
Decoding Weibo Sentiments: Unveiling Nuanced Emotions with
Bidirectional LSTM Analysis
Kaiwen Deng
a
Business School, Beijing Institute of Technology, Zhuhai, China
Keywords: Sentiment Analysis, Weibo Comments, Long Short-Term Memory, Pre-Trained Word Embeddings.
Abstract: This study highlights the critical role that deep learning plays in deciphering the complex emotional subtleties
prevalent in social media interactions via sentiment analysis of Weibo comments. The primary goal is to
deploy a bidirectional Long Short-Term Memory (LSTM) model that is intended to thoroughly analyze and
understand user attitudes, providing priceless information for improving marketing tactics and gauging public
opinion. Utilizing character-level segmentation and Tencent Artificial Intelligence (AI) Lab's pre-trained
word embeddings, the study advances sentiment analysis by enhancing sensitivity to contextual subtleties
within textual data. The study, which used a dataset of Weibo comments with sentiment annotations,
demonstrates the remarkable 96% accuracy with which the bidirectional LSTM model can categorize
sentiments. This result demonstrates how well the model captures complex emotional expressions,
outperforming both other deep learning methods and conventional machine learning techniques in sentiment
analysis tasks. The novel elements of the model's architecture, such character-level analysis and the intelligent
use of pre-trained embeddings, improve its classification accuracy and contextual comprehension. These
aspects represent significant advancements in sentiment analysis, with broad implications for both academic
research and practical applications in understanding social media discourse.
1 INTRODUCTION
The Weibo comment is the text content that users
reply and discuss the content on the Weibo platform,
covering rich emotions, attitudes, and views. The
significance of analyzing Weibo comments is that
being able to understand the emotional relationships,
attitudes, and views of users in social media. This is
of great significance for enterprises to formulate
accurate marketing strategies for public opinion
(Chen, 2022; Yuan, 2019), government
understanding of the people's conditions, and
academic research on social public opinion.
Therefore, this paper aims to use deep learning
technology, especially the text classification model
based on technologies based on long-term memory
(LSTM) to help reveal the motivation and factors
behind user behavior, and provide strong support for
decision-making in related fields (Li, 2019; Halawani,
2023). Scholars in the discipline of analysis of
sentiment have put forth a number of approaches to
handle text data and propel technological progress.
a
https://orcid.org/0009-0008-3657-6112
Deep learning-based techniques have advanced
substantially in the past few years in sentiment
analysis tasks. Among them, for text classification
tasks, recurrent neural network, or Recurrent Neural
Network (RNN), models like LSTM, or long-short-
term memory, are used extensively, particularly in
sentiment analysis (Khan, 2022; Wu, 2023). Through
these models, researchers are able to effectively
capture the semantic and contextual information in
written content, strengthening sentiment analysis's
precision and effectiveness (Yang, 2022).
Furthermore, sentiment analysis tasks have also been
handled by convolutional neural networks (CNNs).
Convolutional and pooling processes are used by
CNN models to extract features from text, which are
subsequently used for sentiment categorization.
Compared to traditional methods based on bag-of-
words models, CNNs can more effectively convey
local information through text, improving the
functionality of sentiment analysis (Kaur, 2023).
Moreover, sentiment analysis heavily relies on
traditional machine learning methods like Naive
Deng, K.
Decoding Weibo Sentiments: Unveiling Nuanced Emotions with Bidirectional LSTM Analysis.
DOI: 10.5220/0012923300004508
Paper published under CC license (CC BY-NC-ND 4.0)
In Proceedings of the 1st International Conference on Engineering Management, Information Technology and Intelligence (EMITI 2024), pages 221-226
ISBN: 978-989-758-713-9
Proceedings Copyright © 2024 by SCITEPRESS – Science and Technology Publications, Lda.
221

Bayes and Support Vector Machines (SVM). These
methods typically rely on manually designed features
and statistical models for text classification. Although
these methods can achieve the goal of sentiment
analysis to some extent, they often perform poorly in
handling complex text data and struggle to capture
deep semantic information in text. In conclusion,
Deep learning-based techniques are gradually gaining
popularity in the past decade and become mainstream
in the field of sentiment analysis, especially LSTM
and CNN models have achieved significant results in
sentiment classification tasks. These methods can
better understand the semantic and contextual
information of text data, therefore raising sentiment
analysis's precision and effectiveness (Alsini, 2023;
Contreras, 2023).
The project's objective is to use LSTMs to
develop a sentiment analysis model for Weibo
comments. By breaking down remarks into individual
characters, it preprocesses the material and improves
comprehension of linguistic subtleties. Leveraging
pre-trained word embeddings from Tencent Artificial
Intelligence (AI) Lab enriches the model's
comprehension of context and sentiment. A
bidirectional LSTM architecture is employed to
capture both past and future context, improving
sentiment classification accuracy. The predictive
performance of the model is contrasted with different
deep learning architectures and conventional machine
learning techniques. The experiment demonstrates
the LSTM model's effectiveness in analyzing Weibo
comments' sentiment, underscoring its robust support
for social sentiment analysis and decision-making.
2 METHODOLOGIES
2.1 Dataset Description and
Preprocessing
The study utilizes a dataset comprising Weibo
comments, aiming to analyze sentiment through an
LSTM-based model. The dataset consists of text
comments which have been annotated for sentiment,
with the intention of facilitating a comprehensive
understanding of public sentiment on various topics
discussed on Weibo (ChineseNlpCorpus, 2018). The
dataset is a collection of Weibo comments, each
associated with a sentiment label indicating the
comment's overall sentiment (positive or negative).
These comments have been meticulously collected to
ensure a diverse representation of topics, linguistic
styles, and sentiments, providing a robust foundation
for analyzing sentiment nuances in social media text.
The preprocessing of the dataset is a critical step
to prepare the raw text data for the LSTM model. The
paper preprocessing pipeline involves several key
stages: Character Segmentation: Given the nature of
the Chinese language, which does not use spaces to
separate words, this paper adopts a character-level
segmentation approach. This method involves
breaking down each comment into individual
characters, thereby capturing the linguistic features
more effectively. Vocabulary Construction: A
vocabulary index is created from the segmented
dataset, with a maximum size set to 10,000 unique
tokens. Special tokens such as <UNK> for unknown
characters and <PAD> for padding are included to
handle out-of-vocabulary words and maintain
uniform comment lengths, respectively. Sequence
Padding and Truncation: To ensure uniform input
sizes for the LSTM model, comments are either
padded or truncated to a fixed length of 50 characters,
as defined by the pad_size parameter. This step
ensures that each input tensor to the model maintains
a consistent shape. Tokenization and Indexing: Each
character in a comment is replaced with its
corresponding index from the vocabulary, converting
the textual data into a numerical format that can be
processed by the model. Characters not found in the
vocabulary are replaced with the index for <UNK>.
Training, validation, and test sets are separated from
the pre-processed dataset with a distribution of sixty
percent, twenty percent, and twenty percent,
accordingly. By splitting the data this way, the model
can be trained on an important part of the data, refined
and confirmed on another portion, and then tested for
generalization on unseen data.
2.2 Proposed Approach
This study explores the sentiment orientation in
Weibo comments by leveraging a model based on
LSTM networks. LSTM, recognized for its capacity
to effectively process sequential data and model long-
term dependencies, emerges as an optimal tool for
addressing Natural Language Processing (NLP)
tasks, especially emotion analysis. The methodology
unfolds in several pivotal phases: data preprocessing,
involving character-level segmentation and sequence
normalization; model construction, which
incorporates pre-trained word embeddings to bolster
the understanding of textual sentiment; and a series of
training, fine-tuning, and evaluation steps, employing
diverse performance metrics such as F1 scores and
accuracy to ascertain the efficacy of the model.
Aimed at conducting a thorough analysis of sentiment
orientations in Weibo comments, the research
EMITI 2024 - International Conference on Engineering Management, Information Technology and Intelligence
222

Figure 1: The pipeline of this study
(Photo/Picture credit: Original).
employs deep learning technologies to delve into
public emotions. The approach not only seeks to
improve the precision of sentiment analysis but also
to introduce new angles and methods for examining
sentiment on social media platforms. The process is
shown in the Figure 1.
2.2.1 LSTM
The core of the proposed approach is an LSTM-based
model for sentiment analysis. LSTM networks, a
special kind of RNN, are made to teach sequence
prediction problems about order dependence. Unlike
traditional feedforward neural networks, LSTM can
handle complete data sequences in addition to
individual data points since it contains feedback
connections. This feature is notably helpful for
applications involving natural language processing,
because sentiment interpretation depends heavily on
word order and context. The sentiment analysis
model based on the LSTM forms the basis of the
suggested methodology. An advanced kind of RNN
called LSTM networks is developed specifically to
identify order dependency in sequence prediction
issues. Because LSTM incorporates feedback
connections, it can handle complete data sequences in
addition to individual data points, unlike traditional
feedforward neural networks. This characteristic is
especially beneficial for natural language processing
tasks where context and order of words play a crucial
role in understanding sentiment. The LSTM model's
defining feature is its ability to remember and utilize
past information through its internal state, commonly
referred to as the cell state, to make informed
predictions. This is particularly important in
sentiment analysis where the sentiment conveyed by
a sentence can be heavily dependent on the context
provided by preceding words or phrases. The use of
LSTM in sentiment analysis of Weibo comments
allows for a more nuanced understanding of user
sentiment, which can be leveraged for market
analysis, public opinion monitoring, or even for
sociological research. In this experiment, the
implementation process begins with data
preprocessing, involving character-level
segmentation, vocabulary construction, sequence
padding and truncation, and tokenization and
indexing. The LSTM model is then initialized with
pre-trained embeddings and configured with
hyperparameters such as hidden layer size quantity of
layers and rate of learning. Cross-entropy loss and the
Adam optimizer are used to train the pre-processed
data, and performance is measured using metrics like
accuracy, precision, recall, and F1 scores. There are
three main parts to the suggested model architecture:
the Embedding Layer, which uses word embeddings
that have already been trained to convert vocabulary
indices into vector representations; the LSTM Layer,
which uses bidirectional LSTM units to gather
information from both previous and subsequent
contexts, making it easier to learn long-term
dependencies from sequential data and the Fully
Connected Layer, which translates abstract features
learned by the LSTM into predictive outputs for
sentiment classification, typically through the
modelling of sentiment scores and conversion into a
probability distribution using the SoftMax function.
2.2.2 Model Configuration
A model architecture is crafted with a careful balance
between complexity and computational efficiency,
selecting 128 units for the size of the hidden layers. A
dual-layer LSTM structure is used to improve
sentiment context recognition and to further
comprehend text sequences. Furthermore, as part of a
regularization strategy to mitigate model overfitting,
a dropout rate of 0.5 is set, randomly ignoring a
fraction of the network's nodes during training.
Additionally, the batch size is determined to be 128,
based on a trade-off consideration between memory
demands and gradient estimation stability during the
model training process.
2.2.3 Loss Function
The Adam optimizer is the optimization function used
in this model. Adam, which stands for Adaptive
Moment Estimation, is based on the idea of
combining the advantages of Momentum and
RMSProp, two additional optimization techniques.
Adam records each weight in the neural network's
first moment vector (m) and second moment vector
(v). The first moment (the mean) and the second
moment (the uncentered variance) of the gradients are
estimated by the parameters m and v, respectively.
Decoding Weibo Sentiments: Unveiling Nuanced Emotions with Bidirectional LSTM Analysis
223
The squared gradient and the gradient's exponential
moving average are calculated mathematically. The
parameters updating guidelines with Adam are as
follows:
11 1
(1 )
tt t
mm g
ββ
−
=⋅ +− ⋅
(1)
2
21 2
(1 )
tt t
vv g
ββ
−
=+−⋅
(2)
1
(1 )
t
tt
mm
β
=⋅−
(3)
2
(1 )
t
tt
vv
β
=⋅−
(4)
1
()
tt t t
vm
θθη ε
+
=−− +⋅
(5)
The gradient and the decay rates for the moment
estimates, which are typically set to 0.9 and 0.999,
respectively, indicate the parameters of the model at
time step t. The rate of learning is denoted by η, and
the tiny scalar, ε, is used to avoid dividing by zero,
usually around 10
ି଼
.
The advantage of Adam is its adaptive learning
rate capability, which allows for individual learning
rates for each parameter. This adaptive mechanism
often leads to faster convergence and has proven to be
effective in various contexts, particularly in complex
tasks such as sentiment analysis with large datasets
and models with a significant number of parameters.
2.3 Implementation Details
The LSTM-based sentiment analysis model was
implemented in the research using Python 3.9 and the
integrated programming environment PyCharm
2023.3.3. For development, a Microsoft Windows 11
Home Edition system with an RTX 3070 graphics
card and a 12th generation Intel(R) Core (TM) i7-
12700H processor operating at the frequencies of
2.30 megahertz frequencies was employed. Data
augmentation techniques were applied to enrich the
dataset and mitigate overfitting issues, ensuring a
robust model training process.
3 RESULTS AND DISCUSSION
In the conducted study, the analysis succinctly
evaluates the model's performance through three
crucial visual representations: an ascending training
accuracy curve indicating swift initial learning, a
descending loss graph signifying effective
optimization, and a confusion matrix that highlights
competent classification with an imbalance in false
negatives, suggesting potential areas for refinement.
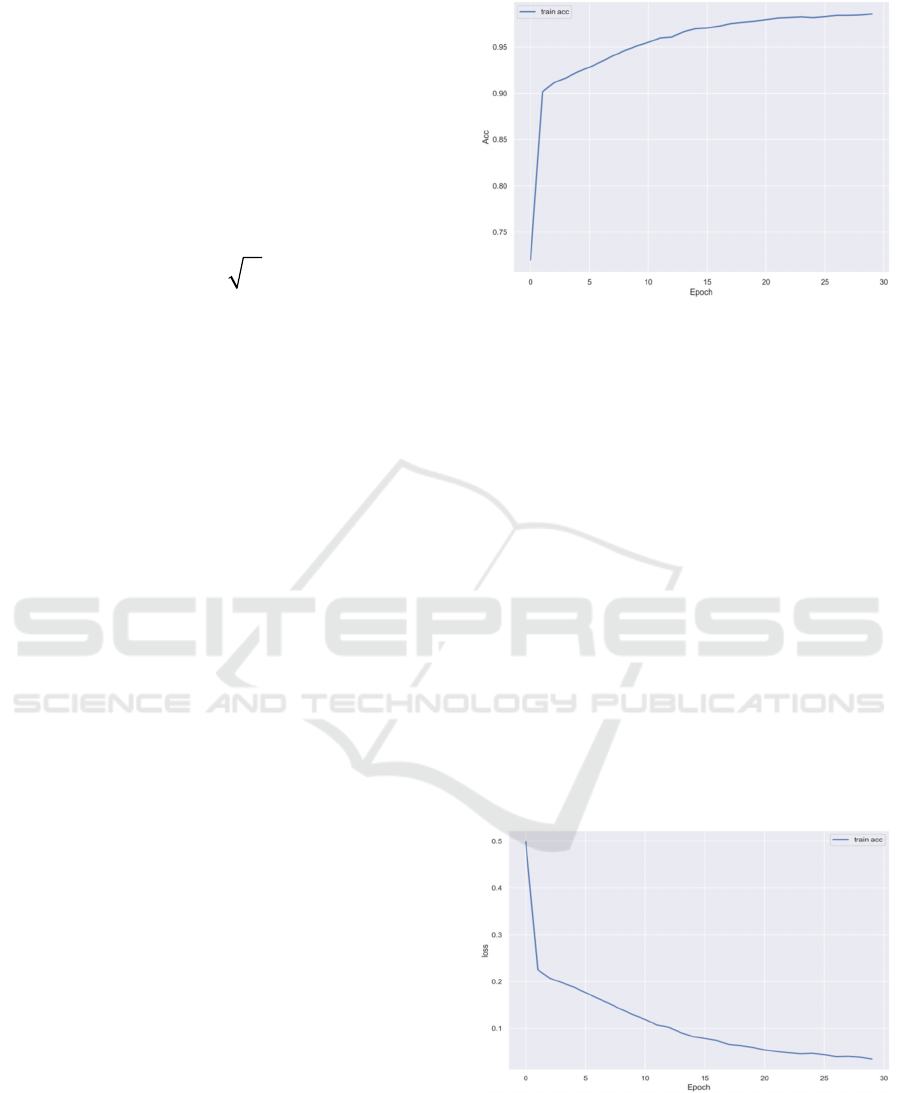
Figure 2: The training accuracy of a model over epochs
(Photo/Picture credit: Original).
As depicted in Figure 2, the model's training
accuracy incrementally increases with the
progression of epochs. The accuracy exhibits a
precipitous climb from approximately 75% to over
85% within the initial epochs, signalling the model's
rapid learning from the training data. Subsequently,
the increment in accuracy decelerates, yet it continues
to demonstrate a slow and steady enhancement until
it plateaus around 96% at the 30-epoch mark. This
pattern indicates that after a period of swift learning,
the model begins to converge, and the stability of
accuracy suggests that it has reached its performance
potential given the current architecture and dataset.
Although the high accuracy denotes strong model
performance on the training set, the absence of
validation or test accuracy precludes a full assessment
of overfitting. Without appropriate regularization,
there is a potential for the model to overfit the training
data, diminishing its generalizability to new data.
Figure 3: The training loss of a model over epochs
(Photo/Picture credit: Original).
Figure 3 portrays the fluctuation in the model's
loss during the training process. The loss markedly
decreases in the initial epochs, which indicates that
EMITI 2024 - International Conference on Engineering Management, Information Technology and Intelligence
224
the model rapidly reduces error, effectively
optimizing towards a superior direction. In
subsequent epochs, the decline in loss decelerates,
suggesting that the model is entering a phase of fine-
tuning and plateaus after 30 epochs. This descending
and stabilization of loss reflect the model's approach
to optimal performance; concurrently, vigilance is
warranted against the risk of overfitting associated
with excessively low loss. Ideally, the decrease in loss
should coincide with the model's enhanced
understanding of data representation, yet an overly
complex model might learn noise rather than
underlying useful patterns.
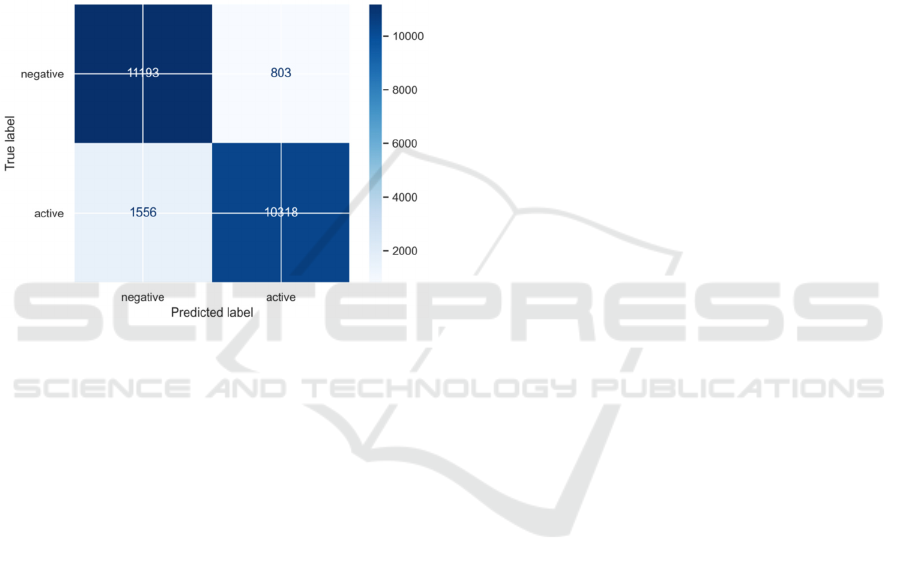
Figure 4: The predictions of the model's confusion matrix
(Photo/Picture credit: Original).
The confusion matrix, shown in Figure 4, offers
an intuitive perspective of the model's predictive
performance. The matrix reveals that 11,193 negative
samples and 10,418 active samples were correctly
classified, signifying a strong predictive accuracy for
both classes. However, there were also 803 false
positives where negative samples were incorrectly
labeled as active, and 1,556 false negatives where
active samples were mistakenly labeled as negative.
The relative abundance of false negatives suggests a
propensity of the model to misclassify active samples
as negative, which may be attributable to dataset
imbalance or improper threshold settings in the
classifier. This imbalance in error distribution could
impact the model's utility in practical applications,
especially if accurate identification of one class is
paramount. Further refinement of the model may
necessitate adjustments in data preprocessing
strategies or further tuning of the model parameters.
In conclusion, the comprehensive experiments
conducted in this chapter have significantly
illuminated both the capabilities and areas of
improvement for the machine learning model under
scrutiny. Through detailed analyses encompassing
training accuracy, loss patterns, and confusion matrix
insights, the experiments have elucidated a trajectory
of rapid learning and convergence, while also
cautioning against the potential for overfitting due to
high training accuracy without corresponding
validation. Furthermore, the analysis of predictive
accuracy through the confusion matrix has
highlighted challenges related to class imbalance and
classification thresholds, underscoring the necessity
for ongoing model refinement. Collectively, these
findings not only validate the significance of the
experimental efforts undertaken but also pave the way
for future enhancements to optimize model
performance.
4 CONCLUSIONS
This study presents a groundbreaking approach to
sentiment analysis within the realm of Weibo
comments, harnessing the power of a bidirectional
LSTM model. By intricately combining character-
level segmentation and pre-trained word embeddings,
this innovative methodology delves deep into the
intricate emotional fabric woven within social media
discourse. Through meticulous experimentation, the
model exhibits remarkable proficiency, achieving a
commendable accuracy plateau of 96% in sentiment
classification, thus solidifying its status as a
formidable tool in the realm of sentiment analysis.
Looking forward, the scope of exploration
extends to the dynamic nature of sentiment within
Weibo comments, with a particular emphasis on
understanding how sentiments evolve over time in
response to various social, political, and cultural
stimuli. It is believed that a deeper analysis of
sentiment fluctuations holds the key to unveiling
invaluable insights into collective social behavior,
thereby informing decision-making processes across
diverse domains. This study demonstrates the
effectiveness of the bidirectional LSTM model and
represents a major advancement in the area of
sentiment evaluation in deciphering the nuanced
emotional undertones embedded within Weibo
comments. As the journey of exploration continues,
the commitment remains unwavering in further
refining the model's sensitivity and applicability,
thereby contributing meaningfully to the ongoing
discourse surrounding sentiment analysis in the
digital age.
Decoding Weibo Sentiments: Unveiling Nuanced Emotions with Bidirectional LSTM Analysis
225

REFERENCES
Alsini, R. 2023. Analysis of Real Time Twitter Sentiments
using Deep Learning Models. Journal of Applied Data
Sciences, vol. 4(4).
Chen, X. 2022. Research on Emotional Tendency Analysis
of Weibo Comments Based on Deep Neural Network.
Health Science and Technology.
ChineseNlpCorpus. 2018. Weibo sentiments.
https://github.com/SophonPlus/ChineseNlpCorpus/blo
b/master/datasets/weibo_senti_100k/intro.ipynb
Contreras, Hernández, S., Tzili Cruz, M. P., Espínola
Sánchez, J. M., & Pérez Tzili, A. 2023. Deep Learning
Model for COVID-19 Sentiment Analysis on Twitter.
New Generation Computing.
Halawani, H. T., Mashraqi, A., Badr, S. K., & Alkhalaf, S.
2023. Automated sentiment analysis in social media
using Harris Hawks optimisation and deep learning
techniques. Alexandria Engineering Journal.
Kaur, G., & Sharma, A. 2023. A deep learning-based model
using hybrid feature extraction approach for consumer
sentiment analysis. Journal of Big Data, 10.
Khan, L., Amjad, A., Afaq, K. M., & Chang, H.-T. 2022.
Deep Sentiment Analysis Using CNN-LSTM
Architecture of English and Roman Urdu Text Shared
in Social Media. Applied Sciences, vol. 12(5), p: 2694.
Li, J., & Dong, D. 2019. Analysis of Weibo Comments
Based on SVM and LDA Models. 2019 Chinese
Control And Decision Conference (CCDC).
Wu, L. 2023. Application of deep learning in social network
public opinion sentiment. International Journal of
Artificial Intelligence.
Yang, H. 2022. Network Public Opinion Risk Prediction
and Judgment Based on Deep Learning: A Model of
Text Sentiment Analysis. Computational Intelligence
and Neuroscience.
Yuan, Z., Yuwei, G., Feng, Z., & Reimei, W. 2019. A
Literature Review of Sentiment Analysis on Chinese
Social Media. Journal of Physics: Conference Series,
vol. 1314(1), p: 012140.
EMITI 2024 - International Conference on Engineering Management, Information Technology and Intelligence
226
