
Evaluation of Open-Source OCR Libraries for Scene Text Recognition in
the Presence of Fisheye Distortion
Mar
´
ıa Flores
a
, David Valiente
b
, Marcos Alfaro
c
, Marc Fabregat-Ja
´
en
d
and Luis Pay
´
a
e
Institute for Engineering Research (I3E), Miguel Hernandez University,
Avenida de la Universidad, s/, 03202, Elche, Alicante, Spain
fl
Keywords:
Scene Text Recognition, Fisheye Distortion, Optical Character Recognition.
Abstract:
Due to the rich and precise semantic information that text provides, scene text recognition is relevant in a wide
range of vision-based applications. In recent years, the use of vision systems that combine a camera and a
fisheye lens is common in a variety of applications. The addition of a fisheye lens has the great advantage of
capturing a wider field of view, but this causes a great deal of distortion, making certain tasks challenging.
In many applications, such as localization or mapping for a mobile robot, the algorithms work directly with
fisheye images (i.e. distortion is not corrected). For this reason, the principal objective of this work is to study
the effectiveness of some OCR (Optical Character Recognition) open-source libraries applied to images with
fisheye distortion. Since no scene text dataset of this kind of image has been found, this work also generates
a synthetic image dataset. A fisheye model which varies some parameters is applied to standard images of a
benchmark scene text dataset to generate the proposed dataset.
1 INTRODUCTION
Over the years, the use of cameras to acquire informa-
tion about the environment has grown notably. This is
due to the huge amount of information about the envi-
ronment that can be extracted from an image. There
are different vision system configurations, but cam-
eras with fisheye lenses are receiving increased atten-
tion (Yang et al., 2023; Flores et al., 2024) because
they can capture a wider field of view in a single im-
age.
The rich semantic information that text provides is
hugely beneficial in a wide range of vision-based ap-
plications. In the same way as for humans, this high-
level information helps achieve a better analysis and
understanding of the environment. As a result, text
detection and recognition have attracted a great deal
of attention in recent years. For instance, Yamanaka
et al. (2022) propose a method that detects text and
arrows on surrounding signage in an equirectangular
image captured by a 360-degree camera. The aim is
to help blind people determine the correct direction
a
https://orcid.org/0000-0003-1117-0868
b
https://orcid.org/0000-0002-2245-0542
c
https://orcid.org/0009-0008-8213-557X
d
https://orcid.org/0009-0002-4327-0900
e
https://orcid.org/0000-0002-3045-4316
to a destination when they navigate through an unfa-
miliar public building. Regarding autonomous nav-
igation, Case et al. (2011) present a system to gen-
erate a map for a robot that navigates in an office
environment, considering that much critical informa-
tion about a location is included in signs and placards
posted on walls. Then, this map collects semantic la-
bels about room numbers, lists of office occupants, or
the name of a room or hall.
Optical Character Recognition (OCR) involves
recognizing and converting the text that appears in an
image into a string-readable format.
The objective of this work is threefold. First,
this work aims to evaluate the effectiveness of some
open-source OCR tools in the presence of fisheye dis-
tortion. To the best of our knowledge, all available
scene text datasets are composed of images that com-
ply with pinhole projection, but none are composed
of fisheye images. Then, this work also aims to gen-
erate a synthetic wide-angle image dataset by apply-
ing transformations to the conventional images of a
benchmark image dataset for this task. Finally, this
work intends to compare two open-source OCR tools
using the benchmark (standard images) and the gen-
erated (fisheye images) dataset.
The remainder of this paper is structured as fol-
lows. In Section 2 and 3, some related works on text
Flores, M., Valiente, D., Alfaro, M., Fabregat-Jaén, M. and Payá, L.
Evaluation of Open-Source OCR Libraries for Scene Text Recognition in the Presence of Fisheye Distortion.
DOI: 10.5220/0012927600003822
In Proceedings of the 21st International Conference on Informatics in Control, Automation and Robotics (ICINCO 2024) - Volume 2, pages 133-140
ISBN: 978-989-758-717-7; ISSN: 2184-2809
Copyright © 2025 by Paper published under CC license (CC BY-NC-ND 4.0)
133

recognition and available datasets for this task are out-
lined respectively. In addition, the problem that this
work addresses is clearly stated in both cases. Section
4 presents some OCR tools, with more emphasis on
those used in this work. Section 5 describes the trans-
formations that have been applied to generate fisheye
images from a standard image. Section 6 is focused
on the experimental part, describing the database used
and the quality measurement for the evaluation. The
results obtained from the experiments are presented
and discussed in Section 7. Finally, Section 8 presents
the conclusions and future works.
2 SCENE TEXT RECOGNITION
Scene Text Recognition (STR) is a computer vision
task that aims to transcribe text that appears in an
image captured by a camera in an environment (i.e.
scene text) into a sequence of digital characters that
encode high-level semantics, which is often essen-
tial to fully understand the scene (Du et al., 2022).
STR involves two fundamental tasks. Firstly, the text
within natural scene images is identified and local-
ized, and its position is often defined by a bounding
box. This first task is known as text detection. Sec-
ondly, the image regions containing text are converted
into machine-readable strings (Lin et al., 2020). This
is known as text recognition.
Challenges in STR. In contrast to the recognition of
text printed in documents, STR is an arduous task.
This complexity can be caused by effects either re-
lated to the scenario (e.g. non-uniform illumina-
tion, hazy effect, noise, distortion, partial occlusion or
background clutter), related to the text (e.g. different
sizes, diverse fonts, geometric distortion, color, orien-
tation of the text, languages) or related to the camera
(e.g. low resolution and motion blurring) (Gupta and
Jalal, 2022; Naosekpam and Sahu, 2022).
Related Works. In view of the latter, STR has re-
cently gained the attention of the computer vision
community, and several methods have been proposed.
There are several reviews and surveys about this task
in the literature, such as (Chen et al., 2020; Naosek-
pam and Sahu, 2022; Long et al., 2021; Lin et al.,
2020). For text detection, Textsnake (Long et al.,
2018) follows a Fully Convolutional Network (FCN)
model, which estimates the geometry attributes (po-
tentially variable radius and orientation) of each over-
lapping disk centered at symmetric axes. These disks
compose an ordered sequence which describes a text
instance. The network architecture is composed of
five stages of convolutions. The outputs of each stage
(i.e. the feature maps) are fed to the feature merg-
ing network. FCENet (Zhu et al., 2021) is featured
by modeling the text instances in the Fourier domain.
The authors also proposed a novel Fourier Contour
Embedding (FCE) method with the objective of rep-
resenting arbitrary shaped text contours as compact
signatures. The framework consists of a backbone,
Feature Pyramid Networks (FPN) and a simple post-
processing with the Inverse Fourier Transformation
(IFT) and Non-Maximum Suppression (NMS).
For text recognition, some of the proposed meth-
ods are described next. Convolutional Recurrent Neu-
ral Network, (CRNN) (Shi et al., 2017) is an end-
to-end trainable method, whose network architecture
consists of convolutional layers, followed by recur-
rent layers and a transcription layer. SAR (Show, At-
tend and Read) (Li et al., 2019) is an approach that
presents good results for regular and irregular text.
This model is composed of a Residual neural network
(ResNet) Convolutional Neural Network (CNN) (31-
layer) for feature extraction, an LSTM based encoder-
decoder framework and a 2-Dimensional attention
module. RobustScanner (Yue et al., 2020) uses a
CNN encoder to obtain the feature map which is then
fed into a hybrid branch and a position enhancement
branch. After that, the outputs of both branches are
dynamically fused by the dynamically-fusing module
at each time step.
Problem Statement. In many computer vision appli-
cations, images captured by an omnidirectional cam-
era are used mainly due to their wide field of view.
The drawback is that these images contain a lot of dis-
tortion, and as a consequence, recognizing text can be
a challenge. The detection and recognition of curved
and distorted text are more challenging than that of
horizontal undistorted text. Taking into account the
imaging projection of the wide-angle images, scene
text, which is horizontal in the original scenario, can
appear in the image curved or with other orientations
depending on the image region where it was captured.
This paper evaluates the robustness of some open-
source OCR libraries in the presence of the distortion
of fisheye images.
3 SCENE TEXT DATASETS
Related Works. A variety of publicly available
benchmark datasets are available for English scene
text detection and recognition techniques. Some of
them are COCO-Text (Veit et al., 2016), Street View
Text (SVT) (Hutchison et al., 2010), Street View Text
Perspective (SVTP) (Phan et al., 2013) or ICDAR
2015 (Karatzas et al., 2015). In these datasets, the text
usually appears horizontal or rotated but in a linear
ICINCO 2024 - 21st International Conference on Informatics in Control, Automation and Robotics
134

(i.e. regular) arrangement. However, the text in the
scene can be arranged in curved or other irregular ar-
rangements. Considering this fact, Total-Text (Chng
and Chan, 2017) and CTW1500 (Yuliang et al., 2017)
datasets were proposed for curved text.
Problem Statement. Some of the mentioned datasets
contain images with text that is curved or multi-
oriented in the scene. However, all images have been
captured with systems that follow a pinhole projec-
tion. Then, these images do not present distortion
produced by the wide field of view, which is the sub-
ject of study of this paper. Then, we apply data aug-
mentation to a benchmark dataset in order to generate
distorted images with word annotations.
4 OCR LIBRARIES
Several open-source OCR libraries have been devel-
oped so far. The pioneer one was Tesseract toolbox,
which Google released in 2006. One of the most re-
cent ones is MMOCR (Multimedia Optical Charac-
ter Recognition) (Kuang et al., 2021). It is an open-
source toolbox with seven text detection approaches
it contains, among others, Mask R-CNN (He et al.,
2017), FCENet (Zhu et al., 2021) and TextSnake
(Long et al., 2018)) and five text recognition algo-
rithms (among which are CRNN (Shi et al., 2017),
RobustScanner (Yue et al., 2020), SAR (Li et al.,
2019)). The next subsections describe in detail Easy-
OCR and PaddleOCR, which are the OCR libraries
that have been used in the evaluation section of the
present work.
4.1 EasyOCR
EasyOCR (JaidedAI, 2020) is a a python-based Py-
Torch library for OCR created and maintained by
Jaided AI. This library, which is implemented us-
ing PyTorch library, supports more than 80 languages
(among them, English and Spanish). The EasyOCR
framework consists of a detection stage and a recog-
nition stage. The former uses CRAFT (Baek et al.,
2019) (or other detection models) to find the regions
of the image that contain text. Also its correspond-
ing bounding boxes are extracted. The latter stage is
based on CRNN (or other recognition models) and is
composed mainly of three components:
• Feature Extraction. The useful features from the
input image are extracted using a standard CNN
without fully connected layers, i.e. ResNet or
VGG.
• Sequence Labeling. The feature maps are fed to
a Recurrent Neural Network (RNN), such as a
Long-Short-Term Memory (LSTM), to interpret
the sequential context. This component’s output
is a sequence of probabilities.
• Decoding. Finally, the sequence of probabilities
are transformed into a text label sequence recog-
nised using the Connectionist Temporal Classifi-
cation (CTC) algorithm (Graves et al., 2006).
4.2 PaddleOCR
PaddleOCR (also knows as PP-OCR) is a practi-
cal open-source OCR toolbox based on PaddlePaddle
with different versions: PP-OCR (Du et al., 2020),
PP-OCRv2 (Du et al., 2021) and PP-OCRv3 (Li et al.,
2022). The pipeline of the latter contains three main
parts:
• Text Detection. In this part, Differentiable Bina-
rization (DB), which is based on a simple segmen-
tation network, is used. This detection model is
trained using CML (Collaborative Mutual Learn-
ing) distillation.
• Detection Boxes Rectification. The followed step
consists in transforming the text box into a hor-
izontal rectangle one. In order to determine if a
text box is reversed (i.e. text direction), a sim-
ple image classification model is employed. In the
case that it is determined reversed, the text box is
flipped.
• Text Recognition. This part is based on SVTR-
LCNet, which is a lightweight text recogni-
tion network fusing Transformer-based network
SVTR (Du et al., 2022) and lightweight CNN-
based network PP-LCNet (Cui et al., 2021)
5 WIDE-ANGLE SYNTHETIC
DATASET
As described in Section 3, the datasets for scene text
recognition are typically composed of conventional
images. Therefore, in the present work, a synthetic
dataset has been generated from a public annotated
dataset using fisheye projections to obtain these im-
ages with distortion as it can be seen in Figure 1.
A fisheye image can present more or less distor-
tion depending mainly on the field of view; this dis-
tortion is more noticeable in the periphery than in the
center of the image. Considering this, in the present
work, a set of synthetic fisheye images is generated
from a conventional image by varying the focal length
value. Also, different 3D motion rigid transforma-
tions are applied so that the text appears in different
regions of the fisheye image.
Evaluation of Open-Source OCR Libraries for Scene Text Recognition in the Presence of Fisheye Distortion
135

(a) Original (b) Synthetic fisheye
Figure 1: The original standard image and the synthetic
fisheye image as result of applying the conversion from pin-
hole to fisheye.
5.1 Data Augmentation
Data augmentation has been applied to achieve a
higher number of possible cases. Transformations re-
lated to the projection from standard image to fisheye
(scale, field of view, and standard focal length) and
rigid motion (translation and rotation) are performed.
Scale. This parameter establishes the size of the fish-
eye image. The generated fisheye images are squared,
that is, the height and the width are equal, and their
values are the minimum dimension of the original im-
ages, i.e. the minimum between the height H
original
and the width W
original
, multiplied by the set scale
value. The synthetic dataset has been generated us-
ing three values for the scale parameter: 1 (see 2a),
2 and 4 (see 2f). Table 1 shows the relation between
the scale parameter and the dimension of the fisheye
image generated.
Table 1: Values of the scale parameter and the dimensions
of the images generated.
Original S = 1 S = 2 S = 4
960x1280 1280x1280 2560x2560 5120x5120
Field of View. In this paper, the focal fisheye length
in the equidistant projection has been established as
the field of view of the virtual fisheye lens in radians
divided by the maximum radius of the fisheye image,
which is half of the height. The synthetic dataset was
generated using three different values for the field of
view: 180. 200 and 220 degrees. Figure 2b shows
a synthetic fisheye image setting the field of view to
180 degrees and Figure 2c to 220 degrees.
Standard Focal Length. The effect produced by this
parameter in the generated image is a zoom out which
is more noticeable the higher this value is. The values
are given by:
f
std
= α · min(H
original
, W
original
) (1)
where H
original
and W
original
are the height and width
of the original dataset image, respectively, and α takes
the following values: 0.6, 0.8 and 1.2. Figure 2d and
Figure 2e show the result of setting this parameter to
0.6 and 1.2, respectively.
Translation. In order to simplify, the translation to
generate different virtual points of view is coded as
a movement to ”left” (see Figure 2h) or ”right” (see
Figure 2g). It implies a translation along the posi-
tive/negative X-axis.
Rotation. A rotation around the vertical axis is also
applied so that text appears in the area of most distor-
tion. In Figure 2j, it can be seen that the text that
initially appears in the center without rotation (see
Figure 2i) now is on the right side. Notice that this
rotation is only applied without translation.
6 EXPERIMENTS
The main objective of this paper is to evaluate the
scene text recognition task in images with high dis-
tortion. Two open-source OCR libraries (EasyOCR
and PaddleOCR) have been applied to recognize the
text appearing in the images. In this way, the scene
text recognition precision of these libraries with fish-
eye images is analyzed and compared.
6.1 Dataset
The dataset used in this study is Total-Text (Chng and
Chan, 2017). This dataset is composed of a total of
1555 images divided into a set of 1255 and another
of 300, which are the training and testing, respec-
tively. In this paper, only the testing set is used. One
of the main features of this dataset is that the text in
the images appears in different orientations, not only
horizontally, as in most datasets. For each annotated
word in the dataset, the type of orientation (horizon-
tal, curved or multi oriented), is provided (i.e., the
ground truth). Considering this, the results have been
separated and analyzed according to this attribute, as
described Section 7. After applying the data augmen-
tation, each image of the Total-Text dataset generates
108 fisheye synthetic images. Thus, the total number
of generated images in the dataset is 300*108.
In brief, two datasets are used in this work: the
original Total-Text (standard images) and the syn-
thetic (fisheye images) dataset generated.
6.2 Evaluation Protocol
Levenshtein distance measures the similarity between
two strings. In more detail, the Levenshtein distance
determines the minimum number of single-character
changes required to convert one word to the other.
The changes can be to insert, delete, or substitute a
character.
ICINCO 2024 - 21st International Conference on Informatics in Control, Automation and Robotics
136

(a) S=1 (b) FOV = 180 (c) FOV = 220 (d) α = 0.6 (e) α = 1.2
(f) S=2 (g) Move right (h) Move left (i) Without rotation (j) With rotation
Figure 2: Synthetic fisheye images with data augmentation.
Table 2: Open-source OCR libraries.
Method Version Model Github repository
Easy-OCR 1.7.1 JaidedAI/EasyOCR
PP-OCR (Du et al., 2020) 2.7.0.3 English ultra-lightweight PP-OCRv3 PaddlePaddle/PaddleOCR
In this paper, word recognition score is one mi-
nus the ratio between the Levenshtein distance and
the number of word characters:
score
word
= 1 −
LevDist(word, word
GT
)
len(word
GT
)
(2)
where word is the string output by a text recognizer
and word
GT
the ground truth string. The lower the
distance (i.e. the fewer the number of changes), the
lower the ratio and, therefore, the higher the score.
Two string sets were obtained for each image: the
set of recognized words and ground truth words. The
procedure followed to determine whether a ground
truth word was found was to search for the most sim-
ilar word in the set of recognized words. In this way,
each ground truth word will have a score value asso-
ciated with it; if it is impossible to find a similar word,
it will have a zero score associated with it. These
associated scores are used to obtain the set of True
Positives (TP) and the set of False Negatives (FN).
FN are ground truth words that have not been recog-
nized, i.e. the score is lower than a threshold, whereas
TP are ground truth words that have been generally
recognized, i.e. the score is higher than a threshold.
This threshold has been established with a score value
equal to 0.65.
Sensitivity is used to perform the study, and some
modifications were made. In this paper, the number
of true positives in the general equations is replaced
by the sum of scores of them, i.e. T P =
∑
N
T P
1
score
i
.
If the ground truth word (word
GT
) is correctly recog-
nized, the Levenshtein distance is zero, and then the
score is equal to one. Thus, the summation could be
described as the number of positives weighted accord-
ing to how similar they are, not just whether they have
been recognized correctly or not.
Taking all the above into account, the Quality
Measurement (QM) is given by:
QM =
∑
N
T P
1
score
i
∑
N
T P
1
score
i
+ N
FN
(3)
where N
FN
is the number of FN.
6.3 Methodology
A synthetic dataset has been created for the evalua-
tion by applying the transformations and procedure
described in Section 5.1. After that, the experiments
were carried out with two datasets: (1) the original
one, composed of standard images (i.e. Total-Text
dataset) and (2) the synthetic dataset created from the
previous one and composed of synthetic fisheye im-
ages. The main objective of this paper is to assess dif-
ferent scene text recognition approaches on these two
datasets. Table 2 shows the setup of the open-source
OCR libraries used during the experiments.
7 RESULTS AND ANALYSIS
The scores obtained using eq. (2) from all the images
of the synthetic and the original dataset are divided
according to the orientation of the text in the scene:
horizontal (h), multi-oriented (m) or curved (c). The
results of the synthetic images are also divided ac-
cording to the parameter values of the data augmenta-
tion. The aim of that latter is to examine the influence
of the data augmentation parameters on the effective-
ness of the OCR tools, also taking into account the
Evaluation of Open-Source OCR Libraries for Scene Text Recognition in the Presence of Fisheye Distortion
137
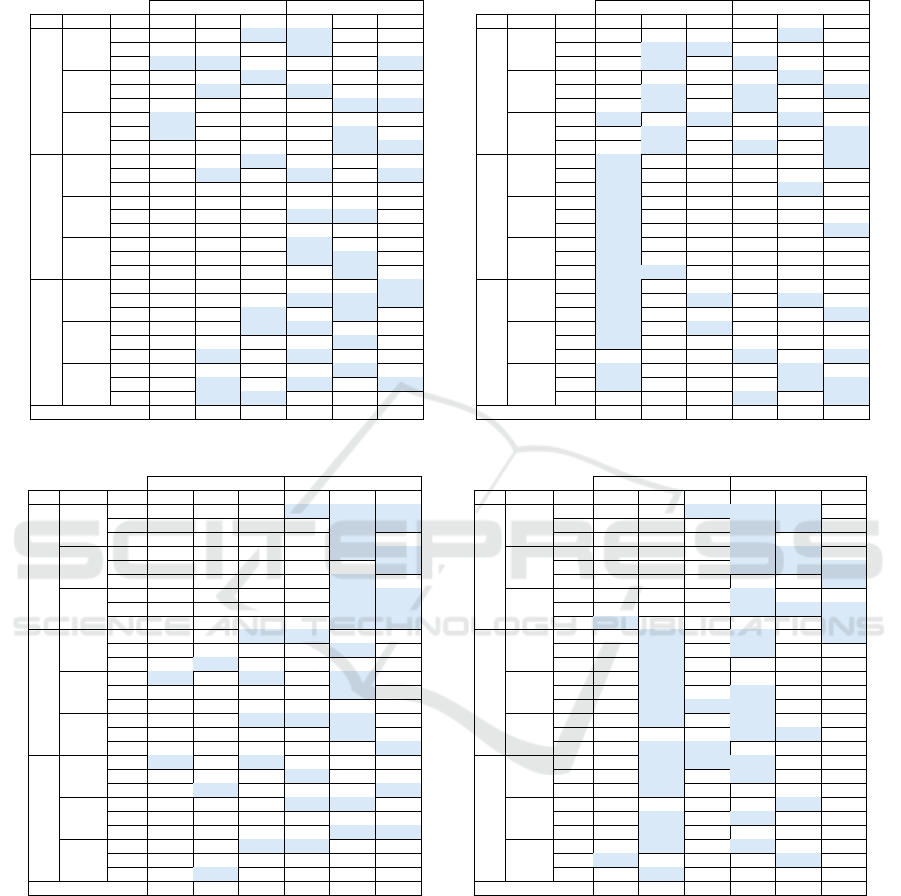
Table 3: The QM values (eq. (3)) of the synthetic fisheye images. Marked in bold if the measure value is greater than or equal
to the one obtained with the original dataset (i.e. with no distortion) (i.e. last row). The best result in terms of the library
(EasyORC or PaddleOCR) is marked with a colored background ■.
EasyOCR PaddleOCR
S FOV α h m c h m c
0.6 0.44 0.50 0.50 0.47 0.50 0.47
0.8 0.44 0.50 0.50 0.47 0.50 0.50180
1,2 0.50 0.50 0.40 0.47 0.40 0.50
0.6 0.50 0.50 0.50 0.50 0.50 0.45
0.8 0.44 0.50 0.50 0.47 0.40 0.50200
1,2 0.50 0.42 0.40 0.50 0.46 0.50
0.6 0.50 0.50 0.50 0.47 0.50 0.50
0.8 0.50 0.40 0.50 0.47 0.50 0.50
1
220
1,2 0.50 0.45 0.40 0.50 0.50 0.50
0.6 0.50 0.50 0.50 0.50 0.50 0.43
0.8 0.44 0.50 0.45 0.47 0.40 0.50180
1,2 0.50 0.50 0.50 0.50 0.50 0.50
0.6 0.50 0.50 0.50 0.50 0.50 0.50
0.8 0.44 0.43 0.50 0.47 0.45 0.50200
1,2 0.50 0.50 0.50 0.50 0.50 0.50
0.6 0.44 0.50 0.50 0.50 0.50 0.50
0.8 0.44 0.43 0.50 0.47 0.50 0.50
2
220
1,2 0.50 0.43 0.50 0.50 0.50 0.50
0.6 0.50 0.50 0.45 0.50 0.50 0.47
0.8 0.44 0.43 0.45 0.47 0.45 0.50180
1,2 0.50 0.43 0.50 0.50 0.50 0.45
0.6 0.47 0.50 0.50 0.50 0.50 0.43
0.8 0.47 0.43 0.50 0.47 0.45 0.50200
1,2 0.44 0.50 0.50 0.50 0.45 0.50
0.6 0.47 0.43 0.50 0.47 0.50 0.50
0.8 0.44 0.50 0.45 0.47 0.40 0.50
4
220
1,2 0.50 0.43 0.50 0.50 0.42 0.40
Standard 0.50 0.50 0.50 0.50 0.40 0.50
(a) No translation and rotation.
EasyOCR PaddleOCR
S FOV α h m c h m c
0.6 0.50 0.45 0.50 0.50 0.50 0.50
0.8 0.47 0.50 0.50 0.47 0.46 0.45180
1,2 0.44 0.50 0.50 0.47 0.42 0.50
0.6 0.47 0.43 0.45 0.47 0.45 0.45
0.8 0.44 0.43 0.45 0.47 0.40 0.50200
1,2 0.47 0.50 0.50 0.50 0.46 0.50
0.6 0.50 0.43 0.50 0.47 0.47 0.45
0.8 0.47 0.43 0.40 0.47 0.42 0.44
1
220
1,2 0.42 0.50 0.40 0.50 0.46 0.50
0.6 0.50 0.50 0.45 0.47 0.50 0.50
0.8 0.50 0.50 0.45 0.47 0.50 0.45180
1,2 0.50 0.40 0.50 0.47 0.50 0.50
0.6 0.50 0.50 0.45 0.47 0.50 0.45
0.8 0.50 0.50 0.50 0.47 0.50 0.50200
1,2 0.50 0.50 0.45 0.47 0.50 0.50
0.6 0.50 0.50 0.45 0.47 0.50 0.45
0.8 0.50 0.45 0.50 0.47 0.45 0.50
2
220
1,2 0.50 0.50 0.45 0.47 0.40 0.45
0.6 0.50 0.50 0.50 0.47 0.50 0.50
0.8 0.50 0.45 0.45 0.47 0.50 0.40180
1,2 0.50 0.50 0.45 0.47 0.50 0.50
0.6 0.50 0.50 0.50 0.47 0.50 0.45
0.8 0.50 0.50 0.50 0.47 0.50 0.50200
1,2 0.44 0.50 0.40 0.47 0.50 0.50
0.6 0.50 0.43 0.45 0.47 0.50 0.45
0.8 0.50 0.45 0.45 0.47 0.50 0.50
4
220
1,2 0.44 0.50 0.40 0.47 0.50 0.50
Standard 0.50 0.50 0.50 0.50 0.40 0.50
(b) Motion left.
EasyOCR PaddleOCR
S FOV α h m c h m c
0.6 0.44 0.43 0.46 0.47 0.50 0.50
0.8 0.50 0.43 0.40 0.50 0.50 0.50180
1,2 0.50 0.43 0.50 0.50 0.44 0.50
0.6 0.50 0.43 0.40 0.50 0.50 0.43
0.8 0.50 0.43 0.44 0.50 0.43 0.50200
1,2 0.50 0.46 0.44 0.50 0.50 0.44
0.6 0.50 0.43 0.42 0.50 0.50 0.50
0.8 0.50 0.43 0.46 0.50 0.50 0.50
1
220
1,2 0.50 0.46 0.42 0.50 0.50 0.43
0.6 0.44 0.50 0.50 0.47 0.50 0.43
0.8 0.50 0.43 0.50 0.50 0.50 0.50180
1,2 0.50 0.43 0.50 0.50 0.42 0.50
0.6 0.50 0.43 0.50 0.47 0.50 0.43
0.8 0.50 0.43 0.50 0.50 0.50 0.50200
1,2 0.50 0.50 0.50 0.50 0.50 0.50
0.6 0.47 0.43 0.50 0.50 0.50 0.43
0.8 0.50 0.43 0.50 0.50 0.50 0.50
2
220
1,2 0.50 0.50 0.46 0.50 0.50 0.50
0.6 0.50 0.50 0.50 0.47 0.50 0.40
0.8 0.44 0.50 0.50 0.50 0.50 0.50180
1,2 0.50 0.50 0.45 0.50 0.42 0.50
0.6 0.44 0.43 0.50 0.47 0.50 0.50
0.8 0.50 0.50 0.50 0.50 0.50 0.50200
1,2 0.50 0.43 0.40 0.50 0.50 0.43
0.6 0.44 0.50 0.50 0.50 0.50 0.43
0.8 0.50 0.50 0.50 0.50 0.50 0.50
4
220
1,2 0.50 0.43 0.50 0.50 0.42 0.50
Standard 0.50 0.50 0.50 0.50 0.40 0.50
(c) Motion to the right.
EasyOCR PaddleOCR
S FOV α h m c h m c
0.6 0.44 0.45 0.50 0.47 0.50 0.43
0.8 0.44 0.43 0.50 0.47 0.50 0.50180
1,2 0.44 0.50 0.50 0.50 0.50 0.50
0.6 0.44 0.40 0.50 0.50 0.50 0.50
0.8 0.44 0.40 0.40 0.47 0.50 0.43200
1,2 0.50 0.50 0.45 0.50 0.50 0.50
0.6 0.44 0.40 0.50 0.47 0.40 0.50
0.8 0.44 0.40 0.40 0.47 0.44 0.50
1
220
1,2 0.50 0.50 0.40 0.44 0.50 0.50
0.6 0.44 0.50 0.45 0.47 0.43 0.47
0.8 0.44 0.43 0.50 0.50 0.40 0.50180
1,2 0.50 0.43 0.50 0.50 0.40 0.50
0.6 0.44 0.43 0.50 0.44 0.40 0.50
0.8 0.44 0.50 0.50 0.50 0.40 0.50200
1,2 0.44 0.43 0.50 0.50 0.40 0.45
0.6 0.44 0.50 0.50 0.47 0.45 0.50
0.8 0.44 0.43 0.50 0.50 0.45 0.50
2
220
1,2 0.50 0.43 0.50 0.50 0.42 0.40
0.6 0.44 0.43 0.50 0.47 0.40 0.43
0.8 0.44 0.43 0.50 0.50 0.40 0.50180
1,2 0.50 0.43 0.50 0.50 0.42 0.50
0.6 0.44 0.43 0.50 0.44 0.45 0.50
0.8 0.44 0.43 0.50 0.50 0.40 0.50200
1,2 0.50 0.43 0.50 0.50 0.40 0.50
0.6 0.44 0.43 0.50 0.47 0.40 0.50
0.8 0.50 0.43 0.50 0.44 0.45 0.50
4
220
1,2 0.50 0.50 0.50 0.50 0.42 0.50
Standard 0.50 0.50 0.50 0.50 0.40 0.50
(d) Rotation
natural orientation of the text in the scene. Then, QM
is calculated using eq. (3) for each group and all of
them will be shown and analyzed in this section. The
results are shown in four tables, depending on the ex-
trinsic parameters: without motion (Table 3a), motion
to left (Table 3b), motion to right (Table 3c) and rota-
tion around the Y-axis (Table 3d). The last row shows
the results for the original dataset (i.e. the one that
contains undistorted images). The results related to
the synthetic fisheye images are compared with this
row. If the QM value is higher or equal, it is marked
in bold. Also, the QM values obtained with both li-
braries in the same setting (row) are compared for the
three orientations. If a library has a higher value than
the other for a given orientation, the background of
this cell is colored.
As shown in Table 3a, PaddleOCR and EasyOCR
output a QM value higher or equal to the case of
undistorted text (last row) the same number of times
when the text orientation the case of undistorted text
ICINCO 2024 - 21st International Conference on Informatics in Control, Automation and Robotics
138

is horizontal (h). However, PaddleOCR returned a
higher QM value in eight configurations more than
EasyOCR. This also occurs when the orientation is
curved, but the difference in this case is lower, Pad-
dleOCR has a higher QM value only in one more
configuration. In the case of multi-orientated (m)
text, PaddleOCR improved or equaled the result of the
standard images in a total of 27 configurations, while
EasyOCR did it in 16. Additionally, PaddleOCR has
improved the results of EasyOCR in four settings.
Considering now the results when the virtual fish-
eye camera is moved to the left (Table 3b), Pad-
dleOCR performs better than EasyOCR when the nat-
ural orientation of the text is multi-oriented or curved.
In these cases, PaddleOCR reached the QM value
of standard images 2 and 16 times and improved it
25 times for multi-oriented text (i.e. the value is
higher than 0.4). In the case of EasyOCR, the same
QM value than using images without distortion is
achieved 17 times for multi-oriented and 11 times for
curved. By contrast, EasyOCR works better for hori-
zontal text, achieving the same value than applied on
standard images 18 times, unlike PaddleOCR, which
achieves it only three times. By comparing both
columns, EasyOCR has a higher QM value than Pad-
dleOCR in 17 settings, whereas the opposite is met in
6 configurations.
After analyzing the results when the virtual fish-
eye camera is moved to the right (Table 3c), the con-
clusion is that PaddleOCR outperforms EasyOCR us-
ing standard images when the text is multi-oriented.
In addition this library works better than EasyOCR
independently of the orientation.
For the results when the virtual fisheye camera is
rotated around the vertical axis (Table 3d), EasyOCR
and PaddleOCR have similar behavior for curved text.
However, PaddleOCR achieved a better or equal QM
value as the obtained without distortion more times
than EasyOCR when the orientation is multi-oriented
or horizontal. On the one hand, if we analyze the
number of cells colored in the second column (m) of
each library, EasyOCR has outperformed PaddleOCR
almost twice as often. On the other hand, if we ana-
lyze the number of cells colored in the first column (h)
of each library, PaddleOCR has outperformed Easy-
OCR more than eight times, 17 using PaddleOCR
against to 2 using EasyOCR.
8 CONCLUSION
In this paper, two open-source libraries for text recog-
nition have been evaluated using fisheye images.
Given that no database with this kind of image (highly
distorted) has been found for this task, this dataset
has been generated by converting standard images of
a benchmark text scene dataset to fisheye for different
projection parameter values.
After applying two well-recognized and publicly
available OCR libraries, the results show that in most
cases, these tools perform worse with distorted im-
ages. By comparing both libraries, EasyOCR and
PaddleOCR, the latter one works better in a larger
number of studied configurations, in terms of the QM
used.
As possible future work, firstly, it is proposed to
evaluate other libraries in this work. Secondly, the
tools will be trained to recognize text in the presence
of this type of distortion.
ACKNOWLEDGEMENTS
This work is part of the project TED2021-130901B-
I00 funded by MCIN/AEI/10.13039/501100011033
and by the European Union “NextGenera-
tionEU”/PRTR. The work is also part of the
project PROMETEO/2021/075 funded by Generalitat
Valenciana.
REFERENCES
Baek, Y., Lee, B., Han, D., Yun, S., and Lee, H. (2019).
Character Region Awareness for Text Detection. In
2019 IEEE/CVF Conference on Computer Vision and
Pattern Recognition (CVPR), pages 9357–9366, Long
Beach, CA, USA. IEEE.
Case, C., Suresh, B., Coates, A., and Ng, A. Y. (2011). Au-
tonomous sign reading for semantic mapping. In 2011
IEEE International Conference on Robotics and Au-
tomation, pages 3297–3303. ISSN: 1050-4729.
Chen, X., Jin, L., Zhu, Y., Luo, C., and Wang, T.
(2020). Text Recognition in the Wild: A Survey.
arXiv:2005.03492 [cs].
Chng, C. K. and Chan, C. S. (2017). Total-Text: A
Comprehensive Dataset for Scene Text Detection and
Recognition. In 2017 14th IAPR International Con-
ference on Document Analysis and Recognition (IC-
DAR), pages 935–942, Kyoto. IEEE.
Cui, C., Gao, T., Wei, S., Du, Y., Guo, R., Dong, S., Lu,
B., Zhou, Y., Lv, X., Liu, Q., Hu, X., Yu, D., and Ma,
Y. (2021). PP-LCNet: A Lightweight CPU Convolu-
tional Neural Network. arXiv:2109.15099 [cs].
Du, Y., Chen, Z., Jia, C., Yin, X., Zheng, T., Li, C., Du, Y.,
and Jiang, Y.-G. (2022). SVTR: Scene Text Recog-
nition with a Single Visual Model. arXiv:2205.00159
[cs].
Du, Y., Li, C., Guo, R., Cui, C., Liu, W., Zhou, J., Lu, B.,
Yang, Y., Liu, Q., Hu, X., Yu, D., and Ma, Y. (2021).
Evaluation of Open-Source OCR Libraries for Scene Text Recognition in the Presence of Fisheye Distortion
139

PP-OCRv2: Bag of Tricks for Ultra Lightweight OCR
System. arXiv:2109.03144 [cs].
Du, Y., Li, C., Guo, R., Yin, X., Liu, W., Zhou, J., Bai,
Y., Yu, Z., Yang, Y., Dang, Q., and Wang, H. (2020).
PP-OCR: A Practical Ultra Lightweight OCR System.
arXiv:2009.09941 [cs].
Flores, M., Valiente, D., Peidr
´
o, A., Reinoso, O., and Pay
´
a,
L. (2024). Generating a full spherical view by mod-
eling the relation between two fisheye images. The
Visual Computer.
Graves, A., Fern
´
andez, S., Gomez, F., and Schmidhu-
ber, J. (2006). Connectionist temporal classification:
labelling unsegmented sequence data with recurrent
neural networks. In Proceedings of the 23rd inter-
national conference on Machine learning - ICML ’06,
pages 369–376, Pittsburgh, Pennsylvania. ACM Press.
Gupta, N. and Jalal, A. S. (2022). Traditional to trans-
fer learning progression on scene text detection and
recognition: a survey. Artificial Intelligence Review,
55(4):3457–3502.
He, K., Gkioxari, G., Doll
´
ar, P., and Girshick, R. (2017).
Mask R-CNN. In 2017 IEEE International Confer-
ence on Computer Vision (ICCV), pages 2980–2988.
ISSN: 2380-7504.
Hutchison, D., Kanade, T., Kittler, J., Kleinberg, J. M.,
Mattern, F., Mitchell, J. C., Naor, M., Nierstrasz, O.,
Pandu Rangan, C., Steffen, B., Sudan, M., Terzopou-
los, D., Tygar, D., Vardi, M. Y., Weikum, G., Wang,
K., and Belongie, S. (2010). Word Spotting in the
Wild. In Daniilidis, K., Maragos, P., and Paragios, N.,
editors, Computer Vision – ECCV 2010, volume 6311,
pages 591–604. Springer Berlin Heidelberg, Berlin,
Heidelberg.
JaidedAI (2020). EasyOCR.
Karatzas, D., Gomez-Bigorda, L., Nicolaou, A., Ghosh, S.,
Bagdanov, A., Iwamura, M., Matas, J., Neumann, L.,
Chandrasekhar, V. R., Lu, S., Shafait, F., Uchida, S.,
and Valveny, E. (2015). ICDAR 2015 competition
on Robust Reading. In 2015 13th International Con-
ference on Document Analysis and Recognition (IC-
DAR), pages 1156–1160, Tunis, Tunisia. IEEE.
Kuang, Z., Sun, H., Li, Z., Yue, X., Lin, T. H., Chen, J., Wei,
H., Zhu, Y., Gao, T., Zhang, W., Chen, K., Zhang,
W., and Lin, D. (2021). MMOCR: A Comprehensive
Toolbox for Text Detection, Recognition and Under-
standing. In Proceedings of the 29th ACM Interna-
tional Conference on Multimedia, pages 3791–3794,
Virtual Event China. ACM.
Li, C., Liu, W., Guo, R., Yin, X., Jiang, K., Du, Y., Du, Y.,
Zhu, L., Lai, B., Hu, X., Yu, D., and Ma, Y. (2022).
PP-OCRv3: More Attempts for the Improvement of
Ultra Lightweight OCR System. arXiv:2206.03001
[cs].
Li, H., Wang, P., Shen, C., and Zhang, G. (2019). Show,
Attend and Read: A Simple and Strong Baseline for
Irregular Text Recognition. Proceedings of the AAAI
Conference on Artificial Intelligence, 33(01):8610–
8617.
Lin, H., Yang, P., and Zhang, F. (2020). Review of Scene
Text Detection and Recognition. Archives of Compu-
tational Methods in Engineering, 27(2):433–454.
Long, S., He, X., and Yao, C. (2021). Scene Text Detection
and Recognition: The Deep Learning Era. Interna-
tional Journal of Computer Vision, 129(1):161–184.
Long, S., Ruan, J., Zhang, W., He, X., Wu, W., and Yao,
C. (2018). TextSnake: A Flexible Representation for
Detecting Text of Arbitrary Shapes. pages 20–36.
Naosekpam, V. and Sahu, N. (2022). Text detection, recog-
nition, and script identification in natural scene im-
ages: a Review. International Journal of Multimedia
Information Retrieval, 11(3):291–314.
Phan, T. Q., Shivakumara, P., Tian, S., and Tan, C. L.
(2013). Recognizing Text with Perspective Distortion
in Natural Scenes. In 2013 IEEE International Con-
ference on Computer Vision, pages 569–576. ISSN:
2380-7504.
Shi, B., Bai, X., and Yao, C. (2017). An End-to-End
Trainable Neural Network for Image-Based Sequence
Recognition and Its Application to Scene Text Recog-
nition. IEEE Transactions on Pattern Analysis and
Machine Intelligence, 39(11):2298–2304.
Veit, A., Matera, T., Neumann, L., Matas, J., and Belongie,
S. (2016). COCO-Text: Dataset and Benchmark for
Text Detection and Recognition in Natural Images.
arXiv:1601.07140 [cs].
Yamanaka, Y., Kayukawa, S., Takagi, H., Nagaoka, Y.,
Hiratsuka, Y., and Kurihara, S. (2022). One-shot
wayfinding method for blind people via ocr and ar-
row analysis with a 360-degree smartphone cam-
era. Lecture Notes of the Institute for Computer
Sciences, Social-Informatics and Telecommunications
Engineering, LNICST, 419 LNICST:150–168.
Yang, L., Li, L., Xin, X., Sun, Y., Song, Q., and Wang, W.
(2023). Large-Scale Person Detection and Localiza-
tion using Overhead Fisheye Cameras.
Yue, X., Kuang, Z., Lin, C., Sun, H., and Zhang, W. (2020).
RobustScanner: Dynamically Enhancing Positional
Clues for Robust Text Recognition. In Computer Vi-
sion – ECCV 2020: 16th European Conference, Glas-
gow, UK, August 23–28, 2020, Proceedings, Part XIX,
pages 135–151, Berlin, Heidelberg. Springer-Verlag.
Yuliang, L., Lianwen, J., Shuaitao, Z., and Sheng, Z.
(2017). Detecting Curve Text in the Wild: New
Dataset and New Solution. arXiv:1712.02170 [cs].
Zhu, Y., Chen, J., Liang, L., Kuang, Z., Jin, L., and
Zhang, W. (2021). Fourier Contour Embedding for
Arbitrary-Shaped Text Detection. In 2021 IEEE/CVF
Conference on Computer Vision and Pattern Recogni-
tion (CVPR), pages 3122–3130, Nashville, TN, USA.
IEEE.
ICINCO 2024 - 21st International Conference on Informatics in Control, Automation and Robotics
140
