
Multi-Criteria Decision-Making Approach for an Efficient
Postproduction Test of Reconfigurable Hardware System
Asma Ben Ahmed, Fadwa Oukhay and Olfa Mosbahi
Universit
´
e de Carthage, Institut National des Sciences Appliqu
´
ees et de Technologie, LR11ES26,
Laboratoire d’Informatique pour les Syst
`
emes Industriels (LISI), 1080, Tunis, Tunisia
Keywords:
Postproduction Test, Multi-Criteria Decision-Making, AHP, Choquet Integral.
Abstract:
This paper proposes a multi-criteria decision-making approach for guiding the postproduction test of reconfig-
urable hardware system (RHS). The latter is a hardware device that allows to change the hardware resources
at runtime in order to modify the system functions and dynamically adapt the system to its environment. The
optimization of the RHS postproduction test process is a matter of concern for manufacturers since the testing
activities have a significant impact on achieving manufacturing objectives in relation to quality, cost and, time
control. Taking into account the fact that testing all potential faults is infeasible in practice, the testing process
hence needs to be optimized by prioritizing faults according to a well-defined set of criteria. Accordingly,
multi-criteria decision-making tools prove their effectiveness in selecting faults to be tested. The proposed
method consists in targeting a limited number of faults that require more attention during the testing process.
Two strategies are investigated through the recourse to analytic hierarchy process and Choquet Integral. This
study helps to determine the most critical faults that have the highest risk priority score. A case study is pro-
vided to illustrate the application of the proposed approach and to support the discussion.
1 INTRODUCTION
Over the last decade, embedded systems have wit-
nessed an outstanding growth to meet technological
advancements. Due to the fact that the new generation
of embedded systems is addressing new criteria such
as flexibility and agility, reconfigurability has become
an evolving approach in real-world applications and
scientific research. Therefore, a new class of systems,
which is fundamentally based on the ability to change
has emerged. An RHS is a hardware device that per-
mits to change the hardware resources at runtime in
order to modify the system functions and therefore
to dynamically adapt the system to its environment
(Ben Ahmed et al., 2018b). As the hardware system
manufacturing process is imperfect, several defects
including open circuits, bridging and stuck-at faults
may occur. Taking into account that these systems are
increasingly fragile and safety-critical and that the ac-
tual industrial world is facing the challenge of zero
defect, testing becomes an essential step for acquir-
ing fault-free and high-quality devices (Eggersgl
¨
uß,
2019). The postproduction test is a crucial phase of
the hardware development process. It ensures that the
system is defect-free before it is released to the cus-
tomers. In industry, the most popular model is the
single stuck-at line (SSL) model (Pomeranz, 2020).
Given a device under test (DUT) and a fault model,
it is possible to construct the initial fault set which
contains all possible faults in the DUT. As the cost
of the testing process is intensely influenced by the
number of faults to be tested as well as the number
of test vectors to be applied, many interesting aca-
demic and industrial techniques have been carried out
to tackle this issue. In this context, the authors in (Eg-
gersgl
¨
uß et al., 2023) introduce a method that aims
to reduce the number of automatic test pattern gen-
eration (ATPG). This issue is addressed by produc-
ing compact test sets and hence minimizing the vol-
ume of test data , test application time, and automat-
ically the cost of testing. The study in (Yang et al.,
2021) concentrates on the generation of high-speed
digital test vector to accelerate the testing process and
therefore allowing the detection of fault rapidly. Fur-
ther approaches, so far, investigate a machine learn-
ing based fault diagnosis (Higami et al., 2022). The
method does not require the performance of fault sim-
ulation or needs fault dictionaries storage for figuring
out the candidate faults. The work in (Kung et al.,
2018) presents a new test pattern generation flow to
Ben Ahmed, A., Oukhay, F. and Mosbahi, O.
Multi-Criteria Decision-Making Approach for an Efficient Postproduction Test of Reconfigurable Hardware System.
DOI: 10.5220/0012862300003753
Paper published under CC license (CC BY-NC-ND 4.0)
In Proceedings of the 19th International Conference on Software Technologies (ICSOFT 2024), pages 511-518
ISBN: 978-989-758-706-1; ISSN: 2184-2833
Proceedings Copyright © 2024 by SCITEPRESS – Science and Technology Publications, Lda.
511

target both stuck-at and transition faults at the same
time in one ATPG run without recourse to changing
the ATPG tool. A compact pattern set can hence
be obtained. It needs less volume of test data and
shorter time of test application without affecting the
fault coverage for both types of faults. The above-
cited works focus in the optimization of the testing
process through the reduction of the number of test
vectors.
As already mentioned, the optimization of the
number of faults is also worth considering. In fact,
testing all faults is practically infeasible as it strongly
increases the manufacturing costs and time delays.
Hence, the number of faults to be targeted during the
testing process crucially requires optimization. Con-
siderable work has focused on reducing the number of
faults particularly for RHS. The work in (Ben Ahmed
et al., 2018b) investigates a new testing methodol-
ogy using the inter-circuits relationships. Such a test-
ing method provides an optimal fault set that can be
efficiently used for testing purposes. The work in
(Ben Ahmed et al., 2019) presents a new extension
of the standardized boundary scan test method. The
endeavor is to work on a test approach that offers
the flexibility and convenience needed to test RHS
based on combinational and sequential logic while
ensuring an optimal time and cost. The authors in
(Ben Ahmed et al., 2018a) introduce concepts of oc-
currence and severity ratings in the RHS testing pro-
cess as a means to target the minimal necessary set of
faults while ensuring an acceptable fault coverage rate
that meets manufacturing quality requirements. For
so doing, the authors propose an alternative for the
overall fault coverage that provides guidance for rank-
ing potential faults in terms of their occurrence and
severity. However, it is possible to take into account
other decision criteria such as controllability and ob-
servability. Multi-criteria decision-making (MCDM)
tools are therefore helpful when considering multiple
factors before making a final choice.
In this research paper, we introduce a guiding
method for prioritizing potential faults according the
following set of criteria: occurrence, severity, control-
lability and observability. To put it differently, a fault
is weighted according to how frequently it can occur,
how serious its consequence on system functionality,
safety, etc. It is also about how controllable and ob-
servable it is. Taking into account that not all faults
are worth pursuing since they do not have the same
degree of the previously mentioned criteria, this pa-
per investigates the use of analytic hierarchy process
(AHP) and Choquet Integral (CI) to identify the most
critical faults. First, the AHP makes it possible to as-
sess the faults based on each criterion and therefore
to provide a global risk priority score (RPS). The lat-
ter enables selecting the subset of faults that need to
be targeted during the testing process. In the second
phase, the CI operator is employed for the aggregation
of the partial scores obtained for the different faults
according to each criterion in order to deal with the
preferential interactions between the criteria. There-
fore, the risk assessment will be more accurate. As
a consequence, targeting a limited number of faults
helps the industry to optimize test resources alloca-
tion without mitigating the correctness of the system.
The originality of this research, compared to ex-
isting works, lies in considering the risk-based cri-
teria needed for selecting faults to be targeted dur-
ing the testing process. This research also differs in
its use of MCDM tools allowing the reduction of the
targeted fault set without affecting the correctness of
the system. It is feasible to note that MCDM tools
are existing concepts in the literature that are used
for supporting complex decision-making processes in
various domains (Oukhay et al., 2021). However, in
this paper they have been coupled with hardware fault
techniques for reconfigurable systems.
The remainder of this paper is organized as fol-
lows: Section II presents the decision-making frame-
work based on risk optimization in the RHS test pro-
cess. Section III introduces the proposed MCDM
method for selecting the targeted faults. Section IV
deals with the suggested case study and highlights
some numerical results that prove the worth of the
contribution. Section V concludes this paper.
2 DECISION-MAKING
FRAMEWORK BASED ON RISK
FOR OPTIMIZING THE RHS
TEST PROCESS
Taking into account that testing all faults is infeasible
in the practice as it strongly increases the manufac-
turing time and cost, the testing process need to be
optimized. For a given DUT and with respect to SSL
fault model, an initial set of faults that includes all po-
tential faults is defined. This fault set can be reduced
through intra-circuit fault collapsing which helps re-
ducing faults via equivalence and dominance relation-
ships (Prasad et al., 2002) (Venkatasubramanian et al.,
2015). The application of this technique minimizes to
some extent faults occurring within the same circuit.
The inter-circuits fault collapsing techniques is there-
fore processed generating a more important reduction
of faults.
As shown in Figure 1, faults generated using the
ICSOFT 2024 - 19th International Conference on Software Technologies
512
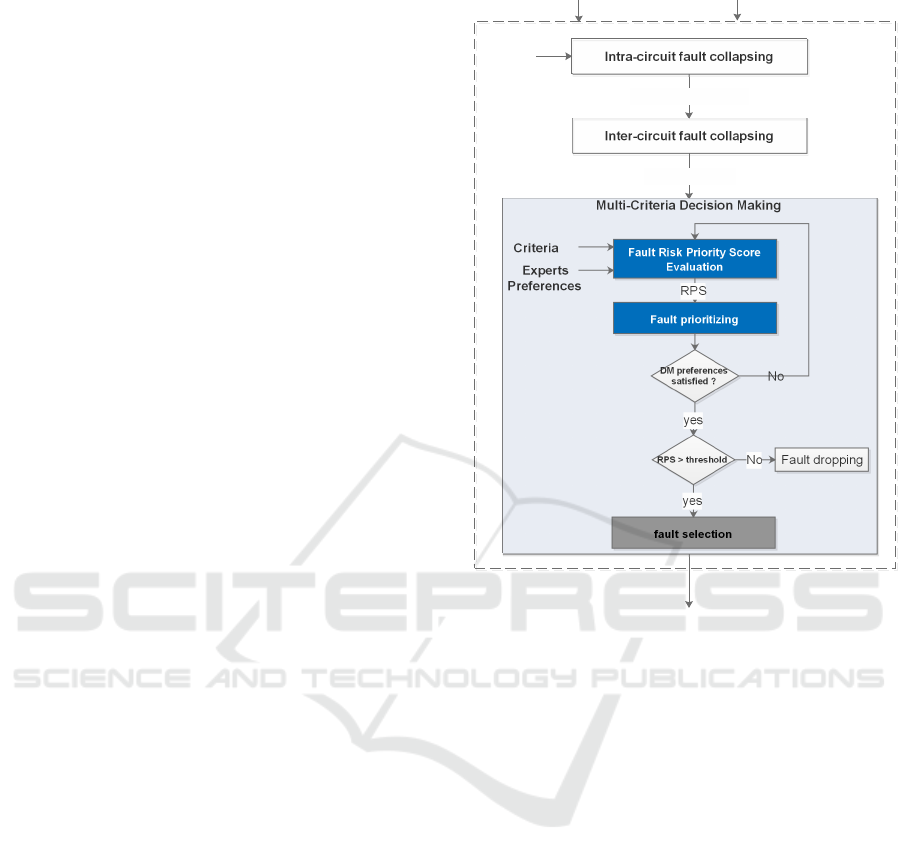
inter-circuit fault collapsing present the starting point
of our current approach. In fact, in order to assure ef-
ficiency, we propose in this work to focus the testing
process on the critical potential faults. The latter are
the faults that present the highest level of risk since
their appearance would engender significant quality
degradation. This is supported by the argument that
pursuing faults having trivial impacts on system func-
tionality would be a waste of resources and time. Ac-
cordingly, identifying the faults to be addressed in
testing can be viewed as a decision-making task in
which assessing the risks associated with the candi-
date faults is needed. In this work, the risk degree of
a fault is assessed by calculating the RPS. The latter
includes multiple criteria: the likelihood of fault oc-
currence, the degree of severity of the effect, the de-
gree of controllability of the fault and, the degree of
its observability. The evaluation of the RPS is based
on the experts knowledge regarding the criticality of
the faults and it incorporates the decision-maker pref-
erences regarding the relative importance of the pre-
viously mentioned criteria. The experts define an ac-
ceptable level of risk (threshold) according to which
a decision about the fault is made. Potential faults
having RPS lower than the threshold do not need to
be tested. On the other hand, critical faults with RPS
that is higher than the threshold are included in the
testing process. In the following part, we provide an
MCDM approach for calculating the RPS.
3 PROPOSED MCDM METHOD
FOR SELECTING THE
TARGETED FAULTS
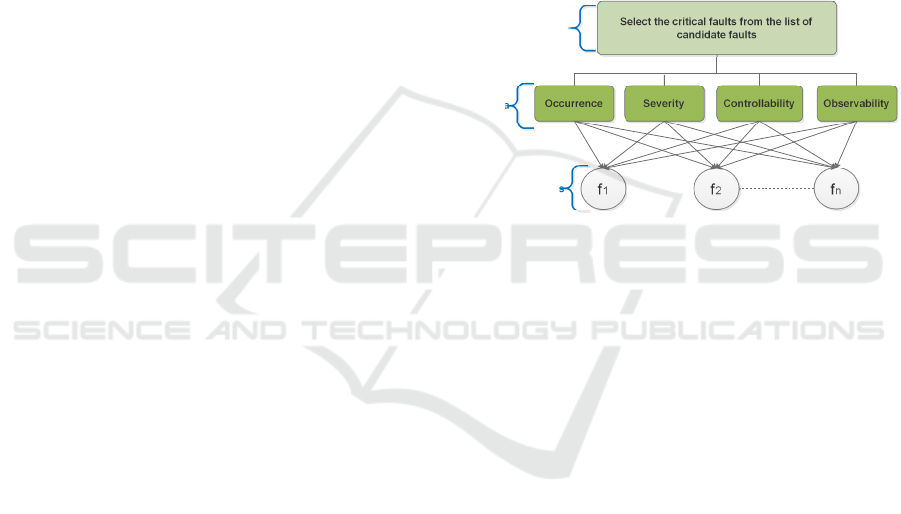
3.1 Method Description
The proposed MCDM method, consisting of five steps
is explained in the following:
Step1: Specify the objective. The goal defined in this
study is to evaluate and prioritize the different faults
occurring within the RHS. The evaluation is done ac-
cording to a finite set of criteria in order to select
faults that require more attention during the testing
process and therefore to reduce testing workload and
allow better resource allocation.
Step 2: Specify the criteria. Let D be a finite set
of criteria denoted by D = {d
1
,d
2
,...,d
p
}. To address
and test faults in a circuit, the concepts of occurrence,
severity controllability and observability play a major
role for so doing. Each criterion is defined as follows:
• Occurrence: It gives us an idea about how often
faults can occur. Occurrence can provide informa-
DUT Fault Model
Initial
fault set
Intermediate fault set
Candidate faults
Minimal target fault set
Figure 1: Decision-making framework based on risk for
RHS test process optimization.
tion that help estimate or foreshadow future fre-
quency. Given that faults are not likely to occur
with the same frequency, they need to be weighted
by an occurrence rate. The latter estimates the
occurrence frequency of a fault. Faults with the
highest occurrence rate need to be addressed in
priority.
• Severity: It means the degree of seriousness of a
fault measured by its impact on system function-
ality, performance, safety, or other critical factors.
It is basically measured on a scale, with higher
levels determining more critical issues that need
immediate attention. Poor severity, however, indi-
cates that faults do not affect the functionality of
the system and therefore can be ignored.
• Controllability: It refers to the quickness of set-
ting 0 or 1 values at any point within a system
through its inputs. Good controllability is defined
by the direct manipulation of the system allowing
to excitation of the fault as well as the observa-
tion of its effects. However, poor controllability
problematizes the quick isolation of the fault due
Multi-Criteria Decision-Making Approach for an Efficient Postproduction Test of Reconfigurable Hardware System
513
to the fact that the application of inputs might not
activate it. Thus, faults having poor controllabil-
ity present high risk level and require the highest
attention during testing.
• Observability: It indicates the ability to determine
the value at any point within a system by observ-
ing its outputs. It permits the understanding of the
impact of the fault on the system outputs. Low
observability, on the contrary, makes it hard to
differentiate the fault from normal system behav-
ior which problematizes the pinpointing of faults.
Therefore, it is mandatory to focus on faults hav-
ing low observability during the testing process.
The faults are then assessed according to each crite-
rion based on the experts judgement using the AHP
method as described in details in the following steps.
Step 3: Specify the candidate faults set. Let F
be a finite set of potantial faults denoted by F =
{ f
1
, f 2,..., f
n
}.
Step 4: Employ AHP method to assess and prioritize
faults. This step is explained in details in Subsection
3.2.
Step 5: Employ the CI to prioritize faults. This step
is explained in details in Subsection 3.3.
3.2 Prioritizing Faults Using the AHP
Technique
The AHP, also known as Saaty method, is a versa-
tile tool for MCDM that can be applied in different
contexts (Saaty, 1990). In this research paper, the re-
course to AHP is justified by the fact that this method
allows the organization of the problem of selecting
a limited number of faults which require more atten-
tion into a hierarchical structure of objective, crite-
ria, and alternatives. Furthermore, the AHP facilitates
the extraction of the relative performance scores of
the alternatives associated with each individual crite-
rion as well as the relevance weights of the criteria
through a series of pairwise comparisons. In addition,
it provides a mechanism for checking and improving
the evaluations consistency, which differentiate AHP
from other multi-criteria tools. The application of this
method for selecting a subset of faults is carried out
through five major steps:
1. Identify the problem and determine the main
objective: selecting a limited number of faults which
require more attention during the testing process.
2. Organize the problem into a hierarchy of lev-
els that comprise the objective, the criteria, the sub-
criteria, and the alternatives as described in Figure 2.
3. Make pairwise comparison matrices for each
element using the Saaty 9-point scale to determine the
relative weights of the criteria and alternatives (candi-
date faults).
4. Determine the weighted average for each can-
didate fault according to the following Equation.
X
i
=
p
∑
j=1
(x
i j
.w
j
) (1)
where w
j
is the weight of criterion j with w
j
>= 0,
sum(w
j
) = 1 and x
i j
is the partial score of the alterna-
tive i according to the criterion j.
5. Based on the obtained risk priority scores of the
faults represented by X
i
, the target faults are selected.
A risk threshold is defined and the faults with RPS
higher than the threshold are chosen to be included in
the testing process.
Objective
Criteria
Alternatives
Figure 2: Hierarchy scheme for faults selection.
3.3 Prioritizing Faults Using the CI
As part of the AHP technique, the weighted aver-
age (equation (1)) is used to aggregate these partial
scores of the candidate faults in order to calculate the
global scores X
i
. Since it assumes the criteria’s in-
dependence, this operator cannot represent preferen-
tial relationships between the criteria. As a result, it
is unreliable because the interactions frequently oc-
cur (Mandic et al., 2015). We suggest utilizing the
CI to address the aggregation problem in order to be
able to consider interaction phenomena among crite-
ria. The CI operator allows to model not only the sig-
nificance of each criterion but also the weighting of
each subset of criteria, based on a monotone set func-
tion known as the Choquet capacity or fuzzy measure
(Marichal, 2000). Fuzzy measurement can describe
three different kinds of criteria interactions (Grabisch
et al., 2008): (1) Negative synergy or negative inter-
action: When two criteria i and j are viewed by the
DM as redundant, they interact negatively; that is, the
significance of the pair {i, j} is nearly equal to the
significance of the individual criterion i and j. (2)
Positive interaction, also known as positive synergy, is
the presence of an interaction between criteria that are
deemed complementary, meaning that while the sig-
nificance of a single criterion is negligible, the signif-
ICSOFT 2024 - 19th International Conference on Software Technologies
514
icance of the pair is considerable. (3) Independence:
When there is no interaction between two criteria, i
and j are said to be independent. The fuzzy measure
is additive in this instance: µ(i, j) = µ(i) + µ( j).
Some numerical indices, including the Shap-
ley value (Shapley, 1953) and the interaction index
(Murofushi and Soneda, 1993), can be computed to
help describe the interaction phenomena more fully.
A criterion’s overall relevance is measured by its
Shapley value, and the average interaction between
two criteria, i and j, is measured by its interaction in-
dex.
Let F be the set of faults and f
i
∈ S ,the global
score X
i
given by the CI according to a fuzzy measure
µ and a set C of criteria, is defined by:
CI
µ
(x
i1
,··· , x
ip
) =
p
∑
j=1
(x
i( j)
[µ(A
( j)
− µ(A
( j−1)
]) (2)
Where the notation
(.)
indicates a permutation on C
such as x
i(1)
≤ ··· ≤ x
i(p)
. Also, A
( j)
= {(1)···(p)} ,
for all j ∈ {1,...n, p} and A
(p−1)
= φ.
The identification of capacities is the main diffi-
culty while working with aggregation using the CI
based on fuzzy measurements. A survey of tech-
niques for capacity identification in multi-attribute
utility theory based on CI is provided by the authors
in (Grabisch et al., 2008). The least squares approach,
which is the most popular optimization technique for
this purpose in the literature, is what we employ in our
work (Grabisch et al., 2008). Further understanding
of the intended overall evaluations Y
i
of the accessi-
ble items S
i
∈ S is necessary. Minimizing the overall
quadratic error E
2
between the global scores deter-
mined by the CI and the targeted scores Y
i
supplied
for each scenario is the aim of the least squares tech-
nique. To further enhance the outcomes, the heuris-
tic least squares approach may be applied. An initial
capacity must be defined in order to use the heuris-
tic approach. The uniform capacity might be utilized
because it is challenging to determine the beginning
capacity (Grabisch et al., 2008). The definition of the
uniform capacity in this instance is as follows:
µ(1) = 0.333333 ; µ(2) = 0.333333;
µ(3) = 0.333333 ; µ(1,2) = 0.666667;
µ(1,3) = 0.666667 ; µ(2,3) = 0.666667;
µ(1,2,3) = 1.000000
4 CASE STUDY
In this section, we provide a case study using an RHS
circuit to demonstrate the proposed contribution.
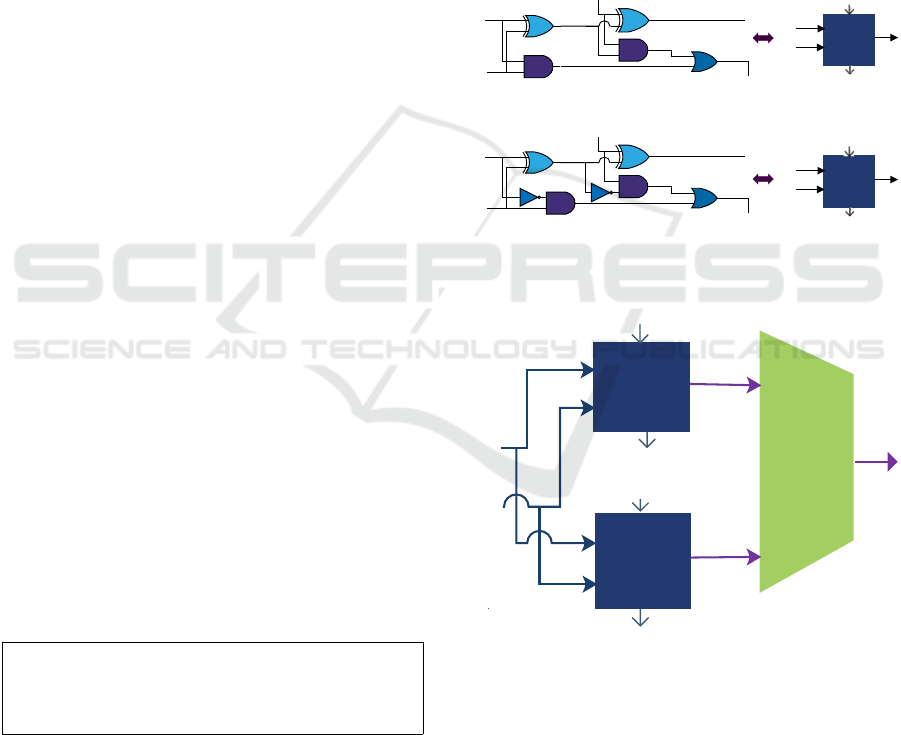
4.1 Presentation
To further illustrate the proposed contribution, we
present a case study where hardware components can
be added, removed or updated to ensure the adequate
functionality of the system when needed. The system
presents two units that can perform addition and sub-
traction operations. These units are designed using
lower-level components such as logic gates, includ-
ing AND, OR, XOR gates and multiplexers and they
are also constructed using reconfigurable hardware as
shown in Figure 3. At a given time, the selection of
the unit is controlled by a multiplexer MUX as shown
in Figure 4.
S
1
S
2
a b
c e
d f
G1
G2
G3
G4
C
in
B
out
G5
g
j
k
h
i
l
o
m
n
p
a- Addition operation (C
111
)
S
1
S
2
a b
c e
d f
G1
G2
G3
G4
G5
g
j
k
h
i
l
o
m
n
p
G
1'
G
3'
c’
i’
B
in
b- Subtraction operation (C
211
)
S
1
1-Bit
Full adder
C
in
C
out
S
2
S
1
1-Bit
Full
subtractor
B
in
B
out
S
2
C
out
Figure 3: Different reconfigurations implementing the pro-
posed RHS.
MUX
S
1
S
2
B
in
B
out
1-bit
Full adder
C
in
C
out
1-bit
Full
subtractor
Figure 4: The proposed RHS.
Assumptions: Let’s assume that stuck-at 1 faults
occur more frequently than stuck-at 0 faults. Addi-
tionally, we assume that the faults in NOT gate are of
high occurrence and faults in AND gate are of a less
higher occurrence. However, faults in XOR and OR
gates are almost non-existent. The severity of faults
in OR gate is much higher than those in AND gate.
Faults in XOR and NOT gates are however of a very
low severity. Let’s assume also that a stuck-at fault, in
Multi-Criteria Decision-Making Approach for an Efficient Postproduction Test of Reconfigurable Hardware System
515
a digital circuit, might be easily controllable only if an
input has a direct impact on the faulty node. Never-
theless, if the fault is hidden deep within the circuit,
controllability might be low. Moreover, determining
the observability of a faulty circuit output is less ap-
parent when the degree of similarity between a fault-
free circuit output and a faulty one is very high.
According to the case study, the application of
previous fault collapsing techniques (Ben Ahmed
et al., 2018b) reduces the number of faults from 34 to
11 faults. Therefore, the list of candidate faults are as
follows:
F={d/0 C111, d/1 C111, e/0 C111, e/1 C111,
e/1 C111, g/0 C111, g/1 C111, i/1 C111,
f/1 C211, i/1 C211, p/0 C211}
where d/0 C111 means that the signal d is stuck-at 0
in the circuit C111 (addition operation).
4.2 Numerical Results
The results of the AHP approach for ranking the
faults based on their risk priority score are shown
in Table 1. Based on the obtained AHP results, the
faults to be included in the test process are those
that have an RPS higher than the risk threshold
defined by the expert. In this case, the threshold is
the mean between all the scores (threshold = 0.091).
Accordingly, the selected faults are;
p/0 C211 ; i/1 C211 ; d/1 C111 ; i/1 C111 ;
f/1 C211 ; f/1 C111
To enhance incorporating the expert’s preferences
into the decision process, the CI is employed in
the second part of the approach to calculate the
RPS instead of the weighted average used in AHP.
Initially, the decision maker is asked to provide a
preference order for a pertinent subset of faults,
meaning a subset that is thought to be especially
helpful in representing his preferences regarding the
criticality of faults:
p/0 C211 ≻ i/1 C211 ≻ f/1 C111 ≻ f/1 C211 ≻
e/0 C111 ≻ e/1 C111
The desired total scores that are associated with
this are Y
i
= [0.2230.1300.1040.1020.0260.025)].
Next, the heuristic least squares method is used to cal-
culate the Choquet capacity. Above are the capacities
attained:
µ({d
1
}) = 0.163;µ({d
2
}) = 0.267;µ({d
3
}) = 0;
µ({d
4
}) = 0.207;µ({d
1
,d
2
}) = 0.527;
µ({d
1
,d
3
}) = 0.488;µ({d
1
,d
4
}) = 0.452;
µ({d
2
,d
3
}) = 0.606;µ({d
2
,d
4
}) = 0.548;
µ({d
3
,d
4
}) = 0.400;µ({d
1
,d
2
,d
3
}) = 0.803 ;
µ({d
1
,d
2
,d
4
}) = 0.788,µ({d
1
,d
3
,d
4
}) = 0.697;
µ({d
2
,d
3
,d
4
}) = 0.606,µ({d
1
,d
2
,d
3
,d
4
}) = 1
The obtained faults RPS using the CI are repre-
sented in Table 1. Accordingly, the faults that have
RPS higher than the threshold (threshold = 0.086)
are:
p/0
C
211;i/1
C
211;i/1
C
111; f /1
C
211; f /1
C
111
We notice that when using the weighted average the
faults to be tested are reduced to 6 faults. However,
when using the CI operator the faults are reduced to
5 faults. This result can be explained by taking into
account the decision maker’s preferences with regard
to the relative weight of the criteria, particularly
the way they interact. This can be analyzed more
thoroughly by computing the Shapley Values φ
µ
and
the interactions indices I
µ
parameters.
φ
µ
(d
1
) = 0.283 ; φ
µ
(d
2
) = 0.323 ; φ
µ
(d
3
) = 0.173 ;
φ
µ
(d
4
) = 0.221 ; I
µ
(d
1
,d
2
) = 0.015 ; I
µ
(d
1
,d
3
) =
0.157 ; I
µ
(d
1
,d
4
) = 0.057 ; I
µ
(d
2
,d
3
) = 0.071 ;
I
µ
(d
2
,d
4
) = −0.05 ; I
µ
(d
3
,d
4
) = −0.017 ;
The severity criterion d
2
in this instance is the
most important, followed by the occurrence, ob-
servability, and controllability criteria. The criteria
{severity, observability} and {observability, control-
lability} interact negatively, i.e., they present some re-
dundancy, whereas the criteria {occurrence, severity}
{occurrence, controllability }, {occurrence, observ-
ability }and, {severity, controllability} have positive
interactions.
To sum up, with respect to the proposed RHS the
application of this approach decreases the number of
faults from 11 to 6 and 5 (almost the half) using the
AHP technique and the AHP combined with CI, re-
spectively. The obtained fault set presents the critical
faults posing the greatest risk. These faults have to
be targeted during the testing process. The proposed
system can be part of a more complex digital circuit
such as the commonly used reconfigurable arithmetic
and logic unit (R-ALU) (Ben Ahmed et al., 2018b).
The n-bit R-ALU can be constructed by chaining n
1-bit R-ALU. For instance, in a 256 R-ALU, we ob-
tain 256*11=2816 candidate faults. The application
of AHP approach decreases drastically the number
of faults to 1536. This reduction reaches 1280 faults
when using AHP combined with CI.
For mass production, supposing that for each tar-
geted fault we need on average two test vectors, and
ICSOFT 2024 - 19th International Conference on Software Technologies
516
Table 1: Priority rankings derived using the AHP technique and CI.
Criteria d
1
: Occurrence d
2
: Severity d
3
: Controllability d
4
: Observability RPS RPS
Weights w
1
= 0.319 w
2
= 0.53 w
3
= 0.044 w
4
= 0.106 with AHP with CI
d/0 C111 0.117 0.072 0.021 0.026 0.0.79 0.057
d/1 C111 0.196 0.072 0.021 0.026 0.104 0.069
e/0 C111 0.016 0.026 0.032 0.041 0.025 0.026
e/1 C111 0.024 0.026 0.032 0.026 0.026 0.025
f/1 C111 0.066 0.109 0.032 0.203 0.102 0.102
g/0 C111 0.04 0.055 0.1 0.031 0.050 0.047
g/1 C111 0.052 0.055 0.1 0.045 0.055 0.052
i/1 C111 0.102 0.082 0.146 0.203 0.104 0.125
f/1 C211 0.057 0.118 0.032 0.203 0.104 0.103
i/1 C211 0.317 0.018 0.145 0.123 0.130 0.130
p/0 C211 0.014 0.37 0.34 0.075 0.223 0.220
that the test application time of a test vector takes
1s and one working hour costs $10, then for a 256-
bit R-ALU the total cost of 1000 256-bit R-ALU de-
vices will be about $15600 using the existing tech-
niques (Ben Ahmed et al., 2018b) (Prasad et al., 2002)
and about $8500 and $7100 using AHP approach and
AHP coupled with CI, respectively. We notice that
the difference between the costs is considered tremen-
dous in mass production industry.
This study is important in a way that (1) it guides
experts to identify faults that necessitate immediate
attention due to their criticality score (2) it supports
allocating resources and efforts more efficiently and
(3) it helps to save the scarcest resource in the indus-
try, which is time and cost.
5 CONCLUSIONS
This study presents a MCDM approach to prioritize
faults that require more attention during the testing
process. This approach is based on a well-defined set
of criteria: occurrence, severity, controllability and
observability and is implemented using the AHP and
CI. The effectiveness of the proposed approach lies
in helping prioritize resources and efforts towards ad-
dressing the most critical faults posing the greatest
risk. It is feasible to note as a conclusion that two
major results of our study can be signaled. First, it in-
troduces a MCDM approach that allows the reduction
of the targeted fault set without affecting the correct-
ness of the system. Second, it implies that resources
are allocated in an efficient manner. In future work,
we plan to add other criteria such as fault coverage
and to incorporate the proposed approach in the soft-
ware tool TnTest
1
.
1
https://lisi-lab-projects.wixsite.com/demo/demonstration
REFERENCES
Ben Ahmed, A., Mosbahi, O., and Khalgui, M. (2018a). En-
hanced test for reconfigurable hardware systems based
on sequential logic. In 2018 IEEE 16th International
Conference on Embedded and Ubiquitous Computing
(EUC), pages 45–53.
Ben Ahmed, A., Mosbahi, O., Khalgui, M., and Li, Z.
(2018b). Toward a new methodology for an effi-
cient test of reconfigurable hardware systems. IEEE
Transactions on Automation Science and Engineer-
ing, 15(4):1864–1882.
Ben Ahmed, A., Mosbahi, O., Khalgui, M., and Li, Z.
(2019). Boundary scan extension for testing dis-
tributed reconfigurable hardware systems. IEEE
Transactions on Circuits and Systems I: Regular Pa-
pers, 66(7):2699–2708.
Eggersgl
¨
uß, S. (2019). Towards complete fault coverage by
test point insertion using optimization-sat techniques.
In 2019 IEEE International Test Conference in Asia
(ITC-Asia), pages 67–72.
Eggersgl
¨
uß, S., Milewski, S., Rajski, J., and Tyszer, J.
(2023). A new static compaction of deterministic test
sets. IEEE Transactions on Very Large Scale Integra-
tion (VLSI) Systems, 31(4):411–420.
Grabisch, M., Kojadinovic, I., and Meyer, P. (2008). A re-
view of methods for capacity identification in choquet
integral based multi-attribute utility theory: Applica-
tions of the kappalab r package. European journal of
operational research, 186(2):766–785.
Higami, Y., Yamauchi, T., Inamoto, T., Wang, S., Taka-
hashi, H., and Saluja, K. K. (2022). Machine learning
based fault diagnosis for stuck-at faults and bridging
faults. In 2022 37th International Technical Confer-
ence on Circuits/Systems, Computers and Communi-
cations (ITC-CSCC), pages 477–480.
Kung, Y.-C., Lee, K.-J., and Reddy, S. M. (2018). Generat-
ing compact test patterns for stuck-at faults and transi-
tion faults in one atpg run. In 2018 IEEE International
Test Conference in Asia (ITC-Asia), pages 1–6.
Mandic, K., Bobar, V., and Deliba
ˇ
si
´
c, B. (2015). Model-
ing interactions among criteria in mcdm methods: a
Multi-Criteria Decision-Making Approach for an Efficient Postproduction Test of Reconfigurable Hardware System
517

review. In Decision Support Systems V–Big Data An-
alytics for Decision Making, pages 98–109.
Marichal, J.-L. (2000). An axiomatic approach of the dis-
crete choquet integral as a tool to aggregate inter-
acting criteria. IEEE transactions on fuzzy systems,
8(6):800–807.
Murofushi, T. and Soneda, S. (1993). Techniques for read-
ing fuzzy measures (iii): interaction index. In 9th
fuzzy system symposium, pages 693–696. Sapporo,,
Japan.
Oukhay, F., Badreddine, A., and Romdhane, T. B. (2021).
Towards a new knowledge-based framework for inte-
grated quality control planning. European Journal of
Industrial Engineering, 15(5):583–615.
Pomeranz, I. (2020). Broadside tests for transition and
stuck-at faults. IEEE Transactions on Computer-
Aided Design of Integrated Circuits and Systems,
39(8):1739–1743.
Prasad, A., Agrawal, V., and Atre, M. (2002). A new algo-
rithm for global fault collapsing into equivalence and
dominance sets. In Proceedings. International Test
Conference, pages 391–397.
Saaty, T. L. (1990). How to make a decision: The analytic
hierarchy process. European Journal of Operational
Research, 48(1):9–26. Desicion making by the ana-
lytic hierarchy process: Theory and applications.
Shapley, L. S. (1953). A value for n-person games. In Kuhn,
H. W. and Tucker, A. W., editors, Contributions to the
Theory of Games II, pages 307–317. Princeton Uni-
versity Press, Princeton.
Venkatasubramanian, M., Agrawal, V. D., and Janaher, J. J.
(2015). Quest for a quantum search algorithm for test-
ing stuck-at faults in digital circuits. In 2015 IEEE In-
ternational Symposium on Defect and Fault Tolerance
in VLSI and Nanotechnology Systems (DFTS), pages
127–132.
Yang, W., Hui, J., Yin, K., Dai, Z., and Deng, K. (2021).
Test vector generation for high-speed digital inte-
grated circuits. In 2021 IEEE 4th Advanced Infor-
mation Management, Communicates, Electronic and
Automation Control Conference (IMCEC), volume 4,
pages 1516–1521.
ICSOFT 2024 - 19th International Conference on Software Technologies
518
