
Evaluating Diversification in Group Recommendation of Points of
Interest
Jadna Almeida da Cruz
1 a
, Frederico Ara
´
ujo Dur
˜
ao
2 b
and Rosaldo J. F. Rossetti
1 c
1
Artificial Intelligence and Computer Science Lab (LIACC) of the Faculty of Engineering,
University of Porto, Porto, Portugal
2
Federal University of Bahia, Salvador, Bahia, Brazil
Keywords:
Diversification, Group, Recommendation, Points of Interest.
Abstract:
With the massive availability and use of the Internet, the search for Points of Interest (POI) is becoming an
arduous task. POI Recommendation Systems have, therefore, emerged to help users search for and discover
relevant POIs based on their preferences and behaviors. These systems combine different information sources
and present numerous research challenges and questions. POI recommender systems traditionally focused on
providing recommendations to individual users based on their preferences and behaviors. However, there is
an increasing need to recommend POIs to groups of users rather than just individuals. People often visit POIs
together in groups rather than alone. Thus, some studies indicate that the further users travel, the less relevant
the POIs are to them. In addition, the recommendations belong to the same category, without diversity. This
work proposes a POI Recommendation System for a group using a diversity algorithm based on members’
preferences and their locations. The evaluation of the proposal involved both online and offline experiments.
Accuracy metrics were used in the evaluation, and it was observed that the level at which the results were
analyzed was relevant. For the top 3, recommendations without diversity performed better, but diversification
positively impacted the results at the top 5 and 10 levels.
1 INTRODUCTION
Recommendation systems are designed to help users
overcome the difficulties generated by the excessive
volume of digital information. They automatically
suggest items of interest to users while respecting
their individual or group preferences. In recent years,
with the development of the mobile Internet, people
have been using apps to find Points of Interest (POIs),
such as restaurants, shopping malls, and tourist
attractions. This trend has led to a significant increase
in the demand for POI data and the development of
various applications and services that leverage this
data to provide users with location-based information
and services. In this context, a Point of Interest
Recommender System is suitable for suggesting the
most appropriate candidate destinations to users,
which can help them save time and improve their
experiences (Yan et al., 2018).
Recommendation systems typically use user
a
https://orcid.org/0000-0002-7456-2888
b
https://orcid.org/0000-0002-7766-6666
c
https://orcid.org/0000-0002-1566-7006
profiles, behavioral histories, and item attributes to
calculate the relevance of items to users. However,
POI recommendation systems also incorporate
geographical location information to understand
user preferences better and provide more accurate
recommendations. This is because the distance
between the points of interest and the user plays a
significant role in determining the travel time and
user preferences. Most users prefer visiting regions
close to activities of interest, such as food, shopping,
or tourism, to minimize distance and increase the
likelihood of visiting multiple points of interest.
(Liu et al., 2024) propose to learn similar users’
POI transfer preferences with the Session-based
Graph Neural Networks, (Liu et al., 2015) propose
a framework for recommending potential customers
to suppliers on location-based social networks. (Lee
et al., 2006) develops a recommendation system
integrating location, personal, and environmental
context. However, these approaches only consider the
geographical distance provided by location services
such as global positioning system (GPS) (Ravi and
Vairavasundaram, 2016).
Almeida da Cruz, J., Durão, F. A. and Rossetti, R. J. F.
Evaluating Diversification in Group Recommendation of Points of Interest.
DOI: 10.5220/0012927000003825
In Proceedings of the 20th International Conference on Web Information Systems and Technologies (WEBIST 2024), pages 35-46
ISBN: 978-989-758-718-4; ISSN: 2184-3252
Copyright © 2025 by Paper published under CC license (CC BY-NC-ND 4.0)
35

The problem of POI recommendation becomes
more complex when it is not just one user but
a group. Group Recommendation Systems are
generally used when the decision-making must
consider all members’ preferences. Examples include
choosing a family travel destination or watching a
movie with friends. According to (Ravi et al.,
2019), the main difficulty of SRGs is associated with
the diversity and dynamics of the user group (Ravi
et al., 2019), making group preference modeling
a challenging task (Quijano-Sanchez et al., 2013).
Members’ particularity and individuality must be
considered when choosing POIs (Masthoff, 2015;
Nguyen and Ricci, 2017). Based on the assumption
that individuals in a group have varied preferences,
it is natural to include mechanisms that promote
diversity in the items recommended for the SRG.
These systems typically rely on user preferences
and behavioral histories to suggest items. Still,
they often neglect the geographical context and
distance between the user and the recommended
points of interest (POIs). This can lead to suboptimal
recommendations that do not consider the practicality
and feasibility of visiting the suggested locations.
In the context of group decision-making, this issue
is particularly relevant. When multiple users are
involved, the distance between the POIs and the group
members becomes crucial in reaching a consensus on
what to do or where to go. For instance, if a group of
friends is planning a trip, they may prioritize locations
closer to each other to minimize travel time and
maximize the overall experience. For example, more
distant places make users lose interest in visiting, as
do nearby places with low ratings. Thus, aggregating
each user’s preferences to create a group profile while
maintaining a constant balance between what each
group member prefers is a task for point-of-interest
recommendation systems for groups.
Motivated by the need to diversify
recommendations for user groups, this paper
aims to develop and evaluate a recommendation
model for groups, considering members’ preferences
on points of interest and the diversity component.
The article is organized as follows. The section 2
presents a theoretical basis for the research object.
The section 3 presents the state of the art. Section 4
presents the proposal in detail. The section 5 shows
the experimental evaluation and discusses the results.
The section 6 concludes the article and presents
future work.
2 RECOMMENDATION
SYSTEMS FOR GROUPS AND
DIVERSITY
Group Recommendation Systems aim to find
recommendations for the users of a given group.
A group can be formed in various ways. In the
literature, the definitions presented that are widely
discussed and accepted are (Carvalho and Macedo,
2014; Boratto and Carta, 2011): i) Established
group: a group of individuals who have chosen to
come together because of some common interest.
ii) Occasional group: a group of people who
occasionally carry out some activity. For the
members of this group, there is some common
interest at that moment, and iii) Random group:
several people who are in the same place at a given
time and may not know each other or share any
common interest.
2.1 Classification of SRGs
Group Recommender Systems (GRS) can
be classified based on how they generate
recommendations for a group of users, considering
the users’ preferences and the recommended items.
Some of these perspectives are listed below:
• Users’ Preferences: The opinions of the group’s
users may be known in advance, as in the case of
Polylens (O’connor et al., 2001), but the system
may also recognize them as they use it. In general,
it is more common for users’ preferences to be
already known by the Group Recommendation
System.
• User Interaction with the Recommendation:
In some cases, users can comment on what has
been recommended to them, such as The Travel
Decision Forum(Jameson, 2004).
• Quantity of Recommended Items: It is possible
that the system only needs to indicate one item
that satisfies the group.
• Aggregation of Recommendations or Profiles
(de Campos et al., 2009): There are two ways:
i) aggregate recommendations for individual
profiles or ii) aggregate individual profiles as a
single one and then perform the recommendation
for that profile.
2.2 Aggregation Strategies
In the literature, several aggregation techniques are
presented (Sen, 1986).
WEBIST 2024 - 20th International Conference on Web Information Systems and Technologies
36

• Average: is a technique in which an arithmetic
average is made of the values assigned by each
user to an item. The Average represents the value
of the item’s importance to the group.
• Least Misery: The lowest rating of the group’s
users for an item is the group’s interest in the item.
• Most Pleasure: The group’s rating for a given
item is the highest rating among the users for this
item.
• Multiplicative: The rating of an item for the
group is obtained as the result of multiplying the
users’ ratings.
• Average without Misery: this strategy is a
combination of the Average and Least Misery
strategies. First, a filter is made on the list of
possible items to be recommended, where items
that score less than or equal to a defined cut-off
point are removed from the list. In this way, we
prevent items similar to those poorly rated by one
of the group members from being recommended.
Next, the Average technique is applied to the new
list of items, and based on this result, the items
will be recommended to the group in question.
2.3 Diversity in Recommender Systems
In Recommender Systems, diversity can be defined as
a factor in a list of items p
1
, p
2
, p
3
,...,p
n
indicating
how different pairs of items are from each other
(Bradley and Smyth, 2001). This diversity factor can
be calculated based on the distance between items,
dist(p
1
, p
2
), using similarity, as shown in Equation
1.
dist(p,k) = 1 − sim(p,k) (1)
In addition to the value itself of the distance
between items, diversity techniques can vary
according to the approach used, as seen in
(Kaminskas and Bridge, 2016) and (Ziegler et al.,
2005): i) Random selection: on a list of candidate
items, C, this approach randomly chooses items from
the final recommendation list R and Goal selection:
on a list of candidate items, C, this approach selects
the item from C that maximizes the total diversity
factor in R, and thus inserts it into R.
3 RELATED WORK
Point of interest (POI) recommendation is widely
studied in the literature, especially in location-based
social networks (LBSNs). The popularity of LBSNs
has driven improvements in POI recommendation
systems. Spatial information is fundamental in most
models since the probability of a user visiting a
location is related to the distance they need to travel,
as suggested by Tobler’s First Law of Geography
(Tobler, 1970). In (Zheng et al., 2010; Kurashima
et al., 2013), the authors analyze GPS records,
encoded as a time series of geographic coordinates,
to identify movement patterns. Our proposal does not
use route learning but explicit preference elicitation.
The MoveAndShot application, which recommends
the best locations for photos, is described in (Silva
and Lacerda, 2017). It suggests POIs based on
geographical location but on individuals, while our
work focuses on groups.
In (Hu and Ester, 2013), the authors explore a
spatial topic modeling approach to predict future
points of interest based on the textual content of
user posts. Although they do not address group
recommendations, similar to our proposal, they
consider textual descriptions of POIs in the similarity
calculation. In (Liu et al., 2013), various aspects
of location profiles are analyzed, resulting in a
joint model for location recommendation. Like our
model, textual information about the POI is used for
group recommendations. (Lian et al., 2015) propose
a collaborative filtering system based on implicit
feedback to incorporate semantic content and avoid
negative samples. While our work does not analyze
negative feedback, it can draw inspiration from this
study to enrich the descriptions of recommended
POIs. In (Ngamsa-Ard et al., 2020), a framework
is developed to recommend POIs for individuals and
groups in location-based social networks. Here,
groups are defined by social connections, unlike our
proposal, which does not use social networks to
form groups. In (Silva et al., 2023), diversification
mechanisms on the Pinterest platform are explored
to improve the representation of skin tones in
fashion and beauty content, positively impacting user
satisfaction.
In the context of group recommendation,
(Kulkarni and Pervin, ) propose a novel Knowledge-
based Context-Aware Group Recommender System
that utilizes a knowledge graph to learn domain-
aware user and POI embedding. These embeddings
are infused with visit context in the second stage
via a feed-forward transformer. The recommender
system learns the group embedding as a weighted
aggregate of context-infused embedding of group
members. (Chizari. et al., 2023) analyze RS
fairness, measuring unfairness toward protected
groups, including gender and age. The authors try
to quantify fairness disparities within these groups
and evaluate recommendation quality for item lists
Evaluating Diversification in Group Recommendation of Points of Interest
37

using a Normalized Discounted Cumulative Gain
(NDCG) metric. The authors argue that most bias
assessment metrics in the literature are only valid
for the rating prediction approach, but RS usually
provides recommendations in the form of item lists.
(Bahari Sojahrood and Taleai, 2021) developed a
POI Recommendation System for groups that take
into account the difference in users’ personalities
and their preferences when they are alone or in
a group, using historical data from check-ins on
LBSNs and in terms of category, distance and time.
The difference with our work is that the diversity
aspect is not considered. (Gottapu and Sriram
Monangi, 2017) have developed a subscription-based
POI Recommendation System using location-based
social networks. The proposal aims to provide
recommendations for groups of people of different
sizes and with various relationships. Similarly,
no aspect of diversity is investigated in that work
either, as is done by our proposal. Similarly to our
proposal, (Bahari Sojahrood and Taleai, ) argue that
the geographical proximity of POIs to users’ location
has a notable influence on the group’s decisions
to visit the POI and their check-in behavior. The
application of diversity in the literature is seen in
(Oliveira and Durao, 2021), in which the authors
developed a group recommendation model using
diversification techniques that explore different
aggregation techniques on the group preference
matrix. In the same way as our research, the authors
carry out experiments that evaluate the accuracy and
diversity targets for group recommendations. The
difference is that they don’t recommend POIs but
movies. In (Nguyen et al., 2018), the authors address
the diversity problem in group recommendation by
improving the chance of returning at least one piece
of information covering group satisfaction. Unlike
our work, the authors combine the preference of
each group member with a function of disinterest
in the items as a diversity factor. (Liu et al., 2024)
bring forward a novel POI recommendation model
for random groups based on Cooperative Graph
Neural Networks (CGNN-PRRG). The authors
propose a new fitted presentation learning method
for generating the fitted representations of random
groups and an edge-learning enhanced Bipartite
Graph Neural Network (EBGNN) to learn similar
users’ POI comprehensive interaction preferences.
Unlike their work, we are not creating graphs to
model group preferences. (Si et al., 2017) propose an
adaptive POI recommendation method (called CTF-
ARA) combining check-in and temporal features
with user-based collaborative filtering. The authors
recommend POIs based on the check-ins of active
users. Similar to our approach, they use cosine
similarity to recommend POIs to users.
4 THE PROPOSAL
The main objective of this work is to recommend
points of interest to groups of users so that they
form a diversified recommendation list. Figure 1
illustrates a scenario that motivates the proposal.
Consider 3 friends who want to meet at a POI.
One lives in the Grac¸a neighborhood, the other
in Rio Vermelho, and the third in the Federac¸
˜
ao
neighborhood in Salvador-Ba, Brazil. Although they
all like Amaralina Beach very much, the proposal
would recommend meeting at Parque Zoobot
ˆ
anico
(park) or Praia de Ondina (beach) because although
they are not the group’s preferred location, they would
be the most suitable considering the distance from
each to the destination. Thus, throughout this section,
the proposal is presented in detail.
Figure 1: Motivating scenario that illustrates the proposal.
4.1 Notations
The formal notations are presented in Table 1.
Table 1: Notations used in the description of the proposed
system.
Symbol Description
P Set of points of interest
p A point of interest
G A group
U Set of users
u A user
d Text description of p
loc Location of u or p
R
u
Set of ratings r of user u
r
u,p
A score r assigned by u to p
MA Matrix of all ratings r
u,p
MD Matrix of distances d
u,p
MG Matrix of ratings r
u,p
of a group G
MGD Matrix MG weighted by distance
MGA Matrix of the aggregate group
RP
Recommendations of Points of Interest
RPD
Diversified Points of Interest Recommendations
A group G comprises n users u ∈ U. Each
point of interest p ∈ P has a unique geographic
WEBIST 2024 - 20th International Conference on Web Information Systems and Technologies
38

location given by the latitude and longitude loc =
(latitude,longitude) and a description d, the POI
being represented as p = (d, loc). Each user u ∈ U
also has a geographical location and is represented as
u = (u
i
,loc). The set of ratings for user u is given as
R
u
= (r
u,p1
,r
u,p2
,...,r
u,pm
), where r
u,p
is a score given
by user u to a POI p, which are in the range [1, 5].
4.1.1 Problem Formalization
For the problem addressed in this study, the database
is conceived as a MA = U xP matrix containing user
ratings of points of interest. The MA matrix is
generally sparse because users do not naturally rate
the points of interest they visit. The matrix MG ⊆
MA is a subset of the general matrix of evaluations,
containing only the points of interest evaluated at least
once by users of a group G = {u
1
,u
2
,··· , u
n
}. We aim
to recommend a set of points of interest for this group,
i.e., RP
p∈PC
−−−→ G.
4.2 Recommendation
Algorithm 1 details the steps for generating
recommendations for POIs with diversity.
Algorithm 1: RECPOI proceduere.
1: procedure RECPOIS(MA, G)
2: MG ← KNN(G,MA)
3: MD ← distance(loc
u
∈ MG, loc
p
∈ MG)
4: MGD ← ponder(MG, MD)
5: MGA ← grouping(MGD)
6: RP ← relevance(MGA,PC)
7: RPD ← diversity(RP)
8: return RPD
9: end procedure
4.2.1 Preparing the Group Matrix
As previously mentioned, the MA rating matrix is
naturally sparse, and to obtain the preferences of the
G group using aggregation techniques, the MG group
matrix must have no unrated points of interest. For
this reason, in Line 2, we applied the K Nearest
Neighbor (KNN) algorithm responsible for predicting
a user’s evaluation of a point of interest. KNN
calculates the ”distance” between the POI to be
inferred and the other POIs and returns the K nearest
neighbor POIs as the most similar recommendations.
In our empirical tests, K=5 obtained the best results
using cosine similarity. Once we have the K
most similar POIs, we apply a weighted average
considering the similarity value and the evaluations
r
u,p
∈ MG to arrive at the predicted value. At this
point, we understand that the MG matrix is dense, and
there are no points of interest without an evaluation
from any user in the group.
4.2.2 Construction of the Distance Matrix and
Preference Weighting
In-Line 4, the MG group’s preference matrix is
weighted by the distance from the user’s location
to the point of interest. The premise is that points
of interest, although very attractive to a group, can
have their concept reduced as the distance increases.
We then built a distance matrix MD, represented
in Line 3, using the Google Maps function called
matrixDistance. Finally, we generate a final MGD
matrix where each position is populated with the
weighting value according to:
r
(
u, p,r
u,p
) ∈ MGD =
r
u
, p
matrixDistance(u
l
oc, p
l
oc)
(2)
4.2.3 Application of Aggregation Techniques
With the MGD matrix, we have defined the individual
preferences weighted by distance; the next step is to
generate the group preference. To do this, we need to
use Aggregation Techniques (see Section 2.2) on the
MGD matrix to obtain a representative value r
G,p
of
group preference on each of the points of interest in
the MGD preference matrix. As seen in Line 5, the
result of the grouping is an aggregated group matrix
MGA.
4.2.4 Recommendation List
The line 6 shows the recommendations generated by
calculating the relevance of the PC candidate points of
interest for the MGA groups. Relevance is calculated
as:
relevance(G, p) =
1
n
sim(G, p)+
r
G,p
max(r ∈ MGA
G
)
(3)
so that MGA
G
corresponds to the aggregate group
matrix of group G and the similarity function yes. In
this context, the cosine similarity was used:
sim(G, p) =
∑
n
i=1
w
i
· sim
i
(G
i
, p
i
)
∑
n
i=1
w
i
(4)
The cosine calculation considers the description
of the points of interest in G and the description of
the candidate point p. The similarity calculation is
applied to all candidate points p ∈ PC. At the end, an
ordered ranking of points of interest is generated, thus
constituting the set PR.
Evaluating Diversification in Group Recommendation of Points of Interest
39

4.2.5 Diversity
Although Equation 3 produces a list of points of
interest PR closest to the group’s profile, this list
can present the problem of overspecialization, i.e.,
recommendation of POIs in the same category.
Preliminary analyses observed that the PR list mostly
comprised POIs in a single category, such as bars or
churches. Because of this, we applied a diversity
function to the PR list to offer the user alternative
POI categories. To do this, we applied the algorithm
proposed by (Bradley and Smyth, 2001) to the PR list:
diversity(PR) =
∑
x∈PR
∑
y∈R/{x}
dist(pr
i
, pr
j
)
|PR| · (|PR| − 1)
(5)
The result of the diversity function generates the
PRD diversified points of interest recommendation
list. The line 7 of the base procedure shows the receipt
of the RP list by the diversity function and the return
of the RPD diversified list.
5 EXPERIMENTAL EVALUATION
The experiment aimed to assess the accuracy of the
proposed recommendation model. In particular, it
sought to answer the questions:
1. Does diversity applied to group recommendation
techniques increase accuracy over techniques
without diversity?
2. What difference does the proposed
recommendation make to groups of different
sizes?
To evaluate the model, two approaches were adopted:
1. An online experiment to obtain an evaluation of
the recommendations generated for participants
through their feedback, as well as to collect this
information to create a data set;
2. An offline experiment to carry out a counter-
proposal of the literature and proposal variations.
Accuracy and ranking metrics were used to evaluate
the recommendations generated.
5.1 Experiment 1 (Online)
5.1.1 Methodology
The experiment was carried out in on-line and hybrid
format. The three stages of the experiment are
presented below.
In the first stage of the evaluation, we invited the
participants. Although we didn’t conduct a more
in-depth analysis of the participants’ profiles, there
was no resistance or difficulty in participating in
the experiment. Participants provided their e-mail
and geographical location (latitude and longitude).
After registering, participants rated points of interest
with scores from 1 to 5 registered in the experiment
database (Section 5.1.2).
In the second stage, groups of 3 and 5 users
were formed to evaluate the recommendations in
asynchronous on-line sessions under the authors’
supervision. No criteria were applied to create the
groups. The users themselves could form the groups
naturally based on their affinities. As the participants
were classmates, no impediment was reported that
would make the experiment unfeasible.
In the third stage, the groups were invited to
evaluate the recommendations in synchronous online
sessions. Group members were instructed to discuss
the recommendations generated until they reached
a consensus on a final score. They were asked to
consider their interest in the location and the distance
from the point of interest to their geographical
position, as reported in the first stage. In total, 19
groups were formed, 10 with 3 participants and 9 with
5 members. For each group, two recommendation
lists with 10 items each were generated, giving 38
recommendation lists.
In all, 66 participants aged between 18 and 40
were asked to rate at least 20 points of interest per
user in the first stage of the experiment. Although the
experiment did not go through an ethics committee
evaluation, all participants were informed that their
e-mails and their preferences about the POIs would
be recorded in our database for the sole purpose of
authentication and generating recommendations, and
that once saved, the data would be automatically
anonymized. Everyone agreed to take part in the
experiment without exception.
5.1.2 Dataset
To ensure the validity of the on-line experiment,
creating a dataset containing points of interest in
the same city as the participants was necessary.
This was the way to obtain a faithful assessment of
the recommendations generated. Although several
studies in the literature use the Gowalla dataset
1
,
this dataset does not have points of interest located in
the city of Salvador-Ba, where the participants in the
experiment live. Given this restriction, a new dataset
was created and is available at POIS-SALVADOR
2
.
The POIs were collected from Google Maps. Table 2
1
https://snap.stanford.edu/data/loc-gowalla.html
2
https://github.com/jadna/poi-salvador.git
WEBIST 2024 - 20th International Conference on Web Information Systems and Technologies
40
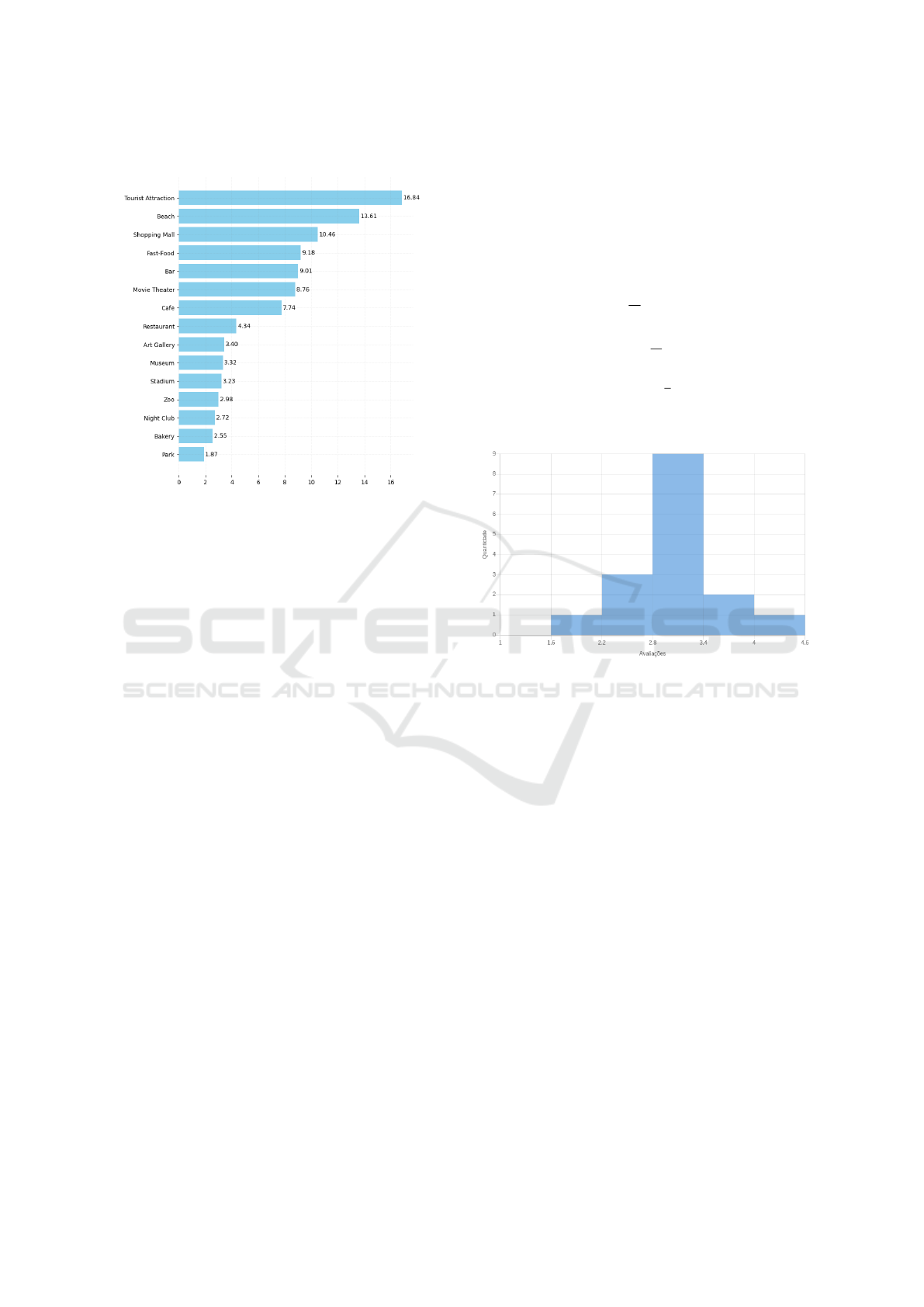
shows an example of the POIs for the city in question.
Figure 2: Distribution of points of interest in category.
This dataset was used in the first stage of the
experiment to collect user preferences. Out of 422
points of interest in the database, only 51 were used
in the on-line experiment. A minimum criterion of
at least 2 points of interest in the same category was
set. Categories such as bars, restaurants, squares, and
shopping centers describe points of interest. Figure
2 shows the distribution of points of interest by
category.
5.1.3 Comparison Algorithms and Metrics
As the focus of the evaluation was to assess the
impact of diversity on the POI recommendation list,
each group evaluated 2 lists of 10 items, one non-
diverse, defined here as Standard (STD), and the
other diverse, called Diversified (DIV). We used
only one aggregation technique for both lists: Most
Pleasure (MP). The choice of this technique is based
on a preliminary analysis in pilot tests between
4 aggregation techniques: Most Pleasure (MP),
Least Misery (LM), Average (AV), Average Without
Misery (AWM). The MAP and Precision@N metrics
were used to evaluate the results. To obtain a
single metric that contributes to the accuracy of the
recommendation method across the entire user group,
the MAP (Parra and Sahebi, 2013) is used.
The MAP value is obtained by calculating
the average over the average accuracy of the
recommendation list for each user in the group as in
Equation 6. In the Equation, AveP(u) is the average
precision for user u ∈ U, i.e., the average precision
values obtained for the top-K recommendations after
each relevant suggestion is retrieved (Manning et al.,
2008). Equation 7 and 8 correspond to the calculation
of the average precision, which is a sum of the
precision at each position in the list p@i where r
is the number of relevant points of interest up to
position i. The metrics presented were applied to
the recommendation lists. Each list has 10 items,
occupying one position in the recommendation list.
MAP =
1
U
∑
AveP(u) (6)
AveP(u) =
1
N
∑
p@i (7)
p@i =
r
i
(8)
5.1.4 Experiment Results On-line
Figure 3: Distribution of the group evaluation averages.
Figure 3 shows the distribution of the averages
of the groups’ evaluations of the POIs. This
analysis was necessary to determine the relevance
of the recommendations. As can be seen from the
distribution, the ratings were primarily concentrated
in the 2.8 to 3.4 range. We, therefore, adopted 3.0
as the relevance threshold for calculating accuracy.
Thus, the scores given to recommended POIs with
a value equal to or greater than 3 were classified as
relevant to the group, if not irrelevant.
Precision. Table 3 shows the precision metric
values (Section 5.1.3) for positions 3, 5 and 10
(p@3, p@5, p@10), considering groups with 3 users.
According to the results obtained, the diversity
algorithm did not produce an expected impact on the
Standard method for analyzing accuracy in positions
3 and 5. However, promising results were observed
when analyzing the accuracy of the first 10 items.
In particular, group 18 judged the recommendations
in diversified mode to be 80% accurate. Group 19
attested to 90% accuracy. The standard deviation
showed no great variability in accuracy in positions
3 and 5, but there was an increase in position 10.
Evaluating Diversification in Group Recommendation of Points of Interest
41
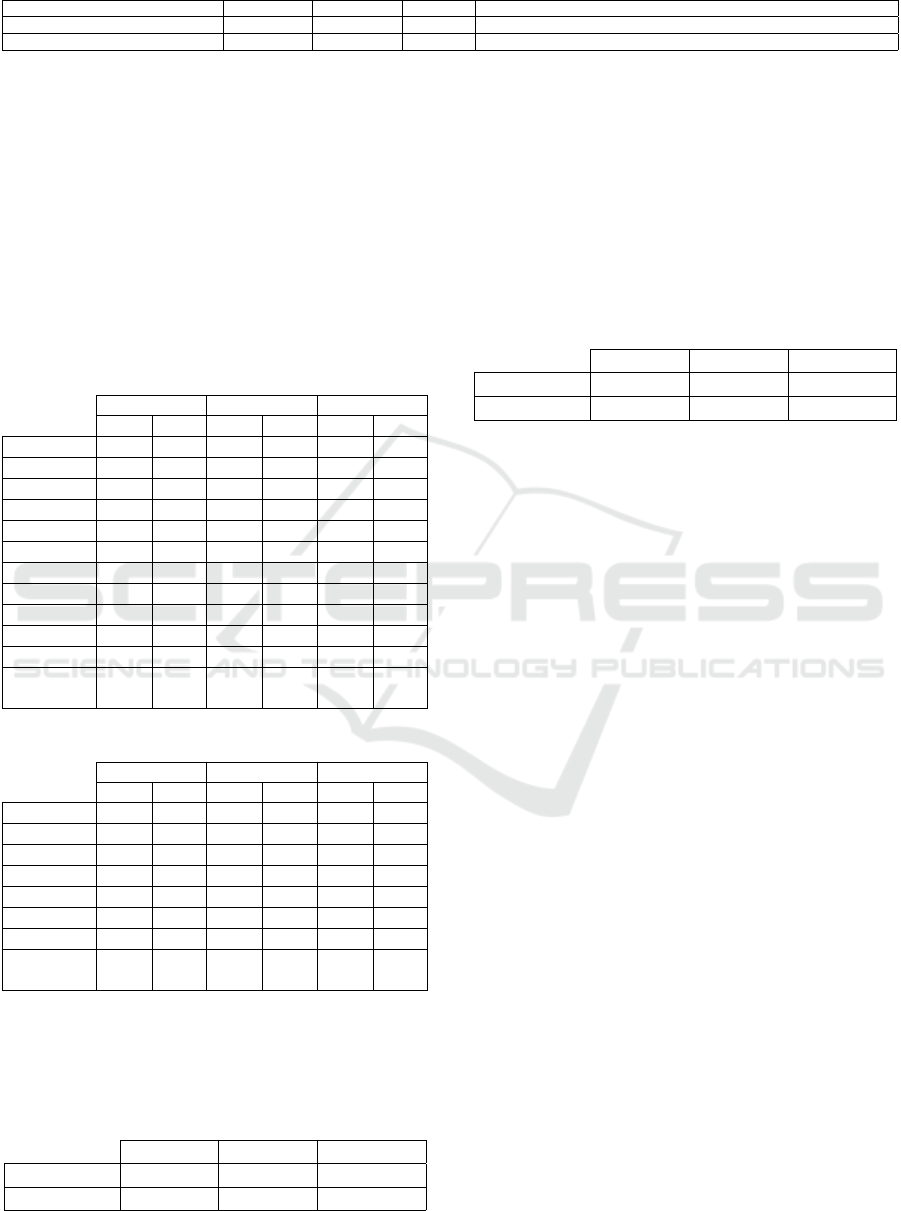
Table 2: Example of the geo-localized data set for Salvador-Ba, Brazil.
Name Latitude Longitude Category Address
Archaeological Museum of Embasa -12.9566984 -38.4949036 Museum R. Saldanha Marinho s/n Caixa Dagua Salvador - BA 40320-475 Brazil
Salvador Zoo and Botanical Park -13.0094574 -38.5047836 Park Tv. Alto de Ondina s/n - Ondina Salvador - BA 40170-110 Brazil
Table 4 shows the accuracies at positions 3, 5, and
10 for groups with 5 users. The results obtained with
groups of 5 people were better than those obtained
with groups of 3. In particular, the accuracy of
the Diversified method was generally better than
the results shown in Table 3. Again, the most
noteworthy results were observed when analyzing the
accuracy of the top 10. On this point, in particular,
the diversity algorithm performed better than the
Standard method. The standard deviation showed no
significant variability in accuracy at positions 3 and 5,
but there was an increase in variability at position 10.
Table 3: Precision (p@i) of groups with 3 users.
p@3 p@5 p@10
STD DIV STD DIV STD DIV
Group 1 0.3 0.2 0.3 0.4 0.7 0.6
Group 2 0.3 0.3 0.5 0.4 0.8 0.7
Group 3 0.2 0 0.4 0.1 0.7 0.5
Group 4 0.1 0 0.1 0 0.2 0.4
Group 5 0.2 0.2 0.4 0.3 0.6 0.6
Group 8 0 0 0 0.1 0 0.2
Group 9 0.2 0 0.2 0.2 0.7 0.6
Group 13 0.3 0.2 0.5 0.4 1 0.9
Group 18 0.3 0.3 0.3 0.5 0.5 0.8
Group 19 0.3 0.3 0.5 0.4 0.8 0.9
Average 0.22 0.15 0.32 0.28 0.6 0.61
Standard
deviation
0.10 0.14 0.18 0.17 0.30 0.21
Table 4: Precision (p@i) of groups with 5 users.
P@3 P@5 P@10
STD DIV STD DIV STD DIV
Group 10 0 0.2 0 0.3 0 0.4
Group 11 0.3 0.2 0.4 0.4 0.8 0.8
Group 12 0.3 0.1 0.3 0.3 0.5 0.6
Group 14 0.1 0.1 0.1 0.1 0.2 0.3
Group 15 0.2 0.2 0.4 0.4 0.6 0.6
Group 17 0.2 0.2 0.3 0.4 0.7 0.7
Average 0.18 0.17 0.25 0.32 0.47 0.58
Standard
deviation
0.12 0.05 0.16 0.12 0.31 0.20
MAP. Table 5 shows the results for MAP@3,
MAP@5, and MAP@10 (Section 5.1.3) for the
groups with 3 users.
Table 5: MAP of groups of 3 users.
MAP@3 MAP@5 MAP@10
Standard 0.22 0.32 0.6
Diversified 0.15 0.8 0.61
According to the results in Table 5, the Diversified
method obtained superior results to Standard only in
position 5, whereas it was inferior in position 3.
Table 6 shows the results for MAP@3, MAP@5,
and MAP@10 groups with 5 users. As with accuracy,
we can see better results for the MAP metric when
analyzing groups with 5 users. In particular, the
Diversified method obtained higher MAP values than
Standard in positions 5 and 10. Nevertheless, we
observed lower values in position 3.
Table 6: MAP of groups of 5 users.
MAP@3 MAP@5 MAP@10
Standard 0.18 0.25 0.47
Diversified 0.17 0.32 0.58
5.2 Experiment 2 (Offline)
In addition to the online experiment, each component
of the proposed model should be evaluated, i.e., the
model being tested only with the user preference
factor and the model being tested only with
the distance analysis factor. We also analyzed
how the decomposed model would behave for
different aggregation techniques. The quality of
the recommendations with and without the diversity
component was analyzed for each combination
mentioned. The methodology, the data set, and the
results are presented below.
5.2.1 Methodology
The main objective of the offline experiment
was to analyze the determining factors of the
model individually (preference and location) and
evaluate how the proposed model behaves when
other aggregation techniques are considered. The
model with and without diversification was always
compared for all the variations analyzed.
1) GRSPOI - model proposed in this work without
diversification.
2) GRSPOID - model proposed in this work with
diversity.
3) DSTD - equivalent to GRPOID considering only
the distance factor without diversification.
4) DDVS - equivalent to GRPOID considering only
the distance factor with diversification.
WEBIST 2024 - 20th International Conference on Web Information Systems and Technologies
42
5) PSTD - equivalent to GRPOID considering only
the preference factor without diversification.
6) PDVS - equivalent to GRPOID considering only
the preference factor with diversification.
Three aggregation techniques were used for the
variations of the proposals: Least Misery (LM),
Average (AV), Average Without Misery (AWM). The
dataset used in the offline experiment was the same
as that described in Section 5.1.2. In addition, the
groups used in the offline experiment were the same
as those formed in the online experiment. In total, 15
groups were formed, with 9 containing 3 participants
and 6 with five members. The reason for carrying
out the offline experiment after the online experiment
was precisely to obtain the groups’ evaluations of the
recommended items. In this way, it was possible to
distinguish which item would be relevant or not for
each group.
5.2.2 Metrics
The metrics used were Precision and MRR. Precision
is described in Equations 7 and 8 presented in Section
5.1.3, which correspond to the calculation of the
average precision, being a sum of the precision in
each position of the list p@i where r is the number of
relevant points of interest up to position i. The metrics
presented were applied to the recommendation lists.
Each list has ten items, so each item occupies a
position on the recommendation list.
The Mean Reciprocal Rank (MRR) is a statistical
measure for evaluating any process that produces a list
of possible answers to a sample of queries, ordered by
probability of correctness. The reciprocal rank of a
query answer is the multiplicative inverse of the rank
of the first correct answer: 1 for first place,
1
2
for
second place,
1
3
for third place and so on. The average
reciprocal ranking is the average of the reciprocal
rankings of the results for a sample of Q queries. If
none of the proposed results are correct, the reciprocal
rank is 0. Equation 9 of the MRR is described below.
MRR =
1
|Q|
|Q|
∑
i=1
1
rank
i
(9)
5.2.3 Results
Below are the results of the offline experiment with
groups of 3 and 5 users.
Groups with 3 users. Figure 4 shows the accuracy
metric values (Section 5.1.3) for position 10 (p@10),
considering groups with three users. According to
the results obtained, the diversity algorithm produced
an expected impact on the Standard method for
analyzing accuracy in positions 10. However,
promising results were observed when analyzing the
accuracy of the first ten items. Group 19 attested to
an accuracy of 90%. In particular, group 18 judged
the recommendations in diversified mode to be 80%
accurate.
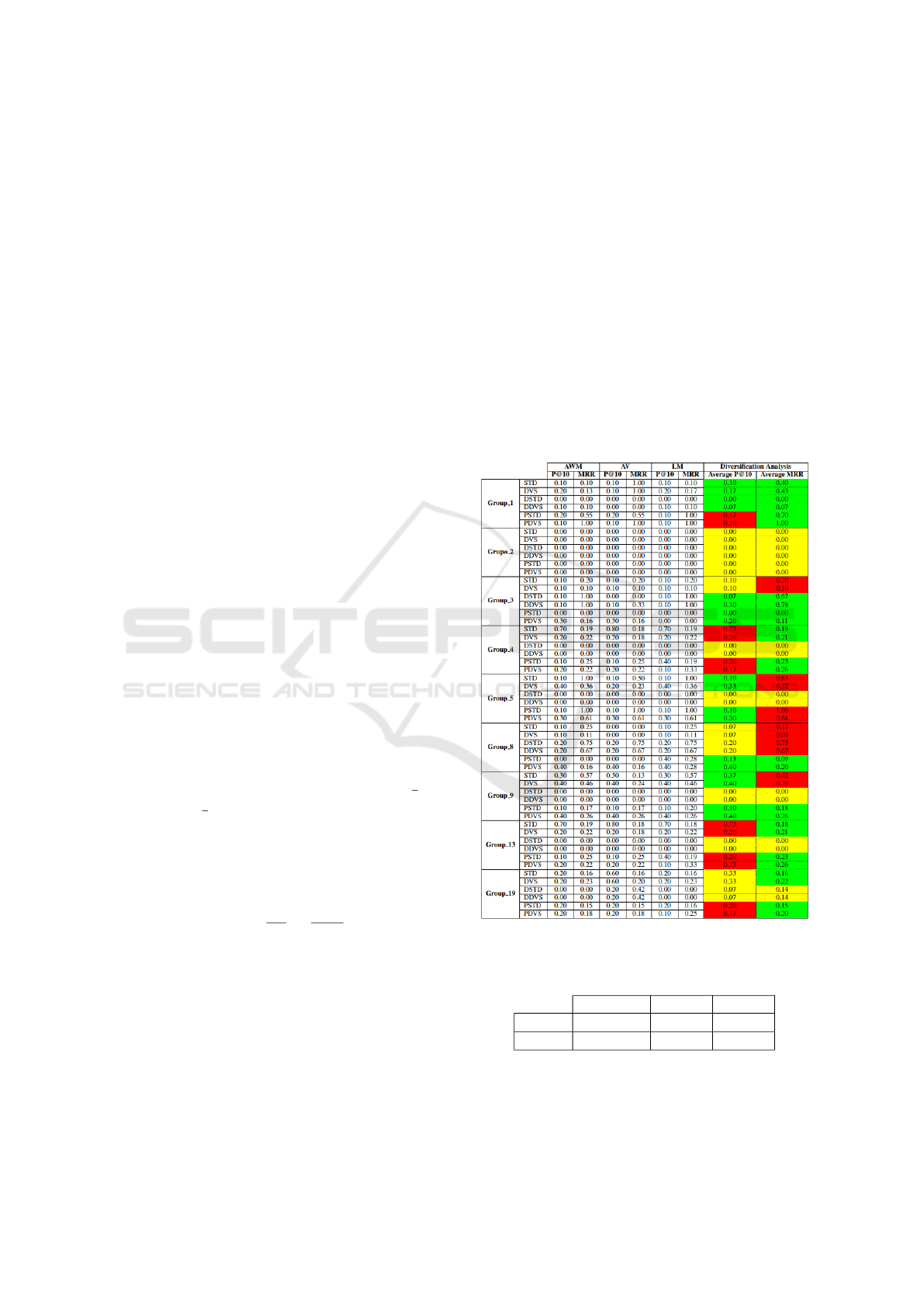
Table 7 shows the number of times the diversified
model obtained better, worse, and similar results over
the non-diversified models for each variation. For
each aggregation technique, the data was presented.
There were more ties between the accuracies of the
variations of the proposal with diversity than without
diversity, followed by the performances. However,
the MRR saw more victories for the diversified
models, followed by similar results between the
models.
Figure 4: Group of 3 users.
Table 7: The final result of the model with diversification
for the group with 3 users.
Victories Defeat Draws
P@10 9 6 12
MRR 13 6 8
Groups with 5 users. Figure 5 shows the accuracy
metric values (Section 5.1.3) for position 10 (p@10),
Evaluating Diversification in Group Recommendation of Points of Interest
43

considering groups with five users. According to
the results obtained, the diversity algorithm produced
an expected impact on the Standard method for
analyzing accuracy in positions 10.
The number of times the diversified model
obtained better, worse, and similar results to the non-
diversified models were presented for each variation
and each data aggregation technique. In Table 8,
there were more victories between the accuracies of
the proposal variations with diversity than without
diversity, and the MRR also performed better,
followed by similar results.
Figure 5: Group of 5 users.
Table 8: Final result of the model with diversification for
the group with 5 users.
Victories Defeat Draws
P@10 10 3 5
MRR 11 4 6
5.3 Discussion, Limitations, and Points
for Improvement
Based on the results obtained, it was possible to
answer the research questions raised in Section
5. Concerning the first question, a satisfactory
increase in accuracy was seen with the insertion of
diversification techniques in the groups with three
users considering ten recommendation items and in
the groups with five users considering 5 and 10
recommendation items. As to the second research
question, it was possible to observe that using the
diversity technique achieved better results in the
group with 5 participants. A natural justification for
this behavior is the profile of the more diverse group.
A limitation of the research regarding method and
results is that the diversity algorithm did not achieve
the expected impact in smaller groups with POIs in
the same category.
Regarding the applications of the proposal,
it is not always possible for the user to visit
the recommended location and evaluate the
recommendation faithfully. In this study, the
average rating was around 3.0. To mitigate the
abovementioned problem, the group was invited to
explore images and videos of the recommended POIs
on the web and proceed to the evaluations with greater
confidence. Despite this effort, it is not guaranteed
that audio-visual information will be available, which
threatens the proposal’s validity. A limitation of the
work is that the descriptions of the POIs are not
always fully described. As a point of improvement, it
is necessary to enrich the descriptions of the points
of interest, as done in (de Almeida et al., 2018).
This point of improvement is fundamental for a
more assertive similarity calculation and consequent
increase in accuracy.
Concerning threats to the experiment’s validity,
not all POIs in the city of Salvador were considered
because we don’t have this complete catalog. In
addition, some POIs, such as bars and restaurants,
may change location or no longer exist. Despite
the care taken, this review should be carried
out frequently in future evaluations. Regarding
the selection of participants, the assessment was
restricted to people who lived in or knew about
POIs in Salvador to record their interests in the
POIs questioned. Another threat to the experiment’s
validity is the evaluation of popular or generic POIs,
such as shopping malls. There is a fear that the
assessment will be given by the ”fame” of the POIs
and not necessarily by an individual analysis and
distance.
6 CONCLUSION
This article proposes developing a point-of-interest
recommendation System for User Groups using
diversity techniques. The recommendation considers
the group’s preference and the group member’s
distance from a point of interest. Aggregation
techniques are used to generate a group profile.
This profile generates recommendations and then
reorders using a diversity algorithm. The solution
was evaluated using an online experiment with 66
participants and 19 groups. In particular, we assessed
the accuracy of the recommendations for the groups
and the impact of the applied diversity technique
on the original recommendation list. The results
WEBIST 2024 - 20th International Conference on Web Information Systems and Technologies
44

point to a better performance of recommendations
with diversity, especially for groups with five users.
As a contribution to the community, a geo-localized
dataset containing POIs from the city of Salvador-Ba
was made publicly available.
As future works, we intend to evaluate the
proposed solution in a scenario without group
preference. In addition, we want to assess the
behavior of the recommendations when inserting
negative feedback into the model. This will
help you determine how well the model adapts
to the user’s preferences and how effective it is
in recommending relevant POIs. We also plan
to investigate the adoption of a component to
explain the recommendations so that the group
understands the suggested points of interest. Further,
we will need to assess whether the explanations
increase the transparency of the recommendation
process and enhance the group’s confidence in the
suggested POIs. An automatic POI extractor will
be implemented based on a ground zero and an
observation radius to make the application generic.
Also, we plan to construct a geographical graph that
represents the spatial relationships between POIs.
This graph will help in modeling the content-aware
correlation between POIs. Last, we intend to include
contextual elements in the recommendation model,
such as environmental conditions and weather.
ACKNOWLEDGEMENTS
This work is a result of Agenda “AET – Alliance
for Energy Transition”, nr. C644914747-00000023,
investment project nr. 56, financed by the Recovery
and Resilience Plan (PRR) and by European Union -
NextGeneration EU.
The authors would like to thank FAPESB and
CAPES for their financial support. Grant Term:
PPF0001/2021. Technical Cooperation Agreement
45/2021 and CAPES – Grant number 001. This
material is partially based upon work supported by
the FAPESB INCITE PIE0002/2022 grant.
REFERENCES
Bahari Sojahrood, Z. and Taleai, M. Behavior-based poi
recommendation for small groups in location-based
social networks. Transactions in GIS, 1(2):10.
Bahari Sojahrood, Z. and Taleai, M. (2021). A poi group
recommendation method in location-based social
networks based on user influence. Expert Systems with
Applications, 171:114593.
Boratto, L. and Carta, S. (2011). State-of-the-Art in Group
Recommendation and New Approaches for Automatic
Identification of Groups, pages 1–20. Springer Berlin
Heidelberg, Berlin, Heidelberg.
Bradley, K. and Smyth, B. (2001). Improving
recommendation diversity. In Proceedings of the
Twelfth Irish Conference on Artificial Intelligence and
Cognitive Science, Maynooth, Ireland, pages 85–94.
Citeseer.
Carvalho, L. and Macedo, H. (2014). Introduc¸
˜
ao aos
sistemas de recomendac¸
˜
ao para grupos. Revista de
Inform
´
atica Te
´
orica e Aplicada, 21(1):77–109.
Chizari., N., Tajfar., K., Shoeibi., N., and N. Moreno-
Garc
´
ıa., M. (2023). Quantifying fairness disparities
in graph-based neural network recommender systems
for protected groups. In Proceedings of the
19th International Conference on Web Information
Systems and Technologies - WEBIST, pages 176–187.
INSTICC, SciTePress.
de Almeida, J. P. D., Dur
˜
ao, F. A., and da Costa, A. F.
(2018). Enhancing spatial keyword preference query
with linked open data. J. Univers. Comput. Sci.,
24(11):1561–1581.
de Campos, L. M., Fern
´
andez-Luna, J. M., Huete, J. F., and
Rueda-Morales, M. A. (2009). Managing uncertainty
in group recommending processes. User Modeling
and User-Adapted Interaction, 19(3):207–242.
Gottapu, R. D. and Sriram Monangi, L. V. (2017).
Point-of-interest recommender system for social
groups. Procedia Computer Science, 114:159–164.
Complex Adaptive Systems Conference with Theme:
Engineering Cyber Physical Systems, 2017, Chicago,
Illinois, USA.
Hu, B. and Ester, M. (2013). Spatial topic modeling
in online social media for location recommendation.
In Proceedings of the 7th ACM conference on
Recommender systems, pages 25–32. ACM.
Jameson, A. (2004). More than the sum of its members:
challenges for group recommender systems. In
Proceedings of the working conference on Advanced
visual interfaces, pages 48–54. ACM.
Kaminskas, M. and Bridge, D. (2016). Diversity,
serendipity, novelty, and coverage: A survey and
empirical analysis of beyond-accuracy objectives in
recommender systems. ACM Trans. Interact. Intell.
Syst., 7(1):2:1–2:42.
Kulkarni, A. and Pervin, N. Knowledge-based context-
aware group recommender system for point of interest
recommendation. Available at SSRN 4710409.
Kurashima, T., Iwata, T., Hoshide, T., Takaya, N., and
Fujimura, K. (2013). Geo topic model: joint modeling
of user’s activity area and interests for location
recommendation. In Proceedings of the sixth ACM
international conference on Web search and data
mining, pages 375–384. ACM.
Lee, B.-H., Kim, H.-N., Jung, J.-G., and Jo, G.-S.
(2006). Location-based service with context data
for a restaurant recommendation. In International
Conference on Database and Expert Systems
Applications, pages 430–438. Springer.
Evaluating Diversification in Group Recommendation of Points of Interest
45

Lian, D., Ge, Y., Zhang, F., Yuan, N. J., Xie, X., Zhou,
T., and Rui, Y. (2015). Content-aware collaborative
filtering for location recommendation based on human
mobility data. In 2015 IEEE international conference
on data mining, pages 261–270. IEEE.
Liu, B., Fu, Y., Yao, Z., and Xiong, H. (2013).
Learning geographical preferences for point-of-
interest recommendation. In Proceedings of the
19th ACM SIGKDD international conference on
Knowledge discovery and data mining, pages 1043–
1051. ACM.
Liu, Y., Zhao, P., Sheng, V. S., Li, Z., Liu, A.,
Wu, J., and Cui, Z. (2015). Rpcv: Recommend
potential customers to vendors in location-based
social network. In International Conference on
Web-Age Information Management, pages 272–284.
Springer.
Liu, Z., Meng, L., Sheng, Q. Z., Chu, D., Yu, J.,
and Song, X. (2024). Poi recommendation for
random groups based on cooperative graph neural
networks. Information Processing & Management,
61(3):103676.
Manning, C. D., Sch
¨
utze, H., and Raghavan, P. (2008).
Introduction to information retrieval. Cambridge
university press.
Masthoff, J. (2015). Group recommender systems:
aggregation, satisfaction and group attributes. In
Recommender Systems Handbook, pages 743–776.
Springer.
Ngamsa-Ard, S., Razavi, M., Prasad, P., and Elchouemi,
A. (2020). Point-of-interest (poi) recommender
systems for social groups in location based social
networks (lbsns): Proposition of an improved model.
IAENG International Journal of Computer Science,
47(3):331–342.
Nguyen, T., Phan, T. C., Nguyen, T. T., Nguyen,
Q. H., and Stantic, B. (2018). Diversifying group
recommendation. page 10.
Nguyen, T. N. and Ricci, F. (2017). Dynamic elicitation of
user preferences in a chat-based group recommender
system. In Proceedings of the Symposium on Applied
Computing, pages 1685–1692. ACM.
Oliveira, A. and Durao, F. (2021). A group recommendation
model using diversification techniques. In
Proceedings of the 54th Hawaii International
Conference on System Sciences, page 2669, Hawaii,
HI, USA.
O’connor, M., Cosley, D., Konstan, J. A., and Riedl, J.
(2001). Polylens: a recommender system for groups
of users. In ECSCW 2001, pages 199–218. Springer.
Parra, D. and Sahebi, S. (2013). Recommender systems:
Sources of knowledge and evaluation metrics. In
Advanced techniques in web intelligence-2, pages
149–175. Springer.
Quijano-Sanchez, L., Recio-Garcia, J. A., Diaz-Agudo,
B., and Jimenez-Diaz, G. (2013). Social factors in
group recommender systems. ACM Transactions on
Intelligent Systems and Technology (TIST), 4(1):8.
Ravi, L., Subramaniyaswamy, V., Devarajan, M.,
Ravichandran, K., Arunkumar, S., Indragandhi,
V., and Vijayakumar, V. (2019). Secrecsy: A secure
framework for enhanced privacy-preserving location
recommendations in cloud environment. Wireless
Personal Communications, pages 1–39.
Ravi, L. and Vairavasundaram, S. (2016). A collaborative
location based travel recommendation system through
enhanced rating prediction for the group of users.
Computational intelligence and neuroscience, 2016.
Sen, A. (1986). Social choice theory. Handbook of
mathematical economics, 3:1073–1181.
Si, Y., Zhang, F., and Liu, W. (2017). Ctf-ara: An adaptive
method for poi recommendation based on check-in
and temporal features. Knowledge-Based Systems,
128:59–70.
Silva, J. and Lacerda, Y. (2017). Moveandshot - um
aplicativo para recomendac¸
˜
ao dos melhores pontos
para captura de fotografias. In Anais do XIII Simp
´
osio
Brasileiro de Sistemas de Informac¸
˜
ao, pages 190–197,
Porto Alegre, RS, Brasil. SBC.
Silva, P., Juneja, B., Desai, S., Singh, A., and Fawaz,
N. (2023). Representation online matters: Practical
end-to-end diversification in search and recommender
systems. In Proceedings of the 2023 ACM Conference
on Fairness, Accountability, and Transparency,
FAccT ’23, page 1735–1746, New York, NY, USA.
Association for Computing Machinery.
Tobler, W. R. (1970). A computer movie simulating urban
growth in the detroit region. Economic Geography,
46:234–240.
Yan, D., Zhao, X., and Guo, Z. (2018). Personalized
poi recommendation based on subway network
features and users’ historical behaviors. Wireless
Communications and Mobile Computing, 2018.
Zheng, V. W., Zheng, Y., Xie, X., and Yang, Q. (2010).
Collaborative location and activity recommendations
with gps history data. In Proceedings of the 19th
international conference on World wide web, pages
1029–1038. ACM.
Ziegler, C.-N., McNee, S. M., Konstan, J. A., and Lausen,
G. (2005). Improving recommendation lists through
topic diversification. In Proceedings of the 14th
International Conference on World Wide Web, WWW
’05, page 22–32, New York, NY, USA. ACM.
WEBIST 2024 - 20th International Conference on Web Information Systems and Technologies
46
