
Semi-Supervised Fuzzy DBN-Based Broad Learning System for
Forecasting ICU Admissions in Post-Transplant COVID-19 Patients
Xiao Zhang and
`
Angela Nebot
Soft Computing Research Group at the Intelligent Data Science and Artificial Intelligence Research Center,
Universitat Polit
`
ecnica de Catalunya, Barcelona, Spain
Keywords:
Fuzzy System, Broad Learning System, ICU, Covid-19, Manifold Regularization, Organ Transplant.
Abstract:
This paper introduces a novel semi-supervised neuro-fuzzy system to predict ICU admissions among post-
COVID organ transplant recipients. Addressing the challenges of small sample sizes and lacking labels in
organ transplantation, our study takes on these issues by proposing a DBN-Based Dual Manifold Regularized
Fuzzy Broad Learning System (D-DMR-FBLS). This system utilizes the streamlined and flat architecture
of the Broad Learning System (BLS), integrating Deep Belief Networks (DBN) and Takagi-Sugeno-Kang
(TSK) systems to enhance representation learning capacities during the Unsupervised Training Phase (UTP).
The system combines the strong feature learning capabilities of DBN with the powerful fuzzy rule extraction
capacity of the TSK system, enhancing the model’s predictive performance and generalization capability.
Moreover, we propose two types of graph-based manifold regularization, sample-based and feature-based,
within this novel D-DMR-FBLS framework. Our method enhances its predictive ability by exploiting both the
similarity among unlabeled and labeled patient samples, as well as the correlations between features within
the fuzzy feature space. Employed to predict ICU admission risks in post-transplant COVID-19 patients, the
method has demonstrated superior performance over existing methods, particularly in scenarios with limited
samples and labels, thereby providing more accurate decision support for medical professionals in optimizing
resource allocation for transplant patients.
1 INTRODUCTION
Since its emergence in late 2019, COVID-19 has led
to over 700 million infections and caused more than
6 million deaths globally, constituting a major public
health crisis (Worldometer, 2024). Organ transplant
recipients, particularly vulnerable due to their com-
promised immune systems and reliance on immuno-
suppressants, have faced increased mortality risks
during this period (Mamode et al., 2021). The pan-
demic has intensified the demand for critical medical
resources such as ventilators and ICU beds, highlight-
ing the urgent need for better medical oversight and
protection for these at-risk patients. Current research
on optimizing medical resource allocation for trans-
plant recipients using machine learning (ML) is in-
sufficient. Utilizing ML to predict the medical needs
of these patients can identify those at highest risk
more effectively, thereby optimizing resource alloca-
tion, reducing the load on healthcare systems, and
potentially decreasing mortality rates in this group.
Moreover, precise predictive models can assist in clin-
ical decision-making and play a vital role in manag-
ing resource distribution during peak demand periods,
ensuring that critical support is directed towards those
most in need.
Current research in organ transplantation increas-
ingly utilizes machine learning (ML) to predict post-
transplant survival rates, with Random Forest (RF),
XGBoost and deep learning (DL) gaining popular-
ity for their accuracy and ease of implementation,
as noted in recent studies (Liu et al., 2020; Mark
et al., 2023). However, the efficacy of advanced
DL models, does not consistently outperform en-
semble learning models in this domain, often show-
ing limited performance improvements despite in-
creased complexity, particularly with data granular-
ity challenges (Zhang et al., 2022; Ershoff et al.,
2020). In contrast, Fuzzy Neural Networks (FNN) are
recognized for their ability to manage non-linearity
and high-dimensional data effectively, crucial for
handling the inherent uncertainty and ambiguity in
complex medical datasets (Shihabudheen and Pillai,
2018).
Zhang, X. and Nebot, À.
Semi-Supervised Fuzzy DBN-Based Broad Learning System for Forecasting ICU Admissions in Post-Transplant COVID-19 Patients.
DOI: 10.5220/0012856300003758
Paper published under CC license (CC BY-NC-ND 4.0)
In Proceedings of the 14th International Conference on Simulation and Modeling Methodologies, Technologies and Applications (SIMULTECH 2024), pages 415-422
ISBN: 978-989-758-708-5; ISSN: 2184-2841
Proceedings Copyright © 2024 by SCITEPRESS – Science and Technology Publications, Lda.
415

The Fuzzy Broad Learning System (FBLS) rep-
resents an innovative integration of fuzzy logic into
the Broad Learning System (BLS), creating a frame-
work particularly adept at handling ambiguous or im-
precise data (Feng and Chen, 2018; Feng and Chen,
2021; Feng et al., 2020; Liu et al., 2021; Gong et al.,
2021; Zhang et al., 2020). FBLS leverages the advan-
tage of fuzzy logic to enhance its capability to pro-
cess uncertain information, thereby increasing its ef-
ficiency in environments characterized by data ambi-
guity. A distinctive feature of FBLS is its streamlined,
flat network architecture derived from BLS. This ar-
chitecture facilitates rapid feature learning and expe-
dites information processing, setting it apart from hi-
erarchical deep learning models. Such a configura-
tion makes FBLS particularly well-suited for manag-
ing high-dimensional and nonlinear data sets.
The transplantation field faces the challenge of a
scarcity of labeled samples, stemming from privacy
concerns and the frequent loss of follow-up among
recipients. This limitation complicates the collec-
tion of adequate labeled data essential for traditional
supervised learning models. Addressing the chal-
lenges of small sample sizes and lacking labels in
the organ transplantation domain, this paper presents
a novel neuro-fuzzy system named the DBN-based
Dual-Manifold Regularized Fuzzy Broad Learning
System (D-DMR-FBLS). In the unsupervised train-
ing phase, DBN (Deep Belief Networks) and TSK
(Takagi-Sugeno-Kang) fuzzy systems are integrated
for representation learning. This system leverages
the strengths of DBN in deep feature extraction and
representational learning, along with the flexibility
of TSK fuzzy systems in handling uncertainty and
fuzzy information. Furthermore, this system also in-
corporates two types of graph-based manifold regu-
larization strategies: feature manifold regularization
and sample manifold regularization. Sample mani-
fold regularization exploits the geometric distribution
of samples to enhance the model’s capability to cap-
ture and utilize the intrinsic associations and similar-
ities among samples. Feature manifold regularization
improves the model’s ability to learn complex patterns
within the fuzzy feature space, thereby effectively uti-
lizing the intrinsic correlations among features. As a
semi-supervised learning approach, this method not
only enhances the feature representation from a lim-
ited number of labeled samples but also leverages
the similarities among samples, including those un-
labeled samples, and the correlations within the fuzzy
feature space, thereby further improving the model’s
predictive performance. Our proposed method has
been applied to predict ICU utilization in recipients
infected with COVID-19 post-transplantation, and the
experimental results demonstrated its effectiveness
compared to other algorithms.
2 THE PROPOSED
METHODOLOGY
The architecture of the proposed D-DMR-FBLS sys-
tem is depicted in Figure 1. The training process is
methodically divided into two distinct phases. The
initial phase, known as the Unsupervised Training
Phase (UTP), focuses on feature representations from
the input data through DBN and TSK fuzzy systems.
The aim is to augment the feature representation ca-
pabilities of the FBLS. During this phase, the DBN
and TSK fuzzy systems extract latent feature rela-
tionships and structure information within the input
data. Following this, the second phase utilizes the
feature representations derived from the first phase as
inputs to the subsystems of the FBLS. Here, a series
of nonlinear transformations are applied to compute
the outputs of the enhancement nodes. An innovation
in this phase is the introduction of a graph-based dual
manifold regularization strategy, designed to not only
unearth intrinsic relationships and correlations within
the fuzzy feature space but also to bolster the system’s
ability in learning from unlabeled samples. Termed
the Supervised Training Phase (STP), this stage in-
volves training the system’s parameters under super-
vision to determine the output layer’s weights.
2.1 Neural Representation Based on
Deep Belief Networks
During the UTP phase, we integrated a neural rep-
resentation based on DBN to enhance the represen-
tation learning capability of FBLS. A DBN consists
of multiple layers of stacked Restricted Boltzmann
Machines (RBM). The input layer nodes correspond
to the dimensionality of the input space, with d fea-
tures in the dataset. The hidden layers form the
complete DBN neural representation. Assuming the
DBN has l hidden layers, the topmost layer nodes are
h
l
= [h
l1
,h
l2
,...,h
ll
], and the layer below has nodes
h
l−1
. This hierarchical structure abstracts high-level
features, progressively reducing or eliminating noise
in the data.
The DBN pre-training starts with the first RBM,
where the visible layer contains d nodes represented
by v
1
= x, and the first hidden layer nodes are h
1
=
[h
11
,h
12
,...,h
1n
1
]. Unlike conventional DBNs requir-
ing supervised fine-tuning, our model utilizes only
the unsupervised pre-training stage to acquire neu-
SIMULTECH 2024 - 14th International Conference on Simulation and Modeling Methodologies, Technologies and Applications
416
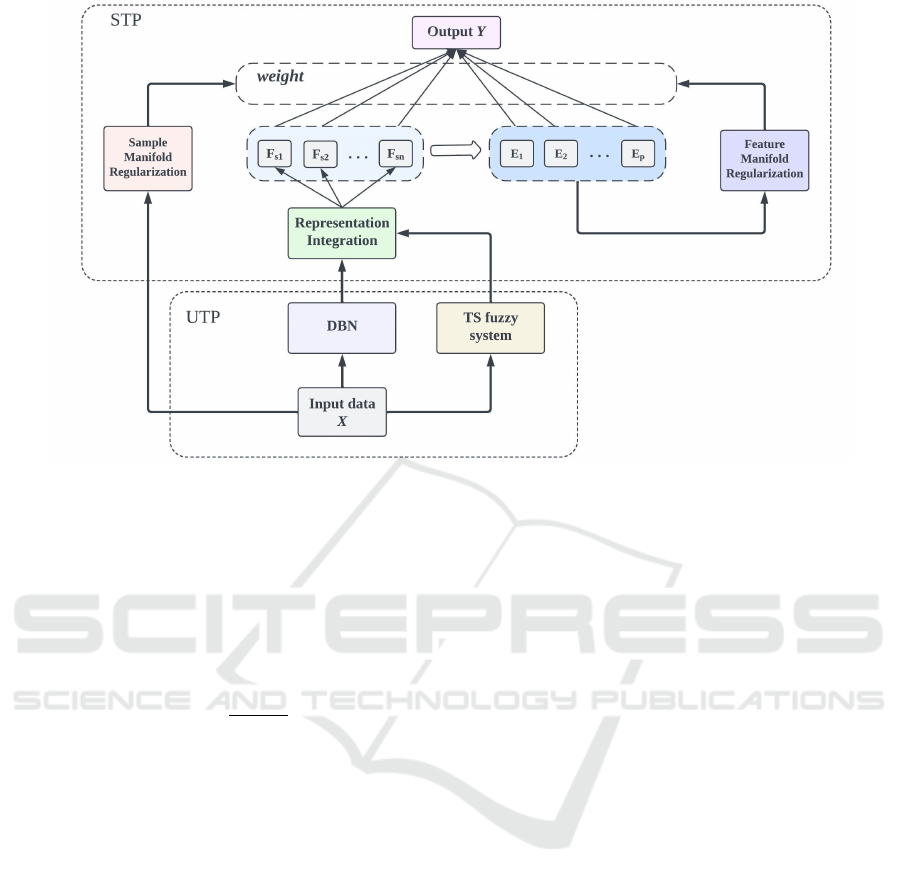
Figure 1: The structure of the proposed D-DMR-FBLS.
ral representations for each hidden layer. The Con-
trastive Divergence (CD) algorithm determines the
weight matrix W
k
, visible layer biases b
k
, and hidden
layer biases c
k
between the layers of each RBM.
For computational convenience, h
k j
and v
r
ki
are set
to 1 if their probabilities exceed a random threshold,
otherwise set to 0. The sigmoid function is defined as
Eq. (1).
sigm(x) =
1
1 + e
−x
(1)
The update formulas for weights w
k
, biases b
k
,
and c
k
during the t-th iteration are defined as Eq. (2):
W
(t)
k
=W
(t−1)
k
+ ε
P
h
(t−1)
k
| v
(t−1)
k
v
(t−1)
k
T
− P
h
r(t−1)
k
| v
r(t−1)
k
v
r(t−1)
k
T
b
(t)
k
=b
(t−1)
k
+ ε
v
(t−1)
k
− v
r(t−1)
k
c
(t)
k
=c
(t−1)
k
+ ε
P
h
(t−1)
k
| v
(t−1)
k
− P
h
r(t−1)
k
| v
r(t−1)
k
(2)
After pre-training each RBM, the first hidden
layer output h
1
becomes the visible layer input for the
next RBM, repeating this process sequentially for all
RBMs. Once training is complete, the DBN parame-
ters (W
k
, b
k
, and c
k
) are fixed. Given an input vector
x = [x
1
,x
2
,...,x
d
], the nodes in the k-th hidden layer
h
k
= [h
k1
,h
k2
,...,h
kk
] are calculated by Eq.( 3).
h
k j
= sigm
n
k
∑
i=1
W
ki j
v
ki
+ c
k j
!
(3)
In the top hidden layer, the feature representation
[h
l1
,h
l2
,...,h
ll
] is integrated with the TSK fuzzy sys-
tem output to form a neural fuzzy system. This sys-
tem leverages the DBN’s data representation capabil-
ities to capture complex features while enhancing the
model’s understanding and capability to address com-
plex data structures.
2.2 Fuzzy Representation Based on
TSK Fuzzy System
FBLS comprises n fuzzy subsystems and p en-
hancement node groups. It accepts input data
denoted as X = (x
1
,x
2
,...,x
N
)
T
within R
N×M
,
where each sample feature is represented as x
s
=
(x
s1
,x
s2
,...,x
sM
),s = 1,2,...,M. Each fuzzy subsys-
tem contains a set of fuzzy rules designed to extract
features from the input data. For the i-th fuzzy sub-
system with k
i
fuzzy rules, a series of first-order TSK
fuzzy system rules are defined based on the input fea-
tures, which can be expressed as:
z
i
sk
= f
i
k
(x
s1
,x
s2
,...,x
sM
) =
M
∑
t=1
α
i
kt
x
st
(4)
where k = 1,2,...,k
i
is the fuzzy rule of the i-th fuzzy
subsystem, α
i
kt
is a coefficient uniformly distributed
on the interval [0,1]. In this study, for the i-th fuzzy
subsystem, the training data is segmented into k
i
clus-
ters, represented by c
k
, utilizing the FCM method.
Semi-Supervised Fuzzy DBN-Based Broad Learning System for Forecasting ICU Admissions in Post-Transplant COVID-19 Patients
417

The FCM clustering method is used to minimize the
objective function:
J
f
(U,C) =
N
∑
s=1
k
i
∑
k=1
u
f
sk
∥
x
s
− c
k
∥
2
2
(5)
In Eq. (5), m represents a fuzzification coefficient,
U = (u
sk
)
N×k
i
is a membership matrix, u
sk
indicates
the degree of membership of x
s
in cluster k, and c
k
is
the centroid of cluster k in M-dimensional space. The
optimization of the objective function J
f
(U,C) can be
solved by iteratively updating the membership u
sk
and
the centroid c
k
, following these formulas:
u
sk
=
k
i
∑
t=1
∥
x
s
− c
k
∥
∥
x
s
− c
t
∥
2
m−1
!
−1
(6)
c
k
=
N
∑
s=1
u
f
sk
· x
s
/
N
∑
s=1
u
f
sk
(7)
Distinct from the k-means method, in the fuzzy
C-means approach, the weighted firing strength in the
i-th fuzzy subsystem is set as w
i
sk
= u
sk
. This elim-
inates the need for defining additional membership
functions for the fuzzy rules. The intermediate out-
put vector of the i-th fuzzy subsystem Z
si
is given by:
Z
si
=
w
i
s1
z
i
s1
,w
i
s2
z
i
s2
,...,w
i
sk
i
z
i
sk
i
(8)
2.3 DBN-Based Fuzzy Broad Learning
System
Integrating the top hidden layer feature vectors of
DBN with the output vectors of the TSK fuzzy sys-
tem, we consider the feature representation vector of
DBN, [h
l1
,h
l2
,...,h
ll
], as well as the system output
vector of the TSK Fuzzy System, Z
si
. Given the
dimensionality of the DBN’s top hidden layer fea-
ture vector as n
l
, and the output of each TSK Fuzzy
subsystem based on k
i
fuzzy rules, we construct a
combined feature representation vector, Z
c
, shown as
Eq. (9).
Z
c
= [h
l1
,h
l2
,...,h
ll
,Z
s1
,Z
s2
,...,Z
sn
] (9)
where Z
c
∈ R
N×
(
n
l
+
∑
n
i=1
k
i
)
. Here, Z
s1
,Z
s2
,...,Z
sn
represent the output vectors from each subsystem of
the TSK Fuzzy System, and h
l1
,h
l2
,...,h
ll
represent
the feature representation vector from the top hidden
layer of the DBN.
Utilizing Z
c
, this method employs nonlinear trans-
formations in the enhancement layer (comprising p
groups of enhancement nodes) to obtain the output
of the enhancement layer, H
p
. This is defined as
Eq. (10).
H
p
= (H
1
,H
2
,...,H
p
) ∈ R
N×
(
E
1
+E
2
+...+E
p
)
(10)
Herein, H
j
( j = 1, 2, . . . , p) is computed as:
H
j
= ϕ
j
(Z
c
W
j
+ β
j
) ∈ R
N×E
j
(11)
Here, E
j
denotes the number of neurons in the j-th
group of enhancement nodes. W
j
and β
j
are respec-
tively the weights and biases for the intermediate out-
put Z
c
from the fuzzy subsystems to the enhancement
layer, which are randomly distributed within the range
of [0,1]. ϕ(·) represents a type of nonlinear transfor-
mation.
Y = [Z
c
| H
p
]
W
c
W
h
= AW
(12)
Here, W
c
is the weight matrix for the combined
feature representation matrix Z
c
to the output layer.
W
h
is the mapping matrix for the enhancement layer.
W is the weight matrix connecting all fuzzy subsys-
tems and enhancement node layers to the output layer,
calculated based on the system’s output. According
to (Cao et al., 2017), W can be derived as:
W =
λI + AA
T
−1
A
T
Y (13)
2.4 Dual Manifold Regularization
Framework
In this study, DMR-FBLS incorporates dual mani-
fold regularization mechanisms: sample-based and
feature-based manifold learning. Sample-based man-
ifold learning preserves the distributional character-
istics of samples in the original space, ensuring that
proximity in the original sample space is maintained
in the lower-dimensional projected space. Feature-
based manifold regularization hypothesizes that sim-
ilar feature dimensions in the fuzzy feature space
should have similar corresponding weights, filtering
out noise and redundant features, thereby improving
learning efficiency and generalization capability. This
dual strategy effectively utilizes the internal struc-
ture of samples and the relations between fuzzy fea-
tures, enhancing learning performance, especially in
datasets with substantial unlabeled data.
2.4.1 Sample Manifold Regularization
If two samples are proximate in the input space, their
outputs should be proximate in the target space. We
use a Gaussian kernel function to measure the dis-
tance between samples:
s(x
i
,x
j
) = exp
−
x
i
− x
j
2
2
2σ
2
s
!
(14)
SIMULTECH 2024 - 14th International Conference on Simulation and Modeling Methodologies, Technologies and Applications
418

Here, σ
s
controls the kernel spread, affecting dis-
tance measurement. The similarity matrix S is con-
structed, treating samples as nodes and their similari-
ties as edges, forming an adjacency graph. The regu-
larization term is defined as:
R
s
(w) =
1
2
N
∑
i, j=1
s
i j
y
i
− y
j
2
2
= tr
(AW )
T
L
s
(AW )
(15)
Here, L
s
= H
s
− S is the Laplacian matrix. This
regularization strategy boosts the model’s generaliza-
tion performance by maintaining sample positions in
the target space and capturing latent structural infor-
mation in unlabeled data.
2.4.2 Feature Manifold Regularization
The FBLS framework may result in a high-
dimensional feature matrix with redundant features.
Inspired by sample-based manifold regularization, we
introduce feature-based manifold learning to reduce
redundant feature influence. We hypothesize that cor-
related feature dimensions in the fuzzy feature space
will have similar weight coefficients. The Gaussian
kernel function quantifies the correlation between fea-
ture dimensions:
f
A
q
,A
t
= exp
−
∥
A
q
− A
t
∥
2
2
2σ
2
f
!
(16)
The manifold regularization term is defined as:
R
f
(W ) =
1
2
N×
(
C+E
1
+E
2
+...+E
p
)
∑
q,t=1
f
qt
W
q
−W
t
2
2
= tr
W
T
L
f
W
(17)
Here, L
f
= H
f
− F is the Laplacian matrix. This
approach effectively captures structural information
in the fuzzy feature space.
2.5 Semi-Supervised DMR-FBLS
The objective function of the original FBLS fuzzy
system is redefined as:
min
W
D∥y − AW ∥
2
2
+ α∥W ∥
2
2
+ βtr
(AW )
T
L
s
(AW )
+ λtr
W
T
L
f
W
(18)
By differentiating and setting the derivative to
zero, we obtain:
A
T
QAW + αW +βA
T
L
s
AW + λL
f
W = A
T
Qy (19)
W can be directly derived from the (19) as:
W =
A
T
QA + αI + βA
T
L
s
A + λL
f
−1
A
T
Qy (20)
In semi-supervised learning, our framework inte-
grates both labeled and unlabeled data. The labeled
dataset is encapsulated as
{
X
l
,y
l
}
=
{
x
i
,y
i
}
l
i=1
, where
l denotes the count of labeled instances. Conversely,
the unlabeled dataset is denoted as X
u
=
x
j
u
j=1
,
with u symbolizing the number of unlabeled samples.
In (20), α, β, λ are coefficients corresponding to the
regularization term, the sample manifold regulariza-
tion, and the feature manifold regularization, respec-
tively. The weight matrix Q, a diagonal matrix, plays
a role in filtering and weighting the samples. In this
study, for the diagonal matrix Q, the diagonal ele-
ments corresponding to the first l rows and columns,
which represent the labeled data, are set to 1. The re-
maining diagonal elements are set to 0. The Laplace
matrices L
s
and L
f
are computed based on similar-
ity measures derived from both labeled and unlabeled
data. This design efficiently exploits the structural in-
formation and feature relationships inherent in the un-
labeled data.
3 EXPERIMENTAL SETUP
In this section, we will provide a detailed description
of the dataset utilized in this experiment, as well as
the classifiers and evaluation metrics employed.
3.1 Dataset
The IDOTCOVID database represents a comprehen-
sive global resource, encompassing data from approx-
imately 1200 patients across 78 transplant centers
in 11 different countries, collected between March
2020 and March 2021. This database incorporates a
wide array of variables, including demographic and
transplant-related information, as well as epidemio-
logical, clinical manifestations, and treatment man-
agement of solid organ transplant (SOT) patients dur-
ing the COVID-19 pandemic. The descriptive statis-
tics for the IDOTCOVID database are shown in Ta-
ble. 1.
3.2 Classifiers and Evaluation Metrics
To evaluate the DMR-FBLS model’s performance
and compare it with other mainstream algorithms,
we selected eight distinct ML models. These mod-
els, including XGBoost, RF, and AdaBoost, repre-
sent various ML categories and have been validated
in their domains, particularly in organ transplanta-
tion research for their accuracy and robustness (Zhang
Semi-Supervised Fuzzy DBN-Based Broad Learning System for Forecasting ICU Admissions in Post-Transplant COVID-19 Patients
419

Table 1: Descriptive Statistics for IDOTCOVID database.
Data Statistics results
Recipients 1267
Average Age 56.17
Gender Female (448), Male (819)
Average Age at SOT 47.39
Total Attribute 206
SOT Type Kidney: 64.88%, Liver: 33.46%
Patient Country Spain (908), Mexico (211), Argetina (147), Italy (69), etc.
Demographic Attributes Age, Gender, Country, DOB, Age at SOT, etc.
Clinical Attributes Type of SOT, Diagnosis, Symptoms, Manifestations, etc.
Treatment Attributes Kaletra, Remdesivir, CsA-Red, etc.
Admission Attributes Blood Pressure, Vasoactive drugs, X-ray, etc.
Categories of Attributes
Various (incl. Demographics, Clinical,
Treatment, Admission)
et al., 2022; Liu et al., 2020). Decision Trees (DT)
are known for their interpretability and efficiency with
categorical data, essential in clinical decision-making.
BLS and Multi-Layer Perceptron (MLP) represent
neural networks with strong function mapping capa-
bilities. FBLS and TSK are fuzzy systems that handle
uncertainty well, showing good performance in mul-
tiple studies (Peng and ChunHao, 2022; Xue et al.,
2018). This diverse selection ensures a thorough as-
sessment of D-DMR-FBLS across different scenarios.
We split each dataset into 70% training and 30% test-
ing sets, optimized hyperparameters using five-fold
cross-validation on the training set, and executed each
algorithm 50 times. Performance was evaluated using
four key metrics: accuracy, AUC, F1-score, and G-
mean.
4 EXPERIMENTAL RESULT AND
DISCUSSION
4.1 Comparative Results and Analysis
The results in Table 2 compare the performance
of various models predicting ICU admission among
COVID-19 infected organ transplant recipients. The
D-DMR-FBLS model excelled across all metrics,
achieving an accuracy of 0.899, AUC of 0.853, G-
mean of 0.727, and F1-score of 0.666, outperforming
other models. This confirms D-DMR-FBLS’s supe-
rior accuracy and balanced classification efficiency.
The mainstream ML algorithms like XGBoost,
RF, and Adaboost performed well in AUC but poorly
in G-mean and F1-score, crucial for handling class
imbalance. The FBLS model outperformed the BLS
model across all metrics, showing its capability in
processing complex data. Integrating the TSK fuzzy
subsystem into BLS improved its recognition of mi-
nority class samples.
Figure 2 shows the performance of four BLS-
based algorithms across four metrics. Ablation ex-
periments highlight D-DMR-FBLS’s superior perfor-
mance, especially in G-mean and F1-score. The
Table 2: The performance comparison for different models
on ICU admission prediction.
Method Accuracy AUC G-mean F1-score
D-DMR-FBLS 0.899 0.853 0.727 0.666
FBLS 0.890 0.833 0.706 0.618
BLS 0.867 0.815 0.678 0.579
TSK 0.875 0.823 0.702 0.611
XGBoost 0.862 0.837 0.629 0.518
RF 0.861 0.842 0.516 0.400
MLP 0.856 0.824 0.687 0.506
Adaboost 0.868 0.839 0.569 0.475
DT 0.846 0.790 0.601 0.468
Figure 2: Comparative results of ablation experiments
across various metrics for D-DMR-FBLS, DMR-FBLS,
FBLS, and BLS.
Table 3: Results of the Wilcoxon signed-rank test, with D-
DMR-FBLS serving as the control algorithm. If the p-value
for a particular method is less than 0.05, it indicates a sig-
nificant performance difference between that method and
D-DMR-FBLS.
Accuracy AUC F-score G-mean
FBLS 0.0409 0.0000 0.0000 0.0012
DMR-FBLS 0.8333 0.0106 0.0037 0.0991
BLS 0.0000 0.0000 0.0000 0.0001
TSK 0.0002 0.0000 0.0000 0.0040
XGBoost 0.0000 0.0048 0.0000 0.0000
RF 0.0000 0.0056 0.0026 0.0000
MLP 0.0000 0.0000 0.0000 0.0001
Adaboost 0.0000 0.0027 0.0012 0.0000
DT 0.0000 0.0000 0.0000 0.0000
FBLS model showed performance improvements
over BLS. Adding graph manifold regularization
(feature-based and sample-based) to DMR-FBLS fur-
ther enhanced performance by uncovering the cor-
relation within feature space and hidden data struc-
ture. Incorporating DBN into DMR-FBLS to form
D-DMR-FBLS improved all metrics. DBN deepens
the model’s representation learning, capturing hidden
data characteristics and boosting classification perfor-
mance when combined with the TSK fuzzy system.
Table 3 uses the Wilcoxon signed-rank test to
compare D-DMR-FBLS against other algorithms.
SIMULTECH 2024 - 14th International Conference on Simulation and Modeling Methodologies, Technologies and Applications
420
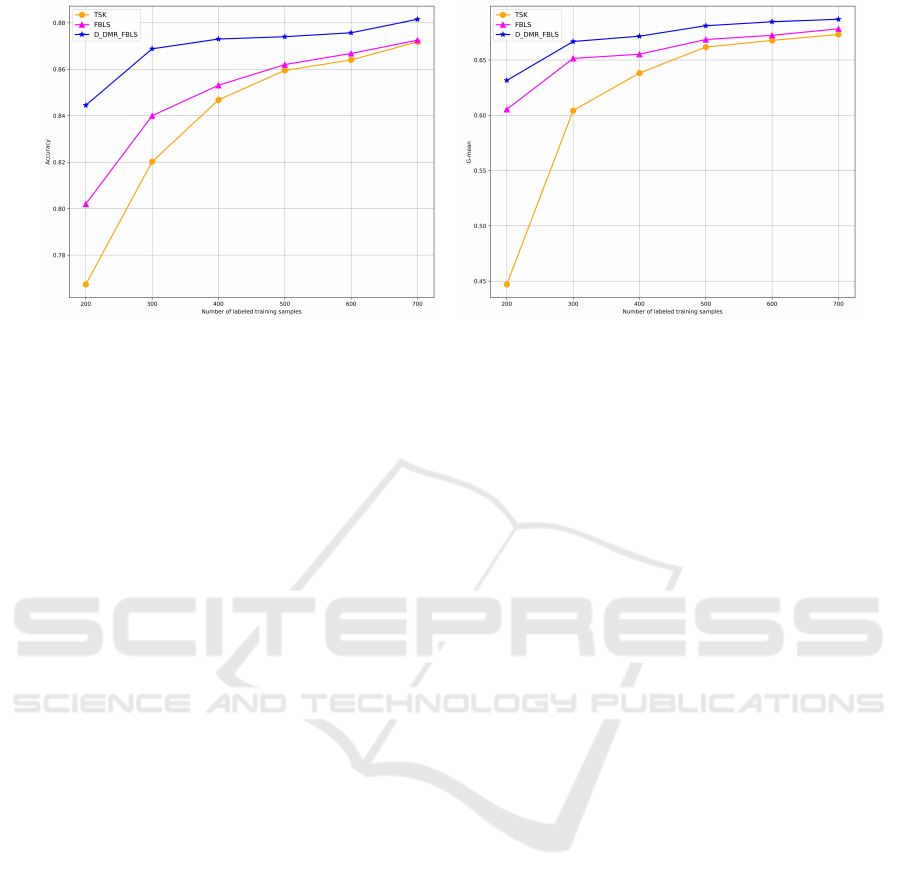
(a) Accuracy comparison. (b) G-Mean Comparison.
Figure 3: Performance of accuracy with unlabeled training samples and varying quantities of labeled training samples.
Except for DMR-FBLS, which showed no significant
difference in accuracy and G-mean (p-values > 0.05),
most other algorithms had p-values < 0.05, indicating
significant differences and rejecting the null hypoth-
esis. This demonstrates D-DMR-FBLS’s substantial
performance advantage.
4.2 Comparative Experiment on Using
Unlabeled and Limited Labeled
Samples
To evaluate our proposed algorithm with limited la-
beled and unlabeled samples, we compared it with
other fuzzy systems. From the original ICU admis-
sion dataset, we extracted 567 samples and concealed
their labels to create an unlabeled dataset. We then
stratified samples according to label categories and
selected 200, 300, 400, 500, 600, and 700 labeled
samples to test the model’s performance with varying
labeled data. This approach assesses the applicabil-
ity and performance of the proposed algorithms in a
weakly-supervised learning context.
In this experiment, we evaluated and compared
the performance of three fuzzy systems—D-DMR-
FBLS, FBLS, and TSK—using unlabeled samples
and a varying number of labeled samples. Through
this experiment, we aim to evaluate the performance
of different fuzzy systems in scenarios with small
sample sizes and lacking labeled samples. As can be
seen from Figure. 3a and Figure. 3b, at fewer labeled
sample sizes (200 and 300 samples), the result reveals
that the accuracy of the D-DMR-FBLS model consid-
erably surpasses that of FBLS and TSK fuzzy mod-
els, indicating D-DMR-FBLS’s effective learning ca-
pability and strong generalization ability with limited
label. As the number of labeled samples increases
to a relatively higher range (from 500 to 700 sam-
ples), the improvement in accuracy and G-mean val-
ues for all three models starts to stabilize. Within this
sample size bracket, the DMR-FBLS model main-
tain the highest accuracy, yet the performance gap
between the TSK and FBLS models begins to nar-
row. In general, the trend suggests that when faced
with a small number of labeled samples and the pres-
ence of unlabeled samples, the D-DMR-FBLS model
demonstrates a significant advantage over the other
two fuzzy systems. However, while the performance
of all models improves with an increase in the num-
ber of labeled samples, the rate of improvement de-
celerates, indicating that additional labeled informa-
tion has a limited impact on enhancing model per-
formance beyond a certain sample volume thresh-
old. Overall, from the experimental results, we can
conclude that the D-DMR-FBLS model demonstrates
strong learning capabilities and robust generalization
abilities compared to the other fuzzy systems under
the scenario with a small number of labeled and unla-
beled samples.
5 CONCLUSION
This study introduces a novel semi-supervised Dual-
Manifold Regularized Fuzzy Broad Learning System
(D-DMR-FBLS), aimed at enhancing the predictive
performance for ICU admissions among post-COVID
organ transplant recipients. Our method enhances
the representation learning capability through the use
of DBN and TSK fuzzy systems in the UTP phase,
thereby enriching the model’s capacity to process and
learn from complex data structures. Besides, our ap-
proach integrates feature manifold regularization and
sample manifold regularization with FBLS, improv-
Semi-Supervised Fuzzy DBN-Based Broad Learning System for Forecasting ICU Admissions in Post-Transplant COVID-19 Patients
421

ing the model’s generalization capability. Accord-
ing to experimental results, the D-DMR-FBLS out-
performed other models in terms of accuracy, AUC,
F1-score and G-mean. Besides, its performance sur-
passes the FBLS and TSK fuzzy systems, especially
in scenarios with limited labeled samples. This new
neuro-fuzzy system shows promise for use in contexts
with limited medical resources, assisting the decision-
making for the allocation of medical care to organ
transplant recipients. Future research could further
explore the application of D-DMR-FBLS across other
medical datasets, validating its effectiveness in varied
medical contexts.
ACKNOWLEDGEMENTS
This paper is part of project
PID2022-143299OB-I00, financed by
MCIN/AEI/10.13030/501100011033/FEDER,UE.
REFERENCES
Cao, B., Mao, M., Viidu, S., and Philip, S. Y. (2017). Hit-
fraud: a broad learning approach for collective fraud
detection in heterogeneous information networks. In
2017 IEEE international conference on data mining
(ICDM), pages 769–774. IEEE.
Ershoff, B. D., Lee, C. K., Wray, C. L., Agopian, V. G., Ur-
ban, G., Baldi, P., and Cannesson, M. (2020). Train-
ing and validation of deep neural networks for the pre-
diction of 90-day post-liver transplant mortality using
unos registry data. In Transplantation proceedings,
volume 52, pages 246–258. Elsevier.
Feng, S. and Chen, C. P. (2018). Fuzzy broad learning
system: A novel neuro-fuzzy model for regression
and classification. IEEE transactions on cybernetics,
50(2):414–424.
Feng, S. and Chen, C. P. (2021). Performance analysis of
fuzzy bls using different cluster methods for classifi-
cation. Science China Information Sciences, 64:1–3.
Feng, S., Chen, C. P., Xu, L., and Liu, Z. (2020). On the
accuracy–complexity tradeoff of fuzzy broad learn-
ing system. IEEE Transactions on Fuzzy Systems,
29(10):2963–2974.
Gong, X., Zhang, T., Chen, C. P., and Liu, Z. (2021). Re-
search review for broad learning system: Algorithms,
theory, and applications. IEEE Transactions on Cy-
bernetics, 52(9):8922–8950.
Liu, C.-L., Soong, R.-S., Lee, W.-C., Jiang, G.-W., and Lin,
Y.-C. (2020). predicting short-term survival after liver
transplantation using machine learning. Scientific re-
ports, 10(1):1–10.
Liu, Z., Huang, S., Jin, W., and Mu, Y. (2021). Broad learn-
ing system for semi-supervised learning. Neurocom-
puting, 444:38–47.
Mamode, N., Ahmed, Z., Jones, G., Banga, N., Motalle-
bzadeh, R., Tolley, H., Marks, S., Stojanovic, J., Khur-
ram, M. A., Thuraisingham, R., et al. (2021). Mor-
tality rates in transplant recipients and transplanta-
tion candidates in a high-prevalence covid-19 environ-
ment. Transplantation, 105(1):212–215.
Mark, E., Goldsman, D., Gurbaxani, B., Keskinocak, P., and
Sokol, J. (2023). Predicting a kidney transplant pa-
tient’s pre-transplant functional status based on infor-
mation from waitlist registration. Scientific Reports,
13(1):6164.
Peng, C. and ChunHao, D. (2022). Monitoring multi-
domain batch process state based on fuzzy broad
learning system. Expert Systems with Applications,
187:115851.
Shihabudheen, K. and Pillai, G. N. (2018). Recent advances
in neuro-fuzzy system: A survey. Knowledge-Based
Systems, 152:136–162.
Worldometer (2024). Worldometer - COVID-19 Coro-
navirus Pandemic. https://www.worldometers.info/
coronavirus/. Accessed: 2024-01-10.
Xue, J., Jiang, Y., Wang, L., Sun, Z., and Xing, C. (2018).
Intelligent prediction of renal injury in diabetic kid-
ney disease patients based on a novel unbalanced zero-
order tsk fuzzy system. Journal of Medical Imaging
and Health Informatics, 8(8):1711–1717.
Zhang, L., Li, J., Lu, G., Shen, P., Bennamoun, M., Shah,
S. A. A., Miao, Q., Zhu, G., Li, P., and Lu, X. (2020).
Analysis and variants of broad learning system. IEEE
Transactions on Systems, Man, and Cybernetics: Sys-
tems, 52(1):334–344.
Zhang, X., Gavald
`
a, R., and Baixeries, J. (2022). Inter-
pretable prediction of mortality in liver transplant re-
cipients based on machine learning. Computers in bi-
ology and medicine, 151:106188.
SIMULTECH 2024 - 14th International Conference on Simulation and Modeling Methodologies, Technologies and Applications
422
