
Utilizing Data Analysis for Optimized Determination of the Current
Operational State of Heating Systems
Ahmed Qarqour
1,2,*
, Sahil-Jai Arora
1,3,* a
, Gernot Heisenberg
2b
,
Markus Rabe
3, c
and Tobias Kleinert
4d
1
Bosch Thermotechnik GmbH, Junkersstraße 20-24, 73243 Wernau (Neckar), Germany
2
Department of Information Management, TH Cologne University, Claudiusstraße 1, 50678 Köln, Germany
3
Department IT in Production and Logistics, TU Dortmund University, 44221 Dortmund, Germany
4
Department of Information and Automation Systems for Process and Material Technology,
RWTH Aachen University, Turmstraße 46, 52064 Aachen, Germany
Keywords: Heating Systems, Time Series Analysis, Air-to-Water Heat Pump System, Knowledge Discovery in Databases,
Random Forest Algorithm, Field Data, Data-Driven Analysis, Fault Prediction.
Abstract: In response to the pressing global challenge of climate change, the emphasis on sustainable energy techno-
logies has escalated, spotlighting the critical role of heat pump systems as eco-friendly alternatives for heating
and cooling. These systems stand at the forefront of efforts to reduce greenhouse gas emissions and improve
energy efficiency. The advent of Internet of Things (IoT) technology has unlocked the potential for
comprehensive data collection on the operational intricacies of heat pump systems in real-world settings,
offering precious insights into their performance and guiding technological advancements. This paper
introduces an analytical approach to optimize air-to-water heat pump systems using time series data from
Bosch Home Comfort Group's systems. Utilizing Fayyad's data-driven analysis model and the Random Forest
algorithm, the study tackles system behavior complexities. Characterized by interpretability crucial for
application, it achieves a 97.6% fault detection accuracy. The method encounters difficulties in accurately
predicting compressor control faults due to limited data quality and a lack of comprehensive system
information. The findings highlight IoT's potential to enhance system efficiency and availability, but also
point to the limitations of relying solely on data-driven models for fault prediction in field systems.
1 INTRODUCTION
In 2021, German households consumed about 670
terawatt-hours of energy, mainly for space heating, as
per the Federal Environment Agency (Icha and Lauf,
2022). Heat pumps are crucial in this regard, known
for their efficiency and ability to reduce utility costs
and emissions by leveraging renewable energy
(Chiang, 2001). However, realizing their full poten-
tial requires understanding their entire lifecycle, from
production to user operation. Key stages of this life-
cycle encompass product development, manufac-
turing, storage, transport, installation, operation, and
a
https://orcid.org/0000-0002-6877-1480
b
https://orcid.org/0000-0002-1786-8485
c
https://orcid.org/0000-0002-7190-9321
d
https://orcid.org/0000-0001-7441-4431
*These Authors contributed equally to this work
maintenance. These stages primarily generate signif-
icant data during the development and operational
phases (Wiedemann and Schnell, 2006).
The Internet of Things (IoT) has upgraded data
collection, allowing for the extensive networking of
devices and sensors with the data stored in the cloud
(Zhang et al., 2010). Analyzing these data aims to
optimize heating systems. The potential incorporation
of suppliers and service providers into this analysis
enhances system lifecycle understanding, supporting
early fault detection and refining system requirements
for future models (Wiedemann and Schnell, 2006).
Fault detection methods in systems are crucial for
200
Qarqour, A., Arora, S., Heisenberg, G., Rabe, M. and Kleinert, T.
Utilizing Data Analysis for Optimized Determination of the Current Operational State of Heating Systems.
DOI: 10.5220/0012876200003838
Paper published under CC license (CC BY-NC-ND 4.0)
In Proceedings of the 16th International Joint Conference on Knowledge Discovery, Knowledge Engineering and Knowledge Management (IC3K 2024) - Volume 1: KDIR, pages 200-209
ISBN: 978-989-758-716-0; ISSN: 2184-3228
Proceedings Copyright © 2024 by SCITEPRESS – Science and Technology Publications, Lda.
improving efficiency, availability, and customer
satisfaction (Chiang, 2001). These methods include
model-based, data-based, and hybrid approaches
(Zhang and Jiang, 2008). Model-based methods simu-
late and diagnose the system behavior with
mathematical precision, but demand thorough
understanding and are complex (Venkatasubramanian
et al., 2003). Data-based strategies, leveraging machine
learning on historical data, suit complex systems, but
need high data quality and substantial resources (Chen,
1999). Hybrid approaches combine the strengths of
models and data to efficiently detect faults, providing
a balanced solution for fault diagnosis in challenging
systems (Yang and Rizzoni, 2016). Data-driven
methodologies employ structured models for
Knowledge Discovery in Databases (KDD), including
the Fayyad KDD framework (Fayyad et al., 1996).
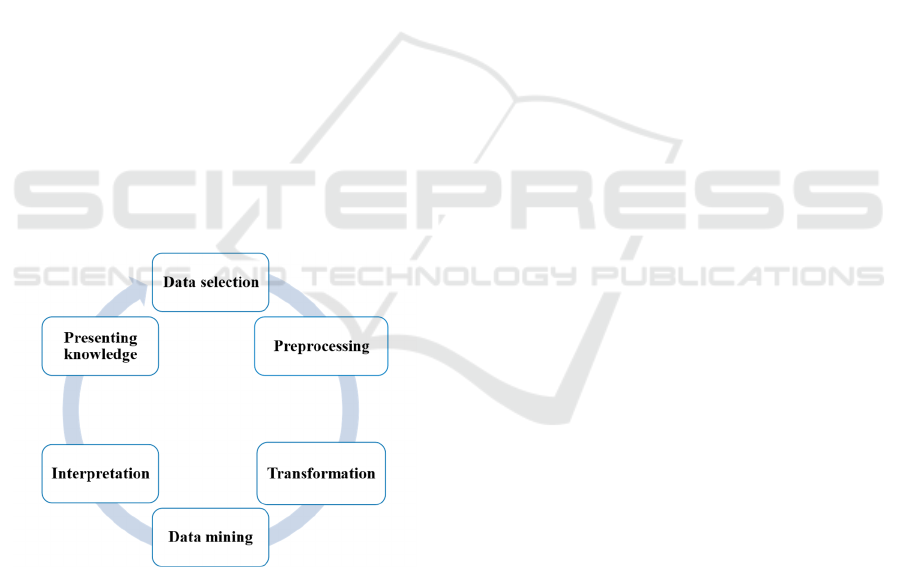
As depicted in Figure 1, this model contains cru-
cial steps for knowledge extraction from databases,
starting with the selection of relevant data, followed
by its cleaning and formatting in the preprocessing
phase. Then, the data are transformed into a format
appropriate for mining, after which mining is conduc-
ted to discover patterns (Fayyad et al., 1996). These
patterns are interpreted to determine their relevance,
and finally the extracted insights are presented. This
comprehensive process is essential for understanding
and enhancing system performance (Garcia et al.,
2015).
Figure 1: KDD process according to Fayyad.
2 RELATED WORK
2.1 Data-Based Approaches in Heating,
Ventilation, and Air Conditioning
Systems
With growing demand for efficient and reliable
heating, ventilation, and air conditioning (HVAC)
systems, the development and application of machine
learning algorithms for fault detection and diagnosis
(FDD) have become increasingly crucial (Li and
O’Neill, 2018). Pioneering work by Gharsellaoui et
al. (2020) leverages the Multiclass Support Vector
Machine (SVM) algorithm to categorize data within
smart buildings effectively. Concurrently, the
approach of Ebrahimifakhar et al. (2020) introduces a
statistical ML-based classification model using SVM
to detect faults in rooftop units by analyzing and
classifying data. Similarly, Bode et al. (2020) have
developed an innovative FDD model that combines a
big data framework with SVMs, aimed at identifying
faulty operations in HVAC terminal units through the
aggregation and evaluation of data from various
sources. Complementing these efforts, Ren et al.
(2020) have proposed a comprehensive FDD proce-
dure that merges SVM with principal component
analysis (PCA), designed to predict system behavior
under new load conditions by extracting pivotal fea-
tures from the dataset. This ensemble of models
underscores the potential and reliability of machine
learning in enhancing fault detection and diagnostic
capabilities in HVAC systems. An extensive over-
view of FDD models within the realm of building
technology, as detailed in the literature, highlights the
eclectic range of approaches and techniques that form
the foundation of this field (Li and O’Neill, 2018).
2.2 Key Challenges in Currently
Applied Approaches
Heating systems are complex and impacted by di-
verse operating conditions. The need for interpretable
models that can handle this complexity and be applied
to different systems is critical. However, challenges
arise with data-driven FDD methods developed based
on black-box models such as artificial neural net-
works (ANN) and SVM, mainly due to their lack of
interpretability (Yan et al., 2016). This limitation
makes it difficult to understand the process of fault
identification within these models. Moreover, the
effectiveness of data-driven methods largely depends
on the quality of the training data (Yang and Rizzoni,
2016). Insufficient data samples and errors in the
training data can lead to incorrect classifications.
Often the available training data do not cover the
entire spectrum of system operation, which limits the
model validity to certain conditions. Especially, very
critical situations appear only rarely in reality, leading
to a deficit of related sensor data. Without
interpretability, evaluating model reliability and
applicability becomes a challenge (Yan et al., 2016).
Utilizing Data Analysis for Optimized Determination of the Current Operational State of Heating Systems
201
2.3 Methodological Contributions
This paper outlines an application-oriented
methodology for heat systems employing the
Random Forest algorithm for extracting knowledge
from data. Central to this approach is its use of deci-
sion trees, distinguishing Random Forest by revealing
causes of faults through key parameter identification
and enhancing model transparency with decision tree
visualizations, a clarity lacking in black-box models.
Moreover, as an ensemble method, Random Forest
reduces overfitting risks by aggregating multiple
trees' predictions, ensuring applicability across varied
operational conditions (Cutler et al., 2012). This
adaptability is essential for analyzing and anticipating
system faults, evaluating system performance
through error rate analysis, and guiding potential
enhancements. Emphasizing its computability,
accuracy, and interpretability, this methodology
underscores the direct applicability of Random Forest
approaches over more complex techniques found in
explainable artificial intelligence (XAI), such as
Shapley values, ensuring the methodology's efficacy
and practical relevance (Başağaoğlu et al., 2022).
Thus, this approach provides a fault detection and
prediction solution for heating systems in the field,
making it particularly valuable for engineers and
practitioners in the domain of heating systems.
3 DATA-DRIVEN
METHODOLOGICAL
FRAMEWORK
This paper presents a structured approach to analyze
and explore air-to-water heat pump systems, with a
focus 1 faults. Concurrently, the regression segment
estimates the remaining time until a fault occurs. These
models undergo testing to validate their accuracy in
assessing the system status and forecasting faults.
The Model Interpretation stage offers a deep dive
into the model's decision-making, elucidating how it
identifies the system status and predicts faults. Expert
knowledge validates the model's underlying logic.
4 APPLICATION OF
METHODOLOGY:
INTRODUCTION TO THE USE
CASE STUDY
The methodology applied in this paper focuses on an
air-to-water heat pump system with a fault in the
compressor control. Such control faults arise from
issues within the heat pump's control unit and can
impact compressor performance. This may lead to in-
efficient operation of the heat pump, adversely affect-
ing its heating and cooling capacity. Potential causes
of these faults include high ambient temperatures
around the compressor leading to sensor failures,
poor wiring, or incorrect control settings. This analy-
sis was conducted at the Bosch Home Comfort
Group. The Heat Pump Development Department
was responsible for providing the parameter data and
fault information.
The primary objective of this study is to analyze
the impact of the fault on the system and to identify
the occurrence of the fault using system data. Addi-
tionally, the research explores the potential for pre-
dicting future fault occurrences. The system data,
which describe the system's state, were collected
through the bus system. The data analysis is based on
time series data with a sampling frequency of 0.83
Hz, covering the period from February 1, 2021, to
May 1, 2022. The findings contribute to enhance
understanding of the field system's behavior. Based
on these insights, strategies to optimize the efficiency
and stability of the heat pump system can be
developed, ensuring smooth operation in the future.
Figure 2: Stages of the methodology.
KDIR 2024 - 16th International Conference on Knowledge Discovery and Information Retrieval
202

5 DATA PREPARATION
This stage is designed to achieve a structured and
complete dataset. This section outlines how each step
of the stage is executed for the investigated use case.
5.1 Data Selection
The data selection for analysis focuses on identifying
critical parameters within the heat pump's bus system,
which characterize the general state and specifically
the control faults in the compressor. This selection is
performed in close collaboration with experts in the
heat pump development team at Bosch Home Com-
fort Group to ensure that the chosen data possess the
necessary relevance and quality for the study. Verify-
ing the availability and integrity of the data in the bus
system is an essential part of this process. Finally, the
resulting parameters considered central to the analy-
sis are detailed as follows:
Power Setpoint: Targeted electrical power
consumption level for the heat pump, setting
the desired performance level for optimal
efficiency and meeting heating or cooling
demands.
Actual Power: Current electrical power
consumption of the heat pump, used to
assess energy efficiency and operational
status.
Actual Compressor Speed: Current speed
at which the compressor is operating, indica-
ting performance level and efficiency of the
heat pump.
Air Temperature at the Evaporator:
Temperature of air entering the evaporator,
helping to evaluate heat exchange efficiency
and system load.
Temperature of the Compressor: Current
temperature of the compressor, used to
monitor compressor health and prevent
overheating.
Temperature of the Hot Gas: Temperature
of the gas after compression, before conden-
sation, indicating the efficiency of the com-
pression cycle.
Evaporator Return Temperature:
Temperature of the fluid returning to the
evaporator, assisting in assessing heat
absorption efficiency.
Outdoor Temperature: Outdoor ambient
temperature, used to adjust operations for
optimal efficiency and performance.
Condenser Inlet Temperature: Tempe-
rature of the fluid entering the condenser,
providing insights into the condensing
process efficiency.
5.2 Data Preprocessing
As long as the values of these parameters remain
constant, the bus system does not report any values.
However, when any value changes, the bus system
communicates this change. In the dataset, this leads
to empty cells between these two values, which need
to be filled to complete the dataset. This is done using
the zero-order hold principle, meaning empty cells
between two known values are filled with the last
known value until a new value is registered.
To detect outliers, data have been visualized using
box plots. This decision was driven by the need for a
straightforward and visually intuitive method,
allowing experts to easily identify and assess unusual
values as potential outliers. Box plots were chosen
over other methods, because they clearly delineate the
range of typical data, making deviations apparent. In
the context of missing operational condition details,
solely data-driven outlier detection proved to be
unreliable (Xu et al., 2020). Instead, combining box
plots with expert insights and system specifications
enabled a more informed decision on whether values
were outliers or relevant variations, ensuring a
nuanced and accurate outlier elimination process.
5.3 Correlation Analysis
As mentioned in the previous section, the necessity of
this step in the data preparation stage is caused by low
data quality. Correlation analysis investigates the
relationship between operational parameters to
determine how accurately the data represent these
physical interactions (Wilcox, 2001). This accurate
representation is essential to deliver valid inputs to
the model during the training phase. Therefore, the
model is enabled to understand the system's status
through the available training data and to produce
reliable predictions about the system status. To
achieve this, three sub-steps are involved: a)
assessing data normality to select an appropriate
correlation method, b) applying the chosen
correlation to the dataset, and c) validating the
correlation results against the parameters' physical
relationships through expert knowledge.
The Shapiro-Wilk test (Ghasemi and Zahediasl,
2012) initially assessed for normal distribution
revealed a non-normal distribution that necessitated
the use of Spearman's correlation method (Wilcox,
Utilizing Data Analysis for Optimized Determination of the Current Operational State of Heating Systems
203

2001) for the analysis. Experts reviewed the correla-
tion coefficients to verify their physical relevance,
ensuring that data faithfully represent the system's
physical dynamics. This step illuminates crucial
relationships between variables and affirms the data's
pertinence to the studied physical phenomena.
5.4 Transformation
Fault information is encoded into binary values, with
0 indicating no fault and 1 indicating a fault occur-
rence, to serve as the target variable for training the
Random Forest model. This conversion sets up a
classification problem, allowing the model to learn
fault detection from parameter data and target
variables.
6 MODEL DEVELOPMENT
The Random Forest model is developed to analyze
the relationship between various operational
parameters and fault occurrences in the air-to-water
heat pump system. It comprises two parts: (1)
classification model that determines the system's
status and (2) regression model predicting the time
until a fault occurs. These models were implemented
using the scikit-learn library in Python and developed
within a Jupyter Notebook.
6.1 System Status Detection
Random Forest Classifier (RFC) employs decision
trees on random data subsets, leveraging ensemble
learning for accurate classifications while mitigating
overfitting and assessing feature importance (Biau
and Scornet, 2016). The steps of the model imple-
mentation are illustrated in Figure 3. To address the
challenge of rare critical situations outlined in Section
2.2, particularly the infrequent occurrence of faults in
the compressor control, a down sampling strategy has
been implemented.
Figure 3: RFC implementation steps.
This method balances the dataset by reducing the
number of non-faulty instances to equal the number
of faulty instances, ensuring uniform representation.
A RFC with three trees (n_estimators=3) and a
random_state of 42 is chosen, targeting a balance of
model complexity and computational efficiency. The
decision to use three trees was based on performance
evaluations against a validation set, where adding
more trees resulted in only minimal improvements in
accuracy, suggesting that further increases would not
yield significant benefits. This choice reflects an
optimization between simplicity and the ability to
capture operational variability, with a random_state
of 42 ensuring result reproducibility. Default para-
meter settings are maintained as detailed in (scikit-
learn, 2024).
6.1.1 Evaluation of the Detection Model
The model was validated using test data to assess its
reliability in predicting on unknown data, using a
confusion matrix for evaluating accuracy and
precision. Results are illustrated in Figure 4.
This analysis revealed 191 true positives,
indicating non-faulty operation status were correctly
identified, and 181 true negatives, which means fault
status were accurately detected as such. Additionally,
the model encountered four false negatives, repre-
senting overlooked fault status, and five false posi-
tives, where faults were incorrectly identified in non-
faulty operation status. Achieving a high accuracy of
97.6% and a precision of 97.4%, the model demon-
strates efficient fault detection and classification.
Maintaining a low rate of false positives is crucial;
they not only lead to unnecessary fault correction
costs, but also could divert resources from actual
issues, potentially leaving real faults undiagnosed.
This emphasis on minimizing false positives is vital
for operational efficiency and cost management. The
results highlight the model's effective performance in
accurately identifying the operation status, balancing
accurate fault detection with the imperative to
minimize false alarms.
6.1.2 Model Interpretation
The RFC algorithm addresses the challenge of lack of
interpretability in data-driven FDD methods based on
black-box models as mentioned in Section 2.2. It
identifies key parameters through parameter
importance calculation – facilitating an
understanding of the classification processes – and
enhancing transparency while validating the model’s
outputs (Breiman, 2001). Through Python's scikit-
learn library, feature importance is determined using
KDIR 2024 - 16th International Conference on Knowledge Discovery and Information Retrieval
204
Figure 4: Confusion matrix of the test data.
the Mean Decrease in Gini (MDG) method, which
assesses how a feature reduces impurity across the
model's trees. MDG values range from 0 (no impact)
to 1 (perfect prediction capability), where higher
values indicate a stronger effect on model decisions
(Biau and Scornet, 2016). This calculation considers
the decrease in node impurity, weighted by the
probability of reaching that node, averaged over all
trees (Breiman, 2001). The key findings of the
parameter importance are illustrated in Figure 5.
It indicates that specific parameters, such as con-
denser inlet and outlet temperatures, hot gas tempera-
ture, external temperature, compressor speed, and
power setpoint are paramount in fault detection,
demonstrating nearly equal importance. Conversely,
parameters like evaporator air temperature, com-
pressor temperature, evaporator return temperature,
and current performance have a lower impact.
These insights emphasize the importance of
temperature-related measurements in detecting the
fault. Through the interpretability of the model, these
insights into model parameters can be traced back to
the faulty state of the system. The relevance of the
parameters to the faulty state are confirmed by the
experiential knowledge of experts.
Figure 5: Visualization of the importance of parameters.
This validation not only enhances the
development steps of the component to prevent the
occurrence of such faults but also expands the
knowledge of relevant factors that can lead to faults.
In the future, this approach can also be applied to
other types of faults to gain valuable insights.
6.2 System Status Prediction
This model aims to predict the remaining time until
the next fault occurs, utilizing an ensemble of
decision trees to make accurate predictions on
continuous values by averaging the outputs of all
trees in the forest. Similar to the classifier model, the
Random Forest Regressor (RFR) applies ensemble
learning, but focuses on estimating continuous
outcomes. The implementation of the RFR mirrors
that of the classifier model, as depicted in Figure 6.
Figure 6: RFR implementation steps.
The process starts with data collection represen-
ting various operational conditions, followed by crea-
ting the target variable time until the next fault, which
is hereafter referred to as "Time to Failure". This is
achieved by reverse iterating through the data to cal-
culate the time until the next fault for each data point,
producing a list of minutes until the next fault. For
this model, a RFR with ten trees (n_estimators=10)
and a random_state of 42 was selected, balancing
model complexity with computational efficiency. The
choice of more trees for the RFR compared to the
RFC reflects the increased complexity needed in
regression models to capture data variability and
nuances accurately (Corrales et al., 2018). With this
optimized tree ensemble, the RFR can more
accurately identify and predict underlying trends,
enabling precise predictions for the time to failure.
The default parameters are retained as described in
(scikit-learn, 2024).
6.2.1 Evaluation of the Prediction Model
The model accuracy was validated using test data to
assess its reliability in predicting on unknown data
using the Mean Absolute Error (MAE). The test
Utilizing Data Analysis for Optimized Determination of the Current Operational State of Heating Systems
205
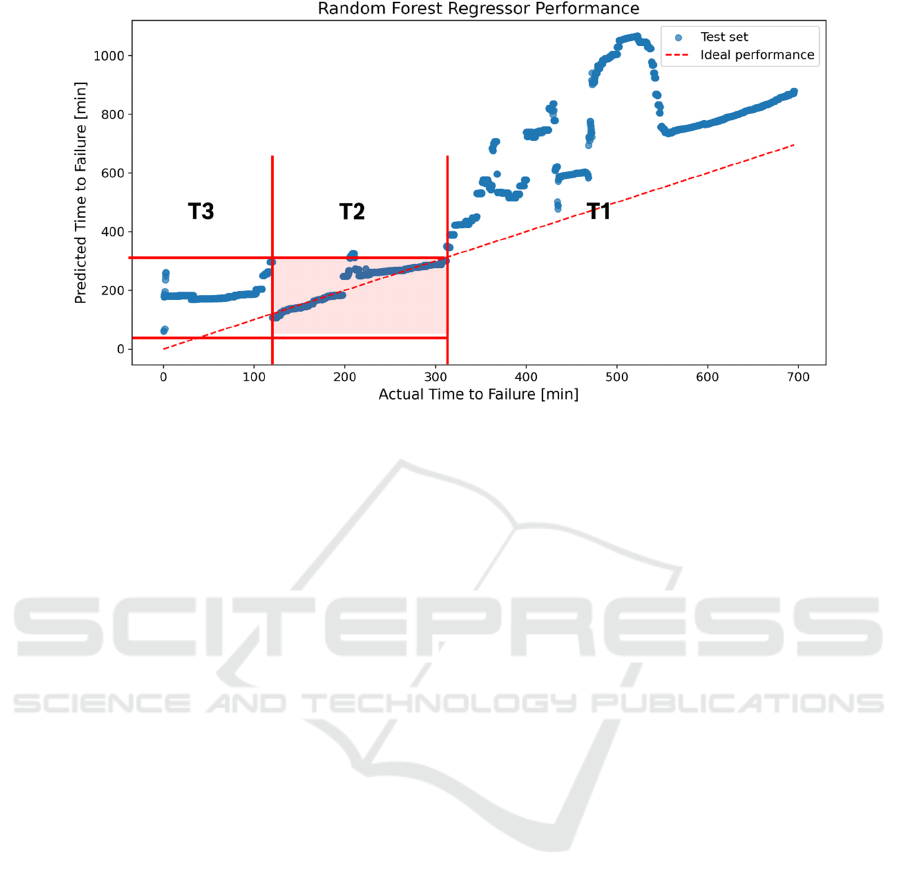
Figure 7: Accuracy of the model with test data.
dataset contains a fault scenario. The results were
visualized in Figure 7, where the X-axis represents
the actual values and the Y-axis the predicted values
of "Time to Failure". Ideal model performance is
achieved when data points closely align along the
ideal performance line, aiming for an MAE value of
0, indicating precise alignment between predictions
and actual events.
The accuracy evaluation of the model reveals
three key insights that provide a nuanced view of the
model's performance across different periods before a
fault event.
Phase T1: Actual Time to Failure > 320
minutes
Phase T2: 320 minutes ≥ Actual Time to
Failure ≥ 120 minutes
Phase T3: 120 minutes > Actual Time to
Failure > 0 minutes
Phase T1 describes long-term predictions, star-
ting from 320 minutes before the fault occurrence. In
this phase, it was observed that the model appears in-
capable of detecting reliable indicators of an
impending fault, resulting in a large discrepancy
between predicted and actual values. This limitation
highlights the challenges in predicting faults over an
extended period. Phase T2 describes mid-term predic-
tions, between 120 and 320 minutes before the fault
occurrence. In contrast to Phase T1, the model de-
monstrates considerably better performance with a
MAE of 18.6 minutes. During this critical period, the
model effectively analyzes and interprets operational
conditions and potential signs of an impending fault,
indicating its capability to utilize relevant information
for fault prediction. Phase T3 involves short-term
predictions made 0 to 120 minutes before a fault
occurs. In this phase, the model's accuracy decreases,
primarily due to a significant deviation of data points
from the ideal line. This reduction in accuracy can be
attributed to insufficient information density in the
parameters, leading to unreliable predictions.
However, the application of the model to other
faulty scenarios has revealed significant limitations,
primarily due to the limited availability of faulty data
and limited understanding of the underlying causes.
This problem is closely linked to the challenge of
data quality and availability, as discussed in Section
2.2. The lack of comprehensive data sets significantly
impairs the model's ability to predict under different
operating conditions. In addition, the complexity of
the heat pump system combined with a limited data
set further reduces the model’s prediction accuracy.
This is compounded by uncertain causes of failure
such as wiring or software issues, which are discussed
in more detail in Section 4. Ultimately, these
challenges emphasize the urgent need for improved
data quality and a deeper understanding of failure
mechanisms.
6.2.2 Model Interpretation
In the RFR model, evaluating parameter significance
is the key to decoding its predictive logic. This
process identifies the extent to which various features
impact the model's ability to predict the timing of a
fault. Understanding the critical features enhances the
insight into the model's operational dynamics. Dif-
fering from the RFC model, the RFR model assesses
KDIR 2024 - 16th International Conference on Knowledge Discovery and Information Retrieval
206

the feature importance via the Mean Decrease in Im-
purity (MDI). MDI reflects how each feature's
variance reduction, averaged across all trees, contri-
butes to the model's accuracy. This method highlights
the influence of specific features on enhancing the
model's precision by reducing prediction variance
through data segmentation.
This analysis reveals that the outdoor temperature
and air temperature at the evaporator exert the stron-
gest influence on prediction accuracy, with a com-
bined importance of 50%. Additionally, the conden-
ser exit temperature and the power setpoint also make
significant contributions to the forecast, both with
importance of 14%. These four parameters collec-
tively account for 78% of the predictive influence.
These results emphasize two major results: (1)
temperature-related measurements and the power
setpoint in the context of precise fault prediction are
crucial and (2) there is a need for the extension of the
knowledge about the selection of relevant parameters
for fault monitoring and the definition of the time
period in which a fault can be predicted. Despite the
limited number of fault cases in the system history,
these findings are valuable for future research and
help in the selection of time periods and relevant
parameters in the model training to reduce model
complexity.
7 DISCUSSION OF RESULTS
The research findings, which were discussed with
engineering experts from the heat pump department
at Bosch Home Comfort Group, focus on four key
questions:
How does interpretability clarify causality
between system parameters and faults while
supporting model scalability?
Which benefits does a system status detec-
tion model offer?
How does the parameter significance de-
rived from the classification model affect
error detection logic and contribute to the
optimization of the regression model for
error prediction?
How could more diverse data improve fault
prediction, and what are the challenges?
Regarding the first aspect (interpretability),
discussions with the experts in the heat pump
department emphasize the importance of
interpretability for scaling the model to systems with
similar data deficiencies. As explained in Section
6.1.2, the interpretability of the model enables the
exact quantification of the meaning of the parameters.
This improves the understanding of how each feature
affects the predictions of the model. This insight is
crucial for accurate adjustments when applying the
model to new systems. This ensures the effectiveness
of the model in different operating environments.
This detailed interpretative analysis also helps to
adapt the model and standardize fault detection
practices across different environments.
Regarding the second aspect (benefits of a
detection model), experts highlight the significant
benefits of a system status detection model, especially
for systems that do not capture fault data. Such a
model enables an understanding of the system's
behavior in operation, identification of common
faults, and efficient resource planning, directly
contributing to the optimization of the system design.
Concerning the third aspect (parameter
significance), discussions with experts emphasize the
importance of specific parameters, such as condenser
inlet and outlet temperatures, hot gas temperature,
and outdoor temperature, identified in Section 6.1 as
crucial for detecting faults within the compressor
control. Expert opinions indicate that future research
could significantly enhance prediction accuracy by
redesigning the error detection logic to reflect
parameter relevance and optimizing the online
monitoring of these parameters. Achieving this
improvement also involves intensified collaboration
with service companies to obtain detailed fault
information, including causes of occurrences. This
collaboration forms the foundation for a more effi-
cient predictive control system, aimed at reducing
downtime and improving overall system perfor-
mance.
The last aspect discussed with the experts
involves analyzing the predictive model’s capability
to determine the precise time phase when a fault can
be anticipated within the system. The model – under
the constraints of current assumptions and data
rarity – identifies early symptoms of errors occurring
between 120 and 320 minutes. This preliminary
insight is crucial as it suggests that expanding our
dataset with a broader range of failure cases could
potentially reduce the need for extensive training data
and help avoid overfitting. Enhancing the dataset in
this manner would improve the model’s accuracy and
its applicability to similar systems.
Utilizing Data Analysis for Optimized Determination of the Current Operational State of Heating Systems
207

8 SUMMARY AND FUTURE
WORK
This paper explores the potential of time series
analysis of sensor data from heating systems in
operation for detecting and predicting errors, a critical
area complicated by the significant distance between
users and manufacturers. A procedure based on
Fayyad's model was implemented and applied to an
air-to-water heat pump system to identify and forecast
specific control faults in the compressor.
A RFC model was developed to recognize system
status and assess the impact of parameter weights on
fault detection. This model successfully determined
the status of the systems, achieving a detection accu-
racy of 97.6% and a precision of 97.4%. A key chal-
lenge was the limited dataset, which complicated the
expert validation and underscored the necessity for a
larger data foundation. The analysis underscored the
significance of certain parameters, particularly tem-
perature readings, in fault detection. Experts valida-
ted these findings, emphasizing the need for ongoing
adjustment of weight factors.
The limited availability of fault data and the lack
of system information restricts the effectiveness of
the RFR model. This limitation stems from the sys-
tem's lifecycle; after sale, third-party service and
maintenance companies oversee installation and
upkeep, while manufacturers conduct field monito-
ring for a brief period. As a result, failure data collec-
tion is primarily limited to this monitoring phase, thus
affecting the model's ability to predict accurately.
Future research directions, inspired by this work,
will explore the potential of Random Forest models
to analyze more extensive datasets with increased
error instances and assess other machine learning
algorithms for error detection and prediction in heat
pump systems. An optimized dataset, including
detailed parameter and fault information, is crucial
for developing models that accurately reflect system
reliability and behavior. Additionally, future studies
should explore the reliability of specific system
components and their impact on overall system
reliability. Future investigations should incorporate
not only existing data but also laboratory results,
simulations, and physical models. The integration of
physics-based models will be explored to establish
causal relationships between system parameters and
fault occurrences, thereby enhancing the model’s
ability to predict and diagnose faults with higher
accuracy. This approach is expected to improve the
overall effectiveness of the system, contributing to a
deeper understanding of system dynamics, and
advancing control strategies for heating systems.
REFERENCES
Arora, S.-J., & Rabe, M. (2023). Predictive maintenance:
Assessment of potentials for residential heating
systems. International Journal of Computer Integrated
Manufacturing, 1--25. https://doi.org/10.1080/
0951192X.2023.2204471.
Başağaoğlu, H., Chakraborty, D., Lago, C. D., Gutierrez,
L., Şahinli, M. A., Giacomoni, M., Furl, C., Mirchi, A.,
Moriasi, D., & Şengör, S. S. (2022). A review on
interpretable and explainable artificial intelligence in
hydroclimatic applications. Water, 14(8), 1230.
https://doi.org/10.3390/w14081230.
Biau, G., & Scornet, E. (2016). A random forest guided
tour. TEST, 25(1), 197--227. https://doi.org/
10.1007/s11749-016-0481-7.
Bode, G., Thul, S., Baranski, M., & Müller, D. (2020).
Real-world application of machine-learning-based fault
detection trained with experimental data. Energy, 198,
323. https://doi.org/10.1016/j.energy.2020.117323.
Breiman, L. (2001). Random forests in machine learning.
Springer, New York, NY, 5--32. https://doi.org
/10.1023/A:1010933404324.
Chen, J. (2013). Model-based fault diagnosis in dynamic
systems using identification techniques. Springer,
London, United Kingdom. ISBN: 978-1-4471-3829-7.
https://doi.org/10.1007/978-1-4471-3829-7.
Chiang, L. H. (2001). Fault detection and diagnosis in
industrial systems. Springer, London, United Kingdom.
https://doi.org/10.1088/0957-0233/12/10/706.
Corrales, D., Corrales, J., & Ledezma, A. (2018). How to
address the data quality issues in regression models: A
guided process for data cleaning. Symmetry, 10(4), 99.
https://doi.org/10.3390/sym10040099.
Cutler, A., Cutler, D. R., & Stevens, J. R. (2012). Random
forests in Ensemble Machine Learning. Springer, New
York, NY, 157--175. https://doi.org/10.1007/978-1-
4419-9326-7_5.
Dey, M., Rana, S. P., & Dudley, S. (2020). Smart building
creation in large scale HVAC environments through
automated fault detection and diagnosis. Future
Generation Computer Systems, 108, 950--966.
https://doi.org/10.1016/j.future.2018.02.019.
Ebrahimifakhar, A., Kabirikopaei, A., & Yuill, D. (2020).
Data-driven fault detection and diagnosis for packaged
rooftop units using statistical machine learning
classification methods. Energy and Buildings, 225, 318.
https://doi.org/10.1016/j.enbuild.2020.110318.
Fayyad, U., Piatetsky-Shapiro, G., & Smyth, P. (1996). The
KDD process for extracting useful knowledge from
volumes of data. Communications of the ACM, 39,
27--34. https://doi.org/10.1145/240455.240464.
García, S., Luengo, J., & Herrera, F. (2015). Data
preprocessing in data mining. Springer International
Publishing, Cham, Switzerland, 19--38.
https://doi.org/10.1007/978-3-319-10247-4.
Gharsellaoui, S., Mansouri, M., Trabelsi, M., Harkat, M.-
F., Refaat, S. S., & Messaoud, H. (2020). Interval-
valued features based machine learning technique for
fault detection and diagnosis of uncertain HVAC
KDIR 2024 - 16th International Conference on Knowledge Discovery and Information Retrieval
208

systems. IEEE Access, 8, 892--902. https://doi.
org/10.1109/ACCESS.2020.3019365.
Ghasemi, A., & Zahediasl, S. (2012). Normality tests for
statistical analysis: a guide for non-statisticians.
International Journal of Endocrinology and
Metabolism, 10(2), 486--489. https://doi.org/10.5812/
ijem.3505.
Icha, P., & Lauf, T. (2022). Entwicklung der spezifischen
Treibhausgas-Emissionen des deutschen Strommix in
den Jahren 1990–2021. Retrieved February 12, 2024,
https://www.umweltbundesamt.de/sites/default/files/m
edien/1410/publikationen/2022-04-13_cc_15-
2022_strommix_2022_fin_bf.pdf.s
Li, Y., & O’Neill, Z. (2018). A critical review of fault
modeling of HVAC systems in buildings. Building
Simulation, 11(5), 953--975. https://doi.org/10.1007/
s12273-018-0458-4.
scikit-learn. (2024).
sklearn.ensemble.RandomForestClassifier. Retrieved April
23, 2024,
https://scikitlearn.org/stable/modules/generated/sklearn.en
semble.RandomForestClassifier.html.
Venkatasubramanian, V., Rengaswamy, R., Yin, K., &
Kavuri, S. N. (2003). A review of process fault
detection and diagnosis: Part I: Quantitative model-
based methods. Computers & Chemical Engineering,
27(3), 293--311. https://doi.org/10.1016/S0098-
1354(02)00160-6.
Wiedemann, B., & Schnell, G. (2006). Bus systems in
automation and process technology. Vieweg+Teubner,
151–344. https://doi.org/10.1007/978-3-8348-9108-
2_4.
Wilcox, R. (2001). Fundamentals of modern statistical
methods. Springer, New York, NY, 67--91.
https://doi.org/10.1007/978-1-4757-3522-2.
Xu, X., Lei, Y., & Li, Z. (2020). An incorrect data detection
method for big data cleaning of machinery condition
monitoring. IEEE Transactions on Industrial
Electronics, 67, 326--336. https://doi.org/10.1109/TIE.
2019.2903774.
Yan, R., Ma, Z., Zhao, Y., & Kokogiannakis, G. (2016). A
decision tree based data-driven diagnostic strategy for
air handling units. Energy and Buildings, 133, 37--45.
https://doi.org/10.1016/j.enbuild.2016.09.039.
Yang, R., & Rizzoni, G. (2016). Comparison of model-
based vs. data-driven methods for fault detection and
isolation in engine idle speed control system. In Proc.
of PHM Conference, 8(1), Oct. 2016. https://doi.
org/10.36001/phmconf.2016.v8i1.2502.
Zhang, Q., Cheng, L., & Boutaba, R. (2010). Cloud
computing: State-of-the-art and research challenges.
Journal of Internet Services and Applications, 1(1),
7--18. https://doi.org/10.1007/s13174-010-0007-6.
Zhang, Y., & Jiang, J. (2008). Bibliographical review on
reconfigurable fault-tolerant control systems. Annual
Reviews in Control, 32(2), 229--252. https://doi.org/
10.1016/j.arcontrol.2008.03.008.
Utilizing Data Analysis for Optimized Determination of the Current Operational State of Heating Systems
209
