NIST
5
.
Risk is a metric defined as the sum of the Likeli-
hood (L) of a threat occurrence on a business asset
times the Impact (I) of the threat manifestation. It
considers the possibility of the threat event (P), the
vulnerability level (V) of an asset or object to that
5
https://csrc.nist.gov/glossary/term/risk
threat and the impact (I) to the business concept sup-
ported by the asset. We use typical Risk scales and
input from Risk analysis on assets and systems to
produce Risk metrics to embed onto the graph’s edges
and nodes.
𝑅𝑖𝑠𝑘=𝐿 𝑥 𝐼=
(
𝑃 𝑥 𝑉
)
𝑥 𝐼
For calculating the risk chain (attack path) we
considered a path graph G’, a subgraph of a graph G
= (V, E) and a path of G. This path forms an attack
path, or a risk chain, comprising n nodes numbered
from N
1
to N
n
, like the one depicted in the figure be-
low:
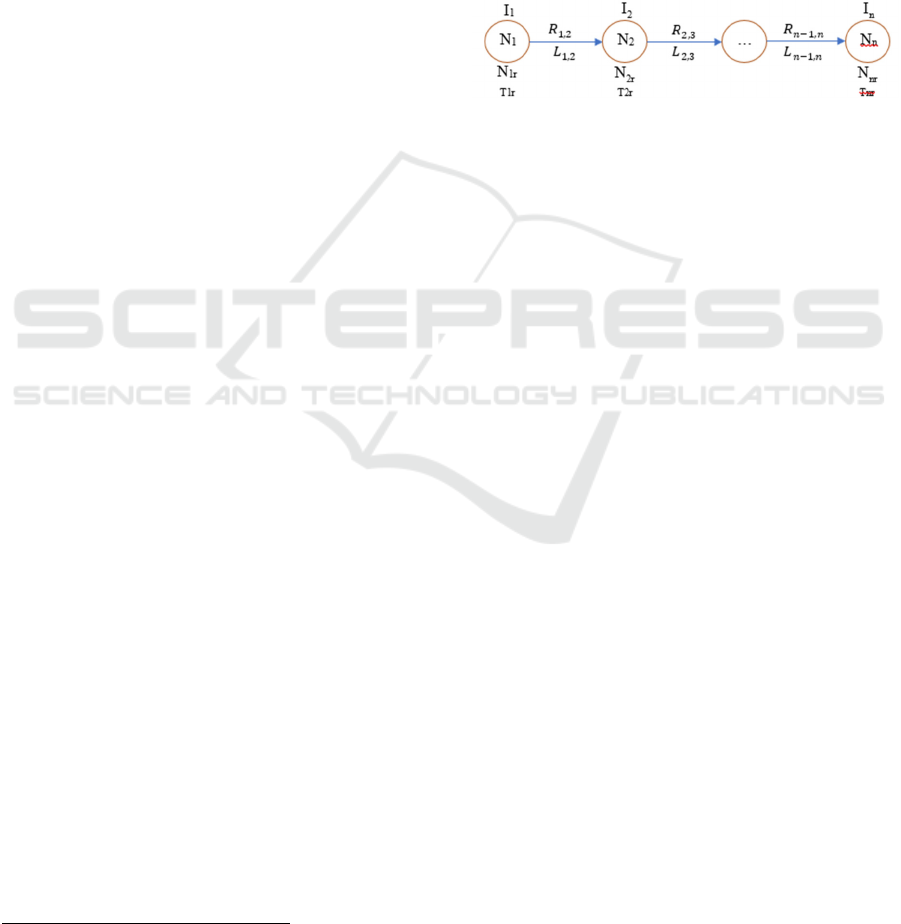
Figure 1: Attack path (risk chain).
Each node 𝑁
,𝑖=1,2,…,𝑛, which is mapped to
a vertex 𝑉
of G, corresponds to a threat event that
incurs an impact I
i
with likelihood L
i,
and each edge
denotes a derivation of a node state, e.g., the likeli-
hood 𝐿
,
,𝑗=1,2,…,𝑛1, to exploit node N
j+1
from its predecessor node N
j
, or the first-order de-
pendency risk 𝑹
𝒋,𝒋𝟏
node N
j
exhibits on N
j+1
.
4 APPROACH FORMULATION
4.1 Algorithmic Process
The whole application is executed using one to five
stages. All stages are controlled by a configuration
file (see snippet below). The five stages are:
1. Random Network Creation (optional),
2. Feature Extraction,
3. Training
4. Active Learning (optional)
5. Testing and validation
The combinations Feature Extraction Active Lear-
ning and Feature Extraction Testing form two or-
dered pairs that we will define as:
[Feature Extraction]
[Active
Learning]
≡
(Feature Extraction, Active Learning)
[Feature Extraction]
Testing
≡
(Feature Extraction, Testing)
SECRYPT 2024 - 21st International Conference on Security and Cryptography
546

• Random Network Creation: Several random-
generated network components (NIs) are created
based on baseline models of real ICT company
networks of assets.
• [Feature Extraction]
Training
: Combined stage in
which the centrality measurements and cumula-
tive risks for all nodes are calculated. Then, this
step evaluates the criticality of nodes using active
learning methods. Both results will be used as in-
puts to the Training stage.
• Training Stage: Results generated at earlier
stages are fed to the Machine Learning process,
which is a feedforward neural network with mul-
tiple inputs and outputs.
• [Feature Extraction]
Testing
: This is a combined
stage in which one node is taken as input (the
graph is stored in the Neo4j database), and using
the Neo4j GDS library, we calculate centrality
measurements and cumulative risks for all nodes.
4.2 Synthetic Dataset for Research
The first step in our approach is to create a random
hierarchical network (tree network) where several
different network components can be simulated. Ran-
dom network generator also supports static network
as templates that can be used as a base to create more
complex networks. To simulate potential attack paths,
most of the random network components allow input
connections and output connections.
Impact values vary from 1 (low impact) to 9 (high
impact). All components get a value based on attack
graph participation and expert knowledge assigned to
the node as an integer. The network components are
connected according to possible attack paths. An at-
tack path can originate from one component and be
directed from one or more of its neighbor components
to other network components. The risk dependency is
calculated as the product of the impact of the attacked
component and the value of the likelihood of the at-
tack.
Within the framework of this research, several
random Network Instances have been created. These
instances were created to train the model on identify-
ing the critical network assets, based on the estimated
overall risk, and their interconnections,
4.3 Feature Extraction
Feature extraction refers to the process of transform-
ing raw data into numerical features that can be pro-
cessed while preserving the information in the origi-
nal data set.
4.3.1 Feature Group 1: Centrality
For the purpose of calculating the significance of each
node the following features where calculated:
• Degree centrality indicates a node's importance
by counting its direct neighbours (Kumar et al.,
2020).
• Betweenness centrality shows the criticality of
connectedness. It is the number of the shortest
paths between a pair of nodes.
• Closeness centrality is the reciprocal of the
mean distance to all other nodes from the current
node. The greater its value, the shortest the node
distances to the rest of the graph.
• Eigenvector centrality measures the importance
and the transitive influence of the node.
4.3.2 Feature Group 2: Νode Risk Metrics
As mentioned previously, the outcome of a risk as-
sessment of a given asset (system, data type or pro-
cess) is a risk score assigned to a particular vulnera-
bility, calculated by considering its likelihood and im-
pact. Each node has an overall node risk N
ir
, which
is the sum of all cascading risks that target node N
i
and its mapped vertex 𝑉
, and a total hit count T
ir
of cascading risks that target node N
i
. The average
node risk AN
ir
is defined as the ratio of overall node
risk over total hit count:
𝐴
𝑁
=
𝑁
𝑇
,𝑖𝑓𝑇
>0,𝑒𝑙𝑠𝑒 0
(1)
The cumulative dependency risk 𝑪𝑹
𝟏…𝒏
is the over-
all risk produced by the nth-order dependency of the
attack path:
𝐶𝑅
…
=𝑅
…
=
𝐿
𝐼
(2)
The cumulative attack risk CR
N
for node N of
graph G is defined as the sum of all cumulative de-
pendency risks of the attack paths that start from this
node.
(𝑁
𝑖𝑟
)
𝑛𝑒𝑤
=
(
𝑁
𝑖𝑟
)
𝑜𝑙𝑑
+𝑅
1…𝑖
(3)
The overall attack graph risk G
r
is the sum of
the cumulative dependency risk for each nth-order de-
pendency of graph G:
𝐺
𝑟
=
𝐶𝑅
1…𝑛
(4)
Utilizing Machine Learning for Optimizing Cybersecurity Spending in Critical Infrastructures
547

4.3.3 Feature Group 3: Dependency Risk
Chains Metrics
With the identification of the dependency chains
(threat vector) the following key findings are ex-
tracted:
• Find a subset of nodes that affect many critical de-
pendency paths. Decreasing the probability of
failure in these nodes by selectively applying se-
curity controls may have a greater overall benefit
in risk reduction.
• Identify nodes of high importance outside the
most critical dependency paths that concurrently
affect many other nodes in these paths or impact
the overall dependency risk of the entire struc-
ture/graph.
Using a simple SI epidemic model (Barabási et al.,
1999) and as per the VoteRank description (Zhang et
al., 2016), a node can be in one of two statuses: Sus-
ceptible (S) or Infected (I). At the outset of the pro-
cess, all nodes are deemed susceptible except for a
designated group of r infected nodes that serve as
source spreaders. During each interval, an infected
node endeavors to infect one of its neighboring nodes
with a likelihood of μ and a consequential impact of
I. This impact is determined by multiplying the prob-
ability of infection (μ) by the influence of the infected
node (I), which ultimately produces the Risk value
(Risk = μ * Ι). Once the infection has been success-
fully transmitted, the neighboring node's vote count
will increase by one.
Furthermore, nodes that exceed a designated risk
level are classified as critical only under specific cir-
cumstances. These include being deemed as "signifi-
cant" (having a high Eigenvector centrality), serving
as bridges or bridging nodes (having a high Between-
ness centrality), or functioning as central nodes (hav-
ing a high Closeness centrality).
4.3.4 Critical Node Classification
To programmatically determine the criticality of each
node, we used “active learning” (Ricci et al., 2015).
Each node determined as critical is labelled with “1”,
while the non-critical ones with “0”. Specifically, for
each centrality measure, the top-ranking nodes are se-
lected that have a rank greater or equal to the midpoint
of the extrema values and are classified as possibly
critical. Then after the calculation of attack paths:
• the overall node risk (when attackPathStrat-
egy=TargetNode), or
• the cumulative attack risk (when attackPath-
Strategy=SourceNode)
are calculated and if its ratio over the maximum value
of all nodes is greater than or equal to a threshold
value (thresholdRiskRatio), the node is also classi-
fied as possibly critical. The final estimation of the
criticality of the node is the combination of overall
node risk (or cumulative attack risk) criticality and
one or more of the Betweenness, Closeness and Ei-
genvector centralities, which provide best results in
determining the criticality of a node.
5 EXPERIMENTAL RESULTS
5.1 Feature Extraction
Using the GDS plugin we calculated several metrics
which then were used for training the model. We
therefore could identify “possibly critical” nodes (i.e.,
node that exceed the midpoint value of each applica-
ble metric), attacks paths and their associated risk
based on the OWASP Severity Risk Levels. Further-
more, the same approach was used to calculate vari-
ous risk levels (e.g., the overall, and average node
risk, etc.), which were fed to the training model.
Using as threshold the thresholdRiskRatio
value, all the overall node risks or cumulative attack
risks which have values above the
𝑡ℎ𝑟𝑒𝑠ℎ𝑜𝑙𝑑𝑅𝑖𝑠𝑘𝑅𝑎𝑡𝑖𝑜 ∗ 𝑚𝑎𝑥{ 𝑁
,𝑁
,…,𝑁
} are
labelled as possibly critical and all the others as not
critical. A node is classified as definitely critical if it
is labelled possibly critical in all measurements.
Finally, using the DFS algorithm (with limited
depth if attackPathMaxDepth > 0, or with unlimited
depth if attackPathMaxDepth=-1), all the attack
paths are determined, and the overall node risk, aver-
age node risk and cumulative attack risk are calcu-
lated for each node of the projected graph.
5.2 Training
First, we created complex ICT networks as graphs by
formulating an isometric topology to the ICT service
network characteristics. These NIs were then fed to
the classifier for training the Machine Learning algo-
rithm based on the following features, (i) the normal-
ized values of the centrality measures, (ii) the overall
node risk, (iii) cumulative attack risk and (iv) depend-
ency path risk. To find all potential nth-order depend-
encies in G and calculate the overall node risks, all
overall node risks are first initialized to zero.
Next, for every node 𝑁∈𝑉, a DFS (Depth-First
Search) algorithm is applied, limiting the maximum
depth to n (when attackPathMaxDepth configura-
tion property has a positive integer value), or without
SECRYPT 2024 - 21st International Conference on Security and Cryptography
548
limiting the depth (when attackPathMaxDepth = -
1). Then, all attack paths that start from N are deter-
mined and the cumulative dependency risk is calcu-
lated for each attack path, along with the new values
of the overall node risks of the nodes belonging to the
attack path. Finally, the cumulative attack risk related
to node N is calculated. The resulted data were fed to
RELU-activated inputs of a Feedforward Neural Net-
work (FNN) and the classification labels to an equal
number of SIGMOID-activated outputs with 1-1 pair-
ing to the input values.
The resulting FNN contains two hidden layers,
one with 64 neurons and one with 32 neurons, and has
a retain probability of neurons of 90%. The optimiza-
tion algorithm that it uses is the Stochastic Gradient
Descent. The following figure showcases the model
and training information and the parameter ratios and
standard deviations:
Figure 2: Overview page with information regarding the
training model.
5.3 Testing
For testing the ML algorithm, we used new ICT net-
works, transposed them as graphs and extracted the
normalized values of the centrality measures and the
overall node risk metrics. The model represents ICT
assets as nodes and their dependencies as edges, using
centrality measures and dependency chains (Ster-
giopoulos, 2015) These were fed to the previously
trained ML algorithm to classify the criticality of each
node based on whether the normalized value of the
overall node risk, or cumulative attack risk, is critical
and over the threshold value specified by:
• thresholdRiskRatio: [Overall Node Risk or Cu-
mulative Attack Risk is critical], and
• [Normalized Overall Node Risk or Cumulative
Attack Risk >= thresholdRiskRatio].
5.3.1 Test Scenario #1
For the purposes of the first test scenario, we used the
network proposed by (Dedousis P., 2019), which in
turn, is based on a real-life industry network imple-
mentation from the Greek private sector. We identi-
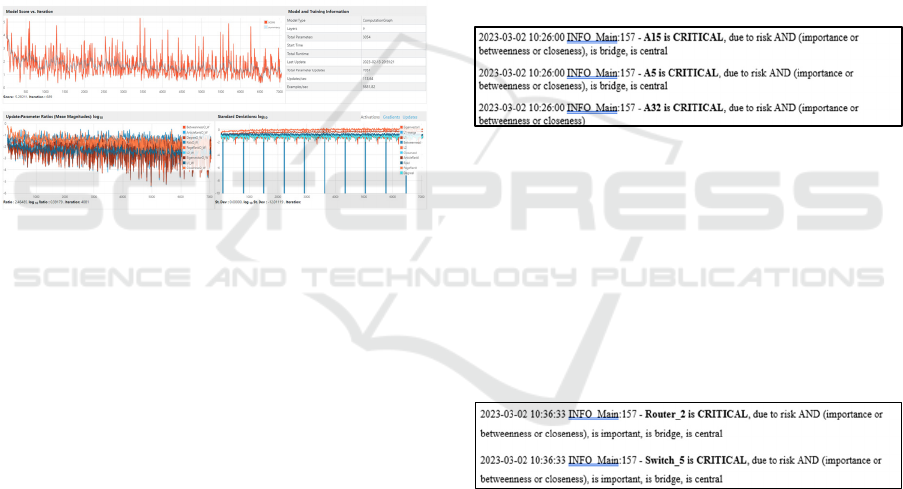
fied (as per the output log, see Figure 6) that Node A5
is critical, as it is the bridging and central node with
the most dependency chains. This means that:
1. Threat attacks originating from node A5 quickly
traverse the whole NI, posing a great risk for the
assets and services.
2. In our example, node A5 constitutes a single point
of failure (SPOF) for the communication network
between assets. SPOFs are undesirable in any sys-
tem with a goal of high availability or reliability,
be it a business practice, software application, or
other industrial system.
3. Nodes A15 and A32 are bridging nodes serving
information to two network subnets. A disruption
of the connection between them affects the busi-
ness carried out by both departments.
Figure 3: Extract from the output log, showcasing critical
nodes.
5.3.2 Test Scenario #2
For the purposes of this test scenario, a network
simulating a real-world scenario of a complex
structure, was used. Three large nodes were created,
representing the various departments of a modern-day
organization, with the appropriate interconnections as
necessitated by the organization’s business processes.
Figure 4: Extract from the output log, showcasing critical
nodes.
The critical nodes reported are shown in bold and
these are: Router_2 and Switch_5. They are bridging
and central nodes (also, Firewall_1 is bridge, but has
less cumulative attack risk than Switch_5 which is
connected to it). They are central due to the maximum
attack path limit set (attackPathMaxDepth=4).
5.4 Validation
To validate our approach, we created an unprotected
network as shown in Figure 9. Our approach is based
Utilizing Machine Learning for Optimizing Cybersecurity Spending in Critical Infrastructures
549

on a real-world scenario, and while it lacks complex-
ity, it does represent a typical networking approach of
an organization. The network components are de-
picted below:
Table 1: Network Components.
Asset
name
Asset type Likelihood Impact
Server_1 HTTP Server 8 7
Server_2 Database Server 7 8
Server_3 Email Server 6 6
Switch_1 Switch 4 3
PC_1 PC 5 2
PC_2 PC 5 2
PC_3 PC 5 2
Using results returned from the model, we can
make a uniform decision regarding the placemenand
type of the safeguard, and then rerun the test. The ex-
pected result should be that the model will identify no
critical node on the protected network. We identified
that in the unprotected network, Switch_1 is the
critical asset due to its high cumulative attack risk
and at least one of the Eigenvector, Betweenness and
Closeness values. To mitigate the risk, we applied the
following security controls, based on best practices:
1. Insert a firewall in gateway mode, connecting all
the servers and the switch to the firewall and all
the rest assets (the PCs) to the switch.
2. Lower the impact of Switch_1 by 2 units since no
critical assets are connected to it.
The respective results clearly show the
improvement in the criticality of Switch_1,:
Figure 5: Extract from the output log.
The following figure shows the ex-post and ex-ante
network configuration. The latter encompasses the
recommendations from the AI model.
Figure 6: Network configuration, prior and after the imple-
mentation of the proposed safeguards as per the AI model.
6 CONCLUSIONS
We have developed and propose a machine learning
model, that can automatically identify and classify
assets within ICT networks, irrespective of their size
or complexity. The model utilizes centrality measu-
res, dependency chains, and machine learning to pro-
vide a predictive risk estimation that can effectively
support the decision-making process in regards to
allocating funds towards the implementation of the
most effective security measures on the most critical
network assets.
The validation of our model confirmed its bene-
fits, demonstrating quick and efficient identification
of optimal safeguards, without affecting network
connectivity and performance. The model can scale
rapidly, without any issues identified. The testing
results highlighted the feasibility of our model, espe-
cially in cybersecurity risk management scenarios,
which are particularly valuable for companies with
limited resources.
This model is a significant advancement in
predicting and prioritizing cybersecurity investments,
since it can optimise resource allocation, focus on
network assets with topological significance and thus
enhancing the cybersecurity posture of the
organizations basing their business models on ICT
infrastructure.
REFERENCES
Aksu, M. U., Dilek, M. H., Tatli, E. I., Bicakci, K., Dirik,
H. I., Demirezen, M. U., & Aykir, T. (2017). A quanti-
tative CVSS-based cyber security risk assessment meth-
odology for IT systems, IEEE. https://doi.org/
10.1109/ccst.2017.8167819
Barabási, A.-L., & Albert, R. (1999). Emergence of Scaling
in Random Networks. In Science (Vol. 286, Issue 5439,
SECRYPT 2024 - 21st International Conference on Security and Cryptography
550

pp. 509–512). American Association for the Advance-
ment of Science. https://doi.org/10.1126/ science.
286.5439.509
Burr Settles. Active Learning Literature Survey. Computer
Sciences Technical Report 1648, University of Wiscon-
sin–Madison. 2009.
Dedousis P. (2019) "Development of software for the auto-
matic restructuring of corporate networks using
graphs" [Master Thesis]. Greece: Athens University of
Economics and Business (online: https://pyxida.
aueb.gr/index.php?op=view_object&object_id=7047 )
Dewri, R., Poolsappasit, N., Ray, I., Whitley, D. (2007).
Optimal security hardening using multi-objective opti-
mization on attack tree models of networks. In: Pro-
ceedings of the 14
th
ACM Conference on Computer and
Communications Security, pp. 204–213.
Grigoriadis, C., Laborde, R., Verdier, A., & Kotzanikolaou,
P. (2021). An adaptive, situation-based risk assessment
and security enforcement framework for the maritime
sector. Sensors, 22(1), 238.
Hermanowski, D., & Piotrowski, R. (2021). Network Risk
Assessment Based on Attack Graphs. In Theory and En-
gineering of Dependable Computer Systems and Net-
works (pp. 156–167). Springer International Publish-
ing. https://doi.org/10.1007/978-3-030-76773-0_16
Kotzanikolaou, P., Theoharidou, M., & Gritzalis, D. (2013).
Cascading Effects of Common-Cause Failures in Criti-
cal Infrastructures. In Critical Infrastructure Protection
VII (pp. 171–182). Springer. https://doi.org/10.1007/
978-3-642-45330-4_12
Kumar, S., & Panda, B. S. (2020). Identifying influential
nodes in Social Networks: Neighborhood Coreness
based voting approach. In Physica A: Statistical Me-
chanics and its Applications (Vol. 553, p. 124215).
Elsevier. https://doi.org/10.1016/j.physa.2020.124215
Kurzenhauser, S. (2003). Natural frequencies in medical
risk communication: Applications of a simple mental
tool to improve statistical thinking in physicians and
patients. Ph.D. thesis, Freie Universitat Berlin
Ray, I., Poolsappasit, N. (2005). Using attack trees to iden-
tify malicious attacks from authorized insiders. In: Pro-
ceedings of ESORICS, Italy, pp. 231–246.
Ricci, F., Rokach, L., & Shapira, B. (Eds.). (2015). Recom-
mender Systems Handbook. Springer. https://doi.org/
10.1007/978-1-4899-7637-6
S. M. Rinaldi, J. P. Peerenboom and T. K. Kelly. Dec.
(2001). Identifying, understanding, and analyzing crit-
ical infrastructure interdependencies, in IEEE Control
Systems Magazine, vol. 21, no. 6, pp. 11-25,
https://doi:10.1109/37.969131
Shivraj, V. L., Rajan, M. A., & Balamuralidhar, P. (2017).
A graph theory based generic risk assessment frame-
work for internet of things (IoT). IEEE.
https://doi.org/10.1109/ants.2017.8384121
Stellios, I., Kotzanikolaou, P., Psarakis, M., & Alcaraz, C.
(2021). Risk assessment for IoT-enabled cyber-physical
systems. Advances in Core Computer Science-Based
Technologies: Papers in Honor of Professor N. Alexan-
dris, 157-173.
Stergiopoulos, G., Dedousis P., & Gritzalis G. (2022). Au-
tomatic analysis of attack graphs for risk mitigation
and prioritization on large-scale and complex networks
in Industry 4.0. International Journal of Information Se-
curity 21.1: 37-59.
Stergiopoulos, G., Dedousis, P., & Gritzalis, D. (2020). Au-
tomatic network restructuring and risk mitigation
through business process asset dependency analysis. In
Computers & Security (Vol. 96, p. 101869). Elsevier
BV. https://doi.org/10.1016/j.cose.2020.101869
Stergiopoulos, G., Theocharidou, M., Kotzanikolaou, P., &
Gritzalis, D. (2015). Using Centrality Measures in De-
pendency Risk Graphs for Efficient Risk Mitigation. In
IFIP Advances in Information and Communication
Technology (pp. 299–314). Springer International Pub-
lishing. https://doi.org/10.1007/978-3-319-26567-4_18
Stergiopoulos, Y. (2015). Securing critical infrastructures
at software and interdependency levels. National Docu-
mentation Centre (EKT). https://doi.org/10.126
81/eadd/36753
Wirth, A. (2017). The Economics of Cybersecurity. In Bio-
medical Instrumentation & Technology (Vol. 51,
Issue s6, pp. 52–59). Association for the Advancement
of Medical Instrumentation. https://doi.org/10.2345/
0899-8205-51.s6.52
Zhang, J.-X., Chen, D.-B., Dong, Q., & Zhao, Z.-D. (2016).
Identifying a set of influential spreaders in complex net-
works. In Scientific Reports (Vol. 6, Issue 1). Springer.
https://doi.org/10.1038/srep27823
Utilizing Machine Learning for Optimizing Cybersecurity Spending in Critical Infrastructures
551
