
Towards a Secure and Intelligent Access Control Policy Adapter for Big
Data Environment
El Mostapha Chakir
1 a
, Marouane Hachimi
1,3
and Mohammed Erradi
2
1
HENCEFORTH, Rabat, Morocco
2
ENSIAS, Mohammed V University, Rabat, Morocco
3
INPT, Rabat, Morocco
Keywords:
Access Control, Policy Adaptation, Time Series, Big Data, Machine Learning.
Abstract:
In today’s digital landscape, Big Data is crucial for business efficiency and decision-making, but it raises
significant Access Control challenges due to its growing scale, complexity, and diversity of user interactions.
These challenges include ensuring data integrity, maintaining privacy, and preventing unauthorized access, all
of which become increasingly difficult as data volumes and access points expand. In this paper, we propose
an approach that combines Time Series Anomaly Detection with Machine Learning (ML) to enable adaptive
Access Control policies that dynamically adjust based on detected anomalies and changing user behaviors
in Big Data environments. By analyzing collected logs, we extract models of users’ behaviors, which are
then utilized to train an ML model specifically designed to identify abnormal behavioral patterns indicative
of potential security breaches or unauthorized access attempts. The Access Control Policy Adapter uses the
anomalies identified by the ML model, along with static and behavioral anomaly detection techniques, to
adjust Access Control policies, thus ensuring that the system remains robust against evolving threats. We
validate this approach using a synthetic dataset, and initial results demonstrate the effectiveness of this method,
underscoring its potential to significantly enhance data security in complex Big Data ecosystems.
1 INTRODUCTION
In today’s digital age, Big Data is crucial for busi-
nesses of all types. It improves operational efficiency
and facilitates data-driven decision-making (John and
Misra, 2017). However, the rapid increase in data vol-
ume makes it difficult to manage permissions effec-
tively across increasingly large data, often resulting
in either overly permissive access or restrictive con-
trols that hinder legitimate data usage. Additionally,
the speed of data generation demands real-time ac-
cess decisions, which traditional access control sys-
tems such as discretionary access control (DAC) and
role-based access control (RBAC) struggle to accom-
modate, potentially leading to bottlenecks or security
vulnerabilities (Shan et al., 2024). As data increases
in size and complexity, securing access to it becomes
essential to maintaining the integrity and confidential-
ity of information systems.
Big Data environments are inherently dynamic
and require equally dynamic access control systems
a
https://orcid.org/0000-0001-7944-6344
(Jiang et al., 2023). Throughout the life cycle of a big
data resource, from its creation to its deletion, the ac-
cess rights of different users must evolve. Consider
the case in a financial services organization where an
anomaly detection system identifies unusual data ac-
cess patterns during non-business hours—a potential
indicator of a data breach. Under traditional access
control systems, adapting the access rights to tem-
porarily restrict data visibility until the anomaly is in-
vestigated would require manual intervention, which
is not feasible outside regular working hours (Karimi
et al., 2021). This delay in response could lead to data
leakage or other security breaches.
Within the Hadoop ecosystem, the leading big
data management platform, Apache Ranger plays a
central role in implementing robust access control
through models such as attributes (ABAC) (Shan
et al., 2024). However, Apache Ranger cannot
dynamically adjust policies in response to constant
changes, or identified anomalies, especially in the big
data environment where access is frequently changed
or the number of users is huge. There is an urgent
need for access control mechanisms that can adapt
Chakir, E., Hachimi, M. and Erradi, M.
Towards a Secure and Intelligent Access Control Policy Adapter for Big Data Environment.
DOI: 10.5220/0012860800003767
Paper published under CC license (CC BY-NC-ND 4.0)
In Proceedings of the 21st International Conference on Security and Cryptography (SECRYPT 2024), pages 345-356
ISBN: 978-989-758-709-2; ISSN: 2184-7711
Proceedings Copyright © 2024 by SCITEPRESS – Science and Technology Publications, Lda.
345

in real time to changes in data attributes and user
roles, ensuring that security measures keep pace with
rapidly changing data and user interactions (Walter,
2023).
To meet this requirement, recent research has in-
creasingly focused on creating adaptive access control
systems (Shan et al., 2024; Jiang et al., 2023; Karimi
et al., 2021). These systems use machine learning
and real-time analytics to automatically adjust access
policies in response to changing data patterns, user
behavior, and the emerging threat landscape. These
adaptive approaches represent a major advancement
in big data security, providing proactive strategies to
identify and mitigate potential security breaches be-
fore they occur.
In this direction, this work introduces a novel ap-
proach within the Hadoop ecosystem, employing Ma-
chine Learning and Time Series Anomaly Detection
to enhance Access Control security. By continuously
monitoring data patterns, user interactions, and secu-
rity threats, this method aims to improve Big Data en-
vironments’ security dynamically.
This work focuses on dynamically updating Ac-
cess Control policies based on real-time evaluations
of user and system behavior. It achieves this by
analyzing Apache Ranger audit logs, which are es-
sential for detecting policy violations and analyzing
user/system behavior. Rigorous testing has proven the
effectiveness of this work in improving the security of
Hadoop environments.
The main contributions of this research are sum-
marized as follows:
• Implements a behavioral model using Apache
Ranger logs to detect policy violations in real-
time and analyze behavior.
• Develops a model that uses machine learning and
time series anomaly detection to adapt access
control policies based on anomalies detected in
user/system behavior.
• The effectiveness of this work to improve big data
security is verified through extensive testing and
evaluation.
2 RELATED WORK
Traditional access control models cannot automat-
ically adjust permissions when an object’s state
changes (e.g., a document being edited). Models like
DAC and RBAC rely on static object names or iden-
tifiers, meaning access policies do not adapt even if
the object’s version or state changes (Basin et al.,
2023). The Attribute-Based Access Control (ABAC)
model offers more dynamic permission management
by adapting to changes in object attributes (Huang
et al., 2022).
(Shan et al., 2024) proposed a method using het-
erogeneous graph neural networks to address redun-
dancy in dependency paths and regional imbalance
in provenance graphs for dynamic access control.
This approach integrates community detection and
key node identification within big data provenance
graphs to efficiently generate lean provenance-based
access control (PBAC) rules.
Another study by (Jiang et al., 2023) presented
the SC-RBAC model that stands out by offering pre-
cise risk evaluation and adaptive access decisions.
Demonstrated as effective through simulation tests,
it acknowledges the need for future enhancements to
address potential inaccuracies in access behavior due
to misaligned goals, aiming to refine the control over
doctors’ access to medical data.
(Karimi et al., 2021) employed a reinforcement
learning approach to dynamically adapt ABAC poli-
cies, leveraging user feedback and access logs. Re-
sults from testing on real and synthetic data suggest
this method competes well with, and sometimes sur-
passes, conventional supervised learning approaches.
A heuristic solution to the NP-complete problem
of adapting policies to ABAC using hierarchical at-
tribute values was proposed in (Das et al., 2019). This
solution uniquely incorporates environment attributes
and highlights the limitation of needing matching at-
tribute sets for policy migration, suggesting future ex-
ploration into ontology-based mapping and heuristic
development for diverse attribute sets.
While existing research such as above, can signif-
icantly improve the field of access control, especially
about ABAC models, machine learning applications,
and policy adaptation mechanisms, they can’t adjust
dynamically the policies based on real-time analysis
of user behavior and data patterns and not all tailored
for Big Data environments (Premkamal et al., 2021).
3 ACCESS CONTROL IN BIG
DATA ENVIRONMENTS
3.1 Access Control Challenges in
Hadoop Big Data Ecosystem
The Hadoop ecosystem is a collection of open-source
software projects that facilitate storing, processing,
and managing big data. It provides a powerful and
scalable platform for organizations to handle massive
datasets that traditional data management tools strug-
SECRYPT 2024 - 21st International Conference on Security and Cryptography
346

gle with. Unfortunately, it presents many challenges
for access control (Awaysheh et al., 2020). Its dy-
namic and distributed nature, with constantly arriving
data and evolving user roles, renders traditional meth-
ods inadequate for granular control. Furthermore, ba-
sic Hadoop security features are insufficient. These
limitations can lead to serious security risks, includ-
ing unauthorized access, data breaches, reputational
damage, legal issues, and even non-compliance with
data privacy regulations (Shan et al., 2024; Gupta
et al., 2017).
Solutions like Apache Ranger offer a robust
ABAC solution for fine-grained access policies based
on user attributes and data characteristics. As illus-
trated in Figure 1, Ranger plugins, integrated with
Hadoop, enforce authorization, pulling user informa-
tion from corporate directories to establish security
policies.
Let H = {HDFS, Hive, HBase, Kafka, Knox}
represent the set of all Hadoop components integrated
with Apache Ranger plugins. Define U as the set
of users, each with attributes A
u
, and R as the set
of resources, each with attributes A
r
. The access
control policies P are functions from user and re-
source attributes to access decisions, {allow,deny}.
The authorization function A, defined as A : U × R →
{allow,deny}, evaluates access permissions based on
these policies:
A(u,r) =
(
allow if ∃p ∈ P : p(A
u
,A
r
) = allow
deny otherwise
The enforcement of this function across the
Hadoop components is encapsulated by:
∀s ∈ H , ∀u ∈ U,∀r ∈ R : R P
s
(u,r) = A(u,r)
where R P
s
denotes the Ranger plugin associated
with each Hadoop service s. This formulation
compactly describes how Apache Ranger manages
and enforces fine-grained access control within the
Hadoop ecosystem.
Beyond its primary function of authorization,
Ranger also comprehensively logs audit activities.
The recorded audit data is invaluable for tracking and
investigating specific actions within the system.
However, Ranger can be complex to set up and
manage, requiring expertise in defining and main-
taining access control policies. Additionally, its re-
liance on external services for authentication and au-
thorization can introduce potential integration chal-
lenges which could lead to misconfigurations in pol-
icy management (Alzahrani et al., 2024). Such issues
could potentially result in policy violations, security
breaches, and other related vulnerabilities.
3.2 Problem Definition
Understanding the complexities of managing Apache
Ranger, especially as users and data grow, is vital for
strong Hadoop security (Gupta et al., 2017). Let’s ex-
plore these challenges through a real-world example.
An organization uses Ranger for HDFS access
control, restricting access to sensitive data. A mis-
configuration in access control policies allows unau-
thorized access, emphasizing the importance of audit
log analysis for identifying and fixing security gaps.
Let:
• Users (U): The set of all users in the system. In
this scenario,
U = {analyst, admin}.
• Resources (R): The set of all resources
that access control policies apply to. R =
{/user/data/financial,/user/data/marketing,
/user/data/security,/user/data/management}.
• Access Types (A): The types of access that can be
granted to resources. A = {READ,WRITE}.
• Policies (P): The set of rules defining access per-
missions. Each policy p
i
∈ P is a tuple (u,r, a),
indicating that user u has access type a to resource
r (u ∈U, r ∈R, a ∈A).
Let’s suppose that the desired policy p
d
∈ P grants
read access only to the marketing data folder for the
data analyst user:
p
d
= {(analyst,/user/data/marketing,READ)}
Let’s Consider a scenario where the analyst has
malicious intentions and has access to the HDFS sys-
tem. The analyst could be attempting to gather in-
formation, expose data, or engage in other malicious
intent.
Let L represent the audit log entries of Apache
Ranger, which are essential for monitoring access and
identifying potential security concerns. An audit log
entry L is represented as a tuple (u,r,a,t,s), where:
• u is the user who performed the access attempt,
• r is the resource that was accessed,
• a is the type of access attempted (e.g., READ or
WRITE),
• t is the timestamp when the access attempt oc-
curred,
• s is the success status of the access attempt
(SUCCESS or FAILURE).
The access logs of the malicious user might look like
Towards a Secure and Intelligent Access Control Policy Adapter for Big Data Environment
347
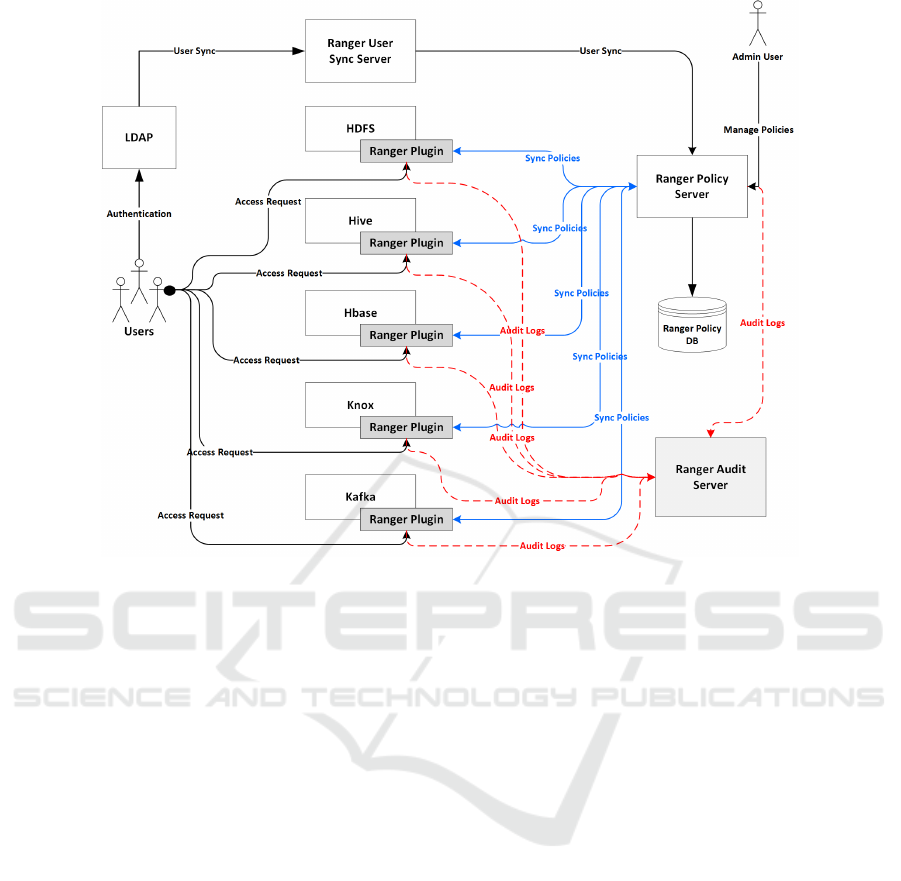
Figure 1: The working of the Apache Ranger.
the following:
L =
(analyst,/user/data/marketing/report.csv,
READ,t
1
,SUCCESS),
(analyst,/user/data/security/report.csv,
READ,t
2
,FAILURE),
(analyst,/user/data/marketing/sales.csv,
READ,t
3
,SUCCESS),
(analyst,/user/data analyst/financial/report.csv,
READ,t
4
,FAILURE),
(analyst,/user/data/management/report.csv,
READ,t
5
,FAILURE)
Audit logs can reveal patterns of suspicious access
attempts, but they rely on analyzing past user behav-
ior. Security teams typically update policies manually
after an incident. This highlights the need for contin-
uous audit log monitoring and adaptive policies.
4 PROPOSED APPROACH
To address access control challenges in Hadoop, the
proposed model leverages Apache Ranger’s audit
logs. It uses behavioral monitoring analysis for real-
time policy adjustments based on these audit logs. By
proactively analyzing audit logs, the model strength-
ens Hadoop security, offering a sophisticated shield
against vulnerabilities.
4.1 Architecture Overview
The proposed model introduces a straightforward ap-
proach for finding and fixing security issues in access
control for big data environments. It uses the Apache
Ranger Audit Log Server to track user activity, which
helps in spotting problems. Figure 2 illustrates the
different components and their interaction in the pro-
posed approach.
We employ a multiple technique for anomaly de-
tection. The Initializer sets up the system and ensures
everything starts correctly. Central to the architecture
is the Ranger Audit Log Server, which records all
user activities. The Retriever continuously extracts
logs from this server for user behavior monitoring.
The Behavioral Model imports user behavior data
and builds user-specific models to understand user
conduct. Detection Agents analyze the system and
identify anomalies. The Cache Server (Redis in this
work) stores data retrieved by agents and provides
it to the Policy Adapter. Local Storage stores data
used for training the ML Model, which analyzes
data to establish user-specific rate limits and detect
suspicious behavior using machine learning. Finally,
the Policy Adapter receives anomaly information
from agents and updates Apache Ranger policies
accordingly.
SECRYPT 2024 - 21st International Conference on Security and Cryptography
348
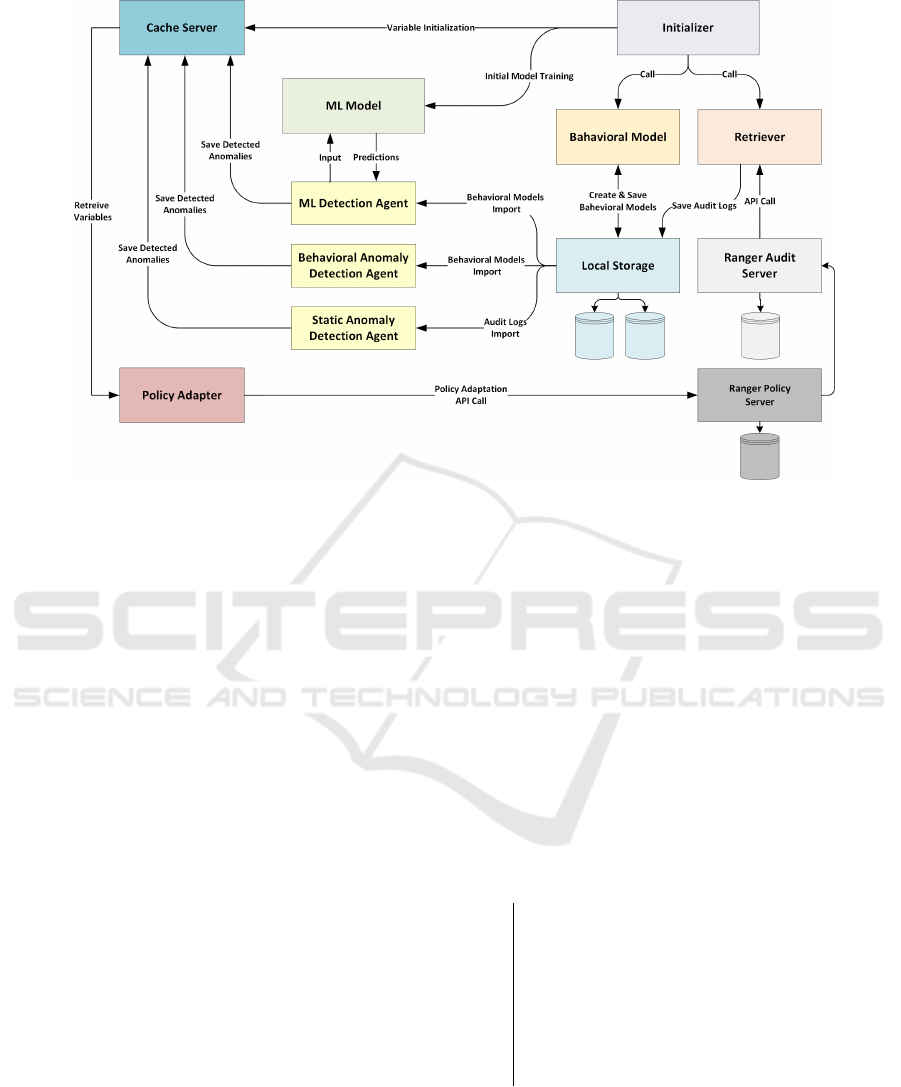
Figure 2: The suggested approach for Access Control Policy Adaptation.
We propose a robust algorithm for continuous
monitoring and dynamic policy adaptation. It ini-
tializes essential variables and stores access logs and
behavioral models in local storage. ML Model, par-
ticularly trained on this data, identifies and predicts
anomalous patterns. The system updates periodically
with new logs and refreshes models to reflect ongoing
user interactions.
As new data arrives, the algorithm applies
anomaly checks using both pre-defined rules and ML
insights. These predictions should inform the policy
adapter to dynamically adjust access control policies,
mitigating risks identified by the anomalies.
Algorithm 1 illustrates the global interaction be-
tween all components.
Let’s define the variables:
• C : Cache variables initialized at the start of the
system for storing intermediate data.
• L: The complete set of access logs collected from
the system for analysis.
• B: The collection of all behavioral models built
from the historical data representing user behavior
patterns.
• A
static
: A set of detected static anomalies based on
predefined rules or scores.
• A
behavior
: A set of detected behavioral anomalies
based on deviations from the established behav-
ioral models.
• A
predicted
: A set of predicted anomalies identified
by the ML Model.
• P : The current set of security policies, which can
be adapted based on detected anomalies.
• M : The machine learning model trained to detect
anomalies.
• T : A period or interval used to define how often
the system should retrieve new logs and update
models.
Input: First Time Setup
Output: Continuous Monitoring and Policy
Adaptation
C ← Initialize();
L ← RetrieveAccessLogs();
B ← RetrieveBehavioralModels();
M ← TrainAIModel(B);
while true do
L
new
← RetrieveNewLogs();
B ← UpdateBehavioralModels(L
new
,B);
A
static
← StaticAnomalyCheck(L);
A
behavior
←
BehavioralAnomalyCheck(B);
A
predicted
←
PredictAnomalies(A
static
,A
behavior
);
P ← AdaptPolicies(A
predicted
);
end
Algorithm 1: Continuous Monitoring, Anomaly Detection
and Policy Adaptation.
The used functions are defined as:
• Initialize(): Initializes the cache variables for
the system.
Towards a Secure and Intelligent Access Control Policy Adapter for Big Data Environment
349

• RetrieveAccessLogs(): Gathers access logs for
analysis.
• RetrieveBehavioralModels(): Retrieves exist-
ing behavioral models from storage.
• TrainAIModel(B): Trains the ML Model using
the behavioral models as a dataset.
• RetrieveNewLogs(T ): Fetches new log entries
that have been recorded since the last retrieval
based on the period T .
• UpdateBehavioralModels(L,B): Updates the
behavioral models with new data from the access
logs.
• StaticAnomalyCheck(L): Identifies static
anomalies in the new logs.
• BehavioralAnomalyCheck(B): Detects behav-
ioral anomalies by comparing new behaviors
against established models.
• PredictAnomalies(A
static
,A
behavior
): Uses the
trained ML Model to predict anomalies from the
static and behavioral anomaly sets.
• AdaptPolicies(A
predicted
): Adjusts the security
policies in response to the predicted anomalies.
4.2 Behavioral Model
The Behavioral Model builds user-specific models
based on access logs from the Ranger Audit Log
Server. It analyzes these logs to identify patterns and
typical behaviors for each user. By capturing unique
usage trends and access habits, the model creates a
distinct profile for every user. This is achieved by
focusing on relevant attributes like id, serviceType,
agentHost, clientIP, eventTime, eventDuration, ac-
cessResult. Inspired by prior research (Argento et al.,
2018), the Behavior Model is designed to generate
individualized user profiles based on access logs. It
systematically examines these logs to extract and or-
ganize behavioral data, identifying user-specific pat-
terns and trends that reflect their interactions within
the Big Data Environment. Algorithm 2 details the
overall structure of the behavioral model.
Given a set of users U and their corresponding set
of log entries L, we seek to construct a behavioral
model B
u
for each user u ∈ U. Each log entry l ∈ L is
a tuple:
l = (id,user,serviceType,agentHost,clientIP,
eventTime,eventDuration, accessResult),
where each element represents a specific attribute of
the log entry. The goal is to analyze and aggregate
these log entries to model user behavior comprehen-
sively.
Input: A set of access logs L
Output: A set of enhanced behavioral
models {B
enhanced
u
} for each user
u ∈ U
Initialize set of users: U ←
/
0;
foreach log entry l ∈ L do
Extract l
user
and add it to U;
end
foreach user u ∈ U do
L
u
← {l ∈ L | l
user
= u} Extract and
aggregate features into
I
u
,S
u
,A
u
,C
u
,T
u
,D
u
,E
u
,R
u
Apply
transformation functions to generate B
u
;
end
foreach model B
u
do
H
u
← sort(A
u
), I
u
← sort(C
u
) Enhance B
u
by incorporating H
u
and I
u
into
B
enhanced
u
;
end
return {B
enhanced
u
}
Algorithm 1: Construction of User Behavioral Models.
Step 1: User-Specific Log Entry Aggregation: For
each user u ∈ U, we identify the subset of logs L
u
related to their activities by filtering operation:
L
u
= {l ∈ L |l
user
= u}.
Step 2: Feature Extraction: We extract features
from each L
u
to capture the user’s behavioral patterns,
defining sets for each attribute:
I
u
= {l
id
|l ∈ L
u
},
S
u
= {l
serviceType
|l ∈ L
u
},
A
u
= {l
agentHost
|l ∈ L
u
},
C
u
= {l
clientIP
|l ∈ L
u
},
T
u
= {l
eventTime
|l ∈ L
u
},
D
u
= {l
eventDuration
|l ∈ L
u
},
E
u
= {l
eventCount
|l ∈ L
u
},
R
u
= {l
accessResult
|l ∈ L
u
}.
Step 3: Pattern Recognition and Model Formula-
tion: The Behavioral Model B
u
for each user u is an
aggregation of the extracted features, formalized as:
B
u
= {I
u
,φ(S
u
),ψ(A
u
,C
u
),η(T
u
,D
u
,E
u
),θ(R
u
)},
where φ, ψ, η, and θ are transformation functions
that derive complex structures from the feature sets,
such as frequency distributions, Cross-Reference of
agentHost and clientIP, time series analyses, and
statistical summaries, to provide insights into user
behavior.
SECRYPT 2024 - 21st International Conference on Security and Cryptography
350

Step 4: Known Hosts and IPs Enhancement: The
model is further enhanced by incorporating sorted
lists of known hosts and IPs, adding contextual depth:
H
u
= sort(A
u
),
I
u
= sort(C
u
),
B
enhanced
u
= B
u
∪ {H
u
,I
u
}.
The aim is to capture the multifaceted aspects of
user behavior from system interactions in a rigorous
way.
4.3 Detection Agents
Detection agents perform a full range of system health
checks, ensuring that any anomalies are quickly
flagged for further investigation.
4.3.1 Static Anomaly Detection Agent
This agent is responsible for performing static
anomaly checks on audit logs. It evaluates attributes
such as event duration and event count, among others,
to detect deviations from normal behavior that may
indicate anomalies.
Let L = {l
1
,l
2
,. .. ,l
n
} be the set of audit log en-
tries, where each log entry l
i
is defined as a tuple:
l
i
= (id
i
,aclEn f orcer
i
,eventCount
i
,eventDuration
i
)
where:
• id
i
is the unique identifier for the log entry,
• aclEn f orcer
i
specifies the ACL enforcement
mechanism (e.g., ’ranger-acl’, ’hadoop-acl’),
• eventCount
i
and eventDuration
i
are the key at-
tributes scrutinized for anomalies.
Define A as the set of anomaly IDs, initially empty.
For each log entry l
i
in L, the following checks update
the set A:
A =
/
0
∀l
i
∈ L :
A := A ∪ {id
i
} if aclEn f orcer
i
/∈
{’ranger-acl’,’hadoop-acl’}
A := A ∪ {id
i
} if eventCount
i
> 1
A := A ∪ {id
i
} if eventDuration
i
> 0
After identifying anomalies, the agent synchro-
nizes this data with the cache server.
The output of Static Anomaly Detection Agent’s
operation is the set A of anomaly IDs, which are syn-
chronized with Redis, providing an updated and real-
time reflection of system anomalies.
4.3.2 Behavioral Anomaly Detection Agent
This agent focuses on anomaly checks on generated
behavioral models. It specifically looks for unusual
logins from unknown IPs or hostnames. By monitor-
ing login activities and comparing them to established
user behavior patterns, It can detect any unauthorized
access attempts or suspicious login patterns.
Given the set of all behavioral models B, where
each model b ∈ B corresponds to a user and is stored
as a JSON file. Define A as the set of anomaly identi-
fiers, initially empty.
For each behavioral model b stored in the direc-
tory ’Bh Models’, the following steps are taken:
1. Extract the user identifier usr from the model file-
name.
2. Retrieve user information usr in f from Redis
database.
3. Load the behavioral data data for usr.
∀b ∈ ’Bh Models’ :
usr ← extract(b,
′
. json
′
),
usr in f ← json.loads(rds.get(usr)),
data ← load(b),
∀i ∈ {0,...,len(data[
′
serviceType
′
]) − 1} :
A := A∪
{data[
′
ids
′
][i]}
if data[
′
serviceType
′
][i] ̸=
′
hd f s
′
,
{data[
′
ids
′
][i]}
if data[
′
agentHost
′
][i] /∈ usr in f [
′
known hosts
′
],
{data[
′
ids
′
][i]}
if data[
′
clientIP
′
][i] /∈ usr in f [
′
known ips
′
]
After identifying anomalies, the Behavioral
Anomaly Detection Agent synchronizes this data with
the cache server.
4.3.3 Machine Learning Detection Agent
This agent is designed to perform anomaly detection
on user behavior models using time series analysis
of access logs (Ren et al., 2019). The main objec-
tive is to identify unusual patterns in denial events
over time, which could indicate unauthorized access
attempts or other forms of anomalous behavior. This
process leverages machine learning techniques to ana-
lyze temporal variations in data and identify potential
security threats.
Given a set of user behavior models generated by
the behavioral model and stored as JSON files in local
storage, let B = {b
1
,b
2
,. .. ,b
n
} represent these mod-
els. Each model b
i
contains sequences of log entries:
data
i
= {(t
1
,r
1
),(t
2
,r
2
),. .. ,(t
m
,r
m
)}
where t
j
denotes the timestamp and r
j
denotes the
access result of each event.
Towards a Secure and Intelligent Access Control Policy Adapter for Big Data Environment
351

For each user model, construct a time series T
i
from the access denial events (r
j
= 0):
T
i
= {(t
k
,r
k
) : r
k
= 0}
Calculate the hourly moving average of denials D
h
i
for
the time series T
i
, which smooths the data over each
hour h:
D
h
i
(t) =
1
h
t
∑
k=t−h+1
r
k
Calculate the variations V
i
in D
h
i
to detect signifi-
cant changes:
V
i
(t) = D
h
i
(t) − D
h
i
(t − 1)
Compute the mean µ and standard deviation σ of
V
i
:
µ = mean(V
i
), σ = std(V
i
)
Identify potential anomalies where the variation
exceeds a threshold defined as three standard devia-
tions above the mean:
Anomalies = {t : V
i
(t) > µ + 3σ}
After identifying anomalies, the ML Detection
Agent synchronizes this data with a cache server (Re-
dis).
4.4 ML Model
ML Model focuses on time-series anomaly detection
using the Isolation Forest algorithm. This unsuper-
vised learning technique excels at identifying outly-
ing data points that deviate from typical patterns over
time (Bl
´
azquez-Garc
´
ıa et al., 2021; Qin and Lou,
2019). It’s well-suited for time-series data due to its
random partitioning mechanism that naturally adapts
to sequential data (Li and Jung, 2023).
Setting up and training the ML Model involves
pre-processing steps specific to time-series data, such
as normalization and extracting features like trends,
seasonality, and autocorrelation. These steps prepare
the data for the Isolation Forest algorithm (Xu et al.,
2023).
Given a time-series dataset D where each data
point x
t
at time t is represented as a vector of features
x
t
∈ R
n
, the Isolation Forest algorithm seeks to iden-
tify points that are anomalies concerning the temporal
distribution of the dataset.
4.4.1 Preprocessing
• Feature Extraction: Let F(x
t
) be a transforma-
tion that extracts relevant features from x
t
ac-
counting for temporal properties such as lagged
values, moving averages, and seasonality.
• Normalization: The features are normalized to
ensure equal weighting during distance compu-
tations. If F
′
(x
t
) denotes the normalized feature
vector, the normalization process can be repre-
sented as:
F
′
(x
t
) =
F(x
t
) − µ(F)
σ(F)
where µ(F) and σ(F) are the mean and standard
deviation of the features across the dataset.
4.4.2 Model Training
• Construct an ensemble of Isolation Trees, T =
{T
1
,T
2
,. .. ,T
m
}, from the transformed time-series
dataset.
• For each tree T
i
, a random subsequence of the
time-series data is selected, and recursive parti-
tioning is applied based on randomly selected fea-
tures and split values.
4.4.3 Anomaly Score Calculation
The anomaly score for a data point x
t
is calculated
based on the path length h(x
t
) within each tree, aver-
aged over the forest, and normalized as follows:
S(x
t
,n) = 2
−
E[h(x
t
)]
c(n)
where:
• E[h(x
t
)] is the expected path length of x
t
over the
forest T .
• c(n) is a normalization factor defined as the aver-
age path length in an unsupervised binary search
tree given n external nodes.
• Shorter path lengths correspond to higher
anomaly scores, indicating a higher likelihood of
x
t
being an anomaly.
4.5 Policy Adapter
The Policy Adapter plays a critical role by dynami-
cally adjusting Apache Ranger access controls in re-
sponse to detected anomalies. It operates through key
components: Policy Retrieval, which fetches exist-
ing policies for modification, and IP Adaptation and
Spike Adaptation functions, which adjust policies to
block unauthorized IPs and manage sudden access
spikes, respectively. The adapter begins by retriev-
ing anomalies from a Redis cache, linking these to
specific policy IDs and user details from access logs.
It then adapts policies based on the type of anomaly
detected (Unknown IPs, Sudden Access Spikes etc.),
using REST API calls to update these policies on the
SECRYPT 2024 - 21st International Conference on Security and Cryptography
352

Input: Anomalies from Redis A, Access
Logs L
Output: Updated policies reflecting adapted
security measures
Load environment variables;
Establish Redis connection;
Configure Ranger API credentials;
A ← Redis.hgetall(’anomalies’);
L ← retriever.retrieve access logs();
Initialize change policies as empty
dictionary;
foreach a ∈ A do
foreach ℓ ∈ L do
if ℓ.id = a.id then
Prepare change request for a;
Add to change policies;
end
end
end
foreach change c ∈ change policies do
switch c.nature do
case ’Unknown IP’ do
policy ←
retrieve policy(c.policyId);
adaptation ← IP policy adapt(c);
Update policy(policy,
adaptation);
end
case ’Deny Spike’ do
policy ←
retrieve policy(c.policyId);
adaptation ←
Spike policy adapt(c);
Update policy(policy,
adaptation);
end
otherwise do
// Handle other anomalies
end
end
end
return Updated policies
Algorithm 2: Dynamic Policy Adaptation Process.
Ranger server and handling responses to ensure up-
dates are successful (See Algorithm 3).
Define the set of all policies as P and the set of all
detected anomalies as A, where each anomaly a ∈ A
is represented as a tuple (id,nature,user, ip).
The policy retrieval function is defined as:
P : N → P
This function P(n) retrieves a policy using its identi-
fier n, returning the policy as a structured object from
the Ranger server.
Define a function F that maps anomalies to poli-
cies:
F : A × P → P
Function F(a, p) applies transformations to policy p
based on the anomaly a.
• IP-related anomalies adaptation:
IPAdapt : A → P
Constructs modifications to policy p to handle
unauthorized IP addresses based on the anomaly
information.
• Access spikes adaptation:
SpikeAdapt : A → P
Modifies p to temporarily deny user access in re-
sponse to detected spikes.
For each anomaly a and corresponding policy p, exe-
cute the adaptation:
∀a ∈ A, p ∈ P : Execute (F(a,P(id(a))))
The update function sends the adapted policy to
the Ranger server and returns the status of the opera-
tion:
Update : P → {Success, Failure}
if nature(a) = ’Unknown IP’ then apply IPAdapt(a)
if nature(a) = ’Deny Spike’ then apply SpikeAdapt(a)
5 IMPLEMENTATION
5.1 Dataset
To evaluate the proposed model, a synthetic dataset
of 10,000 entries was created, simulating real-world
Apache Ranger access logs. Each entry in the dataset
represents an access event with attributes like service
type, agent host, client IP, event time, duration, and
result (permit or deny). This dataset ensures oper-
ational relevance with agent hosts and client IP ad-
dresses set to reflect typical settings. Each log entry
is time-stamped during standard business hours, and
distributed evenly across all days of the week, con-
firming a realistic workweek pattern. Randomization
in the selection of the agent host and client IP address
introduces variability, similar to the unpredictability
of real logs. With a deny rate of approximately 14%,
the dataset effectively emulates the decision-making
process of an access control system.
Table 1 summarizes the attributes of the synthetic
dataset. Each attribute is designed to mimic real-
world access logs within a controlled environment.
Towards a Secure and Intelligent Access Control Policy Adapter for Big Data Environment
353
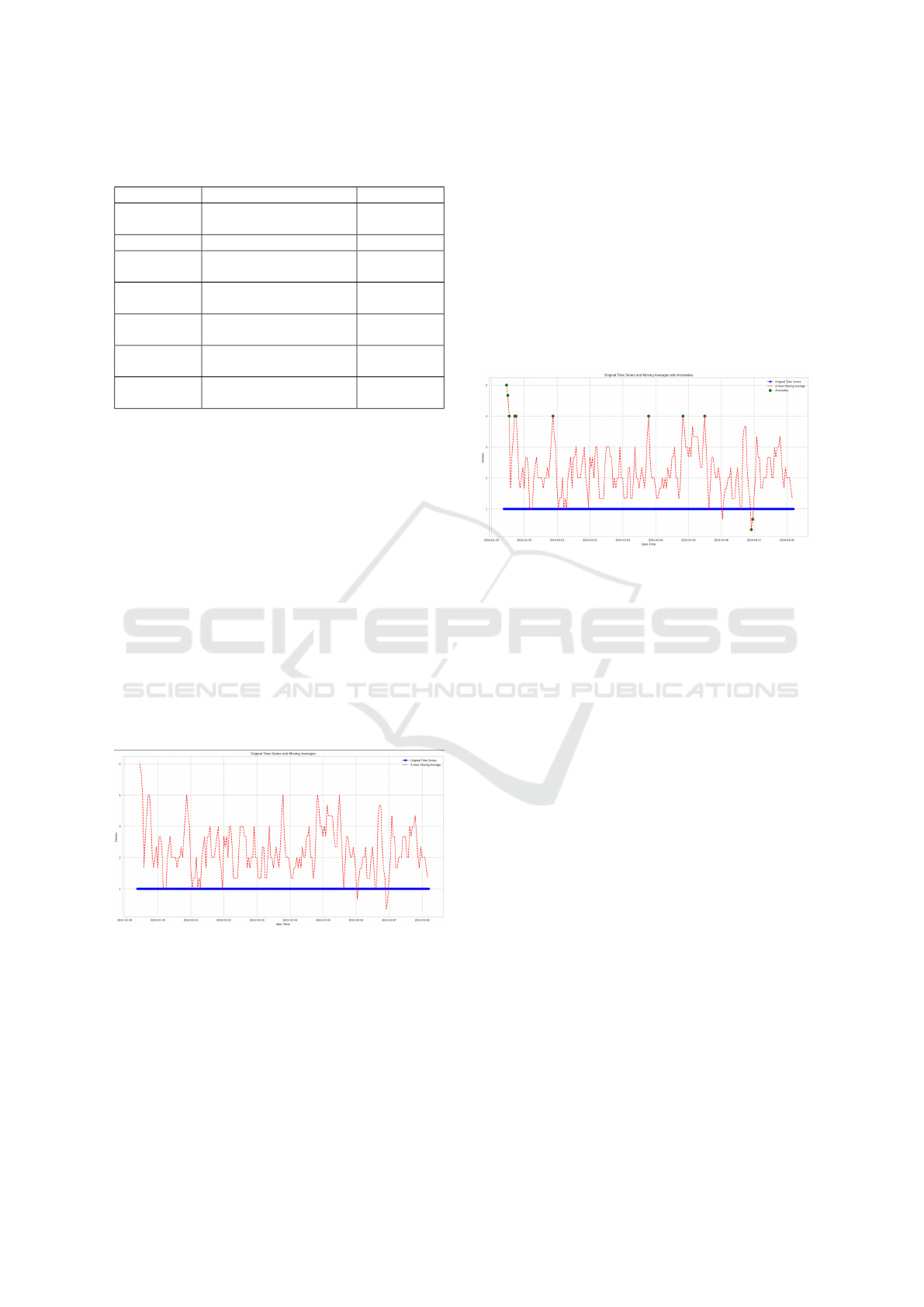
Table 1: Attributes of the Synthetic Dataset used in the anal-
ysis.
Attribute Description Type
Service
Type
Simulates HDFS inter-
actions
Categorical
Agent Host Indicates access node Categorical
Client IP Matches corresponding
agent host
Categorical
Event Time Time-ordered with
added randomness
Temporal
Event Dura-
tion
Set to zero for simplicity Numerical
Event
Count
Represents a single
transaction
Numerical
Access Re-
sult
Binary outcome (suc-
cess or failure)
Categorical
5.2 Experiment
To evaluate the model’s anomaly detection, we de-
veloped the system using Python on a computer (i7-
12800H CPU, 32GB RAM). We used default settings
for the Isolation Forest algorithm to benchmark its
performance.
Our methodology prioritizes data preparation for
effective anomaly detection. Key features were ex-
tracted from the synthetic dataset, and a moving av-
erage calculation over a 3-hour window was applied
to minimize noise and focus the model on signifi-
cant anomalies. This step set the stage for accurate
anomaly detection. PyCaret’s Anomaly Detection
module was used to train the Isolation Forest model,
enabling it to identify anomalies in new data based on
an Anomaly Score.
Figure 3: Time Series Analysis of Access Patterns with
Moving Average Filtering.
We analyzed access denial patterns using time se-
ries analysis for the period February 28 to March 8,
2024 (Figure 3). The original data (blue line) rep-
resents individual access results (0 for success, 1 for
denial), but this doesn’t reveal trends.
To address this limitation, we calculated a three-
hour moving average (red dashed lines). This mov-
ing average represents the sum of access denials ev-
ery 3 hours, highlighting underlying trends in access
attempts. This approach allows us to pinpoint peri-
ods with significant increases or decreases in access
denial occurrences.
We applied the Isolation Forest algorithm to the
access denial time series data. This algorithm excels
at identifying anomalies, allowing us to pinpoint un-
usual activity (Figure 4). Green dots represent anoma-
lies, where access density deviates significantly from
the moving average trend. These anomalies could in-
dicate potential security threats or system issues re-
quiring investigation.
Figure 4: Anomaly Detection in Access Denial Events us-
ing Moving Average Analysis.
To improve the capabilities of the detection sys-
tem, we use an additional experiment using a special-
ized anomaly detection agent with the same dataset
that specifically targets behavioral access patterns.
This agent uses machine learning techniques such as
Isolation Forest, Support Vector Machines (SVM),
and K-Nearest Neighbors (KNN).
This approach is different from previous exper-
iments, which primarily examined ”denied” access
logs, instead focusing on temporal variations in ac-
cess patterns to identify anomalies. Unlike previous
methods, this new experiment introduces an agent fo-
cused on access time data rather than denial events.
It undergoes extensive data preprocessing to normal-
ize access patterns and establish a baseline standard.
Then, the agent uses anomaly detection models with
finely calibrated threshold parameters to improve de-
tection accuracy while minimizing false positives.
Anomaly Threshold = µ + 3σ
where µ is the mean of the anomaly scores, and σ is
the standard deviation of the anomaly scores.
By analyzing the results of the three machine
learning algorithms for anomaly detection in tempo-
ral access data, we observe the following performance
characteristics:
The isolation forest model demonstrates a com-
petent ability to identify anomalies with the adjusted
anomaly threshold. In Figure 5, anomalies are repre-
SECRYPT 2024 - 21st International Conference on Security and Cryptography
354

Figure 5: Anomaly Detection in Access Times Using Isola-
tion Forest Algorithm.
Figure 6: Anomaly Detection in Access Times Using SVM
Algorithm.
Figure 7: Anomaly Detection in Access Times Using KNN
Algorithm.
sented as black dots, representing access times. Black
dots are few in number and distinct from dense clus-
ters of red dots, indicating a lower rate of false posi-
tives and accurate capture of true anomalies.
The SVM model, however, shows considerable
green dots interspersed among the red dots through-
out the timeline (Figure 6). This suggests that the
SVM algorithm is reporting a significant number of
false positives, as it is unable to effectively separate
anomalies from normal data points despite adjust-
ments to the anomaly threshold. The high frequency
of green dots indicates poor discrimination between
normal and abnormal data.
On the other hand, the KNN model outperforms
the other two in terms of accuracy. Anomaly detec-
tion with KNN, marked by green dots, is sparse and
very localized compared to the red dots (Figure 7).
Adjusting the anomaly threshold as described before
appears to have effectively minimized false positives,
focusing only on the most statistically significant out-
liers.
Following anomaly detection, our system imple-
ments a process to dynamically adapt policies within
Apache Ranger, effectively responding to various se-
curity threats as they arise. This process is stream-
lined through a meticulously designed algorithm as
described in section 4.5, that uses a two-phase ap-
proach: building a policy change dictionary and run-
ning a policy adaptation loop.
5.3 Discussion
To effectively manage policy adaptation in a Big Data
environment, it is imperative to select an anomaly de-
tection model that provides both high accuracy and
efficiency. The analysis of the four models (Isola-
tion Forest for temporal access logs and only ac-
cess denied, as well as the implementations of K-
Nearest Neighbors (KNN) and Support Vector Ma-
chine (SVM) for the access logs temporal accesses
provides a comprehensive overview of their ability to
trigger specific policy adaptations.
Isolation forest demonstrates robust performance
in identifying anomalies within a larger dataset of
temporal access logs. Its strength lies in its ability to
effectively separate anomalies from normal instances
without being heavily influenced by noise present in
the dataset, which is typical in large-scale data en-
vironments. Isolation forest applied specifically to
access denials can be particularly effective in envi-
ronments where unauthorized access attempts are a
significant security issue, because it can detect sub-
tle patterns of anomalous denials that broader models
might overlook. KNN demonstrated exceptional ac-
curacy in experiments, especially when finely tuned
with an appropriate threshold. Its main limitation is
the computational cost, which can increase with the
size of the data. SVM, although comprehensive, has
struggled with reliability and high false positive rates
in experiments.
Our study on time series anomaly detection using
machine learning suggests potential security improve-
ments through Apache Ranger log analysis. This
model identifies anomalies indicating possible access
control policy violations, prompting necessary policy
adaptations and suggesting areas for security harden-
ing.
In access control, changing access requests over
time makes it difficult for the model to rely only on
the initial training data. Therefore, it is essential to
continually update the model with new arriving logs
and behaviors. To address this issue, we have chosen
to focus on online learning in our future work, to im-
prove this approach and ensure that the model remains
effective and relevant in real-time scenarios.
Towards a Secure and Intelligent Access Control Policy Adapter for Big Data Environment
355

6 CONCLUSION
We presented an approach that offers a comprehen-
sive framework for anomaly detection in access con-
trol logs using time series analysis and machine learn-
ing. It combines static rules with behavioral pat-
terns to identify unusual activity. Based on identified
anomalies, the proposed system adapt automatically
the Apache Ranger policies, core functionalities like
caching, log storage, ML Model, and initial anomaly
detection using different agents are operational and
show promise.
To ensure our anomaly detection system stays
adaptive and responsive, we plan to implement on-
line learning techniques. This approach will allow
our models to continuously learn and adjust from new
data without the need for retraining, thereby maintain-
ing their accuracy and effectiveness over time. This
strategic focus not only aims to enhance security mea-
sures but also to adapt dynamically to ever-changing
data landscapes, ultimately supporting robust and re-
silient access control policies.
REFERENCES
Alzahrani, B., Cherif, A., Alshehri, S., and Imine, A.
(2024). Securing big graph databases: an overview
of existing access control techniques. International
Journal of Intelligent Information and Database Sys-
tems.
Argento, L., Margheri, A., Paci, F., Sassone, V., and Zan-
none, N. (2018). Towards adaptive access control.
In IFIP Annual Conference on Data and Applications
Security and Privacy, pages 99–109. Springer.
Awaysheh, F. M., Alazab, M., Gupta, M., Pena, T. F., and
Cabaleiro, J. C. (2020). Next-generation big data fed-
eration access control: A reference model. Future
Generation Computer Systems, 108:726–741.
Basin, D., Guarnizo, J., Krstic, S., Nguyen, H., and Ochoa,
M. (2023). Is modeling access control worth it? In
Proceedings of the 2023 ACM SIGSAC Conference
on Computer and Communications Security, pages
2830–2844.
Bl
´
azquez-Garc
´
ıa, A., Conde, A., Mori, U., and Lozano,
J. A. (2021). A review on outlier/anomaly detection
in time series data. ACM Computing Surveys (CSUR),
54(3):1–33.
Das, S., Sural, S., Vaidya, J., and Atluri, V. (2019). Policy
adaptation in hierarchical attribute-based access con-
trol systems. ACM Transactions on Internet Technol-
ogy (TOIT), 19(3):1–24.
Gupta, M., Patwa, F., and Sandhu, R. (2017). Object-tagged
rbac model for the hadoop ecosystem. In IFIP An-
nual Conference on Data and Applications Security
and Privacy, pages 63–81. Springer.
Huang, H., Zhang, J., Hu, J., Fu, Y., and Qin, C. (2022). Re-
search on distributed dynamic trusted access control
based on security subsystem. IEEE Transactions on
Information Forensics and Security, 17:3306–3320.
Jiang, R., Han, S., Yu, Y., and Ding, W. (2023). An access
control model for medical big data based on clustering
and risk. Information Sciences, 621:691–707.
John, T. and Misra, P. (2017). Data lake for enterprises.
Packt Publishing Ltd.
Karimi, L., Abdelhakim, M., and Joshi, J. (2021). Adap-
tive abac policy learning: A reinforcement learning
approach. arXiv preprint arXiv:2105.08587.
Li, G. and Jung, J. J. (2023). Deep learning for anomaly de-
tection in multivariate time series: Approaches, appli-
cations, and challenges. Information Fusion, 91:93–
102.
Premkamal, P. K., Pasupuleti, S. K., Singh, A. K., and
Alphonse, P. (2021). Enhanced attribute based access
control with secure deduplication for big data storage
in cloud. Peer-to-Peer Networking and Applications,
14:102–120.
Qin, Y. and Lou, Y. (2019). Hydrological time series
anomaly pattern detection based on isolation forest.
In 2019 IEEE 3rd information technology, network-
ing, electronic and automation control conference (IT-
NEC), pages 1706–1710. IEEE.
Ren, H., Xu, B., Wang, Y., Yi, C., Huang, C., Kou, X., Xing,
T., Yang, M., Tong, J., and Zhang, Q. (2019). Time-
series anomaly detection service at microsoft. In Pro-
ceedings of the 25th ACM SIGKDD international con-
ference on knowledge discovery & data mining, pages
3009–3017.
Shan, D., Du, X., Wang, W., Wang, N., and Liu, A. (2024).
Kpi-hgnn: Key provenance identification based on a
heterogeneous graph neural network for big data ac-
cess control. Information Sciences, 659:120059.
Walter, M. (2023). Context-based Access Control and At-
tack Modelling and Analysis. PhD thesis, Dissertation,
Karlsruhe, Karlsruher Institut f
¨
ur Technologie (KIT),
2023.
Xu, H., Pang, G., Wang, Y., and Wang, Y. (2023). Deep
isolation forest for anomaly detection. IEEE Transac-
tions on Knowledge and Data Engineering.
SECRYPT 2024 - 21st International Conference on Security and Cryptography
356
