
Personalized Asthma Recommendation System: Leveraging Predictive
Analysis and Semantic Ontology-Based Knowledge Graph
Ayan Chatterjee
a
Dept. of Digital Technology, STIFTELSEN NILU, 2007 Kjeller, Norway
Keywords:
Predictive Analysis, Personalized Recommendation System, Asthma Monitoring, Semantic Knowledge.
Abstract:
Personalized approaches are required for asthma management due to the variability in symptoms, triggers,
and patient characteristics. An innovative asthma recommendation system that integrates automatic predic-
tive analysis with semantic knowledge to provide personalized recommendations for asthma management is
proposed by this paper. Asthma exacerbation are predicted and the recommendations are enhanced by the
system, which leverages automatic Tree-based Pipeline Optimization Tool (TPOT) and semantic knowledge
represented in an OWL Ontology (AsthmaOnto). Furthermore, classifications are explained with Local Inter-
pretable Model-Agnostic Explanations (LIME) to identify feature importance. Tailored interventions based on
individual patient profiles are provided by this conceptual model, aiming to improve asthma management. The
proposed model has been verified using public asthma datasets, and a public weather air-quality dataset has
been utilized to support ontology development and verification. In TPOT, the Gaussian Naive Bayes (Gaus-
sianNB) classifier has outperformed other supervised machine learning models with an accuracy of 0.75, for
the used dataset. To implement and evaluate the proposed model in clinical settings, further development and
validation with more diverse and robust datasets with model calibration are required.
1 INTRODUCTION
Asthma is a significant noncommunicable disease af-
fecting individuals of all ages, particularly children
(WHO, 2019). It is characterized by inflammation
and constriction of the lung’s small airways, leading
to coughing, wheezing, breathlessness, and chest con-
striction (WHO, 2019). In 2019, asthma affected an
estimated 262 million people, resulting in 455,000
deaths (WHO, 2019). Avoiding triggers is crucial
for symptom reduction. Most asthma-related deaths
occur in low- to lower-middle-income countries due
to under-diagnosis and under-treatment. Asthma is
classified as allergic or non-allergic, triggered by fac-
tors like allergens, pollution, weather, tobacco smoke,
and food allergens (Ajami et al., 2022). Symptoms
vary in frequency and severity based on individual
reactions to these triggers (Ajami et al., 2022). The
WHO is committed to improving asthma diagnosis,
treatment, and monitoring to reduce the global bur-
den of noncommunicable diseases and promote uni-
versal health coverage (WHO, 2019). Proper lifestyle
management and personalized recommendations can
a
https://orcid.org/0000-0002-1051-2814
help individuals maintain a normal, active life. Ef-
fective asthma management involves identifying trig-
gers, controlling symptoms, and preventing exacer-
bation. However, the diverse nature of asthma re-
quires tailored approaches, making its management
complex. Traditional monitoring often relies on over-
simplified systems that do not capture the condi-
tion’s complexity. Conventional methods classify pa-
tients as controlled or uncontrolled based on pre-
determined benchmarks. Personalized asthma man-
agement now includes patient-centered care and tai-
lored self-management support, requiring changes in
practice organization, consultation modes, and digi-
tal health options (Pinnock et al., 2023). Anantharam
et al. (Anantharam et al., 2015) developed kHealth,
a system that aggregates multisensory data from sen-
sors and questionnaires from asthma patients to help
doctors more precisely determine the cause, severity,
and control level of asthma, and to alert patients to
seek timely clinical assistance. Alharbi et al. (Al-
harbi et al., 2023) proposed a multi-layered eHealth
framework using telemonitoring, environmental sen-
sors, and machine learning to predict asthma attacks
and provide safe routes, updating recommendations
with real-time data. Another study by Alharbi et al.
Chatterjee, A.
Personalized Asthma Recommendation System: Leveraging Predictive Analysis and Semantic Ontology-Based Knowledge Graph.
DOI: 10.5220/0012894500003838
Paper published under CC license (CC BY-NC-ND 4.0)
In Proceedings of the 16th International Joint Conference on Knowledge Discovery, Knowledge Engineering and Knowledge Management (IC3K 2024) - Volume 2: KEOD, pages 127-134
ISBN: 978-989-758-716-0; ISSN: 2184-3228
Proceedings Copyright © 2024 by SCITEPRESS – Science and Technology Publications, Lda.
127

(Alharbi et al., 2021) presented a smart healthcare
framework that visualized asthma triggers and pro-
vided attack notifications, using deep learning to an-
alyze patient and environmental data, including a dy-
namic air pollution map and safe-route recommenda-
tions. Morita et al. (Morita et al., 2019) designed
Breathe, a web-based mHealth platform for manag-
ing asthma, which showed initial strong utilization but
later declined, with users reporting high satisfaction
and confidence in its assessments. Bose et al. (Bose
et al., 2021) developed machine learning models to
predict persistent asthma in children, with the XG-
Boost model performing best, although direct com-
parisons were difficult due to a lack of similar stud-
ies. Kadariya et al. (Kadariya et al., 2019) introduced
kBot, a personalized chatbot for pediatric asthma pa-
tients, monitoring medication adherence and tracking
health data, which showed high acceptance and us-
ability in preliminary evaluations.
Traditional asthma management often relies on
standardized guidelines, which, while informative,
may not fully account for individual variations in
symptoms, triggers, and treatment responses. Pre-
dicting and explaining asthma exacerbations remains
challenging due to factors like environmental trig-
gers, patient demographics, and medical history. This
research introduces a novel Asthma Recommenda-
tion System designed for personalized asthma mon-
itoring and evidence-based recommendations. The
system integrates an automatic prediction pipeline
with a semantic knowledge graph, leveraging pre-
dictive analysis and semantic reasoning to enhance
decision-making accuracy. By using OWL-based on-
tology and SPARQL querying, the system captures
complex data patterns, enriching personalized recom-
mendations. This approach aims to surpass tradi-
tional methods by offering more tailored and action-
able insights for optimal asthma management (Chat-
terjee et al., 2021b)(Chatterjee and Prinz, 2022)(Cima
et al., 2017)(Chatterjee et al., 2023)(Chatterjee et al.,
2022b). The research questions guiding this study are
as follows: a. How does integrating automatic pre-
dictive analysis with a semantic knowledge graph en-
hance the development of a personalized, evidence-
based asthma recommendation system? b. How
can the system’s predictive analysis be effectively ex-
plained? c. How can recommendations be system-
atically generated and clarified within the proposed
asthma recommendation system?
This research aims to enhance the theoretical
understanding of hybrid recommendation generation
(automatic predictive analysis combined with seman-
tic rule-based methods) and to foster practical ap-
plications for proactive asthma management. The
study serves as a technical proof-of-concept, focus-
ing on the conceptual modeling of a recommenda-
tion system for asthma, validated with publicly avail-
able datasets. Future research will emphasize tech-
nical validation using real-world health monitoring
data. The paper is organized as follows: Section 2 dis-
cusses the proposed system architecture and modeling
approaches. Section 3 details the datasets used for
predictive model evaluation and semantic modeling
for personalized recommendations. Section 4 covers
the experimental setup, outcomes, and research ques-
tions. Finally, Section 5 presents conclusions and fu-
ture directions.
2 PROPOSED WORK
The design and development of the proposed asthma
recommendation system involve following aspects.
2.1 System Architecture
The proposed system architecture comprises multiple
layers distributed across system components, includ-
ing the Front-end User Interface (UI) and the Back-
end server with a database (see Fig. 1). These compo-
nents communicate via REST (Representational State
Transfer) architecture (Barbaglia et al., 2017), ensur-
ing a scalable, secure, and user-friendly framework,
using JSON (JavaScript Object Notation) (Barbaglia
et al., 2017) for data interchange. The system is
composed of the following layers: Data Acquisi-
tion Layer: Collects asthma data and demographics
from electronic health records, surveys, and monitor-
ing devices. Features dashboards, tools, and widgets
for recording data, viewing recommendations, and
monitoring progress. Data Integration Layer: Inte-
grates with healthcare IT systems like EHR, CDSS,
and telemedicine platforms, focusing on scalability
and security, with FHIR and HL7 standards support
(Chatterjee et al., 2022a). Data Processing Layer:
Applies preprocessing techniques to clean, transform,
and standardize data for predictive models. Predic-
tive Analysis Layer: Uses TPOT (Olson and Moore,
2016), an AutoML tool, to predict asthma exacerba-
tions and optimize machine learning pipelines with
scikit-learn compatibility. Knowledge Representation
Layer: Develops an asthma ontology (AsthmaOnto)
for domain-specific knowledge, including symptoms
and treatments. Recommendation Generation Layer:
Combines predictive results with ontology knowledge
to generate personalized asthma management recom-
mendations, mapped to the AsthmaReco ontology.
Automatic Machine Learning Pipeline: TPOT auto-
KEOD 2024 - 16th International Conference on Knowledge Engineering and Ontology Development
128
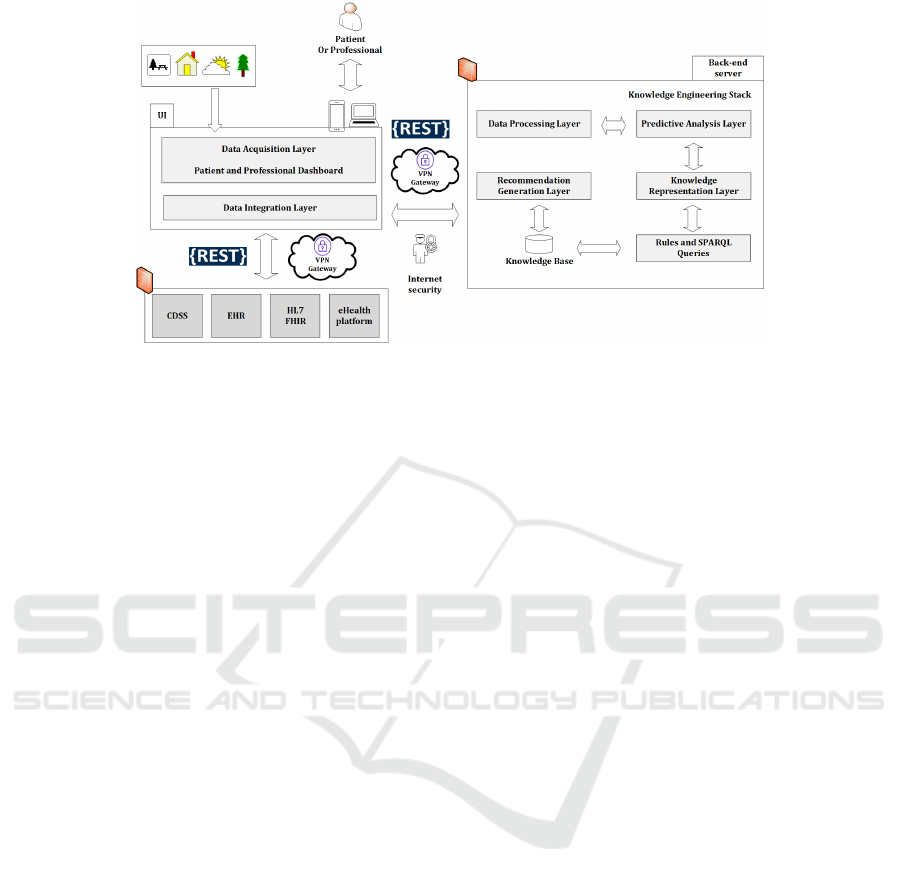
Figure 1: The architecture of the proposed recommendation system.
mates data preprocessing and pipeline construction,
reducing manual effort and time.
2.2 Predictive Analysis
TPOT automates the discovery of optimal data pre-
processing and machine learning model combina-
tions, improving predictive accuracy and robustness.
Using genetic programming, TPOT efficiently evalu-
ates thousands of potential pipelines to identify the
best model for a dataset, including hyperparame-
ter optimization. The process includes generating
random pipelines, evaluating performance, selecting
top performers, and applying crossover and mutation
across generations to refine results, ultimately select-
ing the best pipeline after a set number of generations.
The TPOT configuration customizes feature selec-
tion methods and multiple sklearn classifiers, includ-
ing RandomForest, Logistic Regression, SVC, Deci-
sionTree, KNN, and Naive Bayes (Olson and Moore,
2016). The TPOTClassifier is configured with 100
generations and a population size of 100, allowing
extensive exploration of the feature space. A high
mutation rate of 0.9 and a crossover rate of 0.1 pri-
oritize new solutions over recombination. Models are
optimized for accuracy using 5-fold cross-validation.
TPOT uses following performance metrics to evalu-
ate and select the best pipelines − Accuracy, Preci-
sion, Recall, F1-score, and Matthews Correlation Co-
efficient (MCC) (Chatterjee et al., 2023)(Chatterjee
et al., 2020)(Chatterjee et al., 2021a). Stratification
technique, using a Stratified Split (80% training, 20%
test), ensures that class proportions in training and test
sets match the original dataset (Hutchinson, 1982).
This approach reduces bias and enhances reliability in
training and evaluation by maintaining consistent per-
formance metrics. While TPOT does not directly pro-
vide model explanations, the resulting pipelines has
been analyzed with tools like LIME. LIME approxi-
mates the model locally around specific predictions,
revealing which features significantly influenced the
decision (Garreau and Luxburg, 2020). This approach
enhances transparency and offers actionable insights
to improve patient care and personalized recommen-
dations (Garreau and Luxburg, 2020).
2.3 AsthmaOnto OWL Ontology Model
While traditional databases are effective for struc-
tured data storage and retrieval, they fall short in se-
mantic reasoning and integrating diverse data sources.
Ontologies offer a more dynamic and interconnected
approach, enhancing personalized, context-aware rec-
ommendations. This paper presents an OWL on-
tology for asthma monitoring, encompassing domain
knowledge through classes, properties, relationships,
individuals, logical operators (AND, OR, NOT), in-
ference rules, and axioms using set theory or first-
order predicate logic. The ontology can integrate
multiple relevant ontologies, including Asthma from
BioPortal, weather and environment from COPDol-
ogy, food allergens from FoodOn, and symptoms and
pollen concepts from SNOMED-CT (Ajami et al.,
2022).
Let G = (V, E) be a directed graph where V repre-
sents the set of all concepts and E represents the set of
all relationships (Chatterjee et al., 2021b)(Chatterjee
et al., 2023)(Chatterjee et al., 2022b).
V = {Symptom, Demographic, MedicalHistory, ...}
E = {(Patient, hasSymptom, Symptom), .....)}
SPARQL is a query language for handling RDF
data, representing web information in a graph form
(Chatterjee and Prinz, 2022). It is vital for extracting
Personalized Asthma Recommendation System: Leveraging Predictive Analysis and Semantic Ontology-Based Knowledge Graph
129

and using data from ontologies, particularly in retriev-
ing and managing information from ontology-based
knowledge graphs in asthma recommendations (Cima
et al., 2017). A basic graph pattern in SPARQL can
be represented as:
{?sP?o}
where ?s is a subject variable, P is a predicate, and
?o is an object variable.
A triple pattern is an RDF triple where each of the
subject, predicate, and object may be a variable.
Let T represent the set of all triple patterns:
T = {(?s, P,?o) |?s, ?o ∈ I ∪V ∪ V and P ∈ R}
where V is the set of SPARQL variables. The fur-
ther terminologies are depicted in Fig. 2.
2.4 Personalized Recommendation
Let X be the feature matrix and y be the label vector.
Train a model f : X → y, such as a logistic regres-
sion or random forest. For a new patient x, predict the
probability of an asthma exacerbation: ˆy = f (x). If
ˆy > θ (a chosen threshold), generate and recommend
preventive measures.
The proposed personalized recommendation gen-
eration algorithm (Algo. 1) leverages predictive
analysis and semantic knowledge to generate tai-
lored asthma management recommendations. It starts
by cleaning and normalizing raw asthma data, fol-
lowed by training a machine learning model to predict
asthma exacerbation probabilities. The system loads
an AsthmaOnto ontology, which provides domain-
specific semantic knowledge, to enhance the recom-
mendations. For each patient, the system predicts ex-
acerbation likelihood and queries the ontology based
on patient attributes, generating personalized asthma
management recommendations. The goal is to trigger
logical rules of the form (A IMPLIES B) or (NOT(A)
OR B), providing tailored advice when specific vari-
ables are inferred as true.
Time Complexity − Data Preprocessing: O(n ·
m), where n is the number of records and m is the
number of features. Predictive Analysis: O(t) to
O(t · n · m), with t as training time. Semantic Knowl-
edge: Ontology loading has O(1). Recommenda-
tions: O(k · q), where k is the number of patients and
q is query complexity. Overall: O(n · m + t + k · q).
Space Complexity − Data Preprocessing: O(s) for
data. Predictive Analysis: O(p) for the model. Se-
mantic Knowledge: O(o) for the ontology. Rec-
ommendations: O(r) for storing results. Overall:
O(s + p + o + r). The time and space complexity of
Algo. 1 depends on the dataset size, model complex-
ity, ontology size, and query efficiency.
Algorithm 1: Personalized Asthma Recommendation
Generation.
Require: • Asthma patient data: D = {(x
i
)}
n
i=1
• Asthma ontology
Ensure: Personalized recommendations for each pa-
tient
1: Preprocess data: Clean, engineer features, and
normalize D to obtain D
preprocessed
2: Train predictive model on D
preprocessed
to obtain
model M
3: Load asthma ontology as O
4: for each patient x
i
in D
preprocessed
do
5: Predict exacerbation probability for x
i
using M
6: Query O for personalized recommendations
based on x
i
7: Combine prediction and ontology knowledge
to generate recommendations for x
i
8: end for
9: return List of personalized recommendations for
all patients
Potential recommendation messages for personal-
ized asthma management can be represented using the
AsthmaOnto ontology and their potential types are
mentioned in Table 1.
3 DATA DESCRIPTION
The datasets have been used for predictive analysis
and semantic modeling. The proposed hypothesis
suggests that amalgamating these datasets could cre-
ate an asthma recommendation system for ongoing
surveillance of health metrics and weather patterns.
This system could anticipate potential asthma trig-
gers, generating timely alerts for patients during el-
evated pollen counts, drastic weather changes, or de-
viations in vital signs. The “Asthma Disease Predic-
tion” dataset (Dataset, 2024) on Kaggle offers key
data for predicting asthma, including demographic
details (age, gender), clinical symptoms (tiredness,
dry cough, breathing difficulties, sore throat, nasal
congestion, runny nose), and medical history (treat-
ment in different medical units, specific medical unit,
pneumonia history). In addition to features from the
used dataset, weather data from the OpenWeatherMap
API (OpenWeather, 2024) is utilized for semantic
modeling. The API provides essential weather-related
data relevant to asthma management, including tem-
perature (current, feels like, min/max), humidity, air
pressure, wind, precipitation, visibility, pollution lev-
els (Air Quality Index, PM2.5, PM10, ozone, nitrogen
dioxide, sulfur dioxide, carbon monoxide), and pollen
counts. These factors are critical for asthma manage-
KEOD 2024 - 16th International Conference on Knowledge Engineering and Ontology Development
130

The Terminological box (TBox) (Chatterjee et al., 2021b) contains the vocabulary of the ontology:
Patient(x) → ∀y (hasSymptom(x, y) → Symptom(y))
Patient(x) → ∀y (hasDemographic(x, y) → Demographic(y))
Patient(x) → ∀y (hasMedicalHistory(x, y) → MedicalHistory(y))
Patient(x) → ∀y (hasAllergyFactor(x, y) → ExternalAllergyFactor(y))
Patient(x) → ∀y (hasRecommendation(x, y) → Recommendation(y))
Symptom(x) → ∃y (Patient(y) ∧ hasSymptom(y, x))
Demographic(x) → ∃y (Patient(y) ∧ hasDemographic(y, x))
MedicalHistory(x) → ∃y (Patient(y) ∧ hasMedicalHistory(y, x))
ExternalAllergyFactor(x) → ∃y (Patient(y) ∧ hasAllergyFactor(y,x))
Recommendation(x) → ∃y (Patient(y) ∧ hasRecommendation(y, x))
The Assertional box (ABox) (Chatterjee et al., 2021b) contains assertions about “XYZ” individual:
Patient(XYZ), hasSymptom(XYZ,DryCough),hasDemographic(XYZ,Age 42), hasMedicalHistory(XYZ, Asthma)
Logical rules (Chatterjee et al., 2021b) to infer new knowledge as reasoning can be expressed as:
∀x(Patient(x) ∧ hasSymptom(x,y) → Symptom(y))
∀x(Patient(x) ∧ hasDemographic(x,y) → Demographic(y))
∀x(Patient(x) ∧ hasMedicalHistory(x,y) → MedicalHistory(y))
∀x(Patient(x) ∧ hasAllergyFactor(x, y) → ExternalAllergyFactor(y))
Figure 2: Ontology-Based Representation of Asthma Patients’ Data.
Table 1: Types of recommendations in Asthma management.
Category Key Actions
Preventive Measures Avoid triggers (pollen, dust, pets); use allergen-proof bedding, air purifiers,
and close windows during pollen seasons.
Medication Adherence Take prescribed medications consistently; keep rescue inhaler available.
Environmental Control Maintain humidity below 50%; clean home regularly; use allergen-proof cov-
ers.
Lifestyle Modifications Exercise regularly; eat a balanced diet; avoid tobacco smoke and pollutants.
Symptom Management Monitor symptoms; practice relaxation techniques.
Follow-Up Care Regular appointments; stay current with vaccinations.
ment, as extreme weather conditions, pollution, and
high pollen levels can trigger or worsen symptoms.
4 IMPLEMENTATION
The implementation has been divided into the follow-
ing subsections:
4.1 Experimental Setup
We used Python 3.9.15 with libraries like pandas (v.
1.5.2), NumPy (v. 1.22.4), SciPy (v. 1.7.3), Mat-
plotlib (v. 3.6.2), Seaborn (v. 0.12.0), and scikit-
learn (v. 1.1.3) for data processing and model de-
velopment. The environment was configured on Win-
dows 10 using Anaconda and Jupyter Notebook 6.5.2.
The system had 16 GB RAM and a 64-bit architec-
ture, running models on the CPU due to the dataset’s
small size. Additionally, we used OWL 2 Prot
´
eg
´
e in
the Prot
´
eg
´
e editor to design the ontology model, with
Hermit reasoner for consistency checking.
4.2 Predictive Analysis
The processed asthma dataset contained 3,16,800
records with 19 features, including 100,820 Class:0
and 33,606 Class:1 entries. Feature selection utilized
SelectKBest, which identifies statistically significant
features, and VarianceThreshold, which removes low-
variance features. Correlation analysis confirmed that
features were not highly correlated. TPOT identified
the best pipeline, which exclusively used the Gaus-
sianNB classifier, achieving an accuracy of 0.75 (Pre-
cision: 0.72, Recall: 0.75, F1-score: 0.75, MCC:
0.70). Despite its simplicity, GaussianNB proved
effective, likely due to the dataset’s alignment with
the model’s assumption of normally distributed fea-
tures. Its fewer parameters and simplicity helped pre-
vent overfitting, making it a robust choice for this
dataset. The advantages of GaussianNB stem from
its appropriate assumption of feature distribution, ef-
Personalized Asthma Recommendation System: Leveraging Predictive Analysis and Semantic Ontology-Based Knowledge Graph
131

(a) Top ten features to predict No asthma. (b) Top ten features to predict Asthma.
Figure 3: LIME explanations for predicting class: 0 (No asthma) and class: 1 (Asthma).
∀x, y(Patient(x)∧ hasDemographic(x, y) → Demographic(y))
∀x, y(Patient(x)∧ hasMedicalHistory(x, y) → MedicalHistory(y))
∀x, y(Patient(x)∧ hasAllergyFactor(x, y) → ExternalAllergyFactor(y))
∀x, y(Patient(x)∧ hasRecommendation(x, y) → Recommendation(y))
∀x(Symptom(x) → ∃y(Patient(y)∧ hasSymptom(y, x)))
∀x(Demographic(x) → ∃y(Patient(y)∧ hasDemographic(y, x)))
∀x(MedicalHistory(x) → ∃y(Patient(y)∧ hasMedicalHistory(y, x)))
∀x(ExternalAllergyFactor(x) → ∃y (Patient(y) ∧ hasAllergyFactor(y, x)))
∀x(Recommendation(x) → ∃y(Patient(y)∧ hasRecommendation(y, x)))
Figure 4: Logical Expressions Representing Relationships Between Patients and Associated Data.
fective feature selection, and its probabilistic nature,
which supports good generalization without overfit-
ting. This highlights the value of simple models like
GaussianNB when they align well with data charac-
teristics. GaussianNB was combined with LIME for
predictive explanation, enhancing model transparency
and trust. LIME’s visualizations use blue color to in-
dicate a push towards the negative class and orange
color towards the positive class. The MCC metric
provided a balanced evaluation of classifier perfor-
mance on this imbalanced asthma dataset.
4.3 Semantic Recommendations
The key classes of OWL ontology are shown in Fig.
5 (Axiom: 143, Logical axiom: 82, Declaration ax-
iom: 61, Class: 10, object property: 9, data prop-
erty: 20, individual count: 23, SubClassOf: 2). Using
the Hermit reasoner in Prot
´
eg
´
e, reasoning was com-
pleted in under 40 seconds with no inconsistencies.
When loaded in Jena (TTL format, OWL full), read-
ing time was 0.5-1.0 second, and queries for ontology
elements executed in under 1.0 second. Each ontol-
ogy model, as an RDF graph, links to a document
manager (default: OntDocumentManager”) for doc-
ument processing. In the ontology API, all ontology
classes inherit from OntResource,” sharing attributes
(versionInfo, comment, label, seeAlso, isDefinedBy,
sameAs, differentFrom) and methods (add, set, list,
get, has, remove). These logical inferences, based on
the ontology, ensure data consistency and validity as
depicted in Fig. 4.
The SPARQL queries has been executed success-
fully to retrieve relevant health conditions from the
individual ontology instance to generate personal-
ized recommendations following the criteria: X ∈ R
n
be the feature vector representing an individual or
item. w ∈ R
n
be the weight vector of the predic-
tive model. ˆy ∈ R be the predicted score obtained
from the predictive model. θ ∈ R be the chosen
threshold for making recommendations. The predic-
tive score ˆy is calculated as: ˆy = f (X, w), where f
is the predictive function (e.g., a machine learning
model and here, GaussianNB). The decision rule for
making recommendations is given by: ˆy = f (X, w) >
θ =⇒ Recommend preventive measures. Here are
example of successfully executed SPARQL queries in
this purpose:
KEOD 2024 - 16th International Conference on Knowledge Engineering and Ontology Development
132

Figure 5: The structure of the proposed AsthmaOnto ontology in Prot
´
eg
´
e.
Query 1: Patients with specific symptoms,
age range, and gender
SELECT ?patient
WHERE {
?patient :hasSymptom :DryCough .
?patient :hasSymptom :DifficultyInBreathing .
?patient :hasDemographic ?demographic .
?demographic :age ?age .
?demographic :gender “female” .
?patient :hasMedicalHistory ?medicalHistory .
?medicalHistory :pneumonia true .
?patient :hasSymptom :NasalCongestion .
FILTER (?age > 30 && ?age < 50)
}
Query 2: Patients with runny nose, asthma
prediction and symptom-based recommendations
SELECT ?patient ?recommendation
WHERE {
?patient :hasSymptom :RunnyNose .
?patient :hasDemographic ?demographic .
?demographic :gender “male” .
?patient :hasAsthmaPredicted ?asthmapredicted .
FILTER (?asthmapredicted = true)
?symptom rdf:type :SoreThroat .
?recommendation rdf:type :PreventiveMeasure .
?recommendation :relatedTo ?symptom .
}
For a 40-year-old asthma patient with symptoms
like dry cough and difficulty breathing, a history of
pneumonia, and exposure to high pollen levels, the
most relevant RecommendationType based on the
provided SPARQL example would be “Preventive
Measures”. This involves sending a Recommenda-
tionMessage that emphasizes proactive steps to min-
imize asthma triggers and improve indoor air quality,
helping the patient manage symptoms and reduce the
risk of exacerbations.
The paper integrates automatic predictive analy-
sis with a semantic knowledge graph to enhance per-
sonalized asthma monitoring, a novel approach ac-
cording to the existing literature. It preprocesses
a large asthma dataset using SelectKBest and Vari-
anceThreshold to build a robust GaussianNB model,
which proved highly accurate. To explain predic-
tions, GaussianNB is combined with LIME, offering
visual explanations that increase system transparency.
The paper also develops an OWL ontology and uses
SPARQL queries for personalized recommendations,
ensuring that both predictions and recommendations
are precise, personalized, and grounded in semantic
knowledge.
5 CONCLUSION
The proposed asthma recommendation system inte-
grates automatic predictive analysis with semantic
knowledge representation, offering personalized rec-
ommendations to improve asthma outcomes and pa-
tient care. TPOT automates machine learning pipeline
optimization, identifying the best model and hyper-
parameters for the asthma dataset, while LIME ex-
planations enhance the interpretability of the Gaus-
sianNB model. The use of predictive analysis and the
AsthmaOnto OWL ontology provides significant ad-
vantages in efficiency, performance, interoperability,
and explainability. Future research will focus on re-
fining models, expanding the ontology, and conduct-
ing clinical validation to further assess the system’s
effectiveness.
Personalized Asthma Recommendation System: Leveraging Predictive Analysis and Semantic Ontology-Based Knowledge Graph
133

REFERENCES
Ajami, H., Mcheick, H., and Laprise, C. (2022). First steps
of asthma management with a personalized ontology
model. Future Internet, 14(7):190.
Alharbi, E., Cherif, A., and Nadeem, F. (2023). Adaptive
smart ehealth framework for personalized asthma at-
tack prediction and safe route recommendation. Smart
Cities, 6(5):2910–2931.
Alharbi, E., Nadeem, F., and Cherif, A. (2021). Smart
healthcare framework for asthma attack prediction and
prevention. In 2021 National Computing Colleges
Conference (NCCC), pages 1–6. IEEE.
Anantharam, P., Banerjee, T., Sheth, A., Thirunarayan,
K., Marupudi, S., Sridharan, V., and Forbis, S. G.
(2015). Knowledge-driven personalized contextual
mhealth service for asthma management in children.
In 2015 IEEE international conference on mobile ser-
vices, pages 284–291. IEEE.
Barbaglia, G., Murzilli, S., and Cudini, S. (2017). Defini-
tion of rest web services with json schema. Software:
Practice and Experience, 47(6):907–920.
Bose, S., Kenyon, C. C., and Masino, A. J. (2021). Per-
sonalized prediction of early childhood asthma per-
sistence: a machine learning approach. PloS one,
16(3):e0247784.
Chatterjee, A., Gerdes, M. W., and Martinez, S. G. (2020).
Identification of risk factors associated with obesity
and overweight—a machine learning overview. Sen-
sors, 20(9):2734.
Chatterjee, A., Gerdes, M. W., Prinz, A., and Martinez,
S. G. (2021a). Comparing performance of ensemble-
based machine learning algorithms to identify poten-
tial obesity risk factors from public health datasets. In
Emerging Technologies in Data Mining and Informa-
tion Security: Proceedings of IEMIS 2020, Volume 1,
pages 253–269. Springer.
Chatterjee, A., Pahari, N., and Prinz, A. (2022a). Hl7
fhir with snomed-ct to achieve semantic and structural
interoperability in personal health data: a proof-of-
concept study. Sensors, 22(10):3756.
Chatterjee, A., Pahari, N., Prinz, A., and Riegler, M.
(2022b). Machine learning and ontology in ecoach-
ing for personalized activity level monitoring and
recommendation generation. Scientific Reports,
12(1):19825.
Chatterjee, A. and Prinz, A. (2022). Personalized recom-
mendations for physical activity e-coaching (ontore-
comodel): ontological modeling. JMIR Medical In-
formatics, 10(6):e33847.
Chatterjee, A., Prinz, A., Gerdes, M., and Martinez, S.
(2021b). An automatic ontology-based approach to
support logical representation of observable and mea-
surable data for healthy lifestyle management: Proof-
of-concept study. Journal of Medical Internet Re-
search, 23(4):e24656.
Chatterjee, A., Prinz, A., Riegler, M. A., and Meena, Y. K.
(2023). An automatic and personalized recommenda-
tion modelling in activity ecoaching with deep learn-
ing and ontology. Scientific Reports, 13(1):10182.
Cima, G., De Giacomo, G., Lenzerini, M., and Poggi, A.
(2017). On the sparql metamodeling semantics entail-
ment regime for owl 2 ql ontologies. In Proceedings of
the 7th International Conference on Web Intelligence,
Mining and Semantics, pages 1–6.
Dataset, A. D. P. (2024).
https://www.kaggle.com/datasets/deepayanthakur/
asthma-disease-prediction.
Garreau, D. and Luxburg, U. (2020). Explaining the ex-
plainer: A first theoretical analysis of lime. In Interna-
tional conference on artificial intelligence and statis-
tics, pages 1287–1296. PMLR.
Hutchinson, C. F. (1982). Classification improvement.
Photogrammetric Engineering and Remote Sensing,
44(1):123–130.
Kadariya, D., Venkataramanan, R., Yip, H. Y., Kalra, M.,
Thirunarayanan, K., and Sheth, A. (2019). kbot:
knowledge-enabled personalized chatbot for asthma
self-management. In 2019 IEEE International Con-
ference on Smart Computing (SMARTCOMP), pages
138–143. IEEE.
Morita, P. P., Yeung, M. S., Ferrone, M., Taite, A. K., Made-
ley, C., Lavigne, A. S., To, T., Lougheed, M. D.,
Gupta, S., Day, A. G., et al. (2019). A patient-
centered mobile health system that supports asthma
self-management (breathe): design, development, and
utilization. JMIR mHealth and uHealth, 7(1):e10956.
Olson, R. S. and Moore, J. H. (2016). Tpot: A tree-
based pipeline optimization tool for automating ma-
chine learning. In Workshop on automatic machine
learning, pages 66–74. PMLR.
OpenWeather (2024). https://openweathermap.org/api.
Pinnock, H., Noble, M., Lo, D., McClatchey, K., Marsh,
V., and Hui, C. Y. (2023). Personalised management
and supporting individuals to live with their asthma in
a primary care setting. Expert review of respiratory
medicine, 17(7):577–596.
WHO (2019). https://www.who.int/news-room/fact-
sheets/detail/asthma.
KEOD 2024 - 16th International Conference on Knowledge Engineering and Ontology Development
134
