
A Methodology for Interpreting Natural Language Questions and
Translating into SPARQL Query over DBpedia
Davide Varagnolo
1,3 a
, Dora Melo
2,3 b
and Irene Pimenta Rodrigues
1,3 c
1
Department of Informatics, University of
´
Evora,
´
Evora, Portugal
2
Polytechnic University of Coimbra, Coimbra Business School—ISCAC, Coimbra, Portugal
3
NOVA Laboratory for Computer Science and Informatics, NOVA LINCS, Caparica, Portugal
Keywords:
Natural Language Processing, Question Answering, Knowledge Representation, Knowledge Discovery,
Semantic Web, SPARQL Queries, Ontology.
Abstract:
This paper presents a methodology that allows a natural language question to be interpreted using an ontology
called Query Ontology. From this representation, using a set of mapping description rules, a SPARQL query
is generated to query a target knowledge base. In the experiment presented, the Query Ontology and the
set of mapping description rules are designed over DBpedia as target knowledge base. The methodology is
tested using QALD-9, a dataset of natural language queries widely used to test question-answering systems
on DBpedia.
1 INTRODUCTION
The ability of a system to correctly understand a nat-
ural language question can be useful in solving one
of the most important tasks in the field of Question
Answering (QA), discipline within the fields of nat-
ural language processing (NLP) which concerns the
construction of systems capable of answering ques-
tions posed in a natural language (Hirschman and
Gaizauskas, 2001). A branch of research focuses on
the interpretation of natural language through seman-
tic understanding using ontologies, able to create a
different representation of the natural language ques-
tion. A good representation of the natural language
question is essential to proceed into next step of the
QA process based on Knowledge Bases (KBs), which
is the creation of a query in a target query language
able to retrieve the correct information. In knowl-
edge bases, the query language is SPARQL Proto-
col and RDF Query Language (SPARQL). Several
approaches were presented in last years about the
translation of natural language question into SPARQL
queries(Zlatareva and Amin, 2021; Steinmetz et al.,
2019; Silva et al., 2023). Literature shows that seman-
tic parsing is the predominant paradigm in the Knowl-
a
https://orcid.org/0009-0001-9212-9586
b
https://orcid.org/0000-0003-3744-2980
c
https://orcid.org/0000-0003-2370-3019
edge Base Question Answering (KBQA). Can be ob-
served that an often-used methodology is to break the
problem of semantic parsing a complex question into
more manageable sub-tasks, by a pipeline of three
modules (Omar et al., 2023): understanding the ques-
tion, entity and relation linking, and answer filtering.
Several systems adapt their strategies based on this
type of pipeline approach (Hu et al., 2021; Cornei and
Trandabat, 2023).
These systems are often designed and tested on
DBpedia
1
, one of the largest open source knowledge
bases available on the web based on information in
Wikipedia
2
.
In this paper, it is described in section 2 an
ontology-based Question-Answering system capable
of constructing a SPARQL query from a natural lan-
guage question. In section 3, an ontology for DB-
pedia is presented. From this representation, a strat-
egy based on mapping description rules to build a
SPARQL query is presented in section 4. Section 5
shows the experience of this strategy with a natural
language question dataset, QALD-9
3
.
1
https://www.dbpedia.org/
2
https://www.wikipedia.org/
3
https://github.com/ag-sc/QALD/tree/master/9/data
Varagnolo, D., Melo, D. and Rodrigues, I.
A Methodology for Interpreting Natural Language Questions and Translating into SPARQL Query over DBpedia.
DOI: 10.5220/0012940800003838
Paper published under CC license (CC BY-NC-ND 4.0)
In Proceedings of the 16th International Joint Conference on Knowledge Discovery, Knowledge Engineering and Knowledge Management (IC3K 2024) - Volume 2: KEOD, pages 175-182
ISBN: 978-989-758-716-0; ISSN: 2184-3228
Proceedings Copyright © 2024 by SCITEPRESS – Science and Technology Publications, Lda.
175

2 QUESTION ANSWERING
SYSTEM
In this section, the question-answering system which
create a SPARQL Query for a target KB from a nat-
ural language question is described. In Figure 1, the
full architecture is presented. The architecture, pre-
sented in (Varagnolo et al., 2023), includes a pipeline
with three modules: Partial Semantic Representation,
Pragmatic interpretation, and SPARQL generator.
The Partial Semantic Representation is composed
by two modules: a dependency parser, Stanza, is ap-
plied to the question and the resulting parser tree is
transformed into a set of partial Discourse Represen-
tation Structures (DRSs). DRS refers to a set of Dis-
course Referents (DRs) and the relations on them.
The DRS, like the algorithm used for its construction,
is based on Discourse Representation Theory (Kamp
and Reyle, 2013).
The Pragmatic interpretation module rewrites par-
tial semantic representations into domain-specific
meanings. It uses an ontology-based domain repre-
sentation and multi-objective optimization to find the
best interpretation within the Query Ontology, acting
as an intermediary to the target KB.
Finally, the SPARQL Query Builder uses mapping
description rules to generate a SPARQL query from
the Semantic Query Representation by iteratively an-
alyzing all triples.
This architecture follows the pipeline from related
work: question understanding is done by Partial Se-
mantic Representation and Pragmatic interpretation,
creating a Query Ontology representation. Entity and
relation linking, and filtering occur during mapping to
the reference KB using mapping description rules.
3 QUERY ONTOLOGY
The Query Ontology is used as an intermediate on-
tology between the Partial DRS and the KB Target,
so that a semantic, albeit partial, representation of the
natural language question can be given. The classes
chosen serve to represent the DRs of the application,
which is why classes were chosen to contain the pos-
sible entities that can be found in the question.
In Figure 2 is presented the set of classes that
make up the ontology. The main classes are:
• Action, which encloses the different actions, rep-
resented by a verb, within the Partial DRS;
• Actor, that represent subjects able to make ac-
tions, like people or organisations.
• Object, which represent inanimate objects.
• Concept, that represent immaterial concepts or
feature linked to other entities, like Objects or Ac-
tors.
• Place, which represents places, and finally
• Date, that represents dates.
• Event, which represents events.
Each class is associated with a list of annotations
which are used in the calculation phase of the best
solution to assign the correct class to the discourse
reference in the Partial DRS. In Table 2 a partial list
of annotations is presented, which are used in the best
solution calculation phase to assign the correct class
to the discourse reference in the Partial DRS. The ta-
ble shown a part of the whole set of annotations, the
ones used in example questions. Among the other
Classes, Qualifier and Query are used to represent the
structure of the sentence, and Cselect and Language-
Model, which represent namely the entities that can
be part of the SELECT clause within the SPARQL
Query and the entities that can be used to represent
the elements within the sentence.
The Query Ontology’s object properties model re-
lationships between entities. Table 3 shows a partial
set, only ones used in examples. To select the correct
relationship, additionally to define the domain and
range within the ontology, annotatopns which repre-
sent syntactic relationships between DRs in the Par-
tial DRS are provided, being used similarly to class
annotations.
Table 1: Query Ontology Data Properties used in example
questions.
Data Prop. Domain Range
has name Thing xsd:string
has text Thing xsd:string
has modifier Thing xsd:string
Furthermore, Table 1 shows data properties that
preserve each entity’s lemma and associated adjec-
tives (has text, has modifier), and names for Proper
Names identified (has name).
Three different example questions from the
dataset QALD-9 are presented to understand the pro-
cess to achieve the solution.
3.1 Example Question 1
Question 1 : ‘Which country was Bill Gates born in?’
The partial DRS in Figure 4 and the Stanza anal-
ysis in Figure 3 identify three DRs: X1-country,
X2-Bill Gates, and X3-born. These DRs are linked
through obl in syntactic relation between X3 and X1,
KEOD 2024 - 16th International Conference on Knowledge Engineering and Ontology Development
176
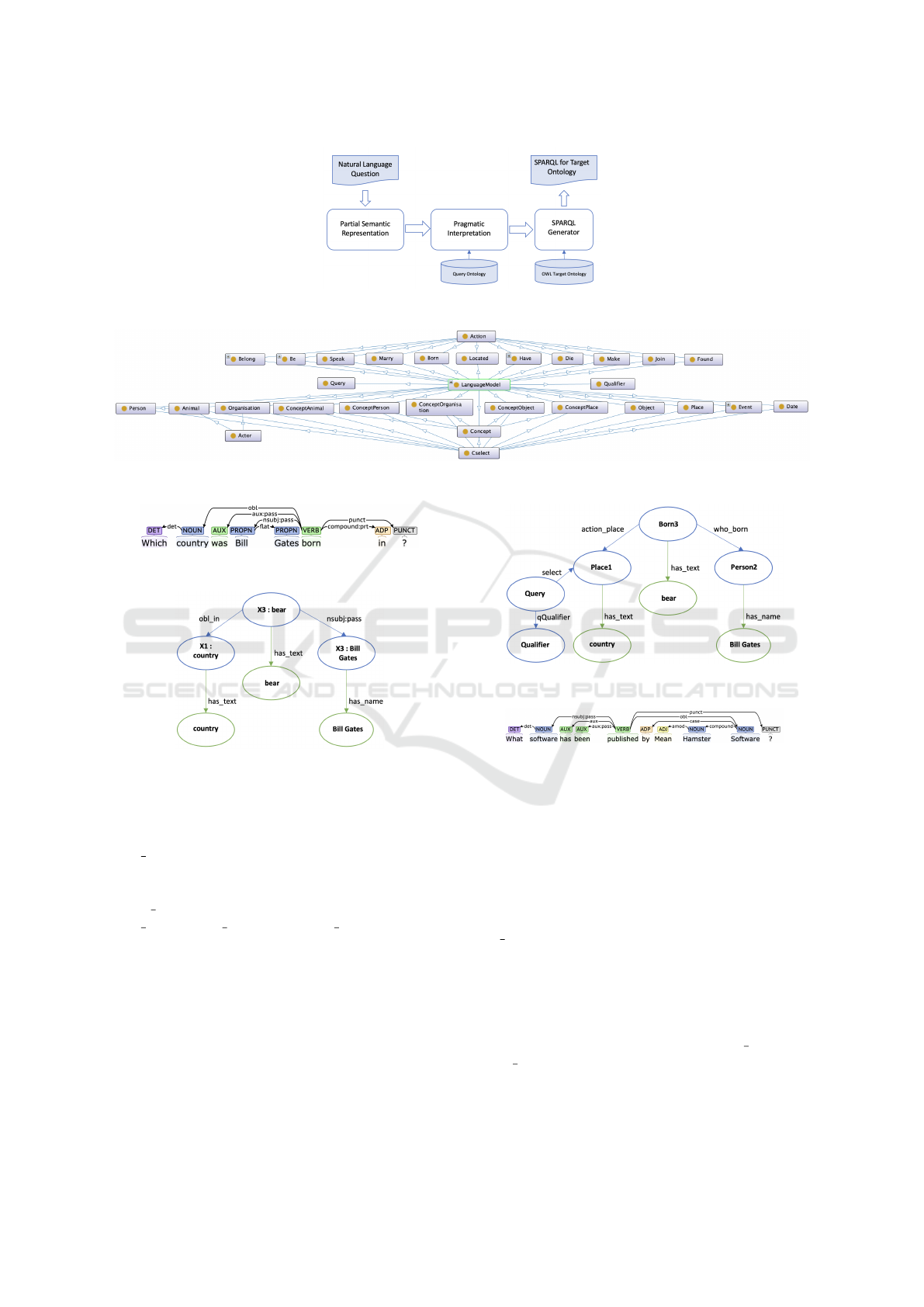
Figure 1: Natural Language Questions Representation as SPARQL Queries Architecture.
Figure 2: Classes of Query Ontology.
Figure 3: Dependency tree for Question 1.
Figure 4: Partial DRS for Question 1.
and the nsubj:pass syintatic relation between X3 and
X2.
Since ‘born’ is defined, the object property
who born is preferred due to its nsubj:pass annota-
tion, as ‘born’ is always passive. X2 will be of type
Animal or Person. The relation between X3 and X1
is obl in. The Born class appears as the domain of
who born, action place, and action date. For the DR
with lemma ‘country’, Place is preferred, as ‘country’
represents a place.
Thus, there are two possible interpretations within
the natural language query, differing only in the inter-
pretation of X2 (as Animal or Person). Chosen solu-
tion is shown in Figure 5.
3.2 Example Question 2
Question 2 : ‘What software has been published by
Figure 5: Query Ontology Solution for Question 1.
Figure 6: Dependency tree for Question 2.
Mean Hamster Software?’.
The partial DRS in Fig. 7 shows three DRs: X1-
software, X2-publish, and X3-Mean Hamster Soft-
ware. X3-Mean Hamster Software was identified as
a unique DR using Named-entity Recognition (NER)
to correct Stanza’s misinterpretations. The syntactic
relationships are: nsubj:pass between X2 and X1, and
obl by between X2 and X3.
The action ‘publish’ can be interpreted as Make,
both involving an Actor creating an Object. The Make
class covers actions like directing a film or writing a
book. The lemma ‘publish’ identifies X2 as an indi-
vidual of the Make class. The Make class has several
object properties, narrowed down to who make and
make what (Table 3). X1 is assigned as Object and
X3 as Actor or a subclass thereof.
In Fig. 8 is presented the solution for the DRS
partial of the natural language question.
A Methodology for Interpreting Natural Language Questions and Translating into SPARQL Query over DBpedia
177

Table 2: Query Ontology Classes used in example questions.
Class subClassOf Annotations
Person Animal, LanguageModel, Cselect [...]
ConceptPlace Concept, LanguageModel, Cselect area code, [...]
Place LanguageModel, Cselect country, [...]
Object LanguageModel, Cselect software, [...]
Organisation Actor, LanguageModel, Cselect [...]
Make Action, LanguageModel publish, [...]
Be Action, LanguageModel be
Born Action, LanguageModel bear
Table 3: Query Ontology Object Properties used in example questions.
Obj. Prop. Domain Range Annotation
what is Be Thing subj
is what Be Thing obj
who make Make Actor subj, obl by
make what Make Object obj, nsubj:pass
who born Born Animal nsubj:pass
action place Action Place obl in, obl on
conceptOfPlace ConceptPlace Place of
qQualifier Query Qualifier n obj, subj
select Query Cselect n subj, obj, nsubj:pass
Figure 7: Partial DRS for Question 2.
Figure 8: Query Ontology Solution for Question 2.
3.3 Example Question 3
Question 3 : ’What is the area code of Berlin?’.
Four different DRs can be found in this case,
which are shown in Fig. 10, result of the Stanza anal-
ysis shown in Figure 9: X1-what, X2-area code, X3-
Figure 9: Dependency tree for Question 3.
Figure 10: Partial DRS for Question 3.
Berlin, and X4-Be.
The verb ‘to be’ does not identify the relation but
defines X1 and X2 as the same class. Since ‘area code’
implies a concept of place (Table 2), X3 is assigned as
ConceptPlace. The relation X1-of-X2 is interpreted
as the object property conceptOfPlace. The final so-
lution is shown in Fig. 11.
KEOD 2024 - 16th International Conference on Knowledge Engineering and Ontology Development
178

Figure 11: Query Ontology Solution for Question 3.
4 SPARQL QUERY BUILDER
The SPARQL Generator module receives as input the
best solution selected by the previous module and
through the application of mapping description rules
generates the SPARQL query for the target KB. Map-
ping description rules are manually defined rules that
allow each class and property of the solution to be
translated into SPARQL. The SPARQL query is gen-
erated through the analysis of all triples in the solu-
tion, which will generate the query.
4.1 Entity Translation
The query ontology solution consists of a set of in-
dividuals related to each other via object properties
and defined via data properties. Within the SPARQL
query creation process, each individual is instantiated
within the query as a variable having the name of the
individual within the solution given by the query on-
tology, which is formed by the class it belongs to plus
the index of the Discourse Reference, inherited from
the partial DRS. Thus in the question 1 ‘Which coun-
try was Bill Gates born in?’, where in the solution
were found the individuals Place1 (X1, country), Per-
son2 (X2, Bill Gates) and Born3 (X3, Bear), three dif-
ferent variables with these names (Place1, Person2,
and Born3) will be instantiated within the generated
query.
4.2 Resource Selection
The first set of properties that will be analysed are
the data properties. They are used by the system to
restrict the set of possible individuals of answers or to
directly choose a particular resource. There are three
main data properties:
• The first case is the has name data property. The
data property is created when, during the Stanza
analysis, a name in the natural language query is
identified as Proper Noun (PROPN). The mapping
description rule written to handle the has name
case takes into account two possible options: that
the name is directly referred to a string or through
all the individuals that contain within the string in
relation with rdf:label the string in the has name
relation. Below, the translation of has name data
property.
has name(X1,nameX1) ->
{ FI LT ER ( re gex (? X1 , n a me X1 ) ). }
UN ION
{? X1 r fds : l abe l ? n X1 .
FI LT ER ( re gex (? nX1 , na me X1 ) ). }
• The has text data property holds the lemma for
each individual in the solution. It accounts for
cases where the lemma defines the object prop-
erty, especially when there is no Action or when
the Action cannot define the relationship (e.g., ‘to
be’). This data property is not directly translated
but is used in other Object Property translations.
This mechanism prevents the system from always
including has text in the query body, excluding
certain actions (like ‘Be’ or ‘Have’) and terms
(e.g., wh-question words or ‘how’).
has text(X1,textX1) ->
if ( ex is tT yp e ( ha sL ab el ( t e xt X1 ) )) {
? X1 rdf : t ype ? tX 1.
FI LT ER ( re gex (? tX1 , te xt X1 ) ).
if ( ge tC la ss ( X1 ) eu qal To Pe rs on ) {
? X1 db o : o cc up at io n ? tX1 .
FI LT ER ( re gex (? tX1 , te xt X1 ) ).
}
}
if ( ex is tP ro pe rt y ( ha sL abe l ( te xt X 1 ) ) ) {
? X1 ? p ro pX1 ? y X1 .
? pr op X1 r dfs : l a be l ? l Pr op X 1 .
FI LT ER ( re gex (? l Pr opX 1 , t ex tX 1 ) ) .
}
• the last data property is has modifier. Here are
present the elements of the sentence marked by
stanza as Adjectives (ADJ) associated with the re-
spective DRs. Similar to the has text data prop-
erty, they are used to define the type of relation-
ship in the object properties, the individual in the
domain or the class of the responding entity and
are not directly translated. The modifier is also
analyzed outside the query body creation phase,
to determine possible groupings or orderings of
the answers, i.e. ’ORDER BY DESC(?x) LIMIT
1’ expressed by keywords like ’highest’.
has modifier(X1,modTextX1) ->
fo r ea ch m in h as _m o di fi er ( X1 , m od Tex tX 1 )
if ( ex is tT yp e ( ha sL ab el ( m. m od Te x tX 1 )) ) {
? X1 rdf : t ype ? tX 1m .
FI LT ER ( re gex (? tX1 m , m. m od Te xtX 1 ) ).
}
if ( ex is tP ro pe rt y ( ha sL abe l ( m . m odT ex tX 1 )) ) {
{? X1 ? pr op X1 m ? yX1 m .
? pr op X1m r df s : lab el ? l Pr o pX 1m .
FI LT ER ( re gex (? l Pro p X 1m , m . mo dTe xt X1 ) ) .}
UN ION
{? y X1m ? p rop X1 m ? X1 .
? pr op X1m r df s : lab el ? l Pr o pX 1m .
FI LT ER ( re gex (? l Pro p X 1m , m . mo dTe xt X1 ) ) .}
}
if ( e x is tI nd iv id ua l ( ha sL ab el ( m. m od Te x tX 1 )) ) {
A Methodology for Interpreting Natural Language Questions and Translating into SPARQL Query over DBpedia
179

{? X1 ? pr op X1 m ? yX1 m .
? yX 1m rd fs : la be l ? l yX 1 m .
FI LT ER ( re gex (? ly X1 m , m . mo dT ex tX 1 )) .}
UN ION
{? y X1m ? p rop X1 m ? X1 .
? yX 1m rd fs : la be l ? l yX 1 m .
FI LT ER ( re gex (? ly X1 m , m . mo dT ex tX 1 )) .}
}
4.3 Entity Linking
Object properties relate different individuals. In the
Query Ontology, actions (verbs) are marked as DRs
during the Partial Semantic Representation phase,
generating an individual of the Action subclass. In
the solution, a ternary relation between the subject
and the object complement (or place/date if the object
complement is absent) is found through the action. In
Example Question 1 can be seen that the subject Per-
son1 is related to Place2 through the action Born3.
In the target KB, i.e. DBpedia, unlike the Query On-
tology, actions are often represented through Object
Properties between objects. Therefore, two different
approaches are used to correctly translate the pair of
triples: the relation representing the subject of the ac-
tion and the latter is translated as equality between the
two individuals of the triple. In this way, the subject
will be directly related to the second triple. the second
triple, on the other hand, is translated using the lemma
present in the Action (thus the verb related to it) to de-
fine the type of object property between the two enti-
ties. Below, the translation of two object properties in
Example Question 2 representing the described case:
who make and make what
who make(X1,X2) -> re pl ace ( X2 , X1 )
ha s_ te xt ( X2 , t ex tX2 )
ha s_ mod ( X2 , t ext X2 )
make what(X1,X3) ->
{? X1 ? p r op M2 O1 ? X3 .
? pr op M2 O1 r dfs : l abe l ? nP ro pM2 O1 .
FI LT ER ( re gex (? n Pro pM2 O1 , t ex tX1 ) ) }
UN ION
{? X3 ? p r op O1 M2 ? X1 .
? pr op O1 M2 r dfs : l abe l ? nP ro pO1 M2 .
FI LT ER ( re gex (? n Pro pO1 M2 , t ex tX1 ) ) }
Since the relation type is based on the lemma, it
must include the possibility that the subject may be
the domain or range of the relation in DBpedia, in-
cluded by UNION. Similar to identifying the class
when analyzing has text, synonyms can define the ob-
ject property in DBpedia. Currently, synonym map-
ping rules are defined manually.
There are two special cases: when the Action is ‘to
be’ or ‘to have’. For ‘to have’, the lemma text is not
analyzed as it does not help identify the relation type.
For ‘to be’, the variables defining three individuals
in the Query Ontology are equated. The correct in-
terpretation is determined by constraints on variables
from other Query Ontology relations. Below are the
mapping description rules for three object properties,
illustrated by Example Question 3.: what is(X1,X2),
is what(X1,X3), and conceptOfPlace(X2,X4).
what is(X1,X2) -> re pl ace ( X2 , X1 )
ha s_ te xt ( X2 , t ex tX2 )
ha s_ mod ( X2 , t ext X2 )
is what(X1,X3) -> re pl ace ( X3 , X1 )
ha s_ te xt ( X2 , t ex tX3 )
ha s_ mod ( X2 , t ext X3 )
conceptOfPlace(X2,X4) ->
ha s_ te xt ( X2 , t ex tX2 )
if ( not ex is tT yp e ( ha s La be l ( te x tX 2 )) an d not e xi s tP ro pe rt y (
ha sL ab el ( te xt X2 ) )) {
FI LT ER ( X2 = X4 )
}
4.4 Query Building Process
In the last section, the construction of a query will
be shown step by step. Although the creation of the
query will be described in steps to understand how it
is done, in practice it is not necessary to use an order
in the analysis of the solution triples.
4.4.1 SPARQL Query for Question 1
In the first step, the SELECT clause is constructed.
The Query Ontology identifies Place1 as the target
via the object property select, with no modifier. Next,
the data property has name for Person2 is translated
in the query body by defining Person2 as individ-
uals labeled ‘Bill Gates’. Next, the object proper-
ties who born and action date are found. who born
equates ?Person2 and ?Born3, while action place is
defined by the class assigned to the property action,
implying the translation ?birthProp with rdfs:label
‘birth place’. Since Place has ‘country’ as the value
of has text, it’s assumed the country is specified. The
translation adds a UNION to handle two triples in
DBpedia: one for ?Person2’s city of birth (?birthProp)
and another linking the city to its country (?country)
with rdfs:label ‘country’.
who born(X1,X2) -> re pl ace ( X2 , X1 )
action place(X1,X3) ->
sw it ch ( ge tC la ss ( X1 ))
ca se " Bor n ":
? bi rt hP ro p rd fs : la bel ? lb P .
FI LT ER ( re gex (? lbP ," bi rth p l ac e " , "i ") ) .
{? X1 ? b i rt hP ro p ? X3 .
if ( ex is tT yp e ( ha sL ab el ( t e xt X3 ) )) {
? X3 rd f : t ype ? tX 3.
? tX3 rd fs : la bel ? l t X3 .
FI LT ER ( re gex (? ltX 3 , te xt X3 , "i ") ) .
}}
UN ION
{? X1 ? b i rt hP ro p ? c it yX3 .
? ci ty X3 ? cP rop ? X3 .
? cP rop rd fs : la bel ? l cP rop .
FI LT ER ( re gex (? lc Pro p ," co un try " ," i" )) .}
[. ..]
Below, the final result of the mapping through the
mapping description rules of the Ontology query so-
lution in a SPARQL query for DBpedia is presented.
SE LE CT D IS TI N CT ? P la c e1
WH ERE {
? Bo rn3 rd fs : la bel ? n Pe rs on2 .
KEOD 2024 - 16th International Conference on Knowledge Engineering and Ontology Development
180

FI LT ER ( re gex (? n Per s o n2 , " Bi ll G ate s " , "i " )) .
? bi rt hP ro p rd fs : la bel ? l bi rth P .
FI LT ER ( re gex (? l bi rth P , " bi rt h p lac e ", "i " ) ) .
{? B orn 3 ? bi rt hPr op ? P la ce1 .
? Pl ac e1 r d f : ty pe ? tP 1 .
? tP1 rd fs : la bel ? tP 1 .
FI LT ER ( re gex (? tP1 , " cou nt ry " ," i" ) ).}
UN ION
{? B orn 3 ? bi rt hPr op ? c it yP la ce 1 .
? c i ty Pl ac e1 ? c P ro p ? P la ce1 .
? cP rop rd fs : la bel ? l c P .
FI LT ER ( re gex (? lcP , " cou nt ry " ," i" ) ).}
}
Listing 1: SPARQL Query result from Query Ontology
solution for Question 1.
4.4.2 SPARQL Query for Question 2
The SELECT clause is composed by the Object1.
There is an has name property for X3, and the indi-
viduals with label ”Mean Hamster Software” will be
matched for variable X3. As object properties, there
are who make and make what, which are translated
as seen before. In addition, the has text for soft-
ware is translated, to put a constraint on the Object
type (software, in this case). As the translation of
who make and make who was previously shown, be-
low is presented the query created for the question
’What software has been published by Mean Hamster
Software?’.
SE LE CT D IS TI N CT ? O bj ect 1
WH ERE {
? Ma ke2 rd fs : la bel ? n Or ga ni sa ti on 3 .
FI LT ER ( re gex (? n Or gan is at i on 3 , " Mea n H a ms te r S o ft wa re " ," i" ) ).
{? O bj ect 1 ? ht Pr op1 ? M ake 2 .
? ht Pr op1 r df s : lab el ? l ht P ro p1 .
FI LT ER ( re gex (? l htP r o p1 , " p u bl is h ", "i ") ) .}
UN ION
{? M ake 2 ? ht Pro p1 ? O bj e ct 1 .
? ht Pr op1 r df s : lab el ? l ht P ro p1 .
FI LT ER ( re gex (? l htP r o p1 , " p u bl is h ", "i ") ) .}
? Ob je ct1 rd f :t ype ? h tt Ob je ct 1 .
FI LT ER ( re gex (? h ttO bj e ct 1 , " sof tw ar e ", "i " ) ) .
}
Listing 2: SPARQL Query result from Query Ontology
solution for Question 2.
4.4.3 SPARQL Query for Question 3
The last example is question 3 : ’What is the area
code of Berlin?’. The SELECT Clause is formed by
ConceptPlace1, which is in select relation. There is
one has name property, linked to Place3, whit value
’Berlin’. The triples fixing Place3 with label ’Berlin’
are added. The object property conceptOfPlace is
translated as shown in subsection 4.3. As exist a
property, the has text translation for object property
is added. At the end, what is and is what are used to
replace the variables in the query, changing the body
and the SELECT too. Below, it is shown the final
query.
SE LE CT D IS TI N CT ? Be 4
WH ERE {
? Pl ac e3 r dfs : l a be l ? n Pl ac e 3 .
FI LT ER ( re gex (? n Pl ace 3 , " Be rl in " ," i" )) .
? Pl ac e3 ? ht Pr op3 ? B e4 .
? ht Pr op3 r df s : lab el ? l ht P ro p3 .
FI LT ER ( re gex (? l htP r o p3 , " ar ea c o d e " ," i " )) .
}
Listing 3: SPARQL Query result from Query Ontology
solution for Question 3.
5 EXPERIMENTS ON DBpedia
In this section, it will described the experiments car-
ried out to evaluate our system. As a target KB, DB-
pedia was chosen, as one of the best known KBs.
5.1 Dataset
The dataset chosen is the one provided by the QALD-
9 Challenge (Ngomo, 2018). The QALD-9 dataset is
divided into 2 parts: a training part (consisting of 408
questions) and the test part (consisting of 150 ques-
tions). The dataset is formatted in JSON and each
question contains: the natural language question (up
to 11 different translations), the SPARQL query and
the answer to the query. Although our objective is not
to participate in the challenge, it was decided to use
this dataset as it is reliable and above all used as a
benchmark by many other systems, making it useful
for comparing performance between our system and
these others.
5.2 Metrics
To evaluate the ontology, the number of questions
which have a Correct Interpretation (CI) in the Query
Ontology are used, which means that there is a possi-
ble correct interpretation of the question in Query On-
tology by the correct assignation of Classes to DRs of
partial DRS and correct assignation of object and data
properties for the relations between DR. For this ex-
periment, the CI evaluation was carried out manually.
To evaluate the mapping description rules, the num-
ber of Equal Answers (EA) out of the dataset is cho-
sen.For each question, the answer from the query gen-
erated with the methodology described is compared
with the answer in the dataset: if they are equal, the
question is marked as equal and counted in the final
EA results, otherwise counted as incorrect. In addi-
tion, it is calculated the number of Correct Answers
(CA). The calculation of this metric is defined as fol-
low: if the resulting answer is coherent with the con-
straints and definitions in natural language question,
it is evaluated as correct, otherwise not. This metric
was chose as methodology presented in this paper use
A Methodology for Interpreting Natural Language Questions and Translating into SPARQL Query over DBpedia
181

a retrieving system based on lemma, which can bring
to retrieve more individuals than the ones in dataset.
5.3 Results Evaluation
The Table 4 presents the results on 100 questions from
test set of QALD-9. The subset includes most of the
wh-questions in dataset, with question about places,
dates, people and organisations. The full results of
the experiment are avaible on a GitHub Repository
4
.
Table 4: Evaluation of Query Ontology and SPARQL
Builder.
Correct Int. Equal Ans. Correct Ans.
1 0.37 0.56
As shown in (Ngomo, 2018), is presented the
maximum precision achieved: 0.293 . Although the
two scores are not directly comparable, as in the ex-
periment presented in this article a portion of the en-
tire dataset is tested and the precision shown in the
cited article is calculated differently, can be stated that
the results obtained are promising when compared
with the other models.
The Table 4 shows a 20% discrepancy between Equal
Answer and Correct Answer values. This is due to
the methodology presented recovering additional an-
swers and some QALD-9 answers being outdated.
The main problems encountered are in the mapping
of the solution given by the Query Ontology through
the mapping description rules, as this is still a work
in progress. This is due to the structure of DBpedia
which includes different information, it is not always
easy to create rules which can generalise certain links.
For instance, many resources are often linked through
the object property dbo:wikiPageWikiLink. It is often
unclear to identify the domain and range of relation-
ships through a given lemma and its properties. This
issue is related to DBpedia’s vocabulary for certain
relations. Sometimes, terms in natural language can
be directly mapped to DBpedia terms. For example,
in the question ‘Who write Harry Potter?’, the action
‘write’ maps to the dbo:author property. This can be
managed by mapping specific terms. For this exper-
iment, the mapping was done manually, but a future
module could automate this. A NER system, espe-
cially for proper names, can aid in interpreting DRs
and defining resources in the target KB. Currently,
a NER system uses manually constructed Gazetteers.
In the future, a Gazetteer-based or different NER sys-
tem may be tested.
4
https://github.com/dvaragnolo/NLP-QA-DBPEDIA
6 CONCLUSIONS
A methodology for translating natural language
queries into SPARQL queries for DBpedia was pre-
sented. The QALD-9 experiment showed promis-
ing results, highlighting the methodology’s potential.
However, current issues, especially in translating On-
tology Queries to SPARQL, were identified. Sug-
gested modifications could improve the methodology
for future experiments.
REFERENCES
Cornei, L.-M. and Trandabat, D. (2023). Dbspark: A sys-
tem for natural language to sparql translation. In In-
ternational Conference on Research Challenges in In-
formation Science, pages 157–170. Springer.
Hirschman, L. and Gaizauskas, R. (2001). Natural language
question answering: the view from here. natural lan-
guage engineering, 7(4):275–300.
Hu, X., Shu, Y., Huang, X., and Qu, Y. (2021). Edg-based
question decomposition for complex question answer-
ing over knowledge bases. In The Semantic Web–
ISWC 2021: 20th International Semantic Web Con-
ference, ISWC 2021, Virtual Event, October 24–28,
2021, Proceedings 20, pages 128–145. Springer.
Kamp, H. and Reyle, U. (2013). From discourse to logic:
Introduction to modeltheoretic semantics of natural
language, formal logic and discourse representation
theory, volume 42. Springer Science & Business Me-
dia.
Ngomo, N. (2018). 9th challenge on question answering
over linked data (qald-9). language, 7(1):58–64.
Omar, R., Dhall, I., Kalnis, P., and Mansour, E. (2023). A
universal question-answering platform for knowledge
graphs. Proceedings of the ACM on Management of
Data, 1(1):1–25.
Silva, J. Q., Melo, D., Rodrigues, I. P., Seco, J. C., Fer-
reira, C., and Parreira, J. (2023). An ontology-based
task-oriented dialogue to create outsystems applica-
tions. SN Computer Science, 4(12):1–17.
Steinmetz, N., Arning, A.-K., and Sattler, K.-U. (2019).
From natural language questions to sparql queries: a
pattern-based approach.
Varagnolo, D., Melo, D., and Rodrigues, I. (2023). An
ontology-based question-answering, from natural lan-
guage to sparql query. In Proceedings of the 15th In-
ternational Joint Conference on Knowledge Discov-
ery, Knowledge Engineering and Knowledge Manage-
ment - Volume 2: KEOD, pages 174–181. INSTICC,
SciTePress.
Zlatareva, N. and Amin, D. (2021). Natural language to
sparql query builder for semantic web applications.
Journal of Machine Intelligence and Data Science
(JMIDS), 2:34.
KEOD 2024 - 16th International Conference on Knowledge Engineering and Ontology Development
182
