
0-DMF: A Decision-Support Framework for Zero Defects Manufacturing
Beatriz Coutinho
1 a
, Eliseu Pereira
1,2 b
and Gil Gonc¸alves
1,2 c
1
Faculty of Engineering of the University of Porto, Portugal
2
SYSTEC-ARISE, Faculty of Engineering of the University of Porto, Portugal
Keywords:
Zero Defect Manufacturing, Decision-Support Systems, Data-Driven Manufacturing, Defect Prediction.
Abstract:
Manufacturing companies are increasingly focused on minimising defects and optimising resource consump-
tion to meet customer demands and sustainability goals. Zero Defect Manufacturing (ZDM) is a widely
adopted strategy to systematically reduce defects. However, research on proactive defect-reducing measures
remains limited compared to traditional defect detection approaches. This work presents the 0-DMF decision
support framework, which employs data-driven techniques for defect reduction through (1) defect prediction,
(2) process parameter adjustments to prevent predicted defects, and (3) clarifying prediction factors, provid-
ing contextual information about the manufacturing process. For defect prediction, Machine Learning (ML)
algorithms, including XGBoost, CatBoost, and Random Forest, were evaluated. For process parameter ad-
justments, optimisation algorithms such as Powell and Dual Annealing were implemented. To enhance trans-
parency, Explainable Artificial Intelligence (XAI) methods, including SHAP and LIME, were incorporated.
Tailored for the melamine-surfaced panels process, the methods showed promising results. The defect predic-
tion model achieved a recall value of 0.97. The optimisation method reduced the average defect probability by
28 percentage points. The integration of XAI enhanced the framework’s reliability. Combined into a unified
tool, all tasks delivered fast results, meeting industrial time constraints. These outcomes signify advancements
in predictive quality through data-driven approaches for defect prediction and prevention.
1 INTRODUCTION
As the industrial sector pursues higher profits and
meets growing customer demands, optimising pro-
duction processes and manufacturing high-quality
products becomes essential. Additionally, imple-
menting effective waste reduction strategies is cru-
cial for achieving sustainability goals. By minimis-
ing waste, companies can not only enhance their en-
vironmental footprint but also improve operational ef-
ficiency and cost-effectiveness.
The emergence of Industry 4.0 has introduced a
profound era of digitalisation, transforming indus-
trial processes through advanced technologies and the
generation of unprecedented volumes of data. These
technologies can be exploited to create real-time mon-
itoring approaches to prevent process problems and
malfunctions. Recently, smart decision-support sys-
tems have been applied in manufacturing for various
applications, including defect reduction and process
a
https://orcid.org/0009-0000-9769-6726
b
https://orcid.org/0000-0003-3893-3845
c
https://orcid.org/0000-0001-7757-7308
optimisation.
Defect occurrence in manufacturing has far-
reaching implications, compromising product quality
and increasing operational costs due to rework. The
wastage of resources, including materials and energy,
further adds to the financial burden and environmental
impact. Tackling defects in a proactive and preventive
way is crucial to minimise the concerns of modern
companies. The Zero Defect Manufacturing (ZDM)
concept stands out as one of the most applied strate-
gies in dealing with defects, demonstrating positive
impacts in industrial settings (Fragapane et al., 2023).
This work aims to develop a smart decision-
support framework, 0-DMF (Zero-Defects Manufac-
turing Framework), tailored for reducing defects in
the wood-based panels industry. The framework
will achieve this by applying prediction and preven-
tion defect strategies, encompassing three main tasks:
(1) real-time defect prediction using Machine Learn-
ing (ML) algorithms, (2) real-time process parame-
ter adjustments to prevent predicted defects by apply-
ing optimisation algorithms, and (3) detailed analy-
sis of prediction factors using Explainable Artificial
Coutinho, B., Pereira, E. and Gonçalves, G.
0-DMF: A Decision-Support Framework for Zero Defects Manufacturing.
DOI: 10.5220/0012924400003822
In Proceedings of the 21st International Conference on Informatics in Control, Automation and Robotics (ICINCO 2024) - Volume 1, pages 253-260
ISBN: 978-989-758-717-7; ISSN: 2184-2809
Copyright © 2025 by Paper published under CC license (CC BY-NC-ND 4.0)
253

Intelligence (XAI). The unified decision-support tool
promises to enhance decision-making for industrial
operators, contributing to improved process efficacy
and waste reduction.
This paper is organised as follows: Section 2
presents the literature review. Section 3 highlights the
framework’s implementation. Section 4 discusses the
main results. Finally, Section 5 provides the conclu-
sions and future work.
2 LITERATURE REVIEW
The following literature review overviews the ZDM
concept, ML applications for process quality moni-
toring, optimisation of process parameters, and XAI
methods. The section concludes with a summary
of the primary conclusions drawn from the reviewed
studies.
2.1 Zero Defect Manufacturing
ZDM is widely employed as a strategy to reduce de-
fects in industrial processes (Caiazzo et al., 2022). It
includes four foundational strategies: Detection, Re-
pair, Prediction and Prevention. Detection and Re-
pair are more traditional methods, with Detection in-
volving the identification of defects and Repair focus-
ing on reworking defective products whenever feasi-
ble. The Prediction strategy aims to anticipate defect
occurrence, and Prevention seeks to avoid defects,
usually by employing quality control and inspection
tools.
Production parameters demonstrate intricate and
complex relationships. To effectively implement
ZDM in response to these complex production chal-
lenges, AI techniques and modern technologies are
indispensable (Lin and Chen, 2024). Therefore, the
effectiveness of ZDM depends significantly on ex-
ploiting new manufacturing technologies introduced
by Industry 4.0, making it particularly suitable for de-
ployment in smart manufacturing environments.
A recent survey on ZDM practices highlighted
significant positive impacts on throughput time, prod-
uct quality, and waste reduction (Fragapane et al.,
2023). Prevention emerged as the most effective strat-
egy, positively influencing production quality perfor-
mance. However, despite these identified benefits, the
application of the Prevention strategy remains limited,
making it the least implemented of the four strategies.
Addressing this gap, exploiting the available mod-
ern technologies, could lead to more effective defect
management and improved overall production perfor-
mance.
2.2 ML-Based Solutions for Defect
Prediction in Manufacturing
The complexity of modern processes, combined with
abundant data, strongly promotes the adoption of
data-driven techniques. ML algorithms have proven
to be highly effective in analysing complex systems
and addressing issues within the manufacturing do-
main, such as quality prediction or process parameter
optimisation.
A recent study of ML applications in manufac-
turing identifies supervised learning as the dominant
ML type for process quality optimisation and moni-
toring (Kang et al., 2020). Regression tasks are often
prioritised for quality optimisation, while classifica-
tion and anomaly detection tasks are used for prod-
uct failure detection. Binary classification is usually
preferred over multiclass classification for defect pre-
diction tasks (Kang et al., 2020; Ro
ˇ
zanec et al., 2022;
Takalo-Mattila et al., 2022).
Commonly employed ML methods for defect pre-
diction include Random Forest (RF), Decision Trees
(DT), Support Vector Machines (SVM), and gradient
boosting algorithms such as CatBoost and XGBoost
(XGB) (Schmitt et al., 2020; Gonc¸alves et al., 2021;
Tiensuu et al., 2021; Dias et al., 2021; Caiazzo et al.,
2022; Ro
ˇ
zanec et al., 2022; Takalo-Mattila et al.,
2022). Among these, boosting algorithms have shown
particularly positive outcomes.
Due to the relative rarity of defects in manu-
facturing processes, the resulting datasets are usu-
ally imbalanced. To address this issue, data balanc-
ing techniques like oversampling, undersampling, or
using the Synthetic Minority Over-sampling Tech-
nique (SMOTE) are often applied (Dias et al., 2021;
Gonc¸alves et al., 2021; Kang et al., 2020). Given this
imbalance, appropriate evaluation metrics such as re-
call and precision are crucial for accurate model as-
sessment.
2.3 Real-Time Process Parameter
Optimisation
In an industrial setting, a recipe is a set of process
parameter values combined to manufacture a product
(Gonc¸alves et al., 2021). Although unlikely, recipe
adjustments may become necessary if a defect is
likely to occur. Real-time recipe recommendations
are crucial for addressing potential defects and en-
hancing product quality, aligning with the ZDM Pre-
vention strategy.
To explore the potential parameter adjustments
and find optimal solutions for reducing the probabil-
ity of defect occurrence, optimisation algorithms such
ICINCO 2024 - 21st International Conference on Informatics in Control, Automation and Robotics
254

as the Powell Method, Basin Hopping, Nelder-Mead
Method, and Dual Annealing can be considered (Dias
et al., 2021; C¸ evik Onar et al., 2016; Ezugwu et al.,
2020). In industrial contexts, optimising parameter
values for defect prevention requires a focus on time-
liness, given the limited time frame available for ad-
justments. The selected optimisation methods must
be able to deliver results quickly, enabling operators
to implement necessary process adjustments without
compromising efficiency or product integrity. Hence,
achieving a balance between optimisation effective-
ness and computational efficiency is crucial for suc-
cessful defect prevention.
2.4 Explainable Artificial Intelligence
Many industrial operators lack formal education in
AI-related domains, which can lead to trust issues
with solutions generated by opaque traditional AI
models (Fragapane et al., 2023). XAI methods ad-
dress this challenge by providing insights into how AI
models make decisions, enhancing transparency and
interpretability (Hoffmann and Reich, 2023).
XAI techniques such as Local Interpretable
Model-agnostic Explanations (LIME), SHapley Ad-
ditive exPlanations (SHAP), and Partial Dependence
Plots (PDP) have been integrated into quality assur-
ance and defect reduction frameworks in related stud-
ies. While researchers widely agree on the benefits
of integrating XAI in manufacturing decision-support
tools, adoption in industrial contexts remains limited
(Hoffmann and Reich, 2023). Overcoming this bar-
rier is crucial for exploiting the full potential of XAI
to enhance operational decision-making.
2.5 Gap Analysis
The reviewed studies emphasise the effectiveness of
ML algorithms, especially gradient-boosting-based
ones, in predicting product quality within manu-
facturing contexts. The application of optimisation
algorithms is crucial for generating real-time recipe
recommendations aimed at preventing defects. More-
over, integrating XAI methods significantly enhances
model transparency, positively influencing their relia-
bility. However, significant gaps persist. Firstly, de-
spite proven effectiveness, there’s a limited adoption
of the Prevention strategy in ZDM compared to other
strategies, suggesting a need for further research.
Additionally, efforts to enhance the adoption of XAI
methods in manufacturing settings are needed to
improve model transparency and interpretability. Ad-
dressing these gaps can result in more accurate, use-
ful, and transparent decision-support frameworks for
manufacturing.
3 IMPLEMENTATION
The 0-DMF draws inspiration from successful strate-
gies identified in the reviewed studies. The frame-
work’s structure, depicted in Figure 1, is organised
into distinct groups of activities: (1) analysis of pro-
cess and production flows, involving the collection
and processing of the data; (2) modelling of pro-
cesses, where the framework establishes a relation-
ship between different process parameters and their
impact on product quality; and (3) specification and
development of the graphical unified decision support
tool, aiding operators in real-time process monitoring,
resulting in (4) a zero-defect product.
Figure 1: Proposed 0-DMF structure.
0-DMF was implemented in Python, using li-
braries such as Pandas, NumPy, SciPy, and Scikit-
learn.
3.1 Use Case Overview
Wood panels, particularly melamine-surfaced boards,
serve a variety of purposes, one of those being decora-
tive applications. These boards consist of wood-based
panels coated with paper impregnated with melamine
resin. During manufacturing, the process involves
pressing the melamine-impregnated paper onto the
raw board surface under controlled conditions of pres-
sure and temperature (Dias et al., 2021). Achiev-
ing proper adhesion and ensuring high-quality final
products requires precise control of these parameters
(Gonc¸alves et al., 2021). The proposed framework,
0-DMF: A Decision-Support Framework for Zero Defects Manufacturing
255

tailored for a Portuguese manufacturer specialising in
wood-based panels, aims to optimise the melamine
impregnation process.
3.2 Data Analysis and Pre-Processing
The data pertaining to the melamine impregnation
process was collected from sensors placed across
two identical production lines from January 2022 to
February 2024. This data was in tabular format and
consisted of 77 distinct feature columns. The sepa-
rate datasets were consolidated into a single unified
dataset to facilitate more accurate analysis and in-
sights, resulting in a total of 105,000 samples.
A ”Defect Code” was associated with each sam-
ple, serving as an identifier for the type of defect
that occurred during the process. Samples produced
with no defects were assigned the ”0” defect code.
Initially, 91 different codes were identified. How-
ever, the analysis revealed that many of these actually
corresponded to the same defect description despite
having different defect codes. To address this issue
samples, with repeated descriptions were merged, re-
taining the code with the most samples, reducing the
number of distinct defect codes to 60. However, pre-
dicting the type of defect that the panel had using 60
classes in a classification task would overly compli-
cate the process. As a solution, all defect codes and
descriptions were grouped into 7 defect categories
based on similar properties. This categorisation en-
sured a more manageable classification.
Given that the dataset had not undergone any prior
cleaning or processing, further preparation was re-
quired to be suitable for subsequent modelling. Ini-
tially, irrelevant features, duplicated columns, and
those with a majority of missing or invalid values
were removed. After, the Pearson correlation coeffi-
cient was calculated for each pair of feature columns.
One feature from each pair with a coefficient equal to
or greater than
|
0.9
|
was removed to eliminate redun-
dancy. Categorical feature columns were then con-
verted to a numerical representation, as most ML al-
gorithms require numerical inputs to process the data
effectively. The mapping between each category and
its numerical representation was saved in an external
file to ensure consistency in later processing. Follow-
ing this, samples with missing or invalid values were
discarded, and boxplots were utilised to identify and
eliminate samples with outlier values.
After completing the data cleaning and pre-
processing, the final dataset contained approximately
72,000 samples, indicating an initial reduction of
nearly 30%. Only around 2% of the samples rep-
resented defects, resulting in an imbalanced dataset.
The number of feature columns was reduced from the
initial 77 to 50.
3.3 Defect Prediction and Explanation
Modelling
Four ML methods were evaluated to predict defective
wood panels. Given the availability of labelled data
and its tabular format, supervised learning methods
were implemented, focusing on classification tasks.
Specifically, CatBoost, RF, XGB, and an ensem-
ble combining CatBoost, XGB, and RF were tested.
These algorithms were implemented using libraries
such as Scikit-learn, CatBoost, and XGBoost. Hyper-
parameter tuning and model optimisation were con-
ducted using the Scikit-learn GridSearchCV method.
The implemented models were trained to perform
three different types of classification:
• Binary classification: Predicting whether a sam-
ple is likely to be defective.
• Multiclass classification (1): Predicting the spe-
cific defect type for a sample previously identified
as defective.
• Multiclass classification (2): Predicting the defect
category for a sample previously identified as de-
fective.
The dataset underwent a chronological train-test
sampling split. The training dataset contained ap-
proximately 56,000 samples, while the testing dataset
comprised around 15,500 samples. As previously dis-
cussed, the available dataset was imbalanced, with de-
fective samples representing only 2% of the data. This
can negatively impact model training, compromising
both its accuracy and efficiency. To mitigate this is-
sue, the SMOTE algorithm was applied to the training
data to balance class occurrences. Figure 2 showcases
the significant variances observed among the different
defect types before applying the SMOTE algorithm.
The model’s performance was evaluated using re-
call and precision metrics, given the imbalanced na-
ture of the dataset. Emphasis was placed on recall as
it focuses on minimising false negatives, ensuring that
the model is proficient at identifying all actual defects.
An added layer of transparency and interpretabil-
ity was integrated using XAI methods. Local model-
agnostic techniques, specifically LIME and SHAP,
were employed for this purpose. LIME uncovered
the specific ”rules” or conditions that influenced each
prediction, while SHAP highlighted the contribution
of each feature to the model’s predictions.
ICINCO 2024 - 21st International Conference on Informatics in Control, Automation and Robotics
256
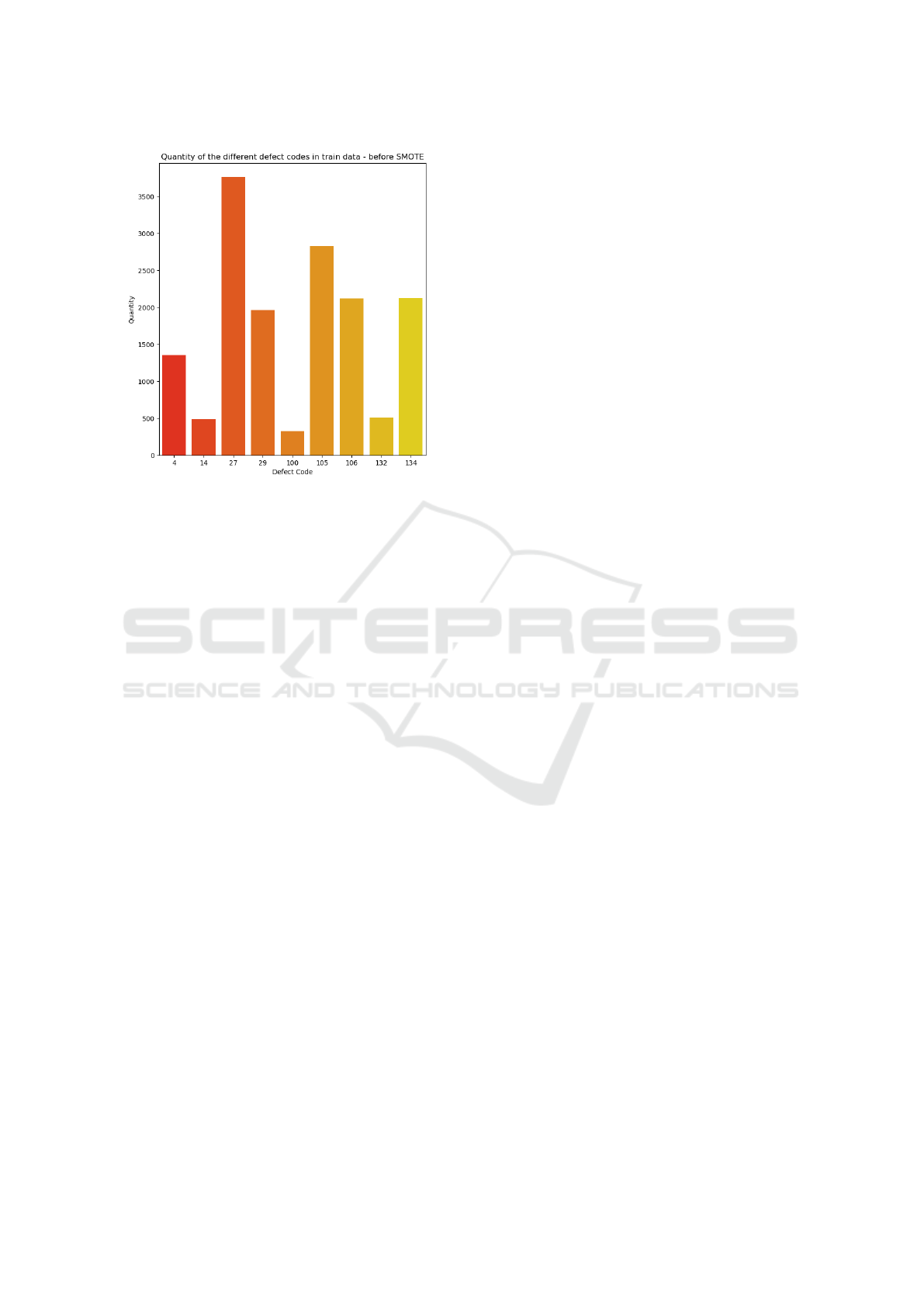
Figure 2: Frequency of the most recurrent defect types (rep-
resented by their codes) before applying SMOTE data bal-
ancing.
3.4 Real-Time Recipe Recommendation
Recognising that not all process parameters are im-
mediately adjustable or adaptable within a short time
frame, consultations with field specialists led to the
identification of 10 real-time adjustable variables. To
meet the real-time constraint, the optimisation algo-
rithm was tasked with ideally identifying optimal pa-
rameter values within a two-minute window.
Four algorithms were tested to find optimal pro-
cess parameters: Dual Annealing, Nelder-Mead,
Powell, and Basin Hopping, all implemented using
the SciPy Optimize module. Search intervals were
established for each adjustable feature based on the
distribution of values observed in non-defective his-
torical samples. However, since practical constraints
must be considered, the optimisation search was con-
strained within ±20% of the current feature value,
within the absolute interval, to facilitate real-time ad-
justments.
Objective functions, namely Mean Squared Error
(MSE), LogCosh, and Mean Absolute Error (MAE),
were employed to guide the algorithms in minimis-
ing the current defect probability relative to a target
probability. These functions were evaluated across
different target defect probability values (0%, 10%,
and 50%), with MSE also assessed without a specific
target defect probability.
3.5 Web Application
To enhance the decision-making process, a Flask web
application was developed to integrate the predic-
tion, explanation, and optimisation tasks. The MQTT
(Message Queuing Telemetry Transport) protocol was
implemented to ensure seamless communication be-
tween the production line and the application, as it is
known for its lightweight and efficient messaging ca-
pabilities, which are particularly suitable for IoT sce-
narios. The application manages raw samples through
the following steps:
• Data Acquisition and Pre-Processing: Raw
samples are received by the application and un-
dergo cleaning and data processing;
• Prediction and Explanation: The clean sample
is processed through the prediction and explana-
tion modules to provide real-time defect predic-
tions and insights. Upon processing, the sam-
ple and corresponding predicted defect probabil-
ity are stored in a PostgreSQL database;
• Recipe Recommendation: Based on the pre-
dicted defect probability, the optimisation module
suggests process parameter adjustments to min-
imise it.
For more intuitive insights, a graphical user inter-
face (GUI) was developed. It facilitates the observa-
tion of real-time predictions, explanations, and statis-
tics. Users can also access historical data, filtering
samples based on date and time ranges. The statis-
tics displayed on the GUI are retrieved through SQL
queries, ensuring the accuracy of the presented data.
Graphical components of the interface were devel-
oped using HTML, JavaScript and CSS. Detailed GUI
mockups were created beforehand using Figma, al-
lowing detailed planning before the implementation.
4 RESULTS AND DISCUSSION
The framework’s performance was assessed using
real production data from wood-panel’s melamine im-
pregnation process.
4.1 Defect Prediction and Explanation
Table 1 presents the results of the implemented ML
algorithms for the three classification tasks. The per-
formance is shown both with and without the applica-
tion of the SMOTE algorithm for data balancing.
Upon analysis, it is evident that binary classifica-
tion performed exceptionally well across all metrics.
0-DMF: A Decision-Support Framework for Zero Defects Manufacturing
257
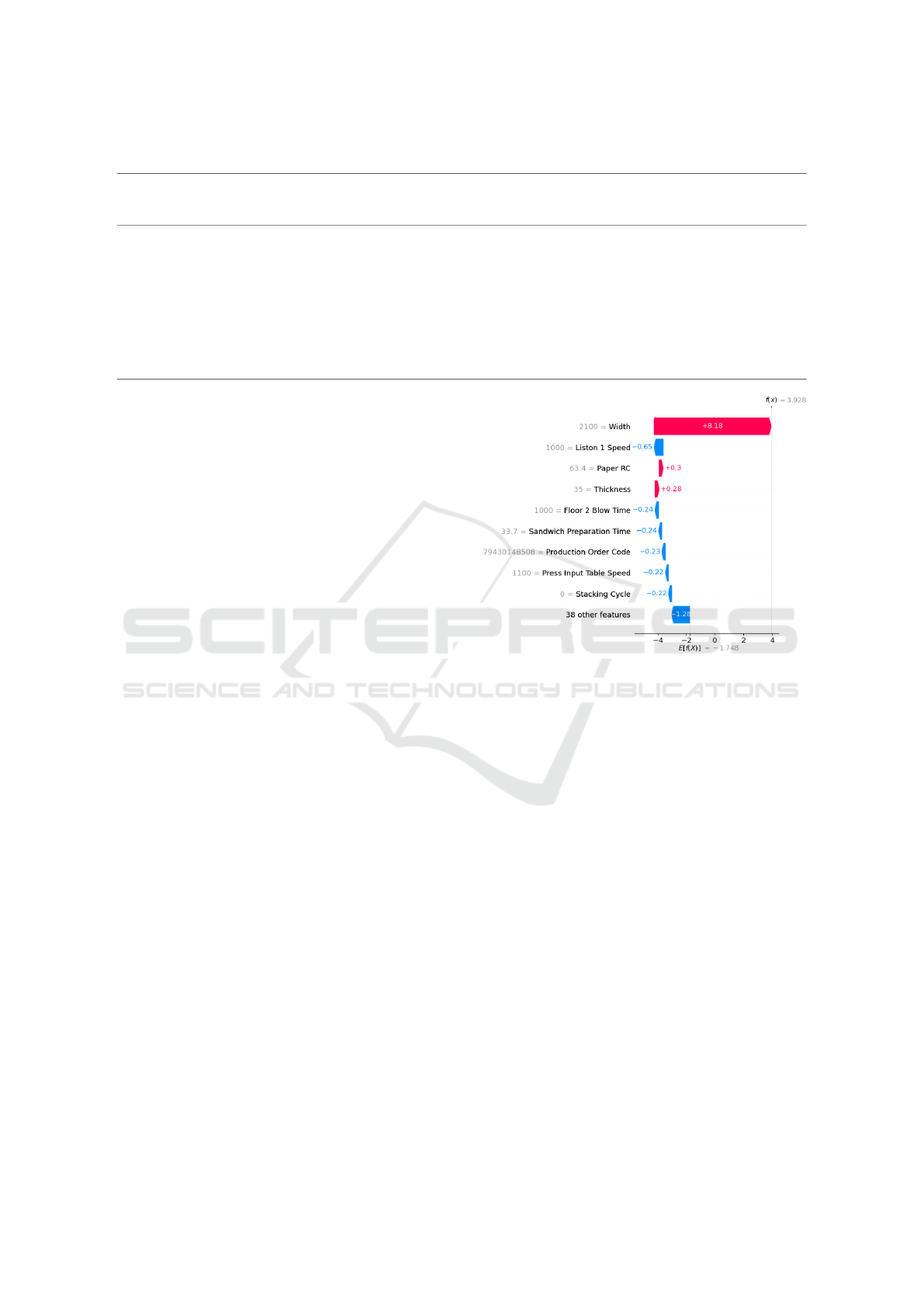
Table 1: Results of the employed Machine Learning algorithms for defect prediction.
CatBoost RF XGB Ensemble
Recall Precision Recall Precision Recall Precision Recall Precision
Binary 0.9664 0.9663 0.9631 0.9629 0.9582 0.9589 0.9659 0.9657
Binary (with SMOTE data balancing) 0.9652 0.9651 0.9548 0.9547 0.9574 0.9582 0.9657 0.9655
Multiclass Defect Types 0.2087 0.2190 0.1929 0.2437 0.2513 0.2113 0.2033 0.2113
Multiclass Defect Types (with SMOTE data balancing) 0.1959 0.1933 0.2174 0.2233 0.2233 0.2014 0.2203 0.2043
Multiclass Defect Categories 0.5788 0.4455 0.5974 0.6373 0.5803 0.4629 0.5956 0.4779
Multiclass Defect Categories (with SMOTE data balancing) 0.5469 0.4661 0.5231 0.4384 0.5360 0.4430 0.5705 0.4480
The CatBoost model, in particular, achieved the high-
est scores, with a recall of 0.9664 and a precision of
0.9663, indicating a high efficiency in predicting de-
fect occurrence. In contrast, multiclass classification
based on defect types achieved poor results across all
metrics. Although the classification considering cat-
egorised defects performed better, the highest preci-
sion achieved was 0.637, and the highest recall was
0.5974 with the RF model. These results are still con-
siderably low for a classification task as they can lead
to many misclassifications. Given the poor results of
the multiclass classifications, a Principal Component
Analysis (PCA) was conducted on the data. The PCA
revealed that the defective sample’s data is not suffi-
ciently differentiable, with minimal variance between
different defect types and categories. This lack of dis-
tinct separation likely contributed to the inferior clas-
sification performance. Considering these findings,
only binary classification was included in the final
system.
Overall, the application of the SMOTE data bal-
ancing technique did not achieve significant improve-
ments in the results. This is likely due to the lack
of distinguishability between classes, causing the syn-
thetic data generated by SMOTE to inaccurately rep-
resent true class boundaries. As a result, the mod-
els struggled to differentiate between classes, reduc-
ing the effectiveness of the data-balancing.
The inclusion of the plots generated by XAI pro-
vides operators with useful information about the
manufacturing process. The SHAP waterfall plot, ex-
emplified in Figure 3, illustrates the impact of the nine
most influential features on model prediction. The
LIME bar plot displays the main rules influencing the
prediction outcome. These explanations were only
generated for samples with a defect probability ex-
ceeding 50%.
Figure 3: SHAP waterfall plot illustrating feature impact in
the prediction.
4.2 Real-Time Recipe Recommendation
The evaluation of the algorithm’s effectiveness was
conducted across 8 subsets of the testing dataset, cat-
egorised based on different ranges of defect proba-
bilities. The performance of each algorithm, consid-
ering each of the different objective functions, was
assessed across these ranges, and the time taken to
reach a solution was measured. The results consider-
ing the MSE objective function are presented in Ta-
ble 2. Dual Annealing emerged as the most effective
algorithm, achieving an average defect probability re-
duction of 28 percentage points (p.p.) and reaching up
to 49.70 percentage points reduction in the [60, 70[%
range.
The ranges of [60, 70[% and [70, 80[% con-
sistently showed the highest reduction percentages
across all algorithms and objective functions. This
is likely because samples in these ranges are still rel-
atively close to the threshold between defective and
non-defective, making them more easily influenced
by optimisation. Small adjustments can push them
from one category to the other. The initial defect
ICINCO 2024 - 21st International Conference on Informatics in Control, Automation and Robotics
258

Table 2: Effect of recipe recommendation algorithms on predicted defect probability, considering the MSE objective function.
Defect
Probability
Range
Avg. Defect
Probability
Before (%)
Dual Annealing Powell Nelder-Mead Basin-Hopping
Avg.
Defect
Probabil-
ity After
(%)
Avg.
Reduction
(p.p.)
Avg.
Duration
(s)
Avg.
Defect
Probabil-
ity After
(%)
Avg.
Reduction
(p.p.)
Avg.
Duration
(s)
Avg.
Defect
Probabil-
ity After
(%)
Avg.
Reduction
(p.p.)
Avg.
Duration
(s)
Avg.
Defect
Probabil-
ity After
(%)
Avg.
Reduction
(p.p.)
Avg.
Duration
(s)
10% - 30% 18.22% 4.38% 13.84 1.31 5.60% 12.62 2.95 17.17% 1.04 1.02 25.38% -7.16 0.37
30% - 50% 40.96% 11.18% 29.78 1.32 13.34% 27.63 3.09 27.31% 13.65 1.05 33.09% 7.87 0.40
50% - 60% 54.49% 17.01% 37.48 1.38 22.03% 32.46 2.95 36.47% 18.02 1.02 41.17% 13.32 0.41
60% - 70% 65.07% 15.37% 49.70 1.32 24.45% 40.62 2.38 38.39% 26.69 1.02 42.12% 22.96 0.40
70% - 80% 74.95% 30.95% 44.01 1.32 36.22% 38.74 2.60 45.86% 29.09 1.03 52.43% 22.53 0.40
80% - 90% 85.99% 53.24% 32.75 1.32 57.66% 28.33 2.34 66.68% 19.30 1.03 70.69% 15.30 0.40
90% - 95% 93.13% 58.58% 34.54 1.30 64.12% 29.01 2.21 77.75% 15.38 1.03 79.47% 13.65 0.43
95% - 99% 98.01% 89.49% 8.51 1.31 91.61% 6.39 1.25 95.30% 2.71 0.70 96.58% 1.42 0.23
99% - 100% 99.70% 97.69% 2.01 1.33 98.44% 1.26 1.56 99.34% 0.36 0.62 99.50% 0.20 0.24
probabilities for samples in these ranges indicated a
high likelihood of defects. Post-optimisation, proba-
bilities were reduced to approximately 15% and 30%,
significantly increasing the likelihood of defect-free
panels. In contrast, the reduction was less effective
for the highest defect probability ranges (over 80%),
with the final defect probabilities still exceeding 50%.
Nonetheless, any reduction in the defect probability
improves the outcome.
When comparing the outcomes of the different al-
gorithms across various objective functions, the MSE
function delivered the most significant reductions.
Setting a target defect probability of 0% consistently
produced better results. Oppositely, when no target
probability was specified, the outcomes were infe-
rior, indicating potential convergence issues with the
algorithms. All optimisation durations were within
the two-minute constraint per sample. Basin Hopping
was the quickest optimisation method, while Powell
was the slowest, with average durations of 2 to 3 sec-
onds. Based on these findings, considering that all
algorithms produced results within the defined time
limit, Dual Annealing with the MSE objective func-
tion and a target defect score of 0% was considered
the optimal choice for the framework’s recipe recom-
mendation module.
4.3 Web Application
To evaluate the functionality of the developed Flask
web application, a simulated MQTT publisher was es-
tablished to dispatch raw production testing samples
every 70 seconds. Using the Python Time module,
measurements were conducted to capture the average
execution time of the application for performing the
required tasks. These tasks include pre-processing,
prediction, explanation, optimisation, saving samples
to the database, and retrieving analytics from the
database, each completed in less than two seconds.
This setup effectively meets the requirement for real-
time insights, as all tasks are comfortably completed
well within the two-minute timeframe.
The final GUI comprises four distinct dynamic
pages. Figure 4 provides a visual representation of
the implemented GUI.
5 CONCLUSIONS AND FUTURE
WORK
In today’s manufacturing landscape, companies in-
creasingly rely on sophisticated systems to evaluate
product quality, aiming to optimise processes and re-
duce waste for enhanced sustainability and economic
viability. This paper introduced the 0-DMF decision-
support framework to help achieve zero defects man-
ufacturing, specifically tailored to the wood panels
processing industry. By integrating defect prediction,
explanation of predictions, and process parameter ad-
justments to mitigate defect occurrence, this frame-
work successfully provides real-time insights for end-
users. The employed ML algorithms for defect pre-
diction achieved promising results, accurately identi-
fying most defect occurrences. The optimisation al-
gorithms quickly identified optimal process param-
eters, giving operators sufficient time to implement
changes and reduce defect probability. Additionally,
the integration of XAI methods enhanced the frame-
work’s transparency and reliability. With these pos-
itive outcomes, 0-DMF promises enhancements to
modern industrial processes, contributing to the pro-
gression and sustainability of contemporary industrial
practices.
Future framework development should focus on
considering more advanced alternative approaches to
distinguish between defect types and allow for effec-
tive multiclass classification. Developing a more gen-
eralised version of the tool to enhance its applicability
across various manufacturing processes is also essen-
tial.
0-DMF: A Decision-Support Framework for Zero Defects Manufacturing
259
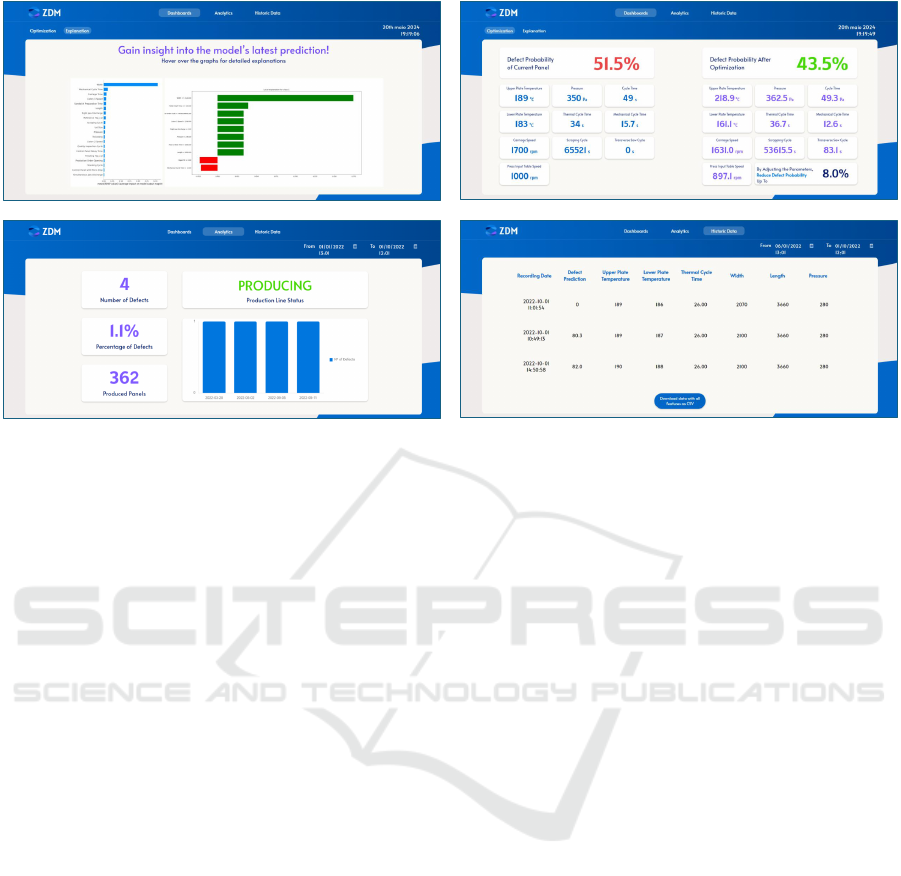
Figure 4: Implemented decision-support framework’s GUI.
ACKNOWLEDGEMENTS
This work was partially supported by the HORIZON-
CL4-2021-TWIN-TRANSITION-01 openZDM
project, under Grant Agreement No. 101058673.
REFERENCES
Caiazzo, B., Nardo, M. D., Murino, T., Petrillo, A., Piccir-
illo, G., and Santini, S. (2022). Towards zero defect
manufacturing paradigm: A review of the state-of-the-
art methods and open challenges. Computers in Indus-
try, 134.
Dias, R. C., Senna, P. P., Gonc¸alves, A. F., Reis, J.,
Michalaros, N., Alexopoulos, K., and Gomes, M.
(2021). Prefab framework - product quality towards
zero defects for melamine surface boards industry. In
IFAC Proceedings, volume 54, pages 570–575. Else-
vier B.V.
Ezugwu, A. E., Adeleke, O. J., Akinyelu, A. A., and Viriri,
S. (2020). A conceptual comparison of several meta-
heuristic algorithms on continuous optimisation prob-
lems. Neural Computing and Applications, 32:6207–
6251.
Fragapane, G., Eleftheriadis, R., Powell, D., and Antony, J.
(2023). A global survey on the current state of prac-
tice in zero defect manufacturing and its impact on
production performance. Computers in Industry, 148.
Gonc¸alves, A. F., Reis, J., and Gonc¸alves, G. (2021). A
data-based multi-algorithm system for an end-to-end
intelligent manufacturing process.
Hoffmann, R. and Reich, C. (2023). A systematic literature
review on artificial intelligence and explainable artifi-
cial intelligence for visual quality assurance in manu-
facturing. Electronics, 12:4572.
Kang, Z., Catal, C., and Tekinerdogan, B. (2020). Machine
learning applications in production lines: A system-
atic literature review. Computers and Industrial Engi-
neering, 149.
Lin, J. S. and Chen, K. H. (2024). A novel decision support
system based on computational intelligence and ma-
chine learning: Towards zero-defect manufacturing in
injection molding. Journal of Industrial Information
Integration, 40.
Ro
ˇ
zanec, J. M., Zajec, P., Trajkova, E.,
ˇ
Sircelj, B., Brecelj,
B., Novalija, I., Dam, P., Fortuna, B., and Mladenic,
D. (2022). Towards a comprehensive visual quality
inspection for industry 4.0. In IFAC Proceedings, vol-
ume 55, pages 690–695. Elsevier B.V.
Schmitt, J., B
¨
onig, J., Borggr
¨
afe, T., Beitinger, G., and
Deuse, J. (2020). Predictive model-based quality in-
spection using machine learning and edge cloud com-
puting. Advanced Engineering Informatics, 45.
Takalo-Mattila, J., Heiskanen, M., Kyllonen, V., Maatta, L.,
and Bogdanoff, A. (2022). Explainable steel quality
prediction system based on gradient boosting decision
trees. IEEE Access, 10:68099–68110.
Tiensuu, H., Tamminen, S., Puukko, E., and R
¨
oning, J.
(2021). Evidence-based and explainable smart deci-
sion support for quality improvement in stainless steel
manufacturing. Applied Sciences (Switzerland), 11.
C¸ evik Onar, S.,
¨
Oztays¸i, B., Kahraman, C., Yanık, S., and
¨
Ozlem S¸ envar (2016). A literature survey on meta-
heuristics in production systems, volume 60, pages 1–
24. Springer New York LLC.
ICINCO 2024 - 21st International Conference on Informatics in Control, Automation and Robotics
260
