
AI-Assisted Debrief: Automated Flight Debriefing
Summarization and Competency Assessment
Mathijs Henquet
a
and Thomas Bellucci
b
NLR - Royal Netherlands Aerospace Centre, Amsterdam, The Netherlands
Keywords: Aviation Training, Speech Recognition, Large Language Models, Performance Indicators, Pilot Competency
Assessment, Human-Machine Interaction, Artificial Intelligence in Aviation, Qualitative Evaluation,
Intelligent Training Systems.
Abstract: This paper seeks to explore the use of speech recognition and large language models (LLMs) to support the
reporting process of flight debriefings in aviation training. We develop a system called AI-Assisted Debrief
(AAD), which automatically transcribes and summarizes flight debriefings, thereby improving reporting and,
in turn, improving knowledge transfer and pilot competency development. In addition, AAD assesses pilot
competencies by identifying associated Performance Indicators (PIs) from the debriefs, yielding an automatic
assessment of desired competencies to guide future training. We qualitatively evaluate the performance of our
system using a dataset of five representative debrief recordings from flight training sessions, which are ana-
lysed by AAD and evaluated by experienced flight instructors. Our evaluation shows AAD to be capable of
automatically extracting feedback and crucial information, recognizing desired pilot competencies. Future
versions of AAD could enable tracking of competency development over time, offering a new method to
guide aviation training. We envision AAD evolving into an interactive system which learns from human
oversight to improve its accuracy and effectiveness. Propelling aviation training into the AI era, AAD paves
the way for a more accurate, efficient, and comprehensive approach to pilot training, setting a new standard
for excellence in the skies.
1 INTRODUCTION
Post-flight debriefing stands as a vital component of
aviation training, serving as a conduit for knowledge
transfer and skill refinement between flight instruc-
tors and trainees, while ensuring safety and opera-
tional standards within the aviation domain. During
flight debriefing, the flight instructor provides verbal
feedback to the trainee, covering various aspects,
from take-off and landing procedures to regulatory re-
quirements and the decision-making process em-
ployed by the pilot. This feedback in turn provides
valuable insights to the pilot to correct performance
(Mavin, Kikkawa, & Billett, 2018).
The efficacy of flight debriefing is enhanced by
its fluid structure, enabling the instructor to tailor
their feedback to the student and act responsively to
their needs; however, while the unstructured nature of
conventional debriefings has been found to aid the
a
https://orcid.org/0009-0005-9688-2558
b
https://orcid.org/0000-0002-9044-585X
learning process (Roth, 2015), it may hamper system-
atic documentation and reporting. The resulting lack
of documentation limits the ability to track progress
over multiple sessions, identify overlooked areas, and
reinforce learning outcomes. In practice, session re-
ports typically encompass only the instructor's prior
observations during the flight, neglecting the nuanced
learning moments that emerge during the debriefing.
Without a third-party documenting these sessions, im-
portant details may go unrecorded or be missed due to
information overload, interruptions, and distractions.
This gap highlights the need for a more structured ap-
proach to document flight debriefings to capture the
full scope of learning moments and discussions.
Recent advancements in Artificial Intelligence
(AI), particularly Large Language Models (LLMs)
(Josh Achiam, 2023), have demonstrated the potential
to revolutionize various areas of society. LLMs have
shown near-human proficiency in tasks that require
72
Henquet, M. and Bellucci, T.
AI-Assisted Debrief: Automated Flight Debriefing Summarization and Competency Assessment.
DOI: 10.5220/0012970200004562
Paper published under CC license (CC BY-NC-ND 4.0)
In Proceedings of the 2nd International Conference on Cognitive Aircraft Systems (ICCAS 2024), pages 72-79
ISBN: 978-989-758-724-5
Proceedings Copyright © 2024 by SCITEPRESS – Science and Technology Publications, Lda.

Figure 1: Envisioned future use of AI-assisted debriefing (AAD), enabling automated reporting, instructor support and as-
sessment of pilot competencies during flight debriefing. In this paper we examine the technical feasibility of this scenario.
common sense reasoning and language understanding,
making them well-suited for language analysis. More-
over, speech recognition systems, such as OpenAI’s
Whisper (Radford, et al., 2022), also referred to as
speech-to-text, have achieved human-level perfor-
mance in automatic transcription of spoken language,
opening up potential applications in aviation training.
This paper seeks to explore the use of speech
recognition and large language models to support the
reporting process of flight debriefings. We investigate
the extent to which debriefs can be automatically tran-
scribed and subsequently analysed by LLM models to
distil summaries and extract pertinent information,
such as competency assessments and performance in-
dicators. Through this examination, we aim to deter-
mine the viability of AI as a tool for supporting the doc-
umentation and assessment of flight debriefings.
2 BACKGROUND
2.1 Aviation Debriefing
Over the past decade, the aviation industry has recog-
nized the need for a strategic overhaul of recurrent
and type rating training to enhance commercial avia-
tion safety. This shift has led to a gradual adoption of
Evidence-Based Training (EBT), which focuses on
developing and accessing pilots' competencies, in-
cluding both technical and non-technical skills,
through a framework of behavioural competency de-
scriptions and performance indicators (PIs) (Sky-
Brary, 2023). The International Civil Aviation Organ-
ization (ICAO) supports EBT, emphasizing core
competencies such as procedure application, commu-
nication, and leadership.
Debriefing sessions, a staple in military and civil
aviation training, play a crucial role in this compe-
tency-based approach. These sessions, which can oc-
cur immediately after a flight or be scheduled later,
cover flight performance, decision-making processes,
leadership, teamwork, and regulatory requirements.
They aim not just to highlight successes but also to
identify areas for improvement, fostering an environ-
ment of constructive feedback. Effective debriefing
involves active self-learning, a clear developmental
intent, reflection on specific events, and input from
multiple information sources (Tannenbaum & Cera-
soli, 2013).
Reflection is a critical component of debriefing,
with models like Mavin's reflective debriefing model
AI-Assisted Debrief: Automated Flight Debriefing Summarization and Competency Assessment
73

(Mavin T. J., 2016) guiding pilots to self-assess their
performance. The European Union Aviation Safety
Agency (EASA) and other experts provide guidelines
for facilitating debriefing sessions, emphasizing the
importance of crew participation, avoiding instructor-
centred sessions, and ensuring all critical topics are
covered (EASA, 2023) (McDonnell, Jobe, & Dis-
mukes, 1997).
2.2 Developments in AI
Automatic distillation of summaries and recognition
of competencies and associated performance indica-
tors from debrief recordings is a challenging task;
however, recent advances in AI technology might be
profitably combined to tackle this problem.
Large Language Models (LLMs). LLMs have
made significant contributions to natural language
processing (NLP) in recent years (Floridi, 2020).
LLMs are trained on large corpora of text data, allow-
ing them to generate human-like text, answer ques-
tions, and complete other language-related tasks with
high accuracy (Kasneci, 2023). Recent developments
include ChatGPT, an LLM trained on a web-scale da-
taset, which has demonstrated state-of-the-art perfor-
mance on a wide range of natural-language tasks, in-
cluding summarization, question answering, essay
writing, and computer programming (Team, 2020). By
leveraging additional fine-tuning on human feedback,
LLMs can learn to follow human instructions, making
them promising tools for problems that require lan-
guage analysis and generation (e.g. summarization).
Speech-to-text. With recent advancements in
NLP and machine learning, the field of speech pro-
cessing has witnessed significant progress, which has
resulted in greatly enhanced accuracy and efficiency
of speech recognition systems. Automated transcrip-
tion can streamline the process of documenting and
analysing instructor-trainee communication, which is
crucial for training and safety reviews. Whisper
(Radford et al. 2022), developed by OpenAI, repre-
sents a leap forward in speech recognition technol-
ogy. This cutting-edge model is proficient in deci-
phering various accents, dialects, and coping with
ambient noise and variation in recording devices. Fur-
thermore, Whisper's robust multilingual capabilities
(Radford et al. 2022) make it an ideal candidate for
the global aviation industry, where pilots often com-
municate in a technical language mixed with English
terms. This system can be used to transcribe the spo-
ken debriefing discussion into written text. This en-
sures an accurate and detailed textual record of the
conversation. The efficiency and accuracy of these
tools allow instructors to focus on the discussion
without the distraction of manual note-taking, or it
can supplement and complete the possibly terse notes
taken by an instructor. Transcripts created by speech-
to-text tools provide accessible and shareable records,
enabling pilots to revisit the feedback at their own
pace and reinforcing the learning process.
2.3 Text-to-Text with LLMs
LLMs are trained to predict which word is likely to
follow after a given sequence of preceding words in a
text, known as its context; this predictive ability can
then be harnessed to generate text by repeatedly sam-
pling the most likely following word, one at a time.
This task is known as autoregressive language mod-
elling, or completion.
To make an LLM perform a task such as summa-
rization, a technique known as prompting is used.
Here, a user provides a textual prompt – a written in-
struction or question – to guide the model’s genera-
tion process. A user might, for example, prompt the
model with "
Summary of take-off procedures:";
enticing the model to complete the prompt with a
summary of take-off procedures.
Simple prompting can sometimes lead to counter
intuitive results. For example, the most likely com-
pletion to a question could be just another question
(completing a list of questions). Therefore, models
are commonly finetuned for instruction following. By
this process the model is tuned to always complete a
question with a relevant and helpful answer. With an
instruction following model the above prompt for ex-
ample can be replaced with the instruction "
Give me
a summary of the take-off procedures
".
Despite the power of instruction following, it is
important to realize that LLMs are fundamentally
word-by-word completers of text. Moreover, the time
spent ‘thinking’ about individual words is the same,
so it cannot spend a lot of time on difficult words.
To use LLMs effectively, one has to be aware of
a few important pitfalls, specific techniques, and se-
lection criteria (Deng, 2022).
Hallucination. When the context expects an an-
swer, fact or definite connection, a large language
model generally prefers to generate something which
looks correct over breaking off and admitting that it
does not know. This is natural behaviour from the point
of view of text prediction while it is not how humans
behave. It is therefore important to always check the
answers to LLMs and not ask it suggestive questions.
Chain of Thought. It is much better to ask a large
language model LLM to first give a step-by-step rea-
soning and then a definitive answer. This allows the
model to first synthesize useful information from the
ICCAS 2024 - International Conference on Cognitive Aircraft Systems
74

context which it can then use to answer the question.
Giving a definitive answer first would force it to com-
mit to a potentially wrong answer which it then tries
to rationalize. After all there are not a lot of text doc-
uments where the author second guesses themselves.
Synthesising over Analysing. When asking the
system analysing questions, especially leading ones,
it is prone to hallucinating connections where there
are none. Synthesizing tasks, which are more open
ended in nature, are much more stable.
Language Proficiency. A crucial component of
the proposed tool is its ability to comprehend Dutch
dialogue as spoken in the aviation domain. Thus it
was important to select a language model that can ac-
curately interpret our domain language and instances
of code switching, where English terminology is used
seamlessly within otherwise fully-Dutch phrases.
Context Window Size. Typical flight debriefs in-
volve discussions between one or more trainees and
an instructor lasting upwards of 20 minutes; to ease
summarization, it is best if the totality of the conver-
sation can fit within the model's context window. The
context window represents the maximum number of
tokens (i.e. word fragments) the LLM is capable of
processing. An inadequate context window may re-
sult in a loss of crucial information for summarization
and limit the tool's ability to provide a comprehensive
and coherent summary of the conversation as a whole.
3 METHOD
An AI-Assisted Debrief (AAD) tool has been devel-
oped, employing an speech-to-text system and LLM
to summarize flight debriefs into concise textual sum-
maries and identify the presence of pilot competen-
cies and PIs, as used in EASA’s EBT. A high-level
diagram of this system is illustrated in figure 2. First,
an audio recording of the debrief is transcribed by a
speech-to-text system, resulting in a plain-text tran-
script of the debrief conversation. As segments of
speech from the debrief can originate from either the
instructor or trainee, we employ a speaker identifica-
tion, or diarization, algorithm to identify the source of
each utterance. We then prefix each utterance in the
transcript with a speaker marker, such as “Instructor:”
or “Trainee:”, enabling the LLM to consider the
speaker in its subsequent processing. Then the- result-
ing speaker-annotated transcripts are summarized by
an LLM to obtain a succinct summary of the debrief.
Through careful prompting of the LLM, the system
can identify main points of feedback from the instruc-
tor and list key take-aways from the debrief.
Figure 2: High level diagram of software architecture.
Moreover, as trainee’s competencies are identifi-
able by a set of measurable PIs as used in EASA’s
EBT, we additionally prompt the LLM to assess the
presence of a list of predefined competencies by re-
lating their associated performance indicators to the
debrief transcript.
In order to support the flight instructor in an ef-
fective manner, it is desirable to obtain concise sum-
maries of the debrief (e.g. in the form of 5-10 bullet
points) which encapsulate the primary points of feed-
back and main take-aways from the debrief. In light
of the criteria of Section 3, two multilingual language
models were examined in our experiments:
• Llama-2 70B (Touvron, 2023), a state-of-the-art
LLM developed by Meta AI
• Yi-34, developed by 01-AI.
In light of privacy and security concerns, our ex-
periments were limited to open-source language mod-
els only, hosted on local machines.
Preliminary assessment of Llama-2 and Yi-34B
showed these models to be proficient in understand-
ing Dutch texts and respond well to instructions. The
Yi-34 model boasts a large context window upwards
of 200k words, allowing the model to summarise and
analyse a debrief transcript in one sweep, eliminating
the need to analyse a transcript in sections. Moreover,
their extensive training on a diverse range of text do-
mains and languages, including English and Dutch,
make Yi-34 and Llama-2 well-suited for processing
aviation-related terminology, allowing them to under-
stand English jargon while capturing contextual nu-
ances specific to flight debriefings in Dutch.
In this study, we opted to have AAD generate out-
puts in English, while processing the Dutch tran-
scripts. This decision was based on preliminary tests
that demonstrated improved grammaticality and fac-
tuality with English. The difference in performance
between languages is a well-known phenomenon in
the field which occurs due to factors such as the avail-
ability of training data.
AI-Assisted Debrief: Automated Flight Debriefing Summarization and Competency Assessment
75

### Input:
[TRANSCRIPT]
### Instruction:
Make a summary of the flight de-
briefing below. Focus on learning
points for the candidate.
### Output:
The candidate had a challenging
flight debriefing, where they
identified several areas for im-
provement in their flying and
procedures execution. The in-
structor provided constructive
feedback and suggested an addi-
tional session to help the can-
didate improve their skills. Here
are some key learning points from
the debriefing: […]
### Input:
[TRANSCRIPT]
### Instruction:
Is anything said in the flight debrief dialogue above related to
the performance indicator (PI) "[PERFROMANCE INDICATOR]".
Start your response with "Good." if the PI is mentioned and the
pilot did well;
Start with "Bad." if it was mentioned but the pilot did not do
well;
Start with "Unknown" if nothing is stated related to the PI at
all. Always explain your reasoning
### Output:
Good. The performance indicator (PI) "Demonstrates practical and
applicable knowledge of limitations and systems and their inter-
action" is mentioned in the flight debrief dialogue, and the
candidate demonstrated a good understanding of it. […]
Figure 3: Left the prompt used for summarization, and right the prompt used for performance indicator extraction, with the
LLM completion in bold.
3.1 Evaluation Dataset
To develop and assess our system, a dataset of audio
recordings was created under the supervision of two
experienced instructor pilots with an average 30 years
of commercial flight experience and 12 years of flight
instruction experience. The pilots were tasked with
re-enacting several representative scenarios of flight
debriefings in which one acted as the instructor and
the other as a pilot-in-training, alternating their roles
between sessions. In total, five debriefings with vary-
ing scenarios were created.
Audio was recorded in a closed room using a
Zoom H2n recorder – a stereo audio recorder. The in-
structor and trainee were positioned along the left-to-
right stereo axis of the recorder, respectively, to ena-
ble identification of the speaker.
To obtain ground-truth transcriptions for evalua-
tion, the audio recordings were first transcribed using
Whisper and manually corrected. For speaker identi-
fication, we employed a simple stereo heuristic that
identified speakers based on the dominant audio
channel. The resulting transcripts were then lightly
post-processed, assigning each utterance the corre-
sponding speaker role, ‘Instructor:’ or ’Candidate:’,
and merging adjacent sentences by a single speaker
into longer paragraphs.
The LLM was subsequently used to do various
tasks such as summarization and competency identi-
fication using prompts like in Figure 3. To make the
LLM perform these tasks we used zero-shot prompt-
ing (Radford, et al., 2019) as described in section 2.3,
where the model is directly asked a question about the
transcript.
For recognition of individual performance indica-
tors, the LLM was instructed to look at the perfor-
mance indicator and rate the candidate on it. This
prompt (see Figure 3) was executed for each of the 8-
10 performance indicators associated to the 9 compe-
tencies as defined by the Evidence Based Training Pi-
lot Competencies competency framework (EASA,
2023).
We will quantitively evaluate the individual steps
of our approach on this dataset. For transcription we
will determine the word error rate (WER) and the dia-
rization error rate (DER) which is simply the rate of
incorrectly transcribed words or misattributed speak-
ers. The large language model outputs will be evalu-
ated on the corrected transcripts so that it’s perfor-
mance can be judged in isolation. The LLM outputs
will be judged qualitatively by expert evaluation.
3.2 Interactive Debrief Tool
To streamline the instructor’s interaction with AAD,
the speech-to-text system and language models were
integrated into a single debrief application. Given an
audio file of the debrief dialogue, the tool first gener-
ates the transcriptions after which a summary of the
debrief is generated using a language model of choice
ICCAS 2024 - International Conference on Cognitive Aircraft Systems
76
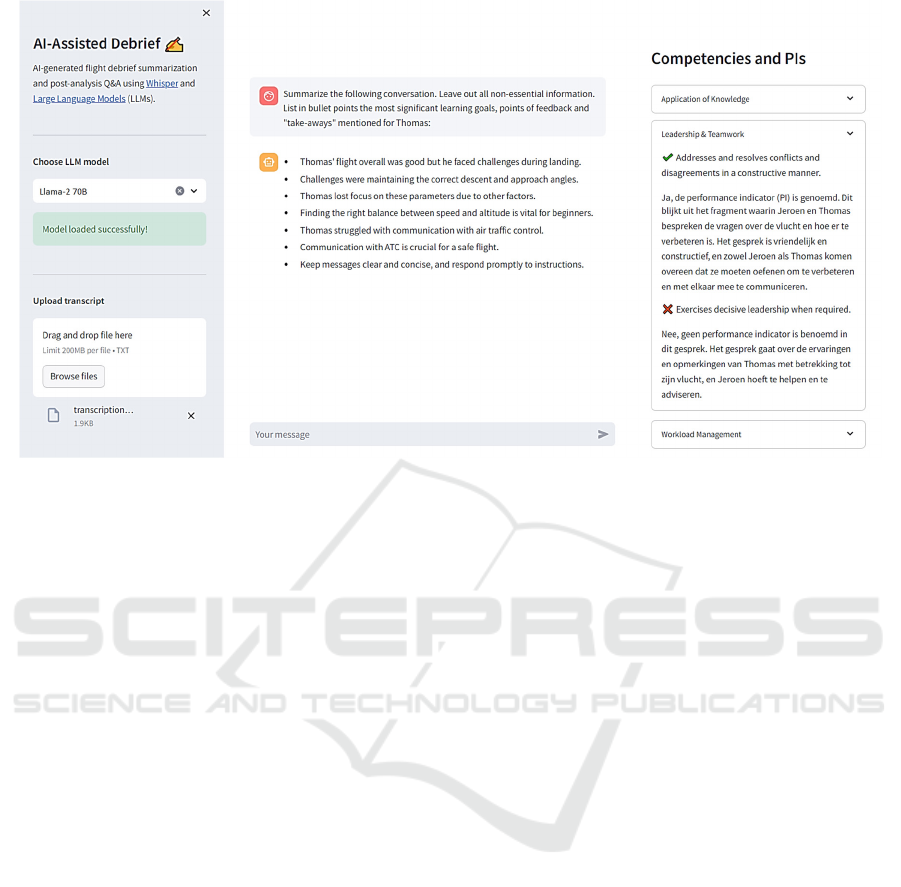
Figure 4: The debrief tool showing a summary of a post-flight debrief in an interactive chat panel (centre column) and a list
of competencies with associated performance indicators (PIs) as identified by the Llama-70B LLM (right).
(centre). The resulting summary is then visualised in-
side an interactive chat panel, allowing the instruc-
tor/trainee to further inquire information about the de-
briefing if desired.
Moreover, to identify the competencies expected
of the trainee, the interface enumerates the competen-
cies listed in the Evidence Based Training Pilot Com-
petencies framework along with their associated PIs
(right); it then verifies, using the LLM, whether the
behaviour of the candidate exhibited signs of the de-
sired competencies by evaluating each PI belonging
to a competency of interest against the debrief dia-
logue, as shown in Figure 4.
4 RESULTS
Our results are summarized in Table 1. Displayed is
various information about the recorded scenarios with
various quantitative and qualitative evaluations of the
applied techniques.
Transcriptions by Whisper yielded an average
Word Error Rate (WER) of around 2-3%. This is bet-
ter than the reported WER on Dutch by OpenAI,
which is 5% for Whisper v3 and 8% for Whisper v2.
As such, quantitative error rates indicate accurate and
reliable dialogue transcription; nonetheless, errors
were observed which would have likely been detri-
mental to downstream performance, while others do
not seem to modify the semantics of the text. Our rel-
atively simple speaker identification technique, based
on the dominant stereo channel, performed reasona-
bly with error rate (DER) of around 5%. This is likely
unacceptable for the downstream LLM tasks as im-
portant semantic information is lost.
The LLM was evaluated on the corrected tran-
scripts where it performed best on the summarization
task. The system can almost always pick out the gen-
eral main points in the ground truth, only sometimes
getting details of individual points wrong. For the
competency task the model was able to identify the
major competency categories but was prone to mak-
ing up details or mixing up student and instructor. Fi-
nally, for the instructor evaluation, the model seemed
unable to criticise the instructor in the last scenario
when they failed to show a lack of attention to the
workload of the trainee.
5 DISCUSSION
5.1 Evaluation
Overall, Whisper was found robust in transcribing do-
main-specific jargon and code-mixed phrases involv-
ing Dutch with English words, although sometimes
this bilingualism also caused it to miss the mark. For
example, Whisper displayed a preference in transcrib-
ing ‘deicing’ to Dutch as ‘deijsen’ and similarly
‘flightpath’ to ‘flypad’ which are hybrid Dutch-Eng-
lish composite words with similar semantics, see fig-
ure 5.
AI-Assisted Debrief: Automated Flight Debriefing Summarization and Competency Assessment
77

I: Maar ben je tevreden met hoe het gegaan
gaas was?
C: Nou, mwah moi. Nee, voor mijn gevoel had
het wel wat strakker gekund.
I: En waar dan? Denk je dat je steken het
teken hebt laten vallen?
C: Ja, dat vind ik een beetje lastig. Het is
meer het overall overal gevoel.
I: Ja, oké. Misschien even concreet dan. Toen
jullie bij de baan stonden.
C: Na het de-icen deijsen bedoel je?
I: Ja. Dus na het de-icen deijsen zijn jullie
naar de baan gereden.
C: Ja.
I: Wat hebben jullie toen allemaal gedaan?
Vanaf het de-icen deijsen naar de baan
Figure 5: Debrief fragment between Instructor and Candi-
date, as transcribed by Whisper large-v2 with
manual corrections, in bold are the corrections to the
strikethrough errors.
In this study, we investigated the application of
current-generation open large language models for
summarization and performance indicator detection
tasks. Our findings indicate that while not perfect
these open models are already quite good. It is not at
the level to be trusted blindly, but its output can serve
very well as a first draft to be checked and supple-
mented by the end user.
Automatic recognition of competencies through
their Performance Indicators (PIs) can be achieved
using LLMs, but we observed several challenges in
accurately identifying competencies from debrief
statements. These challenges include:
Overgeneralization: Models may determine that
the trainee meets or fails to meet competency require-
ments based on vague evidence. For example, a de-
brief mentioning difficulties during a task might be
interpreted as a failure to verify task completion to the
expected outcome, even if the evidence is not direct.
Context Misinterpretation: Despite instructions
to evaluate performance based on specific criteria
(e.g., during the flight), models might consider com-
petencies in the broader context of the debrief conver-
sation. For instance, active listening and understand-
ing demonstrated in a post-flight debrief might be in-
correctly attributed to in-flight performance.
Hallucination: Models may generate false posi-
tives by attributing competencies that were not
demonstrated. For example, claiming resilience in
handling unexpected events during a landing when no
such events were mentioned.
Lack of Explanation: Models might not adhere
to instructions to provide reasoning for their assess-
ment of a competency's presence or absence. This re-
sults in evaluations that lack justification, making it
difficult to understand the model's decision-making
process.
5.2 Future Work
Recent work has shown that fine-tuning Whisper on
air traffic control data can improve its performance on
that domain (van Dorn, 2023). This is an easy way to
improve domain specific performance but requires
training data, on the order of hours, e.g. van Dorn fin-
tuned on 10 hours of ATC data. Relatedly, Whisper
supports a textual context which is can also be filled
with domain relevant terms so that it is nudged to-
wards correctly transcribing these, e.g. by putting 787
in the context the transcription of 787 becomes more
likely than the incorrect 78 / 8. The diarization, or
speaker identification, can likely be improved by
moving to a speaker timbre fingerprinting model like
(Bredin, 2023). This should also be useful in many-
user debriefs as are typical in the industry.
Table 1: Information about the recorded scenarios with results by expert evaluators. WER is the word error rate, DER is the
diarization (speak identification) error rate. LLM analyses were rated correct (🗸 green), correct with incorrect details
(– yellow), incorrect (× red).
Scenario 1 Scenario 2 Scenario 3 Scenario 4 Scenario 5
Short description Candidate
struggles with
procedures
Candidate is
too hasty
The candi-
date has dif-
ficulty with
flying.
Candidate is
passive, co-
pilot forced
to intervene
Candidate not
well prepared,
knowledge
lacking
Length (mm:ss) 13:26 13:12 18:05 12:10 12:10
Transcription
(Whisper)
WER 2.3% 2.8% 2.5% 0.55% 3.8%
DER - - - 5.5% 5.6%
Analysis
LLM
Yi-34B
Summarization 🗸
–
–
🗸🗸 🗸 🗸
–
🗸🗸🗸
–
🗸
–
🗸🗸 🗸 🗸
–
🗸
–
🗸
–
🗸 🗸 🗸
Competencies 🗸
–
–
–
–
🗸 🗸
–
🗸 ×
–
🗸 ×
–
–
–
🗸🗸🗸
–
–
🗸 🗸 🗸 ×
–
Instructor Eval 🗸
–
🗸
–
×
ICCAS 2024 - International Conference on Cognitive Aircraft Systems
78

Analysis performance of the LLM can be en-
hanced by employing larger models or integrating
more task-specific training data. Closed models, like
those developed by OpenAI and Anthropic, expected
to be larger and equipped with superior training data,
may outperform in these tasks. The domain of large
language models, encompassing both open and closed
models, is evolving at an unprecedented pace, with
significant yearly improvements. Future enhance-
ments to our system could be achieved by adopting
newer more advanced models.
Just as with Whisper, an improvement strategy for
the LLM involves fine-tuning on domain-specific
training data, such as transcribed conversations with
high quality summaries or competency assessments.
Likely a few hours of high quality data, such as those
generated for this paper, would already yield positive
results. This approach can further refine the capabili-
ties of an already trained large language model.
Our proposed future iteration of the AI-Assisted
Debrief should incorporate user intervention at every
stage of the process, enabling correcting of the sys-
tem's intermediate outputs. For instance, the system
could automatically flag potentially misinterpreted
words or incorrectly identified speakers, allowing us-
ers to manually rectify these errors. Similarly, users
should have the ability to adjust summaries and PI
identifications as needed.
These corrections made by users would not only
improve the immediate output but also contribute val-
uable data for the fine-tuning of AAD. This creates a
dynamic system that progressively improves its per-
formance and accuracy in executing its designated
tasks. Through this iterative learning process, AAD
would evolve into an increasingly reliable tool.
Given the inherent limitations of current-genera-
tion LLMs, particularly their tendency to hallucinate,
we posit that the most effective application of these
technologies lies in such a human-in-the-loop frame-
work. This approach synergistically combines the
unique strengths of both LLMs and human expertise.
Human experts possess an unparalleled capacity for
critical thinking and the nuanced evaluation of com-
plex scenarios, which LLMs currently cannot match.
Conversely, LLMs excel in rapidly processing and
analysing vast quantities of data, a task that is time-
consuming and labour-intensive for humans.
ACKNOWLEDGEMENTS
We would like to thank Anneke Nabben for pitching
this project and facilitating it throughout; Simone
Caso for his help researching flight debriefings;
Jeroen van Rooij and Thomas Janssen for creating the
evaluation dataset; Asa Marjew for the illustrations;
Astrid de Blecourt for her leadership; Jelke van der
Pal for his helpful guidance and reviews; finally
Marjolein Lambregts and Jenny Eaglestone and for
their help.
REFERENCES
Bredin, H. (2023). pyannote.audio 2.1 speaker diarization
pipeline: principle, benchmark, and recipe. Proc. INTER-
SPEECH 2023.
Deng, J. a. (2022). The benefits and challenges of ChatGPT:
An overview. Frontiers in Computing and Intelligent
Systems, 81-83.
EASA. (2023, 12 18). EASA. Retrieved from EASA EU-
ROPA: https://www.easa.europa.eu/community /top-
ics/post-flight-debrief
Floridi, L. &. (2020). GPT-3: Its nature, scope, limits, and
consequences. Minds and Machines, 681-694.
Josh Achiam, e. a. (2023). GPT-4 Technical Report. OpenAI.
Kasneci, S. K. (2023). ChatGPT for good? On opportunities
and challenges of large language models for education.
Learning and Individual Differences.
Mavin, T. J. (2016). Models for and practice of continuous
professional development for airline pilots: What we can
learn from one regional airline. Supporting learning
across working life: Models, processes and practices,
169-188.
Mavin, T. J., Kikkawa, Y., & Billett, S. (2018). Key contrib-
uting factors to learning through debriefings: commercial
aviation pilots’ perspectives. International Journal of
Training Research, 122-144.
McDonnell, L. K., Jobe, K. K., & Dismukes, R. K. (1997).
Facilitating LOS debriefings: A training manual.
OpenAI. (n.d.). Whisper Github Repository. Retrieved from
https://github.com/openai/whisper
Radford, A., J.W., K., Xu, T., Brockman, G., C., M., &
Sutskever, I. (2022). Robust Speech Recognition via
Large-Scale Weak Supervision. OpenAI.
Radford, A., Wu, J., Child, R., Luan, D., Amodei, D., & &
Sutskever, I. (2019). Language models are unsupervised
multitask learners. OpenAI blog.
Roth, W. (2015). Cultural Practices and Cognition in De-
briefing: The Case of Aviation. Sage Journals, 263–278.
SkyBrary. (2023, December 19). SkyBrary. Retrieved from
https://skybrary.aero/articles/evidence-based-training-
ebt
Tannenbaum, S., & Cerasoli, C. (2013). Do Team and Indi-
vidual Debriefs Enhance Performance? A Meta-Analy-
sis. Human Factors and Ergonomics Society.
Touvron, H. e. (2023). Llama 2: Open Foundation and Fine-
Tuned Chat Models. Meta.
van Dorn, J. L. (2023). Applying Large-Scale Weakly Super-
vised Automatic Speech Recognition to Air Traffic Con-
trol. Retrieved from http://resolver.tu
delft.nl/uuid:8aa780bf-47b6-4f81-b112-29e23bc06a7d
AI-Assisted Debrief: Automated Flight Debriefing Summarization and Competency Assessment
79
