
Research on Face Recognition Technology Based on Real-World
Application Scenarios
Yifan Lan
a
Computer Science and Technology, Bei Jing Jiao Tong University Weihai campus, Weihai, China
Keywords: Face Recognition, Deep Learning, Practical Application Scenarios.
Abstract: Face recognition technology is widely used in various fields has received extensive attention from researchers.
This study classifies and summarizes different face recognition methods based on real life. In more detail, this
paper is categorized into: masked face recognition and non-masked face recognition according to their
application significance. First, each type of face recognition method is summarized and retrospectively
compared based on the time series of development. Second, different face recognition methods are
implemented based on the same de-emphasized dataset, and the recognition accuracy and execution time of
each method are derived. The advantages and disadvantages of different methods are analysed and compared
with the basic criteria of these two data metrics. And the experimental data results are visualized for more
detailed analysis. The experimental results show that face recognition performance can be improved by
introducing deep learning techniques. Therefore, the future direction of face recognition research should be
to explore how to integrate different types of face recognition methods to achieve maximum efficiency. This
study summarizes the face recognition methods from practical application scenarios, which has certain
reference value for enterprises and related technicians.
1 INTRODUCTION
Face recognition technology is a means of identity
verification through the extraction of facial features,
and in recent years has become an area of significant
research in various fields including artificial
intelligence, computer vision, and psychology (Su,
2016). Other biometric features of the human body,
such as iris and fingerprints, have been widely used
for authentication and identification over the past
decade (Su, 2016). As a physiological feature, the
human face has similar special properties as iris and
fingerprints. The face has uniqueness, consistency
and a high degree of non-replicability (Zhi-heng,
2018). Those properties provide stable conditions for
identification. The application scope of face
recognition technology continues to expand,
encompassing various domains such as criminal
investigation, intelligent transportation systems,
access control in physical environments, and internet
services. Unlike traditional disciplines, face
recognition requires a multidisciplinary approach,
integrating concepts from computer vision,
a
https://orcid.org/0009-0008-1116-6336
psychology, and related fields. This underscores the
importance of a comprehensive understanding of
diverse knowledge domains in the study of face
recognition technology.
Initially, during the nascent stages of face
recognition research, scholars delved into the
structural delineations of facial contours, primarily
exploring the silhouette curve of the face (Amarapur,
2006). This foundational exploration set the stage for
subsequent advancements. Subsequently, the field
witnessed a surge in development as elastic graph
matching algorithms emerged as a pivotal technique
for face recognition (Bolme, 2003). Concurrently, a
gamut of 2D face recognition techniques burgeoned,
ranging from linear subspace discriminant analysis to
statistical epistemic models and statistical model
recognition methods (Liao, 2003). However, recent
years have ushered in a shift in focus towards real-
world applications of face recognition, prompting
researchers to confront the challenges posed by
practical scenarios. Based on real-life application
scenarios, face recognition technology has evolved
from initially only recognizing unobstructed faces to
368
Lan, Y.
Research on Face Recognition Technology Based on Real-World Application Scenarios.
DOI: 10.5220/0012938300004508
Paper published under CC license (CC BY-NC-ND 4.0)
In Proceedings of the 1st International Conference on Engineering Management, Information Technology and Intelligence (EMITI 2024), pages 368-374
ISBN: 978-989-758-713-9
Proceedings Copyright © 2024 by SCITEPRESS – Science and Technology Publications, Lda.

later recognizing faces with obstructions such as
sunglasses and masks. Initially, Amarapur and Patil
proposed a relatively simple conventional accessible
face identification method on the basis of facial
geometric features, but the accuracy of this method is
relatively low. Subsequently, Mu and Yan proposed
a face recognition method based on algebraic
features, which is relatively more tolerant to changes
in light and facial expressions (Yanmei, 2016). After
that Liao and Gu proposed a subspace-based face
recognition method SESRC&LDF, which further
improves the accuracy of unobstructed face
recognition (Malassiotis, 2005). After that, several
scientists proposed a face recognition method which
is based on bimodal fusion, which is a state of the art
occlusion-free face verification method (Guan,
2010). In recent years, due to the prevalence of new
coronaviruses, people wear masks more frequently in
their daily life. As a result, there is an increasing
demand for the mask-based face identification
technology by the society, which promotes the
enhancement of the mask-based face recognition
technology. Guan et al. have proposed a new exterior-
based face verification method, tensor subspace
regression (TSR) (Li, 2013). Li et al. have proposed a
structural coding-based method to further improve
the precision rate of masked face identification
(Kunming, 2005). As the technology developed
further, the "shallow" feature extraction based
method proposed by Li et al. improved the speed of
masked face recognition (Prasad, 2020). The deep
learning based face recognition method proposed by
Prasad et al. is among the most widely used face
verification methods (Adjabi, 2020).
The primary objective of this study is to
categorize face recognition methods into two distinct
categories based on their practical usage scenarios:
unobstructed face recognition and obstructed face
recognition. Additionally, this study aims to
summarize the key methods associated with each
category, tracing their developmental history. In a
more detailed analysis, first, unobstructed face
recognition is categorized into traditional
unobstructed face recognition and modern
unobstructed face recognition based on its
development history. Similarly, this study classifies
covert face recognition into traditional concealed face
recognition and modern concealed face recognition.
Next, the core technologies contained in these four
categories are analyzed and introduced respectively.
Finally, this study discusses the advantages and
disadvantages of the key technologies contained
within face recognition as well as the prospects for
future development. This study fills the gap of sorting
out and learning about face recognition technologies
from a practical point of view, and provides a
reference for selecting appropriate face recognition
systems for real-life individuals as well as enterprises.
This chapter begins with a background
introduction and a review of previous work in related
fields, along with a brief description of the research
objectives and methodology of this paper. Secondly,
chapter 2 introduces the core concepts as well as the
principles of the approaches taken in each
classification according to the categorization of
occluded face recognition and unoccluded face
recognition in the order of development. After that,
the results of the study are analyzed and discussed in
Chapter 3. Finally, a summary of the entire study is
presented in Chapter 4.
2 METHODOLOGIES
2.1 Dataset Description and
Preprocessing
The main datasets involved in this study include the
Yale Face Database B, the Olivetti Research
Laboratory (ORL) face dataset, the Augmented
Reality (AR) face database, and the Multi Modal
Verification for Teleservices and Security
(XM2VTS) face database. The Yale Face Database B
contains approximately 5,760 facial images of
subjects in different lighting conditions and different
postures. The ORL face dataset was created by
Olivetti's lab in Cambridge, United Kingdom, and
contains 400 facial images in Portable Gray Map
(PGM) format taken by 40 different subjects at
different times, under different lighting, different
facial conditions, and different facial details. These
images all have the same height and width. The AR
face database contains more than 4000 face images
from 126 different subjects, about 26 images per
person, in 24-bit color at 576*768 pixels. The images
in this database are frontal face images with
variations in expression, lighting, and occlusion. The
XM2VTS database is derived from the European
Union's Ability and Competence Test System
(ACTS) program, which handles access control and
thus improves the efficiency of access through the use
of multimodal recognition of faces. The database
contains frontal face images of 295 subjects when
they are speaking and when they are rotating their
heads (Li, 2018).
Research on Face Recognition Technology Based on Real-World Application Scenarios
369
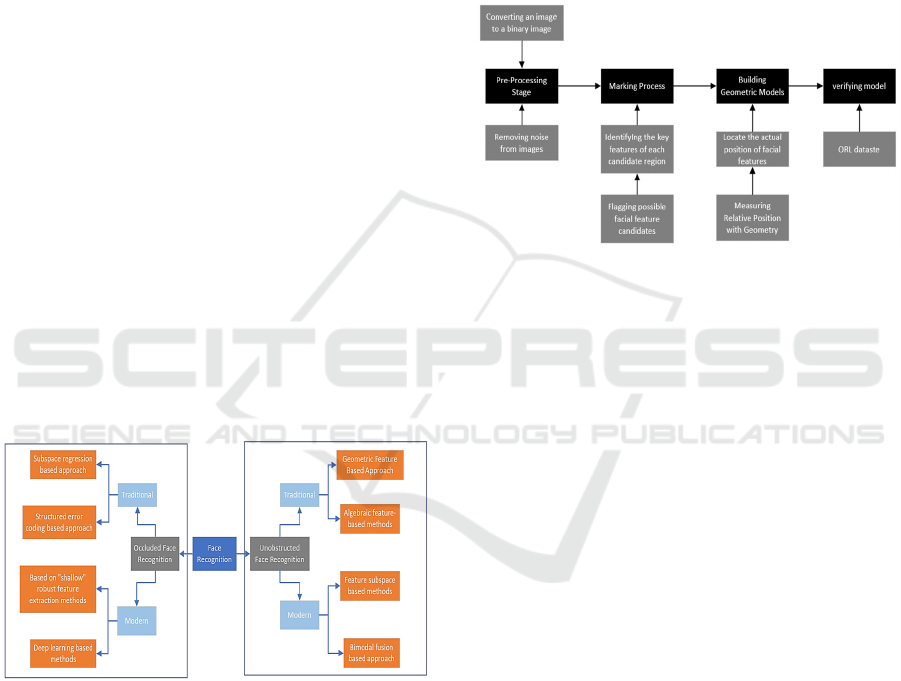
2.2 Proposed Approach
Based on the practical application scenarios of face
recognition techniques, this study divides them into
two categories: unobstructed face recognition and
obstructed face recognition. This study traces the
representative methods in each category according to
the time series and analyses them comparatively.
Specifically, first, occlusion-free face recognition is
divided into traditional occlusion-free face
recognition methods and modern occlusion-free face
recognition methods. According to the chronological
order of its development, the geometric feature-based
face recognition methods are searched first. Then, the
methods based on algebraic features that appeared
afterwards are searched. For modern occlusion-free
face recognition methods, firstly, a face recognition
method based on feature subspace is introduced.
Secondly, a method based on bimodal fusion is
proposed. Similarly, the occluded face recognition
methods are classified into: traditional methods and
modern methods. For the traditional occluded face
recognition methods, firstly, a face recognition
method based on subspace regression is analyzed.
Secondly, the method based on structured error
coding is analyzed. For modern occluded face
recognition methods, firstly, the methods based on
"shallow" robust feature extraction are reviewed.
Secondly, deep learning-based methods are
introduced. The specific flow is shown in Figure 1.
Figure 1: The pipeline of the model
(Picture credit:
Original).
2.2.1 Traditional Unobstructed Face
Recognition Methods
Geometric feature-based methods are traditional in
early face recognition, focusing on facial contours
and organ shapes. However, due to facial non-
rigidity, complex feature extraction necessitates
additional algorithms. While widely used, limitations
with non-rigid bodies must be considered for reliable
recognition systems. Amarapur and Patil introduced
a geometric model integrating features like ears and
chin, enhancing accuracy. Their method includes
image pre-processing, feature labeling, model
construction, and validation, as shown in Figure 2.
Algebraic feature-based methods offer robustness to
lighting and expressions. Yanmei and Mu proposed a
principal component analysis (PCA)-based method
incorporating singular value decomposition (SVD)
and Kullback-Leibler (KL) transform, reducing
correlation between face images and improving
accuracy.
Figure 2: Amarapur and patil experimental procedure for
geometric feature based face modeling
(Picture credit:
Original).
2.2.2 Modern Methods of Unobstructed
Face Recognition
For methods based on feature subspaces, the feature
subspace approach involves transforming a 2D face
image into another space, aiding in distinguishing
face features from non-face features. Common
algorithms for this technique include Principal
Element Analysis, Factor Decomposition, Fisher
Criterion Method, and Wavelet Transform. Liao and
Gu presented face recognition methods based on
subspace extended sparse representation and
discriminative feature learning - subspace extended
sparse representation classifier (SESRC) and
discriminative figure learning (DFL). In SESRC &
DFL, each test image is treated as having either a
small or significant pose change based on its
symmetry. Test images with small pose changes are
recognized using the SESRC, while those with
significant changes are processed using the DFL
method proposed in the paper. Empirical results on
face databases like Yale and AR demonstrate that
SESRC & DFL achieve the highest recognition rate,
surpassing several state-of-the-art algorithms such as
Perceptron Learning Algorithm (PLA) and Random
Forest (FR). For methods based on bimodal fusion, a
bimodal fusion-based approach simultaneously
utilizes information from both 2D and 3D modalities
EMITI 2024 - International Conference on Engineering Management, Information Technology and Intelligence
370
and synthesizes them at three levels: signal, feature,
and decision-making, in order to obtain better face
recognition results than single modalities. Malassiotis
et al. proposed a normalization method that is
efficient and does not require expansion of the
training set.
2.2.3 Traditional Occluded Face
Recognition Methods
For methods based on subspace regression, the
subspace regression method evaluates whether face
samples can be accurately regressed into their
corresponding subspace, considering the high
correlation and occlusion effects in face images
(Zhang, 2020). Guan et al. introduced Tensor
Subspace Regression (TSR), building upon the
traditional Tensor Subspace Analysis (TSA)
algorithm. TSR, like TSA, represents face images in
tensor space but transforms the face subspace
learning into a regression framework, addressing the
time-consuming aspect of TSA. Guan et al. validated
TSR on popular face databases AR, ORL, and Yale
face B, demonstrating its high performance in face
classification and clustering tasks. For methods based
on structured error coding, errors induced by physical
occlusion have a specific spatial structure, e.g.,
sunglasses occlusion, scarf occlusion, etc., which are
different from those induced by Gaussian noise. Li et
al. proposed a morphogram model to describe the
morphological structure of errors based on the feature
of the shape of the occluder in facial recognition.
Experimental validation on the XM2VTS face
database shows that this method is more stable in
dealing with the occlusion problem in facial
recognition compared to other related methods.
2.2.4 Modern Methods of Face Recognition
with Occlusion
For methods based on "shallow" robust feature
extraction, it relies on manually designed methods
closely tied to face recognition but may lack
robustness against mixed light and physical
occlusions. Li et al. introduced a method based on the
Weber operator algorithm, combining directional
difference mode and localized directional difference
excitation accumulation mode to enhance recognition
speed and reduce space consumption. This approach
incorporates chunk-based linear discriminant
dimensionality reduction, achieving a reported
recognition rate of up to 98% on the ORL face
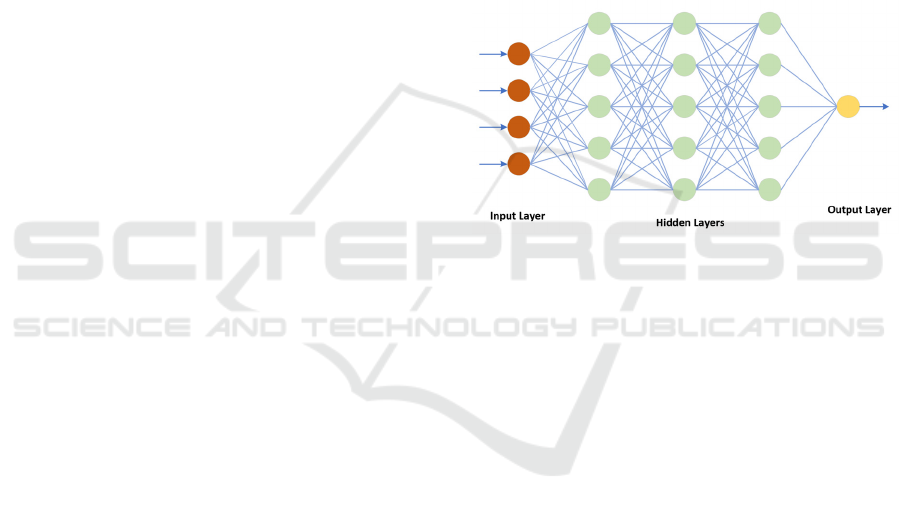
database (Prasad, 2020). For deep learning-based
approach, successful face recognition in occluded
face images relies on understanding higher-order
attributes. Deep learning addresses these challenges
through multi-layer nonlinear mapping and
backpropagation-based feedback learning, surpassing
traditional classifiers in handling transformation
issues, as depicted in Figure 3. Deep networks offer
stable and powerful distributed representations,
enabling the design of effective network structures for
face recognition tasks. Prasad et al. evaluated the
accuracy of deep learning-based face recognition
under diverse conditions, including occlusion,
varying head postures, and lighting variations. Their
experiments with lightweight Convolutional Neural
Networks (CNNs) and Visual Geometry Group
(VGG) models demonstrated robustness to
misalignment and localization errors in intraocular
distance.
Figure 3: Artificial neural network
(Picture credit:
Original).
3 RESULTS AND DISCUSSION
In this section, firstly, representative algorithms for
face recognition in two major categories, masked and
unmasked, are analysed separately and their
advantages and disadvantages are illustrated in tables.
Secondly, the performance of different representative
methods is compared with experimental data and the
optimal method is evaluated. Finally, this study
discusses future research directions in face
recognition related areas.
As shown in Table 1, this study analyses the
advantages and disadvantages of the different face
identification methods mentioned above. The results
of the analysis show that each method has certain
advantages and disadvantages and there is no such
thing as a perfect method that does not have
disadvantage.
Research on Face Recognition Technology Based on Real-World Application Scenarios
371
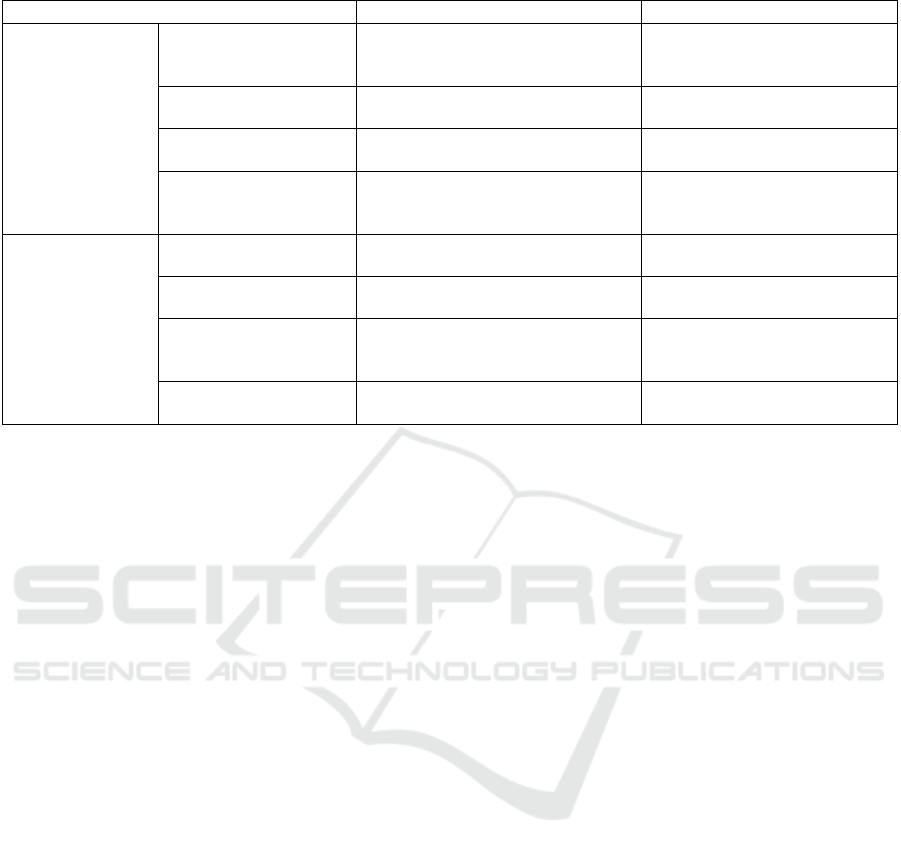
Table 1: Analysis of the pros and cons of face recognition methods.
Approaches Advantages Disadvantages
Unobstructed Face
Recognition
Geometric Feature Based
Approach
Simple
High efficient
Limited by geometric
features
Eas
y
to be interfere
d
Algebraic feature-based
methods
High recognition accuracy High computational
complexit
y
Feature subspace-based
methods
Suitable for large-scale data Data loss
Sensitive to data distribution
Bimodal fusion based
approach
High accuracy and robustness
High stability
High complexity
High complexity of
algorithms
Occluded Face
Recognition
Subspace regression-
b
ase
d
a
pp
roach
High flexibility and adaptability
Hi
g
h data utilisation
Higher requirements for data
Limited abilit
y
to
g
eneralise
Structured error coding-
b
ase
d
a
pp
roach
Highly expressive features
Hi
g
h resistance
Difficulty in tuning model
p
arameters
Based on "shallow" robust
feature extraction
methods
Fast calculation speed Fast calculation speed
Relatively low data
re
q
uirements
Deep learning-based
methods
High accuracy
Simple system setup
Higher data requirements
Incomprehensible
As shown in Table 2, this study evaluates the
experiments of different face recognition methods
under different conditions. For face recognition
without occlusion, the geometric feature approach
shows high recognition accuracy (80.25%) and has a
short implementation time (0.1212 seconds).
Whereas, in the case of occlusion, the deep learning
method performs the best in terms of accuracy
(93.25%) but accordingly has a longer
implementation time (2.4266 seconds).
Comparison of the experimental results with the
addition of light and noise interference factors reveals
that the recognition accuracy of most of the methods
decreases slightly, but the deep learning method still
maintains a high accuracy (83.75%). This indicates
that the effects of light and noise interference are
more significant for geometric and algebraic feature
methods, but relatively small for deep learning
methods. These results reflect the robustness and
adaptability of different face recognition methods
under different conditions.
As shown in Figure 4, this study compares the
average recognition accuracy and execution time of
different face recognition methods. As it can be seen
from the figure, the deep learning method has the best
performance in terms of average recognition accuracy,
which reaches 95%, but accordingly, its average
execution time is also longer, which is 2.4266
seconds. The "shallow" robust feature extraction-
based method, on the other hand, although slightly
lower than the other methods in terms of average
recognition accuracy, has the shortest average
execution time of 0.0512 seconds. This result can be
attributed to the differences in feature extraction and
model complexity between the different methods.
Deep learning methods are able to achieve higher
recognition accuracy through deep feature learning
and model training, but also result in longer execution
times. On the contrary, the "shallow" robust feature
extraction-based methods have lower accuracy, but
their simple feature extraction process leads to a
significant reduction in execution time.
According to the current development trend,
combining deep learning with other complementary
methods will be a key direction for the future
development of face recognition. For example,
combining deep learning with techniques such as
expression correction to design new model
architectures is a promising direction for innovation.
4 CONCLUSIONS
This study reviews and summarises previous face
recognition methods based on realistic use scenarios
of face recognition. The face recognition methods are
categorised according to their real-world
significance: face recognition with occlusion and face
recognition without occlusion. Subsequently, this
study reviews the development of methods in each
category based on time series. Finally, this study
compares and enumerates the advantages and
disadvantages of different methods. Experimental
data on recognition accuracy and execution time of
each method is derived by conducting experiments on
EMITI 2024 - International Conference on Engineering Management, Information Technology and Intelligence
372
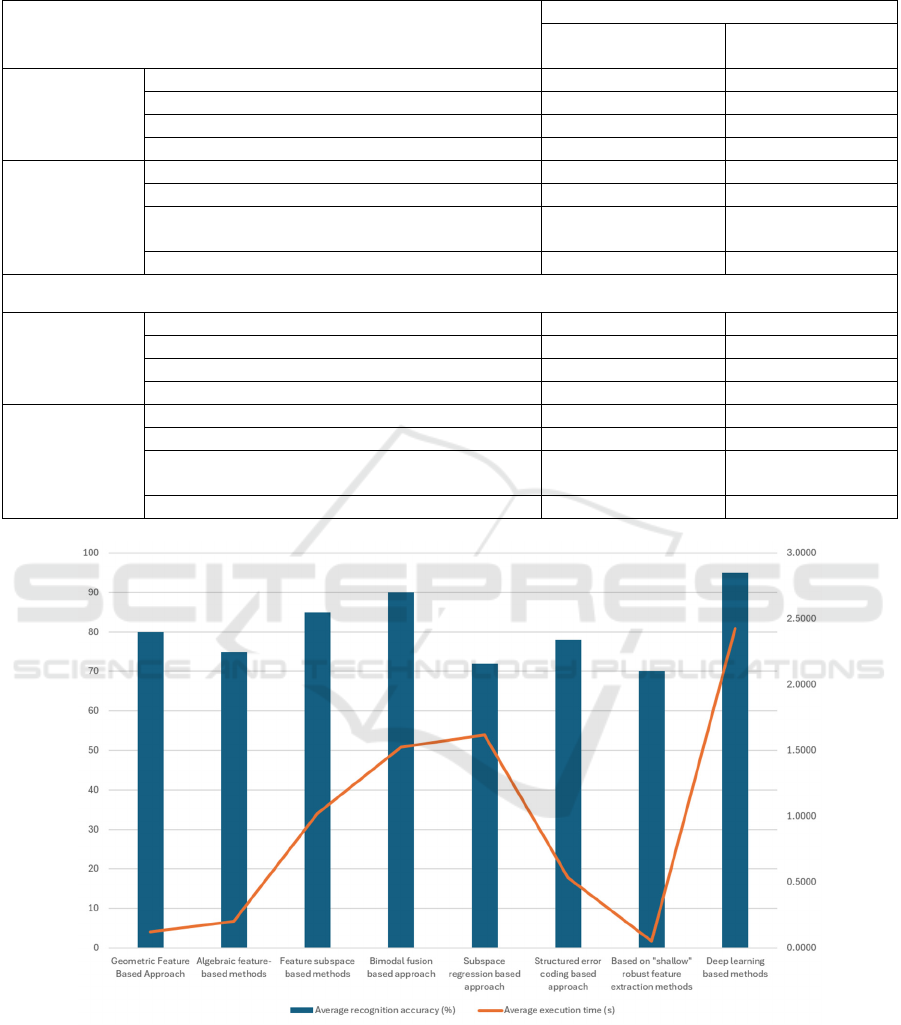
Table 2: Performance of different face recognition methods based on the same dataset.
Approaches
Experimentation
Recognition Accuracy
(%)
Implementation time
(sec)
Unobstructed
Face Recognition
Geometric Feature Based Approach 80.250000 0.1212
Algebraic feature-based methods 75.000000 0.2025
Feature subspace-based methods 85.200000 1.0215
Bimodal fusion based approach 90.000000 1.5250
Occluded Face
Recognition
Subspace regression-based approach 72.500000 1.6152
Structured error coding-based approach 78.000000 0.5325
Based on "shallow" robust feature extraction
methods
70.250000 0.0512
Deep learning-based methods 95.000000 2.4266
Adding interfering factors light and noise
Unobstructed
Face Recognition
Geometric Feature Based Approach 75.250000 0.1212
Algebraic feature-based methods 70.000000 0.2025
Feature subspace-based methods 82.250000 1.0215
Bimodal fusion based approach 84.250000 1.5250
Occluded Face
Recognition
Subspace regression-based approach 68.650000 1.6152
Structured error coding-based approach 75.000000 0.5325
Based on "shallow" robust feature extraction
methods
65.250000 0.0512
Deep learning-based methods 93.250000 2.4266
Figure 4: Performance of different face recognition methods
(Picture credit: Original).
the same dataset, providing real-world data to support
the advantages and disadvantages mentioned above.
The experimental results show that there is no such
thing as one perfect method and each method has
certain advantages and disadvantages. So in recent
years most programmers have been using a
combination of several different face recognition
methods to maximise efficiency. In the future, the
integration of deep learning with other methods is
going to be an essential direction in the evolution of
face recognition, such as combining deep learning
with face light calibration to design new models.
Research on Face Recognition Technology Based on Real-World Application Scenarios
373

REFERENCES
Su, N., Wu, B., Xu, W., & Su, G. D. (2016). Development
of integrated face recognition technology. Information
Security Research, vol. 2(1), pp: 33-39.
Zhi-heng, L., & Yong-zhen, L. (2018). Retracted: The
Research on Identity Recognition Based on Multi-
Biological Feature Awareness. International
Conference on Smart City and Systems Engineering, pp.
796-800.
Amarapur, B., & Patil, N. (2006). The facial features
extraction for face recognition based on geometrical
approach. In 2006 Canadian Conference on Electrical
and Computer Engineering, pp: 1936-1939.
Bolme, D. S. (2003). Elastic bunch graph matching
(Doctoral dissertation, Colorado State University).
Liao, M., & Gu, X. (2020). Face recognition approach by
subspace extended sparse representation and
discriminative feature learning. Neurocomputing, vol.
373, pp: 35-49.
Yanmei, H., & Mu, Y. (2016). Face recognition algorithm
based on algebraic features of SVD and KL projection.
In 2016 International Conference on Robots &
Intelligent System (ICRIS), pp: 93-196.
Malassiotis, S., & Strintzis, M. G. (2005). Robust face
recognition using 2D and 3D data: Pose and
illumination compensation. Pattern Recognition, vol.
38(12), pp: 2537-2548.
Guan, Z., Wang, C., Chen, Z., Bu, J., & Chen, C. (2010).
Efficient face recognition using tensor subspace
regression. Neurocomputing, vol. 73(13-15), pp: 2744-
2753.
Li, X. X., Dai, D. Q., Zhang, X. F., & Ren, C. X. (2013).
Structured sparse error coding for face recognition with
occlusion. IEEE transactions on image processing, vol.
22(5), pp: 1889-1900.
Li, K., Wang, Lin, Y., Hai-stop, & Ji-fu, L., (2014). A face
recognition method fusing multi-modal Weber local
features. Small Microcomputer Systems, vol. 35(7), pp:
1651-1656.
Prasad, P. S., Pathak, R., Gunjan, V. K., & Ramana Rao, H.
V. (2020). Deep learning-based representation for face
recognition. In ICCCE 2019: Proceedings of the 2nd
International Conference on Communications and
Cyber Physical Engineering, pp: 419-424.
Adjabi, I., Ouahabi, A., Benzaoui, A., & Taleb-Ahmed, A.
(2020). Past, present, and future of face recognition: A
review. Electronics, vol. 9(8), p: 1188.
Li, S. Salary, & Liang, R. H. (2018). A review of occluded
face recognition: from subspace regression to deep
learning. Journal of Computing, vol. 41(1), pp: 177-207.
Zhang, S., Yang, Y., Chen, C., Zhang, X., Leng, Q., & Zhao,
X. (2023). Deep learning-based multimodal emotion
recognition from audio, visual, and text modalities: A
systematic review of recent advancements and future
prospects. Expert Systems with Applications, p: 121692.
EMITI 2024 - International Conference on Engineering Management, Information Technology and Intelligence
374
